A Fully Automated Deep Learning Pipeline for Anatomical Landmark Localization on Three-Dimensional Pelvic Surface Scans
Woosu Choi, Jun-Su Jang

TL;DR
This paper introduces an automated deep learning system for identifying pelvic landmarks in 3D scans, improving accuracy and consistency compared to manual methods.
Contribution
A novel modular deep learning pipeline for automated pelvic landmark localization with improved repeatability and real-time performance.
Findings
The system achieved a median error of 11.25 mm in landmark localization.
Automated measurements showed higher intraclass correlation coefficients than manual marking.
The pipeline processes scans in about three seconds, enabling near real-time clinical use.
Abstract
Accurate identification of anatomical landmarks on three-dimensional (3D) pelvic surface scans is essential for musculoskeletal assessment, yet manual procedures remain limited by operator dependence and soft tissue variability. This study presents a fully automated deep learning pipeline for localizing anatomical landmarks on the posterior pelvic region from raw 3D point cloud data. The pipeline integrates three modules: PelvicROINet for extracting the region of interest, PelvicAlignNet for rotation correction to standardize posture, and PelvicLandmarkNet for localizing six anatomical landmarks including the bilateral posterior superior iliac spines, bilateral iliac crests, L1, and L4. The models were trained independently with task-specific annotations and combined sequentially during inference. Under a subject-level split evaluation setting, the fully integrated system achieved a…
Click any figure to enlarge with its caption.
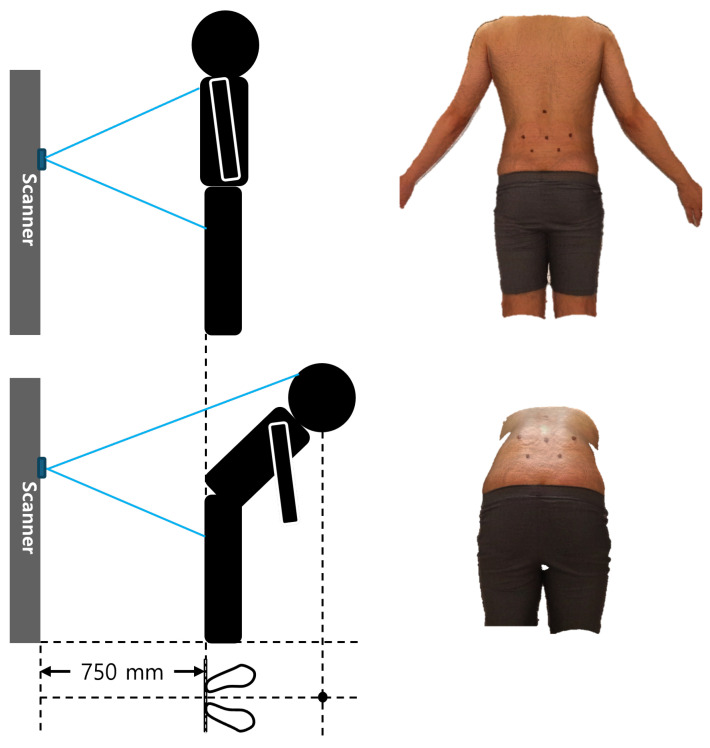 Figure 1
Figure 1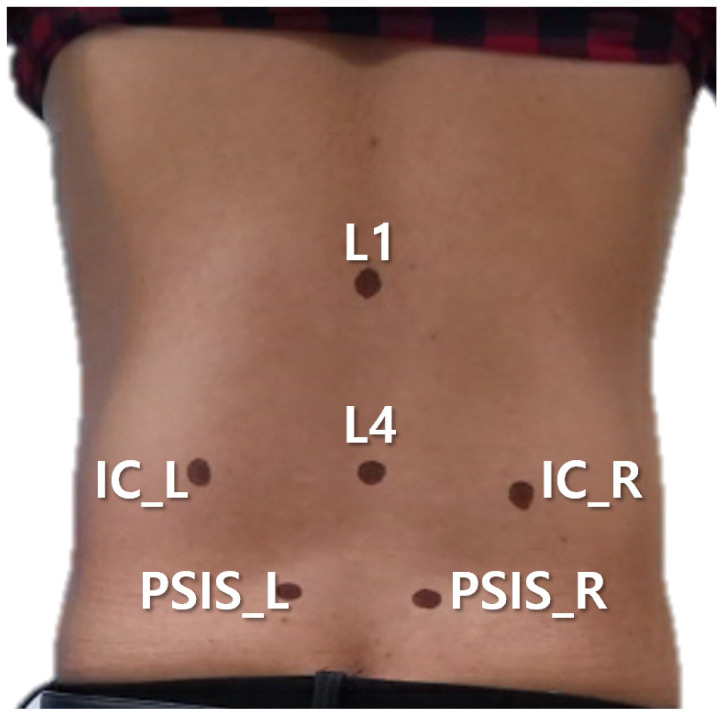 Figure 2
Figure 2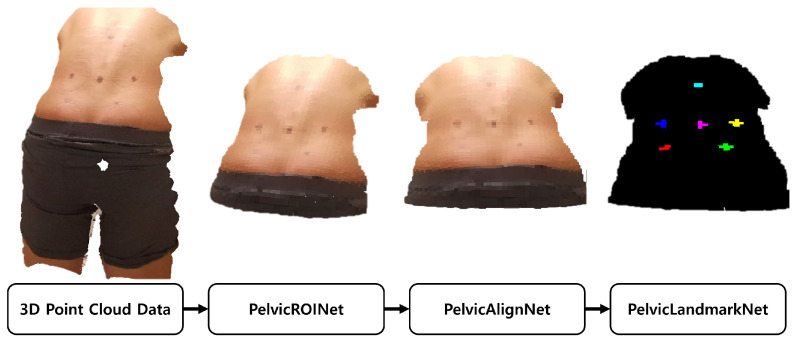 Figure 3
Figure 3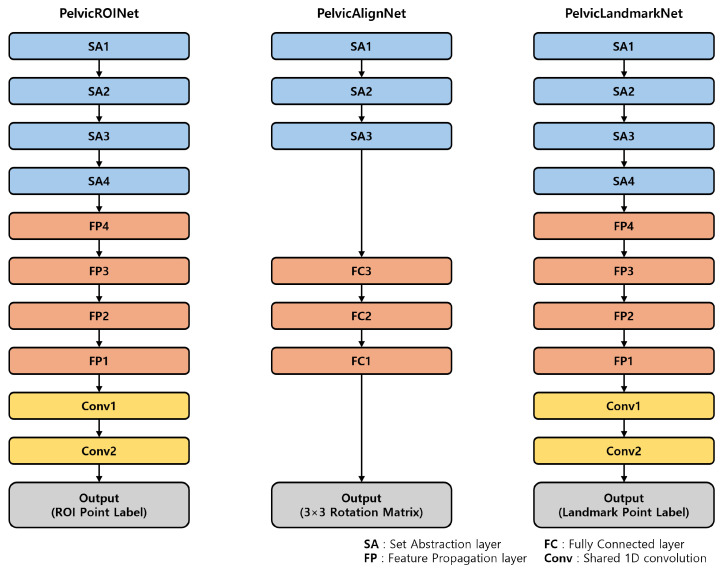 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8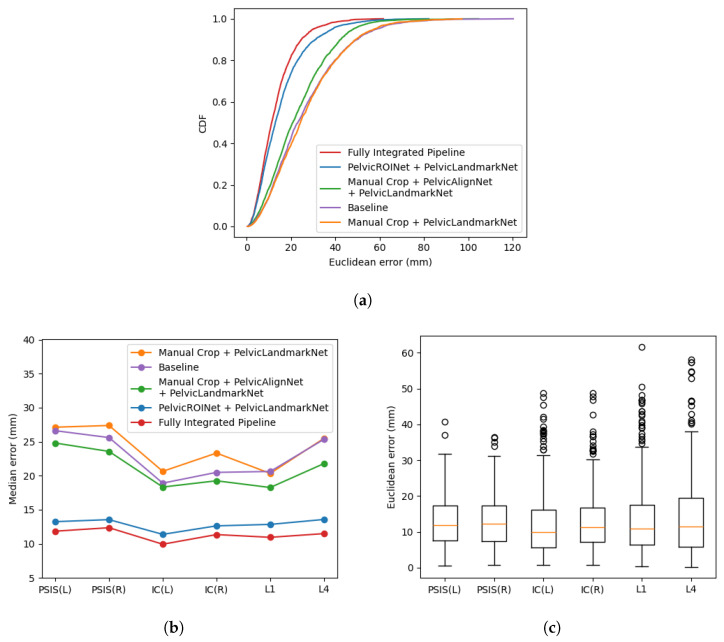 Figure 9
