Beyond monetary incentives: experiments in paid microtask contests modelled as continuous-time markov chains
Oluwaseyi Feyisetan, Elena Simperl

TL;DR
This study explores how contest-based incentives in paid microtask crowdsourcing can enhance task speed and engagement, using a Markov chain model and empirical Twitter annotation experiments.
Contribution
It introduces a contest model for microtask crowdsourcing with a Markov chain framework and empirically evaluates its impact on task throughput and quality.
Findings
Rewarding top performers increases task completion rate.
Higher reward spreads lead to more work from top contestants.
Contests can accelerate results but may affect annotation quality.
Abstract
In this paper, we aim to gain a better understanding into how paid microtask crowdsourcing could leverage its appeal and scaling power by using contests to boost crowd performance and engagement. We introduce our microtask-based annotation platform Wordsmith, which features incentives such as points, leaderboards and badges on top of financial remuneration. Our analysis focuses on a particular type of incentive, contests, as a means to apply crowdsourcing in near-real-time scenarios, in which requesters need labels quickly. We model crowdsourcing contests as a continuous-time Markov chain with the objective to maximise the output of the crowd workers, while varying a parameter which determines whether a worker is eligible for a reward based on their present rank on the leaderboard. We conduct empirical experiments in which crowd workers recruited from CrowdFlower carry out annotation…
Click any figure to enlarge with its caption.
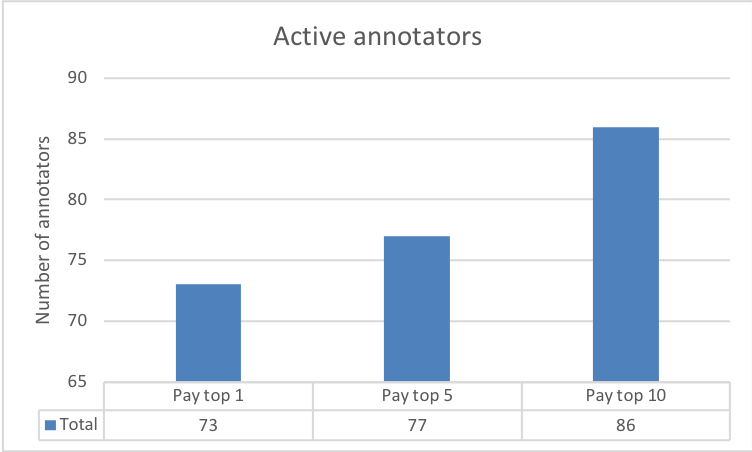 Figure 1
Figure 1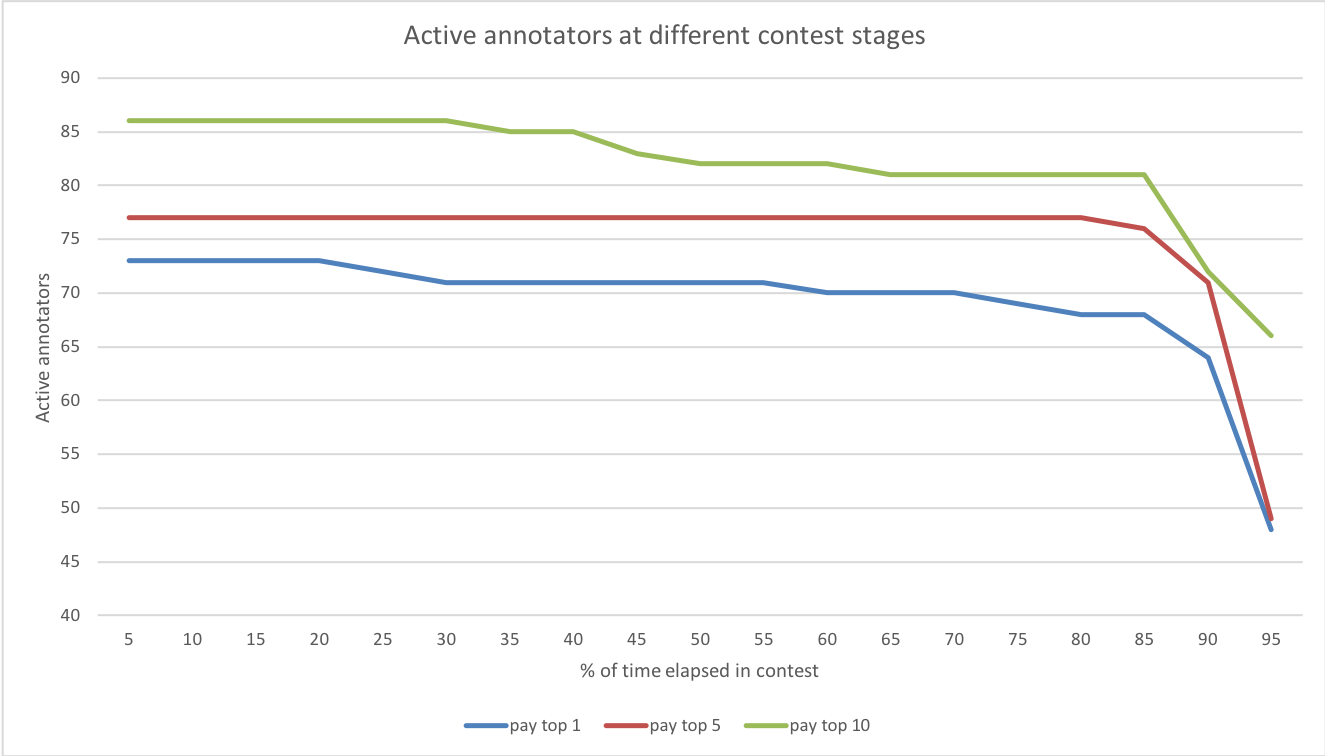 Figure 2
Figure 2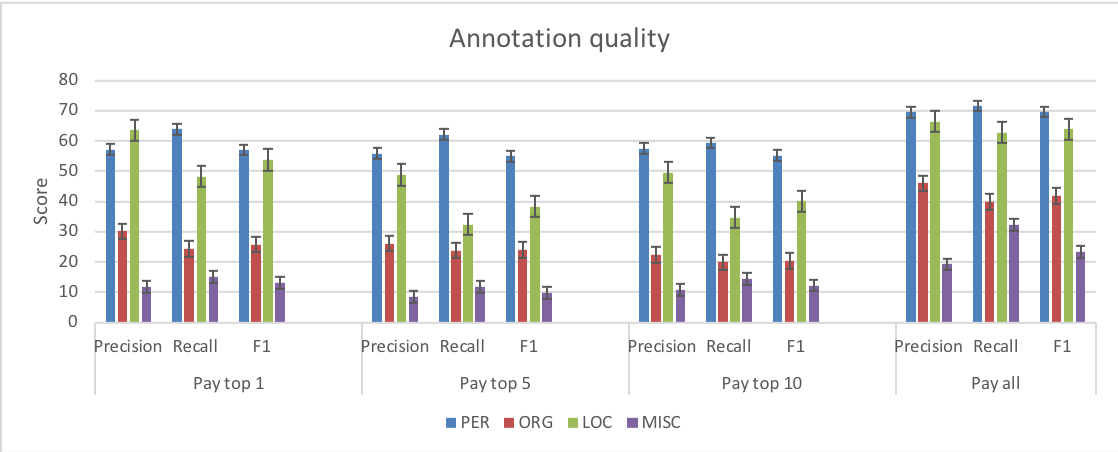 Figure 3
