VINA-SLAM: A Voxel-Based Inertial and Normal-Aligned LiDAR–IMU SLAM
Ruyang Zhang, Bingyu Sun

TL;DR
VINA-SLAM improves LiDAR–IMU mapping in challenging environments by using a voxel map and normal alignment for better accuracy and stability.
Contribution
Introduces VINA-SLAM, a LiDAR–IMU SLAM framework using voxel maps and normal-guided alignment for improved performance in geometrically degenerate scenes.
Findings
VINA-SLAM reduces ATE by 25–40% on average in geometrically degenerate environments.
The system maintains real-time performance at 10 Hz without explicit feature extraction or loop closure.
Planar regularization and tangent-space metrics enhance rotational constraints and cross-view consistency.
Abstract
Environments with sparse or repetitive geometric structures, such as long corridors and narrow stairwells, remain challenging for LiDAR–inertial simultaneous localization and mapping (LiDAR–IMU SLAM) due to insufficient geometric observability and unreliable data associations. To address these issues, we propose VINA-SLAM, a novel LiDAR–IMU SLAM framework that constructs a unified global voxel map to explicitly exploit structural consistency. VINA-SLAM continuously tracks surface normals stored in the global voxel map using a normal-guided correspondence strategy, enabling stable scan-to-map alignment in degenerate scenes. Furthermore, a tangent-space metric is introduced to supplement missing rotational constraints around planar regions, providing reliable initial pose estimates for local optimization. A tightly coupled sliding-window bundle adjustment is then formulated by jointly…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1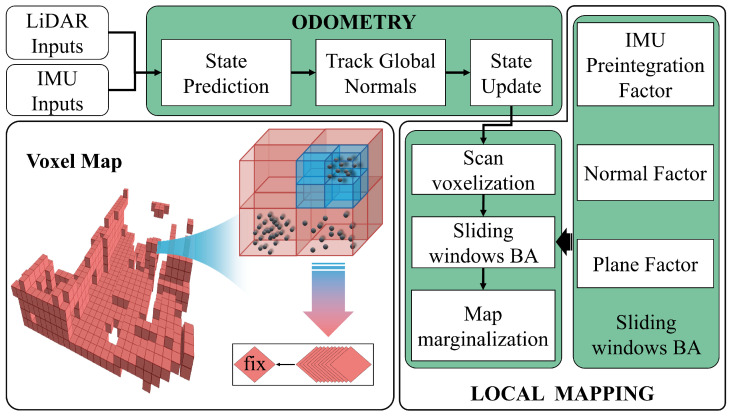 Figure 2
Figure 2 Figure 3
Figure 3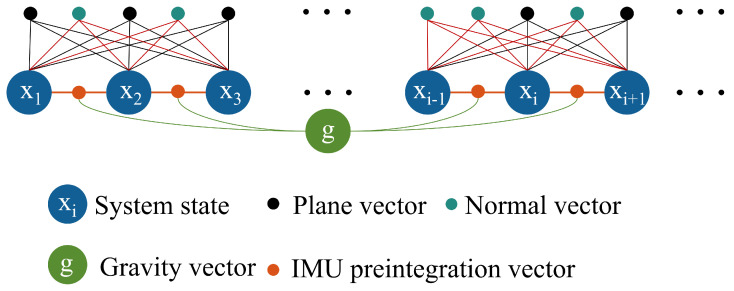 Figure 4
Figure 4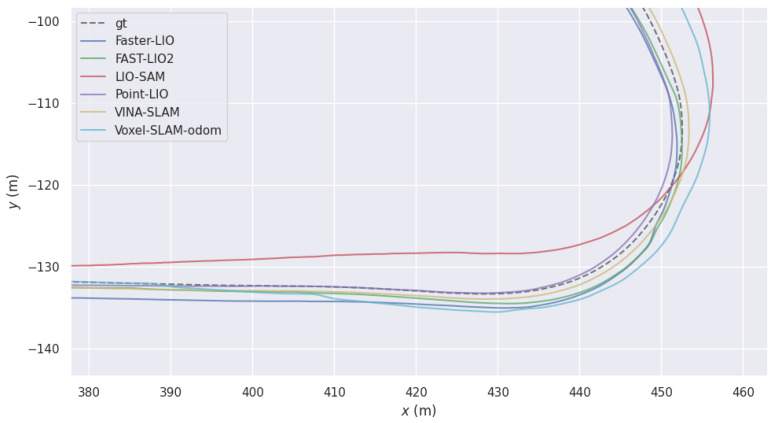 Figure 5
Figure 5 Figure 6
Figure 6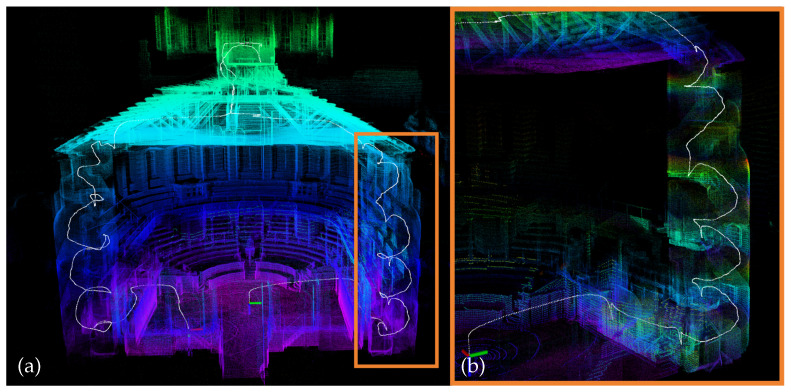 Figure 7
Figure 7 Figure 8
Figure 8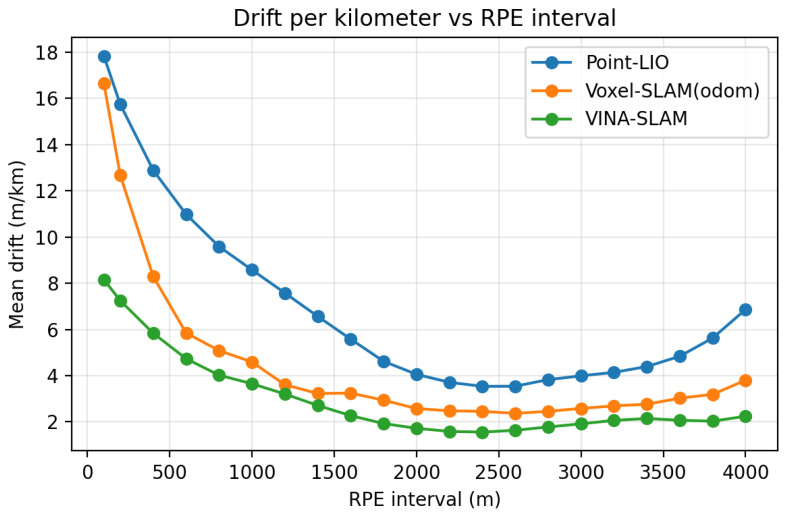 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Advanced Vision and Imaging · Advanced Image and Video Retrieval Techniques
1. Introduction
