Interfacing PDM MEMS microphones with PFM spiking systems: Application for Neuromorphic Auditory Sensors
Angel Jimenez-Fernandez, Daniel Gutierrez-Galan, Antonio Rios-Navarro,, Juan Pedro Dominguez-Morales, Gabriel Jimenez-Moreno

TL;DR
This paper introduces a low-power, FPGA-based interface converting PDM MEMS microphone signals into spike-based representations for neuromorphic auditory sensors, enhancing speed and efficiency in spike domain processing.
Contribution
It presents a novel PDM to spike interface (PSI) that improves neuromorphic auditory processing by eliminating traditional analog/digital conversion delays.
Findings
Achieves -39.51dB THD and 59.12dB SNR
Uses less than 1% FPGA resources
Consumes below 5mW power
Abstract
In neuromorphic engineering, computation is commonly performed asynchronously, mimicking the way in which nervous systems process information: spike by spike. The Neuromorphic Auditory Sensor (NAS) has been implemented under this principle: applying different spike-based Signal Processing blocks. Computation in the spike domain requires the conversion of signals from analog or digital representation to the spike domain, which could present a speed constraint in many cases. This paper presents a spike-based system to convert audio information from low-power pulse density modulation (PDM) MicroElectroMechanical Systems (MEMS) microphones into rate coded spike frequencies. These spikes represent the input signal of the NAS, avoiding the analog or digital to spike conversion, and therefore improving the time response of the NAS. This conversion has been done in VHDL as an interface for PDM…
