Dynamic Power Management for Neuromorphic Many-Core Systems
Sebastian Hoeppner, Bernhard Vogginger, Yexin Yan, Andreas Dixius,, Stefan Scholze, Johannes Partzsch, Felix Neumaerker, Stephan Hartmann, Stefan, Schiefer, Georg Ellguth, Love Cederstroem, Luis Plana, Jim Garside, Steve, Furber, Christian Mayr

TL;DR
This paper introduces a fast, autonomous dynamic power management system for neuromorphic many-core processors, significantly reducing power consumption while maintaining real-time performance.
Contribution
It presents a novel fast DVFS technique enabling individual, rapid voltage and frequency scaling of processing elements in neuromorphic systems.
Findings
Power consumption reduced by 75% in tests
80% baseline power reduction achieved
Energy per neuron and synapse computation halved
Abstract
This work presents a dynamic power management architecture for neuromorphic many core systems such as SpiNNaker. A fast dynamic voltage and frequency scaling (DVFS) technique is presented which allows the processing elements (PE) to change their supply voltage and clock frequency individually and autonomously within less than 100 ns. This is employed by the neuromorphic simulation software flow, which defines the performance level (PL) of the PE based on the actual workload within each simulation cycle. A test chip in 28 nm SLP CMOS technology has been implemented. It includes 4 PEs which can be scaled from 0.7 V to 1.0 V with frequencies from 125 MHz to 500 MHz at three distinct PLs. By measurement of three neuromorphic benchmarks it is shown that the total PE power consumption can be reduced by 75%, with 80% baseline power reduction and a 50% reduction of energy per neuron and synapse…
Click any figure to enlarge with its caption.
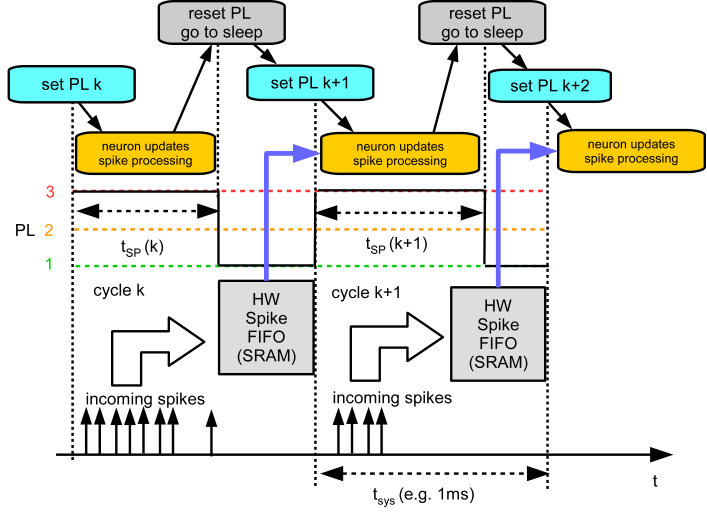 Figure 1
Figure 1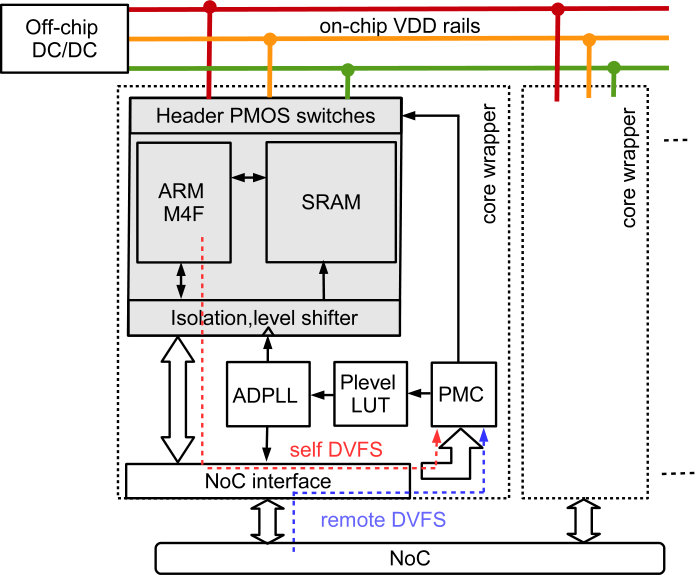 Figure 2
Figure 2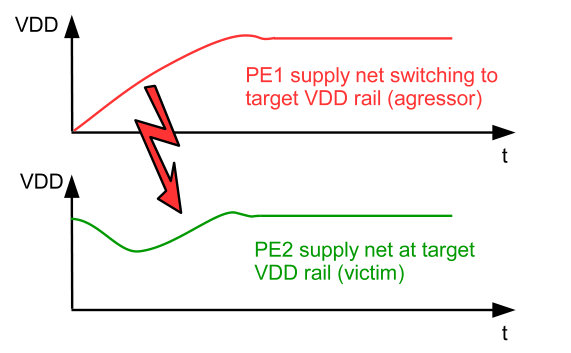 Figure 3
Figure 3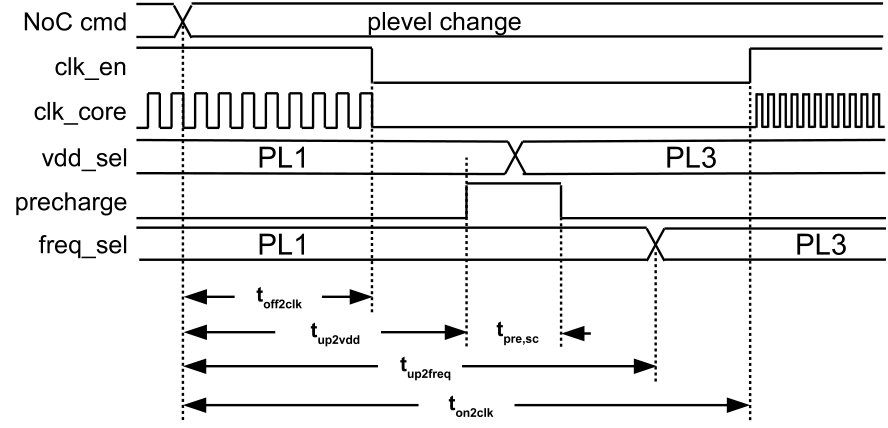 Figure 4