Figure 3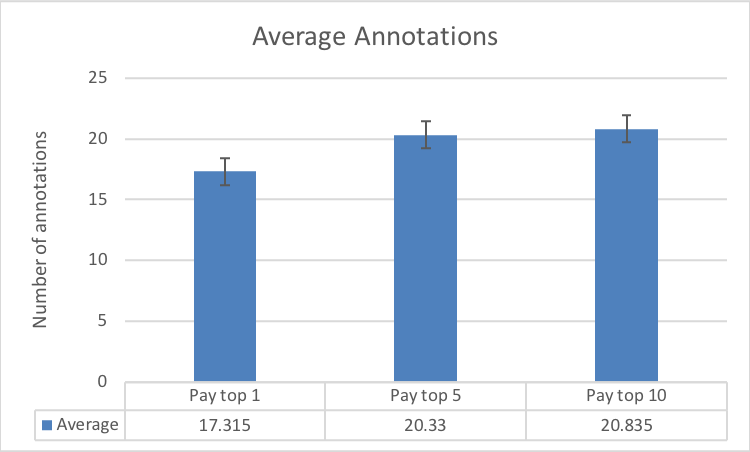 Figure 4
Figure 4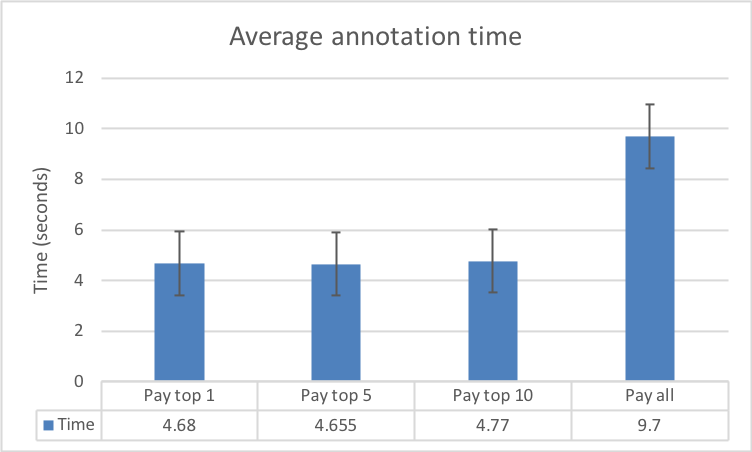 Figure 5
Figure 5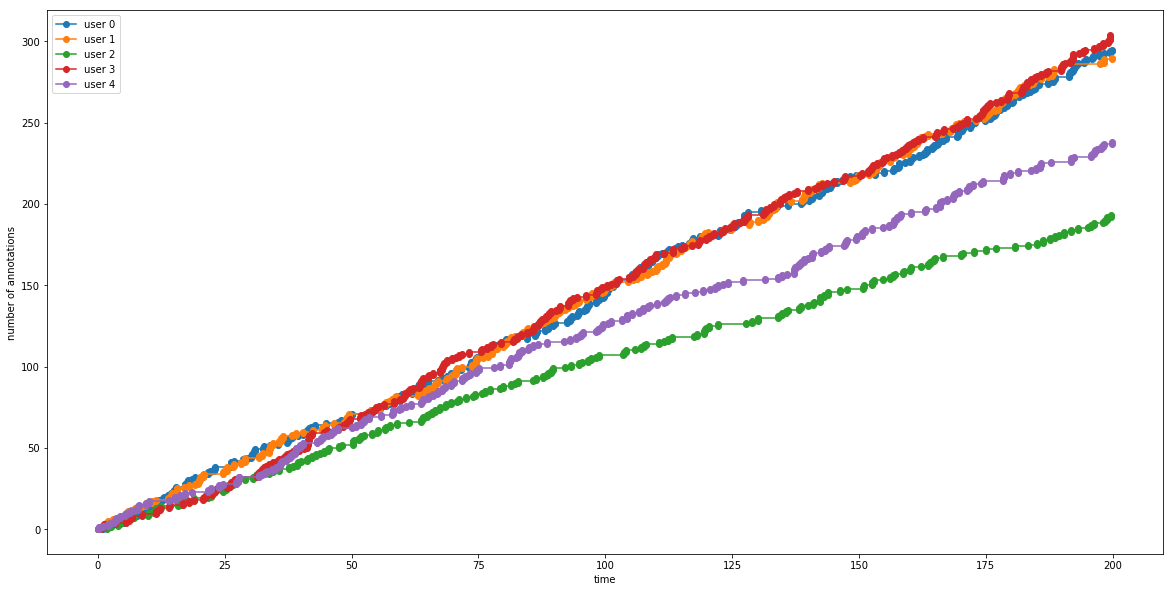 Figure 6
Figure 6 Figure 7
Figure 7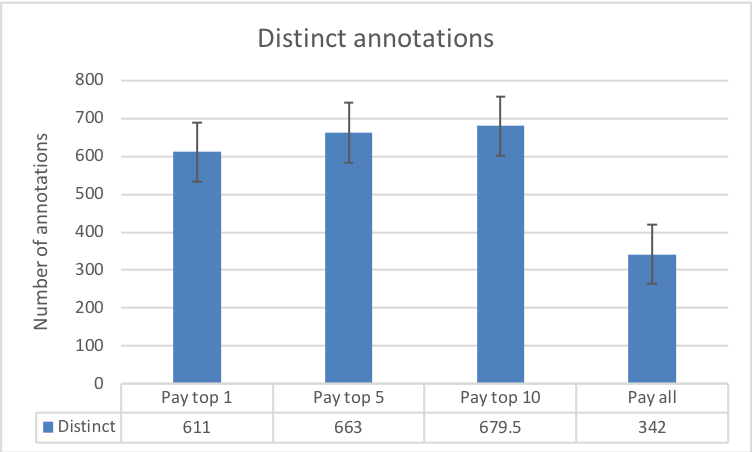 Figure 8
Figure 8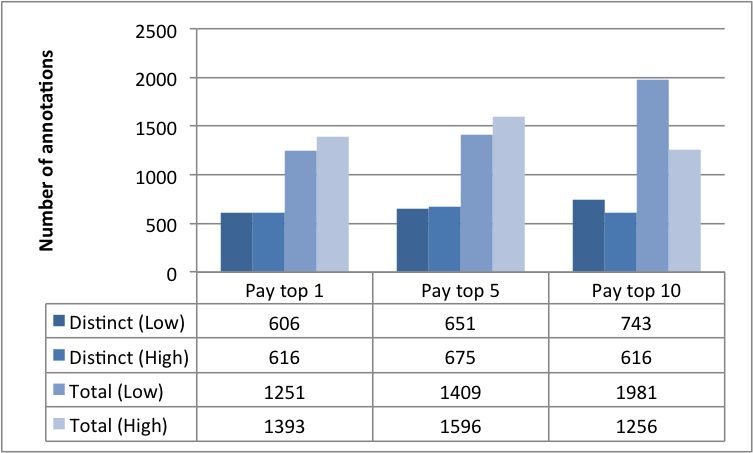 Figure 9
Figure 9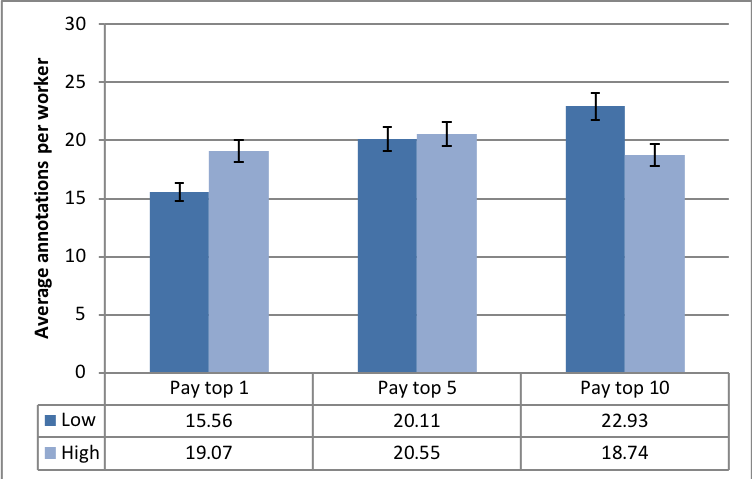 Figure 10
Figure 10 Figure 11
Figure 11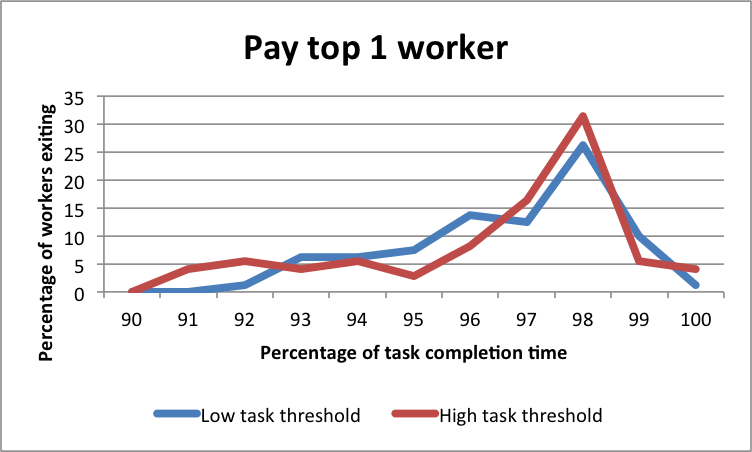 Figure 12
Figure 12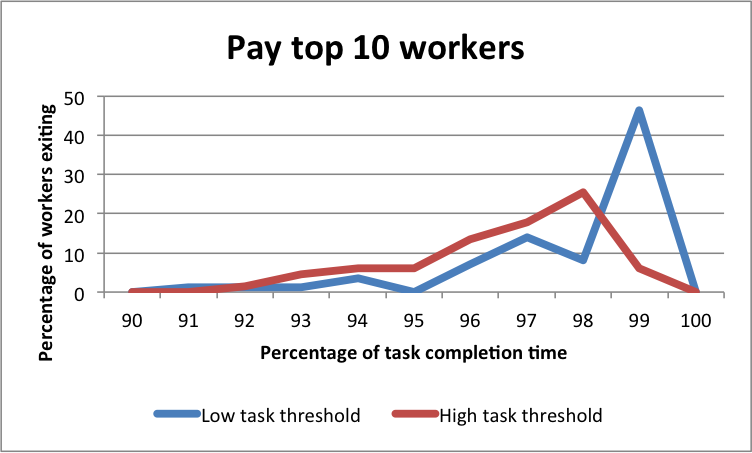 Figure 13
Figure 13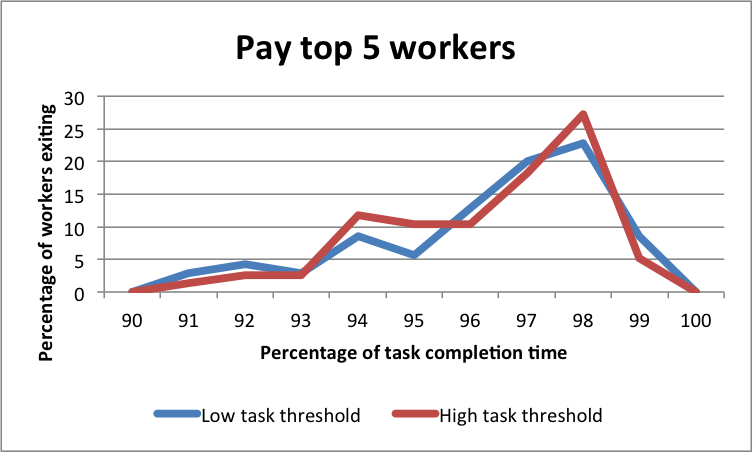 Figure 14
Figure 14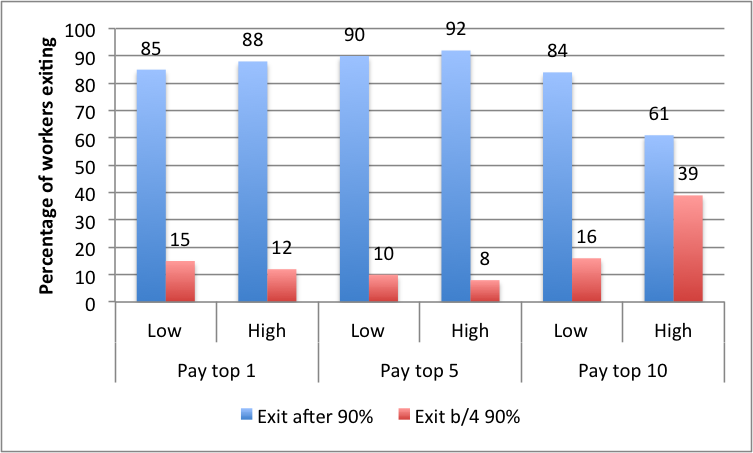 Figure 15
Figure 15 Figure 16
Figure 16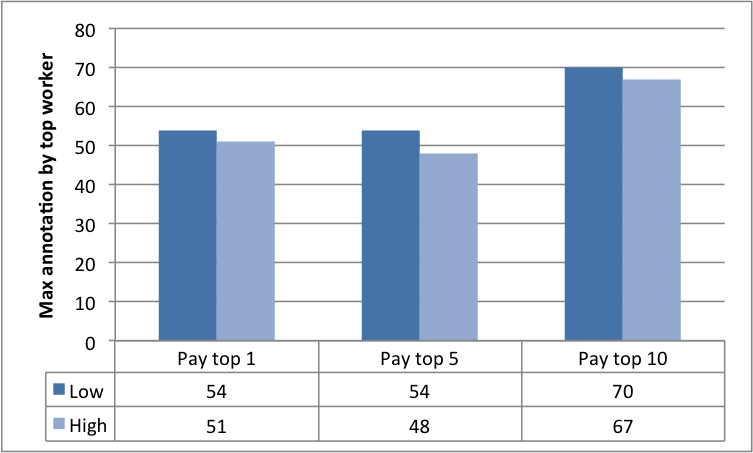 Figure 17
Figure 17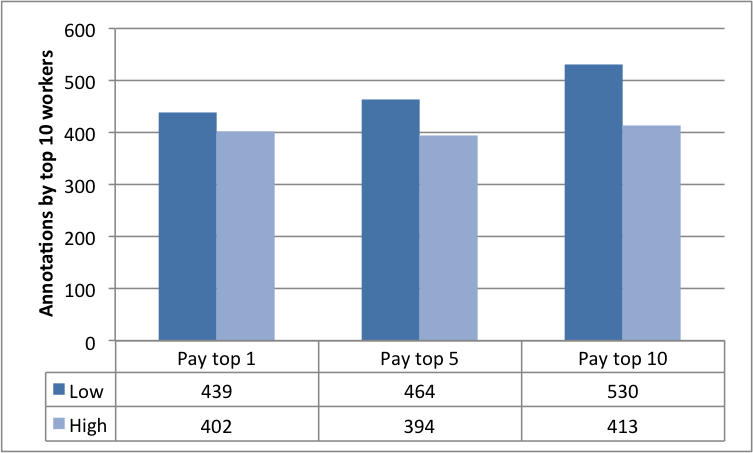 Figure 18
Figure 18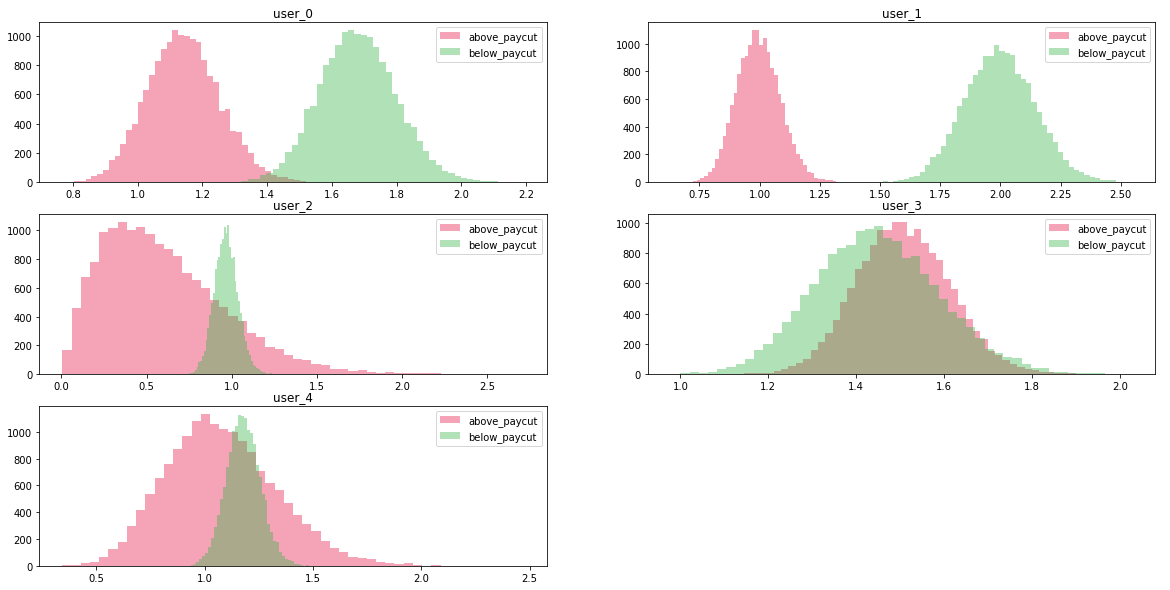 Figure 19
Figure 19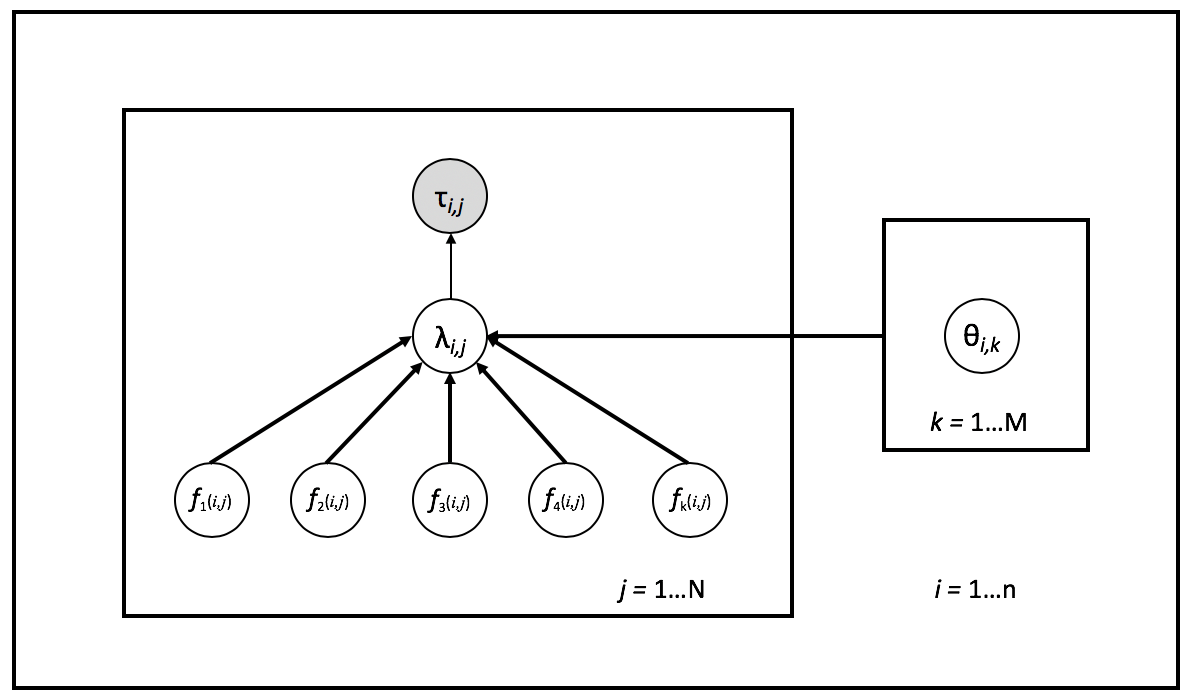 Figure 20
Figure 20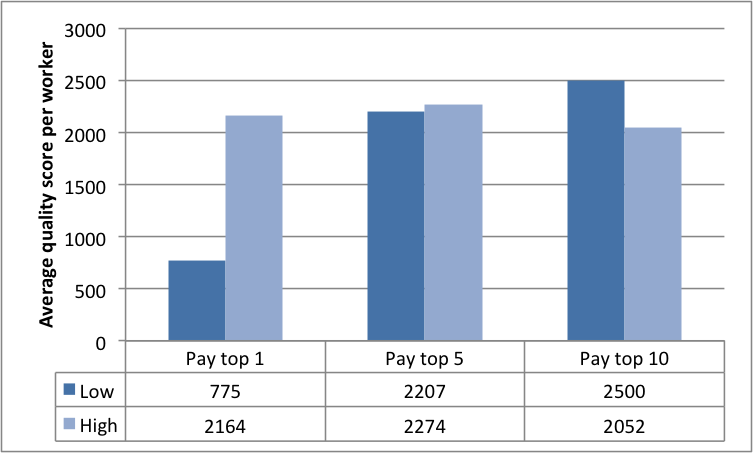 Figure 21
Figure 21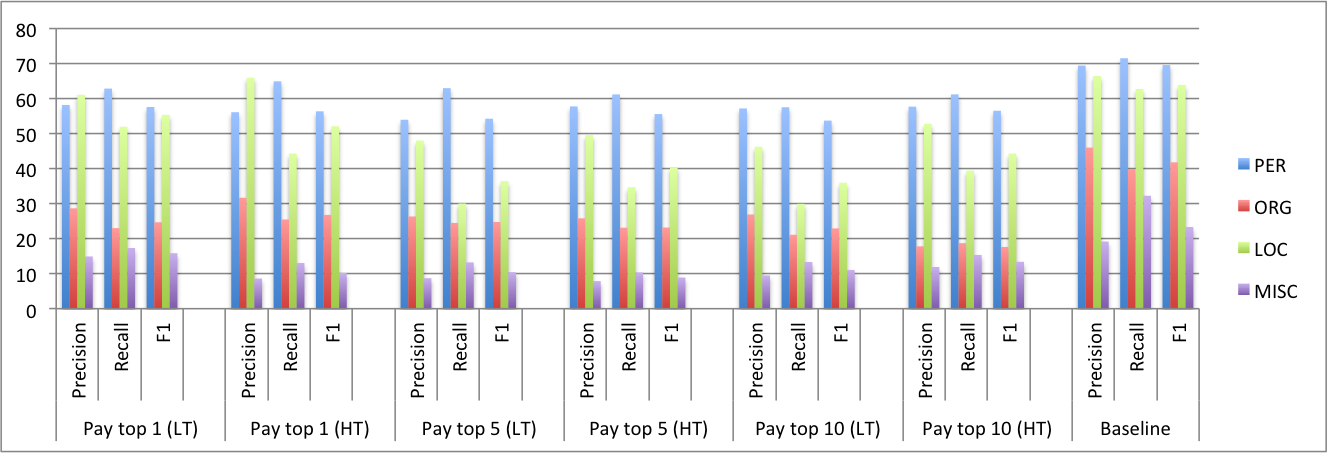 Figure 22
Figure 22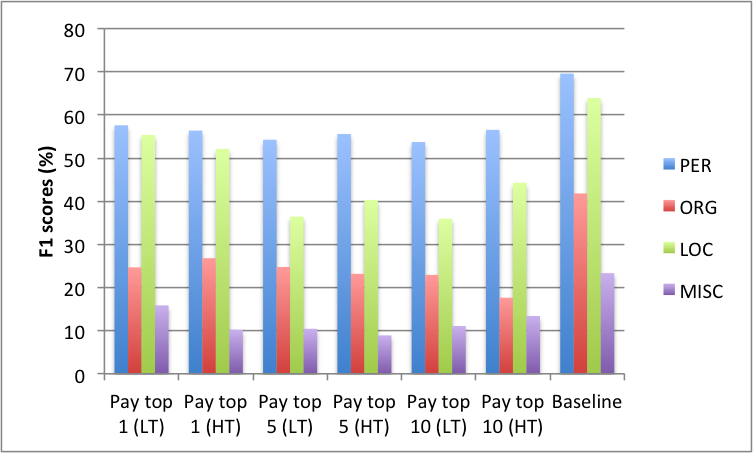 Figure 23
Figure 23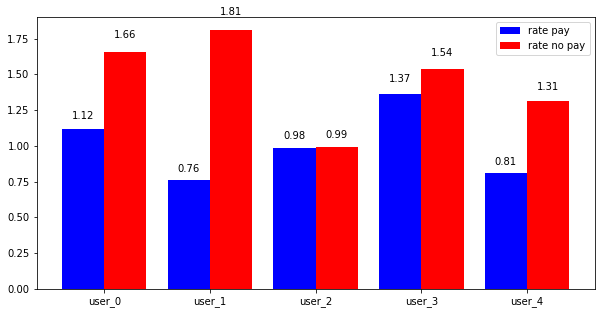 Figure 24
Figure 24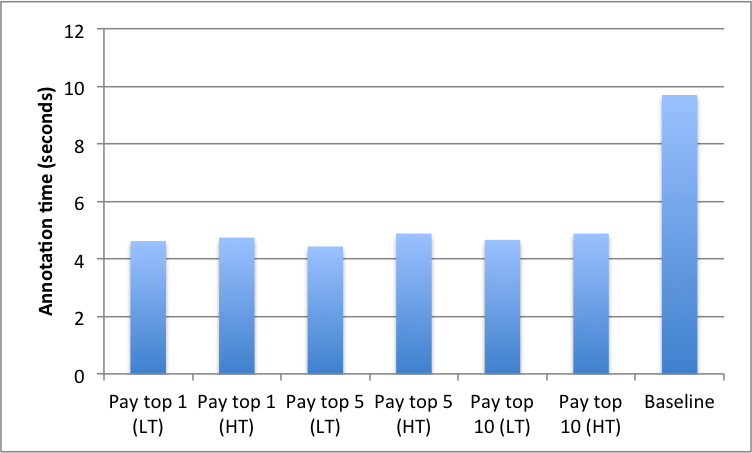 Figure 25
Figure 25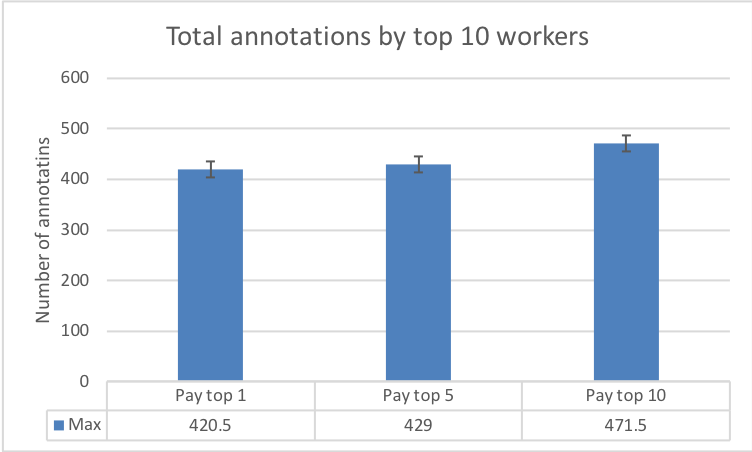 Figure 26
Figure 26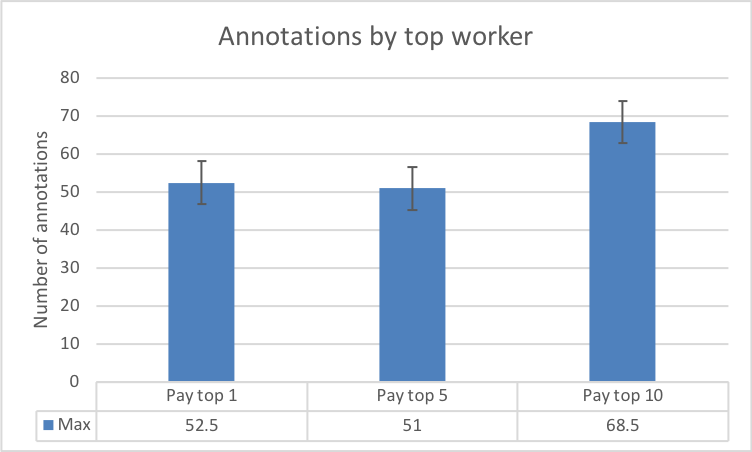 Figure 27
Figure 27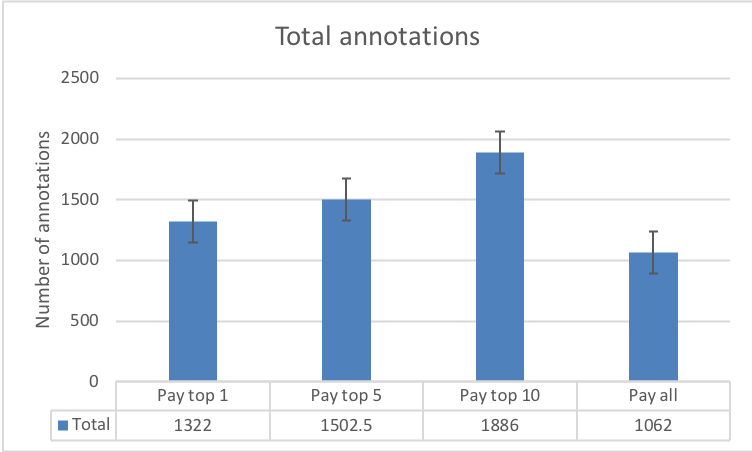 Figure 28
Figure 28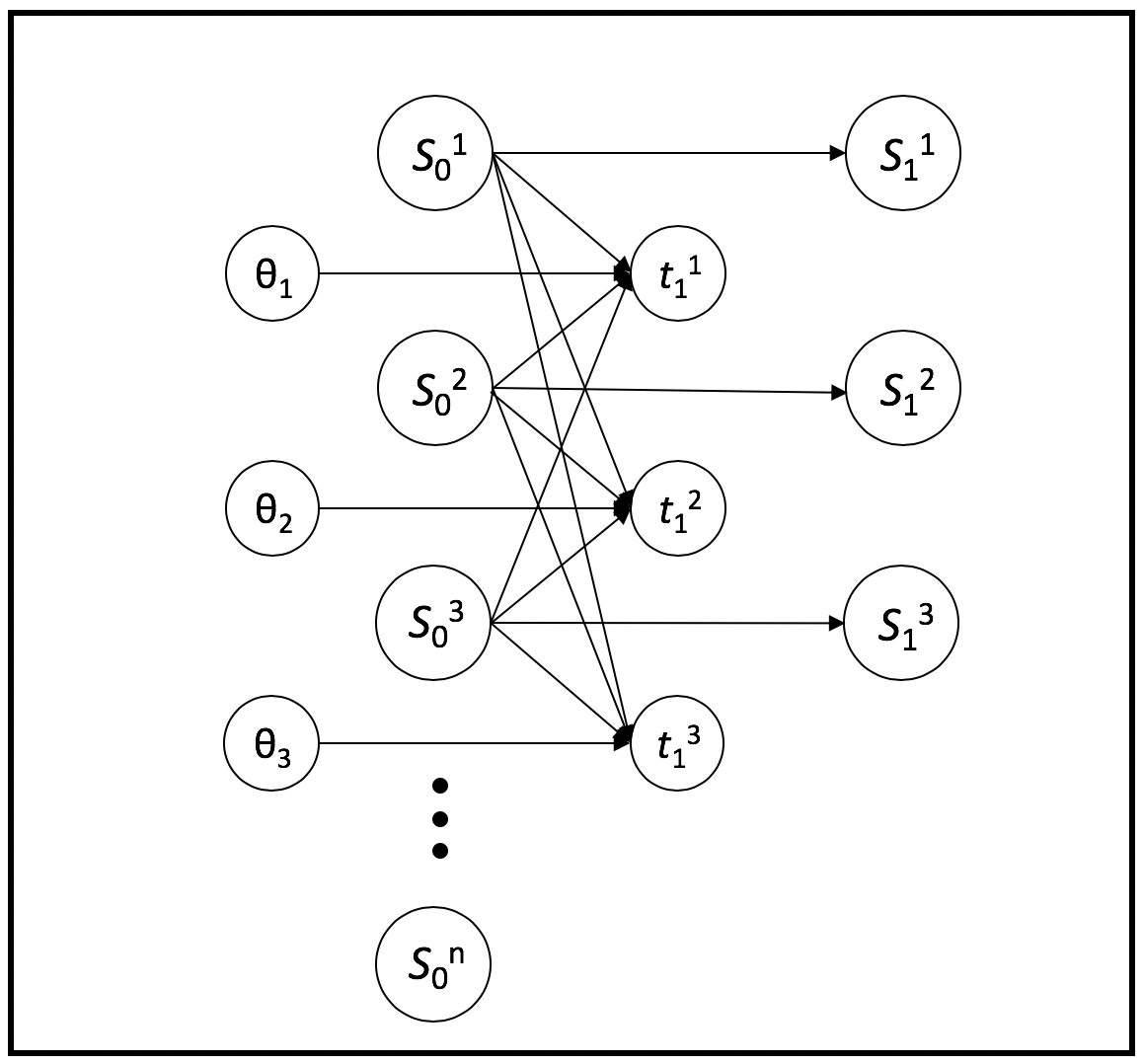 Figure 29
Figure 29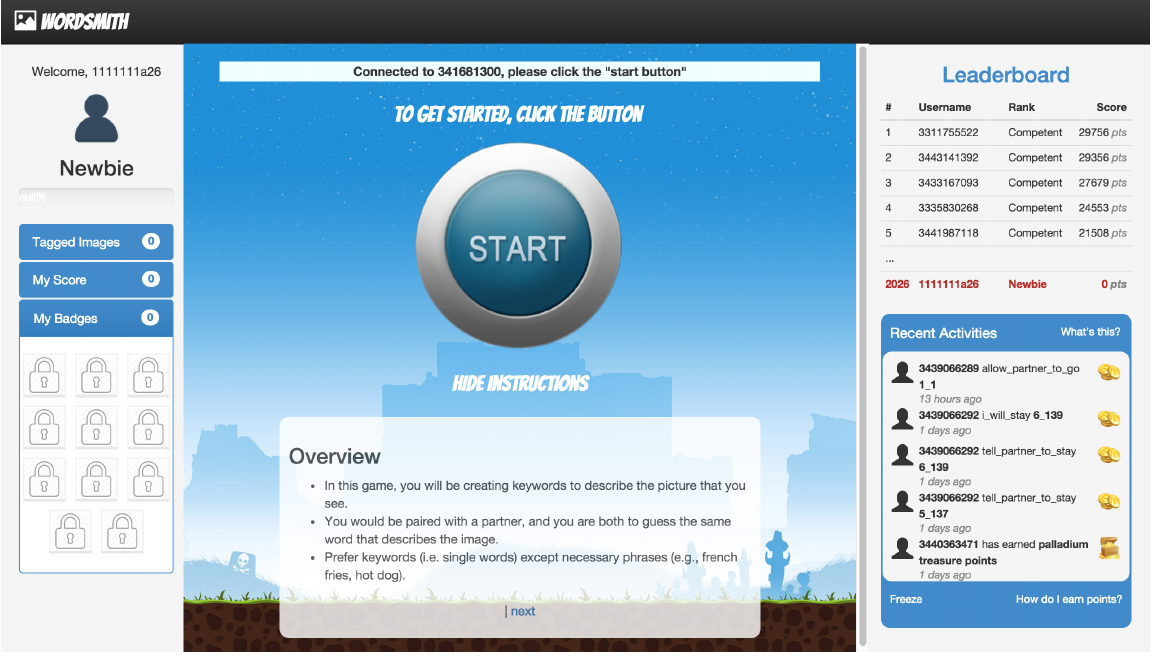 Figure 30
Figure 30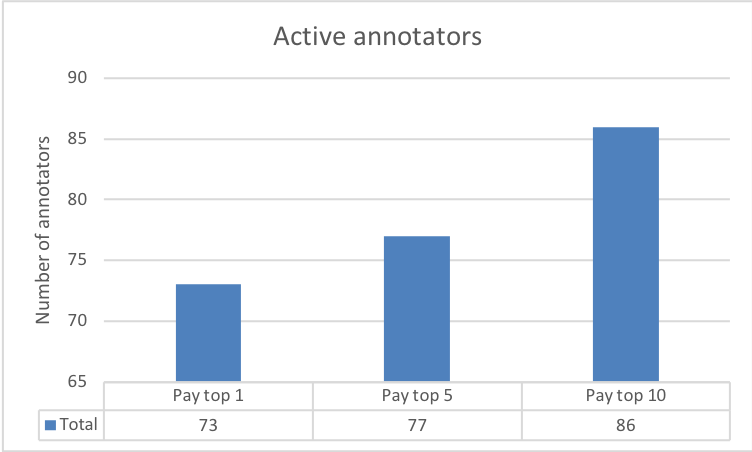 Figure 31
Figure 31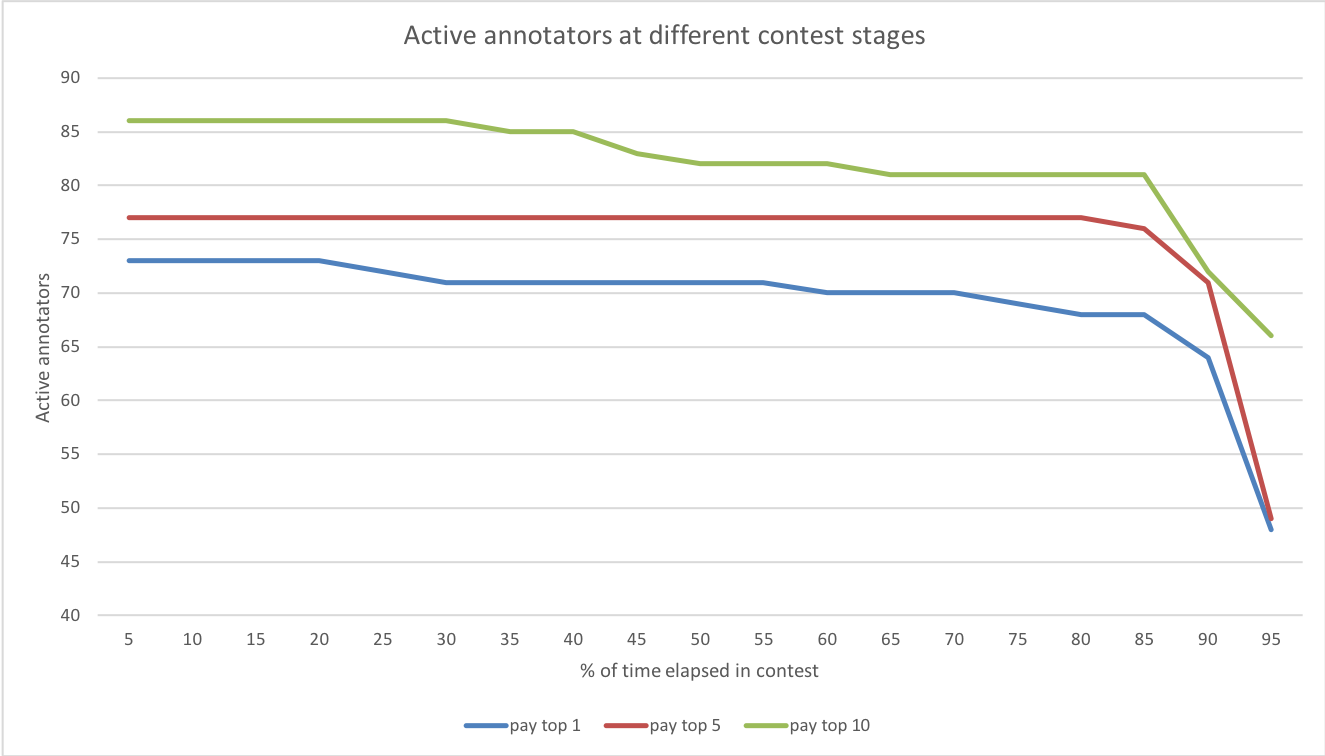 Figure 32
Figure 32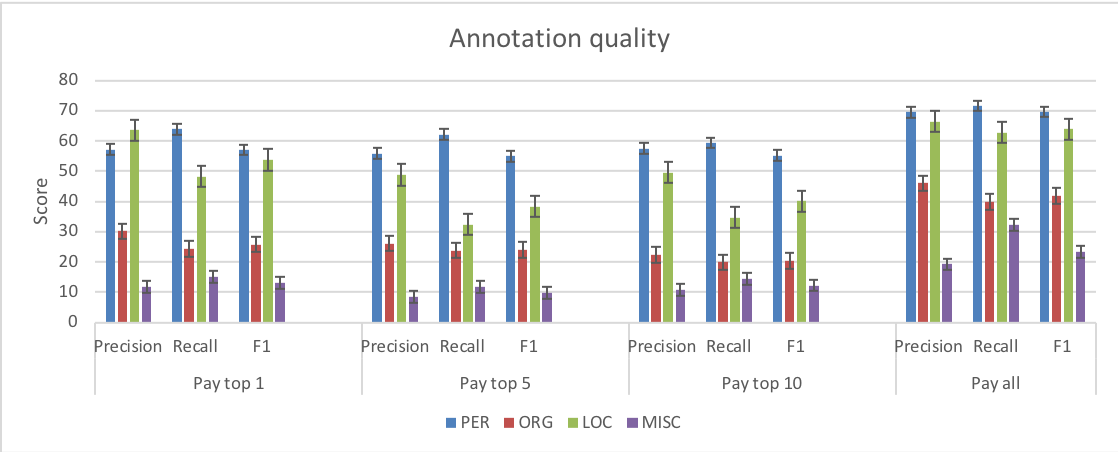 Figure 33
Figure 33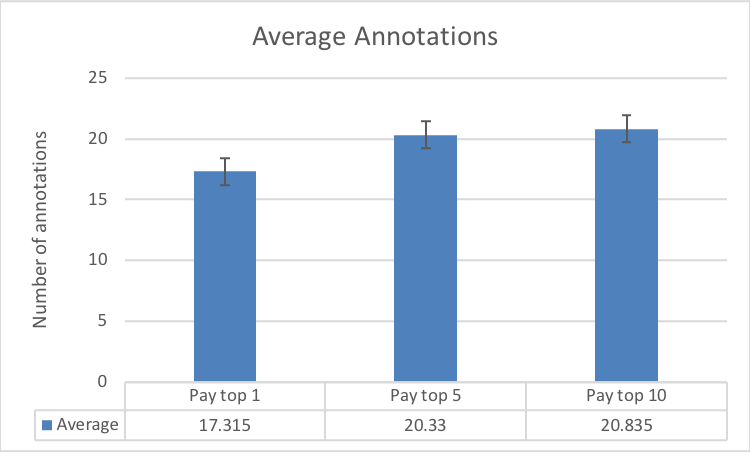 Figure 34
Figure 34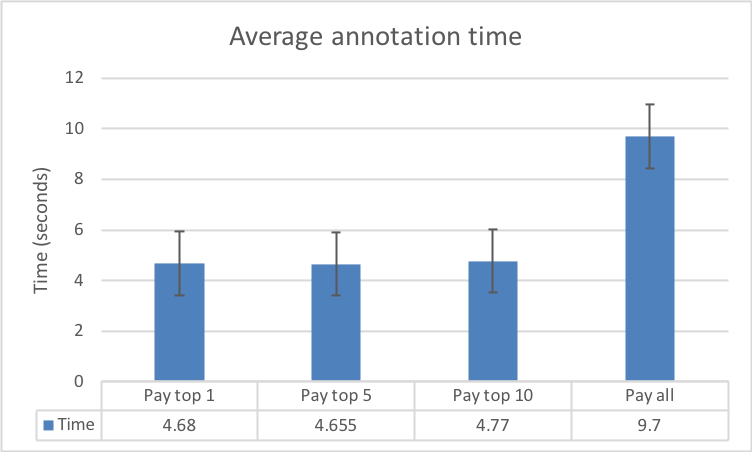 Figure 35
Figure 35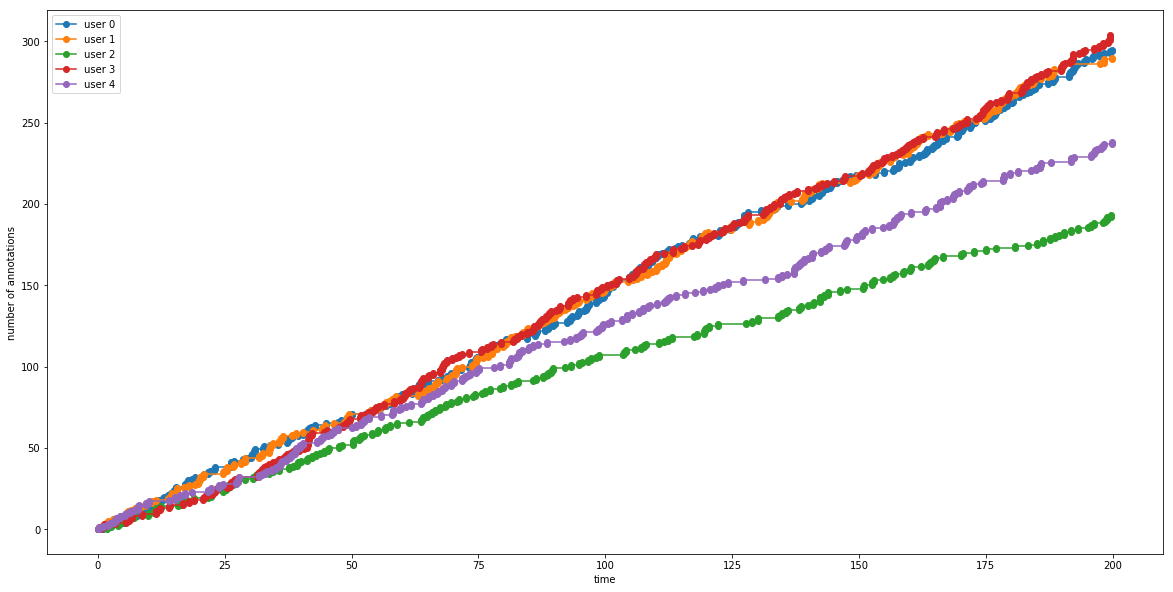 Figure 36
