A suite of large language models for public health infoveillance
Xinyu Zhou, Jiaqi Zhou, Chiyu Wang, Qianqian Xie, Kaize Ding, Chengsheng Mao, Yuntian Liu, Zhiyuan Cao, Huangrui Chu, Xi Chen, Hua Xu, Heidi J. Larson, Yuan Luo

TL;DR
This paper introduces PH-LLM, a new set of large language models for real-time public health monitoring using social media data.
Contribution
The novel PH-LLM suite offers improved multilingual public health infoveillance capabilities compared to existing models.
Findings
PH-LLM outperformed baseline models in both English and multilingual tasks.
PH-LLM-14B and PH-LLM-32B achieved higher performance than larger models like Qwen2.5-72B-Instruct and GPT-4o.
The model provides cost-effective solutions for real-time public health monitoring.
Abstract
Social media is a critical platform for understanding and fostering public engagement with health interventions. However, the lack of real-time social media infoveillance on public health issues may lead to delayed responses and suboptimal policy adjustments. To address this gap, we developed PH-LLM—a novel suite of large language models (LLMs) designed for real-time public health monitoring. We curated a multilingual training corpus and trained PH-LLM using QLoRA and LoRA plus, leveraging Qwen 2.5. We constructed a benchmark comprising 19 English and 20 multilingual held-out tasks and evaluated PH-LLM’s zero-shot performance. PH-LLM consistently outperformed baseline LLMs of similar and larger sizes. PH-LLM-14B and PH-LLM-32B surpassed Qwen2.5-72B-Instruct, Llama-3.1-70B-Instruct, Mistral-Large-Instruct-2407, and GPT-4o in both English tasks (>=56.0% vs. <= 52.3%) and multilingual…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
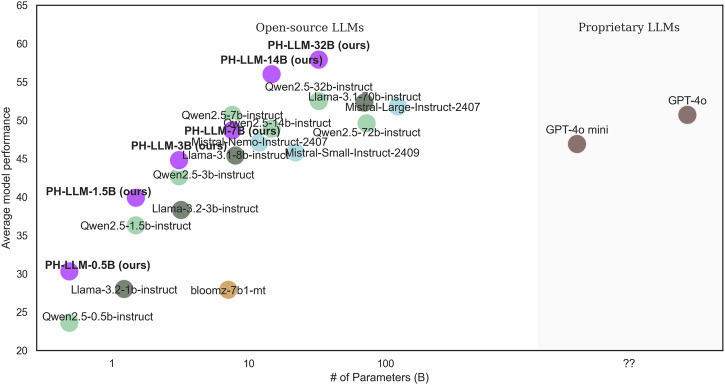 Figure 1
Figure 1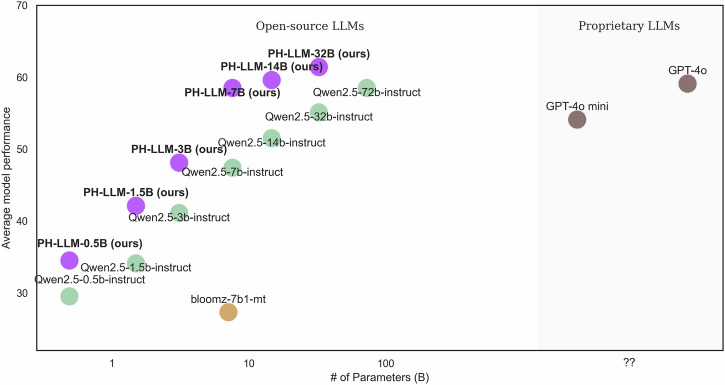 Figure 2
Figure 2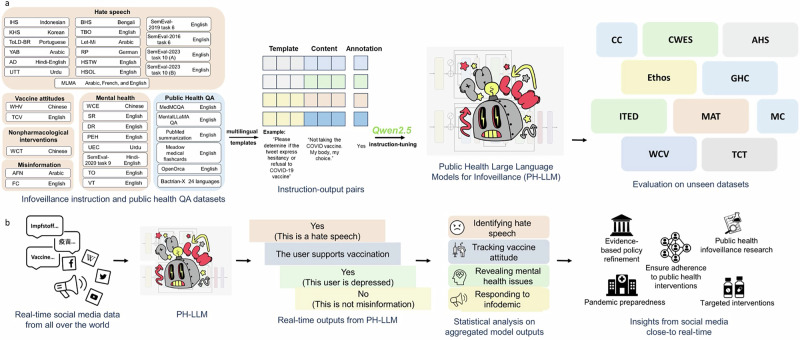 Figure 3
Figure 3- —NIH
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMisinformation and Its Impacts · Data-Driven Disease Surveillance · Mental Health via Writing
Introduction
The effectiveness of public health interventions, such as social distancing, COVID-19 testing, and vaccination, hinges on collective support, participation, and adherence in both physical and virtual platforms. With recent advances in machine learning, infoveillance—the continuous analysis of online text information^1^—has emerged as a supplement to traditional public health surveillance approaches, offering early insights into public responses to interventions. Infoveillance has also been employed to mitigate the infodemic–an overwhelming surge of information and misinformation that may lead to deleterious public health consequences during pandemics, in addition to ensuring public adherence and informing health policy decisions^1–5^.
A growing number of public health researchers and authorities are leveraging social media data to explore vaccine attitudes, mental health issues, adherence to non-pharmaceutical interventions (NPIs), the spread of misinformation, and beyond, with machine learning models such as random forest and naïve bayes^2,6,7^. Despite these efforts, real-time infoveillance on social media platforms remains limited, especially when tracking rapidly evolving public health emergencies like COVID-19^6,7^. Without timely and scalable infoveillance methods, there may potentially be delays in policy refinement and missed opportunities for prompt public health interventions^7^.
Large Language Models (LLMs) hold promising potentials for infoveillance^8–13^. They can perform infoveillance tasks without necessitating the extensive resources, time, and task-specific annotated datasets typically required for training conventional machine learning models for large-scale infoveillance. Moreover, their human-like interactions make them more accessible to public health experts than many other machine learning tools. However, proprietary LLMs such as ChatGPT are associated with high cost and may lead to data leakage. On the other hand, open-source LLMs targeted at general tasks are not optimized for public health information surveillance. There’s a need for developing LLMs tailored for public health infoveillance, which could significantly reduce costs while delivering state-of-the-art performance.
In this study, we introduce PH-LLM (Public Health Large Language Models for infoveillance), which is a novel suite of LLMs specifically trained for multilingual infoveillance on social media platforms. We designed the first multilingual public health infoveillance benchmark, where we evaluated PH-LLM against leading open-source and proprietary LLMs, including GPT-4o. The PH-LLM models and associated Python code can be publicly accessible at https://github.com/luoyuanlab/PH-LLM.