Figure 4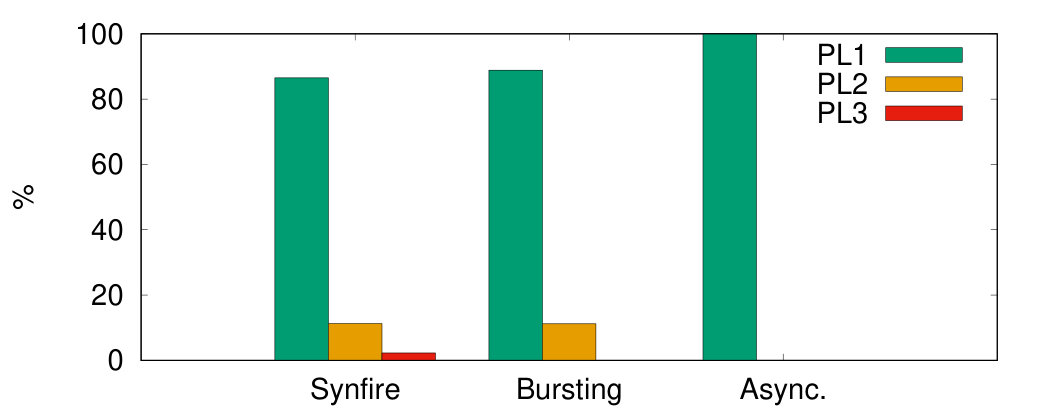 Figure 5
Figure 5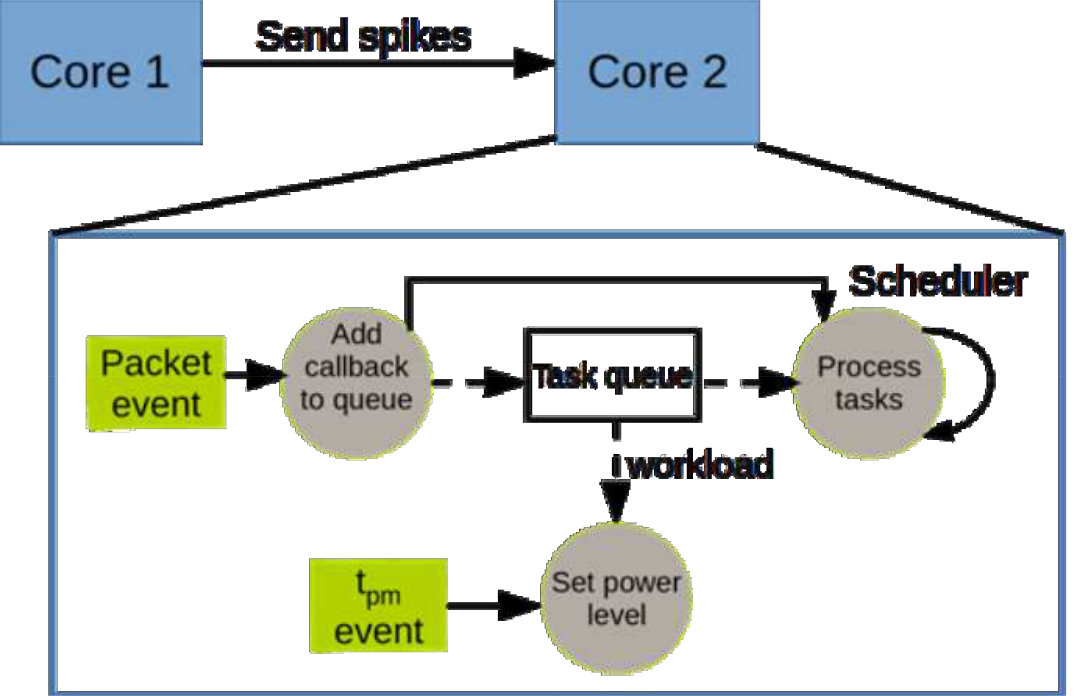 Figure 6
Figure 6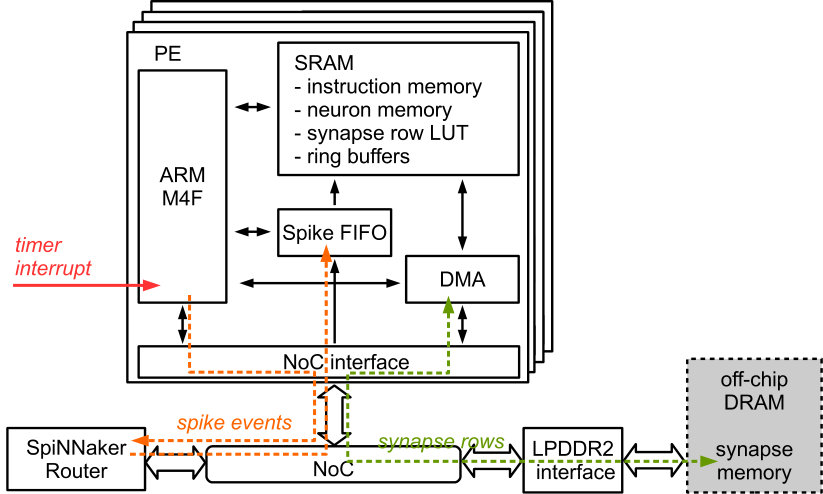 Figure 7
Figure 7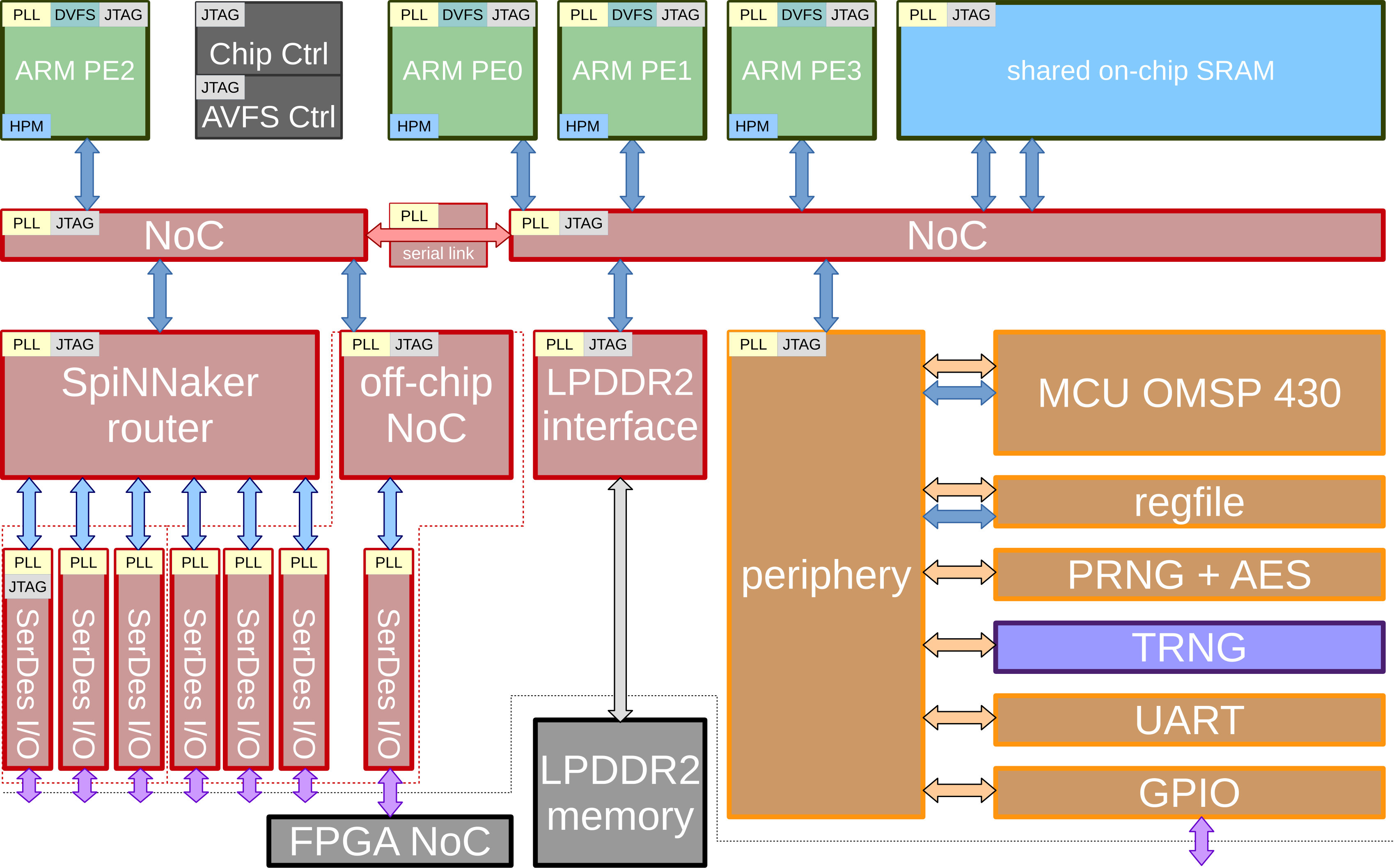 Figure 8
Figure 8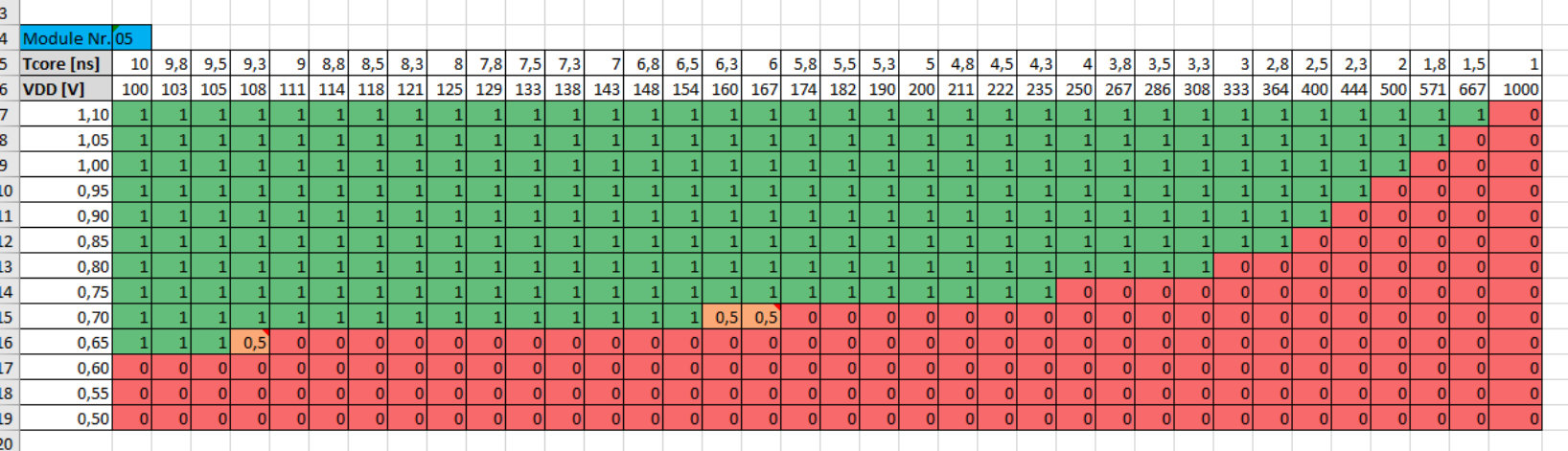 Figure 9
Figure 9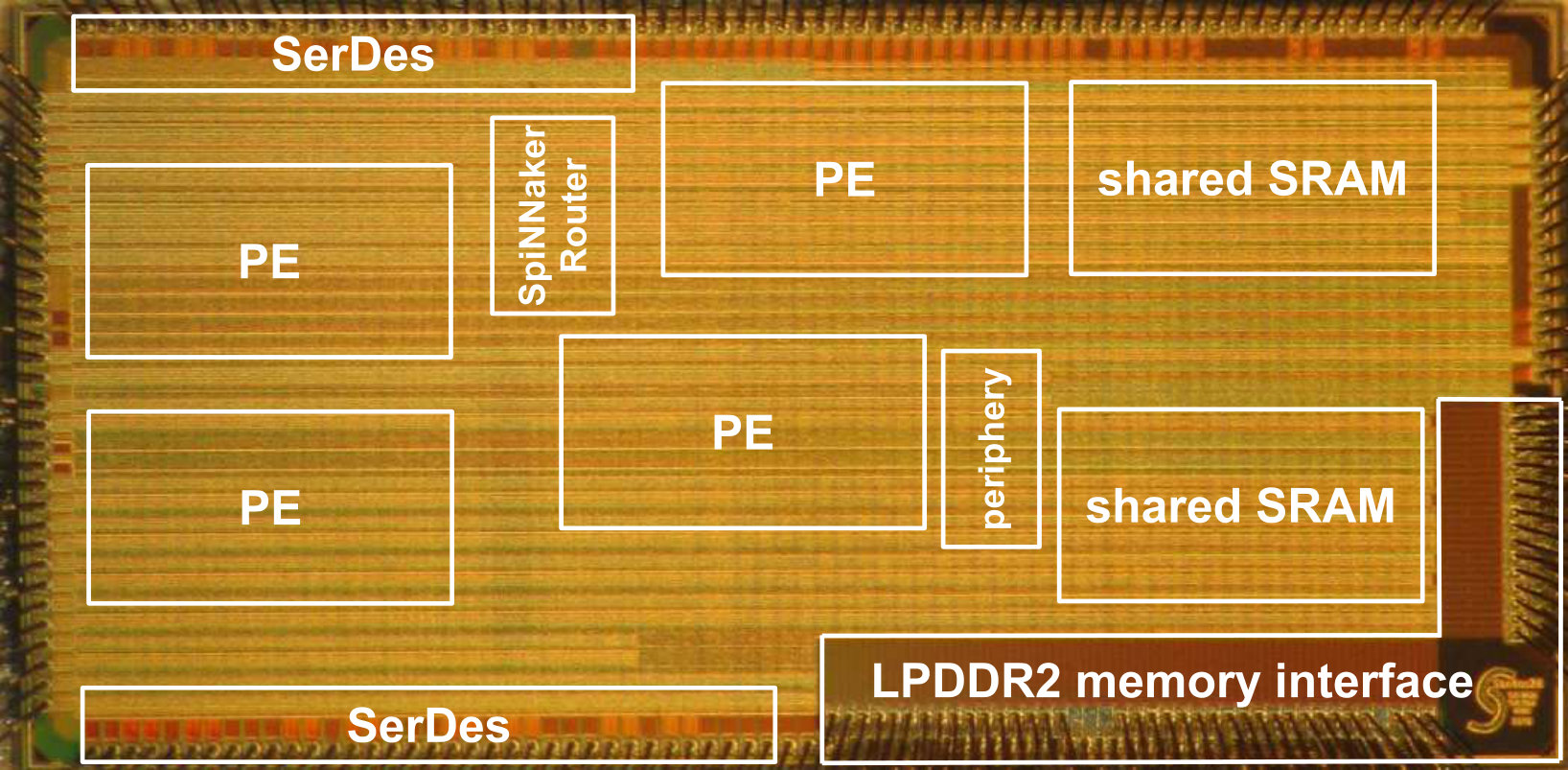 Figure 10
Figure 10 Figure 11
Figure 11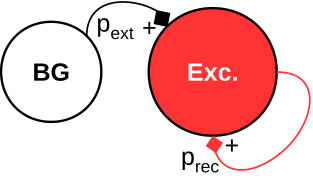 Figure 12
Figure 12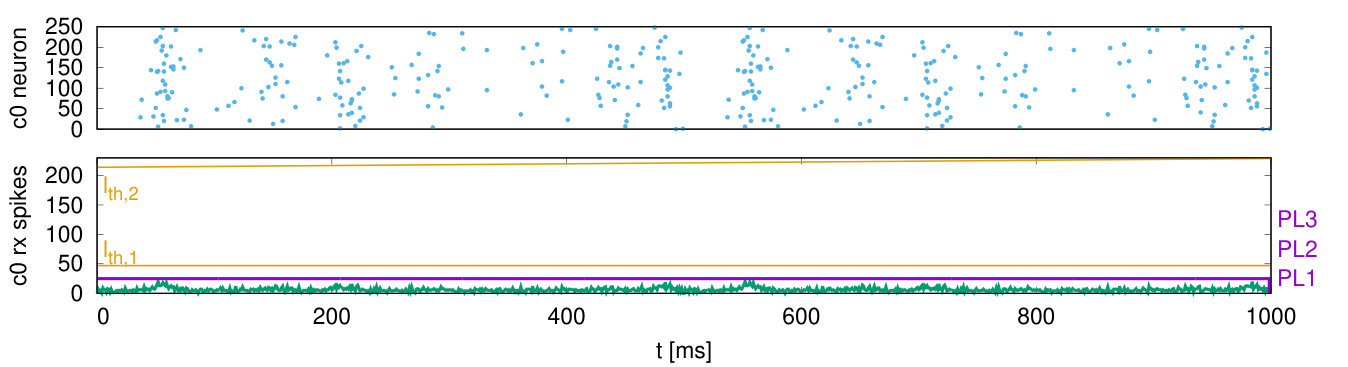 Figure 13
Figure 13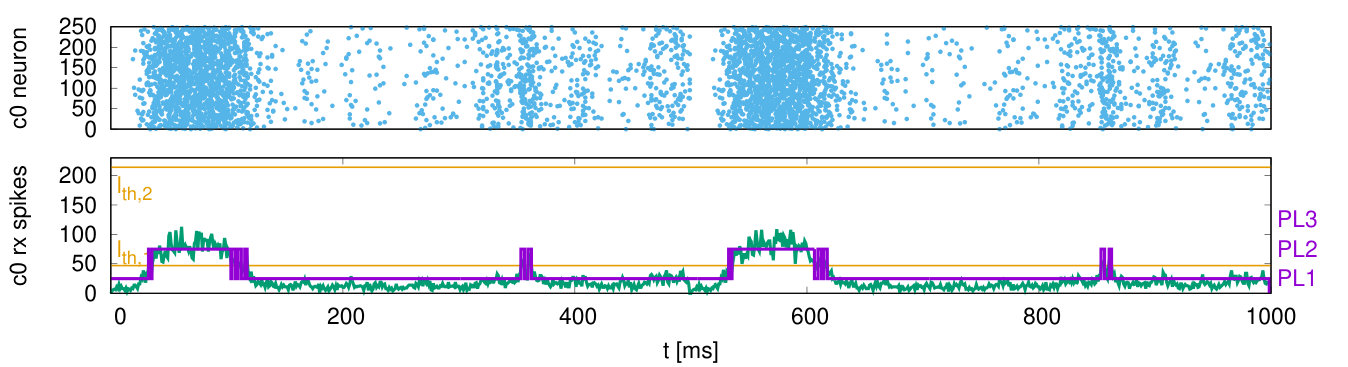 Figure 14
Figure 14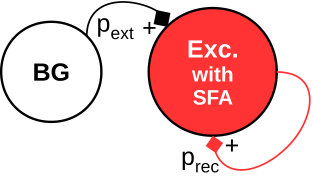 Figure 15
Figure 15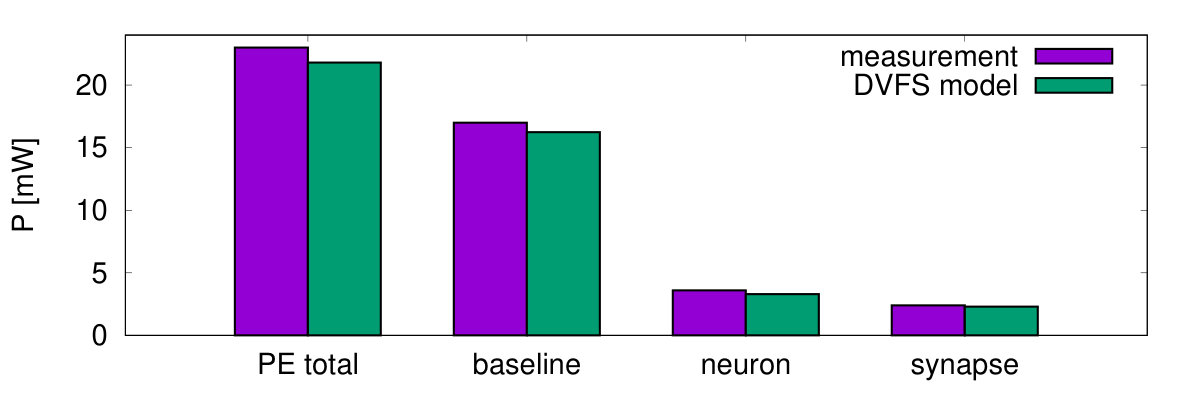 Figure 16
Figure 16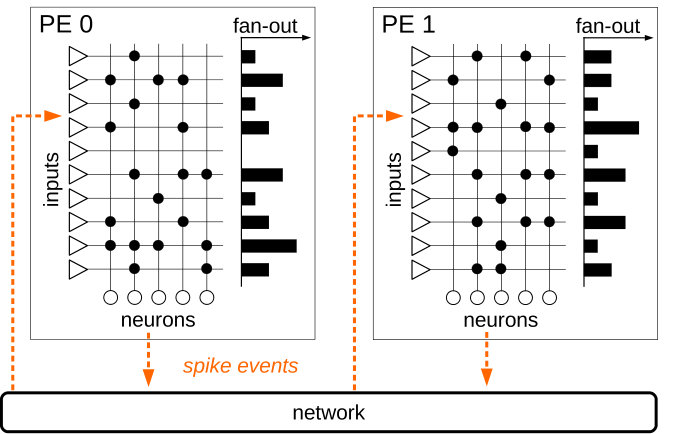 Figure 17
Figure 17 Figure 18
Figure 18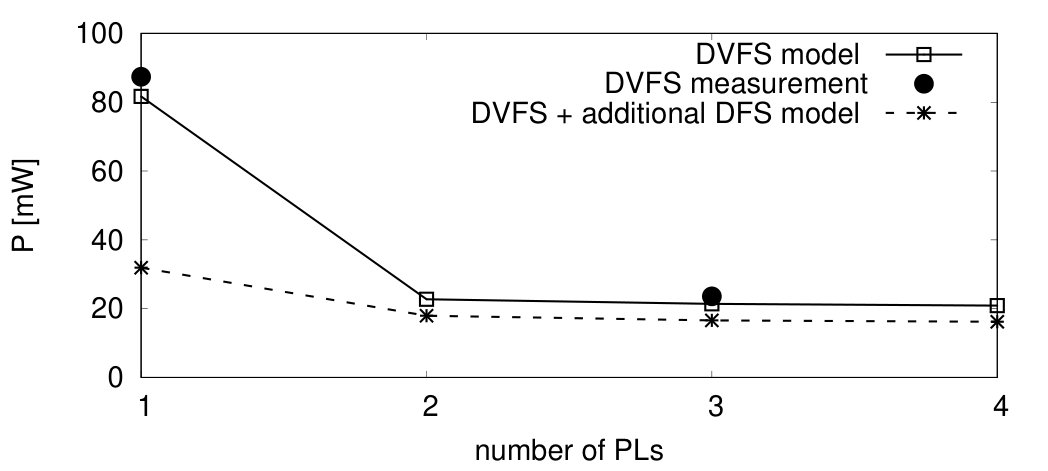 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33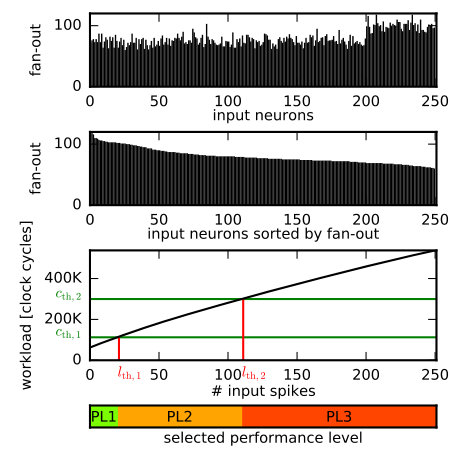 Figure 34
Figure 34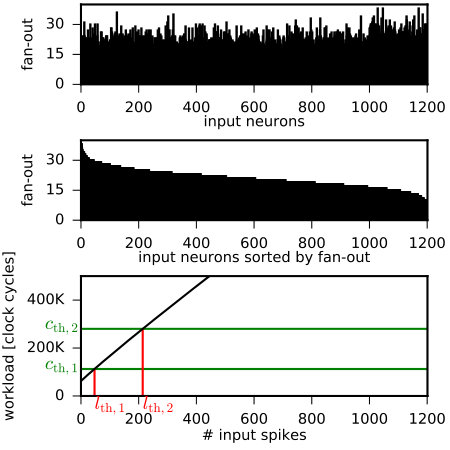 Figure 35
Figure 35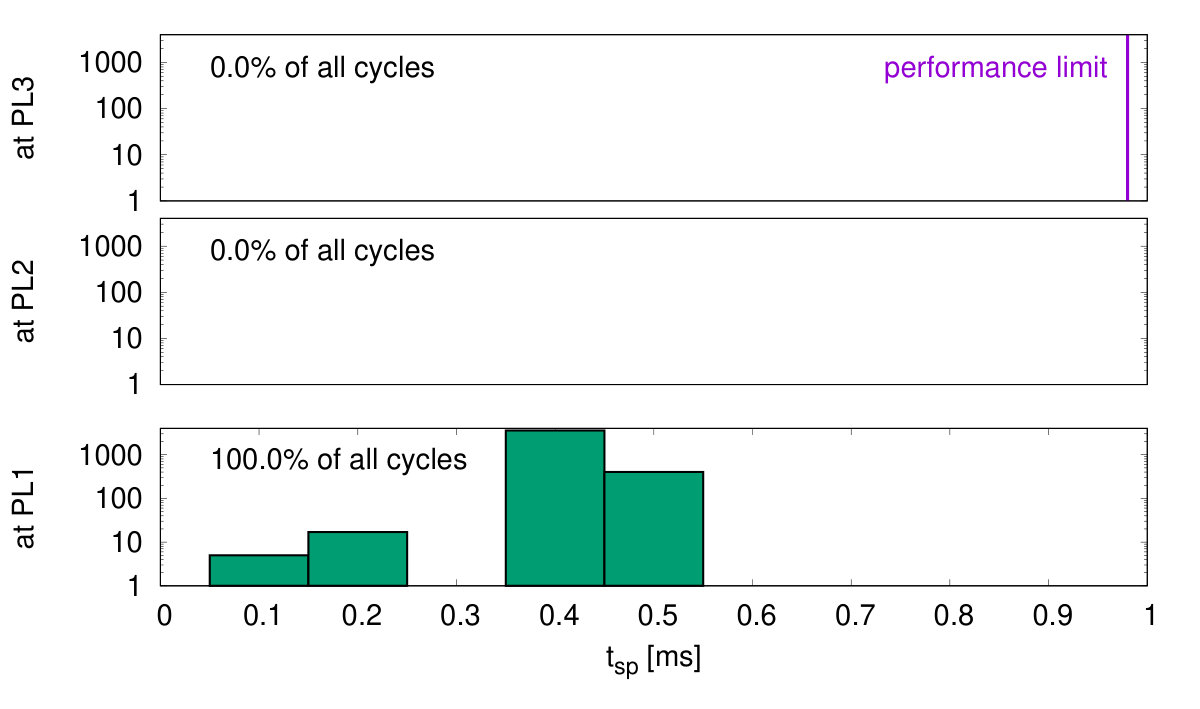 Figure 36
Figure 36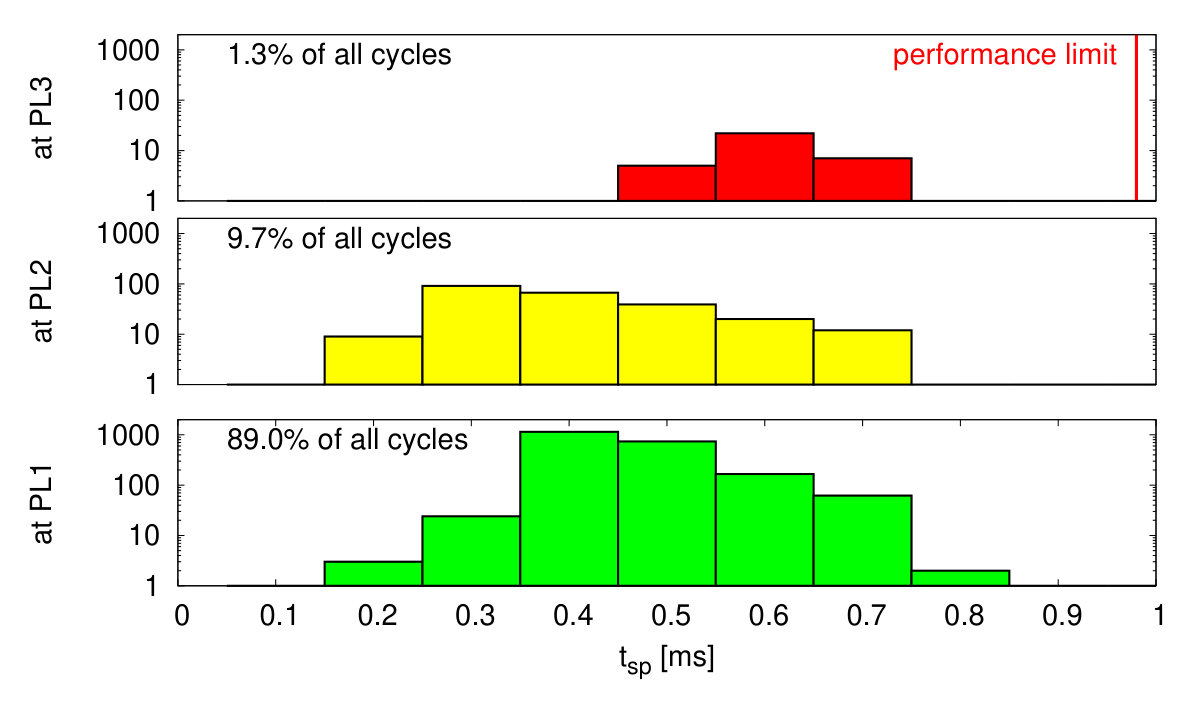 Figure 37
Figure 37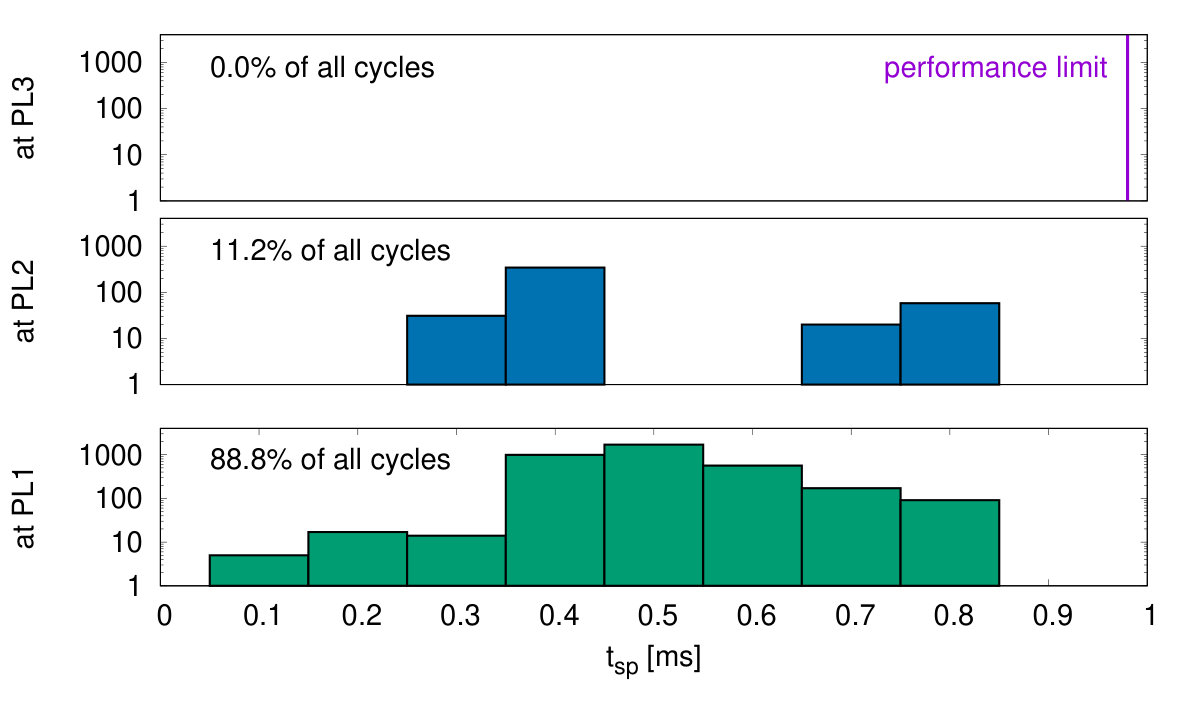 Figure 38
Figure 38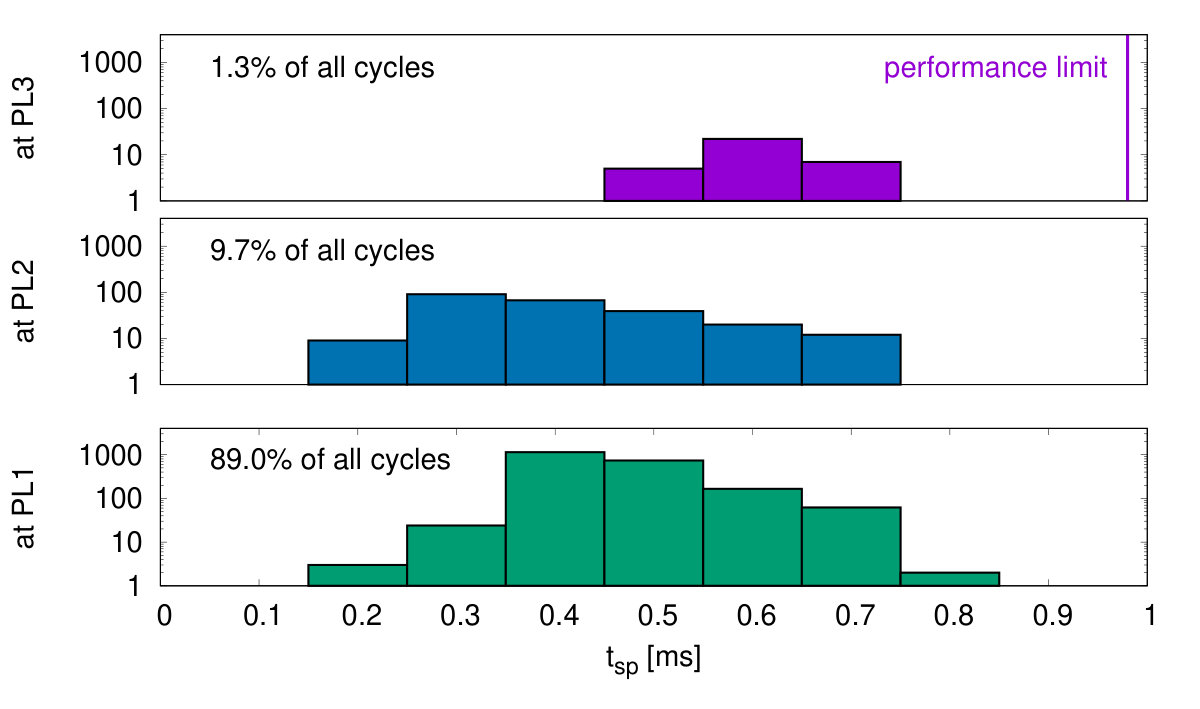 Figure 39
Figure 39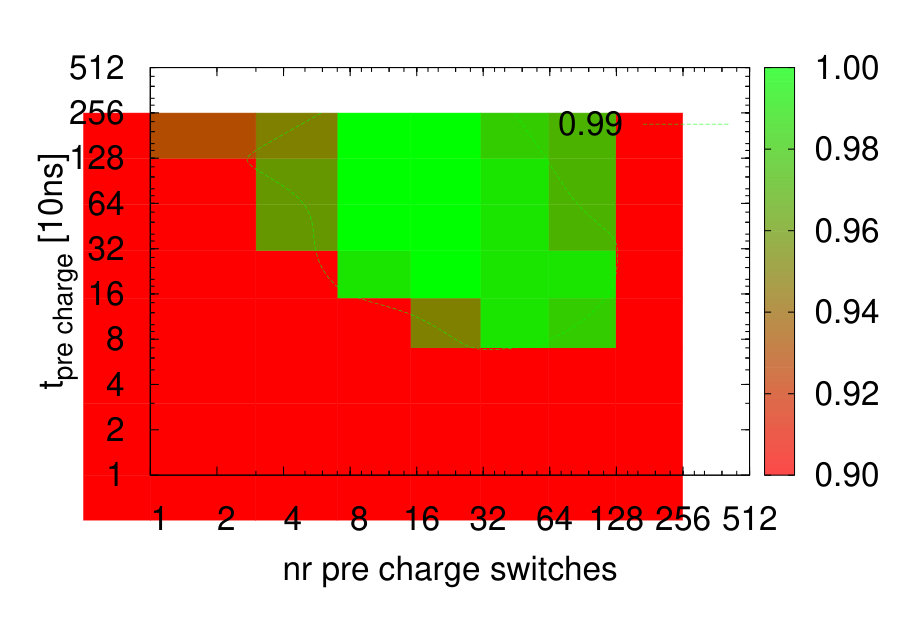 Figure 40
Figure 40| PL1 () | PL2 () | PL3 () | |
| [] | 8.94 | 20.03 | 28.53 |
| [] | 14.92 | 37.44 | 71.17 |
| [] | 1000 | 1410 | 1540 |
| [] | 2.19 | 2.88 | 3.96 |
| [] | 730 | 990 | 1490 |
| [] | 0.45 | 0.65 | 0.90 |
| synfire | bursting | async | |
|---|---|---|---|
| neuron model | LIF + noise | LIF | LIF |
| neurons per core | 250 | 250 | 250 |
| synapses per core | 20000 | 25000 | 10000 |
| avg. fan-out | 80 | 21 | 8 |
| 20 | 47 | 47 | |
| 100 | 214 | 229 |
| local | synfire | bursting | async | ||||||
| only PL3 | only PL1 | only PL3 | DVFS | only PL3 | DVFS | only PL3 | DVFS | ||
| total\footnoteAexcluding unused test chip components | 138.2 | 72.7 | 135.6 | 71.2 | 136.5 | 71.6 | 133.8 | 67.3 | |
