False Discovery Estimation in Record Linkage
Kayané Robach, Michel H. Hof, Mark A. van de Wiel

TL;DR
This paper introduces a new method to estimate false discoveries in record linkage, improving reliability when combining data without unique identifiers.
Contribution
A novel FDP estimation method for record linkage using synthetic data to assess linkage reliability across diverse settings.
Findings
The method uses synthetic records to estimate false discoveries in record linkage.
It works across various RL techniques and complex data settings.
Applied successfully to the Netherlands Perinatal Registry to assess sibling links.
Abstract
Integrating data from multiple sources expands research opportunities at low cost. However, due to different data collection processes and privacy constraints, unique identifiers are unavailable. Record linkage (RL) algorithms address this by probabilistically linking records based on partially identifying variables. Since these variables lack the strength to perfectly combine information, RL procedures yield an imperfect set of linked records. Therefore, assessing the false discovery proportion (FDP) in RL is crucial for ensuring the reliability of subsequent analyses. In this paper, we introduce a novel method for estimating the FDP in RL for two overlapping data sets. We synthesize data from their estimated empirical distribution and use it along with real data in the linkage process. Since synthetic records cannot form links with real entities, they provide a means to estimate the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
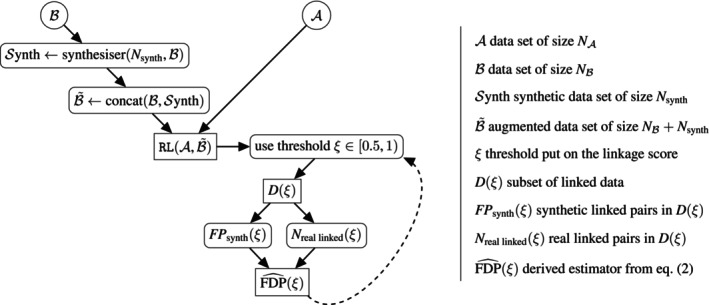 FIGURE 1
FIGURE 1 FIGURE 2
FIGURE 2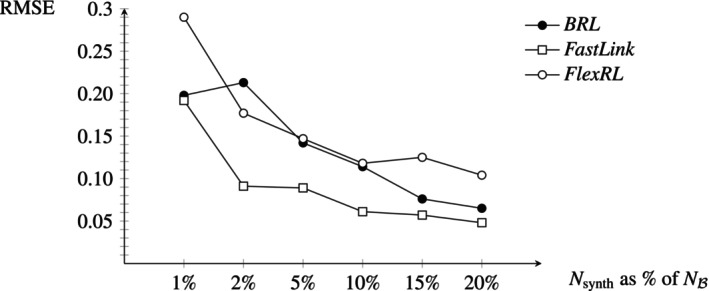 FIGURE 3
FIGURE 3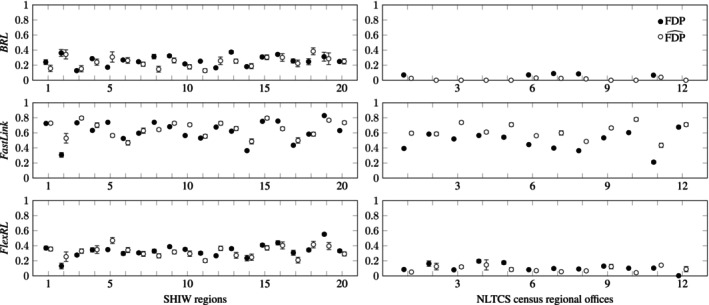 FIGURE 4
FIGURE 4| Overlap 0.35 | Overlap 0.75 | |||
|---|---|---|---|---|
| Discr. level 0.85 | 0.604 (0.001) | 0.416 (0.001) | ||
| bias | 0.003 (0.012) | 0.073 (0.007) | ||
| bias | −0.409 (0.013) | −0.313 (0.011) | ||
| Condition | () | () | ||
| AUC synth | 0.515 (0.003) | 0.518 (0.003) | ||
| Discr. level 0.95 | 0.284 (0.002) | 0.157 (0.001) | ||
| bias | 0.018 (0.008) | 0.033 (0.003) | ||
| bias | −0.246 (0.005) | −0.140 (0.001) | ||
| Condition | () | () | ||
| AUC synth | 0.528 (0.003) | 0.530 (0.004) |
| Links at random | Links depend on variables | |||||
|---|---|---|---|---|---|---|
| Overlap 0.35 | Overlap 0.75 | Overlap 0.35 | Overlap 0.75 | |||
| Discr. level 0.85 | 0.655 (0.009) | 0.475 (0.009) | 0.649 (0.023) | 0.295 (0.030) | ||
| bias | −0.005 (0.066) | 0.046 (0.049) | −0.068 (0.07) | −0.023 (0.047) | ||
| bias | −0.019 (0.013) | 0.133 (0.009) | 0.083 (0.025) | 0.091 (0.022) | ||
| Condition | () | () | () | () | ||
| AUC synth | 0.490 (0.019) | 0.499 (0.018) | 0.476 (0.024) | 0.435 (0.023) | ||
| AUC link | 0.497 (0.016) | 0.500 (0.010) | 1 (0) | 1 (0) | ||
| Discr. level 0.95 | 0.306 (0.014) | 0.170 (0.011) | 0.227 (0.018) | 0.082 (0.010) | ||
| bias | −0.014 (0.054) | 0.018 (0.027) | −0.053 (0.045) | −0.008 (0.022) | ||
| bias | −0.028 (0.014) | 0.086 (0.012) | 0.005 (0.024) | −0.007 (0.009) | ||
| Condition | () | () | () | () | ||
| AUC synth | 0.510 (0.021) | 0.506 (0.023) | 0.492 (0.023) | 0.461 (0.024) | ||
| AUC link | 0.498 (0.015) | 0.502 (0.013) | 1 (0) | 1 (0) | ||
| Discr. level 0.85 | 0.657 (0.006) | 0.471 (0.008) | 0.629 (0.011) | 0.351 (0.010) | ||
| bias | −0.015 (0.048) | 0.042 (0.042) | −0.059 (0.053) | 0.030 (0.038) | ||
| bias | −0.021 (0.006) | 0.132 (0.008) | 0.077 (0.019) | 0.165 (0.022) | ||
| Condition | () | () | () | () | ||
| AUC synth | 0.502 (0.021) | 0.491 (0.016) | 0.506 (0.019) | 0.510 (0.023) | ||
| AUC link | 0.500 (0.012) | 0.504 (0.012) | 1 (0) | 1 (0) | ||
| Discr. level 0.95 | 0.305 (0.009) | 0.168 (0.007) | 0.209 (0.014) | 0.106 (0.007) | ||
| bias | −0.006 (0.037) | 0.019 (0.022) | −0.027 (0.039) | 0.015 (0.019) | ||
| bias | −0.026 (0.011) | 0.087 (0.007) | 0.004 (0.017) | 0.028 (0.013) | ||
| Condition | () | () | () | () | ||
| AUC synth | 0.507 (0.020) | 0.510 (0.018) | 0.524 (0.021) | 0.529 (0.023) | ||
| AUC link | 0.497 (0.012) | 0.499 (0.014) | 1 (0) | 1 (0) | ||
| Overlap 0.35 | Overlap 0.75 | |||
|---|---|---|---|---|
| Discr. level 0.95 | 0.234 (0.013) | 0.165 (0.013) | ||
| bias | −0.010 (0.052) | 0.008 (0.035) | ||
| bias | 0.030 (0.014) | 0.092 (0.016) | ||
| Condition | () | () | ||
| AUC synth | 0.507 (0.020) | 0.512 (0.022) | ||
| 0.276 (0.013) | 0.180 (0.008) | |||
| bias | −0.019 (0.042) | 0.008 (0.022) | ||
| bias | −0.002 (0.016) | 0.077 (0.009) | ||
| Condition | () | () | ||
| AUC synth | 0.515 (0.016) | 0.515 (0.017) |
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
| 0.073 (0.021) | 0.076 (0.028) | 0.222 (0.016) | 0.218 (0.017) | 0.188 (0.11) | 0.187 (0.012) | |
| bias | 0.093 (0.031) | 0.019 (0.070) | −0.001 (0.012) | −0.049 (0.008) | −0.001 (0.024) | −0.077 (0.022) |
| bias | Non‐available | Non‐available | Non‐available | Non‐available | Non‐available | Non‐available |
| Condition | () | () | () | () | () | () |
|
|
|
|---|---|
| SHIW | |
| 0.23 (0.006) | |
| bias | −0.035 (0.001) |
| bias | Non‐available |
| Condition | () |
| NLTCS | |
| Non‐available | |
| bias | |
| bias | |
| Condition | |
|
| Default |
|---|---|
| 0.01 | |
| Intercept | 6.64 (0.83) |
| Int btw pregnancies | −0.00 (0.05) |
| Mother age at 1st | −0.04 (0.02) |
| Duration pregnancy 1 | −0.21 (0.02) |
| ART pregnancy 1 | −0.13 (0.18) |
| DGP | |
|---|---|
| Intercept | −5 |
| 1 | |
| 1 | |
| 20 | |
| Benchmark | |
|---|---|
| Intercept | 0.05 (0.00) |
| 0.67 (0.02) | |
| 0.17 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Quality and Management · Data-Driven Disease Surveillance · Census and Population Estimation
Introduction
1
The development of record linkage (RL) methodologies stems from the concept of assembling a “book of life” for individuals to improve public health and human wellness [1]. This approach enhances research by integrating data from multiple sources to address novel questions. Today, privacy regulations drive the advancement of RL methods to accurately combine observations collected on different occasions using partially identifying variables (e.g., birth year, postal code). These variables are prone to errors and possess limited discriminative power due to a restricted number of unique values, which pose challenges in the linkage process, requiring robust error measurement tools.
