A Vision for VenomsBase: An Integrated Knowledgebase for the Study of Venoms and Their Applications
T A Castoe, M Daly, F Jungo, K N Kirchhoff, I Koludarov, S Mackessy, J Macrander, S Mehr, M V Modica, E E Sanchez, G Zancolli, M Holford

TL;DR
VenomsBase is a proposed platform to unify and standardize venom research data, enabling better discovery and analysis of venom compounds.
Contribution
The novel contribution is the design of a centralized, FAIR-compliant venom knowledgebase with integrated multidisciplinary tools and standardized data.
Findings
VenomsBase will unify venom datasets and standardize terminology for comparative analysis.
The platform will include tools for genomics, transcriptomics, proteomics, and ecological metadata integration.
VenomsBase aims to improve toxin discovery and functional annotation through heuristic scoring and cross-species analysis.
Abstract
Venoms are complex bioactive mixtures that have independently evolved across diverse animal lineages, including snails, insects, sea anemones, spiders, scorpions, and snakes. Despite the growing interest in venom research, data is fragmented across disparate databases which lack standardization and interoperability. A vision for the proposed VenomsBase platform presented here seeks to address these challenges by using the best practices approach in creating a centralized, open-access platform adhering to FAIR principles (Findable, Accessible, Interoperable, and Reproducible). VenomsBase will unify venom datasets, standardize terminology, and enable comparative analyses across species, facilitating novel toxin discovery and functional annotation. Key features of VenomsBase include user-friendly data submission modules with built-in validation, advanced cross-species analysis tools, and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
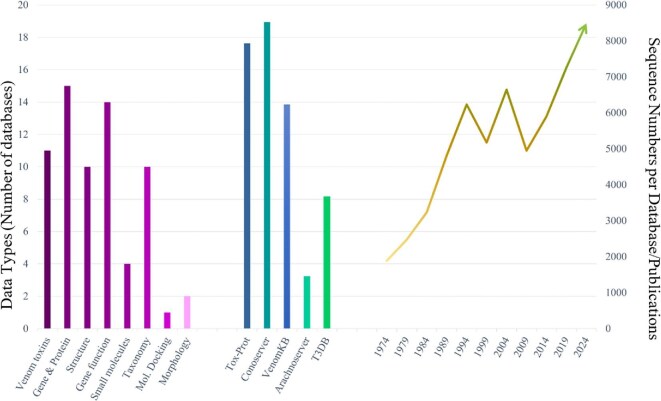 Fig. 1
Fig. 1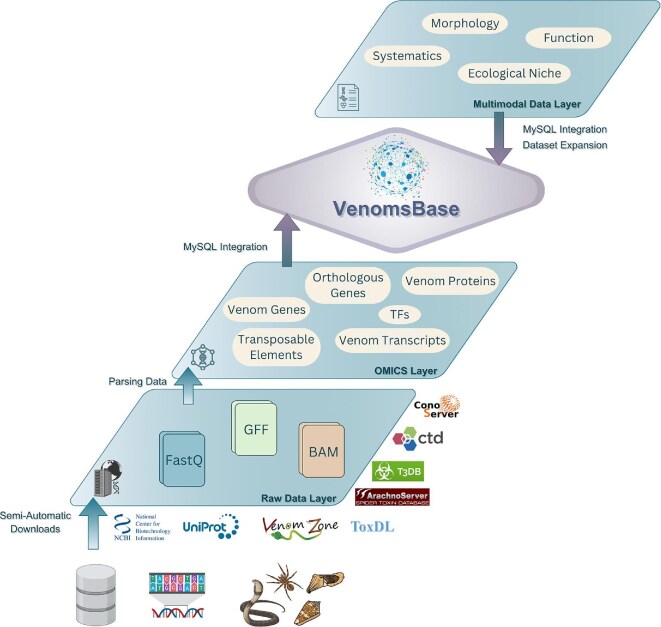 Fig. 2
Fig. 2- —National Science Foundation10.13039/100000001
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVenomous Animal Envenomation and Studies · Yersinia bacterium, plague, ectoparasites research · Bacillus and Francisella bacterial research
Introduction
Venoms are complex bioactive cocktails of proteins, peptides, and other compounds that have evolved independently across diverse animal lineages, including snails, insects, sea anemones, spiders, scorpions, and snakes (Schendel et al. 2019). The venom of a single species may contain >100 biologically active proteins and peptides, encoded by >20 gene families (Casewell et al. 2013). The broad range of animals that produce venom, along with the physiological mechanisms underlying venom production, serve as valuable models for studying the evolution, genetics, and physiology of how new genes, gene regulatory networks, protein function, and phenotypes arise in nature (Vonk et al. 2013; Zancolli and Casewell 2020; Barua and Mikheyev 2021; Perry et al. 2022; Schield et al. 2022). The biochemical effects of venoms, their biotechnological applications and subsequent impact beyond basic biology, intersect with a variety of fields, including pharmacology, neuroscience, and immunology. Many venom components have been harnessed as valuable resources for therapeutic and biomedical applications, leading to breakthroughs in pain management, cardiovascular treatments, and metabolic therapies (King 2015; Holford et al. 2018; Muttenthaler et al. 2021). Venom's applications in biotechnology continue to expand, with venom-derived peptides inspiring the development of drugs like Ozempic for metabolic disorder and obesity treatment (Christou et al. 2019). Conversely, venoms also pose significant