Efficient Blended Models for Analysis and Detection of Neuropathic Pain from EEG Signals Using Machine Learning
Sunil Kumar Prabhakar, Keun-Tae Kim, Dong-Ok Won

TL;DR
This paper proposes efficient blended machine learning models to detect neuropathic pain from EEG signals, achieving high classification accuracy.
Contribution
The novelty lies in the development of two blended models combining advanced feature selection and hybrid classification techniques for neuropathic pain detection.
Findings
The best model achieved a classification accuracy of 92.68% using FCM features and Polynomial Kernel-based PLS-SVM.
Hybrid feature selection techniques like SSO-PSO improved model performance significantly.
Blended models outperformed traditional methods in neuropathic pain classification from EEG data.
Abstract
Due to the damage happening in the nervous system, neuropathic pain occurs and it affects the quality of life of the patient to a great extent. Therefore, some clinical evaluations are required to assess the diagnostic outcomes precisely. A lot of information about the activities of the brain is provided by Electroencephalography (EEG) signals and neuropathic pain can be assessed and classified with the aid of EEG and machine learning. In this work, two approaches are proposed in terms of efficient blended models for the classification of neuropathic pain through EEG signals. In the first blended model, once the features are extracted using Discrete Wavelet Transform (DWT), statistical features, and Fuzzy C-Means (FCM) clustering techniques, the features are selected using Grey Wolf Optimization (GWO), Feature Correlation Clustering Technique (FCCT), F-test, and Bayesian Optimization…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
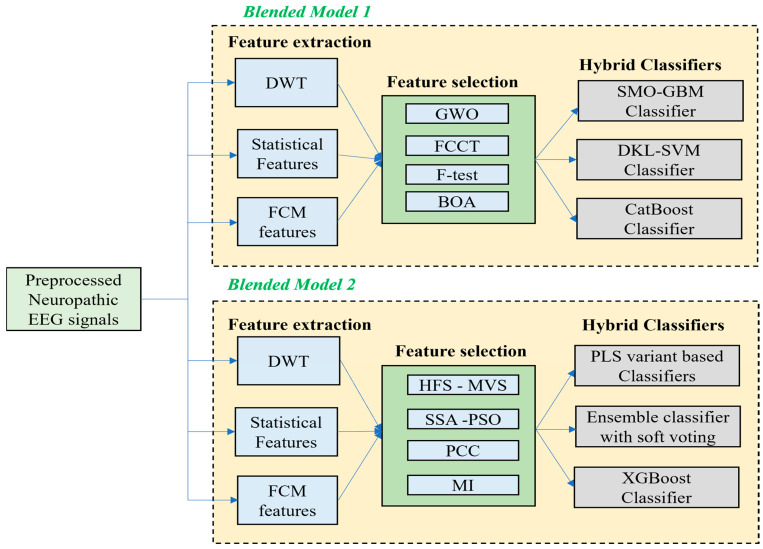 Figure 1
Figure 1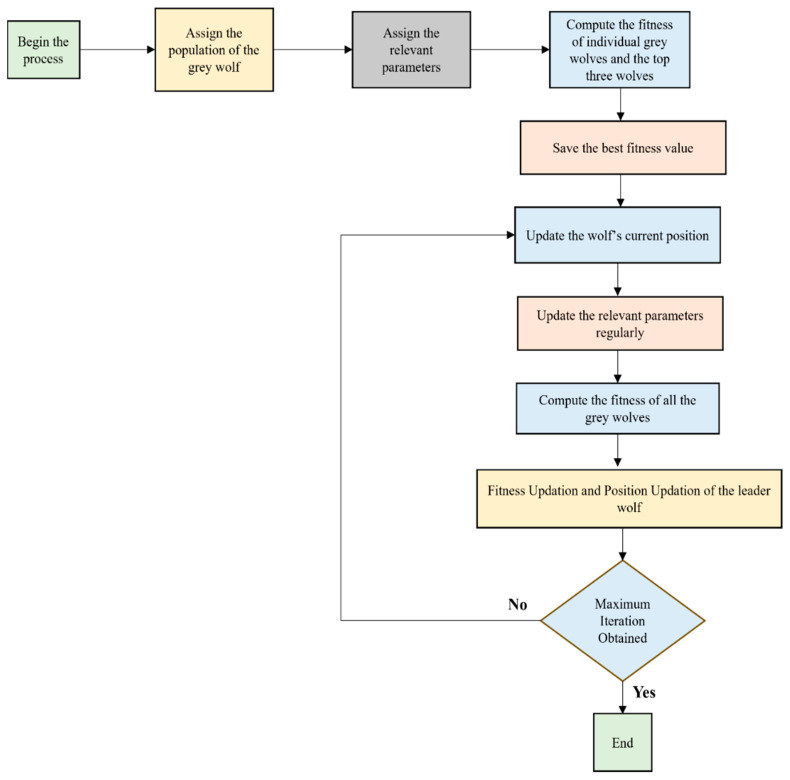 Figure 2
Figure 2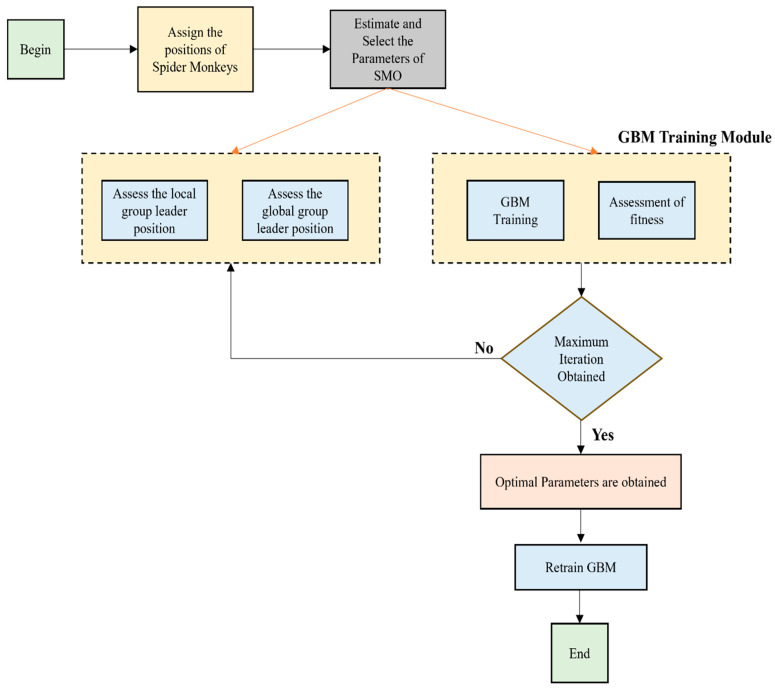 Figure 3
Figure 3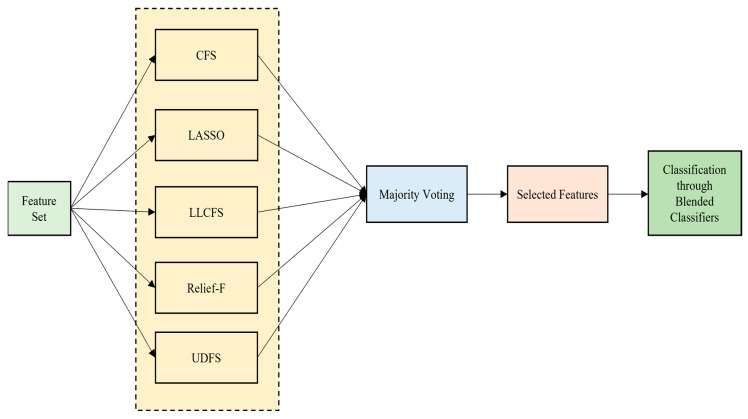 Figure 4
Figure 4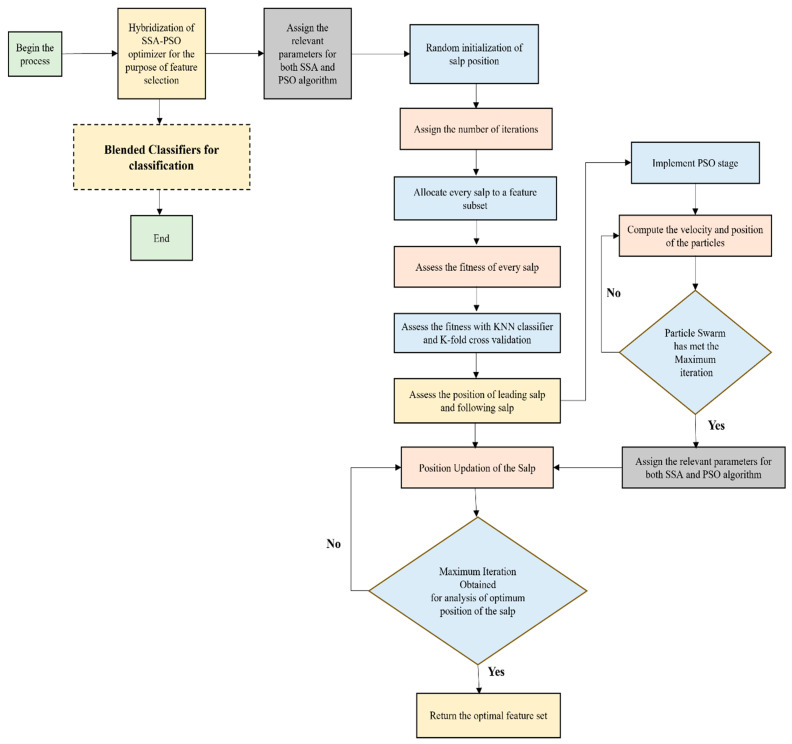 Figure 5
Figure 5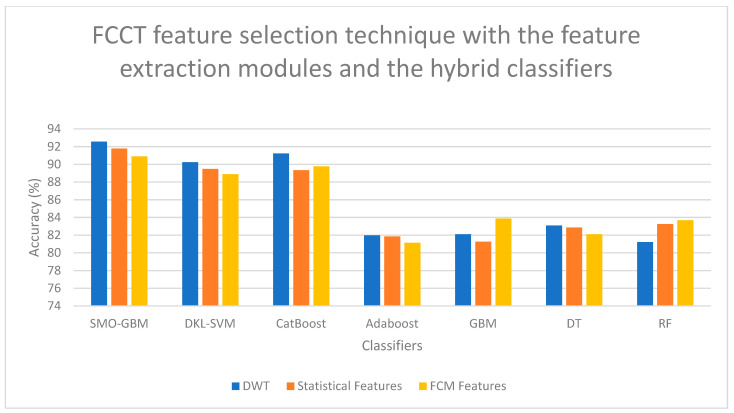 Figure 6
Figure 6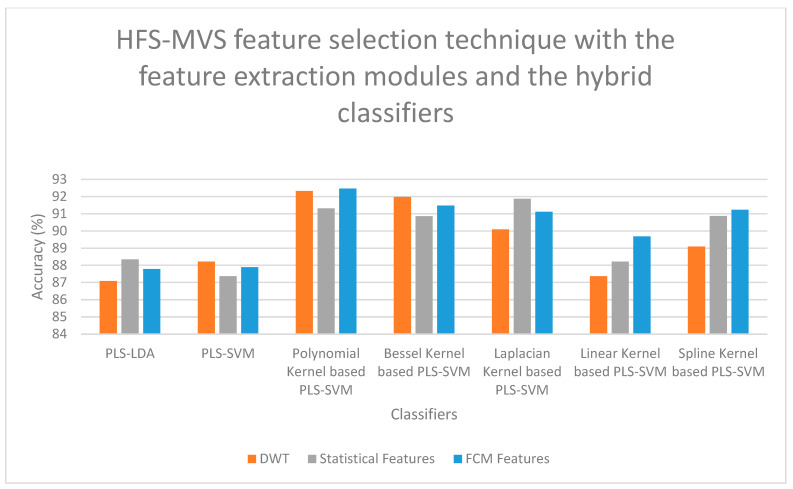 Figure 7
Figure 7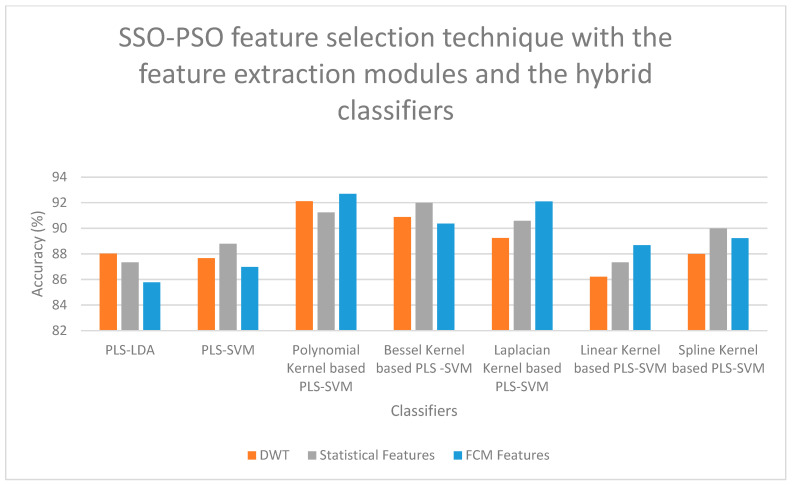 Figure 8
Figure 8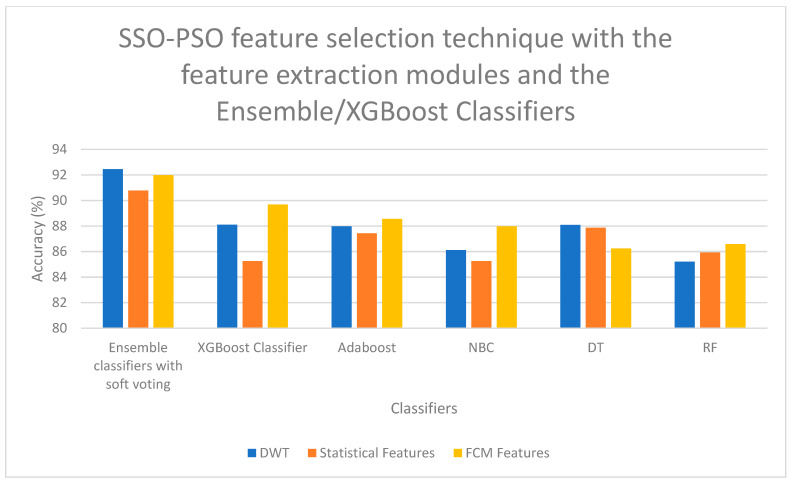 Figure 9
Figure 9- —Korean government (MSIT)
- —Ministry of Education (MOE) and the Gangwon State (G.S.), Republic of Korea
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPain Mechanisms and Treatments · Emotion and Mood Recognition · EEG and Brain-Computer Interfaces
1. Introduction