Linked data contain two types of errors: falsely linked pair and missed link. The implications of linkage errors depend on the linkage structure [2, 3]. We focus on settings where linkage is used to construct the study population which corresponds to the intersection between two sets of records. In that context, the falsely linked pairs introduce noise, diluting true signals thus potentially biasing analyses. They lead to an overestimation of the sample size, creating a misleading impression of the amount of information available in the data. In contrast, missed links reduce the sample size, increase variance and diminish statistical efficiency. The false negative proportion (FNP) quantifies missed links, which are particularly difficult to detect due to registration errors (e.g., missing values, typographical errors) or real‐world changes over time (e.g., individuals relocating). Estimating the FNP requires accounting for such discrepancies, as records referring to the same individual may contain variations. Addressing falsely linked pairs through the false discovery proportion (FDP) is more feasible.
Probabilistic RL methods facilitate FDP estimation, either by leveraging agreement probabilities in linkage variables under the Fellegi‐Sunter framework [4, 5, 6] or by using posterior linkage probabilities [7, 8, 9]. A cutoff rule classifies pairs as linked or non‐linked, from which an FDP estimate can be derived [7, 10]. Nonetheless, evaluating the FDP remains challenging because such an estimate is usually not available in the open‐source implementations of RL, and its reliability is contingent on the RL model used. Hence it is sensitive to the low discriminative power of linkage variables, registration errors, intricate dependencies among variables, increasing number of entities in the population and the often limited overlap between data sets [7, 11, 12]. The Bayesian graphical entity resolution literature notes that the commonly applied uniform prior on the linkage structure tends to overestimate the number of unique individuals across samples [13, 14], leading to unreliable FDP estimates. Empirical studies further confirm this overestimation of linkage scores [7, 9, 15] resulting in an underestimation of the FDP when naively derived from a threshold‐based classification.
Despite the increasing use of linked data in research [15, 16, 17, 18, 19], there is no universally applicable measure of the error made when linking records. Since linkage errors substantially impact inference [20, 21], this underscores the need for robust tools to estimate the FDP in RL. To address this gap, we propose a new procedure for estimating the FDP by incorporating synthetic records into the data. The FDP is estimated by assessing whether these records are erroneously linked. This method is inspired by the target‐decoy search strategy in proteomics, which estimates false discoveries by comparing sequences with both true target data and generated decoy data [22]. Since this approach can be applied to any RL method, it provides a practical and generalizable tool for evaluating linkage error, paving the way for further research to be conducted using reliably linked data.
We illustrate our false discovery estimation procedure using the Perinatal Registry of the Netherlands (PRN), which records births in North Holland between 1999 and 2009. Many have used these data to study preterm birth, post‐term birth, and stillbirth risks by linking siblings records to examine associations between consecutive deliveries [23, 24, 25, 26]. In addition, RL has been used to link these data with external sources to investigate more general pregnancy outcomes [27, 28]. However, without a unique identifier to validate the linkage, the reliability of inferences drawn from these studies remains uncertain. In this paper, we apply RL to reconstruct siblings pairs and we use our FDP estimation method to select a subset of reliably linked records. As an illustrative example, we estimate the risk of preterm birth using the linked data, incorporating maternal characteristics and prior deliveries information. Since the true linkage structure is unknown in this context, we further evaluate the proposed procedure using well‐established labeled data. We demonstrate how the FDP estimation refines the set of linked records and improves inference results on both simulated and real data from the Survey of Household Income and Wealth (SHIW) [29]. Additionally, we apply the method to study the evolution of the frailty index in elderly populations using linked data from the National Long Term Care Survey (NLTCS) [30].
We introduce the problem and develop our method to estimate the FDP in RL in Section 2. We expand on the issue of which source file to use for synthesis in Section 3 and Section 4 and evaluate its scalability and robustness to the key assumptions in Section 5 and Section 6. We appraise the new estimation procedure across different RL methods and real data sets in Section 7. In the same Section, we highlight the importance of the FDP estimation and its robustness, and demonstrate its role in improving inference reliability. We conclude with guidelines toward improving false discovery in RL.
Problem
2
Consider the task of linking records across two overlapping data sources originating from the same population,
to construct a study population defined by their intersection. Let δi,j indicates whether the pair of records (ai,bj)∈𝒜×ℬ belongs to the same entity (a link: δi,j=1) or to different entities (a non‐link: δi,j=0). The RL task therefore targets the set of links:
When no unique identifier is available to perfectly determine which pairs of records belong to the same entities, RL procedures must rely on partially identifying variables present in both data sets (e.g., birth year, postal code) to link the records.
RL allows to control for confounding variables in inference by expanding the analysis to include more variables, linking longitudinal data for studying long‐term outcomes, or exploring secondary outcomes not originally measured. In our task, ℬ is a large file of electronic health records, while 𝒜 comes from clinical research data. In other examples ℬ represents baseline measurements in a clinical study, while 𝒜 contains follow‐up data with fewer patients or, to recall our main motivation, ℬ gathers first‐born babies across a country, while 𝒜 focuses on subsequent deliveries. Since our interest typically lies in the subsequent analysis, RL is often employed as a tool for data integration rather than as the ultimate aim. Hence the importance of acknowledging and addressing linkage errors, as they may lead to bias in inference.
The RL problem is fundamentally hard. Performance in real‐world problems depends on the discriminative power of entity features and the dimensions of data sources and their intersection [3, 11, 12]. This calls for an generic procedure for estimating the FDP, which we develop for settings where distinct entities may share similar or identical linkage variables. In addition, we investigate the scalability of the method with respect to the number of entities in the population and the effect of varying degrees of overlap between the data sources.
