Test case sampling optimization for safety validation of automated driving systems
Chen Qian, Jingbin Xu, Xin Xing, Feng Guo

TL;DR
This paper introduces a method to select test cases for validating automated driving systems, ensuring they reflect real-world conditions and capture rare safety-critical scenarios.
Contribution
The novel Kernel Test Case Sampling method balances representativeness and coverage for efficient safety validation of automated driving systems.
Findings
The method captures long-tailed scenarios while approximating naturalistic driving conditions.
It enables robust accident-rate estimation for fair comparisons between human drivers and automated systems.
The approach supports standardized and scalable safety validation for automated driving systems.
Abstract
Testing and validating automated driving systems require carefully designed test cases that capture the complexity of real-world driving conditions. However, the inherent complexity of driving environments and the rarity of safety-critical situations pose significant challenges to developing reliable and efficient validation frameworks. This paper addresses these issues by selecting appropriate test cases from the largest-scale naturalistic driving study. We introduce a Kernel Test Case Sampling method, which selects cases satisfying two key criteria: representativeness, ensuring alignment with real-world scenarios, and coverage, capturing high-risk corner cases. To demonstrate the proposed method, it is applied to large-scale naturalistic driving study data. By selecting a limited number of cases, the method effectively captures long-tailed scenarios while approximating the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1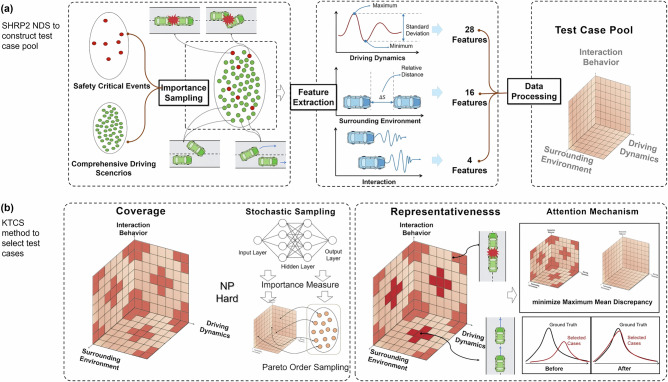 Figure 2
Figure 2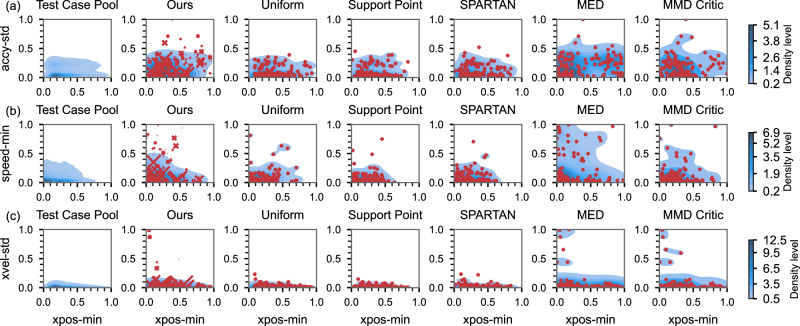 Figure 3
Figure 3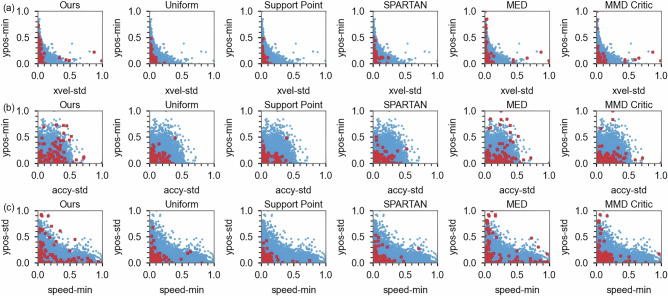 Figure 4
Figure 4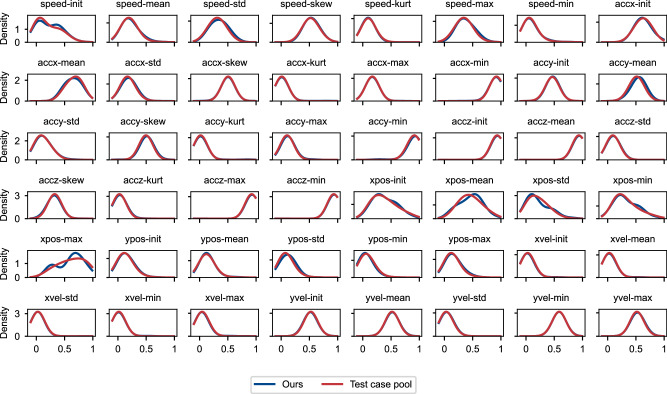 Figure 5
Figure 5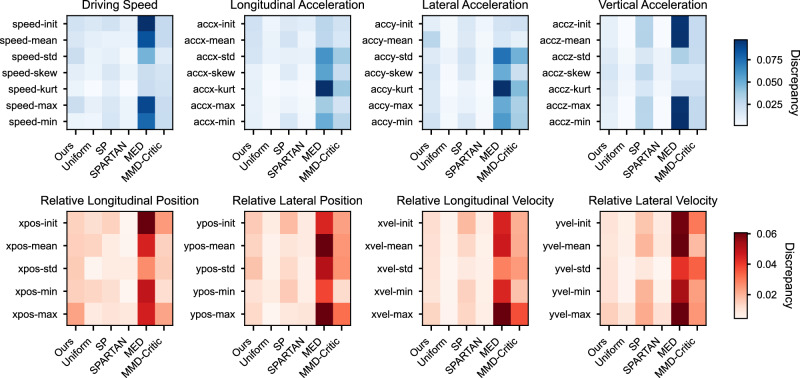 Figure 6
Figure 6 Figure 7
Figure 7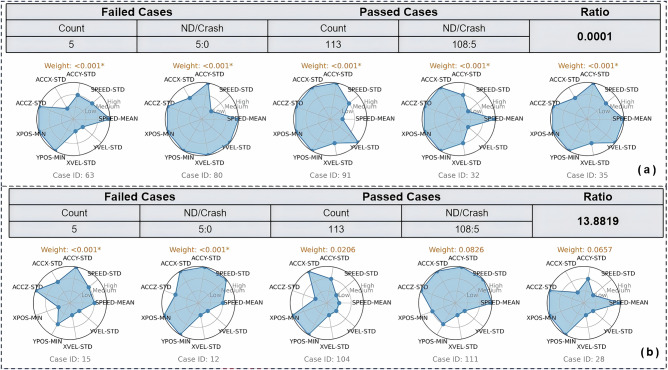 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAutonomous Vehicle Technology and Safety · Vehicle Dynamics and Control Systems · Human-Automation Interaction and Safety
Introduction
The widespread adoption of automated driving systems (ADS) hinges on a reliable framework for safety validation^1^. Researchers, industry professionals, and regulators invested substantial effort^2,3^ in developing test cases that are then evaluated through various validation venues, such as test tracks^4^ or simulators^5^. However, current approaches rely on heuristic rules to select well-defined test cases^6^, such as car following scenarios, which do not fully capture the unexpected edge cases that can arise in real-world driving^7,8^. Furthermore, as ADS safety standards evolve, reliance on static testing procedures can become increasingly inadequate and lead to potential biases^2^. A more strategic approach to test case selection — carefully choosing from the millions of possible driving scenarios — can help mitigate such biases in the testing process. Once testing is completed, it is essential to interpret the results using well-defined safety metrics, such as crash rates and the number of disengagements. Since most transportation regulations depend on human-driving benchmarks to develop safety countermeasures^9^, the deployment of comparable human-driving safety metrics is crucial to build public trust, ensure regulatory compliance, and facilitate the wider deployment of ADS^10^.
The selection of test cases for ADS safety validation involves identifying and prioritizing critical scenarios that challenge the system’s capabilities within its operational design domain. Existing research often relies on surrogate models to approximate the driving behaviors of background vehicles or assumes overly simplified driving actions, such as constant deceleration maneuvers^11^. Notably, these approaches may not fully represent real-world conditions and could have limited coverage of the parameter space. As shown in Fig.1a, these assumptions can diverge significantly from actual on-road conditions and limit the validity of test scenarios. Validating safety is complicated by the challenges of the curse of dimensionality and the curse of rarity, as highlighted in a recent publication^12^. These challenges suggest that a massive number of test cases would be required to comprehensively cover the full spectrum of the testable driving space. However, in practice, the number of selected test cases must be limited, as replicating or reconstructing each test case through downstream validation venues is costly. The test track approach requires test cases to be replicated using strikeable surrogate vehicles to simulate various elements, including location and driving dynamics such as velocity^4^. In the simulation setup, reconstructing each test case is time-consuming, as it requires precisely recreating every potential risk factor by independent third parties to mitigate potential conflicts of interest^13^. Optimizing the selection of test cases to support an efficient test regimen is therefore essential.Fig. 1. Schematic diagram of test case selection for safety validation of automated driving systems.a Overview of the test case selections for ADS safety validation. b The study utilizes naturalistic driving study data from SHRP2, which provides high-quality, comprehensive driving information. SHRP2 NDS collected data from six U.S sites, providing an unbiased benchmark for human driver driving data. c Selected test cases guarantee both representativeness and coverage for effective validation.
