Unifying Summary Statistic Selection for Approximate Bayesian Computation
Till Hoffmann, Jukka-Pekka Onnela

TL;DR
This paper introduces a unifying approach for selecting summary statistics in approximate Bayesian computation, improving inference efficiency and accuracy across various models.
Contribution
The paper proposes minimizing expected posterior entropy as a unifying principle for summary statistic selection in likelihood-free inference.
Findings
Minimizing EPE subsumes many existing methods for summary statistic selection.
EPE-minimizing summaries can outperform likelihood-based approaches in some cases.
The method was successfully tested on diverse models including population genetics and dynamic networks.
Abstract
Extracting low-dimensional summary statistics from large datasets is essential for efficient (likelihood-free) inference. We characterize three different classes of summaries and demonstrate their importance for correctly analyzing dimensionality reduction algorithms. We demonstrate that minimizing the expected posterior entropy (EPE) under the prior predictive distribution of the model provides a unifying principle that subsumes many existing methods; they are shown to be equivalent to, or special or limiting cases of, minimizing the EPE. We offer a unifying framework for obtaining informative summaries and propose a practical method using conditional density estimation to learn high-fidelity summaries automatically. We evaluate this approach on diverse problems, including a challenging benchmark model with a multi-modal posterior, a population genetics model, and a dynamic network…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
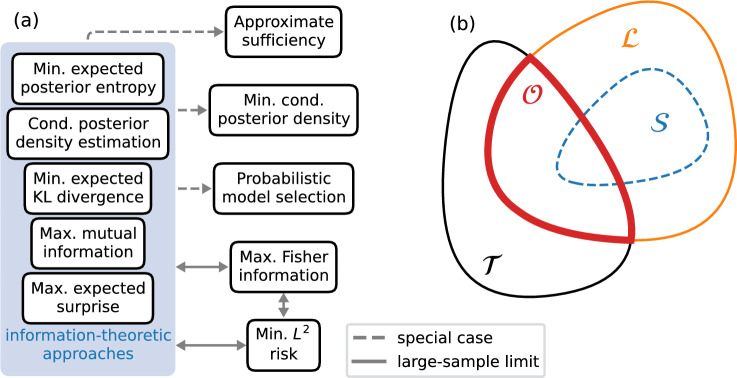 Figure 1
Figure 1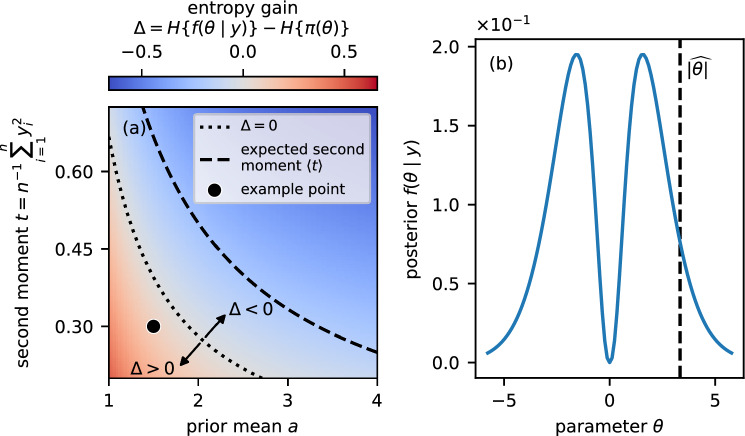 Figure 2
Figure 2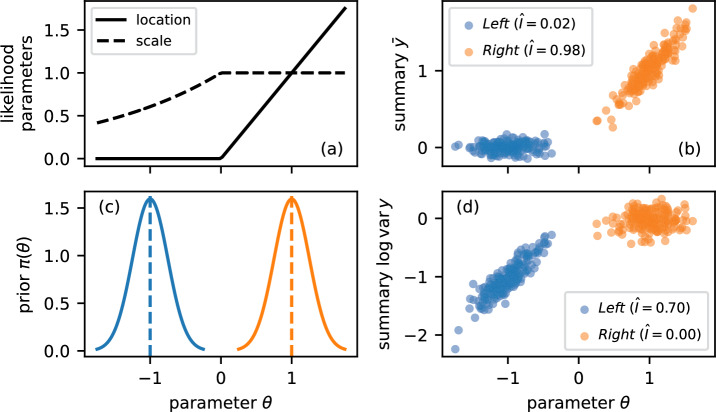 Figure 3
Figure 3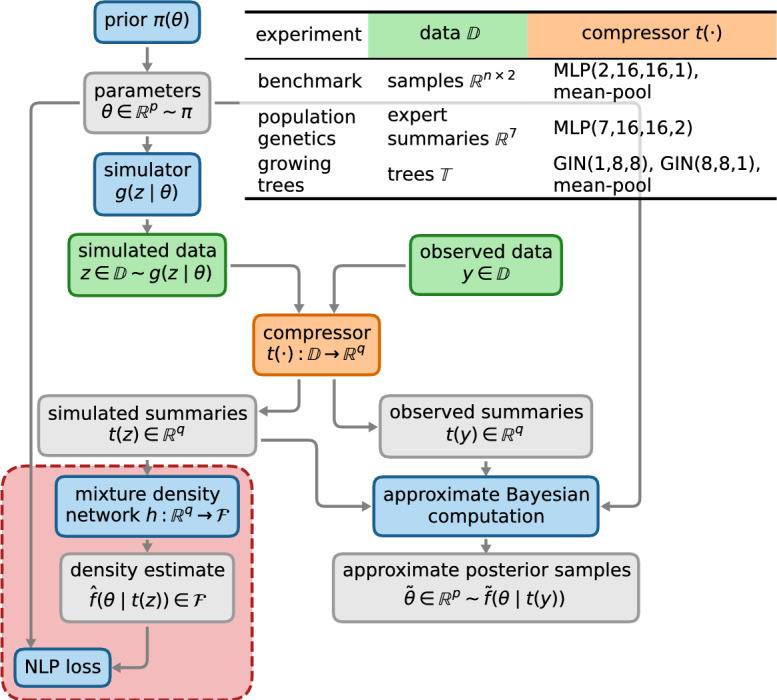 Figure 4
Figure 4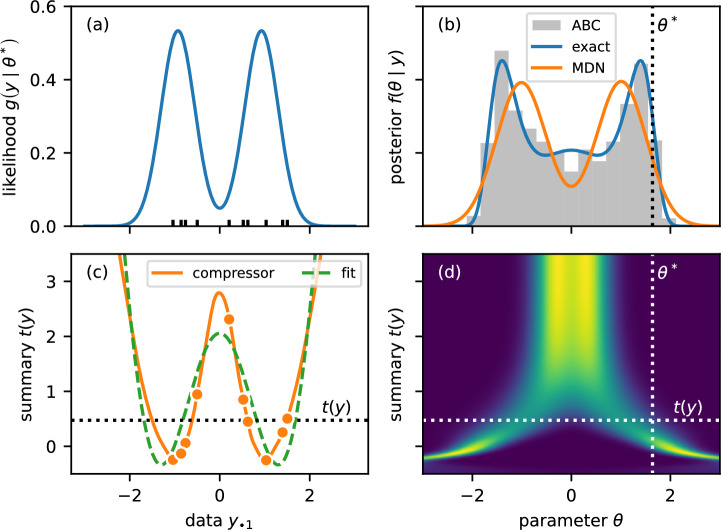 Figure 5
Figure 5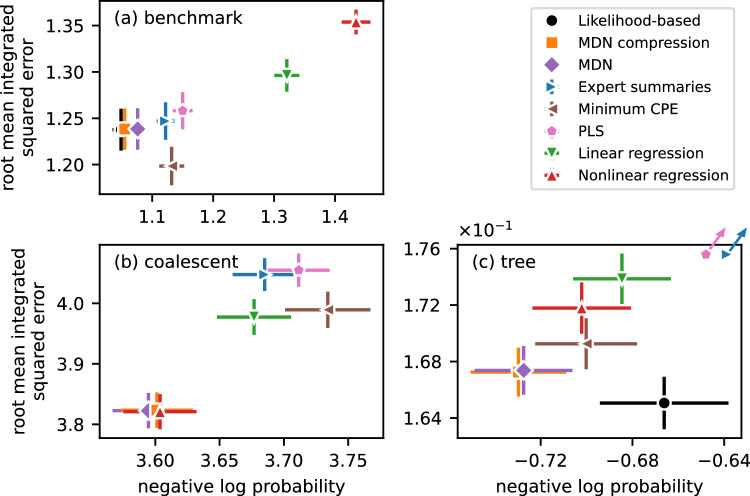 Figure 6
Figure 6- —https://doi.org/10.13039/100000002National Institutes of Health
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGaussian Processes and Bayesian Inference · Markov Chains and Monte Carlo Methods · Generative Adversarial Networks and Image Synthesis
Introduction
Empowered by advances in both scientific understanding and computing, researchers are developing ever more sophisticated simulators. For example, simulated weak lensing maps capture how dark matter affects light propagating through the universe (Merten et al. 2019; Fluri et al. 2021), coalescent simulators predict the evolution of genetic material (Nordborg 2019), and synthetic networks shed light on political opinion formation (Sobkowicz et al. 2012), effective vaccination strategies (Yang et al. 2019), and interactions between proteins (Grassmann et al. 2024).
While simulators can generate data y given parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} , we are often interested in the inverse problem: Constraining parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} given data y. If the likelihood \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g\left( y\mid \theta \right) $$\end{document} is available, we can use Markov chain Monte Carlo samplers (Carpenter et al. 2017) or variational inference (Bishop 2006, Ch. 10) to investigate the posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid y\right) $$\end{document} . But inference is more challenging if the likelihood is intractable or costly to evaluate.
Approximate Bayesian computation (ABC) overcomes this challenge in three steps by comparing observed with simulated data (Beaumont 2019): First, we draw many samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left( \theta _i,z_i\right) $$\end{document} from the prior predictive distribution which form the so-called reference table. Second, we evaluate the distance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i=d\left( y,z_i\right) $$\end{document} between observed data y and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i^\textrm{th}$$\end{document} simulated dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_i$$\end{document} . Finally, we accept \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _i$$\end{document} as a sample from the ABC posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{f}\left( \theta \mid y\right) $$\end{document} if the distance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} is smaller than a threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon $$\end{document} . The smaller \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon $$\end{document} , the better the approximation. Intuitively, ABC samples parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _i$$\end{document} that generate data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_i$$\end{document} which “look like” the observed data y. Hereafter, y and z will denote observed and simulated data, respectively.