We assume all records within a data set belong to different underlying entities; we do not tackle the deduplication problem but we show our method's robustness under non‐deduplicated data in Section 6. Moreover we assume that links happen at random i.e., the fact that two records from different files relate to the same entity is not related to any observed mechanism; we elaborate further on this assumption in Section 1 and Section 6. This setting conveys that the records in both files come from the same distribution, even though registration error mechanisms may differ between the files. It also implies that, within a dataset, the linkage variables of records that form a link have the same distribution as that of records that do not.
Remark 1A central assumption in our methodology is that the distribution of linkage variables is the same for links and non‐links–links happen at random–which allows us to estimate and sample from the distribution of non‐links. This assumption is consistent with the established RL methodologies, the Fellegi‐Sunter model, and the graphical entity resolution framework. It is particularly realistic when linking variables have low discriminative power, leading to similar distributions for links and non‐links [12]. However, it may not hold when links and non‐links differ due to underlying factors (e.g., linking a cohort study to a disease registry). This assumption becomes less restrictive in settings where file ℬ is large with respect to file 𝒜 since most records in ℬ do not form a link. Hence, the synthetic records will reflect the distribution of non‐links. We show in Section 6 that our method remains robust as we deviate from this assumption.
Hereafter, we use N indexed with a set to denote its size, and we index with “synth” any quantity involving a synthetic record in its derivation. By default, when there is no index we refer to (potentially unknown) quantities derived from real records. We use the notation 1 for the indicator function. We use the term overlap to refer to the intersection between the two data sources, and we refer to a record as a set of linkage variables. Finally, without loss of generality, we assume that file ℬ contains more observations than file 𝒜 (N𝒜<Nℬ).
RL Methodology
2.1
Several RL methods are available in R and Python. After reviewing recent developments in the field, we focus on three methods that have been specifically developed for the task of linking two unlabeled data sets and have code available in R: BRL [8], FastLink [7], and FlexRL [9].
- BRL addresses the limitations of the foundational mixture model proposed by Fellegi and Sunter [5] by incorporating dependencies among the linkage decisions. This method uses a Gibbs sampler to link records based on binary comparisons of their information. While it provides high‐quality results, it requires substantial memory to handle large data sets, and, although accessible by inspecting the source code, the package does not explicitly output posterior linkage probabilities.
- FastLink was developed to mitigate the computational burden of BRL. It uses an Expectation‐Maximization (EM) algorithm to link the data based on binary comparisons of the information contained in the records.
- FlexRL avoids the information reduction caused by binary comparisons of records information by modeling the true latent values of the data using an EM algorithm. That way, it can capture more complex relationships between records.
In addition, we use SPLink [31], a method for Scalable Probabilistic Linkage developed in Python for the entity resolution task (it thus tackles RL and deduplication), to investigate the scalability of our method with the number of entities in the population and the intertwined effect of varying degrees of overlap in Section 5, as well as the sensitivity of our method to assumptions deviation in Section 6. Its implementation is based on that of FastLink [7]. Other methods developed in Python tend to rely on older methodologies or require a training set [32, 33, 34].
The different ways in which probabilistic RL estimates Δ are comparable; hereupon we refer to it in terms of classification of the linkage scores (or posterior linkage probabilities). Denote by di,j the linkage score of a pair of records (ai,bj) obtained with one of the RL methods. Assuming the RL procedure has run long enough for the iterative algorithm to converge, we consider the RL result as fixed (not random). We define a threshold ξ∈[0.5,1) to construct a set of linked records and estimate Δ with:
This set must satisfy the one‐to‐one assignment constraint required for establishing coherent links, which is ensured by setting the lower bound for ξ at 0.5 [8, Corollary 1.1], [35, Theorem 4.1]. The linkage scores generally follow a bimodal distribution, and the threshold ξ should separate non‐linked records with low probability from linked records with high probability. The quality of the linkage variables influences the modes; more unique values and fewer registration errors make the RL task easier and the separation of linkage scores clearer. The threshold ξ, above which records are declared linked, may depend on other parameters of the RL model (like in BRL [8]) or may be explicitly set (like in FastLink [7], FlexRL [9] and SPLink [31]).
We define the real and unknown numbers of true positives (TP), false positives (FP), and false negatives (FN), of the set of linked records as functions of the threshold ξ:
We define the FDP in the RL task between 𝒜 and ℬ to be the (unobserved) proportion of false discoveries among linked pairs as a function of the threshold ξ:
The naive probabilistic FDP estimate evoked in the introduction and derived from the RL modeling is defined [7, 10] as follows:
Estimation Procedure
2.2
To estimate the FDP for the RL task linking 𝒜 and ℬ, we propose augmenting file ℬ by sampling Nsynth synthetic records from the estimated empirical distribution of the data contained in ℬ. For that, we use a synthesizer as we explain further on in Section 2.3. We denote ℬ˜ the concatenation of file ℬ and the records synthesized from its estimated empirical distribution. By linking file 𝒜 and the augmented file ℬ˜ with an RL algorithm, we can estimate the amount of falsely linked records thanks to the pairs formed with a synthetic record. This allows us to construct an estimator for the FDP.
We define the number of synthetic false positives and real linked records as functions of the threshold ξ:
Since we assume that the iterative RL process has converged, it does not contribute to the randomness of the results. So all randomness originates from the synthesizer. Henceforth, 𝔼synth[FPsynth(ξ)] represents the average number of synthetic false positives resulting from synthesizing data.
When running RL between file 𝒜 and the augmented file ℬ˜ we differentiate real linked pairs from synthetic false positives in the linkage results, hence we then estimate the FDP as:
As the synthetic records do not correspond to real individuals, we use the RL task linking real and augmented data sets 𝒜 and ℬ˜ to estimate the false discoveries among real data when linking 𝒜 and ℬ. Though, since synthetic records may resemble records that form a link, we need to ensure that the augmented ℬ˜ corresponds to a (theoretical) version of ℬ only augmented with non‐links, to legitimately label synthetic linked pairs as false. We denote ℬ′ this theoretical file composed of records from ℬ and synthetic non‐links. The procedure we propose thus generates an unbiased estimator under the following conditions:
- i.Synthetic records represent records from ℬ that do not form a link in 𝒜,
- ii.Synthetic records minimally affect the RL process.
Condition (i) Induces 𝔼[FDP^RL(𝒜,ℬ˜)(ξ)]=FDPRL(𝒜,ℬ′)(ξ)
2.2.1
The first condition defines pairs involving a synthetic record as non‐links (TN and FP). Note that these records may copy records from ℬ carrying information that is likely to be sampled, reflecting the low discriminative power of linkage variables. Thus, for a record in 𝒜 indexed by i∈{1,…,N𝒜} and a synthetic record in ℬ indexed by j∈{Nℬ+1,…,Nℬ+Nsynth} we set δi,j=0. It follows that there should not be more synthetic linked pairs than real linked pairs (in proportion) since the synthetic records should not be more similar to records in 𝒜 than are the real records in ℬ:
Under (i) the proportions of synthetic FP relative to all synthetic pairs and of real FP to all real pairs should be equal:
With (i), we implicitly assume that we are able to sample from the distribution of non‐links. It is the case when links happen at random, as all records are thus assumed to be independent samples from the population linkage variables, whose distribution can be estimated. One can also achieve this by estimating the empirical data distribution on the provided negative controls (records we are sure should not link). Then, we can apply a resampling strategy to generate records that will legitimately be non‐links. In practice, we estimate the empirical distribution of the population linkage variables with a synthesizer, and sample synthetic records. We mention solutions to evaluate the synthetic data quality in Section 2.3.