To construct the test case pool for safety validation, we adopt the largest-scale naturalistic driving study (NDS), the Second Strategic Highway Research Program (SHRP2)^14^. The SHRP2 NDS follows a well-designed experimental plan^14,15^ to capture nationwide, population-level U.S. driving characteristics, as shown in Fig. 1b. The SHRP2 NDS is a national database representing key traffic safety characteristics^16^ and various operating domains^17^. The advanced data acquisition systems record comprehensive driving data, roadway information, and driver behaviors, which are essential for capturing the parametric driving parameters under real-world traffic conditions. Fig.2a illustrates the construction of the test case pool, in which 0.3 million cases are sampled from the SHRP2 NDS dataset. Each sample represents a specific driving scenario that describes the temporal development of consecutive scenes that include relevant static and dynamic elements. Each sample spans 15 s and includes 48 features extracted from radar and kinematic data, capturing driving dynamics, environmental factors, and interaction behaviors.Fig. 2. Overview of the test case selection framework for ADS safety validation.a The test case pool is constructed from the SHRP2 NDS dataset using importance sampling, with extracted features on driving dynamics, environmental factors, and interaction behaviors organized into a structured dataset. b Test cases are selected through a two-step process: Stochastic sampling for coverage ensures comprehensive representation of the testable space; Attention mechanism for representativeness assigns weights to align selected cases with real-world scenario distributions.
Two key criteria, representativeness and coverage, are introduced to evaluate the proposed test case sampling method, compared to the state-of-art method, to support comprehensiveness of the test case pool. Representativeness ensures that the selected cases, taken together, reflect the realism of actual driving situations observed on public roads (as derived from the SHRP2 NDS). Using these cases, we can create a test set that realistically mirrors how often different driving scenarios occur, enabling more meaningful and credible safety evaluations. As shown in Fig. 1c, a small number of strategically selected green points around the core of the testable space can effectively represent the majority of routine driving scenarios, so as to reduce the total number of required cases. Coverage ensures that selected cases include diverse driving scenarios, particularly those that are less frequent yet carry safety-critical information and might otherwise be missed, marked in red in Fig. 1c. For example, a sudden cut-in by a lead vehicle at high relative speed on a curved highway exit ramp is rare in naturalistic driving but highly critical for ADS safety. These regions are prone to unexpected failures, and their inclusion helps prevent overlooked vulnerabilities in ADS validation. Both criteria are essential for a reliable and effective validation process, ensuring that the ADS is tested comprehensively in both common and rare situations.
In the statistics and machine learning domain, various approaches have been proposed to optimize case selection. Uniform sampling^18^ ensures an even spatial distribution but neglects low-density, high-risk regions critical for safety validation. The support point algorithm^19^ uses convex-concave methods to preserve the statistical properties of the dataset, ensuring representativeness, but it struggles to capture rare, high-risk scenarios. Similarly, SPARTAN^20^ employs optimal transport theory to enhance coverage through space-filling properties, but it does not always match real-world distributions. Approaches that focus on underrepresented data points^21^ or low-probability selections^22^ can effectively target high-risk areas but may lack representativeness. However, none of the existing methods optimizes both representativeness and coverage simultaneously.
We propose the Kernel Test Case Sampling (KTCS) method to simultaneously achieve the properties of representativeness and coverage through a dual optimization approach using kernel methods, as illustrated in Fig. 2. Coverage optimization aims to minimize the information potential (IP)^23^ by framing test case selection as an optimization problem. Since directly solving this problem is NP-hard, we employ a stochastic sampling approach that assigns importance measures to each data point using a neural network, followed by Pareto-order sampling to ensure comprehensive coverage of the testable space. The goal of representativeness optimization is to minimize the maximum mean discrepancy (MMD)^24^, ensuring that the selected cases closely match real-world driving distributions. To achieve this, an attention mechanism is introduced that assigns distribution-alignment weights to the selected cases^25,26^, adjusting the selected subset so that its empirical distribution matches that of the full candidate test case pool. A larger weight assigned by the attention mechanism indicates that the corresponding selected case contributes more to approximating the underlying distribution of the candidate test-case pool. This process ensures that the selected cases accurately represent the distribution of real-world driving scenarios. We establish the optimal properties of the proposed method through theoretical proof and validate its performance through extensive Monte Carlo simulations.
To demonstrate the interpretation of the test results using selected cases, a measure called Scaling Risk (SR) is proposed to quantify the safety level of an ADS system’s performance based on the success or failure of each case, where a case is labeled a success if the SUT completes it without a traffic crash, and a failure if the ADS does not complete it safely and a crash occurs. SR reflects how much more risk the ADS carries compared to human drivers in terms of being involved in traffic crashes. For instance, a score of 2.5 indicates that the ADS system under test is 2.5 times riskier than human drivers.
Addressing the challenge of selecting optimal test cases for ADS safety validation, the proposed framework leverages a small yet informative subset of scenarios drawn from large-scale nationwide NDS data. By strategically selecting test cases that are theoretically guaranteed to be representative of real-world driving conditions, the framework provides a principled foundation for ADS safety validation. Leveraging large-scale NDS data and the proposed KTCS selection method, our approach selects test cases that simultaneously satisfy representativeness and coverage while preserving the realism of real-world driving behavior. The framework further enables reliable performance comparisons between an ADS and human drivers by anchoring evaluation to population-level crash rates and using attention-based, interpretable weights to quantify each test case’s contribution to distribution alignment.
Results
Data
A systematic sampling scheme is used to construct the test case pool based on traffic crash events and normal driving segments extracted from SHRP2 NDS, ensuring a close approximation of population-level driving characteristics. The test cases are categorized into two groups: normal driving and safety-critical events. Each case consists of a 15-s driving segment, treated as a driving scenario. The selection of normal driving cases follows a two-stage stratified design that preserves the original representation of the driver population and mitigates selection bias across drivers^15^. First, the number of normal driving segments is determined proportionally by the total driving time of each driver. Then, a preset number of driving segments is randomly sampled from each driver’s data. In total, about 300,000 randomly selected 15-s driving segments were chosen, covering approximately 50 million meters of driving from the SHRP2 NDS database. Safety-critical events are selected from the full population of crash data in the SHRP2 NDS. Using a validated crash identification method^27^, all crash events are identified and incorporated into the candidate test-case pool. Each crash event case consists of a 10-second driving segment leading up to the collision and a 5-s segment following it. Safety-critical situations include severe level-1 traffic accidents and level-2 police-reportable crashes from the SHRP2 NDS database^14^. To ensure that test cases are relevant to ADS capabilities, single-vehicle conflicts were excluded because, when no other moving vehicles are present, the radar cannot provide the surrounding environment data needed to compute surrogate risk metrics^27^. Besides, single-vehicle conflicts in human drivers primarily result from human errors, such as distracted driving, while ADS are shown to mitigate or avoid.
Data preprocessing is conducted by retaining only cases that include both radar and kinematic data. Additionally, the following criteria are applied to ensure the test cases reliably simulate real-world scenarios. (1) Average speed: The average speed of the 15-s driving segment must exceed 5 mph, as previously adopted^14^. (2)Maximum speed: The maximum speed must be less than 35 m/s (80 mph), which corresponds to the speed limit on most U.S. roads. (3) Longitudinal distance: The maximum longitudinal distance to the nearest vehicle must be under 60 meters, as radar detection accuracy decreases beyond this range^28^. In total, 55,920 normal driving segments and 90 crash events are used for the analysis.
Experiment Setup
Each case within the test case pool comprises two levels of information: kinematics data and radar data. The kinematics data describe the driving state of the subject vehicle (SV), such as the driving speed, while the radar data capture the status of surrounding vehicles. The following set of features is extracted from the driving test case. (1) Driving dynamics: Captures the characteristics of the SV’s driving behavior. (2) Surrounding environment: Represents the spatial distribution and relative driving dynamics of nearby vehicles at a specific moment. (3) Driving interactions: Describes the temporal evolution of the driving scenario, accounting for interactions with surrounding vehicles.
Driving dynamics features are extracted using four types of kinematic data: SV’s longitudinal acceleration (accx), lateral acceleration (accy), horizontal acceleration (accz), and driving speed (speed). For each type of kinematic data, seven statistical features—initiation (init), maximum (max), minimum (min), mean (mean), standard deviation (std), skewness (skew), and kurtosis (kurt) - are calculated to capture initial status, extreme conditions, average driving levels, volatility, frequency and intensity of abrupt maneuvers. For example, speed-min represents the minimum driving speed in the 15-second driving segment. This feature extraction process results in 7 × 4 = 28 kinematic-based features.
The SHRP2 radar system provides relative distance and velocity data for surrounding vehicles in both longitudinal and lateral directions. Features are extracted using the closest vehicle to characterize the surrounding environment^1^, including average (mean), maximum (max), minimum (min), and initial (init) values for relative longitudinal position (xpos), lateral position (ypos), longitudinal velocity (xvel), and lateral velocity (yvel). This results in 16 features reflecting the static environment. An additional 4 features are calculated to assess driving interactions, consisting of the standard deviation for each radar-related metric (xpos-std, ypos-std, xvel-std, and yvel-std).
The feature extraction process generates 48 features: 28 kinematic-based features for driving dynamics, 16 radar-based features for the static environment, and 4 features for driving interactions. Detailed formulas and feature names are provided in the Supplementary Table 4. All features are normalized to [0, 1] for uniform scaling and fair comparisons across 48 dimensions.
