Conditional noise generative adversarial networks with Siamese neural network for longer time series forecasting
Haotian Mao, Xiao Feng

TL;DR
This paper introduces a new GAN-based method for long-term time series forecasting using a Siamese neural network and conditional noise, achieving significant performance improvements.
Contribution
A novel conditional noise GAN with Siamese discriminator and triplet margin loss for improved long-term time series forecasting.
Findings
The method achieves an average 8.42% improvement across eight datasets.
It shows a 192.8% gain in longer-term forecasting performance.
Results improve further on a real-world telecommunications dataset.
Abstract
Generative adversarial networks have achieved strong results in computer vision, but their use in time series forecasting remains limited. This paper proposes a conditional noise generative adversarial network with a Siamese neural network as discriminator for long-term forecasting. The method combines the simplicity of a linear model with a generative framework, introducing a triplet margin loss to capture relationships between samples and conditional noise to improve sample generation. Experiments on eight open-source datasets show an average improvement of 8.42 percent, and a 192.8 percent gain for longer-term forecasting, with further improvement on a real-world telecommunications dataset.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
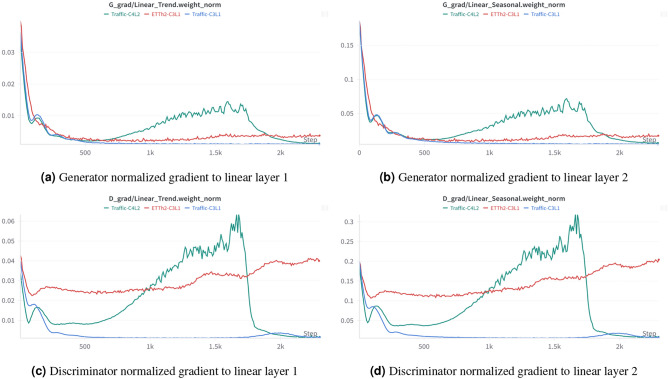 Figure 10
Figure 10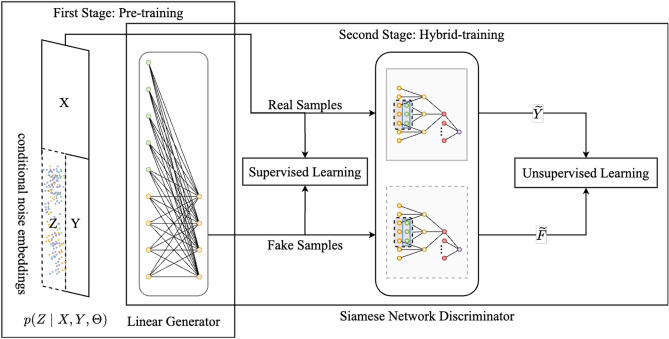 Figure 1
Figure 1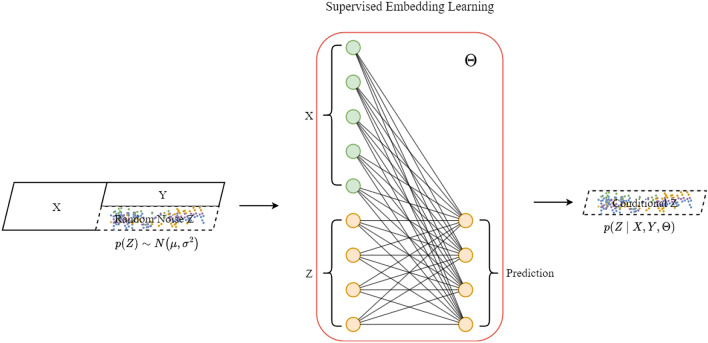 Figure 2
Figure 2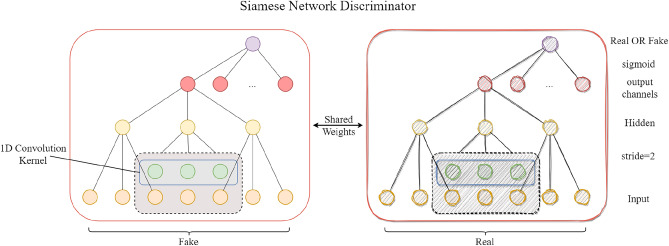 Figure 3
Figure 3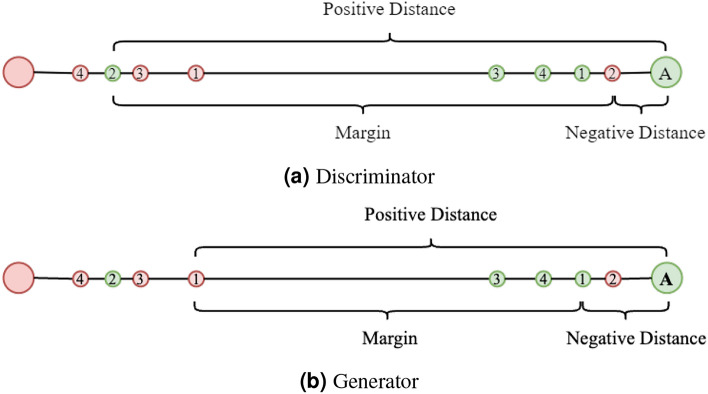 Figure 4
Figure 4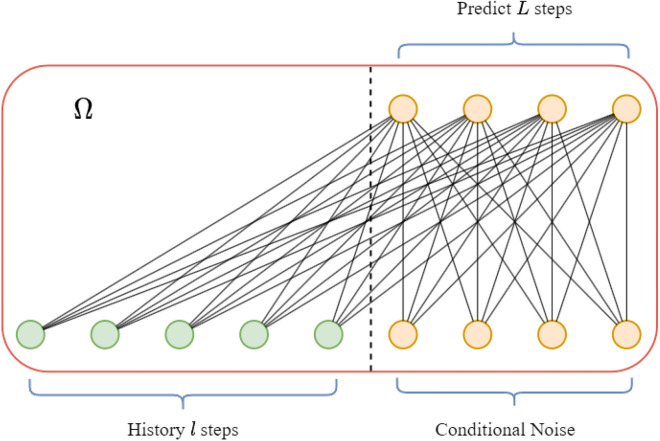 Figure 5
Figure 5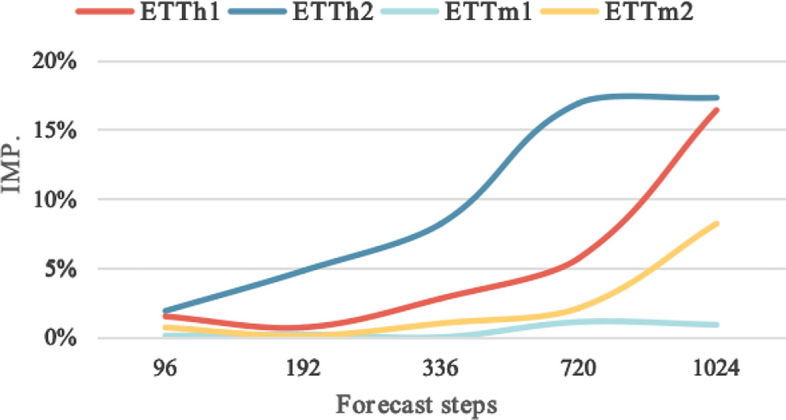 Figure 6
Figure 6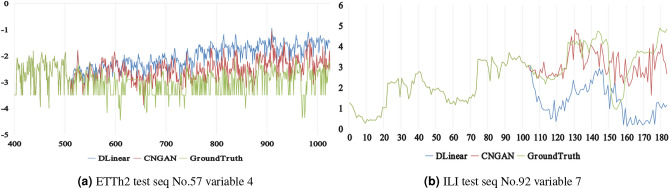 Figure 7
Figure 7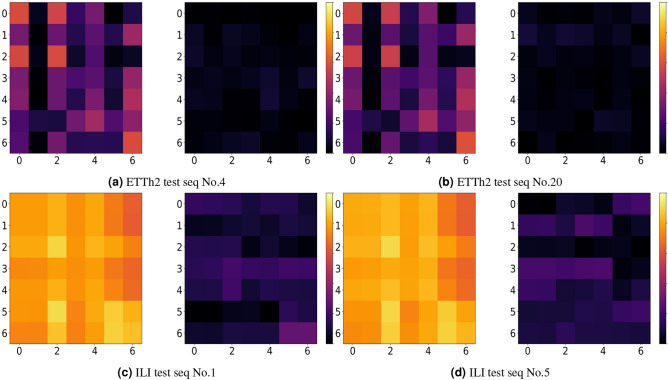 Figure 8
Figure 8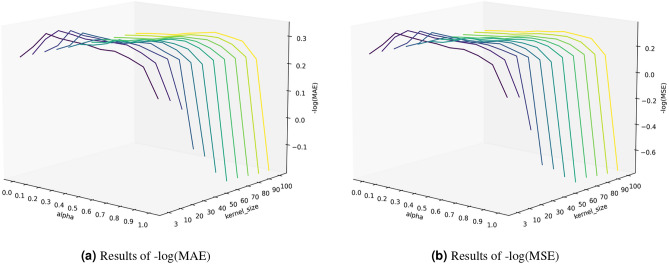 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStock Market Forecasting Methods · Wireless Signal Modulation Classification · Traffic Prediction and Management Techniques
Introduction
Time series forecasting has a wide range of applications across various fields, including traffic flow prediction, weather forecastinging, disease transmission, and power equipment status monitoring and so on. Over the past few decades, time series forecasting methods have evolved significantly. Traditional statistical methods, such as Autoregressive Integrated Moving Average Model^1^ (ARIMA), have been foundational. This evolution continued with machine learning approaches like Gradient Boosting Regression Tree^2^ (GBRT) and advanced to neural network-based methods, including Long Short-Term Memory^3^ (LSTM) and Temporal Convolutional Network^4^ (TCN).
Neural network based methods for time series forecasting can be broadly categorized into Recurrent Neural Network^5^ (RNN) methods and non-RNN methods^6–9^. RNN is a neural network for processing sequence data, with its recurrent structure capable of capturing short-term dependency temporal information. However, RNN often face issues like gradient explosion when dealing with long-term temporal dependencies. Long Short-Term Memory (LSTM) network, a specialized type of RNN, address long-term dependency problems through a sophisticated gate mechanism. Gated Recurrent Units^10^ (GRU) are another variant of RNN, designed to simplify LSTM structures while retaining their ability to capture long-term dependencies. GRU combine the input gates and forget gates of LSTM into two main gates: the update gate and the reset gate, resulting in fewer parameters and higher computational efficiency. Despite their effectiveness, methods based on gating mechanisms, such as LSTM and GRU, come with increased computational complexity and lengthy training processes. These methods are still susceptible to gradient vanishing and exploding issues when processing long sequences. Additionally, their autoregressive nature complicates the parallelization of calculations.
