A Parallel Framework with Block Matrices of a Discrete Fourier Transform for Vector-Valued Discrete-Time Signals
Pablo Soto-Quiros

TL;DR
This paper introduces a new parallel framework for efficiently computing the Fourier transform of vector-valued signals using block matrices.
Contribution
The novel contribution is a parallel implementation of the vector-valued DFT using block matrix operations for multicore processors.
Findings
Using multicore processors reduces execution time for vector-valued DFT computations.
Speedup increases with more logical processors and longer signal lengths.
Abstract
This paper presents a parallel implementation of a kind of discrete Fourier transform (DFT): the vector-valued DFT. The vector-valued DFT is a novel tool to analyze the spectra of vector-valued discrete-time signals. This parallel implementation is developed in terms of a mathematical framework with a set of block matrix operations. These block matrix operations contribute to analysis, design, and implementation of parallel algorithms in multicore processors. In this work, an implementation and experimental investigation of the mathematical framework are performed using MATLAB with the Parallel Computing Toolbox. We found that there is advantage to use multicore processors and a parallel computing environment to minimize the high execution time. Additionally, speedup increases when the number of logical processors and length of the signal increase.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
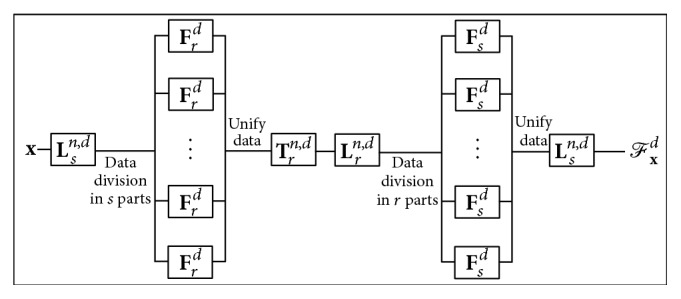 Figure 1
Figure 1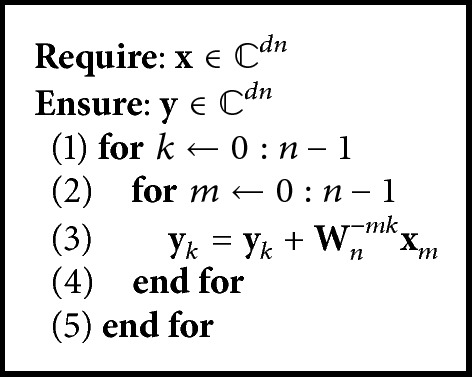 Figure 2
Figure 2 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMathematical Analysis and Transform Methods · Image and Signal Denoising Methods · Digital Filter Design and Implementation
1. Introduction
Let l ^2^(ℤ n, ℂ ^d^) be the space of vector-valued discrete-time signals with n samples, where each sample is a complex vector of length d. The vector-valued discrete-time signals are used very often in several applications in signal processing and electrical engineer, for example, vector quantization of images [1], time-frequency localization with wavelets [2], image coding [3], vector filter bank theory [4], linear time-dependent MISO [5], and analysis of MMSE estimation for compressive sensing of block sparse signals [6].
Now, to analyze the spectra of vector-valued discrete-time signals, a novel tool was developed, and it is called* vector-valued DFT* [7, 8]. This transform has applications in vector analysis in complex, quaternion, biquaternion, and Clifford algebras [8]. Additionally, the vector-valued DFT is used in digital signal processing, for example, the study of new complex valued constant amplitude zero autocorrelation (CAZAC) signals [9], which serve as coefficients for phase coded waveforms with prescribed vector-valued ambiguity function behavior, which is relevant in light of time-frequency analysis, vector sensor, and MIMO technologies [7].
The following paper presents a parallel framework of the vector-valued DFT. The major contributions of this paper are summarized as follows:
- The construction of a new mathematical structure for the vector-valued DFT using block matrix theory such that it allows a parallel implementation in multicore processors.
- Reducing the elapsed time to compute the vector-valued DFT of a vector-valued discrete-time signal using parallel computing through aforementioned new mathematical framework.