Performance comparison
Define M as the number of selected cases and N as the total instances in the test case pool. We set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M=0.5\sqrt{N}$$\end{document} , resulting in 118 selected cases for our analysis. We compare our method against five state-of-the-art approaches: (1) Minimum Energy Design (MED):^22^ Sequentially selects data points based on density estimation using a greedy algorithm. (2) MMD-Critic:^21^ Identifies prototypes and criticisms within the data using kernel methods. (3) The Support Point (SP):^19^ Minimizes energy distance to select representative points. (4)SPARTAN:^20^ Leverages optimal transport theory to ensure uniform data coverage. (5) Uniform Sampling (Nystrom Sampling):^29^ Randomly selects cases uniformly. Each method is applied to the test case pool to select 118 cases.
Figure 3 compares the sampling representativeness performance of the proposed method with state-of-the-art methods using visualization of the statistical density distribution. The density distributions are generated using kernel density estimation, with darker blue indicating higher density regions. Figure 3a shows the joint distribution of xpos-min and accy-std. The feature accy-std measures the volatility of lateral control, while xpos-min represents the minimum relative longitudinal distance to surrounding vehicles. These two features provide insights into lateral stability and proximity to nearby vehicles. Our method effectively captures the negative relationship between these features and covers the tail regions of the distribution. The attention mechanism ensures that the final distribution closely aligns with the original test case pool. Other methods do not reflect this negative relationship, where unstable lateral movements are more likely to occur in crowded or congested environments. MED overly emphasizes corner cases, resulting in a biased estimate of overall distributions. MMD-Critic struggles to balance central modes and corner cases, leading to discrepancies in the central region of the test case pool. Fig. 3b shows the joint density distribution of features speed-min and xpos-std, which reflect the ability of the SV to adapt its behavior to external conditions. SP and SPARTAN fail to cover high-risk corner cases in low-density regions, while MED and MMD-Critic overemphasize these cases. A similar pattern is observed in Fig. 3c. Uniform sampling evenly distributes points across the domain, which lacks realism. Our method achieves the best approximation of corner cases, as the attention mechanism assigns appropriate weights to high-risk scenarios while preserving the overall distribution shape.Fig. 3. Comparison of density distribution based on points selected by different methods.a Joint distribution of features accy-std and xpos-min. b Joint distribution of feature speed-min and xpos-std. c Joint distribution of feature xvel-std and xpos-min. The blue area represents the estimated density distribution, with darker shades indicating higher density. Red points mark the selected cases, and the size of each point reflects the weight of that case.
Figure 4 evaluates the sampling coverage performance of the proposed method compared to state-of-the-art approaches using scatter diagrams. The blue dots represent the original test case pool, and the red points indicate the selected cases for each method. The Uniform, SP, and SPARTAN approaches primarily select cases centered around the mode of the joint distributions, resulting in limited coverage across the entire data space. MMD-Critic selects certain long-tail cases located far from the center of the investigated joint distributions, but it fails to provide comprehensive coverage of the entire long-tail region, as evidenced by the large blue area not spanned by the red points in Fig. 4b, c. While MED demonstrates some capacity to cover long-tailed cases, our method selects points more evenly distributed, particularly near the outer limits of the feasible parameter space. As shown in Fig. 4c, MED-selected points cluster tightly in the tail, with many exhibiting nearly identical values of ypos-std (lateral-distance variability) and speed-min, thereby offering limited new information. In contrast, our method distributes points throughout both the tail and interior regions, reducing redundancy and enhancing test efficiency.Fig. 4. Comparison of selected points across different methods.a Scatter plot of selected points on the features ypos-min and xvel-std. b Scatter plot of selected points on the features ypos-min and accy-std. c Scatter plot of selected points on the features ypos-std and speed-min. The blue dots represent the original test case pool, while the red dots indicate the selected points using different methods.
After visualizing the sampling capacity, we introduce six measures to theoretically verify the statistical realism of the sampling distribution. The results are summarized in Table 1. The first two metrics, IP and MMD, are the optimization objectives of our algorithms. Smaller IP values indicate better coverage, while smaller MMD values indicate better representativeness^24^. To provide a more comprehensive assessment, we employ four additional metrics. To begin with, representativeness is evaluated by assessing how well the density estimation constructed from the selected cases approximates the test case pool. Given the high-dimensional nature of features, we adopt two metrics to assess overall similarity: one for joint distributions and one for marginal distributions. These metrics are the empirical Hellinger distance (H-Dist)^20^ and the Absolute distribution difference (ADD)^30^. Smaller H-Dist and ADD values indicate better approximation capabilities for joint distributions and marginal distributions, respectively. Define the constructed density estimation of the subselected points as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{p}(\cdot )$$\end{document} , and the marginal density estimation for the jth dimension as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{{p}_{j}}(\cdot )$$\end{document} . Similarly, let the density estimations from the candidate case pool be p(⋅), with the marginal density for the jth dimension represented as pj(⋅). The H-Dist and ADD are defined as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\,{{{\rm{H}}}}\; -\; {{{\rm{Dist}}}}\,=1-\frac{1}{N}{\sum }_{i=1}^{N}\sqrt{\widehat{p}({{{{\boldsymbol{x}}}}}_{i})/p({{{{\boldsymbol{x}}}}}_{i})}\,\,\,\,{{{\rm{ADD}}}}\,=\frac{1}{N}{\sum }_{j=1}^{d}{\sum }_{i=1}^{N}| \widehat{{p}_{j}}({{{{\boldsymbol{x}}}}}_{i})-{p}_{j}({{{{\boldsymbol{x}}}}}_{i})|$$\end{document}The results of ADD and H-Dist are reported in Table 1.Table 1. Sampling performance comparison using Empirical Hellinger distance (H-Dist), Empirical Absolute Distribution Difference (ADD), Average L1 and L2 Pairwise Distances for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M=0.5\sqrt{N}$$\end{document} MethodIP*↓MMD↓*H-Dist *↓*ADD *↓*Avg-L1 *↑*Avg-L2 *↑*Ours0.0670.0200.0181.0078.1751.879MED0.0340.3180.3653.7478.9652.072MMD-Critic0.2230.0380.1081.6695.9631.402SP0.3600.0030.0270.9973.5490.844Uniform0.3910.0060.0030.4373.9230.926SPARTAN0.4140.004-0.0050.3643.7960.887Note: ↑ indicates that higher values are better, while ↓ indicates that lower values are better. H-dist is an empirical distance measure that can take negative values^20^.
Next, coverage is assessed through diversity evaluation using pairwise differences between selected points. We follow the widely used method of calculating the average pairwise distances^31^. Larger distance values reflect greater diversity, indicating that the selected samples are more likely to include edge cases and critical regions for safety validation. The L1 and L2 distances are used as the discrepancy measure, defined as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\rm{Avg}}}}\; -\; {{{\rm{L1}}}}\,=\frac{1}{M(M-1)}{\sum }_{i=2}^{M}{\sum }_{j\ne i,j=1}^{M}\parallel {{{{\boldsymbol{z}}}}}_{i}-{{{{\boldsymbol{z}}}}}_{j}{\parallel }_{1}\,\,\, \\ {{{\rm{Avg}}}}\; -\; {{{\rm{L2}}}}\,=\frac{1}{M(M-1)}{\sum }_{i=2}^{M}{\sum }_{j\ne i,j=1}^{M}\parallel {{{{\boldsymbol{z}}}}}_{i}-{{{{\boldsymbol{z}}}}}_{j}{\parallel }_{2}$$\end{document}where ∥zi − zj∥1 and ∥zi − zj∥2 represent the L1 and L2 distances, respectively, between points zi and zj. The results are summarized in Table 1, where higher values for Avg-L1 and Avg-L2 indicate a greater likelihood of covering corner cases^22^.
In summary, Table 1 shows our method achieves competitive scores on both IP and MMD, demonstrating balanced performance across these metrics. Our method outperforms MMD-Critic by achieving lower values on both measures. MED fails to meet the representativeness objective, as its MMD is substantially higher than that of all other methods. Although SP-Uniform and SPARTAN achieve slightly lower MMD values, they produce substantially higher IP scores (all above 0.360). While the points sampled by MED exhibit diverse characteristics, its density estimation fails to align with the test case pool. Uniform sampling, SP and SPARTAN struggle to maintain adequate coverage. Among the five comparison methods, only MMD-Critic attempts to balance representativeness and coverage; however, its performance falls short across all metrics compared to our method.
Statistical realism
In this section, we evaluate whether our method’s performance meets the requirements for effective test case selection. Specifically, we compare the density distribution generated by the 118 cases selected by our method with the distribution derived from the entire test case pool. Fig. 5 illustrates this comparison for each of the 48 features. The red line represents the density distribution of the entire test case pool, while the blue line represents the distribution generated by the cases selected by our method. Our method closely approximates the ground truth density distribution across individual dimensions, demonstrating its ability to reflect real-world driving scenarios realism. Furthermore, the consistency observed across all 48 features underscores the robustness of our approach in preserving the statistical properties of the test case pool.Fig. 5. Comparison of density distributions across all 48 features.The red line represents the density distribution of the entire test case pool, while the blue line represents the density distribution of the 118 cases selected by our method.
