An efficient method of modulo adder design for Digital Signal Processing applications
Subodh Kumar Singhal, Sumit Kumar, Sujit Kumar Patel, K. Anjali Rao, Gaurav Saxena

TL;DR
This paper introduces a more efficient modulo adder design for digital signal processing, reducing area and delay compared to existing methods.
Contribution
A novel diminished-one modulo adder for 2n+1 with reduced area, delay, and improved ADP and PDP metrics.
Findings
The proposed design reduces area by 23.41% and delay by 31.64% compared to existing designs.
Synthesis results show 13.71% less area and 14.5% less delay in the new modulo adder.
The design achieves a 26.2% reduction in ADP and 32.8% improvement in PDP over existing structures.
Abstract
Modulo adder is a widely used arithmetic component in many Digital Signal Processing (DSP) applications such as Finite Impulse Response (FIR), Infinite Impulse Response (IIR) filters, digital signal processors, image processing modules, discrete cosine transform, and cryptography. Therefore, in this paper, the critical path delay and area of modulo adder are analyzed. An optimized diminished-one modulo adder for 2n+1 is proposed based on the analysis results.•Theoretical comparison shows that the suggested modulo adder involves 23.41 % less area (transistors count) and 31.64 % less delay than the best existing design for an average bit-width.•Synthesis result reveals that the proposed modulo adder involves 13.71 % less area and 14.5 % less delay compared to the best existing modulo adder structure design in the literature for an average bit-width.•To observe the overall efficacy of the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
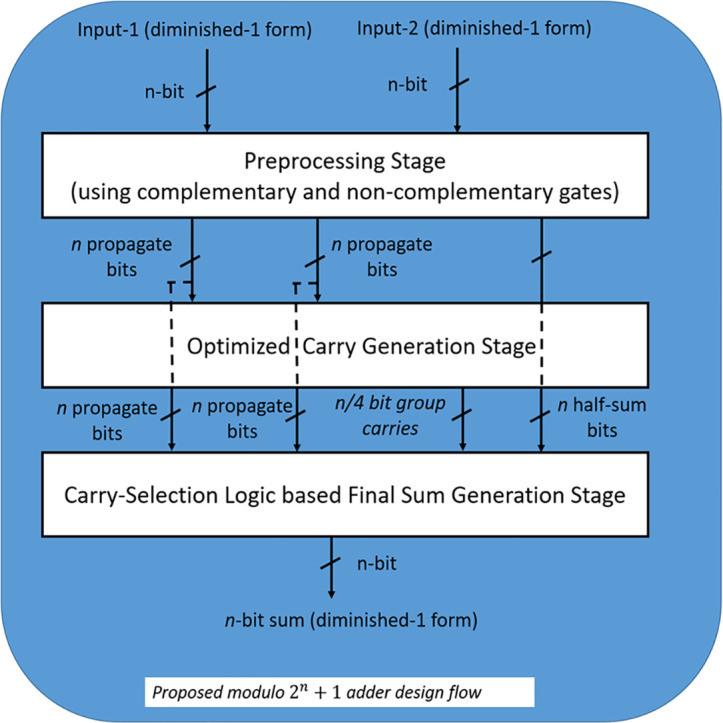 Figure 1
Figure 1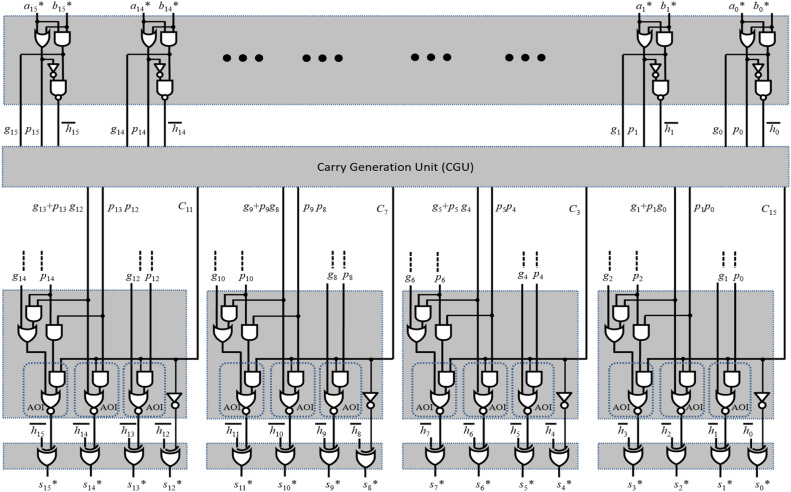 Figure 2
Figure 2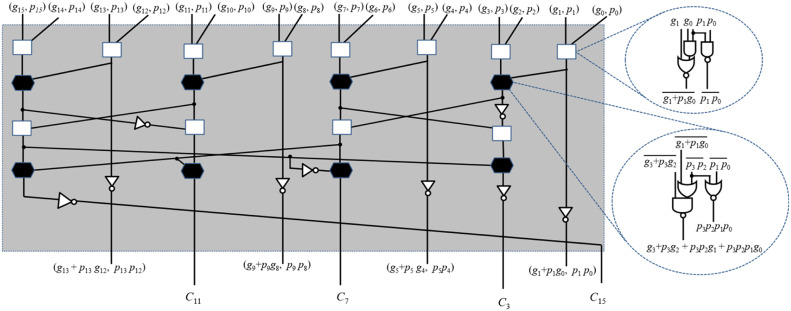 Figure 3
Figure 3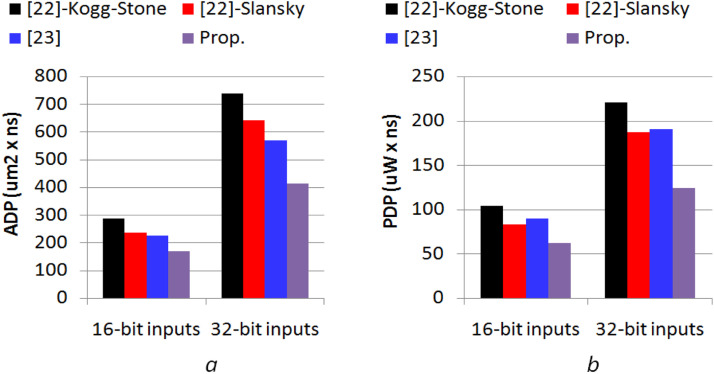 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAnalog and Mixed-Signal Circuit Design · Low-power high-performance VLSI design · Digital Filter Design and Implementation
Specifications tableSubject area:VLSI Architecture DesignMore specific subject area:Modulo AdderName of your method:Diminished-1 modulo adderName and reference of original method:NAResource availability:Synopsys Design Compiler
Introduction