Whether we may assume that links happen at random or instead can use reliable negative controls to estimate the targeted distribution should be assessed per application. Although Equation (4)–which follows from condition (i) and ensures accuracy of our estimator–cannot be verified with unlabeled data, bias can in some cases be detected via Equation (3) which is equivalent to 𝔼synth[FDP^(ξ)]≤1. Indeed, since Equation (4) implies Equation (3), by contraposition, an estimate exceeding one would indicate the presence of bias.
Condition (ii) Induces FDPRL(𝒜,ℬ′)(ξ)=FDPRL(𝒜,ℬ)(ξ)
2.2.2
The second condition ensures that the FDP on real data when linking 𝒜 and a properly augmented ℬ′ is actually equal to the FDP on real data when linking 𝒜 and ℬ. This is important because the FDP usually increases as the overlap between data sets decreases, which would be enforced by augmenting file ℬ. Requirement (ii) ensues if we synthesize records in the right setting. The number of synthetic observations Nsynth must be carefully set to ensure accurate estimation of the FDP while minimizing the impact of synthetic records on the original RL task. We investigate the population from which we should sample and the size of the synthetic set in Section 3 and Section 4.
Given that these conditions hold, it is straightforward to see that FDP^(ξ) is unbiased for the FDP on real data:
Although the choice of a formula in Equation (2) seems natural, an alternative estimate was sometimes used in the literature [22, 36]:
This estimate accounts for all falsely linked pairs (FPsynth and the estimation of real FP) in the numerator and all linked pairs in the denominator. It calculates the FDP on augmented data, where
which results in a biased estimate of FDP on real data as Equation (5) focuses on the actual task on augmented data. Despite a former interest in this formula, which accounts for the impact of the estimation method on the RL method, we argue that synthetic pairs should not be included in the estimate, as concluded in the target‐decoy approaches [22].
We summarize our estimation procedure in Algorithm 1 and Figure 1.
Flow chart summarizing the false discovery estimation procedure in RL.
ALGORITHM 1FDP estimation in RL.
With this approach, our aim is to give researchers a flavor of the FDP associated with linked data. By applying the proposed methodology, one can obtain a sequence of subsets of linked data jointly with the corresponding estimate of the FDP. The higher the threshold ξ∈[0.5,1) used to define a subset of linked data, the more stringent the linked set and therefore the lower the FDP and the estimated FDP. One can plot, for instance, the evolution of the estimated FDP as well as the evolution of the number of linked pairs as functions of the threshold. The minimal threshold one should take is 0.5 in order to ensure coherent links (fulfilling the one‐to‐one assignment constraint). One will have to find the balance between a desirable estimated FDP and an adequate number of observations for the inference; this decision depends on each application. The maximal threshold may not lead to a satisfactory FDP, in which case it becomes evident that the linkage is not reliable.
For a given threshold, one should run multiple procedures to properly estimate 𝔼synth[FPsynth(ξ)] and obtain, for a given threshold, a point estimate for the FDP and its standard error. Such an aggregated estimate of the FDP can be derived either from a truncated average on the estimates upper bounded by 1, or by taking the minimum between the estimates and 1 and averaging it, or else by taking the median over the set of estimates. In the real data applications of Section 7, we only observed some estimates exceeding 1 in small sample size contexts.
To build the above procedure, we explored the possible choices of a formula for the FDP estimate (aforementioned) and the entangled properties required from the synthesizer. Multiple methods have been developed to generate synthetic data; we present two methods in the following Section 2.3. We chose to augment file ℬ with Nsynth=0.10×Nℬ records because this configuration minimizes the impact of synthetic records on the RL process. We elaborate on this aspect in Section 3, where we investigate potential synthetic database constructions, and in Section 4, where we evaluate the impact of data set size on the estimation. The reliability of the FDP estimate depends on all these choices. We evaluate the scalability and robustness of our method in Section 5 and Section 6. We illustrate the efficacy and the value of estimating the FDP in applications in Section 7.
Data Synthesizers
2.3
After reviewing the different possibilities to generate synthetic records (with categorical variables), based on software availability on R and Python and computational feasibility, we selected synthpop [37] and arf [38].
- Synthpop uses sequential modeling to generate each column of the synthetic data from conditional distributions fitted to the original data using classification and regression trees. The first column is generated by random sampling; therefore, we often set as the first column the variable with the largest number of unique values. This method may be slow in practice.
- Arf uses generative modeling, namely adversarial random forest, to synthesize data from the estimated density of the original data. Trees gradually learn the data properties by training the classification of data into real or synthetic. This method is fast in the low‐dimensional context of a few linkage variables and takes advantage of large data sets.
Both methods have been shown to perform similarly in terms of Negative Log‐Likelihood. Other possibilities are provided on Python: gretel‐synthetics, nbsynthetic, DataSynthesizer, but we do not explore them.
RL often relies on categorical variables, which may make the synthesis very slow, especially when these are of high cardinality. Examples of linkage variables are birth year, postal code, socioeconomic status, and sex. To ease synthesis, we suggest grouping values of high cardinality variables into higher‐level categories. While lowering their identifying strength, it encompasses the limitations encountered by the synthesizer. In contexts where names are available (rare in medical data where our primary interest lies), phonetic groups may be formed by converting string data into numerical values using Soundex code [39, 40]. For data covering a country (lots of postal codes or addresses) or a long period of time (lots of birth years), one may need to generate those variables as continuous. Addresses, similarly to postal codes, may be grouped hierarchically by municipality and neighborhood. They may then be interpreted as continuous, assuming an underlying geographical smoothness of the conditional distribution of other variables with respect to it (nearby locations tend to be more similar in demographic variables), and similarly for birth year.
A good data synthesis is crucial for our methodology. Rare categories, data points located on the edge of joint distributions, or complex relationships between variables may be difficult to synthesize. Nevertheless, since most linkage variables are categorical, the task reduces to sampling from multinomial distributions. Flexible data synthesizers often do not rely on strong parametric assumptions about the data and are well suited for this task; they can capture edge and rare cases, and they can model dependencies among linkage variables.
For our method to be valid, we need to ensure that the synthetic data resemble the non‐links. With unlabeled data, this is not verifiable without further assumptions. Thus, we assumed so far that links happen at random, and we show in Section 6 that our method is fairly robust against deviations from this assumption in various realistic settings. Ultimately, we need to certify that the synthetic data resemble the initial records (values, frequencies, and joint variables structures should be preserved). Multiple explainable AI techniques may be used to evaluate synthetic tabular data [41]. In order to confirm the quality of the data synthesized, one may train a classifier to distinguish real data from synthetic data and use the AUC as a primary tool for marginal explanations; we do so in Section 5 and Section 6. In addition, global and local tools, such as feature importance measures, feature effect plots, Shapley values and counterfactuals, may be used for conditional explanations to understand how well variables were generated over their support and how the synthetic data may differ from the real data [41].
Source for Synthetic Data
3
To estimate false positives with synthetic linked pairs, we could synthesize records in 𝒜 or in ℬ. Falsely linked pairs usually are formed of records with nearly identical information, and form legitimate ambiguities in the linkage. This is mostly due to the few numbers of unique values in the linkage variables used in RL, which makes the task non‐trivial. We investigated three procedures to generate synthetic data that represent non‐links.
- (a)Synthesize records based on one file, (either 𝒜 or ℬ), concatenate them with the source file, and run RL between the augmented file and the other source.
- (b)Synthesize records from both data sources and run RL between the two augmented files.
- (c)Generate synthetic sets from both 𝒜 and ℬ and run RL between the synthetic files.