public health challenges, particularly in tropical and subtropical regions where envenomation from snakes, scorpions, and other venomous organisms remains a major cause of morbidity and mortality (Kasturiratne et al. 2008; Patikorn et al. 2022; Puzari et al. 2025), with more than 125,000 dying annually from snakebites alone (Afroz et al. 2024). Research on venoms therefore transcends numerous diverse disciplines. Despite the scientific and commercial promise of venom research (Fig. 1), major obstacles limit its application and potential, stemming from critical gaps in data infrastructure centralization, standardization, and organization (Frisvold et al. 2021).
Venom-related data currently stored across various databases in a highly decentralized manner organized by data types (left; from Zancolli et al. 2024), encapsulating sequence data as either being taxon specific or broad taxonomic groups (center) with an increasing number of publications in NCBIPubMed under the keyword “venom” (right).
The growth in venom research has resulted in venom-related data in disparate databases, such as UniProtKB/Tox-Prot (Jungo et al. 2012), ArachnoServer (Pineda et al. 2018), and Conoserver (Kaas et al. 2011), which vary greatly in size, scope, and curation standards (Fig. 1, Jungo et al. 2010). Currently, venom peptides, proteins, and other bioactive components are analyzed and stored from multiple research disciplines, generating a wide range of databases that host raw, quality-controlled, or specialized datasets. However, the diversity of fragmented datasets, with different standards, and limited cross-disciplinary collaboration have constrained venom research (e.g., Kuzmenkov et al. 2016; Batko and Ślęzak 2022; Dresler et al. 2024). To date, three main databases store venom protein and peptide sequences. UniProtKB/Tox-Prot contains 8055 curated entries (release 2025_01) spanning a wide variety of venomous animals and principally covers toxic compounds with functional characterization. In comparison, ConoServer is dedicated to just cone snail venom compounds, and holds a total of 8523 entries, of which, 3058 correspond to wild-type protein entries (as of February 2025). This distinction allows a more accurate comparison with other databases and highlights the differing standards across venom databases. For its part, ArachnoServer includes 1458 curated spider entries (as of February 2025), representing a slight decrease compared to the 1569 spider entries listed in Tox-Prot. Furthermore, to compare the number of entries in ConoServer and ToxProt, we would have to consider the wild-type entries in Conoserver, that is, 3058 entries. The difference in the number of entries between Tox-Prot and ConoServer stems from their distinct annotation standards. ToxProt displays one entry per gene, incorporating studies on synthetic variant/mutant sequences within these entries. In contrast, ConoServer presents two entries for the same protein (one for the mature peptide and another for the precursor) and provides a new entry for each synthetic variant/mutant sequence. This discrepancy may be attributed to the update frequencies and inclusion criteria between the databases. In addition to the three main databases, the web portal VenomZone offers detailed information on venoms as well as their molecular targets. Users can browse data by taxonomy, activity, or venom protein families, with each page linking to related proteins in Tox-Prot, organized by species or protein family (Zancolli et al. 2024). Fragmented, incomplete, and disconnected taxon-specific datasets with different standards currently limit venom research and its broader potential applications and impact.