| infrastructure\footnoteAtimer, router, LPDDR2 | 48.2 | 48.2 | 48.2 | 48.2 | 48.2 | 48.2 | 48.2 | 48.2 | |
| baseline | 71.2 | 14.9 | 76.2 | 17.0 | 76.0 | 17.0 | 76.4 | 14.7 | |
| neuron | 3.0 | 1.7 | 7.7 | 3.6 | 7.8 | 3.5 | 7.5 | 3.6 | |
| synapse | 15.9 | 7.9 | 3.5 | 2.4 | 4.5 | 2.9 | 1.7 | 0.8 | |
| power [mW] | PE | 90.0 | 24.5 | 87.4 | 23.0 | 88.3 | 23.4 | 85.6 | 19.1 |
| SynEvents/s | 16,000,000 | 3,030,000 | 2,240,000 | 489,000 | |||||
| E/SynEvent\footnoteAtotal power divided by SynEvents/s [nJ] | 8.6 | 4.5 | 44.7 | 23.5 | 61.0 | 32.0 | 274 | 138 | |
| E/SynEvent\footnoteAPE power divided by SynEvents/s (PE only) [nJ] | 5.6 | 1.5 | 28.8 | 7.59 | 39.4 | 10.5 | 175 | 39.1 | |
| System | Reference | Type | Techn. node | Neuron power | E/SynEvent | E/additional SynEvent |
| [] | [/] | [] | [] | |||
| Neurogrid | [6] | analog sub-Vt | 180 | 119 | n.a. | |
| ROLLS | [4, 5] | analog sub-Vt | 180 | n.a. | 0.077 | |
| HiAER-IFAT | [3] | analog sub-Vt | 130 | 50 | n.a. | |
| cxQuad | [44, 5] \footnoteASynaptic input event of is broadcast to all per core. Total power assumes firing at connected to each consuming at . | mixed-signal | 180 | 46 | 0.134 | |
| BrainScales | [45] | mixed-signal accelerated | 180 | 100 | n.a. | |
| Titan | [46, 47] \footnoteAAssuming accelerated operation with speed-up factor of 100, power draw of , 128 inputs firing at connected to each. | mixed-signal | 28 | 18 | n.a. | |
| TrueNorth | [48] | custom digital | 28 | 26 | n.a. | |
| Odin | [49] | custom digital | 28 | n.a. | 9.8 | |
| Loihi | [10] | custom digital | 14 | 0.052 | n.a. | 23.6 |
| SpiNNaker | [29]\footnoteAResults extracted from 1st column of Table III in [29], infrastructure power assumed as per board, cf. Figure 6 of [29] | MPSoC | 130 | 26 | 13300\footnoteAregarding PE power only (19300) \footnoteAregarding total power | 8000 |
| SpiNNaker2 prototype | this work\footnoteAat PL1 | MPSoC | 28 | 2.19 | 1500 (4500) | 450 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Memory and Neural Computing · Ferroelectric and Negative Capacitance Devices · Neuroscience and Neural Engineering
