Enhancing credit card fraud detection with a hybrid approach using machine and deep learning
Nagwa Gamal, Eman M. G. Younis, Waleed M. Makram

TL;DR
This paper proposes hybrid machine and deep learning models to improve credit card fraud detection, especially in handling imbalanced data.
Contribution
The novelty lies in combining ML, DL, and data balancing techniques through stacking ensemble approaches for fraud detection.
Findings
Stacking ensemble models achieved accuracy, precision, recall, F1-score, and AUC of 1.0, 0.9999, 1.0, 1.0, and 1.0 respectively.
Ensemble methods like CatBoost and XGBoost outperformed traditional models.
Deep learning models like FFNN, ANN, and MLP showed strong fraud detection performance.
Abstract
Credit card fraud is an important concern for banks, financial institutions and consumers, resulting in substantial financial losses annually. Traditional fraud detection systems are based on predefined rules, but as fraudsters develop more sophisticated techniques, these methods become less effective. Machine learning (ML) and deep learning (DL) offer powerful solutions to enhance the accuracy and efficiency of credit card fraud detection. However, a major challenge in credit card fraud detection is the highly imbalanced nature of transaction data, where fraudulent transactions are rare compared to legitimate ones. To address data imbalance, techniques such as Synthetic Minority Over-sampling Technique (SMOTE) and Mahalanobis distance Synthetic Minority Oversampling Technique–Edited Nearest Neighbors (SMOTE-ENN) hybrid sampling are applied to balance the dataset and improve model…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
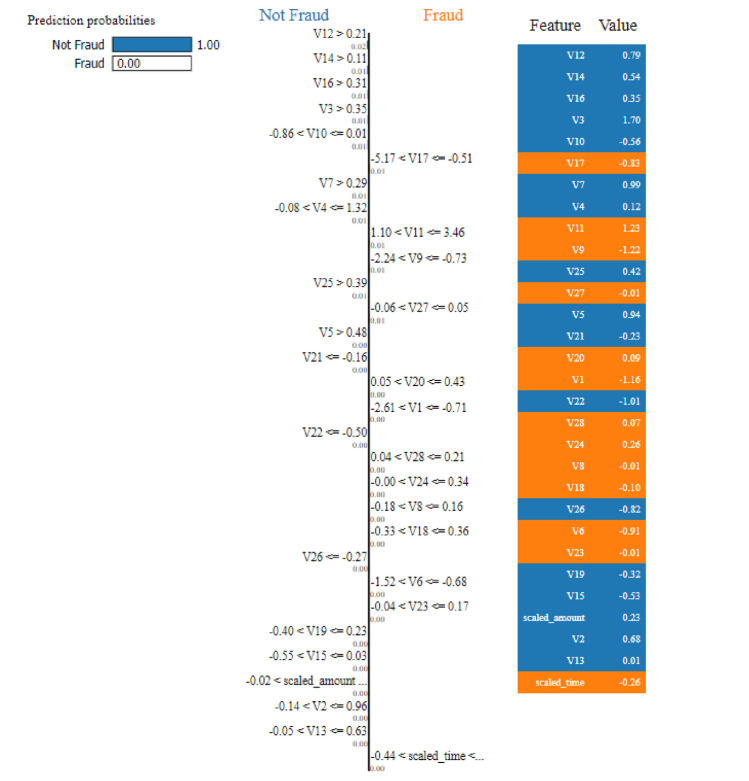 Fig. 17
Fig. 17- —Minia University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsImbalanced Data Classification Techniques · Financial Distress and Bankruptcy Prediction · Artificial Intelligence in Healthcare
Introduction
Fraud is generally defined as a deceptive act intended for financial gain. In the context of credit card transactions, fraud can be categorized into internal or external. Internal fraud occurs when the fraudster assumes a false identity with the collusion of the cardholder and the financial institution. In contrast, external fraud involves unauthorized access to a credit card to extract money or make transactions through deceptive means^1^.
Financial fraud detection has emerged as a critical area of research due to the increasing reliance on digital financial transactions as well as the growing sophistication of fraud schemes. The rapid expansion of e-commerce, online banking, and cashless payment methods has created an urgent need for effective fraud detection systems. These systems are used to mitigate financial losses and protect consumers and institutions^2^. Fraudulent transactions, particularly in credit card payments, often involve unauthorized access through phishing, data breaches, and cyber scams, making traditional rule-based detection methods insufficient in handling modern fraud schemes^3,4^.
The financial impact of fraud is substantial and growing. The Nilson Report estimates that global credit card fraud losses reached 43 billion by 2028^5^. According to the FTC^6^, fraud reports in the United States reached 2.4 million cases in 2024, with losses of approximately $8.8 billion, marking a significant increase from 2023. These escalating losses underscore the need for advanced artificial intelligence-driven detection systems to strengthen security and mitigate economic risks.
Fraud can be mitigated through two primary approaches: prevention and detection. Prevention serves as a protective barrier, stopping fraudulent activities before they occur. Detection, on the other hand, comes into play when preventive measures have failed, identifying and responding to fraudulent actions after they have taken place^7^. While prevention aims to block fraud before it happens, this study focuses on detection identifying fraudulent activities, analyzing patterns, and ensuring timely intervention to minimize damage.
Machine learning (ML) and deep learning (DL) have emerged as powerful tools in financial fraud detection due to their ability to learn complex patterns from large datasets^8^. They offer the advantage of learning from historical data to make accurate predictions and adapt to evolving fraud tactics^9,10^. Supervised learning models, such as logistic regression, decision trees, support vector machines (SVM), and random forests, have been widely used to classify transactions as fraudulent or legitimate^1,9^. Traditional methods have been complemented by more advanced algorithms such as gradient boosting (e.g., XGBoost, LightGBM, and CatBoost), and deep learning architectures including convolutional and recurrent neural networks^3,11^.
However, a major challenge in fraud detection is the high class imbalance present in financial datasets, where fraudulent transactions typically constitute a tiny fraction of overall transactions^12^. To address this issue, various resampling techniques such as SMOTE, ADASYN, and hybrid approaches^10,13,14^, as well as generative models like GANs^12,15^, have been developed to balance datasets and improve model performance.
Additional techniques have proven valuable in enhancing fraud detection. Feature engineering helps extract meaningful transaction patterns, while autoencoders and representation learning improve feature selection and classification accuracy^8^. Recurrent Neural Networks (RNNs), including Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs), have been employed to capture temporal transaction patterns^8^. Ensemble learning approaches, which combine multiple classifiers through strategies such as majority voting and weighted classifiers, have demonstrated significant improvements in fraud detection performance^3,16^.
Contributions
This work makes the following contributions to the field of credit card fraud detection:
- Robust handling of class imbalance: We address the extreme skew in fraud datasets by applying advanced resampling strategies, including Mahalanobis SMOTE-ENN and SMOTE, ensuring fairer and more reliable model training.
- Extensive benchmarking: We systematically evaluate 37 baseline models alongside two newly proposed ensemble models, providing one of the most comprehensive comparative studies in this domain.
- Learning dynamics and efficiency: We analyze learning curves and computational costs, offering insights into scalability and practical deployment feasibility for financial institutions.
- Model interpretability: We integrate explainable AI (XAI) techniques (SHAP and LIME), allowing both local and global interpretability of model decisions, thus enhancing trust and transparency.
- Error analysis: We perform a detailed error analysis to understand failure cases and provide directions for further model refinement.
Together, these contributions not only advance predictive performance but also improve transparency, efficiency, and trustworthiness of fraud detection systems.
The rest of the paper is organized as follows. Section II presents related work. Section III describes the proposed approach for detecting credit card fraud. The experiments conducted and their analyses are presented in Section IV. Section V provides the computational cost analysis. Section VI presents the model generalization assessment for the proposed ensemble models. Section VII discusses the explainable AI (XAI) analysis. Section VIII contains the error analysis and model comparison. Section IX outlines the research limitations. Finally, Section X includes the conclusions of the paper, as well as recommendations for future research.