Figure 36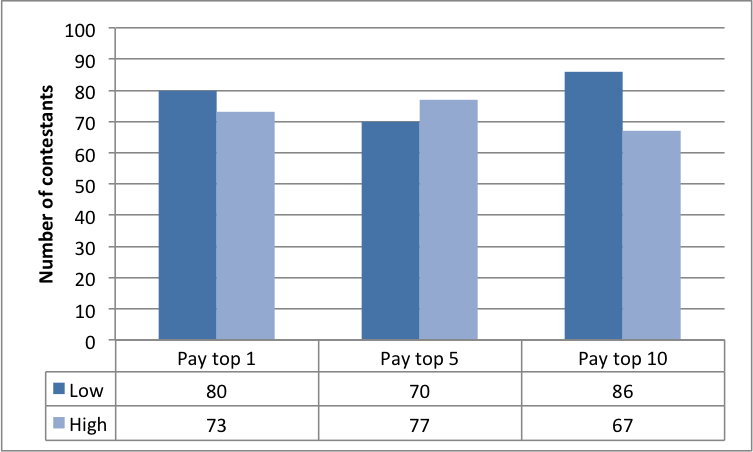 Figure 37
Figure 37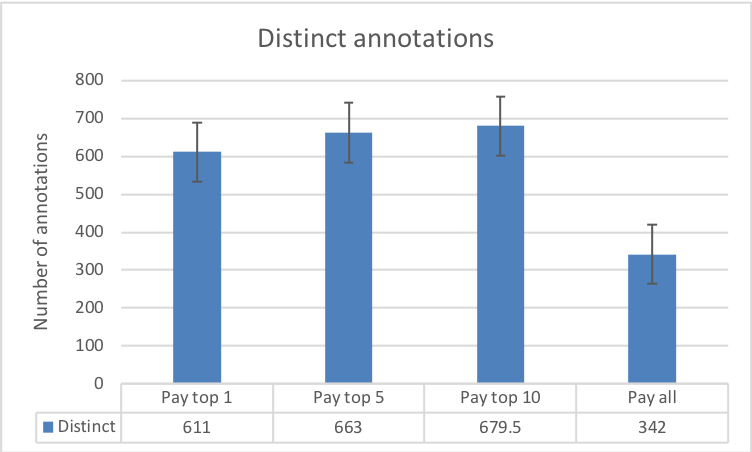 Figure 38
Figure 38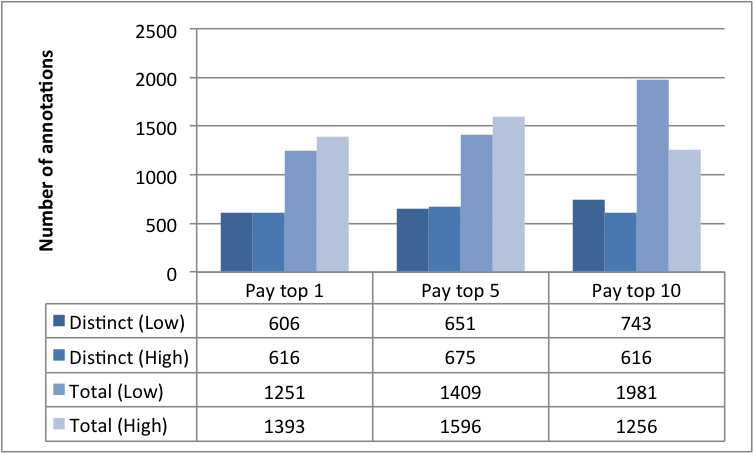 Figure 39
Figure 39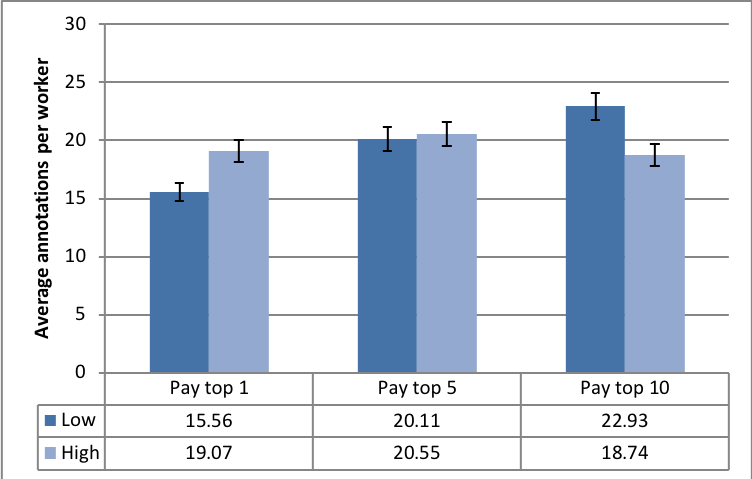 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMobile Crowdsensing and Crowdsourcing · Auction Theory and Applications · Experimental Behavioral Economics Studies
\acmYear
2019 \setcopyrightrightsretained
\issn1234-56789
Beyond monetary incentives: experiments in paid microtask contests modelled as continuous-time markov chains
OLUWASEYI FEYISETAN
ELENA SIMPERL
University of Southampton*
University of Southampton
Abstract
In this paper, we aim to gain a better understanding into how paid microtask crowdsourcing could leverage its appeal and scaling power by using contests to boost crowd performance and engagement. We introduce our microtask-based annotation platform Wordsmith, which features incentives such as points, leaderboards and badges on top of financial remuneration. Our analysis focuses on a particular type of incentive, contests, as a means to apply crowdsourcing in near-real-time scenarios, in which requesters need labels quickly. We model crowdsourcing contests as a continuous-time Markov chain with the objective to maximise the output of the crowd workers, while varying a parameter which determines whether a worker is eligible for a reward based on their present rank on the leaderboard. We conduct empirical experiments in which crowd workers recruited from CrowdFlower carry out annotation microtasks on Wordsmith - in our case, to identify named entities in a stream of Twitter posts. In the experimental conditions, we test different reward spreads and record the total number of annotations received. We compare the results against a control condition in which the same annotation task was completed on