Unfortunately, ABC suffers from the curse of dimensionality. The larger the dimensionality of the data, the larger the number of simulations required to obtain a sample that satisfies \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i<\epsilon $$\end{document} . Compressing the data to lower-dimensional summary statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t=t(y)$$\end{document} (or summaries in short) can overcome the curse of dimensionality but leaves us with the question: How do we choose the compression function t(y)?Fig. 1. Different methods for compressing data to informative summaries are intimately related; distinguishing between classes of summaries is essential. Panel (a) illustrates that five information-theoretic approaches (ITAs) are equivalent. They implicitly minimize the same loss (Sections 2 and 3). Approximate sufficiency (Section 4.1) seeks to achieve lossless compression, and minimizing the posterior entropy (Section 4.2) is a special case of ITAs focused on only the observed data. Maximizing Fisher information (Section 4.3) and minimizing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L^2$$\end{document} Bayes risk (Section 4.4) are equivalent each other and ITAs in the large-sample limit. Probabilistic model selection (Section 4.6) maps onto ITAs if we treat model labels as parameters. A dashed arrow from one method to another indicates that the latter is a specialization of the former. Solid arrows indicate correspondence in the large-sample limit. Panel (b) illustrates relationships between classes of summaries. Sufficient statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {S}$$\end{document} are a subset of lossless statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}$$\end{document} although the former only exist if the likelihood belongs to the exponential family. The intersection of lossless summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}$$\end{document} and the summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {T}$$\end{document} considered by the practitioner are optimal summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {O}$$\end{document} . Optimal summaries are not necessarily lossless, e.g. if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {T}$$\end{document} is restricted to certain parametric transformations
A plethora of methods has been developed to address this question; some are summarized in panel (a) of Fig. 1. They include methods to select informative summaries from a pool of candidates (Blum and François 2010; Joyce and Marjoram 2008; Nunes and Balding 2010; Barnes et al. 2012; Blum et al. 2013) and parameterized transformations that can be optimized to learn summaries (Aeschbacher et al. 2012; Fearnhead and Prangle 2012; Prangle et al. 2014; Jiang et al. 2017; Chan et al. 2018; Charnock et al. 2018; Chen et al. 2021; Radev et al. 2022). Loss functionals quantifying how well the compressor preserves information have been motivated by minimizing the Bayes risk (Fearnhead and Prangle 2012; Jiang et al. 2017), model selection (Prangle et al. 2014; Raynal et al. 2023; Merten et al. 2019), and information theoretic arguments (Nunes and Balding 2010; Chen et al. 2021; Barnes et al. 2012; Charnock et al. 2018; Radev et al. 2022).
We characterize three different classes of summaries in Section 2: sufficient, lossless, and optimal summaries. In Section 3, we argue that all information-theoretic approaches are equivalent. They implicitly minimize the same loss functional between the summary posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid t\right) $$\end{document} given only t and the true posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid y\right) $$\end{document} given the entire dataset y. While these results are well established in information theory, they provide a unifying perspective of different summary extraction approaches. Minimizing the expected posterior entropy (EPE) should be the practitioner’s choice because it is easier to evaluate than either the mutual information (MI) between model parameters and summaries or the Kullback-Leibler (KL) divergence between the posterior given the full data and posterior given only summaries. It also has strong connections with conditional posterior density estimation (Papamakarios and Murray 2016; Lueckmann et al. 2017). But even methods developed to address different problems (such as parameter inference or model selection) in diverse fields (such as cosmology or population genetics), have strong ties to information-theoretic approaches. For example, in Section 4 we show that maximizing the determinant of the Fisher information (Heavens et al. 2000; Charnock et al. 2018) and minimizing the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L^2$$\end{document} Bayes risk (Fearnhead and Prangle 2012; Jiang et al. 2017) are both equivalent to minimizing the EPE in the large-sample limit. Similarly, learning a probabilistic classifier for model selection (Prangle et al. 2014) minimizes the EPE. In Section 5, we discuss concrete steps for learning summaries by fitting conditional posterior density estimators to simulated data. To compare different methods, we devise a benchmark problem with simple likelihood but data that prove challenging for summary selection in Section 5.2. We also compare summary selection approaches on two applied examples: Inferring the mutation and recombination rates of a population genetics model (Section 5.3) and the attachment kernel for a model of growing trees (Section 5.4).
Background
Given data y we seek to infer parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} of a model using summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t=t(y)$$\end{document} that retain as much information about the true posterior as possible. Summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_\text {suff}$$\end{document} with fixed and finite dimensions are Bayes sufficient if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid t_\text {suff}\right) =f\left( \theta \mid y\right) $$\end{document} for all y and any prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi \left( \theta \right) $$\end{document} (Prangle 2018). But they only exist for exponential-family likelihoods (Koopman 1936). We have to relax the concept of sufficiency, and we call statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_\text {lossless}$$\end{document} lossless if
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f\left( \theta \mid t_\mathrm{lossless}(y)\right) = f\left( \theta \mid y\right) \end{aligned}$$\end{document}for all data y of the same sample size and a given prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi \left( \theta \right) $$\end{document} . While lossless statistics always exist (e.g. the identity map), they may not be useful in practice. We say that the statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_\text {opt}$$\end{document} are optimal if they minimize a non-negative loss functional that measures the discrepancy between the posterior given the full data and the posterior given only summaries. Specifically, we consider the loss functional
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}_t=\int dz\,q\left( z\right) \ell \left\{ f\left( \theta \mid z\right) ,f\left( \theta \mid t(z)\right) \right\} , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell $$\end{document} is an instance-level loss functional that measures the discrepancy between true posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid z\right) $$\end{document} and summary posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid t(z)\right) $$\end{document} for a particular dataset z. Instance-level discrepancy measures \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell $$\end{document} include, for example, the KL divergence, Wasserstein distance, and total variation distance (Cai and Lim 2022). As we discuss further in Section 4.5, summaries that are informative for one dataset may be uninformative for another. The weighting function q encodes which parts of the data space we prioritize. The optimal summaries are
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} t_\text {opt}={{\,\textrm{argmin}\,}}_{t\in \mathcal {T}} \mathcal {L}_t, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {T}$$\end{document} is the space of summaries under consideration. Consequently, sufficient statistics are lossless, and lossless statistics are optimal, but the converse is not necessarily true. For example, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {T}$$\end{document} may be restricted to parametric transformations (Fearnhead and Prangle 2012) or selecting at most k summaries from a set of candidate statistics (Raynal et al. 2023). The relationship between different classes of summaries is illustrated in panel (b) of Fig. 1.
The choice of summary statistic t imposes a fundamental limit on the fidelity of the resulting posterior approximation irrespective of the ABC tolerance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon $$\end{document} . In the limit \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon \rightarrow 0$$\end{document} , the distribution of accepted samples converges to the summary posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid t(y)\right) $$\end{document} . This distribution represents the best possible posterior approximation achievable with a given set of summaries. Consequently, even an ideal ABC procedure cannot recover information about the parameters that is lost during the initial data compression step. Minimizing the loss functional in Eq. (3) improves this asymptotic target, ensuring that the best-case outcome of the inference is a high-fidelity approximation of the true posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid y\right) $$\end{document} .
Despite the pursuit of the holy grail of sufficient statistics, we typically have to settle for the weakest concept of optimal statistics. Even the most sophisticated method cannot extract sufficient statistics if the likelihood does not belong to the exponential family (Koopman 1936). Similarly, unless the family of summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {T}$$\end{document} is rich enough, lossless compression is not achievable. Further, even if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {T}$$\end{document} is rich enough, one cannot in general verify that Eq. (1) holds for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} and y given a finite computational budget.
While models with exponential-family likelihoods are theoretically appealing, they may not be sufficiently expressive or intuitive to address real-world problems. Domain knowledge can aid in the development of models that capture salient features of the data, including protein interaction networks (Grassmann et al. 2024), cosmology (Charnock et al. 2018), and population-genetics (Nordborg 2019). But these models often do not have sufficient statistics or even tractable likelihoods, and we need to resort to possibly lossy compression and likelihood-free inference.
Minimizing the expected posterior entropy
A natural loss functional to minimize is the expected KL divergence from the true posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid z\right) $$\end{document} to the summary posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid t(z)\right) $$\end{document} . Similar to the evaluation of the Fisher information (Bishop 2006, Ch. 6), the expectation is taken with respect to the prior predictive distribution p(z) of the model, i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q(z)=p(z)$$\end{document} . This ensures that the summaries are informative for data that are plausible under the model. We propose choosing summaries that minimize the expected posterior entropy (EPE). This approach is equivalent to minimizing the expected KL divergence, conceptually simple, computationally tractable, and has a strong connection with recent inference techniques based on conditional density estimation (Papamakarios and Murray 2016; Lueckmann et al. 2017; Radev et al. 2022).