\foottwocolX
A
© 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
Dynamic Power Management for Neuromorphic Many-Core Systems
Sebastian Höppner, Bernhard Vogginger, Yexin Yan, Andreas Dixius, Stefan Scholze, Johannes Partzsch, Felix Neumärker, Stephan Hartmann, Stefan Schiefer, Georg Ellguth, Love Cederstroem, Luis Plana, Jim Garside, Steve Furber, Christian Mayr Manuscript received . The research leading to these results has received funding from the European Union Seventh Framework Programme (FP7) under grant agreement no 604102 and the EUs Horizon 2020 research and innovation programme under grant agreements No 720270 and 785907 (Human Brain Project, HBP) and the Center for Advancing Electronics Dresden (cfaed). The authors thank ARM and Synopsis for IP and the Vodafone Chair at Technische Universität Dresden for contributions to RTL design.S. Höppner, B. Vogginger, Y. Yan, A. Dixius, S. Scholze, J. Partzsch, F. Neumärker, S. Hartmann, S. Schiefer, G. Ellguth, L. Cederstroem and C. Mayr are with the Faculty of Electrical and Computer Engineering, Technische Universität Dresden, Germany (e-mail: [email protected]) L. Plana, J. Garside and S. Furber are with the Advanced Processor Technologies Research Group, University of Manchester
Abstract
This work presents a dynamic power management architecture for neuromorphic many core systems such as SpiNNaker. A fast dynamic voltage and frequency scaling (DVFS) technique is presented which allows the processing elements (PE) to change their supply voltage and clock frequency individually and autonomously within less than . This is employed by the neuromorphic simulation software flow, which defines the performance level (PL) of the PE based on the actual workload within each simulation cycle. A test chip in SLP CMOS technology has been implemented. It includes which can be scaled from to with frequencies from to at three distinct PLs. By