Interpretable Sensor Change Detection via Conditional Cauchy–Schwarz Divergence
Wenyu Wang, Yuan Shen, Yao Ni, Wangyu Wu

TL;DR
This paper introduces a new method for detecting changes in sensor data that also explains which sensors are involved, making it more useful for safety-critical systems.
Contribution
The novelty is using conditional Cauchy–Schwarz divergence to provide interpretable change detection in multivariate sensor networks.
Findings
The method achieves competitive or better detection performance than existing baselines.
It provides transparent explanations of changes at the sensor level.
It works well on synthetic, generic, and industrial sensor data.
Abstract
Detecting distributional changes in multivariate sensor networks is a fundamental task for monitoring complex systems such as industrial processes, structural health monitoring, and large-scale Internet of Things infrastructures. Despite significant progress, most existing change-point detection methods either operate on high-dimensional observations in a black-box manner or provide limited insight into how inter-sensor dependencies evolve over time, thereby restricting their practical utility in safety-critical applications. In this work, we propose an interpretable change detection framework based on the Cauchy–Schwarz (CS) divergence. By extending CS divergence to conditional distributions over sensor variables, the proposed method detects distributional shifts through changes in sensor-wise conditional relationships. This design enables reliable change detection while simultaneously…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1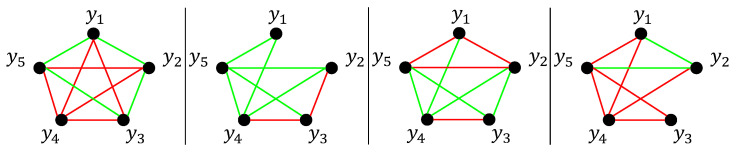 Figure 2
Figure 2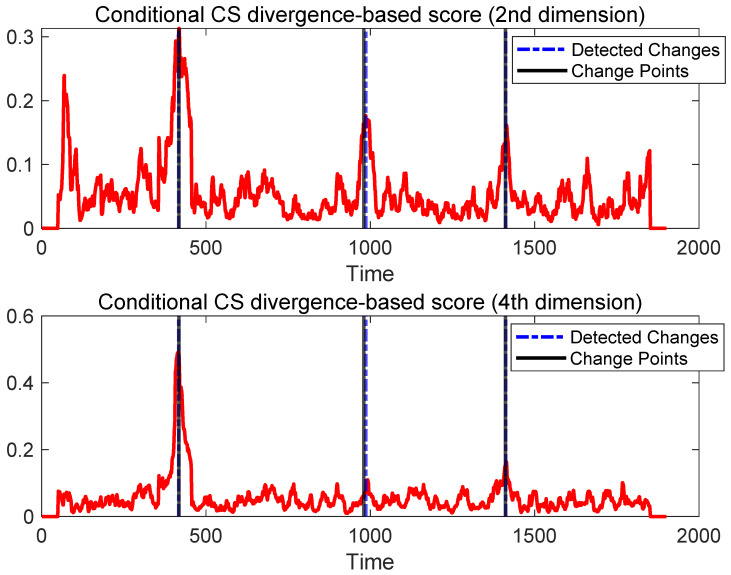 Figure 3
Figure 3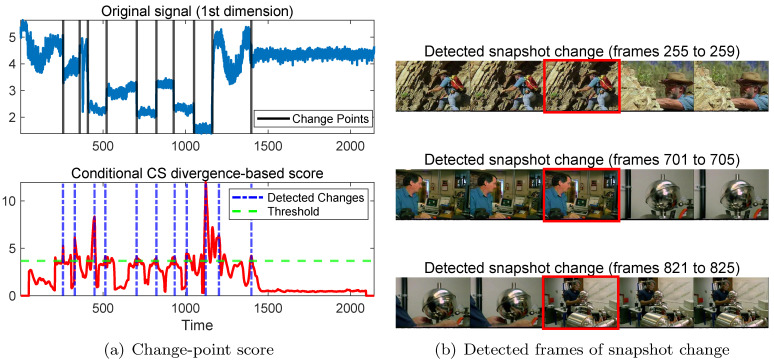 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6- —Guangdong Basic and Applied Basic Research Foundation
- —Science and Technology Projects in Guangzhou
- —Key Science and Technology Program of Henan Province
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Stream Mining Techniques · Advanced Chemical Sensor Technologies · Time Series Analysis and Forecasting
1. Introduction
Quantifying changes in probability distributions is a fundamental problem in statistics and machine learning, with applications ranging from anomaly detection and system monitoring to representation learning and generative modeling [1,2]. In many real-world scenarios, multivariate time series are generated by non-stationary processes whose underlying distributions evolve over time due to environmental variations, system degradation, or external interventions. For example, in industrial automation, subtle changes in conditional dependencies among sensors may indicate early-stage equipment degradation; in healthcare monitoring, distributional shifts in physiological signals may signal abnormal patient states; and in cybersecurity, traffic distribution changes may reveal emerging attacks.