Related work
Various ML and DL techniques have been used in experimental research to detect and predict fraudulent transactions. Many of these studies utilize the European Credit Card Dataset containing 284,807 transactions with 492 fraudulent cases (0.172% fraud rate), highlighting the severe class imbalance challenge inherent in fraud detection. Ensemble and Hybrid Deep Learning Approaches: Multiple studies have demonstrated the effectiveness of ensemble methods combining diverse architectures. An integrated approach combining CNNs, LSTM, and Transformers with XGBoost as a meta-learner achieved 0.972 AUC-ROC on the European dataset and 0.920 on the Taiwan dataset^17^. A combination of Gradient Boosting, Random Forest, and Logistic Regression with hyperparameter tuning achieved 99.59% accuracy^18^. An ensemble combining RUS, two-stage thresholding, and SMOTE achieved 99.07% accuracy with SMOTE enhancement^5^. Research investigating ensemble techniques integrating SVM, KNN, Random Forest, Bagging, and Boosting classifiers found that RF and Boosting achieved 100% accuracy on training samples and 99.98% on testing data using SMOTE^19^. Advanced Sampling and Generative Techniques: Addressing class imbalance remains critical in fraud detection research. R-GAN incorporating spectral normalization and similarity measure loss outperformed traditional oversampling methods with 99.5% accuracy^20^. ADASYN with RFECV feature selection achieved 99.98% accuracy, with XGBoost showing the highest MCC of 0.9994^14^. A hybrid approach combining Tomek links undersampling with BCBSMOTE oversampling on the PaySim dataset achieved 85.20% F1-score^13^. CB-CHL-LightGBM and OS-CHL-LightGBM integrating cost-sensitive learning improved F2-scores from 0.77 to 0.86 across three datasets^21^. Autoencoder and Anomaly Detection Approaches: Autoencoders have proven effective for anomaly detection in fraud detection. CNN-based VAE models for latent space representation achieved 0.92 F1-score and outperformed traditional resampling with machine learning models^22^. GNNs with Lambda Architecture and Autoencoders on Pakistani bank datasets achieved approximately 78% accuracy, with the Gated Temporal Attention Network (GTAN) proving particularly robust in low-label settings^23^. Federated Learning and Privacy-Preserving Approaches: Recent research has emphasized privacy-preserving fraud detection through federated learning. A Structured Data Transformer combined with federated learning and momentum updates achieved AUC-ROC values of 0.982 and 0.994 on two datasets^24^. FedFusion for adaptive model fusion across distributed clients with feature discrepancies achieved detection rates of 99.74%, 99.70%, and 96.61% across three clients while maintaining privacy^25^. Recent Advanced Methods: An anomaly detection framework based on multi-view heterogeneous graph neural networks was proposed by Berkmans et al. ^26^. Their pipeline incorporated FSMOTE for class balancing, MFKF for missing values, a metaheuristic-based feature selection method, and QAHA for hyperparameter tuning, delivering consistently higher accuracy, precision, and F1-scores than existing methods. A deep learning ensemble combining Kolmogorov–Arnold Networks with dynamic oversampling and ensemble feature selection was introduced by Akouhar et al.^27^, applying GAN-based oversampling with adaptive sampling rates and metaheuristic-driven feature selection. Experiments on three benchmark datasets showed it outperformed conventional deep learning approaches. The Balanced Variational AutoEncoder with Attention (Bal-VAE-Attention) was developed by Shi et al. ^28^, integrating an imbalance-aware loss function, LightGBM-based feature selection, and multi-head attention to capture complex fraudulent patterns. A stacking ensemble combining SVM, KNN, and a PSO-optimized Extreme Learning Machine was proposed by Gupta et al. ^29^, enhanced with SMOTE-ENN preprocessing, autoencoder-based dimensionality reduction, and TOPSIS feature selection, achieving 99.95% accuracy and 99.97% recall. XGBoost with Bayesian optimization was applied by Tayebi et al. ^30^, coupling Bayesian hyperparameter tuning with SMOTE and Random Under-Sampling, delivering high accuracy (up to 0.9996) and AUC close to 0.99 while providing interpretable results.
To offer a clearer comparison, the related work is summarized in Table 1.Table 1. Summary of related work.Refs.DatasetMethodsProposed modelResults of the proposed model^17^European Credit Card Dataset (284,807 transactions, 492 fraud cases); Taiwan Credit Card Dataset (30,000 transactions, 1,000 fraud cases)—CNN, LSTM, Transformers, XGBoost as final decision-maker (Stacking Ensemble)Sensitivity: 0.961Specificity: 0.999AUC-ROC: 0.972 (European dataset). Sensitivity: 0.918Specificity: 0.942AUC: 0.920 (Taiwan dataset)^24^Dataset 1: European Credit Card Dataset, Dataset 2: Simulated dataset—Federated Structured Data Transformer (SDT)AUC-PR: 0.884 , 0.892AUC-ROC: 0.963 , 0.998 with federated learning^5^European Credit Card DatasetRandom Under-Sampling (RUS), Two-Stage Thresholding (TST), SMOTELR, KNN, SVM, DT and the proposed ensemble modelAccuracy: 99.1% (SMOTE)Precision: 99.9%Recall: 99.1%F1-score: 99.5%^20^European Credit Card DatasetRandom Over-Sampling, SMOTE, ADASYN, Borderline-SMOTE, WGAN, WGANGP, SNGANRegularized Generative Adversarial Network (R-GAN)Accuracy: 99.5%Precision: 100%Recall: 99.0%F1-score: 99.5%^14^European Credit Card DatasetAdaptive Synthetic Minority Oversampling (ADASYN), Recursive Feature Elimination with Cross-Validation (RFECV)LGBM, RF, DT, LR ,Proposed XGBXGB: MCC 0.999Accuracy: 99.9%LGBM: MCC improved from 0.339 to 0.998^22^European Credit Card Fraud DatasetSMOTE, Under-sampling, Over-samplingCNN-based VAE (VAE-normal and VAE-anomaly)F1-score: 0.92 (VAE-normal), 0.91 (VAE-anomaly); Outperformed traditional ML models^23^Pakistani Banks (Meezan Bank & UBL) (284,807 transactions, 492 fraud cases)Min-Max ScalingGraph Neural Networks (GNNs), AutoencodersGNN Accuracy: 78.1% (Meezan), 78% (UBL).Autoencoder Accuracy: 77.1% (Meezan), 79% (UBL)^19^European Credit Card DatasetUnder-sampling, SMOTESVM, KNN, RF, Bagging, Boosting, Proposed Model (P_M_2)SMOTE: Accuracy 99.98%, Precision, Recall, and F1-score highest for P_M_2^25^Dataset 1: European Credit Card Transactions; Dataset 2: Kaggle Dataset (8 features); Dataset 3: Synthetic dataset (300M transactions)Federated learning techniques for data heterogeneityCNN, LSTM, MLP (MLP as the global model)Detection Rate: 99.7%, 99.7%, 96.6% (Clients 1, 2, and 3);Accuracy: 99.9%, 99.5%, 99.1%^13^PaySim Dataset (6M synthetic credit card transactions)Combines Tomek Links (undersampling) and BIRCH Clustering Borderline SMOTE (BCBSMOTE)Random Forest (RF)Accuracy: 99.9%F1-score: 85.2%Precision: 81.3%Recall: 89.5%AUPRC: 72.7%^21^Three datasets including European Credit Card TransactionsClass Balancing, Oversampling, Cost-sensitive LearningCB-CHL-LightGBM, OS-CHL-LightGBMF2-score: 0.77 to 0.83Cost savings improved from 0.65 to 0.76^18^European Credit Card DatasetUnder-sampling, SMOTERF, Logistic Regression, Voting Classifiers and Gradient Boosting achieved the best performanceAccuracy: 99.6%Precision: 97.3%Recall: 98.5%,F1-score: 98.9%^26^Credit Card Fraud (29k)FSMOTE (balancing), MFKF (missing data), SAA (feature selection)AD-OCCD-MHGNN (MHGNN + QAHA)Accuracy 99.5%Precision 98.9%Recall 98.9%F1 98.7%^27^Three benchmark fraud datasetsSMOTE, GAN oversampling, Ensemble feature selectionKAN + GAN-based ensembleAccuracy 99.9%Precision 98.3%Recall 94.1%F1 96.1%^28^Two open-source CCF datasetsBal-VAE oversampling, LightGBM feature selectionBal-VAE-AttentionRecall 99.9%Precision 99.9%AUC-ROC 99.9%AUC-PR 99.9%^29^Standard CCF datasetsSMOTE-ENN, Autoencoder dim. reduction, TOPSIS feature selectionStacking (SVM, KNN, PSO-ELM)Accuracy 99.9%Precision 99.9%Recall 99.9%AUC = 1.00^30^Two Kaggle CCF datasetsSMOTE, Random Undersampling, CV, Bayesian optimizationXGBoost (BO-optimized)Data 1 (SMOTE): Accuracy 99.9%Precision 94%Recall 87.4%F1 0.87.4%AUC 98.8Data 2 (RUS): Accuracy 83.3%Precision 82.9%Recall 83.8%F1 83.4%AUC 90.9%
The proposed approach for detecting credit card fraud
Dataset description
This study utilizes a real-world dataset, known as “creditcard,”^31^ to ensure the proposed algorithm’s practical applicability. The data set contains 284,807 transaction records collected over two days of credit card use in September 2013. Of these, 492 transactions are fraudulent, accounting for only 0.172% of all transactions, which highlights the highly imbalanced nature of the dataset (as seen in Fig. 1).Fig. 1. Percentage between Frauds and genuine transactions.