When the somatosensory system becomes affected, it leads to neuropathic pain [1]. Long-term neuropathic pain is termed as chronic neuropathic pain and when the duration is more than six months, it affects the brain and spinal cord significantly, affecting the quality of life of the patient to a great extent [2]. Multiple and effective pain management techniques are not available for people affected with neuropathic pain. Understanding and diagnosing neuropathic pain is difficult as its underlying mechanism is tough to understand and interpret. Therefore, this chronic neuropathic pain has a huge clinical challenge as it leads to constant pain for patients. There is no definite biomarker to assess the neuropathic pain condition and hence diagnosing and treating it becomes much more difficult [3]. As neuroplasticity is highly unpredictable, the complexity of neuropathic pain is very tough to understand and analyze. With the help of linear techniques, the neurophysiological correlates are extracted from the EEG signals [4]. Only simple behaviour is assumed by such linear techniques and, in multiple instances, the brain does not function as a linear system, so linear techniques have severe limitations [5]. There is always a constant shifting of neuronal dynamics in the brain so that the changes cannot be easily detected by the brain in both external and internal environments.
When the neural process works in an abnormal manner, it gives rise to severe damage in the nervous system, causing chronic neuropathic pain [6]. Due to many pathological conditions, accidents or injuries, neuropathic pain occurs. Other forms of pain can be clearly distinguished from neuropathic pain based on its chronicity factor. Neural impairment is heavily contributed by chronic neuropathic pain and a lot of other disorders are sometimes accompanied by problems such as multiple sclerosis, epilepsy, diabetic retinopathy, etc. [7]. The quality of life is impacted by this chronic neuropathic pain. The standard therapies provided by the clinical drugs do not improve the symptoms for most of the cases. Apart from the medication, physiotherapy accompanied by neurostimulation is sometimes utilized to alleviate pain [8]. Only when there are continuous efforts, sincerity, and commitment can the treatment be taken fully; otherwise, it will not provide fruitful results. A healthcare professional is required to evaluate and diagnose clinical neuropathic pain to a great extent. The standard procedure involves analyzing the full medical history of the patient followed by an in-depth physical examination and other necessary tests [9]. In spite of following all these tasks carefully, it is still difficult to achieve a definite diagnosis. In this paper, two efficient blended models are proposed for the automated diagnosis and classification of chronic neuropathic pain from EEG signals. Some of the recent and important works proposed in this field are discussed as follows.