When such distributional shifts occur, predictive models trained on historical data may suffer significant performance degradation, potentially leading to unreliable decisions in safety-critical domains such as industrial automation, healthcare monitoring, and large-scale sensor networks. Therefore, accurately detecting and quantifying distributional changes is essential for ensuring robustness, reliability, and trustworthiness in modern machine learning systems.
In this context, change-point detection (CPD) provides a principled framework for identifying time instants at which the data-generating process undergoes significant shifts [3]. A large body of existing CPD methods focuses on comparing probability distributions across temporal windows using divergence measures such as the Kullback–Leibler divergence, maximum mean discrepancy, or Wasserstein distance [4,5]. While effective at signaling the presence of a change, these approaches typically operate at the level of joint or marginal distributions and offer limited interpretability. In practice, however, detecting that a change has occurred is often insufficient: practitioners must also determine which variables are responsible for the observed change, particularly in high-dimensional systems.
Recent advances have begun to address this limitation by incorporating feature-wise or dependency-aware perspectives into change detection. Examples include density-ratio-based methods [6], kernel-based two-sample tests [7,8], and classifier-based approaches that leverage representation learning to enhance detection power [9]. More recently, interpretable formulations have been explored through conditional distribution tests that aim to localize which features have shifted over time [10]. Despite this progress, a unified framework that simultaneously offers distributional sensitivity, computational efficiency, and intrinsic interpretability in high-dimensional settings remains limited.
Large-scale sensor networks exhibit complex inter-variable dependencies arising from physical couplings and shared operational factors. In such systems, distributional changes often manifest as localized shifts in conditional relationships rather than global deviations of the joint distribution. This observation motivates an interpretable change detection framework based on conditional distribution analysis.
Accordingly, we characterize distributional changes through variable-wise conditional relationships and employ the classical Cauchy–Schwarz (CS) divergence [11,12] and its conditional extension [13] as information-theoretic measures of temporal discrepancies. Building on this idea, we develop an interpretable change detection framework that evaluates conditional distribution shifts at the level of individual variables. By decomposing discrepancies across sensors, the proposed approach enables localization of the variables whose dependency structures drive detected changes. Experiments on synthetic data, generic multivariate sensor time series, and a large-scale industrial process benchmark demonstrate competitive detection performance while providing sensor-level interpretability.
To summarize, this work makes the following contributions:
- First, we formulate interpretable change-point detection in multivariate sensor time series from a conditional distribution perspective, explicitly linking distributional changes to shifts in sensor-wise conditional relationships.
- Second, we introduce a conditional form of the classical Cauchy–Schwarz divergence as an information-theoretic tool to quantify conditional distributional discrepancies in a nonparametric and differentiable manner.
- Third, we develop an interpretable change detection framework that decomposes conditional discrepancies across individual sensors, enabling fine-grained localization of the sources of change without relying on black-box learning models.
2. Related Work
2.1. Time Series Change Point Detection
Change point detection (CPD) aims to identify time instants at which the statistical properties of a time series undergo significant changes. It is a classical problem in statistics and machine learning with applications ranging from process monitoring and anomaly detection to finance, biomedical signal analysis, and large-scale sensor networks. Depending on whether data are processed retrospectively or sequentially, CPD methods can be broadly categorized into offline and online settings. We refer interested readers to the comprehensive survey by Truong et al. [3].
From a distributional perspective, many CPD methods formulate the problem as detecting discrepancies between probability distributions across two temporal segments. Given a multivariate time series with , a change point at time is declared if the divergence between the distributions of observations from two adjacent windows exceeds a predefined threshold:
where W denotes the window size and is a suitable measure of distributional discrepancy. This formulation is flexible and model-agnostic, and has become a dominant paradigm for nonparametric change detection in high-dimensional time series.
Early distributional approaches estimate divergences directly via nonparametric density estimation, such as kernel density estimators (KDEs) [14]. However, KDE-based divergence estimation becomes unreliable in high-dimensional settings due to the curse of dimensionality. To address this issue, density-ratio estimation methods have been proposed, which estimate the ratio of two distributions without explicitly estimating the individual densities. Representative examples include the Kullback–Leibler importance estimation procedure (KLIEP) [15] and relative unconstrained least-squares importance fitting (RuLSIF) [6]. These methods are computationally efficient and have been widely adopted in practical change detection systems, particularly in online and streaming scenarios.