This new framework is developed with a set of block matrix operations, for example, Kronecker product, direct sum, stride permutation, vec operator, and vec inverse operator (see Section 2.1 for details). These block matrix operations contribute to analysis, design, and implementation of parallel algorithms in multicore processors [10–12]. This mathematical framework is inspired in the matrix representation of the Cooley-Tukey fast Fourier transform (FFT) algorithm for complex discrete-time signals, corresponding to the decomposition of the transform size n into the product of two factors r and s, which is developed in [10, 12, 13].
The present paper is organized as follows. Section 2 explains a mathematical background about block matrix operations and discrete Fourier transform. Section 3 defines the concept of vector-valued DFT for vector-valued discrete-time signals. Section 4 develops a mathematical framework of vector-valued DFT in terms of block matrix operations for vector-valued discrete-time signals with length n = rs. This mathematical framework contributes to implementation of parallel algorithms. Section 5 explains an implementation and experimental investigation of this mathematical framework using parallel computing in multicore processors with MATLAB. Finally, some conclusions are presented in Section 6.
Throughout the paper, the following notations are used. ℤ n = {0,1,…, n − 1} is the additive group ℤ of integers modulo n, ℂ ^m×n^ is the matrix space of m rows and n columns with complex numbers entries and ℂ ^n^ = ℂ ^n×1^. The rows and columns of A ∈ ℂ ^m×n^ are indexed by elements of ℤ m and ℤ n, respectively. A(j, k), A(j, :), A(:, k), and A ^T^ represent entry (j, k), row j, column k, and transpose matrix of A, respectively. I n ∈ ℂ ^n×n^ is identity matrix.
2. Background
2.1. Block Matrix Operations
A block matrix A ∈ ℂ ^mp×nq^ with m row partitions and n column partitions and a block vector x ∈ ℂ ^mp^ with m row blocks are defined as
respectively, where A j,k ∈ ℂ ^p×q^ designates (j, k) block and x j ∈ ℂ ^p^ designates j block. In this paper, the following block matrix operations are used: Kronecker product, direct sum, stride permutation, vec operator, and vec inverse operator.
The Kronecker product of two matrices A ∈ ℂ ^m×n^ and B ∈ ℂ ^p×q^ is defined as A ⊗ B ∈ ℂ ^mp×nq^ and it replaces every entry (j, k) of A by the matrix A(j, k)B. In the special case A = I n, it is called parallel operation [12].
The direct sum of n matrices constructs a block diagonal matrix from a set of matrices, that is, for {C k}k∈ℤn__, such that C k ∈ ℂ ^pk×qn^:
where C ∈ ℂ ^p×q^, p = ∑j∈ℤn__ p j, and q = ∑j∈ℤn__ q j.
Let n = rs. The stride permutation matrix is defined as L s ^n^ ∈ ℂ ^n×n^ such that it permutes the elements of the input signal x ∈ ℂ ^n^ as jr + k → ks + j, j ∈ ℤ s, and k ∈ ℤ r [12, 14]. This matrix permutation governs the data flow required to parallelize a Kronecker product computation [12]. We clarify that the superscript n is an index, not power.
The vec operator, 𝒱 : ℂ ^m×n^ → ℂ ^mn^, transforms a matrix into a vector by stacking all the columns of this matrix one underneath the other. On the other hand, the vec inverse operator, ℛ m,n : ℂ ^mn^ → ℂ ^m×n^, transforms a vector of dimension mn into a matrix of size m × n.
2.2. Discrete Fourier Transform
Let l ^2^(ℤ n) be the set of ℂ-valued signals on ℤ n; that is, x ∈ l ^2^(ℤ n) if and only if x ∈ ℂ ^n^ [9]. Additionally, for each k 1 ∈ ℤ, x(k 1) = x(k 2), where k 2 ∈ ℤ n and k 1 ≡ k 2_modn. The discrete Fourier transform (DFT) of x ∈ l ^2^(ℤ n) is represented as ℱ x : ℤ n → ℂ such that ℱ x(k) = ∑m∈ℤ_n__ x(m)ω N ^−mk^, where ω n = exp(2πi/n) and .
As mentioned in [14], there are two different approaches of representing the DFT: as matrix-vector products or using summations. Consequently, fast algorithms using parallel computing are represented with either a matrix formalism as in [10, 12–14] or summations as in most signal processing books. Below, the matrix formalism is introduced and used to express the Cooley-Tukey FFT algorithm, corresponding to the decomposition of the transform size n into the product of two factors r and s; that is, n = rs.