Temporal Convolutional Network (TCN) is a new approach for processing sequence data using convolutional neural networks. This study has shown that convolutional architectures can outperform recurrent neural network in certain tasks. LogTrans^11^ introduced a convolutional self-attention mechanism and a sparse Transformer to address the challenges of capturing local context information and the memory bottleneck in long-term time series forecasting, making the Transformer architecture feasible for time series forecasting. Informer^12^ tackled the issues of Transformer’s time complexity and sensitivity to sequence length with a probabilistic sparse self-attention mechanism. Autoformer^13^ introduced the concept of decomposing time series into seasonal and trend-cyclical data. Its decomposition module, combined with an auto-correlation module, offers greater advantages than the traditional self-attention module. Pyraformer^14^ proposed replacing the self-attention mechanism with a resolution pyramid-based approach to extract time dependencies across different ranges. FEDformer^15^ further enhanced long-term time series forecasting by utilizing Fourier transform in the frequency domain to calculate self-attention.
Time series forecasting methods based on the Transformer architecture primarily aim to enhance the effectiveness and efficiency of capturing contextual information by replacing or developing the self-attention mechanism. DLinear^16^ questioned the effectiveness of using the Transformer architecture for long time series forecasting. The single-layer linear model it proposed significantly outperformed more complex Transformer-based models. Based on DLinear, TSMixer^17^ introduced a mixed time series forecasting model based on MLP. TSMixer effectively extracts feature information through mixed operations on the time and feature dimensions, emphasizing the importance of incorporating cross-variable and auxiliary information in long time series forecasting tasks.
The Siamese Neural Network^18^ (SNN) is a specialized neural network architecture primarily used for comparing the similarity between two inputs. It is proposed in 1993, SNN has been widely applied in tasks such as signature verification. SNN has two or more sub-networks with shared weights, which judge the similarity of inputs by calculating the distance between their feature representations. Leveraging the characteristics of SNN, this study designed a discriminator based on the SNN which naturally models the adversarial loss within generative adversarial network.
Related works
Generative Adversarial Network^19^ (GAN) are a neural network-based method with the core idea of generating high-quality data that closely resembles real data through an adversarial process between two neural networks: the generator and the discriminator. GAN have a wide range of applications, including image generation, image super-resolution, data augmentation, and text generation. TimeGAN^20^ introduced a framework that combines unsupervised adversarial training with supervised learning to make the training process more controllable. This framework separates the input into static features and time series features. Initially, an encoder-decoder is trained in a latent space to restore predicted data. Then, a GAN is trained within the same latent space. The generator first undergoes supervised learning with the encoder in the latent space, followed by the decoder restoring the predicted results. Finally, adversarial training is conducted using the discriminator. This framework employs three loss functions for joint training, making the hyperparameters challenging to tune and the training difficult to converge. SocialGAN^21^ proposed using GAN to forecast pedestrian trajectory sequence. The generator in SocialGAN uses an encoder-decoder architecture with LSTM and pooling modules, while the discriminator, also composed of LSTM, measures the social acceptability of real and generated trajectories. SeqGAN^22^ addressed the challenge of generating discrete sequences. Given an input sequence, the generator creates a target sequence from all candidate tokens using an LSTM-based recurrent neural network, while the discriminator is a convolutional neural network. Innovatively, SeqGAN treats the discriminator as a reward model for reinforcement learning, updating the expected reward through Monte Carlo search.