Similarly, we quantitatively compare the per-feature discrepancy across all methods using a heatmap in Fig. 6, where the per-feature discrepancy is measured by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${ADD}_{j}=\frac{1}{N}{\sum }_{i=1}^{N}| \widehat{{p}_{j}}({{{{\boldsymbol{x}}}}}_{i})-{p}_{j}({{{{\boldsymbol{x}}}}}_{i})|$$\end{document} . Here, ADDj represents the contribution of feature j to the overall ADD. The global ADD reported in the main paper is the sum of these 48 per-feature discrepancy values. Figure 6 consists of eight sub-panels: the first row displays all kinematics-based features, and the second row shows all radar-based features. Darker cells indicate larger discrepancies, corresponding to lower statistical realism.Fig. 6. Heat-map of per-feature discrepancies across different methods.The first row presents results for kinematics-based features, while the second row presents results for radar-based features.
To evaluate the coverage achieved by our method, we assess its ability to capture corner cases, as illustrated in Fig. 7. For each test case, we compute its multidimensional distance from the centroid of the candidate test case pool. Larger distances indicate a greater likelihood of being a corner case. Corner cases, characterized by long-tailed characteristics, lie far from the distribution’s mode and provide critical information for safety validation. Figure 7a, b shows the relative distances of each case from the center of the test case pool. These distances provide a quantitative measure of how far a case deviates from the core distribution.Fig. 7. Schematic diagram of coverage evaluation.a Illustration of distance calculation for the central density region. b Identification of corner cases based on different quantile thresholds. c Summary of corner case coverage across varying quantile thresholds.
Using thresholds of 95% and 99.99%, we identify cases with distances greater than the specified proportion of all cases in the pool. For instance, the 99.99% threshold highlights cases that lie further into the extreme tail of the distribution. Of the 118 cases selected, 77 fall beyond the 99% threshold, and all 6 cases beyond the 99.99% threshold are captured, demonstrating the method’s strong ability to cover the most extreme long-tailed driving scenarios. The method effectively represents the central density region while systematically capturing rare long-tailed events, as shown in Figs. 5, 7.
Figure 7c presents a quantitative comparison of long-tail scenario coverage across all baseline methods. The results show that Uniform, SP, and SPARTAN offer limited coverage of long-tail scenarios, as only a few of their selected cases exceed the 99% percentile. The MED method captures the tail almost exclusively, with 117 of 118 selected cases exceeding the 95% percentile. Such strong emphasis on extreme values limits its ability to represent the full distribution, thereby reducing its overall statistical representativeness.
Demonstration
In this section, we introduce a safety measure, namely Scaling Risk, to quantify the safety level of an ADS by comparing its performance in selected testable cases against a human driving benchmark. By using a limited number of test cases, we avoid the need for billions of miles of driving data^32^, enhancing validation efficiency without sacrificing reliability. This approach is supported by the theoretically validated sampling mechanism discussed in the previous section, which ensures the selection of the most representative and safety-relevant test cases.
Given a driving system under test (SUT), it is evaluated on a set of 118 selected test cases. For each test case j, we define a binary indicator Ij ∈ 0, 1, where Ij = 1 indicates that the SUT passed the case, and Ij = 0 indicates a failure (e.g., a crash). To evaluate the safety performance of the SUT, we introduce Accident-Rate-SUT, a metric that converts the binary test outcomes (pass/fail) of the representative test cases into a real-world, safety-oriented measure. This metric is motivated by the golden rule in automated driving system (ADS) safety research: accident rate, defined as the number of crashes divided by the total driving distance^1,33^. The exposure distance, dj, for each case is calculated as the product of the average speed and the fixed test duration (15 s). Our method employs an attention mechanism to assign importance weights λ1,...,λM to each test case. Details of the selected test cases, their scenario features, and the corresponding weights are provided in the Supplementary Figs. 2, 6.
The accident rate for the SUT is then computed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\,{{{\rm{Accident}}}}-{{{\rm{Rate}}}}-{{{\rm{SUT}}}}\,={\Gamma }_{1}{\Gamma }_{2}\frac{{\sum }_{j=1}^{M}{\lambda }_{j}{I}_{j}}{{\sum }_{j=1}^{M}{\lambda }_{j}{D}_{j}}\,\,\\ {{{\rm{where}}}}\,\,j=1,...M,\,\,{{{\rm{and}}}}\,\,{\lambda }_{j}\,{{{\rm{as}}}}\; {{{\rm{the}}}}\; {{{\rm{weight}}}}\; {{{\rm{for}}}}\; {{{\rm{test}}}}\; {{{\rm{case}}}}\,\,j$$\end{document}where Γ1 compensates for the oversampling of traffic crashes during the construction of the test case pool, and Γ2 accounts for the data processing ratio, as only 55,920 normal driving segments out of the 0.3 million cases are used for analysis.
Having calculated the accident rate for the SUT based on driving distance, we now introduce the calculation of Scaling Risk. To establish the human driver benchmark, which serves as the reference Accident-Rate-Human, we use the SHRP2 NDS dataset crash rate as a population-level representation. In the SHRP2 NDS dataset, 90 crashes were recorded over approximately 33 million miles of driving. The crash rate for human drivers derived from the SHRP2 NDS is 1.695 × 10^−9^crashes/meters.
Since the testable cases are drawn from SHRP2 NDS real-world driving events, the safety level of the SUT is determined by evaluating its performance on the testable cases it passes or fails. The scaling risk (SR) in our study is defined as the ratio of the SUT’s crash rate to the crash rate of benchmark human drivers, particularly in terms of being involved in severe traffic crashes. In other words, it is a relative risk measure that compares the SUT’s safety performance with that of human drivers. The SR can be calculated as the follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\,{{{\rm{SR}}}}=\frac{{{{\rm{Accident}}}}\; -\; {{{\rm{Rate}}}}\; -\; {{{\rm{SUT}}}}}{{{{\rm{Accident}}}}\; -\; {{{\rm{Rate}}}}\; -\; {{{\rm{Human}}}}}=\frac{{{{\rm{Accident}}}}\; -\; {{{\rm{Rate}}}}\; -\; {{{\rm{SUT}}}}}{1.695\times 1{0}^{-9}\,\,{{{\rm{crashes/meters}}}}}$$\end{document}Figure 8 presents two demonstration trials, each accompanied by a radar plot that highlights the driving characteristics of the failed test cases. The overall risk assessment of the SUT can vary significantly depending on which specific test cases it fails. In both trials, the SUT fails exactly 5 cases while passing the remaining 113; however, the resulting risk assessments differ significantly. In Fig. 8b, if the SUT fails cases 15, 12, 104, 111, and 28, its risk level would be approximately 13.8 times higher than that of a human driver. The weights of the failed test cases play a critical role in determining the overall risk. Cases with higher weights have a more significant impact on risk assessment. For example, in the second trial, three of the five failed cases also have associated weights greater than 0.02, substantially contributing to the increased risk.Fig. 8. Demonstration of two test trails for ADS safety validation over 118 sampling testable cases.a Five failed cases with low weights leading to a safer outcome than human drivers. b Five failed cases with higher weights leading to a riskier outcome than human drivers. This demonstrates how specific test case ID failures result in different scaling risks compared to human drivers, depending on the associated weights.
The characteristics of the failed test cases reflect the relevance of real-world traffic scenarios. For example, in Fig. 8b, the five failed cases show low values in xvel*—std* and yvel*—std*, indicating minimal interaction with surrounding vehicles. These types of scenarios are relatively common in real-world traffic; thus, failing to handle such cases adequately can significantly increase the overall risk of the SUT.
In contrast, in Fig. 8a, the five failed cases (ID: 63, 80, 91, 32, 35) result in safer performance compared to human drivers. All five of these cases are associated with weights smaller than 0.001. Notably, these cases share common characteristics: large values in accz-std, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$xpos-min$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ypos\,-\,min$$\end{document} , suggesting a bumpy driving scenario with few nearby vehicles. Such conditions are rare in real-world settings, and their low weight reflects their limited impact in determining the overall safety risk of the SUT. The wide range of scaling risk values (0.0001 to 13.38 in Fig. 8) does not mean the ADS’s risk literally fluctuates within this range during a single evaluation. Instead, it indicates that depending on which specific scenarios the ADS fails, the interpretation of the test results could be different. In this demonstration, the extreme values (0.0001 and 13.38) reflect the best and worst case combinations among the five selected failure cases.
We additionally derive SR’s corresponding confidence interval to better quantify the uncertainty of SR. Specifically, the 95% confidence interval for the log value of the scaling risk can be constructed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log SR\pm 1.96\times \sqrt{\frac{{\sum }_{j=1}^{M}{\lambda }_{j}^{2}{r}_{j}(1-{r}_{j})}{{({\sum }_{j=1}^{M}{\lambda }_{j}{r}_{j})}^{2}}}$$\end{document}where rj = (Ij + 0.5)/2. If the lower bound of the established confidence interval is larger than 1, then we have 95% confidence to say the SUT could be riskier than human drivers. Detailed derivations on the confidence interval can be found in the supplementary material.
To validate the consistency of the proposed measure, we treat SHRP2 drivers as the SUT by letting Ij represent crashes in each test case. Given the SHRP2 NDS baseline accident rate, the resulting ratio should be close to 1, and the value of 1 should be within the 95% confidence interval if our calculations are accurate. Using data from the 118 test cases, along with their associated weights and distances, the calculated accident rate for the SHRP2-as-SUT scenario is 1.993 × 10^−9^crashes/meters. This results in an SR value of 1.176, the 95% confidence interval [0.441, 3.138], 95% confidence interval [0.441, 3.138], proving that our method is statistically validated. For Fig. 8b, out of the 118 selected cases, the point estimation of the scaling risk is 13.8819, the 95% confidence interval of [6.53, 29.50], indicating that, under this failure pattern, the SUT is significantly riskier than human drivers.
