TL;DR
This paper introduces a data-driven framework that estimates high-resolution, multi-year dynamic origin-destination demand using multi-source traffic data, revealing demand trends and evolution over several years.
Contribution
It develops a novel GPU-based optimization method and clustering approach to estimate 5-minute OD demand for multiple years, addressing a gap in high-resolution, multi-year OD estimation.
Findings
Efficient estimation of daily 5-minute OD demand from 2014-2016.
Revealed demand patterns and trends over multiple years.
Demonstrated applicability on Sacramento region data.
Abstract
Dynamic origin-destination (OD) demand is central to transportation system modeling and analysis. The dynamic OD demand estimation problem (DODE) has been studied for decades, most of which solve the DODE problem on a typical day or several typical hours. There is a lack of methods that estimate high-resolution dynamic OD demand for a sequence of many consecutive days over several years (referred to as 24/7 OD in this research). Having multi-year 24/7 OD demand would allow a better understanding of characteristics of dynamic OD demands and their evolution/trends over the past few years, a critical input for modeling transportation system evolution and reliability. This paper presents a data-driven framework that estimates day-to-day dynamic OD using high-granular traffic counts and speed data collected over many years. The proposed framework statistically clusters daily traffic data…
Click any figure to enlarge with its caption.
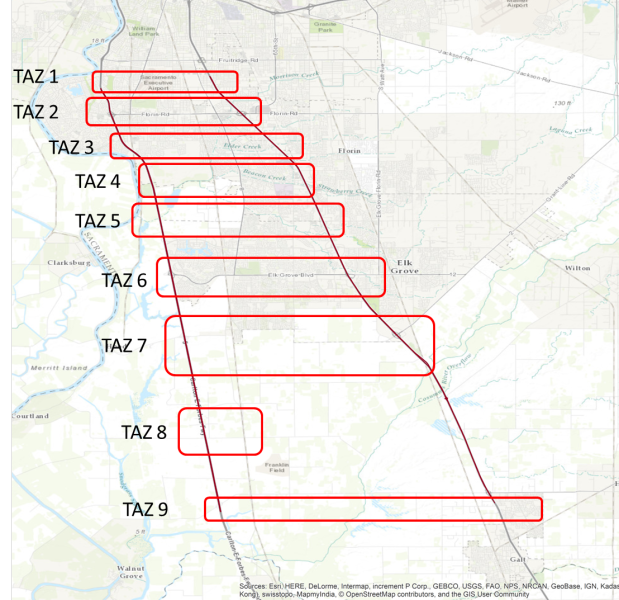 Figure 1
Figure 1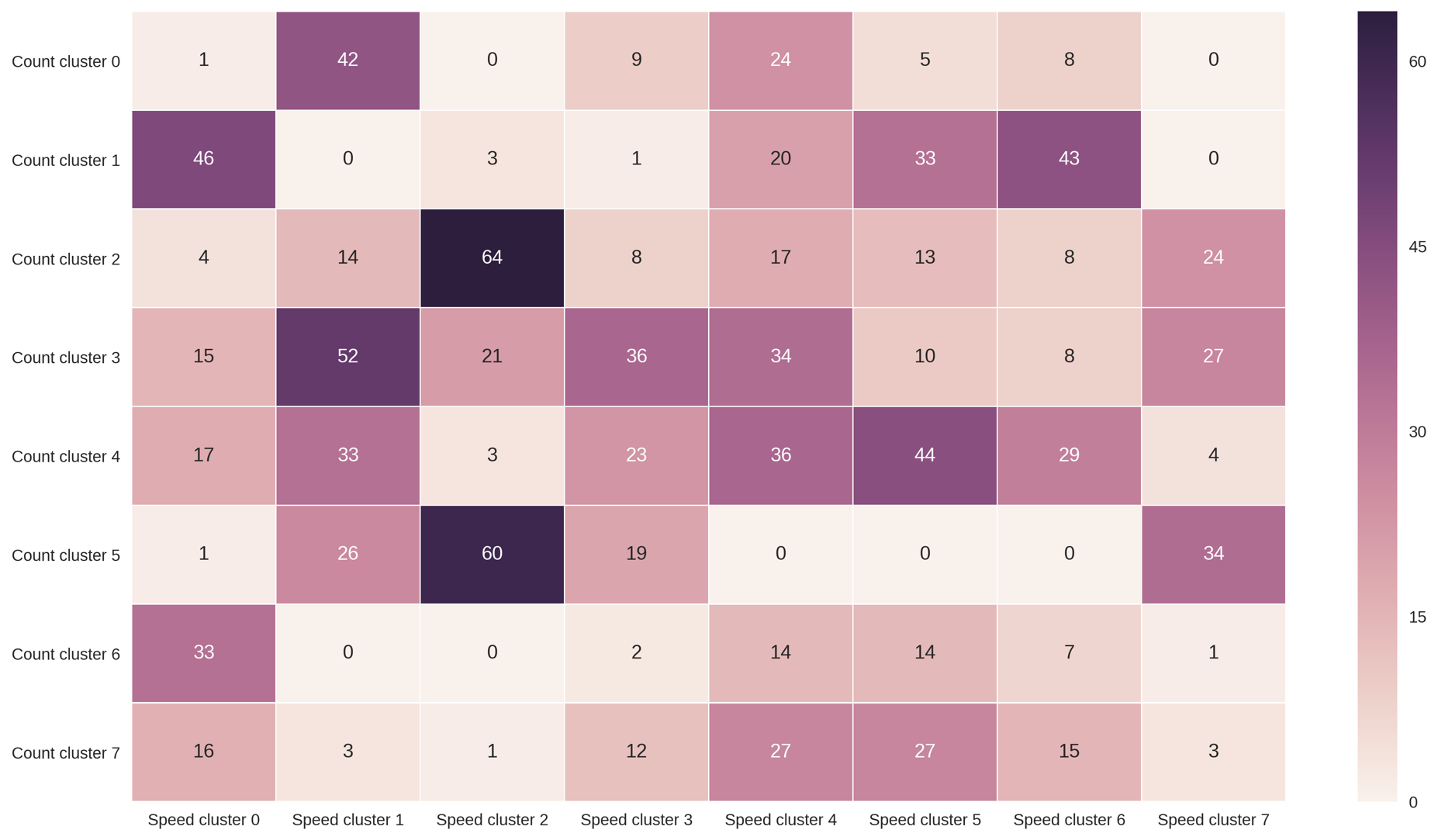 Figure 2
Figure 2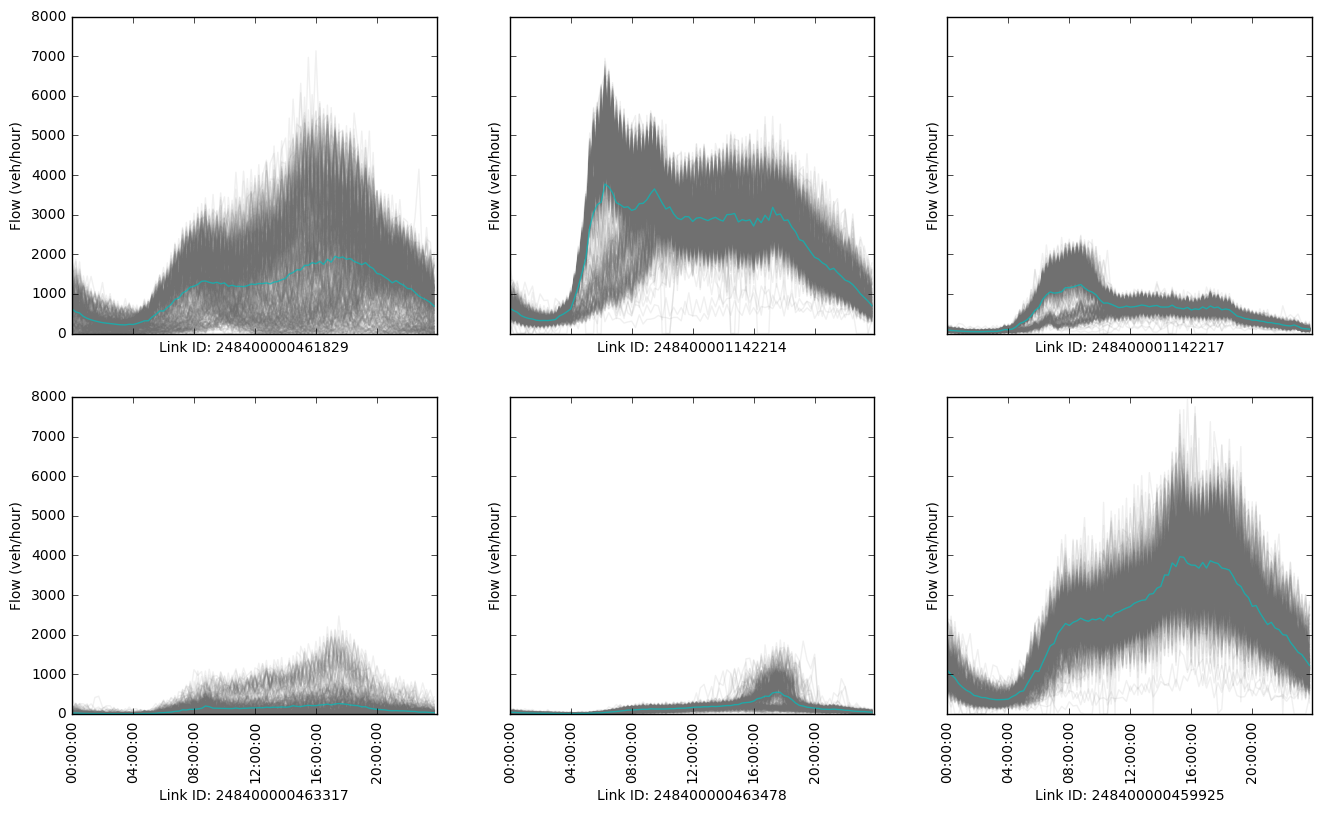 Figure 3
Figure 3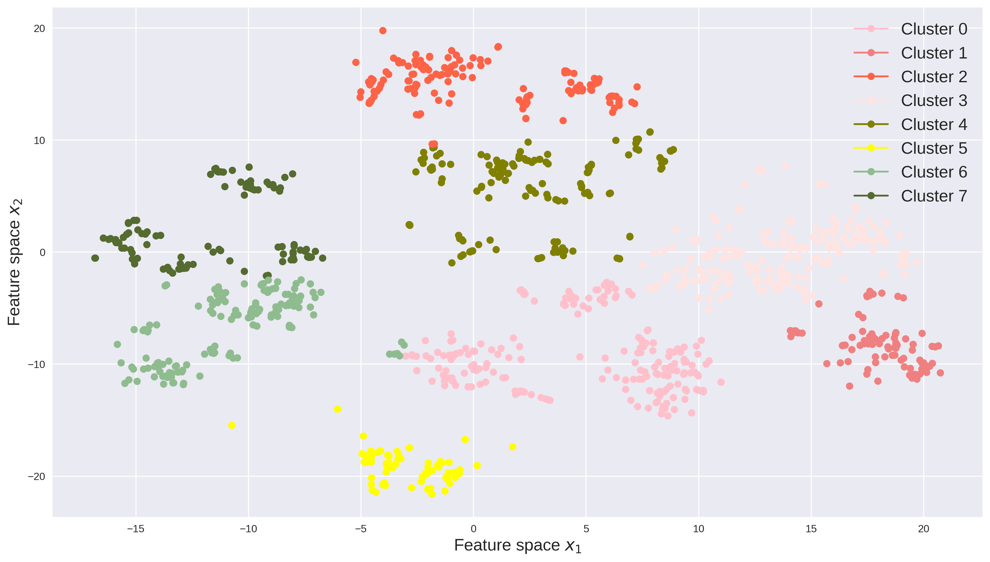 Figure 4
Figure 4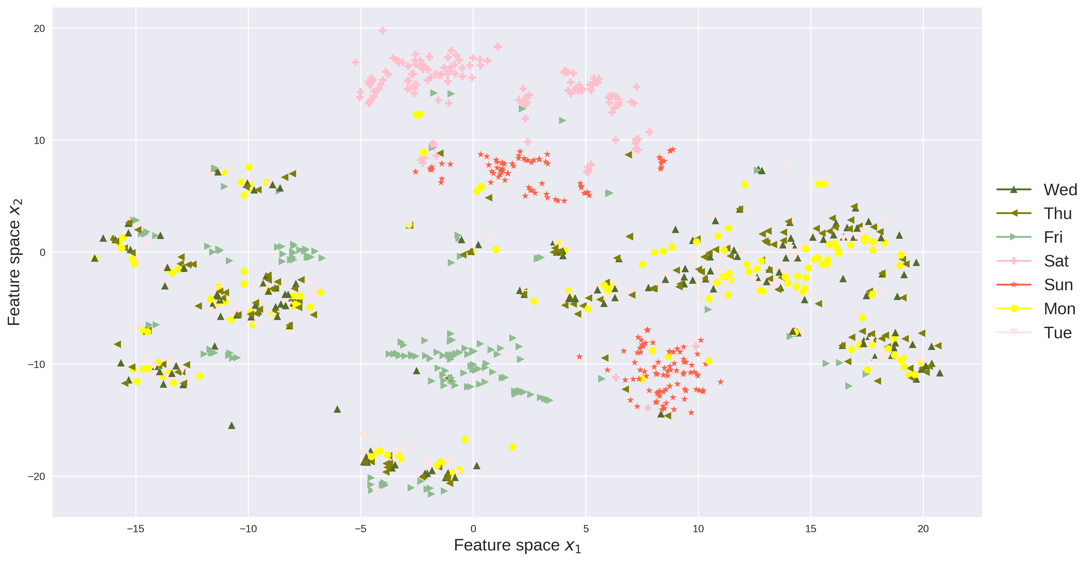 Figure 5
Figure 5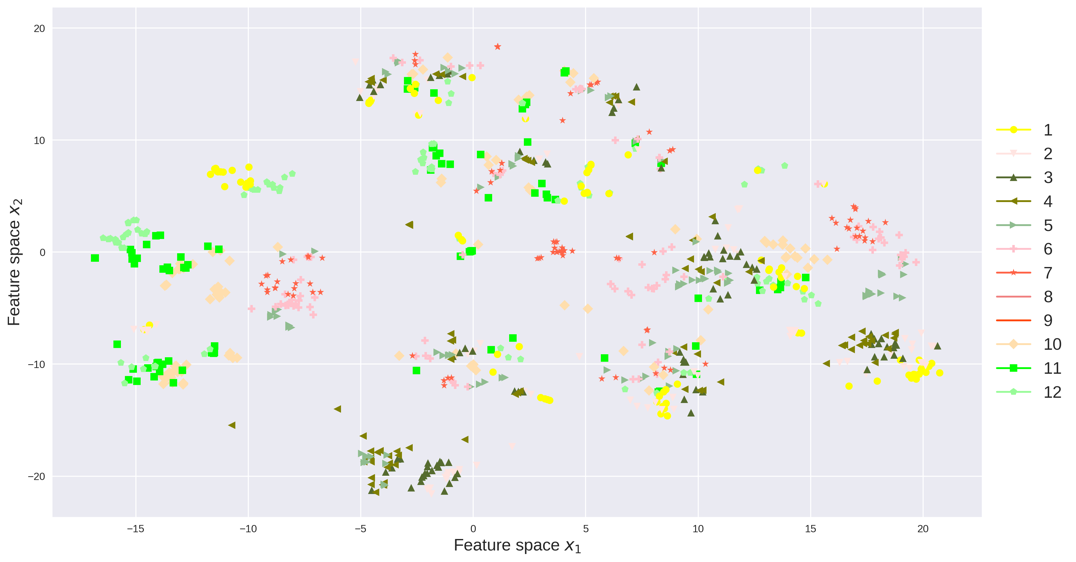 Figure 6
Figure 6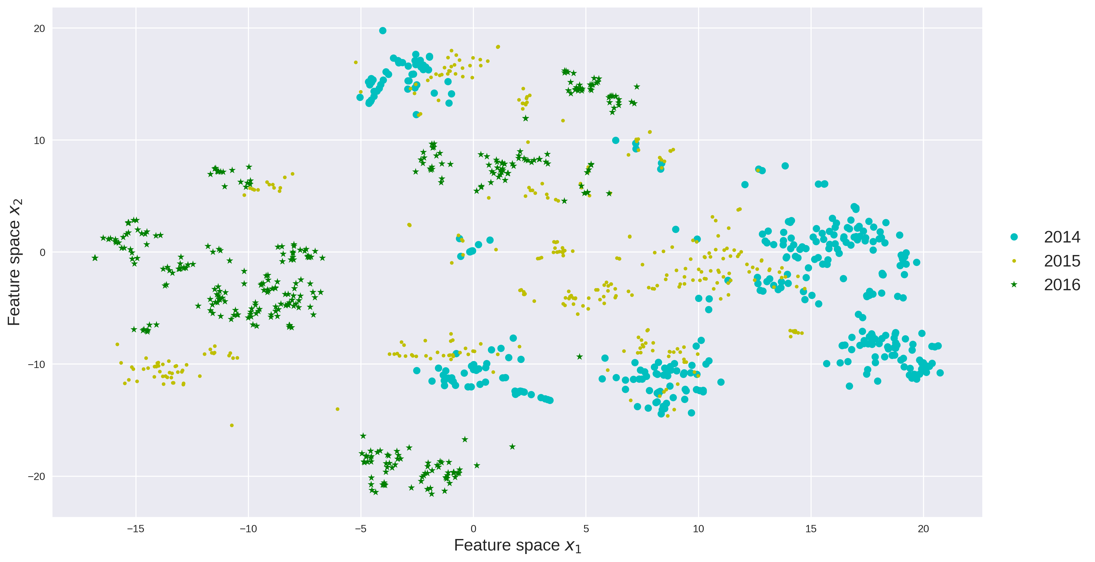 Figure 7
Figure 7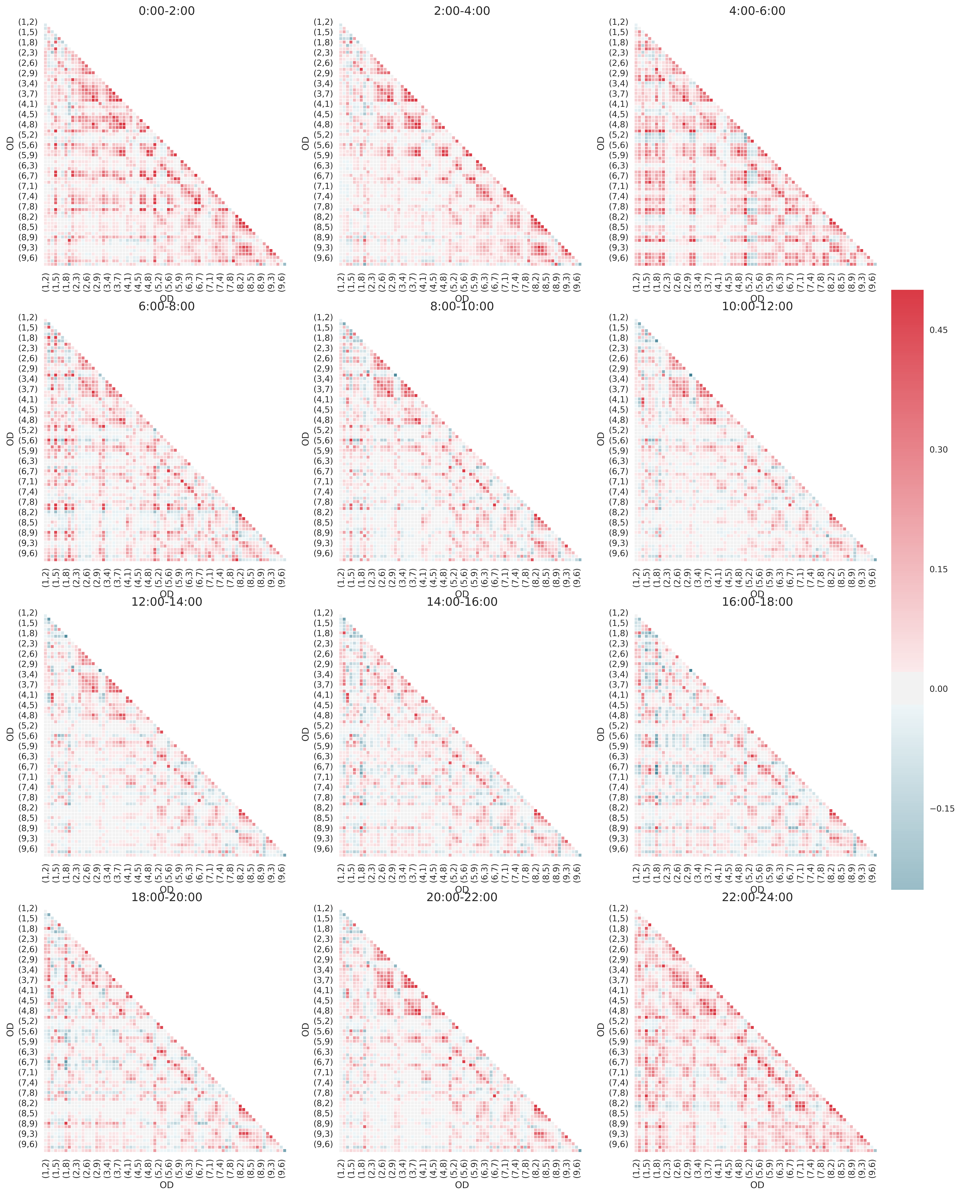 Figure 8
Figure 8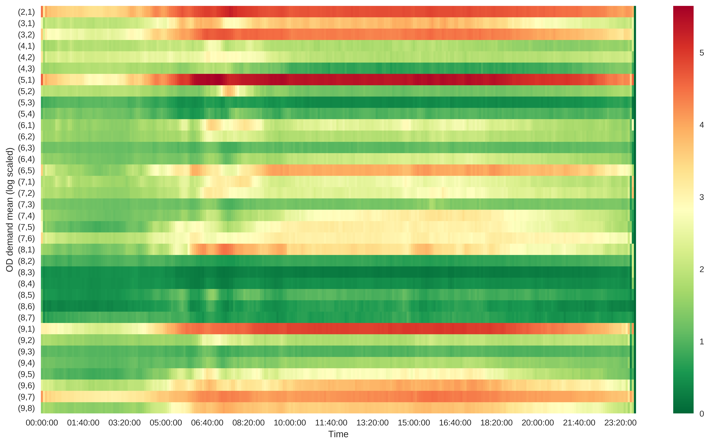 Figure 9
Figure 9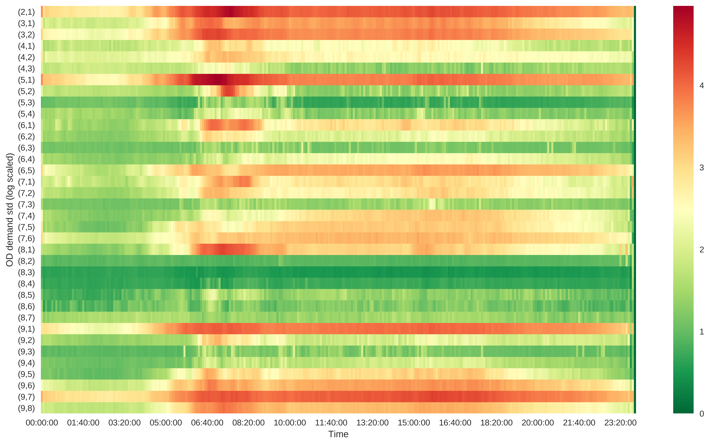 Figure 10
Figure 10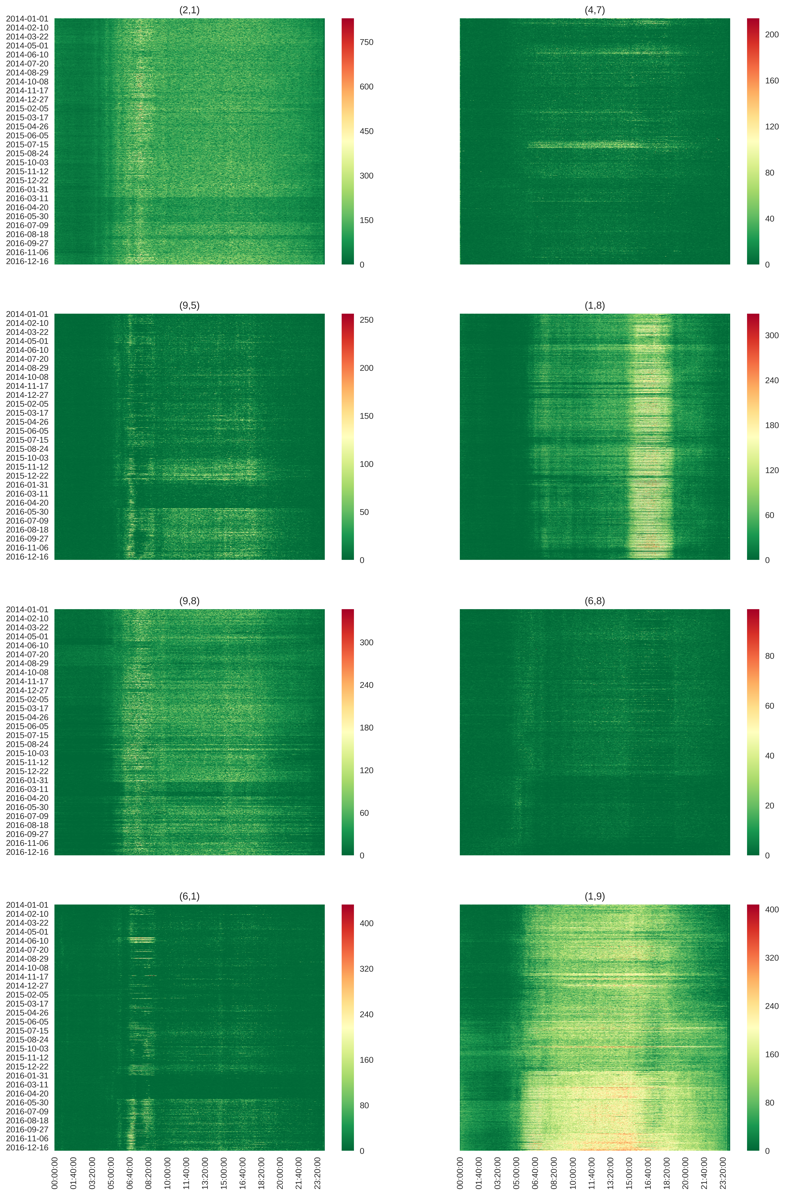 Figure 11
Figure 11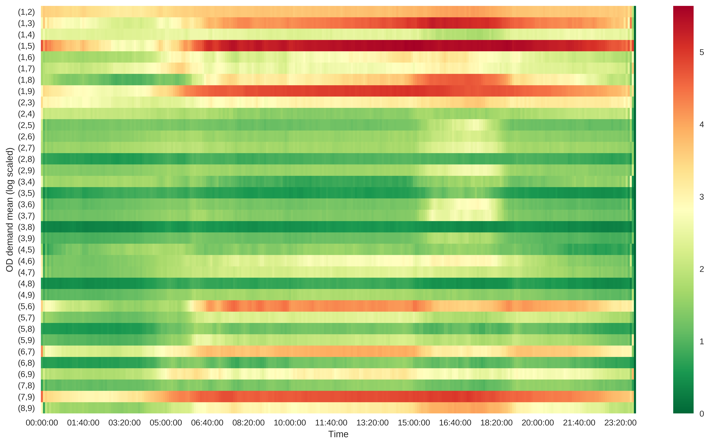 Figure 12
Figure 12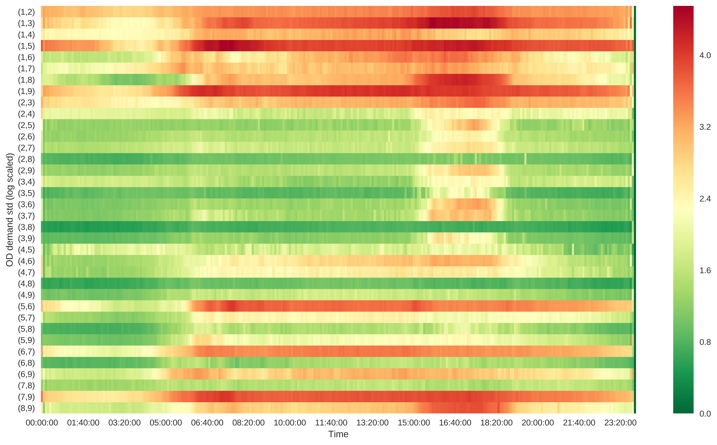 Figure 13
Figure 13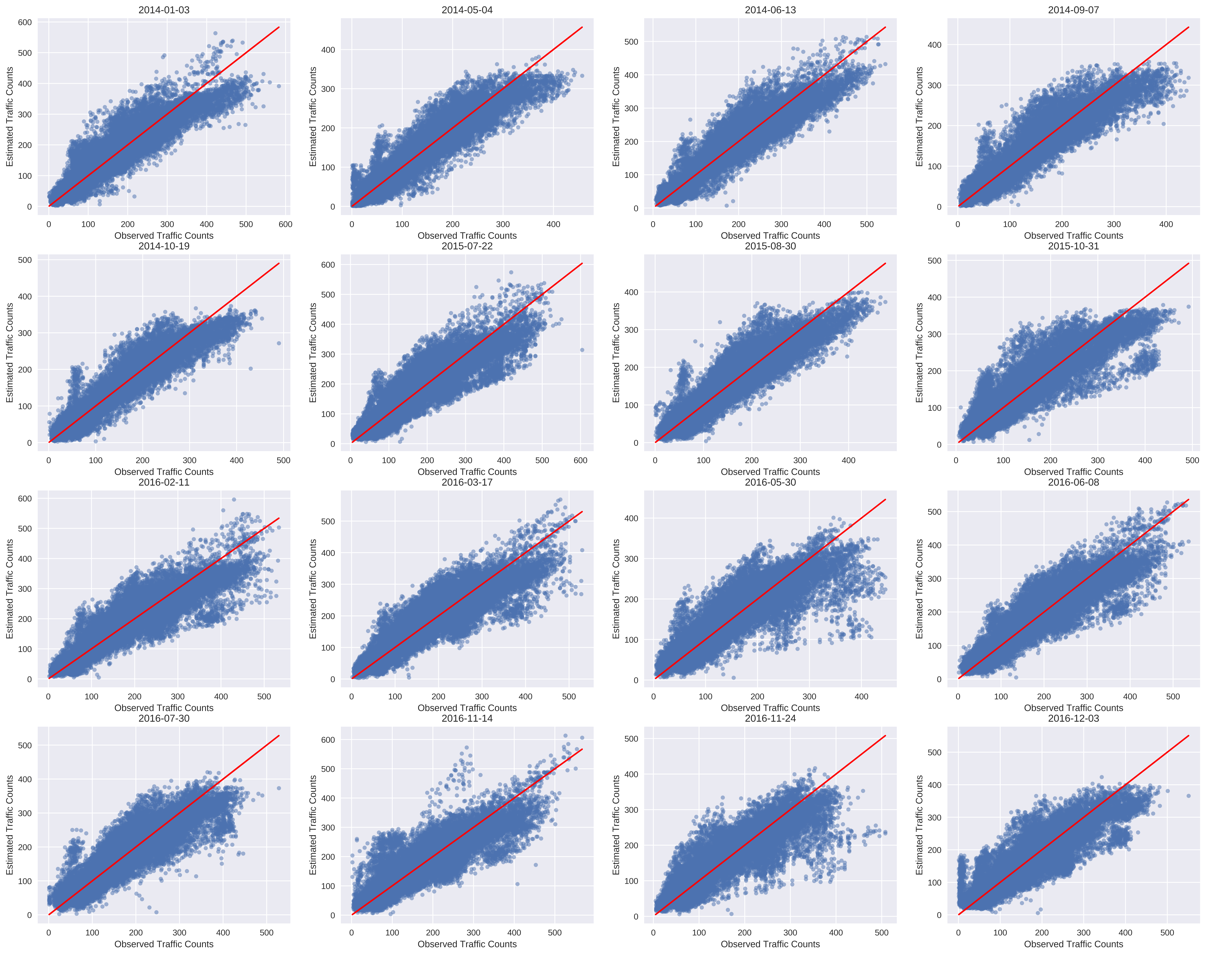 Figure 14
Figure 14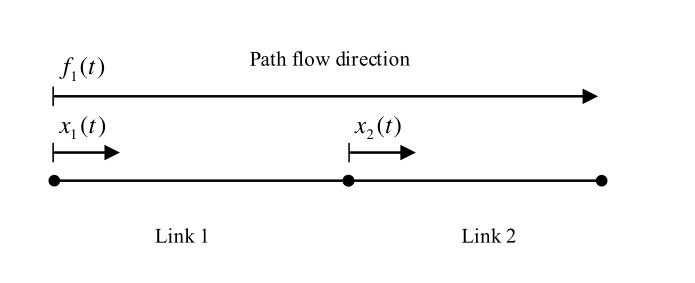 Figure 15
Figure 15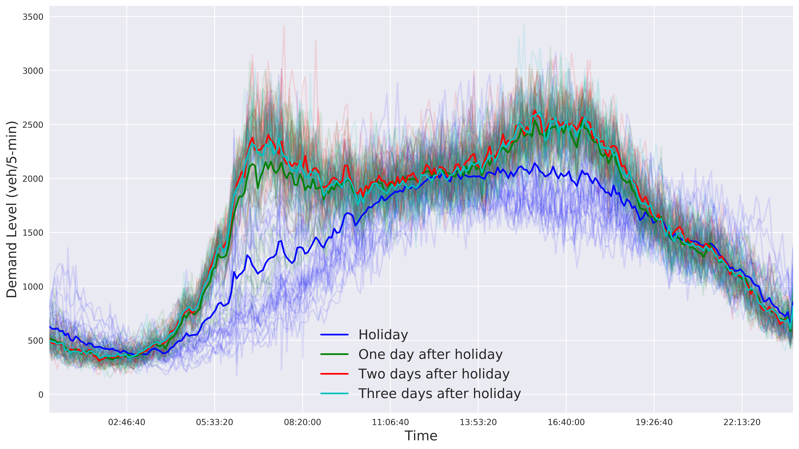 Figure 16
Figure 16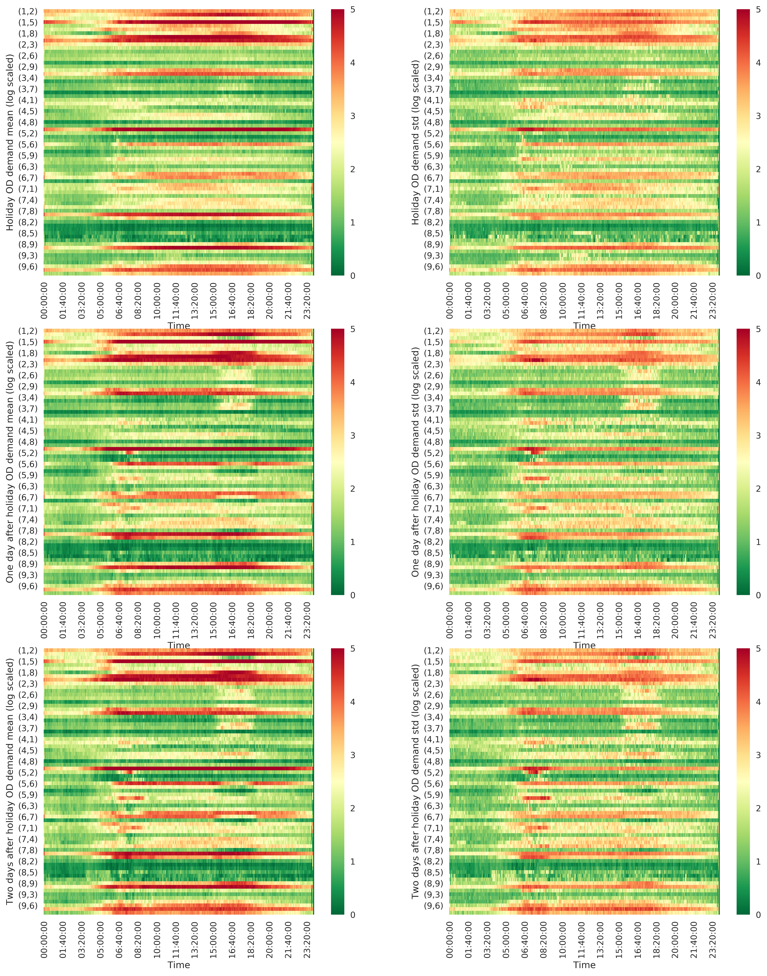 Figure 17
Figure 17 Figure 18
Figure 18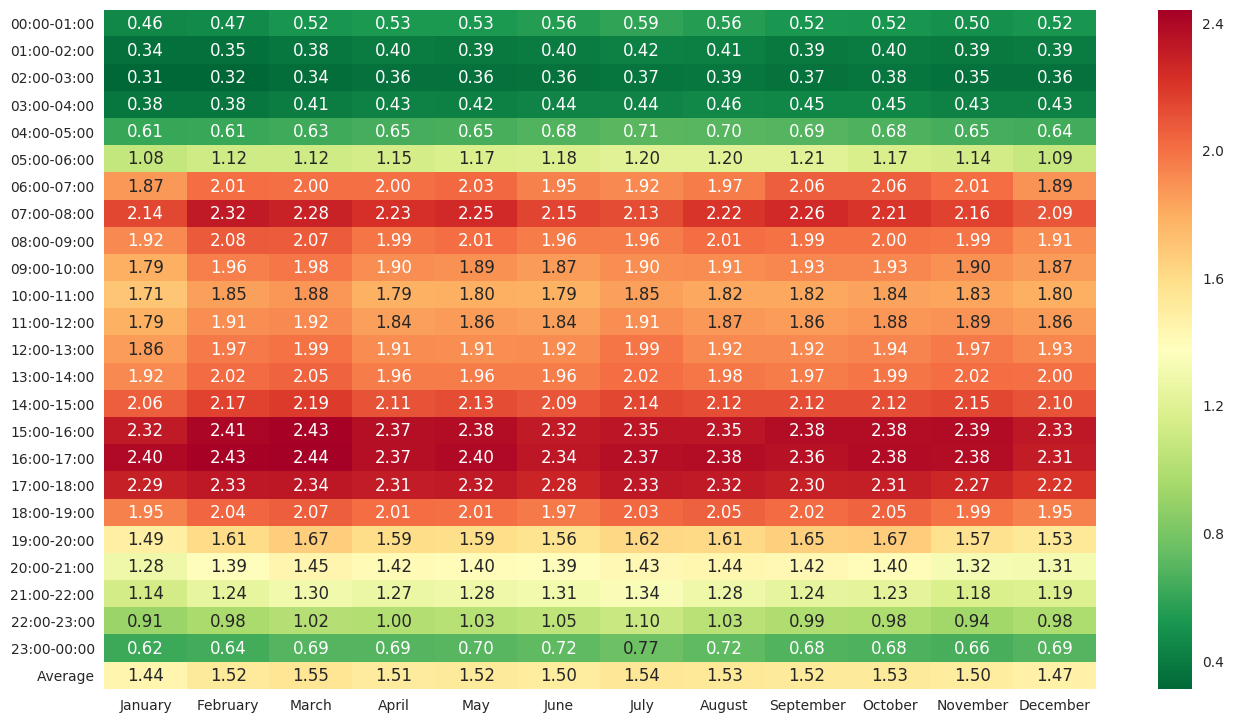 Figure 19
Figure 19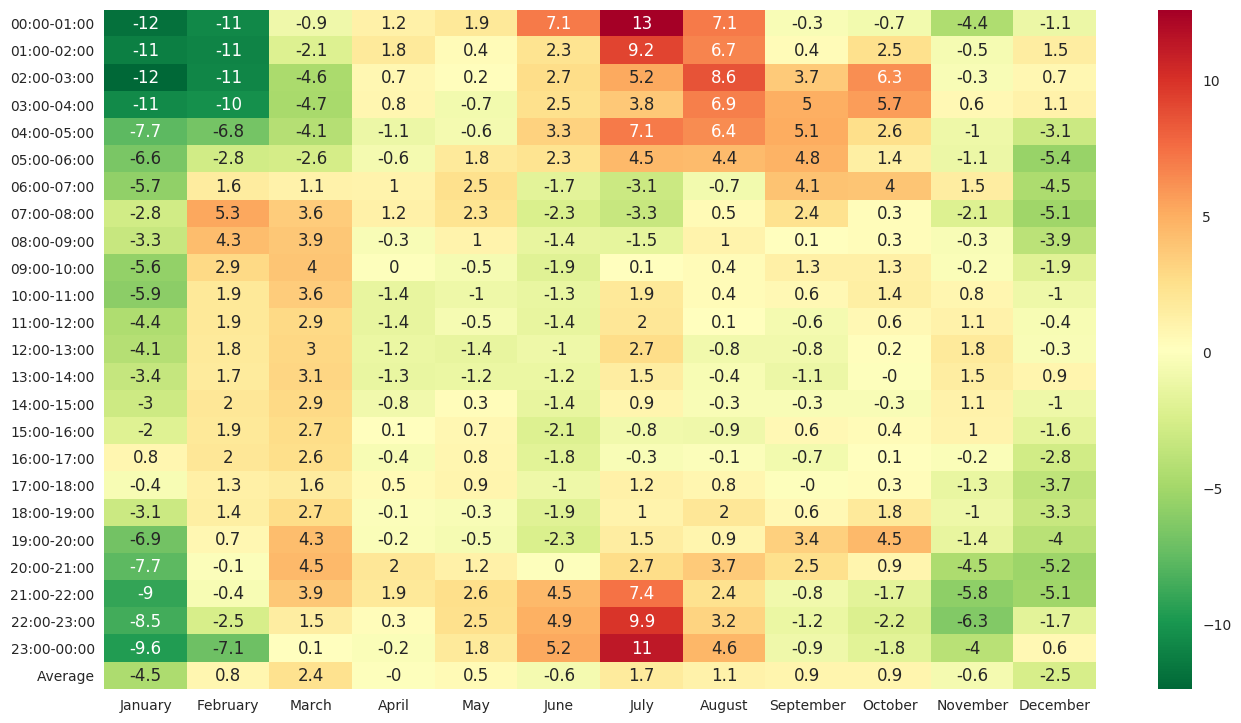 Figure 20
Figure 20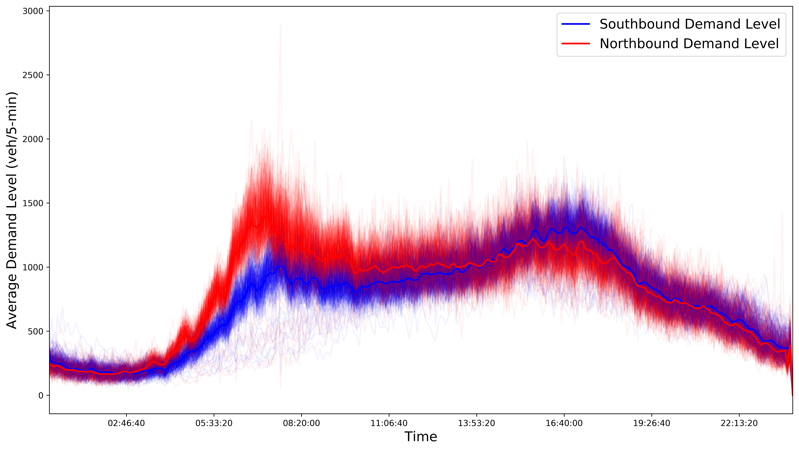 Figure 21
Figure 21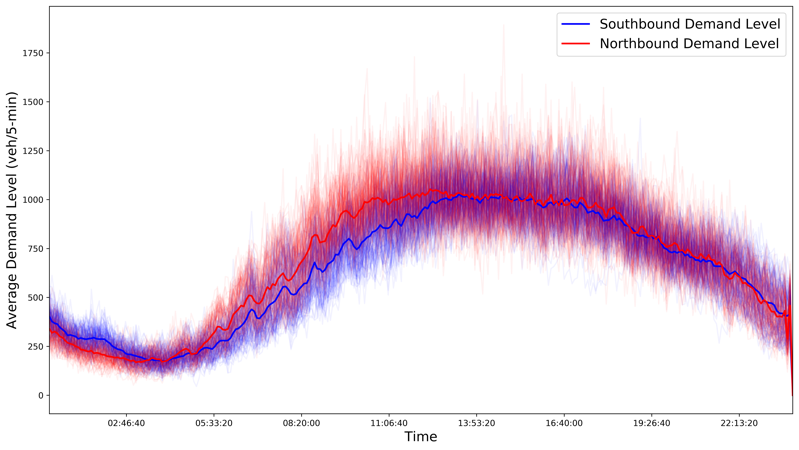 Figure 22
Figure 22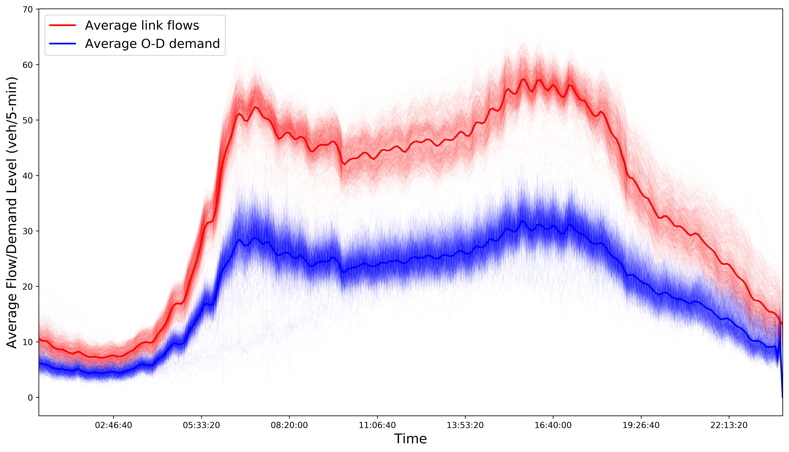 Figure 23
Figure 23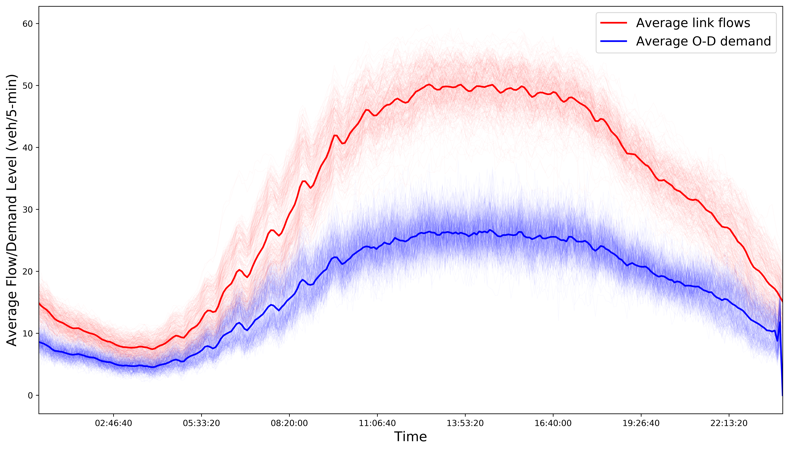 Figure 24