Results
Table 1 compares the zero-shot performance of PH-LLM on 19 tasks across six English-language datasets against other open-source LLMs of similar sizes (Supplementary Fig. 2). PH-LLM models demonstrated superior average performance, as measured by F_1_-score and micro F_1_-score, compared to their counterparts. Specifically, the smallest model, PH-LLM-0.5B, achieved an average model performance of 30.3%, outperforming Qwen2.5-0.5B-Instruct (23.6%) across 14 of 19 tasks. PH-LLM-1.5B achieved 39.9%, surpassing both Qwen2.5-1.5B-Instruct (36.3%) and the similar-sized Llama-3.2-1B-Instruct (28.0%) on 15 and 16 out of 19 tasks, respectively. Among models with ~7 billion parameters, PH-LLM-7B achieved 48.7%, outperforming bloomz-7b1-mt (27.9%) and Llama-3.1-8B-Instruct (45.4%). However, it performed slightly below Qwen2.5-7B-Instruct (50.7%). PH-LLM-14B (56.0%) consistently outperformed Qwen2.5-14B-Instruct (48.9%) across 13 out of 19 tasks and exceeded Mistral-Nemo-Instruct-2407 (47.1%) on 17 tasks. Remarkably, it also surpassed Mistral-Small-Instruct-2409 (45.8%), which has a larger parameter size of 22 billion. The largest model, PH-LLM-32B, achieved an average performance of 57.9%, surpassing Qwen2.5-32B-Instruct (52.5%).Table 1. Comparison of zero-shot performance on English-language datasets between PH-LLM and other open-source LLMs of similar sizesPH-LLM-0.5BQwen2.5-0.5B-InstructPH-LLM-1.5BQwen2.5-1.5B-InstructLlama-3.2-1B-InstructPH-LLM-3BQwen2.5-3B-InstructLlama-3.2-3B-InstructPH-LLM-7BQwen2.5-7B-Instructbloomz-7b1-mtLlama-3.1-8B-InstructPH-LLM-14BQwen2.5-14B-InstructMistral-Nemo-Instruct-2407Mistral-Small-Instruct-2409PH-LLM-32BQwen2.5-32B-InstructModel size0.49B0.49B1.5B1.5B1.23B3.1B3.1B3.21B7.6B7.6B7.1B8B14.7B14.7B12B22B32.5B32.5BDatasetTaskCAVESA12.69.323.11912.52528.310.928.43913.821.634.226.122041.730.5B1815.92417.514.623.422.423.335.232.312.723.437.536.12443.54340C22.421.434.629.222.848.14231.141.451.720.642.859.441.347.6658.955.9D13.610.715.413.911.92219.713.617.724.210.718.42523.915.521.528.824.3E27.525.738.729.926.242.551.637.440.455.825.34444.155.941.559.552.751F36.551.264.158.855.67060.966.772.167.944.868.377.259.274.850.878.573.5G21.524.739.132.8294042.835.441.247.224.335.554.558.439.942.262.154.8CCCC67.93079.487.457.57989.389.191.587.852.278.892.988.490.388.591.286.8Ethos57.556.271.363.951.177.75477.28062.742.781.180.382.785.284.783.885.9GHCA23.913.236.524.714.543.839.728.541.843.815.24548.950.146.521.148.548B29.310.835.416.45.532.623.326.539.94511.432.44947.643.444.24848.1MCA39.69.444.950.114.648.248.35046.851.939.746.5505651.754.952.853.2B37.535.263.762.529.46265.457.967.271.226.670.278.573.869.172.277.677.1C22.116.742.737.621.540.342.142.347.758.722.64952.351.84867.954.555.4D16.416.424.823.313.426.827.424.328.33521.539.44444.943.23538.546.4E5.4316.43019.12015.921.319.210.914.930.520.5124.824.221.9TCTA79.47.855.439.771.763.559.334.87689.468.579.574.259.773.290.584.359.7B41.962.240.751.452.63220.23450.226.140.324.3678.812.22957.429.8C2.427.87.129.227.755.953.827.957.853.925.948.364.444.754.953.974.255.3average30.323.639.936.328.044.842.738.348.750.727.945.456.048.947.145.857.952.5Descriptions of datasets and tasks presented: CAVES: A dataset concerning COVID-19 vaccine (Classification task A: vaccine not necessary, B: freedom, C: companies making money, D: distrust in policymakers, E: clinical trials were not reliable, F: side effects, G: distrust in effectiveness); CC: a dataset classifying personal narrative and news; Ethos: classifying hate speech; GHC: a hate speech dataset (Classification task A: assaults on human diginity, B: offensive language towards individuals); MC: a COVID-19 misinformation dataset (Classification task A: calling out or correction, B: conspiracy, C: politics, D: sarcasm or satire, E: false fact or prevention); TCT: a dataset on COVID-19 test: (Classification task A: tweets sent by individual users about COVID-19 test, B: supporting mass COVID-19 testing, C: mentioning COVID-19 test for certain subpopulations). Boldface and italics are used to mark the best-performing model for each task among models of similar size. Shaded cells highlight the performance of PH-LLM models. Underlining is used to emphasize the average performance within each model. 95% confidence intervals based on bootstrap sampling (n = 1000) are available in Supplementary Data.
Table 2 presents the zero-shot performance of PH-LLM models on 20 tasks across four multilingual datasets with the same set of benchmark LLMs, where PH-LLM consistently outperformed other models of similar sizes. PH-LLM-0.5B improved upon Qwen2.5-0.5B-Instruct (34.5% vs. 29.5%) on 17 out of 20 tasks. Similarly, PH-LLM-1.5B (42.1%) outperformed both Qwen2.5-1.5B-Instruct (34.1%) and Llama-3.2-1B-Instruct (27.7%), while PH-LLM-3B (48.1%) outperformed both Qwen2.5-3B-Instruct (41.1%) and Llama-3.2-3B-Instruct (40.0%). Among models with~7 billion parameters, PH-LLM-7B (58.5%) consistently outperformed blooms-7b1-mt (27.3%), as well as Qwen2.5-7B-Instruct (47.4%) and Llama-3.1-8B (47.2%) on most of the 20 tasks. PH-LLM-14B (59.6%) also surpassed Qwen2.5-14B-Instruct (51.5%), Mistral-Small-Instruct-2407 (42.9%), and Mistral-Small-Instruct-2409 (47.4%) in most tasks. PH-LLM-32B achieved an average performance of 61.4%, exceeding Qwen2.5-32B-Instruct’s 55.1%.Table 2. Comparison of zero-shot performance on multilingual datasets between PH-LLM models and other open-source LLMs of similar sizesPH-LLM-0.5BQwen2.5-0.5B-InstructPH-LLM-1.5BQwen2.5-1.5B-InstructLlama-3.2-1B-InstructPH-LLM-3BQwen2.5-3B-InstructLlama-3.2-3B-InstructPH-LLM-7Bbloomz-7b1-mtQwen2.5-7B-InstructLlama-3.1-8B-InstructPH-LLM-14BQwen2.5-14B-InstructMistral-Nemo-Instruct-2407Mistral-Small-Instruct-2409PH-LLM-32BQwen2.5-32B-InstructModel size0.49B0.49B1.5B1.5B1.23B3.1B3.1B3.2B7.6B7.1B7.6B8B14.7B14.7B12B22B32.5B32.5BDatasetTaskAHSFNA28.81.331.430.514.443.644.214.563.710.121.522.666.75842.28.349.532.2B16.526.956.441.62770.365.850.972.729.76964.679.973.163.267.986.990C26.829.230.931.924.635.14434.56125.363.948.659.438.618.737.260.768D24.222.826.42820.723.335.538.528.4203924.324.540.720.240.127.237.1E44.734.478.764.846.271.679.578.283.628.985.781.881.187.185.785.977.183.5F43.443.251.452.652.156.452.64462.546.258.565.956.456.258.063.265.776.9G13.311.219.813.511.823.418.916.430.411.818.730.622.929.425.430.820.328.7H64.357.663.355.343.175.268.963.582.228.468.278.179.883.185.764.174.481.2I22.8835.95.124.135.74.345.747.433.816.945.338.321.718.337.632.422J10.34.43.1014.918.4014.731.712.833.623.641.524.710.726.541.835.2ITED29.326.753.359.430.457.66255.167.925.472.765.371.873.869.570.173.673.1MAT17.69.125.29.123.328031.44623.837.728.547.847.129.544.157.751.3WCVA76.476.575.263.843.982.877.65386.75174.147.587.471.541.949.389.477.2B73.773.167.544.345.77613.6488253.88.246.982.737.421.622.483.38.7C35.93219.91.724.853.538.535.633.122.728.843.835.530.836.732.95461.2D4035.451.446.827.251.852.242.660.328.756.752.267.959.341.264.573.553.3E28.923.240.728.819.33541.643.668.719.751.453.167.240.842.359.171.259.7F32.529.238.927.811.344.442.534.663.331.949.339.865.252.948.351.760.258.4G37.829.54046.63234.733.736.258.625.552.649.461.95457.355.762.258.3H22.415.633.329.816.344.345.719.140.716.141.131.353.849.441.736.966.745average34.529.542.134.127.748.141.140.058.527.347.447.259.651.542.947.4*61.455.1Descriptions