Discussion
Motivated by the question of how we can effectively select a set of test cases to validate the safety functions of ADS? Given the complexity of real-world driving environments, this task becomes particularly difficult due to the large number of driving scenarios. To address this, we introduce the KTCS approach for selecting test cases from the largest-scale naturalistic driving study. This method strikes a balance between coverage and representativeness of the test case pool by integrating an attention mechanism with stochastic sampling. It helps to accelerate the validation process without compromising its reliability. This paper introduces a method that effectively represents the vast and complex real-world driving space with just a few dozen carefully selected scenarios. We demonstrate the use of the selected test cases with a scaling risk measure, which enables a direct safety performance comparison between ADS and human drivers, providing a theoretical guarantee for the validity of ADS safety evaluations.
Several potential extensions can be explored in future studies. Building on these insights, recent advances in deep generative modeling can be leveraged to create rare or unseen driving scenarios and to sample variations around the identified failure cases^34,35^. By amplifying these challenging situations, generative models can produce a dense cloud of near-miss trajectories, and testing the ADS against this expanded set yields stronger statistical evidence when comparing its safety performance to that of human drivers. Encoding these test cases in a standard format, such as OpenSCENARIO^36^, will enable their integration into a growing, field-validated library that can be shared across industry and regulatory agencies. Insights gained from these evaluations can guide more rigorous simulations and field trials on industry-standard platforms^5^, supporting scalable validation and targeted fine-tuning of ADS performance in controlled yet dynamic virtual environments or on dedicated test tracks. Researchers can also leverage the selected testable cases to inform the development of rigorous ADS safety test protocols, using industry-standard software or constructing field operation tests on dedicated test tracks.
The proposed KTCS algorithm is dataset-agnostic and can be applied to a wide range of naturalistic driving studies. We build test cases from strategically sampled subsets of the SHRP2 NDS. Future research could scale this methodology to the full SHRP2 database or apply it to other naturalistic driving studies and industry crowd-sourcing initiatives. Doing so would capture evolving traffic patterns and vehicle technologies, and refine human-performance baselines for modern ADS evaluations. These extensions could expand the pool of candidate test cases to hundreds of millions. At such a scale, standard kernel operations become computationally expensive. Recent advances in statistical computing offer viable solutions, such as low-rank approximations to compress kernel functions^37^, or mini-batch kernel algorithms that partition data into blocks for parallel processing^38^. These strategies can make large-scale kernel analyses computationally feasible.
Methods
With appropriate data pre-processing, let x1,..,xN represent the test case pool and each data point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\boldsymbol{x}}}}}_{i}\in {{\mathbb{R}}}^{d}$$\end{document} . We select a subset z1,..,zM from the original set x1,..,xN. As we try to use as few samples as possible, trying to approximate the original large sample sizes, here we let M ≪ N. Ideally, this subset z1,..,zM contains both common cases and corner cases, as entire sets, the probability distribution function, constructed based on the selected subsets z1,..,zM, approximates the distribution of x1,..,xN.
Considering the potentially high dimensionality of the feature space (d) and the nonlinear dependencies among the features, we conduct our analysis in the reproducing kernel Hilbert space (RKHS)^24^. As a nonparametric framework, RKHS avoids the need to explicitly estimate the high-dimensional covariance matrix of the input features, a procedure that is often unstable and unreliable in such settings^39^. Beyond this practical advantage, RKHS is well-suited to capture nonlinear relationships and higher-order feature interactions, and has been successfully applied to data with complex covariance structures^40,41^.
Evaluation metrics
We use the kernel methods to measure the two objectives in this study: representativeness and coverage. Consider in space \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb{X}}$$\end{document} , defined \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{K}}}}$$\end{document} as a kernel function mapping \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb{X}}\times {\mathbb{X}}\to {\mathbb{R}}$$\end{document} . For example, the Radial basis function (RBF) kernel \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{K}}}}\left({{{{\boldsymbol{z}}}}}_{t},{{{{\boldsymbol{z}}}}}_{s}\right)=\exp \left(\frac{-\parallel \left(\right.{{{{\boldsymbol{z}}}}}_{t}-{{{{\boldsymbol{z}}}}}_{s}{\parallel }_{d}^{2}}{2{\sigma }^{2}}\right)$$\end{document} is a popular one. We define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu=\int \phi ({{{\boldsymbol{x}}}})d{\mathbb{P}}({{{\boldsymbol{x}}}})$$\end{document} , as the kernel mean embedding at the population level. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi :{\mathbb{X}}\to {{{\mathcal{H}}}}$$\end{document} represents a feature map transforming the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\boldsymbol{x}}}}}_{1},...,{{{{\boldsymbol{x}}}}}_{N}\in {\mathbb{X}}$$\end{document} into Hilbert space. The feature map satisfies \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{K}}}}({{{{\boldsymbol{z}}}}}_{t},{{{{\boldsymbol{z}}}}}_{s})={\langle \phi ({{{{\boldsymbol{z}}}}}_{t}),\phi ({{{{\boldsymbol{z}}}}}_{s})\rangle }_{{{{\mathcal{H}}}}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi ({{{\boldsymbol{z}}}})={{{\mathcal{K}}}}({{{\boldsymbol{z}}}},\cdot )$$\end{document} .
Achieving good coverage performance requires comprehensively spanning the entire data space. Given the inherent complexity of high-dimensional space, we start our discussion by considering a one-dimensional space defined as z1,...,zM. If the relative distances between adjacent points are large, the corresponding point configuration exhibits better space-filling properties, thereby providing more comprehensive coverage of the data space^31,42^. This relative distance among the M points z1,...,zM can be expressed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{1}{2M(M-1)}{\sum }_{i=1}^{M}{\sum }_{j\ne i}^{M}{({z}_{i}-{z}_{j})}^{2}=\frac{1}{M-1}{\sum }_{i=1}^{M}{({z}_{i}-\bar{z})}^{2}=Variance$$\end{document}Thus, in a one-dimensional space, a higher variance among z1,...,zM indicates that these points are more widely dispersed, indicating a better coverage ability. Motivated by the discussion in Eq. (6), we consider using the variance as a measure of coverage within a multi-dimensional space in the RKHS. Based on the properties of reproducing kernel Hilbert space (RKHS),^43^ investigate the variance of multidimensional data. In our case, based on the sub-selected data, z1,..,zM, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\boldsymbol{z}}}}}_{i}\in {{\mathbb{R}}}^{d}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\parallel .{\parallel }_{{{{\mathcal{H}}}}}$$\end{document} denotes the norm under Hilbert space. We denote \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\nu }_{{{{\boldsymbol{z}}}}}^{2}={\mathbb{E}}{{{\boldsymbol{z}}}} \sim {\mathbb{P}}{\left\Vert {{{\mathcal{K}}}}({{{\boldsymbol{z}}}},\cdot )-{\mu }_{{\mathbb{P}}}\right\Vert }_{{{{\mathcal{H}}}}}^{2}$$\end{document} as the variance for the multivariate z in the RKHS, which can be decomposed through the following term:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\nu }_{{{{\boldsymbol{z}}}}}={{\mathbb{E}}}_{{{{\boldsymbol{z}}}} \sim {\mathbb{P}}}\left[{{{\mathcal{K}}}}({{{\boldsymbol{z}}}},{{{\boldsymbol{z}}}})\right]-\underbrace{{{\mathbb{E}}_{{{{\boldsymbol{z}}}},{{{{\boldsymbol{z}}}}}^{{\prime} } \sim {\mathbb{P}}}\left[{{{\mathcal{K}}}}\left({{{\boldsymbol{z}}}},{{{{\boldsymbol{z}}}}}^{{\prime} }\right)\right]}}_{{{{\rm{Information}}}}{{{\rm{Potential}}}}({{{\rm{IP}}}})}$$\end{document}The kernel function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{K}}}}({{{\boldsymbol{z}}}},{{{{\boldsymbol{z}}}}}^{{\prime} })$$\end{document} measures the distance between cases z and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\boldsymbol{z}}}}}^{{\prime} }$$\end{document} by evaluating all the feature coordinates simultaneously. This allows pairwise similarities to embed second-order dependencies among the features in the RKHS^44^. By aggregating these kernel similarities, the Information Potential (IP) approach implicitly incorporates moments of all orders, such as means, variances, and covariances. This ensures that coverage is assessed on the entire joint distribution of the features, rather than just the marginal distributions^23^.