The dataset is publicly available on Kaggle and can be accessed at Credit Card Dataset. It consists entirely of numerical features generated using Principal Component Analysis (PCA). The original features and detailed background information were omitted to maintain confidentiality and privacy. It includes 28 principal components (labeled V1 to V28) derived through PCA, along with two untransformed features: Time, representing the elapsed time (in seconds) since the first transaction, and Amount, indicating the monetary value of each transaction. The target variable, Class, is binary, with 1 representing fraudulent transactions and 0 indicating legitimate ones. A summary of the features is provided in Table 2 .Table 2. Features of the credit card fraud dataset that is used in this paper.Variable nameDescriptionTypeV1, V2, ..., V28Transaction feature after PCA transformationIntegerTimeSeconds elapsed between each transaction with the first transactionIntegerAmountTransaction valueIntegerClassLegitimate or Fraudulent0 or 1
Data pre-processing
The credit card fraud dataset had already been normalized for features V1 to V28, with no anomalies or missing values, so no additional processing was required for those aspects. However, the features Amount and Time showed a significant difference in value distributions (as seen in Fig. 2). Without processing, this could skew the system’s assessment of the importance of these features due to their scale differences. To address this, it was necessary to standardize the data for Amount and Time. A new field, normAmount, was created to store the standardized values for the Amount feature, while the Time values were replaced with normTime to store the standardized equivalents (as shown in Fig. 3).Fig. 2. Values of the amount and time columns in the dataset.Fig. 3. Normalized values of amount and time.
Machine learning and deep learning classifiers
Table 3 presents the 37 classification models employed in this study and the two proposed stacking ensemble models, categorized into Traditional Machine Learning, Boosting Algorithms, Bagging Algorithms, Neural Networks, Recurrent Neural Networks, and Ensemble Methods. These models are analyzed and compared to assess their impact on credit card fraud detection.Table 3. Classification models used for credit card fraud detection.CategoryModelsTraditional machine learningNaive Bayes, Decision Tree, Logistic Regression, Random Forest (RF), K-Nearest Neighbors (KNN), Linear Discriminant Analysis, Bernoulli NB, Ridge Classifier, Extra Trees Classifier, Dummy Classifier, Quadratic Discriminant Analysis, SGD ClassifierBoosting algorithmsGradient Boosting, XGBoost, LightGBM, CatBoost, AdaBoost with Decision Tree base, AdaBoost with Extra Trees base, AdaBoost with Logistic Regression base, AdaBoost with Random Forest base, AdaBoost with Ridge Classifier baseBagging algorithmsBagging Classifier with Decision TreesNeural networksNeural Network, Artificial Neural Network (ANN), Feedforward Neural Network (FFNN), Multilayer Perceptron (MLP), Convolutional Neural Network (CNN) Recurrent neural networksRecurrent Neural Network (RNN), Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), Bidirectional LSTM (BiLSTM), Bidirectional GRU (BiGRU), BiLSTM with Maxpooling, BiGRU with Maxpooling Ensemble methodsStacking Classifier (RF, CNN, LSTM, XGBoost, LogisticRegression as meta-learner), Stacking Classifier (RF, CNN, LSTM, XGBoost as meta-learner), Stacking Classifier (CNN, LSTM, Transformer Base Learners, XGBoost as meta-learner) Proposed modelsStacking Classifier (ET, CNN, LSTM, XGBoost as meta-learner), StackingClassifier (ET, AdaBoostClassifier with ExtraTreesClassifier as base, AdaBoostClassifier with RandomForestClassifier as base, XGBoost as meta-learner)
This study presents a credit card fraud detection approach (as seen in Fig. 4) consisting of two main parts. First, all classification models are trained individually using the original, imbalanced dataset to maintain its natural distribution. Second, the dataset is balanced using two methods SMOTE and a hybrid model that combines Mahalanobis distance and SMOTE-ENN. The balanced dataset is then used to retrain the same 37 classification models along with the two proposed models. These models are evaluated using metrics such as accuracy, precision, recall, F1-score, and AUC diagrams. The steps can be summarized as follows:
- Data Preprocessing.
- Train 39 Classification Models and Evaluate Using Metrics.
- Apply SMOTE oversampling and Mahalanobis Distance SMOTE-ENN Hybrid Sampling Methods.
- Retrain the Models on the Balanced Data and Reevaluate.
- Compare Performance Metrics Before and After Balancing.
This experimental approach assesses the impact of balancing techniques and enhanced training data on credit card fraud detection. It demonstrates how these methods can improve the performance, effectiveness, and robustness of classification models, offering a practical and reliable solution for real-world applications.Fig. 4. The proposed approach for credit card fraud detection.
Ensemble learning
Ensemble learning is a machine learning technique that combines multiple models to improve decision-making in supervised learning tasks. This approach addresses common issues in individual models, such as high bias, variability, and limited accuracy^32^. Instead of relying on a single model, ensemble learning leverages the strengths of multiple classifiers to achieve better performance. It is generally categorized into three main types: bagging, boosting, and stacking. Bagging (bootstrap aggregating) trains several learners independently on bootstrap samples drawn from the training data and aggregates their predictions through voting or averaging, thereby reducing variance and increasing stability, particularly for tree-based models. In contrast, boosting constructs models sequentially, with each new learner emphasizing instances that were misclassified by its predecessors, which helps reduce bias and often yields strong performance, as demonstrated by algorithms such as AdaBoost and XGBoost^33,34^. Stacking involves combining multiple base models, known as base learners, and using a higher-level model, called a meta-learner, to refine their predictions. This process consists of two layers: the base layer, where multiple models generate predictions based on input data, and the meta layer, which integrates these predictions to enhance overall accuracy. By combining different models, stacking improves predictive performance and reduces the likelihood of errors^34^.
Data imbalance handling methods
This section covers the approaches used to address data imbalance in the study, including SMOTE oversampling and the hybrid SMOTE-ENN method based on Mahalanobis distance.
SMOTE
SMOTE is an algorithm designed to address class imbalance in datasets by generating synthetic samples to balance the class distribution^35^. It works by selecting samples from the minority class and identifying several of their nearest neighbors. New samples are then created through random interpolation between the selected samples and their neighbors. By adjusting the interpolation ratio, SMOTE can control the impact of the synthetic samples on the training set^36,37^.
Mahalanobis distance SMOTE-ENN hybrid sampling
The Synthetic Minority Oversampling Technique (SMOTE) is commonly used to address class imbalance by creating artificial examples for the minority class. In contrast, undersampling methods such as Edited Nearest Neighbor (ENN) reduce the number of instances from the majority class to achieve balance. However, this approach can result in the removal of valuable data and tends to be less effective when there is a large disparity between the majority and minority classes, as seen in the credit card dataset under study. Additionally, while oversampling helps balance the data, it may lead to overfitting by duplicating existing samples^16^. To tackle these issues, this study uses the SMOTE-ENN method, a hybrid resampling technique that combines oversampling (via SMOTE) and undersampling (via ENN) to create a balanced dataset. SMOTE generates new synthetic samples for the minority class, while ENN removes overlapping and noisy samples from the majority class using a neighborhood cleaning rule. This rule eliminates instances that differ from at least two out of their three nearest neighbors^16,38^. For this study’s credit card fraud dataset, the data is not only imbalanced but also multidimensional and includes anomalies. To handle this complexity, the Mahalanobis distance is used as the distance metric for SMOTE-ENN. The Mahalanobis distance takes into account the correlation between features and effectively measures the distance between samples in high-dimensional spaces. It is robust against outliers, reducing their influence on distance calculations^39^. By incorporating the Mahalanobis distance, the SMOTE-ENN technique better captures feature correlations, adapts to multidimensional datasets, and improves classification performance. This approach effectively handles imbalanced datasets, making it a suitable solution for credit card fraud detection^39^.
Evaluation metrics
- Confusion Matrix : A confusion matrix (as shown in Table 4) is an n \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} n table that summarizes how a classification model’s predictions align with the actual outcomes. In the case of a 2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 2 matrix, it provides details on true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN)^40^. Table 4. Confusion matrix.Actual valuesPositiveNegative Predicted values PositiveTP (True Positive)FP (False Positive) NegativeFN (False Negative)TN (True Negative)
- Accuracy: The accuracy rate represents the proportion of correct predictions made by a classifier out of the total predictions on a test set. It is essentially the inverse of the error rate, with both metrics offering similar insights into the classifier’s performance^40,41^.