CrowdFlower without a time or contest constraint. The experiments show that rewarding only the best contributors in a live contest could be a viable model to deliver results faster, though quality might suffer for particular types of annotation tasks. Increasing the reward spread leads to more work being completed, especially by the top contestants. Overall, the experiments shed light on possible design improvements of paid microtasks platforms to boost task performance and speed, and make the overall experience more fair and interesting for crowd workers.
doi:
0000001.0000001
keywords:
crowdsourcing, crowd computing, incentives, gamification, paid microtasks, contests, continuous time markov chain
††terms: Crowdsourcing
{CCSXML}
¡ccs2012¿ ¡concept¿ ¡concept_id¿10003120.10003130.10003131¡/concept_id¿ ¡concept_desc¿Human-centered computing Collaborative and social computing theory, concepts and paradigms¡/concept_desc¿ ¡concept_significance¿500¡/concept_significance¿ ¡/concept¿ ¡concept¿ ¡concept_id¿10003120.10003130.10011762¡/concept_id¿ ¡concept_desc¿Human-centered computing Empirical studies in collaborative and social computing¡/concept_desc¿ ¡concept_significance¿500¡/concept_significance¿ ¡/concept¿ ¡concept¿ ¡concept_id¿10003120.10003130.10003131.10003579¡/concept_id¿ ¡concept_desc¿Human-centered computing Social engineering (social sciences)¡/concept_desc¿ ¡concept_significance¿100¡/concept_significance¿ ¡/concept¿ ¡/ccs2012¿
\ccsdesc
[500]Human-centered computing Collaborative and social computing theory, concepts and paradigms \ccsdesc[500]Human-centered computing Empirical studies in collaborative and social computing \ccsdesc[100]Human-centered computing Social engineering (social sciences)
\acmformat
Oluwaseyi Feyisetan and Elena Simperl. X. Beyond monetary incentives: experiments in paid microtask contests.
