A review of recent advances in generative artificial intelligence models for biomolecular sciences
Jian Jiang, Daixin Li, Guilin Wang, Nicole Hayes, Yazhou Shi, Huahai Qiu, Bengong Zhang, Tianshou Zhou, Guo-Wei Wei

TL;DR
This paper reviews recent developments in generative AI models and their applications in biomolecular sciences, such as drug discovery and protein design.
Contribution
The paper provides a systematic overview of generative AI models in biomolecular sciences and identifies key challenges and future directions.
Findings
Generative models like VAEs, GANs, and diffusion models are being used for molecular design and property prediction.
Current challenges include model interpretability, scalability, and the need for better molecular datasets.
Emerging research directions aim to improve the reliability and applicability of these models in biomolecular problems.
Abstract
Generative artificial intelligence (AI) models, a class of AI techniques that learn data distributions to synthesize novel samples, have emerged as impactful tools across scientific disciplines. In recent years, these models have found extensive applications in fields such as natural language processing and biomedical sciences. Despite their growing influence, comprehensive reviews on the application of generative models in biomolecular sciences remain limited. In this review, we provide a systematic overview of recent advances in generative models applied to biomolecular sciences. We discuss several prominent generative architectures, including variational autoencoders, generative adversarial networks, and diffusion models, highlighting their applications in molecular design and bioinformatics. Additionally, we examine how these models contribute to critical challenges such as…
Click any figure to enlarge with its caption.
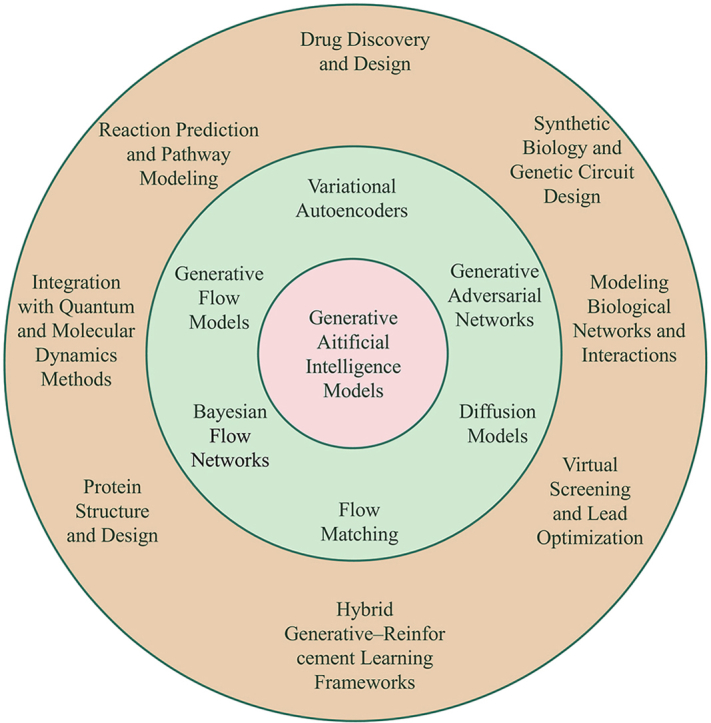 Figure 1