Click any figure to enlarge with its caption.
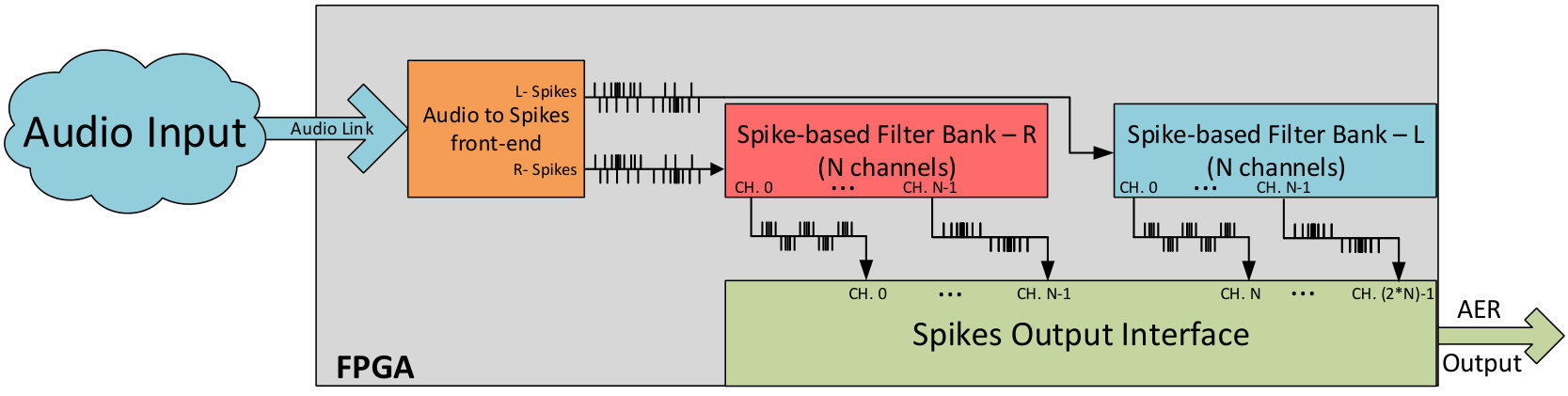 Figure 1
Figure 1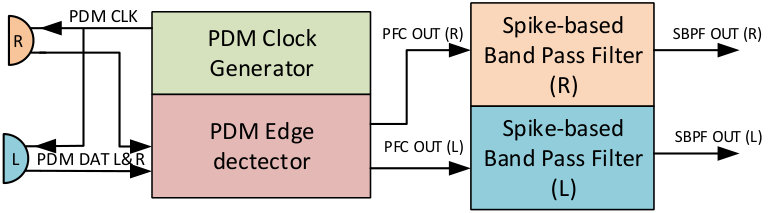 Figure 2
Figure 2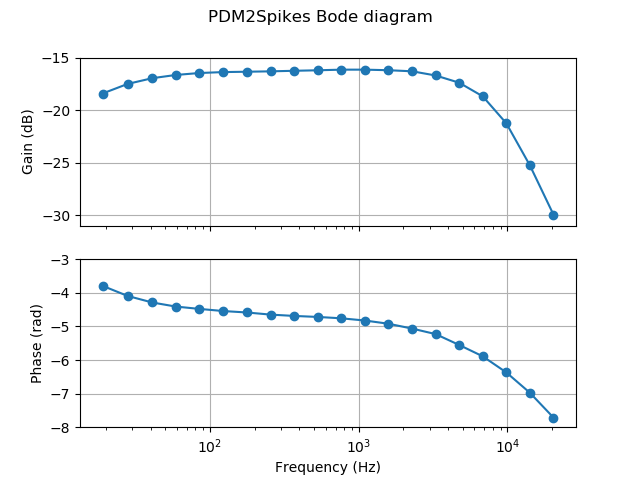 Figure 3
Figure 3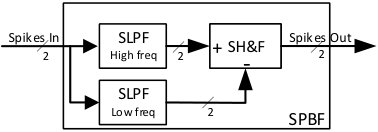 Figure 4
Figure 4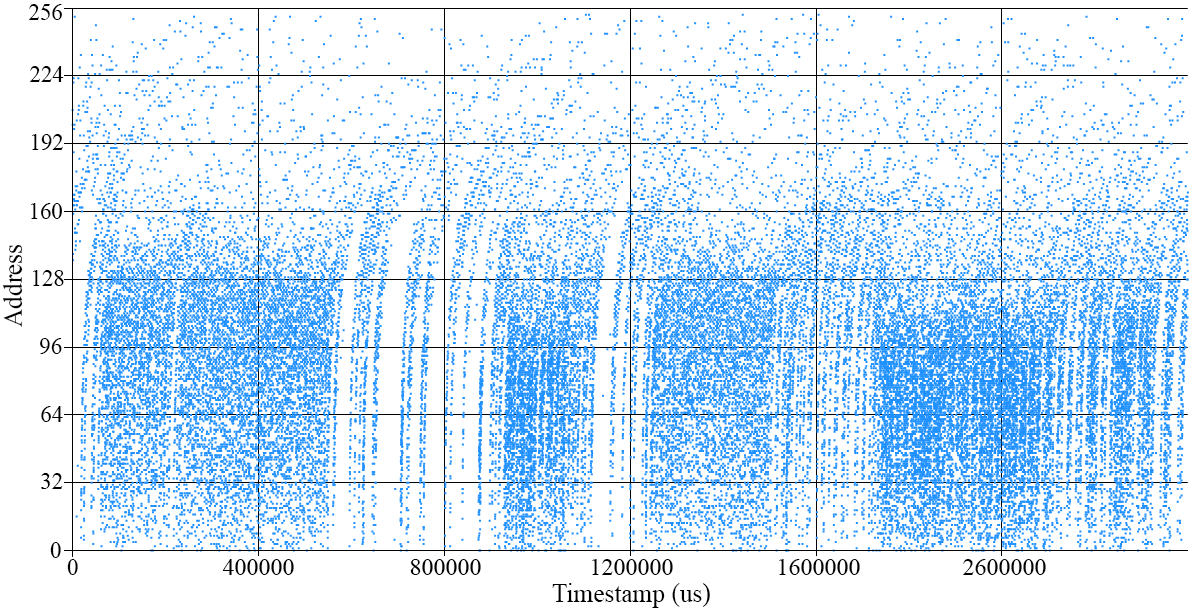 Figure 5
Figure 5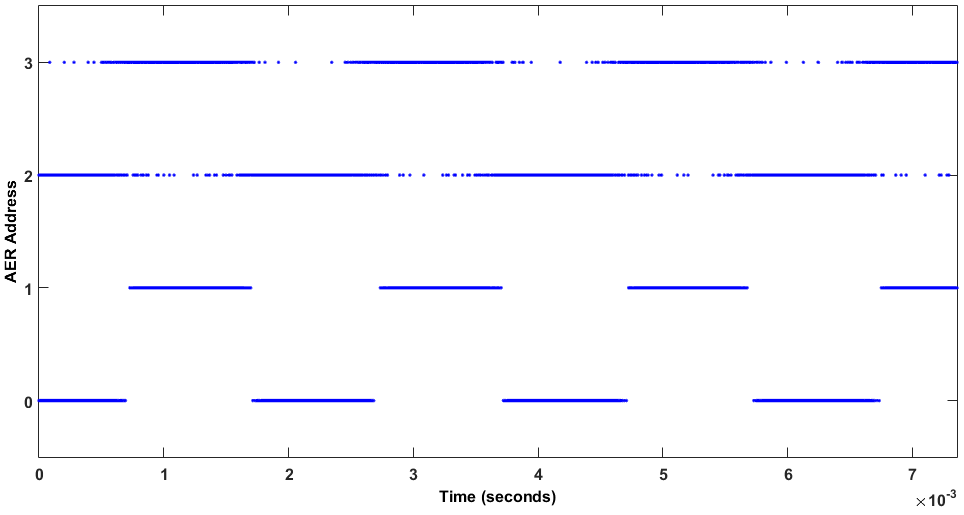 Figure 6
Figure 6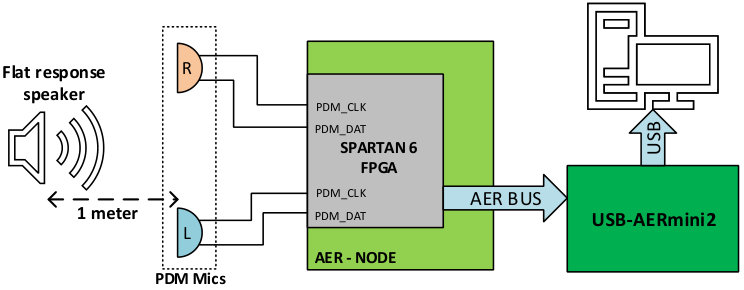 Figure 7
Figure 7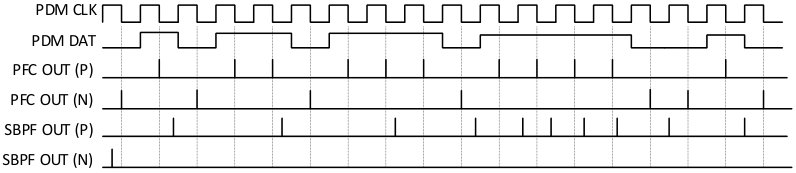 Figure 8
Figure 8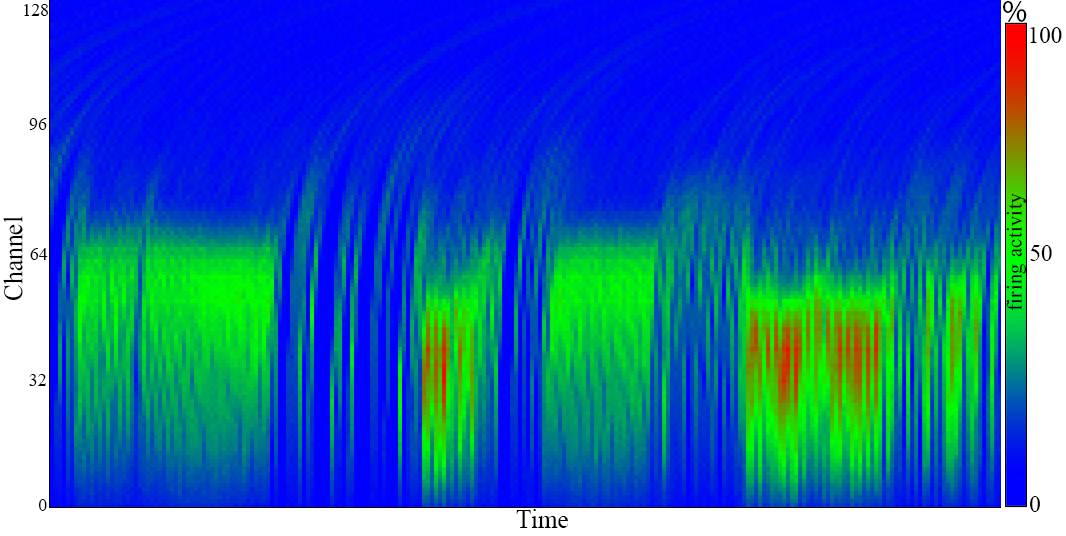 Figure 9
Figure 9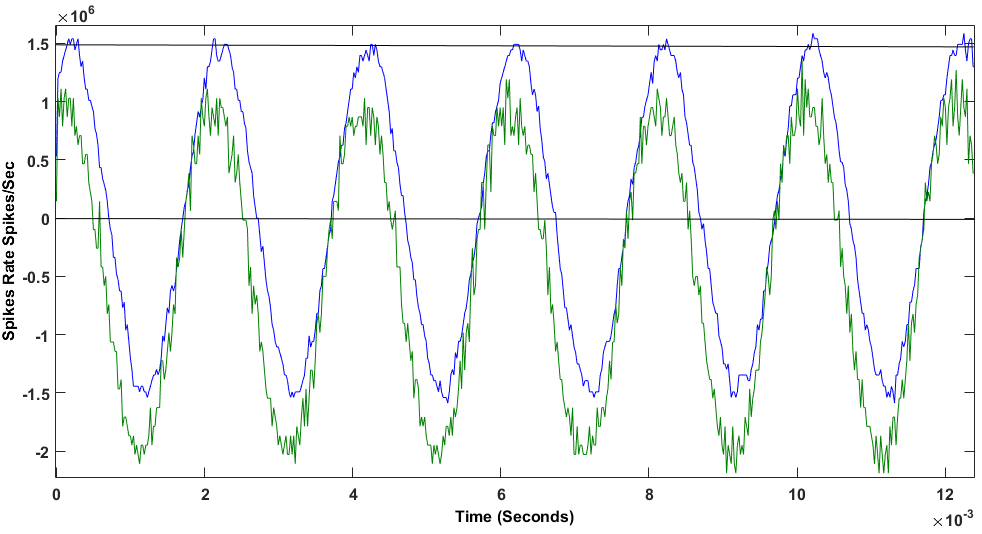 Figure 10
Figure 10 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Memory and Neural Computing · Neural Networks and Reservoir Computing · Neural dynamics and brain function
Interfacing PDM MEMS microphones with PFM spiking systems: Application for Neuromorphic Auditory Sensors
A. Jimenez-Fernandez, D. Gutierrez-Galan, A. Rios-Navarro, J. P. Dominguez-Morales and G. Jimenez-Moreno This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible. This work was supported by the Spanish grant (with support from the European Regional Development Fund) COFNET (TEC2016-77785-P). The work of Daniel Gutierrez-Galan was supported by a Formación de Personal Investigador Scholarship from the Spanish Ministry of Education, Culture and Sport.All authors are with the Universidad de Sevilla,ETS Ingenieria Informatica. Avd. Reina Mercedes s/n, Sevilla, Spain (e-mail: [email protected]).