Cohen et al. discussed the mechanism of neuropathic pain and its clinical implications [10]. The medication analysis and management of neuropathic pain disorders was analyzed by Finnerup et al. [11]. The management of neuropathic pain was analyzed well by Nishikava and Nomoto [12] and the pharmacologic management of neuropathic pain was investigated well by Nudell et al. [13]. The neuropathic pain component and its relationship with the time elapsing concept was discussed by Kim et al. [14]. The brain networks with good connectivity in patients suffering from neuropathic pain were developed by Hasan et al. [15]. The EEG signals with a slow and reduced reactivity in neuropathic pain were analyzed by Boord et al. [16]. The pain severity was quantified with the help of EEG-based functional connectivity by Haghighi et al. [17]. An adaptive neuro fuzzy inference system (ANFIS) adapted Radial Basis Function (RBF) kernel SVM was used for the classification of perceptual pain by Vatankhah et al. [18]. For discriminating against neuropathic and nociceptive pain, the identification of the brief pain inventing score was performed by Erdemoglu and Koc [19]. A novel screening measure to trace the neuropathic components in patients with back pain was identified by Freynhagen et al. [20]. The pain perception was decoded well using EEG signals for a real-time reflex system by Tayeb et al. [21]. For the analysis of the severity of chronic neuropathic pain, the resting state frontal EEG biomarkers were used by Ryu et al. [22]. A systematic review about the resting state EEG biomarkers of chronic neuropathic pain was provided by Mussigmann et al. [23]. A mechanistic review about the EEG neurofeedback for the treatment of neuropathic pain in the elderly was given by Chmiel et al. [24]. A comprehensive analysis in search of a solid biomarker for chronic pain by using EEG and machine learning was performed by Rockholt et al. [25]. The acute pain signals were detected from human EEG by Sun et al. [26]. The convolutional neural networks (CNN) were used to detect pain in the scalp-based EEG by Chen et al. [27] and the subjective perception of pain was objectively quantified with EEG by Elsayed et al. [28]. Five distinct levels of pain were distinguished with the help of EEG signal features by Nezam et al. [29]. The EEG data was analyzed thoroughly for both eyes-open and eyes-closed cases for the chronic neuropathic pain conditions by Zolezzi et al. [30]. Both linear and non-linear approaches were discussed in detail for analyzing the EEG frequency bands so that the neuropathic pain could be classified easily by Zolezzi et al. [31]. The significance of clinical and electrophysiological measures was assessed for the analysis of neuropathic pain in spinal cord injury by Wydenkeller et al. and a binary classification was performed for twenty-six subjects; a classification accuracy of 84% was obtained [32]. The central neuropathic pain was predicted in spinal cord injury based on EEG classifiers by Vuckovic et al. and a binary classification was performed for forty-one subjects; a classification accuracy of 86% was obtained [33]. The Higuchi Fractal analysis of EEG signals was analyzed as a marker of central neuropathic pain in people with spinal cord injury by Anderson et al. and a binary classification was performed for twenty subjects; a classification accuracy of 80% was obtained [34]. A quantum chaos butterfly optimization based on weighted SVM was analyzed for neuropathic pain detection from EEG signals by Bobby et al. and a three-class classification was performed for twenty-eight subjects, with a classification accuracy reported of 77.72% [35]. Multiple machine learning algorithms were developed to doubt the presence of chronic pain using the EEG data by Miller et al. and a binary classification was performed for 186 subjects; a classification accuracy of 79.6% was obtained [36]. A black-white hole pattern was proposed by Tasci et al. for the detection of chronic neuropathic pain where the proposed model gave over 99% classification accuracy across all the scenarios for the thirty-six subjects and three class classification schedules [37]. For the chronic neuropathic pain analysis, deep autoencoders and hybrid Mamba classifiers were used with advanced EEG signal processing techniques where an accuracy of 99% was reported by Senturk [38]. An EEG-based brain functional network methodology was used by Adebisi et al., where under binary classification between the neuropathic pain versus the control subjects, it achieved a higher accuracy of 97% [39]. Apart from neuropathic pain analysis from EEG signals, the EEG signals also aid in the analysis of other disorders like depression [40], and, even to understand the decoding of neural mechanisms, the EEG signals are highly useful [41]. A recent study even explored the foundation model of brain dynamics with gradient positioning and spatiotemporal masking with the help of EEG signals and it was analyzed in depth by Dong et al. [42], showing the versatility and efficacy of EEG signals for various applications.
Figure 1 shows the overall representation of the proposed blended models.
The contributions of this work are summarized as follows.
(a)Once the basic pre-processing of the EEG signals is conducted using a simple Independent Component Analysis (ICA), the following two efficient blended approaches were proposed.(b)In the first proposed efficient blended model, once the features are extracted by using DWT, statistical features, and FCM clustering techniques, the features are selected using GWO, FCCT, F-test, and BOA, and it is classified with the help of three hybrid classification models like SMO-GBM classifier, hybrid deep kernel learning with DKL-SVM classifier, and CatBoost classifier.(c)In the second proposed efficient blended model, once the features are extracted, the features are selected using HFS-MVS technique, Hybrid SSO-PSO technique, PCC, and MI and it is classified with the help of three hybrid classification models like PLS variant classification models, ensemble classification model with soft voting strategy, and XGBoost classifier.
The organization of the paper is as follows. Section 2 discusses the various feature extraction techniques and the proposed blended model 1 is discussed in Section 3. The proposed blended model 2 is discussed in Section 4 followed by results in Section 5. Section 6 explains the discussion part in detail, followed by conclusion and future works in Section 7.
2. Feature Extraction Techniques
In this work, DWT features, statistical features, and FCM features are extracted thoroughly.
2.1. Discrete Wavelet Transform (DWT)
For the analysis of non-stationary signals, one of the most powerful time–frequency techniques is DWT [43]. It is quite easy to use and has a low computational cost, and DWT is used widely for feature extraction purposes. Using the low-pass filters and high-pass filters, the decomposition of the signal can be performed efficiently into a collection of wavelets and the representation of coefficients are performed as follows:
where the transformation level is represented by and the number of coefficients is indicated by . indicate the scaling coefficient and indicate the wavelet coefficient. For the scaled and wavelet functions, the coefficient of the low-pass filter and high-pass filter are specified by and , respectively. The width of the filter is specified by in Equations (1) and (2). The approximate coefficient can be obtained when the removal of the high-frequency ingredients of the raw signals is accomplished successfully. The detailed coefficients can be obtained when the low frequency of the raw signals is removed by the high-pass filter. The separation of a raw signal can be accomplished successfully by shifting to a new and scaled version of a selected wavelet which is procured at any level. The sampling of the scaled coefficients and wavelet coefficients are obtained and so, the filter score length can be computed. Once the desired wavelet decomposition level is attained, the termination process can be implemented. Choosing the wavelet type is of prime importance as every wavelet has unique properties. Daubechies, Haar, Mexican, etc., are some of the commonly used wavelets and in this work (dB4) wavelet (i.e., fourth-order Daubechies is employed).
2.2. Statistical Features
Average Power, Standard Deviation, Kurtosis, Skewness, and Mean Absolute Value are some of the statistical features [44] computed in this work.