Another prominent line of work formulates CPD as a two-sample hypothesis testing problem using kernel methods. The maximum mean discrepancy (MMD) [16] compares distributions via their mean embeddings in reproducing kernel Hilbert spaces, thereby avoiding explicit density estimation. MMD-based detectors are flexible, nonparametric, and applicable to a wide range of data types, and have been successfully applied to change detection in time series [7,8]. More recently, kernel change-point detection has been integrated with deep models to enhance detection power in complex and highly structured data distributions [9,17].
Recent efforts have begun to address the interpretability limitations of conventional CPD methods by explicitly localizing which features or dependencies are responsible for detected distributional shifts. A representative line of work formulates interpretability in terms of conditional distribution changes. Kulinski et al. [10] formalized feature shift detection via conditional distribution tests, framing interpretability as identifying dimensions whose conditional distributions change over time. Nie and Nicolae [18] study detection and localization of conditional distribution shifts from a hypothesis testing perspective. Related perspectives on conditional dependence and invariance have also been explored in the context of causal discovery [19,20].
In parallel, several approaches rely on classifier-based two-sample tests to detect distributional changes [21,22]. While often powerful in high-dimensional settings, such methods typically require post hoc attribution techniques to infer which features drive the detected shift, and their explanations may depend strongly on model inductive biases. Another complementary line of research characterizes changes through variations in dependency or graph structures, such as mutual information matrices or dynamic networks [23,24].
2.2. The Cauchy–Schwarz Divergence and Its Conditional Extension
Before introducing our change detection framework, we briefly review the CS divergence and its conditional extension, which provide fundamental information-theoretic tools for measuring distributional discrepancies and serve as building blocks of the proposed method.
A line of work initiated by Principe and colleagues in the early 2000s proposed divergence measures constructed from classical inequalities in functional analysis [11,12]. A representative example is the CS divergence, which is rooted in the Cauchy–Schwarz inequality applied to probability density functions. Given two densities and defined on a common domain, their inner product satisfies
where equality holds if and only if p and q are linearly dependent in . This inequality motivates measuring distributional discrepancy by comparing the cross-information term against the self-information terms and . Accordingly, the CS divergence is defined as
An equivalent view is that is the negative logarithm of a normalized squared correlation (cosine similarity) between p and q in the Hilbert space , and thus it decomposes naturally into quadratic (self) and cross terms involving p and q.
The CS divergence enjoys several properties that make it attractive for statistical signal processing and change detection. For certain distribution families, such as mixtures of Gaussians, the integrals in Equation (3) admit closed-form expressions [25]. More generally, it can be estimated efficiently using nonparametric density estimators. In contrast to the Kullback–Leibler (KL) divergence, the formulation in Equation (3) avoids explicit density-ratio estimation and logarithms of densities, which often improves numerical stability in practice [26].
Given i.i.d. samples and drawn from and , respectively, the integrals in the CS divergence can be approximated using kernel density estimation (KDE). Employing a Gaussian kernel with kernel width , the CS divergence admits an empirical estimator of the form:
Importantly, the estimator is nonparametric, meaning that it does not impose any predefined parametric assumptions (e.g., Gaussianity) on the underlying data distributions. This property is particularly relevant in our setting. In multivariate sensor monitoring and industrial process analysis, the underlying data-generating mechanisms are often nonlinear, partially unknown, and difficult to model accurately using parametric distributions (e.g., Gaussian or linear models). A nonparametric formulation enables direct comparison of empirical window-based distributions without risking model misspecification, thereby improving robustness in complex real-world systems.
Note that the consistency of the underlying KDE-based estimator follows from standard KDE theory (see Appendix B.4 of [27] for a detailed proof), and therefore the CS divergence estimator inherits these guarantees.
The CS divergence can be naturally extended to conditional distributions. Let and denote two sets of random variables, and consider two conditional distributions and . The conditional CS divergence is defined as [13]:
The conditional CS divergence also admits an efficient empirical approximation based on KDEs, analogous to the unconditional case. This estimator enables practical evaluation of discrepancies between conditional distributions directly from samples, which is essential for interpretable analysis of multivariate distributional changes.
Specifically, let us consider two collections of paired observations and , drawn i.i.d. from joint distributions and , respectively. Let and denote the Gram matrices associated with the variables x and y under distribution p, and similarly let and denote the corresponding Gram matrices under distribution q. Cross-distribution Gram matrices are defined as and , with entries computed using the same kernel functions.
Under this construction, the conditional CS divergence can be approximated empirically by
This estimator avoids matrix inversion or explicit density ratio estimation. As a result, it scales favorably to high-dimensional settings and serves as a practical building block for conditional distribution-based change detection.
Although CS divergence has been explored in reinforcement learning [13], domain adaptation [26], and shape matching [28], its conditional formulation has not, to our knowledge, been leveraged for interpretable change-point detection.
