A Low-Power Domino Logic Architecture for Memristor-Based Neuromorphic Computing
Cory Merkel, Animesh Nikam

TL;DR
This paper introduces a low-power domino logic architecture tailored for memristor-based neuromorphic computing, leveraging memristor RC circuit delays for synaptic operations and synchronization schemes for efficient inter-layer communication.
Contribution
The work presents a novel domino logic design that enhances energy efficiency in memristor-based neuromorphic systems, with a simple power model and synchronization methods for improved performance.
Findings
Achieves 0.61 fJ per classification component energy efficiency.
Outperforms existing designs in energy per accuracy metrics.
Demonstrates effective synchronization for neural network layer communication.
Abstract
We propose a domino logic architecture for memristor-based neuromorphic computing. The design uses the delay of memristor RC circuits to represent synaptic computations and a simple binary neuron activation function. Synchronization schemes are proposed for communicating information between neural network layers, and a simple linear power model is developed to estimate the design's energy efficiency for a particular network size. Results indicate that the proposed architecture can achieve 0.61 fJ per classification per component (neurons and synapses) and outperforms other designs in terms of energy per % accuracy.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1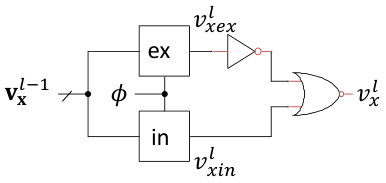 Figure 2
Figure 2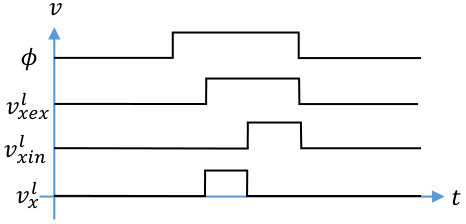 Figure 3
Figure 3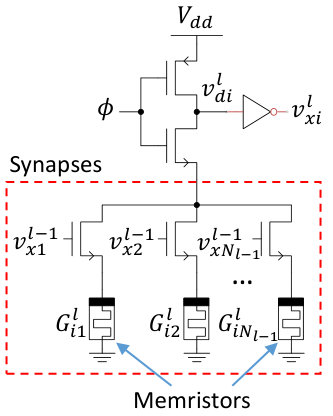 Figure 4
Figure 4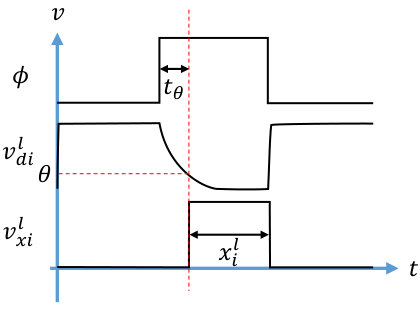 Figure 5
Figure 5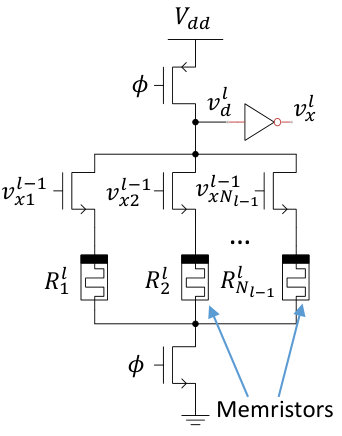 Figure 6
Figure 6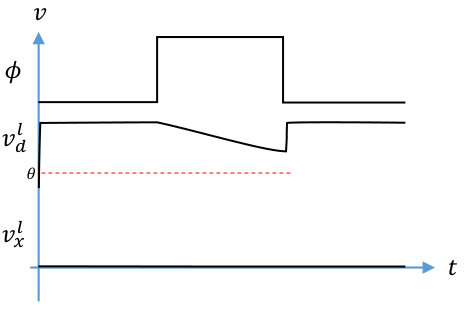 Figure 7