Simultaneous localization and mapping (SLAM) [1] provides a fundamental service of robust autonomous navigation and perception for intelligent devices, which typically rely on accurate environmental modeling and localization. Benefiting from the continuous reduction in sensor cost and the ability of LiDAR to provide dense, active, and high-precision depth measurements, LiDAR-based localization and mapping techniques have been widely applied in the field of robotics [2,3]. Compared with traditional GNSS-based [4,5] and visual-based [6,7] systems, LiDAR localization often shows higher reliability in indoor, underground, and occluded environments. Moreover, in tasks that demand high localization accuracy, such as safe obstacle avoidance and precise path following, SLAM often acts as a practical core component of robotic navigation pipelines.
In real-world scenarios, intelligent robots often operate in semi-enclosed man-made environments such as building corridors, stairwells, long planar facades, and repetitive structural areas. These scenes are degenerate for traditional LiDAR SLAM systems [8] because they offer limited diversity in observation directions despite strong geometric regularities. However, due to the limited diversity of observation directions, the point-to-plane constraints, first introduced in the Chen–Medioni point-to-plane ICP framework [9], become overly sensitive to translational estimation while providing insufficient rotational observability around the plane normal. As a result, the system may suffer from unobservable orientations and incorrect data associations. In such environments, the lack of informative geometric structure and sparse feature correspondences leads to ill-conditioned Hessian (information) matrices in point-to-plane optimization, which has been extensively analyzed in recent degeneracy-aware LiDAR registration works [10,11,12,13]. Moreover, high-speed motion and the resulting motion distortion further weaken data associations and aggravate drift in LiDAR-inertial odometry [14]. Although existing LIO and LOAM frameworks achieve considerable robustness through explicit extraction of edge and planar features (e.g., [15,16,17,18]), they still face fundamental limitations in degenerate environments, where insufficient rotational observability, degraded Hessian conditioning, and weak cross-temporal geometric consistency remain challenging bottlenecks.