3. Interpretable Change Point Detection via Conditional Cauchy–Schwarz Divergence
3.1. Problem Formulation and Framework Overview
We consider an online multivariate time series , where denotes observations collected from m sensors (or variables) at time t. The data stream is generated by an unknown and potentially non-stationary stochastic process, whose underlying distribution may evolve over time.
Given two time instants and (or two temporal windows centered around them), the goal of change detection is to determine whether the joint data-generating distributions differ, i.e.,
where denotes the joint probability distribution of the multivariate observation at time t. This formulation does not assume the existence of a fixed steady-state distribution and naturally accommodates both abrupt and gradual distributional shifts in high-dimensional time series. In practice, a change is declared when the estimated divergence exceeds a predefined threshold determined by the desired false alarm level.
Beyond detecting the presence of a change, we are interested in interpreting detected shifts by identifying which variables are most responsible. Let denote the i-th variable and denote the collection of all remaining variables. A change is attributed to variable i if its conditional distribution with respect to the rest of the system changes across time, namely,
This conditional perspective captures changes in inter-variable dependency structure and provides a principled notion of interpretability: a variable is deemed responsible for a detected change if its conditional relationship with the rest of the system exhibits a significant distributional shift. Figure 1 illustrates the difference between sensor change detection and change interpretation.
Why CS Divergence
As can be seen in Figure 1, our framework, termed Temporal Conditional Divergence (TCD), simultaneously relies on (i) joint distribution comparison for change detection and (ii) conditional distribution comparison for post hoc interpretability. Therefore, the divergence measure must admit both a stable marginal form and a principled conditional extension within a unified functional structure.
While alternative divergences such as KL divergence or MMD could in principle be employed in both stages (e.g., KL with conditional KL, or MMD with conditional MMD), several practical and theoretical limitations arise.
First, commonly used nonparametric estimators of conditional KL divergence, such as k-nearest neighbor (k-NN) estimators [29], are not differentiable and may suffer from instability in high-dimensional sliding-window settings. Second, conditional MMD does not admit a universally agreed-upon definition, and its faithfulness depends strongly on the specific formulation of conditional kernel embeddings [30]. Moreover, conditional MMD often requires Gram matrix inversion or regression operators, leading to increased computational complexity [13].
In contrast, the CS divergence admits a unified quadratic formulation for both marginal and conditional distributions [13]. The conditional extension preserves the same Hilbert-space structure as the marginal case, enabling fully nonparametric, differentiable, and inversion-free estimation via kernel Gram matrices. This structural uniformity ensures consistency between detection and interpretation stages and avoids mixing heterogeneous divergence definitions within a single monitoring framework.
Table 1 summarizes key properties of representative conditional divergences. As shown, the conditional CS divergence simultaneously satisfies differentiability, computational feasibility, and faithfulness, making it particularly suitable for interpretable online change detection in multivariate sensor streams.
3.2. Window-Based Distribution Comparison
To capture local temporal dynamics and enable online monitoring, we adopt a sliding-window representation of the multivariate time series. Given the data stream with , we define at time index k a windowed data matrix
where W denotes the window length. This construction aggregates consecutive observations and is widely used to approximate local distributions in time series analysis and system monitoring.
At each time step, we compare the distribution induced by observations from a reference window and that from a current window. Let and denote the empirical distributions estimated from the reference and current windows, respectively. A distributional change is indicated when the discrepancy between these two distributions exceeds a predefined threshold.
This window-based joint distribution comparison is solely used to determine whether a change has occurred. Interpretation and localization of change sources are addressed separately by analyzing conditional distribution shifts at the variable level, as detailed in the next subsection.
3.3. Variable-Wise Conditional Change Localization
While joint distribution comparison can indicate whether a distributional change has occurred, it does not reveal which variables are responsible for the detected shift. To enable interpretable change detection, we analyze distributional changes at the level of variable-wise conditional distributions.
At a given time interval, the dependence of on the rest of the system is characterized by the conditional distribution . A change is attributed to variable i if this conditional relationship differs across time, i.e., if
To quantify such conditional distribution shifts, we define a variable-wise conditional change score using the conditional CS divergence,
The score measures the extent to which the conditional relationship of variable i with respect to the rest of the system has changed. Importantly, the conditional scores are not used to trigger change alarms. They are computed only at detected alarm times and serve as post hoc interpretability measures that decompose a detected distributional shift into variable-wise contributions, enabling fine-grained localization of the sources of change.
