Multi-adapter SAM-inspired bronchoscopic image segmentation for lung cancer diagnosis
Qian Li, Xinbo Liu, Chao Ye, Sen Cui, Jinze Zhang, Xuanyu Meng, Jin Guo, Xianjun Min

TL;DR
This paper introduces MASA, a new AI model that improves lung cancer detection during bronchoscopy by combining lesion segmentation and diagnosis in one system.
Contribution
MASA is the first end-to-end framework that unifies bronchoscopic lesion segmentation and cancer diagnosis using a dual decoder.
Findings
MASA outperformed ESFPNet in lesion segmentation with +3.01% mDice and +1.24% mIoU improvements.
MASA improved diagnosis with +8.1 Macro-F1 and +14.1 AUPRC gains.
MASA provides pixel-level lesion maps and case-level predictions for clinical use.
Abstract
Lung cancer remains the leading cause of cancer-related mortality. Although bronchoscopy allows direct visualization and tissue sampling, detecting subtle lesions is still challenging owing to limited resolution, variable imaging conditions, and the complex structure of the airway. Most existing approaches treat lesion segmentation and cancer diagnosis as separate tasks, which can reduce diagnostic coherence and limit clinical applicability. We propose a novel Multi-Adapter-based Segment Any Bronchoscope Model (MASA), an end-to-end framework with an encoder that fuses spatial, frequency, and positional information and a dual decoder that performs simultaneous lesion segmentation and lung cancer diagnosis. MASA was trained/evaluated on the public BM-BronchoLC dataset. On BM-BronchoLC, MASA improved lesion segmentation over the strongest baseline (ESFPNet), raising mean Dice coefficient…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
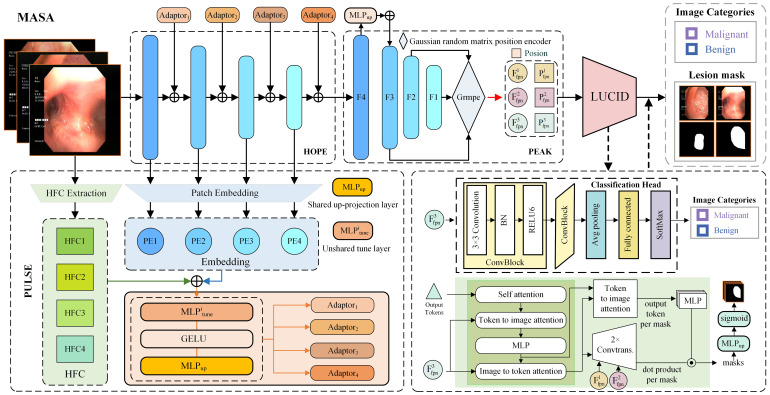 Figure 1
Figure 1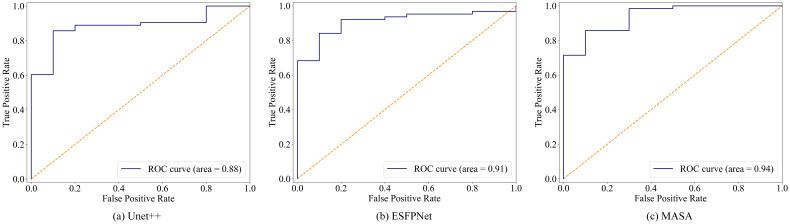 Figure 2
Figure 2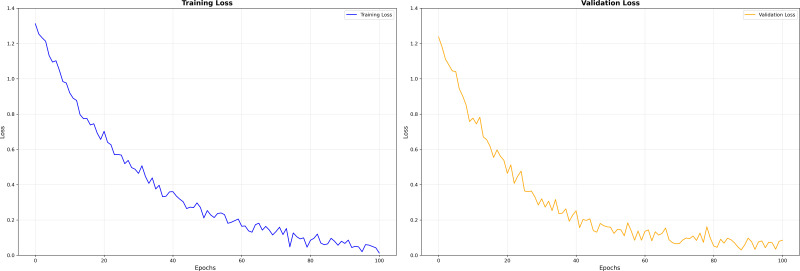 Figure 3
Figure 3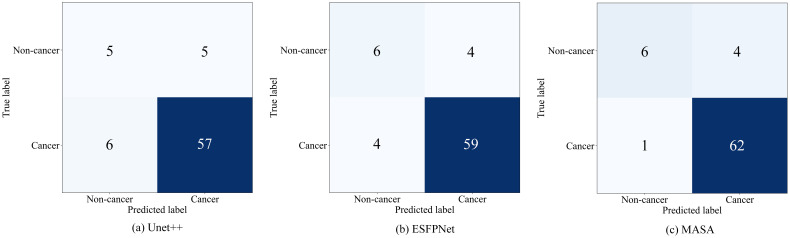 Figure 4
Figure 4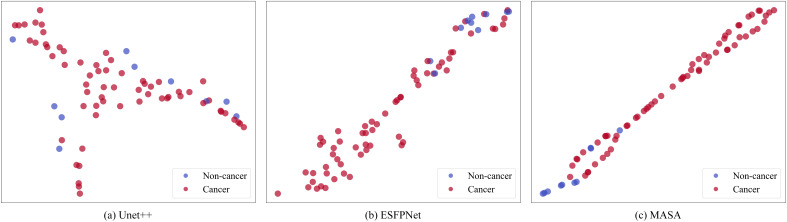 Figure 5
Figure 5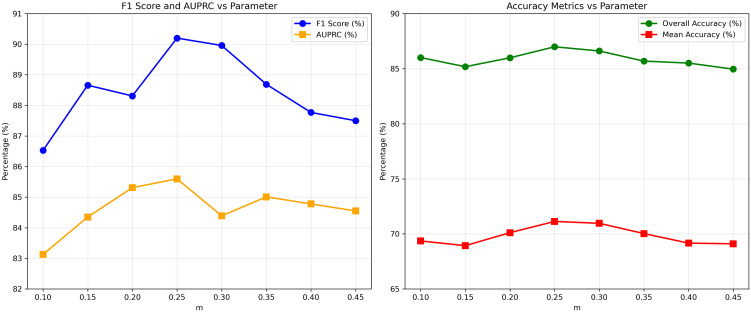 Figure 6
Figure 6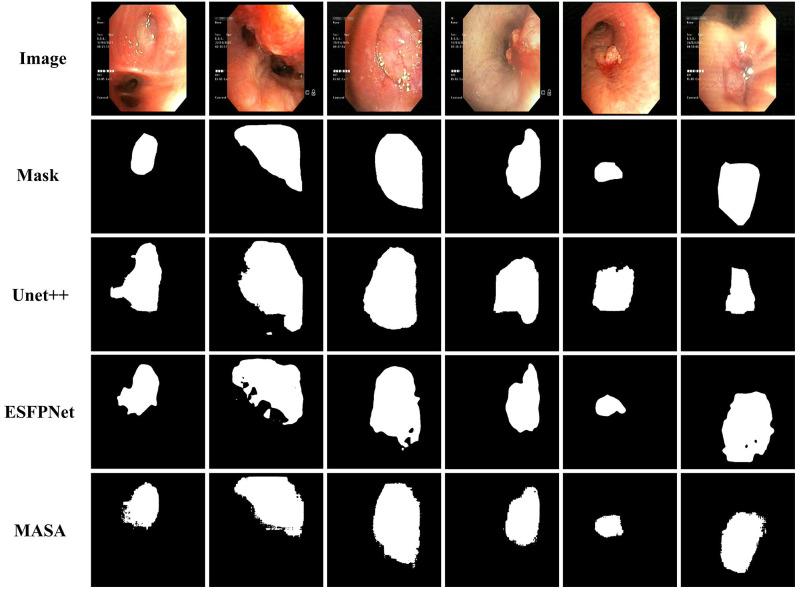 Figure 7
Figure 7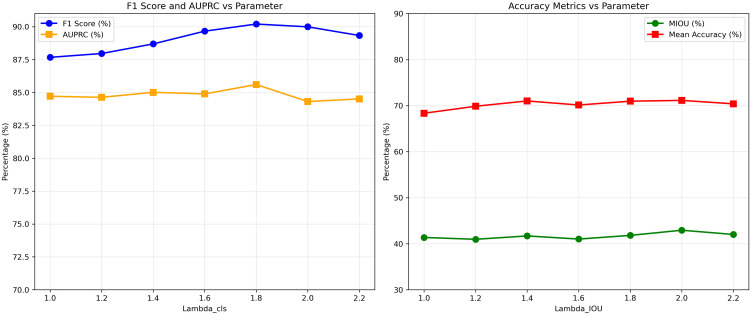 Figure 8
Figure 8| Label | Train set | Val set | Test set | Total |
|---|---|---|---|---|
| Lung cancer | 505 | 59 | 63 | 627 |
| Non-lung cancer | 85 | 7 | 10 | 102 |
| Total | 590 | 66 | 73 | 729 |
| Model | Malignant | Benign | Macro-F1 | AUPRC (benign) | ||
|---|---|---|---|---|---|---|
| Recall | Precision | Recall | Precision | (%) | (%) | |
| U-Net++ | 90.2 | 91.7 | 60.0 | 54.5 | 73.3 | 58.2 |
| ESFPNet | 93.4 | 93.5 | 70.0 | 72.4 | 82.1 | 71.5 |
| MASA (ours) | 98.3 | 93.9 | 80.0 | 88.9 | 90.2 | 85.6 |
| HOPE | PEAK | PULSE | Macro-F1 | AUPRC | mIoU | mDice |
|---|---|---|---|---|---|---|
| ✔ |
|
|
|
|
|
|
| ✔ | ✔ |
|
|
|
|
|
| ✔ |
| ✔ |
|
|
|
|
| ✔ | ✔ | ✔ |
|
| 42.93 | 56.74 |
| Model | oAcc (%) | mIoU (%) | mAcc (%) | mDice (%) | mPrec (%) | mRec (%) |
|---|---|---|---|---|---|---|
| U-Net++ | 84.22 | 36.57 | 60.44 | 48.19 | 46.46 | 63.28 |
| ESFPNet | 85.56 | 41.69 | 68.39 | 53.73 | 51.05 | 68.33 |
| MASA (ours) | 86.99 | 42.93 | 71.13 | 56.74 | 54.77 | 71.06 |
| Model | # Parameters (M) | FLOPs (G) | Inference time (ms/frame) |
|---|---|---|---|
| U-Net++ | 9.2 | 65.7 | 180 |