Figure 9- —Ministry of Health & Welfare, Republic of Korea
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMedical Imaging and Analysis · Surgical Simulation and Training · Scoliosis diagnosis and treatment
1. Introduction
Interest in quantitatively assessing human alignment and posture is steadily increasing in various clinical and biomechanical research fields [1,2]. In particular, the pelvis, as the connection point between the spine and the lower extremities, plays a key role in human alignment. Pelvic asymmetry and positional changes have been reported to be closely associated with back pain, gait abnormalities, and postural imbalances [3,4]. Against this background, there has been an increasing need for objective and non-invasive methods to assess pelvic shape and alignment.
Three-dimensional (3D) body surface scanning technology enables direct acquisition of external body shape [5] and is gaining attention as a suitable alternative for morphological analysis and evaluation of alignment of surface-based anatomical structures such as the pelvis, by offering non-invasive and accurate surface data for applications including posture evaluation [6], musculoskeletal diagnosis [7,8], and rehabilitation monitoring [9]. Conventional computed tomography (CT) or magnetic resonance imaging (MRI) provides high-resolution visualization of internal anatomical structures. However, limitations such as high cost, long acquisition time, and limited accessibility make repeated measurements difficult and restrict their use for evaluating immediate postural changes in clinical settings. In contrast, 3D body surface scanning allows repeated measurements through relatively simple procedures and offers advantages in terms of cost-effectiveness and accessibility, making it well suited for tracking postural or morphological changes before and after treatment [10,11].