3.4. Online Change Detection and Post Hoc Interpretation
Combining the joint distribution comparison in Section 3.2 and the conditional change localization in Section 3.3, we obtain a unified framework for online change detection with post hoc interpretability. A generic implementation is summarized in Algorithm 1. The choice of the detection threshold is application-dependent. For generic multivariate time series, can be set based on empirical statistics or heuristic criteria (e.g., percentile-based thresholds). For industrial process monitoring scenarios, can be calibrated from fault-free data to control the false alarm rate, as detailed in Section 4.4. Algorithm 1: Generic Online Change Detection with CS Divergence and Post Hoc Interpretation
4. Experimental Evaluation
This section provides a comprehensive experimental evaluation of the proposed interpretable change detection framework. The experiments are organized progressively from controlled to realistic settings in order to assess detection accuracy, interpretability, and practical applicability. Specifically, we first describe the experimental setup and competing baselines in Section 4.1. We then evaluate the method on synthetic data with known change sources to validate interpretability (Section 4.2), followed by experiments on generic real-world multivariate sensor time series (Section 4.3). Finally, we demonstrate the effectiveness of the proposed framework on a large-scale industrial process benchmark, the Tennessee Eastman Process (TEP) [31,32], to highlight its relevance for industrial sensor monitoring (Section 4.4).
4.1. Experimental Setup and Competing Baselines
We compare the proposed method with representative baselines from the literature on multivariate time series change-point detection and distributional change detection. These baselines include kernel-based two-sample tests as well as density-ratio and divergence-based approaches, which are widely adopted in unsupervised detection settings.
All selected baselines produce explicit window-based detection statistics under a unified online evaluation protocol. While several recent works (see Section 2.1) investigate conditional dependence or structural changes, they are not formulated as standalone sliding-window change-point detection algorithms and therefore are not directly comparable within the same experimental framework.
Specifically, we include the following methods:
- MMD [7]: the maximum mean discrepancy-based two-sample test, which detects distributional changes by comparing mean embeddings in a reproducing kernel Hilbert space.
- KDE-based divergence [14]: a KDE-based method that approximates the KL divergence using Rényi’s -order divergence with , following common practice to avoid numerical instability when directly estimating KL divergence [33]. The detailed formulation and KDE-based estimation of Rényi’s -order divergence are provided in Appendix A.
- RuLSIF [6]: the relative unconstrained least-squares importance fitting method, which detects changes by estimating relative density ratios.
- KL-CPD [9]: a neural network-based change-point detector that maximizes a lower bound of the test power of kernel two-sample tests using an auxiliary generative model.
- NN-CPD [17]: a deep learning–based offline change-point detection framework that trains a neural network classifier to distinguish between sequences with and without change-points.
These baselines are selected to represent different methodological paradigms in distributional change detection, including density-ratio estimation (RuLSIF), kernel-based two-sample testing (MMD), classical divergence estimation (KDE), and neural network–based approaches (KL-CPD, NN-CPD).
For kernel-based methods, including MMD, KDE-based divergence, and the proposed method, we use a Gaussian kernel. The kernel bandwidth is selected using the median heuristic, i.e., the median of pairwise distances between samples within each window, which is a widely adopted and parameter-free choice in kernel two-sample testing. This ensures a fair comparison by avoiding dataset-specific manual tuning.
For RuLSIF, the kernel bandwidth is selected via 5-fold cross-validation, and the subspace dimension is set to with , following the recommendations of the original authors. For KL-CPD, the regularization parameter is chosen from and the weight is selected from . The best-performing configuration is reported for each dataset.
All methods are evaluated under a unified sliding-window protocol with a stride of 1. The window length W is selected from based on validation performance for each dataset. For the generic detection framework (Algorithm 1), the detection threshold is determined using a permutation test. Specifically, for each time step, samples from the reference and current windows are randomly permuted to generate surrogate distributions under the null hypothesis of no change. The empirical distribution of the resulting divergence statistics is used to set at the 95th percentile, corresponding to a significance level of .
All baseline methods are implemented following their original descriptions under the same window configuration and evaluation protocol to ensure fair comparison.
4.2. Synthetic Data: Interpretability Study
To validate the interpretability of the proposed method under a controlled setting, we first conduct experiments on synthetic data where the source variables responsible for distributional changes are explicitly known. Unlike real-world datasets, this setting allows us to directly assess whether the detected changes and the associated variable-level attributions are consistent with the underlying data-generating mechanisms.
Following [34], we generate a 5-dimensional multivariate time series consisting of 1900 non-Gaussian samples. Three change points are introduced at time indices , resulting in four consecutive segments. Within each segment, the data are generated according to a copula Gaussian graphical model [35], denoted by , where the precision matrix K encodes the conditional dependency structure among variables. Specifically, an edge between nodes i and j exists if and only if .
The precision matrix K is generated as follows. We first uniformly sample locations from the unit square and initialize K as an identity matrix. For each pair , the off-diagonal entries are set to with probability , and to zero otherwise. The resulting graph structures for each segment are illustrated in Figure 2, where red and green edges indicate positive and negative entries of K, respectively.