TimeGAN employs a latent space embedding and recovery mechanism, reconstructing entire time series sequences. It samples random noise inputs into an encoder for generative prediction, which may not fully capture temporal dependencies. In contrast, CNGAN utilizes a linear encoder to generate conditionally noise directly, eliminating the need for additional random noise inputs and encoding steps. This approach enhances the model’s ability to capture temporal information more effectively. SocialGAN features a typical GAN architecture with an LSTM-based encoder-decoder generator and an LSTM discriminator. It generates sequences based solely on historical time series data. However, CNGAN encodes both historical and target prediction data in a single step, providing a richer information context for generation. SeqGAN integrates GANs with reinforcement learning, modeling sequence generation as a reinforcement learning task. The generator acts as a policy, and the discriminator provides reward signals. While innovative, SeqGAN does not leverage the rich information present in historical data, particularly in time series with periodic characteristics.
Recent studies have demonstrated the effectiveness of GANs in time series forecasting and anomaly detection. For instance, the Multi-attention GAN model^23^ for multi-step vegetation index forecasting improves accuracy by capturing long-term temporal patterns. Conditional Wasserstein GAN with Gradient Penalty (CWGAN-GP)^24^ has been proposed to generate synthetic time-series data to overcome data scarcity, enhancing demand prediction for electric vehicles. Additionally, the Predictive Wasserstein GAN with Gradient Penalty (PW-GAN-GP)^25^ has been introduced for anomaly detection in cloud data centers, outperforming baseline models in precision and recall. These approaches highlight the potential of GANs to enhance time series forecasting tasks, aligning with the methodology presented in our work.
Over the past few decades, GAN have achieved significant success in fields such as computer vision, image style transfer, and data augmentation. Numerous studies have demonstrated the potential of GAN to generate desired content from noise. The primary goal of most GAN-based methods is to create simulated data from noise.
This study explores, for the first time, a generative long-term time series forecasting method based on GAN, showcasing the potential of GAN in generating time series forecasting sequences. It is demonstrated that the adversarial training process inherent in GAN can produce forecasting sequences that closely align with the real data distribution, resulting in more robust predictions and improved model generalization. It significantly increases the difficulty of the generator generative prediction because completely random noise is not suitable for time series forecasting which has specific temporal information. To address this, conditional noise is designed and pre-trained that incorporates posterior information to reduces the complexity of the generator generative prediction process. GAN are expected to become a crucial tool in long-term time series forecasting, enabling researchers and practitioners to capture complex temporal patterns more accurately, thereby facilitating more informed decision-making.
The main contributions of this study are:
- This paper proposed parameterized conditional noise and optimized its parameters through supervised pre-training, transforming it from random noise into conditional noise with posterior information which can enhance the quality of the generated prediction.
- This paper introduced the Conditional Noise Generative Adversarial Network (CNGAN) and explored the integration of SNN with GAN. By leveraging the features of SNN and GANs, “real” samples and generated “fake” samples are feed into the SNN in pairs to calculate the triplet margin loss. This architecture naturally models the adversarial nature of GAN which can enable forecasting sequences closely align with the real data distribution, resulting in more robust predictions and improved model generalization.
- This paper conducted extensive experiments on the opensource datasets and Jiangsu Telecom market datasets. The results demonstrate that the proposed method shows significant advancement and adaptability for sparse long-term time series forecasting.
Datasets and definition
As shown in Table 1, for the open-source time series forecasting dataset, time series data is a series of feature vectors that depend on time t, expressed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_{1:L}=[x_1,...,x_L]^T\in \mathbb {R}^{L\times d}$$\end{document} . Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L$$\end{document} represents the total steps, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_t\in \mathbb {R}^{1\times d}$$\end{document} represents the feature vector at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} . The task of time series forecasting is fitting conditional distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(X_{t:t+T-1}|X_{t-h:t-1})$$\end{document} . Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T$$\end{document} represents the forecast steps, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h$$\end{document} represents the history series length. The task aims to capture the conditional distribution of history time series to forecast subsequent time series. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T=1$$\end{document} , it indicates a single-step forecast, and when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T>1$$\end{document} , it indicates a multi-steps forecast. Multi-steps forecast can be further divided into long-term and short-term predictions. The prediction can be either univariable or multivariable. This paper focuses on long-term multivariable forecasting.Table 1. Statistics of datasets.DatasetOpen-sourceNumber of input variables(d)Total steps(L)Graininess ETTh1/h2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} 7174201hour ETTm1/m2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} 76996805min National illness \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} 79661week Weather \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} 215269610min Exchange Rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} 875881day Electricity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} 321263041hour Traffic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} 862175441hour Telecom market✗25141month
Generally, time series forecasting use mean squared error (MSE) and mean absolute error (MAE) as evaluation metrics. These metrics are maintained for the open-source datasets, ETT and National illness.
For the closed-source Telecom market dataset, the data structure is different. This paper collected 14 months of marketing data from January 2023 to February 2024, with a collection granularity of one month. The original data is stored in a large-scale Hive data warehouse, distributed across multiple large tables. First, several hundred lines of HQL code are executed to extract user data for 14 months from the Hive database. Subsequently, it is necessary to filter users based on specific information, such as age, fees, and the products. After that, N/A and outliers values are filtered out, followed by embedding processing for discrete features and temporal information. Finally, the focus is placed on the target feature, which indicates whether a specific product has been subscribed (True or False). After this preprocessing, the final dataset includes 87,650 existing users (where existing users refer to those who were not new as of January 2023). The objective is to predict the propensity of users who have not currently subscribed to a specific product to do so in the future, based on their history data.
For each customer, 26 user features were collected, including network traffic, behavioral preferences, etc. Consequently, this dataset includes an additional user quantity dimension compared to the open-source time series forecasting datasets. The datasets can be expressed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_{1:14}=[x_1,...,x_{14}]$$\end{document} . Here \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X\in \mathbb {R}^{N\times 14\times 26}$$\end{document} represents all user data for the 14 months, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_t=[u_{t,1},...u_{t,N}]^T\in \mathbb {R}^{N\times 1 \times 26}$$\end{document} denotes all user data for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} -month, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{t,i}\in \mathbb {R}^{1\times 26}$$\end{document} is the 26 features of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} -user at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} -month.
According to business needs, the dataset is divided into a training set (from January 2023 to December 2023) and a test set (from January 2024 to February 2024). The task for the training set is to perform single-step forecasting based on the different input sequence length, it can be expressed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(X_t|X_{1:t-1},t\in [2,12])$$\end{document} .It means that when the input sequence length is 1 to 11, a single-step forecasting (multivariate to univariable) is performed, and the target variable is a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$label=\{0,1\}$$\end{document} .
For the closed-source Telecom market dataset, the evaluation metrics differ from the ETT and National illness. Since marketing units typically need to define a fixed number of marketing targets, this study sorts the output probability and selects the top 5%, 10%, and 30% of the user groups as marketing targets (considered as positive). The binary classification metrics, including precision, recall, and F1-score, are then calculated for evaluation. The main difference is the sparsity. Specifically, the sampling step of this dataset is one month, while the sampling interval of most other open source datasets is usually less than one hour. This longer sampling interval makes the data more sparse in the time dimension, and the frequency of information acquisition is lower. So it may face higher challenges. The experimental results in Section 6 show that for sparse dataset, CNGAN we proposed shows significant performance improvements in both accuracy and robustness, especially when processing data with longer time intervals.