If we let the kernel function maintain the property that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{K}}}}({{{\boldsymbol{z}}}},{{{{\boldsymbol{z}}}}}^{{\prime} })\le {{{\mathcal{K}}}}({{{\boldsymbol{z}}}},{{{\boldsymbol{z}}}})=K$$\end{document} , it is easy to verify that the first component is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\mathbb{E}}}_{{{{\boldsymbol{z}}}} \sim {\mathbb{P}}}\left[{{{\mathcal{K}}}}({{{\boldsymbol{z}}}},{{{\boldsymbol{z}}}})\right]=K$$\end{document} . For example, if we are using the RBF kernel as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{K}}}}\left({{{{\boldsymbol{z}}}}}_{t},{{{{\boldsymbol{z}}}}}_{s}\right)=\exp \left(\frac{-\parallel \left(\right.{{{{\boldsymbol{z}}}}}_{t}-{{{{\boldsymbol{z}}}}}_{s}{\parallel }_{d}^{2}}{2{\sigma }^{2}}\right)$$\end{document} , then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\mathbb{E}}}_{{{{\boldsymbol{z}}}} \sim {\mathbb{P}}}\left[{{{\mathcal{K}}}}({{{\boldsymbol{z}}}},{{{\boldsymbol{z}}}})\right]=1$$\end{document} . It is obvious then that, as the first term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\mathbb{E}}}_{{{{\boldsymbol{z}}}} \sim {\mathbb{P}}}\left[{{{\mathcal{K}}}}({{{\boldsymbol{z}}}},{{{\boldsymbol{z}}}})\right]$$\end{document} is a constant, the dominant major term in νz will be the second term, and we define it to be Information Potential (IP) in Eq. (7). A similar technique has also been used in^23^. With the sample data z1,...zM where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\boldsymbol{z}}}}}_{i}\in {{\mathbb{R}}}^{d}$$\end{document} , we can estimate the IP for multivariate z based on the properties of RKHS as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${IP}_{{{{\boldsymbol{z}}}}}=\frac{1}{M(M-1)}{\sum }_{t=1}^{M}{\sum }_{s=1,s\ne t}^{M}{{{\mathcal{K}}}}\left({{{{\boldsymbol{z}}}}}_{t},{{{{\boldsymbol{z}}}}}_{s}\right)$$\end{document}The minimization of the information potential corresponds to maximizing the variance of the feature vectors, which increases the coverage of data samples. In our situation, selecting the corner cases can be represented by minimizing the IP functions, which pushes more diversification in selecting the instances.
Secondly, we utilize the MMD as the statistical criterion to measure representativeness. MMD is an important statistical metric to quantify the statistical distance between two distributions in the RKHS^24^. In our study, we aim to use the selected cases z1,...,zM to approximate the original data sets x1,...,xN. Here, we use the term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\mathbb{P}}}_{{{{\boldsymbol{x}}}}}$$\end{document} to define the probability distribution constructed based on the points x1,...,xN, and we define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\mathbb{P}}}_{{{{\boldsymbol{z}}}}}$$\end{document} as the probability distribution constructed with z1,...,zM. Based on the sample data,^24^ use an approach of U statistic to estimate the squared MMD as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${MMD}_{u}^{2}\left({{\mathbb{P}}}_{{{{\boldsymbol{x}}}}},{{\mathbb{P}}}_{{{{\boldsymbol{z}}}}}\right)=\frac{1}{{N}^{2}}{\sum }_{i=1}^{N}{\sum }_{j=1}^{N}{{{\mathcal{K}}}}({{{{\boldsymbol{x}}}}}_{i},{{{{\boldsymbol{x}}}}}_{j})+\frac{1}{{M}^{2}}{\sum }_{i=1}^{M}{\sum }_{j=1}^{M}{{{\mathcal{K}}}}({{{{\boldsymbol{z}}}}}_{i},{{{{\boldsymbol{z}}}}}_{j})-\frac{2}{MN}{\sum }_{i=1}^{N}{\sum }_{j=1}^{M}{{{\mathcal{K}}}}({{{{\boldsymbol{x}}}}}_{i},{{{{\boldsymbol{z}}}}}_{j})$$\end{document}Smaller values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${MMD}_{u}^{2}\left({{\mathbb{P}}}_{{{{\boldsymbol{x}}}}},{{\mathbb{P}}}_{{{{\boldsymbol{z}}}}}\right)$$\end{document} indicate xthat the selected cases z1,...,zM closely approximate the target distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\mathbb{P}}}_{{{{\boldsymbol{x}}}}}$$\end{document} .^24^ theoretically discuss the asymptotic properties of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${MMD}_{u}^{2}\left({{\mathbb{P}}}_{{{{\boldsymbol{x}}}}},{{\mathbb{P}}}_{{{{\boldsymbol{z}}}}}\right)$$\end{document} toward \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${MMD}^{2}\left({{\mathbb{P}}}_{{{{\boldsymbol{x}}}}},{{\mathbb{P}}}_{{{{\boldsymbol{z}}}}}\right)$$\end{document} based on the properties of U statistics and RKHS. Based on these established theoretical guarantees, we will use this \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${MMD}_{u}^{2}\left({{\mathbb{P}}}_{{{{\boldsymbol{x}}}}},{{\mathbb{P}}}_{{{{\boldsymbol{z}}}}}\right)$$\end{document} to quantify the representativeness of selected cases z1,...,zM.
Stochastic sampling algorithm
One way to generate stochastic samplings from the candidate test case pool x1,...,xN is to sample M points based on a sequence of assigned importance measures w1,...,wN. In this context, larger values of the importance measure wi for the case xi indicate a higher likelihood of inclusion in the subsampled M cases. To ensure the preservation of probabilistic interpretation, we enforce the constraints that the assigned importance measures wj > 0 for all j = 1,..., N and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\sum }_{i=1}^{N}{w}_{i}=1$$\end{document} .
The calculation of IP in Eq. (8) treats each sample in x1,...,xN with an equal importance measure, i.e., each of the cases in the test case pool has the importance measure as 1/N. Here, we consider x1,...,xN to be associated with unequally important measures. The points that accompany more important measures should have higher weights in the estimation of IP, and vice versa. In this context, we define the IP with importance measures for the associated points w1,...wN as I**Px,wg**t in the following:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${IP}_{{{{\boldsymbol{x}}}},{{{\rm{w}}}}gt}={\sum }_{t=1}^{N}{\sum }_{s\ne t,s=1}^{N}{w}_{t}{w}_{S}{{{\mathcal{K}}}}\left({{{{\boldsymbol{x}}}}}_{t},{{{{\boldsymbol{x}}}}}_{s}\right)$$\end{document}Based on Eq. (10), the key is to find optimal values in the importance measures that can minimize IP. Then, such optimal importance measures could be used to generate M sub-samples. With the importance measures w1,...wN, the optimization implemented in Step 1 is equivalent to solving minIPx,wg**t. For this optimization problem, we denote a vector w = (w1,...,wN), and the matrix as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\mathcal{K}}}}}_{XX}$$\end{document} whose (i, j) th entry is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${({{{{\mathcal{K}}}}}_{XX})}_{ij}={{{\mathcal{K}}}}({{{{\boldsymbol{x}}}}}_{i},{{{{\boldsymbol{x}}}}}_{j})$$\end{document} . Thus, we can reformulate I**Px,wg**t as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${IP}_{{{{\boldsymbol{x}}}},{{{\rm{w}}}}gt}={{{{\rm{w}}}}}^{\top }{{{{\mathcal{K}}}}}_{XX}{{{\rm{w}}}}$$\end{document} . Mathematically, minimizing the information potential with importance measures is as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\min {{{\rm{w}}}}\,{IP}_{{{{\boldsymbol{x}}}},{{{\rm{w}}}}gt}=\min {{{\rm{w}}}}\,{{{{\rm{w}}}}}^{\top }{{{{\mathcal{K}}}}}_{XX}{{{\rm{w}}}}\,s.t.\,\parallel {{{\rm{w}}}}{\parallel }_{1}=1$$\end{document}We can easily derive a closed-form solution for this optimization problem and the optimal sampling weight w^^ calculated as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\rm{w}}}}}^{*}=\frac{{{{{\mathcal{K}}}}}_{XX}^{-1}{{{\mathrm{1}}}}_{N}}{{{{\mathrm{1}}}}_{N}^{\top }{{{{\mathcal{K}}}}}_{XX}^{-1}{{{\mathrm{1}}}}_{N}}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathrm{1}}}}_{N}^{\top }$$\end{document} denotes an N-length all ones vector. Unfortunately, calculating the exact / pseudo inverse matrix of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\mathcal{K}}}}}_{XX}$$\end{document} is neither computationally efficient nor accurate when the size N becomes sufficiently large^45^. To this end, we propose a more efficient approach to approximate the optimization problem above. We set the importance measure for case x_i_ as w_i, which results in a weighted set {(x1, w1),...,(xN, wN)}. Larger values in wi_ indicate a higher chance of the corresponding case x_i_ being among the M selected cases. Rather than treating w1,...w_N_ as independent free parameters to be optimized, which would be computationally expensive, we approximate their optimal values using a shared parametric function. That is, we set the importance measure for the case x_i_ as w_θ(xi), where the function is parameterized by θ as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${w}_{\theta }:{{\mathbb{R}}}^{d}\to {\mathbb{R}}$$\end{document} . Specifically, we set this function wθ*_(⋅) as a simple multiple-layer perceptron (one layer in our studies proves very effective), with Softmax as the activation function. The parameter θ should fall on the p-dimensional unit ball, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \in {{{{\mathcal{B}}}}}^{p}$$\end{document} . With these, we define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\mathcal{E}}}}}_{X}(\theta )$$\end{document} as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\mathcal{E}}}}}_{X}(\theta )={\sum }_{i=1}^{N}{\sum }_{j\ne i}^{N}{w}_{\theta }({{{{\boldsymbol{x}}}}}_{i}){w}_{\theta }({{{{\boldsymbol{x}}}}}_{j}){{{\mathcal{K}}}}({{{{\boldsymbol{x}}}}}_{i},{{{{\boldsymbol{x}}}}}_{j})$$\end{document}In order to select the M sub-samples with the minimal IP, we first minimize \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\mathcal{E}}}}}_{X}(\theta )$$\end{document} , so as to approximate the optimal importance measures which lead to the minimum in the IP. We can approximate the optimal importance measures through \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{1}),...{w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{N})$$\end{document} , where the parameters θopt can be achieved through the following optimization process:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\theta }_{{{{\rm{opt}}}}}={{{\rm{argmin}}}}_{\theta \in {{{{\mathscr{B}}}}}^{p}}\,{{{{\mathscr{E}}}}}_{X}(\theta )={{{\rm{argmin}}}}_{\theta \in {{{{\mathscr{B}}}}}^{p}}{\sum }_{i=1}^{N}{\sum }_{j\ne i}^{N}{w}_{\theta }({{{{\boldsymbol{x}}}}}_{i}){w}_{\theta }({{{{\boldsymbol{x}}}}}_{j}){{{\mathcal{K}}}}({{{{\boldsymbol{x}}}}}_{i},{{{{\boldsymbol{x}}}}}_{j})$$\end{document}Based on the optimized function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${w}_{{\theta }_{{{{\rm{opt}}}}}}(\cdot )$$\end{document} for x1, . . , xN, we generate importance measures \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{1}),..,{w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{N})$$\end{document} . Pareto order sampling is then applied to generate exactly M sub-samples z1, . . . , zM based on these importance measures. A more detailed discussion of Pareto order sampling can be found in^46^. We first generate random variables U1, . . . , UN from a Uniform(0,1) distribution. Then, for each case i, we compute the Pareto ranking variables as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Q}_{i}=\frac{{U}_{i}}{1-{U}_{i}}\times \frac{1-{w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{1})}{{w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{i})}$$\end{document} for i = 1, . . . , N. Among all Q1, . . . , QN, we select the M smallest values. The corresponding M samples are then selected as the final sub-sample, weighted according to their importance measures \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{1}),..,{w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{N})$$\end{document} . We summarize the stochastic sampling procedure in Box 1.