For each competing method, the detection threshold is selected to provide a reasonable trade-off between true positive rate (TPR) and false positive rate (FPR). In addition to detection accuracy, we report the root mean square error (RMSE) between the estimated change-point locations and the ground-truth change points. As summarized in Table 2, the proposed method achieves competitive detection performance compared with existing approaches.
More importantly, the synthetic setting enables a fine-grained analysis of interpretability. By examining the variable-wise conditional CS divergence scores ; , we observe that different variables contribute unevenly to different change points. For instance, the fourth variable contributes negligibly to the detection of the second change point, which is consistent with the fact that its conditional dependence structure with respect to remains largely unchanged between segments and (see Figure 2). By contrast, the second variable consistently exhibits large conditional divergence scores across multiple change points, reflecting the pronounced alterations in its dependency structure. A visualization of the variable-wise conditional CS divergence is shown in Figure 3.
These results demonstrate that, beyond detecting distributional changes, the proposed method is capable of correctly attributing changes to the underlying variables whose conditional dependencies are truly affected. This controlled experiment provides strong evidence that the conditional CS divergence offers meaningful and reliable interpretability for multivariate change detection.
We further examine the sensitivity of the TCD to the kernel bandwidth parameter. Specifically, we scale the median heuristic by factors of and to assess robustness under moderate bandwidth variation. As shown in Table 3, the TPR and FPR remain stable across different bandwidth scales. The primary effect is observed in the RMSE of the estimated change-point location, reflecting the expected smoothness–responsiveness trade-off: larger bandwidths produce slightly smoother but delayed detections, whereas smaller bandwidths react faster. Overall, the results indicate that the proposed method is robust to moderate bandwidth perturbations.
4.3. Evaluation on Generic Multivariate Sensor Time Series
We further evaluate the proposed method on three widely used real-world benchmarks that represent generic multivariate sensor time series across different modalities, including physiological signals, audio, and video. These datasets have been extensively adopted in the change-point detection literature and allow us to assess the robustness and general applicability of the proposed framework beyond controlled synthetic settings. A summary of the dataset characteristics is provided in Table 4.
The EEG eye state dataset is obtained from the UCI Machine Learning Repository (https://archive.ics.uci.edu/ml/datasets/EEG+Eye+State, accessed on 1 October 2025) and consists of 14,980 time samples recorded from 14 EEG electrodes and one additional reference channel (15 signals in total) over approximately 117 s. The electrodes follow the standard 10–20 EEG placement system as described in the original dataset documentation. No additional preprocessing or dimensionality reduction was applied beyond using the provided normalized signals. Binary eye states (open/closed) were annotated via synchronized video recordings in the original dataset. In our experiments, a change point is defined as a transition between the annotated eye states. Following prior work [36], we evaluate on the first 2000 samples, which contain four abrupt state transitions at time indices 188, 871, 1335, and 1637.
The Great Barbet dataset is constructed following [37] by concatenating birdsong recordings from the same species obtained from the xeno-canto database. Specifically, we download three recordings and concatenate approximately one-minute segments from each song. Each audio frame is represented by 13 mel-frequency cepstral coefficients (MFCCs) along with the log-energy term, resulting in a 14-dimensional feature vector. We use the first 1900, 1800, and 1000 frames from the three recordings, respectively, forming a 14-dimensional time series of length 4700. Change points correspond to transitions between different acoustic regimes.
The UGS dataset [38] is a documentary video from the Open Video Project that contains fast shot transitions and camera motion. The sequence consists of 2143 frames and 11 shots. For each frame, we extract local binary pattern (LBP) features as appearance descriptors, resulting in a 256-dimensional representation. The objective is to detect abrupt shot changes for video temporal segmentation. This dataset has been widely used as a benchmark for change detection in high-dimensional visual time series.
For quantitative comparison on these generic benchmarks, we adopt the receiver operating characteristic (ROC) curve and the area under the ROC curve (AUC), which are commonly used when change-point annotations are available but detection delays may vary across methods. Following prior work [6,7,9], we define the true positive rate (TPR) and false positive rate (FPR) as
where denotes the number of correctly detected change points, is the total number of true change points, and is the total number of detection alarms. Detection alarms are identified as peaks in the change-point score. An alarm at time index t is considered correct if there exists a true change point at such that , where specifies the acceptable detection tolerance.
In Table 5, we report the AUC values of all competing methods on the three real-world benchmark datasets. As can be observed, the proposed method consistently achieves the highest AUC across all datasets, indicating superior change detection performance. Figure 4 illustrates the detected change point.
4.4. Application to the Tennessee Eastman Process
The experiments in Section 4.3 demonstrate that the proposed method achieves robust change detection performance on a variety of generic multivariate sensor time series across different modalities, including physiological signals, audio, and video. While these benchmarks validate the general applicability of the proposed framework, they do not fully capture the complexity, strong variable coupling, and operational constraints commonly encountered in large-scale industrial process monitoring systems.