Figure 1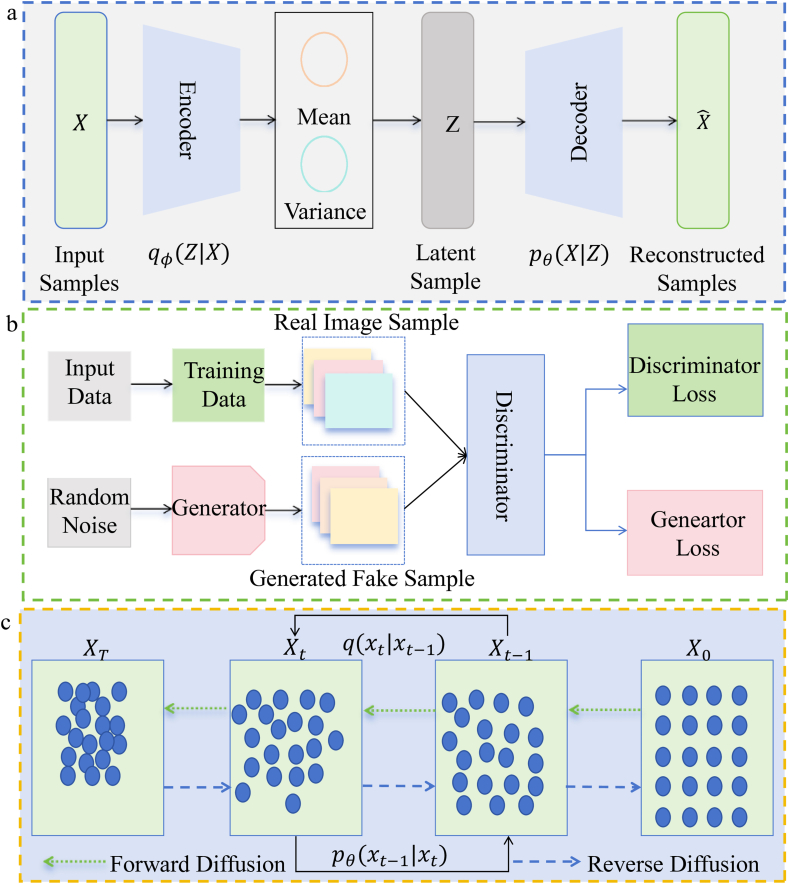 Figure 2
Figure 2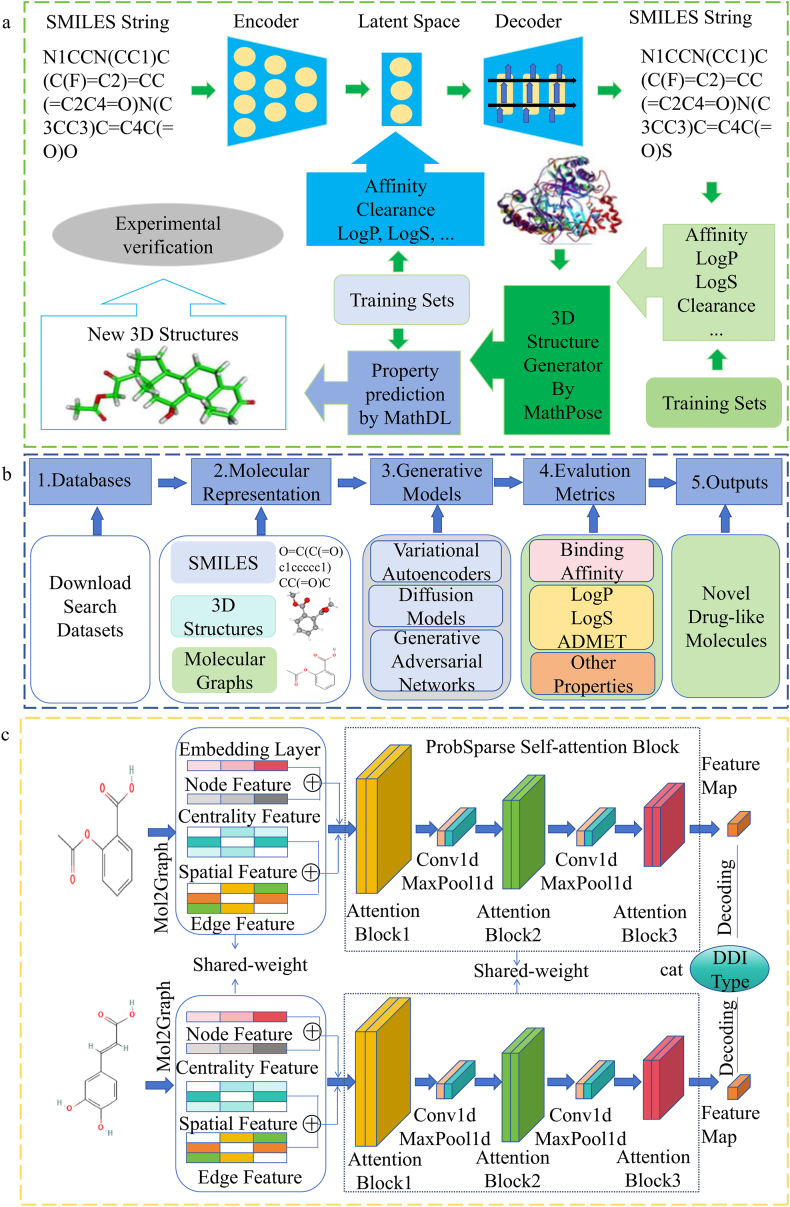 Figure 3
Figure 3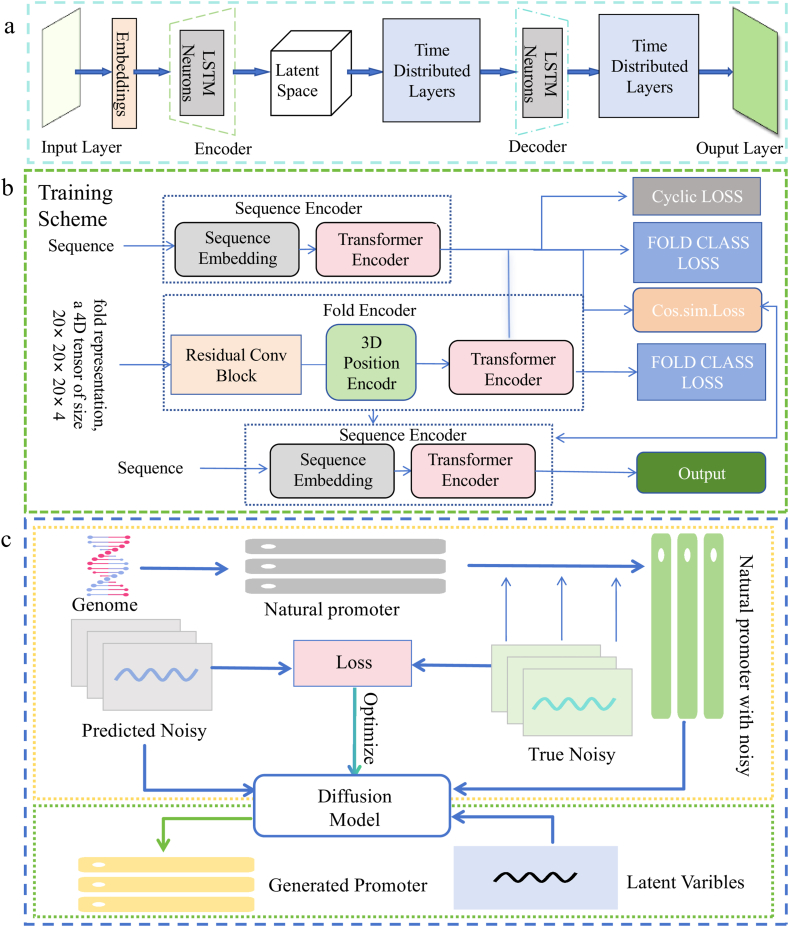 Figure 4
Figure 4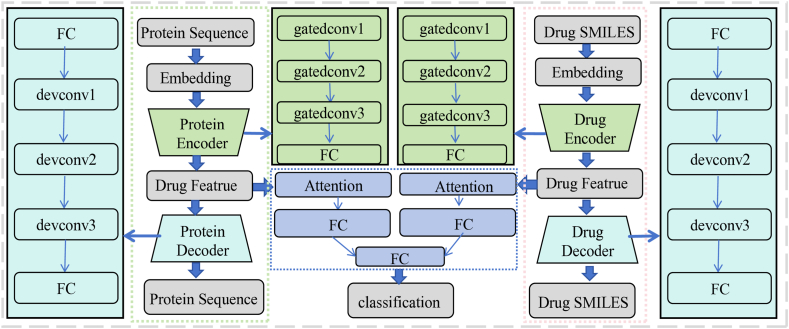 Figure 5
Figure 5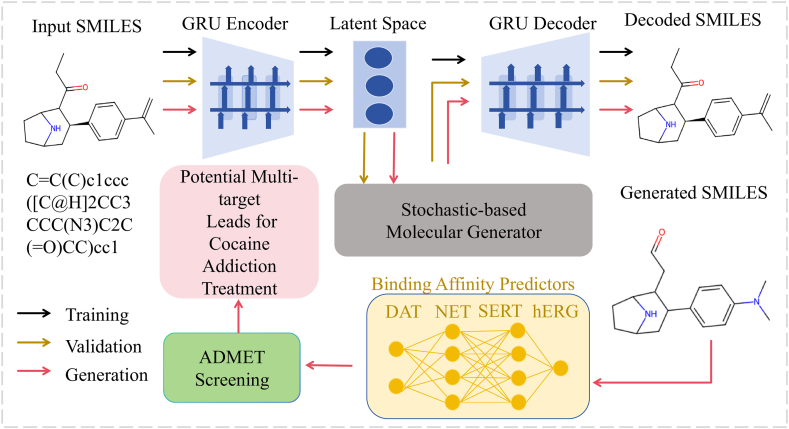 Figure 6
Figure 6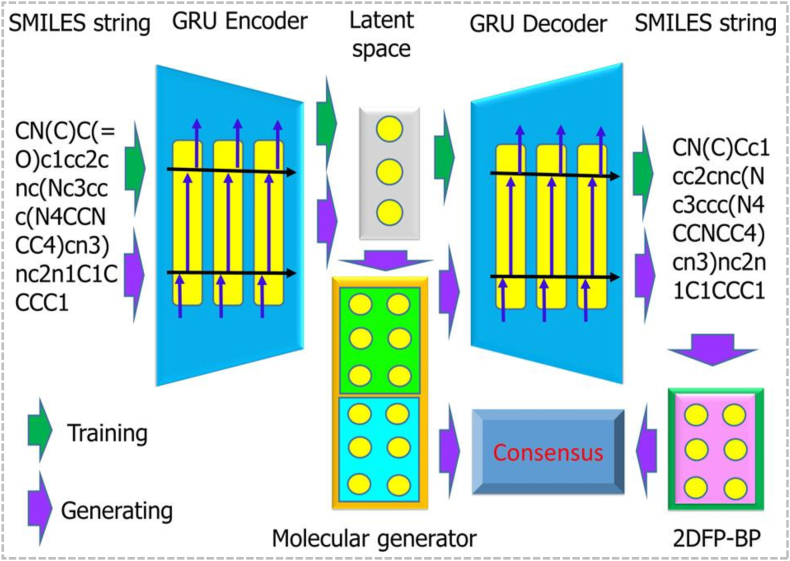 Figure 7
Figure 7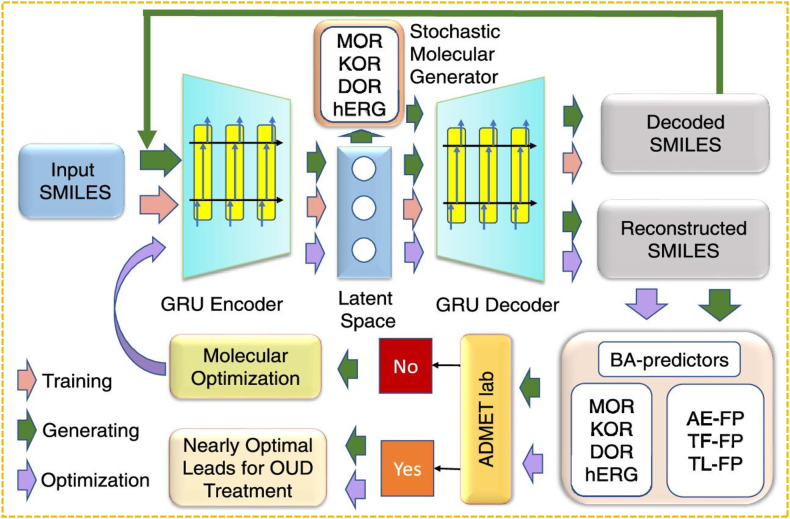 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Materials Science · Machine Learning in Bioinformatics · Generative Adversarial Networks and Image Synthesis
Introduction
1
In the past decade, machine learning (ML) has transformed biomolecular sciences, including molecular biology, biochemistry, and structural biology, allowing researchers to address complex biological questions, design novel compounds, and predict molecular properties1. Among various ML paradigms, generative artificial intelligence (AI) models stand out for their ability to synthesize new molecular structures and properties from learned representations2. This not only accelerates discovery but also enhances creativity in molecular design, reduces experimental time and costs, and facilitates deeper exploration of biomolecular sciences. Generative models learn the data distribution to generate new data similar to real data. By learning the statistical characteristics of the sample data, they can generate new data that mirrors the training set. These models are widely used in biomolecular sciences to accelerate drug discovery and protein engineering, improve experimental efficiency, and reduce development costs2^,^3. Techniques such as generative adversarial networks (GANs)4, variational autoencoders (VAEs)5, and diffusion models (DMs)6 can help researchers efficiently search and optimize within a vast molecular design space, driving technological advancements in multiple fields7.