| ESFPNet | 61.7 | 23.9 | 37 |
| MASA (ours) | 239 | 40.6 | 46 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsLung Cancer Diagnosis and Treatment · COVID-19 diagnosis using AI · Advanced Radiotherapy Techniques
Introduction
1
Lung cancer remains the leading cause of cancer-related mortality worldwide (1–3). Early diagnosis is crucial, as 5-year survival exceeds 90% for Stage I disease but drops below 10% for Stage IV (4). Bronchoscopy is a vital tool for the detection and biopsy of suspicious lesions in the airways, playing a key role in diagnosing lung cancer and other serious respiratory conditions (5). However, bronchoscopic diagnosis is still largely a manual, operator-dependent process that suffers from considerable inter-observer variability (6). Even experienced bronchoscopists may miss subtle mucosal lesions or interpret findings inconsistently, leading to diagnostic delays and the potential for missed early cancers. These limitations underscore the need for computer-aided diagnosis (CAD) systems to assist clinicians during bronchoscopy (7).
Deep learning has dramatically advanced medical image analysis in recent years (8), exhibiting remarkable potential in bronchoscopic imaging. For instance, ESFPNet achieves real-time lesion segmentation in autofluorescence video, attaining a mean Dice score of 0.756 (9), while other studies using multi-scale attention report an expert-level accuracy of approximately 97% in malignancy classification (5). Despite these breakthroughs, two key challenges remain. First, reliable detection of fine-grained lesions is hampered by limited spatial resolution, motion blur, airway complexity, and variable mucosal appearance. Vision transformer–convolutional neural network (CNN) hybrids such as TransFuse (10) and DS-TransUNet (11) demonstrate enhanced multi-scale encoding but have not been extensively validated on bronchoscopic data. Second, most existing methods address segmentation and classification in isolation: segmentation networks like PraNet can delineate lesions precisely (12), but they do not provide malignancy prediction, while classification-only models lack accurate spatial localization (5). This separation complicates clinical integration, as spatial and diagnostic outputs must be manually reconciled.
These limitations motivate our research. Leveraging the rich lesion and malignancy annotations in the BM-BronchoLC dataset (13), we developed the Multi-Adapter-based Segment Any Bronchoscope Model (MASA), a unified framework for simultaneous lesion segmentation and lung cancer classification. MASA incorporates a context-aware encoder that integrates the Hierarchical Overlap-aware Patch Encoder (HOPE), the Patch and Ultra-frequency Learned Semantic Enhancer (PULSE), and the Positional Embedding Aggregated Knowledge (PEAK) modules, enabling the joint fusion of spatial, frequency, and positional information. In parallel, a dual-task Lesion-Unified Classification and Image Decoding (LUCID) decoder enables seamless multi-task prediction. By consolidating localization and diagnosis into a single pipeline, MASA provides consistent, interpretable, and clinically actionable outputs, addressing a critical need for computer-aided bronchoscopy.