Several technical limitations remain in the automatic interpretation of data acquired through 3D body surface scanning and in the reliable extraction of clinically meaningful information. Although most clinical studies acquire 3D body scan data in accordance with standardized operating procedures (SOP), automated interpretation of raw surface point clouds remains challenging due to measurement noise introduced during scanning, their high dimensionality and substantial inter-individual variability [12,13]. Classical image preprocessing methods, such as thresholding, region of interest (ROI) selection, and surface smoothing, have limitations in reliably distinguishing actual body surface changes from measurement noise [14]. As a result, clinically significant surface variations may be unnecessarily removed during preprocessing [15]. Beyond noise-related issues, substantial variations in body surface geometry are inevitable due to inter-subject differences in body shape. Moreover, repeated measurements can vary due to slight changes in posture or unintentional movements during scanning. The Iterative Closest Point (ICP) algorithm [16] has been widely used to align and normalize body surface data by correcting such variations. However, ICP is highly dependent on the initial alignment and frequently converges to local minima when large rotational differences are present or when parts of the surface data are missing [17]. These limitations can reduce reliability in practical clinical settings.
To establish clearer reference standards for clinical analysis, anatomical landmarks on the subject’s skin are sometimes manually marked using pen markers or by attaching physical markers. The resulting marker positions can be used as reference points for algorithm-based analysis and the extraction of clinically significant features. However, the process of manually marking anatomical locations on the body surface is highly dependent on the level of expertise of the examiner, leading to substantial variability both between examiners and across repeated measurements [18]. Furthermore, additional errors may be introduced during the digitization of marker locations after scanning [19]. Consequently, these traditional approaches remain inherently limited and are insufficient as a fundamental solution for fully automated 3D body surface analysis.
Recent advances in computing hardware and artificial intelligence (AI) algorithms have driven the adoption of deep learning techniques across a wide range of research fields, including medical imaging and biomechanical analysis. In particular, the emergence of 3D point cloud processing models such as PointNet [20] and PointNet++ [21] has enabled direct feature learning from raw 3D point sets without requiring complex voxelization procedures. This approach has improved computational efficiency while reducing memory requirements, allowing these models to be applied to real-time analysis and diagnostic tasks. Subsequently, numerous point-based deep learning models, including variants of PointNet/PointNet++ and other alternative architectures, have demonstrated strong performance in object classification [22], segmentation [23], and feature detection tasks [24].
However, extracting clinically significant anatomical features from 3D body surface scans remains a challenge. This difficulty arises because the surface of the human body is covered by soft tissue and internal skeletal landmarks are not directly represented on the external surface. Even for the same anatomical location, its position on the body surface can vary substantially depending on posture [25]. Movement of the subject during scanning can also cause the locations defined in a specific posture to appear in different surfaces [6]. In routine surface scanning workflows, complementary thermal or physical information that could provide additional physiological or biomechanical context is typically unavailable. Consequently, accurate pelvic landmark localization must rely primarily on surface-geometric cues alone, further increasing the difficulty of reliable detection. Although multimodal approaches integrating anatomical and thermal data have been proposed [26], they generally require additional hardware and complex acquisition procedures, limiting their practicality in routine clinical settings. Under these constraints, a single model trained to detect local features from dense 3D point clouds is prone to large errors when newly acquired data differ from the anatomical shapes or imaging conditions present in the training data. This challenge is further compounded by the limited availability of accurately labeled datasets during model training. Although precise labels are essential for supervised learning, annotating 3D scan data in clinical settings is time consuming and requires considerable manual effort [27]. Such processes are also inevitably affected by multiple sources of error, including differences in operator experience, subtle movements of subjects, and human error. To address these challenges and achieve robust generalization in diverse body types, postures, and imaging conditions, a modular architecture that combines multiple specialized models with distinct functions is required. Each model is trained independently to address specific sources of variability and later integrated to enhance the overall reliability of the system.
In this study, we propose a modular analysis framework for 3D human pelvic body surface analysis that sequentially performs body surface segmentation, alignment, and anatomical landmark localization. Three models are designed and optimized for each processing stage and their effectiveness is validated through quantitative and qualitative evaluations at the individual module level, as well as at the integrated pipeline level.
2. Materials and Methods
2.1. Dataset
The data were obtained from a single three-dimensional surface dataset covering both the back and pelvis regions using a structured-light 3D scanner (model: iBalance, TeamElysium, Seoul, Republic of Korea) equipped with a Kinect Azure sensor (model: Azure Kinect, Microsoft, Redmond, WA, USA). The dataset consisted of 1806 scans from 107 participants, all acquired under a standardized scanning protocol following predefined SOP guidelines to ensure consistent measurement conditions and minimize operator-dependent variability. Surface scans were scheduled at four time points: (1) before treatment (screening), (2) after the first treatment, (3) after the 12th treatment, and (4) at a follow-up visit one month after completion of the 12-session treatment course. Because the baseline scans were obtained for screening purposes, some participants had data only at the pre-treatment time point. In addition, several participants dropped out during the treatment course, and thus not all participants completed all four measurements. At each available time point, 2–3 repeated scans were collected to ensure reliability, and scans with minimal artifacts were selected for analysis. Each participant underwent repeated 3D surface scanning under two postures at a distance of 750 mm from the camera: a natural upright standing position (P1) and a forward-bending position starting from the upright posture (P2) (Figure 1). At each scheduled time point, 2–3 scans were collected per posture to ensure reliability. Thus, when all four time points were available, each participant contributed approximately 16–24 scans in total (8–12 scans per posture).