Creating a centralized, standardized, and expertly curated platform for venom research is essential to unify existing and novel data resources, mitigate biases, identify shared patterns, and establish consistent gene and/or protein family classifications (Zancolli et al. 2024). Such venom data integration would facilitate a comprehensive understanding of venom diversity and function, and unlock significant bioeconomic opportunities in the pharmaceutical, biotech, agricultural, and cosmetic sectors. Another issue is defining what counts as a venom protein or compound. This is very much an open question and part of an ongoing sustainability issue without a foundational framework to build onto. Here we propose an initiative to address these issues that we refer to as VenomsBase. This initiative responds to calls to establish a transformative infrastructure platform that removes both the technological (intrinsic) and the organizational (extrinsic) barriers that are preventing venom-focused research in achieving its full potential. The envisioned VenomsBase will support the advancement of venom research by providing a process to explore different approaches, discuss opportunities and challenges, and ultimately enact some transparent approaches to defining venom (or venom proteins). In constructing VenomsBase we are fully considering the openness of these questions as assets and a rationale for building a community-driven resource.
Barriers to progress in venoms research
Understanding the barriers to modern venom research requires examining three key factors: the historical legacy of venom discovery, the complex genetics underlying venom production, and how the negative interaction between these elements has created confusion, scientific siloing, and inconsistencies in the field. For decades, most of the work in the venom field has been at the translational level, surveying the diversity and biological activity of whole venom cocktails or individual venom peptides and proteins. The original emphasis was on a few lineages and approaches, being more descriptive rather than comparative. Consequently, naming conventions for venom components largely represent their observed biological activity (e.g., mastoparan), are not connected across lineages, and do not reflect the genes that encode these venoms or their shared (or distinct) origins (Oliveira et al. 2012; Hargreaves and Mulley 2014). Progress in understanding the genomic basis of venoms has developed only recently, as previously hindered by the unique challenges of how venom genes are encoded in animal genomes (Zelanis and Keiji Tashima 2014; Sunagar et al. 2016; von Reumont et al. 2022a). Venom proteins tend to be encoded by complex multicopy gene arrays, which vary in coding sequence and copy number substantially between and even within species (Wong and Belov 2012; Martinson et al. 2017; Gopalan et al. 2022; Smith et al. 2023). Post-transcriptional and -translational modification (PTMs) further complicate the relationship between genes, proteins, and their function for venoms (Ogawa et al. 2019; Ye et al. 2023). Together, these factors significantly complicate, and thus limit our understanding of basic information about the number and diversity of venoms, post curation, encoded in the genomes of otherwise well-studied species. Accordingly, a fundamental barrier to progress is the disconnection between nearly 50 years of studies on venom-derived peptides/proteins and their biological properties, their fundamental relationships with one another, and with the genetic and genomic elements that encode and regulate these proteins.
Another major barrier is that the existing curated and publicly available resources include broad, but nonspecific databases like NCBI and UniProtKB (The UniProt Consortium 2025) and smaller specific databases like ArachnoServer (Pineda et al. 2018), and ConoServer (Kaas et al. 2011) (Fig. 1). While these databases have been instrumental in advancing venom research, they remain limited in scope, focusing on specific types of data or lineages, and often having unique notation schemes for post-translational modifications or nonstandard amino acids. Critically, they are not designed to address broader cross-disciplinary challenges across diverse venomous lineages, such as the accurate and standardized curation and annotation of venom genes from genome, transcriptome, and protein datasets. The current databases are also not designed to support comparative analyses and are limited in terms of data annotation for both function and taxa. Furthermore, these resources are not scalable: in some cases, data formats and infrastructure render them largely incompatible or restricted in their interoperability, and in other cases the data are presented partially with regard to searchability or summarization (European Commission: Directorate-General for Research and Innovation 2018; Holmes 2018; Sima et al. 2019; Di Muri et al. 2024). Finally, for most of the existing venom databases, the user interface is challenging to navigate, often requiring specialized tools or software. This makes user accessibility a substantial barrier, presenting a steep learning curve for many early career scientists or those without bioinformatics expertise. Taken together, the shortcomings of existing resources indicate that no single researcher or research group possesses the information or technical capability to generate or interpret the scope of data associated with venom research. Consequently, venom research's complexity and interdisciplinary nature emphasize the need for a multimodal integrated database like VenomsBase to improve data accessibility and collaboration (Dresler et al. 2024).