To further assess the proposed framework under industrially realistic conditions, we consider the Tennessee Eastman Process (TEP), a widely used benchmark for industrial process monitoring [31,32]. TEP models a large-scale chemical production system with complex nonlinear dynamics, tightly coupled process variables, and diverse fault mechanisms, and has therefore been extensively adopted for evaluating sensor-based fault detection and diagnosis methods.
In this study, we employ the closed-loop TEP simulation model [32,39] to evaluate the proposed change detection and post hoc interpretability framework in an industrial monitoring setting. The process provides 22 continuous process measurements and 11 manipulated variables, resulting in a 33-dimensional multivariate sensor stream. All variables are sampled at a fixed interval of 3 min, following standard TEP configurations commonly used in the process monitoring literature. The detailed monitoring procedure for applying the proposed framework to the Tennessee Eastman Process is summarized in Algorithm 2, which outlines the complete online monitoring pipeline, including threshold calibration from fault-free data, online alarm triggering, and post hoc sensor-level interpretability analysis.
4.4.1. Monitoring Protocol and Threshold Calibration
Rather than adopting a conventional train–test split as in supervised learning, we follow a process monitoring protocol that reflects practical industrial scenarios. Specifically, a continuous segment of fault-free operation is first used as a reference run to characterize normal process behavior. This reference data is used solely for calibrating the detection threshold and does not involve any fault labels.
Let W denote the sliding window length. At each time index t, two adjacent windows of equal length are constructed from the data stream: a reference window and a current monitoring window. To detect distributional changes in the multivariate sensor stream, we compute a global detection statistic by comparing the joint distributions induced by these two windows using the CS divergence,
where and denote the empirical joint distributions estimated from the reference and current windows, respectively. Algorithm 2: TEP Monitoring with CS-Divergence Alarming and Conditional CS Interpretability
Using the fault-free reference run, we obtain an empirical distribution of under normal operating conditions and set the alarm threshold as a high quantile (e.g., ) of this distribution. This threshold serves as a control limit that regulates the false alarm rate and is fixed for all subsequent online monitoring runs.
4.4.2. Online Fault Detection Performance
To evaluate online fault detection performance, we generate independent monitoring runs of 100 h, in which a single fault is injected exactly 20 h after the start of each sequence. This design ensures a sufficiently long fault-free period for assessing false alarms, followed by a clear transition to a faulty operating regime for evaluating detection capability.
Rather than exhaustively evaluating all 21 predefined fault types in the Tennessee Eastman Process (TEP), we focus on a representative subset of commonly studied benchmark faults that span diverse fault mechanisms and detection characteristics. The selected cases include step-type faults (Faults 1–5), a random disturbance (Fault 8), a slow drift fault (Fault 13), and a sticking-related fault (Fault 14). These faults collectively cover abrupt, stochastic, gradual, and nonlinear behaviors, providing broad coverage for assessing both detection accuracy and sensor-level interpretability of the proposed framework.
During online monitoring, an alarm is triggered whenever the detection statistic exceeds the predefined threshold . Detection performance is quantitatively evaluated using three standard metrics widely adopted in industrial process monitoring: the false alarm rate (FAR) and the fault detection rate (FDR). The FAR measures the frequency of spurious alarms under normal operating conditions, the FDR evaluates the proportion of faulty runs in which at least one alarm is raised after fault onset, and Fault Detection Delay (FDD) characterizes the timeliness of detection by measuring the delay between the true fault occurrence time and the first alarm.
Following standard practice in Tennessee Eastman process monitoring, the FAR is computed on fault-free runs, while the FDD is averaged across the selected fault scenarios. The summary results are reported in Table 6. In contrast, due to the heterogeneous detection difficulty of different fault mechanisms, the FDR is reported on a per-fault basis for the selected fault subset, as shown in Table 7. Note that we additionally compare our approach with RTCSA [40], which is widely regarded as a state-of-the-art method for fault change detection.
4.4.3. Post Hoc Sensor-Level Interpretability
Beyond detecting the occurrence of process changes, it is crucial in industrial monitoring applications to understand which sensors and inter-variable dependencies are most responsible for the detected abnormality. Importantly, the proposed framework explicitly decouples change detection from interpretation: sensor-level analysis is performed only after an alarm is triggered and does not affect the alarming mechanism itself. Detailed descriptions of all TEP sensors and manipulated variables are provided in Appendix B.
For interpretability analysis, we focus on Fault 1, which corresponds to a canonical step-type disturbance in feed composition and is among the most well-studied and interpretable fault scenarios in the Tennessee Eastman Process. This fault provides a representative and intuitive test case for examining whether the proposed conditional analysis yields physically meaningful explanations.
