Controlling and leveraging small-scale information in tomographic galaxy-galaxy lensing
Niall MacCrann, Jonathan Blazek, Bhuvnesh Jain, Elisabeth Krause

TL;DR
This paper introduces an analytic marginalization method that allows the inclusion of small-scale galaxy-galaxy lensing data in cosmological analyses, reducing biases and improving parameter constraints without extra sampling.
Contribution
The authors develop a novel analytic marginalization scheme for small-scale contributions in galaxy-galaxy lensing, enabling the use of smaller scales and shear-ratio information without additional free parameters.
Findings
Reduces parameter biases from unmodeled 1-halo contamination.
Improves cosmological constraints by utilizing small-scale shear-ratio information.
Enables inclusion of small-scale data without extra computational complexity.
Abstract
The tangential shear signal receives contributions from physical scales in the galaxy-matter correlation function well below the transverse scale at which it is measured. Since small scales are difficult to model, this non-locality has generally required stringent scale cuts or new statistics for cosmological analyses. Using the fact that uncertainty in these contributions corresponds to an uncertainty in the enclosed projected mass around the lens, we provide an analytic marginalization scheme to account for this. Our approach enables the inclusion of measurements on smaller scales without requiring numerical sampling over extra free parameters. We extend the analytic marginalization formalism to retain cosmographic ("shear-ratio") information from small-scale measurements that would otherwise be removed due to modeling uncertainties, again without requiring the addition of extra…
Click any figure to enlarge with its caption.
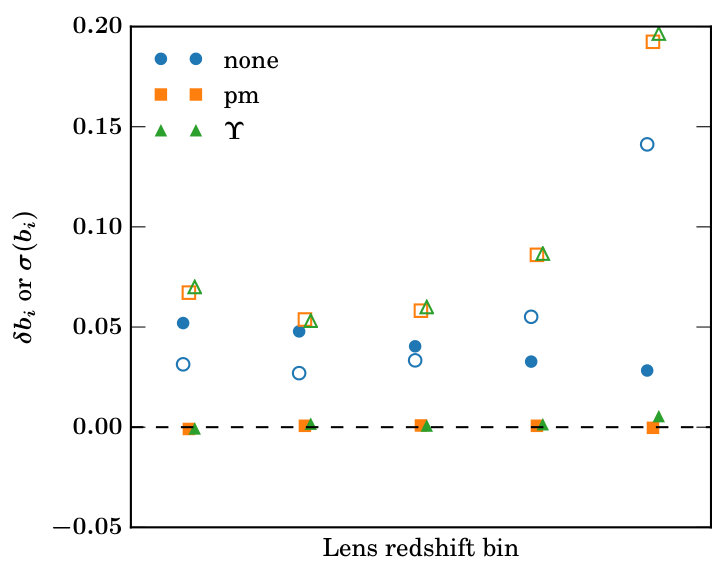 Figure 1
Figure 1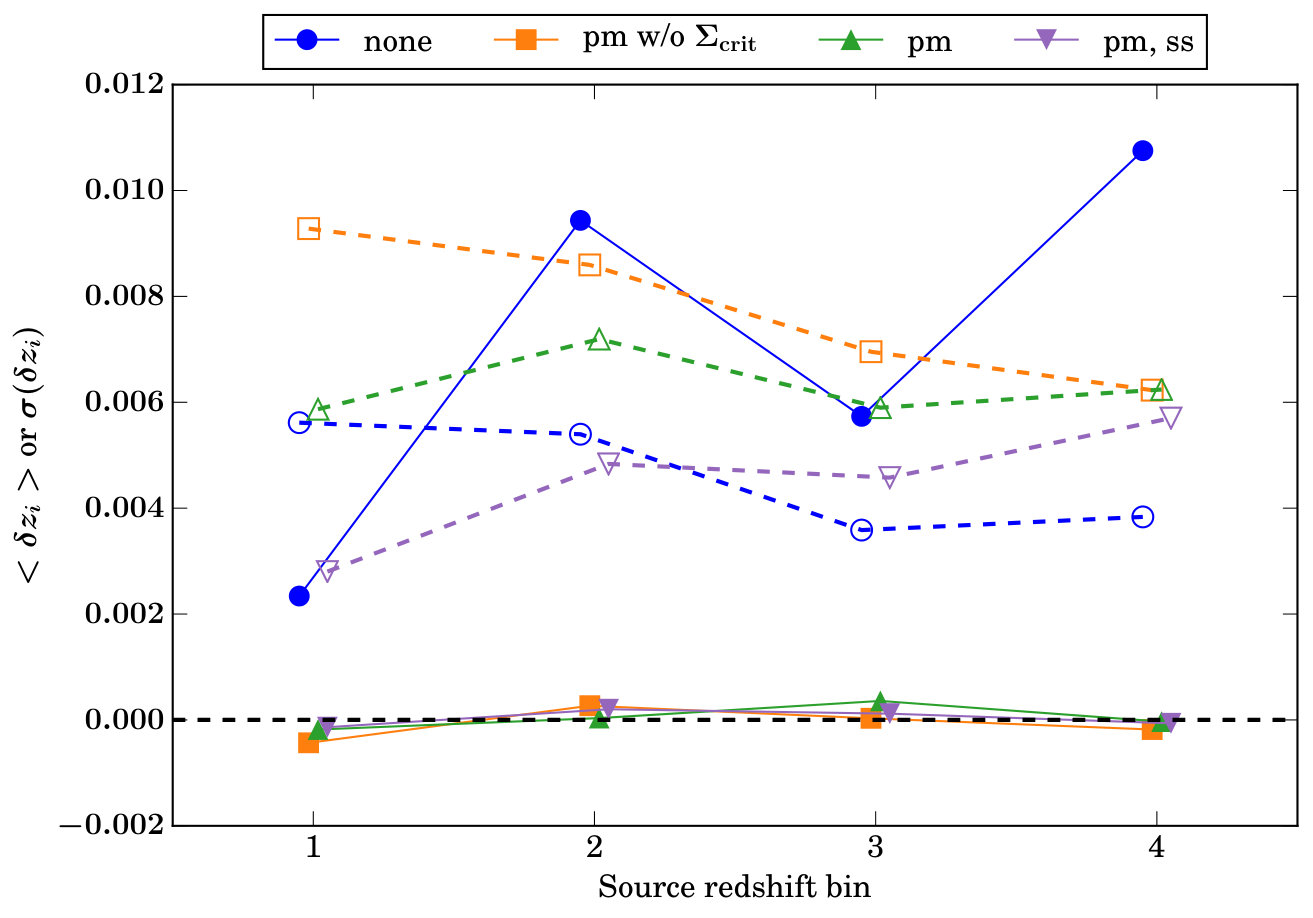 Figure 2
Figure 2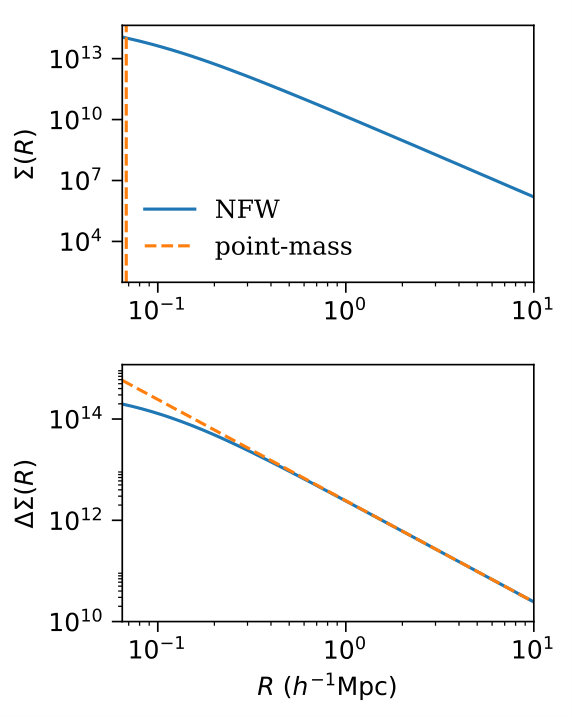 Figure 3
Figure 3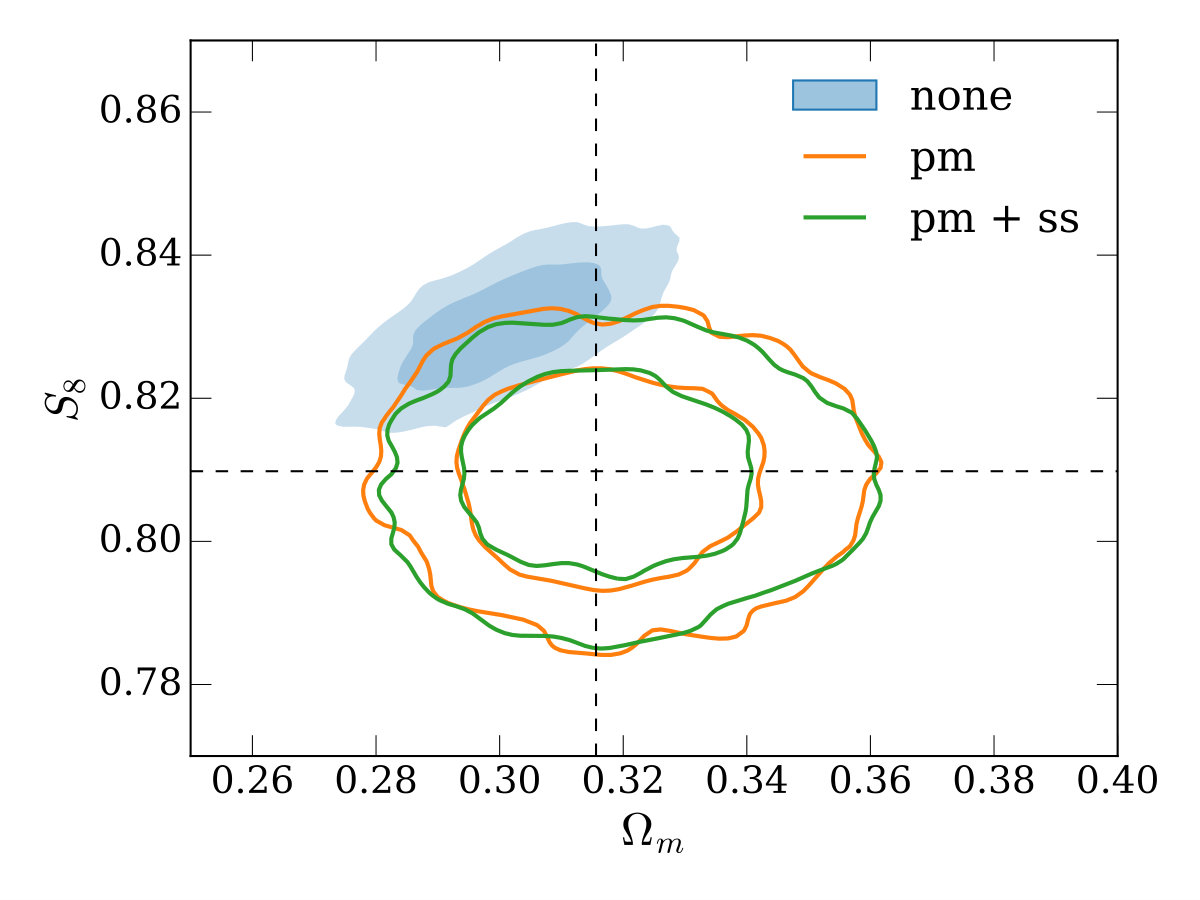 Figure 4
Figure 4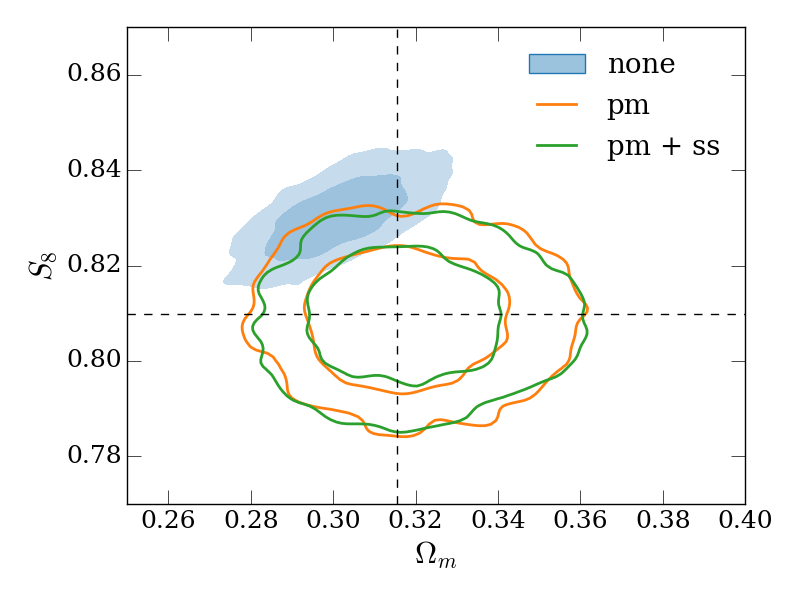 Figure 5
Figure 5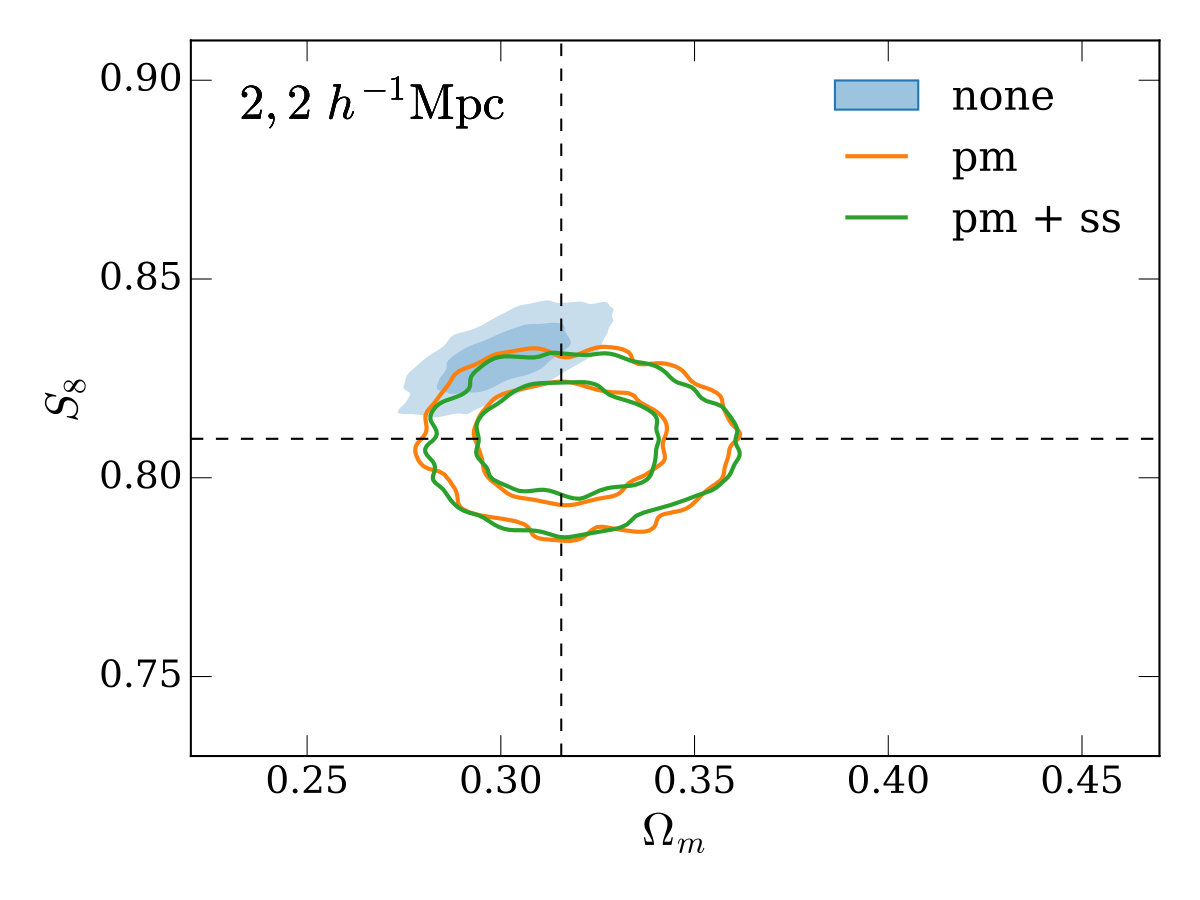 Figure 6
Figure 6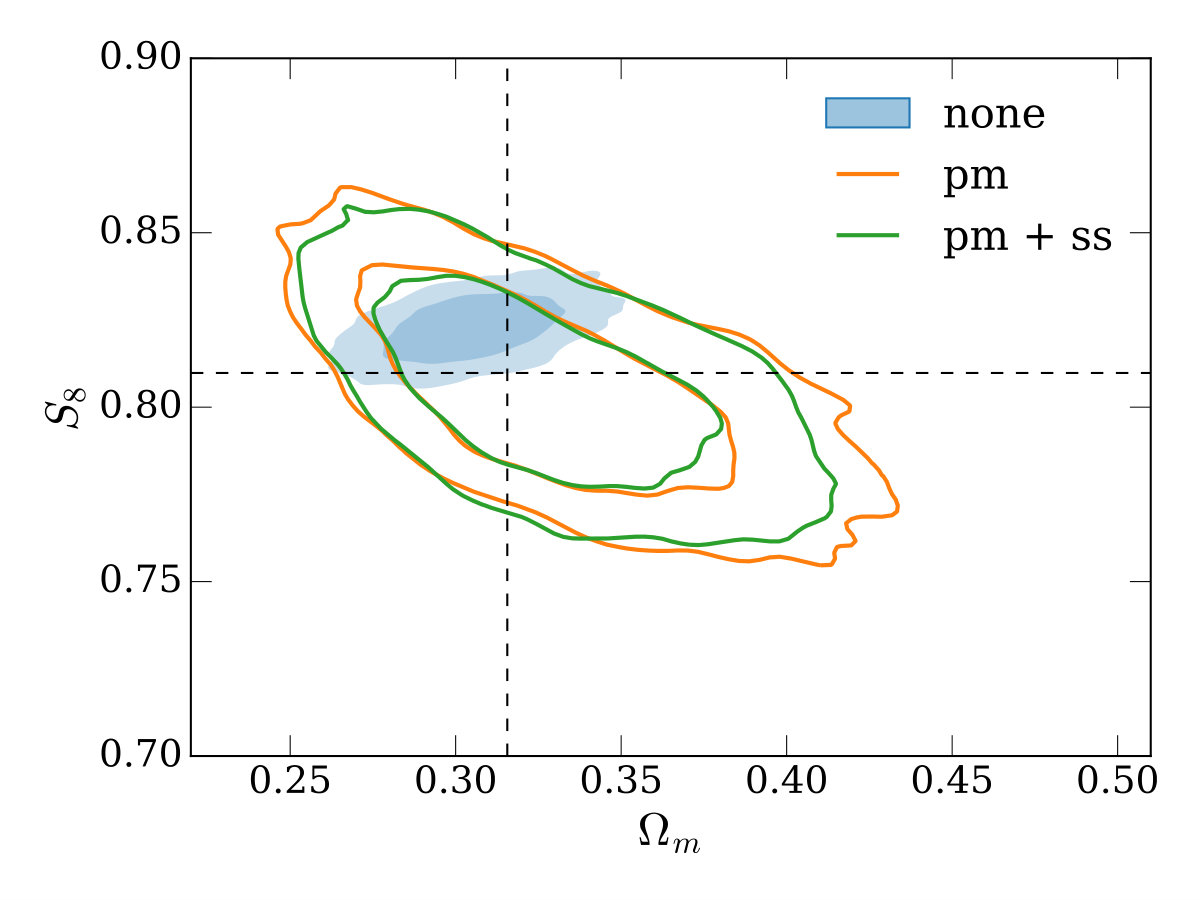 Figure 7
Figure 7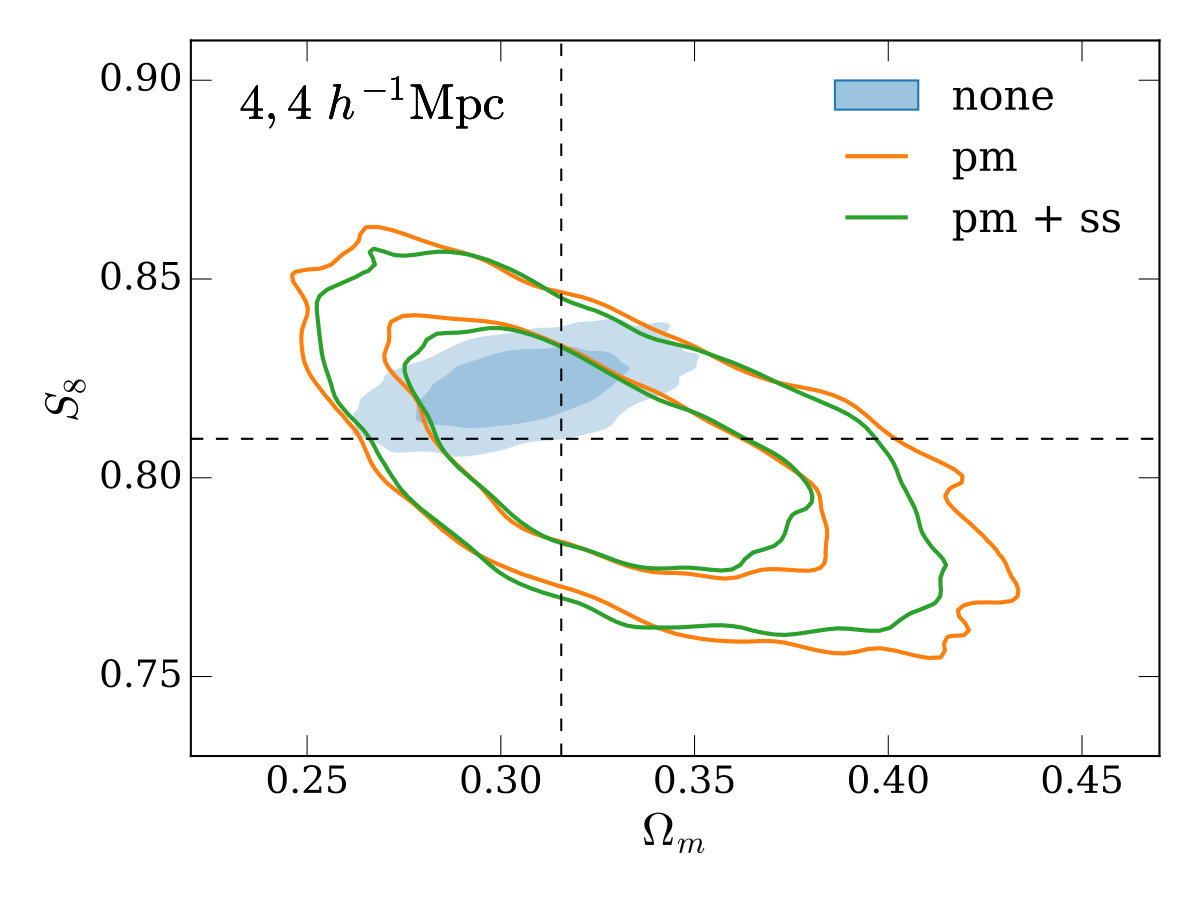 Figure 8
Figure 8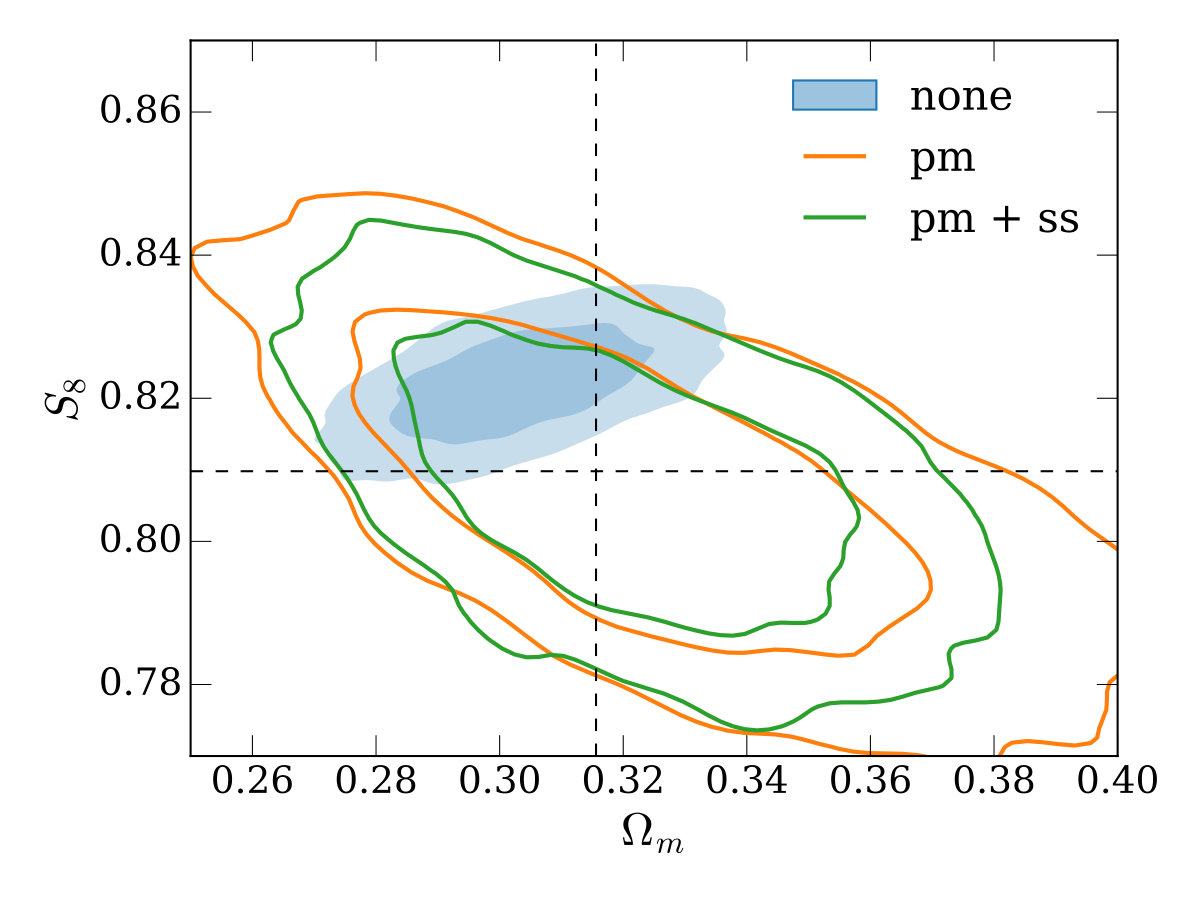 Figure 9
Figure 9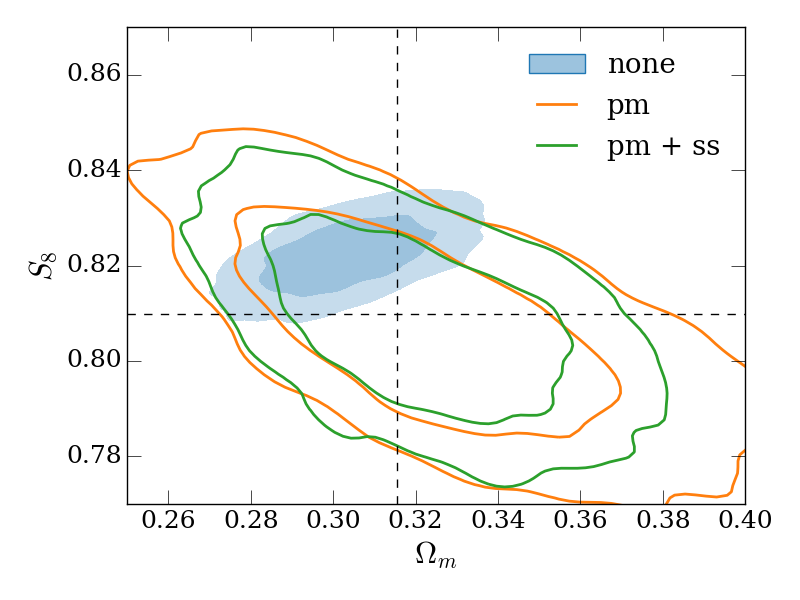 Figure 10
Figure 10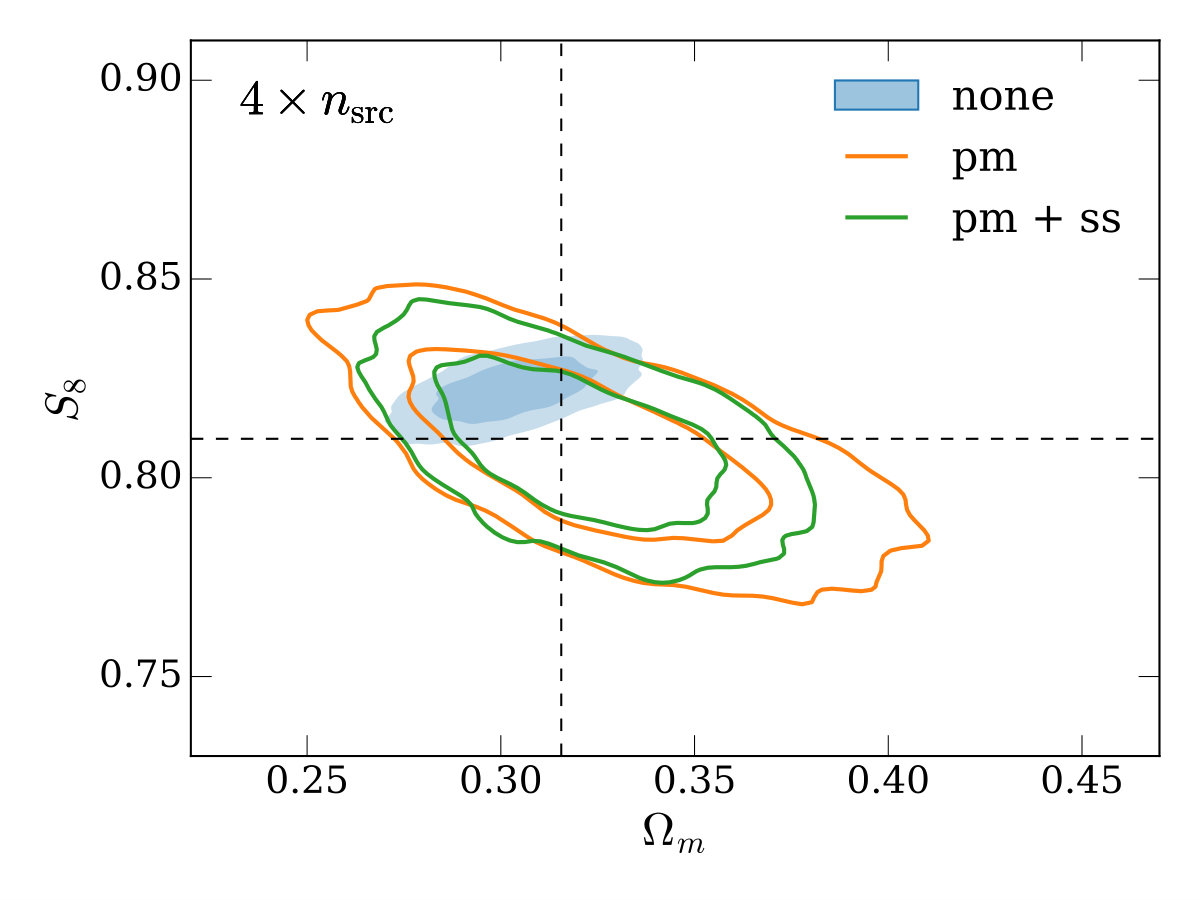 Figure 11