Abstract
In neuromorphic engineering, computation is commonly performed asynchronously, mimicking the way in which nervous systems process information: spike by spike. The Neuromorphic Auditory Sensor (NAS) has been implemented under this principle: applying different spike-based Signal Processing blocks. Computation in the spike domain requires the conversion of signals from analog or digital representation to the spike domain, which could present a speed constraint in many cases. This paper presents a spike-based system to convert audio information from low-power pulse density modulation (PDM) MicroElectroMechanical Systems (MEMS) microphones into rate coded spike frequencies. These spikes represent the input signal of the NAS, avoiding the analog or digital to spike conversion, and therefore improving the time response of the NAS. This conversion has been done in VHDL as an interface for PDM microphones, converting their pulses into temporal distributed spikes following a pulse frequency modulation (PFM) scheme with an accurate Inter-Spike-Interval, known as ”PDM to spikes interface” (PSI). This was tested in two scenarios, first as a stand-alone circuit for its characterization, and then integrated with a NAS for verification. The PSI achieves a Total Harmonic Distortion (THD) of -39.51dB and a Signal-to-Noise Ratio (SNR) of 59.12dB, demands less than 1% of the resources of a Spartan-6 FPGA and has a power consumption below 5mW.
Index Terms:
neuromorphic engineering, FPGA, Address-Event, pulse frequency modulation, pulse density modulation, neuromorphic auditory sensor.
I Introduction
Pulse-density modulation (PDM) is a sigma-delta modulation technique used to digitize an analog signal with a 1-bit data stream and a high sample rate. In recent years, many low-power microelectromechanical (MEMS) microphones designed for mobile applications, such as tablets, laptops and cell phones, among others, have appeared in the market. In PDM data streams, a logic ‘1’ corresponds to a pulse of the maximum positive polarity (+A), and a logic ‘0’ represents the maximum negative polarity (-A). A signal value of 0 is codified by an alternation of ‘1’s and ‘0’s. Commonly, this type of modulation is associated with neuromorphic information codification, in the sense of being a rate-coded signal [1]. This kind of computation allows processing information only when it is needed, avoiding periodic or redundant data processing, thus saving power and computational resources [2].
Currently, we can find diverse neuromorphic cochleae, both analog [3][4][5][6] and digital [7, 8], inspired by Lyon’s cascade model [9] modeling the inner-hair cells (IHC). In [10], a Neuromorphic Auditory Sensor (NAS) is presented, based on spike signals processing (SSP) techniques [11][12].
Fig. 1 shows a global scheme of the NAS architecture. First, the audio information is provided by a digital audio codec, whose discrete audio samples output is converted into spike streams, following the pulse frequency modulation (PFM). The NAS filters these spikes directly, spike after spike, using a set of Spike-based Low-Pass Filters (SLPF) connected in a cascade fashion. Finally, spikes are transmitted to the next layers using the Address-Event Representation (AER) protocol [13].
NAS has been currently used for many practical applications, as pitch frequency detection [14], musical tones identification [15], sound source localization [16], heart murmurs diagnosis [17], and speech recognition [18], among others. Great effort has been dedicated to improve NAS features, as it is the input layer of all these systems, improving responses and spreading for new applications of this technology.
One main disadvantage of the NAS is the need for a discrete audio codec to capture analog audio. Audio codecs provide a set of digital periodic samples that must be converted into spikes. These devices have a sampling period from 22.67s to 10.41s, limiting the temporal capabilities, e.g., sound localization applications. [19]However, PDM microphones provide a stream of rate-coded signals with higher sample rate (3.125MHz in this case, with a time resolution of 320ns), which can represent the NAS input and be directly processed as spiking information. Therefore way, the need to generate spike streams synthetically is avoided, which was a restriction in previous NAS implementations [10].