Figure 24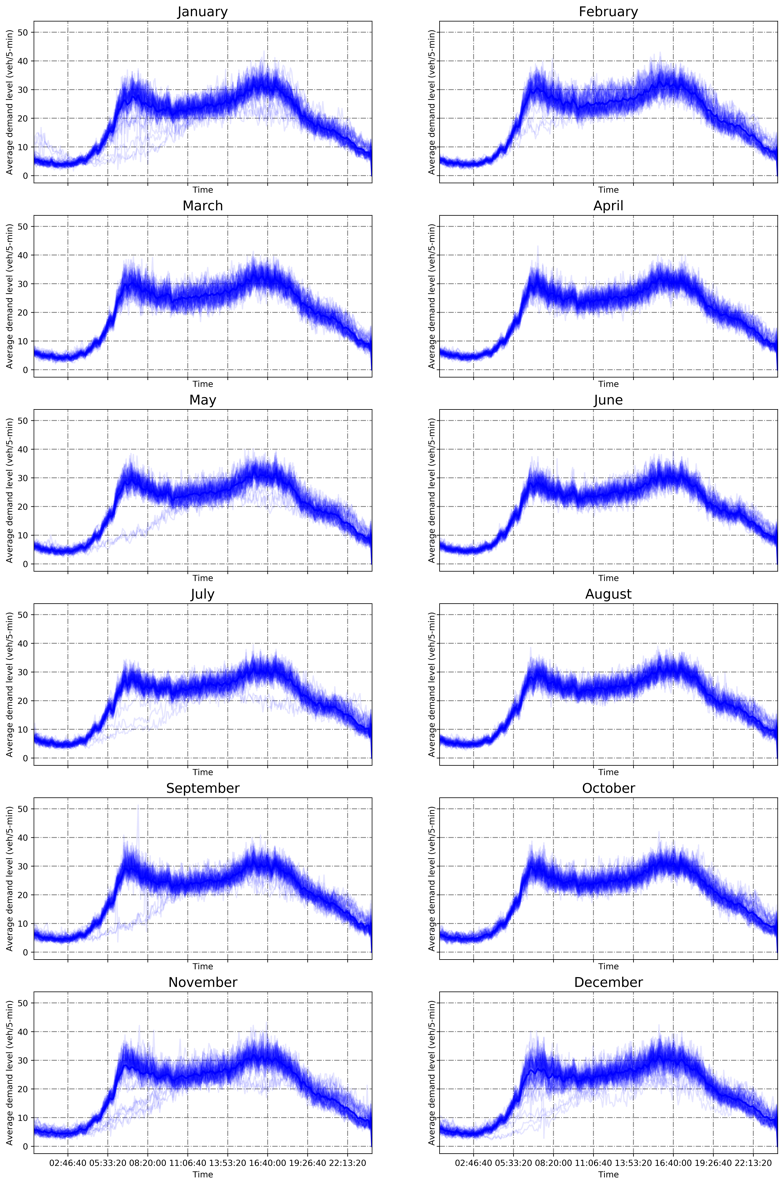 Figure 25
Figure 25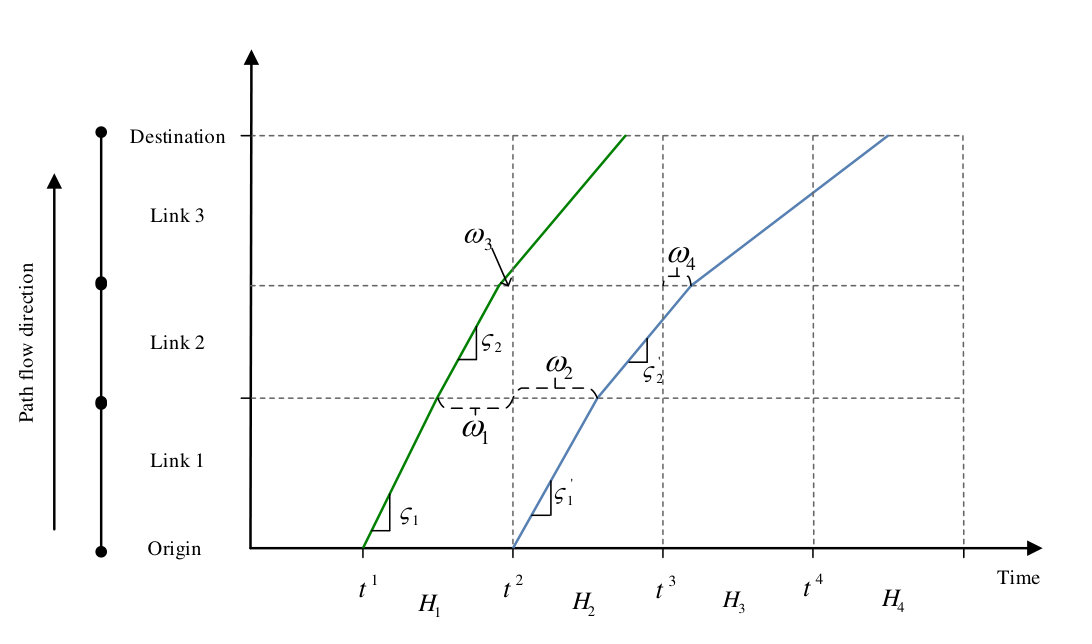 Figure 26
Figure 26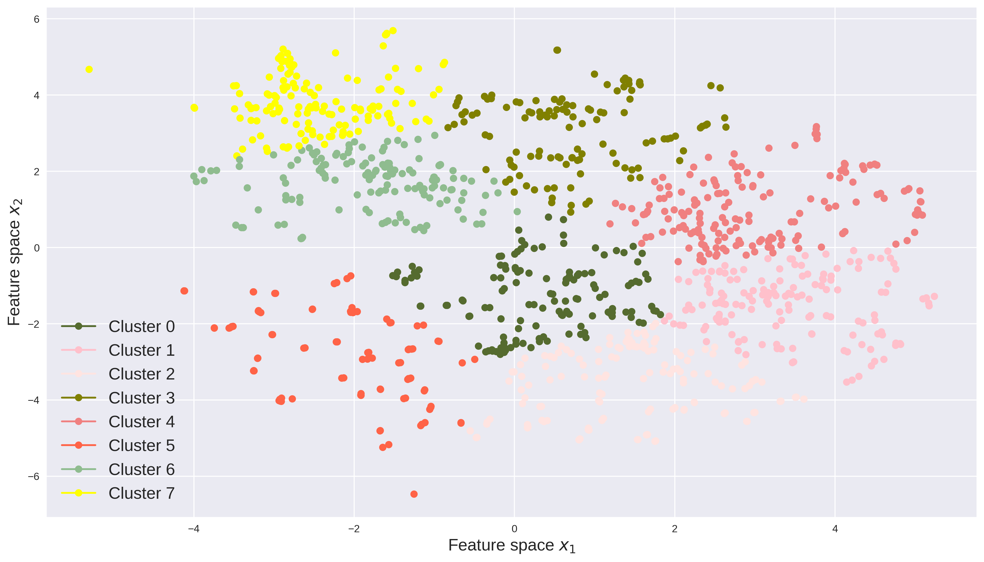 Figure 27
Figure 27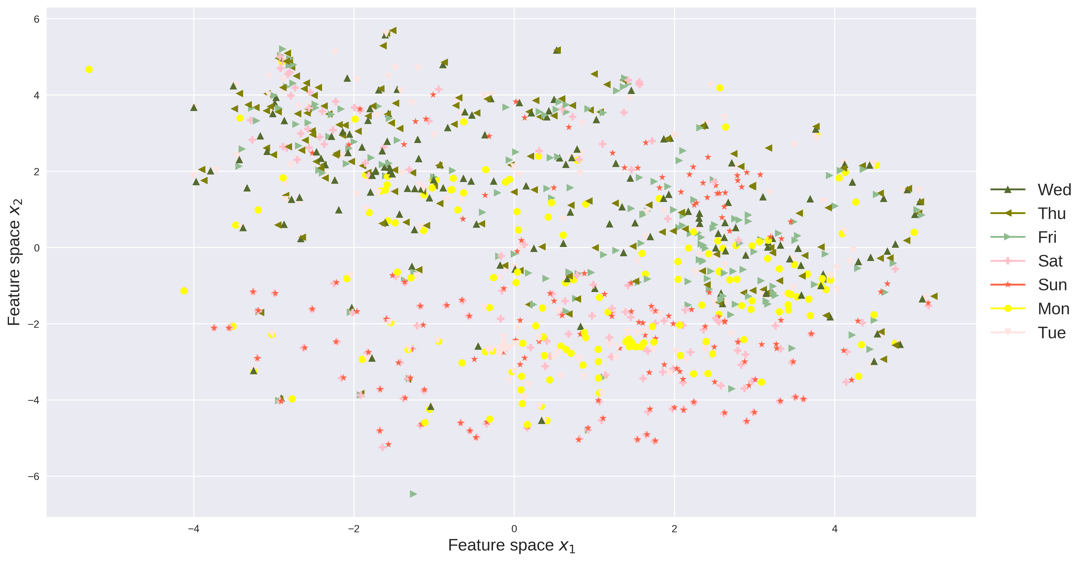 Figure 28
Figure 28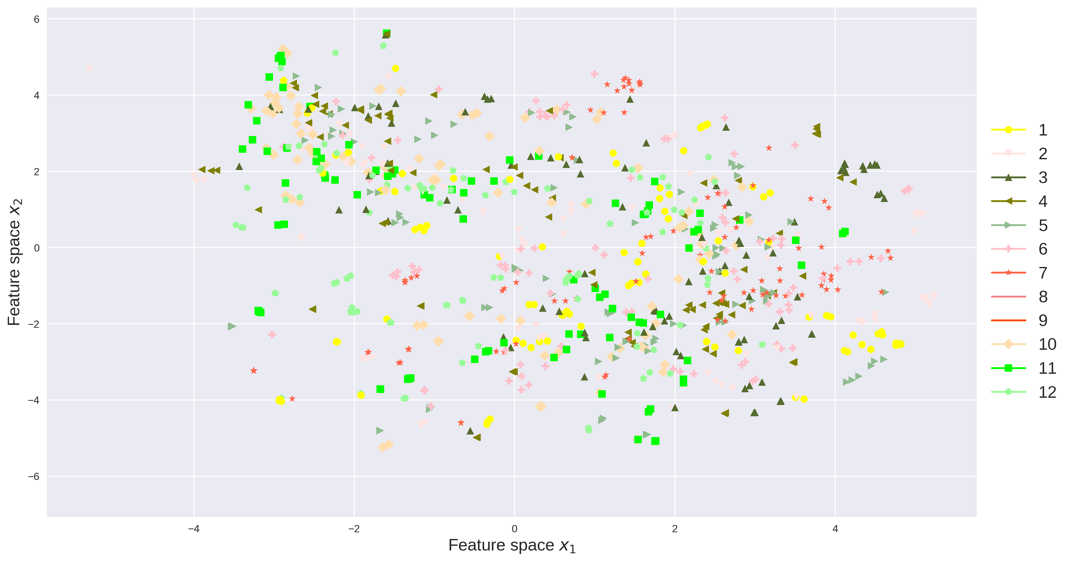 Figure 29
Figure 29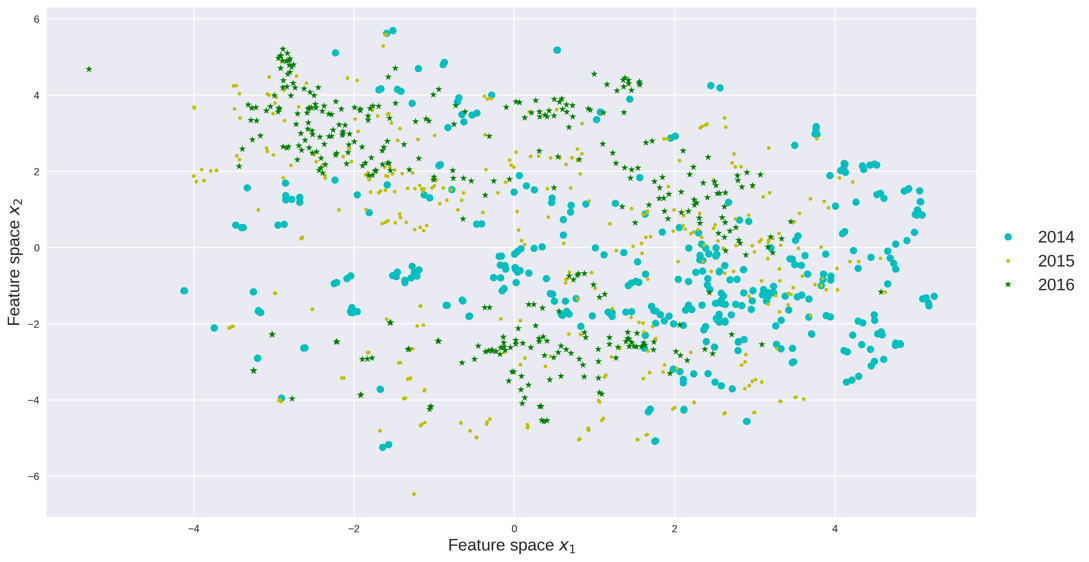 Figure 30
Figure 30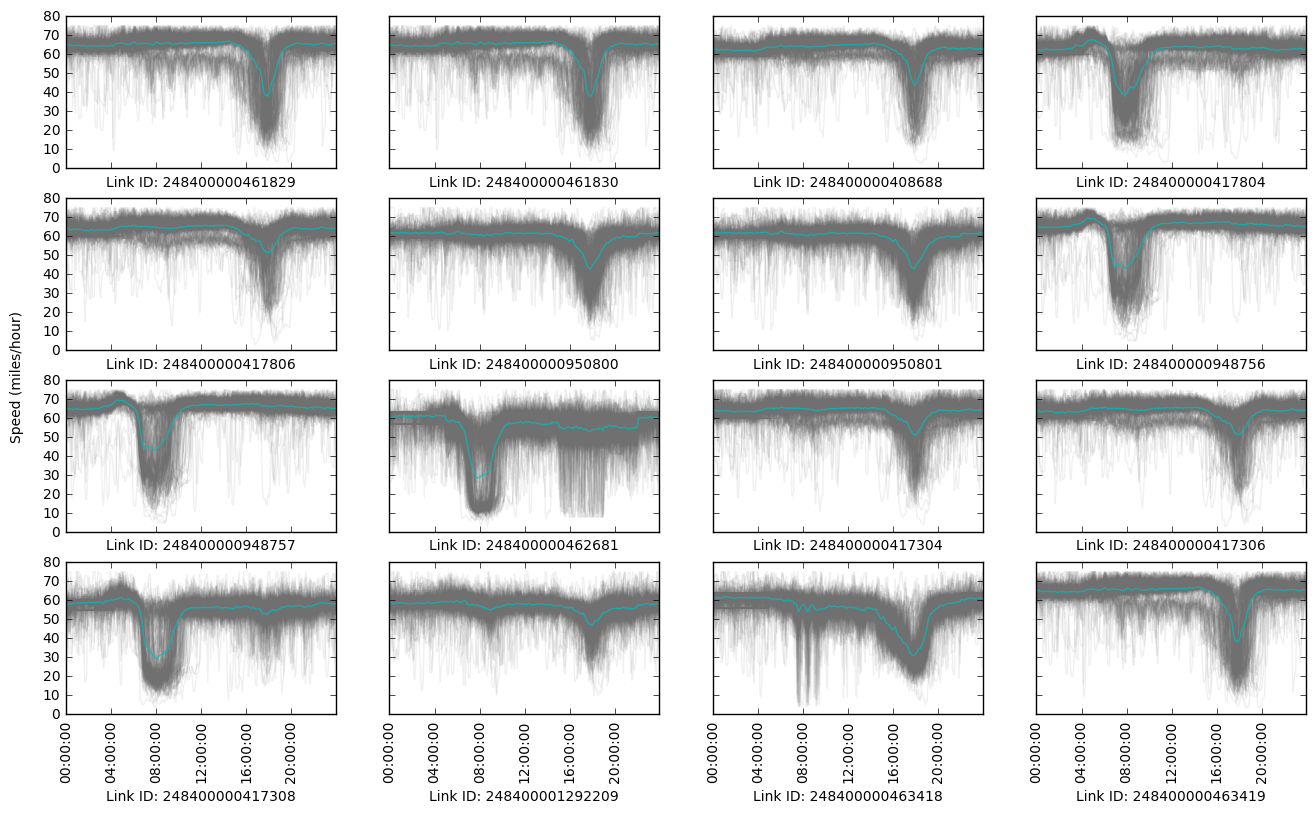 Figure 31
Figure 31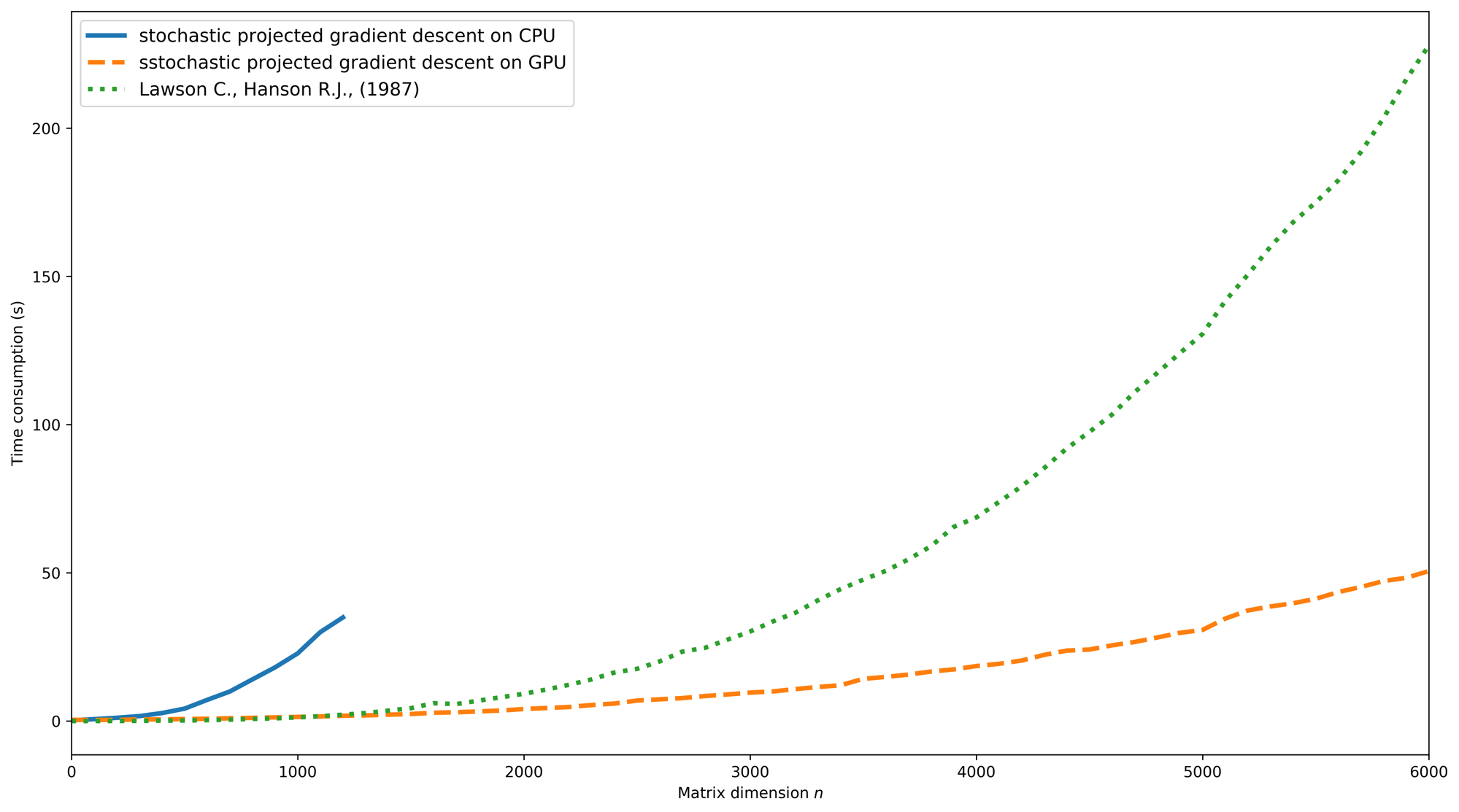 Figure 32
Figure 32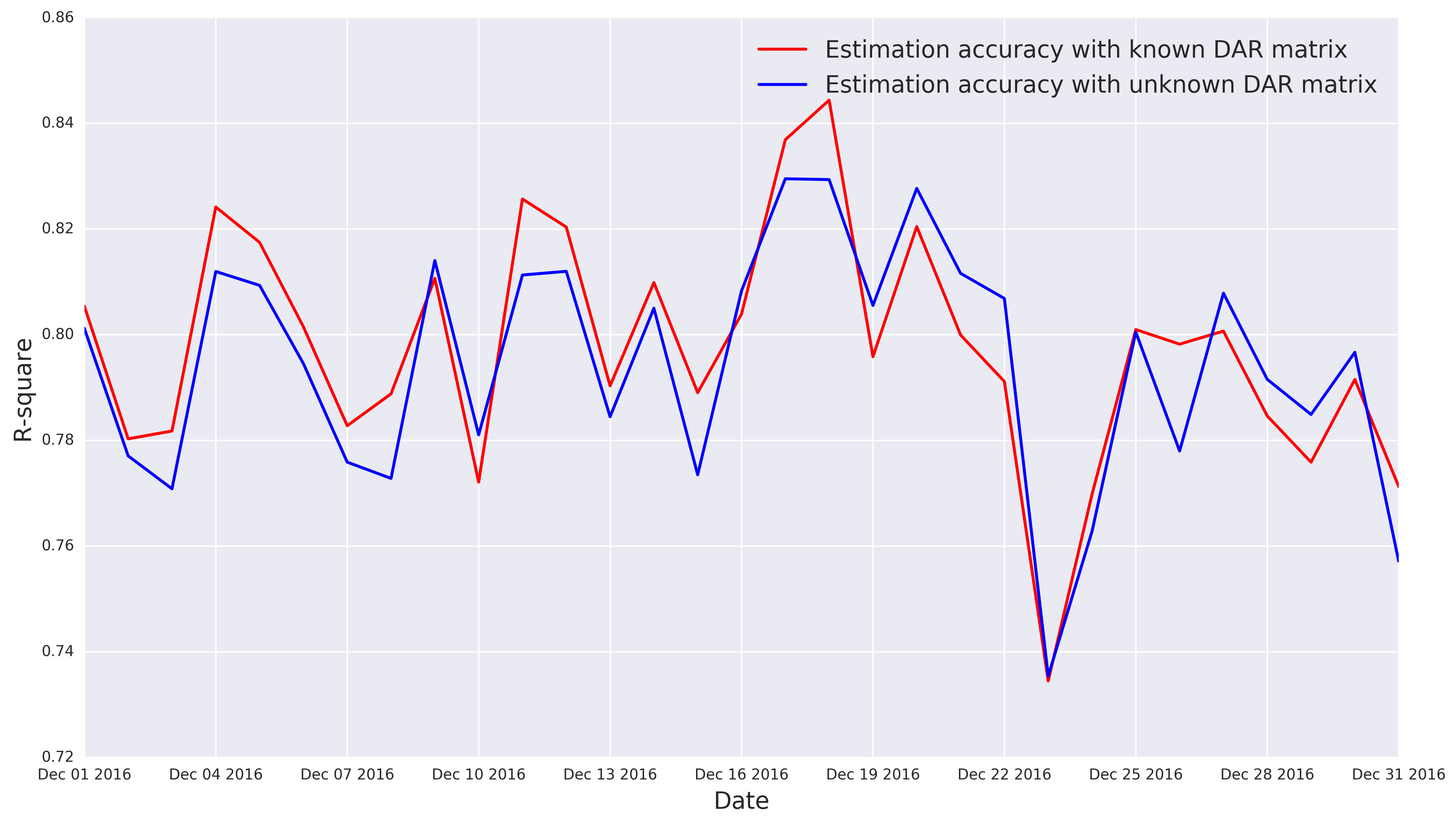 Figure 33
Figure 33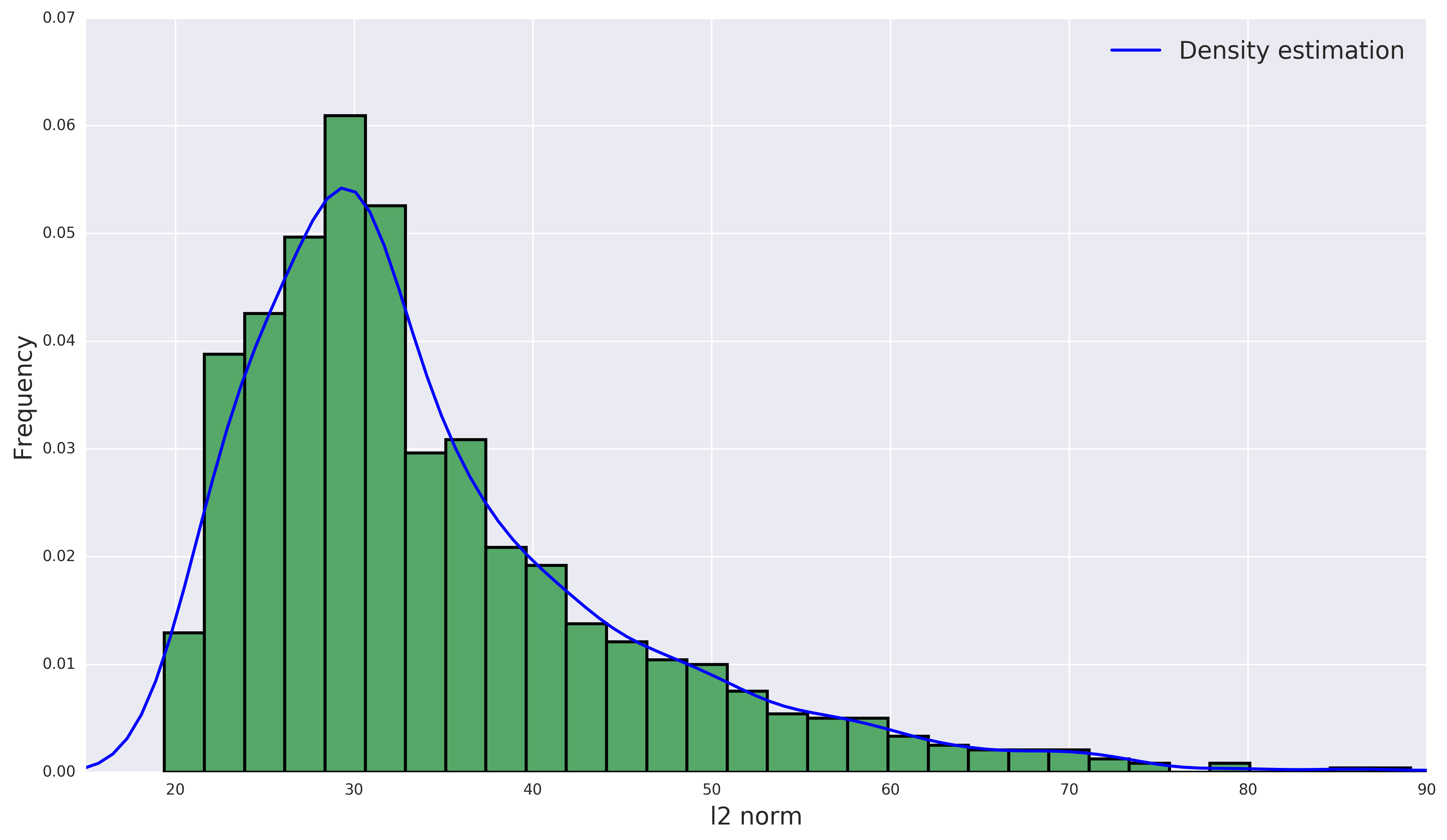 Figure 34
Figure 34| The set of all links | |
| The set of links with flow observations | |
| The set of all OD pairs | |
| The set of all paths between OD pair | |
| Path/link incidence for th path in OD pair and link | |
| Variables in continuous time | |
| The departure time of path flow or OD flow | |
| The arrival time at the tail of link | |
| The set of all possible departure time from any path and link | |
| The set of all possible arrival time at all links | |
| The th path flow rate for OD pair at time | |
| The flow rate at the tail of link at time | |
| The flow rate of OD pair at time | |
| The path cost for path for OD pair departing at time | |
| The portion of choosing path in all paths between OD pair at time | |
| Variables in discrete time | |
| The index of departure time interval of path flow or OD flow | |
| The index of arrival time interval at the tail of link | |