measurement of three neuromorphic benchmarks it is shown that the total PE power consumption can be reduced by , with baseline power reduction and a reduction of energy per neuron and synapse computation, all while maintaining temporary peak system performance to achieve biological real-time operation of the system. A numerical model of this power management model is derived which allows DVFS architecture exploration for neuromorphics. The proposed technique is to be used for the second generation SpiNNaker neuromorphic many core system.
Index Terms:
MPSoC, neuromorphic computing, SpiNNaker2, power management, DVFS, synfire chain
I Introduction
Neuromorphic circuits [1] try to emulate aspects of neurobiological information in semiconductor hardware in order to solve problems that biology excels at, for example robotics control, image processing or data classification. Furthermore, it represents an alternative to general-purpose high-performance computing for large-scale brain simulation [2]. Besides system capacity, energy efficiency is one major scaling target, especially when large scale brain models are to be simulated with reasonable power consumption, which is typically limited by the effort for cooling and power supply. Energy efficiency is mandatory for the application in mobile, battery powered scenarios such as drones or mobile robots.
There exist approaches for low power and energy efficient neuromorphic circuits using analog subthreshold circuits [3, 4, 5, 6] or in recent years memristors [7, 8]. However, these systems show severe device variability and it is challenging to scale them to larger systems. In contrast, digital neuromorphic hardware systems such as TrueNorth [9], Loihi [10] or SpiNNaker [11] emulate neural processing by means of digital circuits or embedded software. Due to their purely digital realization they can be implemented in the latest CMOS technologies, operate very reliably/reproducibly and can be scaled to large system sizes.