1 Introduction
††* prior to Amazon Research, Seattle, USA (work completed at the University of Southampton, UK)
More than a decade after the term was introduced by Jeff Howe in 2006 [Howe (2006)], crowdsourcing seems to be considered by many as a, if not ‘the’, universal means to solve virtually any kind of problem, online and offline, that requires sustained human involvement. We see it used to motivate employees to engage with less rewarding work routines, attract the best possible ideas to boost innovation, enhance artificial intelligence algorithms, and support ambitious social and entrepreneurial initiatives. Achieving a goal by collecting contributions from many individuals has a long tradition, far beyond the most recent developments in the digital world. In fact, some of the most successful exemplars of the ‘wisdom of the crowds’ in modern times, for instance Wikipedia, predate Howe’s article. And yet, with the rise of social networks, smart mobile devices and online platforms, the phenomenon has found a new dimension in terms of scale and achievements - it routinely manages to mobilise very large groups of people in a relatively short period of time, helping organisations from tech and government to the military and marketing improve the ways they operate, decide, and engage with the world.
The crowdsourcing landscape is as diverse as its applications. It includes paid microtask platforms such as Amazon’s Mechanical Turk111https://www.mturk.com/ and CrowdFlower (now Figure Eight),222https://www.figure-eight.com/. In the paper, we will continue to refer to CrowdFlower, as the work was carried on before the rebranding as Figure Eight. alongside online labour marketplaces such as TaskRabbit333https://www.taskrabbit.com/ and UpWork,444https://www.upwork.com/ and open innovation contests in the style of Kaggle555https://www.kaggle.com/ and Innocentive.666https://www.innocentive.com/ It features volunteer citizen science systems such as Galaxy Zoo777https://www.galaxyzoo.org/ and SciStarter,888https://scistarter.com/ and games with a purpose (GWAPs) such as PhraseDetective999http://anawiki.essex.ac.uk/phrasedetectives/ and EyeWire.101010http://eyewire.org/explore Putting aside the principled differences between these forms of crowdsourcing, which make them from the offset amenable only to specific types of problems, the success of any crowdsourcing endeavour will depend on the ability of the ‘requester’ - the person or institution reaching out to the crowd - to benefit from crowd outputs and attract a critical mass of contributors. The frame conditions can be challenging as well: to be effective, crowdsourcing needs to provide a real alternative to existing solutions of the problem the requester is trying to solve, in terms of quality, timeliness, and costs. Getting this mixture right is not trivial, as it requires insight into a wide array of subjects from artificial intelligence and data analysis to user experience design and behavioural sciences [Feyisetan and Simperl (2016), Feyisetan and Simperl (2017)].
Aligning the motivations of the crowd with the goals of the requester and finding the right mix of rewards to drive purposeful crowd engagement are particularly critical. Existing crowdsourcing platforms already provide some level of support - whether paid microtasks, challenges, or citizen science projects, each of these forms of crowdsourcing makes some basic assumptions about what drives people to contribute to their ‘open call’ [Howe (2006)], and offers sometimes bespoke incentives to encourage a certain style of behaviour. For example, people register on Mechanical Turk primarily for financial reasons [Martin et al. (2014), Mason and Watts (2010)], then for learning, and possibly for fun. However, this is sometimes predicated on the task paying well. On the other hand, in contests such as the Netflix prize111111http://netflixprize.com/ or on TopCoder121212https://www.topcoder.com/, the crowd is mostly technology-savvy, and takes part mostly to gain a reputation, and then for the prize, or out of a desire to improve one’s skills [Archak (2010)]. In citizen science, which is often devoid of financial rewards, the main motivator is a blend of learning, fun, and the wish to make a contribution to the world’s knowledge [Raddick et al. (2010), Tinati et al. (2017)]. Designing a successful crowdsourcing campaign may therefore require different incentives, which respond to the different reasons that drive people to engage. This is not easy to achieve, as layering incentives on top of crowd motivations to change behaviour has proven to engender unexpected effects - for example, studies have shown that paying for work completed out of intrinsic reasons may make people contribute less, a phenomenon referred to as ‘crowding out’ or ‘over justification’ [Frey and Jegen (2001)]. Similarly, incentivising people through gamification commonly fails to achieve significant, long-term results when there is a mismatch between the rewards induced through game elements and the needs, expectations and values of the crowd [Rughinis (2013), Zichermann (2011)].
In our work we study the interplay between motivations and incentives in the context of paid microtask crowdsourcing. As financial payments are just one, albeit an important, factor in using crowdsourcing effectively, we explore the use of points, badges, leaderboards and contents to boost task performance and crowd engagement. To do so, we use our own experimental crowdsourced-annotation platform Wordsmith, which features paid microtasks at its core and allows requesters to layer different incentives on top of the financial remuneration and analyse their impact.
An initial study of Wordsmith and the effects of gamified task design on paid crowdsourcing was presented in [Feyisetan et al. (2015)]. It showed that designing a playful interface for annotation tasks - as opposed to the functional style common to most microtask platforms - encourages workers to engage with the task more, independently of the actual monetary reward. In the study, we were consistently able to achieve significantly lower costs ( unique annotations collected via the game vs. unique annotations contributed in the control condition on CrowdFlower) and improve accuracy by almost compared to the baseline. Through furtherance incentives, which were offered to workers when we predicted they were about to leave, we could convince workers to continue annotating, generating up to five times more unique annotations at a comparable level of accuracy. These effects were stronger when the incentives were personalised, with of crowd workers deciding to complete one more image when confronted with a targeted furtherance incentives against in the experiments using a randomly selected one. A follow-up study looked at the effects of social incentives [Feyisetan and Simperl (2016), Feyisetan and Simperl (2017)] - we asked workers to complete annotation tasks in pairs and to encourage their co-worker to continue so that both parties receive their payments. Again, the results were very encouraging. Adding a collaborative component to the default microtask model led to a increase in task uptake, a increase in task output and a increase in inter-annotator agreement. We also demonstrated that social furtherance incentives create a win-win scenario for the requester and for the workers, by helping more workers get paid by re-engaging them before they drop out.
In this paper, we focus on improving another critical success factor of crowdsourcing, delivery time. We developed an extension of Wordsmith that allows crowd workers to pick up tasks in near-real-time and compete. Workers were recruited from CrowdFlower, but instead of carrying out their annotation work at their own pace, they were asked to pay attention to the time-sensitive element of the tasks, and aim for a faster turnaround. Central to the competition was the leaderboard, which decides which workers will receive a payment for their work: unlike in most paid microtasks projects, which pay workers per unit of work accepted by the requester, in our study, workers competed for top positions on the leaderboard to get paid.
Crowd workers used Wordsmith to complete work for a fixed period of time. They were rewarded only if they achieved a high enough position on the leaderboard - in other words, workers competed against each other and only a share of them (captured by a so-called reward spread) received a payoff at the end of the contest. Leaderboard rankings were computed and updated on the fly as a function of the number of tasks completed and a heuristic approximation of their quality. The latter was based on previous work of ours in which we have studied different approaches to crowdsource the same annotation task, using standard paid microtask platforms [Feyisetan et al. (2015), (22)].
The main intuition behind the contest model was that by designing the crowdsourcing exercise as a live contest, which is supposed to be completed in a relatively short period of time, we would create an environment in which results would be delivered quickly and with accuracy. In addition, as we did not pay all workers upfront or merely for being available, we could keep the overall costs lower than in other real-time crowdsourcing approaches, which often reward mere availability as opposed to work being done. In this context, we hypothesised that the number of workers rewarded impacted the output volume.
To test this, we ran experiments with three sets of reward spreads (top worker; top workers; and top workers). The experiments confirmed our initial assumption: the contest model resulted in more annotations at a rate that was twice as fast as the control condition reported in our previous work [Feyisetan et al. (2015)]. Furthermore, increasing the reward spread led to an increase in task output. Rewarding more workers reduced the rate of worker attrition and kept more workers engaged.
These results could help in finding the balance between theoretical guarantees with empirical evidence in order to select appropriate reward spreads, while scaling to data streams comparable to real-world situations.
Summary of contributions Our platform Wordsmith offers a lens through which we can better observe the potentials of different incentive mechanisms in paid microtask crowdsourcing. Our main observations are the following: while financial payments remain important, contests can be extremely effective in encouraging workers to volunteer to carry out work at higher speed. Leaderboards make workers more aware of their performance - they drop off when faced with a potential loss of utility, i.e., when they believe they might not be among the winners of the competitions and hence miss on the payments, but the faster-paced design does not have significant effects on output quality or user experience.
The experiments shed light on possible design improvements of paid microtasks platforms to boost task performance, and make the overall experience more fair and rewarding for the workers. While we are not necessarily arguing for fully-fledged contest-based microtask platforms, considering specific gamification elements that are widely discussed in the literature [Kraut et al. (2012), Zichermann (2011)] is worth further investigation. This is important not just for purely utilitarian motives on the side of the requesters, but also in the context of the ongoing debate on ethical and fair crowdsourcing [Irani and Silberman (2013)]. In the same time, competitions, which are widely used in other forms of crowdsourcing (for example, in citizen science [Tinati et al. (2017)] and in challenges [Tang et al. (2011)]) offer interesting alternatives in situations when having a faster turnaround is important.
Previous work has approached such questions mostly through studies of crowd motivations [Kaufmann et al. (2011)], discussing the rich repertoire of extrinsic and intrinsic reasons that drive people to complete microtasks. Our experiments quantify some of their findings [Feyisetan et al. (2015), Feyisetan and Simperl (2017)]. We deliberately chose a task that is well-known in the crowdsourcing literature [Gadiraju et al. (2014)], as we were aiming for microtask designs which were only minimally influenced by interface or quality control aspects. For the same reasons, we opted for average market prices to reward participation; lower pays would have been less attractive (and unfair) for workers, higher ones might have appealed to people who were exclusively drawn to financially incentives. We believe more research needs to be done to build microtask platforms that are crowd-, as opposed to requester-centric, and reflect and support the values and motivations of the crowd as an integral part of their functionality. Our research gives evidence that such efforts could be beneficial for both workers and requesters - points, leaderboards and contests can be linked to intrinsic motivation. Workers not only completed more tasks than required, but some of them reported positively about the experiments on a community forum - for example, one post read ”Hello everyone! lately I’m hooked on the multiplayer tasks, waiting for people to connect”, while another one claimed: ”Hit the top today. I will hunt this problem again”.
Crowdsourcing, though riddled with its challenges from the technical to the ethical, is here to stay. Even as it morphs continually to the tune of academic and economic forces, it remains a force for good with groundbreaking discoveries being made daily directly and indirectly through the wisdom of the crowd [Good and Su (2011)]. Understanding the impact of incentives brings us one step closer to designing better, more responsible crowdsourcing systems. This is vital not just for research purposes, but also because of the influence crowdsourcing has on fields that have come to rely on it, including artificial intelligence, and those that draw inspiration from it, such as the so-called ‘gig’ economy.
Previous publications This paper builds upon previous work of ours, in particular on [Feyisetan et al. (2014), Feyisetan et al. (2015), Feyisetan et al. (2015)]. [Feyisetan et al. (2015), Feyisetan et al. (2015)] used earlier versions of Wordsmith to carry out their experiments. In [Feyisetan et al. (2015)], we presented a first version of Wordsmith and initial experiments into the effects of gamified task design on paid crowdsourcing. In [Feyisetan et al. (2014), Feyisetan et al. (2015)], we aimed to understand how to collect Twitter entity annotations via paid microtasks effectively. All works implemented a task model where workers complete tasks individually and are rewarded if they provide useful answers. In this work, we used the same Wordsmith platform and Twitter entity annotation task; however, we introduced contests as a new incentive layer on top of the base financial payouts.
2 Background
In this section, we briefly review some of the most relevant prior work pertaining to maximising the effectiveness of incentivised crowdsourcing. In particular, we focus on real-time crowdsourcing approaches that aim to generate results faster; and more generally, on methods that optimise some aspect of crowd performance, be that by offering bespoke incentives, by assigning tasks to those workers who are more likely to do them well and so on. As much of this background literature is inspired by and explained using theories of human motivation and incentives design, we start with a synopsis of fundamental work in this space.
2.1 Incentives in paid microtask crowdsourcing
2.1.1 Motivation theory
Theoretical frameworks such as the Self Determination Theory (SDT) [Deci and Ryan (2010)] make the distinction between intrinsic and extrinsic motivation to study the reasons why individuals decide to contribute to a task. Intrinsic motivation covers tasks that are perceived as rewarding in themselves, and is seen as responsible for engagement in activities such as socialising and participating in volunteering projects [Tinati et al. (2017)]. On the other hand, extrinsic motives are related to factors that are not inherently related to the actual task, but are appealing for some external reason such as status or financial payments.
The SDT theory has been applied to motivation studies on paid microtask platforms. [Kaufmann et al. (2011)] mirrors the motivation types as fun (intrinsic) and money (extrinsic) in a survey of incentives on Mechanical Turk. Similarly, [Malone et al. (2010)] describes incentives as either appealing to love, glory, or money. More relevant to Wordsmith, SDT has also been applied extensively in gamification research [Deterding et al. (2011), Seaborn and Fels (2015)]; collaboration and online communities [Raddick et al. (2010), Nov et al. (2014), Tinati et al. (2017)]; and contests [Bennett and Lanning (2007)].
2.1.2 Monetary incentives
Money is a natural incentive for carrying out work, hence paid microtasks remain one of the most prominent forms of crowdsourcing [Frei (2009)]. Research has shown that increased payment leads to faster task completion, but not to higher quality [Mason and Watts (2010)]. Several other factors play a role in obtaining useful task results: bonuses, worker perception, and the variation of payment sizes across tasks [Difallah et al. (2015), Mason and Watts (2010)]. The drive to engineer optimal quality, speed and volume of work with minimal financial payments has made paid microtasks the subject of numerous discourses on the ethics of compensation [Irani and Silberman (2013)]. While monetary payments can be seen as an extrinsic motivator, other intrinsic factors have been known to contribute to sustained participation in paid crowdsourcing settings, including intellectual curiosity [Law et al. (2016)]; the inherent nature of the task [Frei (2009)]; and interaction with other workers [Kittur (2010)]. One of the questions we are trying to answer with Wordsmith is: How do we expand the currency of transactions on paid microtask platforms to transcend monetary payments, and encompass tasks that have an intrinsic appeal?. We presuppose that framing tasks this way would be more attractive to workers, cost less for requesters, and make workers perform better. This led us to study other incentive mechanisms in our earlier works [Feyisetan et al. (2015), Feyisetan and Simperl (2017)], and the idea to leverage contests as a new incentive strategy.
2.1.3 Gamified incentives
Gamification is the use of game design in non-game contexts, with the aim to achieve the effects of fun and engagement that are created by playing a game [Zichermann (2011)]. It often involves adding game-like rewards to non-game activities, include social elements to encourage teamplay or contests. We understand gamification in a broad context, comprising systems that build a complete game narrative around a task (e.g., FoldIt and EyeWire) [Good and Su (2011)]; employ tactics such as micro-diversions to fend off boredom [Dai et al. (2015)]; further a noble cause or stoke curiosity [Law et al. (2016)]; or engineer game mechanics (such as points, badges, levels and leaderboards) into tasks [Deterding et al. (2011)]. In a work context, each of these classes of systems has been shown to improve productivity, drive engagement and effectiveness, and therefore reduce costs.
Gamification practices have raised concerns about their potential to undermine innate intrinsic motivation via the crowding-out and over-justification effects discussed earlier - although this has been shown to be task-dependent [Mekler et al. (2013), Seaborn and Fels (2015)]. We also know that gamification can be more effective in collaborative settings; in other work of ours [Feyisetan and Simperl (2017)], we designed a multiplayer Wordsmith extension that required consensus among pairs of paid crowd workers. This led to better outcomes when compared to the baseline, which was built around completing the same tasks individually [Feyisetan and Simperl (2017)]. Similar findings were reported in the context of GWAPs [Von Ahn and Dabbish (2008)], which often rely, unlike our work, on voluntary participation.