Figure 11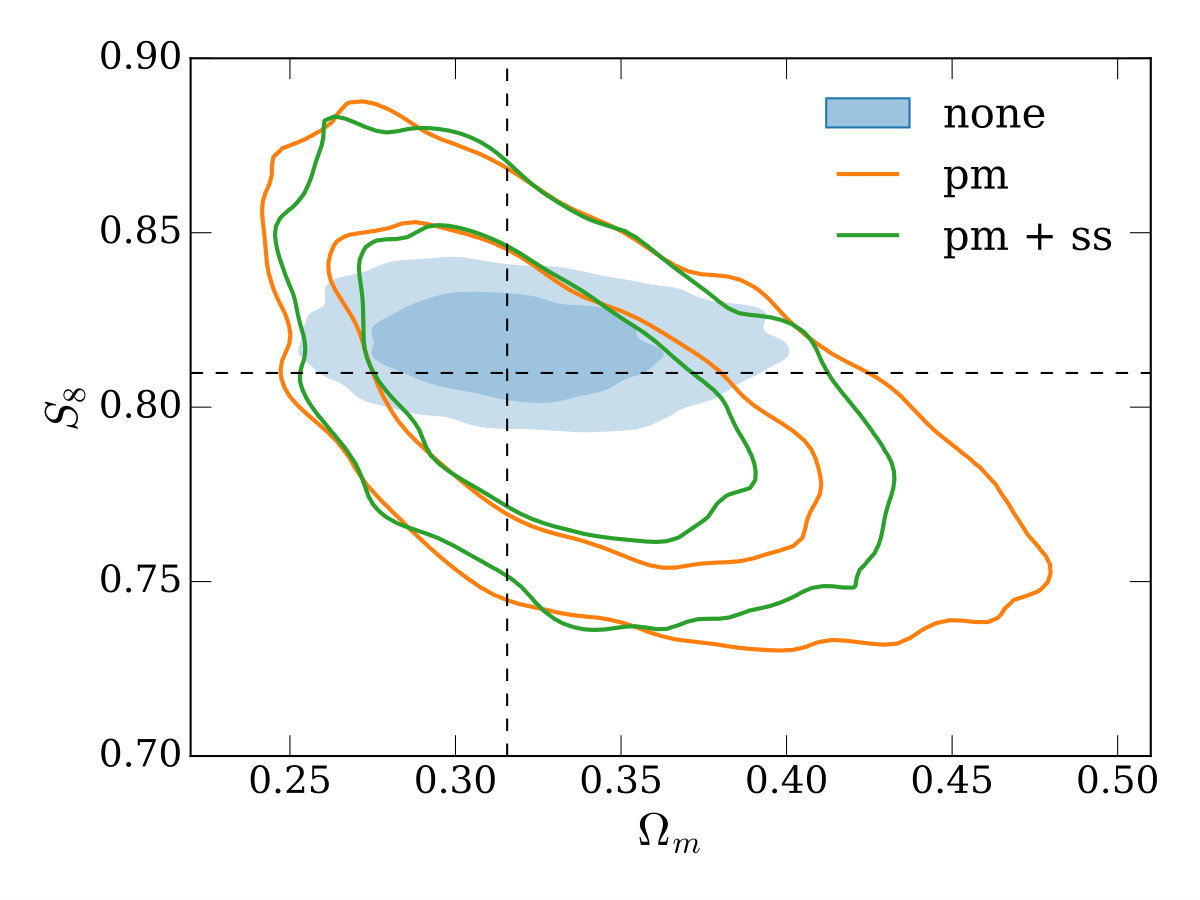 Figure 12
Figure 12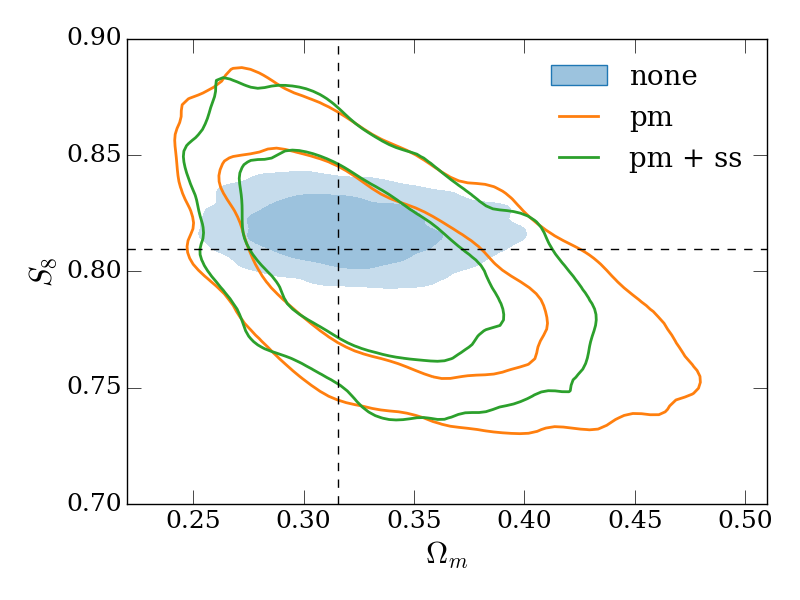 Figure 13
Figure 13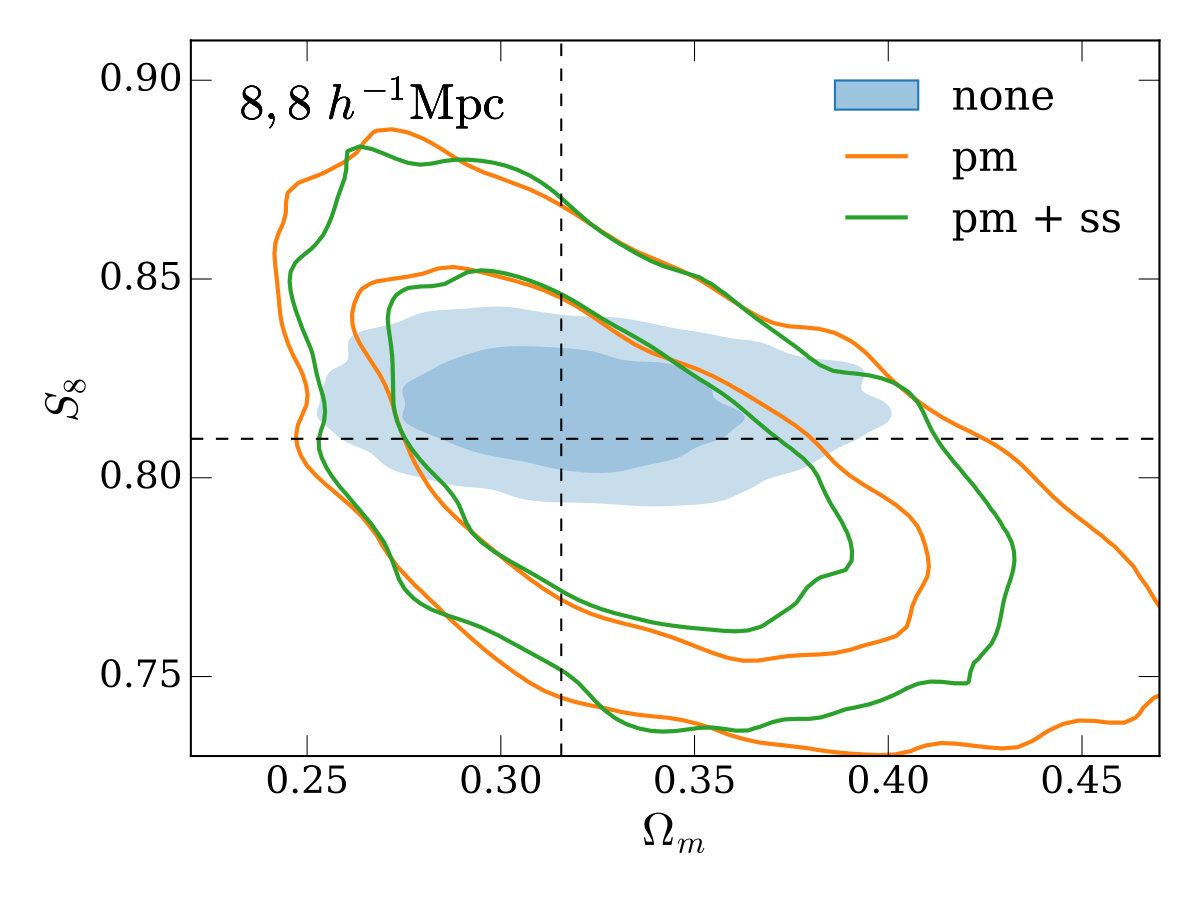 Figure 14
Figure 14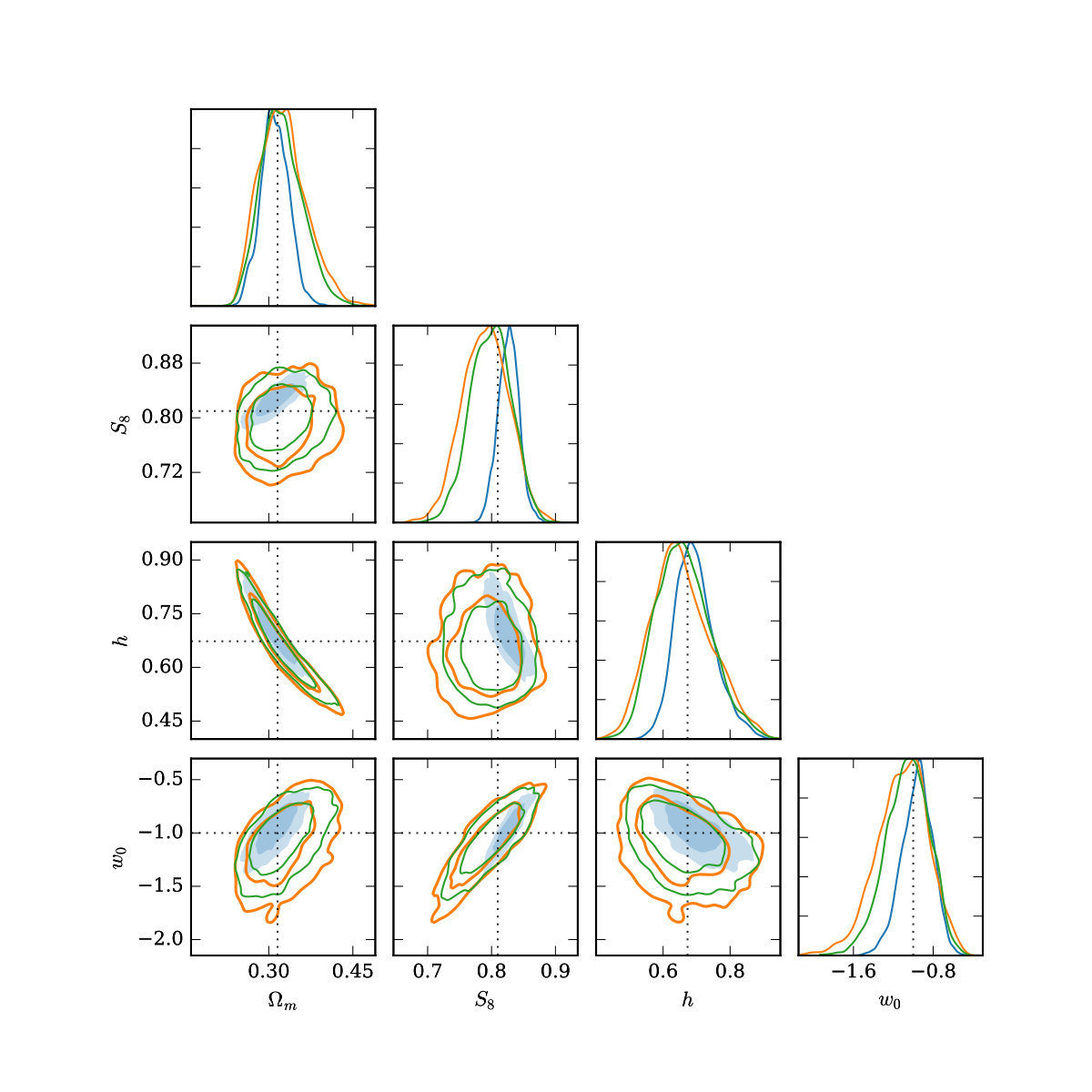 Figure 15
Figure 15Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Controlling and leveraging small-scale information in tomographic galaxy-galaxy lensing
Niall MacCrann1,2, Jonathan Blazek3, Bhuvnesh Jain4 and Elisabeth Krause5
1 Center for Cosmology and Astro-Particle Physics, The Ohio State University, Columbus, OH 43210, USA
2 Department of Physics, The Ohio State University, Columbus, OH 43210, USA
3 Institute of Physics, Laboratory of Astrophysics, École Polytechnique Fédérale de Lausanne (EPFL),
Observatoire de Sauverny, 1290 Versoix, Switzerland
4 Department of Physics and Astronomy, University of Pennsylvania, Philadelphia, PA 19104, USA
5 Department of Astronomy/Steward Observatory, 933 North Cherry Avenue, Tucson, AZ 85721-0065, USA E-mail: [email protected]
(Accepted XXX. Received YYY; in original form ZZZ)
Abstract
The tangential shear signal receives contributions from physical scales in the galaxy-matter correlation function well below the transverse scale at which it is measured. Since small scales are difficult to model, this non-locality has generally required stringent scale cuts or new statistics for cosmological analyses. Using the fact that uncertainty in these contributions corresponds to an uncertainty in the enclosed projected mass around the lens, we provide an analytic marginalization scheme to account for this. Our approach enables the inclusion of measurements on smaller scales without requiring numerical sampling over extra free parameters. We extend the analytic marginalization formalism to retain cosmographic (“shear-ratio") information from small-scale measurements that would otherwise be removed due to modeling uncertainties, again without requiring the addition of extra sampling parameters. We test the methodology using simulated likelihood analysis of a DES Year 5-like galaxy-galaxy lensing and galaxy clustering datavector. We demonstrate that we can remove parameter biases due to the presence of an un-modeled 1-halo contamination of the galaxy-galaxy lensing signal, and use the shear-ratio information on small scales to improve cosmological parameter constraints.
keywords:
