A Lightweight Frozen Multi-Convolution Dual-Branch Network for Efficient sEMG-Based Gesture Recognition
Shengbiao Wu, Zhezhe Lv, Yuehong Li, Chengmin Fang, Tao You, Jiazheng Gui

TL;DR
This paper introduces a new lightweight neural network for recognizing gestures from sEMG signals, which is efficient and suitable for low-power devices.
Contribution
The novel FMC-DBNet uses frozen random convolutional kernels and dual-branch architecture for efficient sEMG gesture recognition.
Findings
FMC-DBNet achieves 96.4% ± 1.9% average accuracy on the Ninapro DB1 dataset.
The model reduces training time by approximately 90% compared to conventional CNNs.
Abstract
Gesture recognition is important for rehabilitation assistance and intelligent prosthetic control. However, surface electromyography (sEMG) signals exhibit strong non-stationarity, and conventional deep-learning models require long training time and high computational cost, limiting their use on resource-constrained devices. This study proposes a Frozen Multi-Convolution Dual-Branch Network (FMC-DBNet) to address these challenges. The model employs randomly initialized and fixed convolutional kernels for training-free multi-scale feature extraction, substantially reducing computational overhead. A dual-branch architecture is adopted to capture complementary temporal and physiological patterns from raw sEMG signals and intrinsic mode functions (IMFs) obtained through variational mode decomposition (VMD). In addition, positive-proportion (PPV) and global-average-pooling (GAP) statistics…
Click any figure to enlarge with its caption.
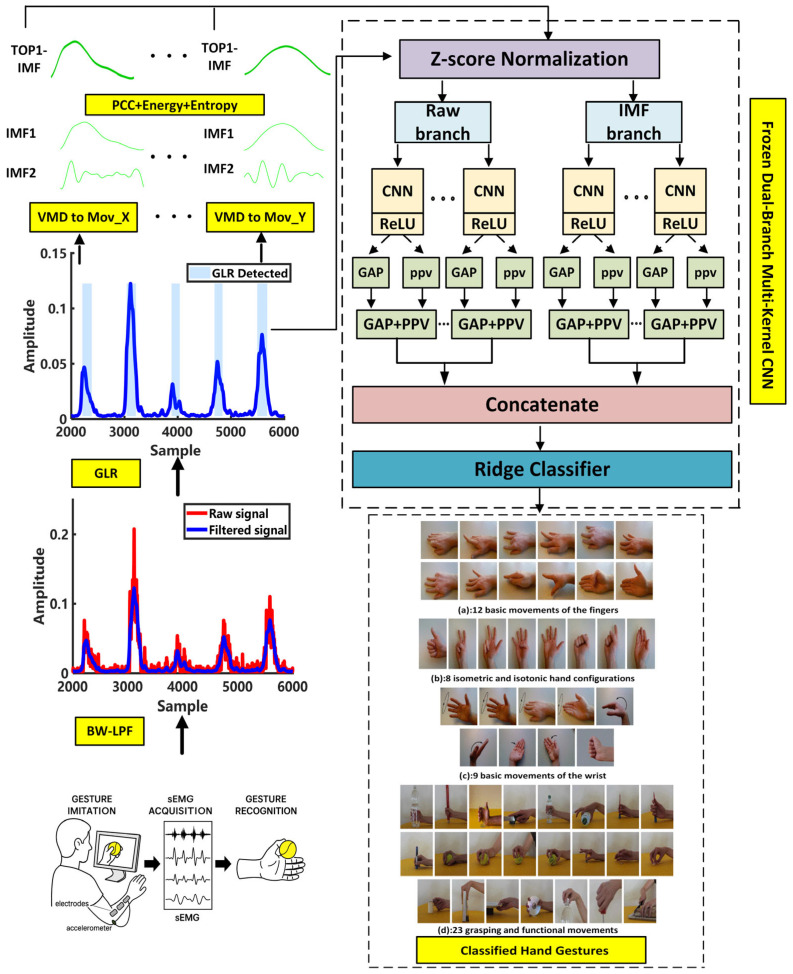 Figure 1
Figure 1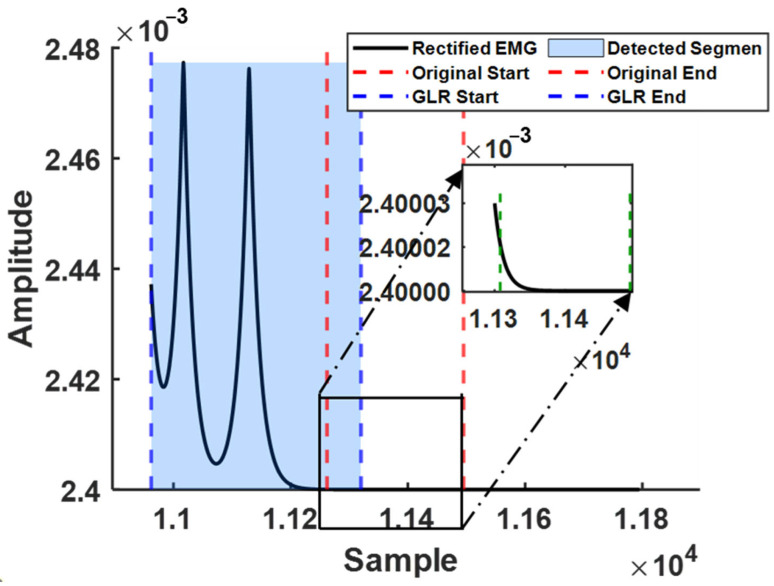 Figure 2
Figure 2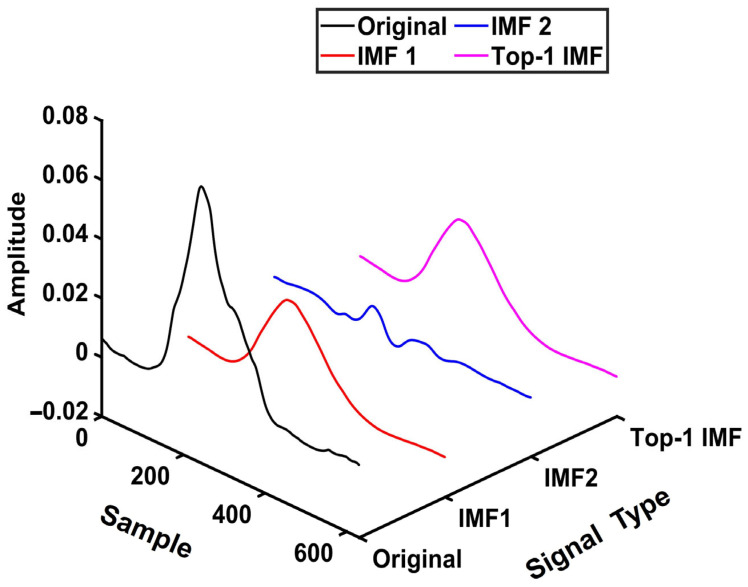 Figure 3
Figure 3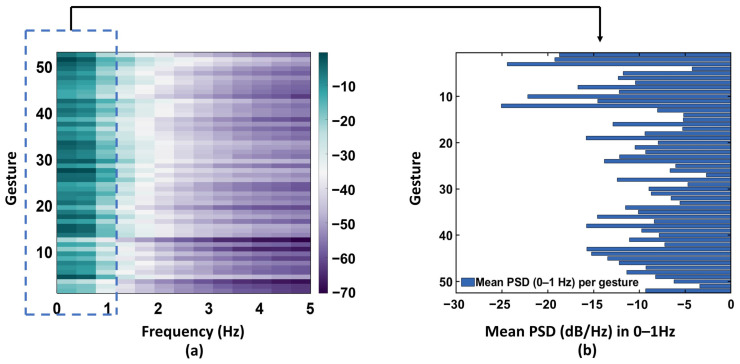 Figure 4
Figure 4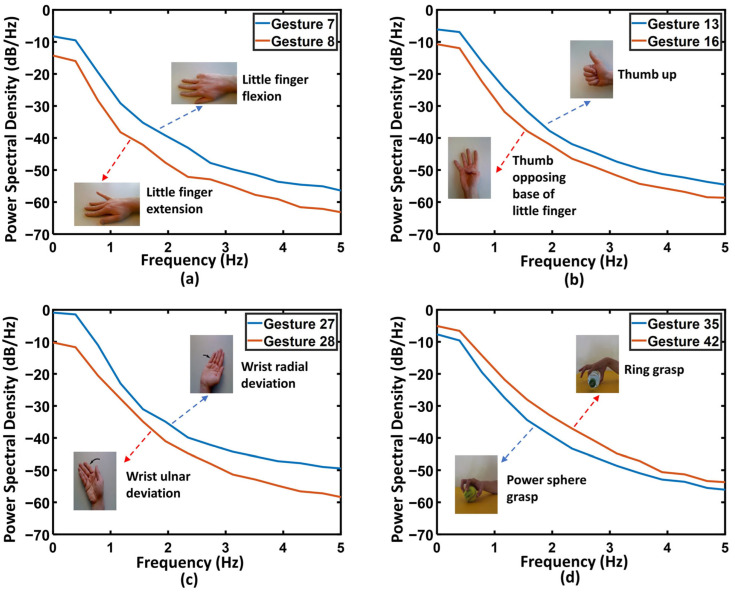 Figure 5
Figure 5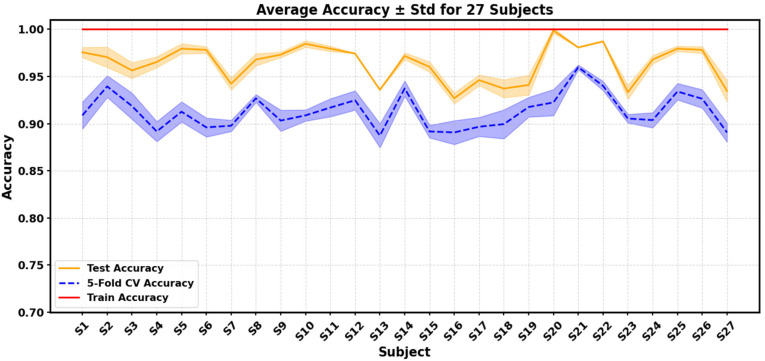 Figure 6
Figure 6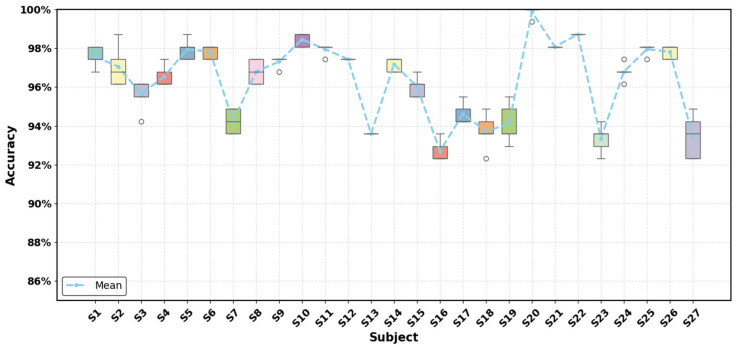 Figure 7
Figure 7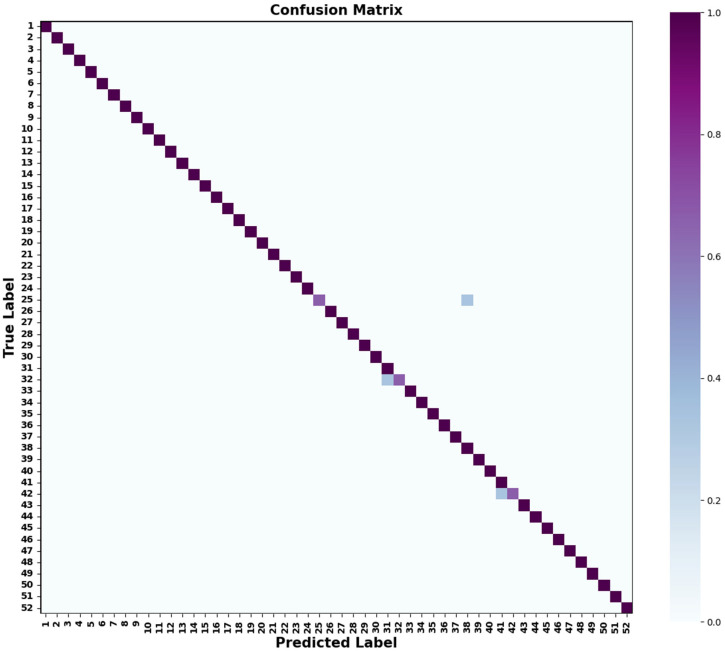 Figure 8
Figure 8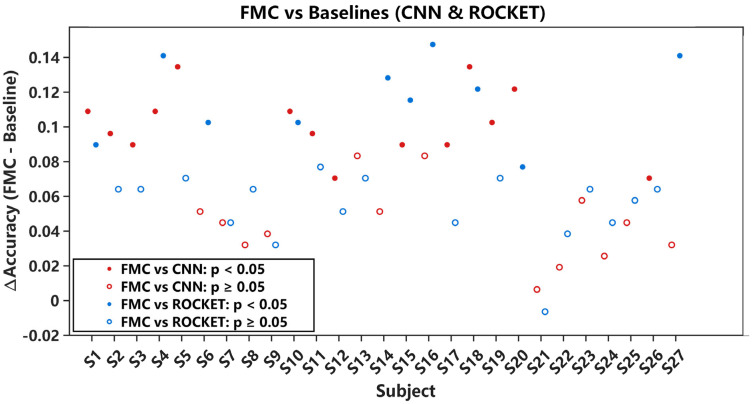 Figure 9
Figure 9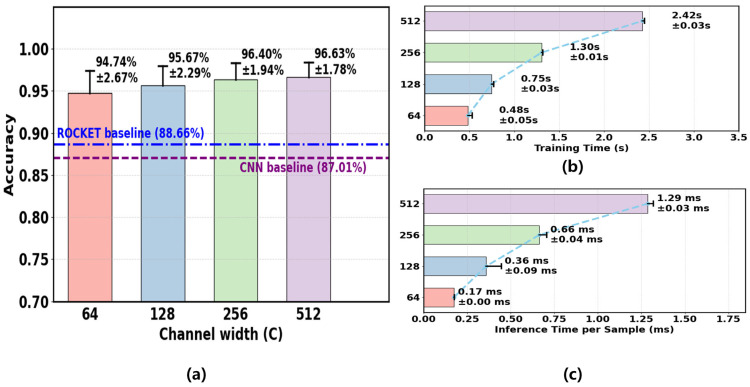 Figure 10
Figure 10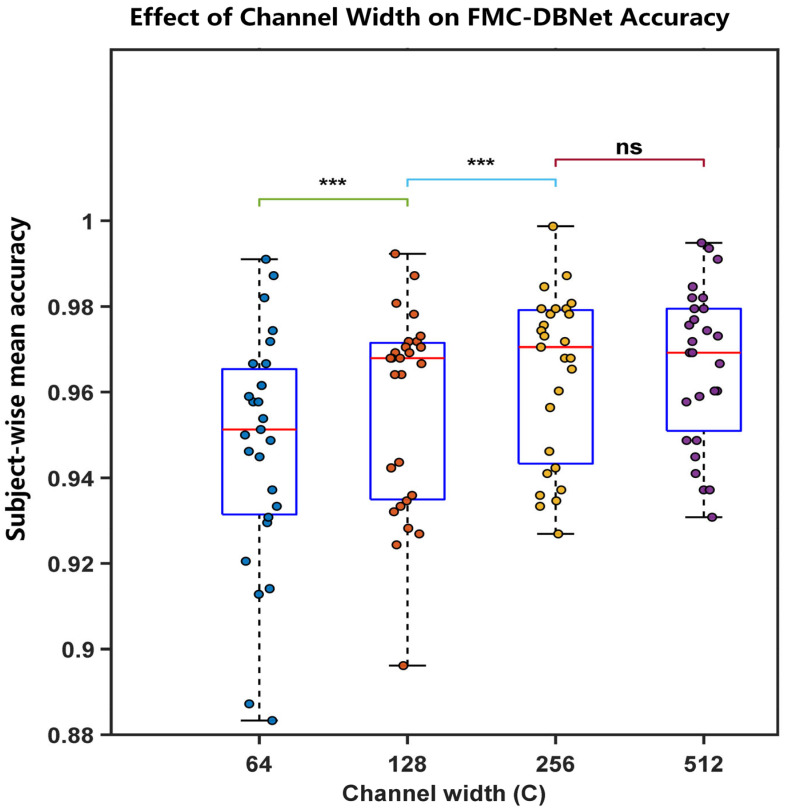 Figure 11
Figure 11- —National Natural Science Foundation of China
- —Jiangxi Provincial Major Science and Technology Research and Development Foundation
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMuscle activation and electromyography studies · Advanced Sensor and Energy Harvesting Materials · Hand Gesture Recognition Systems
1. Introduction
