Global-Token U-Net with Hybrid Loss for Trustworthy Medical Image Super-Resolution
Jiaqi Shang, Zhiyuan Xu, Dongdong Wang

TL;DR
This paper introduces a new method for medical image super-resolution that improves image quality and reliability by using a hybrid loss function.
Contribution
The novel hybrid loss combines adversarial and PSNR-based regularization to enhance trustworthiness in medical image super-resolution.
Findings
The hybrid loss function improves high-frequency texture generation in reconstructed images.
The proposed method maintains high reconstruction quality while increasing trustworthiness.
Using a global-token U-Net with a lightweight VGG discriminator enhances reliability in medical image super-resolution.
Abstract
Super-resolution technology significantly enhances the visual quality of low-resolution medical images, resulting in ultra-high-resolution clear images. Super-resolution technology based on artificial intelligence has achieved great success in reconstruction quality. However, like the image restoration task, super-resolution is also an ill-posed problem, and current work lacks consideration of trustworthiness. Medical image super-resolution needs to ensure clarity and, more importantly, to ensure that the output image is reliable and does not produce false details and mislead the diagnosis. To address the trustworthy issue of medical image super-resolution, we design a novel hybrid loss that combines a hinge-based adversarial term with a PSNR-based regularization. In the designed loss function, the adversarial term makes the reconstructed result close to the distribution of the true…
Click any figure to enlarge with its caption.
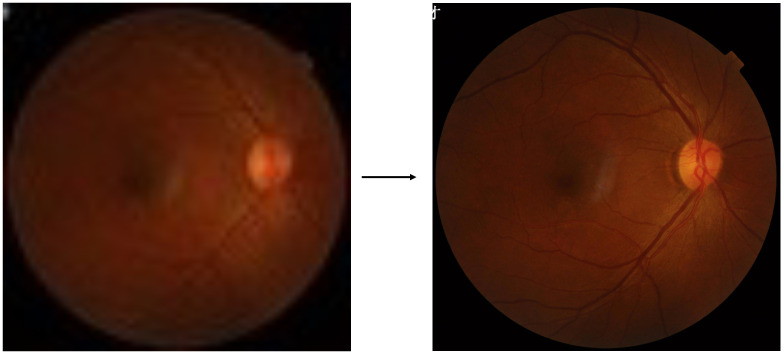 Figure 1
Figure 1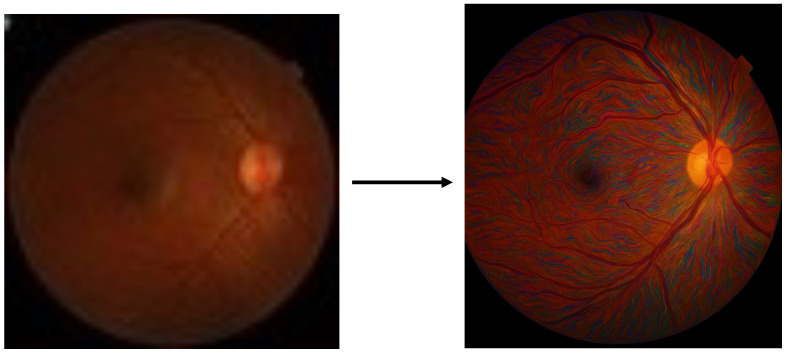 Figure 2
Figure 2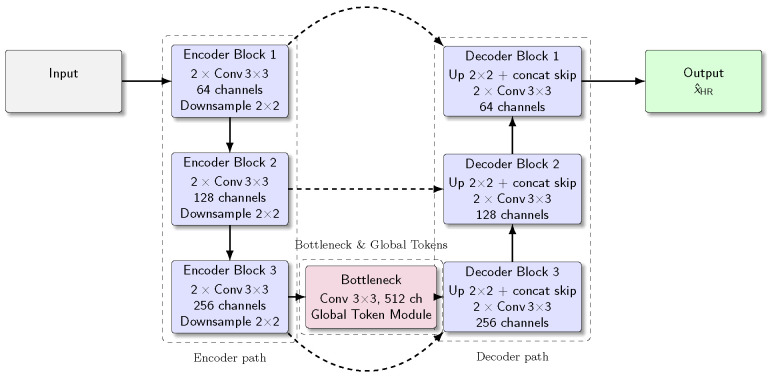 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5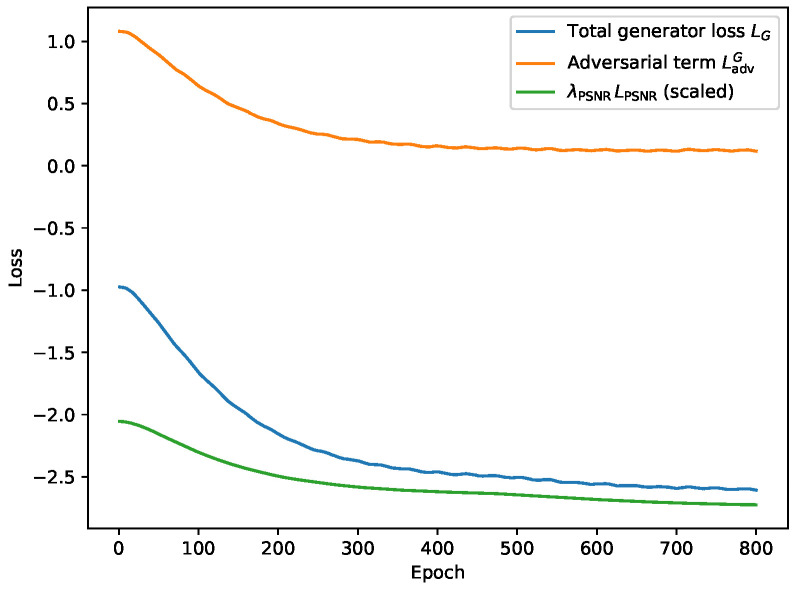 Figure 6
Figure 6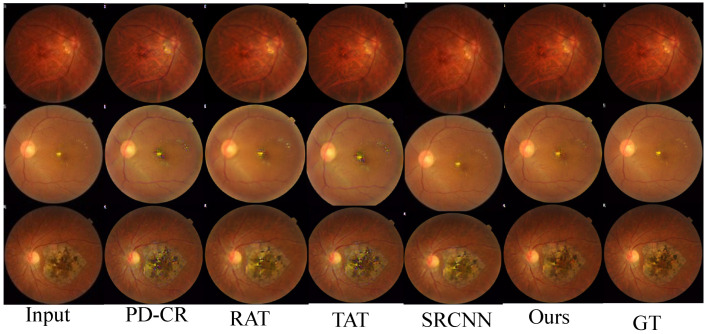 Figure 7
