Complete genome sequencing of Limosilactobacillus fermentum NS2301G2 isolated from kimchi
Ziyao Meng, Kiyeop Kim, Byung Wook Son, Jong Hoon Kim, Sejong Oh

TL;DR
This study reports the complete genome sequence of a lactic acid bacterium isolated from kimchi, offering insights into its genetic makeup and potential probiotic properties.
Contribution
The paper provides the first complete genome sequence of Limosilactobacillus fermentum NS2301G2 isolated from kimchi using hybrid sequencing methods.
Findings
The genome consists of a 2,077,637 base pair circular chromosome.
The GC content of the genome is 51.51%.
The sequencing provides genetic insights into food microbiology and probiotic research.
Abstract
Limosilactobacillus fermentum NS2301G2, isolated from fermented kimchi, underwent nanopore and Illumina sequencing, revealing a 2,077,637 base pair circular chromosome with 51.51% GC content, providing valuable genetic insights into lactic acid bacteria that contribute to food microbiology and probiotic research.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
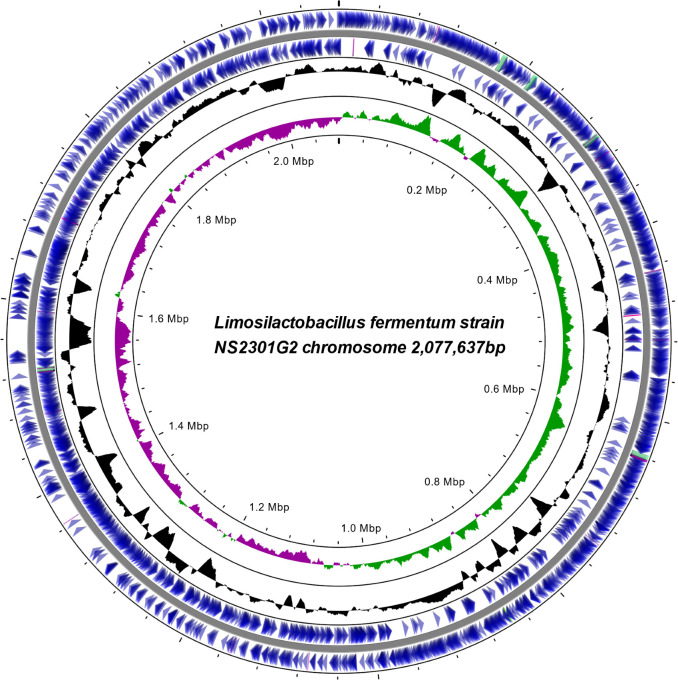 Fig 1
Fig 1| Statistics | |
|---|---|
| Total genome length (bp) | 2,077,637 |
| GC content (%) | 51.51 |
| Illumina Depth (X) | 391.252 |
| Nanopore Depth (X) | 189.986 |
| Genome coverage (x) | ~581 total |
| CDS | 2,059 |
| tRNA | 58 |
| rRNA | 15 |
- —National Research Foundation of Koreahttp://dx.doi.org/10.13039/501100003725
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsProbiotics and Fermented Foods · Genomics and Phylogenetic Studies · Bacteriophages and microbial interactions
ANNOUNCEMENT
Lactic acid bacteria (LAB) play essential roles in food fermentation and health. Limosilactobacillus fermentum, reclassified from the Lactobacillus genus (1), exhibits probiotic features such as acid and bile tolerance, cholesterol-lowering, and antioxidant activity (2). However, strain-specific genomic insights are limited, requiring further analysis. This study reports the complete genome sequencing of L. fermentum NS2301G2, isolated from fermented kimchi in Korea, using hybrid sequencing technologies that combined Illumina and Oxford Nanopore platforms. In a sterile environment, 10 g of kimchi was homogenized with 90 mL of 0.85% NaCl. Serial dilutions were plated onto de Man, Rogosa, and Sharpe (MRS) agar and incubated anaerobically at 37°C for 48–72 h. The isolate was cultivated in MRS broth at 37°C for 24 h under static conditions. Genomic DNA was extracted from 10 mL of culture using the DNeasy PowerSoil Pro Kit (QIAGEN, Hilden, Germany), following the manufacturer’s protocol. The quality and quantity of extracted DNA were assessed using a NanoDrop One spectrophotometer (Thermo Fisher Scientific, USA) and a Qubit 4 Fluorometer with the dsDNA BR Assay Kit (Thermo Fisher Scientific, USA), and integrity was confirmed by 1% agarose gel electrophoresis. Two genomic libraries were prepared for Illumina and Nanopore sequencing. For Illumina sequencing, 300 ng of genomic DNA was sheared to an average fragment size of approximately 400–450 bp using a Covaris M220 Focused-ultrasonicator (Covaris, Woburn, MA, USA) with microTUBE-50 AFA Fiber Screw-Cap tubes under the following parameters: peak incident power 75 W, duty factor 10%, 200 cycles per burst, and 64 s treatment time. Fragment size distribution was evaluated using a TapeStation 4200 system (Agilent Technologies, USA), confirming an average fragment size of ~400–450 bp. Libraries were then prepared using the TruSeq DNA Nano Prep Kit (Illumina, San Diego, CA, USA). Adapter trimming and quality filtering of Illumina reads were performed using Trimmomatic v0.39 (LEADING:10 TRAILING:10 SLIDINGWINDOW:4:20 MINLEN:200) (3). Reads were aligned to the phiX genome using Bowtie2 v2.3.5.1 (4) and filtered with SAMtools v1.9 (5). Sequencing was performed on the Illumina NextSeq2000 (Illumina) in the 300 bp paired-end mode, generating 5,255,888 reads (~1.55 Gb). After trimming, 2,296,328 high-quality pairs (87.38%) remained for downstream analysis. Nanopore libraries were prepared using the Ligation