The Residue Number System (RNS) is extensively utilized in a wide range of DSP applications like finite impulse response filters (FIRs), digital signal processors, image processing modules, discrete cosine transform, cryptography, etc. [[1], [2], [3], [4]], to speed up the arithmetic operations. In RNS, a number is divided into residues (parts). It performs various arithmetic operations (such as addition, subtraction, multiplication etc.) in parallel for each part to reduce the computation time of the operations. The moduli set is mostly used in RNS based systems. In this moduli set, more attention has been paid to modulo arithmetic operation because it works on bits binary operands, increasing delay and logic resources. To accommodate bits binary operand into n bits, diminished-1 representation has been suggested in [5], which reduces the delay and area of the modulo operations. Various modulo arithmetic operations, such as addition, subtraction and multiplication etc., are performed in many applications. In particular, modulo addition is the most commonly used operation in RNS- based systems. An efficient modulo adder design could be crucial in developing VLSI systems optimized for both area delay and power efficiency. Consequently, numerous architectures have been proposed in the literature to efficiently implement of adders. The chronological developments of these architectures are briefly discussed in the next paragraph.
Zimmermann et al. have suggested efficient VLSI architecture for modulo adder in which parallel prefix adder with end-around-carry is used to realize arithmetic operations [6]. In [7], authors have developed diminished-1 modulo adder architectures using two approaches, namely carry look-ahead and parallel prefix for its implementation. Subsequently, select-parallel-prefix addition block based diminished-1 modulo adder has been given in [8], which offers a good trade-off between area and speed. Further, Costas et al. [9] presented the area-delay efficient modulo adder using modified parallel-prefix carry computation and fast carry-increment stage. In [10], researchers have proposed a circular-carry-selection method to design diminished-1 modulo adder to minimize the area-delay and power-delay complexities. Subsequently, Vergos et al. [11] have developed modulo adder, where operands are represented in weighted form. Later on, diminished-1 modulo adder has been suggested in [12] in which authors have introduced new carry look-ahead and parallel-prefix adder structures for the fast implementation of carry computations.