Each scan was represented as a point cloud that contains approximately 200,000 to 600,000 points, depending on the participant’s body shape, body surface area, and posture (P1 or P2). For the measurements, six anatomical landmarks were first identified by trained clinicians through palpation and then marked on the posterior pelvic surface using a fine tipped marker pen (Figure 2): the bilateral posterior superior iliac spines (PSIS), the bilateral iliac crests (IC), and the vertebral levels L1 and L4. After scanning, a clinical research coordinator (CRC) manually identified the centers of six markers on the reconstructed 3D surface plot via mouse-based digitization, thereby obtaining the 3D coordinates corresponding to each anatomical landmark (PSIS_L, PSIS_R, IC_L, IC_R, L1, and L4).
2.2. Overview of the Pipeline
Pelvic ROINet extracts the posterior pelvic region of interest (ROI) from the raw 3D point cloud data covering the region from the bilateral PSIS to L1. The extracted ROI is then processed by PelvicAlignNet, which performs rotation correction to align the point cloud to a standardized posture. Finally, PelvicLandmarkNet localizes the coordinates of six anatomical landmarks (bilateral PSIS, bilateral IC, L1, and L4) on the rotation corrected surface data. Each model was trained independently and their outputs were sequentially integrated during inference (Figure 3). The internal architectures of the three modules were based on a PointNet++ backbone, and their structures are summarized in Figure 4.
2.3. PelvicROINet
2.3.1. Input & Preprocessing
For each point cloud dataset, the 3D coordinates (x, y, z) of the six markers were used to determine the minimum and maximum values along each axis. All coordinates are expressed in millimeters. Based on these values, the posterior pelvic ROI was defined as
Points within the ROI were labeled as 1, whereas outside the ROI were labeled as 0. Each point cloud was downsampled to 16,384 points using random uniform sampling without replacement to ensure computational efficiency during training. The dataset was randomly divided into training and test sets at a ratio of 8:2 at the subject level. To prevent data leakage, all scans from a given subject were assigned exclusively to either the training or the test set. Specifically, 20 % of subjects were randomly selected for the test set, and all scans from those subjects were included only in the test set. For data augmentation, each point cloud was translated to its centroid and randomly rotated between minus twenty and plus twenty degrees around the x, y, and z axes, resulting in a twentyfold increase in the number of training samples. In addition, although scans were acquired under a standardized operating procedure (SOP), the dataset naturally included clinically realistic acquisition artifacts, such as partial obstruction of the pelvic region due to incomplete arm abduction, inclusion of surrounding objects, and variations in sampling density depending on the scanner-to-subject distance and viewing angle. This inherent variability complemented the synthetic augmentation and improved robustness under practical scanning conditions. Each point was represented by six input channels, including the raw 3D coordinates and the normalized coordinates relative to the bounding box. Additionally, the set abstraction (SA) layers of PointNet++ [21] also take the raw XYZ coordinates as separate channels for distance computation, the first SA layer receives a total of 9 input channels.
2.3.2. Network Architecture
The model was designed based on the PointNet++ framework for semantic segmentation [20,21,28], consisting of four SA layers followed by four feature propagation (FP) layers. The SA layers progressively downsampled the input point cloud to 1024, 256, 64, and 16 points, respectively, while aggregating local features through multi-scale grouping. The feature dimension was expanded from 9 input channels to 512 channels across these layers. Subsequently, the FP layers hierarchically interpolated and propagated the features back to the original point resolution, producing 128-dimensional point-wise feature representations. Finally, two shared 1D convolutional layers with 128 and C output channels, where C denotes the number of classes, were applied to the propagated features. Each layer was followed by batch normalization, ReLU activation, and dropout (p = 0.5). Per-point labeling was obtained using a log-softmax activation.
2.3.3. Loss Function
The negative log-likelihood (NLL) loss was employed to measure the discrepancy between the predicted per-point class probabilities and the ground-truth labels. Optional class weighting was applied to mitigate class imbalance. The NLL loss is defined as
where N is the number of points, is the predicted probability of the i-th point for its ground-truth class , and is the corresponding class weight. For PelvicROINet, the training loss is defined as
2.3.4. Training and Evaluation
The model was trained for 20 epochs using the Adam optimizer with a batch size of 32. Evaluation was performed on the held out test set without applying gradient updates. The performance metrics included class-specific Intersection over Union (IoU) and recall for the pelvic ROI.
2.4. PelvicAlignNet
2.4.1. Input & Preprocessing
The point clouds extracted by PelvicROINet were used as input for PelvicAlignNet. Each point cloud was translated so that the midpoint of the bilateral PSIS coordinates aligned with the origin, and then rotated around the y axis to horizontally align the PSIS points. Subsequently, the point cloud was rotated around the x axis to set the z coordinate of L4 to zero, thereby establishing a standardized posture. Data augmentation was performed using the same procedure as in PelvicROINet. Each point was represented by six input channels, including the raw 3D coordinates and the normalized coordinates relative to the bounding box. In the set abstraction layers of PointNet++, the raw XYZ coordinates were additionally used for distance computation, resulting in nine input channels in the first SA layer.