Sequencing Kit (Oxford Nanopore Technologies, Oxford, UK) and sequenced for 24 h on an R10.4.1 GridION flow cell, operated with MinKNOW v5.0.0 and basecalled using Guppy v6.0.6 (Oxford Nanopore Technologies, UK). No mechanical shearing or size selection was performed. Nanopore sequencing generated 65,416 reads (654 Mb), with a read N50 of 12,099 bp and average quality score of 16.7. Guppy v6.0.6 was used for basecalling. Reads were filtered using NanoFilt v2.8.0 (6) (Phred score <7, length <1,000 bp). All bioinformatics tools used default parameters unless noted. Trimmomatic v0.39 trimmed Illumina reads (4). Reads were aligned to the phiX genome using Bowtie2 v2.3.5.1 (5) and filtered with SAMtools v1.9 (6). Unicycler v0.4.8 assembled the genome using filtered Illumina and Nanopore reads (7). Genome annotation was performed with NCBI Prokaryotic Genome Annotation Pipeline v6.9 (PGAP v6.9) (8). Genome completeness was assessed using BUSCO v5.3.2 with the bacteria_odb10 lineage data set (9). The resulting assembly was a single circular contig of 2,077,637 bp with a GC content of 51.51%. Circularity was confirmed by trimming overlaps using Unicycler, and the genome was rotated to begin at the dnaA gene. The circular map (Fig. 1) was generated with Proksee (https://proksee.ca/) based on the PGAP-annotated GenBank file. Genome features are summarized in Table 1. BUSCO analysis indicated 99.2% completeness, with 0.8% fragmented and no missing single-copy orthologs, supporting the reliability of the assembled genome.
Circular chromosome map of Limosilactobacillus fermentum NS2301G2. Marked features are shown from the periphery to the center: protein coding sequences on the forward strand, protein coding sequences on the reverse strand, tRNA, rRNA, GC ratio, and GC skew. bp, base pair; G, guanine; C, cytosine; tRNA, transfer RNA; rRNA, ribosomal RNA.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zheng J, Wittouck S, Salvetti E, Franz CMAP, Harris HMB, Mattarelli P, O’Toole PW, Pot B, Vandamme P, Walter J, Watanabe K, Wuyts S, Felis GE, Gänzle MG, Lebeer S. 2020. A taxonomic note on the genus Lactobacillus: description of 23 novel genera, emended description of the genus Lactobacillus Beijerinck 1901, and union of Lactobacillaceae and Leuconostocaceae. Int J Syst Evol Microbiol 70:2782–2858. doi:10.1099/ijsem.0.00410732293557 · doi ↗ · pubmed ↗
- 2Wu Y, Li X, Tan F, Zhou X, Mu J, Zhao X. 2021. Lactobacillus fermentum CQPC 07 attenuates obesity, inflammation and dyslipidemia by modulating the antioxidant capacity and lipid metabolism in high-fat diet induced obese mice. J Inflamm (Lond) 18:5. doi:10.1186/s 12950-021-00273-w 33531053 PMC 7852154 · doi ↗ · pubmed ↗
- 3Bolger AM, Lohse M, Usadel B. 2014. Trimmomatic: a flexible trimmer for Illumina sequence data. Bioinformatics 30:2114–2120. doi:10.1093/bioinformatics/btu 17024695404 PMC 4103590 · doi ↗ · pubmed ↗
- 4Langmead B, Salzberg SL. 2012. Fast gapped-read alignment with Bowtie 2. Nat Methods 9:357–359. doi:10.1038/nmeth.192322388286 PMC 3322381 · doi ↗ · pubmed ↗
- 5Li H, Handsaker B, Wysoker A, Fennell T, Ruan J, Homer N, Marth G, Abecasis G, Durbin R, 1000 Genome Project Data Processing Subgroup. 2009. The sequence alignment/map format and SA Mtools. Bioinformatics 25:2078–2079. doi:10.1093/bioinformatics/btp 35219505943 PMC 2723002 · doi ↗ · pubmed ↗
- 6De Coster W, D’Hert S, Schultz DT, Cruts M, Van Broeckhoven C. 2018. Nano Pack: visualizing and processing long-read sequencing data. Bioinformatics 34:2666–2669. doi:10.1093/bioinformatics/bty 14929547981 PMC 6061794 · doi ↗ · pubmed ↗
- 7Wick RR, Judd LM, Gorrie CL, Holt KE. 2017. Unicycler: resolving bacterial genome assemblies from short and long sequencing reads. P Lo S Comput Biol 13:e 1005595. doi:10.1371/journal.pcbi.100559528594827 PMC 5481147 · doi ↗ · pubmed ↗
- 8Tatusova T, Di Cuccio M, Badretdin A, Chetvernin V, Nawrocki EP, Zaslavsky L, Lomsadze A, Pruitt KD, Borodovsky M, Ostell J. 2016. NCBI prokaryotic genome annotation pipeline. Nucleic Acids Res 44:6614–6624. doi:10.1093/nar/gkw 56927342282 PMC 5001611 · doi ↗ · pubmed ↗