In addition, the sparse carry computation-based efficient modulo adder architectures have been suggested in [[13], [14], [15]], where only group carries are calculated for the modulo addition. In [16], authors have proposed FFPGA-targeted modulo adder architectures with fast carry chains to speed up the arithmetic operations. Subsequently, delay efficient modulo adder has been realized in [17] using redundant carry-save forms of the operands. The modulo add-multiply component was developed in [18], which offers saving in area and delay compared to using individual adder and multiplier components. Further, Khan et al. [19] have given a comparative analysis of modulo adders using different parallel prefix adder architectures. In [20], authors have suggested modulo-generic adder circuits in which they have maximized sharing of components by merging two adders to optimize cell interconnect overhead. The carry skip logic-based modulo 2^n^ + 1 adder design has been suggested in [21] to achieve area-power efficiency. In [22], authors have recently analyzed diminished-1 modulo 2^n^ + 1 adder and subtractor circuits and suggested improved designs with less area and power consumption.
Further, a modified parallel prefix adder-based diminished-1 modulo adder design has been reported in [23]. This design uses a group-carry selection approach to optimize area and power consumption. From the literature, it is observed that most of the researchers have focused on reducing the area and delay complexities of modulo adder by removing the redundant logic present in the design. However, the logic redundancy in any modulo adder design is limited; therefore, it needs to explore another way to obtain area delay efficient modulo adder design. On the other hand, the majority of digital systems are implemented using complementary metal–oxide–semiconductor (CMOS) technology. Based on the literature, we have set certain objectives for this paper, which are stated below:
- •To explore the CMOS library to find the possibilities of area-delay optimization of the modulo-adder design.
- •To explore the logic redundancy (if any) available in the existing modulo-adder designs to minimize the area and power and improve the speed.
From the CMOS library, it is observed that the delay and area of complementary gates are less than that of non-complementary gates. These observations propose an efficient area delay diminished-1 modulo adder structure. The remaining portion of the article is presented under the section's method details, method validation, limitations, and conclusion.
Method details
Proposed structure for modulo adder
The proposed diminished-1 module adder structure is shown in Fig. 1. It performs modulo addition in three stages. The first stage is a pre-processing stage that receives two diminished-1 numbers as input and produces propagate (p_i_), generate(g_i_), and half-sum bit (in complemented form, i.e., h_i_). The second stage is carry-generation, where all the intermediate group-carries are generated using g_i_ and p_i_ bits. Finally, the third stage is a sum-generation stage in which all the intermediate group carries are combined with the half-sum bits generated in the first stage and produce final sum bits. The detailed design strategies of each stage are explained in subsequent subsections.Fig. 1. Proposed diminished-1 modulo adder.Fig. 1:
Pre-processing stage
Conventionally, in the pre-processing stage, three logic gates (XOR, AND and OR) are used to generate g_i_, p_i_ and h_i_ bits, where . In the proposed design, for the reduction of the delay in the critical path of the carry-generation as well as sum-generation stages, we have designed the pre-processing stage with maximal possible utilization of complementary logic cells. These half-sum bits have to be generated in complementary form, as shown in the pre-processing block of Fig. 1.