2.4.2. Network Architecture
The model is based on the PointNet++ framework and comprises three SA layers. The first two SA layers progressively downsample the point cloud to 512 and 128 points, respectively, while the final SA layer performs global feature aggregation over all input points to produce a global feature vector. This global feature vector is subsequently fed into three fully connected layers to predict a 3 × 3 rotation matrix. Batch-wise singular value decomposition (SVD) is applied to normalize the predicted rotation matrix and enforce its orthonormality.
2.4.3. Loss Function
Training minimizes a weighted sum of three loss terms, including a point-set distance loss between the transformed point cloud and the reference point cloud, a rotation orthonormality regularization loss, and an Euler-angle loss. The point-set distance loss is defined as the average point-wise Euclidean distance between the predicted transformed points and the reference points.
with and denoting the i-th predicted and reference point in the b-th batch, respectively. The rotation regularization term encourages the predicted rotation matrix to be orthonormal.
where is the identity matrix and denotes the Frobenius norm. In addition, the Euler-angle loss is computed as the distance between Euler angles converted from the predicted and reference rotation matrices.
where denotes the Euler-angle representation derived from a rotation matrix. The weighting factors and control the contributions of the rotation regularization and Euler-angle terms, respectively. The total loss of PelvicAlignNet is defined as
2.4.4. Training and Evaluation
The model was trained using the Adam optimizer with a batch size of 32. Evaluation on the held-out test set included the mean distance between the predicted and reference point clouds, as well as the rotation regularization loss.
2.5. PelvicLandmarkNet
2.5.1. Input & Preprocessing
The input to PelvicLandmarkNet consisted of the rotation corrected pelvic surface point clouds obtained from PelvicROINet and PelvicAlignNet. To address the imbalance between background and marker points, all points within a 10 mm radius around each anatomical marker were assigned the same label during training, the average coordinates of the predicted regions were then compared with the ground-truth marker coordinates. For each of the six anatomical markers, points within a 10 mm radius from the marker center were labeled as 1–6, respectively, while all other points were labeled as 0. Data augmentation followed the same procedure as in PelvicROINet. Each point was represented by six feature channels, including the raw 3D coordinates and normalized coordinates relative to the bounding box. Additionally, the SA layers of PointNet++ use the raw XYZ coordinates as separate input channels, resulting in a total of nine input channels for the first SA layer.
2.5.2. Network Architecture
The network architecture of PelvicLandmarkNet is similar to PelvicROINet. Both networks use the same PointNet++ backbone and share the same overall structure.
2.5.3. Loss Function
The total loss used for training the PelvicLandmarkNet model consists of two terms, a negative log-likelihood loss for point-wise label prediction and a distance-based loss that penalizes deviations between the predicted and ground-truth marker centers. The negative log-likelihood loss follows the same formulation as defined in Equation (2).
The distance-based loss is designed to encourage accurate localization of marker centers. It is computed as the average Euclidean distance between the predicted and ground-truth marker centers over all valid markers and batches.
where denotes the number of surface markers present in the ground truth for the b-th batch, and and represent the predicted and ground-truth centers of the k-th marker, respectively. The overall objective is given by
where the weighting factor controls the contribution of the distance-based term.
2.5.4. Training and Evaluation
The model was trained for 20 epochs with the Adam optimizer and a batch size of 32. Evaluation on the held-out test set was performed using the mean Euclidean distance between predicted and ground-truth landmark coordinates and the overall point-wise labeling accuracy.
3. Results
The quantitative and qualitative performance of each module and the fully integrated pipeline are summarized below. For ROI extraction, class-specific metrics were analyzed to avoid bias from class imbalance. On the evaluation dataset, PelvicROINet achieved an IoU of 0.908 and a recall of 0.957 for the pelvic surface region, while the corresponding IoU and recall for the others region were 0.955 and 0.975, respectively. These results indicate that the model reliably captures the pelvic ROI while maintaining high segmentation performance across both classes. Figure 5 shows qualitative examples of segmentation results obtained by PelvicROINet. The green regions correspond to the pelvic surface, whereas the black regions indicate the other region. To further illustrate model behavior under challenging conditions, representative failure cases are shown in Figure 6. These examples include partial occlusion by clothing, over-segmentation toward adjacent upper-body regions, and unintended inclusion of portions of the upper limb within the predicted ROI.
PelvicAlignNet effectively learned the rigid alignment between augmented and original point clouds. During training, the model minimized both the Euler loss (radian) and the mean normalized point-to-point Euclidean distance (millimeter), achieving 0.0228 rad and 2.19 mm, respectively. In the test phase, the corresponding losses were 0.0369 rad and 4.64 mm, confirming that the model maintained stable performance on unseen data. The small differences between training and test losses suggest that PelvicAlignNet generalized well without noticeable overfitting. Figure 7 visualizes representative alignment results. The black points indicate the original input point cloud before rotation correction, while the rotation-corrected points are overlaid and color-coded according to their distances from the ground-truth reference, ranging from green (0.0 mm) to red (10.0 mm), with greener areas indicating smaller deviations from the reference alignment.
