Benchmark evaluation of large language models for clinical decision support in headache management
Shi Chen, Dong Liang, Xu Qiu, Chengqi Dong, Jiayi Deng, Li Xu, Xiaoxue Dong, Yonglei Zhao, Xuemei Fan, Xiaoyu Liu, Yali Wu, Jianliang Sun, Feifang He, Ke Ma, Liang Yu, Hanbin Wang

TL;DR
This study evaluates how well large language models assist in diagnosing and managing headaches, finding that while some models perform better in certain areas, none match expert-level accuracy for clinical use.
Contribution
The study introduces a structured benchmark for evaluating LLMs in headache management, comparing models and prompting strategies.
Findings
ChatGPT-4o outperformed Grok-3 in diagnostic accuracy with the ask-in-sequence strategy.
Grok-3 and DeepSeek-R1 showed higher supplementary value depending on the prompting strategy.
Readability varied significantly, with Gemini 2.5 Pro having the best readability across strategies.
Abstract
Background: Headache disorders are a major cause of disability worldwide. In routine practice, diagnosis and guideline-based management are difficult because symptoms can overlap between primary and secondary headaches, and clinicians must combine clinical, imaging, and pathological information. Large language models (LLMs) are being proposed to assist clinical reasoning, but their performance on headache cases and their sensitivity to prompting have not been systematically assessed. Methods: We evaluated seven leading LLMs using 13 headache cases from the New England Journal of Medicine (NEJM). We compared two prompting strategies: ask-in-sequence (AS) and ask-at-once (AO). Using a 5-point Likert rubric, three headache specialists independently scored six dimensions: rationality of diagnostic thinking, comprehensiveness of differential diagnosis, diagnostic accuracy,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