Carry generation stage
Generally, the carry generation stage involves levels of parallel-prefix logic cells (PPLCs) to generate the intermediate carries. The PPLC comprises of two AND and one OR gate. The critical path delay of this cell includes one AND and one OR gates. Therefore, the total delay of carry generation unit is , where are the delay of 2-input AND and OR gates, respectively. This type of carry generation stage involves more delay and requires more area. However, in the literature, the group carry selection-based carry generation stage has recently been utilized to reduce the area by minimizing the number of PLCs. But, to reduce delay, the optimization of PPLC is required. Therefore, we have gone through the Taiwan semiconductor manufacturing company (TSMC) 65 nm CMOS library for logic gates and observed that the delay of complementary gates AND-OR-Inverter (AOI) and OR-AND-Inverter (OAI) is less over complex gates (AND-OR and OR-AND). Based on this study, the complementary gates are utilized for the development of PPLCs with less delay. Apart from this, it is also observed that these complementary gates-based PPLCs give outputs in complementary forms, which is unsuitable for directly replacing the conventional PPLCs in the carry computation unit. Therefore, the existing carry computation unit needs to be modified so that complementary PPLCs are accommodated within it to reduce delay. Based on these modifications, two new PPLCs and modified carry computing structures are proposed, as shown in Fig. 2.Fig. 2. Proposed carry generation unit.Fig. 2
Sum generation stage
In the sum generation stage, all the intermediate carries required for the final sum are calculated using group carries generated in the second stage. Later, these intermediate carries and half sum bits (generated in the first stage) are used to generate final sum bits of modulo addition. In the existing design, the sum generation unit is developed using AND, OR, AND-OR (AO), OR-AND (OA), and XOR gates, which consumes more area and delay. As discussed in the previous subsection, complementary gates are more area- and delay-efficient than non-complementary complex gates (AO and OA). Therefore, an existing sum-generation unit is analyzed to optimize area and delay. This analysis reveals that the complementary complex gates can be utilized only when the structure is redesigned. Based on these observations, the complementary gates (as much as possible) based sum generation circuit is derived and shown in Fig. 2.
Theoretical comparison
The theoretical comparison is discussed in this section to observe the efficacy of the proposed modulo-adder design. Area (in the form of transistor counts) and delay (in ps) of different logic gates are extracted from the TSMC 65 nm library [24] and supplied in Table 1 for the theoretical comparison of the proposed design with the state-of-the-art designs. The area and delay of the suggested and current designs are computed and shown in Table 2 using Table 1. It is evident from Table 2 that the suggested modulo adder involves 47.62 %, 35.86 %, and 23.41 % less area (transistors count) compared to the Kogg-Stone parallel prefix adder (PPA) based design of [22], Skansky PPA-based design of [22] and design of [23] respectively, on an average bit-width. Similarly, the Proposed design takes 25.62 %, 25.62 %, and 31.64 % less delay in comparison to the Kogg-Stone PPA-based design of [22], Skansky PPA-based design of [22] and design of [23], respectively, on an average bit-width. The following section presents synthesis results and a discussion to verify the theoretical findings.Table 1. Area and delay of the CMOS logic cells (TCBN65GPLUS TSMC 65 nm core library data-book.Table 1. GatesCell-NameDelay (ps)Are (Transistor Count)ANDAN2D026.156OROR2D028.56NORNR2D013.954NANDND2D012.754NOTINVD09.42XORXOR2D04212AOIAOI21D018.656AOAO21D033.458OAIOAI21D017.556Table 2Comparison of theoretical results for modulo adders.Table 2. AdderDesignbit-width(m)Area(Transistors)Delay(ps)Design based on Kogg-Stone PPA [22]163214623350235.4268.85Design based on Sklansky PPA [22]163212242664235.4268.85Design of [23]163210422194254.2287.65Proposed16328021672178196.65 , Excess energy over the proposed modulo adder.
Method validation
The proposed and existing modulo-adder designs are coded in VHDL for bit-width 16 and 32 for the method validation. The intended and contemporary modulo adder designs are coded in VHDL for bit-width 16 and 32 to enable experimental investigation. Furthermore, using TSMC 65 nm CMOS Library cells, these designs are synthesized in Synopsys Design Compiler. Table 3 lists the reported values for area, delay, and power. From the synthesis results given in Table 3, it can be seen that the proposed modulo adder involves 34.64 %, 23.21 %, and 13.71 % less area compared to the Kogg-Stone PPA-based design of [22], Skansky PPA-based design of [22] and design of [23] respectively, on an average bit-width. Similarly, the Proposed design takes 12.05 %, 11.14 %, and 14.5 % less delay in comparison to the Kogg-Stone PPA-based design of [22], Sklansky PPA-based design of [22], and design of [23], respectively, on an average bit-width. It is clear from the comparison analysis that the suggested designs are more efficient in terms of area, delay, and power than existing designs, which is also supported by the theoretical comparison covered in the preceding section.Table 3. Comparison of synthesis results for intended and contemporary modulo adders.Table 3:Modulo AdderWidth(m)Delay(ns)Area(µm2)Power(µW)Design based on Kogg-Stone PPA [22]16320.490.59586.81252.0212.85374.30Design based on Sklansky PPA [22]16320.480.59489.61088.5172.60317.76Design of [23]16320.510.60444.3948.4175.47317.83Proposed16320.430.52393.8796.3144.13238.31
The area-delay-product and power-delay-product values are computed using the synthesis data provided in Table 3 to observe the overall efficacy of the suggested modulo adder design. These calculated values of ADP and PDP are plotted in the form of bar-graph shown in Fig. 3(a and b) for comparison. From the bar graph, it can be seen that the proposed modulo adder design gives an improvement in ADP and PDP by 42.52 % and 42.23 % over the Kogg-Stone PPA-based design of [22]; 31.73 % and 29.54 % over Sklansky PPA based design of [22]; 26.24 % and 32.88 % over [23], respectively. Consequently, it is evident from the explanation above that the suggested modulo adder is more efficient and can be utilized to create effective VLSI digital systems.Fig. 3. Comparison of (a) ADP and (b) PDP.Fig. 3
Limitations
The limitation of the proposed design is that the bit-width (n) should be in the order of to get maximum efficiency in terms of area, delay, and power.