The posterior entropy given summaries t(z) for a fiducial dataset z is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & H\left\{ f\left( \theta \mid t(z)\right) \right\} =\nonumber \\ & \,\quad -\int \text {d}\theta \, f\left( \theta \mid t(z)\right) \log f\left( \theta \mid t(z)\right) . \end{aligned}$$\end{document}Here, a fiducial dataset refers to a dataset generated based on known parameters. Taking the expectation with respect to the data under the model yields the EPE
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {H}{{\phantom{a}}} & \equiv \mathbb {E}_{z\sim p\left( z\right) }\left[ H\left\{ f\left( \theta \mid t(z)\right) \right\} \right] \nonumber \\ & =-\int \text {d}z\,\text {d}\theta \,p\left( z\right) f\left( \theta \mid t(z)\right) \log f\left( \theta \mid t(z)\right) , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left( z\right) =\int \textrm{d}\theta \,\,g\left( z\mid \theta \right) \pi \left( \theta \right) $$\end{document} is the marginal likelihood, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {E}_{z\sim p\left( z\right) }\left[ \cdot \right] $$\end{document} denotes the expectation with respect to z under the distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left( z\right) $$\end{document} . Changing variables of integration from data z to summaries t leaves us with the simple expression
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {H}{{\phantom{a}}}=-\int \textrm{d}t\,\textrm{d}\theta \, p\left( t,\theta \right) \log f\left( \theta \mid t\right) , \end{aligned}$$\end{document}where the Jacobian has been absorbed by the joint density \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left( t,\theta \right) $$\end{document} . With a slight abuse of notation, we use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left( \cdot \right) $$\end{document} for both the marginal likelihood and joint distribution where the distinction is unambiguous. Given a posterior density estimator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{f}}\left( \theta \mid t\right) $$\end{document} that seeks to approximate the summary posterior, we can construct a Monte Carlo estimate of the EPE
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\mathcal {H}{{\phantom{a}}}}=-m^{-1}\sum _{i=1}^m\log {\hat{f}}\left( \theta _i \mid t(z_i)\right) , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_i$$\end{document} are joint samples from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left( \theta ,z\right) $$\end{document} , and m is the number of samples. This estimate is the widely used loss function for learning the posterior from simulated data (Papamakarios and Murray 2016; Lueckmann et al. 2017; Radev et al. 2022), where m is the size of the mini-batch, i.e.a subset of the data used to train the model.
We consider three well-established connections to other information-theoretic approaches (Bishop 2006, Ch. 1) although with a specific focus on the selection of summaries for ABC. First, we evaluate the difference between the prior entropy and EPE
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} H\left\{ \pi \left( \theta \right) \right\} - \mathcal {H}{} = \int \textrm{d}t\,p\left( t\right) \int \textrm{d}\theta \, f\left( \theta \mid t\right) \log \left( \frac{f\left( \theta \mid t\right) }{\pi \left( \theta \right) }\right) , \end{aligned}$$\end{document}where we have been able to combine the two integrals because
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \int \textrm{d}\theta \,\pi \left( \theta \right) \log \pi \left( \theta \right) =\int \textrm{d}t\,\textrm{d}\theta \,p\left( t,\theta \right) \log \pi \left( \theta \right) \end{aligned}$$\end{document}by the law of total probability. The inner integral of Eq. (6) is the KL divergence from the prior to the posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_\textrm{KL}\left( f\left( \theta \mid t\right) \;\Vert \;\pi \left( \theta \right) \right) $$\end{document} , sometimes called surprise because it measures the degree to which an observer updates their belief in light of new data (Itti and Baldi 2009). Minimizing the EPE thus maximizes our expected surprise from observing the summaries because the prior entropy does not depend on the choice of summaries.
Second, we note that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid t\right) =p\left( t,\theta \right) / \pi \left( t\right) $$\end{document} and Eq. (6) simplifies to the MI between the summaries t and parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} I\left\{ \theta , t\right\} = \int \textrm{d}t\,\textrm{d}\theta \, p\left( t,\theta \right) \log \left( \frac{p\left( \theta , t\right) }{\pi \left( \theta \right) p\left( t\right) }\right) . \end{aligned}$$\end{document}As the MI is non-negative, the EPE is not larger than the prior entropy, i.e. we reduce uncertainty on average. Minimizing the EPE is equivalent to maximizing the MI which has been proposed in the context of subset selection (Barnes et al. 2012) and neural summaries (Chen et al. 2021). However, estimating MI is difficult in high dimensions (Jeffrey et al. 2020), making the approach computationally challenging.
Third, we consider the difference between the EPE given only summaries t and the EPE given a full fiducial dataset z
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \mathcal {H}{}-\mathbb {E}_{z\sim p\left( z\right) }\left[ H\left\{ f\left( \theta \mid z\right) \right\} \right] \\ & \quad =\int \text {d}z\, p\left( z\right) \int \text {d}\theta \, f\left( \theta \mid z\right) \log \left( \frac{f\left( \theta \mid z\right) }{f\left( \theta \mid t\right) }\right) , \end{aligned}$$\end{document}and we can identify the inner integral as the KL divergence from the summary posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid t\right) $$\end{document} to the true posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid z\right) $$\end{document} (see App. A). The difference of expected entropies is thus equal to the expected KL divergence between the posteriors
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \mathcal {H}{} - \mathbb {E}_{z\sim p\left( z\right) }\left[ H\left\{ f\left( \theta \mid z\right) \right\} \right] \\ & \quad =\mathbb {E}_{z\sim p\left( z\right) }\left[ D_\text {KL}\left( f\left( \theta \mid z\right) \;\Vert \;f\left( \theta \mid t\right) \right) \right] \end{aligned}$$\end{document}which Chan et al. (2018) used to infer recombination hotspots in population genetics and Radev et al. (2022) targeted for amortized Bayesian inference. Minimizing the EPE is equivalent to minimizing the expected KL divergence because the true posterior entropy given the complete dataset does not depend on the summaries. The KL divergence is non-negative which allows us to draw two conclusions. First, the EPE given only summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t\left( z\right) $$\end{document} is greater than or equal to the EPE given the full dataset z, i.e. we lose information in expectation by conditioning on the summaries t instead of the data y unless the summaries are lossless. Second, minimizing the EPE implies that the loss functional in Eq. (3) is the expected KL divergence. Similar to the MI, evaluating the expected KL divergence is challenging because neither the true posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid z\right) $$\end{document} nor the summary posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid t\left( z\right) \right) $$\end{document} are known in practice.
To summarize, minimizing the EPE, maximizing the MI between parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} and summaries t, maximizing the expected surprise, and minimizing the expected KL divergence between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid z\right) $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid t\left( z\right) \right) $$\end{document} are equivalent, as illustrated in panel (a) of Fig. 1. But minimizing the EPE is preferable because it can be estimated using Eq. (5) for functional approximations of the posterior and nearest-neighbor entropy estimators for posterior samples (Singh et al. 2003).
Related work and connections with expected posterior entropy
Approximate sufficiency
Joyce and Marjoram (2008) cast the task of selecting summaries as a sequence of hypothesis tests to select a subset of candidate summaries. Specifically, they considered
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \log R_k\left( \theta \right) =\log \tilde{f}\left( \theta \mid t_{k},\ldots ,t_1\right) \\ & \quad - \log \tilde{f}\left( \theta \mid t_{k-1},\ldots ,t_1\right) , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{f}\left( \theta \mid t_{k-1},\ldots ,t_1\right) $$\end{document} is the ABC posterior given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k-1$$\end{document} summaries already selected and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{f}\left( \theta \mid t_{k},\ldots ,t_1\right) $$\end{document} is the posterior resulting from including an additional statistic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_k$$\end{document} . Intuitively, if the error score \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _k=\max _\theta {{\,\text {abs}\,}}\left( \log R_k\left( \theta \right) \right) $$\end{document} is zero, i.e. the two posteriors are identical, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^\textrm{th}$$\end{document} statistic does not capture additional information and can be ignored. If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _k$$\end{document} differs significantly from zero, we reject the null hypothesis that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{f}\left( \theta \mid t_{k},\ldots ,t_1\right) $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{f}\left( \theta \mid t_{k-1},\ldots ,t_1\right) $$\end{document} are the same distribution and include \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_k$$\end{document} . They consider a set of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k-1$$\end{document} summaries to be “approximately sufficient” if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _k$$\end{document} does not significantly differ from zero for any additional summary statistic.
This iterative process cannot minimize a loss functional of the form of Eq. (2) globally. Yet it approximately minimizes a loss functional that assigns all weight to the observed data y and uses the maximum log density ratio to distinguish between true and summary posteriors as the instance-level loss functional, i.e.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} q(z)&=\delta \left( z - y\right) \\ \ell&= \max _\theta {{\,\text {abs}\,}}\left[ \log f\left( \theta \mid z\right) -\log f\left( \theta \mid t(z)\right) \right] , \end{aligned}\end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} denotes the Dirac delta function.
Importantly, the error score \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _k=\max _\theta {{\,\textrm{abs}\,}}\left( \log R_k\right) $$\end{document} assigns equal importance to all subsets of the parameter space, even regions we know to be irrelevant. For example, suppose that the posterior given the currently selected \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k-1$$\end{document} summaries is normal with variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _{k-1}^2$$\end{document} , and the posterior after adding the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^\textrm{th}$$\end{document} summary is identical except for a different variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _{k}^2$$\end{document} . Even if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _k$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _{k-1}$$\end{document} differ by an infinitesimal amount, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _k$$\end{document} is unbounded because
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \Delta _k = \frac{1}{2}\max _\theta {{\,\text {abs}\,}}\left( \log \left( \frac{\sigma _k^2}{\sigma _{k-1}^2}\right) +\left( \frac{\sigma _{k-1}^2-\sigma _k^2}{\sigma _k^2\sigma _{k-1}^2}\right) \theta ^2\right) =\infty . \end{aligned}$$\end{document}The error score is dominated by regions of the parameter space that have virtually no posterior mass. The expected value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {E}_{\theta \sim f\left( \theta \mid t_k,\ldots ,t_1\right) }\left[ \log R_k\left( \theta \right) \right] $$\end{document} instead weights discrepancies between the two distributions by the posterior mass. This quantity is in fact the KL divergence considered by Barnes et al. (2012) (see Section 4.5 for details).
The notion of “approximate” sufficiency is necessarily a statement about limited computational resources: If we had unlimited resources, only candidate statistics that are uninformative or redundant would be excluded. This observation applies to any subset selection algorithm, such as minimizing posterior entropy (Nunes and Balding 2010) in Section 4.2, regression-based subset selection methods (Blum and François 2010; Blum et al. 2013) in Section 4.4, or maximizing MI (Barnes et al. 2012) in Section 4.5.
Minimizing the conditional posterior entropy
Nunes and Balding (2010) proposed choosing a subset of summaries t by minimizing the conditional posterior entropy (CPE) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H\left\{ f\left( \theta \mid t\left( y\right) \right) \right\} $$\end{document} given data y. They ran rejection ABC for different subsets of summaries and evaluated the CPE using a nearest-neighbor estimator (Singh et al. 2003). The proposal is appealing because low-entropy posteriors give precise parameter estimates.