2.3. FCM Clustering Algorithm
To trace the natural patterns in a dataset, clustering can be widely used in the context of machine learning. The assigned observations in a cluster are interrelated to each other in the clustering technique. A lot of hidden data can be obtained with the help of clustering techniques in the entire dataset. The samples are divided into distinct clusters by these clustering techniques so that samples within a similar cluster are aligned closer to the samples within a dissimilar cluster. A widely used clustering algorithm is FCM and, in this algorithm, the data is prioritized to be assigned to two, three, four, or multiple clusters depending on the need of the problem [45]. Due to its practicality and easy usage, it is widely used for multiple applications in the field of pattern recognition. Most of the data is assigned to a well-prioritized cluster. Depending on the objective function minimization, the FCM is expressed as follows:
where the probability of a feature belonging to the cluster is indicated by . The feature is indicated by and the center coordinates of the cluster are assigned by . The Euclidean norm is indicated by and the number of features in the database is specified by . The number of clusters is indicated by and the fuzziness index is indicated by . The objective function is optimized iteratively and is used to accomplish the fuzzy partitioning. The updation of the membership and cluster centers is indicated as follows:
The data owned by multiple clusters can be reflected by the probability coefficients. A feature has a specific probability of which belongs to a cluster , and it is represented as follows:
With every cluster, a prediction probability is shared and indicated by the membership functions and the distance between the class center, and the prediction probability can be assessed well.
3. Proposed Blended Model 1
3.1. Feature Selection Techniques Used in Blended Model 1
Assuming the dataset to be which comprises samples, each having a total of number of features. The aim of the feature selection problem is to choose features from the features so that the objective function is optimized. When the feature selection issue is solved, feature selection schemes can be encoded in a simple manner by utilizing a binary string so that the solution of the feature selection issue can be specified well. Here, the feature selection method is indicated by where every binary string length equals the entire number of features . Every feature corresponds to a particular bit in the string. If the value is one, then it implies that the feature is chosen and if the value is 0, then it implies that the feature is not chosen. Thus, a solution can be obtained by a binary string of length comprising chosen features and it is expressed in the following equation:
The feature selection scheme is indicated by in the feature selection problem and implies that the selection of the feature is performed. For classification purposes, is known as the error rate. Minimizing is the main intention of the feature selection where the best combination of features is found out so that the classification error is mitigated and is expressed in the following equation as follows:
The above Equation (8) indicates equality constraint.
3.1.1. Grey Wolf Optimization (GWO)
The social behaviour of grey wolves gave an inspiration to develop the GWO algorithm [46]. The grey wolves are modelled or rather assigned into four unique levels such as and . The dominant wolf in the pack is denoted by and it is responsible for making major decisions and assigning leadership positions. The wolf is secondary to wolf and helps in hunting activities. The wolf acts as a security keeper and is responsible for providing protection to the team. The rest of the wolves are categorized as wolves and fully follow the commands of the wolves. Therefore, the solutions of the optimization problem are specified as and wolves, respectively. With the guidance of the leader wolves, the prey is surrounded and hunted successfully. There is excellent cooperation among the values during hunting process so that it can track the prey efficiency and in an analogous manner, this optimization algorithm helps to find the optimal solution. The hunting procedure is categorized into three major steps.
The initial phase is called the encirclement phase. Here the prey is tracked, located, and surrounded by grey wolves usually in a pack. Depending on the approximate location of the prey, every wolf updates the position so that a siege can be formed around it successfully. When the wolf surrounds the prey, it is mathematically expressed as follows:
where Grey Wolf position after updation is indicated by . The corresponding distance between the prey and wolf is indicated by and the number of iterations is indicated by . The position vector of wolf is represented as and the position vector of prey is represented as .
The correlation coefficient vectors are termed as and is computed as follows:
The and indicate the random vectors in the range of [0,1]. When the number of iterations increases, the vector value decreases in a linear manner and is computed as follows:
where represents the highest number of iterations and represents the current number of iterations.
The second phase is known as hunting phase. Once the prey location is assessed, the values precede the wolves successfully. The prey is captured successfully by the wolves based on mutual adjustments and cooperations. The and wolves help to assess the prey’s potential position. Once it is done, their respective positions are updated using wolves. The leader wolf assigns a lot of information to other wolves based on the position update. Mathematically, it is expressed as follows:
The vectors , , and are expressed as follows:
The vectors are represented as follows:
where the distance between the search agents and wolves are indicated by , , and , respectively. At a time , the position of the wolves are indicated by the vectors , , and , respectively, and they are considered as the best solutions. Random weights are assigned by the correlation coefficients to the wolves so that the premature convergence is avoided easily. In the search space, a good diversity can be maintained with the help of these coefficients in the actual hunting process. After iterations, the search agent positions are indicated by the vector .
The final phase is the attack-prey phase. Here the movement of the prey is stopped and the grey wolves easily charge and attack it. By means of mitigating the values of , the controlling of this process can be performed. The range of the values of the , and lies in the range of [−1, 1] in this work. If the values of the decreases, then there is a gradual diminishing of these values as well. When , the grey wolves attack the prey so that good exploitation is achieved. When , the prey moves away from the grey wolves and a new prey is effectively searched in the process so that a good exploration is achieved. The simplified flowchart of the GWO is shown in Figure 2 below.
3.1.2. Feature Correlation Clustering Technique (FCCT)
It is a commonly used filter technique where the collinearity problem is solved well in any dataset. When there are several features in a dataset, the model tends to become collinear, and so the ultimate performance of the model does not lie in permitting the features so that the similar data can be predicted again. The best technique is to trace the collinear features so that the number of input features can be filtered easily in the classification model. The correlation matrix is computed for every feature in the dataset utilizing any correlation technique, like Spearman’s correlation model. If a high correlation is present in between the features, then it proves that it has a lot of similar information. A hierarchical clustering is then implemented using the information obtained from the correlation data. So, a hierarchical cluster plot is developed and a specific threshold is defined so that the feature set can be targeted and extracted well [47]. From every group, a single feature is chosen so that it is made sure that it analyzes the threshold. If this threshold value is close to zero, then the generation of a greater number of clusters is prioritized and a greater number of features can be chosen. Once the feature subset is obtained, this method is stopped and the collinearity is removed easily.
3.1.3. F-Test
A statistical analysis is utilized to estimate a precise maximum likelihood function so that the input features can be ranked easily by the F-test technique [48]. The significance of each feature on the output is evaluated by the F-test. F-statistics are used to quantify the importance of features. The inconsistency of the obtained features can also be quantified by the F-value. With the help of three steps, the F-test is conducted. For the individual features, the F-value is assessed. Depending on the F-values, these factors are arranged in a descending order, and then, finally, the top k-features are identified, which would possess the maximum F-value. The redundant features are eliminated by the F-test so that it is quite useful for handling multi-dimensional datasets. The overall risk of overfitting is reduced by this model to a greater extent.
3.1.4. Bayesian Optimization Algorithm (BOA)
It is one of the simplest but most powerful optimization schemes which help in managing the objective functions effectively. It works in an autonomous manner and there is no need to depend on genetic operators and other conventional population-based operators. To estimate a function, a Gaussian technique is utilized so that the performance of the function is forecasted accurately. By means of considering the previously stored historical data, the efficacy of Bayesian Optimization is improved [49]. The optimal solutions can be easily searched for with the help of previously stored statistical information. When comparing both the random search and grid search algorithm, Bayesian Optimization Algorithm is highly effective when compared to even some of the newly proposed optimization algorithms.
3.2. Classifiers Used in Blended Model 1
The classifiers used here in the Blended Model 1 are SMO-GBM, DKL-SVM classifier, and CatBoost classifier.
3.2.1. SMO-Based GBM Classifier
In this work, SMO algorithm is used with GBM classifier as follows.
(A) Spider Monkey Optimization (SMO) algorithm:
The social activities of the spider monkeys were considered and analyzed and based on this, SMO was developed [50]. A category termed as fission-fusion was created and it was ensured that the spider monkey belonged to this category for foraging activities. The main characteristics of the fission-fusion mortals are analyzed as follows. In a population of about 40 to 50 beings, the fission-fusion category is present and can split themselves so that they can trace their food. When tracing the food particles, feminine creatures can direct the entire group. The entire group can be split into a lot of subgroups so that food can be searched efficiently if there is no sufficient food found. A solid search strategy is found by every subgroup of feminine numbers so that a good decision about the search path can be made. There is good correspondence of the individual creatures in the similar group and the neighbouring groups. To make a proper conclusion, two important parameters are required to guide the leaders, efficiently known as Local Leader (LL) limit and Global Limit (GL) limit. The spider monkey vectors are initialized with basic vector dimensions and it is indicated as follows:
Assuming that there are totally variables in the process, every value is assigned as shown in the following equation:
At local group alignment, the assignment of a new position is performed to every member. Based on the leader and the efficient knowledge of all the members in the local group, the assignment is performed as follows:
Considering the global leader and analyzing the knowledge of all the members in the local group, the assignment of a new position is performed to every member at a global level and is represented as
The threshold limit cannot be crossed by the leader position in a local group, and so the individual portions are renewed by SMO, as per the following equation:
Algorithm 1 shows the depiction of the entire process of SMO algorithm. Algorithm 1: SMO Algorithm.