Figure 7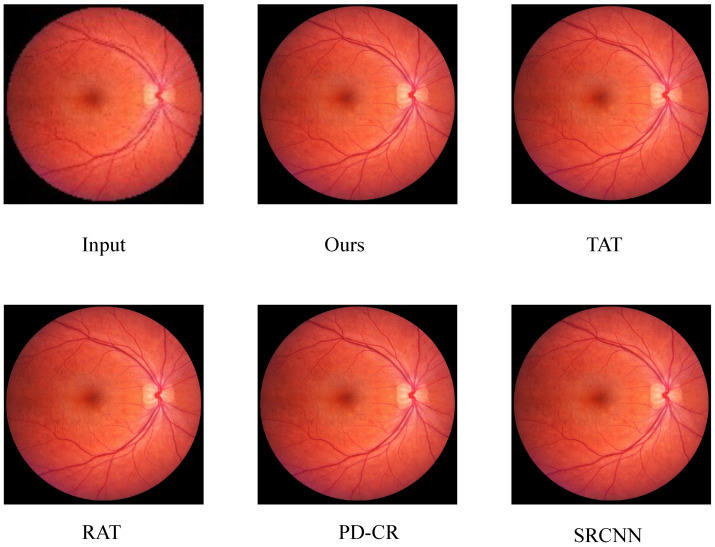 Figure 8
Figure 8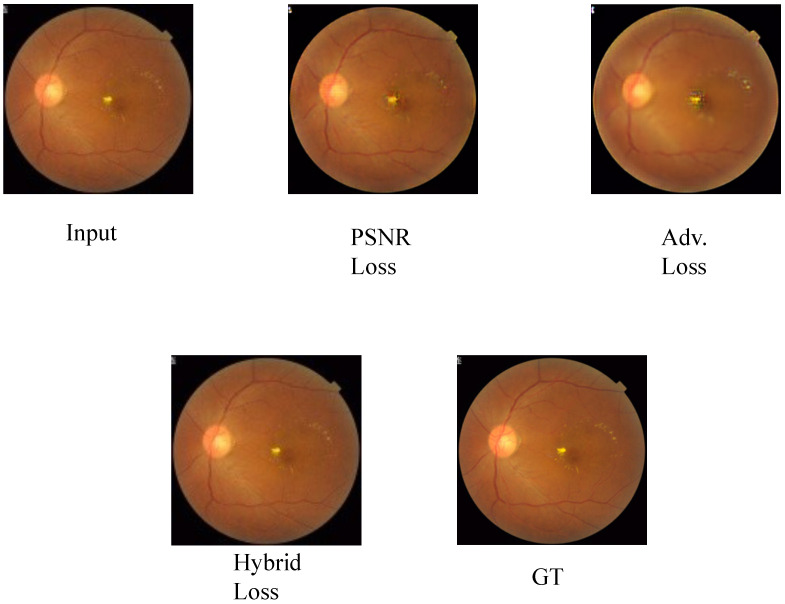 Figure 9
Figure 9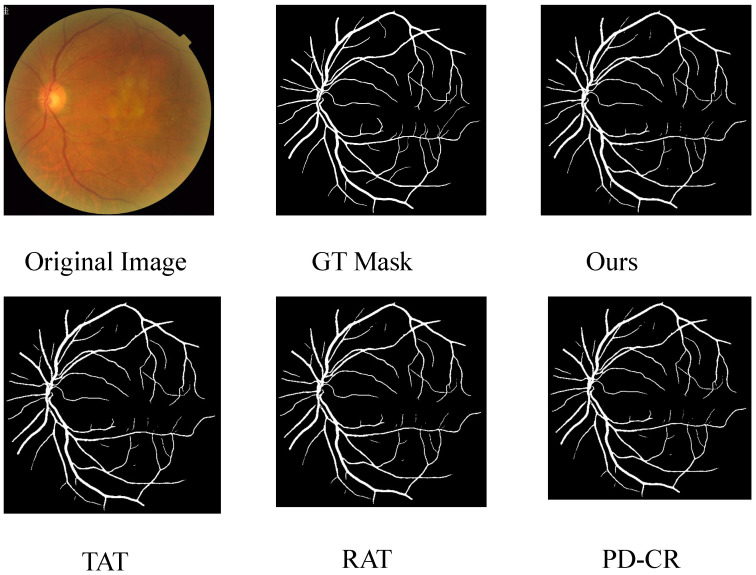 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image Processing Techniques · Image and Video Quality Assessment · Advanced Image Fusion Techniques
1. Introduction
Super-resolution is an image processing technology aimed at significantly enhancing the resolution of images, thereby improving visual quality [1,2]. For medical imaging, low-resolution medical images can hinder diagnosis. Super-resolution technology can bring additional knowledge to improve the diagnostic effect [3]. As shown in Figure 1, super-resolution technology can significantly improve the visual quality of blurred medical images. Higher visual knowledge can assist human experts in diagnosis and can also be used to enhance the performance of advanced machine intelligence tasks, such as further instance segmentation and classification.