Indeed, a decade of community-building among researchers studying venoms has identified the need for data standardization and integration. Convening events, such as the biennial Gordon Research Conference (Venom Evolution, Function and Biomedical Applications) and the annual World Congress of the International Society of Toxinology, often include community planning and prioritizing sessions that routinely highlight how existing infrastructure fails to adequately support the large-scale, multidisciplinary data sharing and analysis necessary to accelerate venom research outcomes. This key issue was also thoroughly discussed within the COST Action European Venom Network (EUVEN), an EU-funded community-building initiative that gathered researchers in the field in the past 4 years (Zancolli et al. 2024). These conversations echo nearly all recent review manuscripts in the field of venom research, which call for approaches that facilitate the cross-interrogation of diverse data, across lineages and datatypes, to explore shared attributes of venoms, model the structure of venom molecules, and search for bioactive compounds in community-accessible formats (von Reumont et al. 2022b; Prentis et al. 2018; Schendel et al. 2019; Arbuckle 2020; DiFrisco and Jaeger 2020; Kini 2020; Smallwood and Clark 2021; Avella et al. 2022; de Oliveira et al. 2023; Calvete et al. 2024). VenomsBase was conceptualized as a response to this community need by providing leading-edge infrastructure that enables comparative investigation of venoms and their associated genomic regions across species and facilitates curated multispecies genotype-to-phenotype datasets.
Proposed solution: creation of an integrated knowledgebase—VenomsBase
The VenomsBase initiative described here would establish a global venom data integration platform to resolve critical challenges in venom research, such as data fragmentation, inconsistent characterization between venom proteins and the genes that encode venoms, and inconsistent terminology for venom protein families (Oliveira et al. 2012; Hargreaves and Mulley 2014). The transformative impact of VenomsBase's infrastructure is based on its overarching theme of integrating standardized knowledge across biological scales to associate venom proteins to the genes and genomes that encode them, and from the physiological secretory systems and whole organisms that produce them, spanning the animal tree of life (Fig. 2). Given the high level of multidisciplinary venom research, data consistency and robust quality are inherently challenging and require coordinated curation and participation at a community scale. VenomsBase is intended to fill this gap by integrating genome-to-phenome datatypes to centralize, standardize, and make accessible naming conventions for venom proteins, gene families, and isoforms, while further developing standardized reference sets of venom gene/transcript models coupled to the proteins these genes produce. Our vision for the VenomsBase initiative would enable robust data curation and refinement over time and provide the community with a highly vetted standard foundation for studying, comparing, and applying research on venoms and venomous animals. We argue that such an ambitious initiative could be accomplished through three distinct phases of prioritized development: (1) Establishment of a standardized and scalable platform for integration of diverse platinum-quality venomous reference species; (2) Development of cross-species search and analysis tools and expansion of taxa representation; and (3) Integration of multidisciplinary data types through collaborator engagement and feedback.
Schematic overview of VenomsBase's modular structure for data processing and integration. The Raw Data Layer gathers datasets via semi-automatic downloads, which are processed in the Parsing Data Step for high-quality integration. The OMICS Layer curates venom-related omics data for comprehensive curation and standardization. The Dataset Expansion Step continuously incorporates new datasets into the Multimodal Data Layer, enabling cross-disciplinary analyses. This modular framework enhances scalability, interoperability, and data diversity in venom research.