- Input Variables: LL limit, GL limit, Population, Pr
- Steps:
- (a)Assess the fitness level.
- (b)Trace the local leader.
- (c)Trace the global leader.
- (d)While (Termination Condition is False) do
- (e)Assignment of novel positions is performed now
- (f)Implement Greedy Selection to Compute Fitness
- (g)Assess Fitness level as
- (h)Allocate the new positions to the chosen depending on using Equation (22)
- (i)Utilize Greedy Selection to update positions of the leader of entire group and the local group leader.
- (j)If position updation is not performed after crossing limit, then is reassigned to another new group using Equation (24)
- (k)Investigate the global leader position for updates.
- (l)Subdivide the entire group if no update is found.
- (m)End while loop.
(B) Gradient Boosting Machine (GBM):
An ensemble classification model comprises various simple models and is considered versatile instead of as a single classification model. The accuracy of the response parameters is improved by this GBM classification model as it tries to iteratively fit the multiple weak models [51]. At the end of every iteration, a model can be added and it utilizes a boosting centric strategy. The base classifiers are matching each other and the overall loss function is low here. The error functions are considered as squared error in this case, and though the loss function is low here, it can be chosen from a particular collection of available functions, and so a lot of flexibility is avoided by the GBM algorithm.
Assume the data provided as for the supervised learning problem. The input vector is specified as and its respective label is considered as . The loss function must be minimized, and so a function is learned by the classifier as . The sum of the GBM algorithm is shown in Algorithm 2 as follows. Algorithm 2: GBM Algorithm.
- Input Variables:
- Iteration Count , loss function
- Base Classifier model
- Input dataset
- Procedure:
- (i)Allocate an arbitrary value
- (ii)For to
- (iii)Compute the negative gradient
- (iv)Fitting of another suitable base classifiers
- (v)Compute a step size for the analysis of gradient descent as follows:
- (vi)Allocate a normal value to and it is represented as follows:
- (vii)End the loop.
(C) SMO Optimized GBM:
In SMO, the solution is learned thoroughly by means of food-searching techniques by the spider monkey. Both the local best and global best values are present in the search space of the SMO solution so that the search space is utilized efficiently. The fittest survival rate must be obtained and so this SMO highly values the parameters of food-searching technique. The present positions are renewed by the spider monkeys which are heavily involved in the process of searching for food. In SMO, the experiences of the global group leader, local group leader and individual experiences are highly valued. Efficient self-organization is framed well and so the various members can be sent in different directions to search for food. Once the stagnation of the global group leaders happens, then the subdivision of that specific group happens so that the food is searched for in an efficient manner. The GBM is trained efficiently with the help of the SMO parameters as follows:
- (A)The random values are initially designated.
- (B)Depending on the basic optimization necessity, the robustness and versatility of every solution is examined.
- (C)The global best and local best are modified accordingly.
- (D)The position of the solution set is now standardized and the estimated of the stopping criteria are determined.
The flowchart of the SBO Fine-tuned GBM classifier is shown in Figure 3 as follows.
3.2.2. Hybrid Deep Kernel Learning with SVM Classifier (DKL-SVM) Classifier
SVM solves many classification problems easily. A major splitting line is utilized by SVM with two more lines termed as hyperplane [52]. Classification of an SVM can be performed into a linear or non-linear separable data. For the classification of non-linear separable data, the modification of SVM algorithm is mandatory and it is performed with the help of kernel learning. For the classification of signals, the following equations are utilized as follows:
where the ordinary space is denoted by and the corresponding location to the coordinates of the center space is denoted by . By means of solving the optimization problem, the splitting line is traced as follows:
The optimization problem can be solved by utilizing higher multipliers. The resolution function value is assessed easily so the determination of test data class is managed as follows:
where the support vector is denoted by .
The support vector number is indicated by and the data to be classified is denoted as . Multiple kernel learning [53] aims to hybridize some kernel functions into one single function as follows:
Subject to
where the number of kernel function is expressed by . Initially, for a single kernel, an optimal hyperplane is obtained so that the optimization problem is solved as follows:
Subject to
The total number of misclassification data must be reduced, and so an added variable denoted as is incorporated and denotes the penalty value.
The formulation of the optimization problem is expressed as follows:
where the broad range multipliers are indicated by and .
3.2.3. Categorical Boosting (CatBoost)
By hybridizing the words category and boosting, CatBoost is formed [54]. It has the capability to manage multiple data like text, numeric, signal, image, etc. Multiple categorical data can be overseen very well by this exceptionally proficient model and datasets of huge or limited size too can be managed by this model. A symmetric tree model is utilized by CatBoost, where similar characteristics are implemented to every tree level so that the division of the training samples can be performed into equal partitions. So, a tree can be formed which would have a depth of and a count of leaves. In a sequential manner, the decision trees are built where the minimization loss of every tree is designed approximately. The number of trees is controlled by the initial parameters and it helps to mitigate overfitting. In case the detection of overfitting is found out, then this algorithm can stop the training early by managing the settings of the training model.
4. Proposed Blended Model 2
4.1. Feature Selection Techniques Used in Blended Model 2
The feature selection techniques used here are HFS-MVS, hybrid SSO-PSO algorithm, PCC, and MI.
4.1.1. HFS-MVS Technique
When an efficient machine learning system must be built, feature selection plays quite a key role in eliminating all the noisy, redundant, irrelevant, and insignificant features. The computing time can be mitigated and the efficiency of the system can be enhanced greatly. A minimal collection of the best features can be chosen by the hybrid feature selection strategies. In an independent manner, all the techniques are utilized for feature selection and, depending on the majority voting concept, the final selection is implemented.
(A) Correlation-based feature selection (CFS):
The pairing of the features which are aligned together in correlation are given more importance in this technique [55]. In this technique, a low correlation value is possessed by the irrelevant features with class labels.
(B) Least Absolute Shrinkage and Selection Operator (LASSO)
This model penalizes the regression coefficients so that some of them are shrunk to a value of zero here [56]. The implementation of regularization process is performed here in this scheme and during the feature selection strategy, the choosing of the variables with non-zero coefficients is performed.
(C) Local learning dependent clustering feature selection (LLCFS)
On the clustering conceptualization idea, local learning regularization is performed so that the features can be chosen effectively [57]. In an iterative manner, the Laplacian graph is updated well.
(D) Relief-F
To manage multi-classification problems, the standard Relief algorithm was extended and it became Relief-F algorithm [58]. This idea is dependent on the concept of nearest neighbours and it is a supervised feature-weighted technique. In the neighbourhood of similar classes, if there is a difference in feature value, there is a decrease in the feature score. In the neighbourhood of the dissimilar classes, if there is a difference in feature value, there is an increase in the feature score.
(E) Unsupervised Discriminative Feature Selection (UDFS):
In this technique, the selection of features is performed in batch mode. The implementation of a versatile framework comprising both normalization and a discriminant analysis is considered here [59]. Once the features are selected, it is incorporated with the concept of a majority voting scheme [60] and the features are selected before proceeding to classification. The overall illustration of the HFS-MVS classification model is shown in Figure 4 as follows.
4.1.2. Hybrid SSO-PSO Algorithm for Feature Selection
To manage the feature vectors efficiently, a binary encoding is utilized by the feature set. A good and optimum feature set could be easily obtained by swarm optimization techniques so that the overall computation time could be less. The constructive search abilities of these algorithms are high when dealing in real time. Due to its robustness and versatility, PSO and SSO are selected in this work. In the entire search space, a solution is provided by the PSO depending on the particle and velocity. A global optimum result is provided by the PSO as the best positions are searched continuously by the particles. The problem of premature convergence occurs in PSO; it thereby affects the stabilization between the abilities of exploitation and exploration. So, the local optima trap can be prevented by incorporating SSO with PSO so that even a high performance could be obtained. While choosing the feature set, the hybrid optimization algorithm plays a vital role. The performance in the search space is improved by hybridizing SSO and PSO and the quality approximation of the optimal solution is improved.