Method
Architecture
This paper proposes a novel long-term time series forecasting method based on conditional noise and generative adversarial networks (Conditional Noise Generative Adversarial Networks, CNGAN). The overall architecture of CNGAN is shown in Fig. 1. It consists of three main components: conditional noise generator, SNN discriminator and Linear Generator.Fig. 1. Architecture of CNGAN. The training process is divided into two stages. In the first stage, the conditional noise embeddings and its generator are pre-trained in a supervised manner. In the second stage, the generative adversarial network is trained using a joint loss that combines supervised and unsupervised learning.
The training process is divided into two stages. In the first stage, the conditional noise embeddings and its generator are pre-trained in a supervised manner. In the second stage, the generative adversarial network is trained using a joint loss that combines supervised and unsupervised learning. This architecture can incorporate valuable additional information, including posterior conditional noise that encodes the complete input sequence information in the latent space, supervised learning information for time series forecasting, and unsupervised adversarial information).
Conditional noise
Generation of synthetic samples by tradition GAN from completely random noise causes deficiency in the quality and diversity since the unutilization of the posterior knowledge. This paper introduces posterior knowledge to random noise, incorporating more contextual information into the generation process to enhance the quality of the generated data. Random initialization \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z\in \mathbb {R}^{L\times d}$$\end{document} represents a non-informative prior. The pretrained embedding and generator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(Z,\Theta |X,Y)$$\end{document} can be viewed as a posterior representation and an encoder derived from the pretraining data, respectively.
In the pretraining stage, conditional information derived from the data distribution and target labels is incorporated, enabling the learned conditional noise to carry posterior knowledge such as class-specific features and structural patterns of the target data. As a result, the generator receives more informed and goal-directed inputs rather than relying solely on random exploration. This posterior-guided input enhances the contextual consistency and realism of the generated samples. Additionally, this approach encourages the generator to learn a wider variety of data combination patterns, making the generated data more representative of the actual distribution and reducing the likelihood of mode collapse. As shown in Fig. 2, this study uses a linear layer as the conditional noise generator. The conditional noise embeddings are initialized using a Gaussian distribution as Eq. (1):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Initiate(Z)=p(Z)\sim \mathcal {N}(\mu ,\sigma ^2) \end{aligned}$$\end{document}During pre-training, both the embeddings \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z\in \mathbb {R}^{L\times d}$$\end{document} and the conditional noise generator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Theta \in \mathbb {R}^{(l+L)\times L}$$\end{document} are optimized.Fig. 2. Conditional noise. The model takes the historical sequence X and conditional noise Z as inputs, and generates the predicted sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{Y}$$\end{document} . The object is minimizing the mean squared error (MSE) loss between the ground-truth sequence Y and the predicted sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{Y}$$\end{document} , thereby optimizing the conditional noise embedding Z.
The parameterized Z and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Theta$$\end{document} is optimized to minimize the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$loss_c$$\end{document} as Eq. (2):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \underset{Z,\Theta }{\min }~loss_c(Z,\Theta )=\frac{1}{n}\sum _{i=1}^n(y_i-[x_i;Z]^T\cdot \Theta )^2 \end{aligned}$$\end{document}which supervised pre-training process can be expressed as Eq. (3)(4):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\nabla loss_c(Z,\Theta )=(\frac{\partial loss_c}{\partial Z},\frac{\partial loss_c}{\partial \Theta })^T \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&(Z,\Theta )^T\leftarrow (Z,\Theta )^T-\eta \nabla loss_c(Z,\Theta ) \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta$$\end{document} represents the learning rate of the noise embedding model, y represents the target vector, n represents the dimensions of features. Through this supervised pre-training process, we obtains a conditional noise embedding and corresponding generator that encode complete sequence information as Eq. (5):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Conditional Noise = p(Z|X,Y,\Theta ) \end{aligned}$$\end{document}Generative adversarial networks
SNN discriminator
As shown in Fig. 3, the SNN discriminator consists of two sub-networks with the same structure and shared parameters. In this study, each sub-network of the SNN employs a multi-layer one-dimensional convolutional neural network. One-dimensional convolution is effective for processing time series data, capturing time series features at various resolutions along the sequence dimension.
The adoption of a Siamese network is a natural and intuitive choice, owing to its inherent ability to process sample pairs in parallel. This architectural characteristic aligns seamlessly with the use of a triplet loss function, enabling the model to naturally capture the relative relationships between real and synthetic samples, rather than making independent and absolute judgments about their authenticity.Fig. 3SNN Discriminator. the SNN discriminator consists of two sub-networks with the same structure and shared parameters.
Each sub-network first processes the input data through a series of one-dimensional convolutional layers. The convolutional operation extracts local features through a sliding window mechanism, retaining the overall structure of the time series. Finally, a fully connected layer integrates these features across the variable dimension. The output is a scalar value mapping the features to a low-dimensional space. Assuming the input data is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X\in \mathbb {R}^{d\times (l+L)}$$\end{document} , the forward process can be expressed as Eq. (6):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f(X,W_1,W_2)=Sigmoid(FC(CNN(X,W_1),W_2))\in (0,1) \end{aligned}$$\end{document}Here, FC represents the Full-Connected Layer, CNN represents 1D-Convolution, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_2$$\end{document} represent the parameter of CNN and FC, X is inputs. Intuitively, as shown in Fig. 4a, this study naturally inputs paired real and fake data into the SNN discriminator and calculates the triplet margin loss relative to an “Anchor”.Fig. 4. Triplet margin of discriminator and generator. Naturally inputs paired real and fake data into the SNN discriminator and calculates the triplet margin loss relative to an “Anchor”.
As shown in the Eq. (7), the task of the discriminator is to minimize the distance of the real data relative to the Anchor and maximize the distance of the fake data relative to the Anchor. For instance, in the case of real sample 2 and fake sample 2 in Fig. 4a, the SNN discriminator aims to minimize the positive distance and simultaneously maximize the negative distance. This objective can be reformulated as minimizing the difference between these two distances, ultimately yielding a discriminator capable of effectively distinguishing between real and fake samples. The triplet margin loss enables the network to learn the relative relationships between real and fake samples, rather than focusing on absolute classification information.
The objective of discriminator training is to minimize the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$loss_D$$\end{document} by optimizing the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_2$$\end{document} as Eq. (7):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \underset{W_1,W_2}{\min }~loss_D(W_1,W_2)=\max \{(A-f(X,W_1,W_2))^2-(A-f(\widetilde{X},W_1,W_2))^2+m,0\} \end{aligned}$$\end{document}which training process can be expressed as Eq. (8)(9):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\nabla loss_D(W_1,W_2)=(\frac{\partial f_{X}}{\partial W_1}-\frac{\partial f_{\widetilde{X}}}{\partial W_1},\frac{\partial f_{X}}{\partial W_2}-\frac{\partial f_{\widetilde{X}}}{\partial W_2})^T \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&(W_1,W_2)^T\leftarrow (W_1,W_2)^T-\epsilon \nabla loss_D(W_1,W_2) \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{X}$$\end{document} represent real samples and fake samples generated by the generator, respectively. Hyper-parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m$$\end{document} is defined as the minimum separation that should exist between the distance of the anchor–positive pair and the anchor–negative pair. The margin enforces that the negative sample must be at least margin units farther from the anchor than the positive sample. A larger margin imposes a stricter constraint, encouraging greater inter-class separation but potentially making optimization more difficult, while a smaller margin relaxes the constraint, possibly leading to faster convergence but weaker feature discrimination. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} represents the learning rate for training discriminator.