Through these prioritized development strategies, VenomsBase would establish valuable infrastructure to the research community by lowering barriers to entry in terms of expertise and access to analytical tools, thereby accelerating collaboration, discovery, and applications of venom-related research. This will be done via collaborative message boards and GitHub repositories to establish a centralized communication platform to coordinate discussions, share updates, and solicit feedback from community members. The envisioned VenomsBase platform would address gaps of siloed and species-specific datasets by developing a central infrastructure for submitting, standardizing, and analyzing multispecies venom-related data across labs worldwide that is open-access and Findable, Accessible, Interoperable, and Reproducible (FAIR) (Wilkinson et al. 2016, 2024). VenomsBase will draw on successful aspects of VenomKB v2.0 as described by Romano and Tatonetti (2015) and of established databases like EchinoBase (Arshinoff et al. 2022), ArachnoServer (Pineda et al. 2018), and ConoServer (Kaas et al. 2011) to create a centralized, structured resource that consolidates venom taxonomy, bioactivities, sequences, and structural data (Fig. 2). VenomsBase will incorporate elements of other successful annotation pipelines, like Funannotate (Palmer and Stajich 2020) or similar to standardized annotation workflows, and incorporate Ensembl-guided gene model predictions (Dyer et al. 2025) that will be functional across species in order to track annotations and expand with VenomsBase. Via an ontology-driven structure, VenomsBase would ensure consistency in data classification while integrating diverse data types, such as genomic sequences, gene/transcript annotations, proteomic profiles, functional assays, taxon images, and pharmacological interactions, thus establishing a comprehensive resource for biological and chemical diversity, computational toxinology, and bioeconomic development. VenomsBase would prioritize user accessibility and data quality, adopting features like heuristic annotation scoring to guide users toward the most robust entries and programmatic access through a REST API, as exemplified by VenomKB v2.0 (Romano and Tatonetti 2015). By incorporating features from other databases, such as visualization tools for post-translational modifications and curated protein structural data links, such as UniProtKB/Tox-Prot (Jungo et al. 2012), VenomsBase will provide a streamlined interface for venom research, allowing users to explore data by specific compounds, molecular targets, species, and translational applications (Jungo et al. 2010). Taken together, VenomsBase will integrate with the community to establish new standards and data practices, using tractable and informative methods, and test new processes to integrate data across broad scales.
By unifying knowledge of the genes and regulatory networks that produce venoms with the structure and function of venom proteins and peptides, VenomsBase aims to create a comprehensive resource that links venom composition to its biological targets and physiological effects (Fig. 2). Our multi-institutional team is leading the initial curation effort to secure infrastructure grants and establish a long-term consortium for sustainability and maintenance. This effort is modeled on successful large-scale data repositories such as the World Register of Marine Species (WoRMS), which relies on a distributed network of backend and scientific experts with clearly defined roles (Ahyong et al. 2025), including taxonomists, web developers, and various programmers. VenomsBase will require not only scientific curators but also dedicated developers and database administrators. Developers will maintain platform infrastructure, while database administrators will manage data ingestion from generalist repositories (e.g., NCBI, UniProt), validate submission formats, and coordinate public data releases. Automated workflows will follow lineage-specific filtering rules (e.g., taxonomic identifiers, venom-related GO terms, expression in venom glands) to ensure relevant data capture. This tiered structure mirrors existing systems such as UniProt, which handles diverse types of submitted sequences, including rejections and redirection to repositories like GenBank or PRIDE. This integration is expected to lead to transformative research across biological scales, from evolutionary to organismal–encompassing genomes, gene regulatory networks, transcripts, proteins, cell morphology, and biological activity and applications of venoms for selected number of species. As VenomsBase grows, we plan to formalize these roles through institutional partnerships and funded positions. From a global health perspective, VenomsBase would assist with the discovery and development of treatments for envenomations, which remain a significant challenge around the globe in tropical and subtropical regions.