Figure 7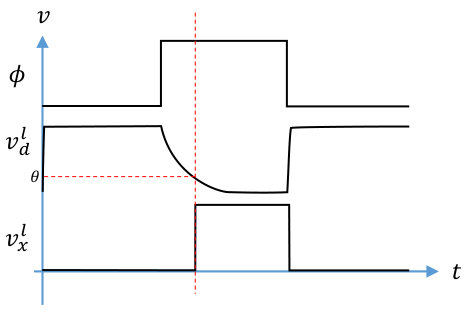 Figure 8
Figure 8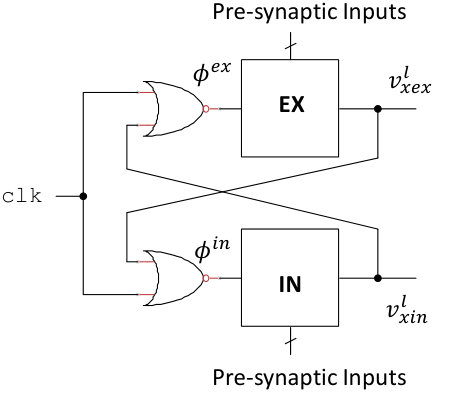 Figure 9
Figure 9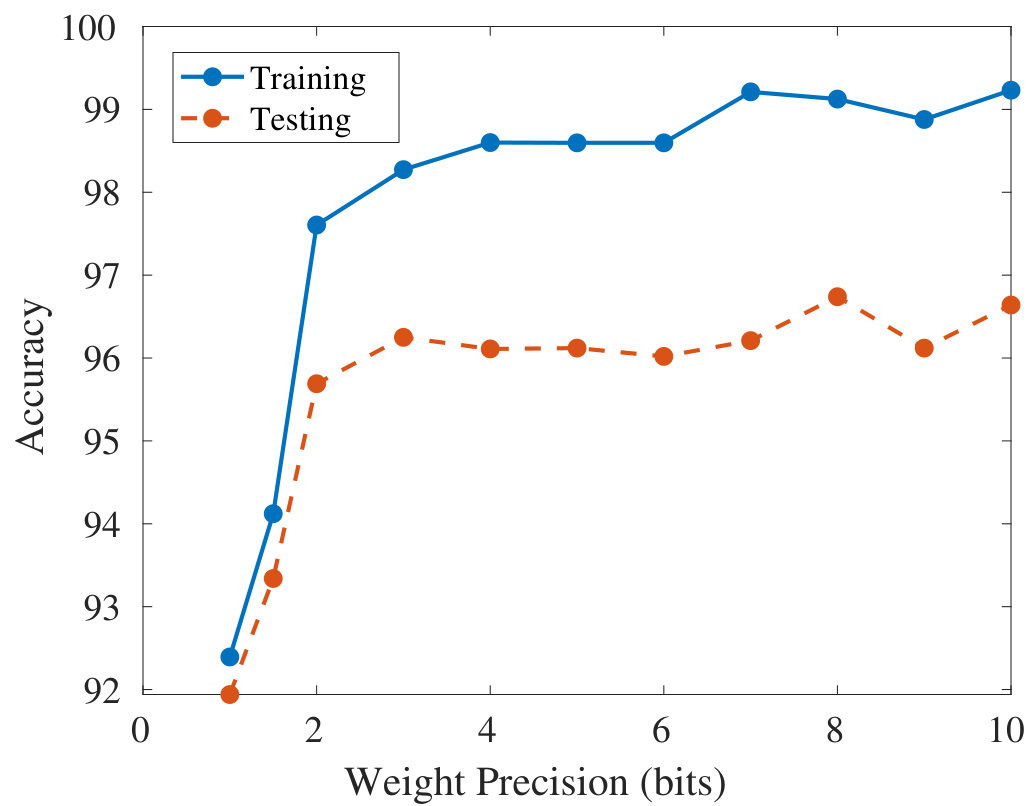 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12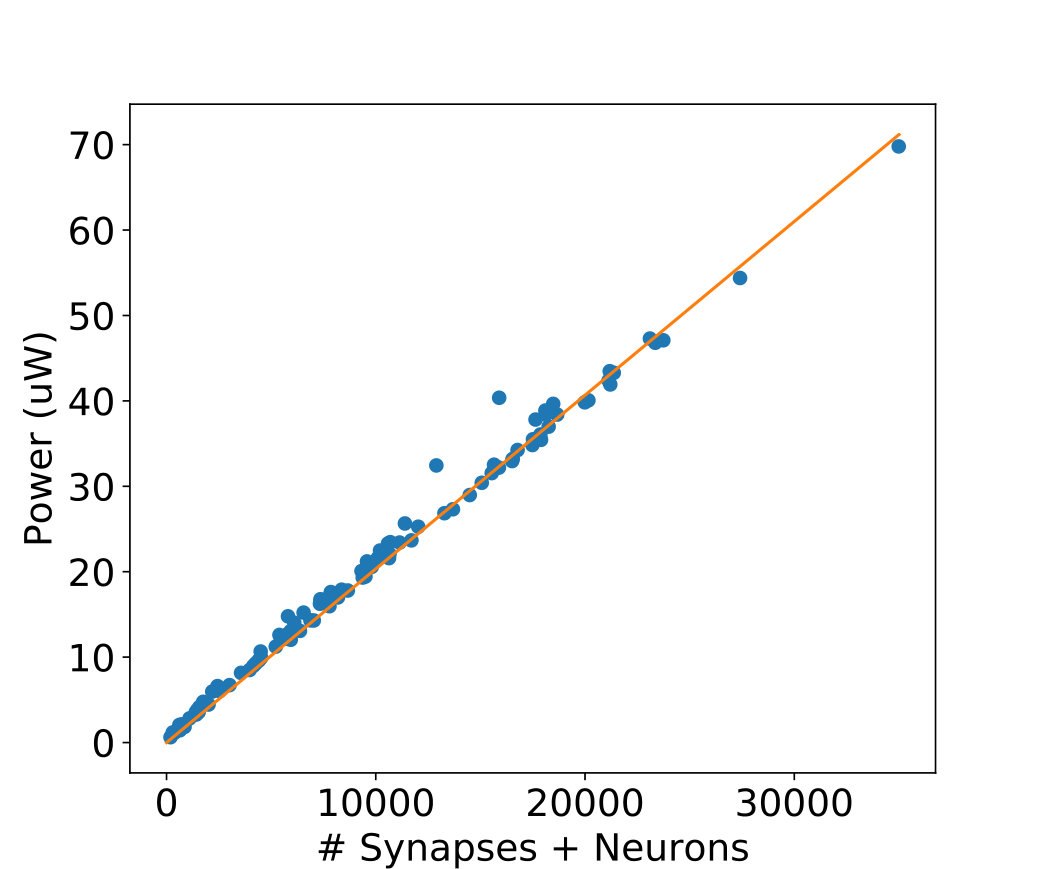 Figure 13
Figure 13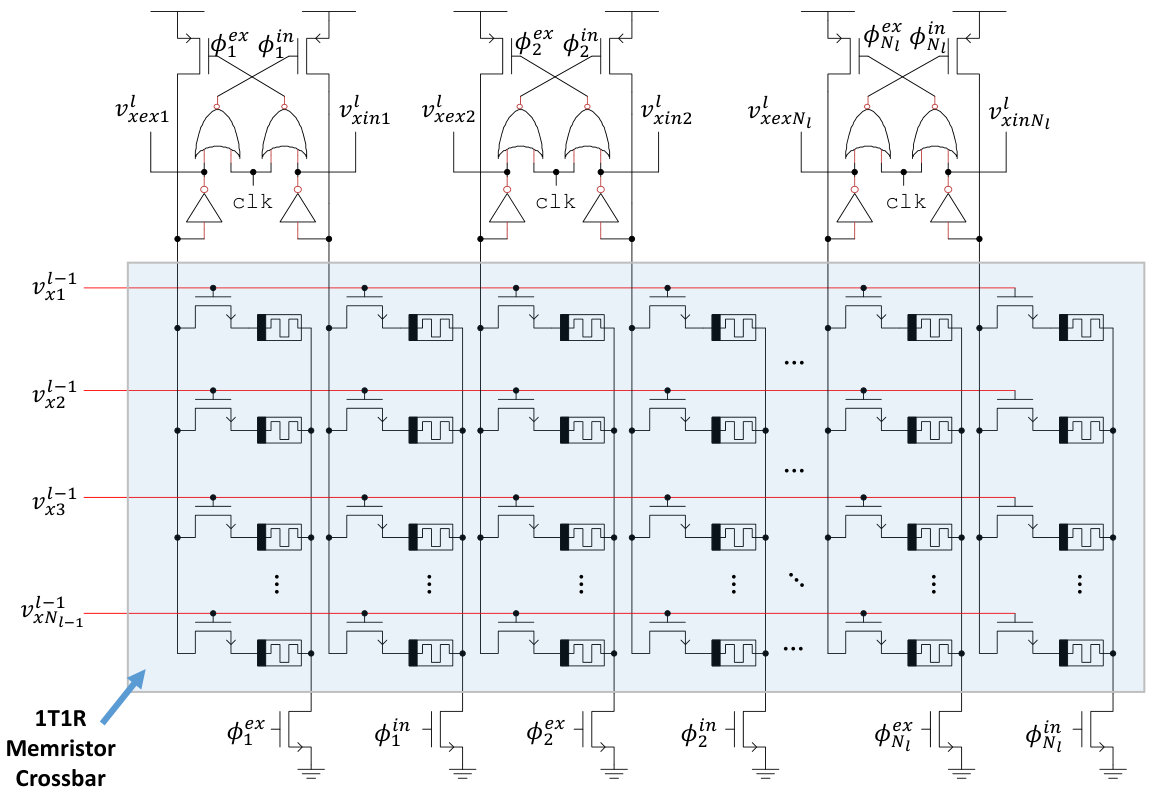 Figure 14
Figure 14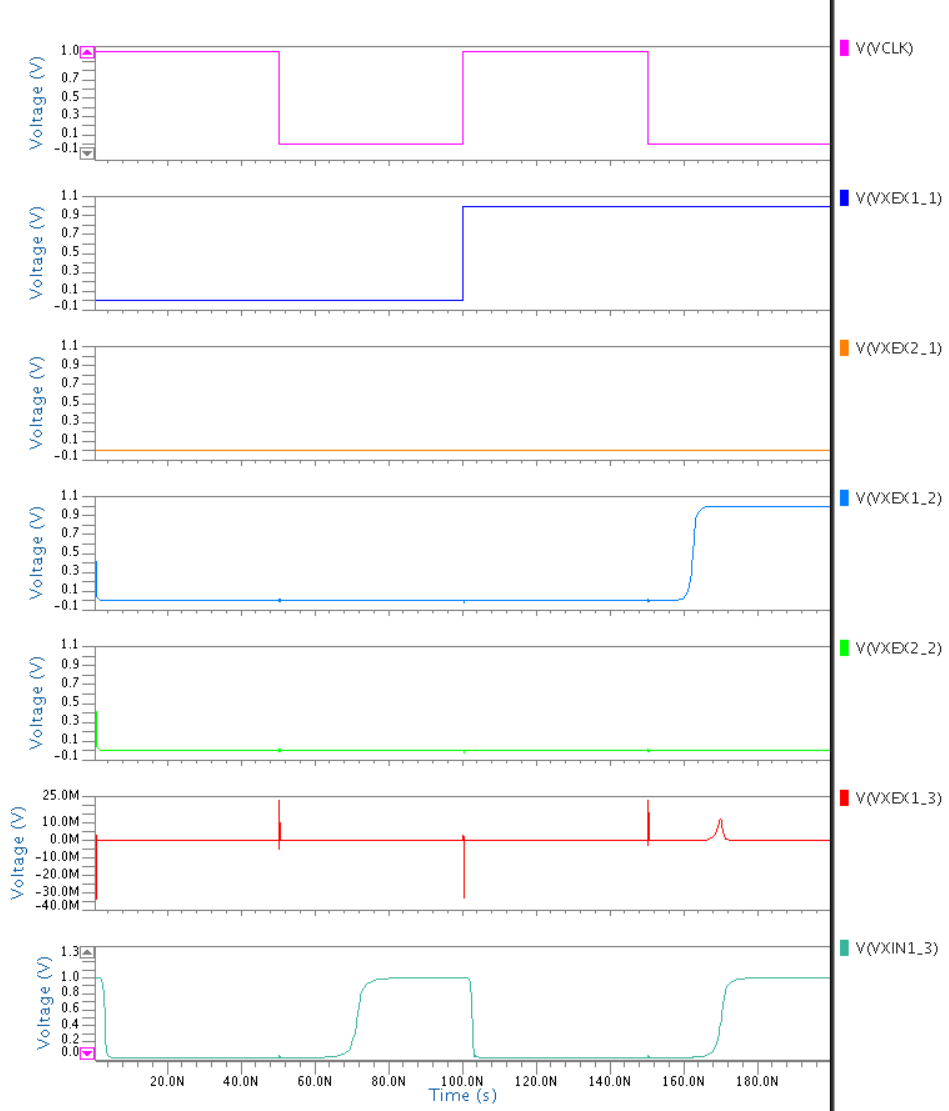 Figure 15
Figure 15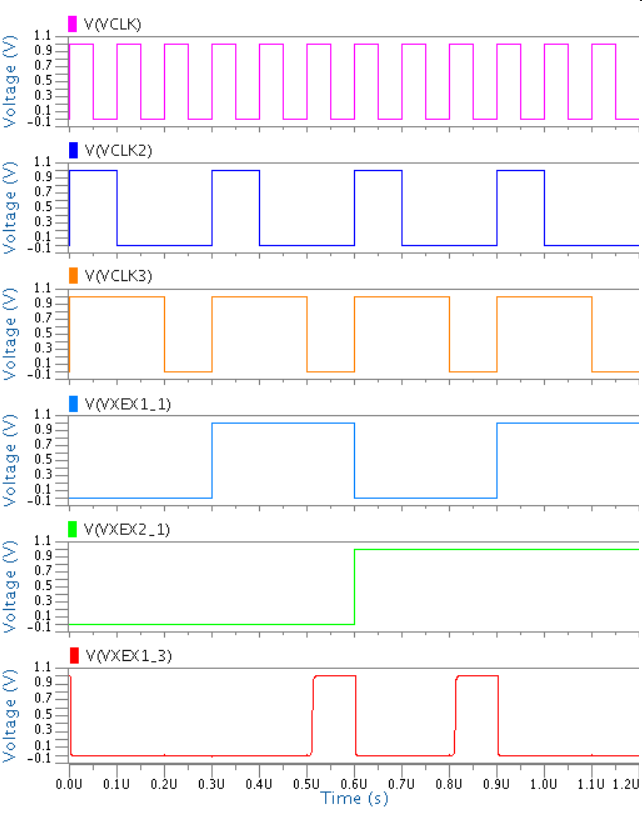 Figure 16
Figure 16Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A Low-Power Domino Logic Architecture for Memristor-Based Neuromorphic Computing
Cory Merkel
and
Animesh Nikam
Brain Lab
Rochester Institute of Technology1 Lomb Memorial DriveRochesterNew York14624
(2019)
Abstract.
We propose a domino logic architecture for memristor-based neuromorphic computing. The design uses the delay of memristor RC circuits to represent