- Precision : It is the ratio of true positives to the total number of positive predictions made by the classifier, including both true positives and false positives that were mistakenly identified as positives^40,42^.
- Recall : Also known as sensitivity or the true positive rate, it measures a model’s ability to correctly identify true positive cases^40^.
- The F1 score : Also called the F-measure, it represents the harmonic mean of precision and recall, providing a balanced evaluation of a classification model’s performance^41,42^.
- Receiver Operating Characteristic (ROC) Curve/Area Under the ROC Curve: The ROC curve is a visual representation of a classification model’s performance across various thresholds. It plots the True Positive Rate (TPR) against the False Positive Rate (FPR) at each threshold^40,43^.
Experimental setup and reproducibility
To ensure full reproducibility of our experimental results, all implementation details are documented below.
Software environment
All experiments were conducted using Python 3.11.5 with the following libraries: TensorFlow 2.18.0, scikit-learn 1.2.2, XGBoost 2.0.3, NumPy 1.24.0, and Pandas 1.5.3.
Hardware configuration
All experiments were conducted on a VMware virtual machine with Intel Xeon Gold 6338 CPU @ 2.00GHz, 64GB RAM, and 280GB HDD storage.
Hyperparameter selection rationale
Hyperparameters were selected based on established literature and preliminary experiments: Input shape (30, 1) reflects dataset structure; CNN filters (64, 128) and LSTM units (100, 50) follow recent practices for deep learning on tabular data; Extra Trees n_estimators=100 aligns with ensemble learning literature; AdaBoost/XGBoost parameters follow validated configurations; deep learning training (20 epochs, batch size 32, Adam optimizer) determined through convergence monitoring and standard practices^44,45^.
Model configuration
Complete hyperparameter specifications, random seed settings, and training configurations for both proposed models are documented in Tables 5 and 6.Table 5. Hyperparameter configuration for proposed model 1: extra trees-CNN-LSTM stacking ensemble.Model ComponentParametersTraining ConfigCNN ModelInput Shape: (30, 1)Conv1D Layer 1: 64 filters, kernel size 3, ReLU activationMaxPooling1D Layer 1: pool size 2Conv1D Layer 2: 128 filters, kernel size 3, ReLU activationMaxPooling1D Layer 2: pool size 2Flatten LayerDense Layer: 64 neurons, ReLU activationOutput Layer: 1 neuron, sigmoid activationOptimizer: Adam (learning rate=0.001, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} =0.9, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _2$$\end{document} =0.999, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} =1e-07)Loss Function: Binary CrossentropyMetrics: AccuracyEpochs: 20Batch Size: 32Verbosity: 0LSTM ModelInput Shape: (30, 1)LSTM Layer 1: 100 units, return_sequences=TrueLSTM Layer 2: 50 unitsDense Layer: 64 neurons, ReLU activationOutput Layer: 1 neuron, sigmoid activationOptimizer: Adam (learning rate=0.001, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} =0.9, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _2$$\end{document} =0.999, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} =1e-07)Loss Function: Binary CrossentropyMetrics: AccuracyEpochs: 20Batch Size: 32Verbosity: 0Extra Trees Classifiern_estimators: 100criterion: ginimax_depth: Nonemin_samples_split: 2min_samples_leaf: 1max_features: sqrtbootstrap: Falserandom_state: Nonen_jobs: Noneverbose: 0Used as base learner in stacking ensembleXGBoost Classifier (Meta-Learner)objective: binary:logisticeval_metric: loglossuse_label_encoder: Falsen_estimators: 100 (default)max_depth: 6 (default)learning_rate: 0.3 (default)subsample: 1.0 (default)colsample_bytree: 1.0 (default)random_state: NoneTrained on meta-features from base learnersStacking Classifier ConfigurationBase Learners: Extra Trees, CNN, LSTMFinal Estimator: XGBooststack_method: autopassthrough: Falsen_jobs: Noneverbose: 0Cross-validation strategy for generating meta-featuresTable 6Hyperparameter configuration for proposed model 2: ensemble boosting stacking.Model componentParametersTraining ConfigExtra Trees Classifiern_estimators: 100criterion: ginimax_depth: Nonemin_samples_split: 2min_samples_leaf: 1max_features: sqrtbootstrap: Falserandom_state: 42n_jobs: Noneverbose: 0Used as base learner in stacking ensembleAdaBoost + Random ForestBase Estimator: RandomForestClassifier - n_estimators: 10 - criterion: gini - max_features: sqrt - bootstrap: Truealgorithm: SAMME.Rn_estimators: 50learning_rate: 1.0random_state: 42Boosting iterations: 50AdaBoost + Extra TreesBase Estimator: ExtraTreesClassifier - n_estimators: 100 (default) - criterion: gini - max_features: sqrt - bootstrap: Falsealgorithm: SAMME.Rn_estimators: 50learning_rate: 1.0random_state: 42Boosting iterations: 50XGBoost Classifier (Meta-Learner)objective: binary:logisticeval_metric: loglossuse_label_encoder: Falsen_estimators: 100 (default)max_depth: 6 (default)learning_rate: 0.3 (default)subsample: 1.0 (default)colsample_bytree: 1.0 (default)random_state: NoneTrained on meta-features from base learnersStacking Classifier ConfigurationBase Learners: Extra Trees, AdaBoost+RF, AdaBoost+ETFinal Estimator: XGBooststack_method: autopassthrough: Falsen_jobs: Noneverbose: 0Cross-validation strategy for generating meta-featuresParameters marked as ”default” refer to the default values of the respective library versions listed above. All experiments were conducted in the same software environment to ensure consistency
Experimental results
This section covers the results of this study. We started by preprocessing the data, which included the cleaning and normalization, to prepare the data for analysis. Following this, we applied and evaluated 37 ML and DL classifiers, along with the two proposed models. To address data imbalance, we utilized SMOTE oversampling and a hybrid SMOTE-ENN method based on Mahalanobis distance. Finally, we re-evaluated the performance of all 37 classifiers and the two proposed models.
Performance evaluation of classifiers without data resampling
In this step, we trained 37 machine and deep learning classifiers, along with the two proposed stacking ensemble models, as described in Section 3.3, using the original dataset. All classifiers were implemented with their default settings and parameters. We evaluated their performance using an independent dataset obtained by splitting the original dataset into training and testing sets with a ratio of 80:20. The accuracy, precision, recall, AUC-ROC, and F1-score for all classifiers are summarized in Table 7.Table 7. Evaluation of 37 classifiers and the two proposed models on the original dataset.AlgorithmPrecisionRecallF1 scoreAUCAccuracyNaive bayes0.0540.8160.1010.9600.978Decision Tree0.8890.4590.6060.7700.999Logistic Regression0.8290.5520.6620.9700.999Random Forest0.9100.7010.7920.9800.999KNN0.8870.7240.7970.9400.999XGBoost0.9290.7470.8280.9800.999LGBMClassifier0.3290.6320.4330.7500.998LinearDiscriminant Analysis0.8210.7360.7760.8700.999BernoulliNB0.7610.5860.6620.9600.999CatBoost0.9320.7930.8570.9900.999Neural Network0.9750.4480.6140.9600.999RidgeClassifier0.7250.3330.4570.9800.999AdaBoostClassifier with DecisionTreeClassifier as base0.7610.6210.6840.9900.999AdaBoostClassifier with ExtraTreesClassifier as base0.9430.7590.8410.9600.999AdaBoostClassifier with LogisticRegression as base0.6920.4140.5180.9700.999AdaBoostClassifier with RandomForestClassifier as base0.9400.7240.8180.9500.999AdaBoostClassifier with RidgeClassifier as base0.7270.1840.2940.9600.999ExtraTreesClassifier0.9560.7470.8390.9700.999BaggingClassifier with Decision Trees as base0.9080.7930.8470.9400.999MLP0.9400.7240.8180.9600.999CNN0.9120.5980.7220.9600.999RNN0.8050.7590.7810.9600.999LSTM0.7560.7470.7510.9800.999GRU0.8240.7010.7580.9800.999BiLSTM0.8310.7360.7810.9800.999BiGRU0.8290.7820.8050.9850.999Gradient Boosting0.8620.5750.6890.7900.999Dummy Classifier0.00.00.00.50.999Quadratic Discriminant Analysis0.0500.8740.0950.9200.975SGDClassifier0.7500.4480.5610.7200.999ANN (Artificial Neural Network)0.9400.7240.8180.8600.999Feedforward Neural Network (FFNN)0.8380.7130.7700.8600.999BiLSTM-Maxpooling0.8570.7590.8050.9880.999BiGRU-Maxpooling0.9520.6780.7920.9870.999Stacking Classifier (RF, CNN, LSTM, XGBoost, Logistic Regression as meta-learner)0.9550.7240.8240.8600.999StackingClassifier (RF, CNN, LSTM, XGBoost as meta-learner)0.91670.7590.8300.8800.999StackingClassifier (CNN, LSTM, Transformer Base Learners, XGBoost as Meta Learner)0.7530.8050.7780.900.999The first proposed model: StackingClassifier (ET, CNN, LSTM, XGBoost as meta-learner)0.9550.7240.8240.860.999The second proposed model: StackingClassifier (ET, AdaBoostClassifier with ExtraTreesClassifier as base, AdaBoostClassifier with RandomForestClassifier as base, XGBoost as meta-learner)0.8780.7470.8080.870.999
As shown in Table 7, the CatBoost classifier achieved the highest accuracy, outperforming all other classifiers. The Accuracy for CatBoost was 0.9996 , Precision was 0.9324, Recall was 0.7931, AUC-ROC was 0.99 while the F1-score was 0.8571.