PelvicLandmarkNet achieved precise localization performance under the subject-level split setting. The average Euclidean distance between the predicted and ground-truth landmark coordinates was 5.99 mm in training and 11.97 mm in testing when = 10, while the point-wise labeling accuracy reached 98.05 % and 97.05 %, respectively, reflecting accurate assignment of surface points to their corresponding landmark regions. These results confirm that PelvicLandmarkNet effectively localized the anatomical landmarks with high accuracy under a subject-level split, where inter-subject morphological variability presents a more challenging generalization scenario. Figure 8 presents qualitative examples of landmark localization results: gray points represent the pelvic surface after augmentation, magenta points indicate the predicted landmark positions, and green points mark where the predicted and ground-truth landmarks overlap.
To quantitatively evaluate the effect of each processing module on anatomical landmark localization, five model configurations were tested and compared. The evaluated configurations included: (1) the baseline model, which directly applied PointNet++ to the raw body-surface point cloud; (2) manually cropped configuration (Manual Crop) followed by PelvicLandmarkNet; (3) manually cropped region with PelvicAlignNet and PelvicLandmarkNet; (4) PelvicROINet followed by PelvicLandmarkNet; and (5) the fully integrated pipeline combining PelvicROINet, PelvicAlignNet, and PelvicLandmarkNet. The dataset was split at the subject level to avoid subject leakage between training and testing. The test set consisted of 22 independent subjects, yielding 396 point-cloud acquisitions and 2376 landmark instances (6 landmarks per scan). The baseline model directly localized landmarks using PointNet++ on the body-surface point clouds without PelvicROINet or PelvicAlignNet, with uniform random downsampling applied for computational efficiency. For the Manual Crop configurations, the region of interest was defined using the same bounding formulation as in Equation (1), with the fixed 100 mm margin replaced by randomly sampled offsets ranging from 50 to 150 mm for each lower and upper bound along all three axes. Independent random offsets within ±50 mm of 100 mm were applied to the minimum and maximum coordinates for each axis on a per-sample basis to approximate the variability inherent in clinician-guided visual ROI selection. The resulting point clouds were then used as input for the landmark localization and alignment modules.
Figure 9 presents the landmark localization performance across different model configurations. As shown in Figure 9a, the cumulative distribution functions (CDFs) indicate that the fully integrated pipeline dominated the other configurations across most distance thresholds, exhibiting a steeper cumulative rise and consistently lower localization errors. In contrast, the baseline model exhibited the broadest error distribution. The progressive contribution of each module is further reflected in Figure 9b, where the median localization error decreases as preprocessing components are incrementally introduced. The fully integrated pipeline achieved the lowest overall median error of 11.25 mm. The boxplot in Figure 9c illustrates the variability of localization errors for the fully integrated pipeline. Although several outliers were observed, the interquartile range remained compact, with per-landmark median errors ranging from 10.02 to 12.12 mm, indicating stable performance across most cases. At the subject level (n = 22), the fully integrated pipeline yielded a mean localization error of 13.22 mm (95% CI: 11.76–14.68 mm), consistent with the overall median-based observations. In addition to localization performance, computational efficiency was evaluated for each configuration. As summarized in Table 1, the baseline model exhibited the fastest processing time (0.73 ± 0.10 s/sample), whereas the fully integrated pipeline required 3.11 ± 0.43 s/sample due to the additional preprocessing modules. Despite the increased computational cost, the integrated framework achieved substantially improved localization accuracy, demonstrating a favorable trade-off between precision and processing time.
Following the comparison of localization performance, the repeatability of landmark localization was further examined to validate the reliability of the proposed model under repeated measurement conditions. Two or three repeated surface scans acquired within the same visit were analyzed. Within-visit repeatability was evaluated by calculating the standard deviation (STD) and coefficient of variation (CV) of the distances between paired anatomical landmarks (PSIS_L–PSIS_R, IC_L–IC_R, and L1–L4). In addition, the intraclass correlation coefficient (ICC) was computed to assess measurement consistency across repeated scans. The same analyses were applied to the landmarks manually annotated by clinical experts to serve as a reference. The results are summarized in Table 2. Overall, the fully integrated pipeline demonstrated smaller STD and CV values and higher ICC values than manual landmark digitization, indicating improved repeatability and more consistent measurements. The improvement was most evident in the PSIS region, where the CV decreased from 6.39% (manual) to 4.20%, and the ICC increased from 0.62 to 0.91, suggesting that the fully integrated pipeline effectively reduced variability arising from user dependent factors during repeated data acquisition.