The main contributions of our work are as follows:
Firstly, we propose the MASA, a fully integrated system for bronchoscopy that performs both lesion segmentation and lung cancer diagnosis within a single pipeline.Secondly, we design a novel multi-adapter feature encoder that jointly integrates multi-scale spatial information, frequency-domain cues, and positional context to construct enriched, hierarchically informed feature representations. By adaptively capturing both fine-grained details and global structural patterns, this encoder significantly enhances the model’s sensitivity to subtle lesions in bronchoscopic images.Thirdly, we devised a LUCID module that simultaneously produced segmentation masks and classification outputs. Through cooperative optimization on shared encoder representations while keeping task-specific decoders independent, the dual-task design yielded accurate and reliable diagnostic results and streamlined the clinical workflow.Finally, MASA was validated on the public BM-BronchoLC dataset. Results indicated that MASA outperformed the compared baselines U-Net++ and ESFPNet.
Related work
2
Bronchoscopic image analysis with deep learning
2.1
Recent years have seen growing research into artificial intelligence (AI)-assisted bronchoscopy (5, 14, 15). Early deep learning models focused on classifying bronchoscopic findings, attaining impressive accuracies. Sun et al. (5), for example, reported over 97% accuracy in distinguishing malignant from benign bronchoscopic images using a multiscale attention CNN, approaching the performance of expert pulmonologists. Deng et al. (15) developed a deep recognition model to differentiate lung cancer subtypes in bronchoscopic views, while Yan et al. (16) proposed a knowledge-distillation network (PKDN) that infused prior medical knowledge to enhance bronchoscopic image classification. Beyond supervised learning, unsupervised anomaly detection has also been explored. For instance, Liu et al. (17) introduced a memory-augmented autoencoder that learns normal bronchoscopy appearances and flags deviations (tumors) without manual labels, achieving high sensitivity for intratracheal lesion detection. In the gastrointestinal (GI) endoscopy domain, AI systems have already demonstrated clinical value in detecting lesions: deep learning models can localize colorectal polyps and early GI cancers in real time with expert-level sensitivity (18, 19), and such systems are beginning to assist clinicians in practice (20). These successes in related fields underline the potential for AI to improve bronchoscopic diagnostics, provided the unique challenges of airway imagery are addressed.
However, most existing approaches remain constrained by suboptimal performance on subtle or small lesions, limited robustness to image artifacts (e.g., motion blur, specular highlights, and uneven illumination), and a lack of integrated frameworks capable of jointly performing lesion localization and pathological diagnosis. These shortcomings underscore the need for more advanced, unified deep learning models specifically designed to address the unique challenges of bronchoscopic imaging.
Segmentation techniques in endoscopic imaging
2.2
Lesion segmentation is a critical component of endoscopic image analysis. CNN architectures like U-Net (21) have become ubiquitous for medical image segmentation, including in endoscopy. U-Net++ (22) and other variants introduce redesigned skip connections and nested decoders to better capture multi-scale features, which has proven effective for segmenting lesions in complex scenes. For example, Wang et al. (23) combined multi-scale context and attention to improve GI lesion segmentation performance. Advanced attention mechanisms—such as the reverse attention in PraNet for polyp segmentation (12)—further refine the delineation of subtle lesions against surrounding mucosa. More recently, transformer-based architectures have been adopted to capture global context in segmentation. Chen et al. proposed TransUNet, which integrates vision transformers as encoders to enhance long-range feature modeling (24). In bronchoscopy, Chang et al. (9) introduced ESFPNet, an efficient transformer-based network that achieves real-time segmentation of airway lesions in autofluorescence bronchoscope videos. Sun et al. (25) developed a deep learning system using a Multiscale Attention Residual Network (MARN) for analyzing bronchoscopic images. MARN incorporates a Multiscale Convolutional Block Attention Module (MCBAM) to better capture lesion-relevant spatial and channel features, and integrates Grad-CAM for improved interpretability. Tang et al. (26) proposed TransMT-Net, a multi-task network combining transformers for global context and CNNs for local details to jointly classify and segment GI endoscopic images. Integrated active learning mitigates limited labeled data. Evaluated on a composite dataset from CVC-ClinicDB, Macau Kiang Wu Hospital, and Zhongshan Hospital, it effectively leverages sparse annotations for accurate lesion identification and delineation. Despite these developments, conventional segmentation methods alone output only a binary mask; without an integrated diagnosis, a segmented lesion still requires a separate classification step by either an algorithm or a physician.
Multi-task learning for segmentation and classification
2.3
To provide comprehensive assistance, there is a growing interest in multi-task learning frameworks that jointly perform lesion segmentation and disease classification. The motivation is that segmentation can provide precise localization to inform classification, while classification imparts semantic context that can prioritize relevant regions for segmentation. Tang et al. (26) demonstrated this synergy in GI endoscopy by proposing a transformer-based multi-task network (TransMT-Net) that achieved 96.9 classification accuracy and 77.8% Dice for segmentation, outperforming separate single-task models. Generally, multi-task deep learning can improve data efficiency and generalization by sharing representations between tasks (27). In bronchoscopy, the recently released BM-BronchoLC dataset has enabled initial explorations of joint learning: Vu et al. (13) reported baseline models that perform simultaneous anatomical landmark segmentation and lesion classification. These works indicate that an integrated approach can yield more robust performance, supporting the design of end-to-end systems that align with real clinical workflows. MASA builds upon this idea, uniquely coupling segmentation and malignancy prediction for lung cancer assessment within one model.
Building on this foundation, we propose MASA—a unified deep learning framework that uniquely couples pixel-level lesion segmentation with image-level lung cancer diagnosis within a single architecture. In this work, we specifically aim to address key limitations of existing methods by enhancing sensitivity to subtle or small lesions, improving robustness against common bronchoscopic artifacts (e.g., motion blur, specular highlights, and uneven illumination), and delivering clinically interpretable outputs that support reliable, real-time decision-making during bronchoscopy.
Proposed approach
3
Overview
3.1
In this study, we propose MASA for lung cancer diagnosis, a unified end-to-end framework that consists of a Multi-Adapter Hierarchical Spatial-Frequency Encoder and a LUCID decoder. As illustrated in Figure 1, the encoder integrates three specialized modules: the HOPE module for extracting multi-scale spatial features, the PULSE module for frequency-domain enhancement, and the PEAK module for positional context aggregation. The decoder, implemented as the LUCID module, simultaneously generates precise lesion segmentation masks and lung cancer diagnostic predictions. This comprehensive design addresses the core challenges of bronchoscopic imaging and offers substantial clinical value by improving diagnostic accuracy and supporting clinical decision-making.