Dong et al. used convolutional neural networks to achieve universal image super-resolution [4], which was the first time that artificial intelligence technology was applied in the field of image super-resolution. Since then, super-resolution methods based on artificial intelligence have become mainstream, and many new models and methods have been proposed [5,6,7,8]. With the development of intelligent medical care, dedicated super-resolution models for medical images have also been proposed, achieving ideal results [9,10,11].
Deep learning has achieved great success in image restoration fields, including super-resolution [12,13]. However, all image restoration technologies based on artificial intelligence involve the process of deep scene synthesis. Scene synthesis models with high perceptual quality often generate results that are difficult to distinguish from real data; that is, details that seem clear but do not actually exist appear [14,15]. In the medical field, the consequences of this kind of image hallucination are serious [16]. Figure 2 is an extreme example of super-resolution using our other high-perception visual models. It can be seen that the super-resolution result looks very clear, but there are a lot of falsified details. This kind of medical imaging will hinder the diagnostic process and draw our attention to trustworthiness.
In this paper, we propose a method to enhance the trustworthiness of medical image super-resolution. Prior works have pointed out that medical images have global features [17,18]. Considering long-distance semantics, we adopt global-token U-Net as the backbone network. We design a new hybrid loss function that combines PSNR loss [19] and adversarial loss [20]. The adversarial term uses a lightweight VGG as the discriminator, mainly considering the reconstruction effect to generate fine and clear textures. The PSNR term uses explicit regularization constraints to reduce the difference between the output results and the ground truth. With this combination of hybrid loss and global modeling, we can achieve a sufficiently clear super-resolution result and improve the level of trustworthiness. The main contributions of this work are threefold:
- We revisit medical image super-resolution from the perspective of trustworthiness and identify hallucinated high-frequency details as a critical failure mode of deep learning-based restoration for ill-posed inverse problems. We argue that trustworthy medical image super-resolution should jointly pursue visual clarity and anatomical fidelity, rather than perceptual quality alone.
- We propose a global-token U-Net-based generator and a novel hybrid loss, which jointly aim to achieve trustworthy medical image super-resolution by capturing global anatomical context and suppressing hallucinated high-frequency details. The backbone augments a U-shaped convolutional network with global tokens to efficiently capture long-range anatomical context, while the hybrid loss combines a hinge-based adversarial term driven by a lightweight VGG discriminator with a PSNR-based regularization term to enhance perceptual sharpness and explicitly suppress hallucinated details.
- We conduct extensive experiments on medical image super-resolution benchmarks, showing that the proposed method maintains high reconstruction accuracy while achieving consistently perceptual quality. Qualitative and quantitative analyses further demonstrate that our approach produces fewer falsified structures and improves the trustworthiness of the reconstructed medical images.
The remainder of this paper is organized as follows: Section 2 reviews related work on universal and medical image super-resolution and discusses hallucination risks in ill-posed restoration. Section 3 presents the proposed global-token U-Net architecture and the hybrid adversarial–PSNR loss. Section 4 reports experimental settings and quantitative/qualitative results, including cross-domain evaluation and ablation studies. Finally, Section 5 concludes this paper and outlines future directions.
2. Related Work
2.1. Universal Image Super-Resolution
Early image super-resolution methods were mainly based on computer graphics and multimedia information processing technology [21]. Later, convolutional neural networks achieved outstanding performance in various computer vision tasks, and some super-resolution methods based on convolutional networks were proposed [4,5]. Modern super-resolution techniques mainly employ models with strong representational capabilities, such as transformers [8,22,23] and diffusion models [1,7].
The learning-based works include specific models for super-resolution and universal models for image restoration, and both achieve very clear reconstruction results. However, these works lack consideration of trustworthiness, which limits their application in real-world scenarios.
2.2. Medical Image Super-Resolution
Medical imaging has unique proprietary prior knowledge, so medical image super-resolution models can be designed [24,25,26,27]. Some common medical image restoration techniques also take into account super-resolution [11,18]. The acquisition of medical images involves multiple modalities and higher dimensions. Therefore, researchers have designed super-resolution models for multimodal medical imaging [10,28,29].