Specifically, at the alarm time , we compute for each sensor i the conditional CS divergence
which quantifies the change in the conditional dependency between sensor i and the remaining sensors. For ease of interpretation, the conditional scores are normalized and used to rank sensors according to their relative contributions to the detected change.
For Fault 1, the top-ranked sensors identified by the proposed method are Sensor 1 (A feed flow), Sensor 2 (D feed flow), and Sensor 8 (reactor level). These sensors are directly associated with upstream feed streams and the resulting reactor operating state, which is consistent with the physical nature of a step-type feed composition disturbance. In particular, changes in the feed flow variables (Sensors 1 and 2) propagate through the process and induce shifts in reactor inventory and dynamics, which are reflected by the reactor level (Sensor 8).
Notably, the prominence of reactor level as a top contributor indicates that the detected change is characterized by altered inter-variable dependency structure rather than isolated marginal deviations in individual sensor readings. This observation highlights the advantage of conditional analysis: while marginal statistics may capture local signal fluctuations, the conditional CS divergence explicitly reveals how relationships between variables evolve under abnormal operating conditions.
Overall, this post hoc analysis demonstrates that the proposed framework not only detects process changes reliably, but also provides physically meaningful and actionable interpretations by localizing the sensors and dependencies most responsible for the detected fault.
5. Conclusions and Future Work
In this work, we proposed an interpretable change-point detection framework for multivariate sensor time series based on conditional Cauchy–Schwarz (CS) divergence. By shifting the focus from joint distribution shifts to changes in sensor-wise conditional relationships, the proposed method enables fine-grained attribution of detected changes to specific sensors and their dependencies. The conditional CS divergence can be efficiently estimated in a fully nonparametric manner using kernel density estimation, without density-ratio learning or matrix inversion, making it well suited for online monitoring in high-dimensional settings.
Extensive experiments on synthetic data, generic multivariate benchmarks, and the Tennessee Eastman Process demonstrate that the proposed approach achieves reliable change detection performance while providing transparent, sensor-level interpretations that are not available in conventional CPD methods. In particular, the industrial case study shows that the identified key sensors are consistent with known fault mechanisms, highlighting the practical value of conditional distribution analysis for interpretable monitoring of complex industrial processes.
Beyond the experimental validation presented in this work, the proposed conditional CS divergence-based framework has the potential to support a range of real-world monitoring applications. In large-scale sensor networks and industrial automation systems, it could facilitate early detection of abnormal operating regimes while providing interpretable sensor-level insights into dependency changes. In cybersecurity and network monitoring, conditional distribution analysis may help localize shifts in traffic patterns or feature dependencies, offering improved transparency compared to purely black-box detectors. Similarly, in environmental and structural monitoring contexts, the framework could assist in identifying evolving inter-sensor relationships caused by external disturbances or gradual system degradation.
A natural direction for future work is to extend the current variable-wise attribution framework to explicitly characterize coordinated shifts across subsets of sensors. Although the proposed detection mechanism operates on the full joint distribution and thus captures multivariate changes at the global level, the interpretability module presently evaluates conditional shifts at the level of individual variables. In high-dimensional systems, distributional changes may arise from collective variations among interacting sensors. Extending the conditional CS framework to subset-wise conditioning could enable richer attribution of joint dependency shifts while preserving its distributional, model-agnostic nature.
Moreover, exploring extensions toward directional or causal change analysis, such as integrating transfer entropy measures [41], may further enhance the ability to characterize structural evolution in complex systems.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Basu A. Shioya H. Park C. Statistical Inference: The Minimum Distance Approach CRC Press Boca Raton, FL, USA 2011
- 2Müller A. Integral probability metrics and their generating classes of functions Adv. Appl. Probab.19972942944310.2307/1428011 · doi ↗
- 3Truong C. Oudre L. Vayatis N. Selective review of offline change point detection methods Signal Process.202016710729910.1016/j.sigpro.2019.107299 · doi ↗
- 4Gretton A. Borgwardt K.M. Rasch M.J. Schölkopf B. Smola A. A kernel two-sample test J. Mach. Learn. Res.201213723773
- 5Arjovsky M. Chintala S. Bottou L. Wasserstein generative adversarial networks Proceedings of the International Conference on Machine Learning PMLR Westminster, UK 2017214223
- 6Liu S. Yamada M. Collier N. Sugiyama M. Change-point detection in time-series data by relative density-ratio estimation Neural Netw.201343728310.1016/j.neunet.2013.01.01223500502 · doi ↗ · pubmed ↗
- 7Li S. Xie Y. Dai H. Song L. M-statistic for kernel change-point detection NIPS’15: Proceedings of the 29th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015 MIT Press Cambridge, MA, USA 2015
- 8Zou S. Liang Y. Poor H.V. Shi X. Nonparametric detection of anomalous data via kernel mean embeddingar Xiv 20141405.2294