To make digital neuromorphic systems as energy-efficient as analog ones, we can take inspiration from biology: The brain seems to maximize the ratio of information transmitted/computed to energy consumed [12]. That is, it consumes energy proportional to task complexity or activity levels. The brain also seems to use this in a spatial dimension, i.e. energy is allocated to different regions according to task demand [13]. The cost of a single spike limits the number of neurons that are concurrently active to one percent of the brain.
Transferring this concept to digital neuromorphic hardware, where large neural networks are mapped to many processing cores, leads to the requirement for local, fine-grained scalability for the trade-off between processing power and energy efficiency for highly dynamic workloads, i.e. spikes to be processed in biological real time. The temporal demand for high computational performance to be able to process large neural networks in biological real time requires high processor clock frequencies, and thereby the operation at nominal or even overdrive supply voltages, leading to high-power consumption. In contrast, low power operation can only be achieved by operating the processor core at lower supply voltages at the cost of higher logic delays and thereby slower maximum clock frequencies. Dynamic voltage and frequency scaling (DVFS) during system operation can break this trade-off, by lowering supply voltage and frequency during periods of low processor performance requirements and increasing supply voltage and clock frequency only if peak performance is required temporarily [14].
DVFS is widely used in modern MPSoCs, like for mobile communication [15, 16, 17] or database acceleration [18]. In the mentioned scenarios DVFS is typically controlled by a task scheduling unit which assigns supply voltage and frequency settings to the worker processing elements dynamically. In contrast, neuromorphic many core systems do not contain a central task management unit, since the neuromorphic application runs in parallel on processing elements [11]. Their actual workload for neuron state updates and synaptic event processing mainly depends on both the neural network topology and the input (e.g. spikes) of the experiment or application. It is therefore not known in advance or by any central control unit. However, the DVFS technique is beneficial for those systems, since neural networks show significant temporal variations of activity, making them very energy efficient for the neuromorphic task to be solved. This technique is to be employed by future digital neuromorphic hardware, such as the second generation of the SpiNNaker [11] system, which is currently in the prototyping phase.
This work presents a DVFS architecture for neuromorphic many core systems, where each processing element can autonomously change its supply voltage and frequency, only determined by its local workload. It extends a conference publication [19] by a technique for workload estimation and performance level selection for neuromorphic DVFS and a numerical energy consumption model for architecture exploration. Both aspects are demonstrated by means of chip measurement results for several benchmarks. In Sec. II the architecture of the neuromorphic SoC is presented including the hardware architecture and software flow for DVFS and Sec. III describes the corresponding power consumption model. Sec. IV presents a test chip in 28nm CMOS, with measurement results including 3 neuromorphic benchmarks summarized in Sec. V. Sec. VI shows an exploration of DVFS architecture parameters for future neuromorphic many core systems, such as SpiNNaker2.
II Neuromorphic SoC Architecture
II-A Overview
Fig.1 shows the block diagram of the many core system, based on the SpiNNaker architecture [11]. The neuromorphic computation problem is mapped to processing elements (PEs), which are responsible for neuron state computation and synaptic processing. In this work, the PEs are based on ARM M4F processors with local SRAM and a globally asynchronous locally synchronous (GALS) clocking architecture for dynamic power management. Off chip DRAM serves as synaptic weight storage. A SpiNNaker router [20] is used for on-chip and off-chip neuromorphic spike communication. The on-chip components are connected by a packet based network-on-chip (NoC), carrying spike packets, DMA packets for DRAM access and various types of control packets. In the periphery, shared modules are included, such as true random number generators (TRNGs) [21] and timers for the neuromorphic real time simulation time step (e.g. 1ms) generation.
II-B Power Management Hardware Architecture
The power management architecture of the PE is shown in Fig. 2. It is based on the concepts from [22] and [16]. The PE is equipped with a local all-digital phase-locked-loop ADPLL [23] with open-loop output clock generation [24], enabling ultra-fast defined frequency switching. The core domain, including the processor and local SRAM is connected to one out of several global supply rails by PMOS header power switches. If all switches are opened, the core is in power-shut-off. This allows for individual, fine-grained power management and GALS operation.
A PE performance level (PL) consists of a supply voltage and frequency pair. Switching between PLs is scheduled by the power management controller (PMC) [22]. The supported scenarios include the change between two PLs when the core is active as well as power-shut-off (PSO) and power-on after PSO. Therefore, the PMC schedules a sequence of the events clock disable, supply selection, net pre-charge, frequency selection and clock enable as shown in Fig. 3. The timings are derived from the reference clock signal (period typically ) and are fully configurable.
When connecting a PE to another supply rail at a new target level, rush currents must be reduced to prevent unwanted supply voltage drops of other PE, being currently operated at the target rail, as illustrated in Fig. 4. Therefore, a pre-charge scheme is used, where a small (configurable) number of power switches is connected to the target supply net to reduce the slew rate of the switched net [22]. Measurement results of this scheme for the SoC implementation in this work are shown in Sec. IV-B. As result PL changes of active PEs can be achieved within approximately , i.e., instantaneously from the perspective of the software running on the PE.
PL changes are triggered by sending commands via the NoC interface to the PMC. For power-up or remotely controlled DVFS, these commands can be sent by another core, orchestrating system boot-up. During PE operation (e.g. distributed neuromorphic application) the PE can trigger PL changes on its own by sending a NoC packet to its own PMC (self DVFS). Thus, the PE software can actively change its PL without significant latency or software overhead. The application specific power management algorithms can be completely implemented in software at the local PEs.
II-C Spiking Neural Network Simulation
We follow the approach of SpiNNaker [25] to implement real-time spiking neural networks (SNN). Each core simulates the dynamics of a number of neurons and their inbound synapses (Fig. 5(a)). A real-time tick from a peripheral timer regularly triggers the neuron state updates and synapse processing which must complete within each simulation cycle (e.g. ) otherwise the neurons may fall out of sync. The spike communication between neurons is established by the SpiNNaker router that forwards multicast packets containing the identifiers of the sending neurons to target PEs according to a configurable routing table. At the target PE the spike events are inserted into a hardware FIFO attached to the local SRAM and processed in the subsequent cycle. Note that this is different to the typical SpiNNaker operation where incoming spikes are processed immediately.
Details about the memory layout for neural processing are shown in Fig. 5(b). Being accessed in every simulation cycle, the neuron state variables and parameters are stored in local SRAM. The synapse parameters, which require more memory and are only needed at an incoming spike, are stored in external DRAM. They are organized in so-called synapse rows which are contiguous memory blocks containing the synapses between one source neuron and all neurons of a core [26]. In the synapse row each existing synaptic connection is represented by a 32-bit word with a 16-bit weight, an 8-bit target neuron identifier, one synapse type bit (excitatory/inhibitory), and a 4-bit delay. The size of a synapse row depends on the fan-out of each source neuron, cf. Fig. 5(a).
When processing a received spike event, the core extracts start address and size of the synapse row belonging to the source neuron from a lookup table in the SRAM. Then, a direct memory access (DMA) for reading the synapse row from the external DRAM is scheduled with a dedicated DMA controller. During the DMA transfer the processor is not idle but can execute other tasks like neuron updates from a job queue [27]. Upon completion of the DMA, the synapses are processed and the weights are added to input ring buffers of the target neurons. These ring buffers accumulate the synaptic inputs for the next cycles and enable configurable synaptic delays. When calculating the neuron state update, the synaptic input from the buffer corresponding to the current cycle is injected into the neuron model. If neurons have fired, spike events are generated and sent to the SpiNNaker router.
II-D Power Management Software Architecture
The computational load in neuromorphic simulations is determined by the neuron state updates and synaptic events. While the neuron processing cost is constant in each simulation cycle, the number of synaptic events to be processed per time and core strongly varies with network activity. Our approach for neuromorphic power management exploits this by periodically adapting the performance level to the current workload. Fig. 6 visualizes the flow of a neuromorphic simulation with DVFS. Within a simulation cycle of length spikes are received by the PE and registered in the hardware spike FIFO. While spikes of cycle are received those from cycle are processed without interrupting the processor at incoming spikes. At the beginning of each cycle the workload is estimated based on the spikes in the queue and the performance level is set to the lowest possible level that guarantees the completion of the neural processing within the cycle .
II-E Workload Estimation
The workload for neuron processing is constant in each cycle and depends on the number of neurons per core and the cost for each neuron state update (in clock cycles):
[TABLE]
Instead, the cost for synapse processing varies with the number of spike events received and the fan-out of respective source neurons to the neurons on this core (Fig. 5(a)). The cost for decoding the synapse words and applying the weights to the input buffers of the neurons is given by
[TABLE]
where is the cost for processing one synapse.
In addition, there is a non-negligible overhead for each received presynaptic spike for looking up the synapse row address and the DMA transfer, which we summarize as
[TABLE]
Hence, the total workload in clock cycles is given by
[TABLE]
where subsumes all remaining tasks such as the main experiment control or sending of spike events.
II-F Performance Level Selection
In each cycle the lowest perfomance level is chosen that achieves the completion of neuron and synapse processing within time step . The PL is determined by comparing the workload to thesholds and representing the compute capacities of PL1 and PL2 (in clock cyles per time step):
[TABLE]
Then synaptic event processing and neuron state computation is performed at . When these tasks are completed after the spike processing time the processor is set back to PL1 and sleep mode (clock gating) is activated. It reads
[TABLE]
The optimization target for PL selection is to maximize within a single period, since this relates to the usage of the minimum required PL to complete the neuron and synapse processing tasks while maintaining biological real-time operation.
To obtain a good estimate of the workload at the beginning of the simulation cycle, we must compute and iterate over all spike events in the FIFO and add up their fan-outs which are implicitly contained in the synapse row lookup table as the synapse row sizes. This extra loop over the spike events creates an additional workload that consumes part of the compute performance per simulation cycle and increases the energy demands at the first glance. Yet, the possibility to precisely adapt the performance level to the workload offers great power saving capabilities, and it must be evaluated for each application whether the detailed strategy (Eq. 5) pays off.