Gesture recognition plays a crucial role in intelligent prosthetic control and rehabilitation assistance, serving as a key pathway toward natural human–machine interaction [1,2,3]. Surface electromyography (sEMG), a non-invasive signal reflecting neuromuscular activity, has been widely applied in upper-limb rehabilitation, prosthetic control, and human–machine interface research [4]. Despite recent advances in sensor technology and computational platforms, sEMG-based gesture recognition remains challenging due to its strong non-stationarity, substantial inter-subject variability, and fluctuations across repetitions and muscle conditions [5,6]. These characteristics complicate the design of models that are both robust and computationally efficient, particularly when targeting embedded or low-power systems with limited resources.
Traditional sEMG-based gesture recognition methods primarily rely on handcrafted features in the time, frequency, and time–frequency domains, combined with classifiers such as support vector machines (SVMs) and hidden Markov models (HMMs) [7,8,9,10]. Although such approaches are computationally lightweight, manually designed features struggle to capture the nonlinear, transient, and task-dependent properties of sEMG signals, which show pronounced non-stationary and subject-specific behaviors [11,12,13,14,15]. As a result, these systems often require careful feature engineering and suffer from performance degradation when the recording conditions, subjects, or tasks deviate from those seen during design.
Deep learning techniques have alleviated many of these limitations by enabling end-to-end feature learning directly from raw or minimally processed sEMG data [16,17,18,19]. Convolutional neural networks (CNNs) have become the dominant paradigm in recent years, owing to their ability to learn hierarchical temporal–spatial representations [20,21]. On this basis, a variety of architectures have been proposed, including CNN–LSTM hybrids for dynamic gesture recognition [22], CNN models constructed on Gramian angular field representations of sEMG [23], and dual-branch CNNs that integrate global and local cues [24]. Multi-scale convolutions and attention mechanisms have further enhanced the representational capacity of these networks [25,26]. However, these deep models typically rely on a large number of trainable parameters and backpropagation-based optimization, leading to high computational cost and long training time, which limit their deployment on low-power or resource-constrained devices.