Finally, to strengthen methodological robustness and support parameter sensitivity validation, we conducted additional sensitivity analyses on key hyperparameters affecting the final landmark localization performance. The results are summarized in Table 3. For the loss formulation in Equation (9), we evaluated while fixing the ROI margin to 10 mm. The results indicate that achieved the lowest localization error on the test set. However, performance variations across the tested values were minimal, suggesting that the proposed framework is not highly sensitive to moderate changes in the loss weight. In addition, the sensitivity of the landmark labeling radius was evaluated using radii of 10, 15, and 20 mm while fixing = 10. During label generation, points within the specified radius from each ground-truth marker coordinate were assigned to the corresponding landmark class. The lowest mean Euclidean error was observed at a radius of 15 mm. However, performance differences across 10–15 mm remained within approximately 0.5 mm on the test set. Given this minimal variation and to maintain methodological consistency with the training configuration, a radius of 10 mm was adopted for the final model.
4. Discussion
This study demonstrates that a modular, hierarchical pipeline enables reliable anatomical landmark localization on 3D human surface data. By sequentially applying region of interest (ROI) extraction, pose alignment, and landmark localization, the proposed system achieved low localization error under a subject-disjoint evaluation protocol. Notably, the fully integrated pipeline dominated alternative configurations across most distance thresholds in the cumulative distribution analysis and exhibited a stepwise reduction in median error as preprocessing modules were incrementally introduced. These findings indicate that hierarchical preprocessing substantially enhances localization stability compared with single-stage regression directly applied to raw point clouds.
The quantitative comparison across five model configurations provides clear evidence of progressive module contribution. The baseline PointNet++ model showed broader error distributions and higher median localization error, suggesting sensitivity to posture variation, irrelevant surface regions, and anatomical ambiguity. Introducing a manually defined ROI yielded only marginal improvement, indicating that non-learned cropping is insufficient to ensure input consistency. In contrast, replacing manual cropping with PelvicROINet significantly reduced irrelevant spatial information, and the addition of PelvicAlignNet further stabilized geometric orientation. The fully integrated pipeline achieved the lowest overall localization error, confirming that learned ROI restriction and explicit geometric alignment act synergistically to improve downstream landmark localization. A closer inspection of the segmentation results further reveals characteristic failure patterns that provide insight into the model’s practical robustness, despite the high overall segmentation performance of PelvicROINet. As illustrated in Figure 6, partial occlusion by clothing occasionally reduced the visible surface, leading to incomplete ROI coverage. In addition, over-segmentation toward the shoulder region was observed in some cases, particularly when upper-body posture deviated from the standardized operating procedure. Furthermore, partial inclusion of the upper limb occurred when arm abduction was insufficient, resulting in spatial proximity between the arm and pelvic boundary. Nevertheless, although occasional mis-segmentation artifacts were observed, the predicted ROI generally provided sufficient coverage of the six target landmark regions. Consequently, the performance of the downstream alignment and landmark localization modules was not substantially degraded, suggesting a degree of robustness to moderate ROI imperfections. The structural roles of the individual modules explain this collective effectiveness. The ROI extraction step restricts analysis to anatomically relevant posterior pelvic regions, reducing noise from surrounding body surfaces. The alignment module minimizes pose-induced variability, enabling the subsequent landmark localization module to learn orientation-invariant geometric features rather than posture-dependent cues. This hierarchical design closely mirrors the clinical workflow in which clinicians first define the region of interest, standardize the patient’s posture, and then identify anatomical landmarks. Such alignment between computational and clinical workflows enhances the interpretability and applicability of the proposed system.
Under the subject-level split setting, the fully integrated pipeline achieved a mean landmark localization error of 13.22 mm (95% CI: 11.76–14.68 mm), with a median error of 11.25 mm. Kilby et al. reported mean localization errors of approximately 15–20 mm for lumbar and pelvic landmarks, with limits of agreement approaching ±27 mm relative to ultrasound reference standards [29]. More recently, Hvidkær et al. observed a mean palpation precision of approximately 13 mm (95% CI: 11–15 mm) using 3D surface-based assessment [30]. The error magnitude and confidence interval observed in the present study closely overlap with the range reported for experienced clinicians and remain below the mean errors reported in earlier ultrasound-referenced investigations. These findings suggest that the proposed fully integrated pipeline achieves a level of landmark localization precision comparable to skilled manual palpation in routine clinical settings, while providing consistent and reproducible measurements across subjects.
The repeatability analysis further supports this interpretation. Across repeated within-visit scans, the integrated pipeline demonstrated lower standard deviation and coefficient of variation values compared with manual landmark marking, particularly in the PSIS region where the CV decreased from 6.39% to 4.20%. Intraclass correlation coefficients ranged from 0.78 to 0.91 for the automated pipeline, clearly exceeding the reliability range observed for manual measurements. These results indicate that automated landmark estimation reduces operator-dependent variability inherent in manual digitization procedures and provides greater consistency under repeated acquisition conditions, which may reduce the impact of posture-related soft tissue displacement on repeated measurements [6,25]. Improved repeatability strengthens the suitability of the proposed system for longitudinal monitoring, post-treatment follow-up evaluation, and routine musculoskeletal assessment.
To assess methodological robustness, sensitivity analyses were conducted for key hyperparameters affecting landmark localization. Variations in the loss weight and labeling radius resulted in changes of less than approximately 0.5 mm in test error, indicating stable performance across reasonable parameter ranges. These findings suggest that performance gains primarily stem from the hierarchical pipeline design rather than narrow hyperparameter tuning.
