A robust sampling technique for realistic distribution simulation in federated learning
Robin Hoepp, Leonhard Rist, Alexander Katzmann, Raghavan Ashok, Andreas Wimmer, Michael Sühling, Andreas Maier

TL;DR
This paper introduces a sampling method to simulate realistic data distributions in federated learning, showing how client biases can degrade model performance.
Contribution
A novel sampling algorithm using chi-squared and Gini impurity to simulate non-IID label distributions in federated learning.
Findings
The proposed sampling technique realistically simulates client-biased label distributions.
A global model's performance dropped by 25.3% on weight and 28.7% on height estimation due to biased distributions.
The method is architecture-agnostic and applicable to various non-IID problems.
Abstract
Federated Learning helps training deep learning networks with diverse data from different locations, particularly in restricted clinical settings. However, label distributions overlapping only partially across clients, due to different demographics, may significantly harm the global training, and thus local model performance. Investigating such effects before rolling out large-scale Federated Learning setups requires proper sampling of the expected label distributions. We present a sampling algorithm to build data subsets according to desired mean and standard deviations from an initial global distribution. To this end, we incorporate the chi-squared and Gini impurity measures to numerically optimize label distributions for multiple groups in an efficient fashion. Using a real-world application scenario, we sample train and test groups according to region-specific distributions for 3D…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
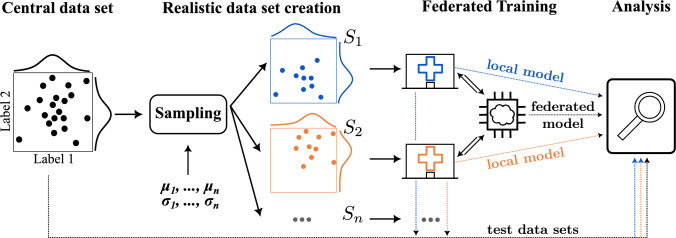 Figure 1
Figure 1 Figure 2
Figure 2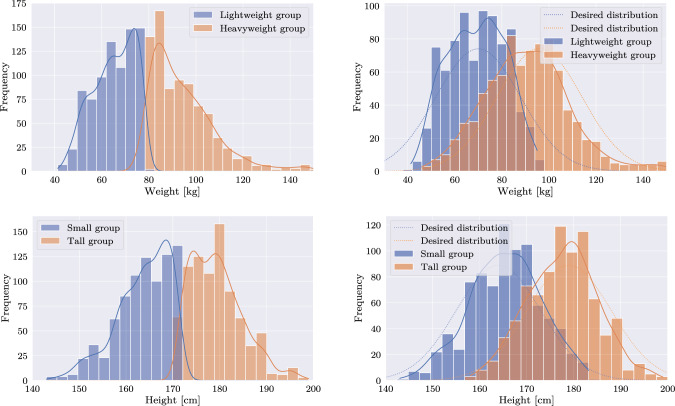 Figure 3
Figure 3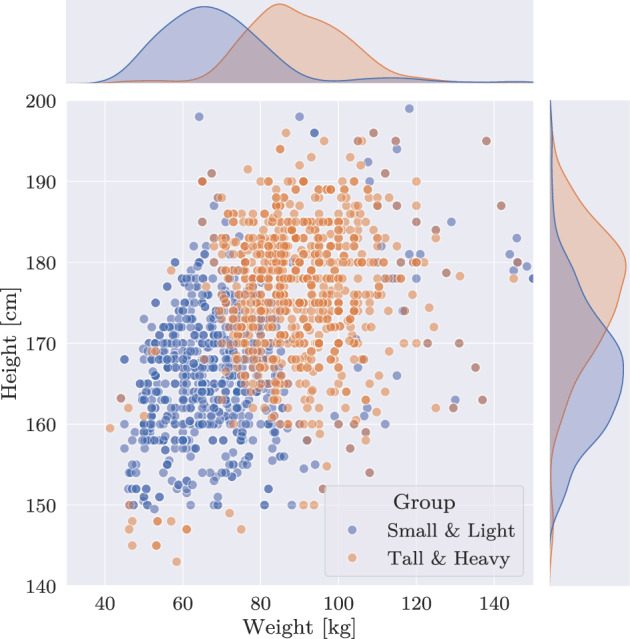 Figure 4
Figure 4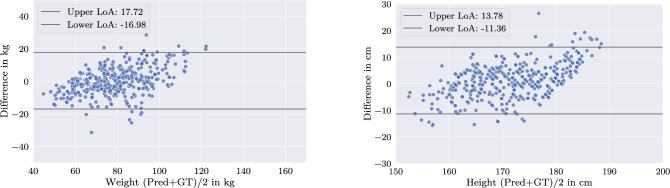 Figure 5
Figure 5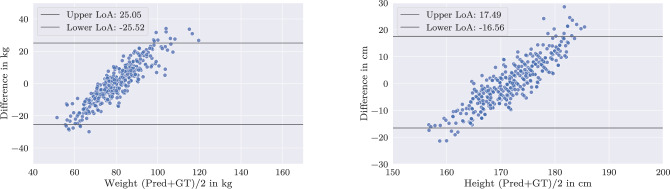 Figure 6
Figure 6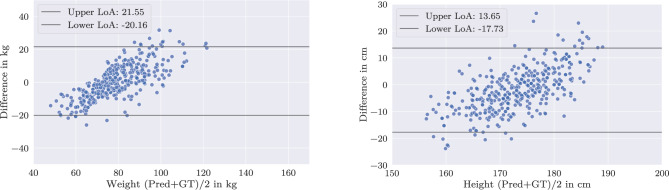 Figure 7
Figure 7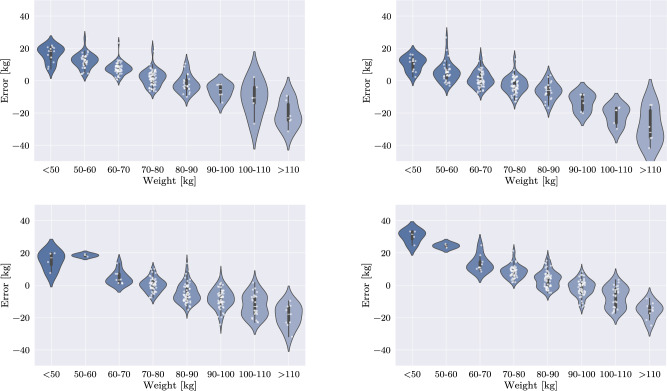 Figure 8
Figure 8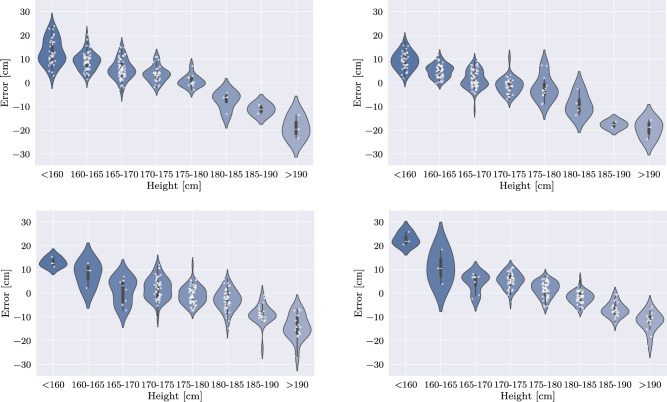 Figure 9
Figure 9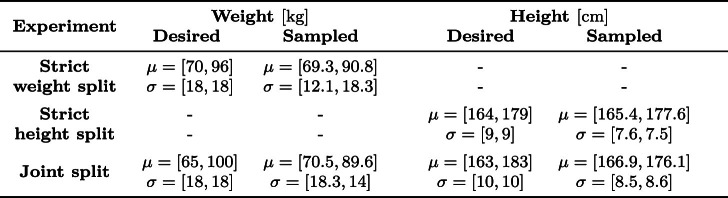 Figure 10
Figure 10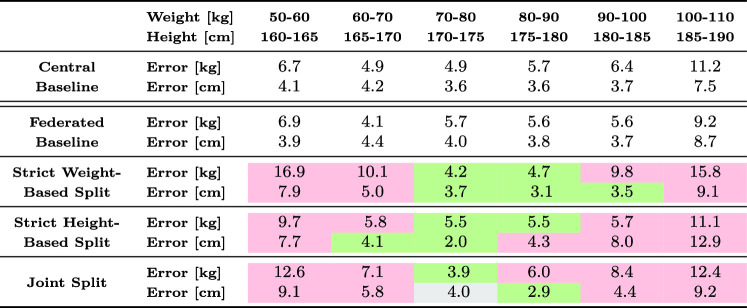 Figure 11
Figure 11 Figure 12
Figure 12Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPrivacy-Preserving Technologies in Data · Domain Adaptation and Few-Shot Learning · Colorectal Cancer Screening and Detection