Machine learning prediction of multiple distinct high-affinity chemotypes for α-synuclein fibrils
Xinning Li, Ryann M. Perez, Zhude Tu, Robert H. Mach, Sam Giannakoulias, E. James Petersson

TL;DR
A machine learning model predicted new high-affinity ligands for α-synuclein aggregates, useful for PET imaging.
Contribution
A novel machine learning approach enabled ligand discovery with strong generalization from limited training data.
Findings
Five high-affinity binders were experimentally validated from a large compound library.
The model demonstrated robust generalization despite being trained on fewer than 300 binding measurements.
Scaffold-guided curation improved the efficiency of ligand selection for testing.
Abstract
To identify new ligands for positron emission tomography imaging of α-synuclein aggregates, we developed a machine learning model trained on <300 binding measurements. We used scaffold-guided curation to select a 30 compound prospective set from a 140-million-member library. Experimental validation yielded five high-affinity binders, showing robust generalization for ligand discovery. Machine learning model predicts α-synuclein ligands.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
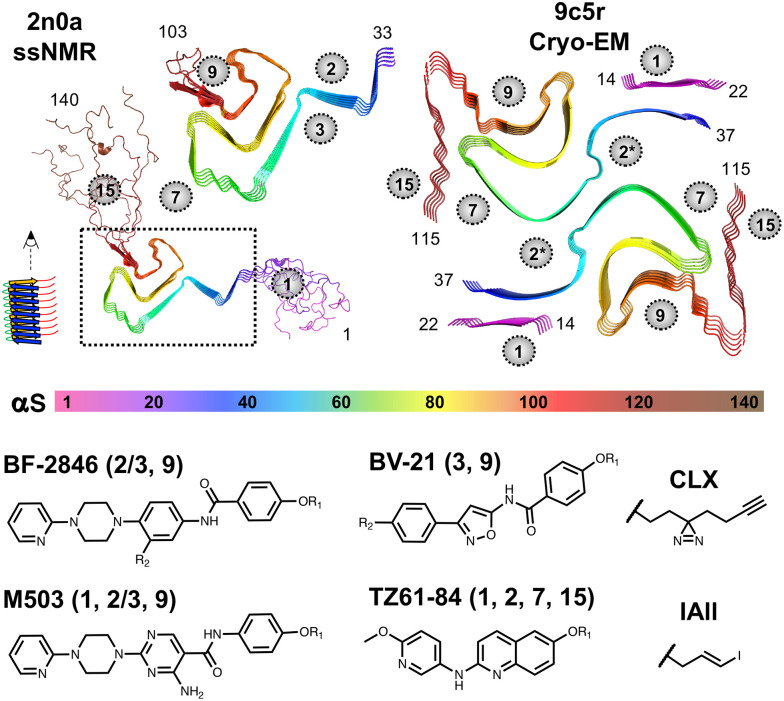 Figure 1
Figure 1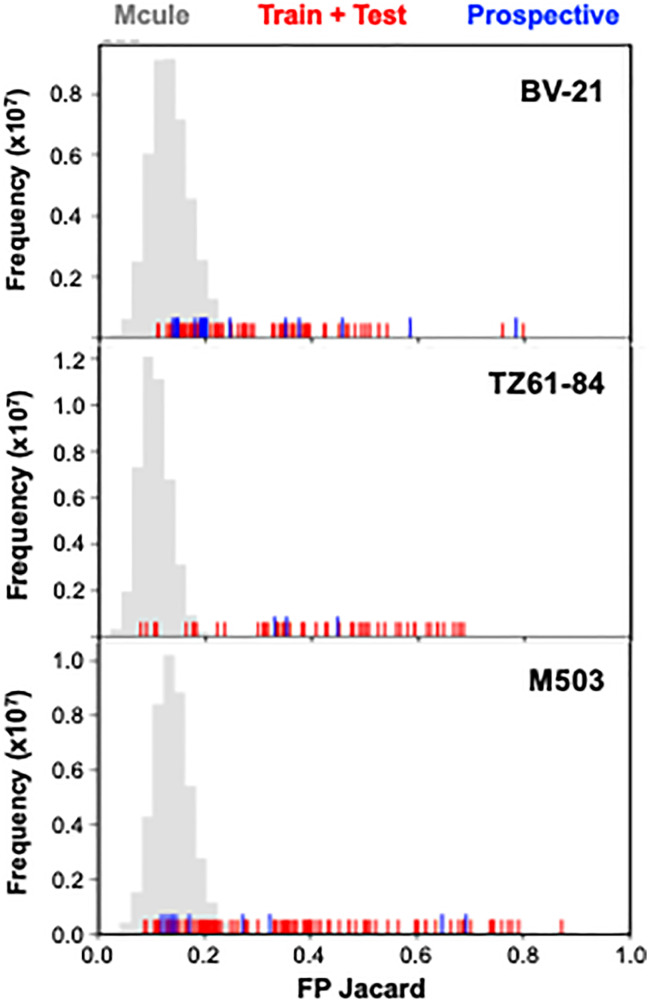 Figure 2
Figure 2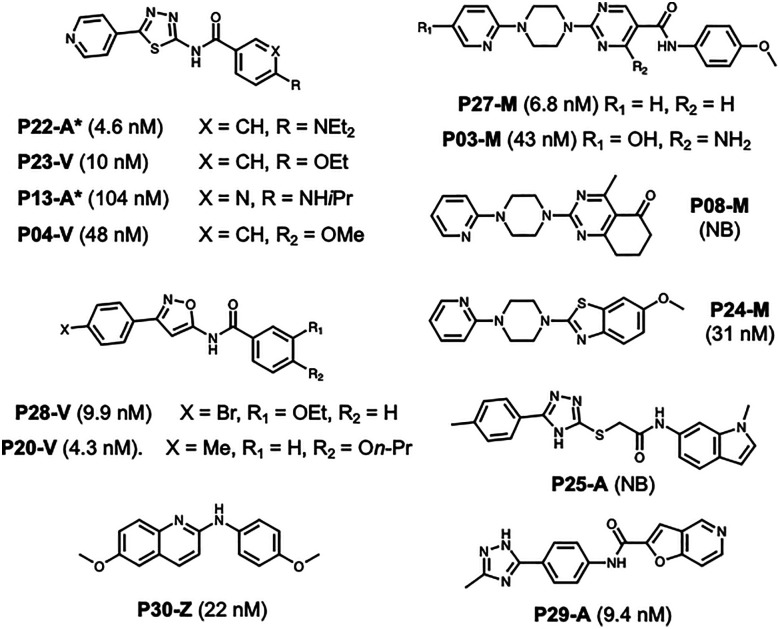 Figure 3
Figure 3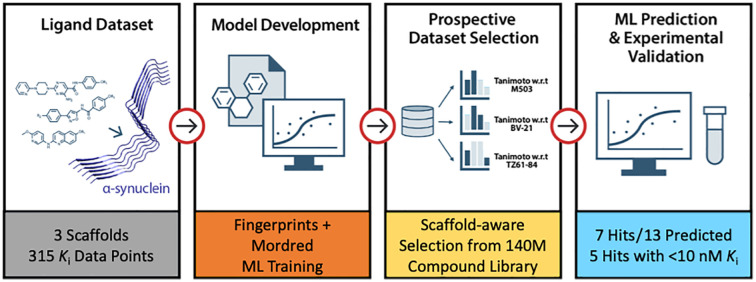 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsParkinson's Disease Mechanisms and Treatments · Computational Drug Discovery Methods · Organometallic Complex Synthesis and Catalysis