Procedures (b) and (c) potentially have some undesirable properties, which may render a violation of the aforementioned requirements to obtain an unbiased estimator. When synthesizing records from both files (and running RL on the synthetic sets either concatenated with real data or separately), sampling from the distribution of records that do not form a link becomes more restrictive. Particularly, we need to assume some structure on file 𝒜 unlikely to hold in the setting we tackle, where 𝒜 is a smaller file containing more specific data. In such a context, we have fewer records, not forming a link to learn the targeted distribution. Moreover, we are more likely to affect the RL process due to the uncertainty introduced by more synthetic records. Indeed, synthetic pairs would be of several forms: a synthetic from 𝒜 (respectively ℬ) with a record in ℬ (respectively 𝒜), or two synthetic records. When two synthetic records carry identical information, labeling the pair as either true or false becomes ambiguous. In addition, we have no interest in comparing synthetic to synthetic since we do not target matching patterns but rather the confusion any RL method faces when selecting a pool of records in ℬ, all looking alike and matching the information contained in a given record from 𝒜.
In practice, in the SHIW and the NLTCS applications, we observed that procedures (b) and (c) create too many records carrying identical linkage variables to some real records, introducing too much uncertainty in the RL processes tested. BRL tends to avoid linking records when the data sources become larger or when the noise coming from synthetic records is excessive. FastLink links as many pairs between two fully synthetic sets (FPsynth) as it does between two real data sources (FP+TP), whereas FPsynth should estimate FP. This aligns with findings from the original paper, noticing larger error rates with a smaller proportion of links [7]. Finally, FlexRL fails to build the expected bimodal distribution of linkage scores in the presence of many synthetic records. Figure 2 shows the distributions of the linkage scores in the proposed procedure using augmented file ℬ˜ and in the original RL task between 𝒜 and ℬ. We observe that the linkage scores are not affected by procedure (a), i.e., RL(𝒜,ℬ˜) and RL(𝒜,ℬ) yield similar outputs. We make the same observation on the linkage scores of TP and real FP. In addition, we show the distribution of the linkage scores when augmenting both files, like in procedure (b) or (c), to be damaged by the excessive uncertainty introduced by the amount of synthetic pairs. We therefore rule out these methods and synthesize records either in 𝒜 or in ℬ, estimating the false positives with pairs involving one synthetic record.
Linkage scores obtained from FlexRL on the SHIW data, Center of Italy (3450 and 3046 records with 45% of overlap). From left to right, when using only real records: RL(𝒜,ℬ), when using procedure (a): RL(𝒜,ℬ˜) and when using procedures (b) or (c). The bimodal distribution represents the mixture between linked and non‐linked.
In the RL task we depicted, file 𝒜 should be seen as the reference and, for each of its records, one should look for the most coherent link to build in file ℬ (if any). Generating records from source 𝒜 and using the concatenation of real and synthetic records as the reference file in the RL process thus poses philosophical challenges. For practical matters, it is also convenient that 𝒜 remains the smallest file. Moreover, the synthesizer will better learn the multivariate distribution of the data from the largest source. We therefore argue that it is more sensible to synthesize records in ℬ (the largest file) and estimate the FP with pairs linking a real record from 𝒜 with a synthetic record in ℬ. Henceforth, we run RL between file 𝒜 and the augmented file ℬ˜ made of its original records as well as synthetic records generated from the same distribution.
Impact of the Size of the Synthetic Set
4
The performance of RL depends on the size of the sets to be linked. Indeed, for a given record in 𝒜 with the same linkage variables, there are more potential records in ℬ to form a link with when the files are larger. Ideally, to minimally alter the results from RL by adding synthetic data, a single synthetic record should be generated in file ℬ. By repeating the procedure many times, one could obtain an estimate of the number of false positives with the counts of runs where the synthetic record was linked. However, since most modern RL methods are computationally expensive, this approach is impractical.
Because of time and resources constraints, RL is often applied with blocking strategies [8, 42, 43], i.e., the data sources are partitioned into blocks based on a variable (e.g., same postal code, same decade of birth) which is supposed to be free from registration errors. Notwithstanding the inherent restriction of blocking, RL is often more accurate on such a smaller scale. It is therefore necessary to investigate the estimation of the FDP with and without blocking. Moreover, since we expect the FDP estimation procedure to be affected by the scale of the sources to be linked, we explored the appropriate size of the synthetic data set, as a fraction of Nℬ: Nsynth=α×Nℬ, with α∈(0,0.20].
Across datasets of all scales (both with and without blocking), we observed larger variability in the bias of the FDP estimate when generating 1% to 5% of Nℬ synthetic records (Nsynth≤0.05×Nℬ). However, this variability decreases as Nsynth increases. In RL applied to both small and large data sets, with and without blocking, the FDP estimate stabilizes when generating at least 10% of Nℬ synthetic records(Nsynth≥0.1×Nℬ). We illustrate the evolution of the root mean square error combining bias and variance as a function of Nsynth using a subset of the SHIW data in Figure 3.
RMSE of the FDP estimates over 10 runs of the procedure on the SHIW data, Center of Italy (3450 and 3046 records with 45% of overlap). The true FDP decreases from 0.27 to 0.23 for BRL and from 0.43 to 0.40 for FlexRL, while it remained at 0.73 for FastLink. The sensitivity decreases from 0.16 to 0.1 for BRL, from 0.19 to 0.15 for FastLink and from 0.43 to 0.40 for FlexRL. We observed the same behavior on other areas of the SHIW data and on the NLTCS data.
We initially expected that estimating the FDP in RL by adding synthetic records to the data would negatively affect the RL process, as it would hinder the task. However, we do not observe such an impact. Instead, we note that as Nsynth increases–thereby introducing more noise–RL methods become more conservative: the true FDP decreases, but the sensitivity also declines; fewer links are detected and fewer errors are made.
As we observe a leveling off from 10% onwards in Figure 3, in the applications we generate Nsynth=10%×Nℬ synthetic records which we concatenate to file ℬ. We apply RL to file 𝒜 and the augmented file ℬ˜. However, the number of synthetic records required for a stable FDP estimation may vary depending on factors such as the overlap between data sets and the discriminative power of linkage variables. While adding more synthetic records can reduce the estimator variance, it also increases the computational effort and may alter the behavior of the RL algorithm, making it more conservative. The size of the synthetic set should balance these aspects.
Scalability
5
RL modeling is sensitive to the low discriminative power of linkage variables, to the increasing number of entities in the data sets, and to the often‐limited overlap between data sets, not to mention registration errors and dependencies among linkage variables [11]. In this section, we illustrate the scalability of the method with respect to the underlying number of entities in the data sets. To wit, we use a method for Scalable Probabilistic Linkage developed in Python: SPLink [31] which allows us to show the scalability of our estimation procedure on very large data files.
In Table 1, we simulated data with five discretized linkage variables with different distributions and created links at random. Files 𝒜 and ℬ contain respectively 100 000 and 200 000 records, which is a setting on which SPLink can be used on a standard computer. We compare scenarios with different overlap degrees (defined as a fraction of the smallest file 𝒜) and different degrees of difficulty defined by the discrimination level of the information contained in records (proportion of unique sets of linkage variables). We synthesize data with arf, adapted for large scales.
We present the bias of the aggregated FDP estimate (over several runs of the procedure) as well as the true value of the FDP and the probabilistic FDP estimate from Equation (1), which we can derive from the output of SPLink. We also indicate with “condition 4” the order of magnitude of the difference between the proportions of FPsynth and FP to assess the condition from Equation (4). In addition, as mentioned in Section 2.3, we train a classifier to distinguish real data from synthetic data. Thus, “AUC synth” assessing the synthetic data quality should be around 0.5 for the synthetic data to be indistinguishable from the real data.
As expected, the true FDP decreases with the increasing overlap. Even though the bias of our estimator is larger for smaller FDP, the percentage bias does not exceed 20%. The probabilistic FDP is generally very biased and significantly underestimates the FDP. With these simulations, we demonstrate the feasibility of our procedure at a large scale. In all the cases presented in Table 1, our procedure yields a reliable estimate of the FDP.