Performance evaluation of classifiers after SMOTE resampling and mahalanobis distance SMOTE-ENN hybrid sampling
This section presents the experimental results of the classification models listed in Table 3. The results of these algorithms are presented in Table 8. SMOTE oversampling demonstrated superior performance across all evaluation metrics and proved highly effective in managing the imbalanced dataset. Among the individual models tested, CNN achieved an accuracy of 0.9917 with recall of 0.9958, indicating challenges in capturing all fraudulent transactions. LSTM showed improved performance with an accuracy of 0.9983 and recall of 0.9997, demonstrating better capability in capturing temporal dependencies. Extra Trees further enhanced performance with near-perfect results: precision of 0.9998, recall of 1.0, F1 score of 0.9999, and accuracy of 0.9999. XGBoost also achieved strong performance with perfect recall of 1.0 and accuracy of 0.9998, demonstrating its robustness in handling imbalanced datasets. Building upon these strong individual results, we developed two novel stacking ensemble models that achieved superior performance. Tables 5 and 6 provide the parameters for each algorithm used in the proposed stacking ensemble. The first proposed model combines Extra Trees, CNN, and LSTM as base learners with XGBoost as the meta-learner. This ensemble achieved perfect performance with precision of 0.9999, recall of 1.0, F1 score of 1.0, AUC of 1.0, and accuracy of 1.0 (Fig. 5). In contrast, when applying the second balancing method, SMOTE-ENN hybrid sampling with Mahalanobis distance, the model reached an accuracy of 0.9986, precision of 1.0, recall of 0.2143, F1 score of 0.3529, and AUC of 0.6100 (Fig. 6). The second proposed model integrates Extra Trees, AdaBoostClassifier with ExtraTreesClassifier as base, and AdaBoostClassifier with RandomForestClassifier as base, with XGBoost as the meta-learner. This ensemble also achieved perfect performance: precision of 0.9999, recall of 1.0, F1 score of 1.0, AUC of 1.0, and accuracy of 1.0. Both proposed stacking ensemble models demonstrated the best overall results, significantly outperforming individual classifiers. The training and inference procedures of the two proposed stacking ensembles are summarized in Algorithms 1 and 2.Fig. 5. The first proposed stacking ensemble performance metrics using SMOTE.Fig. 6. The first proposed stacking ensemble performance metrics using Mahalanobis distance SMOTE-ENN hybrid sampling.Table 8. Evaluation of 37 classifiers and the two proposed models on the balanced dataset.AlgorithmImbalance methodPrecisionRecallF1 scoreAUCAccuracyNaive BayesSMOTE0.9690.8480.9050.9500.910Mahalanobis distance SMOTE-ENN hybrid sampling0.0520.8780.0980.9600.972Decision TreeSMOTE0.9940.8780.9330.9600.936Mahalanobis distance SMOTE-ENN hybrid sampling0.0790.8060.1450.8800.984 Logistic RegressionSMOTE0.9740.9190.9460.9900.947Mahalanobis distance SMOTE-ENN hybrid sampling0.0590.9180.1110.9700.975 Random ForestSMOTE0.9950.9250.9590.9900.960Mahalanobis distance SMOTE-ENN hybrid sampling0.8990.8160.8560.9700.999KNNSMOTE0.9971.00.9991.00.999Mahalanobis distance SMOTE-ENN hybrid sampling0.5660.8780.6880.9400.999XGBoostSMOTE0.9991.00.9991.00.999Mahalanobis distance SMOTE-ENN hybrid sampling0.8370.8370.8370.9700.999 LGBM ClassifierSMOTE0.9990.9990.9991.00.999Mahalanobis distance SMOTE-ENN hybrid sampling0.7780.8570.8160.9500.999 Linear Discriminant AnalysisSMOTE0.9830.8490.9110.9800.917Mahalanobis distance SMOTE-ENN hybrid sampling0.0940.8470.1690.9600.986BernoulliNBSMOTE0.9890.8220.8980.9600.906Mahalanobis distance SMOTE-ENN hybrid sampling0.1590.8370.2670.9600.992CatBoostSMOTE0.9991.00.9991.00.999Mahalanobis distance SMOTE-ENN hybrid sampling0.7460.8670.8020.9700.999 Neural NetworkSMOTE0.9991.00.9991.00.999Mahalanobis distance SMOTE-ENN hybrid sampling0.6490.8670.7420.9600.999 Ridge ClassifierSMOTE0.9830.8490.9110.9800.917Mahalanobis distance SMOTE-ENN hybrid sampling0.0940.8470.1690.9600.986 AdaBoost Classifier with DecisionTree Classifier as baseSMOTE0.9760.9500.9631.00.963Mahalanobis distance SMOTE-ENN hybrid sampling0.0830.8980.1520.9700.983 AdaBoost Classifier with ExtraTrees Classifier as baseSMOTE0.9991.00.9991.00.999Mahalanobis distance SMOTE-ENN hybrid sampling0.9210.8270.8710.9600.999 AdaBoost Classifier with Logistic Regression as baseSMOTE0.9740.8990.9350.9800.937Mahalanobis distance SMOTE-ENN hybrid sampling0.0490.8880.0930.9700.970 AdaBoost Classifier with RandomForest Classifier as baseSMOTE0.9991.00.9991.00.999Mahalanobis distance SMOTE-ENN hybrid sampling0.9070.7960.8480.9500.999 AdaBoost Classifier with Ridge Classifier as baseSMOTE0.9860.8790.9300.9800.934Mahalanobis distance SMOTE-ENN hybrid sampling0.0810.8880.1490.9600.985 ExtraTrees ClassifierSMOTE0.9991.00.9991.00.999Mahalanobis distance SMOTE-ENN hybrid sampling0.9210.8270.8710.9600.999 Bagging Classifier with Decision Trees as baseSMOTE0.9990.9990.9991.00.999Mahalanobis distance SMOTE-ENN hybrid sampling0.7840.7750.7790.9100.999MLPSMOTE0.9991.00.9991.00.999Mahalanobis distance SMOTE-ENN hybrid sampling0.6890.8370.7560.9600.999CNNSMOTE0.9880.9960.9920.9990.992Mahalanobis distance SMOTE-ENN hybrid sampling0.1690.8980.2840.9690.992RNNSMOTE0.9940.9980.9960.9990.996Mahalanobis distance SMOTE-ENN hybrid sampling0.2150.8670.3440.9400.994LSTMSMOTE0.9970.9990.9980.9990.998Mahalanobis distance SMOTE-ENN hybrid sampling0.4490.8570.5890.9650.998GRUSMOTE0.9960.9990.9980.9990.998Mahalanobis distance SMOTE-ENN hybrid sampling0.4830.8670.6200.9520.998BiLSTMSMOTE0.9980.9990.9990.9990.999Mahalanobis distance SMOTE-ENN hybrid sampling0.6070.8670.7140.9550.998BiGRUSMOTE0.9990.9990.9990.9990.999Mahalanobis distance SMOTE-ENN hybrid sampling0.6590.8670.7490.9580.999 Gradient BoostingSMOTE0.9870.9670.9770.9770.977Mahalanobis distance SMOTE-ENN hybrid sampling0.1760.8980.2940.9450.993 Dummy ClassifierSMOTE0.00.00.00.50.498Mahalanobis distance SMOTE-ENN hybrid sampling0.0021.00.0030.50.002 Quadratic Discriminant AnalysisSMOTE0.9660.8860.9240.9270.927Mahalanobis distance SMOTE-ENN hybrid sampling0.0450.8880.0850.9270.967SGDClassifierSMOTE0.9720.9220.9470.9470.947Mahalanobis distance SMOTE-ENN hybrid sampling0.0610.9180.1150.9470.976 ANN (Artificial Neural Network)SMOTE0.9991.00.9990.9990.999Mahalanobis distance SMOTE-ENN hybrid sampling0.7170.8270.7670.9130.999 Feedforward Neural Network (FFNN)SMOTE0.9991.00.9990.9990.999Mahalanobis distance SMOTE-ENN hybrid sampling0.7280.8470.7830.9230.999 BiLSTM-MaxpoolingSMOTE0.9991.00.9990.9990.999Mahalanobis distance SMOTE-ENN hybrid sampling0.5930.8470.6980.9730.999 BiGRU-MaxpoolingSMOTE0.9990.9980.9990.9990.999Mahalanobis distance SMOTE-ENN hybrid sampling0.7370.8570.7930.9550.9992 Stacking Classifier (RF, CNN, LSTM, XGBoost, Logistic Regression as meta-learner)SMOTE0.9991.00.9990.9990.999Mahalanobis distance SMOTE-ENN hybrid sampling0.8470.8470.8470.9200.999 Stacking Classifier (RF, CNN, LSTM, XGBoost as meta-learner)SMOTE0.9991.00.9990.9990.999Mahalanobis distance SMOTE-ENN hybrid sampling0.9440.3470.5080.6700.999 Stacking Classifier (CNN, LSTM, Transformer Base Learners, XGBoost as Meta Learner)SMOTE0.9990.9940.9970.9970.997Mahalanobis distance SMOTE-ENN hybrid sampling0.7890.8370.8120.9200.999 The first proposed modelSMOTE0.9991.01.01.01.0Mahalanobis distance SMOTE-ENN hybrid sampling1.00.2140.3530.6100.999 The second proposed modelSMOTE0.9991.01.01.01.0Mahalanobis distance SMOTE-ENN hybrid sampling1.00.2250.3670.6120.999
Algorithm 1First proposed model: Extra Trees–CNN–LSTM stacking ensemble with XGBoost
Algorithm 2Second proposed model: ensemble boosting stacking with XGBoost meta-learner
Discussion of simpler baselines
Although our primary focus was on ensemble methods, we also included several simpler baseline models such as Logistic Regression, Decision Tree, k-NN, and Naïve Bayes in our evaluation. These models are widely recognized for their efficiency and interpretability, but as our results demonstrate, they consistently underperform compared to the proposed ensembles, particularly in detecting fraudulent transactions.