gravitational lensing: weak – cosmological parameters
††pubyear: 2015††pagerange: Controlling and leveraging small-scale information in tomographic galaxy-galaxy lensing–Controlling and leveraging small-scale information in tomographic galaxy-galaxy lensing
1 Introduction
The observed shapes of distant galaxies are distorted due to variations in the gravitational potential experienced by emitted light on its path to the observer, an effect known as gravitational lensing. In the weak lensing regime, a small change in the observed ellipticity of such a source galaxy is generated, known as a shear. Coherent structure in the intervening density field generates coherent patterns in the observed shear field. For example, a net tangential alignment or tangential shear of source galaxies is produced around overdense regions in the intervening density field.
Since galaxies also trace overdense regions, we can measure the average tangential shear of source galaxies around these tracers, also known as lens galaxies, to probe the relationship between lens galaxy and matter densities. This sort of measurement is known as galaxy-galaxy lensing, and since early detections by Tyson et al. (1984) and Brainerd et al. (1996), it has been measured at increasing signal-to-noise (e.g. Choi et al. 2012; Cacciato et al. 2013; Mandelbaum et al. 2013; Velander et al. 2014; Clampitt et al. 2017; Prat et al. 2018b), and precision measurements from state-of-the-art photometric imaging surveys have been used for cosmological parameter estimation (DES Collaboration et al., 2017; van Uitert et al., 2018; Joudaki et al., 2018; Singh et al., 2018).
The galaxy-galaxy lensing signal depends on the total matter distribution around the lens galaxies, or the galaxy-matter cross-correlation function . In the halo-model picture (Seljak, 2000; Peacock & Smith, 2000), on small scales the measurement is most sensitive to the properties of the halos populated by the lens galaxies, for example the mean halo mass. Hence galaxy-galaxy lensing has been used to characterize the relation between halo mass and baryonic content of galaxies (e.g. Leauthaud et al. 2012; Viola et al. 2015; van Uitert et al. 2016). On larger scales, galaxy-galaxy lensing has been combined with galaxy clustering to simultaneously constrain the galaxy bias, and cosmological parameters, in particular the matter density and matter clustering amplitude at low redshift. Especially