To address these challenges, this paper proposes a tightly coupled LiDAR–IMU framework centered on voxel normal consistency (VNC), which enhances system performance through a unified geometric representation. Specifically, without introducing additional sensors or computational overhead, the system employs an adaptive voxel map as a global geometric carrier. On the front end, both point-to-plane and normal-consistency observations are directly registered to the global voxel map, explicitly reinforcing rotational observability and improving the robustness of the front end in degenerate environments. On the back end, a sliding-window local bundle adjustment introduces a regularization term based on the minimum eigenvalue of the voxel covariance, , to improve the Hessian condition number, while a tightly coupled integration of normal-alignment and IMU preintegration factors ensures long-term consistency and numerical stability. The main contributions of this paper are summarized as follows:
- VNC-based Front-end Constraint: We propose a novel observation model based on voxel normal consistency (VNC). By aligning the surface normals of the scan frames with the global voxel normals in the tangent space, the method explicitly strengthens rotational observability under highly dynamic and degenerate conditions, improving front-end rotation estimation in the evaluated scenarios (see Section 4).
- Statistically Driven Local BA: A voxel minimum eigenvalue ( ) is introduced as a planarity regularization term in the sliding-window BA, which improves the Hessian condition number. Moreover, the normal-alignment factor provides inter-frame rotational priors (see Section 5). Its tight coupling with IMU preintegration improves the numerical stability and information fusion capability of the back end.
- Unified Voxel Map and Tightly Coupled Implementation: A unified adaptive voxel map is shared between the front and back ends, reducing representational discrepancy and information loss. Through tight coupling with IMU preintegration, the system achieves consistent mapping and real-time performance without relying on loop closure (see Section 3).
- Comprehensive Validation and Reproducibility: Extensive evaluations are conducted on 25 representative sequences from the HILTI 2022 and 2023 datasets and the MARS-LVIG dataset. Compared with existing open-source approaches, the proposed method yields lower ATE on most evaluated sequences while maintaining deployable latency and memory usage (see Section 6). The source code and configurations will be released in accordance with journal policies to support reproducibility.
Experimental results show that the proposed method reduces trajectory errors and yields more consistent convergence in typical degenerate scenarios such as narrow corridors, stairwells, repetitive structures, and high-speed maneuvers. As illustrated in Figure 1, our method reconstructs clearer planar structures and yields more consistent local geometry compared with FAST-LIO2. With a 10 Hz LiDAR input, the system maintains real-time performance and low memory consumption, while achieving consistent mapping without relying on loop closure. These results indicate that the joint modeling of voxel normal consistency and statistically regularized BA improves rotational observability, numerical conditioning, and cross-temporal geometric consistency, and provides a basis for incorporating global loop closure and large-scale consistent mapping in future work.
2. Related Works
2.1. LiDAR(-Inertial) Odometry and SLAM
At present, most 3D LiDAR-SLAM systems are built upon the LOAM framework [15], which mainly consists of three modules: feature extraction, odometry, and mapping. In the feature extraction stage, edge and planar points are identified based on the local smoothness of the point cloud, and these feature points are subsequently used for pose estimation to improve computational efficiency. To mitigate long-term drift, LeGO-LOAM [19] introduces ground segmentation and loop closure mechanisms, further enhancing overall system performance. Subsequent extensions, such as LOAM-Livox [20], R-LOAM [21], and F-LOAM [22], focus primarily on improving computational efficiency and robustness.
Integrating an IMU into the SLAM framework significantly enhances the accuracy and robustness of odometry, playing a crucial role in compensating for motion distortion during LiDAR scanning. The high-frequency IMU data provides more accurate initial pose estimates for ICP, thereby improving both convergence and final registration quality. LION [23] adopts a loosely coupled optimization approach to process point cloud data, while LIO-SAM [24] tightly couples IMU and LiDAR measurements within a factor graph, achieving improved accuracy and convergence at the cost of higher computational complexity when handling large-scale data. To further improve system efficiency, LiLi-OM [25] introduces a smaller optimization window.
LINS [26] introduces a tightly coupled iterative Kalman filter into the LIO framework, leveraging the Kalman gain formulation to reduce computational complexity from the measurement dimension to the state dimension. FAST-LIO [16] proposes a novel Kalman gain formulation and optimizes point cloud registration using an incremental k-d tree, further alleviating computational burden. FAST-LIO2 [17] improves the incremental k-d tree structure, eliminating the need for explicit feature extraction and enhancing overall efficiency. Faster-LIO [18] introduces parallel sparse incremental voxels to further accelerate processing speed. Point-LIO [27], built upon FAST-LIO2, incorporates IMU saturation checks to improve robustness against mechanical vibrations.