Box 1 Algorithm for stochastic samplings through optimizations
- Do the optimization \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\theta }_{{{{\rm{opt}}}}}={{{\rm{argmin}}}}\theta \,{\sum }_{i=1}^{N}{\sum }_{j\ne i}^{N}{w}_{\theta }({{{{\boldsymbol{x}}}}}_{i}){w}_{\theta }({{{{\boldsymbol{x}}}}}_{j}){{{\mathcal{K}}}}({{{{\boldsymbol{x}}}}}_{i},{{{{\boldsymbol{x}}}}}_{j})$$\end{document}
- Calculate the importance measures as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{1}),..,{w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{N})$$\end{document}
- Pareto order sampling^46^ is implemented:
- Generate U1, . . . UN ~ Uniform(0,1)
- Calculate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Q}_{i}=\frac{{U}_{i}}{1-{U}_{i}}\times \frac{1-{w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{i})}{{w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{i})}$$\end{document} for i = 1, . . . , N
- Rank Q1, . . . , QN, we select the M smallest ones.
- The corresponding cases labeled as z1, . . . zM
- Output: z1, . . . zM as the selected points through stochastic sampling.
Attention-based mechanism
Based on the selected points, we next investigate how to assign distribution alignment weights λ1, . . , λM to each of the selected points z1, . . . , zM so as to increase representativeness. The objective in optimizing the weights is to minimize the MMD between the weighted version of z1, . . . , zM and the original dataset x1, . . . , xN. Here, under this setup, we can estimate the MMD between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\mathbb{P}}}_{{{{\boldsymbol{x}}}}}$$\end{document} and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\mathbb{P}}}_{{{{{\boldsymbol{z}}}}}^{*}}$$\end{document} as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${MMD}_{u}^{2}\left({{\mathbb{P}}}_{{{{\boldsymbol{x}}}}},{{\mathbb{P}}}_{{{{{\boldsymbol{z}}}}}^{*}}\right)=\frac{1}{{N}^{2}}{\sum }_{i=1}^{N}{\sum }_{j=1}^{N}{{{\mathcal{K}}}}({{{{\boldsymbol{x}}}}}_{i},{{{{\boldsymbol{x}}}}}_{j})+{\sum }_{i=1}^{M}{\sum }_{j=1}^{M}{\lambda }_{i}{\lambda }_{j}{{{\mathcal{K}}}}({{{{\boldsymbol{z}}}}}_{i},{{{{\boldsymbol{z}}}}}_{j})-2\frac{1}{N}{\sum }_{i=1}^{N}{\sum }_{j=1}^{M}{\lambda }_{j}{{{\mathcal{K}}}}({{{{\boldsymbol{x}}}}}_{i},{{{{\boldsymbol{z}}}}}_{j})$$\end{document}As the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{1}{{N}^{2}}{\sum }_{i=1}^{N}{\sum }_{j=1}^{N}{{{\mathcal{K}}}}({{{{\boldsymbol{x}}}}}_{i},{{{{\boldsymbol{x}}}}}_{j})$$\end{document} is a constant as long as the original dataset is fixed, so as optimizing the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${MMD}_{u}^{2}\left({{\mathbb{P}}}_{{{{\boldsymbol{x}}}}},{{\mathbb{P}}}_{{{{{\boldsymbol{z}}}}}^{*}}\right)$$\end{document} is equivalent with optimizing the remaining terms. We use a vector λ to represent \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\boldsymbol{\lambda }}}}={({\lambda }_{1},...,{\lambda }_{M})}^{\top }$$\end{document} as a M × 1 vector, and for simplicity, we define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{{{{\bf{K}}}}}=\frac{1}{N}{{{\mathrm{1}}}}_{N}^{\top }{{{{\mathcal{K}}}}}_{{{{\boldsymbol{x}}}}{{{\boldsymbol{z}}}}}$$\end{document} as an M × 1 vector, so as minimizing the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${MMD}_{u}^{2}\left({{\mathbb{P}}}_{{{{\boldsymbol{x}}}}},{{\mathbb{P}}}_{{{{{\boldsymbol{z}}}}}^{*}}\right)$$\end{document} is equivalent as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\rm{minimize}}}}\,{{{\boldsymbol{\lambda }}}}\,\frac{1}{2}{{{{\boldsymbol{\lambda }}}}}^{\top }{{{{\mathcal{K}}}}}_{{{{\boldsymbol{zz}}}}}{{{\boldsymbol{\lambda }}}}-{{{{\boldsymbol{\lambda }}}}}^{\top }\overline{{{{\bf{K}}}}}\,\,{{{\rm{s.t.}}}}\,\,{\sum }_{i=1}^{M}{\lambda }_{i}=1\,\,{{{\rm{and}}}}\,\,{\lambda }_{1},...,{\lambda }_{M} > 0$$\end{document}Thus, we can achieve the selected points z1, . . . , zM and associated weights as λ1, . . . , λM. These λ-weights serve as the distribution alignment weights, used to realign the empirical distribution of the subset z1, . . . , zM with that of the entire candidate test case pool x1, . . . , xN.
KTCS algorithm
The KTCS algorithm, designed to simultaneously achieve a balance between representativeness and coverage. The logic of the KTCS method is to construct a weighted subset of data that allows for closely approximates the inference using the entire test case pool. Coverage ensures that the selected data points encompass a diverse range of scenarios, while representativeness ensures the selected subset closely approximates the behavior of the entire dataset. Achieving optimal coverage and representativeness is equivalent to minimizing IP and MMD simultaneously, as smaller values in IP and MMD indicate greater diversity and better representativeness. We state our optimization objective as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\,{{{\rm{Step}}}}\; 1\; :\,{{{\rm{argmin}}}}_{{{{\boldsymbol{z}}}}_{1},...{{{{\boldsymbol{z}}}}}_{M}}\,{IP}_{{{{\boldsymbol{z}}}}}={{{\rm{argmin}}}}_{{{{\boldsymbol{z}}}}_{1},...{{{{\boldsymbol{z}}}}}_{M}}\,\frac{1}{M(M-1)}{\sum }_{t=1}^{M}{\sum }_{s=1,s\ne t}^{M}{{{\mathcal{K}}}}\left({{{{\boldsymbol{z}}}}}_{t},{{{{\boldsymbol{z}}}}}_{s}\right)\,\,{{{\rm{where}}}}\,\,{{{{\boldsymbol{z}}}}}_{1},...{{{{\boldsymbol{z}}}}}_{M}\in \{{{{{\boldsymbol{x}}}}}_{1},...,{{{{\boldsymbol{x}}}}}_{N}\}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\rm{Step}}}}\; 2\; :\,{{{\rm{argmin}}}}_{\lambda _{1},...{\lambda }_{M}}{{{\rm{MMD}}}}_{u}^{2}\left({{\mathbb{P}}}_{{{{\boldsymbol{x}}}}},{{\mathbb{P}}}_{{{{{\boldsymbol{z}}}}}^{*}}\right)={{{\rm{minimize}}}}_{{{\boldsymbol{\lambda }}}}\,\frac{1}{2}{{{{\boldsymbol{\lambda }}}}}^{\top }{{{{\mathcal{K}}}}}_{{{{\boldsymbol{zz}}}}}{{{\boldsymbol{\lambda }}}}-{{{{\boldsymbol{\lambda }}}}}^{\top }\overline{{{{\bf{K}}}}}\,\,{{{\rm{s.t.}}}}\,\,{\sum }_{i=1}^{M}{\lambda }_{i}=1\,\,{{{\rm{and}}}}\,\,{\lambda }_{1},...,{\lambda }_{M} > 0$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\mathbb{P}}}_{{{{{\boldsymbol{z}}}}}^{*}}$$\end{document} means that the distribution is established by the points z1, . . . , zM with associated weights λ1, . . . λM. The kernel mean embedding for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\mathbb{P}}}_{{{{{\boldsymbol{z}}}}}^{*}}$$\end{document} is as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mu }_{{{\mathbb{P}}}_{{{{{\boldsymbol{z}}}}}^{*}}}={\sum }_{j=1}^{M}{\lambda }_{j}\phi ({{{\boldsymbol{z}}}})$$\end{document} .