| The th path flow rate for OD pair in time interval | |
| The flow rate at the tail of link in time interval | |
| The flow rate of OD pair in time interval | |
| The portion of choosing path in all paths between OD pair in time interval | |
| The portion of the th path flow departing within time interval between OD pair which arrives at link within time interval (namely, an entry of the DAR matrix) | |
| Variable | Notations | Dimension | Type | Description |
|---|---|---|---|---|
| OD flow | Dense | th OD flow in time interval is place at entry | ||
| Path flow | Dense | th path flow in time interval is placed at entry | ||
| Link flow | Dense | th link flow in time interval is placed at entry | ||
| DAR matrix | Sparse | Dynamic assignment ratio of th path in OD in time interval for link in time interval is placed at entry | ||
| Link/path indices matrix | Sparse | is if path for OD pair passes link | ||
| Route choice matrix | Sparse | Route choice for path for OD pair in time interval is placed at entry |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsSPEED: Separable Pyramidal Pooling EncodEr-Decoder for Real-Time Monocular Depth Estimation on Low-Resource Settings
Estimating multi-year origin-destination demand using high-granular multi-source traffic data
Wei Ma, Zhen (Sean) Qian
Department of Civil and Environmental Engineering
Carnegie Mellon University, Pittsburgh, PA 15213
{weima, seanqian}@cmu.edu
Abstract
Dynamic origin-destination (OD) demand is central to transportation system modeling and analysis. The dynamic OD demand estimation problem (DODE) has been studied for decades, most of which solve the DODE problem on a typical day or several typical hours. There is a lack of methods that estimate high-resolution dynamic OD demand for a sequence of many consecutive days over several years (referred to as 24/7 OD in this research). Having multi-year 24/7 OD demand would allow a better understanding of characteristics of dynamic OD demands and their evolution/trends over the past few years, a critical input for modeling transportation system evolution and reliability. This paper presents a data-driven framework that estimates day-to-day dynamic OD using high-granular traffic counts and speed data collected over many years. The proposed framework statistically clusters daily traffic data into typical traffic patterns using t-Distributed Stochastic Neighbor Embedding (t-SNE) and k-means methods. A GPU-based stochastic projected gradient descent method is proposed to efficiently solve the multi-year 24/7 DODE problem. It is demonstrated that the new method efficiently estimates the -minute dynamic OD demand for every single day from to on I-5 and SR-99 in the Sacramento region. The resultant multi-year 24/7 dynamic OD demand reveals the daily, weekly, monthly, seasonal and yearly change in travel demand in a region, implying intriguing demand characteristics over the years.