of datasets and tasks presented: AHSFN: an Arabic dataset regarding hate speech and misinformation regarding COVID-19 (Classification tasks A: hate speech, B: cure or vaccine mentions, C: advice, D: encouraging tweets, E: news vs. opinions, F: dialects, G: blame and negative speech, H: whether the tweet can be verified, I: worth fact-checking, J: contain fake information); ITED: an Indonesian emotion detection dataset (classifying (1) anger, (2) happy, (3) sadness, (4) fear, (5) love); MAT: an Arabic dataset regarding classifying misinformation; WCV: a Chinese dataset regarding COVID-19 vaccine sentiment (Classification task A: classifying Weibo posts from personal accounts, B: vaccine acceptance, C: vaccine refusal, D: vaccine is effective, E: vaccine is not effective, F: vaccine is important, G: risk perception, H: negative information and misinformation). ***** indicates that language included in the dataset are not officially supported by the model. Boldface and italics are used to mark the best-performing model for each task among models of similar size. Shaded cells highlight the performance of PH-LLM models. Underlining is used to emphasize the average performance within each model. 95% confidence intervals based on bootstrap sampling (n = 1000) are available in Supplementary Data.
Table 3 and Table 4 present further comparison of PH-LLM models with larger open-source models and proprietary LLMs for both English-language and multilingual datasets (Supplementary Fig. 2). For English-language comparison (Table 3) across 19 tasks, the largest PH-LLM model, PH-LLM-32B (57.9%), demonstrated not only competitive but superior overall performance to other larger open-source models, such as Qwen2.5-72B-Instruct (49.6%) and Llama-3.1-70B-Instruct (52.3%), and Mistral-Large-Instruct-2407 (51.8%). Furthermore, PH-LLM-32B achieved state-of-the-art performance, outperforming both proprietary LLMs (46.9% of GPT-4o mini and 50.7% of GPT-4o). In Table 4, for multilingual datasets, PH-LLM-32B continues to outperform all other state-of-the-art models, achieving an average model performance of 61.4% across 20 tasks, specifically Qwen2.5-72B-Instruct (58.5%), Llama-3.1-70B-Instruct (57.7%), Mistral-Large-Instruct-2407 (56.6%), as well as GPT-4o mini (54.1%) and GPT-4o (59.1%).Table 3. Comparison of zero-shot performance on English-language datasets between PH-LLM-32B and larger open-source models, flagship open-source models, and proprietary LLMsPH-LLM-32BQwen2.5-72B-InstructLlama-3.1-70B-InstructMistral-Large-Instruct-2407GPT-4o miniGPT-4oModel size32.5B72.7B70B123BDatasetTaskCAVESA41.725.129.13228.627.1B4324.536.937.734.440.4C58.934.147.25447.849.3D28.816.722.823.616.929.8E52.740.751.251.43647.8F78.578.973.47675.876.7G62.160.645.154.735.948.3CCCC91.290.390.890.683.889.9Ethos83.884.584.786.886.488.8GHCA48.549.841.148.741.441.9B484434.944.234.933.3MCA52.85761.550.556.655.7B77.676.377.678.579.181.7C54.555.452.96448.757.5D38.540.756624955.5E24.225.123.524.524.924.1TCTA84.36382.527.740.125.8B57.421.131.815.236.242.3C74.25551.262.135.247.1average57.949.652.351.846.950.7Descriptions of datasets and tasks presented: CAVES: A dataset concerning COVID-19 vaccine (Classification task A: vaccine not necessary, B: freedom, C: companies making money, D: distrust in policymakers, E: clinical trials were not reliable, F: side effects, G: distrust in effectiveness); CC: a dataset classifying personal narrative and news; Ethos: classifying hate speech; GHC: a hate speech dataset (Classification task A: assaults on human diginity, B: offensive language towards individuals); MC: a COVID-19 misinformation dataset (Classification task A: calling out or correction, B: conspiracy, C: politics, D: sarcasm or satire, E: false fact or prevention); TCT: a dataset on COVID-19 test: (Classification task A: tweets sent by individual users about COVID-19 test, B: supporting mass COVID-19 testing, C: mentioning COVID-19 test for certain subpopulations). Boldface and italics are used to mark the best-performing model for each task among models of similar size. Shaded cells highlight the performance of PH-LLM models. Underlining is used to emphasize the average performance within each model. 95% confidence intervals based on bootstrap sampling (n = 1000) are available in Supplementary Data.Table 4. Comparison of zero-shot performance on multilingual datasets between PH-LLM-32B and larger open-source models, flagship open-source models, and proprietary LLMsPH-LLM-32BQwen2.5-72B-InstructLlama-3.1-70B-InstructMistral-Large-Instruct-2407GPT-4o miniGPT-4oModel size32.5B72.7B70B123BDatasetTaskAHSFNA49.543.935.928.639.839.6B86.988.587.489.98790.4C60.768.260.9675870.6D27.234.535.942.635.633.8E77.185.180.583.483.784.3F65.780.875.478.759.779.9G20.335.635.9**34.231.635.1H74.488.291.5**9088.690I32.433.94037.540.729.4J41.842.635.23122.222.9ITED73.676.274.974.577.278.1MAT57.756.737.251.139.652.1WCVA89.481.984.181.68381.8B83.38.244.714.238.643.1C5463.465.35754.260.6D73.559.261.854.564.168.5E71.263.261.866.755.467.1F60.260.745.852.344.350.7G62.257.359.158.451.262.2H66.742.34039.128.141.7average61.4**58.557.756.654.159.1Descriptions of datasets and tasks presented: AHSFN: an Arabic dataset regarding hate speech and misinformation regarding COVID-19 (Classification tasks A: hate speech, B: cure or vaccine mentions, C: advice, D: encouraging tweets, E: news vs. opinions, F: dialects, G: blame and negative speech, H: whether the tweet can be verified, I: worth fact-checking, J: contain fake information); ITED: an Indonesian emotion detection dataset (classifying (1) anger, (2) happy, (3) sadness, (4) fear, (5) love); MAT: an Arabic dataset regarding classifying misinformation; WCV: a Chinese dataset regarding COVID-19 vaccine sentiment (Classification task A: classifying Weibo posts from personal accounts, B: vaccine acceptance, C: vaccine refusal, D: vaccine is effective, E: vaccine is not effective, F: vaccine is important, G: risk perception, H: negative information and misinformation). * indicates that language(s) included in the dataset are not officially supported by the model. Boldface and italics are used to mark the best-performing model for each task among models of similar size. Shaded cells highlight the performance of PH-LLM models. Underlining is used to emphasize the average performance within each model. 95% confidence intervals based on bootstrap sampling (n = 1000) are available in Supplementary Data.