II PDM to spikes interface (PSI)
PDM information codification is substantially different from rate-coded spike-based signals. In rate-coded spike-based signals, the information is given by the spikes frequency, which means that the information is inversely proportional to the temporal Inter-Spike-Interval (ISI). This means that, with only two spikes, it is possible to reconstruct the amplitude of the original signal. Spike-based systems use PFM to distribute the spikes in time properly, in order to accurately represent the signal’s information. In PDM signals, the information is contained in the density of pulses, and one pulse is generated every clock cycle, where a logic ’1’ represents a positive value, and a logic ’0’ a negative one. For example, when there are more ‘1’s than ‘0’s the information is positive, and the more ‘1’s, the higher the amplitude is. Thus, for reconstructing the signal’s amplitude, it is necessary to collect PDM pulses during a temporal window, performing a downsampling operation.
Digital systems convert PDM signals to digital values using the pulse coded modulation (PCM). PCM is reconstructed from PDM with a digital decimation stage, commonly performing a downsampling by a factor of 64, and providing a multiple-bits word (e.g., 16 bits @ 48.8kSamples/s) with high frequency noise added. After this stage, an infinite impulse response (IIR) filter is commonly used as a band-pass filter (BPF) to remove DC components and high frequency quantization noise.
The main goal of this work is to design an HDL circuit able to read PDM pulses and redistribute them in time as rate-coded spikes, with an ISI proportional to the sound pressure. Fig. 3 briefly shows how signals evolve from PDM pulses to PFM spikes.
To convert PDM information into rate-coded spikes, a two stages circuit (Fig. 2) is proposed. The first stage is a finite state machine (FSM) circuit that works as an edge detector, and generates a spike of a single clock cycle for each PDM pulse. The next stage consists in one (monaural) or two (binaural) banks of spike-based band-pass filters (SBPF), which process raw spikes from the FSM to give a temporal distributed spikes stream.
Since spikes can be both positive and negative, we use two wires to represent signed spikes. The FSM output generates a stream of signed spikes that are still not distributed in time, with the ISI being constant and equal to the PDM clock period. Fig. 3 presents an example of a positive increasing audio signal, and how spikes evolve.
II-A PDM front-end circuit
The PDM front-end circuit (PFC) has two main functionalities: to generate the PDM clock and to convert long PDM pulses into one clock cycle spikes. The hardware platform used to implement these blocks is called AER-Node [20] and it has a clock frequency of 50MHz. Dividing this clock by a factor of 16, we get a PDM clock of 3.125MHz, which is the maximum value allowed by this kind of MEMS microphones. In every PDM clock cycle there is a PDM pulse in the PDM DAT line. If PDM DAT has a value of ‘1’ then a positive spike is transmitted to the next stage, and if there is a ‘0’ it will be a negative spike.
II-B Second-order Spikes Band-Pass Filter (SBPF)
The next stage is a Spike Band-Pass Filter (SBPF), whose functionality is detailed in [21]. This filter is composed of two first-order Spike-based Low-pass filters (SLPF) and one Spike Hold & Fire (SH&F) (see Fig. 4). SH&F is a SSP building block that subtracts the spike rate between two spiking signals (detailed in [12]). The SLPF that is connected to the SH&F’s positive input has a cut-off frequency that is higher than the SLPF connected to the negative input. Subtracting the output from both spike-based filters, only the information in the middle band remains, rejecting the DC and high-frequency components. These filters are connected with 2-bit buses (for positive and negative spikes). These blocks use positive and negative activity to represent the bipolar nature of audio.