synaptic computations and a simple binary neuron activation function. Synchronization schemes are proposed for communicating information between neural network layers, and a simple linear power model is developed to estimate the design’s energy efficiency for a particular network size. Results indicate that the proposed architecture can achieve 0.61 fJ per classification per component (neurons and synapses) and outperforms other designs in terms of energy per % accuracy.
Memristor, neuromorphic, low-power
††copyright: acmcopyright††journalyear: 2019††doi: 10.1145/1122445.1122456††conference: ICONS ’19: ACM International Conference on Neuromorphic Systems; July 23–25, 2019; Knoxville, Tn††booktitle: ICONS ’19: ACM International Conference on Neuromorphic Systems, Knoxville, Tn††price: 15.00††isbn: 978-1-4503-9999-9/18/06
1. Introduction
Custom neuromorphic hardware platforms are gaining popularity for the acceleration of neural network algorithms, owing to their ability to perform complex tasks that are analogous of the physical processes underlying biological nervous systems (Douglas et al., 1995). A key feature of these systems is that they overcome the limitations caused by the von Neumann bottleneck by collocating computation and memory (Nandakumar et al., 2018). While modern digital complementary-metal-oxide-semiconductor (CMOS) technology is used to replicate the behavior of the neurons, the absence of a device that can efficiently perform synaptic operations stunted progress for several years. However, recent advancements in nanoscale materials and realization of devices such as memristors have opened possibilities for developing compact memory device arrays that are potentially transformative for the design of ultra energy-efficient neuromorphic systems.