VenomsBase uses a standardized and scalable approach
Developing a standardized and scalable approach is critical to ensuring VenomsBase's success and adoption by the research community and its utility for ecologists, pharmacologists, and others working with any venomous species across the Tree of Life. This will involve designing workflows and pipelines based on multiple “platinum-quality” species as proof-of-concept and as a means of developing gold-standard practices. Platinum-quality species are those for which there are diverse, high-quality data of multiple types—from genomic, transcriptomic, proteomic resources to anatomical, ecological, and toxinological observations. Gold standard practices include rigorous data validation steps to ensure data integrity and quality, a robust system for annotating and curating datasets, and clear protocols for integrating new data types as they become available.
The key elements of the envisioned VenomsBase platform include:
Data collection and submission modules: A user-friendly interface to allow researchers to upload datasets to NCBI with built-in validation steps to ensure correct formatting and metadata inclusion. This feature will maintain consistency and quality across datasets. The design should incorporate public datasets as a gateway to support existing practices to curate data in the National Center for Biotechnology Information (NCBI) and the Sequence Read Archive (SRA).2. Standardization protocols: Reproducibility, shareability, and comparability of results are critical in overcoming the challenges of interdisciplinary research, despite increasing data availability and computational power. The infrastructure should employ a terminology editor application to ensure uniform naming conventions and nomenclature. This approach will minimize inconsistencies and improve data interoperability (Lehne et al. 2019; Politano et al. 2019; Rahrooh et al. 2024; Zancolli et al. 2024).3. Cross-species tools: Advanced search and analysis tools will enable researchers to perform comparative analyses across species, leveraging insights from shared genetic and phenotypic traits. The platform should support taxonomically diverse lineages and predicted homologous or analogous molecular models through tools like MetamORF (Choteau et al. 2021), Orthofinder (Emms and Kelly 2019), and methods targeting short open reading frames (Coelho et al. 2024) for annotating novel toxin discovery (Nachtigall et al. 2021) across multiple venomous lineages (Nachtigall et al. 2024). In doing so, the platform would incorporate expert manual curation. As the platform grows, experts across relevant fields will guide manual curation through a tiered model, with a core team for quality control, invited experts for lineage-specific review, and community volunteers who contribute annotations or feedback through the open platforms.4. Integration of multidisciplinary data types: The infrastructure should incorporate diverse datasets, including genomic sequences, transcriptomic data, proteomic profiles, species distributions, and ecological metadata, to create a resource spanning biological scales. Although such a multimodal dataset does not yet exist for venoms, successful frameworks such as the Global Biodiversity Information Facility (GBIF.org. 2025) or platinum-quality species-specific repositories (e.g., Berardini et al. 2015; Sternberg et al. 2024; Öztürk-Çolak et al. 2024) can serve as models for developing this infrastructure.5. Scalability and modular design: The platform should employ modular, cloud-based architecture to allow for growth and adaptation to emerging research needs. It should also integrate heuristic annotation scoring systems to guide users toward high-confidence data entries. Similar heuristic processes have been successfully implemented in genomic next-generation sequencing pipelines (e.g., McLaren et al. 2016; Afgan et al. 2018), particularly in open-source and modular applications (Treangen et al. 2013; Breitwieser et al. 2022).6. Training and outreach: To ensure accessibility and usability for researchers at all levels, the platform should provide regular webinars, training sessions, and user feedback loops. Case studies and tutorials can demonstrate the platform's ability to streamline venom NGS workflows while promoting accessibility through educational resources (Lowman et al. 2009; Shaffer et al. 2010; Brazas and Ouellette 2013; i5K Consortium 2013; Clark et al. 2016; Wilkinson et al. 2016; Attwood et al. 2019; Auwera and O'Connor 2020).
By adopting these elements, VenomsBase would establish a reliable and adaptable foundation to the evolving needs of the venoms and ecological research communities. Incorporating platinum-quality species and agreed-upon protocols will provide a benchmark for data quality, setting a new precedent for collaborative research and discovery.