Linear generator
The work of paper^16^ has demonstrated that using a simple linear model can achieve competitive results in long-term time series forecasting. As shown in Fig. 5, this study employs a linear model similar to the noise generator as the generator of GAN. The difference from ^16^ lies in the addition of conditional noise to the input sequence as information with posterior knowledge. This enhancement helps the generator capture more contextual information and temporal patterns, thereby improving the quality of generated data and preventing pattern collapse.Fig. 5. Linear generator. Serves as the generator in the GAN architecture.
The input to the generator is the concatenation of historical sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H\in \mathbb {R}^{l\times d}$$\end{document} and conditional noise \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z\in \mathbb {R}^{L\times d}$$\end{document} , and its output is the forecasting result for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L$$\end{document} steps \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(X_{t:t+T-1}|X_{t-l:t-1})$$\end{document} . The goal of the generator is to make the prediction result as “accuracy” and “real” as possible. Here, “accuracy” refers to minimizing the mean squared error loss between the predicted data and the ground truth, while “real” refers to minimizing the triplet margin loss calculated using the SNN discriminator. As shown in Fig. 4b, the adversarial loss during the training of the generator aims to minimize fake “positive” distance and real “negative” distance. As shown in the Eq. (10), this objective is also transformed into minimizing the difference between two distances.
The objective of generator training is to minimize the unsupervised \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g(\Omega )$$\end{document} by optimizing the generator parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega$$\end{document} and supervised mse loss with hyper-parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} as Eq. (10):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \underset{\Omega }{\min }~loss_G=\alpha g(\Omega )+(1-\alpha )(Y-[H;Z]^T\cdot \Omega )^2 \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_(\Omega )$$\end{document} is expressed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \underset{\Omega }{\min }~g(\Omega )=\max \{(A-f([H;Z]^T\cdot \Omega ,W_1,W_2))^2-(A-f(X,W_1,W_2))^2+m,0\} \end{aligned}$$\end{document}Then the training process can be expressed as Eq. (12)(13):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\nabla loss_G(\Omega )=\alpha \frac{\partial g}{\partial f}\frac{\partial f}{\partial \Omega }-2(1-\alpha )[H;Z]^T(Y-[H;Z]^T\cdot \Omega ) \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\Omega \leftarrow \Omega -\mu \nabla loss_G(\Omega ) \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} is a hyper-parameter that controls the strength of the adversarial loss, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu$$\end{document} is the learning rate for training generator. The loss of the generator consists of two parts: one is the supervised loss that measures “accuracy”, and the other is the unsupervised loss that measures “authenticity”. This method introduces valuable supervisory information, and the unsupervised loss utilizes the gradient of the discriminator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\partial f}{\partial \Omega }$$\end{document} to optimize the parameters of the generator. This approach allows the entire network to simultaneously optimize both “accuracy” and “authenticity”. By sharing information between two tasks, the model enhances its generalized ability and improves overall performance.
Main results
This study conducted extensive experiments on five open-source time series forecasting datasets using the following hardware environments: 12th Gen Intel(R) Core(TM) i5-12600KF 3.69 GHz processor, NVIDIA GeForce RTX 3070 Ti 8G graphics card, and 32 GB of memory. Additionally, the study collected a closed-source Telecom market dataset from Jiangsu Telecom’s database for further experiments, using Intel(R) Xeon(R) Gold 5220 CPU @ 2.20 GHz processor, NVIDIA Tesla T4 16G graphics card, and 32 GB of memory. The Experiment settings are presented in Table 2.Table 2. Experiment settings.TaskDatasetMetricSteps of inputSteps of forecast Time series forecastETTh1/h2, ETTm1/m2MAE, MSE51296 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 720National illnessMAE, MSE10424 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 60WeatherMAE, MSE51296 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 720Exchange RateMAE, MSE51296 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 720ElectricityMAE, MSE51296 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 720TrafficMAE, MSE51296 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 720ClassificationTelecom marketPrecision, Recall, F1-score1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 111
Results on open-source datasets
The results on the open-source datasets are shown in Table 3. This study compared the linear methods and five Transformer-based methods. All results marked with * are from the paper ^16^. The best results are indicated in black, and the second best are underlined. CNGAN is the method proposed in this study. The simple but SOTA linear methods, Linear and DLinear, showed improvements ranging from 20% to 50% compared to the Transformer-based methods. CNGAN improved totally by 138.3%(The sum of the IMP. in Table 3. IMP. quantifies the performance gain of CNGAN by summing the differences in MSE and MAE metrics relative to other baseline methods.) compared with DLinear on all open-source datasets.