Schematic of the proposed MASA framework, consisting of four modules: HOPE for hierarchical feature extraction, PULSE for residual prompt generation, PEAK for multi-scale positional fusion, and LUCID for joint segmentation and classification from bronchoscopic images.
Multi-adapter hierarchical spatial-frequency encoder
3.2
Hierarchical overlap-aware patch encoder
3.2.1
The MASA pipeline begins with the HOPE module, which conducts low-level feature extraction through a hierarchical transformer backbone. Specifically, we instantiated Hiera, a recent hierarchical vision transformer (28), to generate a pyramid of feature maps at multiple resolutions. The overlap patch embedding layers in Hiera divide the bronchoscopic image into overlapping patches, preserving continuity of local tissue structures at patch boundaries. By leveraging self-attention within and across hierarchical scales, the backbone yields rich multi-scale representations that encompass both fine-grained mucosal details and broader bronchial context.
Formally, for an input bronchoscopic image , the HOPE module produces feature maps at hierarchical levels, where :
where each has spatial dimensions and channels. The resolution decreases and the channel capacity increases with network depth, enabling early layer ( ) to capture fine textures and lesion boundaries, while deeper layers ( ) encode more abstract and global anatomical information.
Patch and ultra-frequency learned semantic enhancer
3.2.2
To further enhance lesion sensitivity in bronchoscopic imaging under challenging conditions such as low illumination, motion blur, and specular highlights from moist mucosa, MASA introduces the PULSE module. This component generates frequency-aware residual prompts that adaptively modulate HOPE features, enabling the network to focus on lesion-relevant edges and texture variations by incorporating high-frequency visual information.
We derive a high-frequency enhancement signal from the input image via frequency filtering. Let and ^−1^ denote the Fourier and inverse Fourier transforms, respectively. We first compute the image’s frequency spectrum , with zero-frequency component shifted to the center. To isolate the high-frequency components of the image spectrum, a binary mask B_m_(u,v) is applied to suppress the central low-frequency region, which corresponds to a small proportion m of the total spectral power. Specifically, the mask is defined as:
This formulation eliminates the low-frequency components from the frequency domain representation by setting the corresponding coefficients to zero, thereby emphasizing edge-like and textural details in subsequent processing. The high-frequency component image
is then obtained by filtering and transforming back:
The result preserves only the rapid intensity variations from I, which are often indicative of lesion boundaries and texture.
Next, PULSE uses learnable adapter networks to fuse this frequency information with the semantic features from HOPE. For each scale in the hierarchy, we construct a residual prompt as follows. First, the corresponding HOPE feature is passed through a small tuning layer to reduce its dimension (controlling the number of parameters). In our design, we use a linear projection that compresses by a factor to produce a patch embedding cue . This focuses the high-level semantic content of into a compact embedding. In parallel, we extract a similarly shaped frequency embedding from the high-frequency image . This is achieved by feeding through the same overlapping patch embed and transformer layers up to level , yielding an embedding that aligns spatially with . The two embeddings and are then combined by a learnable adapter. We simply add them and apply a nonlinearity, then project back to the original channel dimension :
where GELU(·) denotes the activation, and both ρ and ϕ are up-projection operators that map the fused embedding back to C_s_ channels. The adapter parameters are trained to produce an effective prompt for each transformer stage.
Finally, the residual prompt injection is performed: at each hierarchy level s, the prompt is added to the original feature map F^s^ before it is passed to the next network stage:
In summary, functions as a learned residual that guides the model’s attention toward lesion-specific frequencies and patterns at each hierarchy level. This design allows PULSE to enhance the encoding of subtle edges and textural details essential for accurate bronchoscopic lesion detection.
Positional embedding aggregated knowledge
3.2.3
Following feature extraction by HOPE and frequency-enhanced prompting from PULSE, the PEAK module aggregates semantic information across scales and injects spatial awareness to support accurate lesion delineation in bronchoscopic imagery. Lesions in such images often exhibit subtle boundaries and variable morphology, requiring both localized texture analysis and global anatomical context. PEAK addresses these needs through a twofold strategy: top-down semantic feature fusion and learnable positional encoding.
To enrich spatial detail with deep semantic context, PEAK performs a selective top-down fusion. Classic Feature Pyramid Networks (FPNs) build semantic feature maps at every scale via a full top-down pathway with lateral connections (29). In contrast, PEAK transfers semantic information only from the deepest feature layer to its immediately preceding layer. This focused approach retains multi-scale semantics while reducing complexity.
Let denote the output feature at level s, with increasing s corresponding to lower spatial resolution and higher semantic abstraction. We define the fused feature as:
Here, U(·) denotes nearest-neighbor interpolation to match spatial resolution. This formulation allows the highest-level feature , which contains the most abstract lesion semantics, to influence level while leaving the finer-scale levels and structurally intact.
After fusion, the deepest layer is discarded to avoid redundancy, and the final fused outputs are defined as . This design ensures that high-resolution detail is preserved while incorporating selective semantic guidance, enabling the model to better differentiate subtle lesion textures from artifacts or airway bifurcations.
To further augment spatial coherence, PEAK assigns positional encodings to each fused feature map. These encodings help the network interpret anatomical location and orientation, which are essential for distinguishing between airway zones in bronchoscopic views.
Given a pixel location , normalized to the range [−1, 1], we compute its positional embedding using the following formulation:
Here, is a learnable Gaussian matrix, randomly initialized and optimized during training. Each fused feature is paired with its positional embedding, forming three aligned pairs: , and . These outputs carry both texture-rich and position-aware representations across multiple scales, ready to be decoded into segmentation masks and image-level classifications.
Lesion-unified classification and image decoding
3.3
The LUCID module converts the multi-scale features generated by PEAK into two outputs: a high-resolution binary segmentation mask and an image-level lung cancer diagnosis. Designed as a dual-headed decoder, the LUCID module enables efficient multi-task learning by sharing feature representations while maintaining task-specific processing.
Image-level classification head. For lung cancer diagnosis, LUCID extracts the lowest-resolution fused feature from PEAK, which contains the most informative semantic abstraction. This feature is first upsampled to enhance spatial detail and then passed through a lightweight classification network comprising sequential convolutional layers, batch normalization, activation, global average pooling, and a fully connected layer. The classification process is defined as:
where denotes the lowest-resolution fused feature from PEAK, U(·) represents the upsampling operation, and Classifier(·) encapsulates the classification network. During training, classification gradients are detached from the encoder to avoid interference with segmentation learning.
Lesion segmentation decoder. The segmentation branch of LUCID builds on a modified prompt-based decoding approach; it converts feature representations into pixel-level binary lesion masks via a transformer-guided decoding process. This process involves token-conditioned spatial interaction, multi-scale upsampling, and mask generation using dynamic weight prediction.