However, it implicitly assumes that the data we have observed are the only data that could ever be observed, similar to the non-parametric bootstrap. More formally, the weighting is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q(z)=\delta \left( z-y\right) $$\end{document} as in Section 4.1, and the instance-level loss functional is the entropy of the summary posterior, i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell =H\left\{ f\left( \theta \mid t(z)\right) \right\} $$\end{document} . When the maximum likelihood estimate of the parameters lies in the tail of the prior distribution, the CPE \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H\left\{ f\left( \theta \mid y\right) \right\} $$\end{document} can be larger than the prior entropy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H\left\{ \pi \left( \theta \right) \right\} $$\end{document} because the true posterior is a “compromise” between prior and likelihood (Blum et al. 2013).Fig. 2Extracting summaries can be non-trivial even for toy models. Panel (a) shows the difference between posterior and prior entropy for a model with zero-mean normal likelihood and conjugate gamma prior for the precision \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} (inverse variance). For a subset of the prior and data space, minimizing the posterior entropy discards the second moment t, a sufficient statistic. Panel (b) shows the bimodal posterior for the example point in (a) that arises when the precision of the likelihood is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\,\textrm{abs}\,}}\left( \theta \right) $$\end{document} (see Section 4.4). The posterior mean is zero and not informative of the parameter. The vertical dashed line represents the maximum likelihood estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{{{\,\textrm{abs}\,}}\left( \theta \right) }$$\end{document} of the precision \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\,\textrm{abs}\,}}\left( \theta \right) $$\end{document}
We consider a simple example with closed form posterior because it illustrates important concepts and challenges associated with learning summaries. Suppose we draw \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=4$$\end{document} samples y from a zero-mean normal distribution with unknown precision (inverse variance) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} . We use a gamma prior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} because it is the conjugate prior for a normal likelihood with known mean. The distribution is parameterized by a shape parameter a and rate parameter b. We use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b=1$$\end{document} such that the prior mean is a. More formally,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \theta \mid a, b&\sim \textsf {Gamma}\left( a, b\right) \\ y_i\mid \theta&\sim \textsf {Normal}\left( 0, \theta ^{-1}\right) , \end{aligned} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i\in \left\{ 1,\ldots ,n\right\} $$\end{document} . The closed-form posterior is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \theta \mid y, a, b \sim \textsf{Gamma}\left( a + \frac{n}{2}, b + \frac{n t}{2}\right) , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t=n^{-1}\sum _{i=1}^n y_i^2$$\end{document} is the second moment, a sufficient statistic. If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a=1.5$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t=0.3$$\end{document} , the prior entropy is 1.36 and the CPE is 1.47. Minimizing the CPE would discard the sufficient statistic t such that the posterior is equal to the prior: We have not learned anything from the data. Panel (a) of Fig. 2 shows the entropy gain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta =H\left\{ f\left( \theta \mid y\right) \right\} -H\left\{ \pi \left( \theta \right) \right\} $$\end{document} in light of the data for different priors and sample variances. Indeed, generating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^5$$\end{document} samples from the prior predictive distribution with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a=1.5$$\end{document} , we find that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$30\%$$\end{document} of samples lead to a CPE increase. Interestingly, this situation is more likely to arise when the “surprise” (Itti and Baldi 2009) is large, and we should substantially update our beliefs in light of the data. In contrast, the EPE \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {H}=0.87$$\end{document} given t is smaller than the prior entropy, and minimizing it would select t as a useful summary. Monte Carlo standard errors of the EPE and proportion of entropy increases are smaller than the reported significant digits.
The instance-level loss functional, the entropy of the summary posterior, is not a discrepancy measure between the true and summary posteriors, and Nunes and Balding (2010) also considered a two-stage method: First they used the above approach to select candidate summaries and identify simulated datasets close to the observed data. Second, they drew posterior samples for each identified dataset and evaluated the root mean integrated squared error (RMISE) of posterior samples for each subset of summaries. This is possible because the parameters of simulated datasets are known. The summaries with the lowest RMISE were then selected. We do not consider this two-stage approach further here because of its computational burden and because posterior mean estimation methods optimize a similar objective, as discussed in Section 4.4.
Maximizing the Fisher information
Even when the likelihood is tractable, compressing the data y to summaries t has computational benefits. Heavens et al. (2000) developed an optimal linear compression scheme for Gaussian likelihoods in the sense that the Fisher information is preserved. Information-maximizing neural networks (Charnock et al. 2018) seek to maximize the determinant of the Fisher information matrix when linear compression is not sufficient, and methods to maximize the Fisher information for non-Gaussian likelihoods have recently been developed (Alsing and Wandelt 2018; Fluri et al. 2021). Fisher information methods are fundamentally likelihood-based and do not fit into the loss functional framework of Eq. (2). However, we can establish a connection to minimizing the EPE in the large-sample limit.
We consider the large-sample limit \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n\rightarrow \infty $$\end{document} of n i.i.d. observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z=\left( z_1,\ldots ,z_n\right) $$\end{document} and summaries of the form \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t\left( z\right) =n^{-1}\sum _{i=1}^n h\left( z_i\right) $$\end{document} where h is a potentially nonlinear function. This restriction preserves the i.i.d. structure required for the Bernstein–von Mises theorem and is consistent with the observation that summaries often have well-behaved likelihoods when they are means of i.i.d. data (Alsing and Wandelt 2018). According to the Bernstein–von Mises theorem, the posterior approaches a multivariate normal distribution under certain regularity conditions (van der Vaart 1998). Specifically,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \theta \mid t\sim \textsf{Normal}\left( \theta _0,F^{-1}\left( \theta _0\right) \right) , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _0$$\end{document} is the true parameter that generated the summaries t, and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & F_{ij}\left( \theta _0\right) \nonumber \\ & \quad =\mathbb {E}_{z\sim p\left( z\right) }\left[ \left( \frac{\partial }{\partial \theta _i} \log g\left( t(z)\mid \theta \right) \right) \left( \frac{\partial }{\partial \theta _j}\log g\left( t(z)\mid \theta \right) \right) \right] _{\theta =\theta _0}\end{aligned}$$\end{document}is the Fisher information of the summaries evaluated at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _0$$\end{document} (Bishop 2006, Ch. 6). The limiting entropy of the posterior can thus be readily evaluated and is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \lim _{n\rightarrow \infty }H\left\{ f\left( \theta \mid t\right) \right\} =-\frac{1}{2}\log \det F\left( \theta _0\right) + \text {constant}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\det F$$\end{document} denotes the determinant of F. We take the expectation with respect to the prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} to obtain the EPE
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \lim _{n\rightarrow \infty }\mathcal {H}= -\frac{1}{2}\int \textrm{d}\theta _0\, \pi \left( \theta _0\right) \log \det F\left( \theta _0\right) + \text {constant}. \end{aligned}$$\end{document}We do not need to take an expectation over summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t\mid \theta _0$$\end{document} because the Fisher information in Eq. (9) does not depend on the realization t. Maximizing the expected log determinant of the Fisher information matrix is thus equivalent to minimizing the EPE in the large-sample limit. This observation agrees with our intuition that the effect of the prior on the posterior decreases as the sample size increases.
We argue that minimizing the EPE is more appealing than maximizing the Fisher information for three reasons. First, it can incorporate prior information in the small-n regime to yield the most faithful posterior approximation. Second, it does not require the choice of a fiducial value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} at which to evaluate the Fisher information. Finally, when the likelihood is not available, we need to approximate it to evaluate the Fisher information. For example, Charnock et al. (2018) assume that the likelihood of the learned summaries can be approximated by a Gaussian, and Alsing and Wandelt (2018) argue that candidate summaries often have a Gaussian likelihood if they are the mean of i.i.d. data.
Minimizing the Bayes risk
Fearnhead and Prangle (2012) proposed the posterior mean of the parameters as summaries. Of course, the posterior mean is not known, but we can estimate it by minimizing the quadratic loss
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \ell =\mathbb {E}_{z,\theta \sim p\left( z,\theta \right) }\left[ \left( \theta -t_\beta (z)\right) ^\intercal A\left( \theta -t_\beta (z)\right) \right] \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_\beta (z)$$\end{document} is a predictor of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} parameterized by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta $$\end{document} , A is a positive-definite matrix, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^\intercal $$\end{document} denotes the transpose. The approach fits into the loss functional framework of Eq. (2) with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q(z)=p\left( z\right) $$\end{document} (the prior predictive distribution) and instance-level loss functional
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \ell =\int \textrm{d}z\,f\left( \theta \mid z\right) \left( \theta -t_\beta (z)\right) ^\intercal A\left( \theta -t_\beta (z)\right) , \end{aligned}$$\end{document}where t is constrained to be the posterior mean. Fearnhead and Prangle (2012) considered linear predictors, but neural networks (Jiang et al. 2017) and boosted regression (Aeschbacher et al. 2012) have also been proposed. In practice, the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta $$\end{document} are learned by minimizing a Monte Carlo estimate of Eq. (10) akin to Eq. (5). Using the estimated posterior mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_\beta \left( \cdot \right) $$\end{document} as summaries implicitly chooses as many summaries as there are parameters.
Considering again the large-sample limit, the quadratic loss becomes (adapted from Theorem 3 of Fearnhead and Prangle (2012))
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \ell ={{\,\textrm{tr}\,}}\left[ A\int \textrm{d}\theta \,\pi \left( \theta \right) F^{-1}\left( \theta \right) \right] , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\,\textrm{tr}\,}}$$\end{document} denotes the matrix trace. Consequently, minimizing the quadratic loss in Eq. (10) is intimately related to maximizing the determinant of the Fisher information because both A and F are positive-definite. However, the details depend on the form of A.