1 Introduction
The increasing complexity and inter-connectivity of mobility systems call for large-scale deployment of dynamic network models that encapsulate traffic flow evolution for system-wide decision making. As an indispensable component of dynamic network models, time-dependent Origin-Destination (OD) demand plays a key role in transportation planning and management. Obtaining accurate and high-resolution time-dependent OD demand is notoriously difficult, though the dynamic OD estimation (DODE) problem has been intensively studied for decades. A number of DODE methods have been proposed, most of which aim at estimating dynamic OD demand for a typical day or even several hours on a typical day. To our best knowledge, there is a lack of research estimating dynamic OD demand for a long time period over the years. The OD demand and its behavior, though are generally repetitive in an aggregated view, can vary from day to day. The day-to-day variation of OD demand would need to be considered in estimate OD demand for a long period of many consecutive days. For example, estimating the dynamic OD demand for every -minutes in an entire year is computationally implausible using most of the existing DODE methods. In view of this, this paper presents an efficient data-driven approach to estimate time-dependent OD demand using high-granular traffic flow counts and traffic speed data collected over many years.
Dynamic OD demand represents the number of travelers departing from an origin at a particular time interval heading for a destination. It reveals traffic demand level, and is critical input for estimating and predicting network level congestion in a region. In addition, policymakers can understand the travelers’ departure patterns and daily routines through the day-to-day OD demand. As a result, many Advanced Traveler Information Systems/Advanced Traffic Management Systems (ATIS/ATMS) require accurate time-dependent OD demand as an input. A tremendous number of studies estimate time-dependent OD demand using observed traffic data which includes traffic counts, probe vehicle data and Bluetooth data. Oftentimes those data collected over multiple days are taken daily average before being input to dynamic network models, which represent the average traffic pattern and OD demand on a typical day.
With the development of cutting edge sensing technologies, many traffic data can be collected in high spatial and temporal granularity at a low cost. For example, traffic count and traffic speed for a road segment of 0.1 mile can be sensed and updated every minutes throughout the year. This is a dimension of counts/speed data for a single road segment on one day. Most of existing DODE methods become computationally inefficient or even implausible when dealing with large-scale networks with thousands of observed road segments and thousands of days of high dimensional data. How to efficiently obtain high-resolution OD demand on a daily basis over many years remains technically challenging. In this research, we estimate high-resolution dynamic OD demand for a sequence of many consecutive days over several years, referred to 24/7 OD demand throughout this paper.
Dynamic OD estimation (DODE) was formulated as either a least square problem or a state-space model. Cascetta et al. [12] extended the concepts of static OD estimation problem and formulated a generalized least square (GLS) based framework for estimating dynamic OD demands. Tavana [49] proposed a bi-level optimization framework which solves for a GLS problem in the upper level with a dynamic traffic assignment (DTA) problem in the lower level. The bi-level formulations for OD estimation problem were also discussed by Nguyen [40], LeBlanc and Farhangian [32], Fisk [17], Yang et al. [58], Florian and Chen [18], Jha et al. [26] for static OD demand. Zhou et al. [64] extended the bi-level formulation to incorporate multi-day traffic data. To implement efficient estimation algorithms on real-time traffic management systems, Bierlaire and Crittin [9] proposed a least square based real-time OD estimation/prediction framework for large-scale networks. Zhou and Mahmassani [63], Ashok and Ben-Akiva [5] established a state-space model for real-time OD estimation based on on-line traffic data feeds. Hazelton [23] built a statistical inference framework using Markov chain Monte Carlo algorithm for generating posterior OD demand.
The bi-level OD estimation framework can be solved using heuristically computed gradient, convex approximation or gradient free algorithms. Yang [56] proposed two heuristic approaches for the bi-level OD estimation problem, the iterative estimation-assignment (IEA) algorithms and sensibility-analysis based algorithm (SAB). Josefsson and Patriksson [28] further improved the sensitivity analysis procedures adopted in SAB process. A Dynamic Traffic Assignment (DTA) simulator is also used to determine the numerical derivatives of link flows. Balakrishna et al. [6], Cipriani et al. [14] fitted such an estimation process into a stochastic perturbation simultaneous approximation (SPSA) framework. Lee and Ozbay [33], Vaze et al. [53], Ben-Akiva et al. [8], Lu et al. [36], Tympakianaki et al. [51], Antoniou et al. [2] further enhanced the SPSA based methods. Verbas et al. [54] compared different gradient based methods to solve the bi-level formulation of DODE problem. Flötteröd et al. [19] proposed a Bayesian framework that calibrates the dynamic OD using agent-based simulators. In addition to numerical solutions, research has been looking into computing the analytical derivatives for the lower-level formulations [22, 20, 43, 44]. Other machine learning and computational technologies are also employed to enhance the efficiency of OD estimation methods [30, 29, 24, 55].
The general bi-level formulation for OD estimation is proved to be non-continuous and non-convex, and thus its scalability is limited. Nie and Zhang [41, 42] formulated a single-level static and dynamic OD estimation framework that incorporates User Equilibrium (UE) path flows solved by the variational inequality, which is further improved by Shen and Wynter [46] under the static cases. Recently, Lu et al. [35] formulated a Lagrangian relaxation-based single-level non-linear optimization to estimate dynamic OD demand.
A large number of data sources are feeding to DODE methods. Zhang, Nie and Qian [60] evaluated the roles of count data, speed data and history OD data in the effectiveness of DODE. Van Der Zijpp [52], Antoniou et al. [3], Zhou and Mahmassani [62], Rao et al. [45] used automated vehicle identification (AVI) data together with flow counts to estimate dynamic OD demand. Emerging technologies such as Bluetooth [7], mobile phone location [11, 25], probe vehicles [4] data were also employed to estimate dynamic OD demands.
Two important issues are yet to be addressed. Firstly, many existing DODE methods [5, 28, 41, 35, 36] require a dynamic traffic loading (DNL) process (either microscopic or mesoscopic) to endogenously encapsulate the traffic flow evolution and congestion spillover. As the DNL process requires relatively high computational budget, it can take hours to estimate dynamic OD demand on a network of thousands of links/nodes for a single day. Not only does it have hard time converging under the data fitting optimization problem, but estimating the OD demand for several years becomes computationally impractical. The other issue is that most studies estimate OD demand for a few hours or a single day. OD demand varies from day to day, but is also repetitive to some extent. The day-to-day features of OD demand has not be taken into consideration of the DODE methods. For this reason, demand patterns that evolve daily, weekly, monthly, seasonally and yearly have not been explored, despite of high-granular data collected over many years.
In this paper, we develop a data-driven framework that estimates multi-year 24/7 dynamic OD demand using traffic counts and speed data collected over the years. The framework builds the relationship between dynamic OD demand and traffic observations using link/path indices matrix, dynamic assignment ratio (DAR) matrix, and route choice matrix. These three matrices enable the estimate framework to circumvent the bi-level formulation, since each of the matrices can be directly calibrated using high-granular real-world data rather than from complex simulation. The proposed framework utilizes data-driven approaches to explore the daily, weekly, monthly and yearly traffic patterns, and group traffic data into different patterns. The proposed estimation framework is computational efficient: 5-min dynamic OD demand for three years can be estimated within hours on an inexpensive personal computer.
In order to address computation issues, this paper uses a Graphics Processing Unit (GPU) which is currently attracting tremendous research interests from various fields. Neural network models can be performed more deeply and widely [48] with GPU computing. It is also widely used in probabilistic modeling [47] and finite element methods [37]. To our best knowledge, this paper is among the first to design and implement GPU computing in the DODE method, since the traditional DODE methods are not suitable for GPU computing. We present a stochastic gradient projection method that well suits the GPU computing framework. As we will show in the case study, the proposed GPU friendly method is over times more efficient than the state-of-art CPU based method. The implies that GPU computing makes possible to make full use of the massive traffic data comparing to traditional models.
The main contributions of this paper are summarized as follows:
It proposes a framework for estimating multi-year 24/7 dynamic OD demand using high-granular traffic flow counts and speed data. It takes into account day-to-day features of flow patterns by defining and calibrating the dynamic assignment ratio (DAR) matrix using real-world data, which enables realistic representation and efficient computing of network traffic flow. 2. 2)
It adopts t-SNE and k-means methods to cluster daily traffic data collected over many years into several typical traffic patterns. The clustering helps better understand typical daily demand patterns and improve the DODE accuracy. 3. 3)
It proposes a stochastic projected gradient descent method to solve the DODE problem. The proposed method is suitable for GPU computation, which enables efficiently estimating high-dimensional OD over many years. 4. 4)
A numerical experiment on a large-scale network with real-world data is conducted. -minute dynamic OD demands for every day from to are efficiently estimated. As a result, OD demand evolution over the years can be presented and analyzed.
The remainder of this paper is organized as follows. Section 2 discusses the formulation. Section 3 presents the solution algorithm for the proposed framework. Section 4 proposes the entire DODE framework. In section 5, a real-world experiment for estimating -minute dynamic OD from to on a regional Sacramento Network is presented. Finally, conclusions are drawn in Section 6.
2 The model
In this section, we present a framework that utilizes the high-granular traffic counts and speed data to estimate dynamic OD. We first model and discretize continuous-time traffic flow evolution on general networks. The dynamic assignment ratio (DAR) matrix is proposed to characterize the traffic flow evolution in discrete time. Unsupervised dimension reduction and clustering methods are adopted to group data of multiple years into several typical traffic patterns. We use the Logit-based route choice model to characterize travelers’ behavior in each cluster. Finally, we formulate the DODE as a high-dimensional non-negative least square (NNLS) problem and propose an efficient solution algorithm.
2.1 Notations
Please refer to Table LABEL:tab:notation. The hat symbol, , indicates the variable is an estimator for the true (unknown) variable.
2.2 Model the continuous time traffic flow
Before proposing the estimation method, we first formulate the model for continuous time traffic flow on general networks. We denote the path flow as the th path flow rate for OD pair at time and link flow as the flow rate at the tail of link at time . The relationship between path flow and link flow is presented by Equation 1.
[TABLE]
where is the set of all OD pairs, and is the path set for OD pair . is the set of possible departure time for any path and link. In this paper we always denote departure time of path flow or OD flow as , and the arrival time at the tail of link as , respectively. The time-dependent path/link indices matrix is defined as follows:
[TABLE]
Assuming the traffic flow is FIFO (First-In-First-Out) and continuous, the arrival time of all departure flows can be determined explicitly. Therefore, the time-dependent path/link indices matrix can be simplified as in Equation 3.
[TABLE]
where is if path for OD pair passes link and [math] otherwise. is the departure time function for th path in OD , and is the departure time of th path in OD pair arriving at the tail of link at , . Combining Equation 1 and Equation 3 by replacing the time-dependent path/link indices matrix with a static path/link indices matrix, the relationship between link flow and path flow can be formulated as Equation 4.
[TABLE]
Example 1** (Link flow and path flow).**
Consider a two-link network presented in Figure 1. The path flow is , and the link flow for link and are and , respectively. The travel time to traverse link is constantly . Then at the starting time , we have
[TABLE]
After , we have
[TABLE]
2.3 Objective function in discrete time
The objective function of DODE problem computes the norm between the observed link flow and the estimated link flow . The estimated link flow is aggregated by the estimated path flows , then the optimization problem is presented in Equation 9.
[TABLE]
where is the set of possible arrival time for all links, which is usually the observation time period for all links. Equation 9 formulates the objective function on the link set , we can use the observed link set to replac if only a subset of links are observed. Based on Equation 4, we rewrite the objective function as Equation 10.
[TABLE]
Typically, the data collected from traffic sensors are discretized in terms of time intervals. Therefore, the objective function needs to be discretized as well. We divide the entire time period into time intervals, and the sequence of time intervals is denoted as . We further denote , which represents the beginning of each time interval.
Example 2** (Time interval discretization).**
In Figure 2, we discretize the whole time period into intervals. are the time intervals and are time points denoting the starting time of each time interval.
The discretized objective function is presented in Equation 11.
[TABLE]
where
[TABLE]
We denote as the range of function with domain being , . The cumulative link flow and cumulative estimated path flow are integrated from and over time interval and , respectively. The weight function denotes the portion of the th path flow departing within time interval between OD pair which arrive at link within time interval .
[TABLE]
We can use this weight function to trace the discretized path flow to link , as presented in Equation 15.
[TABLE]
It can be seen that the discretized objective function approaches to the continuous objective function when . The weight function reflects the link-level flow progression from time interval to . The flow progression and evolution aggregated at the link level can be captured by the time-varying link-level traffic speed and counts. However, its evolution within each link, such as within-link shockwave, can be hardly calibrated or learned unless trajectory level data are available. In fact, link-level flow evolution is proven to be realistic, stable and efficient [27]. Thus, in this research, we assume vehicles on the network are evenly spread in space and link flow rate at the tail of each link within each time interval is also constant (evenly spread in time), resulting the weight function presented in Equation 16.
[TABLE]
The formulation 16 is further simpled using equal time intervals, as presented by . Then we are ready to present the dynamic assignment ratio (DAR) as in Equation 18.
[TABLE]
where is the inverse function of since is monotonically increasing based on the FIFO rule. represents the range of function with domain being . For each path , Equation 18 can be interpreted as the portion of vehicles arriving at link in time interval among all the vehicles departing at interval . As we assumed that the vehicles are spread evenly in time and space, the portion can be computed either at departing time 17 or at arriving time 18. The DAR matrix is computed through the weight function .
Example 3** (DAR matrix computation).**
As presented in Figure 3, we demonstrate an example for computing the DAR matrix in a three link network. The path flow passes three links on the network. To compute non-zero entries of the DAR matrix with , we derive the trajectories of path flow departing at time and . The speeds of links are the slopes of the trajectory, which are denoted as . The probe vehicle speeds of links are available from various sources, such as HERE, INRIX and TomTom. We plot the two approximate trajectories of the leading vehicle departing from the origin at time and , and measure the length of each time segment as . Based on the definition of , we have
[TABLE]
Then the DARs can be computed as follows based on Equation 18.
[TABLE]
Given Equation 18, the discrete time objective function is formulated as Equation 29:
[TABLE]
2.4 Link/path travel time
In previous sections, we derive the objective function based on the DAR matrix. As shown in Example 3, the DARs are computed through . These variables can be computed based on the link travel time, for example
[TABLE]
In a general form, let denote the travel time of link flow for departing from the tail of link at time . We denote as the travel time of path flow in OD pair departing at time . Let represent the sequence of links passed by flow , represent the th link in sequence , and represents the number of links passed by flow . Then can be calculated by Equation 31.
[TABLE]
We note the link travel time can be obtained from either dynamic network loading models (traffic simulation) or the real-world data. In this research, we use the speed data from probe vehicles (such as INRIX or HERE) to circumvent the simulation process. The link/path travel time can be directly calibrated from the high-granular probe vehicle speed data.
2.5 Traffic pattern clustering
In the following sections, we will build the relationship between dynamic OD flow and dynamic path flow. Behavior models determines the route choice portions based on the traffic conditions and travelers perception errors, which are used to distribute OD flow onto different paths. Travelers’ route choices are likely to be stable when traffic conditions are recurrent. In this research, we speculate that there exist several typical repetitive traffic conditions at the network level, each of which carries weekday/weekend, seasonal or other demand/supply characteristics. In each typical traffic pattern, we assume the network condition follows a statistical equilibrium defined by Ma and Qian [38, 39]. Travelers will select their route based on the traffic pattern they observe historically, and their route choice portions remains stable for those days with the same typical traffic pattern. To estimate the route choice portions in each traffic pattern, we first cluster the traffic data into patterns using day-to-day traffic data in this section. Then the route choice portions for each pattern are estimated based on a generalized route choice model in the following section.
In addition to statistical equilibrium approach, the day-to-day traffic assignment model can also be used to utilize temporal correlation of traffic patterns, and the OD demand can be estimated by a filtering approach. One novelty that stems from the statistical equilibrium approach, to be further examined in the next step, is that the weekly/monthly/seasonal O-D variation can be learned directly from real-world data rather than being a prior to be imposed to the day-to-day dynamics model. In this paper we focus on the statistical equilibrium approach to modeling the temporal correlation of traffic patterns.