Moreover, compared to other GAN-based methods, such as TimeGAN, TimeGAN was unable to achieve competitive performance compared to the proposed CNGAN method. TimeGAN employs a latent space embedding and recovery mechanism, reconstructing entire time series sequences. It relies on purely random noise as input to the encoder for generative prediction, without incorporating pretrained knowledge or prior information, which may limit its ability to fully capture temporal dependencies. In contrast, CNGAN utilizes a linear encoder to generate conditional noise directly, leveraging pretrained information and eliminating the need for additional random noise inputs and encoding steps. This approach enhances the model’s ability to capture temporal patterns more effectively.Table 3. Results for multivariate time series forecasting.MethodsLinearDLinearTimeGANCNGANDatasetsStepsIMP. (%)MSEMAEMSEMAEMSEMAEMSEMAEETTh1961.50.3750.3970.3750.3990.3990.4200.368****0.3911920.70.4180.4290.4050.4160.4150.4230.402****0.4123362.80.4790.4760.4390.4430.4500.4640.426****0.4287205.70.6240.5920.4720.4900.4970.5040.444****0.461ETTh2961.90.2880.3520.2890.3530.3040.3870.279****0.3441924.80.3770.4130.3830.4180.3880.4210.358****0.3953368.20.4520.4610.4480.4650.4590.4880.404****0.42772019.60.6980.5950.6050.5510.5110.5540.4770.483ETTm1960.10.3080.3520.2990.3430.3320.3690.3000.3411920.20.3400.3690.3350.3650.3530.3850.334****0.3643360.00.3760.3930.3690.3860.3950.4020.3700.3857201.10.4400.4350.4250.4210.4370.4430.421****0.414ETTm2960.70.1680.2620.1670.2600.2020.2940.165****0.2551920.10.2320.3080.2240.3030.2540.3130.2250.3013361.00.3200.3730.2810.3420.3170.3590.276****0.3377202.10.4130.4350.3970.4210.4180.4440.389****0.408ILI2432.61.9470.9852.2151.0812.1641.4182.0510.9193632.62.1821.0361.9630.9632.0341.2941.737****0.8634859.72.2561.0602.1301.0242.3181.1161.701****0.8566082.62.3901.1042.3681.0962.4461.1931.744****0.894Weather962.40.1760.2360.1760.2370.1930.2550.168****0.2211922.70.2180.2760.2200.2820.2310.2810.214****0.2613362.80.2620.3120.2650.3190.2840.3370.257****0.2997200.00.3260.3650.3230.3620.3420.3790.3290.356Exchange Rate96− 0.90.0820.2070.081****0.2030.1250.2810.0850.208192− 1.30.1670.3040.157****0.2930.2700.3450.1640.2993361.10.3280.4320.3050.4140.3160.4620.2930.4157206.30.9640.7500.6430.6010.5930.6740.586****0.595Electricity960.80.1400.2370.1400.2370.1640.2760.136****0.2331920.40.1530.2500.1530.2490.1820.2830.151****0.2473360.30.1690.2680.1690.2670.2510.2970.167****0.266720− 0.40.2030.3010.203****0.3010.2470.3320.2060.302Traffic96− 4.70.4100.2820.410****0.2820.4550.3320.4220.317192− 4.60.4230.2870.423****0.2870.4640.3780.4340.322336− 12.50.4360.2950.4360.2960.5010.4220.4910.366720− 109.40.4660.3150.466****0.3150.6120.4971.1690.706MethodsFEDformerAutoformerInformerPyraformerLogTransDatasetsStepsIMP. (%)MSEMAEMSEMAEMSEMAEMSEMAEMSEMAEETTh1961.50.3760.4190.4490.4590.8650.7130.6640.6120.8780.7401920.70.4200.4480.5000.4821.0080.7920.7900.6811.0370.8243362.80.4590.4650.5210.4961.1070.8090.8910.7381.2380.9327205.70.5060.5070.5140.5121.1810.8650.9630.7821.1350.852ETTh2961.90.3460.3880.3580.3973.7551.5250.6450.5972.1161.1971924.80.4290.4390.4560.4525.6021.9310.7880.6834.3151.6353368.20.4960.4870.4820.4864.7211.8350.9070.7471.1241.60472019.6**0.463*0.4740.5150.5113.6471.6250.9630.7833.1881.540ETTm1960.10.3790.4190.5050.4750.6720.5710.5430.5100.6000.5461920.20.4260.4410.5530.4960.7950.6690.5570.5370.8370.7003360.00.4450.4590.6210.5371.2120.8710.7540.6551.1240.8327201.10.5430.4900.6710.5611.1660.8230.9080.7241.1530.820ETTm2960.70.2030.2870.2550.3390.3650.4530.4350.5070.7680.6421920.10.2690.3280.2810.3400.5330.5630.7300.6730.9890.7573361.00.3250.3660.3390.3721.3630.8871.2010.8451.3340.8727202.10.4210.4150.4330.4323.3791.3383.6251.4513.0481.328ILI2432.63.2281.2603.4831.2875.7641.6771.4202.0124.4801.4443632.62.6791.0803.1031.1484.7551.4677.3942.0314.7991.4674859.72.6221.0782.6691.0854.7631.4697.5512.0574.8001.4686082.62.8571.1572.7701.1255.2641.5647.6622.1005.2781.560Weather962.40.2170.2960.2660.3360.30.3840.8960.5560.4580.491922.70.2760.3360.3070.3670.5980.5440.6220.6240.6580.5893362.80.3390.380.3590.3950.5780.5230.7390.7530.7970.6527200.00.4030.4280.4190.4281.0590.7411.0040.9340.8690.675Exchange Rate96− 0.90.1930.3080.2010.3170.2740.3680.3860.4490.2580.357192− 1.30.2010.3150.2220.3340.2960.3860.3860.4430.2660.3683361.10.2140.3290.2310.3380.30.3940.3780.4430.280.387206.30.460.50.5090.5241.6721.0361.8741.1721.6591.081Electricity960.81.1950.8411.4470.9412.4781.311.9431.2061.9411.1271920.40.5870.3660.6130.3880.7190.3912.0850.4680.6840.3843360.30.2460.3550.2540.3610.3730.4390.3760.4450.2830.376720− 0.40.1480.2780.1970.3230.8470.7520.3761.1050.9680.812Traffic96− 4.70.2710.380.30.3691.2040.8951.7481.1511.040.851192− 4.60.6040.3730.6160.3820.6960.3790.8670.4670.6850.39336− 12.50.6210.3830.6220.3370.7770.420.8690.4690.7340.408720− 109.40.6260.3820.660.4080.8640.4720.8810.4730.7170.396Bold and underlined text indicate the best and second-best performance, respectively.
Across all forecast step settings on the ETTh1/h2 and ETTm1/m2 datasets, CNGAN outperformed the DLinear method. The most significant improvement was observed when the forecast step was 720 on the ETTh2 dataset, achieving an MSE of 0.477 and MAE of 0.483, which was 19.6% higher than the comparison method. On the National illness dataset, improvement of the forecast performance ranges from 32% to 82%. However, it is poor on the other datasets. Even it shows a significant declines on Traffic dataset.
As shown in Fig. 6, the results demonstrate that CNGAN surpasses both DLinear and Transformer-based methods, showing a gradually increasing trend in performance at longer forecast steps.Fig. 6. Improvement of different forecast steps. CNGAN surpasses both DLinear and Transformer-based methods, showing a gradually increasing trend in performance at longer forecast steps.
As shown in Table 4, on five open source datasets, CNGAN achieved an impressive improvement of 192.8% for the longer forecast step settings of 1024 and 80. As the forecast steps increased, CNGAN significantly improved the forecast ability. However, there appears to be a shortcoming in shorter forecast steps.Table 4. Results for longer steps on time series forecasting.MethodsLinearDLinearCNGANDatasetsStepsIMP. (%)MSEMAEMSEMAEMSEMAEETTh1102416.40.5450.5360.6120.5780.519****0.507ETTh2102417.30.8040.6340.7540.6160.642****0.555ETTm110240.90.4650.4490.4580.4390.454****0.434ETTm210248.20.4380.4380.4930.4730.440****0.444ILI80150.02.6731.1752.9631.2831.822****0.924Bold and underlined text indicate the best and second-best performance, respectively.
Results on Jiangsu Telecom market dataset
This study also conducted experiments on Jiangsu Telecom’s closed-source market dataset, which possesses characteristics that differ from open source datasets: a short total step length, large granularity, and a user dimension in addition to time and feature dimensions. These differences collectively necessitate training with a fixed context window and sampling along the customer dimension, rather than sliding sampling across a longer sequence of data like open-source datasets. Shorter contexts also increase prediction difficulty. This experiment reports precision, recall, and F1-score as binary classification metrics. The model outputs the probability that a user may purchase a certain business. The group of users ranked in the top 5%, 10%, and 30% by probabilities are treated as target groups.
Currently, Jiangsu Telecom employs a method that integrates multiple machine learning methods(e.g., xgboost, catboost, lightgbm) to build model. This study conducted experiments using autoregressive (LSTM) and non-autoregressive modules (iTransformer^26^ and TSMixer) based on CNGAN. The training data was collected from January 2023 to December 2023, and the test data was collected from January 2024 to February 2024. For the non-autoregressive method, time dimension embedding was used to model time series information. For all methods, city dimension embedding was used to model regional information. Before forward to the generator, the input was self-masked by noise to meet business requirements and the model was trained in parallel and step-wise.