In biomolecular sciences, generative models are used to predict and design molecular structures and properties, especially in drug design, protein design, and chemical reaction prediction. These models, as a subset of ML, learn from existing data to generate new structures with desired properties by capturing the relationship between structure and function. Unlike other models, generative models focus on sampling data distributions to design molecules with specific properties, saving both time and cost8.
The field of generative models is rapidly evolving. Existing reviews on the application of generative models in biomolecular sciences are limited, and further exploration is needed. This paper examines their potential to transform biomolecular sciences by offering innovative solutions and advancing our understanding of molecular systems. Despite challenges such as data scarcity, interpretability, and computational demands, future developments should focus on improving model accuracy, interpretability, and integration with experimental research. We analyze the strengths, limitations, and prospects of generative models, demonstrating how they can accelerate scientific discovery and innovation in biomolecular sciences9.
The remainder of this article is organized as follows. Section 2 introduces generative technologies, methods, and theoretical foundations. Sections 2.2–2.3 provide detailed overviews of different generation methods and mathematical foundations. Section 3 discusses the applications of generative models in biomolecular sciences. Section 4 addresses current challenges and limitations, while Section 5 explores future prospects in biomolecular sciences.
Overview of generative models
2
Introduction to generative modeling techniques
2.1
Model generation is a subfield of ML that focuses on learning data distribution and generating relevant features of the original data10. Unlike discriminative models, it focuses on understanding the data generation process and enhancing data by capturing patterns and characteristics. It is derived from statistical methods, similar to Gaussian mixture models and Markov chains11. Baum et al.12 developed hidden Markov models in the 1960s. These early models paved the way for subsequent generative models to comprehensively evaluate molecular designs.
The core goal of generative modeling is to learn the joint probability distribution of the data, where represents the data (e.g., images, texts, or audios)13. By learning this distribution, generative models reveal the underlying structure and generate new samples that preserve statistical properties such as texture, structure, and pattern. In biomolecular fields such as molecular biology, structural biology, and biochemistry, these models are used to learn and generate the distribution and structural properties of complex molecules, aiding in the design of new molecules and accelerating the exploration of chemical space.
Text generation models have been used in various fields, including image generation, drug discovery, protein structure prediction, and protein engineering. Some of the key advantages of generative models are the ability to synthesize new data, which plays an important role in data augmentation, and to enable probabilistic reasoning to enhance the creativity of AI systems14.
As generative models continue to demonstrate their vast potential in various fields, particularly in biomolecular sciences, understanding the strengths and limitations of different generative approaches becomes increasingly important. To better evaluate and select the most suitable generative model, the following section will provide a detailed comparison of key models, including VAEs, GANs, DMs. By examining these models, we can gain deeper insight into their performance and challenges in various applications, offering more targeted guidance for real-world use cases.
Comparison of different generative approaches
2.2
The landscape of generative modeling has evolved, with various techniques excelling in different domains. VAEs, GANs, and DMs are among the most widely adopted methods, and their flowcharts are shown in Fig. 1. Next, we compare these approaches along key dimensions, such as their architecture, training process, strengths, and weaknesses.Figure 1. Flowcharts of three different generation methods for generating models. (a) Variational autoencoder extracts the encodings mainly through the encoder. In the hidden space , these encodings are treated as latent representations of the latent variables, and then passed to the decoder to produce an output close to the original input data. (b) The process diagram of generative adversarial network uses the generator model and the discriminator model to perform mutual game learning to generate output. (c) The diffusion model includes forward diffusion process and reverse diffusion process. The green line segment represents the forward diffusion. The blue line segment represents the reverse diffusion.Figure 1
VAEs are probabilistic generative models that combine autoencoders with variational inference. As shown in Fig. 1a, the model consists of an encoder, which learns a function to map input data to a latent variable , assumed to follow a Gaussian distribution. The decoder reconstructs the data using a conditional probability . VAEs are advantageous in providing probabilistic interpretation, enabling smooth interpolation in latent space, and effective anomaly detection. However, generated samples often appear blurry, and training can be challenging due to the need to balance reconstruction loss and regularization terms15.
GANs consist of two neural networks, a generator and a discriminator, that are trained in a competitive setting. The generator creates synthetic data, while the discriminator distinguishes between real and fake data. Both networks are trained simultaneously in a minimax game, and their specific flowchart is depicted in Fig. 1b. GANs excel at generating high-resolution, realistic images and are widely used in image generation, style transfer, super-resolution, and video synthesis. However, they face challenges such as unstable training, mode collapse, and vanishing gradients. Additionally, their lack of a clear probabilistic structure makes them more complex and difficult to analyze than VAEs16.
DMs are generative models that involve forward and reverse diffusion processes. In the forward process, real data is progressively corrupted by noise, becoming Gaussian noise through a Markov chain. The reverse process attempts to restore the original data distribution from the noise, with representing the conditional probability of the previous state17. The detailed flowchart is presented in Fig. 1c. DMs are highly effective at generating high-quality, realistic images, often surpassing GANs in sample quality. Their training process is more stable, avoiding issues like unstable training. However, DMs suffer from slow sampling speed due to multiple refinement steps, which require significant computational resources and time, especially for high-dimensional data like images.
Of course, in addition to the above-mentioned classic generative models, several novel models have emerged, such as flow matching, Bayesian flow networks (BFNs), and generative flow models. Flow matching is a generative approach based on continuous normalizing flows, which directly regresses noise onto the vector field along the data's conditional probability path, avoiding the complex reverse diffusion process and accelerating training and sampling18. BFNs, introduced by Graves et al.19 in 2023, employ Bayesian inference to update the independent distribution parameters of noise samples and then input them into a neural network to generate new distributions. Unlike DMs, BFNs does not require explicit forward diffusion, and it supports both discrete and continuous data, excelling in image and language tasks. Generative flow models refer to a class of models based on normalizing flows, which use a series of invertible, differentiable transformations to map simple initial distributions (such as standard Gaussian) to complex data distributions, offering precise probability density modeling, expressiveness, and interpretability20.
Generative modeling techniques have advanced rapidly, with VAEs, GANs, and DMs demonstrating strong performance in image synthesis, drug design, and molecular generation. Recently, emerging approaches such as flow matching, BFNs, and generative glow models have been introduced, offering advantages like faster training, uncertainty modeling, and exact likelihood estimation. Their applications have also expanded into molecular dynamics (MD) modeling, drug–target interaction prediction, and biomedical data analysis. To facilitate systematic comparison, Table 1 summarizes the advantages and disadvantages of six representative generative models and their main application areas, providing guidance for model selection and application.Table 1. Summary of several commonly used generative models.Table 1. Generative modelAdvantagesDisadvantagesMain application domainsRef.Variational Autoen-coders
-
-Probabilistic framework with evidence lower bound optimization
-
-Stable training
-
-Continuous latent space
-
-Samples can be blurry
-
-Difficulty capturing high-frequency details
-
-Small molecule and protein design
-
-3D molecular
-
Conformation embedding
-
-Text generation and latent semantic
-
Modeling Wei et al. [15]Zhang et al. [21]Ochiai et al. [22]Generative adversarial networks
-
-High-fidelity sample generation
-
-Mature architectures
-
Facilitate stable variants
-
-Smooth latent-space interpolation
-
-Training instability
-
-Mode collapse risks
-
-Molecular structure and reaction synthesis
-
-Drug reaction outcome prediction
-
-Text generation and style transfer Maziarka et al. [23]Zhang et al. [24]Macedo et al. [25]Diffusion models
-
-Fine, sharp sample quality
-
-Stable optimization (no adversarial loss)
-
-Flexible conditioning on properties
-
-Slow sampling due to many steps
-
-3D molecular conformation and drug design
-
-Molecular graph diffusion modeling
-
-Molecular graph diffusion design
-
-High-quality image generation and restoration Yang et al. [6]Lin et al. [26]Morehead et al. [27]Flow matching
-
-Direct regression of data—noise vector field
-
-Fast training convergence
-
-Adaptive path selection
-
-Sensitive to path choice
-
-Stability on complex distributions
-
-Conformer sampling
-
-Molecular dynamics trajectory modeling
-
-Inverse design of small molecules Lipman et al. [18]Hassan et al. [28]Bayesian flowNetworks
-
-No explicit forward diffusion required
-
-Support for discrete & continuous data
-
-Unified likelihood ^training^
-
-Expensive posterior computation
-
-High sampling cost in large spaces
-
-Uncertainty-aware molecule generation
-
-Bayesian estimation of binding modes
-
-Probabilistic conformer ensembles Wu et al. [19]Graves et al. [29]Song et al. [30]Generative flowModels
-
-Invertible transforms with exact densities
-
-Efficient sampling
-
-High interpretability
-
-Challenging design of invertible layers
-
-Limited multimodal flexibility
-
-Molecular density and reaction pathway
-
Modeling
-
-Property-to-structure inverse design in drug discovery
-
-Speech generation and conversion Zang et al. [31]Bengio et al. [32]
Key theoretical concepts and mathematical foundations
2.3
Generative models are grounded in key mathematical concepts from probability theory, optimization, and information theory. These foundations are essential for understanding how generative models work and why some models are more suitable for specific tasks. Next, we discuss the relevant concepts and mathematical foundations.