2.1.4 Contest-based incentives
Paid microtask crowdsourcing has traditionally been approached as an individualistic endeavour. Workers complete their tasks without depending on, or interacting with others. Other forms of crowdsourcing, such as volunteer citizen science, have experimented with models that encourage the crowd to discuss, exchange ideas, collaborate on tasks, or compete to improve their standing in the community [Reeves et al. (2018), Tinati et al. (2017)]. In this context of paid microtasks, we seek to apply contest-based incentives to improve the delivery time of crowd responses.
In order to carry out crowdsourcing in a contest setting, timely worker recruitment and task uptake are critical. This comes as a result of scenarios with near-real-time constraints - for example, when crowdsourcing is applied to fact-checking in news media, disaster management, or live data feeds. However, most solutions proposed in the literature are often too costly for large numbers of microtasks (see also Section 2.3 below for an overview of near-real-time crowdsourcing research). Contests recruit crowd workers who are attracted to the thrill of ‘glory’ and competition to carry out tasks quickly. This model has been seen on software coding platforms such as TopCoder [Archak (2010)], where over a million workers vie to complete challenges, or in citizen science [Reeves et al. (2018)]. Contests leverage on the urgency that comes from a fixed completion time-frame, and the satisfaction brought by a sense of winning. They are primarily deployed when the requester seeks one best, or final answer (as opposed to an aggregation of worker results, which is more typical in microtask crowdsourcing), or to increase participation. For example, the Netflix $1 million dollars challenge to build a better recommendation algorithm [Bennett and Lanning (2007)] falls in this ‘single best result’ category. EyeWire, a game with a purpose which creates a visual map of the human brain, routinely uses different kinds of challenges to increase the volume of tasks completes and keep the crowd engaged [Reeves et al. (2018)]. Remuneration in contests range from a winner-takes-it-all model, which compensates only the best participant, to more relaxed models that pay contributors who make submissions above a certain threshold, with several theoretical frameworks set up to determine the optimal allocation of prizes [Moldovanu and Sela (2001)]. In this paper, we designed our contest to cover tasks that required an aggregation of results (as opposed to a single best response), while obtaining responses as quickly as possible. This type of approach is relevant in domains such as disaster relief and real-time visual aids for blind people [Bigham et al. (2010)].
The literature on contests goes well beyond the focus of our work, which is paid microtasks. The history of contests dates back to as far as , when the British Parliament ran one to determine the longitude at sea to within half a degree [Moldovanu and Sela (2001)]. Several theoretical studies have looked at optimal contest design [Chawla et al. (2015)] and the optimal allocation of prizes [Moldovanu and Sela (2001)]. A survey of experimental research of contests is available from [Dechenaux et al. (2015)]. Researchers have investigated how contents unfold on existing platforms such TaskCN [Liu et al. (2011)], TopCoder [Archak (2010)] or EyeWire [Reeves et al. (2018)]. Empirical studies have shown the effects of increased payoff as an indicator of contestant performance. Further on, [Boudreau et al. (2011)] considered over contests hosted on the same platform in order to understand the effect of participant numbers on the performance of individuals. A second group of empirical work focused on bespoke experimental setups for crowdsourcing. For example, [Rokicki et al. (2014)] looked at the effect of varying monetary schemes and information policies in individual contests, while [Rokicki et al. (2015)] explored the same problem alongside team formation strategies. Both papers bear similarities to our scenario, in which contestants strategically decide whether they continue to take on more tasks or leave Wordsmith. However, they do not propose ways to predict worker exit to optimise task completion and delivery. [Norrander (2006)] introduced a duration model, which we also attempt to analyse in our work, which shows the length of candidacies and factors associated with candidate exits.
Finally, our work builds on literature which studies the war of attrition. In contests, each participant enters knowing their own skill and costs, but not those of the other contenders. Participants consider dropping out when they learn their opponents’ strengths and discover that staying would be unprofitable. A theory of how this phenomenon operates in duopolies was presented by [Fudenberg and Tirole (1986)]. [Krishna and Morgan (1997)] presented its relation to an all-pay auction while, while [Norrander (2006)] discussed attrition and exit in political primaries. [Moldovanu et al. (2012)] looked at contests with exits where contestants have the option to drop out or not to participate with the introduction of costless punishments. Since our objective was to maximise the total utility generated in real-time, we did not use punishments, which some early pilots we carried out revealed to increase the attrition rate.
2.2 Making microtask crowdsourcing more effective
Several descriptive frameworks have been proposed in the literature to capture the nuances of incentives engineering beyond simplistic ’fun or money’ considerations. Some of these include MICE (Money, Ideology, Coercion, Excitement) [Burkett (2013)]; RASCLS (Reciprocation, Authority, Scarcity, Commitment, Liking, Social Proof) [Burkett (2013)]; and SAPS (Status, Access, Power and Stuff) [Zichermann (2011)]. The latter is intended to represent a system of incentives from the most desired to the least desired, and from the cheapest to the most expensive. We adopted this framework in Wordsmith.
Mechanisms for the effective allocation of incentives have been studied in market and auction platforms, wireless and peer-to-peer networks and corporate organisations. In the context of crowdsourcing, several studies have been carried out that apply game-theory techniques to incentive design [Xie et al. (2014), Yang et al. (2012)]. These papers focus on financial incentives and a premise of inter-player strategy dependency. Not all crowdsourcing tasks can be modelled in this way; we adopt a probabilistic approach based on prior player behaviours to predict appropriate incentives beyond the purely financial (see also [Feyisetan et al. (2015)]). Similar techniques are used for various purposes in crowdsourcing design, in particular to inform the assignment of tasks to workers or to predict task completion [Demartini et al. (2013), Sheng et al. (2008)].
A large body of work has been dedicated to task and workflow design, as well as quality control (see, for instance, [Michelucci (2016)] for a good compilation). We take their findings into account when implementing the basic CrowdFlower interfaces, checking for spam and validating and aggregating the results.
2.3 Improving delivery time
Longitudinal studies of crowdsourcing marketplaces such as Mechanical Turk [Difallah et al. (2015)] reveal how microtasks have evolved to support scenarios in which work cannot take days or hours, but must be delivered in seconds and under [Bernstein et al. (2011)]. For near-real-time behaviour, two components are critical: prompt recruitment of workers and fast completion of tasks. In this section, we compare our approach with previous research in microtask crowdsourcing, which has proposed improvements to these components.
2.3.1 Timely worker recruitment
Several models have been put forward to ensure timely availability of crowd workers. For example, Adrenaline [Bernstein et al. (2011)] employed a retainer model, while in Viz-Wiz [Bigham et al. (2010)] workers signed up in advance and were kept engaged, at a cost, until the work arrived. Other approaches relied on very large crowds [Lasecki et al. (2014)], using queuing theory or predictive recruitment to model workers’ arrival and task assignment [Bernstein et al. (2012)], or repeatedly posting the tasks to make them more visible to workers [Bigham et al. (2010)]. In our experiments, we incorporated a combination of these ideas to generate our on-demand crowd: we repeatedly posted tasks, recruited in advance, requested for a larger crowd than required, and used an audio alert to prompt workers when the contest started. At the same time, by virtue of our contest model, we rewarded only a small share of the workers, hence keeping the costs down.
2.3.2 Timely task completion
Some of the techniques found in the related literature include: rapid refinement, which dynamically narrows the search space following signs of worker agreement [Bernstein et al. (2011)]; stream parallelism, which splits the task into sub-tasks and assigns them to different pools of workers in parallel [Bigham et al. (2010)]; temporal division, which breaks the task down into time slices as more work becomes available [Lasecki et al. (2011)]; warping time [Lasecki et al. (2013)], which allows workers to listen to audio streams at reduced speeds; and a Map Reduce alike to organise complex workflows [Kittur et al. (2011)]. Our model uses stream parallelism to assign work to several groups of workers, and variants of temporal division and time warping to display tasks to each overlapping batch of workers for an extended period of time. Combined with the mixed cardinal-ordinal contest, these techniques create a powerful mechanism to solve tasks twice as fast as the evaluation baseline (see Section 7).
3 Contest-based annotation task
In our experiments, we used a text annotation task model in relation to real-time crowdsourcing. For this reason, the task consists of a total of n posts, , each containing m entities to be annotated, where and is equal to the number of text tokens in post . The posts arrive at a constant rate and each has a processing rate of . There are n workers in a pool to serve the task queue such that, to keep up with the requests, the ingress load (task intensity) stays less than the number of workers n, i.e., .
Tasks that are not solved are dropped of the queue as opposed to being kept indefinitely in the buffer [Bernstein et al. (2012)]. They are solved using a first-in-first-out scheduling and processing scheme, in which already recruited workers are sought to carry out new tasks (as opposed to recruiting additional workers for new tasks). Therefore, the requester is looking for an optimal processing rate , and needs to keep workers motivated to carry out as many tasks as possible.
Requester The requester asks the crowd to complete a series of tasks in real-time. The requester needs to determine the experiment setup in terms of: (i) the number of contestants; (ii) the number and size of prizes; and (iii) the contest constrains to maximise the effort exerted by all contestants . This is different from contests such as the Netflix Challenge [Bennett and Lanning (2007)], where the principal’s objective was to elicit a single best response to a task.
The requester does not only desire to maximise the total exerted effort, but also to maximise some utility function of output quality . The requester therefore needs to maintain incentives for highly skilled workers, and motivate low skilled workers to exert more effort while adjusting the prize spread.
The requester defines: (i) a completion time constraint T, which depends on the number of posts n and their arrival rate ; and (ii) a quality constraint Q, which denotes the minimum number of labels expected from each worker to be eligible for payment. The latter is essential in hybrid tasks; for example, the task might have been pre-labelled by a machine to determine the probable number of named entities (this serves as the quality constraint Q), while the crowd workers identify those entities and type them [Feyisetan et al. (2015)].
The requester is able to observe the baseline quality of each worker’s output, based on the pre-computed number of entities and the number of entities submitted by the worker. The requester is then able to use this information to construct the contest by assigning a quality score to every crowd answer - therefore, contestants are ranked not only based on their effort (number of posts annotated), but also on the quality of their output. The reward mechanism awards a prize to a worker within a reward spread (e.g., the worker was within the top or top ).
Workers There is a set of n workers, participating in the contest, each with the ability to carry out entity annotations. Each worker has a private skill level (also known as expertise or ability), and for each post in an annotation task, chooses to exert a level of effort . The skill level is drawn independently of other workers from the interval , according to a distribution function F with density .
The effort exerted is drawn from the interval , in which the maximum effort expendable is constrained by the running time t of the contest, which in turn is a function of posts per unit time and total number of posts. The quality of each worker is determined by: (i) the skill level ; (ii) the effort exerted ; and (iii) a requester variable . The requester variable is a function of the requester’s review process and perception of quality, in comparison with the worker’s internal tagging bias, which is markedly present in human judgement tasks. This value is constant across annotation posts ; therefore, two workers exerting the same effort to annotate the same post would differ only on their skill, since the requester’s variable is constant for that post. The quality of a submission is thus given as: . In our experiments, the requester’s variable was a measure of results in a pre-computed gold standard set [Feyisetan et al. (2015)].
Each worker seeks to maximise their expected utility. This depends on the number and value of prizes, and on the number of contestants and value of their efforts. A worker’s utility is given by , if the worker wins prize , or by otherwise, where is one of k prizes to be awarded by the requester, and is the worker’s cost function, which is a strictly increasing function dependent on exerted effort where . Each prize above point k is positive, or zero otherwise. We did not model negative rewards (punishments), as they did not seem to have the desired effects in early pilots we carried out.
During the contest, crowd workers are shown a list of tasks which arrive in near-real-time (in our experiments we used Twitter posts, but they could equally be images as in [Bigham et al. (2010)] or other objects). The workers are to annotate as many of them as possible within a time window. The incentives mechanism awards a prize to a worker within a reward spread (for example, the worker is within the top or top ).
Exit A worker would always seek to maximise their expected utility given the number and value of prizes; the number of contestants; and the value of their efforts. In our experiments, it was possible for workers to view their ranked position in real-time with respect to their closest contenders using a -neighbours leaderboard, as presented in the medium information policy contest strategy by [Rokicki et al. (2014)]. A worker far outside the reward spread might inadvertently decide to exit the contest to avoid further loss of utility. The worker close to the reward spread might, however, decide to remain in the contest in the hope of displacing a close contender.
4 Contests as continuous time Markov chains
4.1 Model
We modelled the contest-based annotation task as a continuous time Markov chain (CTMC). To understand CTMCs, we first define some key concepts.
A stochastic process is defined as a collection of random variables. It describes the evolution in time of a random phenomenon. Therefore, we say that the stochastic process is indexed by time i.e., the random variables for each time point is given by . When , it is a discrete-time process, however, when , it is a continuous time process.
The Markov property refers to the memoryless property of a stochastic process. A stochastic process has the Markov property if the conditional probability distribution of its future evolution depends only on its current position, not on how it got there. i.e. given with state space , we say it has the Markov property if:
[TABLE]
where is a sequence of times and are states in the state space. Therefore, a continuous time stochastic process is called a continuous-time Markov chain if it exhibits the memoryless Markov property.
Revisiting our contest-based annotation task, we assume that the Twitter posts arrive according to a Poisson process with rate . This Poisson process is a continuous-time Markov chain with state space representing the worker annotations. Therefore, at any time , a worker is in a state of annotating the tweet. The time it takes for the worker to annotate this tweet is represented as an exponential random variable, which transitions the worker to state .
The question then is: what ‘explains’ the rate at which a worker annotates each tweet. In our modelling in this section, and in subsequent empirical experiments, we evaluate one variable to explain the annotation rate. We have earlier described this as the reward spread which governs, at any time , if worker is currently eligible to receive a payment based on their leaderboard rank.
To model our contest-based annotation task as a continuous time Markov chain, we define the following variables:
Observed variables:
- •
: the number of annotations of worker in finite time
- •
: the time of the annotation of worker
- •
: the annotation time for worker after the annotation
Hidden variable(s):
- •
: the annotation rate parameter for worker
The time a worker spends on annotating a tweet is calculated as:
[TABLE]
Furthermore, the time of the next annotation, and the next state can be expressed as:
[TABLE]
The parameter describes the annotator ‘behaviour’ within the reward spread. This biases workers to either exert more or less effort based on their rank i.e., if a worker is currently eligible to be paid, they might either choose to exert more effort to extend their lead, or they might relax since they are already in the top ranks. Similarly, a worker outside the reward spread might either give up or exert more effort to displace one of the top workers. We modelled using the gamma distribution , and half-normal distributions , where and . The half-normal distribution biases our belief that some workers will increase their effort, especially when they are outside but close to the reward spread.
[TABLE]
Therefore, simplifying and expressing this for a single worker:
[TABLE]
Computing this for all the workers, we get:
[TABLE]
Expressing this as a log loss for training a learning model, we obtain:
[TABLE]
Fig. 2 represents a graphical model that presents the variables , , and in our model. The arrows describe how each variable influences or affects another. Therefore, obtaining the values (i.e., for each worker at every annotation point ) helps us predict how much time the annotator will spend in the entire contest.
4.2 CTMC simulations
We ran a series of simulations to test the CTMC model for contest annotations tasks. The independent variable is the reward spread which we hypothesise can explain the annotation rate of workers in the contest.
To aid visualisation, we ran the simulation using annotators, annotations and time steps. First, we generated values which represent the behaviour of each of the workers when they are within the payment or no payment leaderboard ranks.