To reduce training overhead while retaining strong discriminative power, researchers have started to explore random-feature-based learning paradigms. Random vector functional link (RVFL) networks employ fixed random weights in the hidden layer to project inputs into a high-dimensional feature space, after which only a linear readout needs to be trained [27,28,29]. The ROCKET method extends this idea to the convolutional domain by applying fixed random convolutional kernels to capture multi-scale temporal patterns, achieving classification performance comparable to that of fully trainable CNNs without backpropagation [30,31,32,33]. Related work on convolutional RVFL (CRVFL) architectures further demonstrates the feasibility of random convolutional structures for image and physiological signal processing [34,35]. Nevertheless, most existing random-feature or random-convolution approaches are designed for single-source or single-channel inputs and lack mechanisms to jointly model multiple physiological components of sEMG, such as the raw signals and intrinsic mode functions (IMFs) obtained via variational mode decomposition (VMD).
To address these limitations, this study follows the efficient learning paradigm of fixed feature extraction with a lightweight classifier and proposes a Frozen Multi-Convolution Dual-Branch Network (FMC-DBNet) for sEMG-based gesture recognition. The model employs randomly initialized and fixed convolutional kernels to perform training-free multi-scale feature mapping, substantially reducing computational overhead. A dual-branch architecture is adopted to separately process raw sEMG signals and VMD-derived IMFs, enabling physiological-level signal decoupling and complementary modeling of neuromuscular activity. Furthermore, by integrating multi-scale convolutions with positive-proportion (PPV) and global-average-pooling (GAP) statistics, the proposed network constructs lightweight multi-resolution representations of both temporal and physiological patterns. Experiments on the Ninapro DB1 dataset demonstrate that the proposed FMC-DBNet can markedly reduce training time while maintaining high recognition accuracy, indicating that frozen random-convolution structures offer a practical and effective solution for efficient sEMG gesture recognition.
2. Materials and Methods
Figure 1 illustrates the overall framework of the proposed Frozen Multi-Convolution Dual-Branch Network (FMC-DBNet) for sEMG-based gesture recognition. The system consists of four main stages: (1) signal preprocessing and motion-segment detection; (2) variational mode decomposition (VMD) and IMF selection; (3) dual-branch feature extraction using fixed multi-scale convolutions; and (4) feature fusion and linear discrimination. The following subsections provide detailed descriptions of the design and implementation of each stage.