To democratize access to its resources, the design of databases underlying VenomsBase would prioritize FAIR principles (Wilkinson et al. 2016, 2024). Accessibility is particularly critical for researchers in biodiversity-rich regions like Southeast Asia, Africa, and Latin America, where researchers often face barriers to accessing advanced bioinformatics tools (Geneviève et al. 2018) and where envenomation poses the most significant public health risk. Developing accessible online educational programs tailored to venom research would be another crucial step in bridging the resource gap. Establishing international collaborations between researchers in biodiversity-rich but resource-limited regions and institutions in well-funded countries would enable comprehensive comparative studies, linking venom composition and actions to ecological variables such as climate, prey availability, and habitat type. Additionally, regional connectivity would facilitate the identification of overlooked venomous species, ensuring that antivenom research is informed by an accurate understanding of local venom and species diversity.
Development of an infrastructure that keeps pace with innovation across fields
To ensure success, VenomsBase future data infrastructure and pipelines must actively facilitate interdisciplinary collaboration, enabling contributions from scientists both within and on the periphery of venom research. This inclusiveness will make the platform more robust and nimble to anticipate new technologies, data types, and analyses. It also expands the scope of questions that can be addressed and reinforces and extends the quality of the protocols through broad and rigorous cross-validation. This approach is also critical for integrating diverse perspectives and expanding the boundaries of the field. Achieving the degree of inclusive flexibility needed hinges on the standardization of data formats, ensuring that datasets are accessible, interpretable, and compatible for researchers across disciplines, including bioinformatics, ecology, physiology, evolutionary biology, and many others (Kaas and Craik 2015). Standardization would enable a seamless exchange of data, fostering collaboration and driving innovation.
Many current bioinformatic techniques used to generate genomic, transcriptomic, and proteomic datasets for venomous organisms may have relied on methods that have since been improved or changed or that are nonstandard. These limitations stem partly from the fact that many venomous organisms are often categorized as “nonmodel organisms” by the broader scientific community, which has historically prioritized the development of advanced ‘omics approaches for model species (Armengaud et al. 2014; Muth et al. 2018; Calvete et al. 2021). This has led to a significant gap in the tools and resources available for studying the unique and often complex biology of venomous taxa that VenomsBase (Fig. 2) would address. Visualization tools built into VenomsBase accompanying genome browsers and protein structure renderings would enable intuitive access to complex datasets, making it easier for interdisciplinary researchers to interact with these diverse data types. These tools could foster collaboration between traditionally distinct fields.
VenomsBase will transform venom research by centralizing and standardizing data, bridging disciplines, and enhancing interdisciplinary collaboration. By unifying fragmented datasets and enabling comparative analyses, it will advance fundamental research while unlocking applications in pharmaceuticals, biocontrol, and cosmetics. This integrated platform exemplifies the power of centralized infrastructure to drive scientific innovation.
VenomsBase: infrastructure that both serves and integrates research communities
VenomsBase will serve as a critical infrastructure for data integration, collaboration, and innovation, providing an equitable platform for researchers across disciplines and geographic regions (Fig. 2). By enabling the sharing of protocols and methodologies, VenomsBase will help standardize best practices in venom research while supporting global accessibility. Through its open-access design and commitment to FAIR principles, it will foster cross-disciplinary knowledge exchange. It will ensure researchers have access to cutting-edge techniques, such as transcriptomic workflows, venom protein isolation methods, and bioinformatic analysis pipelines. Experts could contribute specialized protocols, which others could adopt or adapt. It can incorporate existing cloud platforms such as Cyverse (Swetnam et al. 2024) with integrated GitHub repositories and UCSC genome browser (Lee et al. 2020) for new organisms, environments, or experimental conditions, promoting inclusivity and innovation. Additionally, the database could provide training resources, facilitate knowledge exchange, and create opportunities for researchers from underrepresented regions to participate in collaborative projects.