The matrix representation of DFT of x is ℱ x = F n x, where F n ∈ ℂ ^n×n^ such that F n(j, k) = ω N ^−jk^. If n = rs, then the matrix formalism can be used to express F n as factorizations of matrices using block matrices operations [10, 12, 13]:
Here, T r ^n^ is a diagonal matrix containing the twiddle factors. We clarify that the superscript n is an index, not power. This factorization of F n is the matrix representation of the Cooley-Tukey FFT for n = rs. In addition, this representation of F n allows the implementation using parallel computing [14].
3. DFT for Vector-Valued Signals
Based on [2, 6–9, 15, 16], the space of vector-valued discrete-time signals with n samples is defined as
The space l ^2^(ℤ n, ℂ ^d^) is the set of ℂ ^d^-valued signals on ℤ n; that is, x ∈ l ^2^(ℤ n, ℂ ^d^) if and only if x ∈ ℂ ^nd^. Additionally, for each k 1 ∈ ℤ, x k1 = x k2, where k 2 ∈ ℤ n and k 1 ≡ k _2_modn. Furthermore, if d = 1, then l ^2^(ℤ n, ℂ ^d^) = l ^2^(ℤ n). Now, for x ∈ l ^2^(ℤ n, ℂ ^d^), there is a kind of DFT for vector-valued signals called* vector-valued DFT*. This transform is defined as ℱ x ^d^ : ℤ n → ℂ ^d^ such that
where W n ∈ ℂ ^d×d^ is the matrix kernel. Algorithm 1 shows the implementation of (5). This implementation is a sequential algorithm.
From the reviewed literature, there are two kinds of kernels for this transform: the first one is* hypercomplex DFT kernel* [8]:
where J ∈ ℂ ^d×d^ such that J ^2^ = −I d, and the second one is* DFT frame kernel* [7]:
where 𝒜 = {α 0, α 1,…, α d−1} ⊂ ℤ n with α j < α k for j < k. It is called DFT frame kernel because {e j}j∈ℤn__ ⊂ ℂ ^d^, where is a DFT frame. In this paper, subsets 𝒜 ⊂ ℤ ^+^ are used, such that card(𝒜) = d, although it does not represent a DFT frame.
Lemma 1 . Let W n ∈ ℂ ^d×d^ be a hypercomplex DFT kernel or DFT frame kernel. Then
- (1) W n ^j+r^ = W n ^j^ · W n ^r^.
- (2) W n ^0^ = W n ^n^ = I d.
- (3)If k ∈ ℤ and r ∈ ℤ N, then W n ^nk+r^ = W n ^r^.
- (4)If n = rs, then W n ^rk^ = W s ^k^.
ProofFor hypercomplex DFT kernel, the proof of each case is similar to proof of nth roots of unity. For DFT frame kernel, W n is a diagonal matrix, and then the proof of each case is straightforward.
4. A Parallel Framework for n = rs
In this section, the main results of this paper are presented. Firstly, a block matrix representation of the vector-valued DFT is given. Secondly, a new mathematical framework from matrix representation of vector-valued DFT is derived, using a block matrix formalism (i.e., Theorem 2). This new result is inspired in the matrix representation of the Cooley-Tukey FFT algorithm for complex discrete-time signals, corresponding to the decomposition of the transform size n into the product of two factors r and s, which is developed in [10, 12, 13]. The result obtained in Theorem 2 is transformed in a new block matrix representation such that it contributes to analysis, design, and implementation of parallel algorithms (i.e., Corollary 3). This new result is inspired in (3). Finally, a computational complexity analysis of new algorithm is developed.
Similar to the DFT matrix representation explained in Section 2.2, there are two different approaches of representing the vector-valued DFT: as summations (see (5)) or using matrix-vector products. Both approaches allow a parallel implementation. In fact, the proof of Theorem 2 is developed using summation notation.