This highlights an important trade-off: simpler models are computationally lighter and easier to explain, whereas ensemble approaches achieve substantially higher accuracy and robustness. While we did not explicitly measure the computational efficiency of the simpler baselines in this study, their advantages in this regard are well established in the literature. A detailed comparative analysis of efficiency across both simple and complex models is left as a promising direction for future work.
Comparison with other studies
The performance of the proposed model was compared to the most effective methods from previous studies, as shown in Table 8. The results indicate that our model outperforms the methods presented in other studies. Specifically, by comparing these metrics, it is clear that the combination of SMOTE oversampling and the proposed stacking ensemble (which incorporates ExtraTrees, CNN, LSTM, and XGBoost as a meta-learner or incorporates ExtraTrees, AdaBoostClassifier with ExtraTreesClassifier as base, AdaBoostClassifier with RandomForestClassifier as base and XGBoost as meta-learner) is more effective in predicting fraud risk.Table 9. Comparison with studies that used european credit card dataset.Refs.Pre-processingMethodResults without data resamplingResults with data resampling^10^SMOTE-ENNProposed DL En-semblesensitivity= 0.905specificity = 0.966sensitivity= 1.000specificity = 0.997^11^NADecision TreeSensitivity= 0.792Precision= 0.851NA^36^SMOTE, GAN, VAE, VAEGAN and The improved VAEGANXGBoost with The improved VAEGANPrecision =0.958Recall =0.704F1_score =0.812Specificity =0.999Precision =0.924Recall =0.839F1_score =0.879Specificity =0.999^46^feature selection techniques, removing non fraudulent transactions from the dataset.the proposed 20-layer CNN modelAccuracy =0.932Accuracy =0.997^16^SMOTE-ENNProposed LSTM EnsembleSensitivity = 0.839Specificity =0.982AUC =0.890Sensitivity =0.996Specificity =0.998AUC =0.990^7^PCA And EDARandom Forest and XGBoostNot mentionedRF Accuracy =0.986XGBoost Accuracy =0.984^8^OneHotEncoding, PCA, Silhouette Scoring, IFM, SMOTERXT-J (proposed)Not mentionedAccuracy =0.981^3^feature selection, class weight hyperparameter tuning to deal with the problem of data unbalanceProposed LightGBM , Proposed approachNot mentionedProposed LightGBM Accuracy = 0.999Proposed approach Accuracy = 0.999^12^GANsGANsNot mentionedAUC = 0.989^1^PCA , random under-samplingLRNot mentionedAccuracy =0.959^9^Feature Scaling, undersampling with borderline SMOTESVM with undersampling with borderline SMOTEAccuracy =0.860Accuracy =0.938^47^SMOTEXGB-AdaBoost and ET-AdaBoostNot mentionedAccuracy of XGB-AdaBoostET-AdaBoost = 99.98Ours SMOTEStacking Classifier (ET, CNN, LSTM, XGBoost as meta-learner)Precision = 0.955Recall= 0.724F1 score = 0.824AUC= 0.860Accuracy= 0.999Precision = 0.9999Recall= 1.0F1 score= 1.0AUC= 1.0Accuracy= 1.0Stacking Classifier (ET, AdaBoostClassifier with ExtraTreesClassifier as base, AdaBoostClassifier with RandomForestClassifier as base, XGBoost as meta-learner)Precision = 0.878Recall= 0.747F1 score = 0.808AUC= 0.870Accuracy= 0.999Precision =** 0.9999**Recall= 1.0F1 score= 1.0AUC= 1.0Accuracy= 1.0
Computational cost analysis
This section evaluates the computational efficiency of the two proposed ensemble models for credit card fraud detection. The computational cost analysis includes training time and peak memory usage across different dataset sizes.
Computational cost comparison
Figures 7 and 8 illustrate the computational requirements of both proposed models across different dataset sizes, while Table 9 provides detailed numerical comparisons.Fig. 7. Computational cost for Model 1 (Deep Ensemble Stack).Fig. 8. Computational cost for Model 2 (Tree Ensemble).Table 10. Computational cost comparison between proposed models.Dataset fractionModel 1 (deep ensemble)Model 2 (tree ensemble)Time (s)Memory (MB)Time (s)Memory (MB)0.212,0001600180018000.425,0002000350019500.638,0002350520021000.851,0002800600022501.065,000320082002350
Computational efficiency analysis
Training time complexity
The computational cost analysis reveals significant differences between the two proposed models:
- Model 1 (Deep Ensemble): Exhibits substantial computational overhead due to deep neural network components. Training time scales from 12,000s (0.2 fraction) to 65,000s (full dataset), representing a 5.4 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} increase.
- Model 2 (Tree Ensemble): Demonstrates superior computational efficiency with training times ranging from 1,800s to 8,200s, achieving a 4.6 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} increase with dataset size.
- Efficiency Ratio: Model 2 achieves approximately 87% faster training time compared to Model 1 across all dataset sizes, with the efficiency gap remaining consistent.
Memory utilization
Memory consumption patterns differ significantly between the models:
- Model 1: Peak memory usage ranges from 1,600MB to 3,200MB, showing a 2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} increase with full dataset utilization. The neural network components require substantial memory for gradient computations and model parameters.
- Model 2: More memory-efficient with usage ranging from 1,800MB to 2,350MB, representing only a 1.3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} increase. Tree-based algorithms demonstrate better memory scalability.
- Memory Overhead: Model 1 requires 36% more peak memory at full dataset capacity, primarily due to CNN and LSTM layer computations.
Scalability assessment
Both models exhibit near-linear scaling characteristics, but with different computational complexity coefficients:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} T_{Model1} \approx 65,000 \times f_{data} + C_1 \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} T_{Model2} \approx 8,200 \times f_{data} + C_2 \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{data}$$\end{document} represents the data fraction and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_2$$\end{document} are model-specific constants.
Practical deployment implications
Real-time processing considerations
For production deployment in credit card fraud detection systems:
- Model 2 offers superior suitability for environments with computational constraints or real-time processing requirements
- Model 1 may be preferable when computational resources are abundant and maximum predictive performance is prioritized over efficiency
- Both models can be deployed in distributed computing environments, but Model 2 requires significantly fewer computational resources
Cost-benefit analysis
The computational efficiency of Model 2 provides several operational advantages:
- Reduced infrastructure costs due to lower computational requirements
- Faster model retraining capabilities for adapting to new fraud patterns
- Lower energy consumption and carbon footprint
- Enhanced scalability for processing large transaction volumes
Model generalization assessment for proposed ensemble models
To address concerns about potential overfitting given the exceptionally high performance metrics, we conducted comprehensive learning curve analyses for both of our proposed ensemble models. Learning curves provide crucial evidence of model generalization by visualizing training and validation performance across different training set sizes.