Robustness to Assumptions
6
In this section, we show the robustness of our method to deviation from our key assumptions using SPLink, which was built for the entity resolution task and thus tackle deduplication. The main assumption is that we are able to sample from the distribution of records that do not form a link. In order to do so, we assumed so far that links happen at random. Table 2 shows the robustness of our method to deviation from this assumption. Moreover, we examine the robustness of our method when duplicated data are present in the data in Table 3. We use the same simulation scheme as in Section 5.
It is known that when there is a systematic difference between links and non‐links, RL methods have higher error rates [3]. Therefore, as we deviate from the assumption that links happen at random, we expect the true FDP to increase. Moreover, our estimation procedure might be hampered in the process of sampling from the distribution of the non‐links. Consequently, more synthetic pairs may get linked, which would introduce positive bias as Equation (4) is violated; we expect to overestimate the FDP. Our method would likely remain useful in that case, as the estimated FDP would represent an upper bound on the true FDP. However, two other effects interplay. First, the larger ℬ is (the smaller the overlap), the fewer records from ℬ that form a link, meaning that their impact on the estimated distribution becomes limited. Second, when the RL task becomes harder due to a lower discriminative power of linkage variables, their distribution narrows, making the links and non‐links distributions indistinguishable [12]. We are thus supposedly able to sample under the distribution of non‐links unless there is a relatively high discriminative power of the linkage variables and a relatively high overlap.
We observe in Table 2 that our method is fairly robust to deviation from the “links happen at random” assumption. We compare scenarios where links happen at random and where the linkage status depends on the values of the linkage variables, which exhibit different distributions. To further understand the mechanisms at stake, we also compare scenarios where 𝒜 and ℬ are of similar scale and where 𝒜 is significantly smaller than ℬ. Moreover, we consider varying overlap degrees (defined as a fraction of the smallest file 𝒜) and different degrees of difficulty defined by the discrimination level of the information contained in records (proportion of unique sets of linkage variables). As in the previous section, we report the bias of the aggregated FDP estimate, the true value of the FDP, and the probabilistic FDP estimate. We also indicate with “condition 4” the order of magnitude of the difference between the proportions of FPsynth and FP to assess the condition from Equation (4). “AUC synth” measures how well a classifier distinguishes synthetic from real records. “AUC link” measures how well a classifier distinguishes records from ℬ that form a link in the other file from records that do not.
When links happen at random, the true links form a random sample from the population linkage variables. This contrasts with situations where the linkage status or registration errors depend on certain variables. In the first case, records that form a link and those that do not carry different distributions with respect to their linkage variables. In the second case, RL would be hindered in linking these specific pairs exhibiting more mistakes or more missing values. While our results show that the proposed methodology is robust to cases where linkage depends on variables in many realistic settings, it may be valuable to detect such discrepancies in the data and appraise their impact on the RL task. This could be addressed as a separate task, using synthetic data to assess potential linkage bias [44]. Specifically, one could identify associations among variables and examine how these relationships affect both the linkage process and the final output.
We note from Table 2 that the true FDP depends on the overlap (as defined by the smallest data set) and does not change between the scenarios N𝒜<<Nℬ and N𝒜=0.90×Nℬ. It decreases with the increasing overlap and with the increasing discrimination level. Surprisingly, SPLink performs better when links depend on the identifying features (the true FDP is lower), which is not generally the case with RL methods [3]. Our method is slightly affected by the meaningful links: the percentage bias of our estimator does not exceed 10% when links happen at random, while it goes up to 20% when the linkage status depends on the linkage variables. SPLink does not enforce the one‐to‐one assignment constraint required to establish coherent links. As a result, the interpretation of the linkage scores is unclear. In the settings presented in Table 2, whenever the discrimination level of the linkage variables was low, the linkage scores of SPLink were lower than 0.5. In these cases, we defined the linked pairs based on the median score returned by the algorithm. We therefore do not comment on the probabilistic FDP estimate here.
Note that the different methodologies for RL (the Fellegi‐Sunter model and the graphical entity resolution framework) make different assumptions and are likely to be differently affected by the discriminative power of linkage variables, registration errors, dependencies among variables, number of entities in the population, and the overlap between data sets. Here, we conducted a sensitivity analysis to assess the impact of deviations from our assumptions with SPLink; one can expect the impact of these deviations to be slightly different for other RL methods. For instance, methods based on the Fellegi‐Sunter model like SPLink might be more affected by the varying degrees of overlap and discriminative power of linkage variables, but less by the differences in distribution between links and non‐links. On another note, some recent RL supervised algorithms have been developed which can learn to distinguish links and non‐links [31, 33, 34]. They are expected to perform well in scenarios where the distributions of linkage variables differ. On such algorithms, our estimation procedure may not perform effectively.
So far in this work, we assumed the data to be deduplicated (all records within a data set belong to different underlying entities). In Table 3, we demonstrate the robustness of our methodology to the presence of duplicated records in the data. We use the same simulation scheme as previously, and we add 5% of duplicates in each data source (2.5% of the duplicates form a link in the other file and 2.5% do not).
We observe in Table 3 that our method is robust to the presence of duplicated data. When comparing results to Table 2 for the same settings, we can see that SPLink becomes more conservative and therefore has a lower true FDP. We do not notice strong differences when the overlap degree is high; however, the bias of our procedure is larger when the overlap degree is low. Nevertheless, our estimation of the FDP is reliable in all cases. Like in Table 2 the percentage bias of our procedure remains below 10%.
Applications
7
We evaluate our estimation method on Italian census data (SHIW) as well as on American data from a longitudinal survey (NLTCS), which provide a unique identifier. We then apply the method to Dutch perinatal data (PRN). Our procedure is generic and can be applied to any RL algorithm, facilitating the comparison of estimation performance among RL methods. We thus show the performance of the aggregated FDP estimate (average over several runs of our approach for false discovery estimation in RL) for different RL methods, data synthesizers, and data sets in Section 7.1. Then, we expand on the improvement of inference results enabled by optimizing the RL algorithm thanks to our FDP estimation procedure in Section 7.2.
FDP Estimation on Real Data Applications
7.1
The SHIW data come from a survey that has been conducted every two years since 1989 on the Italian population. The data are made available by the Bank of Italy for research purposes [29]. We link the data sets of 2016 and 2020, with approximately 15 000 and 16 500 records, respectively, of which 6500 are common to both files. A unique identifier can be inferred from the family and member identifiers in each sample, so that we can deduce the true linkage structure. We use the sex, birth year, regional code, marital status, and education level to link the records. A simplistic matching of the records that carry identical information in all these linkage variables results in 18 000 linked pairs (among them 14 000 are false positives and 4000 are true positives), which corresponds to an FDP of about 0.77. With this matching, all false positives are due to matching identifying information between records that pertain to distinct individuals, witnessing the difficulty of the task.
The NLTCS data come from a longitudinal study on the elderly population health in the United States. The survey was sponsored by the National Institute of Aging and was conducted by the Duke University Center for Demographic Studies. They are available upon request to the National Archive of Computerized Data on Aging (NACDA). We link the data sets of 1982 and 1994, with approximately 20 500 and 9500 records respectively, of which 7500 are common to both files. We use the birth month and year, the sex, and the state code to link the records; a unique identifier is provided, useful to evaluate our procedure. A simplistic matching, which links records with identical values across all linkage variables, leads to 20 000 linked pairs (of which 12 000 are false positives and 7000 are true positives), yielding an FDP of about 0.60, demonstrating the difficulty of the task.
