Benchmarking large language models for personalized, biomarker-based health intervention recommendations
Hans Jarchow, Christoph Bobrowski, Steffi Falk, Andreas Hermann, Anton Kulaga, Johann-Christian Põder, Maximilian Unfried, Nikolay Usanov, Bijan Zendeh, Brian K. Kennedy, Sebastian Lobentanzer, Georg Fuellen

TL;DR
This paper benchmarks large language models for personalized health recommendations based on biomarkers and finds that proprietary models perform better but still have limitations.
Contribution
The study introduces an open-source framework for benchmarking LLMs in personalized longevity interventions with clinician-validated test cases.
Findings
Proprietary models outperformed open-source models in comprehensiveness of recommendations.
LLMs struggled with medical validation requirements and age-related biases even with RAG.
The framework provides a foundation for future AI benchmarking in medical contexts.
Abstract
The use of large language models (LLMs) in clinical diagnostics and intervention planning is expanding, yet their utility for personalized recommendations for longevity interventions remains opaque. We extended the BioChatter framework to benchmark LLMs’ ability to generate personalized longevity intervention recommendations based on biomarker profiles while adhering to key medical validation requirements. Using 25 individual profiles across three different age groups, we generated 1000 diverse test cases covering interventions such as caloric restriction, fasting and supplements. Evaluating 56000 model responses via an LLM-as-a-Judge system with clinician validated ground truths, we found that proprietary models outperformed open-source models especially in comprehensiveness. However, even with Retrieval-Augmented Generation (RAG), all models exhibited limitations in addressing key…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
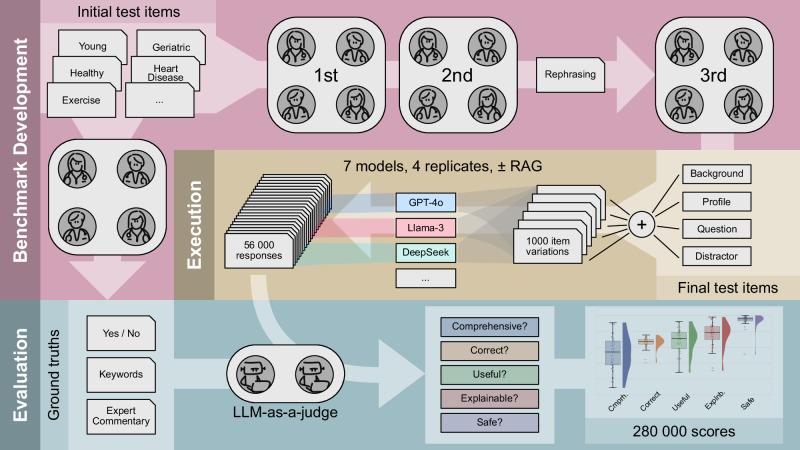 Figure 1
Figure 1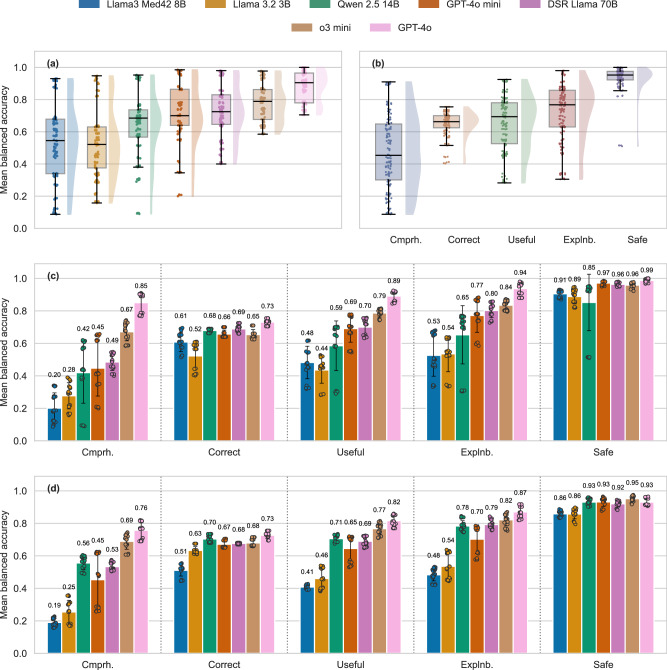 Figure 2
Figure 2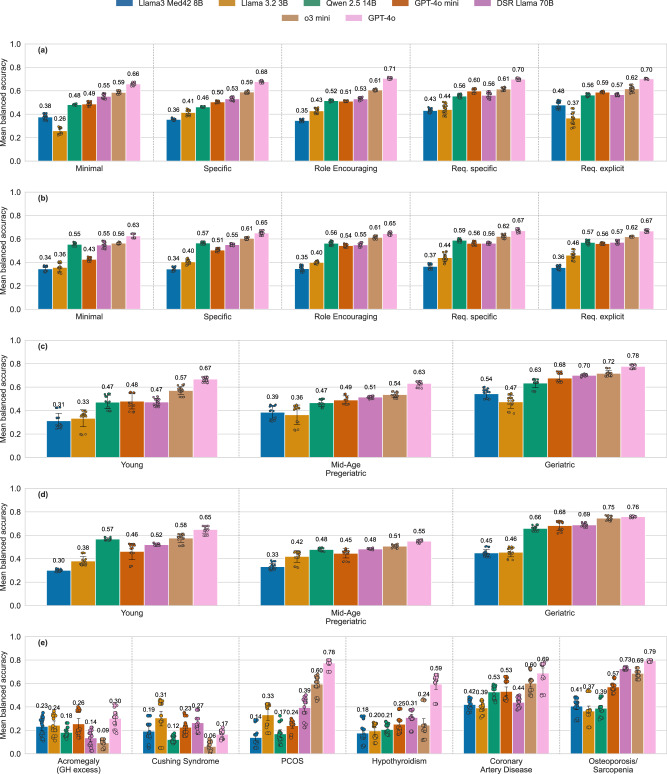 Figure 3
Figure 3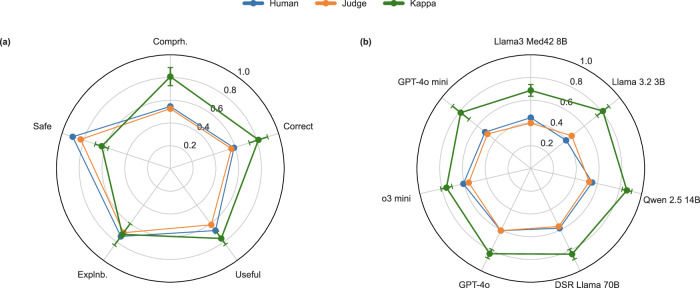 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Healthcare · Artificial Intelligence in Healthcare and Education · Topic Modeling