Fig. 3 displays randomly generated values for each workeri. From Fig. 2, we know influences , therefore, we can simulate a contest run to see how the worker’s strategies pan out: worker1 who exerts significantly more effort only when they are not getting paid, or worker3 that exerts much effort even when they are in the lead.
The results in Fig. 4 paint a picture of how the change in annotation rates within and outside the reward spread affect how the entire contest turns out. This becomes more evident as the race progresses, in this case, with worker3 coming out at the top with their annotation strategy.
Therefore, Fig. 4 illustrates that we can go from defining values for to simulating an entire contest run. The challenge then is to do the reverse, that is, to infer the values of from observing the transition s in a contest. Learning this would allow us to modify the reward spread in a real-life contest, which would in turn modify , resulting in a desired contest outcome. The desired outcome from a requester’s point of view would be to maximise the total annotations from all workers.
Using the loss function derived in Eq. 2, we trained a model to learn the rates of each of our workers. We used the worker’s rank at each time step, the elapsed time, the number of annotations left, and whether the worker was within or outside the reward spread as features to train the model.
The results in Fig. 5 illustrate that we can learn the rates of workers which describe how they perform when they are within and outside the reward spreads. For example, observing the results of worker0 in Fig. 5 shows that the rate when the worker is outside the reward spread is normally distributed around a mean value of which is very close to the value of generated and displayed in Fig. 3. Similarly, the rate when worker0 is within the reward spread is normally distributed around which is close to the generated value of .
5 The Wordsmith platform
Having laid the theoretical models underpinning our experiments, we now give a general overview of the Wordsmith platform and elaborate on those components that are relevant to our contest experiments.
5.1 Overview
Wordsmith is a platform for carrying out paid microtask crowdsourcing; Fig. 6 depicts a screenshot. It supports a range of annotation tasks, including text and image annotation. Further on, Wordsmith features multiple task, feedback and interface elements that allow for single-worker, multi-worker and contest-based task completion.
The general task annotation works as follows: Workers are recruited from an existing microtask platform, for instance CrowdFlower, and redirected to our platform; the entry on CrowdFlower explains the task (e.g. identify people in tweets); the requirements (e.g. annotate at least ten images); and the financial remuneration. It also includes a a tutorial consisting of screenshots of the task interface on Wordsmith to give workers a step-wise idea on how to approach the task effectively.
Requesters specify the conditions for workers to receive their payments – for instance, a minimum number of annotations being carried out. However, workers are generally allowed to carry out as many tasks as they wish, beyond the task threshold which guarantees their payment. The requester can hence take advantage of the fun factor and game-like immersion that comes from completing the task in a gamified setting. Workers are also allowed to skip tasks - they can still receive their reward as long as overall they meet the conditions of the requester.
Requesters can also define game levels associated with an increasing volume of work to be completed or, if possible, with work of increasing difficulty. They also determine which worker activities are rewarded with gamification elements, including points, badges, and, as in [Feyisetan et al. (2015)], additional payments.
5.2 Contest design
The contest setting on Wordsmith allowed for multiple workers to connect to the system at once and carry out annotations simultaneously.
The current implementation of contests in Wordsmith builds upon the crowdsourced NER work which was presented in [Feyisetan et al. (2015), (22)]. In that work, we discussed the basic design of a text annotation microtask for Twitter posts, while here the focus is on the specific challenges arising from the fact that the annotations need to be delivered under significant time constraints. While the contest model was tested for NER on microposts, it can be used for other types of labelling tasks that arrive in a real-time feed, with or without predefined label categories, for example for images like in [Bigham et al. (2010)]. For other text streams, the system would need first to divide the text into smaller chunks, which can still be treated by workers as microtasks in terms of the length of the text. [Bernstein et al. (2015)] offers interesting insights into how to process larger text documents via paid microtask crowdsourcing.
5.2.1 Input and output
The system takes in a raw input of streaming posts and performs an initial sequence of processing on it. For our study, we focus on filtering out non-English tweets using the language tag of the incoming tweets. We then carry out part-of-speech tagging to recognise tweets with proper nouns. This is used to build a pseudo-quality score for each annotation (presented earlier as the requester’s variable ) i.e., if our POS tagger detects two different contiguous proper noun sets, we can expect an annotation result of at least two entities (although this does not hold strictly if there are no proper nouns e.g., entities might be recognised as noun phrases by some taggers).
The system outputs a processed stream of English tweets, (tweet1, …, tweetN), where each tweet is represented as a tuple containing a reference identifier, the tweet string and the associated requester’s variable . Each tweet in the stream advances in linear discrete time at a constant rate, with each time point represented as unique integer value in seconds (although, worker annotation and exit is represented in milliseconds).
5.2.2 Temporal division and stream parallelism
The stream is bucketed into distinct time intervals using windows. A window consists of a constant number of microtasks emitted per unit time, which may or may not have been built over a buffer depending on varying throughput levels. Within each window task slice, microtasks are clustered and parallelized to different workers. Each cluster is a task unit consisting of a list of objects which is allocated to each worker for annotation. This follows a Map Reduce paradigm wherein each worker has a small task unit to solve, which is recursively built up to the final solution for the requester. The Map process involves local processing on individual nodes (annotating workers), while the Reduce process involves the merging of results to select best responses for overlapping task annotations.
5.2.3 Contest interface
The contest interface consisted of a central annotation panel, in which the workers saw the current list of text snippets as described in [Feyisetan et al. (2015), (22)]. After selecting the piece of text to analyse, the workers could either annotate the entities using predefined categories, mark the post as having no entities, skip the task all together, or go back to the list. Fig. 7 shows a screenshot.
Each worker received a baseline score for annotating a tweet with an arbitrary number of entities and a higher score for correctly annotating the pre-computed number of entities (based on the gold standard tags). These figures were drawn from a series of observations and early pilots, which also ruled out the use of negative scores and qualifying questions, as both led to a very sharp rate of exits. As noted earlier, workers had access to a -neighbours leaderboard, which lists contenders immediately above or below.
5.2.4 Requester parameters
Wordsmith affords the requester a number of configurable parameters including:
- •
Number of workers : count of those who could connect to the platform. All the workers had to be connected before the task starts.
- •
Leaderboard: requesters can choose between listing the workers; or displaying the contenders above and below the worker.
- •
Number of tasks : this represents the total number of tasks which are to be processed, each consisting on objects to be annotated.
- •
Window size : this is number of tasks which is sent out to a number of workers per time slice (see below).
- •
Task unit time : this is the delay time, for which a list of tasks remains available for annotation to a worker before the next set of tasks arrive.
- •
Task arrival rate : this variable measures the number of tasks, which are channelled to the platform per unit time.
- •
Task intensity (or ingress load): this is computed as , based on the task arrival rate and the agent processing rate .
- •
Task unit size: represents the number of tasks that a worker actually sees on screen at any given time, which is a fixed percentage of the window size .
- •
Total task time : computes how long the contest would take as a function of the number of tweets and the window size: .
- •
Reward spread : the reward spread denotes the number of workers to be paid in the current contest.
5.2.5 Warping time
Warping time is a strategy, in which a workers task slice in a real-time assignment is deliberately slowed down to afford for maximal worker cognition in undertaking the required task. For example, [Lasecki et al. (2013)] used time warping to slow down audio playback so crowd workers could effectively transcribe a given portion of speech. This was recursively done for each worker, after which the individual results were successively merged to create a single result. Following our stream parallelism approach to dividing up the incoming microposts, a window of tweets was presented to workers.
We adopted the approach by [Lasecki et al. (2013)] denoting: (i) an in-period where the annotation stream for a worker group comes in; (ii) a speed reduction rate rr; and (iii) the compensating out-period where the worker group rejoins the live real-time stream. We used a speed reduction rate rr of i.e., the workers experienced a streaming rate of (i.e. one tenth speed, seconds rather than second) while annotating. During these seconds, the workers were presented with static list of tweets, from which they could select individual entities to annotate. The stream of tweets in the buffered out period was then emitted at a speed of:
[TABLE]
In our experiments we made certain assumptions, which would be handled differently on a live data feed. For example, all members of a worker group ( workers in our case) were presented with the annotation tasks at the same input period , which was a function of our streaming approach. We re-purposed existing datasets from literature into a streaming API. In actual practice, each worker would have a unique input period similar to [Lasecki et al. (2013)].
5.2.6 Task allocation
There are several approaches to distribute the incoming stream of tasks to the available workers in parallel. In a round robin assignment, each bin would be sequentially assigned from the window of current annotation tasks to the next available worker, e.g., in our experiments, we assigned each worker tasks from out of bins derived from the streaming window of tasks.
6 Experiments
In this section, we describe how we carry out empirical contest-based crowdsourcing experiments using Wordsmith.
6.1 Datasets
The dataset consisted of aggregated tweets from four corpora from the literature. These datasets were from different time frames and all come along with gold standards, which we used to perform quality checks and compute contest scores.
- •
The Ritter corpus by [Ritter et al. (2011)] which consists of tweets. The tweets were randomly sampled, however the sampling method and original dataset size are unknown. It is estimated that the tweets were harvested around September .
- •
The Finin corpus by [Finin et al. (2010)] consists of tweets which was the gold standard for a crowdsourcing annotation exercise. It is not stated how the corpus was created, however our investigation puts the corpus between August to September .
- •
The MSM 2013 corpus, the Making Sense of Microposts Concept Extraction Challenge dataset by [Cano Basave et al. (2013)], which includes training, test, and gold data; for our experiments we used the gold subset comprising tweets.
- •
The Wordsmith corpus, reported in one of our previous works [Feyisetan et al. (2015)]. From the a corpus of six billion tweets, we sampled out English ones using reservoir sampling - a family of randomized algorithms for sampling items from a list of items.
6.2 Experimental setup
6.2.1 Overview
Our experiments were designed for time-bound microtask crowdsourcing scenarios, which require speedy human-cognitive intervention. The workers were presented with a time-delayed view of streaming tweets. Each experiment competition ran for about six minutes, during which, workers labelled as many tweets as possible, identifying instances of people, locations and organisations. The objective of each worker was to qualify for a set of top reward spots, which guaranteed a payoff. Unlike traditional paid microtasks, only a few of the workers got paid even if they produced correct annotations. This added to the urgency and the competitive drive that sped up the task to near real-time completion rates. We considered several questions, chief of which was: how does the reward spread affect the total task output of all the contest participants. Other questions naturally follow, such as: the relationship between reward spread and annotation time, annotation quality and worker exit. These formed the basis of our experimental conditions.
6.2.2 Timely worker recruitment strategies
In order to achieve timely worker recruitment, we adopted a combination of several strategies:
- •
We posted our tasks repeatedly in order to maintain visibility within the recent tasks view of workers.
- •
We created multiple tasks that pointed to our Wordsmith platform, but ensured that workers could connect only once by keeping track of the connection IP address.
- •
We attempted to recruit, on the average, times the number of workers than we required (around workers).
- •
We posted the tasks in bits as a work around for the scheduling mechanism which CrowdFlower uses in displaying unfinished tasks to new workers.
- •
We introduced an acoustic signal to notify workers once the requisite number of contestants had connected to the system.
Workers could see in real-time how many more contestants were required to connect before the task started. We also ensured that impatient workers were reconnected whenever they refreshed their screens, however, once the required number of workers were connected, no further connection was allowed.
6.2.3 Requester parameters
In each experimental condition, the number of workers was , viewing a neighbours leaderboard; the number of tasks (in our case Twitter posts) desired to be processed was ; the window size was ; the task unit time was seconds, the task unit size was . This means that a worker saw tweets out of the current stream of tweets for a period of seconds during which the worker was to label as many as possible before the next set of tasks arrived. The task arrival rate was , which means tweets per second, and the total contest time was = seconds ( minutes seconds).
Each contest had a payoff of \0.10for each prize payment, replicating [[Feyisetan et al. (2015)](#bib.bib19), [(22)](#bib.bib22)]. Our model rewarded each winner with the same payment, as opposed to other variants which take into account the ranking of the participants or implement some other form of reward sharing. A reward spread of110$, the top ten workers are paid. The parameters have been explained earlier in Sec. 5.2.
6.3 Experimental design
6.3.1 Overview
We set up our experiment using the between-subjects design. Each worker could only be assigned to one of the experiment conditions. This was enforced using the worker’s connection IP address as stated earlier in Sec. 6.2.2. Each user was randomly assigned to one of the experiment conditions and they were not able to pre-select which condition they ended in. The multiple tasks posted on CrowdFlower and referenced in Sec. 6.2.2 served as an identical entry point for each worker. From there, they are redirected to a centralized server that randomly assigns the workers to a certain treatment.
Our experiments had one independent variable: the reward spread, and one dependent variable: the task output. As we described in our theoretical modelling in Sec. 4, our hypothesis is that the reward spread can ‘explain’ the changes in the contest output (referenced as the total annotations carried out by the workers). Therefore, the variable that a requester seeks to optimize is the total output, and they seek to control this by varying the reward spread.
- •
Independent variable: reward spread
- •
Dependent variable: task output
6.3.2 Conditions
The experiments in this paper are compared against a control condition from an identical task reported in [Feyisetan et al. (2015), (22)]. In that study, workers were also required to annotate named entities in tweets, however, they were not under any time constraint to carry out the task, and every worker that successfully completed the task got paid. In this paper however, the experimental conditions or treatments are based on the different reward spreads that crowd workers are randomly assigned to, with the contest setting inducing the time constraint.
- •
Control Condition Pay all workers
- •
Experimental Condition Pay top worker
- •
Experimental Condition Pay top workers
- •
Experimental Condition Pay top workers
We evaluated task performance in terms of task output (i.e., volume of work done). To assess the task output, we measured the total and average number of texts annotated by the annotators.
7 Results
In this section, we discuss the results of our experiment runs, specifically, how the task output from contests yields a significant increase when compared to the baseline control condition. We then discuss the difference in annotation times across the control and experimental conditions, which is a direct consequence of the contest setting.
Then, we touch on the speed vs. quality trade-off that we incur as an aftereffect of the gain in task output. Finally, we revisit the subject of exits, which comes as a result of potential loss of utility on the part of the crowd workers. We tie this to the reward spread to explain how a change in reward spread can potentially stave off task abandonment.
7.1 Task output
The results in Fig. 8 illustrate how a change in reward spread leads to a change in the number of annotations submitted by workers. The central aim of the requester is to elicit as many annotations from the workers as possible (within the time constraint). Therefore, Fig. 8(a) and Fig. 8(b) paint a picture of how an increase in the reward spread realises this objective. Both figures compare the total and distinct number of annotations in each of our experimental conditions, against the annotations from the baseline control condition.
From Fig. 8(a), the null hypothesis would lead us to believe that the population mean of worker annotations (given by the control condition) is a total of labels in the given time window. The alternative hypothesis from our experimental conditions suggest otherwise: that setting the task as a contest leads to a different mean, which varies by the reward spread. The resulting hypothesis that contests leads to more annotations is statistically significant. A corollary can be drawn from the distinct annotations in Fig. 8(b).
We then carried out a one-way ANOVA test on the total annotations from the different experimental conditions to see if there was statistical significance as a result of a change in the reward spreads. Across the conditions: pay top worker (, ), pay top 5 workers (, ) and pay top 10 workers (, ), we obtained results that give evidence to the significance of the results. The F-ratio value is , the -value is ¡ , and the result is significant at ¡ .
Fig. 8(c) highlights the fairly constant average number of annotations by all the workers. This at first appears to contradict the results we described in Figures 8(a) and 8(b). However, Fig. 8(d) illustrates that the number of active annotators varied across the three experimental conditions. This result also buttresses the significance of the different reward spreads in retaining more annotators. Furthermore, a clearer picture of the number of annotations among workers is evidenced in the the last two Figures 8(e) and 8(f). The results make plain the effect of varying the reward spread which has stronger impacts on the top workers.