Conclusion
Modulo adder is a widely used arithmetic component in many DSP applications, such as FIR, IIR filters, digital signal processors, image processing modules, discrete cosine transform, and cryptography. Therefore, in this paper, the CMOS library and logic redundancy available in the existing designs were explored to find the possibilities of area delay optimization of the modulo-adder design. From the CMOS library, it is observed that the delay and area of complementary gates are less than that of complex gates. These observations propose area delay efficient diminished-1 modulo 2 to the n plus 1adder structure. The theoretical comparison shows that the suggested modulo adder involves 23.41 % less area (transistor count) and 31.64 % less delay than the best existing design for an average bit-width. Synthesis results reveal that the proposed modulo adder involves 13.71 % less area and 14.5 % less delay compared to the best available existing modulo adder structure design in the literature for an average bit-width, which validates the theoretical comparison achievements of the proposed design. Overall, the values obtained for ADP and PDP reveal that the proposed design achieves a 26.2 % reduction in ADP and a 32.8 % improvement in PDP compared to the best available modulo-adder structure. Thus, the proposed modulo-adder design is superior for developing area- and delay-efficient VLSI digital systems. In the future, this design can be explored to develop the area-delay efficient modulo multiplier structure.
Ethics statements
This research did not involve research on humans or animals, and no data is involved from social media platforms.
CRediT authorship contribution statement
Subodh Kumar Singhal: Validation, Visualization. Sumit Kumar: Funding acquisition, Validation, Methodology, Writing – original draft. Sujit Kumar Patel: Conceptualization. K. Anjali Rao: Supervision, Writing – review & editing. Gaurav Saxena: Writing – original draft.
Declaration of competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Freking W.L.Parhi K.K.Low-power FIR digital filters using residue arithmetic Conference Record of the Thirty-First Asilomar Conference on Signals, Systems and Computers (Cat. No. 97CB 36136)11997 IEEE 739743
- 2Cardarilli G.Nannarelli A.Re M.Residue number system for low-power DSP applicationsproc. 41st asilomar conf.signals, syst 2007
- 3Eseyin J.B.Gbolagade K.A.A residue number system based data hiding using steganography and cryptography KIU J. Social Sci.522019345351
- 4Schinianakis D.Stouraitis T.Multifunction residue architectures for cryptography IEEE Transactions on Circuits and System I: Regular Papers 61201411561169
- 5Leibowitz L.A simplified binary arithmetic for the fermat number transform IEEE Trans Acoust 2451976356359
- 6Zimmermann R.Efficient VLSI implementation of modulo (2n + 1) addition and multiplication Proceedings 14th IEEE Symposium on Computer Arithmetic (Cat. No. 99CB 36336)1999 IEEE 158167
- 7Vergos H.T.Efstathiou C.Nikolos D.Diminished-one modulo 2n + 1 adder design IEEE Trans. Comput.5112200213891399
- 8Cao B.Chang C.-H.Srikanthan T.An efficient reverse converter for the 4-moduli set {2n − 1, 2n, 2n + 1} based on the new chinese remainder theorem IEEE Trans. Circuits Syst. I: Fundam. Theory Appl.5010200312961303