Most existing LIO methods rely primarily on point-to-plane residuals for pose estimation [16,17,18,23,25,26]; however, in degenerate environments such as long corridors, narrow stairwells, and repetitive structural regions—where strong geometric priors exist but observation directions are limited—they still suffer from significant deficiencies [11]. In particular, under high-speed motion and sparse measurement conditions, insufficient rotational observability, degraded numerical conditioning, and weak long-term consistency become especially pronounced [14].
In contrast, visual SLAM methods have demonstrated unique advantages in addressing similar challenges, particularly in indoor environments. Since drift in SLAM systems is largely caused by inaccurate rotation estimation [28,29,30], visual SLAM enhances robustness in low-texture scenes by leveraging the geometric structure of the environment. For instance, Structure-SLAM [31] utilizes line features and surface normals combined with spherical mean-shift clustering under a weak Manhattan-world assumption to estimate drift-free rotation, thereby improving pose estimation robustness. Similarly, ManhattanSLAM [32] constructs a Manhattan map to detect and track Manhattan frames, decoupling pose estimation and providing drift-free rotational constraints, thus enabling robust tracking in challenging scenes and further enhancing the stability of visual SLAM in complex indoor environments.
Although these visual SLAM methods have demonstrated outstanding performance in indoor environments, the point-to-plane residual remains the dominant approach for pose estimation in LiDAR-based SLAM. Inspired by the advantages of visual SLAM in handling complex environments, VINA-SLAM introduces an explicit rotational normal constraint to effectively enhance rotational observability. This innovation mitigates the adverse effects of high-speed motion and sparse measurements, further improving the robustness and accuracy of LiDAR-based SLAM systems.
2.2. LiDAR Point Cloud Registration Strategies
Point cloud registration is one of the key techniques in SLAM. Traditional registration methods such as ICP and GICP [33,34] have been widely adopted; however, these approaches are prone to cumulative errors, leading to noticeable drift during long-term operation. To alleviate this issue, researchers have introduced the bundle adjustment (BA) framework for global optimization. BALM [35] unifies point-to-plane and point-to-line registration constraints into a BA formulation, significantly reducing drift and improving global consistency. BALM2 [36] further accelerates computation by introducing point clustering, thereby enhancing overall efficiency.
-LSAM [37] incorporates planar geometric priors commonly observed in indoor environments by modeling planes as explicit landmarks, thereby enhancing robustness in low-texture conditions. EigenFactor [38] proposes a two-layer optimization framework that pre-aggregates point cloud statistics for each plane, improving computational efficiency. As scene complexity and data scale increase, the computational burden of factor-graph optimization grows rapidly. BALM3 [39] introduces a Majorization–Minimization (MM) framework that decomposes the original problem into a series of convex subproblems, effectively accelerating computation while ensuring global consistency.
VINA-SLAM integrates both pairwise and multi-view registration strategies. In the odometry stage, an efficient planar map (VoxelMap) is employed for scan-to-map registration. For local mapping, the framework follows the philosophy of the BALM series by performing LiDAR–Inertial bundle adjustment (BA) optimization, achieving a balance between efficiency and accuracy while enhancing robustness, particularly in low-texture environments.
3. System Overview
The overall workflow of VINA-SLAM is illustrated in Figure 2. First, based on IMU preintegration, the system provides motion priors for LiDAR points sequentially sampled within each scan period, compensating for motion distortion and reconstructing a temporally consistent point cloud. We define the system state of the IMU in the world frame at the end of the i-th LiDAR scan as
where , , and denote the orientation, position, and velocity of the IMU in the world frame, respectively, while and represent the gyroscope and accelerometer biases in the local frame.
The corrected point cloud is then projected into the world frame according to the IMU-predicted pose and voxelized using the voxel size of the current global map. Each voxel is analyzed via principal component analysis (PCA) and spectral decomposition to determine whether it represents a planar surface, from which the corresponding normal vector is extracted. Both the global map voxels and the projected scan voxels are managed using a hash table, ensuring that voxels sharing the same spatial coordinates in the world frame possess identical hash keys, thereby enabling efficient normal-vector lookup. To ensure reliable matching, voxels containing fewer than points are excluded from planar fitting.
The odometry module performs real-time state estimation—including pose and velocity—by tightly fusing point-to-plane constraints, normal-vector consistency constraints, and IMU measurements within an extended Kalman filter (EKF) framework (red dashed box, see Section 4). After the current pose is estimated, the corresponding scan is inserted into a sliding window. Within this window, the system continues to track global normals following the same procedure and performs LiDAR–inertial joint bundle adjustment (BA) to simultaneously optimize all states and the local map (blue dashed box, see Section 5). The oldest keyframe is subsequently marginalized, and the global voxel map is updated, achieving continuous and consistent mapping and localization.