2.1. NinaPro Dataset
This study employs the DB1 dataset from the publicly available NinaPro database [36]. NinaPro is a multimodal open-access repository designed to support research on electromyography and prosthetic control by providing standardized data resources for gesture-recognition studies. As one of its primary subsets, DB1 contains a diverse set of gesture classes, a sufficiently large subject cohort, and rigorously standardized acquisition and annotation procedures. These characteristics make DB1 a widely recognized benchmark for sEMG-based gesture recognition, enabling fair comparison, reproducibility, and scientifically reliable model evaluation.
DB1 includes sEMG recordings from 27 subjects (20 males, 7 females; average age ≈ 28 years). Each subject performs 52 gestures (including rest), covering finger motions, static and dynamic gestures, wrist movements, and grasping actions. Signals are recorded using ten Otto Bock MyoBock 13E200 (Otto Bock HealthCare GmbH, Duderstadt, Germany) surface electrodes at a 100 Hz sampling rate, providing stable forearm muscle-activity measurements for subsequent analysis.
A within-subject evaluation protocol is adopted. For each subject, repetitions {2, 5, 10} are used for testing, while {1, 3, 4, 6, 7, 8, 9} serve as the training set, following commonly used partitioning strategies in prior work [37,38,39]. Model performance is assessed using five standard metrics: accuracy (ACC), precision (PRE), recall (REC), F1-score (F1-S), and Matthews correlation coefficient (MCC). Definitions of these metrics are provided in Table 1.
2.2. Signal Preprocessing
The raw sEMG signals are affected by intrinsic and external noise and therefore require systematic preprocessing. Following the Ninapro DB1 acquisition and classification protocol, the signals are first subject to interference suppression at the acquisition stage. Subsequently, a first-order Butterworth low-pass filter with a cutoff frequency of 1 Hz is applied prior to classification to attenuate high-frequency fluctuations. Rest segments are removed, and only motion segments are retained for subsequent analysis [36].
The motion labels provided in DB1 are obtained by visual inspection, and their onset/offset boundaries may contain inaccuracies caused by reaction delays or early terminations. Such boundary deviations can lead to incomplete motion segments or mislabeled rest intervals, which may hinder the learning of discriminative gesture patterns.
To mitigate this issue, an automatic motion-boundary refinement method is employed, which combines multi-channel generalized likelihood ratio (GLR)-based change-point detection with a voting-based fusion strategy. Specifically, for each annotated segment, the temporal window is expanded to include surrounding context, and each channel is modeled under a two-state statistical hypothesis corresponding to rest and motion. The motion onset and offset are estimated using a likelihood-based criterion within the expanded window.
To improve robustness against channel-specific noise, a voting fusion is applied across channels, where the earliest detected onset and the latest detected offset are selected as the final global boundaries. This procedure enables consistent boundary refinement across subjects and repetitions. Figure 2 illustrates a representative example (Subject S1, Channel 6, Gesture 2, Repetition 4), in which the refined segment exhibits a more complete and continuous motion pattern, demonstrating the effectiveness of the proposed boundary-refinement approach.
2.3. Variational Mode Decomposition (VMD)
sEMG signals acquired during gesture execution exhibit pronounced nonlinearity and non-stationarity. To effectively separate frequency components and suppress non-stationary noise, this study adopts an improved variational mode decomposition (VMD) method. Unlike empirical mode decomposition (EMD) and wavelet-based approaches, VMD is formulated within a strict variational optimization framework, achieving a more favorable balance between time–frequency localization and decomposition stability [40].
VMD decomposes a signal into a set of bandwidth-limited intrinsic mode functions (IMFs) by minimizing the sum of their individual bandwidths. In Algorithm 1, denotes the one-sided analytic spectrum of the input sEMG segment; is the frequency-domain representation of the -th IMF at iteration ; is its center frequency; and is the Lagrange multiplier enforcing reconstruction consistency. The algorithm employs the alternating direction method of multipliers (ADMM) to iteratively update each IMF and its corresponding center frequency until convergence. The key parameters are: number of modes , bandwidth penalty , dual-ascent step , and convergence tolerance . Each iteration updates the IMFs, adjusts center frequencies using spectral centroids, and then updates the multiplier to accelerate convergence.
To improve the practical applicability of VMD, three refinements are incorporated:
- DC-component correction, which mitigates baseline drift;
- Amplitude calibration using full-length least-squares normalization to ensure energy consistency;
- Quality indicators, including reconstruction error, energy ratio, and fallback rate.
Experimental results show that the median reconstruction error across all subjects ranges from 0.9% to 1.6%, with the 95th percentile below 10%. The IMF energy ratio remains stable at approximately 0.50, demonstrating numerically stable and highly reproducible decomposition. The resulting IMFs effectively suppress low-frequency drift and non-stationary noise while preserving the original time–frequency structure, thereby providing more robust inputs for subsequent feature extraction and gesture recognition. The sensitivity of the VMD parameters, particularly the number of modes K and the bandwidth penalty factor α, is systematically analyzed in the experimental section to assess the robustness of the adopted configuration. Algorithm 1: sEMG signal decomposition using improved VMDInitialize repeat for k = 1: K doUpdate each IMF in the frequency domain: Update the center frequency: end forUpdate the Lagrange multiplier (dual ascent): until convergence:
2.4. IMF Selection Based on Weighted Feature Indicators
After VMD decomposition, each sEMG segment is decomposed into several intrinsic mode functions (IMFs). Because some IMFs mainly contain noise or weakly correlated components, relying on a single selection criterion may overlook important structural characteristics of the signal [41]. To address this issue, we adopt a weighted multi-feature evaluation strategy to automatically identify the most discriminative IMFs.
High-quality IMFs generally exhibit three properties: (1) a high energy ratio, indicating a dominant contribution to the signal; (2) strong correlation with the original sEMG, preserving major motion-related information; and (3) low complexity, reflecting stable structural behavior. Accordingly, three complementary indicators—energy ratio , Pearson correlation coefficient , and sample entropy —are used. All indicators are normalized using the min–max method:
The overall IMF score is then defined as:
where the weights , , and are determined following established multi-criteria evaluation principles and validated through extensive cross-validation. For each channel, IMFs are ranked in descending order of , and the top-N scoring modes are retained for subsequent feature extraction and modeling.
Table 2 shows that, for Subject S1 (Gesture 5, Repetition 8, Channel 1), IMF1 achieves higher correlation, higher energy ratio, and lower entropy than IMF2, resulting in the highest overall score and being selected as the effective IMF. Figure 3 presents the three-dimensional waveform comparison among the raw signal, decomposed IMFs, and the selected top-1 IMF, illustrating the fidelity and representativeness of the selected mode.
To ensure consistent input dimensions, all motion segments are standardized to a fixed window length of 1100 samples. Segments shorter than this length are zero-padded, whereas longer segments are truncated according to the statistical distribution of valid segments in the Ninapro DB1 dataset.