when combined with external constraints from e.g. the cosmic microwave background, this combination can also provide competitive constraints on the dark energy equation of state (Weinberg et al., 2013). These constraints will only improve with upcoming stage IV surveys such as the Large Synoptic Survey Telescope111http://www.lsst.org (LSST), Euclid222http://sci.esa.int/science-e/www/area/index.cfm?fareaid=102 and the Wide-Field Infrared Survey Telescope333http://wfirst.gsfc.nasa.gov (WFIRST), which will dramatically increase the volume of high quality weak-lensing data available.
There are typically significant observational and theoretical challenges in performing a galaxy-galaxy lensing analysis (Mandelbaum, 2018). In the former category, the shear must be estimated with high accuracy from images of faint source galaxies that are typically noisy and blurred by a point spread function, an ongoing challenge in the weak lensing community (e.g. Bridle et al. 2009; Kitching et al. 2012; Mandelbaum et al. 2014). Furthermore, interpreting the signal requires redshift information for both lens and source galaxies, which generally requires estimating photometric redshifts from noisy flux estimates in a small number (typically around 5) of optical or near-infrared bands (e.g. Hildebrandt et al. 2017; Hoyle et al. 2018; Tanaka et al. 2018).
There are also significant theoretical challenges when attempting to model the galaxy-galaxy lensing signal, which generally becomes more difficult at smaller scales. In order to predict the signal, an accurate prediction for the galaxy-matter correlation function is required for some range of physical scales . On sufficiently large scales we expect linear bias to hold (e.g. Fry & Gaztanaga 1993; Kaiser 1984), such that , where is the linear galaxy bias, an unknown constant that can be marginalized over and is the matter correlation function. A higher-order perturbative modelling approach may be successful in predicting at smaller, mildly nonlinear scales (see Desjacques et al. 2018 for a recent review). A perturbative approach will likely fail on scales approaching the 1-halo regime, but here a model which assumes some halo occupation distribution (Peacock & Smith, 2000; Seljak, 2000; Berlind & Weinberg, 2002; Wechsler & Tinker, 2018) combined with an accurate prediction for the clustering of dark matter halos may be successful (e.g. Cacciato et al. 2013; Nishimichi et al. 2018; Wibking et al. 2019). Even this approach will break down on galactic scales where galactic astrophysics will affect the matter distribution in and around the lens galaxy.