First, we estimate the FDP for three RL methods and two data synthesizers on the area's subsets of the SHIW data (blocking on North, Center, and South of Italy) in Table 4. As we observe that synthpop and arf perform similarly well (the AUC synth assessing the synthetic data quality for both methods is similar), we then show estimation results with synthpop on the full SHIW and NLTCS data in Table 5, as well as on the regional subsets of the SHIW and NLTCS data (blocking on 20 regions of Italy and on 12 census regional offices of the U.S.) in Figure 4.
FDP^ (mean and standard error) and true FDP (mean and standard deviation). We truncated the few estimates exceeding 1. We generate for each region a synthetic set of 10% of the biggest set. SHIW (regions) with between 60 and 1791 records, on the left. The overlapping set, common to both data sources, is between 34% and 64% of the smallest set. Only 60 and 62 records come from region 2. Other regions gather at least 150 records in both sources. NLTCS (census regional offices) with between 502 and 2860 records, on the right. The overlapping set, common to both data sources, is between 67% and 77% of the smallest set.
We repeat the procedure for false discovery estimation in RL ten times. We provide in the following tables and figures (Tables 4, 5 and Figure 4) the mean and standard error over the sample of FDP estimates obtained.
We present in Table 4 the bias of the aggregated FDP estimate as well as the true value of the FDP and, when possible, the probabilistic FDP estimate from Equation (1), for the North, Center, and South subsets of the SHIW data sets. We also indicate the order of magnitude of the difference between the proportions of FPsynth and FP to assess the condition from Equation (4).
We notice one bad estimation of the FDP for BRL with synthpop on the first area (0.09 bias for a true FDP of 0.07). In all the other cases, our procedure leads to a reliable estimate of the FDP. The probabilistic FDP, which may be computed on the output of FastLink and FlexRL, always has a larger bias and is particularly unreliable for FastLink. The estimations obtained from synthetic data generated with arf and synthpop are similarly good.
We present similar results in Table 5 for the full SHIW and NLTCS data sets. FastLink links a lot of records compared to the other methods, explaining the high FDPs. The probabilistic FDP (computed for FastLink and FlexRL) always has a larger bias than our estimate. We only rely on four linkage variables to link the NLTCS data, which may explain the relatively bad FDP estimation of FastLink (0.15 bias) and that BRL did not link any record.
We present in Figure 4 the true value of the FDP and the aggregated FDP estimate for each regional subset of the SHIW data sets and for each census regional office subset of the NLTCS data sets. The second region of the SHIW data contains less than a hundred observations in both sources, probably explaining the bad estimation of the FDP with FastLink compared to the other regions. Like on the full NLTCS data, BRL does not link any records on several of the census regional offices subsets. We truncated the few estimates exceeding 1. The FDP tends to be overestimated with FastLink and underestimated with FlexRL.
Overall, the percentage of bias (compared to the true FDP value) lies around 15% on average over the different RL methods and data synthesizers. Our FDP estimation procedure performs well on large and small data sets (with and without blocking) and is able to provide an accurate order of magnitude of the FDP. The overlap degrees in these real data applications varied between 30% and 80%, and as we already saw in the precedent Section 5 and Section 6, the bias of our estimator is not affected by the overlap. Our methodology is reliable under various real‐world settings with different scales, different degrees of overlap, and of difficulty. The probabilistic estimate becomes more reliable with higher overlap between data sets and more discriminative linkage variables. When available, it can be assessed alongside our approach, but in general, our method remains the more accurate and applicable option.
FDP Estimation: A Tool for Improving Inference on Linked Data
7.2
Inference drawn from linked data suffers from inherent weaknesses due to the linkage process. We saw from the previous tables that the probabilistic FDP estimate of Equation (1), which we can compute on FastLink or FlexRL is usually not reliable: its percentage bias (compared to the true FDP value) varies between 20% and 200%. This estimate is derived from the RL model, which in turn relies on simplifying assumptions. As such models are rarely well calibrated in real‐world settings, the resulting bias in the probabilistic estimate is to be expected. Hence, the need for a procedure for false discovery estimation in RL, that is independent of the linkage process itself, in order to estimate the FDP of any linkage method in any context, and to inform the analysis on the reliability of its data. Our procedure answers these needs. We are able to evaluate the RL error depending on the RL parameters. Therefore, by tightening the parameters, we can effectively tune the RL algorithm in order to minimize the FDP, and we can assess the reliability of the optimal set of linked records obtained.
As mentioned in Section 2.1, RL methods have different ways of classifying linked and non‐linked pairs. FastLink and FlexRL return pairs of records and their linkage scores, allowing explicit “tuning” of the threshold ξ. By increasing its value, one can lower the FDP (hence FDP^). BRL does not allow explicit adjustment of the threshold ξ on linkage scores, but some equivalent parameters which control the set of linked records returned. For this method, the FDP (hence FDP^) may be lowered by taking λFNM<λFM1,λFM2 while keeping 0<λFNM≤λFM1 and λFNM+λFM1≤λFM2 [8]. For instance, λFNM, whose default value is 1, may be lowered. The default values for BRL parameters: λFNM=λFM1=1,λFM1=2 are equivalent [8, Corollary 1.1] to the default threshold value ξ=0.5 on the linkage scores for FastLink and FlexRL.
In this section, we show results from inference done with the default parameters of the RL methods and the associated FDP^. We compare it with the results obtained after adjusting the parameters of the RL methods in order to obtain a lower FDP^. We target a FDP^ lower than 10%; however, in some cases, the optimal set of linked pairs does not allow us to reach such a threshold. In these cases, neither the linkage nor the inference is reliable. Otherwise optimizing the linkage and assessing its error allows to improve the inference. It is important to note that by choosing more stringent parameters, we also lose observations, affecting the statistical power of the inference results. Therefore, we present results obtained from the full data sets (with blocking when relevant) to obtain enough linked observations.
First, we apply RL to assemble the first and second born children of the PRN data, and we estimate the preterm birth risk on the linked data using characteristics of the mother and of the previous delivery. The PRN data are available upon request from the Dutch PRN organization. Information was collected at the scope of the pregnancy. We have access to the delivery date, birth order of the baby among the siblings, sex of the baby, pregnancy duration, an indicator for congenital malformation, an indicator for twin pregnancy, an indicator for the use of Assisted Reproductive Technology (ART), as well as characteristics on the mother namely, the birth date, date of the previous delivery (if any), ethnicity, postal code, and an indicator for low socioeconomic status. The data source initially contained nearly 2 million observations. We therefore selected a smaller sample with complete data, the most common ethnicity, no congenital malformation, single pregnancy, mother aged between 20 and 45 years old, low socioeconomic status. To link the data, we use the mother's birth date and the siblings' birth dates (birth date of the first‐born child and birth date of the previous delivery for the second‐born child), as well as the postal code. We present the results in Table 6.
All the methods have a very low estimated FDP (0.01 maximum) with their default parameters, supporting the use of these linked data in the literature. They all link around 65% of the records (as a fraction of the smallest file). We estimate the preterm birth risk at the second delivery on the linked data using a logistic regression on the interval between pregnancies, the mother's age at the first delivery, the duration of the first pregnancy, and the use of ART for the first pregnancy. The coefficients of the logistic regression are similar over all the methods, except that the data linked with FlexRL show a weaker effect of the ART during the first pregnancy on the preterm birth risk at the second delivery.
Second, we apply RL to gather the records pertaining to the same individuals in the SHIW data. We generated an outcome in one file as a linear function of three covariates simulated in the other file for the links. Non‐linked outcomes were sampled from the outcome empirical cumulative distribution function of links using inverse transform sampling. We fit a linear regression on these variables and we show how to use the FDP estimation to refine the set of linked records by potentially decreasing λFNM in BRL or increasing ξ in FastLink and FlexRL. That way, we can improve the inference results. We present the results in Table 7.