To cluster the traffic patterns, t-SNE (t-Distributed Stochastic Neighbor Embedding) is adopted to project high-dimensional traffic data points to low dimensional feature space. K-means method is then used to cluster the data points in the feature space. Each cluster obtained from k-means method represents traffic patterns under different traffic conditions.
2.5.1 Dimension reduction and data visualization
For a traffic state variable, e.g. link flow from all sensors on a network, we adopt state-of-art dimension reduction method t-SNE (t-Distributed Stochastic Neighbor Embedding) to project traffic state variables to low dimensional space. The dimension reduction process can significantly reduce the influence of noise and outliers to the clustering methods. The t-SNE method minimizes Kullback-Leibler divergence between a joint probability distribution in the high-dimensional space and a joint probability distribution in the low-dimensional space, as presented in Equation 32.
[TABLE]
where are the indices of the data. and measure the pair-wise similarity between data points, which are defined as:
[TABLE]
where are data points from original high-dimensional space and are data points from low-dimensional space that we want. is assumed to follow a Student t-distribution with one degree of freedom as one heavy-tailed distribution in low-dimensional space. The computational and space complexity of t-SNE are , but it can be efficiently solved using stochastic gradient descent (SGD) methods with limited number of iterations.
In this research, t-SNE is used as the dimension reduction method, but other clustering methods, such as principal component analysis (PCA), can be potentially adopted as well for the same purpose [13]. Among all the dimension reduction methods, t-SNE is able to handle the non-linear relationship between variables and hence form smaller groups compared to other methods [21]. Many studies have demonstrated the effectiveness of t-SNE in handling very high-dimensional datasets [10, 50]. in the numerical example, we also compare the t-SNE with other PCA-based methods and demonstrate the effusiveness of t-SNE.
We set as the vector of observed traffic counts or traffic speed on each day and denotes the index of the dates. is a one-dimensional vector with length , where is the number of time intervals in a day and is the number of observations per time interval. Then we minimize the objective function to search for the low dimensional feature , where also denotes the index of dates. Then we are able to use the feature to represent the high dimension variable for each day.
One important feature of the projected dimension by t-SNE is that it has state-of-art visualization properties of data. The low dimensional space not only retains the local structure of the data, but also reveals the global structure in the high dimensional space.
2.5.2 Clustering
Clustering methods group day-to-day traffic data into different patterns. Since t-SNE projects traffic data onto low dimensional feature space, which reflects the structure of high dimensional space. Even a simple clustering method works well on the feature space. In this research, we adopt k-means method to cluster the feature space.
We project traffic speed and traffic counts to feature space and build the clustering models, respectively. Suppose there are data available for days, we will have clusters for speed data and clusters for count data after t-SNE and K-means. Then we define clusters as .
The intuition behind the clustering process is two-fold: 1) Count data and speed data have different structures in the high dimensional space. Count data have larger variance than the speed data. Thus, parameter tuning for t-SNE should be different for count versus speed data. 2) Travelers’ route choice is a combined decision process based on the traffic demand (count data) and traffic congestion (speed data) together. Hence we use the composite of count clusters and speed clusters to represent different patterns.
The clustering method we adopt is data-driven. Hard-coding the clusters using prior knowledge such as weekday/weekends or seasons is not necessary. Later we will show in the case study that the clustering results actually reflect not only weekday/weekend traffic patterns, but also other non-trivial factors such as incidents and events.
2.6 Route choice portions
For each traffic pattern, we compute the route choice portions for all OD pairs. Define route choice portion such that it distributes OD demand to path flow by Equation 35.
[TABLE]
where represents the route choice portion of th path flow in OD pair departing at time . The time-dependent route choice portion can be determined through a generalized route choice model, as presented in Equation 36.
[TABLE]
where denotes the route choice portions for th path in OD at time for pattern . represents the traffic conditions (flow, travel time, speed, travel time reliability, etc.) of all those days within the pattern . is a generalized route choice model that takes any information within the traffic pattern and compute the route choice portion for travelers in th path in OD . To simplify the notation, we ignore the pattern index in the rest of the paper.
For instance, we can use a Logit-based model based on mean travel time for each traffic pattern as shown in Equation 37.
[TABLE]
where represents the mean travel time of path flow in OD departing at time for all days within the cluster (or pattern). is the dispersion factor in Logit model. To discretize the time, we further assume that the route choice portions stay the same in each time interval, then,
[TABLE]
The discrete time link flow and path flow can be formulated as in Equation 39.
[TABLE]
2.7 Estimate the dynamic OD demand
Now we are ready to present the formulation for solving the DODE problem. Combining Equations 9, 29 and 39, the DODE formulation is presented in Equation 40.
[TABLE]
In the formulation 40, link flows are observed from sensors, path/link indices matrix is from network topology in section 2.2, DAR matrix can be computed through real-time traffic speed data by section 2.3 and route choice matrix is determined by the clustering results in section 2.5 and the route choice model in section 2.6. We can formulate the multi-day 24/7 DODE problem as one large non-negative least square (NNLS) problem by viewing the as the entire observation time period (e.g., years in the case study). However, to ensure computational efficiency, a best practice is to decompose the NNLS problem of multiple years into subproblems for each of those days separately. This does not come without a price, though. The vehicles departing at the end of day and arriving in the beginning day are overlooked in this simplified process. This is still acceptable in practice since midnight OD is usually minimal and of less interest in general. One nice feature of solving NNLS on the daily basis is that it convenient to utilize the parallel computational power to estimate the dynamic OD of each day separately. In the reminder of this paper, the optimization problem 40 applies for each day separately and we simply ignore the index for days.
In formulation 40, the link capacity constraints (the estimated link flow should be less and equal than the maximum flow capacity) are not explicitly enforced, since these constraints are usually satisfied by 1) achieving the minimum of the objective function close to zero; and 2) enforcing proper route choice models. As can be seen in the following case study, this is generally satisfied. In practice, if it is not the case, enforcing the link flow capacity as additional linear constraints to formulation 40 is straightforward under an iterative balancing framework [61].
We denote as the assignment matrix, the entries of can be computed as in Equation 41.
[TABLE]
Formulation 40 is a non-negative least square (NNLS) problem in terms of and , which can be solved very efficiently in a low dimensional space [31] using the standard NNLS solver. But the standard method can be very inefficient in a high dimensional space, as it computes the inverse of during the solving process. The dimension of is usually in billions for a typical DODE problem that estimates daily dynamic OD. In the following section, we will propose a stochastic projected gradient descent method to solve the high-dimensional NNLS problem and implement it on GPU. The DODE problem on a single day can be solved in seconds using this proposed method.
3 Solution algorithm
In previous section, we formulate the 24/7 DODE problem as a non-negative least square (NNLS) problem, as presented in Equation 42.
[TABLE]
where and are the tensor representations of link flows and the OD flows in all time intervals, respectively. is the assignment matrix. The construction of the tensor representations will be presented in the following section.
With the increasing granularity of traffic data, the dimensions of tensor and matrix grow quickly. Thus, we have to work on a high dimensional space for the proposed DODE framework. In this section, we discuss the technical details of each component of the solution algorithm that ensures computationally efficient implementation of the proposed framework.
3.1 Tensor representation
To enable tensor manipulation and computation during the DODE framework, all the variables involved need to be vectorized. For sparse matrices in the formulation, we use coordinate format sparse representation of the matrices.
For intervals, denote total number path is , . The vectorized variables are presented in Table 2. Multiplications between sparse matrix and sparse matrix, sparse matrix and dense vector are very efficient, especially on multi-core CPUs or Graphics Processing Units (GPU).
3.2 Constructing the dynamic assignment ratio (DAR) matrix
The assignment matrix is the multiplication of Link/path indices matrix, DAR matrix and route choice matrix. As shown in Table 2, the largest matrix among the three matrices is the dynamic assignment ratio (DAR) matrix. DAR matrix is constructed by network topology and speed data, and the construction process turns out to be the most time-consuming part in the DODE framework.
The construction process for DAR matrix requires iterations over all departure/arriving time intervals, paths and links. We find a way to construct DAR matrix by only iterating over departure time intervals and paths. The links and arriving time intervals will be iterated implicitly when we compute the travel time of each path. For specific time interval and path, we iterate over all the links in the path from origin to destination and compute the arrival time of each link. Using the arrival time, we can compute assignment ratio and put it to its corresponding entry in DAR matrix.
We can also use multi-process computing to construct DAR matrix for multiple days simultaneously. The parallel construction framework can significantly reduce the total computation time.
3.3 Non-negative least square on GPU
After constructing assignment matrix , the 24/7 DODE problem is simplified to a non-negative least square problem presented in Equation 42. However, solving such NNLS problem in high-dimensional space is non-trivial. For a general network, the dimension of OD vector is usually above ten thousand, and standard NNLS solver [31] is not able to handle such a high dimensional problem.
We propose a stochastic projected gradient descent method to solve the high dimensional NNLS problem. The process of the solution method is presented in Algorithm 1.
In the algorithm, the batch size , learning rate and number of epoch are parameters for the SPGD method. Larger batch size implies better convergence rate but larger memory consumption; learning rate is dependent on the problem scale and larger learning rate implies better convergence rate; and larger number of epoch implies the better solution for the NNLS but longer computational time. The permutate function permutates the sequence in random order, make_chunk function divide a sequence to small chunks with same size. Adagrad is a variant of stochastic gradient (SGD) descent method, it outperforms the SGD during the experiments. Adagrad is an adaptive step size for SGD that is often used to optimize neural networks. Details of the Adagrad method can be found in Duchi et al. [15].
We implemented the proposed Algorithm 1 in PyTorch, all the matrices multiplication can be evaluated on GPU. As we will show in later section, the implemented method can solve NNLS with a thousand dimension in seconds.
4 Estimation framerwork
In this section, we present the proposed DODE pipeline given the network topology, speed data and count data. Path set of each OD pair needs to be generated prior to the estimation framework. For small networks, path enumeration is possible. When the networks are large, we can simply enumerate shortest paths [59, 16] for each OD pair and then search for the solution in the prescribed path set.
Count data and speed data need to be cleaned and imputed (if missing) before the estimation framework. Network topology and OD pairs will be converted to a directed graph with weighted edges. The entire DODE framework is summarized as follows,
[TABLE]
5 Numerical experiment: a Sacramento Regional Network
In this section, we conduct a case study on I-5 and Hwy-99 towards Sacramento. 5-min count and speed data for the years of 2014 to 2016 are used to estimate -minute dynamic OD demands over years. Efficiency of the proposed methods and goodness of fit are evaluated. We visualize the evolution of estimated OD demand in several ways and discuss the benefits of the high-granular traffic data.
All the experiments below are conducted on a desktop with Intel Core i7-6700K CPU @ 4.00GHz 8, 2133 MHz 2 16GB RAM, GeForce GTX 1080 Ti/PCIe/SSE2, 500GB SSD.
5.1 Data acquisition and preprocessing
We first describe the network, traffic count and speed data used in the case study. The data preprocessing involves the graph construction, data geocoding, data cleaning, data imputation and data interpolation.
5.1.1 Network
I-5 and SR-99 are the two highway corridors in this network. The OD connectors are constructed based on the residence region and interchanges/ramps of two highways. We divide the entire network into traffic analysis zones (TAZs), and attach one origin and one destination to each TAZ. The overview of all TAZs are shown in Figure 4.
The TAZs are across two major highways towards Sacramento downtown. The main purpose of this case study is to characterize the traffic demand in the southern region of Sacramento heading/leaving Sacramento downtown. Northern regions of TAZ are not modeled since there are too many highway exits/entrances and local roads, our data are not rich enough to accurately model the demand profile in those regions. The north of TAZ are not modeled since there is few resident area in this area. We further enumerate all paths to generate the path set for each OD pair.
5.1.2 Counts
The flow count raw data are obtained from Caltrans Performance Measurement System (PeMS), which is a combined source from various types of vehicle detector stations, including inductive loops, side-fire radar, and magnetometers. The count data contain the traffic counts from locations in every minutes for years. There exist several sensors on the same road segment. In this case, we take the average of counts for that segment. On each day, there are time intervals, thus the traffic count data for each day is a vector in . We randomly select locations and visualize the day-to-day traffic counts. The average traffic counts over the years for each time interval are also plotted in Figure 5. Each grey time-of-day trace represents traffic counts over one day, and the blue line represents the average daily time-of-day traffic counts over three years.
As can be seen from Figure 5, traffic counts data on most of days follow similar trends but contain large day-to-day variation. Some sensors pick up morning peaks and afternoon peaks, while others can only capture either or neither of the traffic peaks.
5.1.3 Speeds
Traffic speed data were obtained from National Performance Management Research Data Set (NPMRDS). The traffic speed data are provided at the geographic level of Traffic Message Channel (TMC), one of the geo-reference protocols. NPMRDS data contain traffic speed observations for TMCs in every minutes from to . On each day, there are 288 time intervals, and thus the traffic speed data for each day is a vector in . We geocode the TMCs to the network and compute the time-dependent travel time for each road segment. There exist several TMCs attached to the same road segment, we take the average of the traffic speed over those TMCs for that road segment. We visualize the day-to-day traffic speed data for randomly selected TMCs, as well as the mean time-of-day speed, plot in Figure 6. Each grey time-of-day trace represents traffic speed over one day, and the blue line represents the average traffic speed over three years. Similar pattern as in Figure 5 can be observed in Figure 6. Similar to counts data, traffic speeds show clearly patterns where speed drops during morning peaks or afternoon peaks, but day-to-day variations are quite large.
There are less than data missing in the speed data. We use linear interpolation across different time intervals on one day and several neighboring days to impute data. For example, if the traffic speed at 10:00 is missing,then we take the average of traffic speed at 9:55 and 10:05 to impute the traffic speed at 10:00. If data for day 2 are missing, we take the average of traffic data for day 1 and day 3 as the imputed value. Note the former method is always preferred. Only when there are data missing in a large chunk of time intervals, the latter method will be used.
5.2 Clustering and route choice analysis
After processing the data, we use t-SNE to project the dimension of both traffic counts and traffic speed data to a lower dimensional feature space. Then a clustering method is adopted on this feature space to obtain traffic patterns.
5.2.1 Dimension reduction
We project both traffic data and speed data to a two-dimensional space so that we can visualize the data easily. TSNE package in scikit-learn is used to conduct t-SNE algorithm. The parameters for t-SNE are set as follows:
- •
Count data: perplexity , early exaggeration , learning rate
- •
Speed data: perplexity , early exaggeration , learning rate
The perplexity, early exaggeration and learning rate are parameters in the t-SNE algorithm. These parameters are data dependent and can be tuned through cross validation. We visualize the count data and speed data in the feature space, respectively. Each point represents traffic data for one day, x-axis and y-axis represent the coordinates of the feature space. The absolute coordinates of each data point does not matter, while the relative positions of these data points matter. The relative positions of the data points indicate whether the data points are similar to each other and how the data points are clustered. We also colored each data point with respect to its year, month and weekday as in Figure 7.
Feature space, like the principle component in PCA, is the base of the low-dimensional space extracted by t-SNE. As can be seen, the count data are more separable as the variance of count data is greater than the variance of speed data. The feature space reflects the yearly, monthly and daily pattern of traffic data. For example in Figure 7(a) and Figure 7(b), traffic data in 2014 and 2016 are each grouped and far away between each other. Traffic data in 2015 lie in between groups of 2014 and 2016. In Figure 7(c), traffic flow in each month is grouped into several clusters, meaning traffic counts data has clearly monthly patterns. While in Figure 7(d), the speed data does not have very clear monthly patterns. Figure 7(e) and Figure 7(f) indicate both count data and speed data have strong weekly patterns, as Saturday/Sunday are clustered together and Wednesday/Thursday are clustered together.