4. Front-End LIO with Normal Consistency Constraint
Conventional LIO systems typically perform registration updates by minimizing the Euclidean point-to-plane distance [15,17]. However, in plane-dominant environments such as building facades, corridors, and ground surfaces, the single point-to-plane constraint provides insufficient rotational observability around the plane normal. This often leads to attitude drift under pure translation, rotation about the normal direction, or planar degeneracy. Inspired by the concept of structured constraints [31,32,40], we explicitly introduce a normal consistency factor in the front end. This factor acts solely on the rotational degrees of freedom and complements the point-to-plane constraint, thereby enhancing attitude observability and overall robustness in degenerate geometries.
4.1. Surface Normal Tracking
To obtain stable rotational observations, VINA-SLAM performs global normal tracking on voxel grids that share identical resolutions and hash keys between the scan frame and the global map (Figure 3). The process consists of four stages: temporal alignment and world projection, voxelization and planar detection, normal and uncertainty estimation, and hash-based pairing with angular gating.
4.1.1. Temporal Alignment and World Projection
For LiDAR points sequentially sampled within a single scan period, the prior pose is obtained through IMU preintegration to correct motion distortion and reconstruct a temporally consistent scan. The corrected point is then projected into the world frame as:
4.1.2. Spatial Voxelization and Planar Detection
The corrected points are voxelized with a voxel size of s, and voxel blocks are accessed via a hash table in complexity. For each voxel , we accumulate the number of samples N, centroid , and covariance matrix:
and perform eigen-decomposition ( ). To ensure high-quality matching, voxels with are discarded. A dual-threshold criterion is used to identify planar voxels:
where and , ensuring both a noise lower bound and relative flatness.
4.1.3. Normal and Uncertainty Estimation
For planar voxels, the normal vector is defined as the eigenvector corresponding to the smallest eigenvalue, ( ), and the plane center is set to the centroid . Based on eigenvalue perturbation analysis, the sensitivity of the smallest eigenvector with respect to the covariance matrix can be approximated as
from which a first-order approximation of the normal covariance is obtained as , used for subsequent uncertainty weighting.
4.1.4. Hash-Based Pairing and Angular Gating
The scan voxel map and the global voxel map share the same resolution and hash key structure, such that voxels with identical indices in the world frame directly form candidate pairs. For each candidate voxel pair with normals , a sign disambiguation is first performed (if the inner product , the normal is negated), followed by angular gating:
The surviving “center–normal” observation pairs and , along with their corresponding uncertainties, are preserved for use in the front-end EKF and back-end BA optimization.
4.2. Normal Consistency Residual and EKF Update
4.2.1. State and Propagation
At the end of the i-th frame, the system state is defined as , where , , and denote the gyroscope and accelerometer biases, respectively. The IMU preintegration [41] is employed to propagate the state from frame i to , yielding the predicted mean and covariance .
4.2.2. Normal Consistency Residual in the Tangent Space
Given the prior attitude , the normal of the scan is rotated into the world frame, and the consistency is measured in the tangent space of :
The Jacobian with respect to the small rotational perturbation is
while the Jacobians with respect to are all zero. The residual covariance is defined as
4.2.3. Joint Update with Point-to-Plane Constraint
The point-to-plane residual is given by
with its Jacobians expressed as and zeros for the remaining terms. Stacking the normal and point-to-plane measurements yields
The EKF update is then performed as
The attitude is updated via right-multiplicative exponential mapping , while the remaining state components are updated linearly to obtain the posterior estimate .
5. LiDAR-Inertial BA Optimization
In LiDAR scanning environments, geometric information along certain directions may be missing or weakened, leading to poor attitude observability and an ill-conditioned Hessian matrix, which in turn amplifies instability in pose estimation. To alleviate such degeneracies, joint optimization using multi-view observations has proven to be an effective strategy, typically formulated within the framework of bundle adjustment (BA). Conventional approaches often adopt a “two-layer” structure: relative poses between selected scan pairs are first estimated through pairwise registration, followed by global optimization at the pose-graph level. This decoupled strategy offers good computational efficiency for real-time SLAM systems; however, its representation of the original point cloud constraints is indirect, providing insufficient geometric “curvature” in degenerate dimensions. Consequently, when relying solely on relative pose constraints, the improvement in attitude observability remains limited.
Alternatively, directly incorporating all raw points and geometric features into the BA formulation can enhance constraint strength, but the computational complexity scales rapidly with the number of observations, making real-time operation infeasible. To balance geometric representation and computational efficiency, we adopt the concept of point clustering from the BALM series [35,36,39], and integrate IMU factors [41], planar factors [38], and normal-vector factors to construct a LiDAR–inertial bundle adjustment (BA) optimization. This formulation jointly estimates multiple states in parallel and, when necessary, includes gravity estimation within the optimization process.