Figure 1 shows the relationship between average model performance and model size of LLMs evaluated across 19 English evaluation tasks. A positive relationship was observed between the number of parameters in open-source models and their performance. Notably, PH-LLM models demonstrated superior performance compared to models of similar sizes and even larger counterparts. PH-LLM-14B (56.0%) and PH-LLM-32B (57.9%) outperformed strong baselines, including GPT-4o (50.7%), Mistral-Large-Instruct-2407 (51.8%), and Llama-3.1-70B-Instruct (52.3%).Fig. 1. Relationship between model size and average zero-shot performance of LLMs in English evaluation datasets.Each point represents a model, plotted by parameter size (x axis) and average performance (y axis).
Figure 2 shows the relationship between average model performance and model size across 20 multilingual evaluation tasks. PH-LLM consistently outperformed models of similar sizes and, in some cases, larger models. PH-LLM-7B (58.5%), in particular, matched the average performance as Qwen2.5-72B-Instruct (58.5%). Moreover, both PH-LLM-14B (59.6%) and PH-LLM-32B (61.4%) surpassed state-of-the-art baseline models, including GPT-4o (59.1%), Qwen2.5-72B-Instruct (58.5%), and GPT-4o mini (54.1%).Fig. 2. Relationship between model size and average zero-shot performance of LLMs in multilingual evaluation datasets for multilingual LLMs officially supporting all languages in the multilingual evaluation.Each point represents a model, plotted by parameter size (x axis) and average performance (y axis).
PH-LLM models also demonstrated strong performance in 2-shot settings. (Supplementary Table 3, Supplementary Table 4).
Discussion
In this study, we introduced PH-LLM, a novel suite of LLMs specialized in public health infoveillance. PH-LLM is available in six model sizes: PH-LLM-0.5B, PH-LLM-1.5B, PH-LLM-3B, PH-LLM-7B, PH-LLM-14B, and PH-LLM-32B. Across diverse public health infoveillance tasks, PH-LLM models consistently demonstrated strong performance, outperforming baseline models of comparable or larger sizes in most scenarios. Notably, PH-LLM-14B and PH-LLM-32B achieved superior overall performance on 39 tasks from 10 held-out datasets in public health infoveillance settings, surpassing all baseline models, including Llama-3.1-72b-instruct, Mistral-Large-Instruct-2407, Qwen2.5-72b-instruct, and GPT-4o.
PH-LLM can reach higher zero-shot performance in public health infoveillance tasks with a smaller number of parameters. It reduces the need for extensive GPU resources and complex infrastructure during model deployment and inference, lowering operational costs and making public health infoveillance more accessible, particularly for resource-constrained settings. PH-LLM’s adaptability enables localized and contextualized responses to diverse public health challenges, offering transformative potential for LMICs and other underserved regions.
Recent years have also seen the development of domain-specific LLMs in health, such as Med-PaLM and PMC-LLaMA^14,15^. However, these models are designed for clinical tasks rather than public health infoveillance. To the best of our knowledge, PH-LLM is the first suite of LLMs specialized in public health infoveillance, which is multilingual and publicly available. Previous studies have utilized general-purpose LLMs to advance public health infoveillance on social media platforms, including tasks like data augmentation in social media datasets^9,16^, and analyzing public health topics such as vaccine sentiment, mask-wearing behaviors, and mental health^8,10–13,17^. LLMs have also shown potential in assisting public health practice beyond infoveillance, including pandemic forecasting and information extraction^18,19^. However, almost all these studies applied general-purpose LLMs like LLaMA and ChatGPT rather than developing LLMs tailored for public health settings^20,21^, and they focused predominantly on English-language scenarios. PH-LLM emphasizes multilingual capabilities, extending its utility to non-English contexts, which addresses the diverse linguistic needs of global public health.
PH-LLM is designed to be accessible to public health professionals without requiring a background in computer science. With metadata (time, location, social-economic status, and beyond) associated with each social media post, aggregating predictions from PH-LLM can reveal spatiotemporal trends of opinions and behaviors, from nuances on social media platforms, and subsequently underline their public health significance. For example, to inform an HPV vaccination program, public health agencies can apply PH-LLM to stay updated with sudden changes in vaccine acceptance and confidence, trending concerns and misinformation on vaccines, and potential distrust in public health professionals, pharmaceutical companies, or the government. Additionally, tools like LlamaFactory enable users to interact with PH-LLM and effortlessly analyze large-scale data through a user-friendly interface^22^. PH-LLM exhibited strong zero-shot performance for analyzing social media posts relevant to public health. Its performance could be further enhanced potentially through prompt engineering and integration with retrieval-augmented generation and knowledge graph—incorporating contextualized and localized knowledge from public health experts.
PH-LLM equips public health systems with a tool to address future emerging infectious diseases and global health challenges. PH-LLM was trained and evaluated using datasets surrounding vaccine hesitancy, mental health, nonadherence to NPIs, hate speech, and misinformation, and similar challenges may re-emerge in future outbreaks and pandemics^23^. The generalizability of LLMs also allows PH-LLM to address new and evolving infoveillance topics with greater flexibility towards variations in geographies, languages, populations, and cultural, social, economic, and political contexts, which is an advantage over the pretrain-finetune paradigm. We mitigated potential biases during data collection by incorporating multilingual and cross-platform social media sources covering diverse populations and cultural contexts, then we further ensured fairness during evaluation by assessing model performance across multiple languages and tasks. However, we acknowledge that social media users represent a non-random subset of the population, potentially underrepresenting older adults and those with lower digital literacy. Future work should evaluate model performance across demographic subgroups where such metadata is available. Additionally, inherent biases in source annotations may propagate to model outputs, warranting continued research into fair and equitable infoveillance systems.
This study has several limitations. First, every LLM, including PH-LLM, demonstrated suboptimal results in specific tasks. This is because most of the evaluation tasks are imbalanced and could be challenging. Also, we did not optimize prompt templates to ensure fair comparisons and avoid overfitting. Task-specific prompt engineering and evaluations are recommended before deployment of LLMs in zero-shot public health infoveillance. Second, the training set included only 96 infoveillance tasks, which may limit the performance of PH-LLM on tasks less represented within the training corpus. Third, PH-LLM’s training datasets were derived from various previous studies, which may reflect inconsistency in annotation quality and potential biases introduced by annotators. Forth, social media data, which underpins PH-LLM’s training and evaluation, represents a biased subset of the population. Predictions based on such data should be interpreted with caution, especially in contexts involving censorship or self-censorship.