The results are reported in Table 5. CosW indicates whether cosine dynamic weights are used in joint loss. The best results are indicated in black, and the second best are underlined. I indicates the percentage improvement of the best result relative to the integrated model.Table 5. Results on Telecom market dataset.MethodTOP%PrecisionRecallF1 iTransformer w.o. CosW50.1360.1130.123100.1170.1950.146300.0990.4930.164 TSMixer w.o. CosW50.2330.1940.211100.1780.2970.223300.1170.5840.195 LSTM w.o. CosW50.0530.0440.049100.0560.0940.070300.0620.3070.102 iTransformer w. CosW50.3890.3240.353100.2860.4760.357300.1470.7320.244 TSMixer w. CosW50.5970.4970.542100.3780.6300.473300.1570.7820.261 LSTM w. CosW50.0560.0470.051100.0670.1120.084300.0620.3070.102 Current model50.0430.2200.070100.0340.3500.061300.0210.6360.041 Improvement555.41%27.63%47.27%1034.38%27.99%41.12%3013.53%14.62%22.01%Bold and underlined text indicate the best and second-best performance, respectively.
From the results, it is evident that current model is weak. CNGAN using LSTM modules performs the worst, while CNGAN with non-autoregressive modules has achieved significant improvements. Specifically, CNGAN with TSMixer as the generator has comprehensively outperformed the integration model. The three indicators increased by 55.41%, 27.63%, and 47.27% for the top 5% user group, by 34.38%, 27.99%, and 41.12% for the top 10% user group, and by 13.53%, 14.62%, and 22.01% for the top 30% user group, as a result of average 31.5% increase. And the average improvement is 11.2% compared with CNGAN using iTransformer.
The deep learning method based on generative adversarial networks has comprehensively surpassed the current model. However, a major challenge of deep learning methods in business applications is their unexplained. The black box nature of deep learning fails to provide logical explanations, making it difficult to effectively integrate technology with experts experience. Although the current model has weaker forecasting ability, it offers relatively good explainability. Using tools such as SHAP^27^ (SHapley Additive exPlanations), it can provide explanations for the output probability, effectively helping business staff understand the modeling principles and the meaning of the output probabilities. This understanding aids in organizing marketing language and strategies. The method proposed in this paper can complement the current model, further assisting marketing units in improving marketing success rates. This has significant practical implications, as it combines the forecasting capability of deep learning with the explainability needed for practical business applications, thereby enhancing the overall effectiveness of marketing strategies.
Other experiments and analysis
Forecasting visualization
Figure 7 visualizes the results on the ETTh2 and ILI test split, comparing ground truth, CNGAN, and the baseline method DLinear. The visualization uses the 57th sequence and 4th variable with 512 history steps and 720 forecast steps in the test split on ETTh2. On ILI, it uses the 92th sequence and 7th variable with 104 history steps and 80 forecast steps in the test split. Due to length constraints, Fig. 8a truncates the visualization results.Fig. 7. Results visualization. CNGAN achieves better fitting performance in time series forecasting compared to the baseline methods.
The visualization results in Fig. 7 provide clear evidence of the superior performance of CNGAN over DLinear in time series forecasting. As shown in Fig. 8(a), although DLinear captures the overall temporal trend of the ETTh2 dataset, it exhibits significant deviations from the ground truth. CNGAN shows a markedly improved performance on the ETTh2 dataset. As shown in Fig. 8(b), DLinear do not able to capture the overall temporal trend, and it exhibits more significant deviations. However, CNGAN can not only capture the temporal trend, but also has a smaller deviation. The visualized results demonstrate the clear advantages of CNGAN over DLinear in long-term time series forecasting.
Noise visualization
In this section, this study visualizes the impact of conditional noise and random noise for forecasting. Since this paper uses a linear generator, we consider the difference in linear correlation between pre-trained conditional noise and random noise with ground truth. The calculation process is as Eq. (14):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} CM(i,j)=r(Z_i,Y_j,L) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r(Z_i,Y_j,L)$$\end{document} can be expressed as Eq. (15):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} r(Z_i,Y_j,L)=|\frac{\sum _{k=0}^{L-1}(Z_{i,k}-\overline{Z_{i}})(Y_{j,k}-\overline{Y_{j}})}{\sqrt{\sum _{k=0}^{L-1}(Z_{i,k}-\overline{Z_{i}})^2}\sqrt{\sum _{k=0}^{L-1}(Y_{j,k}-\overline{Y_{j}})^2}}| \end{aligned}$$\end{document}where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&Z_i=Z(:,i) \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&Y_j=Y(:,j) \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$CM$$\end{document} represents the linear correlation matrix, L is sequence length, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y_j$$\end{document} are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} -th column vector of noise matrix and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j$$\end{document} -th column vector of ground truth matrix respectively. This calculation measures the linear correlation between the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} -th variable of the noise and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j$$\end{document} -th variable of ground truth.
As shown in Fig. 8, we presents visualizations of the linear correlation matrix between conditional noise, random noise, and ground truth from the ETTh2 and ILI datasets. For ETTh2, sequences 4 and 20 from the test split are used, while for ILI, sequences 1 and 5 from the test split are used. The horizontal and vertical axes denote variable dimensions of two matrixs. Each position in the correlation matrix indicates the degree of linear correlation between corresponding multi-steps variables. The values closer to 0 indicate less correlation, while the values closer to 1 indicate higher correlation.Fig. 8. Noise visualization. For each group, the left shows the conditional noise, while the right shows the random noise. The conditional noise exhibits stronger correlation.
Figure 8a, b illustrates that random noise exhibits almost no linear correlation with the ground truth on the ETTh2 dataset. Conditional noise shows weak linear correlation with variable 1, but relatively high correlation in other variables. Figure 8c, d illustrates a large difference with the ILI dataset. Here, random noise maintains extremely low linear correlation across nearly all variable dimensions, whereas pre-trained conditional noise exhibits extremely high linear correlation with ground truth. These results intuitively demonstrate that a linear generator can easily generate more high-quality synthetic data from conditional noise, while generating from random noise is more challenging. Conditional noise provides crucial posterior information for the linear generator, enabling it to produce more accurate forecasting results.
Ablation study
This paper quantitatively analyzes the impact of the proposed conditional noise and adversarial loss through ablation experiments. We remove the conditional noise and adversarial loss one by one and observe their effects on performance metrics. The results of the ablation experiments are summarized in Table 6, using the ETTh1, ETTh2, and ILI datasets, with the same evaluation metrics as the main experiment. For the ETT datasets, the forecasting steps are 720 and 1024, and for the ILI dataset, the forecasting steps are 60 and 80. The IMP. column records changes in metrics.Table 6. Ablation results.DatasetsStepsFull-Conditional noise-Adversarial lossMSEMAEMSEMAEIMP.MSEMAEIMP.ETTh17200.4440.4610.4620.483− 0.0400.4670.485− 0.04710240.5190.5070.5180.513− 0.0050.5250.518− 0.017ETTh27200.4770.4830.6680.574− 0.2820.7660.620− 0.42610240.6420.5550.8290.642− 0.2740.8620.663− 0.328ILI601.7440.8942.1531.032− 0.5472.4231.102− 0.887801.8220.9242.2391.046− 0.5392.6871.168− 1.109
The ablation results show that removing either conditional noise or adversarial loss leads to a decrease in metrics. Overall, adversarial loss has a greater impact compared to conditional noise. From a data perspective, the influence of conditional noise and adversarial loss on the ETTh1 dataset is extremely small. However, on the ETTh2 and ILI datasets, both conditional noise and adversarial loss have a significant impact.