Venoms hold untapped potential for addressing global health challenges, including envenomation, which affects over 5 million people annually. Snakebites alone cause significant morbidity and mortality, particularly in under-resourced regions (Simpson 2008; Williams et al. 2011; Patikorn et al. 2022). By developing centralized, open-access databases and fostering collaborative networks, researchers in these regions could gain access to critical venom protein sequencing data, genomic datasets, and bioinformatic tools without incurring prohibitive costs. Additionally, investing in local venoms research capacity, through partnerships with universities, hospitals, and public health organizations, could lead to improved diagnostics and antivenom development tailored to regional snake, spider, or scorpion species (Fry et al. 2003; Yu et al. 2020). Addressing the global disparities in venom research by providing cost-effective and scalable solutions would reduce the burden of snakebite envenomation and also empower researchers in low-resource settings to contribute meaningfully to scientific discoveries in toxinology, evolutionary biology, and pharmacology.
Online educational infrastructure would also help bridge the research gap among educational and research institutions that would benefit from applying these resources. An online infrastructure hosting standardized high-quality venom resources, along with tutorials and instructional resources, would provide hands-on data analysis training and introductory opportunities for functional genomics (Brown 2016; Gao and Guo 2023). This infrastructure could bridge the gap between basic research and translational applications, accelerating the development of antivenoms and novel drugs.
In conclusion, by outlining best practices toward collaborative venom-based research, VenomsBase represents a transformative leap in venoms research (Fig. 2). A centralized platform like VenomsBase would pave the way for groundbreaking discoveries in evolutionary biology, pharmacology, and ecological science by addressing the limitations of fragmented datasets, standardizing nomenclature, data collection, and integrating multidisciplinary and multimodal datasets. VenomsBase exemplifies the power of centralized, interdisciplinary infrastructure to drive scientific innovation by unifying resources, increasing comparative studies and facilitating flexibility in data analyses.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Afgan E, Baker D, Batut B, van den Beek M, Bouvier D, Čech M, Chilton J, Clements D, Coraor N, Grüning BA et al. 2018. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2018 update. Nucleic Acids Res 46:W 537–44. 29790989 10.1093/nar/gky 379PMC 6030816 · doi ↗ · pubmed ↗
- 2Afroz A, Siddiquea BN, Chowdhury HA, Jackson TN, Watt AD. 2024. Snakebite envenoming: a systematic review and meta-analysis of global morbidity and mortality. P Lo S Negl Trop Dis 18:e 0012080.38574167 10.1371/journal.pntd.0012080 PMC 11020954 · doi ↗ · pubmed ↗
- 3Ahyong S, Boyko CB, Bernot J, Brandão SN, Daly M, De Grave S, de Voogd NJ, Gofas S, Hernandez F, Hughes L et al. 2025. World Register of Marine Species. https://www.marinespecies.org at VLIZ. Accessed 2025-05-23. 10.14284/170 · doi ↗
- 4Arbuckle K . 2020. From molecules to macroevolution: venom as a model system for evolutionary biology across levels of life. Toxicon: X 6:100034. 32550589 10.1016/j.toxcx.2020.100034 PMC 7285901 · doi ↗ · pubmed ↗
- 5Armengaud J, Trapp J, Pible O, Geffard O, Chaumot A, Hartmann EM. 2014. Non-model organisms, a species endangered by proteogenomics. J Proteom Spec Issue Proteom Non-model Org 105:5–18.10.1016/j.jprot.2014.01.00724440519 · doi ↗ · pubmed ↗
- 6Arshinoff BI, Cary GA, Karimi K, Foley S, Agalakov S, Delgado F, Lotay VS, Ku CJ, Pells TJ, Beatman TR et al. 2022. Echinobase: leveraging an extant model organism database to build a knowledgebase supporting research on the genomics and biology of echinoderms. Nucleic Acids Res 50:D 970–9. 34791383 10.1093/nar/gkab 1005 PMC 8728261 · doi ↗ · pubmed ↗
- 7Attwood TK, Blackford S, Brazas MD, Davies A, Schneider MV. 2019. A global perspective on evolving bioinformatics and data science training needs. Briefings Bioinf 20:398–404. 10.1093/bib/bbx 100PMC 643373128968751 · doi ↗ · pubmed ↗
- 8Auwera Gvd, O'Connor BD. 2020. Genomics in the cloud: using Docker, GATK, and WDL in Terra O'Reilly Media, Incorporated. https://catalog.nlm.nih.gov/discovery/fulldisplay/alma 9917773213406676/1445500