The vector-valued DFT can be presented as matrix-vector products. The block matrix representation of vector-valued DFT of x ∈ l ^2^(ℤ n, ℂ ^d^) is defined as ℱ x ^d^ = F n ^d^ x, where F n ^d^ ∈ ℂ ^dn×dn^ such that (F n ^d^)j,k = W n ^−jk^ ∈ ℂ ^d×d^, for j, k ∈ ℤ n. We clarify that the superscript d is an index, not power. In this section, a block matrix factorization of F n ^d^ is developed, and it is inspired in (3). First, a generalization of stride permutation is defined. Let n = rs. The block stride permutation matrix [14, 17] is defined as L s ^n,d^ ∈ ℂ ^dn×dn^ such that L s ^n,d^ = L s ^n^ ⊗ I d, and, for each x ∈ ℂ ^dn^ with n blocks x j ∈ ℂ ^d^, the operation L s ^n,d^ x permutes each block of the input block x as jr + k → ks + j, j ∈ ℤ s, and k ∈ ℤ r.
Theorem 2 . Let n = rs and let F n ^d^ ∈ ℂ ^dn×dn^ be the block matrix of DFT for vector-valued signals. Then
where T r ^n,d^ = ⨁j∈ℤs__ D r ^j^ such that D r = ⨁k∈ℤr__ W n ^−k^.
ProofLet x ∈ ℂ ^dn^, let l 1, k 1 ∈ ℤ r, and let l 2, k 2 ∈ ℤ s. The block vector y = (I s ⊗ F r ^d^)L s ^n,d^ x is defined. Then
Now, let z = T r ^n,d^ y. From Lemma 1, W r ^−k1l1^ = W n ^−sk1l1^; then
Let w = (F s ^d^ ⊗ I r)z. Then
But rk 2 l 2 + sk 1 l 1 + k 2 l 1 ≡ (k 2 + k 1 s)(l 1 + l 2 r)modn; then
Let m = sk 1 + k 2, let k = l 1 + l 2 r, and let m, k ∈ ℤ n because l 1, k 1 ∈ ℤ r, l 2 k 2 ∈ ℤ s, and n = rs. Then
Now, if n = rs, A ∈ ℂ ^r×r^, and B ∈ ℂ ^ds×ds^, the following equality [17] is obtained:
From Theorem 2 and (14), the following corollary presents a matrix factorization of F n ^d^ such that it permits an implementation using parallel computing.
Corollary 3 . Let n = rs and let F n ^d^ ∈ ℂ ^dn×dn^ be the block matrix of DFT for vector-valued signals. Then
where T r ^n,d^ was defined in Theorem 2.
Algorithm 2 shows a parallel implementation of (15).
r independent processes in Steps (3)–(5), and 2s independent processes in Steps (6)–(8) and (12)–(14) are observed, making this approach a parallel operation. A model of Algorithm 2 is shown in Figure 1.
4.1. Computational Complexity Analysis
In this section, the computational complexity analysis of (15) is developed. First, consider the matrix operation L s ^n,d^ v. The computational complexity (CC) of L s ^n,d^ v is 𝒪(nd) [8] because it is the multiplication between a block matrix in ℂ ^dn×dn^ and a block vector in ℂ ^dn^. But the operation L s ^n,d^ v can be implemented with a CC 𝒪(sd) (see, e.g., [12, 14]).
Let F n ^d^ ∈ ℂ ^dn×dn^ be the block matrix and vector-valued signal x ∈ l ^2^(ℤ n, ℂ ^d^), where n = rs. It is known that the CC of operation y = F n ^d^ x is 𝒪(n ^2^ d ^2^) = 𝒪(r ^2^ s ^2^ d ^2^). Now consider operation y = F n ^d^ x using (15). If we consider each matrix-vector multiplication, we obtain the following:
- (1)The CC of y 1 = L s ^n,d^ x is 𝒪(sd).
- (2)The CC of y 2 = (I s ⊗ F r ^d^)y 1 is 𝒪(sr ^2^ d ^2^), because it is a block diagonal matrix multiplication.
- (3)The CC of y 3 = T r ^n,d^ y 2 is 𝒪(nd), because T r ^n,d^ is a diagonal matrix multiplication.
- (4)The CC of y 4 = L r ^n,d^ y 3 is 𝒪(rd).
- (5)The CC of y 5 = (I r ⊗ F s ^d^)y 4 is 𝒪(rs ^2^ d ^2^), because it is a block diagonal matrix multiplication.