The above argument crucially depends on the assumptions of the Berstein–von Mises theorem holding. In particular, the model needs to be identifiable such that different values of the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} are distinguishable in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n\rightarrow \infty $$\end{document} limit (van der Vaart 1998). We consider a variant of the toy model presented in Section 4.2 that is not identifiable and discuss the impact on learning summaries. In particular, we use the absolute value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\,\textrm{abs}\,}}\left( \theta \right) $$\end{document} of a parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} as the precision such that the conditional distributions are
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned}{\text {abs}\,}\left( \theta \right) \mid a,b&\sim \textsf {Gamma}\left( a,b\right) \\y_i\mid \theta&\sim \textsf {Normal}\left( 0,{\text {abs}\,}\left( \theta \right) ^{-1}\right) . \end{aligned} \end{aligned}$$\end{document}The real-valued \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} is distributed as a mixture of a gamma distribution and its reflection about the origin under the prior. The closed-form posterior is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {{\,\textrm{abs}\,}}\left( \theta \right) \mid y,a,b \sim \textsf{Gamma}\left( a+\frac{n}{2}, b+\frac{nt}{2}\right) , \end{aligned}$$\end{document}where t is the second moment of y as in Eq. (8) and a sufficient statistic. The posterior is bimodal and symmetric under reflection, as shown in panel (b) of Fig. 2. The posterior mean is zero, and it is not possible to extract information by minimizing Eq. (10).
This example may seem contrived, but multimodal posteriors that render the posterior mean uninformative are not uncommon. For example, mixture models are invariant under label permutation (Stephens 2000), and latent-space models of networks (Hoff et al. 2002) as well as latent factor models for Bayesian PCA (Nirwan and Bertschinger 2019) are invariant under rotations. The limitation of the Bayes risk approach arises because the instance-level loss functional measures concentration around a point rather than comparing full posterior distributions. Using information theoretic approaches ensures we stay focused on the task at hand: Approximating the true posterior.
The relationship between parameters and data can be complex, and regression approaches, especially linear regression, may not be able to capture the relationship globally. Local relationships in regions of high posterior mass can be learned using pilot runs (Fearnhead and Prangle 2012) or weighting samples (Blum and François 2010). Local regression methods have also been adapted for subset selection: A model is fit to predict parameters from candidate summaries, and a candidate is selected if it increases a metric such as the Bayesian evidence (Blum and François 2010), Akaike information criterion, or Bayesian information criterion (Blum et al. 2013).
Maximizing the mutual information
Barnes et al. (2012) proposed choosing summaries from a pool of candidates that maximize the MI \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I\left\{ \theta ,t\right\} $$\end{document} between parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} and the statistics t. Assuming that the candidate set includes sufficient statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_\text {suff}$$\end{document} such that
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f\left( \theta \mid t_\text {suff}\right) =f\left( \theta \mid y\right) \end{aligned}$$\end{document}for all possible y, they constructed a set of summaries sequentially. At the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^\textrm{th}$$\end{document} step, they included the summary that maximizes the surprise given the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k-1$$\end{document} statistics that have already been selected. The approach is similar to the approximate sufficiency method reviewed in Section 4.1, but candidates are prioritized by their surprise at each stage. Together, the steps select the summaries that maximize the surprise \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_\textrm{KL}\left( f\left( \theta \mid t\right) \;\Vert \;\pi \left( \theta \right) \right) $$\end{document} for the observed data. Like Joyce and Marjoram (2008) and Nunes and Balding (2010), this approach considers only the observed dataset with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q(z)=\delta (z-y)$$\end{document} in the loss functional framework of Eq. (2). Consequently, it maximizes the conditional surprise \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell =D_\textrm{KL}\left( f\left( \theta \mid t(y)\right) \;\Vert \;\pi \left( \theta \right) \right) $$\end{document} rather than the MI, which is the expected surprise under the prior predictive distribution.
However, recall from Eqs. (6) and (7) that the MI is equal to the expected surprise under the generative model. In general, maximizing the surprise for a particular observed dataset is thus not equivalent to maximizing the MI. The approach may select different summaries if the candidate set does not include sufficient statistics.
Similarly, Chen et al. (2021) sought to maximize the MI using a neural network. They suggested that “t(z) is a sufficient statistic for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g\left( z\mid \theta \right) $$\end{document} if and only if” (p. 2) it maximizes the MI and “that the sufficiency of the learned statistics is insensitive to the choice of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi \left( \theta \right) $$\end{document} ” (p. 4) such that “[their approach] is globally sufficient for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} ” (p. 6)1. As we shall illustrate with a toy model, these propositions do not hold in general because of the difference between sufficient and optimal statistics discussed in Section 2 (see App. B for details).Fig. 3Optimal summaries depend on the prior. Panel (a) shows the parameters of a piecewise likelihood with qualitatively different behaviour on either side of the transition at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta =0$$\end{document} . Panel (c) shows two priors with the bulk of their mass on either side of the transition. Panels (b) and (d) show the relationship between the parameter and the sample mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{y}}$$\end{document} and log variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log {{\,\textrm{var}\,}}y$$\end{document} , respectively, as a scatter plot. Mutual information estimates highlight that the optimal choice of summary depends on the prior: The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{y}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log {{\,\textrm{var}\,}}y$$\end{document} summaries are informative for the priors centred at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$+1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-1$$\end{document} , respectively
Consider the piecewise likelihood
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y_i\mid \theta \sim {\left\{ \begin{array}{ll} \textsf{Normal}\left( 0, \exp \theta \right) & \text {if }\theta < 0\\ \textsf{Normal}\left( \theta ,1\right) & \text {if }\theta \ge 0 \end{array}\right. } \end{aligned}$$\end{document}which is continuous at the transition, as illustrated in panel (a) of Fig. 3. We consider two different normal priors with common standard deviation of 0.25 centred at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm 1$$\end{document} , as shown in panel (c). For the purpose of this example, we may choose one summary from the candidate set comprising the sample mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{y}}$$\end{document} and the natural logarithm of the sample variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log {{\,\textrm{var}\,}}y$$\end{document} , i.e. we restrict the space of compression functions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal {T}}$$\end{document} 2. Intuitively, the latter is informative for the “left” region of the parameter space and the former for the “right”. This intuition is confirmed by simulation: We consider \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m=10^5$$\end{document} independent samples from each prior and draw \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=100$$\end{document} observations from the likelihood in Eq. (12). The relationship between the parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} and sample mean as well as log sample variance are shown in panels (b) and (d), respectively. For quantitative comparison, we also estimate the MI for all pairs of priors and summaries using a nearest-neighbor entropy estimator (Singh et al. 2003). On the one hand, the log sample variance ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{I}}=0.70$$\end{document} ) is the optimal summary for the left prior because the sample mean provides little information ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{I}}=0.02$$\end{document} ). On the other hand, the sample mean is highly informative for the right prior ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{I}}=0.98$$\end{document} ) whereas the log sample variance is not informative ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{I}}=0.00$$\end{document} ). As Bayesians, we cannot escape the prior, and the optimal summaries depend on it.
Model selection
Prangle et al. (2014) used logistic regression to learn summaries that can discriminate between different models: The predicted class probabilities. Similarly, Merten et al. (2019) applied deep convolutional neural networks to weak lensing maps to learn features that can discriminate between nine different cosmological models, although not in the context of ABC. Such probabilistic approaches to model classification are equivalent to minimizing the EPE: Consider a one-hot encoding of the model index such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _j = 1$$\end{document} if model j generated the data and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _j=0$$\end{document} otherwise. The log summary posterior is thus
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \log f\left( \theta \mid t\right) =\sum _{j=1}^r \theta _j \log f\left( \theta _j=1\mid t\right) , \end{aligned}$$\end{document}where r is the number of models under consideration, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta _j=1\mid t\right) $$\end{document} is the posterior probability that the data were generated by model j. Equation (13) is familiar as the negative cross-entropy loss widely used for multiclass classification in machine learning (Bishop 2006, Ch. 4). In other words, any machine learning classifier that minimizes the cross-entropy loss for model selection minimizes the EPE of the model labels.
Conditional posterior density estimation
As briefly discussed in Section 3, recent approaches to likelihood-free inference based on conditional density estimation minimize the EPE using the mini-batch estimator in Eq. (5) as a loss function (Papamakarios and Murray 2016; Lueckmann et al. 2017; Radev et al. 2022). These methods are appealing because they can automatically compress large datasets, although at the cost of having to choose an architecture for the density estimator, which is an active area of research (Papamakarios et al. 2021). Chan et al. (2018) proposed exchangeable neural networks such that the output is invariant under permutations of i.i.d. data generated by the model. While neural density estimators can in principle learn such invariances, it is beneficial to encode symmetries in the architecture to improve efficiency and reduce the amount of training data required. In practice, conditional density estimators can have computational advantages over rejection ABC because they interpolate the posterior density in the parameter space, requiring fewer simulations (Papamakarios and Murray 2016). However, they cannot offer the same asymptotic guarantees as ABC: As the tolerance parameter of the acceptance kernel is reduced, the sampling distribution converges to the summary posterior (Beaumont 2019).
Partial least squares regression
Wegmann et al. (2009) obtained summaries using partial least squares regression (PLSR), a latent variable model for supervised dimensionality reduction. The method projects data z (or candidate summaries) to a latent space such that the embeddings are most predictive of the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} as measured by the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_2$$\end{document} norm. The latent variables are used as summaries instead of the predictions of the model as in Section 4.4. The number of latent components is chosen using leave-one-out cross-validation based on the ability of the model to predict parameters. Similar to the subset selection methods discussed in Sections 4.1 and 4.2, the number of components chosen by cross-validation is determined by computational constraints: For sufficiently large reference tables, the dimensionality of the candidate summaries is maintained provided each candidate summary encodes some information, however weak.
Experiments
Evaluation criteria and model architecture for nonlinear methods
We consider three experiments to compare methods for extracting summaries: A benchmark model with i.i.d. observations and tractable likelihood in Section 5.2, a population genetics model with data comprising candidate summaries in Section 5.3, and a model of growing trees in Section 5.4. We first discuss the approach for consistently evaluating summary extraction methods and subsequently consider each experiment in depth.