Hallucinations can lead to serious consequences, so the reconstruction of medical images has very strict requirements for trustworthiness [16]. This inspires us to propose novel solutions for trusted medical image super-resolution.
2.3. Ill-Posed Inverse Problems and Hallucination in Restoration
Image restoration tasks such as denoising, deblurring, inpainting, and super-resolution can all be formulated as inverse problems of an underlying degradation process. Image restoration models are often more concerned with synthetic datasets, and models that perform well in their settings may not be effective in real-world applications.
Learning-based image restoration is clearly an ill-posed problem. Restoring high visual quality from a degraded image may yield different results, and these seemingly high-quality clear images may contain details that do not exist in real scenes. Cohen et al. provide an information-theoretic analysis of hallucinations in generative restoration models, revealing that there is a certain contradiction between better perceptual quality and keeping true details [15].
In medical imaging, such hallucinated structures can have serious consequences. Bhadra et al. point out that images reconstructed by intelligent models can lead to false clear details that mislead the diagnosis [16]. As a deep synthesis reconstruction technology, super-resolution also faces similar risks. Therefore, it is important to design restoration schemes that explicitly account for the ill-posed nature of the problem and control hallucinated content. This perspective motivates us to focus on trustworthy medical image super-resolution and to develop methods that balance visual clarity with fidelity.
2.4. Discussion
Super-resolution is an inherently ill-posed inverse problem: multiple high-resolution images can correspond to the same low-resolution observation under the degradation operator, making the mapping from LR to HR non-unique and under-constrained. Based on the above analysis of hallucination, we discuss the hallucination risk for the methods in Section 2.1 and Section 2.2 and summarize the results in Table 1. The synthetic paths for generating processing results using different methods are different, which leads to different risks of false details and other credibility issues. This work aims to enhance the credibility of super-resolution by imposing constraints on the loss function.
3. Method
3.1. Model Architecture
We adopt the classic U-Net [30] architecture and add global-token-aware mechanisms at the bottleneck layer as the backbone network. The pipeline is shown in Figure 3. At the bottleneck level, given the encoder feature , we first project it into a sequence of local tokens via a convolution and flattening:
where denotes the projection and flattening operator, d is the token dimension, and each row of is a local token.
We introduce K learnable global tokens
and form the initial token matrix by concatenation
The global-token module applies T layers of multi-head self-attention to . For , we write
where denotes multi-head self-attention. Given an input token matrix , the multi-head self-attention is defined as
with query, key, and value matrices
where indexes attention heads, is the head dimension, and are learnable projection matrices.
After T layers, we obtain the updated token matrix and split it back into global and local parts:
Finally, the refined local tokens are reshaped back to the bottleneck feature map
which is then fed into the decoder path of the U-Net. The resulting global-token module is shown in Figure 4.
3.2. Hybrid Adversarial–PSNR Loss
The core of our method is to use the newly designed hybrid loss. To introduce adversarial loss, we use a lightweight VGG as the discriminator for the output of global-token U-Net, and its structure is shown in Figure 5. As such, global-token U-Net is a generator and its output also needs to be constrained by differences with the ground truth. Let G denote the generator and D the discriminator. Given a mini-batch of low-resolution inputs and corresponding high-resolution ground-truth images , the generator produces . We adopt a hinge-based adversarial loss combined with a PSNR-based regularization term.
Adversarial loss. This module was mainly inspired by Lucic et al. [20]. For the discriminator, the hinge adversarial loss is defined as
The generator is trained to fool the discriminator via
PSNR-based regularization. This module was mainly inspired by Chen et al. [19]. For each sample, we compute the mean-squared error (MSE) between and as
where and denote the height and width, respectively. Given the maximum possible pixel value and a small constant for numerical stability, the per-sample PSNR is
We define the PSNR-based loss as the negative batch-averaged PSNR:
Minimizing is therefore equivalent to maximizing the PSNR of the reconstructed images.