PointNet++ was selected as a validated and reproducible baseline architecture for geometric feature learning from raw point clouds. The primary contribution of this study lies not in proposing a novel backbone network, but in the modular integration of learned ROI restriction, geometric alignment, and landmark regression within a clinically structured workflow. While more advanced architectures may provide additional modeling capacity, the present study emphasizes workflow-oriented design and surface-geometry-driven consistency.
From a computational perspective, the entire inference process required approximately 3.11 s per sample on a workstation equipped with an AMD Ryzen 7 5800X CPU and an RTX 4090 GPU. In a practical clinical workflow, near-immediate landmark output supports a clinician-in-the-loop process in which predicted landmarks can be rapidly reviewed and corrected if necessary, potentially reducing operator workload and fatigue-related variability.
Several limitations should be acknowledged. The dataset used for training mainly included upright and forward bending postures, which may limit generalization to more diverse body configurations. Landmark annotations were based on clinician judgment [31,32] and may incorporate subtle soft tissue displacement effects [33,34], which could influence the learning process. In addition, the present model focuses on six posterior pelvic landmarks, and extension to other anatomical regions requires further validation.
Despite these limitations, the proposed modular framework demonstrated robust performance in a region characterized by relatively subtle anatomical surface cues. The modular architecture allows each component to be independently retrained or replaced in future studies, enabling extension to other anatomical regions or alternative module configurations for broader clinical and biomechanical applications. Future work may include incorporation of larger and more diverse datasets, exploration of advanced geometric learning architectures, optimization for lightweight deployment environments, and multimodal fusion strategies combining point cloud data with complementary imaging modalities. With continued validation and methodological refinement, the proposed framework may contribute to more objective and repeatable surface-based assessments for musculoskeletal evaluation and longitudinal monitoring.
5. Conclusions
This study developed a modular deep learning pipeline for automatic localization of anatomical landmarks from 3D pelvic surface point clouds. By integrating PelvicROINet, PelvicAlignNet, and PelvicLandmarkNet, the system enabled fully automated analysis without manual intervention, improving both accuracy and reproducibility. The fully integrated pipeline achieved reliable landmark localization under a subject-level split evaluation setting, with a median error of 11.25 mm. These results confirm the feasibility of near real time clinical application and highlight the potential of the proposed modular framework as a foundation for future AI-assisted musculoskeletal assessment and diagnosis.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1D’Amico M. Kinel E. D’Amico G. Roncoletta P. A Self-Contained 3D Biomechanical Analysis Lab for Complete Automatic Spine and Full Skeleton Assessment of Posture, Gait and Run Sensors 202121393010.3390/s 2111393034200358 PMC 8201118 · doi ↗ · pubmed ↗
- 2Balasubramanian M. Sheykhmaleki P. Emerging Roles of 3D Body Scanning in Human-Centric Applications Technologies 20251312610.3390/technologies 13040126 · doi ↗
- 3Cruz-Medel I. Rodrigues-de Souza D.P. Alburquerque-Sendín F. Comprehensive Analysis of Pelvic Asymmetries in Low Back Pain, Scoliosis, Post-Traumatic Pelvic Dysfunctions and Obstetric Changes: A Narrative Review Focused on Clinical Relevance Symmetry 202416130410.3390/sym 16101304 · doi ↗
- 4Bibrowicz K. Szurmik T. Ogrodzka-Ciechanowicz K. Hudakova Z. Gąsienica-Walczak B. Kurzeja P. Asymmetry of the pelvis in Polish young adults Front. Psychol.202314114823910.3389/fpsyg.2023.114823937034935 PMC 10075204 · doi ↗ · pubmed ↗
- 5Rayward L. Pearcy M. Izatt M. Green D. Labrom R. Askin G. Little J.P. Predicting spinal column profile from surface topography via 3D non-contact surface scanning P Lo S ONE 202318 e 028263410.1371/journal.pone.028263436952526 PMC 10035928 · doi ↗ · pubmed ↗
- 6Wolf C. Betz U. Huthwelker J. Konradi J. Westphal R.S. Cerpa M. Lenke L. Drees P. Evaluation of 3D vertebral and pelvic position by surface topography in asymptomatic females: Presentation of normative reference data J. Orthop. Surg. Res.20211670310.1186/s 13018-021-02843-234863230 PMC 8642978 · doi ↗ · pubmed ↗
- 7Kang T.H. Jang S. Seo I. Choi M. Park Y. Lee Y. Lee J.H. Cho M. A new 3D full-body scanner analyzing the sagittal and coronal balance of the adult spine: A preliminary prospective observational study Acta Neurochir.20251672210.1007/s 00701-024-06411-539853437 PMC 11761465 · doi ↗ · pubmed ↗
- 8Harrison D.E. Janik T.J. Cailliet R. Harrison D.D. Normand M.C. Perron D.L. Oakley P.A. Upright Static Pelvic Posture as Rotations and Translations in 3-Dimensional From Three 2-Dimensional Digital Images: Validation of a Computerized Analysis J. Manip. Physiol. Ther.20083113714510.1016/j.jmpt.2007.12.00918328940 · doi ↗ · pubmed ↗