7.2 Annotation time
In Fig. 9 we compare the time spent annotating an entity in the different experimental conditions against the time spent by workers in the control condition.
In the control condition, workers were not placed under any specific time constraint, however, inherent timely completion was required to receive their task compensation. Therefore, they still had an incentive to complete the annotations without any delay. In the control condition, workers needed on average seconds to identify and annotate an entity in a tweet. The calculated times in the experimental conditions were as follows: pay top worker (s, ), pay top workers (s, ) and pay top workers (s, ).
The results from the contests are significant when compared to the baseline condition which didn’t have the explicit time constraint. Contest annotators needed an average of s to recognise a type of an entity while regular annotators spent s per entity. This is equivalent to an increased annotation factor of almost across all contests. Contest annotators spent an average of s annotating one tweet (at entities per tweet) and the top contestants averaged s per entity, resulting in a gain factor of against the baseline.
7.3 Annotation quality
An increase in annotation speed however led us to incur a hit in annotation quality as reflected in Fig. 10.
The results presented in Fig. 10 reflect a fine grained analysis of precision, recall and F1 scores on the entity types (PER, ORG, LOC and MISC) across the experimental and baseline conditions. The results follow the same pattern i.e., the same entity types are equally difficult to identify across all conditions. However, the baseline condition which was free from time constraints resulted in better scores. The scores were computed against the gold standards published with the four datasets used for the experiments.
This result helps inform us as to what tasks contests might be better suited for. A requester seeking to adopt contests needs to be able to tolerate a certain level of false positives and false negatives which would be compensated for by the timeliness of the responses. Verifying the quality of worker submissions (without using inter-annotator agreement scores) however leads to a recursive chicken and egg scenario; for if we were able to automatically compute the quality of the annotations (i.e., by using a gold standard), then what did we need the crowd for? Or better yet, how can we design contests, and assign ranks in a way that creates quality output without falling prey to malicious workers who make quick but incorrect submissions?
In this case, we posit that the task design should be one that satisfies the following two conditions: (a) the worker solution could not have been easily computed automatically; but (b) the worker solution can be computationally verified easily without a gold standard. An example of such a scenario is in the fold.it game [Cooper et al. (2010)] where players fold the structures of selected proteins. Determining a protein’s structure is computationally demanding, however, humans are able to intuitively arrive at the best structural composition. Once this has been done, the verification process becomes straightforward making this task a prime candidate for carrying out this form of contest based crowdsourcing without a gold standard.
7.4 Contest exit behaviour
Only a subset of contestants received a monetary payoff. The longer workers engaged with a task, the more utility they potentially lost given their ranking relative to the reward spread. Some workers therefore opted to leave the contest prematurely. Figure 11 presents the exit behaviour of workers across the experimental conditions. The results imply that the beginning of the contests sees fewer exits with most of the contestants choosing to continue for up to of the total time period. The exit rates increase towards the end. This behaviour would be peculiar to microtask contests unlike more longitudinal contests such as presidential elections (studied by [Norrander (2006)]), in which most contenders exit at the beginning of the race leading up to much fewer participants at the final elections.
8 Discussion
In this section, we highlight lessons learned from the experiments, the challenges of scaling contests to real-time annotations, and the limitations of our approach and results.
8.1 General considerations
Crowdsourcing remains a mechanism with tremendous potential to grow economies by engaging a large workforce on demand and at scale. This translates into improved productivity and significant benefits for task requesters and crowd workers alike. Requesters gain task scalability, quick completion and lower price margins for their projects, while workers achieve additional income and learn new skills. In addressing crowdsourcing as a sociotechnical construct, in this paper we focus on one of the crowdsourcing challenges from the list discussed in [Kittur et al. (2013)]: real-time crowd work. Tackling this challenge, we developed a model which encourages workers to perform well even in time-sensitive situations by using micropayments and contests.
8.2 Layering incentives on top of payments
Our experiments showed that competitions could work in paid microtask crowdsourcing, both as an alternative to common task models and as a means to complete tasks faster. On average, workers carried out their tasks twice as fast as the baseline workers, while top performers were three times as fast. When we varied the number of workers who got paid in the experiments from to to , we noticed that the average volume of work also went up, with workers perceiving a greater chance to receive part of the available reward. As expected, in all the contest experiments, the gain in speed came at a cost and this was a trade-off for quality. When we compared the quality of submissions in the baseline experiments with that in the contest, we reported a drop in precision of entity identification and total recall of various entity types. In studying the exit patterns of workers from the task, we were keen to understand at what time in the contest do most players quit (potentially due to their inability to potentially finish in the reward spots). Given the intrinsic fun that comes from participation asides from receiving a potential financial payout, many workers (a minimum of per condition) were willing to stay for almost the entire contest time. It was also quite intriguing that workers rated the contest experience as out of , despite only of them receiving an actual payout, which makes us believe there must have been some form of satisfaction derived from the competition.
Our experiments give further insight into the dynamics of crowd behaviour. Workers posted on forums to notify others when a new contest was set up in order to quickly get workers into the task. This was consistent to our prior image-labelling experiments that used Wordsmith - in [Feyisetan et al. (2015)] we noted that some workers even promoted the game to their friends. During the study Wordsmith was used to label images by users who were not recruited via CrowdFlower who found out about the platform via social channels.
8.3 The role of financial rewards
With the contests, we investigated the interplay between the reward spread and crowd behaviour. Allowing more workers to be eligible for payment improved the overall performance. With more winning spots came an increase in the total and average task output by all participants. Having a higher reward spread also ensured that workers stayed in the context and did not drop out early, thus leading to more tasks completed. This further meant that more effort was required to achieve one of the top spots in the ranking, which would receive a payment.
However, indefinitely increasing the reward spread would defeat the purpose of adopting a contest model, converging towards a traditional microtask system. Our results show that the linear result growth begins to break down as expected at some point. It is important to note that the motivation of crowd workers covers a wide spectrum of intrinsic and extrinsic factors, hence, having a wider reward spread (and a higher task threshold as seen in ) led to a plummet in task output (over repeated experiment runs). An investigation into the discussion forums indicated that this experiment was probably less challenging – as stated by one worker, ”… to get into the top 10 is not too difficult …” - and hence might not have been as attractive to top performers. Understanding where to draw the line would be the subject of further empirical studies paired up with theoretical analysis.
8.4 Scaling towards real-time annotations
Microtask crowdsourcing has often been praised for its ability to produce results quickly and accurately. Yet, an increasing number of applications come in with much harder time constraints, which push the boundaries of the traditional microtask model to deliver in seconds or less [Bernstein et al. (2011)]. Examples of such real-time crowdsourcing applications include machine learning for image recognition [von Ahn and Dabbish (2004)] and text-to-speech conversion [Lasecki et al. (2013)]; accessibility design [Bigham et al. (2010), Lasecki et al. (2012), Lasecki et al. (2013)]; and disaster management [Gao et al. (2011)].
The study lends support to our hypothesis that the microtask contest model leads to timely task completion without the associated overhead costs. Our results show an increase in speed by an average factor of , and up to more among the top performers. These metrics could be used to inform decisions on the number of workers that would be needed to annotate the entire dataset of tweets in real-time - taking into consideration the total number of non-unique annotations and worker exit e.g., in experiment , workers annotated tweets, equivalent to workers required to make one pass at the entire stream. Our experiments were carried out on a stream of tweets per second; the live Twitter stream is currently estimated at tweets per second or English tweets per second ( of the full stream) [Feyisetan et al. (2014)]. Annotating of the live stream could be potentially carried out by designing a contest for workers (i.e., workers * (( of ) / tweets per second)).
8.5 A diverse crowd
Across all experimental conditions, we have observed a range of responses to the incentives we layered on top of micropayments, which varied depending on a range of factors, including the amount of work already completed and the likelihood to be rewarded. During the contests, top contributors showed a different behaviour in the conditions with larger reward spreads. These findings suggest the need for additional experiments, which would investigate the effects of the different incentives on different groups of workers - for example, those who contributed a lot in terms of output, but also those who over achieve in terms of quality. This would potentially allow us to predict exit behaviour more accurately, and offer finer grained incentives - for instance, one could imagine different bonus levels based on how many objects a worker has annotated so far.
8.6 Application to active learning
Active learning is a machine learning paradigm that seeks to minimise the time and crowdsourced labels required to train a machine learning model [Settles (2012)]. Since the objective of active learning is to scale down the the amount of labels required, it is of necessity that the labels be of high quality. However, in large scale real-time active learning and crowdsourcing scenarios [Vijayanarasimhan and Grauman (2014), Yan et al. (2011)], a single ‘oracle’ providing labels will not suffice. Just as active learning algorithms refine the model and suggest the few training examples required, crowdsourcing contests refine the annotator pool to provide the ‘expert crowd’ required to improve the model’s decision boundary. Applying the contest model in an active learning setting suggests that contest incentives do not always have to optimise for speed (unlike in the real-time scenario). This opens up avenues for future research into incentives in high-value judgement tasks that are aligned more towards annotator skill and less towards completion speed.
8.7 Payments and ethical considerations
Crowd worker motivation remains a constant research area in understanding why people partake in microtasks. This is essential in order to design systems that are fair and rewarding to the workers. A requester would always seek to minimise cost, however, a worker’s complete range of motivations is not yet fully understood. Our investigations revealed that the task model was relatively well received: in one of the baseline experiments, workers rated the payment of \0.1045493.59874910100$ contestants: ”Yesterday I came across this, but [they] recruited 100 people, [I] was not allowed to play”.
On task payment, we favoured a higher than average payment of \0.10as against the annotation averages reported by [[Difallah et al. (2015)](#bib.bib18)], however, it would be interesting to see the effects of increased payments on the results. In a related set of experiments we noted that raising the reward to as much as$0.25$ rather created an anchoring effect than a trend in results. We would like to investigate this further and also analyse the effect of task payment ordering. A greater understanding of worker intrinsic motivations would help in the design of better payment schemes, wrapped around task models that workers find inherently engaging and rewarding; and lend insights into the ongoing debate on ethical and fair crowdsourcing [Irani and Silberman (2013)].
8.8 Limitations
While the results of our experiments were very promising, we are aware of several limitations of our work. The experiments are run on text annotation tasks. It would be interesting to test the models on the other five types of tasks from [Gadiraju et al. (2014)]. While our experiments and theories could be easily adapted to similar task types, in particular to output-agreement ones [von Ahn and Dabbish (2004)], they are less suitable for settings in which a diversity of answers is sought. As a result, there is much latitude for future work across the different incentive schemes and the concept of furtherance incentives as a whole. The tasks we tested do not require a high cognitive load, time investment or creativity. Other types of tasks might be less suitable for a casual game model like the one in Wordsmith. Moreover, the results will probably vary when the tasks are carried out by a community who is intrinsically motivated (for example, to advance science as in citizen science projects, or to help, as in disaster relief). Those motivations would probably overshadow the simpler mechanisms tested here. In addition, such intrinsic motivation settings have been shown to be more prone to overjustification effects, and any attempt to use incentives to reward contributions might have negative effects.
Just like most empirical research in paid microtask crowdsourcing, none of the experiments considered temporal effects. While contests may produce positive effects short-term, it would be interesting to understand whether workers would continue to engage more with no additional incentives as tasks run over longer periods of time. One common concern related to virtual rewards is that they are not always aligned with the needs and values of the user and that this mismatch becomes more obvious with time [Deterding et al. (2011)]. In our experiments we have not carried out an in-depth study of the types of workers who used Wordsmith or try to understand what drives them. While the experiments were successful, we anticipate that we would need to have a much more nuanced approach to contest-based incentives when workers engage with us over longer periods of time.
Our contest experiments allowed us to get a sense of the number of contributors required to annotate a substantial share of the data feed in near-real-time. However, our findings might not transfer to scenarios with contests that stretch over days or longer. In the same time, in a real-world scenario, most human labelling projects that operate with large amounts of data would also include an algorithmic component, trained by labels created by the crowd.
Finally, our work assumes that there is a gold standard to verify crowd answers. This is particularly important in time-sensitive scenarios.
9 Conclusions and future work
Our experiments have explored the effects of layered incentive mechanisms on a base financial payment model on crowd performance and engagement. The results suggest that we can build better crowdsourcing systems for task requesters and workers alike; and that money need not be the only currency for transacting on paid microtask platforms
In line with the research on timely task completion, we intend to carry out new real-time crowdsourcing experiments which feature automatically verifiable task output which is currently a limitation of our current approach. We would also carry out cross studies between social incentives-based microtasks and contest-based tasks in a bid to understand how the former could be used to facilitate the latter. Our approach to use competitions to deliver timely annotations naturally engenders worker exit given the varying utilities gained by individual workers during the contest. By doing so, it offers us a way to gain insight into how the different parameters we use to our probabilistic exit predictor impact behaviour.
Overall, our results reinforced the role of motivation and incentives beyond cash payments as the primary means to reward participation on some of the most popular crowdsourcing platforms of our times. Our experiments give crowdsourcing researchers and platform designers new empirical evidence into crowdsourcing as a fully fledged sociotechnical construct with challenges requiring as much a social touch as the technical. Worker motivations cover a wide spectrum, which extends beyond the simplistic spectrum of ‘fun and money’. Understanding how to keep the crowd engaged is essential not just to yield superior returns for requesters, but also to create a more humane experience, as crowdsourcing continues to take its place as the model for the future of work.
{acks}
The work has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement no 732194 (QROWD), and from the UK EPSRC under grant EP/J017728/2 (SOCIAM: The Theory and Practice of Social Machines). We would also like to acknowledge Karen Hovsepian for all the helpful conversations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1]
- 2Archak (2010) Nikolay Archak. 2010. Money, glory and cheap talk: analyzing strategic behavior of contestants in simultaneous crowdsourcing contests on Top Coder. com. In Proceedings of the 19th international conference on World wide web . ACM, 21–30.
- 3Bennett and Lanning (2007) James Bennett and Stan Lanning. 2007. The Netflix Prize. In Proceedings of KDD Cup and Workshop , Vol. 2007. 35.
- 4Bernstein et al . (2011) Michael S Bernstein, Joel Brandt, Robert C Miller, and David R Karger. 2011. Crowds in two seconds: Enabling real-time crowd-powered interfaces. In Proceedings of the 24th annual ACM Symposium on User Interface Software and Technology . ACM, 33–42.
- 5Bernstein et al . (2012) Michael S Bernstein, David R Karger, Robert C Miller, and Joel Brandt. 2012. Analytic methods for optimizing realtime crowdsourcing. Collective Intelligence (2012).
- 6Bernstein et al . (2015) Michael S Bernstein, Greg Little, Robert C Miller, Björn Hartmann, Mark S Ackerman, David R Karger, David Crowell, and Katrina Panovich. 2015. Soylent: a word processor with a crowd inside. Commun. ACM 58, 8 (2015), 85–94.
- 7Bigham et al . (2010) Jeffrey P Bigham, Chandrika Jayant, Hanjie Ji, Greg Little, Andrew Miller, Robert C Miller, Robin Miller, Aubrey Tatarowicz, Brandyn White, Samual White, et al . 2010. Viz Wiz: nearly real-time answers to visual questions. In Proceedings of the 23nd annual ACM Symposium on User Interface Software and Technology . ACM, 333–342.
- 8Boudreau et al . (2011) Kevin J Boudreau, Nicola Lacetera, and Karim R Lakhani. 2011. Incentives and problem uncertainty in innovation contests: An empirical analysis. Management science 57, 5 (2011), 843–863.