II-C Hardware resources and power consumption
The PSI design was synthesized and implemented on a Xilinx Spartan 6 FPGA (XC6LX150T) to measure the required resources and its power consumption. Table I presents the resources that are needed to implement PSI in FPGA. As can be seen, the amount of resources needed is under 0.45% of the total slice registers and logic (LUT) of the FPGA. The PSI can operate at a clock frequency up to 147.18 MHz. After the synthesis, the power consumption was simulated using Xilinx XPower tool assuming a 50% of signal transitions, obtaining a power consumption estimation of 2.67mW for the PSI. This power consumption should be added to the MEMS microphones’ power, which depends on the ones that are used. In our case, each of the microphones demands 0.98mW (according to the documentation provided by the manufacturer). Therefore, the whole system demands a total of 4.63mW for a binaural NAS.
III Experimental setup
For testing purposes, a scenario was built to analyze the PSI’s standalone behavior. Fig. 5 presents the testing setup, where two PDM microphones from ST Microelectronics (MP34DT02) were connected to an AER-Node board, which was in turn connected to an USB-AERmini2 board. MP34DT02 are omnidirectional MEMS microphones with PDM interfaces, with an acoustic overload point of 120dBSPL, an SNR of 60dBm, a dynamic range of 86dB, and a maximum power consumption of 0.98mW (as previously described).
The AER-Node board has a Xilinx Spartan 6 FPGA (XC6S150T), which holds the PSI, a 128-channel binaural NAS, and a set of AER interfaces. Its parallel AER output was connected to the USB-AERmini2 board [22], which works like a bridge between AER buses and USB ports, allowing the AER events to be sent from the AER-Node board to a host computer. In the computer, two software tools were running: jAER [23], to visualize and log AER information; and MATLAB, to analyze and process the events. The sound used to excite the system was played using a flat response audio speaker, in this case a BEHRITONE C5A from Behringer, placed at a 1-meter distance from the PDM microphones and at a fixed gain in order to have an audio level of 65dBSPL on the microphones’ side. This kind of equipment was used to avoid the influence of audio equalizers and the compensation that domestic Hi-Fi equipment presents. Thus, no preprocessed sounds were used and, instead, we tried to reproduce sound waves in the most ideal way possible. This will potentially open our system to many stand-alone applications, such as robotics.
III-A PSI Experimental results
For the first experiment, the system was stimulated with a clear 500Hz pure tone audio signal played by the flat response speaker. Fig. 6 represents the spikes from each stage of the PSI. Higher addresses (3 and 2) correspond to the spikes fired by the PDM front-end circuit, and lower addresses (1 and 0) to the SPBF output. Spike addresses 3 and 1 are positive, whilst 2 and 0 are negative.
Fig. 6 depicts how the addresses that contain the output of the PDM front-end overlap the information between positive and negative, which does not happen after filtering it with the PSI. In PDM, information makes sense for the average activity of a temporal window. However, in the spikes domain, the information is coded with the time between two consecutive spikes. From the signal sign point of view, we can say that zero-crossing is performed when the polarity of the spikes changes(i.e. after a positive spike, a negative one is produced). In the case of the PDM front-end output, there are several spikes overlapping positive (address 3) and negative activity (address 2). From the point of view of ISI, this represents a considerable amount of high-frequency noise. However, if we check the SBPF output spikes, there is no overlapping between positive (address 1) and negative (address 0) activity, rejecting high frequency noise.
Fig. 7 shows the reconstruction of the original signal using the spikes’ ISI. First, the green signal represents the reconstruction from PDM front-end’s output. This is a noisy signal and it has an offset introduced by the PDM microphones. On the other hand, the blue signal is the reconstruction from SBPF’s output. A clear tone with neither noise nor offset can be seen, improving the previous audio signal quality. Analyzing this response, we achieve a Total Harmonic Distortion (THD) of -39.51dB and a Signal-to-Noise Ratio (SNR) of 59.12dB.
To measure the number of zero-crossings, a one second recording was analyzed and the amount of changes from positive spike to negative and vice versa were counted. In the PDM front-end’s output, more than 80k zero-crossings were found. However, in SBPF’s output, 1k zero-crossings were found, which exactly matches a 500Hz signal.