The important point is that whatever modeling approach is taken, it is crucial to ensure that the measurement is only sensitive to scales in where that modelling approach is sufficiently accurate. In Section 2.1 we describe how the galaxy-galaxy signal receives a non-local contribution that depends on scales in that are much smaller than the separation at which the measurement is made (i.e. the impact parameter in the lens plane). It was this potential non-local contribution that motivated the use of a larger minimum scale for galaxy-galaxy lensing than for galaxy clustering in the combined clustering, galaxy-galaxy lensing and cosmic shear analysis of Dark Energy Survey (DES) Year 1 data in Krause et al. (2017); DES Collaboration et al. (2017). We demonstrate how this non-local contribution can be accounted for in parameter estimation, and use analytic marginalization (Bridle et al., 2002) to avoid adding extra sampling parameters.
When galaxy-galaxy lensing of a given lens sample is measured from multiple sources redshifts, some limited information can be extracted even in the absence of a model for the galaxy-matter correlation function. This is often referred to as shear-ratio information; since the ratio of the signals measured from two different source redshifts depends only on the Universe’s geometry (Jain & Taylor, 2003; Hu & Jain, 2004; Bernstein & Jain, 2004). In Section 3 we extend the aforementioned analytic marginalization formalism to allow the retention of shear-ratio information from small-scale galaxy-galaxy lensing measurements that would otherwise be excluded due to modelling uncertainties. Our use of analytic marginalization for both these problems makes our methods much more useful for cosmological parameter estimation from weak lensing surveys; without this the extra tens or hundreds of sampling parameters may lead to significant increases in convergence time for MCMC-based inference. We demonstrate the utility of our methodology by simulating cosmological parameter inference from a DES Year 5-like galaxy-galaxy lensing and galaxy clustering datavector in Section 4.
We conclude and discuss some potential limitations of the methodology in Section 5.