Salp Swarm Optimization (SSO):
Depending on the foraging attitude of salps, this population-based algorithm was developed [61]. A chain structure is formed and a leader initiates the process while the rest of the salp follows the leader quietly. In every search space, the salp position is represented as . The position of the food particles is analyzed as where the optimal solution is projected as . The simplified expression of SSO is formulated as follows:
where in the dimension, the position of the leader is represented as . The indicates the position of food particles, represents the upper-bound salp position and represents the lower-bound salp position. Within an interval of [0,1], the random variables are specified by and . The parameter helps to maintain the exploration and exploitation capabilities of salp and is mathematically expressed as
where the current number of iterations are represented as and maximum iterations are represented as . In a particular search space dimension, depending on its starting speed, the position of the salps which are following the leader can be changed.
Particle Swarm Optimization (PSO):
PSO helps to mimic the intelligent behaviour of foraging of the bird flocks [62]. In the entire search space, a swarm population is present and it comprises multiple particles. Unless an optimal solution is procured, the process continues throughout. For a particle, the assessment of position and velocity is performed as follows:
where represents the particle position and represent the velocity vectors.
The position and velocity are updated as follows:
The initial and of SSO is utilized to update the position using the above Equation (40). The swarm search ability can be improved by adopting such a methodology and there is less probability of occurrence of local optima. The updation strategy of PSO is improvised so that the higher positions of the salp population are also improvised. To affect the best positions of the particles, two constants are used here such as and . The and are random numbers assigned in the range of [0,1]. The parameter is the weight parameter assigned which assesses the present velocity depending on the iteration count. The exploration ability of SSO and exploitation ability of PSO is enhanced by the position update easily so that both solutions can be located easily. Many local solutions can be avoided because of this hybridization, and only the best set of features can be produced.
For the assessment of the hybrid optimizer, KNN output is used as an objective function. A solid balance must be maintained between the features and their respective performance. The fitness function is analyzed here as follows:
where the significant features are denoted by and the total number of features are represented by . and are constants where the value is represented in the range of [0,1] that helps to assess the feature performance. The simplified illustration of the hybrid SSO-PSO algorithm is shown in Figure 5.
4.1.3. Pearson Correlation Coefficient (PCC)
This technique is heavily dependent on the filter technique of the feature selection approach [63]. The range of PCC lies in the range of [−1, 1] and the association between the two continuous variables is quantified very well so that a stable relationship can be established well. Depending on the relationship between the target variable and the features, a good association is formed so that the input attributes are selected wisely.
4.1.4. Mutual Information (MI)
This technique is also a type of filter method of feature selection approach where a score is provided for every feature [64]. Statistical analysis and measurements are used heavily here and then the attributes are formed initially. Once the attributes are formed it is then ranked depending on the score values in a descending format. A threshold value is set and then the feature subset is selected accordingly. The optimal feature characteristics are chosen and this technique requires less computation time too.
4.2. Classifiers Used in Blended Model 2
The classifiers used in the blended model include the PLS with LDA, SVM and Kernel-based classification techniques, ensemble classification model with soft voting strategy, and XGBoost classifier.
4.2.1. PLS with LDA, SVM and Kernel-Based Classification Models
(A)PLS—LDA classification model:
There are quite a lot of variants of PLS and the basic algorithm considered for analysis is PLS with orthogonal scores in the context of statistical learning [65]. The modelling of the data matrix is performed so that the class response can be analyzed well, and it is performed with the help of , where the PLS vector parameters are indicated by and is residual in nature. By means of scaling and , the algorithm is initiated. PLS is considered as an iterative method where the components are utilized to indicate the iterations. The computation of weights, scores, and loading along with the deflation components and are performed in every iteration. PLS is utilized as a dimension reduction technique and so, computing PLS scores where leading to . Therefore, the small sample-sized data can be managed efficiently by utilizing classification techniques over the score of PLS. For the PLS—LDA-based classification, the execution of this algorithm is performed for a total of number of iterations, where . The computation of scores, weights, and loading, etc., in every iteration can be performed as follows. The calculation of the loading weights is performed as follows:
The covariance of is reflected by . The loading weights are normalized so that the length is made equal to one by utilizing the following equation as follows:
The significance of sample-wise score is expressed as follows:
The data matrix is regressed by using the loading indicated by in the on the score vector and indicated as follows:
The Q-loading is represented as follows:
The fitting of LDA is performed on the PLS scores for the sake of discrimination, where scores are assumed for the class and it has a normal distribution with a covariance and mean . The discriminant function is indicated as follows:
which leads to obtaining .
The computation of the deflated components is specified as and is indicated as follows:
If , the procedure is returned to the starting step itself. From every PLS iteration, the loading weights and scores are obtained and it is assimilated as follows:
In regression coefficient matrix, the results are presented as follows:
(B)PLS-SVM model:
A multivariate normal distribution must be followed by means of loading scores for class . Here, for every class, a common structure of variance-covariance is followed. The assumption of LDA is tough to follow if the sample size is very small and so, SVM is utilized as an alternative of LDA where a common structure of variance-covariance is not needed and the multivariate normal distribution scores are only required. Over the PLS scores , an SVM-dependent classification is introduced so that high-dimensional data is classified with an exceedingly small sample size. For the sake of classification over PLS scores , a hyperplane is built in an extremely high-dimensional space and is represented as follows:
where the normal vector to the hyperplane is represented by . The hyperplane offset present along the normal vector is assessed by the parameter . Kernel choices are important to assess the different SVM variants so that the PLS scores could be applied successfully over SVM algorithm.
(C)Kernel-based PLS-SVM model:
To improve classification accuracy, kernel tricks are utilized. If there is data separability issue, then the dimensions can be added so that the classification accuracy is improved. Various Kernels are present in SVM such as hyperbolic, Gaussian, Laplacian, Polynomial, Bessel, Linear, Radial Basis Function (RBF), Spline, etc. [66]. In this work, polynomial, Laplacian, Bessel, linear, and Spline Kernel-based PLS-SVM models are used.
The Polynomial Kernel-based PLS-SVM can be mathematically expressed as follows:
The Bessel Kernel-based PLS-SVM can be mathematically expressed as follows:
The Laplacian Kernel-based PLS-SVM can be mathematically expressed as follows:
The Linear Kernel-based PLS-SVM can be mathematically expressed as follows:
The Spline Kernel-based PLS-SVM can be mathematically expressed as follows:
Therefore, five different Kernel-based PLS-SVMs are utilized in this work.
4.2.2. Ensemble Classification Model with Soft Voting Strategy
To solve a particular issue, the understanding of multiple classifiers is required and it is obtained only by using an ensemble model. An accurate and good decision can be obtained by the ensemble model. Even if the performance of one classifier deviates, the performance of other classifiers can compensate for it, and so ensemble models have a higher classification power when compared to that of a single classifier. Four classifiers are used in this ensemble model, such as Decision Trees (DT), Naïve Bayesian (NB), Generalized Linear Model (GLM), and SVM.
(A) DT:
The user intervention is quite minimal when DT is used and so it is widely preferred in machine learning concept [67]. With the help of simple rules, the interpretation can be performed easily, and so it is quite famous for classification purposes. A root node initiates from a tree which helps to indicate a specific attribute. Branches are later developed based on the attribute value unless a particular value is obtained. Signal processing models developed on DT are quite versatile as multiple simple tests could be analyzed depending on a single prediction. The current outcome is mostly the consequence of previous outcomes at any levels in DT, and so a specific target could be achieved easily. For unobserved instances, the generalization is much better and a good understanding is provided by the tree architecture, proving its computational efficiency.
(B) NB:
Depending on Baye’s theorem, this simple and efficient classification model was developed [68]. An elevated level of scalability is provided by this classifier even when the feature space of input is much higher. For a clear analysis of the results, probabilistic knowledge is enabled by this classifier. The prior probability of a class is considered before any data is encountered by using the likelihood of the data. The mapping function can be assessed accurately so that a label of an unknown example can be predicted well during the classification analysis.
(C) GLM:
One of the famous parametric modelling schemes is GLM as probability interval can be predicted well by means of assuming the data distribution [69]. This model produces a variety of statistical indicators so that it is quite convenient for analysis and interpretation. A binary logistic regression model which has a logit link function along with a binomial variance has been utilized in this work. In between the dependent and obtained responses, the logistic regression classification model has identified a solid relationship. The predictors here mostly denote the explanatory variables and, with the help of the following equation, the logistic regression can be represented as follows:
The probability of outcomes is indicated by . The regression coefficients are specified by . The descriptive predictors are indicated by in this linear combination and the intercept value is denoted by .