- (6)The CC of y = L s ^n,d^ y 5 is 𝒪(sd). Therefore, the CC of F n ^d^ x using (15) is
Thus, the CC of operation F n ^d^ x is 𝒪(r ^2^ s ^2^ d ^2^) and the CC of operation F n ^d^ x using (15) is 𝒪(sr(r + s)d ^2^). The above mentioned shows the efficiency of matrix formulation in (15).
5. Implementation and Experimental Investigation
5.1. General Information
The investigations have been carried out on a computer with multicore processor. The computer consists of 4 cores with Intel Core i7-3632QM CPU processor, system clock of 2.20 GHz, and 8 GB of RAM. The experiment develops the implementation and testing of Algorithms 1 and 2 with the hypercomplex DFT kernel and the DFT frame kernel is developed. Algorithm 1 does not use any parallel implementation, unlike Algorithm 2. A CAZAC signal in l ^2^(ℤ n, ℂ ^d^) is used; it is generated using a Wiener CAZAC signal in l ^2^(ℤ n) [9] with d = 5 and n = rs, where n = 1024 = 32 · 32, n = 2048 = 64 · 32, n = 4096 = 64 · 64, n = 8192 = 128 · 64, and n = 16384 = 128 · 128.
The implementation of Algorithms 1 and 2 to compute the vector-valued DFT is performed using MATLAB. Algorithm 2 is computed using Parallel Computing Toolbox. MATLAB uses built-in multithreading and parallelism using MATLAB workers. Parallelism using MATLAB workers is used. We can run multiple MATLAB workers (MATLAB computational engines) on a multicore computer to execute applications in parallel with the Parallel Computing Toolbox. This approach allows more control over the parallelism compared to built-in multithreading. With programming constructs, such as parallel-for-loops (parfor) and batch, we write the parallel MATLAB programs of the parallel framework for the vector-valued DFT.
5.2. Results and Discussion
Let T ∗ be the execution time of Algorithm 1 without any parallel implementation, and let T p be the execution time of Algorithm 2, where p is the number of cores. The value of T p needs to be less than that of T ∗ for two reasons: Algorithm 2 has a parallel implementation and the matrix multiplication size is different. Algorithm 2 is computed with matrices in ℂ ^dr×dr^ and ℂ ^ds×ds^. Algorithm 1 is computed with matrices in ℂ ^dn×dn^, where n = rs.
The computational performance analysis of Algorithm 2 is evaluated using the metrics speedup (or acceleration) and efficiency. The speedup is the ratio between the execution times of parallel implementations with one core and parallel implementations with two or more cores [18]. The speedup is represented by the formula S = T 1/T p. The efficiency estimates how well utilized the processors are in solving the problem compared to how much effort is wasted in communication and synchronization [18]. The efficiency is determined by the ratio between the speedup and the number of processing elements, represented by the formula E = T 1/(pT p).
Table 1 shows the execution time, in seconds (s), of both algorithms. A significant reduction in the parallel execution time of the vector-valued DFT is observed. Table 1 shows that Algorithm 1 with hypercomplex kernel for a Wiener CAZAC signal in l ^2^(ℤ 8192, ℂ ^5^) produces a time of serial execution T ∗ = 13408 s. Using Algorithm 2, however, we obtain T 1 = 106.7 (0.80% of T ∗), T 2 = 80.44 s (0.60% of T ∗), T 3 = 57.35 s (0.43% of T ∗), and T 4 = 32.67 s (0.24% of T ∗). This result shows the advantage of using multicore processors and a parallel computing environment to minimize the high execution time in the vector-valued DFT. This is because parallel computing is a form of computation in which many calculations are carried out simultaneously [19, 20], operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently, and minimize the execution time [20, 21]. The difference between T ∗ and T p is because T p is computed with matrices in ℂ ^dr×dr^ and ℂ ^ds×ds^. Algorithm 1 is computed with matrices in ℂ ^dn×dn^, where n = rs.
Table 2 represents the speedup of Algorithm 2. The acceleration of the vector-valued DFT increases when p increases regardless of the value of n. The results show that, using the proposed parallel implementation with p cores, where p = 2,3, 4, the speedup to compute the vector-valued DFT of a Wiener CAZAC signal is 1.09, 1.47, and 2.99, respectively. These results imply that, to get the highest speedup, one should prefer the approach with four cores.