We initialize a learnable dense prompt embedding and inject it into the deepest semantic feature from PEAK, denoted as . The two are combined to produce the input spatial feature for the transformer:
We then define an initial set of learnable mask tokens , where by default but can be generalized to any number of output masks. Along with these, we introduce continuous positional encoding . The triplet is passed into a Two-Way Transformer to enable bidirectional conditioning:
where is the updated spatial feature and is the refined token set.
To progressively recover the full spatial resolution and refine features with earlier-scale information, we apply two stages of upsampling and feature fusion. The first upsampling output is computed as:
Here, ConvTrans is a transposed convolution that halves the channel dimension and doubles the spatial size; LN denotes Layer Norm. The second upsampling and fusion stage yields:
For each refined mask token we apply a lightweight MLP to produce a query vector . This vector interacts with the spatial embedding , which is first flattened to . The dot product at each spatial location yields the mask logits:
The resulting logit map is then bilinearly upsampled to match the original input resolution :
A pixel-wise sigmoid function is applied to obtain the final probability mask:
Finally, the probability mask is binarized using a fixed threshold to generate the final segmentation output . This decoder architecture facilitates accurate lesion delineation by fusing coarse semantic and fine spatial features under internal prompt guidance, producing detailed segmentation masks that align with clinical bronchoscopic imagery.
Dual-task cooperative optimization
3.4
To jointly optimize segmentation and classification performance, we adopted a multi-objective loss composed of pixel-level and image-level terms.
To penalize pixel-level classification errors, the Binary Cross-Entropy (BCE) loss is defined as:
where is the number of pixels, denotes ground truth, and is the predicted logit at pixel .
To improve lesion boundary localization, we incorporate the soft Intersection-over-Union (IoU) loss:
with as the predicted probability and as the binary ground truth.
The overall segmentation loss combines BCE and IoU with empirically chosen weights:
The classification supervision employs a standard cross-entropy loss:
where is the output logit from the classification branch, and is the ground-truth malignancy label.
Finally, the total multi-task loss is expressed as:
where , , , and are empirically chosen weights balancing segmentation and classification objectives.
This cooperative loss structure ensures that the network learns both local lesion boundaries and global diagnostic signals in a mutually reinforcing manner. Here should be added a sentence. The overall optimization is summarized in Algorithm 1.
Algorithm 1
Experiments
4
Dataset
4.1
The performance of the proposed MASA framework was comprehensively evaluated on the public BM-BronchoLC dataset (13), which provides high-resolution bronchoscopic images annotated with pixel-level lesion masks and verified malignancy labels. Two clinically significant tasks were investigated: (1) precise segmentation of lesion regions and (2) binary classification of each lesion as malignant (lung cancer) or benign (non-lung cancer). Low-quality or ambiguously annotated images were excluded to ensure the reliability of the experimental data. The BM-BronchoLC clinical cohort consists of 208 patients with a total of 2,921 images, collected from Bach Mai Hospital (Vietnam) between 2020 and 2023. All images were acquired from flexible bronchoscopy examinations using standard white-light imaging. Bronchoscopy videos were recorded and representative frames were extracted at 1 frame per second, after which experienced bronchoscopists selected at least 10 high-quality images per patient for annotation. The final curated dataset includes 2,132 images containing anatomical landmarks and 789 images containing lung-cancer-related lesions.
For all experiments, the dataset was partitioned into training, validation, and test subsets to enable rigorous and unbiased evaluation by 10-fold cross-validation. Specifically, approximately 80% of the images were allocated for training, 10% for validation, and 10% for testing. Table 1 summarizes the distribution of malignant and benign lesions across these subsets.
Evaluation metrics
4.2
For a comprehensive evaluation, we adopted several widely recognized quantitative metrics for both classification and segmentation tasks. All metrics are computed with the malignant (lung cancer) category as the positive class.
Classification metrics
4.2.1
The classification performance is assessed using accuracy (Equation 21), precision (Equation 22), recall (Equation 23), and F1-score (Equation 24). Their mathematical definitions are as follows:
where TP, FP, TN, and FN represent the number of true positives, false positives, true negatives, and false negatives, respectively.
The area under the precision–recall curve (AUPRC) is then computed as the integral of precision with respect to recall (Equation 25):
Segmentation metrics
4.2.2
For lesion segmentation, six quantitative metrics were adopted: overall Accuracy (oAcc) (Equation 26), mean Intersection-over-Union (mIoU) (Equation 28), mean Accuracy (mAcc) (Equation 27), mean Dice coefficient (mDice) (Equation 29), mean Precision (mPrec) (Equation 30), and mean Recall (mRecall) (Equation 31). These metrics are defined as follows:
Here, represents the total number of classes, which is two in this study (lesion and background). denotes the number of pixels of class that are predicted as class , indicates the number of pixels correctly predicted as class , is the total number of pixels belonging to class in the ground truth, and is the total number of pixels predicted as class . Collectively, these metrics evaluate pixel-level agreement, region-level overlap, and the balance between sensitivity and precision for lesion delineation.
Implementation details
4.3
The MASA framework was implemented in PyTorch and trained on two NVIDIA RTX 4090 GPUs using distributed data parallelism. Optimization was performed with the AdamW optimizer, an initial learning rate of 2 × 10^−4^, and a batch size of 1. Training was conducted for up to 100 epochs with early stopping based on validation loss, and a cosine-annealing learning-rate schedule was adopted. The frequency mask ratio m in Equation 2 was set to 0.25. Within the segmentation loss defined in Equation 18, the weights for the BCE and IoU terms were set to and , respectively. For multi-task optimization in Equation 20, the segmentation and classification branches were weighted as IoU = 2.0 . The training data were augmented using the MedAugment framework (30), which applies spatial transformations including rotation, horizontal and vertical flipping, scaling, translation along the x- and y-axes, and shearing in both directions prior to model fitting.
Classification task
4.4
To evaluate the effectiveness of MASA in automated lung cancer diagnosis, we conducted a comprehensive comparison on the binary classification of bronchoscopic lesions. The task is defined as distinguishing between lung cancer (malignant) and non-lung cancer (benign) based on bronchoscopic image features. All experiments were performed on the BM-BronchoLC dataset, using the metrics described in Section 4.2.
Comparison with other advanced models
4.4.1
The class-wise performance of all compared methods on the BM-BronchoLC test set is summarized in Table 2. Given the pronounced class imbalance, 627 malignant versus 102 benign lesions evaluating models solely by oAcc would be misleading. Instead, we report per-class recall (sensitivity for malignant and specificity for benign), precision, macro-averaged F1-score, and the AUPRC for the benign (minority) class, which are more informative under such imbalance.