Previous work has studied several aspects of memristor-based neuromorphic systems, including device properties, reliability, crossbar implementation, on-chip training, quantization, and much more (Sung et al., 2018; Schuman et al., 2017). One of the most power-efficient design approaches is combining memristor synapses with an integrate-and-fire (IF) neuron design. The energy efficiency of the IF neuron comes from i.) all-or-nothing representation of information and ii.) little-to-no short-circuit current between the neuron’s input and the synapses driving it (since they are just driving the membrane capacitor). In this work, we explore a similar idea applied to networks of binary neurons inspired by domino logic. Domino logic, a type of dynamic logic, separates a circuit into pre-charge and evaluation phases to avoid short circuit current and reduce power consumption. Here, we propose a domino logic style neuron that uses memristor-based RC delays for evaluation and offers good power efficiency. The building blocks of the proposed design are outline in Section 2. Then, Section 3 discusses scaling the design up to a multi-layer neural network. In Sections 4 and 5, we detail the power consumption model and quantization approach. Section 6 discusses results on the MNIST dataset and concludes this work.
2. Circuit Building Blocks
The core building block of our design is shown in Figure 1. When the clock signal is low, the dynamic node (input to the inverter) is precharged to . Then, during the evaluation phase, is high, and the dynamic node discharges at a rate dependent on the pull-down network’s RC time constant. Once the dynamic node falls below the inverter threshold, the output will go high.
During the evaluation phase, the voltage on the dynamic node evolves as
[TABLE]
where is the equivalent pulldown conductance. A memristor only contributes to the pull-down conductance when its select transistor is on. Assuming that memristor conductance values are constant during the evaluation phase and input voltages are digital, i.e. , then is a piecewise constant function written as:
[TABLE]
In this work, the inputs to a neuron are constant during each evaluation period. In addition, each neuron’s output will be considered as ’1’ if it switches from ’0’ to ’1’ at any point during the evaluation period. Otherwise, it is ’0’. This is illustrated in Figures 1 and 1. In Figure 1, the neuron’s dynamic node does not discharge to the inverter threshold before the end of the evaluation period, so the output is ’0’. In contrast, the dynamic node in Figure 1 discharges quickly, well before the end of the evaluation period, so its output is ’1’.
In order to get an inhibitory effect on the post-synaptic neuron, we introduce a second domino circuit, as shown in Figure 1, where the two boxes represent the circuit in Figure 1. The top domino circuit is an excitatory neuron, where large memristor conductances will tend to cause the excitatory output to be ’1’ and the inhibitory output to be ’0’. The bottom domino circuit is an inhibitory neuron, where large memristor conductances will tend to cause the inhibitory output to be ’1’ and the excitatory output to be ’0’. The circuit uses a built-in arbiter (cross-coupled NOR gates) to decide which neuron reached its inverter threshold first and then re-charge the dynamic node of the other neuron so its output will be ’0’. One design issue that should be considered in future work is the detection and cancellation of metastability in the feedback loop, as it could cause unstable behavior and larger power consumption. On the other hand, it may be a useful tool for implementing stochastic neuorn behavior. However, this is outside the scope of the present work.
Now, we can define a linear mapping between a weight between -1 and 1 and the two conductance values associated with it:
[TABLE]
[TABLE]
The above two equations set the inhibitory conductance to when the weight is positive and the excitatory conductance to when the weight is negative. Then, the excitatory conductance will range from for a weight of 0 to for a weight of +1. The inhibitory conductance will range from for a weight of 0 to for a weight of -1. Note that and are the minimum and maximum conductance values of the memristors and vary considerably based on the type of device (i.e. material properties, fabrication process, etc.) (Burr et al., 2017). In this work, we have chosen values of and , however our design will work for other conductance ranges.
3. Multi-Layer Networks
3.1. Crossbar Implementation
For multilayer neural networks, we propose a 1T1R memristor crossbar, as shown in Figure 2. Here, the word lines are connected to the pre-synaptic neuron outputs from the previous layer. The two terminals of each 1T1R synapse are connected to the crossbar columns. Each neuron uses two crossbar columns to implement excitatory and inhibitory synapses. Footer transistors are used to eliminate short circuit power consumption during pre-charge. Note that secondary pre-charge transistors may be needed to avoid charge sharing between each domino circuit’s dynamic node and the drain of the footer transistors. For fully-connected neural networks, the simplest design would employ one crossbar for each layer . However, more advanced methods will likely be needed for sharing crossbars across layers and efficiently mapping sparse connectivity networks to dense crossbar structures.