For subset selection methods (such as minimizing the CPE in Section 4.2) and simple projections (such as linear posterior mean estimation in Section 4.4), we evaluated candidate summaries that were supplied to each algorithm. For more flexible nonlinear posterior mean estimation, we developed experiment-specific neural compressors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t:\mathbb {D}\rightarrow \mathbb {R}^q$$\end{document} to compress the raw data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z\in \mathbb {D}$$\end{document} to q low-dimensional summaries. The networks were trained by minimizing the quadratic loss in Eq. (10).Fig. 4Mixture density networks with a bottleneck can learn informative summaries. The stack left of the compressor t illustrates the generation of training data and MDN training procedure: p-dimensional parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} and synthetic data z are drawn from the prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} and simulator g, respectively. Synthetic data are compressed to summaries using a compressor t. The stack right of the compressor t illustrates approximate Bayesian computation using learned summaries: The compressor evaluates summaries of observed data y, and parameter samples are accepted if corresponding simulated summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t\left( z\right) $$\end{document} are sufficiently close to observed summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t\left( y\right) $$\end{document} . The red dashed box indicates components specific to training MDN compression: A mixture density network (MDN) h estimates a posterior approximation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{f}}\left( \theta \mid t(z)\right) $$\end{document} given learned summaries t(z). Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {F}$$\end{document} are the supported posteriors, e.g. MDNs with certain component distributions. The network is trained by minimizing the negative log probability (NLP) loss. The table lists the type of data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {D}$$\end{document} and compressor architecture for each experiment (see Sections 5.2 to 5.4 for details)
Summaries minimizing the EPE are appealing, but a concrete algorithm is required to make them useful in practice. We employed a conditional mixture density network (MDN) (Papamakarios and Murray 2016) with a bottleneck akin to an autoencoder (Kramer 1991). The network comprises two parts: First, for fair comparison, we used the same neural compressor as for nonlinear posterior mean estimation. Consequently, the number of summaries q is equal to the number of parameters p, although, in general, a different number of summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q>p$$\end{document} could be chosen (Chen et al. 2021). Second, we extended the network with a conditional MDN to estimate the posterior density given only the summaries. The whole network comprising compressor and MDN was trained end-to-end by minimizing the Monte Carlo estimate of the EPE defined in Eq. (5). After training, the bottleneck architecture ensures any information that may be useful for minimizing the EPE is captured by the output of the compressor; we dub this approach MDN compression. The inference pipeline for all methods is illustrated in Fig. 4. For MDN compression, the compressor is trained by jointly optimizing a mixture density network on simulated data (shown in red) to minimize the expected posterior entropy. Once trained, summaries are extracted and used in ABC like other methods. A similar approach was used by Jeffrey et al. (2020) for summaries fed to a likelihood estimation network. Radev et al. (2022) used a similar architecture of compression and density estimation networks, although using a normalizing flow for the latter. They used 128 summaries which is prohibitively large for ABC.
For each experiment, we generated a training, validation, and test set by sampling from the prior predictive distribution. Neural compressors were trained by mini-batch gradient descent using the Adam optimizer with default parameters and an initial learning rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^{-2}$$\end{document} (Kingma 2015). The learning rate was decreased by an order of magnitude if the loss evaluated on the validation set did not decrease for ten consecutive epochs; training was stopped if it did not decrease for twenty consecutive epochs.
After extracting summaries for each example in the test set, we obtained samples from the approximate posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{f}}\left( \theta \mid t\left( y\right) \right) $$\end{document} in three steps: First, to ensure a common scale across summaries, we standardized them independently to have zero mean and unit variance based on the training set. Second, we evaluated the Euclidean distance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} between standardized summaries of each example y and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i^\text {th}$$\end{document} element of the training set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_i$$\end{document} . Third, we accepted a small fraction of the training set as posterior samples such that they had the smallest distance to each example (Beaumont 2019), i.e. the training set served as the reference table. The same training, validation and test sets were used for different methods for fair comparison. In addition to ABC, we drew samples from the prior as a baseline as well as directly from the MDNs trained to obtain EPE-minimizing summaries.
We used two metrics to evaluate approximate posterior samples. First, the root mean integrated squared error (RMISE)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {RMISE} = \left[ \frac{1}{s}\sum _{i=1}^s \left\| {\tilde{\theta }}_i -\theta \right\| ^2\right] ^{1/2}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\theta }}_i$$\end{document} denotes the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i^\text {th}$$\end{document} sample from the ABC posterior and s is the number of samples. This metric has been widely used in the ABC literature to evaluate summary extraction methods (Joyce and Marjoram 2008; Nunes and Balding 2010; Fearnhead and Prangle 2012; Blum et al. 2013; Burr and Skurikhin 2013; Jiang et al. 2017). It measures how concentrated ABC posterior samples are around the true parameter value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} (Bishop 2006, Ch. 3). The RMISE is a suitable metric for unimodal but not multimodal posteriors, as illustrated in panel (b) of Fig. 2. Second, to address this shortcoming, we also evaluated the negative log probability (NLP) using kernel density estimation. Specifically,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {NLP} = -\log \left[ \frac{1}{s}\sum _{i=1}^s K_h\left( {\tilde{\theta }}_i-\theta \right) \right] , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K_h$$\end{document} is a Gaussian kernel with bandwidth h chosen by Scott’s rule (Scott 2015). For each experiment, metrics reported in Fig. 6 and Table 2 in the appendix are averaged over the corresponding test set.
Benchmark model
Fig. 5A conditional mixture density network (MDN) that minimizes the expected posterior entropy learns highly informative summaries. Panel (a) shows the likelihood for the true parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta ^*\approx 1.6$$\end{document} that generated the example dataset y together with a rug plot for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=10$$\end{document} observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{\bullet 1}$$\end{document} . Panel (b) shows the true posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left( \theta \mid y\right) $$\end{document} together with the learned posterior density estimator. While the two-component mixture is not flexible enough to approximate the true posterior well, it learns highly informative summaries: MDN-compressed ABC samples using these summaries are shown as a histogram. Panel (c) shows the learned summary function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t: \mathbb {R}^{10 \times 2} \rightarrow \mathbb {R}$$\end{document} which maps the full data matrix to a scalar; the plot shows t(y) as a function of the first column values \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{\bullet 1}$$\end{document} (the informative data, with the second column being uninformative noise). The dashed line shows how t can be approximated using polynomial basis functions of the candidate summaries (the first three even moments). Panel (d) illustrates the relationship between the posterior density estimator and the summary as a heat map; lighter colours indicate higher posterior density
We considered a benchmark model with multimodal true posterior set up to be challenging for extracting summaries. The model has a tractable likelihood that allowed us to compare the posterior given summaries with true posterior samples. In particular, we sampled a univariate parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} from the standard normal distribution and drew \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=10$$\end{document} independent samples from the mixture distribution
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} z_{i1}\mid \theta \sim \frac{1}{2}\sum _{u\in \left\{ -1,1\right\} }\textsf{Normal}\left( u\times \tanh \theta , 1 - \tanh ^2\theta \right) , \end{aligned}$$\end{document}as illustrated in panel (a) of Fig. 5. We also sampled a standard normal distractor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{i2}$$\end{document} (uninformative noise) for each observation i such that the full dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z=[z_{ij}]$$\end{document} is a matrix with n rows and 2 columns. Learning or selecting summaries is non-trivial because all elements of z have zero mean and unit variance under the generative model irrespective of the parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} . The first moment is zero by symmetry; the second moment of each mixture component is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {E}\left[ z_{i1}^2\right] =\mathbb {E}\left[ z_{i1}\right] ^2+{{\,\textrm{var}\,}}z_{i1}=\tanh ^2\theta + 1 - \tanh ^2\theta =1$$\end{document} such that the mixture has unit variance. Sampling from the prior predictive distribution, we generated training, validation, and test sets of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^6$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^4$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^3$$\end{document} independent realizations, respectively. The test set was used to evaluate and compare different methods. We employed the likelihood-based inference framework Stan (Carpenter et al. 2017) to draw 1, 000 posterior samples for each example in the test set (see App. C for details). These samples formed the gold standard which we compared other methods to. Figure 5 illustrates the learned summaries for a particular example dataset y generated with true parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta ^* \approx 1.6$$\end{document} .
For ABC using candidate summaries, the CPE minimization method (Nunes and Balding 2010), PLS (Wegmann et al. 2009), and linear posterior mean estimation (Fearnhead and Prangle 2012), we used the first three even moments of each column of z as candidate summaries, giving rise to six statistics in total. Odd moments are not informative as the likelihood is symmetric, and we did not include them in our set of candidate summaries.
For the nonlinear posterior mean approximation (Jiang et al. 2017), we used a multilayer perceptron (MLP) that acts on each row of z independently before compressing to a scalar summary. This architecture shares weights across all observations and is permutation invariant (Chan et al. 2018). The MLP has three fully connected layers (16, 16, and 1 hidden units) followed by mean-pooling across the n observations; we used \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tanh $$\end{document} activation functions throughout. The network was implemented in PyTorch (Paszke et al. 2019) and trained as described in the preceding section with a mini-batch size of 512.
Finally, we used a conditional MDN with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=2$$\end{document} Gaussian components to estimate the posterior and learn MDN-compressed summaries (Bishop 1994; Papamakarios and Murray 2016). To evaluate mixture logits \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta (t)$$\end{document} , locations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu (t)$$\end{document} , and log-scales \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa (t)$$\end{document} as a function of the summary t we used independent two-layer MLPs (16 and k hidden layers). The posterior density estimator is thus
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \hat{f}\left( \theta \mid t\right) =\sum _{j=1}^k {{\,\text {softmax}\,}}_j \left( \eta \left( t\right) \right) \\ & \quad \times \textsf {Normal}\left( \theta \mid \mu _j\left( \textrm{t}\right) ,\exp \left( 2\kappa _j\left( \textrm{t}\right) \right) \right) , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\,\textrm{softmax}\,}}_j \left( \eta \right) = \exp \eta _j / \sum _{l=1}^k\exp \eta _l$$\end{document} .Fig. 6The quality of summaries significantly impacts the fidelity of posteriors. Panels (a), (b), and (c) report the negative log probability loss and root mean integrated squared error of different methods for the benchmark, coalescent, and growing tree experiments, respectively. “MDN” refers to drawing samples directly from the learned mixture density network, “likelihood-based” refers to samples obtained with Stan for the benchmark problem and pseudo-marginal MCMC for the growing tree model, and all other methods use ABC after extracting summaries. Error bars are standard errors based on a test set of 1,000 i.i.d. samples for each experiment. Expert summaries and PLS perform poorly for the growing tree experiment and are indicated as off-the-chart by arrows. See Sections 5.2 to 5.4 for details on the expert summaries for the benchmark, coalescent, and growing tree models, respectively
A comparison of the performance of different methods based on 1, 000 approximate posterior samples ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.1\%$$\end{document} of the reference table) is shown in panel (a) of Fig. 6 (see Table 2 in the appendix for a table of results). We report the RMISE for completeness, but it is a poor metric for multimodal posteriors. For example, a point mass at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta =0$$\end{document} would have \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {RMISE} = 1$$\end{document} —lower than any of the methods we considered. As expected, linear and nonlinear posterior mean estimators performed worst in terms of NLP because the posterior is bimodal. Because of its flexibility, the nonlinear estimator was able to accurately estimate the posterior mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {E}_{\theta \sim f\left( \theta \mid z\right) }\left[ \theta \right] =0$$\end{document} which, ironically, led to the worst performance: The NLP is equal to the prior entropy (1.42). The linear estimator performed better because the regression coefficients are entirely determined by noise in the training set, i.e. the scalar summary is a random projection of the candidate summaries. Similarly, extracting features using PLS regression is driven by noise: Here, three random orthogonal projections of candidate features were selected based on five-fold cross-validation, allowing PLS to outperform both linear and nonlinear regression. Minimizing the conditional posterior entropy and using candidate summaries without selection performed similarly and better than regression-based approaches.