KTCS algorithm has two steps. Step 1 focuses on a discrete design, where the key idea is to select M cases from the original pool of N candidate test cases. The optimization variables are w1, . . , wN for x1, . . . , xN, and the objective is to minimize the IP. Minimizing IP promotes well-dispersed selections in the feature space, serving as a surrogate for diversity and coverage. In Step 2, we re-weight the M selected cases so that their empirical distribution aligns as closely as possible with that of the full candidate pool. The optimization variables are λ1, . . , λM for z1, . . . , zN, and the objective is to minimize MMD in Eq. (17), which quantifies representativeness. Together, this dual-step process creates a computationally efficient framework that selects and weights data points to maintain both diversity and representativeness, enabling accurate and scalable inference. Extensive Monte Carlo simulations to validate the performance of the KTCS algorithm are shown in the supplementary part.
Theoretical discussion
This section presents the theoretical guarantees of the KTCS method. We first examine its ability to ensure scenario coverage. In particular, we analyze the theoretical behavior of the proposed approach by investigating the asymptotic properties of the IP metric, which quantifies coverage, under stochastic sampling of selected scenarios. Theorem 1 shows that when N is sufficiently large, I**Pz approximates well to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\mathcal{E}}}}}_{X}({\theta }_{{{{\rm{opt}}}}})$$\end{document} , that is, the minimize of the information potential with weighted importance measures.
Theorem 1
Define I**Pz as the information potential with the selected points through Pareto order sampling. When the size N goes sufficiently large, the following holds:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${IP}_{{{{\boldsymbol{z}}}}}\to {{{{\mathcal{E}}}}}_{X}({\theta }_{{{{\rm{opt}}}}})\,\,{{{\rm{as}}}}\,\,N\to \infty \,\,{{{\rm{where}}}}\,\,{{{{\mathcal{E}}}}}_{X}({\theta }_{{{{\rm{opt}}}}})={\sum }_{i=1}^{N}{\sum }_{j\ne i}^{N}{w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{i}){w}_{{\theta }_{{{{\rm{opt}}}}}}({{{{\boldsymbol{x}}}}}_{j}){{{\mathcal{K}}}}({{{{\boldsymbol{x}}}}}_{i},{{{{\boldsymbol{x}}}}}_{j})$$\end{document}We next establish the asymptotic behaviors of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\mathcal{E}}}}}_{X}({\theta }_{{{{\rm{opt}}}}})$$\end{document} towards global minimization in the Information Potential defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{E}}}}({\theta }^{*})$$\end{document} in the following theorem. Based on the discussions in Theorem 2, we find that the minimize of the IP with weighted importance measures \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\mathcal{E}}}}}_{X}({\theta }_{{{{\rm{opt}}}}})$$\end{document} will finally converge towards global minimization in the IP defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{E}}}}({\theta }^{*})$$\end{document} when the size N goes sufficiently large,
Theorem 2
Assume that the parameter θ falls on the p dimensional unit ball (i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \in {{{{\mathcal{B}}}}}^{p}$$\end{document} ) ϵ is some constant, and wθ(x)≤s. With at least a probability of 1 − δ:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{E}}}}({\theta }^{*})-{{{{\mathcal{E}}}}}_{X}({\theta }_{{{{\rm{opt}}}}})\le {R}_{N}+\frac{{s}^{2}K}{\sqrt{N}}\sqrt{2\log (2/\delta )+2p\log \left(1+\frac{2}{\epsilon }\right)}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\theta }^{*}={{{\rm{argmin}}}}\,\theta \in {{{{\mathcal{B}}}}}^{p}\,{{{\mathcal{E}}}}(\theta )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{E}}}}(\theta )=\int {{{\boldsymbol{x}}}}\in {\mathbb{X}}\int {{{{\boldsymbol{x}}}}}^{{\prime} }\in {\mathbb{X}}{{{\mathcal{K}}}}({{{\boldsymbol{x}}}},{{{{\boldsymbol{x}}}}}^{{\prime} }){w}_{\theta }({{{\boldsymbol{x}}}}){w}_{\theta }({{{{\boldsymbol{x}}}}}^{{\prime} })d{\mathbb{P}}({{{\boldsymbol{x}}}},{{{{\boldsymbol{x}}}}}^{{\prime} })$$\end{document} and RN is the empirical Rademacher complexity.
Theorem 1 and Theorem 2 show that the KTCS can select test cases with optimized coverage when the number of instances within the test case pool goes sufficiently large, as the IP of the subselected cases will finally converge to the global minimization in the IP, achieving the goal of Step 1 in Eq. (16).
Next, we theoretically investigate the ability of KTCS to ensure representativeness. We investigate the theoretical properties of the proposed method, KTCS. We define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu=\int \phi ({{{\boldsymbol{x}}}})d{\mathbb{P}}({{{\boldsymbol{x}}}})$$\end{document} as the population level kernel mean embedding. Our estimator, based on the selected samples with optimized weights, is constructed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{\mu }}_{M}={\sum }_{j=1}^{M}{\lambda }_{j}\phi ({{{{\boldsymbol{z}}}}}_{j})$$\end{document} . The following theorem states the error bound from our proposed estimator and the population level μ. Theorem 3 shows that N goes sufficiently large, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{\mu }}_{M}$$\end{document} approximates μ.
Theorem 3
Assumes the kernel function satisfying \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{K}}}}({{{\boldsymbol{z}}}},{{{{\boldsymbol{z}}}}}^{{\prime} })\le {{{\mathcal{K}}}}({{{\boldsymbol{z}}}},{{{\boldsymbol{z}}}})=K$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\boldsymbol{z}}}}\ne {{{{\boldsymbol{z}}}}}^{{\prime} }$$\end{document} . Define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta,c,{c}^{{\prime} },\lambda$$\end{document} as some constants and δ ∈ (0, 1), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\mathcal{N}}}}}_{\infty }(\lambda )$$\end{document} as some constant depending on λ. Then with at least a probability of 1 − δ, the following bound holds:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\left\Vert {\widehat{\mu }}_{M}-\mu \right\Vert }_{{{{\mathcal{H}}}}}\le \frac{2K\sqrt{2\log (6/\delta )}}{\sqrt{N}}+{c}^{{\prime} }K\frac{\sqrt{2\log (6/\delta )}}{\sqrt{M}} \\+\sqrt{3\lambda }\times \left(\frac{4\sqrt{{{{{\mathcal{N}}}}}_{\infty }(\lambda )}\log (12/\delta )}{M}+\sqrt{\frac{2c{\nu }_{{{{\boldsymbol{z}}}}}\log (12/\delta )}{M}}\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\nu }_{{{{\boldsymbol{z}}}}}^{2}={\mathbb{E}}\left(\right.\parallel \phi \left({{{{\boldsymbol{z}}}}}_{j}\right)-{\mathbb{E}}\left(\phi \left({{{{\boldsymbol{z}}}}}_{j}\right){\parallel }_{{{{\mathcal{H}}}}}^{2}\right)$$\end{document} is established on the selected points.
Remark 1
If set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M={{{\mathcal{O}}}}({N}^{1/2})$$\end{document} , under some mild conditions discussed in the supplementary part, then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\left\Vert {\widehat{\mu }}_{M}-\mu \right\Vert }_{{{{\mathcal{H}}}}}={{{\mathcal{O}}}}(\frac{1}{\sqrt{N}})$$\end{document} .
Remark: Theorem 3 shows that, when setting the number of selected cases to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M={{{\mathcal{O}}}}({N}^{1/2})$$\end{document} , then the KTCS method can achieve sufficient representativeness because the constructed density distribution using the selected cases can approximate the original test case pool. All technical proofs are presented in the supplementary part.
Supplementary information
Supplementary Information Transparent Peer Review file
Source data
Source Data
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Rahmani, S. et al. A systematic review of edge case detection in automated driving: Methods, challenges and future directions. ar Xiv preprint ar Xiv:2410.08491 (2024).
- 2Chatalic, A., Schreuder, N., Rosasco, L. & Rudi, A. Nyström kernel mean embeddings. In International Conference on Machine Learning, 3006–3024 (PMLR, 2022).
- 3Kim, B., Khanna, R. & Koyejo, O. O. Examples are not enough, learn to criticize. Criticism for interpretability. Advances in Neural Information Processing Systems 29, (2016).
- 4Vaswani, A. et al. Attention is all you need. Advances in Neural Information Processing Systems. 30, (2017).
- 5Chai, J. & Wang, X. Fairness with adaptive weights. In International Conference on Machine Learning, 2853–2866 (PMLR, 2022).
- 6Guan, Y. et al. World models for autonomous driving: An initial survey. IEEE Transactions on Intelligent Vehicles. (2024).
- 7ASAM. Open scenario. https://www.asam.net/standards/detail/openscenario/v 200/ (2024).
- 8Teymur, O., Gorham, J., Riabiz, M. & Oates, C. Optimal quantisation of probability measures using maximum mean discrepancy. In International Conference on Artificial Intelligence and Statistics, 1027–1035 (PMLR, 2021).