2.5. Model Architecture
2.5.1. Theoretical Motivation
Convolutional neural networks (CNNs) have been widely applied in time-series analysis owing to their ability to automatically extract local temporal features without handcrafted design [42]. In addition to the conventional spatial interpretation, recent studies provide a frequency-domain perspective, showing that convolutional kernels function as tunable filters capable of capturing multi-scale spectral structures in the input signal [43,44,45].
Saxe et al. further demonstrated that even randomly initialized kernels exhibit inherent frequency selectivity and naturally respond to specific spectral components without any training [46]. This phenomenon forms the theoretical basis of Random CNNs, in which fixed random filters combined with lightweight linear classifiers enable highly efficient feature extraction.
Motivated by this paradigm, the proposed Frozen Multi-Convolution Dual-Branch Network (FMC-DBNet) employs multi-scale random convolutions to achieve stable, training-free feature mapping. The dual-branch architecture further enhances physiological representation by jointly modeling raw sEMG signals and VMD-derived components.
2.5.2. Overall Model Architecture
The FMC-DBNet consists of two frozen random convolutional feature extraction branches and a linear classification module, as illustrated in Figure 1. After standardization, the input signals are fed separately into the raw signal branch (Raw Branch) and the VMD component branch (IMF Branch). The two branches share an identical architecture but do not share parameters. Each branch contains multiple one-dimensional random convolutional layers, where different combinations of kernel sizes and dilation rates are used to capture multi-scale temporal characteristics. The convolution kernels remain frozen after random initialization and are not updated through backpropagation.
The convolution operation is defined as follows:
where denotes the input signal at time step for channel ; represents the convolution kernel; is the bias term; and denotes the nonlinear activation function (ReLU in this study). The convolutional weights are randomly initialized according to:
denotes the number of input channels, and represents the kernel length. A “same” padding strategy is employed, and the corresponding calculation formula is given by:
This configuration ensures that the temporal length of the feature sequence remains consistent across layers during propagation.
2.5.3. Feature Extraction and Statistical Mapping
To enhance the stability and discriminability of the extracted features, two statistical measures are computed after each convolutional output: Global Average Pooling (GAP) and Proportion of Positive Values (PPV). The former reflects the overall activation strength of each channel, while the latter represents the proportion of positive outputs after ReLU activation. Their definitions are given as follows:
where denotes the temporal length, and represents the activation value of channel at time .
For each convolutional kernel, the GAP and PPV features are concatenated to form a multi-scale subspace representation. Subsequently, the features extracted from the Raw and IMF branches are fused along the channel dimension to construct an integrated multi-scale time–frequency feature vector. This architecture preserves both the global trends of the raw signal and the local details of the VMD components, enabling robust modeling of sEMG signals.
2.5.4. Feature Fusion and Classification
The fused global features are input into a linear discriminant classifier for final recognition. This study employs a Ridge classifier, a linear regression model with an L_2_ regularization term, in which the weights are estimated by minimizing the following objective function:
Here, denotes the feature matrix of the training samples, is the one-hot encoded class indicator matrix, and represents the regularization coefficient. The closed-form solution is given as:
During the testing phase, the feature vector is linearly projected to obtain class scores, and the predicted label is determined by the index corresponding to the maximum score:
The Ridge classifier features a simple structure and low computational cost. It achieves high recognition accuracy while avoiding the backpropagation process of deep networks, making it suitable for lightweight scenarios with frozen convolutional feature extractors.
2.5.5. Summary of Model Architecture
In summary, the proposed FMC-DBNet is centered on a dual-branch frozen random convolutional architecture that performs hierarchical representation of sEMG signals through multi-scale convolution and statistical mapping. The model comprises four main components—signal input, feature extraction, feature fusion, and linear classification—providing a complete implementation framework for the subsequent experiments.
3. Results
3.1. Experimental Setup
All experiments were conducted on a Windows 10 (64-bit) system equipped with an Intel i5-9300H CPU (Intel Corporation, Santa Clara, CA, USA), 16 GB RAM, and an NVIDIA GTX 1650 GPU (NVIDIA Corporation, Santa Clara, CA, USA). The implementation was developed using PyTorch 1.13.1 (CUDA 11.6, cuDNN 8) and scikit-learn 1.6.1, with fixed random seeds to ensure reproducibility.
The experimental pipeline followed Section 2.2, Section 2.3 and Section 2.4, including GLR-based boundary correction, VMD decomposition, IMF selection, and segment standardization. According to the protocol in Section 2.1, repetitions {2, 5, 10} were used for testing, while {1, 3, 4, 6, 7, 8, 9} served as training data. All motion segments were truncated or zero-padded to 1100 samples to ensure consistent input length. The frozen CNN feature extractor remained unchanged, and only the final Ridge classifier was trained. The detailed experimental configuration and implementation settings are summarized in Appendix A.
For each subject, five independent experiments were performed using random seeds {42, 123, 777, 2024, 2025}, and a five-fold cross-validation procedure was applied within each experiment. Training time was defined as the total duration of feature extraction and classifier training, and the reported values represent the mean and standard deviation over five runs. Model performance was evaluated using five metrics—ACC, PRE, REC, F1-S, and MCC—computed on the designated test set.
3.2. Frequency-Domain Feature Analysis
To verify whether the sEMG signals used in this study exhibit discriminative characteristics in the frequency domain and to provide theoretical support for the design of multi-scale convolutional kernels, this section conducts a frequency-domain analysis on the training samples. We employed the Welch method (Hamming window, 50% overlap, 512-point FFT) to estimate the power spectral density (PSD) within the 0–5 Hz range and analyzed the spectral distributions associated with different gesture classes.
Figure 4 summarizes the global spectral characteristics of the 52 gesture classes from Subject S1. As shown in Figure 4a, clear low-frequency differences appear across gestures within the 0–5 Hz band, particularly in the 0–1 Hz range. Some gestures exhibit pronounced low-frequency energy peaks, whereas others show relatively flat spectral responses. To further emphasize these distinctions, Figure 4b presents the mean PSD in the 0–1 Hz band for each gesture class, where the largest inter-class variations are observed.
To examine gesture-specific spectral behavior in more detail, four representative gesture categories—Finger, Posture, Wrist, and Grasping—were selected, and pairwise spectral comparisons were conducted for gestures with similar visual appearances or physiological characteristics (Figure 5). The comparisons show that within the 0–1 Hz band, the energy-decay patterns and spectral shapes differ substantially across gestures—for example, between Little finger flexion and Little finger extension (Figure 5a), and between Thumb up and Thumb opposing (Figure 5b).
Overall, the results indicate that the sEMG signals used in this study contain their most discriminative information within the 0–1 Hz low-frequency range. These findings directly support the multi-scale convolution-kernel design in FMC-DBNet: randomly initialized kernels with different receptive fields can capture distinct frequency components without training, thereby enhancing the network’s ability to model multi-scale temporal structures.
3.3. Network Configuration
As shown in Table 3, the proposed FMC-DBNet adopts two structurally symmetric but parameter-independent 1D convolutional branches for processing raw sEMG signals and VMD-derived IMF components.