5.1. State Definition
Assume that the sliding window contains N LiDAR frames, and the state corresponding to the i-th frame is defined in Equation (1).
The set of all optimization variables is expressed as
The gravity vector g is shared within the sliding window. To improve computational efficiency, g is only jointly optimized when the system observes persistent geometric degeneration during front-end pose estimation (see Appendix C).
5.2. BA Residual Function Modeling
As illustrated in Figure 4, to enhance attitude observability and improve the Hessian condition number, the proposed optimization jointly incorporates IMU preintegration factors, planar factors, and normal-vector factors into an optimization function as follows:
Here, denotes the IMU factor, the planar factor, and the normal-vector factor.
5.2.1. IMU Factor
The IMU factor includes residuals of orientation, velocity, position, and bias, with the covariance derived from discrete noise propagation. The partial derivatives with respect to gravity are given by
5.2.2. Planar Factor
Each LiDAR frame in the sliding window is transformed into the world frame using the current state as . Points are then grouped into voxels according to their world coordinates. For the j-th voxel, the aggregated statistics are computed with points, where . The mean and covariance are thus given by:
Performing PCA on yields the ordered eigenvalues , where characterizes the voxel thickness along the estimated normal direction; voxel j is incorporated into the back-end optimization if (set to 5) and (with ). We use in the front-end (Section 3 and Section 4) but in the back-end, since multi-view aggregation over a sliding window of frames (where denotes the window size and is set to in our implementation) allows a voxel to accumulate on the order of points (i.e., ∼50 under our settings), which is typically sufficient for normal uncertainty convergence [42].
5.2.3. Normal-Vector Factor
For the j-th voxel, the corresponding reference normal is retrieved from the global map. The smallest eigenvector is used to approximate the normal vector of the scan voxel, and the projection residual is defined as
The cost function in Equation (13) is optimized iteratively using the second-order Levenberg–Marquardt (LM) solver. To accelerate the optimization process, the analytical Jacobian and Hessian matrices of the cost function are derived in closed form. Detailed derivations of the Jacobian, Hessian, and solver implementation are provided in Appendix A.
6. Experimental Results
6.1. Datasets and Metrics
We evaluate the proposed system on two publicly available datasets with distinct characteristics: HILTI [43,44] and MARS-LVIG [45], comprising a total of 25 sequences (the complete sequence list is provided in Table A1). The HILTI dataset was collected in structured indoor and outdoor construction environments, using a Hesai XT-32 LiDAR (Hesai Technology, Shanghai, China) and a Bosch BMI085 IMU at 400 Hz (Robert Bosch GmbH, Stuttgart, Germany), and provides an official online evaluation server. The MARS-LVIG dataset, in contrast, was recorded by an unmanned aerial vehicle (UAV) equipped with a Livox Avia LiDAR (Livox Technology Company Limited, Shenzhen, China) with an integrated BMI088 IMU (Robert Bosch GmbH, Stuttgart, Germany) operating at 200 Hz, flying at an altitude of approximately 100 m. Across all sequences, the LiDAR sampling frequency is 10 Hz.
All estimated trajectories are saved in TUM format. Temporal alignment is achieved through linear interpolation to match ground-truth timestamps, with a maximum time difference threshold of 50 ms. For HILTI, we follow the official online evaluation protocol for alignment and metric computation, and report the translation RMSE. For MARS-LVIG, we compute ATE (RMSE) using EVO [46] with SE(3) alignment enabled. The same evaluation protocol is used for the sequence-level cumulative drift curves reported later in Figure 5. In addition to ATE, we report the distance-normalized ATE (RMSE) as a long-term drift indicator:
where denotes the traveled distance computed by cumulatively summing the ground-truth trajectory increments.
6.2. Baselines and Implementation Details
In this section, the proposed VINA-SLAM is compared against several representative open-source LiDAR (and LiDAR–Inertial) SLAM methods, including LeGo-LOAM [19], LiLi-OM [25], LINS [26], LIO-SAM [24], FAST-LIO2 [17], Faster-LIO [18], Point-LIO [27], and Voxel-SLAM [47]. For LeGo-LOAM [19], LiLi-OM [25], LINS [26], LIO-SAM [24], FAST-LIO2 [17], Faster-LIO [18], and Point-LIO [27], the results are taken directly from the public benchmark values reported in Voxel-SLAM [47]. The “odom” results of Voxel-SLAM [47] are reproduced and evaluated under the same experimental protocol for consistency. Unless otherwise specified, all baseline methods use their default parameters and official sensor configurations. We further conduct ablation studies to analyze the contribution of each module: Ours (Odom) represents the front-end odometry (point-to-plane constraint + normal consistency constraint), while Ours (Odom + BA) includes the local BA module on top of the front-end.