Despite these limitations, PH-LLM represents a significant enhancement as a novel suite of LLM tailored for public health infoveillance. Its public availability and state-of-the-art performance demonstrate its potential in public health monitoring and evidence-based policymaking, including in LMICs and among at-risk populations. PH-LLM aspires to equip public health agencies at all levels—global, national and local—with the power of AI to promote public health awareness, inform policy and interventions, and address future global health challenges.
Methods
In this study, we developed a suite of LLMs named PH-LLM, available in six sizes for various computing settings: PH-LLM-0.5B, PH-LLM-1.5B, PH-LLM-3B, PH-LLM-7B, PH-LLM-14B, and PH-LLM-32B. These PH-LLM models were instruction-based fine-tuned on top of Qwen 2.5^24^, using a curated dataset of 593,100 instruction-output pairs based on 30 infoveillance datasets with a total of 96 public health infoveillance tasks and six question-answering datasets. We evaluated the PH-LLM models on 39 tasks with a total of 52,158 instruction-output pairs, across 10 datasets in English, Chinese, Arabic, and Indonesian. Notably, the evaluation datasets were distinct from those used during the development of PH-LLM. The performance of PH-LLM was benchmarked against state-of-the-art instruction-tuned LLMs, including GPT-4o (version 2024-05-13), Llama-3.1-70B-Instruct, Mistral-Large-Instruct-2407, and Qwen2.5-72B-Instruct^24–27^. An overview of this study is provided in Fig. 3.Fig. 3. Overview of this study.a Construction and evaluation of PH-LLM, including collecting multilingual datasets, template-based instruction–output pairs generation, instruction tuning, and evaluation on unseen datasets. b Workflow of real-time infoveillance using PH-LLM. Social media data are processed by the model to generate outputs for infoveillance tasks, such as hate speech detection, vaccine attitude tracking, mental health signals, and misinformation identification, followed by statistical analysis to inform public health decision-making.
Data source
We conducted a Google search to compile an initial list of publicly available, manually annotated infoveillance datasets based on social media data. Two researchers (XZ and JZ, or XZ and CW) assessed the annotation quality of each dataset. The evaluation criteria included subjective impressions of the study’s quality, the robustness of the annotation process described, and the popularity of the paper and dataset as indicated by metrics such as citations and GitHub stars. Discrepancies between researchers were resolved through discussions. Only datasets that were manually annotated and deemed high quality by both researchers were recruited, either as the training set or the evaluation dataset. We prioritized datasets requiring API access for inclusion in the evaluation set. Datasets annotated using machine learning models were excluded. Ultimately, a total of 40 infoveillance datasets were collected. Of these, 30 datasets, encompassing 96 public health infoveillance tasks concerning vaccine sentiment, hate speech, mental health, NPIs, misinformation, and beyond, were included in the training set. In addition, six additional QA datasets were incorporated to enrich the training corpus. Details of the training set are provided in Supplementary Table 1. The remaining 10 datasets, comprising 39 unseen infoveillance tasks and 52,158 instruction-output pairs, were excluded from model training and reserved for evaluation. Details of the evaluation datasets are presented in Table 5. Importantly, there was no overlap between the training and evaluation sets.Table 5. Evaluation benchmarkDataTaskLanguageTask descriptionPrompt templateDistribution of labelsEvaluation metricEnglish datasetsCAVES (A Dataset to facilitate Explainable Classification and Summarization of Concerns towards COVID Vaccines)^38^AEnglishVaccine not necessaryPlease determine if the tweet below indicates COVID is not dangerous, vaccines are unnecessary, or that alternate cures (such as hydroxychloroquine) are better. \n If so, respond with ‘yes’. Otherwise, respond with ‘no’.\n Do not explain your rationale. Please directly respond with ‘yes’ or ‘no’.\n Tweet: [INSERT DATA HERE]\n Please respond with ‘yes’ or ‘no’.145/1832F_1_-scoreBFreedomPlease determine if the tweet below is against mandatory vaccination and talks about their freedom\n If so, respond with ‘yes’. Otherwise, respond with ‘no’.\n Do not explain your rationale. Please directly respond with ‘yes’ or ‘no’.\n Tweet: [INSERT DATA HERE]\n Please respond with ‘yes’ or ‘no’.157/1820F_1_-scoreCCompanies making moneyPlease determine if the tweet below indicates that the Big Pharmaceutical companies are just trying to earn money, or is against such companies in general because of their history\n If so, respond with ‘yes’. Otherwise, respond with ‘no’.\n Do not explain your rationale. Please directly respond with ‘yes’ or ‘no’.\n Tweet: [INSERT DATA HERE]\n Please respond with ‘yes’ or ‘no’.255/1722F_1_-scoreDDistrust in policymakersPlease determine if the tweet below expresses concerns that the governments / politicians are pushing their own agenda though the vaccines\n If so, respond with ‘yes’. Otherwise, respond with ‘no’.\n Do not explain your rationale. Please directly respond with ‘yes’ or ‘no’.\n Tweet: [INSERT DATA HERE]\n Please respond with ‘yes’ or ‘no’.125/1852F_1_-scoreEClinical trials were not reliablePlease determine if the tweet below expresses concerns that the vaccines have not been tested properly, have been rushed or that the published data is not accurate\n If so, respond with ‘yes’. Otherwise, respond with ‘no’.\n Do not explain your rationale. Please directly respond with ‘yes’ or ‘no’.\n Tweet: [INSERT DATA HERE]\n Please respond with ‘yes’ or ‘no’.295/1682F_1_-scoreFSide effectsPlease determine if the tweet below expresses concerns about the side effects of the vaccines, including deaths caused.\n If so, respond with ‘yes’. Otherwise, respond with ‘no’.\n Do not explain your rationale. Please directly respond with ‘yes’ or ‘no’.\n Tweet: [INSERT DATA HERE]\n Please respond with ‘yes’ or ‘no’.762/1215F_1_-scoreGDistrust in effectivenessPlease determine if the tweet below expresses concerns that the vaccines are ineffective, not effective enough, or are useless.\n If so, respond with ‘yes’. Otherwise, respond with ‘no’.\n Do not explain your rationale. Please directly respond with ‘yes’ or ‘no’.\n Tweet: [INSERT DATA HERE]\n Please respond with ‘yes’ or ‘no’.334/1643F_1_-scoreCC (COVID category)^39^EnglishPersonal narrative vs. newsPlease categorize a given tweet text into either being a personal narrative or news.\n Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n Please respond with “news” or “personal”.211/493Micro F_1_Ethos^40^EnglishHate speechPlease classify if the following social media post contain hate speech: [INSERT DATA HERE]. Now the post ends. Hate speech is a form of insulting public speech directed at specific individuals or groups of people on the basis of characteristics, such as race, religion, ethnic origin, national origin, sex, disability, sexual orientation, or gender identity. Please response with “Yes” if the post contains hate speech, and “No” if it does not.84/116F_1_-scoreGHC (Gab Hate Corpus)^41^AEnglishAssaults on human dignityPlease determine if the following Gab post should be classified as assaults on human dignity (HD) or not: [INSERT DATA HERE]. Now the post ends. If so, respond with ‘yes’, otherwise respond with ‘no’.A document should be labeled as assaults on human dignity if it assaults the dignity of group by: asserting or implying the inferiority of a given group by virtue of intelligence, genetics, or other human capacity or quality; degrading a group, by comparison to subhuman entity or the use of hateful slurs in a manner intended to cause harm; the incitement of hatred through the use of a harmful group stereotype, historical or political reference, or by some other contextual means, where the intent of the speaker can be confidently assessed.In the evaluation of slurs against group identity (race, ethnicity, religion, nationality, ideology, gender, sexual orientation, etc.), we define such instances as hate-based if they are used in a manner intended to