We also apply the PCA, Latent Dirichlet Allocation (LDA) and kernel PCA with degree polynomial kernel to the same count data and speed data, and the weekly/monthly/yearly patterns are not clear from those results. The figures similar to Figure 7 can be found in the supplementary materials. The t-SNE tends to divide the data points into small groups, while other methods usually generate a cluttered visualization. To better cluster the data points, we use the results by t-SNE for the rest of the experiments.
5.2.2 Clustering
After dimension reduction, we use k-means to cluster the data points on the feature space. We choose the number of clusters for both count and speed data, k-means method converges very quickly and the results are shown in Figure 8.
Travelers can make different route choices based on traffic patterns related to both traffic volumes (traffic counts) or traffic congestion (traffic speed). We define different traffic patterns to take into account characteristics of different count and speed clusters. The number of traffic data in each pattern are presented in Figure 9. We drop all the patterns with no data point. There are in all valid traffic patterns.
The outliers are also picked out during the clustering process. For example only one data point falls in the combination of count cluster [math] and speed cluster [math]. This data point can be viewed as one outlier that does not share similarity with any other traffic patterns. We compute travelers’ route choice portions of this outlier day using its unique traffic conditions.
For patterns with more than one data points (i.e., days), we compute the route choice portions using the average traffic speed of all days within each pattern, as discussed in section 2.6. We adopt since the magnitude of the travel time is around hundreds of seconds. In this demonstrative case study, is determined without careful calibration, which can be improved in the future research using methods proposed by Lu et al. [36], Yang et al. [57].
5.3 Dynamic OD estimation
Having the DAR matrix of each day computed by section 2.3 and route choice portion matrix of each pattern computed by section 2.6, we estimate the dynamic OD demand using the proposed stochastic projected gradient descent method.
5.3.1 Goodness of fit
In the stochastic gradient method, the configurations are set as follows:
- •
number of epochs:
- •
batch size:
- •
step size:
- •
use GPU: True
The entire estimation process for three years takes around hours, with an average of minute for each day. We randomly selected days to visualize the observed traffic counts and estimated traffic counts in Figure 10. The average R-square between the observed link flow and estimated link flow is for three years. The estimated OD demands are able to reproduce the traffic counts observations, implying satisfactory results.
The true OD demand is difficult to obtain in real-world networks, so the comparison between the estimated OD demand and true OD demand is infeasible in the case study. To further validate the estimation results, we propose a novel interpretation of DODE formulation as follows: we view the observed link flow as the “data”, the DAR matrix as the “model” and estimated OD as “target” in the DODE formulation. The terms “data”, “model” and “target” are used to assimilate a typical machine/statistical learning task. Under this setting, the DODE formulation can be described as follows: given an observed “data”, we train the “model” with the speed data and then compute the “target” by inputting the “data” to the “model”. We first examine the stability of the “model”. We compute the average DAR matrix across three years and plot the histogram of distance between the DAR matrix on each day and the average DAR matrix in Figure 11(a). One can clearly see the distribution of distance is unimodal, which implies the daily perturbation of traffic conditions has a bounded impact to the DAR matrix, thus the OD estimation results are robust to the observation errors and inaccurate DAR matrix. We also adopt a modified cross-validation approach as follows: we assume the DAR matrices (“model”) in December 2018 are unknown and estimated by the average traffic conditions in the other months. We compute the between the observed link flow and estimated link flow using the estimated DAR matrix and the true DAR matrix, respectively. The results are presented in Figure 11(b). The DODE with estimated DAR matrix (average is ) slightly underperforms the DODE with true DAR matrix (average is ), as expected. The estimation results are still satisfactory, indicating the robustness of the proposed DODE method.
5.3.2 Algorithm efficiency
We also conduct an experiment to demonstrate the computational efficiency of our proposed algorithm. To compare the CPU based SPGD method, GPU based SPGD and traditional active set based NNLS method [31], we random generate a matrix , we compute and solve NNLS(, ) using these three methods. The number of iteration is set from to . As a result, the time consumptions of the three methods are presented in Figure 12.
The CPU based SPGD method is very slow so we have to terminate it early. As can be seen, the GPU based SPGD method is significantly the most efficient of all. The gap between standard NNLS method and GPU based gradient project method will increase rapidly as increases.
In this case study, the dimension of is for the Sacramento regional network. It only takes GPU based SPGD method around minute to solve it for each day, while the standard active set method will take more than one hour. In this case study, only the GPU based SPGD method can solve the problem of three years in an acceptable amount of time.
5.4 Aggregated demand over all OD pairs
With the estimated -minute dynamic OD demand over the three years, we now examine the characteristics of the traffic demand. We start with the aggregated demand over all OD pairs on each day of the three years.
5.4.1 Weekdays v.s. Weekends
We first look at the differences in aggregated OD demands between weekdays and weekends. For each day, we compute the aggregated OD demand over all OD pairs at each 5-min time interval, and the aggregated traffic counts over all counting locations. Then daily average is computed over the three years. We plot time-of-day aggregated OD and counts for each day (in transparent colors), along with the daily average (in solid colors), in Figure 13. Generally, dynamic OD demand patterns on weekdays and weekends are quite different, as expected. There are two clear spikes on weekdays corresponding to morning and afternoon peaks, respectively. There is only one spike on weekends, and the OD demand on weekends are fairly stable from 11:00am to 17:00pm.
The results show that the aggregated OD demand and aggregated counts have similar time-of-day profiles, but in different scales. Total counts, as commonly used to approximate total demand level in practice, can substantially overestimate the demand level, since they tend to double count the same vehicles that pass through several counting locations. Though both generally follow similar time-of-day profiles, OD demand seems to have spikes and declines slightly earlier than what the total counts read. This indicates that spillover of congestion queues is not too long on both highway corridors, possibly only locally or in the vicinity of a bottleneck.
5.4.2 Monthly and seasonal effects on OD demand
For all working days (excluding any holidays on weekdays) in each month, we plot the daily aggregated OD demand over all OD pairs, total counts over all locations, along with their respective daily average for each month, in Figure 14. The general time-of-day profiles are similar across different months. However, the day-to-day variation of OD demand in November, December and January are greater than other months, which may be largely attributed to the travel demands affected by holiday or winter seasons. We also compute the aggregated OD demand by hour, averaged over all working days in each month, in Figure 15, as well as the percentage change in aggregated OD demand by hour in Figure 16 where the base is set as the average of aggregated OD demand taken over all months.
OD demands during the morning peaks in June - August and December - January are slightly lower than other months, resulting less congestion during morning peaks. Among those, morning peak demand in July drops the most considerably compared to other months. On the other hand, summer time (from May to September) shows higher demand during off-peak hours, especially July and August. Overall, the total travel demand in December and January are the lowest throughout the years. Those monthly and seasonal demand change may be related to the summer/winter breaks of schools, and effects of summer/winter weather. These phenomena are consistent with our perception, and can be demonstrated and validated by three years’ data, which cannot be discovered by examining speed/counts data directly.
5.4.3 Northbound v.s. Southbound
We plot the aggregated OD demand by weekdays and weekends, and over all northbound and southbound OD pairs, respectively, in Figure 14.
Northbound demand heads to the Sacramento downtown, and southbound demand heads to the southern region. On weekdays, the northbound OD demand is greater than southbound OD demand during morning peaks, and slightly less during afternoon peaks. Morning commute clearly shows more day-to-day variation than other time periods. One interesting observation is that the discrepancy between northbound/southbound OD demand in afternoon peaks is less than that in morning peaks. Congestion during the day is usually more widely spread than morning commute congestion that mainly applies to northbound only.
On weekends, the OD demand per hour is considerably less than the demand rate during morning commute on weekdays. Northbound sees a higher demand level and earlier weekend peak than southbound. However, during midnight, more demand travels on southbound than northbound, possibly as a result of midnight activities in Sacramento Downtown.
5.4.4 Holidays v.s. weekdays immediately after holidays
OD demand during holidays appears quite different comparing to the regular weekdays and weekends. Thus, we pick out all the holidays (excluding the weekends), and those working days immediately after holidays to visualize their respective demand patterns. For example, September 5 2016 is a Labor day on Monday, then September 6 2016 is one weekday immediately after the holiday. We compute the aggregated OD demand for the two types, and present the results in Figure 18.
As can be seen from Figure 18, holiday traffic patterns are closer to the weekend patterns then to the weekday patterns, with one big spike during the day. However, a small morning peak can exist for some holidays, possibly attributed to different nature of daytime activities from a regular weekend. Another interesting finding for the holiday OD demand pattern is that the midnight OD demand can be as high as , almost half of the aggregated demand during morning peaks.
Though a morning commute peak resumes after holidays, we see that the peak on the weekday immediately after holidays is considerably lower than that of a regular weekday. OD demand patterns become normal from the second weekday after the holidays.
5.5 Disaggregated demand
Now we examine 24/7 OD demand of each OD pair over the years.
5.5.1 Northbound v.s. Southbound
We draw a figure with pixels, is the number of days and is the number of time intervals on each day. We set y axis to be the dates from to , and x axis to be the time of day from to . Each pixel is color coded to indicate the OD demand level. This figure demonstrates the daily time-of-day demand change over the years for each OD pair in high granularity. We randomly selected northbound and southbound OD pairs, and plot them in Figure 19. OD demand between the zone has increased substantially especially during the year of , resulting an increased demand level throughout the entire 24 hours. Also for OD pair , there are clearly spikes during morning commute, and demand for morning commute increases considerably in . However, other OD pairs plot in Figure 19 do not necessarily witness demand increase over time.
One can clearly see that there exist some strips with green color, implying temporary effects on travel demand for some OD pairs. For instance, OD demand is significantly reduced during Jan-Apr 2016 between the OD pair . This could be possibly induced by construction projects in the regional networks that have more impacts on those OD pairs than others.
5.5.2 Mean and variance of dynamic OD demand
We compute the average and standard deviation of each OD pair for each 5-min time interval over years, and plot them on a heatmap in Figure 20. We set y-axis to be each OD pair, x-axis to be the time from to . Each pixel is color coded to indicate the OD demand level.
As can be seen from Figure 20, the mean and variance of each OD pair roughly follow similar patterns, and the variance increases with respect to the increase in mean. Origin zones are the most important origins generating demand for southbound direction. Similarly, origin zones are the important demand origins for northbound direction.
In addition, there exist several OD pairs, such as , , with low demand mean and relatively high flow variability. The high variability of the demand among these OD pairs may be caused by accidents or events, so in a way, they may be more vulnerable under non-recurrent traffic conditions.
The correlation between OD pairs is useful when making the transportation planning policies. We compute the Pearson correlation factor between all OD pairs by time of day, and present the results in Figure 21. The demand among majority of OD pairs is positively correlated. Only a small portion of OD pairs are negatively correlated, which may be worth further investigating the reasons. Generally correlations are higher during peak hours and midnight than those from 10:00 to 16:00.
5.5.3 Holidays v.s. weekdays immediately after holidays
We visualize the day-to-day mean and variance of OD demand for each OD pair on holidays and two weekdays immediately after holidays in Figure 22. The results are consistent with before, generally demand variance increases with respect to the mean for each OD pair. There is no significant morning or afternoon peak hours for holiday travel demand. Though the total OD demand level on holidays is lower than weekdays, the holiday demand variance is much higher. The first weekday after holidays and the second weekday after holidays follow a similar pattern, while the latter demand is overall higher than the former demand. This again validates our finding for the aggregated OD demand.
6 Conclusion
This paper proposes a data-driven framework for estimating multi-year 24/7 dynamic OD demand using high-granular traffic counts and speed data. The proposed framework defines a dynamic assignment ratio (DAR) matrix to encapsulate the traffic flow dynamics and congestion spill-over in the large-scale network. The DAR matrix can be calibrated through high-granular speed data (such as probe vehicle speeds), which alleviates the complexity of non-linear large-scale network simulation for DODE.
The purposed framework adopts t-SNE and k-means methods to reduce the dimensionality of multi-source high-granular data, and cluster those data into typical daily traffic patterns. The t-SNE method projects the multi-source data onto a low dimensional feature space that enables examination of the daily, weekly and monthly patterns of traffic data. The k-means method clusters the projected counts and speed data into traffic patterns. The framework works with any general route choice models that considers day-to-day and within-day travel time and cost. In particular, a Logit-based route choice model is demonstrated to compute the route choice portions under each traffic patterns separately.
The DODE framework can be cast into a standard non-negative least square (NNLS) problem with, however, very high dimensions provided with high-granular data. A novel stochastic projected gradient descent (SPGD) method is purposed to solve for NNLS. The SPGD method can be implemented on GPU, which is able to solve the high dimensional NNLS efficiently compared to the traditional active set method for the NNLS problem. The entire solution framework is implemented in Python and open sourced.
Finally, a case study is conducted on a regional Sacramento network consisting with I-5 and SR-99 corridors, interchanges and ramps. High-granular counts and speed data are used to estimate -minute dynamic OD demands over the three years from 2014 to 2016. The estimation takes around hours on an inexpensive GPU-based desktop. The estimated dynamic OD demand can fit the large-scale high-granular data fairly well. We also examine daily, monthly, seasonal and yearly changes in OD demand that vary by time of day, by holidays, weekdays and weekends. Those new information regarding travel demand can help city planners and policymakers better understand the characteristics of dynamic OD demands and their evolution/trends in the past few years. The estimated dynamic OD can also be used to compute the variability of day-to-day OD demand, a critical input for network reliability studies [34].
Supplementary materials
The proposed framework is implemented in Python and open-sourced on Github111https://github.com/Lemma1/DPFE. The Github repository also contains the dimension reduction results by PCA, Latent Dirichlet Allocation (LDA) and kernel PCA with degree polynomial kernel.
Acknowledgements
This research is funded in part by National Science Foundation Award CMMI-1751448 and Carnegie Mellon University’s Mobility21, a National University Transportation Center for Mobility sponsored by the US Department of Transportation. The contents of this report reflect the views of the authors, who are responsible for the facts and the accuracy of the information presented herein. The U.S. Government assumes no liability for the contents or use thereof.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1]
- 2Antoniou et al. [2015] Antoniou, C., Azevedo, C. L., Lu, L., Pereira, F. and Ben-Akiva, M. [2015], ‘W-spsa in practice: Approximation of weight matrices and calibration of traffic simulation models’, Transportation Research Part C: Emerging Technologies 59 , 129–146.
- 3Antoniou et al. [2004] Antoniou, C., Ben-Akiva, M. and Koutsopoulos, H. [2004], ‘Incorporating automated vehicle identification data into origin-destination estimation’, Transportation Research Record: Journal of the Transportation Research Board (1882), 37–44.
- 4Antoniou et al. [2006] Antoniou, C., Ben-Akiva, M. and Koutsopoulos, H. N. [2006], Dynamic traffic demand prediction using conventional and emerging data sources, in ‘IEE Proceedings-Intelligent Transport Systems’, Vol. 153, IET, pp. 97–104.
- 5Ashok and Ben-Akiva [2000] Ashok, K. and Ben-Akiva, M. E. [2000], ‘Alternative approaches for real-time estimation and prediction of time-dependent origin–destination flows’, Transportation Science 34 (1), 21–36.
- 6Balakrishna et al. [2008] Balakrishna, R., Ben-Akiva, M. and Koutsopoulos, H. [2008], Time-dependent origin-destination estimation without assignment matrices, in ‘Second International Symposium of Transport Simulation (ISTS 06). Lausanne, Switzerland. 4-6 September 2006’, EPFL Press.
- 7Barceló et al. [2010] Barceló, J., Montero, L., Marqués, L. and Carmona, C. [2010], ‘Travel time forecasting and dynamic origin-destination estimation for freeways based on bluetooth traffic monitoring’, Transportation Research Record: Journal of the Transportation Research Board (2175), 19–27.
- 8Ben-Akiva et al. [2012] Ben-Akiva, M. E., Gao, S., Wei, Z. and Wen, Y. [2012], ‘A dynamic traffic assignment model for highly congested urban networks’, Transportation research part C: emerging technologies 24 , 62–82.