All experiments are conducted on the same desktop workstation equipped with an Intel i9-13900K CPU (32 threads, 5.5 GHz), 128 GB RAM, and dual NVIDIA GPUs (RTX 4070), running Ubuntu 24.04 LTS (Linux kernel 6.8.0). For the HILTI dataset, the voxel sizes for indoor and outdoor scenes are set to m and m, respectively, with a voxel downsampling resolution of m. For the MARS-LVIG dataset, m and m are used. The maximum map hierarchy level is . The minimum number of points for planar fitting is fixed at , and the planarity criterion is , where are the eigenvalues of the covariance matrix satisfying . The window size for the local BA is set to 10.
6.3. Comparison on the HILTI Dataset
The HILTI dataset targets realistic construction and building environments under GNSS-denied conditions, encompassing typical degenerate scenarios such as corridors, stairwells, open floors, pipe shafts, scaffolding, and metallic or glass reflective surfaces. The presence of numerous repetitive structures and reflective materials increases the likelihood of false data associations and outlier ratios, while narrow passages often induce tangential drift. Table 1 summarizes the translation RMSE results of all evaluated methods. Compared with systems that rely solely on explicit geometric feature extraction and matching, VINA-SLAM mitigates false associations in repetitive structures through its adaptive-resolution voxel map and normal-consistency constraints (see Figure 6), and reduces tangential drift in narrow corridors (see Figure 7). Figure 6 and Figure 7 are qualitative case visualizations with different focuses: Figure 6 highlights association ambiguity in repetitive or scaffolding regions and its mitigation by the voxel-map-based design, while Figure 7 illustrates trajectory and map consistency in a narrow stairwell scenario. Quantitative evidence is reported in Table 1 and Table 2, and the sequence-level drift curves in Figure 5. In most sequences, the inclusion of the local BA module in VINA-SLAM further reduces cumulative drift and achieves the best or second-best accuracy.
As shown in Table 2, VINA-SLAM reports lower distance-normalized errors on the HILTI dataset, with values ranging from 0.04 to 1.53 m/km. On the degenerate sequence hilti07, Ours (odom + BA) achieves 1.53 m/km, compared with 5.54 m/km (FAST-LIO2) and 3.46 m/km (Point-LIO).
6.4. Comparison on the MARS-LVIG Dataset
Unlike the HILTI dataset, which features small-scale, highly structured, and slow-moving indoor and construction environments, the MARS-LVIG dataset was collected in large-scale outdoor environments with flight speeds reaching up to 12 m/s, containing unstructured elements such as islands, hills, and rivers. Under such highly dynamic and long-range conditions, the local observability of point clouds becomes insufficient, and both IMU noise and temporal synchronization errors are magnified, degrading front-end registration accuracy. Nevertheless, the proposed method maintains consistent mapping behavior in degenerate regions (see Figure 8). This can be attributed to two main factors: first, the planarity term reduces “thickness” dispersion under sparse and long-range observations, improving the Hessian condition number; second, the normal-consistency constraint directly enhances rotational observability within the attitude subspace, mitigating heading drift during high-speed maneuvers. Furthermore, in locally degenerate scenes, the local BA provides inter-frame geometric aggregation, while IMU integration maintains local motion estimation, ensuring consistent map constraints over long trajectories. As summarized in Table 3, the proposed method shows competitive and often lower errors in unstructured and high-dynamic aerial scenarios.
As shown in Table 4, VINA-SLAM reports distance-normalized errors of 0.06–0.77 m/km, including long sequences exceeding 5 km (Mars3 series), indicating bounded long-term drift without explicit loop closure.
6.4.1. Sequence-Level Cumulative Drift Analysis
To further analyze long-term drift without loop closure at the sequence level, we report cumulative APE versus traveled distance and interval-dependent drift rate on Mars4-1 (Figure 9) under the same evaluation protocol described in Section 6.1. These sequence-level curves characterize within-trajectory error accumulation behavior. The degradation region is around 3000 m; after that the accumulated error begins to increase gradually, while before that it tends to be flat, indicating that our method can to some extent mitigate the accumulation of accumulated error. They complement (rather than replace) the dataset-level distance-normalized ATE (RMSE) reported in Table 4.