wound; this naturally excludes the casual or colloquial use of hate slurs. As an example, the adaptation of the N-slur (replacing the -er” with -a”) often implies colloquial usage.Language which dehumanizes targeted persons/groups will also be labeled as HD. In coding dehumanizing rhetoric, we refer coders to Haslam (2006), who developed a model for two forms of dehumanization. In mechanistic forms, humans are denied characteristics that are uniquely human (p. 252). Depriving the other from such traits is considered downward, animalistic comparison. Put another way, the target has been denied the traits that would separate them from animals.In another form of dehumanization as categorized by Haslam (2006), the target may be denied qualities related to human nature. These characteristics are traits that may not be unique to humans, but define them. These traits will represent the concept’s core but may not the same ones that distinguish us from other species” (p. 256). When these traits are denied from the target, this is considered upward, mechanistic dehumanization. The result of denial is often perceiving the target as cold, robotic, and lacking deep-seated core values and characteristics.Documents which invoke cultural, political, or historical context in order to voice negative sentiment/degradation toward a particular sub-population, empower hateful ideology (hate groups), or reduce the power of marginalized groups, are to be considered HD as well. This would include messages which indicate support for white supremacy (e.g. advocating for segregated societies/apartheid), those which make negative assertions and/or implications about the rights of certain groups (e.g. Immigrants in this country need to go back to their country), and those that reduce the power/agency of particular segments of the population.Now, please provide a response of either ‘yes’ or ‘no’ to the question above. You don’t need to provide any explanation.491/5019F_1_-scoreBOffensive language towards individualsPlease determine if the following Gab post should be classified as vulgarity/offensive language directed at an individual (VO) or not: [INSERT DATA HERE]. Now the post ends. If so, respond with ‘yes’, otherwise respond with ‘no’. You don’t need to provide any explanation.369/5141F_1_-scoreMC (Misinformation during COVID-19)^42^AEnglishCalling out or correctionPlease determine if the tweet below meets any of the following conditions. If so, respond with “yes”, otherwise respond with “no”. The conditions are:1. The tweet calls out or makes fun of a fake cure, a fake prevention, fake treatment, or a conspiracy theory.2. The tweet links out to a site that debunks, calls out or makes fun of a fake cure, a fake prevention, fake treatment, or a conspiracy theory.3. The tweet calls out or make fun of violations of social distancing rules or public health responses.4. The tweet reports/quotes a (news) story related to consequences of a false fact, fake prevention, fake cure, fake treatment, or conspiracy theory.5. The tweet reports/quotes a (news) story debunking a false fact, fake prevention, fake cure, fake treatment, or conspiracy theory.Please answer with “yes” or “no”. You don’t need to provide any explanation.Tweet: [INSERT DATA HERE]. Now the Tweet ends.193/418F_1_-scoreBConspiracyPlease determine if the tweet should be classified as conspiracy. If so, respond with “yes”, otherwise respond with “no”.A tweet shall be classified as a conspiracy if it endorses a conspiracy story. Some examples of conspiracy themes related to COVID-19 include:1. It is a bioweapon.2. Electromagnetic fields and the introduction of 5 G wireless technologies led to COVID-19 outbreaks.3. This was a plan from Gates Foundation to increase the Gates’ wealth.4. It leaked from the Wuhan Labs or Wuhan Institute of Virology in China.5. It was predicted by Dean Koontz.Tweet: [INSERT DATA HERE]. Now the Tweet ends.Please answer with “yes” or “no”. You don’t need to provide any explanation.100/511F_1_-scoreCPoliticsPlease determine if the tweet should be classified as politics. If so, respond with “yes”, otherwise respond with “no”.A tweet shall be classified as politics if the tweet mentions a political individual, institution, or government organization (eg. Congress, Democratic or Republican party), and any of the following conditions are met:1. The tweet implicitly comments on actions taken by the political actor.2. The tweet provides commentary on actions taken by the political actor.Tweet: [INSERT DATA HERE]. Now the Tweet ends.Please answer with “yes” or “no”. You don’t need to provide any explanation.77/534F_1_-scoreDSarcasm or satirePlease determine if the tweet below meets any of the following conditions. If so, respond with “yes”, otherwise respond with “no”. The conditions are:1. The tweet contains clear signs of a satire calling out a fake cure, a fake prevention or a conspiracy.2. The tweet includes a clear joke about a fake cure, a fake prevention or a conspiracy.Concretely, this is a tweet where the information in the post is false but is presented using humor, irony, exaggeration, or ridicule to expose and criticize people’s stupidity or vices, particularly in the context of contemporary politics and other topical issues. This kind of post is used to ridicule other false statements or people.Tweet: [INSERT DATA HERE]. Now the Tweet ends.Please answer with “yes” or “no”. You don’t need to provide any explanation.76/535F_1_-scoreEFalse fact or preventionPlease determine if the tweet below meets any of the following conditions. If so, respond with “yes”, otherwise respond with “no”. The conditions are:1. The tweet mention a false fact or prevention against COVID-19 that cannot be verified by the World Health Organization (WHO) or the Centers for Disease Control and Prevention (CDC).2. The tweet mention a false fact or prevention against COVID-19 that is not supported by a peer-reviewed scientific study, or a preprint from reputable academic sources.Tweet: [INSERT DATA HERE]. Now the Tweet ends.Please answer with “yes” or “no”. You don’t need to provide any explanation.52/559F_1_-scoreTCT (Twitter COVID test)^43^AEnglishTweets sent by individual users about COVID-19 testPlease read a tweet and follow a data labeling request below.\n Tweet: [INSERT DATA HERE].\n Data labelling request: Please tell me if this is a tweet that is either a news report, sent by the government or government officials, sent by companies, advertisement, sent by bot, sent by any other non-personal accounts, retweet (RT/QT) from others without adding personal comments, or not related to coronavirus testing at all.\n If so, answer ‘yes’; otherwise, respond with ‘no’.417/88F_1_-scoreBSupporting mass COVID-19 testingPlease read a tweet and follow a data labelling request below.\n Tweet: [INSERT DATA HERE].\n Data labelling request: Please tell me if this is a tweet that expresses understanding, supporting, accepting mass COVID-19 testing.\n If so, answer ‘yes’; otherwise, respond with ‘no’.194/223F_1_-scoreCMentioning COVID-19 test for certain subpopulationsPlease read a tweet and follow a data labelling request below.\n Tweet: [INSERT DATA HERE].\n Data labelling request: Please tell me if this is a tweet that mentions COVID-19 test for certain subpopulations.\n If so, answer ‘yes’; otherwise, respond with ‘no’.67/350F_1_-scoreMultilingual datasetsAHSFN (Arabic Hate Speech and Fake News dataset regarding COVID-19)^44^AArabic data and English prompt templatesHate speechPlease determine if the provided tweet below contains hate speech. If so, respond “yes”. If not, respond “no”.\n. Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n. Please respond with ‘yes’ or ‘no’.137/1602F_1_-scoreBCure or vaccine mentionsPlease determine if the provided tweet below contains any information or discussion about a cure, a vaccine, or other possible COVID-19 treatments. If so, respond “yes”. If not, respond “no”.\n. Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n. Please respond with ‘yes’ or ‘no’.272/1468F_1_-scoreCAdvicePlease determine if the provided tweet below tries to advise people or government institutions. If so, respond “yes”. If not, respond “no”.