The first concept is about variational inference and evidence lower bound (ELBO). The goal of these models is to maximize data likelihood, which is often computationally intractable. To address this, VAEs introduce the ELBO as a tractable lower bound to the likelihood. The core objective is to maximize the ELBO, and its formula can be written as:
where is the reconstruction loss, in order to measure the decoder's ability to reconstruct data. is the regularization term that ensures the latent space distribution approximates a prior, typically Gaussian. VAEs optimize training using variational inference and ELBO, mapping latent space to data space. They generate complex samples and provide training stability, making them a key method in deep generative models33.
The next key idea is GANs and the minimax game. GANs are based on an adversarial game between two networks where the generator and the discriminator interact. The generator creates realistic data to deceive the discriminator, while the discriminator distinguishes real data from fake. The objective function of GANs can be expressed as:
in this case, is the distribution of the real data, and is the distribution of the latent variables. GANs have advanced generative modeling through the adversarial interplay between and . The term helps the discriminator better distinguish real data, while encourages the generator to improve the quality of generated samples. They are capable of generating highly realistic images and data with wide applications34.
The following concept is the diffusion process and reverse sampling. The DMs transform data into noise through the forward process and gradually recover the real data through the reverse process. This process is described using a Markov chain, allowing the generation of data from simple to complex, demonstrating its powerful generative capability6.
The mathematical basis of the diffusion process is the stochastic differential equation, which is used to describe the dynamics of the forward and reverse processes35. Among them, the forward process is to gradually add noise to the data through the diffusion process, and this process is formulated as:
to clarify, represents the state of the data at time , is the drift term, which dictates the deterministic direction of data evolution, is the diffusion term, modulating the intensity of the stochastic variation, and corresponds to the increment of standard Brownian motion, capturing the inherent randomness in the process. The reverse process aims to recover data from noise, and its equation is represented as:
specifically, is the score function, guiding the denoising process. Through the reverse process, DMs recover data that closely matches the original distribution, making them powerful tools in generative modeling.
The theoretical frameworks of probabilistic inference in VAEs, adversarial optimization in GANs, and noise modeling in DMs form the foundation of generative models. They support the development of more efficient models in fields like image and text generation36, and are also transforming applications in biomolecular sciences, particularly drug discovery and protein engineering2.
While these theoretical constructs establish the bedrock of generative modeling, their true impact emerges when they are deployed to tackle real-world challenges. In the following section, we turn our attention to the applications of these techniques within biomolecular sciences, examining how VAEs, GANs, and DMs are being used to accelerate drug discovery, guide protein engineering, and drive innovative molecular design.
Applications in biomolecular sciences
3
Drug discovery and design: generating novel drug candidates
3.1
Drug discovery and design have traditionally been time-consuming and resource-intensive. Generative models, a branch of AI, have the potential to revolutionize this field. Techniques such as VAEs, GANs, and transformer-based architectures can design novel drug candidates with specific properties, including molecule design, property optimization, and target-specific drug discovery. These innovations accelerate and optimize drug development37^,^38. Moreover, recent perspectives have suggested that generative AI may play an increasingly influential role throughout the drug discovery pipeline39.
Scientists have combined generative model-based structure predictions with AlphaFold's capabilities to advance drug discovery. For example, in 2019, Grow et al.40 proposed the generative network complex (GNC) platform, which utilized the SMILES autoencoder, deep neural networks, and a three-dimensional (3D) generative network to generate new compounds, predict their properties, and screen drug candidates. The schematic diagram of this approach is presented in Fig. 2a. In 2023, Gao et al.41 advanced molecular generation by combining molecular fragments with hierarchical chemical graph representations, employing a multi-resolution graph VAEs for deep molecular generation. Their goal was to generate drug molecules with chemical diversity and potential bioactivity through deep learning. Additionally, in 2023, Wang et al.42 integrated deep generative models with stochastic optimization and showcased ChatGPT as a virtual assistant to enhance drug development efficiency. In 2024, Qi et al.43 introduced perturbation-conditioned generative model, a perturbation-conditioned deep generative model trained on nearly 100 million high-throughput screening data. It predicted transcriptional responses of 175,549 compounds in 188 cell lines and has demonstrated effective candidate drug screening in multiple metabolic disease models. In 2024, Kanakala et al.44 summarized recent advances in generative AI technologies, tools, and practical applications for small molecular drug design. The workflow of drug design is illustrated in Fig. 2b.Figure 2(a) A schematic illustration of a generative network complex. It consists of an autoencoder that takes SMILES strings into a drug-property regulated latent space, a regulated latent space, a LSTM based autodecoder, a multitask network for the evaluation of binding affinity (BA), partition coefficient (LogP), solubility (LogS), clearance, etc., a three-dimensional (3D) structure generator named MathPose, and MathDL45^,^46, a refined 3D multitask druggable property predictor based on algebraic topology, differential geometry, and graph theory, to select new drug candidate structure40. (b) This is an AI-driven drug discovery process diagram44. The process begins with extracting relevant information from the collected dataset and representing molecules using SMILES, 3D structures, and molecular graphs. Then, generative models such as variational autoencoders, generative adversarial networks, and diffusion models are employed to generate candidate molecules. These candidates are evaluated based on properties such as BA, logP, logS, and ADMET (absorption, distribution, metabolism, excretion, and toxicity), ultimately leading to the identification of novel compounds with potential therapeutic value. (c) The overview of Molormer. The original drug graph goes through an embedding layer to form four feature embeddings representing the spatial structure of the drug. These features are processed by two ProbSparse self-attentive blocks, connected and fed to the decoder for final prediction. Drug–Drug Interaction (DDI) refers to the effects that occur when two or more drugs are taken together, potentially altering the effectiveness or side effects of one or both of the drugs47.Figure 2
Generative models have shown immense potential in drug discovery and design, particularly in accelerating chemical library screening, reducing costs, and exploring new chemical spaces. Despite challenges such as scaffold homogenization, inaccurate ADMET predictions for novel chemical types, conflicts in multi-objective optimization (MOO), target bias, and poor generalization to new scaffolds persist, generative models have made significant progress in generating novel drug molecules and optimizing lead compounds44, and are expected to accelerate the discovery of new tracers and optimize their in vivo tracking performance and imaging contrast in the field of radio pharmaceuticals and molecular imaging48. Looking ahead, improvements in datasets quality, the introduction of explainable AI, and the integration of multi-omics data could provide more comprehensive drug design solutions. Cross-disciplinary research and collaboration will be key to overcoming current limitations, accelerating precision drug development, and driving the revolution of AI-powered drug discovery.