MDN-compressed ABC performed as well as the gold standard likelihood-based inference ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {NLP} = 1.05\pm 0.01$$\end{document} ) and better than samples drawn directly from the MDN ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {NLP} = 1.08\pm 0.02$$\end{document} ), as illustrated in panel (b) of Fig. 5 for a particular example. While the bottleneck forces the network to compress data to an informative summary statistic, the architecture of the MDN with only two mixture components is too restrictive to approximate the true posterior well. Increasing the number of components to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=10$$\end{document} provides a better approximation with the same performance as both the likelihood-based approach and MDN-compressed ABC. Here, we deliberately restricted the architecture to illustrate that ABC with good summaries can remain competitive because it does not rely on parametric assumptions about the density.
Due to the simplicity of the benchmark problem, we can inspect the MDN and learned summary, as shown in panel (c). The appropriate summary is obvious in retrospect: It should discriminate between data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{\bullet 1}$$\end{document} clustered around \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm 1$$\end{document} (corresponding to large absolute values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} ) and data near zero or large absolute value (corresponding to small absolute values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} ). The dashed line shows a polynomial approximation of the learned summary t using the candidate summaries (the first three even moments of each column) as basis functions. This fit illustrates that the candidate summaries are rich enough to provide a high-quality summary in principle, but most methods struggled to extract the information. We obtained the fit by minimizing squared residuals on the interval \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left( -3,3\right) $$\end{document} weighted by the prior density. Finally, the density of the MDN, shown in panel (d), exhibits the expected behaviour: Large summaries give rise to unimodal distributions centred at the origin, and small summaries yield bimodal posterior estimates.
The choice of compressor architecture is not unique. For example, we could have included further layers after the mean-pooling operation or used a fully-connected network throughout. However, using the mean-pooled latent features has several advantages: First, the number of compressor parameters is independent of the sample size. Second, they are unbiased estimates of the population mean of the features independent of sample size. The architecture was motivated by the observation that the likelihood of exponential family distributions can be expressed in terms of sums (or means) of transformations of the data and preserves the i.i.d. structure required to connect Fisher information maximization with EPE minimization as discussed in Section 4.3. We thus expect the learned summaries to remain informative for different sample sizes. To test this hypothesis, we repeated the analysis with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=100$$\end{document} instead of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=10$$\end{document} observations per example. The NLPs are smaller because we had access to more data: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.68\pm 0.01$$\end{document} for likelihood-based inference and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.70\pm 0.01$$\end{document} for MDN-compressed ABC, where the MDN was trained on the larger dataset using the same methodology as before. Running MDN-compressed ABC with the network trained on the smaller dataset yielded a NLP of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.72\pm 0.01$$\end{document} , i.e. the performance is almost indistinguishable from the network trained on the larger dataset despite being exposed to an order of magnitude fewer observations. Importantly, the posterior density estimator itself cannot achieve this generalization because the model was trained on data with a fixed sample size. BayesFlow seeks to provide amortized inference even for variable sample sizes although at the cost of further simulations (Radev et al. 2022).
Population genetics model
We inferred the mutation and recombination rates of a population genetics model, a problem that has been extensively studied using ABC in general and in the context of identifying summaries in particular (Joyce and Marjoram 2008; Nunes and Balding 2010; Blum et al. 2013). Data were generated using the coalescent approach which considers the history of a sample of haplotypes, a set of DNA variations that tend to be inherited together because they are close together on the DNA strand (Nordborg 2019). We present the process in terms of the equivalent forward model because it is more accessible. Under the neutral Fisher-Wright model, diploid organisms (each having paired chromosomes) reproduce sexually in discrete generations without selection pressure. Haplotypes are subject to random mutations under an infinite-sites assumption, i.e. the DNA sequence is sufficiently long that the probability of multiple mutations occurring at the same site is negligible. The model also allows for recombination, i.e. the haplotype of a gamete can be a combination of parental haplotypes. We consider a finite-sites recombination model (Hudson 1983), i.e. the strands may only cross over at specific locations during meiosis. This may seem at odds with the infinite-sites mutation model, but we can think of the haplotype as a sequence of atomic segments, each comprising many bases.
We used a dataset of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^6$$\end{document} simulations from the above model generously provided by Nunes and Balding (2010). The mutation and recombination rate parameters were drawn from a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textsf{Uniform}\left( 0,10\right) $$\end{document} prior. For each simulation, 50 haplotypes with 5, 001 base pairs were generated. Seven candidate summaries comprised a uniform distractor and six expert summaries (such as the number of unique haplotypes or “the frequency of the most common haplotype” (p. 8); see Nunes and Balding (2010) for details). We split the dataset into training, validation, and test sets comprising \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$9.89\times 10^5$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^4$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^3$$\end{document} samples, respectively.
For the non-linear regression model, we used a three-layer MLP with 16, 16, and 2 hidden units without mean-pooling because the input to the neural network was a set of candidate statistics. We employed the same architecture for the compressor of the mixture density network. Instead of two Gaussian components, we used ten beta distributions rescaled to the interval \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left( 0,10\right) $$\end{document} as components. We used the same architecture as in Section 5.2 to estimate the mixture logits and the logarithm of the beta shape parameters. Both networks were trained as previously described with mini-batch size of 256.
We drew 1, 000 posterior samples for each example in the test set (comprising \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx 0.1\%$$\end{document} of the reference table as for the benchmark dataset). Kernel density estimates of the NLP are biased for bounded parameters because probability mass can “leak” out of the support (Scott 2015). We used a reflection-based bias correction technique to estimate the NLP (Boneva et al. 1971), i.e. each approximate posterior sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\theta }}$$\end{document} is reflected at the boundaries such that both tails of the kernel contribute to the density estimate. The results are shown in panel (b) of Fig. 6 and Table 2 in the appendix. Nonlinear regression and MDN-compressed ABC not only performed comparably, but the two methods also learned very similar summaries: After standardizing and aligning the summaries using a Procrustes transformation (Schönemann 1966), they had a pointwise MSE of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M^2 = 0.20$$\end{document} (p-value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$<10^{-3}$$\end{document} under a permutation test). MDN samples performed slightly, but not statistically significantly, better in terms of EPE and RMISE. The minimum CPE method performed worst in terms of NLP because it targets highly concentrated posteriors, although not necessarily near the true value. We did not implement the two-stage method of Nunes and Balding (2010) due to its computational cost and similarity with posterior mean estimation approaches (Fearnhead and Prangle 2012; Jiang et al. 2017). Similarly, we omitted approximate sufficiency (Joyce and Marjoram 2008) because it is sensitive to the number of histogram bins chosen for density estimation and is not suitable for multidimensional parameter spaces due to the curse of dimensionality.
Growing tree model
Inferring the parameters of dynamic network models is challenging, especially when only cross-sectional data are available. Cantwell et al. (2021) developed a pseudo-marginal Markov chain Monte Carlo (PM-MCMC) algorithm to infer the parameters of a growing tree model. Under the model (Krapivsky and Redner 2001), a tree is grown from a single isolated node. At each step, a new node j is added and connected to an existing node i with probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\propto k_i^\theta $$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_i$$\end{document} is the degree of node i, i.e. the number of connections it has. The parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} controls the strength of preferential attachment: The larger \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} the more likely nodes are to connect to nodes that already have many connections. The likelihood is intractable because the history, i.e. the order of addition of nodes, is unknown. There are combinatorially many possible histories, and evaluating the likelihood exactly is infeasible save for very small trees. The PM-MCMC algorithm estimates the marginal likelihood by sampling a set of histories consistent with the observed graph and averaging the conditional likelihood for each history (Cantwell et al. 2021).
Here, we employed ABC to infer the preferential attachment parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} and compared different methods to extract informative summaries from graph data. Synthetic data were generated by sampling the kernel parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} from a uniform distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textsf{Uniform}\left( 0, 2\right) $$\end{document} and simulating trees with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=100$$\end{document} nodes for each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} . We generated a training set of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^5$$\end{document} samples; the validation and test sets both comprised \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^3$$\end{document} samples.
For subset selection methods, we used one uniform distractor and four candidate summaries: The standard deviation and Gini coefficient of the degree distribution because heavy-tailed degree distributions are indicative of large \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} ; the diameter of the network and the maximum betweenness centrality because the existence of a central hub connecting disparate parts of the tree is indicative of large \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} (Newman 2018). For nonlinear posterior mean estimation and MDN compression, we used a two-layer graph isomorphism network (GIN) where each layer comprised a two-layer MLP with eight hidden units per layer (Xu et al. 2019). We used the constant vector of ones as input features for the GIN because nodes are indistinguishable. Features were mean-pooled across the graph after applying the GIN, and training used 32 trees per mini-batch.