\n Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n Please respond with ‘yes’ or ‘no’.276/1464F_1_-scoreDEncouraging tweetsPlease determine if the provided tweet below contains encouraging, helpful, and positive speech. If so, respond “yes”. If not, respond “no”.\n Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n Please respond with ‘yes’ or ‘no’.204/1536F_1_-scoreENews vs. opinionsPlease determine if the provided tweet below is news or opinion.\n News: if the tweet report news or a fact.\n Opinion: if the tweet expresses a person’s opinion or thoughts.\n Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n Please respond with ‘News’ or ‘Opinion’.597/1143Micro F_1_FDialectsPlease determine Whether the tweet is written in Modern Standard Arabic (MSA), North African dialect, or Middle Eastern dialect.\n Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n Please respond with MSA, North Africa, or Middle East.898/209/596Micro F_1_GBlame and negative speechPlease determine if the provided tweet below contains blame, negative, or demoralizing speech. If so, respond “yes”. If not, respond “no”.\n Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n Please respond with ‘yes’ or ‘no’.108/1625F_1_-scoreHWhether the tweet can be verifiedPlease determine if the provided tweet below contains information that can be verified and classified as Fake or Real. Note that this is NOT classifying Fake or Real. It is about determining if the tweet contains information that can be verified.\n Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n Please respond with ‘Is Not Verifiable’ or ‘Is Verifiable’.775/449Micro F_1_IWorth fact-checkingPlease determine if the provided tweet below contains an important claim or dangerous content that maybe be of worth for manual fact-checking.\n Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n Please respond with ‘Maybe’, ‘Yes’, or ‘No’.360/229/205F_1_-scoreJContain fake informationPlease determine if the provided tweet below contains any fake information.\n Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n Please respond with ‘Maybe’, ‘Yes’, or ‘No’.323/70/397F_1_-scoreITED (Indonesian Twitter emotion detection)^45^Indonesian data and an English prompt templateClassify (1) anger, (2) happy, (3) sadness, (4) fear, (5) love\n This is a data labeling task. The task is emotion classification of a tweet.\n You need to find ONE emotion that best describe the provided tweet among the following 5 categories: anger, happy, sadness, fear, and love.\n Based on the content of the tweet, please choose the most appropriate category as your response.\n Tweet content: [INSERT DATA HERE]. Now the tweet ends.\n Please answer: Which one of the five emotion categories best does this tweet: anger, happy, sadness, fear, or love? Answer with one of them.229/214/200/119/119Micro F_1_MAT (Misinformation on Arabic Twitter)^46^Arabic data and an English prompt templateClassify (1) tweet that contained misinformation from (2) othersPlease respond ‘yes’ if the provided tweet below contains misinformation. Otherwise, respond ‘no’.\n Tweet: “[INSERT DATA HERE]”. Now the tweet ends.\n Please respond with ‘yes’ or ‘no’.189/1095F_1_-scoreWCV (Weibo COVID vaccine)^47^AChinese data and Chinese-English code-mixing prompt templatesWeibo posts from personal accountsWeibo post: [INSERT DATA HERE]. End of Weibo post. Please label whether this Weibo post is from a personal account about the COVID-19 vaccine. A post from a personal account could be expressing personal experiences, attitudes, thoughts, etc., as opposed to posts from governments, corporations, communities, or bots that do not contain personal opinions. Posts completely unrelated to the COVID-19 vaccine or simply reposting someone else’s post should also be excluded from this category. Answer yes or no.568/349F_1_-scoreBVaccine acceptanceWeibo post: [INSERT DATA HERE]. End of Weibo post. Please label whether this Weibo post mentions willingness to receive the COVID-19 vaccine. This refers to expressing support, acceptance, or willingness to get vaccinated. Answer yes or no.323/245F1-scoreCVaccine refusalWeibo post: [INSERT DATA HERE]. End of Weibo post. Please label whether this Weibo post expresses unwillingness to receive the COVID-19 vaccine. Such posts typically express concerns about vaccination, skepticism, refusal, opposition, or lack of support for COVID-19 vaccination. Concerns about safety, effectiveness, etc., are also included in this category. Answer yes or no.109/459F_1_-scoreDVaccine is effectiveWeibo post: [INSERT DATA HERE]. End of Weibo post. Please label whether this Weibo post mentions that the COVID-19 vaccine is effective. Effectiveness here refers to generating antibodies or having the effect of preventing COVID-19 (a positive evaluation of effectiveness). For example, statements like “can prevent infection” or “reduces severe cases and deaths” would qualify. Answer yes or no.121/447F_1_-scoreEVaccine is not effectiveWeibo post: [INSERT DATA HERE]. End of Weibo post. Please label whether this Weibo post mentions that the COVID-19 vaccine is ineffective or has poor efficacy. Such posts may express doubts about the vaccine’s effectiveness, believe it to be ineffective, or suggest that mutations in the virus make it unable to generate antibodies or prevent COVID-19 (a negative evaluation of effectiveness). For example, statements like “cannot prevent infection,” “still got infected after vaccination,” or “the disease was still severe after vaccination” would qualify. Answer yes or no.74/494F_1_-scoreFVaccine is importantWeibo post: [INSERT DATA HERE]. End of Weibo post. Please label whether this Weibo post mentions that the COVID-19 vaccine is important. This refers to posts stating that the vaccine is important, necessary, essential, etc. Answer yes or no.97/471F_1_-scoreGRisk perceptionWeibo post: [INSERT DATA HERE]. End of Weibo post. Please label whether this Weibo post mentions a high-risk perception of the COVID-19 pandemic. This refers to posts that perceive the risk of the virus as high, the pandemic as very serious, or the threat to health as significant. Answer yes or no.98/470F_1_-scoreHNegative information and misinformationWeibo post: [INSERT DATA HERE]. End of Weibo post. Please label whether this Weibo post is about negative information regarding vaccines, such as vaccine rumors, anti-vaccine movements, anti-intellectual or anti-science movements, or negative vaccine-related incidents. Answer yes or no.49/519F_1_-scoreThe evaluation benchmark is based on manually annotated social media datasets. The source of the datasets, language, and the distribution of labels were presented. None of the evaluation datasets were used during the training of PH-LLM models. Note: The prompt templates for the WCV dataset were initially written in Chinese. Therefore, the original prompts were presented in our GitHub repository (https://github.com/luoyuanlab/PH-LLM), whereas English translation was shown in this table. We construct the prompt templates according to the original data annotation strategy described by the creator of the source datasets without any paraphrasing, whenever possible.
Constructing Infoveillance Instructions (I2) Dataset
The I^2^ dataset was developed using 30 social media datasets included in the training corpus. Figure 3 illustrated the process of transforming previously annotated social media-based public health infoveillance datasets into instruction datasets, which was applied to create I^2^, an integrated instruction-tuning datasets for training PH-LLM. The datasets in I^2^ were sourced from a total of 30 manually annotated social media datasets from prior studies and were either monolingual or multilingual. Detailed information about each training dataset in I^2^ is provided in Supplementary Table 1. Typically, social media datasets collected from the Internet contain two primary entries: the social media post (or its ID), and corresponding annotation(s) (e.g., 0 and 1). For datasets containing only post IDs (all sourced from X, formally known as Twitter), we retrieved the actual textual content of the post (excluding replies) via the official X API^28^. Each post was transformed into an instruction comprehensible to humans, and its annotation(s) were converted into the gold-standard response for that instruction. Templates were applied to transform social media posts into instructions, as shown in Fig. 3.