Although the two branches share the same architecture, their convolutional kernels are not shared, allowing each branch to learn domain-specific and complementary frequency patterns. Each branch contains three parallel convolutional modules whose kernel lengths and dilation rates are determined through a Tree-structured Parzen Estimator (TPE) search. The search space was and . Using the average five-fold test accuracy across 27 subjects as the objective, 200 optimization rounds yielded the optimal multi-scale configuration , corresponding respectively to local, mid-range, and long-range temporal receptive fields.
Each convolutional module outputs 256 channels with weights initialized by Kaiming Normal initialization and then frozen to ensure stability and reproducibility. Same padding is used to maintain the input length of 1100 samples, and ReLU activation is applied after convolution. From each module, two statistical descriptors are extracted: global average pooling (GAP), representing mean activation strength, and the proportion of positive values (PPV), reflecting sparsity and activation distribution. Concatenating GAP and PPV results in a 512-dimensional feature vector per module, and combining the three modules produces a 1536-dimensional multi-scale representation for each branch. The raw-signal and IMF branches are then fused into a final 3072-dimensional feature vector.
Since all convolutional parameters remain fixed, an -regularized Ridge classifier serves as the only trainable component. The regularization coefficient was optimized within using TPE with logarithmic sampling, yielding . This “frozen convolution + linear readout” design eliminates backpropagation-related overhead, significantly reduces training cost, and improves robustness, while still retaining high recognition performance. Overall, FMC-DBNet combines multi-scale convolutions, dual-branch feature extraction, and statistical aggregation to effectively capture the time–frequency characteristics of sEMG signals without relying on trainable convolution kernels.
3.4. Model Training and Evaluation
To evaluate the proposed FMC-DBNet, independent experiments were conducted on 27 subjects from the Ninapro DB1 dataset. All subjects used GLR-corrected motion segments and VMD-selected IMF features as inputs. Throughout training, all convolutional kernels remained frozen, and only the Ridge classifier parameters were optimized. To analyze model robustness, each subject was trained under five random seeds (42, 123, 777, 2024, 2025), with five-fold cross-validation performed in each run.
As shown in Figure 6, the trends of training, cross-validation, and test accuracy across subjects are highly consistent, with most standard deviations below 2–3%, indicating low sensitivity to initialization randomness and stable performance across repeated runs. A few subjects (e.g., S16 and S20) exhibit slightly lower accuracy, possibly due to weaker sEMG amplitudes or higher noise levels, yet the overall pattern remains consistent.
Figure 7 further illustrates the distribution of test accuracy across the five runs for each subject. For most subjects, the boxplots are highly compact with minimal variance, and several subjects even exhibit identical results across all five runs, demonstrating strong robustness to random perturbations.
To examine class-level performance for a stable subject, Figure 8 provides the 52-class confusion matrix for subject S21.
Most predictions cluster near the diagonal, indicating strong overall recognition capability. Minor confusions occur between a few gesture pairs (e.g., 25/38, 32/31, 42/41), primarily among gestures with similar motion characteristics, suggesting room for enhancing inter-class separability in future work.
Overall, the results demonstrate that the proposed dual-branch multi-convolution frozen CNN model achieves stable, repeatable, and reliable recognition performance across subjects and random initializations, indicating strong potential for practical deployment.
3.5. Baseline Model
3.5.1. CNN Baseline
To ensure a fair and controlled comparison with the proposed FMC-DBNet, a conventional trainable single-branch 1D CNN was implemented as the baseline model. This network processes only the raw sEMG signals obtained after GLR-based segmentation and standardized to a fixed length of 1100 samples, without incorporating IMF information or frozen convolutional modules.
The baseline CNN consists of three sequential 1D convolutional layers with channel sizes of 64, 128, and 256 and kernel sizes of 5, 3, and 3, respectively. Each convolutional layer is followed by a ReLU activation and an adaptive average pooling layer. The pooled outputs from the three layers are concatenated and fed into a fully connected layer to produce predictions for the 52 gesture classes. Unlike FMC-DBNet, all parameters in the convolutional and fully connected layers are optimized through standard backpropagation.
To maintain strict fairness, the baseline model adopts the same training–test protocol described in Section 3.1, where repetitions {2, 5, 10} serve as the test set and the remaining repetitions are used for training. During training, 20% of the training portion is further split as a validation set for monitoring convergence and applying early stopping. This internal split does not alter the designated test set and therefore preserves full comparability with FMC-DBNet.
Training is performed using the Adam optimizer (learning rate of 1 × 10^−3^) with cross-entropy loss for a maximum of 50 epochs. The batch sizes are set to 64 and 32 for training and validation, respectively. To ensure reproducibility, the entire training procedure is repeated five times using random seeds {42, 123, 777, 2024, 2025}.
This baseline establishes the performance upper bound of a fully trainable CNN under the same data preprocessing and input constraints. Its results are reported in Section 3.6 alongside FMC-DBNet to enable a fair quantitative comparison in terms of accuracy, training cost, and model efficiency.
3.5.2. ROCKET-Based Random Convolution Baseline
In addition to the trainable CNN baseline, a ROCKET-based model was included as a lightweight, training-free baseline for time-series classification. ROCKET employs a large set of randomly initialized and fixed one-dimensional convolutional kernels, followed by simple statistical feature extraction and a linear classifier, without using backpropagation.
In this work, ROCKET is applied only to the raw sEMG signals (without IMF information) after GLR-based segmentation and temporal normalization to a fixed length of 1100 samples. A total of 5000 random convolutional kernels are generated, with kernel lengths randomly sampled from {7, 9, 11}. Convolutional weights are drawn from a zero-mean Gaussian distribution and mean-centered, while bias terms are uniformly sampled. Dilation factors and zero-padding are randomly assigned following the original ROCKET formulation. All kernel generation and feature extraction procedures strictly follow the original ROCKET design.
For each kernel and each input channel, two features are extracted: the maximum convolution response (MAX) and the proportion of positive values (PPV). These features are concatenated and classified using a Ridge classifier, with the regularization parameter selected via cross-validation on the training set using a logarithmically spaced candidate set.
To ensure fair comparison, the ROCKET baseline follows the same repetition-based training–test protocol as FMC-DBNet, where repetitions {2, 5, 10} are used for testing. During cross-validation, a repetition-wise GroupKFold strategy is adopted to prevent information leakage between correlated repetitions.
3.6. Model Efficiency and Comparative Analysis
3.6.1. Comparison with CNN and ROCKET
Under the subject-dependent evaluation protocol, FMC-DBNet was compared with two representative baselines: the fully trainable single-branch 1D-CNN described in Section 3.5 and a ROCKET-based random convolution classifier implemented under the same data setting. All methods followed the identical preprocessing pipeline and the fixed subject-wise train/test splits specified in Section 3.1, so that the observed performance differences were attributable to model design under a consistent evaluation protocol.
In addition to average accuracy, subject-level statistical analysis was performed using McNemar’s test on paired test-set predictions. For each subject, FMC-DBNet and the corresponding baseline were evaluated on exactly the same test samples, forming a paired 2 × 2 contingency table from which exact two-sided McNemar p-values were computed. To control the family-wise error rate across the 27 subject-wise comparisons, Holm–Bonferroni adjustment was applied separately for the FMC-DBNet vs. CNN and FMC-DBNet vs. ROCKET comparisons. A subject-level difference was considered statistically significant when the Holm-adjusted p-value was below 0.05. Figure 9 shows the subject-wise accuracy differences (ΔAccuracy = − ).