2 The point-mass contribution to tangential shear
We start in Section 2.1 by describing how physical scales in contribute to the galaxy-galaxy lensing signal, and how the non-local contribution from small physical scales can be marginalized over. We draw in particular on Baldauf et al. (2010) (also see a recent treatment in Singh et al. 2018). We discuss the use of analytic marginalization in Section 2.2, and compare to the approach of Baldauf et al. (2010) in Section 2.3. We extend the formalism to a tomographic tangential shear measurement in Section 2.4.1, and demonstrate the effectiveness of our approach in recovering unbiased parameters in Section 2.5.
2.1 Theory
A lens galaxy sample at angular diameter distance generates a mean tangential shear, (e.g. Hu & Jain 2004)
[TABLE]
where
[TABLE]
and is the excess mean surface mass density at transverse physical separation from the lens, given by the projection of the three-dimensional galaxy-matter correlation function over line-of-sight distance :
[TABLE]
where is the mean matter density. is the mean surface mass density averaged between and
[TABLE]
is a geometrical factor that determines how the amplitude of the signal depends on lens and source redshift, and for a single source redshift plane at angular diameter distance , is given by
[TABLE]
where is the lens redshift.
The presence of in equation 2 makes clear the non-locality of (and therefore ); this term depends on the distribution of mass around the lens on all scales up to , or equivalently, on for all . As a consequence, and can be sensitive to the mass distribution on one-halo scales, where a perturbative modeling approach will break down, even when measured at separations that correspond to much larger physical scales in the lens plane. There is extensive discussion of this effect in Baldauf et al. (2010) who propose an estimator-based approach for dealing with this non-locality that we discuss in Section 2.3. We note here that a projected galaxy clustering measurement, does not suffer from this effect - here the minimum physical scale probed in the three-dimensional correlation function is the same as the transverse separation .
If we assume we can model the galaxy-matter correlation function only down to some minimum scale , we can account for the contribution from scales below in the following way. For we can decompose into two terms
[TABLE]
Only the first term in equation 6 is beyond our ability to model accurately (the second term requires only at ). This first term has scale dependence, so for , any bias in our model due to inaccurate prediction of has a simple scale dependence.
Hence, for , we can model as
[TABLE]
where is the prediction based on a model for that is correct for scales , but can be arbitrarily wrong for , and is some unknown constant that we can marginalize over.
Note that the first term in equation 6 is just the tangential shear contribution from the excess mass enclosed in a cylinder of radius . For transverse scales larger than this has the same lensing signal as a point-mass located at , hence in the following we will refer to this contribution as the point-mass contribution. However, the constant in equation 7 does not correspond exactly to this enclosed mass if our model for makes a non-zero prediction for . In this case
[TABLE]
where is the bias in the model prediction for the enclosed mass i.e. this term accounts for inaccuracies in the enclosed mass prediction. We note that for a given lens galaxy sample, will be a function of lens redshift as well as i.e. .
We can also write in terms of systematic bias on the galaxy-matter correlation function prediction, i.e. the difference between our model for and the truth,
[TABLE]
A prior on could then be constructed from a scale-dependent prior on (see e.g. Baldauf et al. 2016 for more discussion of the inclusion of such theoretical uncertainties in cosmological parameter esitmation).
In Section 2.5, we perform tests of our formalism using the signal from a truncated NFW profile (see that section for details). The blue solid lines in Figure 1 shows (top-panel) and for a truncated NFW profile, as well as these same quantities for a point-mass with the same total mass as the truncated NFW profile (orange-dashed lines). For the point-mass case, is simply a delta function at , while . This plot demonstrates the point that 1-halo contributions with very different scale dependence in and therefore have very similar scale dependence in on all but the smallest scales. This is why marginalizing over a point-mass contribution can effectively account for an uncertain one-halo contribution.
Of course, by marginalizing over we lose some information, which will result in a loss in constraining power. However, we believe this is well justified, since the physical scales informing our model are now well-controlled. Assuming that biases in the prediction increase at smaller physical scales, accounting for the non-local contribution in this way should allow for the robust use of smaller scales in the measurement than if the non-local contribution is ignored. As discussed above, if one does have a motivated prior on the potential size of biases in at small scales, that information can be naturally included, and the loss in constraining power will be reduced.
2.2 Analytic marginalization of the enclosed mass contribution
We have described in Section 2.1 how uncertainty in the model prediction for that arises from uncertainty in the model prediction for (r<) can be accounted for my marginalizing over a term with dependence (equation 7). The simple form of this contamination model (e.g. the scale dependence is not dependent on cosmology or the lens galaxy properties) makes this term suitable for an analytic marginalization approach (see e.g. Bridle et al. 2002). The likelihood desired for our parameter estimation is where, as in equation 7, is the prediction based on a model for that is correct only for scales . This likelihood must be marginalized over the unknown constant , via
[TABLE]
In the case that is Gaussian distributed with covariance matrix C, and we have a Gaussian prior on with mean zero and width , one can show that (Bridle et al., 2002) P(|) is also Gaussian distributed with covariance matrix
[TABLE]
where has elements .
This powerful result means that operationally, in order to marginalize over the free parameter , we need only perform this simple operation on the original covariance matrix C, rather than explicitly sampling over possible values of in e.g. an MCMC chain.
In the case that we want to use an “uninformative” or very wide prior on (i.e. very large ), N may become close to singular, which will be problematic when numerically calculating which is required to compute the Gaussian likelihood. We can circumvent this issue by using the Shermann-Morrison formula to directly calculate
[TABLE]
Indeed with this form we can even use an infinitely wide Gaussian prior on by taking the limit in which case
[TABLE]
2.3 Relation to ADSD
Baldauf et al. (2010) introduced the Annular Differential Surface Density (ADSD) statistic which they label , defined
[TABLE]
This statistic removes the contribution from by effectively using the measured signal at to estimate the non-local contribution. We can see this by substituting equation 7 into equation 15, and observing that terms containing cancel:
[TABLE]
We demonstrate in Section 2.5.1 that this approach has very similar performance to marginalizing over the non-local contribution with infinite prior. Which approach is preferred will likely depend on the details of the analysis. As described in Baldauf et al. (2010), a nice feature of the statistic is that is is estimator based, and does not require the introduction of a new free parameter.
Explicitly marginalizing over the point-mass contribution as in our approach (while using analytic marginalization to avoid extra computational cost) allows one to more naturally include a prior, which may allow one to retain more information. We also show that our point-mass marginalization approach can naturally be extended to tomographic measurements where shear-ratio information can be retained, as described in Section 2.4.1.
2.4 Extension to
Particularly for photometric lens galaxy samples, can be a more convenient observable to use than (and in fact the latter is not a direct observable since a cosmological model must be assumed to calculate from the angular separation). In the flat-sky and Limber approximations, we can relate to by integrating over lens and source redshift distributions, and :
[TABLE]
The term in equation 7 contributes
[TABLE]
where is the angular diameter distance to the lens redshift . Note that the bias in the enclosed mass prediction can now in general depend on the lens redshift and the radius corresponding to the angular separation at redshift .
Hence for , we can similarly remove the impact of modelling inaccuracies in at scale by marginalizing over a term with scale dependence , for angular scales where is the distance to the lowest redshift lenses considered (i.e. for angular scales corresponding to physical scales greater than in the lens plane).
2.4.1 The tomographic case
For photometric surveys it is convenient and, given the limited photometric redshift precision, often close to optimal to perform a tomographic analysis where lenses and/or source are split into multiple bins in redshift and correlations between all pairs of lens and source redshift bins are used. In this case, our prediction for the tangential shear for lens bin , and source bin is
[TABLE]
where
[TABLE]
If the lens redshift distribution is sufficiently narrow, or evolves with redshift sufficiently slowly across the width of the lens redshift bin, then we can make the approximation
[TABLE]
i.e. only a single free parameter is required for each lens redshift bin (rather than a free parameter for each lens-source redshift bin pair), with the impact on each lens-source pair modulated by the effective inverse , . We’ll call this the narrow lens bin assumption. Of note here is that if we can make this narrow lens bin assumption, then we can extract shear-ratio information from the enclosed mass term, without any assumption about the amplitude of that mass. In effect, we gain constraining power on the relative sizes of the , which contain geometric information through their dependence on the angular diameter distances which enter (see equation 5), and thus information on cosmological parameters (e.g. Jain & Taylor 2003; Taylor et al. 2007; Miyatake et al. 2017) and nuisance parameters quantifying e.g. photometric redshift uncertainties (e.g. Heymans et al. 2012; Prat et al. 2018a). We note that one can of course choose the width of the lens redshift bins in order to attempt to satisfy this narrow lens bin assumption. The success of this approach will depend on whether the lens galaxy redshift uncertainties allow the construction of sufficiently narrow redshift bins.
In the tests below (Section 2.5, Section 4), we do not explore realistic cases of the redshift evolution of , which would require realistic galaxy simulations, and is beyond the scope of this work. We instead focus on demonstrating the usefulness of this formalism in idealized cases where the narrow lens bin assumption can be safely assumed.
2.4.2 Analytic marginalisation
In the case that we have lens redshift bins and source redshift bins we need a model for the full length- tangential shear vector (i.e. the concatenation of all angular scales for all lens and source redshift bin pairs) .
In the case that we can make the narrow lens bin assumption in equation 25, we can use the following form:
[TABLE]
where and are the lens and source redshift, and again is based on a prediction that is accurate only down to some scale . It is useful to write this in vector notation:
[TABLE]
where
[TABLE]
where is the source redshift bin and is the angular separation for element of the full datavector. We note that in the above, and throughout, we use and as redshift bin labels rather than vector indices; in equation 26 does not represent element of a vector , rather one of a set of vectors. When we do provide a piece-wise definition of a vector we use an index as in equation 28.
Analytic marginalization over all can again be performed by updating the covariance matrix to N given by
[TABLE]
where C is the original covariance and is width of the Gaussian prior on .
We can also write N in the form
[TABLE]
where U is a matrix with th column , and is the number of elements in the datavector. We will refer to U as a template matrix since its columns are template modes to be marginalized over. We can use the Woodbury matrix identity (the generalization of the Sherman-Morrison formula introduced in Section 2.2) to get the inverse:
[TABLE]
where I is the identity matrix.
Again, we may want to consider the case where we allow maximal freedom in the model by taking the limit . In this case equation 31 reduces to
[TABLE]
where V is a matrix with th column .
If we cannot make the narrow lens bin assumption, then we have
[TABLE]
where we now use to label the lens-source redshift bin pair, and
[TABLE]
We can again marginalize over the free parameters analytically, transforming the covariance matrix C according to equation 30. In this case U is a matrix, where , the total number of lens-source redshift bin pairs. The th column (where ) is given by where is the width of the Gaussian prior on .