Reaction prediction: learning reaction pathways and outcomes
3.2
Chemical reaction prediction is key for designing druggable molecules and macromolecules, advancing drug discovery and synthetic biology. Traditional methods rely on expert rules but struggle with the complexity of the chemical space. Recently, deep learning-based generative models have emerged, with recurrent neural networks, graph neural networks (GNNs)49, and transformers driving rapid progress in reaction prediction50.
The core task of generative models in reaction prediction is to learn the underlying patterns for generating reaction products. These models understand the language of chemical reactions through large-scale chemical reaction datasets and are able to predict reaction products given the reactants. For example, in 2019, Schwaller et al. developed the molecular transformer, a transformer-based model for reaction prediction. By treating reactions as a sequence-to-sequence problem, this model achieved state-of-the-art accuracy on benchmark datasets51. Additionally, in 2024, Jiang et al.47 applied the Molorme framework to the transformer model, creating a drug–drug method interaction method that incorporates a lightweight attention mechanism, enhancing performance and reducing computational costs. The general framework is illustrated in Fig. 2c.
Generative models have shown exceptional capabilities in chemical reaction prediction, particularly in biomolecular science, such as enzyme catalysis and drug synthesis pathway design. Their advantages include scalability, flexibility (e.g., GNNs for molecular graph modeling), strong generalization, and simplified prediction for non-experts. However, challenges remain in generating reaction pathways, including difficulties in capturing transition state information, prediction biases due to sensitivity to substrate stereochemistry, the tendency to produce unrealistic outcomes in multi-component complex reaction systems, and the inability to accurately model dynamic changes at catalyst active sites. Despite these challenges, generative models are essential in modern chemical reaction prediction. Future research will focus on hybrid models, improving interpretability, and integrating with automated synthesis platforms to accelerate the discovery of new proteins and drugs, driving innovation in biomolecular research and biopharmaceuticals52.
Virtual screening and optimization of lead compounds
3.3
Virtual screening and lead compound optimization are key steps in drug discovery. In recent years, the introduction of generative models has significantly transformed the identification and optimization of drug candidates. While traditional virtual screening relies on methods such as molecular docking and dynamics simulations to assess binding affinity (BA), generative models enable the creation of novel molecules with desirable properties, providing a more efficient and diverse approach53.
In generative models, especially those based on deep learning architectures such as VAEs, GANs, and reinforcement learning (RL) methods54, there has been an increasing application in virtual screening and lead compound optimization55. In 2023, Danel et al.56 proposed a method combining generative models with molecular docking to accelerate the discovery of new drug candidates and improve virtual screening efficiency. In 2023, Chakraborty and Hasija explored how deep learning methods, particularly generative models such as VAEs and GANs, can efficiently explore potential drug molecular spaces and provide strong support for the drug discovery process57. The structure of this model is depicted in Fig. 3a. In 2024, Lu et al.58 proposed DynamicBind, a generative model for predicting protein-ligand complexes. By integrating MD with generative techniques, it effectively captures the flexibility and dynamics of binding conformations.Figure 3(a) The architecture makes use of embeddings to encode the characters within the text data. It employs a long short-term memory (LSTM) encoder to process the embedded data and map it to a latent space. Additionally, it uses an LSTM decoder to reconstruct the original text data from the latent space representation57. (b) The training framework of the Fold2Seq model comprises three key components: the Sequence Encoder, the Fold Encoder, and the Sequence Decoder. The Sequence Encoder transforms the input sequence data into a high-dimensional representation. The Fold Encoder processes this sequence through folding to capture its structural information. Finally, the Sequence Decoder generates the output sequence based on the encoded representation. Together, these components optimize the model's sequence generation capability59. (c) Workflow for designing synthetic promoters using a diffusion model. The yellow box represents the training phase. In this phase, random noise is progressively introduced into the natural promoter sequence until the sequence expression matrix is entirely transformed into a random matrix. The diffusion model is employed at each step to predict the noise added, based on natural promoters with noise, thereby facilitating the gradual generation of noise. The green box represents the generation phase. In this phase, latent variables with the same dimensions as the natural promoters are input. The trained diffusion model then denoises these inputs to generate synthetic promoters26.Figure 3
Generative models in virtual screening and lead optimization efficiently predict the activity of novel compounds, explore chemical spaces, and optimize molecular properties. However, they still face several unique challenges in virtual screening, such as generating molecules that often lack core scaffold innovation and tend to get trapped within known chemical spaces, insufficient prediction accuracy for rare structural active sites, and limited capability to assess risks related to potential off-target activities and metabolic transformation pathways. Although generative models can design molecules with strong biological activity, experimental synthesis remains challenging, and deep learning models incur high computational costs in large-scale screening60. Future developments will improve the accuracy of generative models by integrating MD, quantum calculations, and docking techniques, while improving drug generation through diverse datasets that include biological activity and ADMET (absorption, distribution, metabolism, excretion, and toxicity) properties9. Incorporating synthetic feasibility and real-time feedback optimization will drive the application of generated compounds in experimental synthesis, accelerating the drug discovery process61.
Protein structure prediction and design
3.4
Prediction and design of protein structures are crucial for understanding protein function and mechanisms, with applications in drug design, protein engineering, and directed evolution62^,^63. Generative models have shown great potential in this field, as they can directly generate or optimize 3D protein structures from raw sequences, unlike traditional methods such as homology modeling and MD, which rely on existing data.
In generative models, particularly VAEs, GANs and deep neural networks, have been applied in protein structure prediction and design. These models not only predict the 3D structures of unknown proteins, but also generate entirely new protein molecules and optimize their structures to improve functional performance62. In 2021, Cao et al.59 proposed Fold2Seq, a transformer-based generative model for the design of protein sequences based on target folds. It jointly learned protein sequences and 3D structures, capturing complex sequence-structure relationships, and showed strong performance in handling low-quality or incomplete input structures. The training scheme framework of this model is demonstrated in Fig. 3b.
Generative models in protein structure prediction offer advantages such as efficiency, diversity, and functionality-driven design. They can identify key factors affecting protein folding and function, generating a variety of protein structures. However, they also face several challenges, including difficulties in modeling transient intermediate conformations along folding pathways, limited accuracy in predicting the effects of post-translational modifications, and difficulty in capturing the conformational dynamics of membrane proteins and large multi-domain proteins. Future research should focus on building comprehensive databases for disease-related and species-specific proteins to enhance data support, and improving protein synthesis practicality for experimental validation. Integrating multi-task learning (e.g., protein folding, function prediction, and drug design) will improve model accuracy, while incorporating biophysical and chemical principles will further enhance prediction reliability. Generative models have made significant progress in protein structure prediction, showing great potential in drug discovery and bioengineering2.
Synthetic biology: designing genetic circuits and pathways
3.5
A key task in synthetic biology is to design genetic circuits and metabolic pathways for precise cellular control, with applications in biofuel production, drug development, and environmental sensors. Traditional methods are slow and costly, relying on iterative experimentation. Recently, generative models such as VAEs, GANs, DMs, and RL have been applied to automate the generation of new genetic circuits or pathways, accelerating design and reducing costs, thus advancing synthetic biology towards more efficient solutions64.
Generative models can learn from large amounts of known gene sequences and metabolic network data to generate new design solutions. For example, GANs can be used to design new promoter sequences. In 2020, Zhang et al.24 proposed HpGAN, a GAN-based model to generate specific sequences, while VAEs optimize key enzymes in metabolic pathways, facilitating biological sequence design and gene circuit optimization. In 2024, Lin et al.26 introduced a DMs-based generative method for de novo design of synthetic promoter sequences, and the method's flowchart is available in Fig. 3c. This method used a stepwise denoising process to generate and optimize high-dimensional promoter sequences, producing several synthetic promoters with high expression efficiency, which showed superior performance compared to traditional designs in experimental validation.
Generative models in synthetic biology offer efficiency, diversity, and customization by rapidly exploring design options for gene circuits and metabolic pathways. For example, HpGAN and DMs generate efficient promoter sequences using large-scale data24. However, several challenges remain, such as the unpredictability of in vivo behavior due to context-dependent regulation, and difficulties in modeling nonlinear metabolic fluxes under fluctuating environments or cellular states. Future developments will focus on building comprehensive gene sequence and metabolic pathway databases, integrating data from various species and environments, and combining them with automated platforms to accelerate validation. Improving the model interpretability and incorporating MOO will balance factors such as stability, yield, and tolerance, driving the design of more practical gene circuits and pathways65.