(D) SVM:
In this classification model, an optimal hyperplane can be easily found so that the margin can be maximized between itself and the corresponding training samples embedded in the high-dimensional space. The overall generalization error can be mitigated well in this classification model. No amount of information is required with respect to the correlation among variables during the prediction or classification process. The upgrading of the original model can be performed for the non-linear data by means of mapping the data into a higher dimensional space so that a hyperplane can be produced and it can separate the two different classes in that space. For classification of both small-sized samples and exceptionally enormous-sized samples, SVM is utilized and it can be suited well for the signal processing applications [52]. The training of the classifiers was performed individually, and then it was hybridized into various combinations depending on the soft computing technique which was incorporated successfully on the classification outcomes. The probability of outcome can then be assessed and analyzed successfully.
(E) Soft Voting Computing:
When classifiers have probabilistic outcomes, then they can be computed well with soft voting technique [70]. A weighted soft voting technique can be measured at an instance level or classifier level. The certainty of every classifier is considered carefully by the soft voting technique as more weights are assigned to this confident vote, and so soft voting is preferred often when compared to hard voting. The output probabilities are hybrid for every classifier, and then a final decision is computed. For every target class, the average probability is analyzed and the decision can be made. With the help of soft voting technique, the classifiers are hybrid and it is presented in Pseudocode 1 as follows: Pseudocode 1: Soft Voting Computing and hybridizing classifiersInput: Features, -number of hybrid algorithmsOutput: Predicted class outputStep 1: StartP_positive(i) indicates outcome probability is positiveP_negative(i) indicates outcome probability is negativeStep 2: for each iteration doFor to doIf predicted class is positiveP_positive(i) = P_positive(i) + probability elseP_negative(i) = P_negative(i) + probability end ifend forif P_positive(i) > P_negative(i) doOutput predicted class = positiveelseOutput predicted class = negativeend ifend for
For this ensemble classification model, the results can be easily analyzed and shown in terms of classification accuracy.
4.2.3. XGBoost
If the optimized gradient boosting algorithm is improved, then it indicates an XGBoost algorithm which has a high probability, versatility, and efficiency [71]. It can be applied equally to both regression and classification tasks as it is a tree-dependent supervised algorithm. The conventional GBM framework is enhanced by the XGBoost algorithm by using multiple enhancements in the algorithm and optimization level. A parallelized tree-construction procedure is employed so that the sequential construction of trees is performed while equal focus is given on the concept of parallel computation. The concentration here is on a tree pruning method where trees grow to a maximum depth initially and, depending on a threshold of a loss function, it can be pruned back easily. Cache awareness concept is utilized by XGBoost so that an effective handling of both memory capacity and computational time is performed successfully. To avoid overfitting, the integration of regularization techniques is performed so that the model is regulated by means of reducing the coefficients. The missing values are handled quite efficiently and there is a smaller number of iterations required in this algorithm as it has an efficient cross-validation mechanism scheme. It is highly flexible, yet it requires extensive hunting. The model is enhanced and generalized by incorporating the concept of regularization concepts and . The training process is faster when compared to GBM and the parallelization occurs clusters is made simpler with the help of this classification model.
5. Results
The experiment was conducted on a publicly available dataset obtained from 36 patients suffering from chronic neuropathic pain [30,31]. The patient pool comprised 28 females and 8 males, and the average age of the participants in this dataset was about 44 with a standard deviation value of ±13.98. Their pain levels were evaluated by means of completing two primary questionnaires. The two important conditions were present such as Pain detect Questionnaire (PDQ) and Brief Pain Inventory (BPI). The PDQ is a tool used for Spanish language validation and the neuropathic components of pain are used as well. The BPI is also a tool used for Spanish language validation and its primary form is on pain severity and its influence in the everyday life of the patient. Under three categories, the severity of pain can be stratified depending on the BPI scores such as low pain, moderate pain, and high pain. Using the standard 10/20 International system, the recordings of the EEG were conducted utilizing an EASYCAP electrode cap. With the aid of SMARTING EEG amplifier, the recordings are analyzed at a resolution of 24 bits, sampling frequency of 250 Hz, and a bandwidth ranging between 0.1 and 100 Hz. With the help of Openvibe software, signal acquisition was conducted. To minimize artefacts and noise and to ensure good data quality, an overall impedance level was assessed below 5 kΩ. The offline reference electrodes used here are the right mastoid and left mastoid. In a resting state, the recording was performed for both the conditions of eyes-open and eyes-closed cases. To maintain good data quality, patients with other neurological disorders were prevented from entering the investigation. In the dataset, it is made sure that the patients were given quality pharmacological treatments so that variability could be reduced, which is caused due to different medication effects.
A computer with 64 GB main memory, Intel i7 processor, 4.6 GHz processing unit, and MATLAB R2022b programming tool was utilized to perform the experiment. In our work, classification accuracy was analyzed in detail. A 10-fold cross-validation method was utilized in this work to compute the performance metric. As far as the parameters of the GWO are concerned, the population size is set to 200 and the number of iterations is set as 500 in our experiment. The population size is set to 250 in SMO algorithm; the global leader limit is assigned as 50 and the local leader limit is assigned as 75. The perturbation rate is fixed at 0.5 and the number of iterations is set as 500 in our experiment. When GBM is considered, the number of estimators is set as 100, the learning rate is set as 0.2, the number of subsamples is set as 1, max_depth is set as none, and the min_samples_leaf is set as 1 in our experiment. For SVM, the regularization problem is set as 1 and the kernels used in this work include linear, polynomial, RBF, sigmoid, etc. For CatBoost classifier, the hyperparameters are set as follows. The iterations are set as 500 and the learning rate is set as 0.08; the maximum depth of each tree is set as 4 and the L2 regularization term is set as 3. For PLS model, the number of components, also called latent variables, are set as 10 in this work. For SSO, the maximum number of iterations are set as 1000 as a higher iteration allows a good exploration and exploitation process. The population size is set to 600 in our experiment and the random coefficient are set in the range of [0,1] randomly. For PSO, an inertia weight of 0.5 is set and the cognitive constant value of 2 is set in the experiment. The social constant value is, again, set as 2 in our experiment. For XGBoost classifier, the eta value is set as 0.4, the gamma value is set as 0, and the max_depth value is set as 5 in our experiment. The number of samples are set as 1 initially and gradually increased, lambda value is set as 0.5 and alpha value is set as 0, and the max_leaves parameter are assigned as 4 in the experiment.
On examining Table 1, it is observed that for the DWT features, when selected with GWO feature selection technique and classified with SMO-GBM Classifier, a high classification accuracy of 92.18% is obtained. If Table 2 is analyzed, it is observed that for the DWT features, when selected with FCCT feature selection technique and classified with SMO-GBM Classifier, a high classification accuracy of 92.56% is obtained. On the analysis of Table 3, it is observed that for the DWT features, when selected with F-test feature selection technique and classified with SMO-GBM Classifier, a high classification accuracy of 89.45% is obtained. If Table 4 is analyzed, it is observed that for the DWT features, when selected with BOA feature selection technique and classified with SMO-GBM Classifier, a high classification accuracy of 87.34% is obtained. On examining Table 5, it is observed that for the FCM features, when selected with HFS-MVS feature selection technique and classified with Polynomial Kernel-based PLS-SVM Classifier, a high classification accuracy of 92.47% is obtained. If Table 6 is analyzed, it is observed that for the FCM features, when selected with SSO-PSO feature selection technique and classified with Polynomial Kernel-based PLS-SVM Classifier, a high classification accuracy of 92.68% is obtained. On the analysis of Table 7, it is observed that for the FCM features, when selected with PCC feature selection technique and classified with Polynomial Kernel-based PLS-SVM Classifier, a high classification accuracy of 86.11% is obtained. If Table 8 is analyzed, it is observed that for the FCM features, when selected with MI feature selection technique and classified with Polynomial Kernel-based PLS-SVM Classifier, a high classification accuracy of 85.68% is obtained. On examining Table 9, it is observed that for the DWT features, when selected with HFS-MVS feature selection technique and classified with ensemble classifier with soft voting method, a high classification accuracy of 91.56% is obtained. If Table 10 is analyzed, it is observed that for the DWT features, when selected with SSO-PSO feature selection technique and classified with ensemble classifier with soft voting method, a high classification accuracy of 92.45% is obtained. On the analysis of Table 11, it is observed that for the FCM features, when selected with PCC feature selection technique and classified with ensemble classifier with soft voting method, a high classification accuracy of 89.34% is obtained. If Table 12 is analyzed, it is observed that for the DWT features, when selected with MI feature selection technique and classified with ensemble classifier with soft voting method, a high classification accuracy of 87.45% is obtained.