The estimated FDP of BRL of 0.09 with its default parameters leads to a coefficient of determination of 98% in the regression model; all the coefficients are well estimated. The FDP^ of FastLink with the default threshold is 0.75. The strictest set of linked records we can obtain by increasing the threshold ξ leads to a FDP^ of 0.65, which is not satisfying. We can suspect here that the coefficient of determination of 1% results from a signal diluted in the noise of falsely linked records. In the same fashion, FlexRL with the default threshold leads to a FDP^ of 0.39, associated with a R2=38%. By tuning this parameter, we can obtain a coefficient of determination of 58%, the FDP^ associated with the linkage in that case is 0.18.
Third, we apply RL to gather the records pertaining to the same individuals in the NLTCS data. We fit a linear model to explain the frailty index (FI) of individuals from 1994 using their FI from 1982. The FI appears as a measure of the health and quality of life of the individuals. We define it following the methodology of previous studies [45, 46, 47] as a proportion of deficits. Explicitly, we computed the mean over 45 indicators recording difficulty with: eating, dressing, going out, walking around, getting in/out of chairs and of bed, bathing, going to the toilets, cooking, doing easy task like laundry or washing the dishes, shopping, handling money, taking medicine, calling, reading, speaking, understanding, as well as health issues: rheumatism, paralysis, numbness, scleroses, epilepsy, cerebral palsy, Parkinson's disease, glaucoma, diabetes, cancer, constipation, trouble sleeping, headaches, overweight, arteriosclerosis, mental retard senility, history of heart attack or stroke, heart problems, hypertension, pneumonia, flu, emphysema, asthma, bronchitis, blood circulation problems, broken bones, missing fingers or toes. We present the results in Table 8.
If the estimated FDP of FastLink with the default threshold is 0.63, the linkage in that case is not reliable. By tuning this parameter, we obtain a FDP^ of 0.35 and a coefficient of determination of 11% (compared to 17% on the true links), and the coefficients are better estimated. The FDP^ of FlexRL of 0.08 with the default threshold leads to a coefficient of determination of 14% in the regression model, and the estimated coefficients are closer to the ones obtained from fitting the model on the true links.
Therefore, these examples show the importance of the ability to estimate the FDP and thereby to tune the RL parameters to obtain reliably linked data.
Discussion
8
Providing reliable tools for estimating the FDP is essential for downstream applications of RL to be meaningfully pursued. In the absence of a robust method to evaluate the error when linking data through RL, the reliability of the linkage cannot be assessed. While the final decision of which FDP is acceptable for a particular analysis should rest within the researcher's hand, it is important to appraise the complexity of the RL task and to be informed about the magnitude of the error in the resulting linked data. We therefore provided an unbiased procedure to derive an estimate of the FDP in RL, which accordingly allows to optimize the RL parameters to improve the inference.
Our method proves particularly useful for complex RL tasks with weak linkage variables, where standard simplifying assumptions (i.i.d. records, independent comparison vectors and linking variables, no duplicates, registration errors at random) affect the linkage scores. Such context allows us to properly sample synthetic records, well representing the original records which do not form links, to delude the RL process and measure the error made when linking records. It relies on the realistic assumption that the linkage status does not depend on any observed mechanism but remains robust against deviations from it. Moreover, it is not sensitive to the presence of duplicate records in the data sources. It is a generic method that can be used with any RLalgorithm, hence independent of the underlying RL model. Several procedural options, which we investigated in this research work, from the synthesis of records to the choice of an estimator, have consequences on the accuracy of the method. We demonstrated robustness across a variety of scenarios and illustrated the gain of our procedure over the existing model‐dependent probabilistic estimate.
An adequate set of synthetic records enables a good FDP estimation. We put light on two existing methods, synthpop and arf whose syntheses are adapted to the FDP estimation procedure. Whereas synthpop may be slow on large data sets with categorical data of high cardinality and complex structures, arf takes advantage of a larger amount of data. Although the performance of RL changes with the scale of the data sources, we do not recommend adapting the FDP estimation by including the contributions of synthetic records, in line with the conclusions drawn from target‐decoy approaches [22]. The estimate we derived scales well with the different complexities coming from the RL task, it adapts to the size of the data sources, to the degree of overlap, and to the discriminative power of linking variables. When the RL method provided an FDP estimate contingent on the linkage modeling, it was always highly underestimating the FDP. The procedure we proposed as an alternative for false discovery estimation is more reliable and accommodates well to real‐world RL settings.
Based on those results, we recommend synthesizing a small set of records comprising 10% of the number of records in the largest original source to avoid compromising the RL process. The number of records to synthesize should be sufficient to stabilize the estimator, as indicated by the decreasing variance, without extending so far that the variance reduction reflects a shift in the RL behavior rather than genuine convergence of the FDP. Using the synthetic linked data to approximate the real quantity of falsely linked records allows to derive an unbiased estimate of the FDP. We argue that following this simple methodology to estimate the FDP in RL could substantially broaden the applicability of RL methods, as we have shown that it is important to tune RL to obtain a set of linked data with an acceptable FDP, which then improves inference. The ultimate optimization of the RL parameters enabled by our procedure should balance the estimated FDP and the number of observations available for inference. Further research should investigate the reliability of our approach across additional RL algorithms and data sets, as this is essential for addressing real applications challenges. This common effort will enable the development of new research in diverse fields using linked data.
Since the FDP only focuses on falsely linked records, it cannot capture linkage bias: situations where registration errors correlate with certain variables, making it more difficult to recover links involving specific values, thereby impacting inference. While not the focus of our work, synthetic data could also be used in a complementary way to detail missed links and assess linkage bias [44], extending beyond its role in our FDP estimation procedure. Most likely, methods supporting the development and evaluation of data linkage can benefit from ongoing advances in synthetic data generation and from broader research on model interpretability, which offers tools to better understand statistical mechanisms at stake in RL.
Author Contributions
Kayané Robach implemented the estimation method conceptualized by MW. Kayané Robach conducted the data applications and the analysis. She prepared the first manuscript draft, reviewed and edited by Michel H. Hof and Mark A. van de Wiel. All authors read and approved this manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1H. L. Dunn , “Record Linkage,” American Journal of Public Health and the Nations Health 36, no. 12 (1946): 1412–1416.PMC 162451218016455 · pubmed ↗
- 2K. L. Harron , “Assessing Data Linkage Quality in Cohort Studies,” Annals of Human Biology 47 (2020): 218–226, 10.1080/03014460.2020.1742379.32429765 PMC 7261400 · doi ↗ · pubmed ↗
- 3J. C. Doidge and K. L. Harron , “Reflections on Modern Methods: Linkage Error Bias,” International Journal of Epidemiology 48, no. 6 (2019): 2050–2060, 10.1093/ije/dyaa 028.31633184 PMC 7020770 · doi ↗ · pubmed ↗
- 4T. R. Belin and D. B. Rubin , “A Method for Calibrating False‐Match Rates in Record Linkage,” Journal of the American Statistical Association 90, no. 430 (1995): 694–707.
- 5I. P. Fellegi and A. B. Sunter , “A Theory for Record Linkage,” Journal of the American Statistical Association 64, no. 328 (1969): 1183–1210.
- 6D. Resnick and J. Asher , “Measurement of Type I and Type II Record Linkage Error,” in Government Statistics Section. Joint Statistical Meetings (Proceedings of the American Statistical Association, 2019).
- 7T. Enamorado , B. Fifield , and K. Imai , “Using a Probabilistic Model to Assist Merging of Large‐Scale Administrative Records,” American Political Science Review 113, no. 2 (2019): 353–371, 10.1017/S 0003055418000783. · doi ↗
- 8M. Sadinle , “Bayesian Estimation of Bipartite Matchings for Record Linkage,” Journal of the American Statistical Association 112, no. 518 (2017): 600–612.