Understanding biological networks and interactions
3.6
Biological networks, including protein-protein interaction networks, gene regulatory networks, and metabolic pathways, are key to systems biology, helping to understand biological functions and responses to environmental conditions. However, their complexity and dynamic nature present challenges in analysis and modeling. Recently, deep learning-based generative models have shown great potential in modeling networks, predicting interactions, and generating novel hypotheses. These models capture intricate relationships and can generate new network structures, predicting previously undiscovered phenomena, even without comprehensive experimental data, offering powerful tools to advance systems biology research66.
Generative models have increasingly emerged at the forefront of biological network research, with several pivotal studies demonstrating their effectiveness in network prediction and highlighting their potential to discover unknown interactions and generate hypothetical networks. In 2022, Gomari et al.67 showed that VAEs can learn nonlinear transferable latent representations from metabolomics data, providing a useful tool for analyzing metabolic networks and disease-related changes. In 2024, Zhang et al.21 proposed a VAE-based model with an attention mechanism to predict drug–protein interactions, using deep learning to identify interaction patterns from large-scale drug and protein data, thus accelerating drug discovery and target identification. The schematic diagram of this model is provided in Fig. 4.Figure 4. The model comprises three key components: the encoder, the decoder, and the prediction module. Both the encoder and decoder are used to predict drug-protein interactions (DPI). The architecture extracts features from drugs and proteins, applies an attention block to highlight important parts, and passes the output to a fully connected layer for DPI prediction. The feature extraction for drugs and proteins is similar. Text sequences representing drugs and proteins are converted into numerical vectors and then transformed into embedding matrices. The encoding layer contains three Gated Convolutional Neural Networks (GatedCNNs), with Rectified Linear Unit activation after each layer, and a max-pooling layer follows the third GatedCNN to compress the extracted features21.Figure 4
Generative models hold great potential in biological network research, enabling faster network design, structural optimization, and prediction of unknown biological relationships, thus reducing experimental burdens. They are particularly useful in drug discovery, precision medicine, and synthetic biology, where they can identify new drug targets, predict drug interactions, customize treatment plans, and design biological networks, accelerating bioengineering advancements. However, their broader application is hindered by challenges such as high uncertainty due to sparse or incomplete interactome maps, and limited capacity to model dynamic, context-dependent network changes. Despite these obstacles, ongoing technological progress will establish generative models as essential tools in systems biology, advancing the study of complex biological interactions and driving breakthroughs in related fields66^,^68.
The integration of generative models with quantum mechanics and molecular dynamics
3.7
The integration of generative models with quantum mechanism and MD holds great potential in biomolecular sciences. They accelerate molecular design and property prediction, reducing the computational cost of quantum calculations, and provide efficient initial structures or conformational evolution pathways for MD simulations69. This combination drives molecular discovery, enabling the design of new molecules with specific functionalities.
Quantum mechanism methods play a crucial role in predicting molecular structures and properties, but their high computational costs and complexity limit their application. Generative models can reduce computational costs and improve predictive accuracy through adaptive basis set generation and uncertainty quantification70. In 2021, Li et al.71 proposed a new quantum GAN mechanism with a hybrid generator and classical discriminator for drug discovery, which supported various number of qubits and quantum circuit layers. Their model with less than 20% of the original parameters can learn molecular distributions as efficiently as its classical counterpart.
In MD simulations, generative models can quickly generate initial conditions and simulate molecular conformation evolution, reducing computational time and enhancing efficiency. They can predict molecular behavior under various conditions and help simulate complex systems. The integration of generative models with quantum mechanics and MD enables efficient conformational sampling but faces domain-specific challenges including potential energy surface inaccuracies and timescale mismatches between MD simulations and generative sampling timescale mismatches between MD simulations and generative sampling69.
Development of hybrid models combining generative techniques with reinforcement learning
3.8
The integration of generative models and RL offers an efficient solution for molecular design and optimization. Generative models learn chemical space distributions to generate candidate molecules, but struggle to directly optimize target properties68. RL, on the other hand, optimizes multi-objective properties through reward mechanisms but faces challenges in exploring high-dimensional and discontinuous spaces. Combining these approaches allows generative models to generate initial molecular structures while RL optimizes target properties, achieving a synergistic effect in molecular generation and optimization37, with significant potential in drug design and protein engineering.
For example, in 2021, Hu72 applied molecular deep Q-networks to optimize molecular structures for multi-objective problems by treating the molecular construction process as a Markov decision process and using deep Q-learning to guide step-wise modifications. This approach enables the agent to sequentially add atoms or bonds to maximize long-term rewards, demonstrating flexible control over molecule generation. In another study, Koshino et al.73 developed a molecular GANs framework that integrates GANs with RL to generate molecules with specific properties. By combining adversarial training with property-based reward signals, this model facilitates goal-directed molecule generation, optimizing features like drug-likeness and synthetic accessibility. Additionally, methods using pretrained generative models and RL mechanisms have shown success in drug design. For example, variational graph autoencoder (VGAE) with Monte Carlo tree search (MCTS), proposed by Iwata et al.74 in 2023, combines a VGAE-MCTS to explore the chemical space and optimize molecular properties. The VGAE captures latent molecular representations, while the MCTS navigates the space efficiently through reward-guided search. Similarly, graph-based autoregressive flow, introduced by Han et al.75, employs a sequential generation strategy where molecular graphs are built node by node. RL is used to fine-tune the generation process based on the reward of stability and chemical property. Key challenges for hybrid models include discrete action space limitations in molecular graph construction and delayed reward signals in multi-step generation74, requiring specialized optimization approaches.
Future research could address these issues through efficient search and optimization strategies, automated reward function design, and collaborative training methods. Incorporating synthetic feasibility prediction models and Pareto-based optimization methods could enhance MOO capabilities76. Cross-disciplinary collaboration and quantum-assisted computation could further improve efficiency and applicability in drug discovery and biological science.
Other applications
3.9
Although generative models have made significant progress in drug discovery and protein structure prediction, their applications extend far beyond these areas. With ongoing research, generative models demonstrate enormous potential in various biomedical fields, particularly in epigenetics77, microbiome modeling78, clinical practice79, as well as mRNA vaccine design and nucleotide modification optimization80.
Generative models are increasingly being applied in biomedicine, showing significant potential in epigenetics, microbiome modeling, clinical practice, as well as mRNA vaccine design and nucleotide modification optimization. In 2025, Mandal et al.77 proposed the supervised GANs method, which effectively combines supervised learning and GANs to apply to labeled genomic or epigenomic data, providing an innovative solution for labeled data analysis in genomics and epigenomics. In 2023, Choi et al.78 employed a deep learning method based on GANs to propose DeepMicroGen, a tool to impute missing values in longitudinal microbiome data while preserving the diversity of microbial communities and time-series characteristics. In 2025, Wang et al.79 proposed a self-improving generative model that enhances the quality and diversity of generated images. It was successfully applied to clinical decision support, disease prediction, and personalized treatment, providing new solutions for medical imaging and precision medicine. In 2024, Tang et al.80 presented the first deep generative framework specifically designed for m1 -modified mRNAs, termed smart 5 untranslated region (UTR). The model accurately predicted and generated optimized 5′UTR sequences, enhancing mRNA translation efficiency. These advancements highlight the transformative potential of generative models in biomedicine, paving the way for more accurate data analysis, improved medical imaging, and better personalized healthcare solutions. As research continues, the scope of their applications is likely to expand, offering innovative tools for precision medicine and disease management.
Despite the significant potential of generative models in biomedicine, their clinical applications still face some challenges, including the inability to capture patient-specific heterogeneity and inter-individual variability. There is also a risk of generating biologically implausible or unsafe candidates, along with difficulties in designing mechanistic validation and conducting prospective clinical trials. Moreover, ensuring the reliability and accuracy of these models in real-world applications remains a critical challenge.