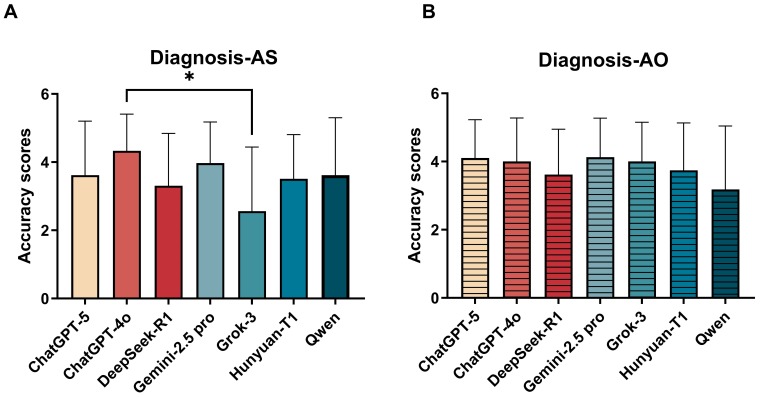 Figure 1
Figure 1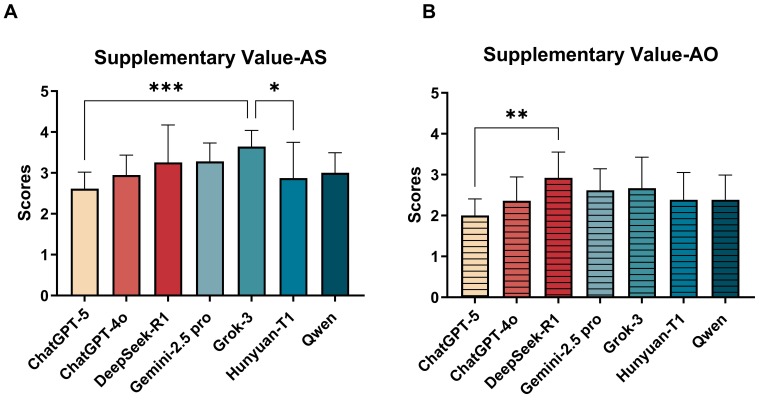 Figure 2
Figure 2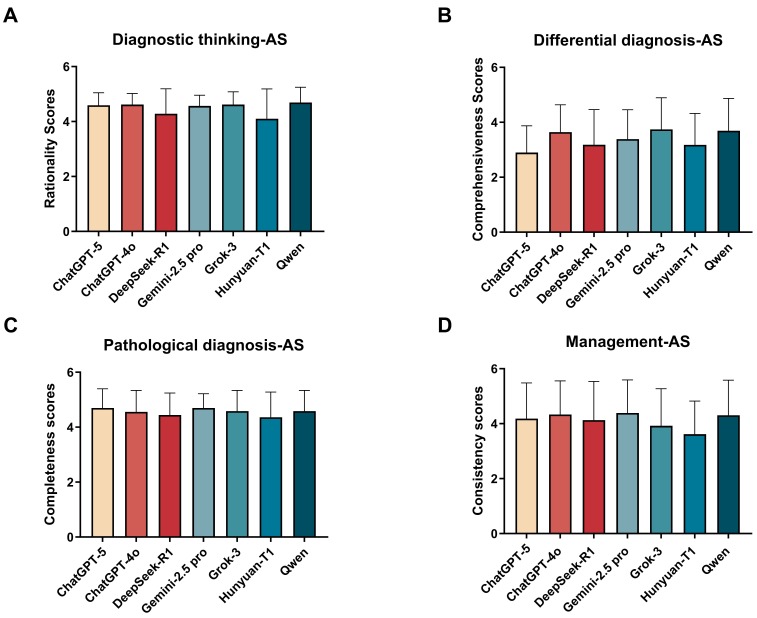 Figure 3
Figure 3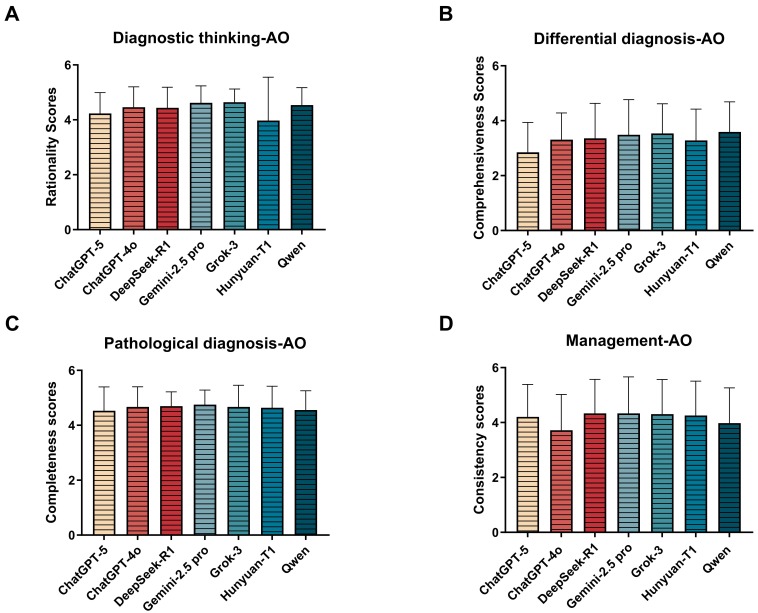 Figure 4
Figure 4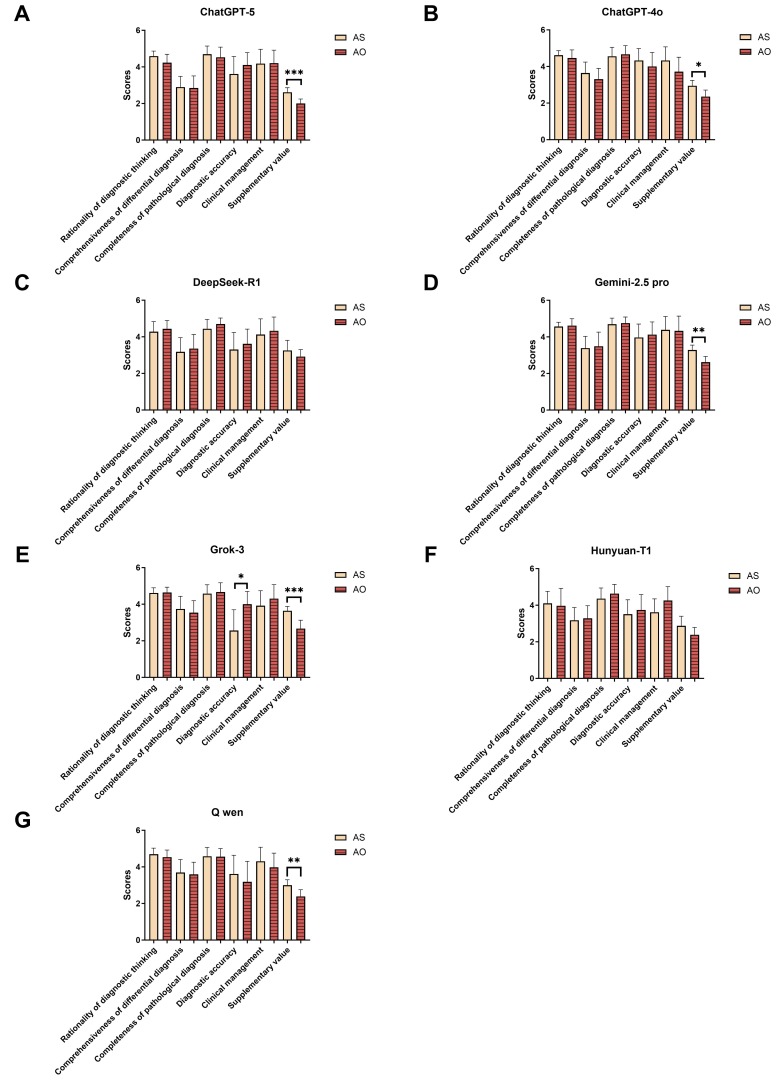 Figure 5
Figure 5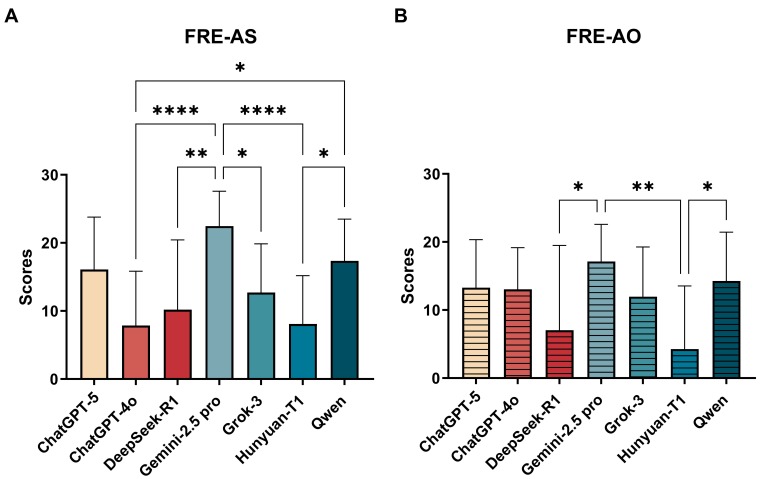 Figure 6
Figure 6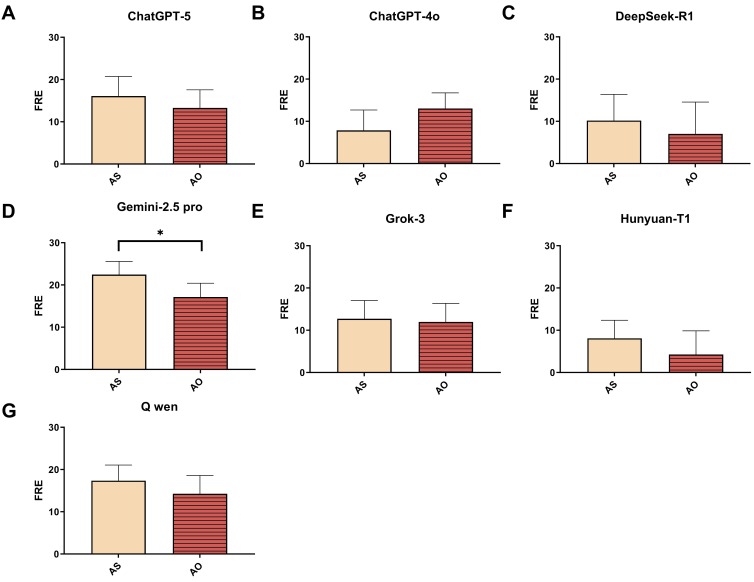 Figure 7
Figure 7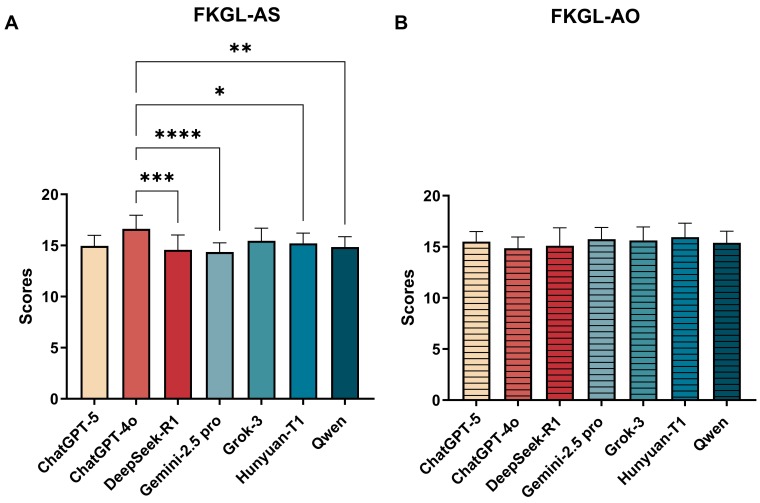 Figure 8
Figure 8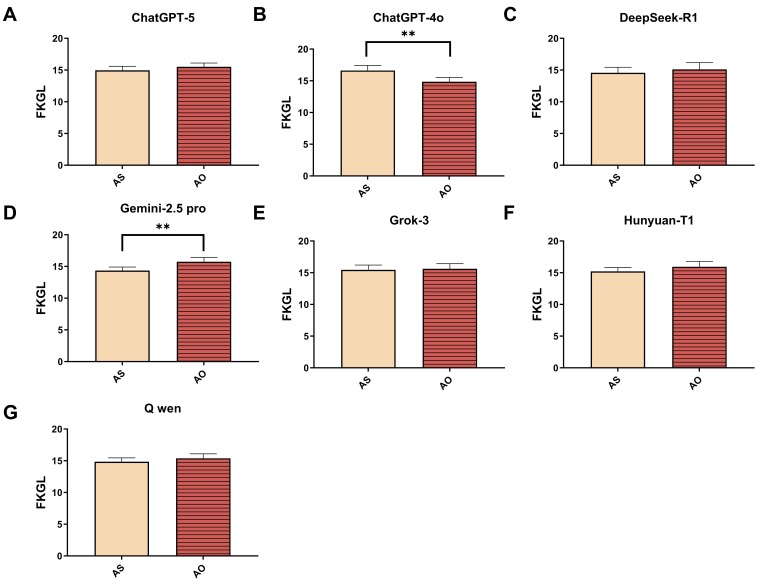 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Machine Learning in Healthcare · Clinical Reasoning and Diagnostic Skills