Generator objective. The final generator loss is given by
where is a hyperparameter that refers to a weighting coefficient.
The adversarial term encourages perceptually realistic, high-frequency details, while the PSNR-based regularization explicitly penalizes deviations from the ground truth, thereby suppressing hallucinated structures and improving the trustworthiness of the reconstructed medical images.
4. Experiments
4.1. Dataset
Our experiment is based on the FIVES dataset [31]. This is a dataset with 800 fundus images taken by the same device. It is balanced across four categories: normal eyes, diabetic retinopathy, age-related macular degeneration, and glaucoma (200 images per category). All images are scanned in a consistent style at resolution. To obtain the super-resolution dataset, we use the bicubic method to downsample the images:
where denotes bicubic downsampling by a factor of s. The resulting pairs constitute the supervised training set for medical image super-resolution. s is set to 8, thereby producing low-resolution images with a resolution of . Then we divide the training set and the test set in a ratio of 8:2.
4.2. Implementation Details
We implement our method using the deep learning framework PyTorch 2.5.1 [32] and the Adam [33] optimizer. The learning rate is set to and gradually reduced to using the cosine annealing method. The batch size is set to 8 and the model is trained using two Nvidia VGPUs (32 G, NVIDIA Corporation, Santa Clara, CA, USA) for a fixed 800 epochs. The hyperparameter in the designed loss function is set to 0.1.
The training curve of the hybrid loss during the training process is shown in Figure 6. As the training converges, the PSNR loss decreases more significantly, while the effect of the adversarial loss gradually decreases.
4.3. Metrics
We use SSIM to assess how similar the reconstructed results are to the ground truth in terms of structure and visual quality, and we use the PSNR to measure the pixel-level fidelity [34,35].
In addition to this, to evaluate the trustworthiness, we use LR-PSNR and LR-SSIM. These two metrics are calculated by downsampling the super-resolved image to the original resolution and calculating the related metrics with the original input image. Higher LR-PSNR and LR-SSIM indicate that the super-resolution results are faithful to the original details and have higher reliability.
In addition to the metrics for measuring fidelity to the original details, we have also introduced three general indicators of trustworthiness. LR-LPIPS is computed between and (lower is better). GradCons is the mean error of Sobel gradients, e.g., (images normalized to ). HF-Err is the mean error of Laplacian/high-pass responses, e.g., (lower is better).
4.4. Results
Table 2 compares the quantitative evaluation under the previous setting using indicators, including the general super-resolution methods and medical image super-resolution algorithms. The method we proposed demonstrates good reconstruction quality. Meanwhile, our method has reached a state-of-the-art level in LR-PSNR and LR-SSIM, demonstrating a higher degree of trustworthiness and reliability. Although PD-CR [7] and DiT4SR [36] based on diffusion models achieve higher PSNRs, their restoration of original details is still weaker.
The intuitive qualitative comparison is shown in Figure 7, from which it can be seen that our method maintains the original details while achieving high visual quality.
4.5. Cross-Domain Evaluation
To demonstrate the generalization ability of the proposed method, we conducted cross-domain tests on the trained model using low-resolution fundus images without any ground-truth references. ODIR [38] is a multi-class fundus dataset. We performed super-resolution processing on the blurred downsampled images within this dataset and obtained ideal results, indicating that the proposed method can be applied to real super-resolution tasks on different devices, as shown in Figure 8.
4.6. Ablation Study
Our method obtains competitive LR-PSNR and LR-SSIM, fully ensuring the credibility of the original semantics of medical images. The source of trustworthiness lies in the combined influence of the hybrid loss function. To verify this, we conduct ablation experiments using a single loss function (PSNR or Adv.), and the quantitative results are shown in Table 3.