2.5 Simple Tests
In this section we test the the above formalism by using it in parameter estimation on galaxy-galaxy lensing datavectors with reasonable one-halo contamination. For all tests where we use analytic marginalization we use the infinite prior case. For the point-mass marginalization, this means we make no assumption about below .
We first describe our simulated datavector, which is used here and in Section 4. We generate a galaxy-galaxy lensing and galaxy clustering datavector based on that used in the DES Year 1 analyses of Krause et al. (2017); DES Collaboration et al. (2017). The galaxy clustering part of the datavector is not used in this section, but is used in Section 4. The lens sample has 5 redshift bins spanning a range of in redshift. The source sample has 4 redshift bins, roughly spanning a range in redshift (see Figure 1 of DES Collaboration et al. (2017) for more details). Both galaxy-galaxy lensing and galaxy clustering signals are generated according to a linear bias model, with values of the galaxy bias, . Simulated measurements are generated for 20 log-spaced bins between angular scales and . Again following DES Collaboration et al. (2017); Krause et al. (2017), in our linear bias model the galaxy-galaxy and galaxy-matter power spectra for redshift bin are in fact generated as and , where is the nonlinear matter power spectrum calculated using halofit (Smith et al., 2003; Takahashi et al., 2012). Throughout, we use the CosmoSIS444https://bitbucket.org/joezuntz/cosmosis/ package (Zuntz et al., 2015) for theory predictions and parameter inference, implementing in custom modules the 1-halo contamination and Gaussian covariance calculation described below, as well as our analytic marginalization scheme.
We generate a Gaussian covariance matrix corresponding to this datavector which has roughly DES Year 5 statistical power - we assume an area of , a lens galaxy number density of galaxies per square arcminute, a source galaxy number density of 2 per square arcminute for each redshift bin (i.e. totalling 8 source galaxies per square arcminute), and (the total ellipticity dispersion) for all source redshift bins.
We add to the galaxy-galaxy lensing simulated datavector a simple 1-halo contribution (on top of the linear bias term already present). For each lens redshift bin, based on the fiducial linear bias values above, and the mean redshift of the bin, we calculate a fiducial halo mass value following Tinker et al. (2010) and concentration, following Duffy et al. (2008). The 1-halo contribution is then calculated as the tangential shear from a truncated NFW profile with mass and concentration at the mean redshift of the lens redshift bin only - meaning we can safely make the narrow lens assumption for this contamination term. For convenience, we use the smoothly truncated NFW density profile in Equation A.3 of Baltz et al. (2009), with , since this allows for analytic calculation of .
We note that our model for the galaxy-matter correlation function, which is the sum of a linear bias 2-halo contribution, and a one-halo term, is not very realistic. We do not include satellite galaxies in the model, or a realistic distribution of halo mass and concentration. It is unlikely to be accurate in the transition regime, where the one and two-halo contributions are of comparable size. Additionally, our 2-halo term does not have a cut-off at small scales to account for halo exclusion (e.g. Smith et al. 2007) so may make too large a contribution here. We stress that this model, while of limited realism, is well-suited to demonstrate the usefulness of the techniques presented here, where we marginalize over the impact of the 1-halo contribution without making assumptions about its functional form or even amplitude. We defer the study of more realistic one-halo contamination to future work using galaxy simulations, focusing here instead on proof-of-concept type tests.
Unless otherwise stated, we throughout impose minimum angular scales in our simulated datavector corresponding to 4\text{\,}\mathrm{\mbox{h^{-1}}}\text{\,}\mathrm{Mpc} at the mean redshift of the lens redshift bin, which equate to for the five lens redshift bins.
2.5.1 Recovering the linear galaxy bias from
As a first simple step we test the recovery of the linear bias, for each lens redshift bin , from the galaxy-galaxy lensing signal only. We fix all other parameters fixed and analyse the datavector with and without using our analytic marginalization scheme to account for the 1-halo contamination. The solid markers in Figure 2 shows the bias in the recovered , calculated as where is the mean of the marginalized posterior and is the galaxy bias value used to generate the datavector. For the blue circles marginalization over the point-mass contribtution was not performed, and hence biased values for the galaxy bias are recovered, while for the orange markers point-mass marginlaization was included, and the correct galaxy bias values are recovered. The corresponding open markers indicate the uncertainty on the recovered linear bias parameter, demonstrating that as expected, there is some degradation in constraining power when using the point-mass marginalization scheme.
We also implement the analogous ADSD statistic for ,
[TABLE]
This shows very similar performance to the point-mass marginalization approach. For simplicity, we use as simply the smallest angular bin in the measurement remaining after applying the scale cuts. When the ADSD statistic has been used on data, an estimate of has typically been made by fitting a power-law over a range of scales around (e.g. Mandelbaum et al. 2013). We do not attempt to compare to this more complex approach here, although we note that analogous information could be added to the point-mass marginalization.
2.5.2 Shear-ratio information
As described in Section 2.4.1, if we make the narrow lens bin assumption we can straightforwardly retain the shear-ratio information in the point-mass term. One way to demonstrate this is to allow some freedom in the redshift distributions of the source redshift distributions, and test our constraining power on these distributions. Shear-ratio measurements have already been used for this application by Prat et al. (2018b) who extracted competitive constraints on these shift parameters using DES Year 1 galaxy-galaxy lensing measurements. Using the same contaminated galaxy-galaxy lensing datavector described above, we allow a simple shift for source redshift bin . For this test we keep the linear bias and cosmological parameters fixed to their true values. We produce constraints on the with three different modeling approaches, introduced here with the same labelling used in Figure 3:
‘none’: we do not marginalize over the point-mass contribution and hence expect this approach to produce the tightest, but also biased constraints. 2. 2.
‘pm w/o ’: we analytically marginalize over the point-mass contribution but allow a fully independent contribution for each lens-source redshift bin pair (following equation 33, thereby not retaining shear-ratio information from the point-mass contribution. 3. 3.
‘pm’: we analytically marginalise over an independent point-mass contribution for each lens redshift bin i.e. assume a perfectly correlated contribution to all source redshift bins for a given lens bin (following equation 27).
Figure 3 shows the mean of the posterior on (solid markers, solid lines) and its uncertainty (open markers, dashed lines) for the three cases above (blue circles, orange squares, and green triangles respectively). We see again that there is a degradation in constraining power when performing the point-mass marginalization with either method (ii) or (iii), but that this degradation is smaller for the case (iii) where shear-ratio information in the point-mass contribution is retained, particularly for the two lower source redshift bins.
3 Making use of all measured scales in the tangential shear
We can extend the above formalism to make use of all measured scales in our measurement. As above, we assume that for each lens redshift bin, , there is an angular scale which corresponds to a physical scale in the lens plane , below which we do not have a trustworthy model for the galaxy-matter correlation function . We therefore cannot make a reliable model prediction for ) (even if a point-mass contribution were marginalized over). However if we can make the narrow lens redshift bin assumption, we do know how the relative amplitudes of the different lens-source bin combinations for a given lens redshift bin are related i.e.
[TABLE]
For any measured scale we can therefore write down our model for lens redshift bin and source redshift bin as:
[TABLE]
The second term is the point-mass contribution described in Section 2 and is not included for scales . We have now added a third term containing a function that is zero for , and allowed to vary freely for scales . Physically, for we are allowing the value of to vary freely for , while enforcing that it takes the same value for a given angular scale and lens redshift bin, and hence is simply modulated in by . We refer to marginalization over the as small-scale marginalization.
One may ask if we are introducing too much freedom in the model, since the point-mass contribution at large scales is determined by the density profile at small scales, which we are also now marginalizing over. However, the density profile is never fully determined down to zero, since the shape noise on the measurement diverges in the limit of zero angular separation. Using some parameterization for the projected density profile down to zero would allow the information from these small scales to constrain the point-mass contribution to larger scales, potentially reducing degradation in the constraints when marginalizing over the point-mass term. We leave further investigation of this approach for future work.
Analytic marginalization is again extremely useful here, since we may want to marginalize over 10s or 100s of values. In order to perform analytic marginalization, it is again useful to recast in vector notation, with the full datavector given by
[TABLE]
where is the number of angular bins for lens bin with , and
[TABLE]
where is the source redshift bin for datavector element and
[TABLE]
We also update the definition of such that the point-mass contribution is not marginalized over for scales :
[TABLE]
The in equation 38 are the set of free parameters we introduce to marginalize over the density profile at small scales. We note again that , and in the above are not vector or tensor indices, but rather labels for lens redshift bin and angular bin respectively i.e. and are from sets of scalars and vectors respectively. As in the case of the point-mass contribution, we can perform this marginalization analytically by updating the covariance matrix according to equation 30, where now , the concatenation of the template matrices for the point-mass marginalization and the small-scale marginalization over the described in this section. is a matrix with dimensions , where , the total number of datapoints with . It has columns where is the Gaussian prior width for the free parameter .
We repeat the test in Section 2.5.2 in which we analyse a datavector, which contains unmodelled contamination by a 1-halo term, while allowing shifts in the source bin redshift distributions . To increase the usefulness of the small-scale marginalization described here, we extend the simulated measurements down to smaller scales - adding another 10 logspaced angular bins between 0.25 and 2.5 arcminutes. When not using the small-scale marginalization scheme, these extra scales are removed by the scale cuts, so have no bearing.
The results are again plotted in Figure 3. The purple downwards facing triangles represent the case where both point-mass and small-scale marginalization are used. Compared to the “pm" case where only point-mass marginalization is used, the inferred values remain unbiased, but uncertainties are significantly reduced. In the two lowest redshift bins, the extra information reduces statistical uncertainties to below those in the “none" (no point-mass or small-scale marginalization) case. We conclude that this double-pronged approach of marginalization over both the point-mass contribution, and the underlying signal at too-small-to-model scales, is the most successful at recovering unbiased shear-ratio information.
4 Tests of cosmological parameter estimation
We perform some simple simulated-likelihood tests to show how our analytic marginalization scheme helps with unbiased cosmological inference. We simulate parameter estimation on the joint galaxy-galaxy lensing and galaxy clustering datavector described in Section 2.5. For each lens redshift bin , we again cut out angular scales less than corresponding to 4\text{,}\mathrm{\mbox{}}\text{,}\mathrm{Mpc}$$ in the lens plane for both the galaxy-galaxy lensing and clustering measurements, except in the case that we retain these scales for the small-scale marginalization scheme described in Section 3. In this case angular scales less than are retained in galaxy-galaxy lensing only, and are only used for the small-scale marginalization scheme, rather than being modeled explicitly.