Challenges and limitations
4
Data quality and availability: addressing biases in training datasets
4.1
The application of generative models in biomolecular sciences relies on high-quality training data, but such data often suffer from uneven distribution, noise, and biases. The complexity of molecular structures, especially large macromolecules, makes it difficult to standardize molecular features, affecting data quality. Additionally, the limited availability of molecular samples challenges the development of accurate ML models. Researchers often use physical models and theoretical methods (e.g., molecular mechanics, dynamics, and quantum mechanics) to generate molecular properties and expand datasets7. However, these methods have limitations, and biases in simulated data can still affect model accuracy and generalizability. Therefore, ensuring data quality, diversity, and addressing biases are key challenges in applying generative models in biomolecular sciences68. Publicly available datasets such as MoleculeNet and therapeutics data commons offer standardized benchmarks and curated molecular data, helping alleviate issues of datasets bias and scarcity. These data sets support tasks such as prediction of molecular properties, estimation of toxicity and modeling of drug–target interaction, making them essential resources for training robust generative models.
Data biases during training can significantly impact model performance and output quality. These biases arise from limitations in training datasets, often dominated by certain molecule categories, restricting the model's ability to generate novel molecules81. Strategies like data augmentation, diversity-focused objective functions, and fairness constraints can help improve data diversity and balance. These approaches aim to improve model generalization and improve the quality of generative models in biomolecular sciences9.
Balancing innovation and feasibility is crucial, as generated molecules must meet drug design requirements and be experimentally validated. Ensuring the diversity and comprehensiveness of the training datasets is essential for the success of generative models in drug discovery82.
Interpretability of generative models in biological contexts
4.2
As the interpretability of generative models in ML gains increasing attention, it is crucial to explore how these models can be made understandable, especially in complex fields such as biology83. Currently, there is no unified standard, and traditional methods like disentanglement have limitations in practical applications. This highlights the need to evaluate the interpretability of generative models in biological contexts, as understanding the decision-making process can provide valuable insights for applications such as drug discovery.
One method to enhance interpretability is through the use of attention mechanisms, which have been widely applied in natural language processing84. In drug discovery, attention mechanisms help identify key features of molecular structures, improving the transparency and interpretability of generative models. Visualization techniques also help improve interpretability, allowing researchers to intuitively understand the decision making process of generative models in drug design85, revealing how the model generates drug-like molecules while focusing on key biological concepts during the process.
Integrating generative models with quantum mechanism and MD further enhances interpretability68. Several explainable AI frameworks have emerged for generative modeling, such as feature attribution methods and graph explanation tools, which help clarify how molecular features influence generation outcomes86. For instance, explainable VAE-based models have been applied in identifying latent variables related to toxicity or solubility, facilitating property-driven molecule design. This integration not only optimizes molecular structures but also helps researchers better understand the decision-making process behind generation, improving transparency and verifiability in drug discovery87.
Resource limitation
4.3
In recent years, generative models have experienced a leap from hundreds of millions to trillions of parameters (e.g., OpenAI's GPT-3, GPT-4, Google's Gemini series, DeepSeek's DeepSeek series, etc.), significantly improving generation quality and broadening their range of applications through the expansion of parameter sizes and training data88. Beyond traditional text generation, multimodal models for drug design, protein design, and protein structure prediction (such as ChemBERTa, MolGPT, GraphDF, AlphaFold, etc.) showcase the broad applicability of generative technology across various domains. Architectural innovations like transformers, DMs, and GANs have further improved performance, but this comes with increased computational demands and more complex training processes.
Resource demands vary significantly by model type, with VAEs being memory-efficient but requiring extended training periods89, while DMs incur high FLOPs per sampling step90, creating distinct opti-mization requirements. For example, training GPT-3 requires millions of dollars and spans weeks or even months91. In fields like biological and molecular generation, DMs (e.g., BioDiffusion or MatDiff) necessitate multiple iterations in latent space, resulting in exponential increases in flops requirements, further escalating computational demands. Consequently, the multi-step iteration in DMs not only exacerbates computational burdens but also challenges real-time performance and system response speed. To address this, more efficient optimization strategies and computational architectures are needed to balance performance with resource consumption90.
Future directions
5
Large language model assisted generation
5.1
Rapid advancements in AI are transforming pharmaceutical research. Foundation models, including large language models (LLMs) like GPT-4, can analyze vast literature, propose hypotheses, optimize molecular structures, and support complex decision-making. Their use in drug discovery aims to improve efficiency, reduce costs, and speed up the identification of new therapeutic compounds. Unlike the lengthy and expensive traditional pipeline, AI-driven methods, particularly generative models, offer a data-centric framework. They complement existing computational and experimental approaches and reshape pharmaceutical innovation92.
LLMs, as a subclass of foundation models specialized in processing textual and symbolic information, play an important role in drug development. For example, in 2023, Wang et al.42 incorporated GPT-4 into the full drug design workflow. The system facilitated idea generation, methodological analysis, and programming support. They developed a randomly generated network complex using AI-driven molecular design, combined with Langevin equation simulations and DMs analysis. Debugging and optimization were implemented throughout the process. The framework integrated multiple components including a seq2seq autoencoder, affinity prediction models, a Langevin dynamics-based molecule generator, and ADMET screening protocols Ultimately, this approach yielded 15 promising drug candidates for combating cocaine addiction. The workflow for generating a network complex is visualized in Fig. 5.Figure 5. Workflow of the stochastic-based generative network complex (SGNC)42. ChatGPT was extensively involved in the building process of the SGNC. Dark arrows show the training process, brown arrows indicate the validation process, and red arrows show the generation process. The SGNC comprises five primary structures: a sequence-to-sequence AutoEncoder in blue, binding affinity predictors in yellow, a stochastic-based molecular generator in grey, ADMET (absorption, distribution, metabolism, excretion, and toxicity) screening via ADMETlab 2.0 in green, and potential multiple targets for cocaine addiction treatment in pink.Figure 5
LLMs show significant potential in drug development, yet challenges persist. Future efforts should focus on integrating LLMs with molecular generation models like DMs and VAEs. RL could be employed to optimize molecular structures, balancing binding scores, biological activity, and synthetic feasibility. Enhancing fact-checking capabilities through cross-validation with authoritative databases (e.g., PubChem, ChEMBL, AlphaFold) will improve reliability. Robotic lab automation could streamline automated synthesis and testing workflows. Additionally, domain-specific fine-tuning of models may further enhance predictions of drug-likeness, toxicity, and ADMET properties93. The case of anti-cocaine addiction drugs shows that LLM-assisted generation can significantly accelerate drug development, but fully autonomous AI-driven drug development still needs further breakthroughs in hybrid modeling, RL and experimental verification.
Generation based on foundation models
5.2
By learning complex patterns within vast datasets, generative models can generate biologically relevant structures or sequences that possess desired pharmacological activities, and combining these generative approaches with foundation models can further elevate their capabilities. Foundation models, such as large-scale GNNs and molecular transformers pretrained on diverse chemical and biological datasets, can encode a broader range of domain-specific knowledge and effectively capture generalizable molecular representations. Integrating generative models with foundation models improves their predictive power, stability, and generalization abilities, thus producing more meaningful and experimentally viable biomolecular designs with fewer computational resources94.
The GNC method proposed by Gao et al.95 in 2020 employed autoencoders and deep neural networks to optimize multiple chemical properties through gradient descent to automatically generate optimized drug molecules. This method has generated more than 1000 new molecules and provided alternative molecules that were superior to the original drugs for 8 marketed drugs (such as Ceritinib and Ribociclib), which has wide applications in small molecule drug design, MOO, and personalized drug discovery. Its schematic illustration is given in Fig. 6.Figure 6. Schematic diagram of the generative network complex. First, the input SMILES string is encoded into the latent space. Then, the molecule generator optimizes the molecule in the latent space and reconstructs it into a new SMILES string through the decoder. Finally, the properties or activities of the generated molecules are evaluated by consensus, utilizing modules such as 2DFP-BP, thereby achieving a complete closed loop from training to molecule generation. The green arrows indicate the training process, while the purple arrows indicate the generation process95.Figure 6
In the future, generative models built up on domain-specific foundation models are expected to become even more sophisticated and integral to the drug discovery pipeline. The main directions include combining more powerful foundation models (such as molecular transformers or graph-based transformer architectures) to improve the molecular characterization ability and the smoothness of the generation process, combining experimental data to optimize the actual feasibility of molecules, developing efficient MOO and improving generation algorithms (such as explainable AI models, quantum computing acceleration)96. Additionally, the conversion of peptides into small molecules also provides a feasible path for generative model-driven molecular design to convert candidate molecules into synthesizable and administrable drugs97. These advances will promote computer-aided drug design based on technologies such as GNC, assist in new-drug development and precision medicine, and further expand the application potential of AI in drug discovery.