Learning curve analysis
Figures 9, 10, 11, and 12 present the learning curves for our first and second proposed ensemble models, respectively. Both analyses examine accuracy performance across training set sizes ranging from 80,000 to 350,000 samples. Model 1 Performance: Training accuracy remains consistently at 1.0000 while cross-validation accuracy improves from 0.9995 to 0.9999 as training data increases. The final gap between training and validation curves is only 0.0001 (0.01%). The error bars in Figure 9 show small standard deviations that decrease with larger training sets, indicating stable performance estimates.
Model 2 Performance: Training accuracy maintains perfect 1.0000, while cross-validation accuracy shows a steeper initial improvement, rising from 0.9995 to 0.9999. The model demonstrates more rapid convergence around 150,000 training samples, with a final gap of approximately 0.0001, matching Model 1’s convergence behavior.
Comparative analysis
The two models show distinct learning patterns:
- Convergence Speed: Model 2 achieves faster early convergence (80,000–150,000 samples), while Model 1 shows gradual, consistent improvement throughout.
- Data Efficiency: Model 2 reaches near-optimal performance with smaller training sets, making it suitable for limited data scenarios.
- Final Performance: Both models achieve identical convergence gaps (0.0001), indicating comparable generalization capabilities.
- Stability: Both demonstrate smooth learning curves with minimal variance across cross-validation folds.
Overfitting assessment
The learning curves provide strong evidence against overfitting:
The minimal training-validation gaps ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\le$$\end{document} 0.01%) are far below typical overfitting indicators. Both models show progressive validation improvement rather than the characteristic overfitting pattern where validation performance plateaus while training performance continues improving. The decreasing error bars with larger training sets indicate increasing confidence in performance estimates, and the healthy convergence patterns demonstrate genuine learning rather than memorization.
Implications for fraud detection applications
The results have practical implications for deployment:
- Production Reliability: Minimal overfitting ensures both models will maintain performance on new fraud cases.
- Resource Optimization: Model 2’s faster convergence suits scenarios with limited training data, while Model 1’s consistent improvement benefits from abundant data.
- Deployment Confidence: The 0.01% performance gaps validate that reported metrics (>99.9% accuracy) reflect genuine capabilities rather than artifacts.
These findings establish that our exceptionally high performance metrics represent legitimate model capabilities with strong generalization to real-world fraud detection scenarios.Fig. 9. Learning curve with error bars for the first proposed ensemble model showing minimal training-validation gap and decreasing variance with larger training sets.Fig. 10. Learning curve for the first proposed model demonstrating consistent validation improvement without overfitting.Fig. 11. Learning curve with error bars for the second proposed ensemble model showing rapid early convergence and stable generalization.Fig. 12. Learning curve for the second proposed model demonstrating efficient learning with fast convergence to optimal performance.
Explainable AI (XAI) analysis
This section provides a comprehensive analysis of the explainability results for two proposed credit card fraud detection models using SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) techniques. The analysis demonstrates the interpretability and transparency of both models through various visualization approaches.
Model 1: Explainability analysis
The first proposed model’s explainability is analyzed through multiple XAI techniques, providing insights into its decision-making process and feature importance patterns.
LIME analysis
The LIME analysis reveals the hierarchical decision-making process of Model 1, as illustrated in Figure 13. The model achieves perfect classification confidence with prediction probabilities of 1.00 for Not Fraud and 0.00 for Fraud for the analyzed instance. The decision tree structure demonstrates clear logical progression through key features:Fig. 13LIME visualization for Model 1 showing prediction probabilities and feature thresholds.
The primary decision nodes include splits on features V14 (> 0.11), V12 (> 0.21), V16 (> 0.31), and V3 (> 0.35), with specific threshold values that guide the classification process. The feature value panel shows the actual values for each feature in the analyzed instance, providing transparency in the decision-making process.
SHAP analysis
The SHAP analysis for Model 1 provides multiple perspectives on feature importance and contribution patterns. Figure 14 presents the beeswarm plot showing the relationship between feature values and their impact on model predictions.Fig. 14SHAP beeswarm plot for Model 1 showing feature importance and directional impact on predictions.
The beeswarm visualization reveals that V12, V14, V17, V11, V4, V16, V3, V10, and V19 are the most influential features. The color coding indicates feature values (red for high, blue for low), while the x-axis position shows the magnitude and direction of impact on the model output.
Figure 15 quantifies the feature importance through mean absolute SHAP values:Fig. 15SHAP feature importance ranking for Model 1 with mean absolute SHAP values.
The analysis reveals that V12 and V14 demonstrate the highest mean SHAP values (0.08 each), indicating their strongest predictive power. Secondary features including V17, V11, V4, V16, V3, V10, and V19 contribute moderately with values ranging from 0.02 to 0.04. Notably, the sum of 21 other features collectively contributes 0.36, suggesting the model leverages a comprehensive feature space.
The distribution of feature impacts is further illustrated in Fig. 16:Fig. 16SHAP violin plot for Model 1 showing the distribution of feature impact values.
The violin plot demonstrates the variability in feature contributions across different instances, with V12, V14, V17, V11, and V4 showing the most substantial and consistent impacts on model predictions.
Model 2: Explainability analysis
The second proposed model exhibits enhanced complexity and refined feature utilization patterns, as demonstrated through comprehensive XAI analysis.
LIME analysis
The LIME analysis for Model 2, shown in Fig. 17, reveals a more sophisticated decision tree structure with additional branching levels This enhanced LIME surrogate structure suggests that the underlying complex model requires deeper feature interactions for local explanations and more nuanced decision boundaries. The LIME explanation maintains high confidence levels with similar prediction probabilities (1.00 for Not Fraud) while incorporating multiple pathways for local classification through various feature combinations.
LIME visualization for Model 2 showing enhanced decision complexity.
SHAP analysis
Model 2’s SHAP analysis demonstrates notable improvements in feature utilization efficiency. Figure 18 illustrates the refined impact patterns. The beeswarm plot reveals more concentrated feature impacts, with clearer separation between positive and negative contributions. The feature ordering shows V14, V12, V17, V11, V4, V16, V3, V10, and V18 as the primary contributors.Fig. 18SHAP beeswarm plot for Model 2 showing refined feature impact distributions.
The quantitative feature importance analysis in Fig. 19 confirms the enhanced model performance. Model 2 maintains V14 and V12 as the top performers (0.08 each) while demonstrating improved feature utilization. V17 shows increased importance (0.06 compared to 0.04 in Model 1), and the collective impact of other features is significantly reduced to 0.07, indicating more focused feature utilization.Fig. 19SHAP feature importance ranking for Model 2 with optimized contribution values.
Figure 20 presents the distribution analysis. The violin plot demonstrates more concentrated and stable feature contributions, with reduced variability compared to Model 1, suggesting improved model calibration and consistency.Fig. 20SHAP violin plot for Model 2 showing concentrated feature impact distributions.
Comparative model analysis
Feature consistency and evolution
The comparative analysis between both models reveals remarkable consistency in critical feature identification. Both models consistently identify V12 and V14 as the primary fraud indicators, with mean SHAP values of 0.08 each across both architectures. This consistency validates the robustness of these features as reliable fraud detection indicators.
The evolution from Model 1 to Model 2 demonstrates several key improvements:
- Enhanced Feature Focus: Model 2 reduces reliance on collective ”other features” from 0.36 to 0.07, indicating more efficient primary feature utilization
- Improved V17 Utilization: V17 shows enhanced importance in Model 2 (0.06) compared to Model 1 (0.04)
- Maintained Core Features: V11, V4, V16, V3, and V10 maintain stable importance rankings across both models
- Refined Distribution Patterns: Model 2 exhibits more concentrated SHAP value distributions, suggesting improved model calibration
Explainability validation
The XAI analysis validates both models’ reliability through multiple dimensions:
Consistent Feature Importance: The stability of critical features (V12, V14, V17) across different model architectures builds confidence in their genuine predictive value rather than spurious correlations.
Logical Decision Patterns: SHAP values align with expected fraud detection patterns, where specific transaction characteristics consistently contribute to fraud probability assessments.
Transparent Predictions: The clear visualization of feature contributions through beeswarm plots, importance rankings, and violin plots enables stakeholder understanding and facilitates model validation processes.
Practical implications and applications
The comprehensive XAI analysis provides several actionable insights for fraud detection system implementation:
Feature Prioritization: Organizations should focus monitoring and feature engineering efforts on V12, V14, and V17, as these features demonstrate consistent high importance across both model architectures.