All methods, including using candidate summaries directly, significantly reduced uncertainty about the attachment parameter. As shown in panel (c) of Fig. 6 and Table 2 in the appendix, the PM-MCMC algorithm had the lowest RMISE, but MDN-compressed ABC and direct sampling from the MDN performed best in terms of NLP. Similar to the benchmark experiment in Section 5.2, we repeated the experiment for larger trees with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=748$$\end{document} nodes. MDN compression trained on large trees performed best ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {NLP}=-1.67\pm 0.02$$\end{document} ), but summaries learned on trees with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=100$$\end{document} nodes generalized to larger trees with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {NLP}=-1.65\pm 0.02$$\end{document} . The relative NLP performance of other methods remained unchanged, but PM-MCMC performance was sensitive to the size of the grown tree and degraded severely with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {NLP}=1.7\pm 0.2$$\end{document} , much larger than the prior entropy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H\left\{ \pi \left( \theta \right) \right\} =0.69$$\end{document} . For superlinear preferential attachment, i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta > 1$$\end{document} , almost every new node connects to a central hub (Krapivsky and Redner 2001). This phenomenon is particularly pronounced for larger graphs, and it is challenging to infer histories accurately which leads to poor inference. In this experiment, ABC with MDN-compressed summaries outperformed the dedicated (pseudo-marginal) likelihood-based approach.
Computational cost
Table 1Computational costs for data generation, training of neural compressors, and inference. Times are as hours:minutes:seconds. “MDN” refers to drawing samples directly from the learned mixture density network, “likelihood-based” refers to samples obtained with Stan for the benchmark problem and pseudo-marginal MCMC for the growing tree model, and all other methods use ABC after extracting summaries. “Small” and “Large” refer to different sample sizes for the benchmark ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=10$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=100$$\end{document} samples) and growing tree ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=100$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=748$$\end{document} nodes) experiments. Training times for MDN and nonlinear regression reflect a single training run. Inference times are for the complete test set of 1,000 examples. For methods using candidate summaries (expert summaries, linear regression, minimum CPE, and PLS), times include evaluating those summaries. Data generation times for the coalescent experiment are unknown as the dataset was provided by Nunes and Balding (2010)BenchmarkCoalescentGrowing treeStep or MethodSmallLargeSmallLarge Data generation Training set00:0200:08unknown01:2401:08:06Validation set00:0200:02unknown00:0300:48Test set00:0200:02unknown00:0300:47 Training MDN04:1807:1305:1403:2821:30Nonlinear regression00:3602:5500:5903:2219:54 Inference Likelihood-based02:2907:43not applicable07:5101:11:01Expert summaries00:0500:1300:0400:5225:19MDN compression00:0300:0500:0200:0700:20MDN00:0200:0200:0300:0200:03Nonlinear regression00:0300:0500:0200:0700:19Linear regression00:0400:1300:0300:5225:19Minimum CPE17:0414:1530:385:3930:17PLS00:0800:1700:1600:5225:19Prior00:0300:0300:0200:0200:02
Training neural compressors, especially MDNs, is more computationally demanding than simpler linear regression or using expert summaries directly if they are cheap to evaluate. However, as shown in Table 1, the relative cost of optimizing an MDN compared with non-linear regression decreases with increasing problem complexity as the neural compressor is responsible for the majority of the computational cost. For the benchmark with a simple compressor architecture, MDN training is approximately seven times slower than nonlinear regression. For the growing tree experiment with a graph neural network compressor, the additional cost is only 8%. Training an MDN is comparable with (small benchmark) or more computationally efficient (all other experiments) than likelihood-based inference using Stan or pseudo-marginal MCMC for the growing tree experiment. Further, optimizing an MDN is a one-time expense and can extract summaries efficiently once trained. For example, computing network summaries can be costly and must be repeated for each element of the training and test sets before running ABC (Raynal et al. 2023). This is much slower than using a graph neural network compressor in our experiments: more than 25 minutes compared with only 20 seconds. Training and applying neural compressors is also more efficient than greedy subset selection using CPE minimization because ABC needs to be run multiple times for each example to iteratively select promising summaries.
Discussion
We have shown that five information-theoretic approaches to devising summaries are equivalent in Section 3. Furthermore, as shown in Section 4, other methods can be understood as special or limiting cases of minimizing the expected posterior entropy (EPE) which should be the practitioner’s choice because it is straightforward to evaluate compared with MI or KL divergence, can incorporate prior information, and is conceptually simple. We also characterized the notion of sufficient, lossless, and optimal summaries in Section 2—distinctions that are important for developing compression algorithms and resolving misunderstandings, as discussed in Section 4.5.
We compared various methods on a benchmark problem (Section 5.2), a population genetics model (Section 5.3), and a model for growing trees (Section 5.4). Minimizing the EPE yields highly informative summaries while achieving the long-standing goal of “find[ing] methods which do not require a preliminary subjective feature selection stage” (Prangle 2018, p. 147). But there is no free lunch: We instead have to choose a compression and density estimation architecture. Choosing appropriate architectures can improve performance, reduce the number of simulations required (Chan et al. 2018), and even allow summaries to generalize across datasets of different sizes as demonstrated in the benchmark and growing trees experiments.
Sequential methods can reduce the computational burden of likelihood-free inference (Lueckmann et al. 2017; Papamakarios and Murray 2016; Chen et al. 2021), but we focused on learning summaries for rejection ABC for two reasons: First, we wanted to isolate the effect of summary selection without introducing confounders. We omitted regression adjustment for ABC samples (Beaumont et al. 2002) for the same reason. Second, learning global summaries allows for amortized inference because we do not need to retrain models for each example. Investigating the interaction between sequential methods and learning summaries could shed light on how different aspects of the data inform parameters in different regions of the parameter space, as illustrated in Fig. 3.Table 2The quality of summaries has a significant impact on the fidelity of posteriors. The table reports the negative log probability loss (NLP) and root mean integrated squared error (RMISE) for combinations of methods and experiments. “MDN” refers to directly sampling from the learned mixture density network, “likelihood-based” refers to samples obtained with Stan for the benchmark problem, and all other methods use ABC after extracting summaries. Reported errors are standard errors, and methods that are within one standard error of the best method are highlighted in bold. See Sections 5.2 to 5.4 for details on the benchmark, coalescent, and growing tree experiments, respectivelyBenchmarkCoalescentGrowing treeMethodNLPRMISENLPRMISENLPRMISELikelihood-based \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {1.05 \pm 0.01}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.24 \pm 0.02$$\end{document} not applicable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.666 \pm 0.028$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.165 \pm 0.002}$$\end{document} Expert summaries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.12 \pm 0.01$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.25 \pm 0.02$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.685 \pm 0.025$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4.05 \pm 0.03$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.579 \pm 0.014$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.208 \pm 0.002$$\end{document} MDN compression \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {1.05 \pm 0.01}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.24 \pm 0.02$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {3.601 \pm 0.028}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {3.82 \pm 0.03}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {-0.730 \pm 0.021}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.167 \pm 0.002}$$\end{document} MDN \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.08 \pm 0.02$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.24 \pm 0.02$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {3.595 \pm 0.028}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {3.82 \pm 0.03}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {-0.727 \pm 0.021}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.167 \pm 0.002}$$\end{document} Nonlinear regression \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.43 \pm 0.02$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.35 \pm 0.01$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {3.604 \pm 0.028}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {3.82 \pm 0.03}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {-0.702 \pm 0.021}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.172 \pm 0.002$$\end{document} Linear regression \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.32 \pm 0.02$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.30 \pm 0.02$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.677 \pm 0.029$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.98 \pm 0.03$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.685 \pm 0.021$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.174 \pm 0.002$$\end{document} Minimum CPE \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.13 \pm 0.02$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {1.20 \pm 0.02}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.734 \pm 0.033$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.99 \pm 0.03$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {-0.700 \pm 0.022}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.169 \pm 0.002$$\end{document} PLS \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.15 \pm 0.02$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.26 \pm 0.02$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.712 \pm 0.024$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4.05 \pm 0.03$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.525 \pm 0.013$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.225 \pm 0.002$$\end{document} Prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.44 \pm 0.03$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.36 \pm 0.01$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4.621 \pm 0.003$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$5.69 \pm 0.03$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.696 \pm 0.002$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.801 \pm 0.006$$\end{document}
The summaries of the mixture density networks in Section 5 can have arbitrary scales which can be problematic for ABC. We standardized summaries after extraction to mitigate this problem, but metric learning approaches could further improve ABC with MDN-compressed summaries (González-Vanegas et al. 2019). Investigating the impact of model misspecification on ABC is an active area of research (Frazier et al. 2020), and comparing the robustness of different methods should be considered in future work.
Neural density estimation is a powerful tool for likelihood-free inference, “but there is no uniformly best algorithm” (Lueckmann et al. 2021, p. 1). ABC remains a compelling approach because of its theoretical properties, and it can produce high-fidelity posteriors, especially when low-dimensional but rich summaries can be extracted from complex data.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Boneva, L.I., Kendall, D., Stefanov, I.: Spline transformations: Three new diagnostic aids for the statistical data-analyst. J. R. Stat. Soc. Ser. B Stat. Methodol. 33(1), 1–37 (1971). 10.1111/j.2517-6161.1971.tb 00855.x
- 2Cai, Y., Lim, L.-H.: Distances between probability distributions of different dimensions. IEEE Trans. Inf. Theory 68(6), (2022). 10.1109/TIT.2022.3148923
- 3Cantwell, G.T., St-Onge, G., Young, J.-G.: Inference, model selection, and the combinatorics of growing trees. Phys. Rev. Lett. 126(3) (2021) 10.1103/physrevlett.126.038301
- 4Fearnhead, P., Prangle, D.: Constructing summary statistics for approximate Bayesian computation: semi-automatic approximate Bayesian computation. J. R. Stat. Soc. Ser. B Stat. Methodol. 74(3), 419–474 (2012) 10.1111/j.1467-9868.2011.01010.x
- 5Joyce, P., Marjoram, P.: Approximately sufficient statistics and Bayesian computation. Stat. Appl. Genet. Mol. Biol. 7(1), (2008). 10.2202/1544-6115.1389
- 6Nunes, M.A., Balding, D.J.: On optimal selection of summary statistics for approximate Bayesian computation. Stat. Appl. Genet. Mol. Biol. 9(1), (2010). 10.2202/1544-6115.1576
- 7Stephens, M.: Dealing with label switching in mixture models. J. R. Stat. Soc. Ser. B Stat. Methodol. 62(4), 795–809 (2000). 10.1111/1467-9868.00265