Our second experiment consisted in a frequency sweep from 20Hz to 20KHz to analyze the behavior of the system with different frequencies. Fig. 8 shows the frequency sweep results as a bode diagram. The top curve in Fig. 8 presents the gain for diverse frequencies. PSI gain starts to increase from 70Hz to 12KHz, and then decreases rejecting higher frequencies. This bandwidth is enough for many applications related to speech and speakers recognition. The spike-based filters in the PSI introduce a temporal deviation. It was measured as signal phase (in rads) and the results are included in Fig. 8 bottom. PSI has a mean phase of -4.5 rads, approximately, increasing when frequency is close to the cut-off frequency, as expected from a low-pass filter.
III-B NAS integration
In order to validate the PSI on a real scenario, it was integrated in a 128-channel binaural NAS. This NAS was fed with a male voice saying: “Si vis pacem, para bellum”, and the output activity was recorded using an USB-AERMini2 board as an AER-DATA file. Fig.9 contains the cochleogram and the sonogram of this recording, respectively. Each word is clearly distinguishable, and activates middle channels between 200Hz and 5kHz. These figures were obtained by using NAVIS software [24].
IV Conclusions
In this paper, a PDM to PFM Spikes circuit is presented. PDM MEMS microphones are useful for low-power, stand-alone, embedded applications. Their output is based on spike density, and it needs to be adapted in order to be used as input to the NAS. A two-stage circuit for FPGA was designed, which is able to convert PDM information to PFM spikes with a consistent ISI. The PSI was synthesized for a Spartan 6 FPGA with low resources and power requirements. It was then tested with real audio stimulus, analyzing its behavior in terms of temporal response and zero-crossings. The PSI was also integrated in a full NAS to demonstrate the viability of the combination of this kind of systems. The use of PDM microphones with NAS considerably simplifies the system, enabling compact and portable spike-based auditory systems with lower power consumption.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] L. S. Smith, “Neuromorphic systems: past, present and future,” in Brain Inspired Cognitive Systems 2008 . Springer, 2010, pp. 167–182.
- 2[2] S. Liu, B. Rueckauer, E. Ceolini, A. Huber, and T. Delbruck, “Event-driven sensing for efficient perception: Vision and audition algorithms,” IEEE Signal Processing Magazine , vol. 36, no. 6, pp. 29–37, Nov 2019.
- 3[3] V. Chan, S.-C. Liu, and A. van Schaik, “Aer ear: A matched silicon cochlea pair with address event representation interface,” IEEE Transactions on Circuits and Systems I: Regular Papers , vol. 54, no. 1, pp. 48–59, 2007.
- 4[4] T. J. Hamilton, C. Jin, A. Van Schaik, and J. Tapson, “An active 2-d silicon cochlea,” IEEE Transactions on biomedical circuits and systems , vol. 2, no. 1, pp. 30–43, 2008.
- 5[5] B. Wen and K. Boahen, “A silicon cochlea with active coupling,” IEEE transactions on biomedical circuits and systems , vol. 3, no. 6, pp. 444–455, 2009.
- 6[6] S.-C. Liu, A. Van Schaik, B. A. Mincti, and T. Delbruck, “Event-based 64-channel binaural silicon cochlea with q enhancement mechanisms,” in Proceedings of 2010 IEEE International Symposium on Circuits and Systems . IEEE, 2010, pp. 2027–2030.
- 7[7] C. Mugliette, I. Grech, O. Casha, E. Gatt, and J. Micallef, “Fpga active digital cochlea model,” in 2011 18th IEEE International Conference on Electronics, Circuits, and Systems . IEEE, 2011, pp. 699–702.
- 8[8] C. S. Thakur, T. J. Hamilton, J. Tapson, A. van Schaik, and R. F. Lyon, “Fpga implementation of the car model of the cochlea,” in 2014 IEEE International Symposium on Circuits and Systems (ISCAS) . IEEE, 2014, pp. 1853–1856.