Model Trustworthiness: The consistent feature importance patterns across models build confidence for production deployment, as the models demonstrate stable and interpretable decision-making processes.
Regulatory Compliance: The transparent decision-making processes revealed through SHAP and LIME analyses support explainability requirements in financial applications, particularly important for regulatory compliance and audit purposes.
System Optimization: Understanding feature contributions enables targeted improvements in data collection pipelines, preprocessing procedures, and real-time monitoring systems.
Risk Assessment Enhancement: The detailed feature impact analysis allows for more nuanced risk scoring and enables financial institutions to better understand the characteristics that drive fraud predictions.
The XAI analysis confirms that both proposed models maintain high interpretability while achieving strong predictive performance, making them suitable candidates for production deployment in credit card fraud detection systems where explainability is paramount.
Error analysis and model comparison
The comprehensive error analysis reveals distinct performance characteristics between the two proposed models through detailed examination of confusion matrices, probability distributions, and feature importance patterns. The first model’s confusion matrix (Fig. 21) demonstrates exceptional precision with only 3 false positives out of 56,461 legitimate transactions, achieving a false positive rate of 5.3e-05 as shown in its normalized confusion matrix (Fig. 22). In contrast, the second model’s confusion matrix (Fig. 23) exhibited 4 false positives from 56,457 legitimate cases, resulting in a slightly higher false positive rate of 7.1e-05 (Fig. 24). Both models maintained perfect recall with zero false negatives across 56,841 fraud cases.Fig. 21. Confusion matrix (Model 1).Fig. 22. Normalized confusion matrix (Model 1).Fig. 23. Confusion matrix (Model 2).Fig. 24. Normalized confusion matrix (Model 2).
The error rate analysis by probability bins reveals critical behavioral differences between models. The first model shows error concentration in specific probability ranges (Fig. 25 with errors occurring predominantly in the highest confidence region (0.9–1.0 range). Conversely, the second model’s error rate by probability bins (Fig. 26) demonstrates a more distributed error pattern, with a notable spike in the 0.6-0.8 confidence range, indicating less consistent confidence calibration.Fig. 25. Error rate by bins (Model 1).Fig. 26. Error rate by bins (Model 2).
The probability distribution analysis further illuminates model behavior differences. The first model’s probability distributions (Figs. 27 and 28) show false positives concentrated exclusively in the high-confidence region (0.9–1.0), suggesting consistent but occasionally overconfident predictions.Fig. 27. Predicted probability distribution (counts)—Model 1.Fig. 28. Predicted probability distribution (proportions)—Model 1.
The second model’s probability distributions (Figs. 29 and 30) reveal false positives distributed across multiple confidence levels, with cases appearing in both the 0.6-0.8 and 0.9-1.0 probability ranges, indicating broader confidence intervals and less decisive boundary decisions.Fig. 29. Predicted probability distribution (counts)—Model 2.Fig. 30. Predicted probability distribution (proportions)—Model 2.
Feature importance analysis demonstrates notable shifts in predictive patterns between models. The first model’s feature importance (Fig. 31) prioritized V12 and V14 as primary features, with V11, V17, and V4 following in importance hierarchy.Fig. 31. Feature importance (Model 1).
The second model’s feature importance (Fig. 32) elevates V14 as the dominant feature, followed by V12 and V17, showing a reordering of feature priorities. Notably, the scaled_amount feature maintains consistently low importance across both models, reinforcing that transaction value is less predictive than behavioral patterns in fraud detection.Fig. 32. Feature importance (Model 2).
Both models achieve perfect precision-recall curves with AUC scores of 1.0000 (Figs. 33 and 34), indicating optimal threshold performance across all operating points. However, the distribution of prediction probabilities and error patterns suggests the models operate with different underlying decision boundaries despite similar aggregate performance metrics.Fig. 33. Precision–Recall curve (Model 1).Fig. 34. Precision–Recall curve (Model 2).
The comprehensive analysis indicates that while both models achieve near-perfect classification performance, the first model demonstrates superior confidence calibration with more consistent error patterns concentrated in high-confidence regions. The second model, while maintaining excellent overall performance, exhibits broader error distribution across confidence levels, potentially indicating less reliable uncertainty estimation. These findings suggest the first model may be more suitable for production deployment where prediction confidence is crucial for downstream decision-making processes and risk management protocols.
Research limitations
Despite the strong performance of the proposed model, several limitations merit consideration. First, high dimensionality can lead to overfitting, slower training/inference, and reduced interpretability, underscoring the need for careful feature selection or dimensionality reduction. Second, model accuracy depends on effective feature engineering; if salient patterns are not captured, performance may degrade. Third, models trained on historical data may struggle to adapt as fraud strategies evolve over time (concept drift).
In addition, our evaluation relies on synthetic oversampling (e.g., SMOTE/SMOTE-ENN), which can distort class boundaries and increase the risk of overfitting; alternatives such as cost-sensitive losses, focal loss, or generative/anomaly-detection approaches warrant investigation. One of the proposed stacking ensemble is also computationally expensive to train and, in some configurations, to deploy. Finally, scaling to real-time transaction monitoring introduces latency and throughput constraints, as well as continued exposure to drift; a practical deployment may adopt a two-stage pipeline (a fast filter for all transactions followed by the heavier ensemble on flagged cases), streaming/online updates with periodic retraining, and explicit drift detection to sustain performance over time.
Conclusions and future work
This research focused on improving credit card fraud detection using machine learning, deep learning, and ensemble learning. To handle imbalanced datasets, SMOTE and SMOTE-ENN based on Mahalanobis distance were tested, with SMOTE consistently outperforming SMOTE-ENN across all evaluation metrics. When combined with the proposed ensemble model, SMOTE further improved performance. Among the 37 baseline classifiers and 2 proposed stacking ensemble models, the proposed ensembles demonstrated superior performance. The first model integrates Extra Trees (ET), Convolutional Neural Networks (CNN), Long Short-Term Memory (LSTM), and XGBoost as a meta-learner. The second model combines ET, AdaBoost (with ET and Random Forest as base learners), and XGBoost as the meta-learner. Both models showed outstanding performance.
Experiments using European credit card transaction data confirmed the models’ robustness and adaptability, achieving near-perfect metrics: accuracy, precision, recall, F1 score, and AUC of up to 1.0. These results highlight their potential for real-world deployment.
Deployment guidance
Use a two-step setup: a fast model scores every transaction, and the heavier ensemble runs only on the flagged ones. Set the alert threshold based on your fraud/false-alarm costs and refresh it with recent data. Track precision and recall, watch for data changes, and retrain on a schedule or when performance drops. Give simple reasons for each alert and keep audit logs. Keep latency low with a smaller/distilled model and autoscaling. Roll out in stages before full production.
Future research could explore adding more machine and deep learning models or applying this ensemble strategy to other financial fraud types. Investigating real-time detection and scalability for large datasets would further validate its practicality. As fraud tactics evolve, ongoing innovation is crucial, and this ensemble framework offers a strong foundation for future advancements. In addition, addressing concept drift—the natural evolution of fraud patterns over time – will be essential. Future studies may investigate strategies such as periodic retraining, drift detection, and online updating to ensure long-term adaptability and robustness.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Itoo, F., Singh, M. & Singh, S. Comparison and analysis of logistic regression, naïve bayes and knn machine learning algorithms for credit card fraud detection. Int. J. Inform. Technol. 13, (2021).
- 2Mniai, A., Tarik, M. & Jebari, K. A novel framework for credit card fraud detection. IEEE Access. 11, (2023).
- 3Hashemi, S.K., Mirtaheri, S.L. & Greco, S. Fraud detection in banking data by machine learning techniques. IEEE Access. 11, (2023).
- 4Ghaleb, F.A., Saeed, F., Al-Sarem, M., Qasem, S.N. & Al-Hadhrami, T. Ensemble synthesized minority oversampling-based generative adversarial networks and random forest algorithm for credit card fraud detection. IEEE Access. 11, (2023).
- 5Almubark, I. Advanced credit card fraud detection: An ensemble learning using random under sampling and two-stage thresholding. IEEE Access. 12, (2024).
- 6Wang, J., Zhang, L., Liang, X. & Qian, X. The dynamic emotional experience of online fraud victims during the process of being defrauded: A text-based analysis. J. Criminal Justice. 94, (2024).
- 7Mienye, I. D. & Sun, Y. A deep learning ensemble with data resampling for credit card fraud detection. IEEE Access. 11, (2023).
- 8Almarshad, F.A., Gashgari, G.A., Alzahrani, A.I.A. Generative adversarial networks-based novel approach for fraud detection for the European cardholders dataset. IEEE Access. 11, 2023 (2013).