Combining the adversarial term with the PSNR-based regularization yields the best full-resolution PSNR/SSIM and restores LR-PSNR/LR-SSIM compared with the adversarial-only variant. This confirms that the proposed hybrid loss can effectively balance perceptual sharpness and input consistency, thereby enhancing the trustworthiness of medical image super-resolution. The qualitative visual quality in Figure 9 further illustrates this point.
The evaluations of different ablations are summarized in Table 4, indicating that the proposed method can take into account both visual quality and reliability.
4.7. Effect on High-Level Task
We give the practical auxiliary diagnosis application to demonstrate the effectiveness and credibility of the proposed method. The results show that the proposed method can effectively support the application of classification. The FIVES dataset [31] is naturally classified into four balanced categories based on different pathologies. We take all the super-resolution datasets formed after downsampling as the classification dataset. We employ a ResNet-50 network as the backbone and train it for 100 epochs for classification. Table 5 summarizes the accuracy comparison, indicating that our method can effectively assist in automatic classification diagnosis.
Segmentation is another important high-level task for clinical diagnosis. We construct a segmentation dataset using the super-resolved images generated by different methods, paired with the corresponding vessel masks provided in the FIVES dataset. The dataset is split into training and testing sets with a ratio of 0.8:0.2. A classical U-Net is trained for 100 epochs under the same settings for all methods. The quantitative and qualitative segmentation results are presented in Table 6 and Figure 10, respectively. The results demonstrate that the proposed method achieves better downstream performance, indicating stronger compatibility with high-level tasks and further supporting its credibility.
5. Conclusions
To address the trustworthiness issue of medical image super-resolution, we propose a comprehensive method. This method uses global-token U-Net as the backbone network, adds a lightweight VGG as the discriminator, and employs a hybrid PSNR and adversarial loss. Empirical results show that the proposed method can balance visual quality and reliability and ensure fidelity to the original details and is more suitable for auxiliary diagnosis. Future work can explore the role of other loss functions such as perceived loss.Some of the theoretical analyses of the methods presented in this paper still require exploration in future research. The validity of 3D imaging or other modalities still needs to be verified through more universal experiments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Li G. Xing W. Zhao L. Lan Z. Sun J. Zhang Z. Zhang Q. Lin H. Lin Z. Self-Reference Image Super-Resolution via Pre-trained Diffusion Large Model and Window Adjustable Transformer Proceedings of the 31st ACM International Conference on Multimedia (MM ’23)Ottawa, ON, Canada 29 October–3 November 202379817992
- 2Han L. Zhang X. Scalable Super-Resolution Neural Operator Proceedings of the 32nd ACM International Conference on Multimedia (MM ’24)Melbourne, Australia 28 October–1 November 20241003610045
- 3Chen Z. Guo X. Woo P.Y.M. Yuan Y. Super-Resolution Enhanced Medical Image Diagnosis With Sample Affinity Interaction IEEE Trans. Med. Imaging 2021401377138910.1109/TMI.2021.305529033507866 · doi ↗ · pubmed ↗
- 4Dong C. Loy C.C. He K. Tang X. Image Super-Resolution Using Deep Convolutional Networks IEEE Trans. Pattern Anal. Mach. Intell.20163829530710.1109/TPAMI.2015.243928126761735 · doi ↗ · pubmed ↗
- 5Kim J. Lee J.K. Lee K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)Las Vegas, NV, USA 27–30 June 201616461654
- 6Zhang Y. Li K. Li K. Wang L. Zhong B. Fu Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks Proceedings of the European Conference on Computer Vision (ECCV)Munich, Germany 8–14 September 2018294310
- 7Cho H. Shin H.-K. Jang Y. Ko S.-J. Jung S.-W. PD-CR: Patch-Based Diffusion Using Constrained Refinement for Image Restoration IEEE Signal Process. Lett.20243194995310.1109/LSP.2024.3381908 · doi ↗
- 8Song J. Sowmya A. Zhang W. Sun C. Efficient Transformer with Compressed-Attention for Stereo Image Super-Resolution Knowl.-Based Syst.202533111484410.1016/j.knosys.2025.114844 · doi ↗