On examining Figure 6, a high classification accuracy of 92.56% is obtained for DWT features when selected with FCCT feature selection technique and classified with SMO-GBM Classifier, and a second-best classification accuracy of 91.78% is obtained for statistical features when selected with FCCT feature selection technique and classified with SMO-GBM Classifier. On examining Figure 7, it is observed that for the FCM features, when selected with HFS-MVS feature selection technique and classified with Polynomial Kernel-based PLS-SVM Classifier, a high classification accuracy of 92.47% is obtained, and a second-best classification accuracy of 92.33% is obtained for DWT features when selected for HFS-MVS feature selection technique and classified with Polynomial Kernel-based PLS-SVM Classifier. If Figure 8 is examined, it is observed that for the FCM features, when selected with SSO-PSO feature selection technique and classified with Polynomial Kernel-based PLS-SVM Classifier, a high classification accuracy of 92.68% is obtained, and a second-best classification accuracy of 92.11% is obtained for FCM features when selected for SSO-PSO feature selection technique and classified with Polynomial Kernel-based PLS-SVM Classifier. If Figure 9 is examined, it is observed that the DWT features when selected with SSO-PSO feature selection technique and classified with ensemble classifier with soft voting method, a high classification accuracy of 92.45% is obtained and the second-best classification accuracy of 91.98% is obtained when FCM features are selected with SSO-PSO feature selection technique and classified with ensemble classifier and soft voting methodology.
6. Discussion
The results of the present work are compared with the previous work and are tabulated in Table 13 for an elaborate understanding.
Not much work has been proposed in the literature for efficient classification of neuropathic pain from EEG signals. Out of the limited works proposed in the literature so far, a performance comparison has been made and reported in Table 13. On the analysis of Table 13, it is quite evident that the proposed works show good results when compared to the previous works. Though one work [37] has reported a very high classification accuracy of 99% and the current results do not match up with the results of that work, it is to be noted that, in this work, a variety of approaches have been blended efficiently and worked out together to check out its efficiency on the EEG signals for neuropathic pain detection and classification. The authors have tried hard to incorporate a variety of methods and models to see whether their hybridization can bring out some excellent results. Other than this work reported in [37], the results of the current work seem to have much improvement from the previously reported results for the three class classification scenarios. Most of the previously reported works have concentrated mostly on binary classification and the authors in this paper have tried hard to concentrate on three-class classification.
For the proposed blended models, the computational complexity was analyzed and it was found to be moderate only in this experiment in the range of . As far as statistical tests are considered, the standard Cohen’s Kappa coefficient test and the 2-sided Wilcoxon test were conducted for the obtained features. All the feature values passed the good agreement category and ranged above 0.5 in this experiment when the Cohen’s Kappa coefficient test was implemented. A very high confidence level was attained for all the selected features when a 2-sided Wilcoxon test was implemented, showing the efficacy, suitability, and versatility of these features for classification. The computational time was computed and shown in Table 14 for the proposed models as follows.
On examination of Table 14, a least computational time of 4.213 s was obtained when FCM features are utilized with SSO-PSO feature selection technique and classified with Polynomial Kernel-based PLS-SVM Classifier. The next best computational time of 5.119 s was obtained when DWT features are utilized with FCCT feature selection technique and classified with SMO-GBM Classifier. The major limitation of this work can be said to be that this analysis was based on only on a small dataset, and in the future, the analysis and experimentation are planned to be conducted on massive neuropathic EEG datasets with deep learning analysis. The primary advantage of deep learning is that it aids in automatic feature learning and can handle large complex data with ease. The main drawback of deep learning is that it can be computationally intensive and it could perform poorly on any new data if it is not properly regularized. The hyperparameter tuning and managing the optimal settings like learning rate, layers, etc., can be challenging and iterative sometimes. Only when massive datasets are present, deep learning is applicable and for small datasets, deep learning is not suitable, and so, in the future, the implementation of this work will be applied to massive neuropathic EEG datasets with deep learning concepts.
7. Conclusions and Future Works
A patient’s life can be severely impacted with this chronic pain condition. The characterization of neuropathic pain has been reliant mostly on subjective perception, and so there are a lot of hinderances in the analysis of clinical decisions. The neuroplasticity factor is quite unpredictable and highly dynamic in nature, and so the characterization of neuropathic pain is complex to understand. In the field of clinical neuroscience, neuropathic pain detection and classification is of utmost importance with the help of machine learning. To understand the neural dynamics associated with neuropathic pain, EEG is highly useful, and when it is coupled with feature extraction and machine learning, it can work wonders. In this work, two approaches are proposed in terms of very efficient blended models for the classification of neuropathic pain through EEG signals. The best results are shown when the FCM features are selected with SSO-PSO feature selection technique and classified with Polynomial Kernel-based PLS-SVM Classifier, reporting a high classification accuracy of 92.68% in this work. The second-best classification result of 92.56% is obtained when DWT features are chosen with FCCT feature selection technique and classified with SMO-GBM Classifier. Future works aim to develop this model by incorporating a variety of other feature extractions, feature selections, and classification schemes. Also, deep learning is planned to be implemented by making a lot of modifications so that best results can be obtained. Future works also plan to implement this framework for telemedicine-based clinical applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Qu G. Wu H. Sethi I. Hartrick C.T. Neuropathic Pain Scale Based Clustering for Subgroup Analysis in Pain Medicine Proceedings of the 2010 Ninth International Conference on Machine Learning and Applications Washington, DC, USA 12–14 December 2010299304
- 2Saitoh Y. Maruo T. Yokoe M. Matsuzaki T. Sekino M. Electrical or repetitive transcranial magnetic stimulation of primary motor cortex for intractable neuropathic pain Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC)Osaka, Japan 3–7 July 20136163616610.1109/EMBC.2013.661096024111147 · doi ↗ · pubmed ↗
- 3Hooshmand H. Hashmi M. Phillips E.M. The role of infrared thermal imaging (ITI) in management of neuropathic pain Proceedings of the First Joint BMES/EMBS Conference, 1999 IEEE Engineering in Medicine and Biology 21st Annual Conference and the 1999 Annual Fall Meeting of the Biomedical Engineering Society Atlanta, GA, USA 13–16 October 1999 Volume 21102
- 4Marturano F. Gomez-Cid L. Straney D. Chen I.Y.-C. Albrecht A.M.C. Yu X. Ay I. Bonmassar G. High-Frequency Trans-Spinal Magnetic Stimulation for Chronic Neuropathic Pain Treatment Proceedings of the 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC)Orlando, FL, USA 15–19 July 20241410.1109/EMBC 53108.2024.1078160840039395 · doi ↗ · pubmed ↗
- 5Villiger M. Hepp-Reymond M.-C. Pyk P. Kiper D. Eng K. Spillman J. Virtual reality rehabilitation system for neuropathic pain and motor dysfunction in spinal cord injury patients Proceedings of the 2011 International Conference on Virtual Rehabilitation Zurich, Switzerland 27–29 June 201114
- 6Pu C. Fu B. Guan X. Xu H. Peng C. Focused Ultrasound-Mediated Neuromodulation Reduces Neuropathic Pain in Diabetic Rats: Preclinical Evidence Proceedings of the 2025 IEEE International Ultrasonics Symposium (IUS)Utrecht, The Netherlands 15–18 September 202514
- 7Twyman A.R. Bandres M.F. Mc Pherson J.G. Nonlinear Firing Dynamics in Spinal Interneurons May Delineate the Presence or Absence of Spinal Cord Injury-related Neuropathic Pain Proceedings of the 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC)Orlando, FL, USA 15–19 July 20241410.1109/EMBC 53108.2024.1078249640040229 · doi ↗ · pubmed ↗
- 8Erthal V. Nohama P. Treatment for neuropathic pain and chronic inflammation using LASER in animal models Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC)Milan, Italy 25–29 August 20151315131810.1109/EMBC.2015.731861026736510 · doi ↗ · pubmed ↗