Solid markers indicate subjects with statistically significant differences after Holm–Bonferroni adjustment, whereas hollow markers denote non-significant differences. FMC-DBNet shows higher recognition accuracy than the trainable CNN for most subjects, and a substantial portion of these improvements remains significant after adjustment. Compared with ROCKET, FMC-DBNet also achieves higher accuracy on the majority of subjects, while fewer differences reach statistical significance, indicating the strong competitiveness of random convolution–based baselines under the same protocol.
For the McNemar analysis, predictions were aggregated across multiple runs with different random seeds into a single final decision for each test sample, enabling a one-to-one paired comparison at the sample level.
As a supplementary comparison, we summarize the recognition accuracy and computational cost of FMC-DBNet and the two baselines under the same evaluation protocol. Training time is defined as the total time for feature extraction and classifier fitting per subject, while single-sample inference time denotes the average prediction time per test sample.
The trainable CNN baseline achieved an average accuracy of 87.01% ± 4.30%, and the ROCKET baseline reached 88.66% ± 4.80%. In contrast, FMC-DBNet attained higher accuracy (e.g., 96.40% under the default setting) with substantially lower training overhead due to its frozen-convolution design.
Regarding computational cost, timing results are reported under standard execution settings and an additional CPU-only setting. Under standard settings, ROCKET (CPU) required 52.02 ± 0.38 s for training and 137.4 ± 0.7 ms/sample for inference; the trainable CNN (GPU) required 14.39 ± 0.11 s and 0.344 ± 0.07 ms/sample; and FMC-DBNet (GPU feature extraction + CPU Ridge) required 1.30 ± 0.01 s and 0.655 ± 0.077 ms/sample. Under CPU-only execution, FMC-DBNet required 8.53 s for training and 9.35 ms/sample for inference, whereas the trainable CNN required 155.49 s and 3.368 ms/sample, respectively.
Overall, these results indicate that FMC-DBNet provides a favorable accuracy–efficiency trade-off by achieving high recognition performance with markedly reduced computational cost while avoiding backpropagation-intensive optimization.
3.6.2. Internal Analysis of FMC-DBNet
To assess the accuracy–efficiency trade-off, FMC-DBNet was evaluated with channel widths . For each setting, 200 rounds of TPE-based hyperparameter search were conducted. The convolutional layers were randomly initialized and kept frozen, and an -regularized Ridge classifier was used. Data partitioning followed Section 3.1.
As shown in Figure 10a, accuracy increased with channel width and saturated at . The mean test accuracy reached 96.63% at , while already achieved 94.74%. Figure 10b,c report the corresponding training time and per-sample inference latency, both of which increased with model capacity. The training time in Figure 10b corresponds to the total training time per subject on the entire training set, rather than the time of a single batch.
A subject-wise nonparametric analysis (Figure 11) confirmed a significant overall effect of channel width (Friedman test, ). Holm-corrected Wilcoxon tests showed significant gains up to , whereas the difference between and was not significant. Therefore, was selected as the default configuration for subsequent experiments.
Under , FMC-DBNet achieved an average accuracy of 96.40%, with a precision of 97.25%, a recall of 96.40%, an F1-score of 96.22%, and an MCC of 96.35%.
3.6.3. Sensitivity Analysis of VMD Parameters
To examine the robustness of the proposed method with respect to VMD parameter selection, a sensitivity analysis was conducted on two key parameters: the number of modes and the bandwidth penalty factor . These parameters directly affect the decomposition characteristics of the extracted intrinsic mode functions (IMFs).
In this study, is varied from 2 to 4, and is selected from . All other settings, including preprocessing, IMF selection strategy, network architecture, and classifier configuration, are kept identical to ensure a fair comparison. The same subject-wise training and testing protocol described in Section 3.1 is adopted.
The results, summarized in Table 4, indicate that the recognition performance remains generally stable across different parameter combinations. Increasing beyond 2 does not lead to further performance improvement and instead introduces slight accuracy degradation, which is likely caused by redundant or weakly informative IMFs. Regarding , smaller values may yield marginally higher accuracy in some cases; however, the performance differences across different settings are minor.
Considering both classification performance and decomposition stability, and are selected as a robust and well-balanced configuration. Overall, the proposed framework demonstrates low sensitivity to VMD parameter variations, confirming the robustness of the adopted settings.
3.7. Ablation Study
To assess the contribution of each component in FMC-DBNet, we conducted a series of ablation experiments under a consistent data split and evaluation protocol. The results are summarized in Table 5.
First, we compared GAP, PPV, and their combination as feature types. The results show that GAP + PPV achieves the highest accuracy (96.40%), outperforming the use of GAP alone (94.79%) or PPV alone (95.66%). This indicates that energy statistics and activation sparsity offer complementary temporal characteristics.
Second, regarding the input branches, the dual-branch configuration (Raw + IMF) outperforms either single-branch model, confirming the value of IMF components in providing complementary frequency-domain information and enhancing noise suppression.
In terms of convolutional structure, three configurations were evaluated: single-kernel convolution, multi-kernel without dilation, and multi-kernel with dilation. The accuracy increased from 94.37% with a single kernel to 95.92% with multiple kernels, and further to 96.40% after adding dilation. This indicates that multi-scale convolutions and dilated mechanisms better model both short- and long-term temporal dependencies.
Finally, in terms of the classifier, Ridge regression on frozen features clearly outperforms the trainable FC + Softmax approach (96.40% vs. 91.71%). This suggests that a linear classifier better preserves the stability of random frozen features, whereas end-to-end Softmax training tends to undermine their robustness.
In addition to the ablation results, we examined whether the GAP and PPV feature groups are utilized by the final linear classifier. Using the learned Ridge coefficients, the mean absolute weight is 0.00417 ± 0.00045 for GAP and 0.00708 ± 0.00071 for PPV, aggregated across subjects and random seeds. Both feature groups show consistently non-zero and stable weight magnitudes, suggesting that GAP and PPV jointly contribute to gesture discrimination, with PPV having a higher average contribution. This lightweight analysis provides quantitative evidence for the usefulness of the proposed statistical features without changing the overall model design.
3.8. Comparison with State-of-the-Art Methods
To further assess the effectiveness of the proposed FMC-DBNet, we compare it with several representative NinaPro DB1–based approaches reported in recent years. Table 6 summarizes the recognition performance of the compared models on the DB1 dataset.
All competing methods employ the same 52 gesture classes, the same set of 27 subjects, and comparable data-splitting protocols to ensure a fair evaluation. The comparison covers a diverse range of deep architectures, including the feature-enhanced PFNet, the multi-view fusion model HVPN, the multimodal framework sEMG-XCM, the multi-scale fusion network MCMP-Net, and the spatiotemporal hybrid model STMS-Net.