For this paper, however, we consider a simple performance level selection model based on the number of received spikes in the spike queue:
For this paper, however, we consider a simple performance level selection model that compares the number of received spikes in the spike queue with thresholds and :
[TABLE]
The relation between selected performance level and the thresholds can be seen at the bottom of Fig. 7. This strategy was used in the preceding work [19] and allows a fast selection of the performance level as is immediately available at the beginning of the cycle . In turn, the thresholds and must be tuned for each application for the best exploitation of energy savings. Care has to be taken that all spike events can be processed at the chosen PL before the end of the time step. To ensure this, we employ a worst-case strategy for setting the performance level thresholds based on the fan-out of source neurons per core, as illustrated in Fig. 7: For spikes received, the worst case for the workload is when these spikes belong to the input neurons with the highest fan-out. As we know the fan-out of each neuron before the simulation, we can set the perfomance level thresholds according to this worst case: For this, we sort the fan-out of all inputs per core in descending order, and compute the worst-case workload for spikes received according to Eq. 4. Then, the thresholds and are given by the intersection points of the worst-case workload and the compute capacities and , as sketched in the bottom of Fig. 7. The advantage of this approach is two-fold: On the one hand, it guarantees the completion of synapse processing within the time step, on the other hand it is universal and can be employed to any network architecture. In real applications, however, higher thresholds might suffice when the worst-case that the input neurons with the highest fan-out fire at the same time never occurs.
III Power and Energy Model
To derive a model for power consumption and energy efficiency [28] of the PE within the many core system, a breakdown into the individual contributors (from application perspective) is required. Based on the definitions from [29], the total PE power consumption is split into baseline power, and the energies for neuron and synapse processing in the simulation cycles, as explained in the following. The parameter extraction is shown in Sec. IV-C.
III-A Baseline Power
The baseline power is consumed by the processor running the neuromorphic simulation kernel without processing any neurons or synapses. The timer events are received but trigger no neuron processing or synapse processing of the PEs. The baseline power also includes the PE leakage power, when connected to the particular rails of the PL. The baseline power of PL is .
III-B Neuron Processing Energy
The neuron processing energy per simulation time step at PL is modeled by,
[TABLE]
assuming a linear relation with an offset energy (as extracted in Sec. IV-C) and an incremental neuron processing energy per neuron. The total energy depends on the number of neurons mapped to the particular PE, independent from the network activity.
III-C Synapse Processing Energy
The synapse energy is the PE contribution caused by processing synaptic events within each simulation time step. The PE synapse energy at PL is modeled by,
[TABLE]
assuming a linear relation with an offset offset energy and an incremental energy per synaptic event. The total energy depends on the number of synaptic events within a simulation cycle on the particular PE, and thereby from the network activity.
From these definitions, the total energy consumed within a simulation cycle of length at PL reads
[TABLE]
assuming that after the completion of neuron and synapse processing within that cycle after the PE is set back to PL1 (as illustrated in Fig. 6). This reduces baseline power in that idle time of length . The average power consumption over the total experiment of cycles reads
[TABLE]
IV Test Chip
IV-A Overview
A test chip of the SpiNNaker2 neuromorphic many core system has been implemented in GLOBALFOUNDRIES SLP CMOS technology. Its block diagram is shown in Fig. 8. It contains 4 PEs with ARM M4F processors and hardware accelerators for exponentials [30] and true random number generators [21]. Each PE includes local SRAM and the proposed power management architecture with three PLs. off-chip DRAM is interfaced by LPDDR2. All on-chip components are connected by a NoC, where the longer range point to point connections are realized using the serial on-chip link [31]. The chip photo is shown in Fig. 9. For lab evaluation a power supply PCB is used which hosts up to 4 chip modules. This is connected to an FPGA evaluation board via SerDes links which then connects to the host PC via standard Ethernet. The setup is shown in Fig. 10, consisting of a power supply PCB hosting up to 4 chip modules and an FPGA board for host PC communication over Ethernet. A graphical user interface running on the host PC allows exploration of the DVFS measurements [32].
IV-B PE Measurement Results
Fig. 11(a) shows the measured maximum PE frequency versus the supply voltage including a polynomial fitting curve. The PE is operational with high yield (including SRAM) down to . In this testchip the three PLs for the neuromorphic application are defined as PL1 (, ), PL2 (, ) and PL3 (, ) spanning a range from the nominal supply voltage of this process node of down to the minimum SRAM supply of . The design has been implemented for target performance at PL3. Hold timing has been fixed in all corners. The achieved performance at PL1 and PL2 has been analyzed from sign-off timing analyses. Fig. 11(b) shows the scaling of the PE energy-per-task metric and power consumption when scaling and . The dynamic energy consumption of the operating processor, consisting of internal and switching power of logic gates and interconnect structures dominates in this design implementation. Therefore a fitting of , where is the normalized energy per specific task, is applicable here. By voltage and frequency scaling in the mentioned ranges, the energy consumption per task can be reduced by and the power consumption by relative to the nominal operation point of PL3 (,).
The robustness of the PL switching has been analyzed by measurements in which a particular PE (aggressor) performs PL switches to a target supply net while another PE (victim) is actively operating at this target net, performing a task which can be checked for successful execution. The PL switching is repeated multiple times. The experiment is repeated for various settings of supply net pre-charge time and number of activated pre-charge switches (see Sec. II-B). Fig. 12 shows the measurement results for various scenarios for power-up (PU) and supply (PL) change (SC).
In Fig. 12(a) PU to the rail (PL1) is measured, which is very robust versus the switching time and the number of pre-charge switches. This is caused by the fact that the frequency setting of PL1 has significant headroom to the maximum possible frequency of (see Fig. 11(a)), thereby tolerating temporary supply drops during switching.
In case of PU to PL2 (Fig. 12(b)), a strong dependency of the robustness on the pre-charge time and number of switches is visible. For a large number of pre-charge switches the victim PE fails due to the large rush current induced voltage drop at PL2. A smaller number of pre-charge switches anyway requires a minimum pre-charge time, which decreases with increasing number of switches. This is caused by the fact that if the pre-charge time is too short, all power switches are activated although the PE supply net has not yet settled to PL2, resulting in a significant rush current and PL2 supply drop directly after the pre-charge phase. The PU behavior to PL3 is similar (Fig. 12(c)) but much more robust, since the supply net PL3 is the always on-domain of the chip toplevel, therefore having high on-chip decoupling capacitance which tolerates larger rush currents during power switching. Fig. 12(d) shows the SC scenario from PL1 to PL2 which is most critical (PL2 has smaller on-die decoupling capacitance than PL3). Also high switching robustness is achieved here. In summary, for safe operation well within the PASS regions of Fig. 12, a setting of 31 pre-charge switches enables save PU in and SC in 100\text{,}\mathrm{n}\mathrm{s}$$.
IV-C DVFS Power Model Parameter Extraction
The power management model parameters from Sec. III have been extracted. For baseline power extraction the simulation kernel without neuron processing code and synapse processing code has been executed at different PLs, including the trigger to the PE. The neuron processing power has been determined by running the neuron state calculation for different numbers of leaky integrate-and-fire (LIF) neurons with conductance-based synapses as shown in Fig. 13. The power for synapse processing has been measured by running the synapse calculation code with a varying number of synaptic events. Therefore, we used a locally-connected network with 80 neurons per core that are connected to all neurons on the same core, but not to other cores. Then we modified the number of spiking neurons per core and time step to vary the number of synaptic events. This network topology is identical to the local network used in [29] and allows the direct comparison of energy efficiency to the first generation SpiNNaker system in Sec. V-C.
The results of the power model parameter extraction are shown in Fig. 13. Linear interpolation has been applied to extract the model parameters for neuron energy and and synapse energy and , respectively. All parameters are summarized in Tab. I. As expected, the energy per task ( or ) scales with , while the baseline power at PL1 is only of the power at PL3, which is consistent with the results in Sec. IV-B.
V Results
V-A Benchmark Networks
To show the capabilities of neuromorphic power management we implement three diverse spiking neural networks for execution on the chip. The benchmarks were selected to cover the wide range of neural activity found in the brain [33], ranging from asynchronous irregular activity over synchronous spike packets to network bursts. In all networks we use leaky integrate-and-fire neurons with conductance-based synapses. Table II lists characteristics of the networks and the thresholds of received spikes used for the performance level selection. The thresholds were determined using the worst-case approach described in Section II-F, except for the synfire network, which uses the same numbers as in the preceding work [19] for consistency.
V-A1 Synfire Chain
The first benchmark is a synfire chain network [34] which was already used in the preceding work [19]: Synfire chains are feedforward networks that propagate synchronous firing activity through a chain of neuron groups [35]. We implement a synfire chain with feedforward inhibition [34] consisting of (Fig. 14(a)), each with (E) and (I) neurons. As in [34] the neurons receive a normally distributed noise current. Excitatory neurons are connected to both excitatory and inhibitory neurons of the next group, while inhibitory neurons only connect to the excitatory population of the same group. There are connections per neuron from I to E and connections per neuron from E of the previous group, the delays are within a group and between groups. There are no recurrent connection within a population. We simulate one group per core and connect the last group to the first one. At start, the first group receives a Gaussian stimulus pulse packet generated on core 3 (, 2.4\text{,}\mathrm{m}\mathrm{s}$$). As shown in Fig. 15, the pulse packet propagates stably from one group to another, where the feedforward inhibition ensures that the network activity does not explode.
As shown in Fig. 15, cores adapt their PLs to the number of incoming spikes within the current simulation cycle. Fig. 18(a) shows histograms of the cycles being processed at a particular PL versus . Within some cycles being processed at PL3 many spikes occur simultaneously such that their processing requires up to , where is the real-time constraint. Thus, the system is close to its performance limit. A conventional system without DVFS would have to be operated at PL3. In the DVFS approach only a little percentage of cycles are processed at higher PLs, thereby achieving nearly the energy efficiency of the low voltage operation at PL1.