Table 3 represents efficiency of Algorithm 2. The information in this table shows that a good efficiency (greater than 65%) is reached with p = 2. But the efficiency of the vector-valued DFT decreases (until 36%) when p increases regardless of the value of n. It is attributed to a decrease in the share of simultaneous computation of the partial vector-valued DFT in Algorithm 2 (steps (3)–(5) and (12)–(14)), which is responsible for the main effect. The results obtained in Table 3 imply that, to get a better efficiency, one should prefer the approach with two cores, because we obtain the highest efficiency.
6. Conclusion
This work presented a parallel framework of vector-valued DFT for vector-valued discrete-time signals. This mathematical framework was inspired in the matrix representation of the Cooley-Tukey FFT algorithm for complex discrete-time signals, corresponding to the decomposition of the transform size n into the product of two factors r and s, which is developed in [10, 12]. It was expressed in (15) and Algorithm 2. This parallel framework was performed in terms of a matrix representation using a set of block matrix operations: Kronecker product, direct sum, stride permutation, vec operator, and vec inverse operator. These operations contributed to analysis, design, and implementation in parallel. Two kernels are used in the vector-valued DFT: hypercomplex DFT kernel and DFT frame kernel.
The experimental investigation indicated there are profit using MATLAB with the Parallel Computing Toolbox in a computer with multicore processors. First, there was advantage to use multicore processors and a parallel computing environment to minimize the high execution time (with hypercomplex DFT kernel, we obtained T ∗ = 13408 s, T 1 = 106.7, T 2 = 80.44 s, T 3 = 57.35 s, and T 4 = 32.67 s). Second, speedup increased when p increased regardless of the value of n, and a good efficiency too was obtained when p = 2 (above 65%).
As future work, we would like to extend the proposed parallel framework to vector-valued discrete-time signals in l ^2^(ℤ n, ℂ ^d^), where n = 2^k^, using the idea of Pease algorithm for complex discrete-time signals [22]. Additionally, we would like to take advantage of more design tradeoffs of different approaches besides what have been shown in this paper, for example, the approach developed in [23].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wegmann B.Zetzsche C.Feature-specific vector quantization of images IEEE Transactions on Image Processing 19965227428810.1109/83.4807632-s 2.0-003008169018285111 · doi ↗ · pubmed ↗
- 2Huang J.Lv B.-Q.A feasible algorithm for designing biorthogonal bivariate vector-valued finitely supported wavelets Physics Procedia 2012251507151410.1016/j.phpro.2012.03.269 · doi ↗
- 3Li W.Vector transform and image coding IEEE Transactions on Circuits and Systems for Video Technology 19911429730710.1109/76.1207692-s 2.0-0026366570 · doi ↗
- 4Xia X.-G.Suter B. W.Multirate filter banks with block sampling IEEE Transactions on Signal Processing 199644348449610.1109/78.4890222-s 2.0-0030109347 · doi ↗
- 5Avdonin S. A.Ivanov S. A.Sampling and interpolation problems for vector valued signals in the Paley-Wiener spaces IEEE Transactions on Signal Processing 200856115435544110.1109/TSP.2008.928702 MR 24728442-s 2.0-54949121834 · doi ↗
- 6Vehkapera M.Chatterjee S.Skoglund M.Analysis of MMSE estimation for compressive sensing of block sparse signals 1Proceedings of the IEEE Information Theory Workshop (ITW '11)October 2011 Paraty, Brazil IEEE 55355710.1109/ITW.2011.6089563 · doi ↗
- 7Benedetto J. J.Donatelli J. J.Frames and a vector-valued ambiguity function 1Proceedings of the 42nd Asilomar Conference on Signals, Systems and Computers October 2008 Pacific Grove, Calif, USAIEEE 81210.1109/ACSSC.2008.5074350 · doi ↗
- 8Sangwine S. J.Ell T. A.Complex and hypercomplex discrete Fourier transforms based on matrix exponential form of Euler's formula Applied Mathematics and Computation 2012219264465510.1016/j.amc.2012.06.055MR 2956994 ZBL 1286.420052-s 2.0-84865011794 · doi ↗