PFNet and HVPN achieve accuracies of approximately 87–88%, while sEMG-XCM and MCMP-Net reach around 91%. In contrast, the proposed FMC-DBNet attains 96.40% under the same experimental settings, substantially outperforming these representative approaches. This result indicates that, even with fully frozen convolutional kernels and no backpropagation, the multi-scale dual-branch architecture can still effectively capture stable discriminative temporal patterns, yielding superior accuracy and computational efficiency.
It is worth noting that minor differences exist in the experimental splits adopted by different studies, and we have aligned the settings as closely as possible to ensure fair comparison. Overall, the results show that FMC-DBNet offers a markedly better balance between accuracy and computational efficiency than most trainable deep models, demonstrating stronger practical value for small-sample sEMG recognition tasks.
4. Discussion
The proposed lightweight Frozen Multi-Convolution Dual-Branch Network (FMC-DBNet) achieves an average accuracy of 96.4% with a training time of only 1.30 s on the Ninapro DB1 dataset, substantially outperforming the conventional trainable CNN (87.0%), a ROCKET-based random convolution baseline, and several hybrid architectures [22,24]. Across 27 subjects and multiple random trials, the model maintains consistently stable performance, indicating that the frozen convolutional structure preserves strong cross-subject generalization despite its extremely low computational cost.
From the perspective of feature learning, the dual-branch design explicitly decouples raw sEMG signals from their VMD-derived IMFs, enabling complementary modeling of high-frequency muscular activation patterns and low-frequency modal trends. The time–frequency locality of VMD suppresses non-stationary components, and in combination with the multi-criteria IMF selection strategy [41], provides cleaner and more interpretable time–frequency representations without increasing model complexity. This improved representation contributes directly to the network’s robustness against noise and inter-subject variability.
In terms of convolutional feature extraction, the model employs randomly initialized and frozen multi-scale kernels, following the paradigm of random feature mapping used in RVFL [27,28,29], ROCKET [30], and edRand-CNN [34]. The statistical aggregation of PPV and GAP further compensates for the absence of trainable kernels, enabling the network to capture both localized activation patterns and global energy structures under fixed weights. The experimental results confirm that this “frozen convolution + statistical aggregation” strategy can still produce highly discriminative features without relying on backpropagation.
In terms of efficiency, FMC-DBNet requires only 1.30 s for training, making it roughly ten times faster than a trainable CNN. Together with the findings of Saxe et al. [46] and Ovadia et al. on the stability of random-weight networks, our results further demonstrate that random convolutional architectures exhibit strong generalization and robustness to distributional shifts in sEMG recognition tasks.
Despite its strong performance, this study has several limitations. The model relies on VMD hyperparameters and the IMF selection strategy, which may be sensitive to signal quality variations across different data sources. In addition, the current evaluation is restricted to Ninapro DB1, and its cross-database and cross-device generalizability remains unverified. Future work may explore adaptive mode decomposition, end-to-end decomposition networks, and further validation on datasets such as DB2, DB5, and CapgMyo. Integrating transfer learning or incremental learning strategies may also enhance the model’s adaptability in real-world, complex environments.
In summary, FMC-DBNet achieves efficient, lightweight, and interpretable sEMG feature modeling through temporal–spectral decoupling, multi-scale random convolutions, and statistical feature aggregation, offering a promising solution for low-power wearable devices and real-time myoelectric control systems.
5. Conclusions
This study proposes a lightweight Frozen Multi-Convolution Dual-Branch Network (FMC-DBNet) for sEMG-based gesture recognition. The method extracts temporal–spectral features from both raw signals and IMFs via VMD and aggregates them through PPV and GAP without any trainable parameters. Without relying on backpropagation, the model achieves an average accuracy of 96.4% on Ninapro DB1 while reducing training time by approximately 90% compared with a trainable CNN, demonstrating the effectiveness and computational advantages of frozen random convolutions for myoelectric recognition.
From a theoretical perspective, FMC-DBNet extends random feature learning into the convolutional domain by integrating the random mapping principle of RVFL with the random convolution mechanisms of ROCKET and edRand-CNN, while incorporating a VMD-based physiological feature pathway. This design remains lightweight while offering both interpretability and robustness.
Future research may proceed along three directions. First, exploring adaptive or end-to-end mode decomposition approaches to reduce reliance on VMD hyperparameters. Second, evaluating cross-subject and cross-device generalization on datasets such as DB2, DB5, and CapgMyo. Third, deploying the model on low-power hardware platforms to support real-time applications in rehabilitation aids and wearable devices.
Overall, FMC-DBNet provides a new direction for applying random convolutions to physiological signal recognition and achieves a well-balanced trade-off among performance, efficiency, and deployability.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Copaci D. Arias J. Gomez-Tome M. Moreno L. Blanco D. s EMG-Based Gesture Classifier for a Rehabilitation Glove Front. Neurorobot.20221675048210.3389/fnbot.2022.75048235706550 PMC 9190783 · doi ↗ · pubmed ↗
- 2Montazerin M. Rahimian E. Naderkhani F. Atashzar S.F. Yanushkevich S. Mohammadi A. Transformer-based hand gesture recognition from instantaneous to fused neural decomposition of high-density EMG signals Sci. Rep.2023131100010.1038/s 41598-023-36490-w 37419881 PMC 10329032 · doi ↗ · pubmed ↗
- 3Wang H. Li N. Gao X. Jiang N. He J. Analysis of electrode locations on limb condition effect for myoelectric pattern recognition J. Neuroeng. Rehabil.20242117710.1186/s 12984-024-01466-y 39363228 PMC 11448204 · doi ↗ · pubmed ↗
- 4Wei Z. Zhang Z.Q. Xie S.Q. Continuous Motion Intention Prediction Using s EMG for Upper-Limb Rehabilitation: A Systematic Review of Model-Based and Model-Free Approaches IEEE Trans. Neural Syst. Rehabil. Eng.2024321487150410.1109/TNSRE.2024.338385738557618 · doi ↗ · pubmed ↗
- 5Zandigohar M. Han M. Sharif M. Gunay S.Y. Furmanek M.P. Yarossi M. Bonato P. Onal C. Padir T. Erdogmus D. Multimodal fusion of EMG and vision for human grasp intent inference in prosthetic hand control Front. Robot. AI 202411131255410.3389/frobt.2024.131255438476118 PMC 10927746 · doi ↗ · pubmed ↗
- 6Guerra B.M.V. Schmid M. Sozzi S. Pizzocaro S. De Nunzio A.M. Ramat S. A Recurrent Deep Network for Gait Phase Identification from EMG Signals During Exoskeleton-Assisted Walking Sensors 202424666610.3390/s 2420666639460147 PMC 11510922 · doi ↗ · pubmed ↗
- 7Jiang B. Wu H. Xia Q. Xiao H. Peng B. Wang L. Zhao Y. An efficient surface electromyography-based gesture recognition algorithm based on multiscale fusion convolution and channel attention Sci. Rep.2024143086710.1038/s 41598-024-81369-z 39730496 PMC 11680932 · doi ↗ · pubmed ↗
- 8Rahman M.M. Uzzaman A. Khatun F. Aktaruzzaman M. Siddique N. A comparative study of advanced technologies and methods in hand gesture analysis and recognition systems Expert Syst. Appl.202526612592910.1016/j.eswa.2024.125929 · doi ↗