U-Net++ achieves high recall (90.2%) and precision (91.7%) on malignant lesions but performs poorly on benign cases, with only 60.0% recall (i.e., specificity) and 54.5% precision. This implies that 40% of benign lesions are misclassified as malignant, potentially leading to a substantial number of unnecessary biopsies. ESFPNet improves upon this, attaining 70.0% benign recall and 72.4% benign precision, yet still mislabels 3 out of every 10 benign cases as malignant.
In contrast, our proposed method, MASA, demonstrates significant gains across all metrics. It achieves near-perfect sensitivity for malignancy (98.3% recall), missing only one malignant case in the test set—critical in clinical settings where false negatives carry severe consequences. More importantly, MASA substantially improves performance on the minority class: it correctly identifies 80.0% of benign lesions (specificity) with a high precision of 88.9%, meaning that among all lesions predicted as benign, nearly 89% are truly benign. This translates to only 2 false positives out of 10 benign cases, a notable reduction compared to baseline models. Consequently, MASA achieves the highest macro-F1 score (90.2%), reflecting balanced performance across both classes, and the highest AUPRC for the benign class (85.6%), confirming its superior ability to discriminate the minority class under precision–recall trade-offs.
These results indicate that MASA effectively mitigates the bias introduced by class imbalance while maintaining clinical safety: it minimizes missed cancers and simultaneously reduces unnecessary invasive procedures. The combination of high sensitivity and improved specificity makes MASA particularly suitable for real-world bronchoscopic lung cancer screening workflows.
These results underscore the advantages of MASA’s multi-adapter architecture and its cooperative optimization strategy. By leveraging shared multi-scale spatial, frequency, and positional representations while maintaining independent task-specific decoders, MASA generated more discriminative features and achieved superior diagnostic consistency compared with conventional single-task networks.
Visual results of ROC analyses, confusion matrices, and t-SNE
4.4.2
Discriminative performance was characterized on the BM-BronchoLC test set with receiver operating characteristic analyses and confusion matrices. As shown in Figure 2, MASA achieved the largest area under the curve, AUC = 0.94, compared with ESFPNet at 0.91 and U-Net++ at 0.88. The upward shift of MASA’s curve across operating points indicated consistently stronger trade-offs between sensitivity and specificity for differentiating malignant from benign lesions. Figure 3 shows training and validation loss over 100 epochs. Both curves decrease steadily, indicating effective learning. The validation loss remains slightly higher than training loss, typical for well-regularized models, but does not diverge or increase, suggesting no significant overfitting. The fluctuations in validation loss may stem from batch variability or a small validation set. Overall, the model converges well, with consistent improvement on both seen and unseen data, demonstrating stable training and generalization.
ROC curves of the proposed MASA and baseline classification models. (a) Unet++ with an area of 0.88, (b) ESFPNet with an area of 0.91, (c) MASA with an area of 0.94.
Training and validation loss.
Figure 4 summarizes the confusion matrices at the operating point used for metric reporting. MASA markedly reduced missed cancers, with a false negative rate of 1 out of 63, or 1.6%, while maintaining a similar number of false positives to the baselines. This pattern was consistent with the higher recall and F1-score in Table 2.
Confusion matrices of the proposed MASA and baseline classification models. (a) Unet++: True non-cancer 5, predicted as cancer 5, true cancer 6, predicted as cancer 57. (b) ESFPNet: True non-cancer 6, predicted as cancer 4, true cancer 4, predicted as cancer 59. (c) MASA: True non-cancer 6, predicted as cancer 4, true cancer 1, predicted as cancer 62.
To assess the separability of learned representations, Figure 5 shows two-dimensional t-SNE projections of the feature embeddings. MASA formed tighter intra-class clusters and clearer inter-class boundaries, whereas U-Net++ and ESFPNet exhibited more overlap between classes. The improved separability corroborated the ROC and confusion matrix findings.
t-SNE visualization of feature distributions for MASA and baseline classification models. Panel (a) Unet++ shows mixed clustering of red and blue dots. Panel (b) ESPNet displays more distinct clustering, predominantly red dots. Panel (c) MASA shows a clear linear separation with red and blue dots. Blue represents non-cancer, red represents cancer.
Collectively, these visual and quantitative results substantiate the effectiveness of the proposed multi-adapter architecture and cooperative optimization on shared multi-scale representations. By integrating spatial, frequency, and positional cues within a unified feature space while retaining independent task-specific decoders, MASA produced more discriminative features and demonstrated reliable image-level diagnosis. These properties indicate strong potential for deployment as decision support in bronchoscopic assessment of suspected lung cancer.
Ablation study
4.5
Table 3 summarizes the impact of the three core submodules—HOPE, PEAK, and PULSE—on both segmentation and classification performance, evaluated using Macro-F1, AUPRC, mIoU, and mDice. All configurations retain the HOPE module, and the results illustrate the incremental benefits introduced by PEAK and PULSE.
(1) Baseline: HOPE only. With only the HOPE backbone enabled, the model obtains moderate performance (Macro-F1: 80.36%, AUPRC: 73.36%, mIoU: 33.11%, mDice: 49.01%). These results confirm that HOPE provides a solid foundational representation but lacks mechanisms for enhanced spatial refinement or temporal consistency. (2) Introducing PEAK on top of HOPE produces consistent improvements across all metrics, yielding gains of +3.27% in Macro-F1, +3.03% in AUPRC, + 3.26% in mIoU, and +1.29% in mDice. This indicates that the positional-aware fusion strategy in PEAK effectively strengthens spatial feature aggregation, enhancing lesion-focused attention and segmentation detail. (3) Replacing PEAK with PULSE (HOPE + PULSE) leads to even larger performance gains, achieving 86.29% Macro-F1 and 80.30% AUPRC, with substantial boosts in segmentation metrics (mIoU: 40.66%, mDice: 52.22%). The notable improvements—particularly the +7.55% increase in mIoU and +6.94% in AUPRC over the baseline—suggest that PULSE’s frequency-aware prompting plays a more dominant role in reinforcing lesion textures and boundaries. (4) The complete architecture yields the highest performance across all evaluation metrics, achieving 90.20% Macro-F1, 85.60% AUPRC, 42.93% mIoU, and 56.74% mDice. The continued gains over HOPE + PULSE (e.g., +4.52% in Macro-F1 and +2.27% in mIoU) highlight the complementary strengths of PEAK and PULSE. PEAK contributes fine-grained spatial refinement, while PULSE enhances high-frequency and semantic sensitivity; together, they form a balanced and synergistic encoder.
Overall, the interaction between PEAK and PULSE is essential for achieving state-of-the-art segmentation and classification performance in bronchoscopic imaging.