V-A2 Bursting Network
The second benchmark is a sparse random network generating network bursts, where the neurons collectively switch between UP states with high firing rate and DOWN states with low baseline activity. Such network events have been found both in-vitro and in-vivo at different spatial and temporal scales [36]. The implemented model is based on [37] and consists of excitatory neurons recurrently connected with probability (Fig. 14(b)). The neurons are equally distributed over the 4 cores. Spike frequency adaptation (SFA) is implemented by creating an inhibitory synapse from each neuron to itself with a long synaptic decay time constant . A background population (BG) of 200 Poisson neurons is connected with to the excitatory population to generate a baseline firing activity in the network. Spikes from the BG population are stored before simulation in the DRAM and thus do not add significant workload. Typical network dynamics are shown in Fig. 16: The network quickly enters an UP state with average firing rate higher than until the SFA silences the neurons into a DOWN state until the next network burst is initiated. The histogram of simulation cycles versus is shown in Fig. 18(b). Here the peak performance PL3 is not utilized.
V-A3 Asynchronous Irregular Firing Network
A sparse random network with asynchronous irregular firing activity serves as the third benchmark. The limited size of the prototype system does not allow to implement the standard benchmark for sparse random networks [38], which is commonly used to benchmark SNN simulators [39, 40] or neuromorphic hardware [41]. Instead, we use the same network architecture as for the bursting network (Fig. 14(c)) and disable the spike frequency adaption. Additionally, the recurrent connection probability is reduced to such that the network stays in a low-rate asynchronous irregular firing regime, as can be seen in Fig. 17. Fig. 18(c) shows the corresponding histogram of simulations cycles versus . In this case only the lowest PL is required. The system automatically remains in its most energy efficient operation mode.
V-B Power Management Results
To assess the benefit of the dynamic power management, we compare the power consumption for the benchmarks at the highest performance level (PL3) and using DVFS. The power measurement is done differentially. First the total power is measured with the neuromorphic experiment running on the chip. Then spike sending is deactivated and the power is measured. Since no spike is sent, no spike is received and processed. The difference is the synapse processing power. Then all neural processing is deactivated and upon timer interrupt only empty interrupt handlers are called. The power at this stage is measured as . is the neuron processing power. Then the ARM cores are deactivated and the power is measured as . is the baseline power. When DVFS is enabled, the PL is determined by the network activity. Thus, after measuring with the complete software autonomously switching PLs during simulation, the percentage of simulation time at the are recorded and then applied to the simulations when measuring and .
Tab. III summarizes the power measurement results of the system for the benchmarks. For comparison, we also include the locally-connected network used for the power model parameter extraction in Sec. IV-C. The testchip as shown in Fig. 8 contains only 4 PEs for prototyping purposes, for which the relative impact of infrastructure power, including the LPDDR2 memory interface is relatively high. It is expected that for future neuromorphic SoCs the infrastructure overhead is somehow balanced with respect to the number and performance of the PEs on the chip. Thus, the further comparison of energy efficiency is focused on the PEs only, which benefit from the proposed DVFS technique. Using DVFS, baseline power can be reduced by 80\text{,}%, neuron power by up to $\approx$50\text{\,}\% and synapse power by between 35\text{,}% and $\approx$50\text{\,}\%, depending on the experiment. The total PE power reduction by means of DVFS is 73\text{,}%$$. For comparison with other systems, we also calculate the energy per synaptic event (total energy vs. total synaptic events), which reaches its minimum value of PE energy at highest utilization within the locally connected network, similar to the benchmark used in [29].
V-C Results Comparison
Although this work is focused on a dynamic power management technique for event-based digital neuromorphic systems, thereby not being directly comparable to other neuromorphic approaches, Tab. IV compares the achieved energy consumptions also of different neuromorphic systems. For realistic comparison two metrics for synaptic energy are considered. First, the energy per synaptic event as in total energy divided by synaptic events processed across the system and second the incremental energy for one more synaptic event. These metrics are not scaled to the semiconductor technology, since completely different circuit approaches provide their optimal results in different technology nodes. For a fair comparison these metrics would have to be extracted from the same benchmark running on the different neuromorphic hardware systems [42]. We did not put memristor systems in the table, as the approach seems too different and no large-scale memristor systems have been reported. However, for comparison we would still name a few figures for memristor synapse arrays: Du et al. [7] report measurements of for potentiation/depression at a single synapse, but without the circuit overhead. Chakma et al. [43] simulate memristors and CMOS neurons, reporting between 0.1 and for both learning and passive memristors, with additional for the CMOS neurons. Analog subthreshold systems [6, 4, 3, 44] and mixed-signal systems [45, 46, 47] use analog circuits to mimic neural and synaptic behavior. Custom-digital neuromorphic chips [48, 49, 10] use event-based processing in custom non-processor units. They can be implemented in nanometer CMOS technologies and show low energy per synaptic event regarding total power in the same order of magnitude as the analog and mixed-signal approaches. Multi-processor-based neuromorphic systems, such as this work, trade off much higher system flexibility due to software defined neuromorphic processing by two to three orders of magnitude higher energy consumption. However, the scaling of semiconductor technology together with dynamic power management techniques such as the proposed DVFS in this work reduces this gap. Compared to SpiNNaker approximately reduction of neuron processing energy and PE energy per synaptic event is achieved. For our benchmarks on this work, as summarized in Tab. III, the application of DVFS results in 73% total PE power reduction. The proposed technique is also applicable to custom-digital neuromorphic systems which operate in an event-driven fashion.
VI DVFS Architecture Exploration
Based on a numerical power management model from Sec. III and the extracted model parameters from the test chip, an exploration of the DVFS architecture is performed. The synfire chain from Sec. V-A1 is chosen as benchmark, since it shows highly dynamic workload with the temporary demand for peak performance at the highest PL. Fig. 19 shows the measured PE power consumption compared to the DVFS model parameters, extracted with a fanout of 80 similar to the synfire chain configuration as shown in Sec. IV-C. The power values match with acceptable accuracy.
For DVFS architecture exploration the number of PLs with dedicated supply rails is considered as parameter, since the hardware overhead of separated supply rails, power switches and external voltage regulators is the main system overhead of the DVFS approach. Therefore, the power saving potential versus the number of PLs is analyzed. It is based on the workload threshold method described in this paper, based on . If the number of PLs is lower, e.g. 2, it is directly switched to PL3 when is achieved. PL2 is omitted in this case. Fig. 20 shows the simulated and measured PE power for different numbers of PLs. They always include the at PL, since this one provides the required peak performance. It can be seen that already with the PE power can be reduced by . Addition of a third level results in power reduction. A hypothetical 4th PL has been added to a scheme of (0.70V, 0.80V, 0.90V, 1.0V) with (125MHz, 300MHz, 400MHz, 500MHz) and analyzed using the model. Adding this results in only additional power reduction compared to three PLs. From this it is concluded that more than with distinct supply rails do not gain much additional efficiency, justifying their additional overhead.
Without the insertion of an additional supply rail, a dynamic frequency scaling (DFS) performance level can be added. This is based on the supply rail selection of the lowest PL but has a much lower ADPLL clock generator frequency setting. The PE can switch to this DFS level, after the neuron and synapse computation within a simulation time step is done after . This allows the reduction of baseline power after the computation is done, while still allowing the core to react on interrupts. Fig. 20 shows an example DFS analysis result where an additional DFS level with clock frequency is assumed. This reduces the total PE baseline power after close to the leakage power value of , and , respectively. Due to the high baseline power portion in this particular implementation, this results in power reduction at the highest PL. Adding one or two more PLs, power can be reduced by additionally and , respectively.
VII Conclusion
A DVFS power management approach for event-based neuromorphic real-time simulations on MPSoCs has been presented. Its effectiveness has been demonstrated with a CMOS prototype. For a neuromorphic benchmark application, the PE power including baseline power and energy consumption for neuromorphic processing can be significantly reduced by up to 73\text{,}%$$ compared to non-DVFS operation while maintaining biological real-time operation. Using the presented neuromorphic power management model, energy consumption of the next generation large scale neuromorphic many core systems can be estimated. It helps to design both the power management hardware architecture, the software flow and the strategy for mapping a neuromorphic problem to the system with energy awareness. The results will directly flow into the SpiNNaker2 neuromorphic many core system, which is currently under development.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. Furber, “Large-scale neuromorphic computing systems,” Journal of neural engineering , vol. 13, no. 5, p. 051001, 2016.
- 2[2] S. J. van Albada, A. G. Rowley, J. Senk, M. Hopkins, M. Schmidt, A. B. Stokes, D. R. Lester, M. Diesmann, and S. B. Furber, “Performance comparison of the digital neuromorphic hardware spinnaker and the neural network simulation software nest for a full-scale cortical microcircuit model,” Frontiers in neuroscience , vol. 12, 2018.
- 3[3] T. Yu, J. Park, S. Joshi, C. Maier, and G. Cauwenberghs, “65k-neuron integrate-and-fire array transceiver with address-event reconfigurable synaptic routing,” in Biomedical Circuits and Systems Conference (Bio CAS), 2012 IEEE . IEEE, 2012, pp. 21–24.
- 4[4] N. Qiao, H. Mostafa, F. Corradi, M. Osswald, F. Stefanini, D. Sumislawska, and G. Indiveri, “A reconfigurable on-line learning spiking neuromorphic processor comprising 256 neurons and 128k synapses,” Frontiers in neuroscience , vol. 9, p. 141, 2015.
- 5[5] G. Indiveri, F. Corradi, and N. Qiao, “Neuromorphic architectures for spiking deep neural networks,” in Electron Devices Meeting (IEDM), 2015 IEEE International . IEEE, 2015, pp. 4–2.
- 6[6] B. V. Benjamin, P. Gao, E. Mc Quinn, S. Choudhary, A. R. Chandrasekaran, J.-M. Bussat, R. Alvarez-Icaza, J. V. Arthur, P. A. Merolla, and K. Boahen, “Neurogrid: A mixed-analog-digital multichip system for large-scale neural simulations,” Proceedings of the IEEE , vol. 102, no. 5, pp. 699–716, 2014.
- 7[7] N. Du, M. Kiani, C. G. Mayr, T. You, D. Bürger, I. Skorupa, O. G. Schmidt, and H. Schmidt, “Single pairing spike-timing dependent plasticity in bifeo 3 memristors with a time window of 25 ms to 125 μ 𝜇 \mu s,” Frontiers in neuroscience , vol. 9, 2015.
- 8[8] H. Mostafa, A. Khiat, A. Serb, C. G. Mayr, G. Indiveri, and T. Prodromakis, “Implementation of a spike-based perceptron learning rule using tio 2- x memristors,” Frontiers in neuroscience , vol. 9, 2015.