This work further investigates the impact of two key hyperparameters: the adversarial strength coefficient (alpha) and the kernel size of the 1D convolution used for temporal data. Considering computational efficiency, experiments were conducted on the relatively small ETTh2 dataset. Specifically, a grid search was performed over 11 values of alpha (ranging from 0.0 to 1.0 in increments of 0.1) and 11 values of kernel size (3, 10, 20, ..., 100), running each combination 10 times and averaging the performance metrics. Early stopping was used with a patience of 30, and each run took approximately \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2\tilde{3}$$\end{document} minutes, resulting in a total runtime of about 3 × 11 × 11 × 10 = 3630 minutes.Fig. 9. Visualization of the effects of key hyperparameters alpha and kernel size on model performance.
The results are illustrated in Fig. 9. For better readability, the MAE and MSE metrics were transformed into –log(MAE) and –log(MSE). The results were visualized in a three-dimensional space, where the x-axis represents alpha, the y-axis represents kernel size, and the z-axis corresponds to the transformed metric. Higher values on the z-axis indicate better performance. The experimental results demonstrate the influence of both hyperparameters, with consistent trends observed across both -log(MAE) and -log(MSE) metrics.
For alpha, the results generally show a trend which performance first improves and then declines as adversarial strength alpha increases. The optimal alpha is found to be between 0.2 and 0.3. At the two extreme points, when alpha = 0.0 (purely supervised training), the best performance is not achieved, and when alpha = 1.0 (pure adversarial training), the performance significantly drops. These results highlight the importance of Supervised signals in the CNGAN framework. Overall, these findings underscore the effectiveness of combining adversarial training with supervised learning in a hybrid training approach.
Regarding the 1D convolution kernel size, larger kernels generally lead to performance degradation, suggesting that fine-grained convolutions are more beneficial for processing temporal data. It is also observed that the sensitivity to kernel size varies with the value of alpha: the model is more sensitive to kernel size when the adversarial strength is lower and less sensitive when the adversarial strength is higher. This indirectly demonstrates the robustness and scalability of the generative adversarial network architecture for time-series data. One potential direction for future work is to further exploit this property to optimize model performance.
What traffic happened?
A more in-depth investigation was conducted to analyze the low performance on the traffic dataset. The traffic dataset is substantially larger than the other datasets used in this study. Specifically, it contains approximately 1.79 times more data than the electricity dataset and 2236 times more than the ILI dataset. Such high information density may exceed the discriminator’s capacity, resulting in weaker feedback during adversarial training. To facilitate further experimentation, an A100 GPU was utilized. Earlier experiments were limited by the memory constraints of a 3070Ti GPU, which restricted the use of large batch sizes, thereby reducing training efficiency and scalability. With the enhanced computational resources, a comparative analysis of training dynamics was performed between the traffic and ETTh2. The normalized gradients provided from both the generator and the discriminator were monitored throughout the training process.Fig. 10. Normalized gradients during training process.
Figure 10 shows the normalized gradients provided from both the generator and the discriminator during the training process. The normalized gradient magnitude serves as an indicator of the strength of the learning signal each component contributes during optimization. C3L1 means that a discriminator comprises three convolutional layers and one fully connected layer, while C4L2 consists of four convolutional layers and two fully connected layers.
First, it was observed that during GAN training, the discriminator contributes the majority of the gradient signal, relative to the generator, emphasizing its critical role in driving effective model optimization. Furthermore, the results indicate that dataset complexity has a significant impact on the gradient signal strength from the discriminator. The same generator exhibits significantly different performance on ETTh2 and traffic datasets. This suggests that, on complex datasets such as traffic, lightweight discriminator is more susceptible to gradient vanishing. As shown in Table 7, at 720 forecasting steps, increasing the depth of the discriminator alleviate this issue to some extent.Table 7MAE and MSE metrics of different discriminator architectures at 720 forecasting steps.Discriminator ArchitectureMAEMSE C3L10.7061.169 C4L10.6040.743 C5L10.6110.758 C3L20.5540.605 C3L30.4960.508 C4L10.4210.487 C4L20.334****0.430 C4L30.3560.498Bold and underlined text indicate the best and second-best performance, respectively.
Compared to the C3L1 discriminator architecture, scaling the discriminator resulted in varying degrees of improvement. In the experiments conducted in this study, the best results were achieved with a discriminator consisting of four convolutional layers and two fully connected layers. This observation suggests that exploring how to adjust or replace the discriminator with more effective architectures is a promising direction for future research.
Conclusion
This study proposes CNGAN to prove the feasibility of generative methods in long-term time series forecasting. CNGAN introduces conditional noise and SNN discriminator. Visualization results demonstrate that conditional noise effectively encodes posterior information, enhancing the generator ability to capture context. The SNN discriminator naturally models the adversarial aspect of generative adversarial networks. It is confirmed that combining supervised learning with unsupervised adversarial learning can improve model performance by ablation experiments. Visualization of forecasting results shows that CNGAN outperforms the DLinear method while maintaining simple characteristic. Furthermore, this study explores the practical implications in Telecom market scenarios. Research results verify that the forecasting capability of CNGAN can enhance the accuracy of marketing recommendations. Future research could explore the combination of other encoder and decoder modules to further extend the application of generative adversarial networks into new fields. To the best of our knowledge, this work is one of the first studies to utilize the generative adversarial framework for long-term time series forecasting. We hope this study will inspire further research, open up new directions and methodologies, and provide valuable references for the academic community. Moreover, it also offers practical solutions that can be applied to real-world scenarios.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ariyo, A. A., Adewumi, A. O. & Ayo, C. K. Stock price prediction using the arima model. In 2014 UK Sim-AMSS 16th international conference on computer modelling and simulation, 106–112 (IEEE, 2014).
- 2Friedman, J. H. Greedy function approximation: a gradient boosting machine. Annals of statistics 1189–1232 (2001).
- 3Graves, A. & Graves, A. Long short-term memory. Supervised sequence labelling with recurrent neural networks 37–45 (2012).
- 4Bai, S., Kolter, J. Z. & Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. ar Xiv preprintar Xiv:1803.01271 (2018).
- 5Cho, K. et al. Learning phrase representations using rnn encoder-decoder for statistical machine translation. ar Xiv preprintar Xiv:1406.1078 (2014).
- 6Li, S. et al. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Advances in neural information processing systems 32 (2019).
- 7Zhou, H. et al. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence 35, 11106–11115 (2021).
- 8Liu, S. et al. Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting. In International conference on learning representations (2021).