Segmentation task
4.6
To assess the efficacy of MASA for lesion delineation, we conducted a comprehensive evaluation on the BM-BronchoLC dataset. The objective was to accurately contour lesion regions in bronchoscopic images, which is central to diagnosis and interventional planning. All experiments adhered to the metrics defined in Section 4.2.
Comparison with other advanced models
4.6.1
Table 4 reports comprehensive lesion segmentation results on the BM-BronchoLC test set, comparing our proposed MASA framework against two strong baselines: U-Net++ (22) and ESF-PNet (9). All metrics are computed per lesion mask and averaged across the test set; “oAcc” denotes overall pixel accuracy, while “mIoU”, “mAcc”, “mDice”, “mPrec”, and “mRec” represent mean Intersection-over-Union, mean Accuracy, mean Dice coefficient, mean Precision, and mean Recall, respectively, averaged over the foreground (lesion) class.
U-Net++, while achieving a high overall pixel accuracy (84.22%), exhibits limited performance on the lesion region itself, with a low mIoU of 36.57% and a Dice of 48.19%. This discrepancy arises because oAcc is dominated by the abundant background pixels in bronchoscopic images, masking poor foreground localization. ESFPNet improves lesion-specific metrics notably—boosting mIoU to 41.69% and Dice to 53.73%—demonstrating better lesion delineation through its edge-enhanced features.
Our method, MASA, achieves consistent improvements across all lesion-centric metrics. It attains the highest mIoU (42.93%), mDice (56.74%), and mRec (71.06%), reflecting superior spatial alignment with ground-truth lesion boundaries and reduced under-segmentation. Notably, MASA also achieves the highest mPrec (54.77%), indicating tighter contour prediction with fewer false-positive regions compared to baselines. The gain in mAcc (71.13%) further confirms that MASA better balances correct foreground and background classification at the lesion level.
Although the absolute mIoU values may appear modest, this is characteristic of challenging medical segmentation tasks involving small, irregular, and low-contrast lesions in bronchoscopic video frames. Crucially, the 1.24% absolute improvement in mIoU over ESFPNet—and more substantial gains in Dice (3.01%) and Recall (2.73%)—translates to clinically meaningful enhancements in lesion coverage, which directly support downstream tasks such as targeted biopsy planning and longitudinal monitoring. The low standard deviations across repeated runs (≤0.14%) further attest to the stability of MASA’s segmentation output.
Effect on frequency mask ratio
4.6.2
We analyze the influence of the frequency mask ratio (m) on both classification and segmentation performance by varying m from 0.10 to 0.45. Figure 6 reports the corresponding F1-score, AUPRC, oAcc, and mAcc.
Analysis of frequency mask ratio (m).
As shown in Figure 6 on the Macro-F1 and AUPRC metrics, performance first increases as m grows from 0.10 to 0.25 and then gradually declines for larger values. Specifically, the Macro-F1 score improves from 86.53% at m = 0.10 to a peak of 90.20% at m = 0.25, while AUPRC reaches its maximum value of 85.60% at the same setting. This trend indicates that moderate emphasis on high-frequency components effectively enhances discriminative cues relevant to classification. When m > 0.25, both Macro-F1 and AUPRC decrease, suggesting that overly aggressive masking may suppress informative mid-frequency structures or introduce noise into the representation.
A similar pattern is observed for segmentation-related metrics. The oAcc increases steadily from 86.01% at m = 0.10 to a maximum of 86.99% at m = 0.25, while the mAcc reaches its highest value (71.13%) at the same point. The subsequent decline in mAcc for larger m values indicates that excessive removal of low-frequency content can negatively impact class-wise segmentation consistency, particularly for regions that rely on global context rather than sharp boundaries.
Across both classification and segmentation tasks, the results consistently indicate that m = 0.25 provides the optimal balance between enhancing high-frequency structural information and preserving low- and mid-frequency semantic context. Smaller values of m fail to sufficiently highlight discriminative details, whereas larger values overemphasize high-frequency components, leading to performance degradation. These observations empirically justify our choice of m = 0.25 as the default configuration and demonstrate that the proposed frequency adapter is sensitive to controlled spectral emphasis rather than trivial high-pass filtering.
Visual qualitative results
4.6.3
Figure 7 presents qualitative segmentation outcomes for six cases with morphologically diverse lesions. The ground-truth masks display variable size, shape, and boundary irregularity. Across these cases, MASA generated contiguous masks that closely matched the reference in both extent and geometry. Boundaries adhered to mucosal edges with limited spillover into background, internal voids were largely suppressed, and small targets were preserved without fragmentation.
Segmentation qualitative result.
In comparison, U-Net++ often truncated peripheral regions or leaked beyond lesion margins, resulting in systematic oversegmentation or undersegmentation. ESFPNet frequently produced perforated interiors and scattered spurious regions, particularly near specular highlights and textured mucosa. Overall, MASA maintained coherent shapes with minimal false regions and fewer holes, yielding the closest visual agreement with the ground truth among the three methods. These observations are consistent with the quantitative advantages in Table 4 and indicate robust delineation under varied appearance and illumination conditions.
In summary, the qualitative evidence indicates that MASA mitigated artifacts characteristic of the baselines. U-Net++ often exhibited boundary leakage and mask fragmentation, whereas ESFPNet frequently showed perforated interiors and scattered spurious regions; these issues were markedly reduced in MASA’s outputs. The visual consistency aligns with the quantitative results in Table 4 and suggests strong potential for reliable decision support in bronchoscopic assessment.
Sensitivity study
4.7
We conducted a sensitivity analysis to investigate the impact of task-weighting coefficients on model performance. Specifically, we evaluated different values of the classification branch weight while fixing the segmentation loss weights as and .
As shown in Figure 8, the Macro-F1 (short for F1) score and AUPRC generally improve as the classification weight increases from 1.0 to 1.8, reaching the best performance at λcls = 1.8 (F1 = 90.20%, AUPRC = 85.60%). Further increasing the weight leads to a noticeable degradation, indicating that excessive emphasis on the classification branch adversely affects overall performance.
Sensitivity study on lambda.
For segmentation, the mIoU and mAcc exhibit a gradual upward trend with increasing classification weight, peaking approximately . However, performance gains beyond are marginal and accompanied by fluctuations, suggesting diminishing returns and potential task imbalance.
Based on these observations, we set the multi-task loss weights to and , which provides a favorable trade-off between segmentation and classification performance. This choice ensures stable optimization while maintaining strong performance across both tasks.
Model complexity comparison
4.8
Table 5 compares the model complexity of MASA against two representative baselines, U-Net++ (22) and ESFPNet (9), in terms of the number of trainable parameters (in millions) and computational cost (GFLOPs).