3.2. Synchronization Across Layers
The proposed design is based on the timing of RC delays in each domino circuit. Since each neuron’s output is binary, it is important that the domino circuits do not perform an evaluation until all of their inputs are ready (i.e. the evaluation period of the inputs has completed). For this reason, it is critical to have some form of synchronization across layers. We propose three different methods. The first method uses non-overlapping clocks with varying duty cycles for each network layer in the following manner: First, all of the clocks are ’1’ to pre-charge all of the domino circuits. Next, the clock for the first layer becomes ’0’ for evaluation of the network inputs. After enough time has passed for evaluation of the first layer (this will depend on the size of the network, weight values, etc.), the clock for the second layer will become ’0’, and so on until the clock for the final layer becomes ’0’. Then, the process starts over. The advantage of this approach is that no circuitry has to be added to the neuron circuits. This disadvantage is that each layer has to wait for all of the previous layers to finish before it can perform any computation. The second synchronization method is to add flipflops to the output of each neuron. This way the entire network can be pipelined across layers and each neuron can perform computations on every clock cycle. Of course, the disadvantage of this approach is that it adds overhead to the neuron design. A final method is to use asynchronous handshaking across layers. In this case, a global reset signal would be asserted every time a new input arrives to the network, causing all domino circuits to be pre-charged. Then, an OR gate would be connected to each neuron’s excitatory and inhibitory outputs. Once the OR gate’s output becomes ’1’, we know that the neuron has finished evaluation. When all such signals for a whole layer become ’1’ (which could be detected with an AND tree), that layer has finished evaluating, and the next layer can continue evaluation. The main advantage of this approach is that a global clock is not needed, which may significantly reduce power consumption. In this work, we performed simulations using the first method. Figure 3 shows the simulation results for a 2-input network with 2 hidden layer neurons and 1 output. The network was trained to perform the XOR function of its inputs. The top subplot shows the clock signal, while the second two subplots show the clocks distributed to layers 2 and 3, repsectively. During the first clock cycle, all of the neurons in the network pre-charge. During the second clock cycle, the second layer clock goes low, and then the third layer clock goes low during the third clock cycle. Therfore, the output of the network has a valid result after three cycles from the time that the input changes.
4. Power Consumption
The power consumption of the proposed design was modeled by assuming that most of the power is consumed when a neuron pre-charges. The justification for this is that, especially for neurons with high fan-in the switching capacitance of the neuron’s dynamic node will be much larger than the capacitance at other nodes in the circuit. Therefore, the power can be formulated as
[TABLE]
where is a fitting parameter that comes from the extra power associated with the inverter, arbiter, etc., is the switching activity factor, and is the total switching capacitance of the layer. The factor of 3 comes from the fact that each synapse will have approximately 3 units of capacitance associated with it from the access transistor’s source, drain, and the memristor itself. Note that a unit of capacitance is calculated as , where is the transistor channel area, is the permittivity of free space, and is the transistor gate oxide thickness. For an layer network with the chosen synchronization scheme, , since the neuron circuit only pre-charge once every clock cycles. In addition, the value of is times the sum of the number of synapses and neurons of each layer (both excitatory and inhibitory). We have empirically found . In Figure 4, we show the power consumption for 100 randomly-sized 3-layer networks vs. the number of synapses and neurons in the network. For each network, both the inputs and weights were generated randomly. Furthermore, the network used a clock frequency of 10 MHz. The results are based on a 130 nm bulk CMOS process (ptm, [n. d.]), and all simulations were performed using Synpopsys HSPICE. From this data, we estimate the energy efficiency of our design to be approximately 0.61 fJ per classification per component, where a component is either a neuron or a synapse.