We analyse the datavector (again using the DES Year 5-like covariance) with three modelling approaches:
No marginalization (point-mass or small-scale) is performed 2. 2.
only point-mass marginalization is performed 3. 3.
both point-mass and small-scale marginalization are performed
Firstly, we vary only a linear bias parameter for each lens redshift bin, the matter density, in the range , the amplitude of the primordial power spectrum, in the range 0.5\text{\times}{10}^{-9}\text{,}5\text{\times}{10}^{-9}\text{,} and in the range (with the Hubble constant given by 100\text{,}\mathrm{\mbox{}}\ \mathrm{(}\mathrm{k}\mathrm{m}\mathrm{/}\mathrm{s}\mathrm{)}\mathrm{/}\mathrm{Mpc}$$). We assume a flat CDM cosmology with all other cosmological parameters fixed. is recorded in our MCMC chains as a derived parameter. For our fiducial setup, the resulting constraints on and are shown in the top-left panel of Figure 4 (here and throughout, contours represent the 68% and 95% credible intervals). As expected, modelling approach (i) results in the tightest, but biased constraints, since potential contamination by the 1-halo term is not marginalized over. Cases (ii) and (iii) recover the true cosmology (indicated by the dashed lines) correctly. For this parameter space there is a modest gain in constraining power when using the small-scale marginalizaiton (i.e. the gain in case (iii) over case (ii)), with a decrease in the uncertainty on .
In the other three panels of Figure 4, we study how the different modeling approaches perform under variations to our fiducial setup. The top-right and bottom-left panels use larger and smaller minimum scales in both galaxy-galaxy lensing and clustering (corresponding to 8\text{\,}\mathrm{\mbox{h}}^{-1}\mathrm{Mpc} and 2\text{\,}\mathrm{\mbox{h}}^{-1}\mathrm{Mpc} in the lens plane), with a couple of trends becoming apparent. Firstly, when using smaller scales, the bias when not performing point-mass marginalization (the contour labelled ‘none’) is increased in significance. Secondly, when using smaller scales, the gain from using the small-scale marginalization relative to point-mass marginalization only is reduced (this is expected since there is simply less information for the small-scale marginalization to reclaim).
Finally, in the bottom-right panel, we re-compute the covariance matrix with four times the density of source galaxies (keeping our fiducial scale cuts). This is potentially useful to gain an intuition on how the results here may apply to other lensing surveys which have a higher source galaxy density than DES, like the Hyper Suprime-Cam Subaru Strategic Survey555https://hsc.mtk.nao.ac.jp/ssp/ (HSC, Mandelbaum et al. 2018), LSST or WFIRST. Increasing the source galaxy number density decreases the shape noise on the galaxy-galaxy lensing measurement, which is the dominant contributer to the covariance on small scales. This makes the bias in inferred parameters when no point-mass marginalization is performed (the ‘none’ case) more significant than in the fiducial case. The extra signal-to-noise on small scales also leads to a greater gain in constraining power when using small-scale marginalization compared to point-mass marginalization only, with the uncertainty on reduced by 23%.
An impression one may take from Figure 4 is that the decrease in constraining power when using the point-mass marginalization (orange and green outlined contours) is rather large compared to the parameter bias when not using it (blue solid contour). We note that the size of this bias here is a direct result of the highly simplified, order-of-magnitude model we’ve chosen for inaccuracy in the model (contamination by a simple 1-halo term), our chosen scale cuts (e.g. using smaller scales would result in greater bias), and survey properties. In reality, for a given galaxy sample and observational setup, biases could be much larger or smaller. Furthermore, unlike in the test presented here, one would be unlikely to use the same minimum scale cut in the two approaches - a more conservative minimum scale would likely be required when not marginalizing over the point-mass to meet some requirement on the ratio between inferred parameter bias and uncertainty. We further note that informative priors on the point-mass contribution can be naturally included in our framework and would reduce the degradation when including the point-mass marginalization.
Next, (returning to our fiducial scale cuts and source galaxy density) we additionally allow , the (constant with redshift) dark energy equation of state parameter, to vary from its CDM value of , in the range . Figure 5 shows marginalized constraints on , and . Again, modeling approach (i) recovers the tightest constraints, but biases with respect to the truth values are present, with the truth lying outside the credible interval in the and planes for example. Again, when using small-scale marginalization, modest gains in constraining power are apparent in most of the 2d projections of the posterior, and the constraint on is improved by with respect to the case when only point-mass marginalization is used.
5 Discussion
We have described and demonstrated a methodology which uses an analytic marginalization approach to target two issues with small scale galaxy-galaxy lensing measurements. Firstly, the galaxy-galaxy lensing signal measured at physical separation in the lens plane receives significant contributions from scales in the galaxy-matter correlation function . We have described how uncertainty in the model prediction for this contribution can be straightforwardly marginalized over by including in the model a (for ) or (for ) dependence with free amplitude. We demonstrate that this approach can successfully remove biases in inferred parameters when an un-modeled one-halo contribution is present in the galaxy-galaxy lensing signal, and that this marginalization can be performed analytically, to avoid adding extra sampling parameters to the parameter inference. We note that the approach of Baldauf et al. (2010) also achieves this goal, although our approach may more naturally allow the use of priors and retention of shear-ratio information in a tomographic analysis.
Secondly, we demonstrate that an analytic marginalization approach can also be used to extract shear-ratio information from small scale galaxy-galaxy lensing measurements that would otherwise be excluded due to modelling uncertainties i.e. those corresponding to physical separation in the lens plane , where is the smallest physical scale for which a prediction is accurate. Again, the use of analytic marginalization allows us include many extra nuisance parameters without having to explicitly sample over them in a Monte Carlo chain, making the approach tractable for cosmological parameter estimation. We have shown that this extra shear-ratio information allows improved constraints on parameters which account for photometric redshift uncertainties, as well as cosmological parameters. Our approach here is an example of including theoretical uncertainties in the model, which is explored in detail by Baldauf et al. (2016). Our case is an extreme one in that we allow complete freedom in below some scale.
When it comes to using such methodology in an analysis of real data, there are several factors to consider that merit some discussion. Firstly, when using the point-mass marginalization, one must still choose a minimum scale for which the prediction is trustworthy. We have discussed the rough scales on which typical modeling approaches are likely to break down at a level relevant to current and future large-scale structure surveys: \text{,}\mathrm{Mpc}$$ for a linear bias model, a few megaparsecs for a higher-order perturbative approach, while an HOD approach could potentially be reliable to tens or hundreds of kiloparsecs.
Ultimately, realistic, large volume galaxy simulations are required to inform this decision. Cosmological hydrodynamical simulations, which attempt to include some of the hydrodynmical processes important for galaxy formation, have advanced significantly in the past decade both in terms of simulation volume, and matching observed properties of the real universe (e.g. Schaye et al. 2010; Vogelsberger et al. 2014; Schaye et al. 2015; Springel et al. 2018). However, there is still much uncertainty in the sub-grid prescriptions required to implement physical processes on scales below the resolution of these simulations. While uncertainty in the sub-grid modelling may not strongly impact the mass distribution on larger scales, it will impact the dependence of observable galaxy properties on that mass distribution, and hence the galaxy-galaxy lensing and clustering signals of a galaxy sample selected on observable properties.
It is likely therefore that empirical approaches where galaxies are added to gravity-only simulations using recipes calibrated against cosmological observables (e.g. Tasitsiomi et al. 2004; Conroy et al. 2006; Hearin et al. 2014; Crocce et al. 2015; DeRose et al. 2019) will continue to play an important role in understanding the relation between the distributions of galaxies and the distribution of matter in the Universe (see Wechsler & Tinker (2018) for a recent review).
Such simulations are also likely required to estimate the impact of redshift evolution of lens properties across the width of lens redshift bins, a potential systematic effect when extracting shear-ration information using the methods presented here. We are hopeful however that given that galaxy-galaxy lensing analyses have typically been performed using lens galaxies with spectroscopic or high quality photometric redshifts, sufficiently narrow lens bins could usually be constructed.
Finally, we note the potential problems due to intrinsic galaxy alignments. If photometric redshift uncertainties in the source galaxy sample allow some overlap in redshift between the lens and source samples, there may be some net alignment of source galaxies’ intrinsic shapes around lens galaxy positions (Hirata et al., 2004; Troxel & Ishak, 2014; Joachimi et al., 2015; Blazek et al., 2012). Significant contamination from intrinsic alignments could bias the shear-ratio information extracted from small-scale galaxy-galaxy lensing signals, since the intrinsic alignment contribution will not scale according to equation 36. So far, detections of this intrinsic alignment signal have largely been limited to bright, red galaxies (e.g. Mandelbaum et al. 2006; Hirata et al. 2007; Joachimi et al. 2011; Blazek et al. 2011; Singh & Mandelbaum 2016). It is possible that this contamination can be mitigated by removing these galaxies from the source sample, through improved photo-z methods, or with modelling approaches (e.g. Crittenden et al. 2001; Hirata et al. 2004; Bridle & King 2007; Hui & Zhang 2008; Blazek et al. 2015; Blazek et al. 2017).
Acknowledgements
Thanks to Gary Bernstein, Joe DeRose, Chris Hirata, Shivam Pandey, Judit Prat, Carles Sanchez and David Weinberg for useful discussions. JB is supported by a Swiss National Science Foundation Ambizione Fellowship. BJ is supported in part by the US Department of Energy grant desc0007901. This work used resources at the Ohio Supercomputing Center (Ohio Supercomputer Center, 1987).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Baldauf et al. (2010) Baldauf T., Smith R. E., Seljak U., Mandelbaum R., 2010, Phys. Rev. D , 81, 063531 · doi ↗
- 2Baldauf et al. (2016) Baldauf T., Mirbabayi M., Simonović M., Zaldarriaga M., 2016, ar Xiv e-prints,
- 3Baltz et al. (2009) Baltz E. A., Marshall P., Oguri M., 2009, Journal of Cosmology and Astro-Particle Physics , 2009, 015 · doi ↗
- 4Berlind & Weinberg (2002) Berlind A. A., Weinberg D. H., 2002, Ap J , 575, 587 · doi ↗
- 5Bernstein & Jain (2004) Bernstein G., Jain B., 2004, Ap J , 600, 17 · doi ↗
- 6Blazek et al. (2011) Blazek J., Mc Quinn M., Seljak U., 2011, Journal of Cosmology and Astro-Particle Physics , 2011, 010 · doi ↗
- 7Blazek et al. (2012) Blazek J., Mandelbaum R., Seljak U., Nakajima R., 2012, Journal of Cosmology and Astro-Particle Physics , 2012, 041 · doi ↗
- 8Blazek et al. (2015) Blazek J., Vlah Z., Seljak U., 2015, J. Cosmology Astropart. Phys. , 8, 015 · doi ↗