U-Net++ has 9.2M parameters and requires 65.7 GFLOPs, reflecting its relatively lightweight design based on nested dense U-Net architectures. ESFPNet, which incorporates efficient transformer blocks and edge-aware feature enhancement, increases complexity moderately to 61.7M parameters and 23.9 GFLOPs, enabling real-time lesion segmentation in autofluorescence bronchoscopy.
Our proposed MASA model has 239M parameters and 40.6 GFLOPs. The higher complexity arises from its multi-adapter encoder (HOPE, PULSE, and PEAK) and the dual-task LUCID decoder, which jointly process spatial, frequency, and positional information for unified segmentation and classification. Despite the increased scale, MASA remains computationally tractable—trained efficiently on dual RTX 4090 GPUs with a batch size of 1—and achieves significant performance gains in both lesion delineation and malignancy diagnosis.
Thus, MASA introduces moderate computational overhead compared to ESFPNet but delivers substantial improvements in both segmentation fidelity and diagnostic reliability, making it well-suited for deployment in clinical bronchoscopy workflows where both accuracy and interpretability are paramount.
Conclusion
5
In this study, we developed the MASA, a unified encoder–decoder framework for joint lesion segmentation and lung cancer diagnosis in bronchoscopic images. The encoder integrates the HOPE, PULSE, and PEAK modules, enabling the joint fusion of spatial, frequency, and positional information for comprehensive feature representation. Coupled with the dual-task LUCID decoder, MASA addresses the limitations of conventional approaches that handle segmentation and classification separately, producing more consistent and clinically interpretable outputs. MASA operates directly on visual evidence of lesions, enabling spatially precise diagnosis. Furthermore, whereas approaches like CHASHNIt rely on post-hoc explainability that may lack fidelity to internal model reasoning, MASA provides intrinsic interpretability via its dual output: a clinically aligned segmentation mask and a classification decision derived from the same spatially grounded features. Its multi-adapter architecture—integrating spatial, frequency, and positional cues—enhances robustness without resorting to synthetic data. Thus, MASA balances architectural sophistication with clinical transparency, offering a diagnostically actionable and inherently explainable pipeline uniquely suited to real-time bronchoscopic decision support.
Although the LUCID decoder shares conceptual similarity with the SAM two-way transformer, direct comparison with SAM or MedSAM was not included because these models require user prompts and are not designed for the fully automatic bronchoscopy setting. Furthermore, MedSAM variants are tailored to CT or MRI and do not account for the illumination variability, mucosal deformation, and nonrigid geometry of airway imagery. MASA differs fundamentally by integrating multi-adapter encoding and a unified segmentation classification decoder, enabling prompt-free inference and superior lesion sensitivity. Future work will include SAM baselines using standardized synthetic prompts to provide a controlled comparison under the bronchoscopy domain.
Extensive experiments on the BM-BronchoLC dataset demonstrate MASA’s superior performance over established baselines. For lesion segmentation and classification, MASA outperforms the representative methods. Qualitative analysis further confirmed MASA’s ability to delineate subtle lesions and reduce diagnostic errors under challenging imaging conditions. With its unified and modular design, MASA not only streamlines the diagnostic workflow but also enhances interpretability in clinical practice. Future work will focus on prospective clinical validation, testing in diverse patient populations, and extending the framework to multi-class and multi-modal bronchoscopic analyses. Overall, MASA provides a robust and interpretable solution with strong potential to advance computer-aided bronchoscopy for early lung cancer detection.
In the future, we will focus on rigorous clinical validation of MASA in real-world bronchoscopy settings. This will include the design of well-defined retrospective and prospective clinical studies with clearly specified patient cohorts, standardized image acquisition protocols, and expert-driven annotation procedures. Comprehensive patient-wise evaluation will be conducted using clinically relevant metrics for both lesion segmentation and diagnostic classification. In addition, validation across multiple centers and diverse patient populations will be pursued to assess generalizability and robustness. Beyond binary diagnosis, future extensions will explore multi-class lesion characterization and multi-modal integration with complementary clinical information, further advancing the applicability of MASA for computer-aided bronchoscopy and real-time clinical decision support.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bray F Ferlay J Soerjomataram I Siegel RL Torre LA Jemal A . Global cancer statistics 2018: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: Cancer J Clin. (2018) 68:394–424. doi: 10.3322/caac.21492, PMID: 30207593 · doi ↗ · pubmed ↗
- 2Sung H Ferlay J Siegel RL Laversanne M Soerjomataram I Jemal A . Global cancer statistics 2020: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: Cancer J Clin. (2021) 71:209–49. doi: 10.3322/caac.21660, PMID: 33538338 · doi ↗ · pubmed ↗
- 3Ganti AK Klein AB Cotarla I Seal B Chou E . Update of incidence, prevalence, survival, and initial treatment in patients with non–small cell lung cancer in the us. JAMA Oncol. (2021) 7:1824–32. doi: 10.1001/jamaoncol.2021.4932, PMID: 34673888 PMC 8532041 · doi ↗ · pubmed ↗
- 4Ning J Ge T Jiang M Jia K Wang L Li W . Early diagnosis of lung cancer: which is the optimal choice? Aging (Albany NY). (2021) 13:6214. doi: 10.18632/aging.202504, PMID: 33591942 PMC 7950268 · doi ↗ · pubmed ↗
- 5Sun W Yan P Li M Li X Jiang Y Luo H . An accurate prediction for respiratory diseases using deep learning on bronchoscopy diagnosis images. J Advanced Res. (2024) 76:423–38. doi: 10.1016/j.jare.2024.11.023, PMID: 39571731 PMC 12793794 · doi ↗ · pubmed ↗
- 6Zirek F Özcan G Tekin MN Özsezen B Sunman B Bayav S . Intra-observer and interobserver consistency in the diagnosis of lower airway malacia using dynamic flexible bronchoscopy in pediatric patients. Pediatr Pulmonology. (2025) 60:e 71099. doi: 10.1002/ppul.71099, PMID: 40257402 · doi ↗ · pubmed ↗
- 7Cold KM Vamadevan A Laursen CB Bjerrum F Singh S Konge L . Artificial intelligence in bronchoscopy: a systematic review. Eur Respir Rev. (2025) 34:240274. doi: 10.1183/16000617.0274-2024, PMID: 40436614 PMC 12117383 · doi ↗ · pubmed ↗
- 8Litjens G Kooi T Bejnordi BE Setio AAA Ciompi F Ghafoorian M . A survey on deep learning in medical image analysis. Med image Anal. (2017) 42:60–88. doi: 10.1016/j.media.2017.07.005, PMID: 28778026 · doi ↗ · pubmed ↗