To enhance the multilingual capabilities of PH-LLM models, templates for developing the I^2^ dataset were translated into 29 languages supported by Qwen 2.5. The list of supported languages is available in Supplementary Material 1.
The original social media posts were not translated. Instead, for each post in I^2^, a template in one of the 29 languages was randomly assigned. Each instruction was a combination of one social media post and one template^27^. Templates were initially crafted in Chinese or English, and subsequently translated into 28 additional languages using the web interface of ChatGPT-4o (https://chatgpt.com/).
Constructing Public Health Question Answering (PHQA) Dataset
To construct the PHQA dataset, we employed a two-step process. First, we applied a keyword-based filtering approach to extract public health-related instruction-output pairs from three datasets: PubMed summarization, Meadow medical flashcards, and OpenOrca, as a supplement to the training set^29–31^. The keywords used for filtering are presented in Supplementary Material 1. Second, we selected subsets from the MedMCQA dataset, focusing specifically on two subjects: Social/Preventive Medicine and Psychiatry^32^. We further sampled 10,000 records from the MentalLLaMA collection, a question-answering dataset regarding mental health derived from gpt-3.5-turbo^13^. We also supplemented the PHQA with a subset of Bactrian-X^33^, a multilingual instruction-output dataset generated by gpt-3.5-turbo, to reinforce the multilingual capabilities of our instruction-tuned model.
Merging I^2^ and PHQA yielded our training set consisting of 593,100 instruction-output pairs (Supplement Table 1).
Constructing evaluation datasets
For the evaluation benchmark, we selected 10 high-quality, manually annotated social media datasets (Table 5) that were distinct from the training datasets. We included tasks in these datasets where minority classes comprised at least 5% of the data, as extremely imbalanced tasks can cause metric fluctuations and may be less relevant to public health. As illustrated in Fig. 3, we transformed each record in the evaluation datasets into instruction-output pairs based on prompt templates. The original evaluation datasets, prior to the application of instruction templates, were in English, Chinese, Arabic, or Indonesian, whereas the prompt templates for the evaluation datasets were in English or Chinese-English code-mixing (Table 5). Putting datasets and prompt templates together yielded six evaluation datasets with 19 tasks in English and four multilingual evaluation datasets (two in Arabic-English code-mixing, one in Indonesian-English code-mixing, and one in Chinese-English code-mixing), encompassing 20 tasks. In total, we collected 52,158 instruction-output pairs from 39 tasks across 10 datasets in the evaluation benchmark. Detailed prompt templates for each evaluation task are shown in Table 5.
Instruction-tuning of the PH-LLM Models
Qwen-2.5, a foundation model developed by Alibaba, was pretrained using up to 18 trillion tokens across more than 29 languages. The model family includes both base model (pretrained only), and instruction models (further trained through instruction-tuning and other methods)^24^. We chose the instruction-tuned version of Qwen2.5 as the backbone for the PH-LLM models, given its multilingual capabilities and superior performance in following human instructions^24^. Supporting over 29 languages, Qwen 2.5 enhances the potential applicability of PH-LLM in global health contexts, including low- and middle-income countries (LMICs).
To enable efficient LLM finetuning, we utilized quantized low-rank adaption (QLoRA)^34,35^. For instruction-tuning, we followed previous studies and trained our models over 3 epochs^15,36^, with an effective batch size of 256, a cut-off length of 1024 tokens, a learning rate of 0.00005, incorporating cosine annealing with a warm-up ratio of 0.1, and LoRAPlus learning rate ratio of 16. LoRAPlus builds upon standard LoRA by introducing separate upward and downward scaling coefficients, which makes more stable optimization and improved adaptation efficiency. The training process involved a total of 20 H100 GPUs at Northwestern University^37^. The instruction-tuning process also adhered to Qwen 2.5’s prompt format to maintain consistency. Elaborations on instruction tuning are available in Supplementary Material 1.
Model evaluation
We evaluated the zero-shot performance of PH-LLM models—PH-LLM-0.5B, PH-LLM-1.5B, PH-LLM-3B, PH-LLM-7B, PH-LLM-14B, and PH-LLM-32B—against a wide array of open-source and proprietary LLMs, including GPT-4o (version 2024-05-13), Llama-3.1-72B-Instruct, Mistral-Large-Instruct-2407, and Qwen2.5-72B-Instruct^24–27^. During the evaluation of the open-source models (PH-LLM, Llama, Mistral, BLOOMZ, and Qwen 2.5), we used 4-bit quantization with QLoRA to enhance computational efficiency, using a total of 20 H100 GPUs at Northwestern University. GPT-4o (version 2024-05-13) and GPT-4o mini (version 2024-07-18) were deployed on the Microsoft Azure platform.
Performance metrics
All evaluation datasets focused on a classification task, which represents the predominant type of annotated datasets in public health infoveillance. For classification tasks where only one category was relevant to public health, model performance was assessed using the F_1_-score. For tasks involving multiple categories of public health significance, we reported the micro F_1_-score to account for class imbalance. The formulas for calculating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm{precision}$$\end{document} , recall, F_1_-score, and micro F_1_-score are presented in Supplementary Material 1. Bootstrap sampling (n = 1000) was used to estimate the confidence intervals of model performance (see Supplementary Data).
Supplementary information
Supplementary materials Supplementary Data
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Infodemic. https://www.who.int/health-topics/infodemic#tab=tab_1.
- 2Espinosa, L. & Salathé, M. Use of large language models as a scalable approach to understanding public health discourse. med Rxiv 10.1101/2024.02.06.24302383 (2024).10.1371/journal.pdig.0000631 PMC 1147290739401186 · doi ↗ · pubmed ↗
- 3He, L., Omranian, S., Mc Roy, S. & Zheng, K. Using Large Language Models for sentiment analysis of health-related social media data: empirical evaluation and practical tips. med Rxiv 10.1101/2024.03.19.24304544 (2024).PMC 1209934040417506 · pubmed ↗
- 4Shah, S. M., Gillani, S. A., Baig, M. S. A., Saleem, M. A. & Siddiqui, M. H. Advancing depression detection on social media platforms through fine-tuned large language models. Online Social Networks and Media 46, 100311 (2025).
- 5Yang, K. et al. Menta L La MA: interpretable mental health analysis on social media with large language models. In Proc. ACM on Web Conference 2024, 4489–4500 (2024).
- 6Wu, C. et al. PMC-L La MA: toward building open-source language models for medicine. J. Am. Med. Inform. Assoc.31, 1833–1843 (2024).10.1093/jamia/ocae 045PMC 1163912638613821 · doi ↗ · pubmed ↗
- 7Jiang, Y., Qiu, R., Zhang, Y. & Zhang, P.-F. Balanced and explainable social media analysis for public health with large language models. In Australasian Database Conference, 73–86 (Springer, 2023).
- 8Li, W. et al. Zero-shot Explainable Mental Health Analysis on Social Media by Incorporating Mental Scales. In Companion Proc. ACM on Web Conference 2024, 959–962 (2024).