Expanding the role of generative models in multi-modal biomolecular sciences
5.3
Generative models play a key role in multi-modal biomolecular sciences by integrating diverse data types, such as molecular structures, chemical properties, and phenotypic data. These models capture relationships between data sources, facilitating data fusion and overcoming the limitations of single-modal data98. In drug discovery and protein design, they optimize properties like drug efficacy or protein stability while generating novel molecular structures. They also enable cross-modal learning for better predictions of drug potency, safety, and efficacy99. Additionally, generative models help fill gaps in datasets by predicting missing data, such as chemical properties or experimental outcomes. These capabilities accelerate discovery, improve predictive accuracy, and drive innovation in biomolecular sciences, aiding drug development and molecular optimization100.
However, their application faces challenges, such as the heterogeneity of multi-modal data, which complicates unified representation and processing, affecting model performance101. Capturing complex, nonlinear relationships between modalities requires models to integrate data while preserving important features, demanding advanced model design and training102. The quality and completeness of multi-modal data, often noisy or imbalanced, also affect model generalization, and high-quality annotated datasets are scarce in biomolecular sciences. Complex architectures for data integration increase computational costs and may lead to training instability. Furthermore, ensuring the reliability and interpretability of generated outputs, especially in MOO, adds to the challenges. Lastly, the high computational demands of training multi-modal generative models limit their accessibility to resource-limited labs and institutions.
Future progress should focus on building high-quality multi-modal datasets, innovating model architectures, and ensuring reliable validation of results103. Developing lightweight models for resource-constrained environments will expand accessibility, accelerating breakthroughs in drug development, protein science, and precision medicine.
Multi-objective generation
5.4
Multi-objective generation is a method in drug design that optimizes multiple molecular properties simul-taneously, balancing factors such as multi-target BA, pharmacokinetics, toxicological properties, ADMET, and molecular novelty and synthesizability. Recently, the integration of generative models has advanced MOO, enabling efficient chemical space exploration and automated generation of potential drug molecules that meet multiple constraints104. Unlike traditional drug discovery methods, generative models driven by MOO use deep learning to analyze existing data distributions, ensuring the chemical validity of generated compounds while speeding up the process of creating and optimizing high-quality drug candidates. This approach significantly improves the efficiency and success rates of drug development.
In the field of molecular generation, Feng et al.99 proposed a multi-target stochastic generation network complex to optimize molecules targeting opioid receptors (MOR, KOR, DOR). This method combined GNC with MOO, integrating stochastic differential equations and autoencoder-based latent space optimization to enhance molecular diversity. It balanced BA, ADMET, and molecular novelty, which ensured high activity, favorable pharmacokinetics, and innovative structures. Key innovations included latent space optimization with DMs, using Langevin equations for molecular evolution, and employing pretrained autoencoders for filtering unstable candidates. Multi-step optimization improved drug activity and drug-likeness, offering new insights for opioid drug design. The schematic diagram of this multi-target stochastically generated network complex is presented in Fig. 7.Figure 7. Schematic illustration of multitarget stochastic generative network complex, used to design novel compounds for the treatment of opioid use disorder (OUD). Three different paths, i.e., model training, molecular generation, and lead optimization are colored in pink, green, and purple, respectively. The pink path represents the model training process of the pretrained autoencoder network. The blue path signifies the compound generation process: the SMILES string of a given compound undergoes encoding in the encoding network, and its latent space representation is then fed into the stochastic molecular generator. The generated compounds are subsequently processed through the decoding–encoding network. The resulting molecules that have stable SMILESs are evaluated for their BA and ADMET (absorption, distribution, metabolism, excretion, and toxicity) properties. Molecules exhibiting desired BA and ADMET properties are regarded as nearly optimal leads. In cases where the properties are not satisfactory, molecular optimization (the purple path) is performed to generate more potential druglike compounds99.Figure 7
Future multi-objective generation in drug discovery will advance by integrating GNNs with RL to enhance model robustness-capturing molecular topology more accurately and dynamically optimizing generation strategies105. Additionally, the multi-target stochastic generation network complex method is expected to extend to drug design for neurodegenerative diseases, cancer, and infectious diseases, aligning with the trend toward polypharmacology. Improved ADMET predictions through self-supervised learning and high-throughput virtual screening will further accelerate lead compound selection and optimization, ultimately speeding up new drug development106.
Conclusions
6
Generative models are expected to revolutionize biomolecular sciences by offering innovative strategies for designing, predicting, and optimizing molecular structures in biochemistry, molecular biology, and protein science107. By generating new molecular entities from learned representations, these models hold significant promise in drug discovery, reaction prediction, protein structure design, and the development of molecules with customized properties. They simplify the discovery process and minimize dependence on conventional trial-and-error approaches, facilitating a more efficient exploration of extensive chemical and biological spaces.
Despite these advancements, challenges in data quality and model interpretability must be addressed to ensure the responsible use of generative models in molecular research9. Integrating models such as VAEs, GANs, and DMs with techniques such as quantum chemistry, MD, and RL can improve prediction accuracy.
Hybrid and multi-modal models, combined with experimental feedback, will further improve the practical utility of generative models in molecular challenges68.
Future trends in generative modeling will increasingly draw on automated generation using LLMs to autonomously encode chemical and biological knowledge, enabling simplified molecular discovery workflows. Simultaneously, multi-objective generative approaches will gain prominence, facilitating the concurrent optimization of multiple molecular properties, thus efficiently navigating complex chemical spaces for practical applications in drug discovery, bioengineering, and advanced protein design. Another trend is to utilize advanced mathematics, such as algebraic topology, combinatorial theory, and differential geometry, to regulate molecular generation and enhance structure prediction46.
By overcoming current limitations and using advances in ML and computational biology, these models can drive progress in personalized medicine, synthetic biology, and sustainable protein design, ultimately reshaping biomolecular sciences and accelerating innovation in medicine, material, and biology science9.
This review highlights the growing importance of generative models and calls for interdisciplinary collaboration to address challenges such as data quality and model interpretability, unlocking their full potential in advancing drug discovery, protein science, and synthetic biology.
Author contributions
Jian Jiang was responsible for study design, manuscript writing, reviewing, and editing. Daixin Li and Guilin Wang collected relevant literature and prepared the initial draft. Nicole Hayes, Yazhou Shi, Huahai Qiu, Bengong Zhang reviewed and edited the manuscript. Tianshou Zhou, and GuoWei Wei supervised, conceptualized the manuscript, and revised the manuscript.
Conflicts of interest
The authors declare no conflict of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1NoéF.Tkatchenko A.Müller K.-R.Clementi C.Machine learning for molecular simulation Annu Rev Phys Chem 7120203613903209228110.1146/annurev-physchem-042018-052331 · doi ↗ · pubmed ↗
- 2Qiu Y.Wei G.W.Artificial intelligence-aided protein engineering: from topological data analysis to deep protein language models Briefings Bioinf 242023 bbad 28910.1093/bib/bbad 289PMC 1051636237580175 · doi ↗ · pubmed ↗
- 3Qiu Y.Wei G.W.Persistent spectral theory-guided protein engineering Nat Comput Sci 320231491633763777610.1038/s 43588-022-00394-y PMC 10456983 · doi ↗ · pubmed ↗
- 4Goodfellow I.Pouget-Abadie J.Mirza M.Xu B.Warde-Farley D.Ozair S.Generative adversarial networks Commun ACM 632020139144
- 5Kingma D.P.Welling M.An introduction to variational autoencoders Found Trends Mach Learn 122019307392
- 6Yang L.Zhang Z.Song Y.Hong S.Xu R.Zhao Y.Diffusion models: a comprehensive survey of methods and applications ACM Comput Surv 562023139
- 7Dou B.Z.Zhu Z.L.Merkurjev E.Ke L.Chen L.Jiang J.Machine learning methods for small data challenges in molecular science Chem Rev 1232023873687803738481610.1021/acs.chemrev.3c 00189 PMC 10999174 · doi ↗ · pubmed ↗
- 8Jørgensen P.B.Schmidt M.N.Winther O.Deep generative models for molecular science Mol Inform 372018170013310.1002/minf.20170013329405647 · doi ↗ · pubmed ↗