5. Quantization Approach
Quantization methods for deep learning are becoming popular for accelerating training, reducing model size, and mapping neural networks to specialized hardware. The simplest quantization methods use rounding to reduce activation and weight precision after training. This usually results in large drops in accuracy between the full-precision and quantized models. Other methods quantize weights, activations, and sometimes gradients during training, resulting in better performance (Zhou et al., 2016). In this work, we only quantize weights and activations. The core idea is to use quantized values during forward propagation and full-precision gradient estimates during backward propagation. For activations, we use a simple threshold model on the forward pass:
[TABLE]
where is 1 if the argument is non-negative and -1 otherwise. Since the has a gradient that is zero everywhere111except when the argument approaches zero from the left, where the gradient is undefined. it will stall the backpropagation algorithm and nothing will be learned. To fix this, we approximate the gradient as
[TABLE]
where was empirically chosen as 2. In other words, on the backward pass, the gradient is calculated as if the activation had been a logistic sigmoid function. Of course, we note that the threshold activation function is indeed a logistic sigmoid with a value of .
For weights, we use the following quantization technique:
[TABLE]
where is the desired number of quantization steps, rounds to the nearest integer and , where . For backpropagation, we estimate the gradient as
6. Results and Conclusions
We tested our design using the MNIST dataset of handwritten digits (mni, [n. d.]), which contains 60,000 training samples and 10,000 test samples of 2828 grayscale images. Our network is parameterized with 784, 64, 64, and 10 neurons for the input, first hidden, second hidden, and output layers, respectively. We used Tensorflow with Keras to perform all training and testing. We have not considered any process variations in this work, so we assume that the results of Tensorflow simulations can be directly mapped to our circuit. In the future, we plan to explore techniques for mitigating the effects of process variations using hardware-in-the-loop training. Figure 5 shows the test accuracy vs. weight precision. We observe a large increase in accuracy from 1 to 2-bit precision, which then levels off. Note that we haven’t used any regularization (dropout, etc.) in this work. Table 1 compares this work to other memristor-based neuromorphic systems that studied MNIST classification with low-bit weight precision. The proposed design outperforms (Jiang et al., 2018) by 2 orders of magnitude and is comparable to (Yakopcic et al., 2015) in terms of energy per percent accuracy. Power results for our design are estimated from the model presented in (5). Note that (Yakopcic et al., 2015) was simulated at a 45 nm technology node, so the dynamic power would increase at 130 nm. While these initial results are encouraging, a number of avenues for future work should be pursued to better determine the robustness of the proposed architecture, including studies on device variability and clock skew. Also of interest for future work is the exploration of pipelined and asynchronous handshaking for coordination across layers.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2ptm ([n. d.]) [n. d.]. Predictive Technology Models. http://ptm.asu.edu/ .
- 3mni ([n. d.]) [n. d.]. The MNIST Database of Handwritten Digits. http://yann.lecun.com/exdb/mnist/index.html .
- 4Burr et al . (2017) Geoffrey W Burr, Robert M Shelby, Abu Sebastian, Sangbum Kim, Seyoung Kim, Severin Sidler, Kumar Virwani, Masatoshi Ishii, Pritish Narayanan, Alessandro Fumarola, et al . 2017. Neuromorphic computing using non-volatile memory. Advances in Physics: X 2, 1 (2017), 89–124.
- 5Douglas et al . (1995) Rodney Douglas, Misha Mahowald, and Carver Mead. 1995. Neuromorphic analogue VLSI. Annual review of neuroscience 18, 1 (1995), 255–281.
- 6Jiang et al . (2018) Hao Jiang, Kevin Yamada, Zizhe Ren, Thomas Kwok, Fu Luo, Qing Yang, Xiaorong Zhang, J Joshua Yang, Qiangfei Xia, Yiran Chen, et al . 2018. Pulse-width modulation based dot-product engine for neuromorphic computing system using memristor crossbar array. In 2018 IEEE International Symposium on Circuits and Systems (ISCAS) . IEEE, 1–4.
- 7Nandakumar et al . (2018) SR Nandakumar, Shruti R Kulkarni, Anakha V Babu, and Bipin Rajendran. 2018. Building brain-inspired computing systems: Examining the role of nanoscale devices. IEEE Nanotechnology Magazine 12, 3 (2018), 19–35.
- 8Schuman et al . (2017) Catherine D Schuman, Thomas E Potok, Robert M Patton, J Douglas Birdwell, Mark E Dean, Garrett S Rose, and James S Plank. 2017. A survey of neuromorphic computing and neural networks in hardware. ar Xiv preprint ar Xiv:1705.06963 (2017).