6.4.2. Failure Cases and Current Limitations
Although VINA-SLAM improves accuracy on most sequences, it is not uniformly best across all conditions. In Table 1, Ours (odom + BA) is not the best on hilti06 (1.04 cm vs. 0.9 cm for Point-LIO), hilti07 (19.9 cm vs. 11.42 cm for Voxel-SLAM (odom)), and hilti11 (3.11 cm vs. 2.7 cm for Faster-LIO). A similar trend appears in Table 2 (hilti06, hilti07, and hilti11). These cases suggest several remaining limitations of voxel-map-based modeling: (i) a fixed voxel resolution introduces a trade-off between geometric fidelity and robustness under sparse long-range observations; (ii) aggressive rotations and rapidly changing viewpoints can temporarily reduce reliable voxel-plane correspondences; and (iii) when local coplanarity assumptions are violated, voxel-plane aggregation can accumulate bias. These limitations motivate future work on adaptive-resolution mapping, uncertainty-aware plane aggregation, and stronger outlier rejection under abrupt motion.
6.5. Performance Testing
Among the eight sequences of the HILTI 2022 dataset, three representative scene types are covered: corridors, outdoor areas, and indoor environments. Therefore, for the 25-sequence dataset used in this paper, we report the average computation time and memory consumption based solely on the HILTI 2022 sequences. All LiDAR scans are processed at a frequency of 10 Hz. In addition, memory usage serves as an important metric, as the system must store all necessary information in memory to support long-term data association and retrieval. As shown in Table 5, even on resource-limited industrial PCs (typically equipped with 8 GB of RAM), the memory consumption remains below the physical limit in most scenarios.
7. Conclusions and Future Works
This paper proposed VINA-SLAM, a tightly coupled LiDAR–Inertial SLAM framework to mitigate pose drift in geometrically degenerate or repetitive environments (e.g., long corridors and stairwells), where rotational observability and data association are often unreliable. The core contribution is the Voxel Normal Consistency (VNC) constraint, which injects rotation-sensitive geometric cues into both the front-end odometry and the sliding-window back-end optimization, thereby improving stability along degenerate directions and reducing drift. Extensive evaluations on 25 sequences from the HILTI and MARS-LVIG datasets show that VINA-SLAM achieves lower ATE on the majority of sequences compared with representative open-source baselines (e.g., FAST-LIO2 and Point-LIO), while remaining suitable for real-time deployment. On the 10 Hz HILTI sequences 01–08, the end-to-end latency stays within the LiDAR scan interval and the memory footprint remains bounded (Table 5).
Future work will focus on (i) integrating loop closure and global pose-graph optimization using normal and structural cues to improve global consistency, (ii) extending the current planar modeling to richer primitives (e.g., lines and cylinders) or learning-assisted residuals for strongly unstructured regions, and (iii) incorporating visual and semantic information to further enhance robustness under extreme degeneracy.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Smith R.C. Cheeseman P.C. On the Representation and Estimation of Spatial Uncertainty Int. J. Robot. Res.19865566810.1177/027836498600500404 · doi ↗
- 2Liu W. Ren Y. Guo R. Kong V.W.W. Hung A.S.P. Zhu F. Cai Y. Wu H. Zou Y. Zhang F. Slope inspection under dense vegetation using Li DAR-based quadrotors Nat. Commun.202516741110.1038/s 41467-025-62801-y 40790039 PMC 12339984 · doi ↗ · pubmed ↗
- 3Li Y. Ibanez-Guzman J. Lidar for autonomous driving: The principles, challenges, and trends for automotive lidar and perception systems IEEE Signal Process. Mag.202037506110.1109/MSP.2020.2973615 · doi ↗
- 4Zhang S. Liu Z. Xu B. Wang J. Li Y. Fusion GNSS/INS/vision with path planning prior for high precision navigation in complex environment IEEE Sens. J.2025259045905510.1109/JSEN.2025.3525842 · doi ↗
- 5Liu J. Gao W. Hu Z. Optimization-based visual-inertial SLAM tightly coupled with raw GNSS measurements Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA)IEEE New York, NY, USA 20211161211618
- 6Mur-Artal R. Montiel J.M.M. Tardos J.D. ORB-SLAM: A versatile and accurate monocular SLAM system IEEE Trans. Robot.2015311147116310.1109/TRO.2015.2463671 · doi ↗
- 7Taketomi T. Uchiyama H. Ikeda S. Visual SLAM algorithms: A survey from 2010 to 2016 IPSJ Trans. Comput. Vis. Appl.201791610.1186/s 41074-017-0027-2 · doi ↗
- 8Wang W. Zhang Q. Hu Y. Gallay M. Zheng W. Guo J. Recent Advances in SLAM for Degraded Environments A Review IEEE Sens. J.202525278982792110.1109/JSEN.2025.3584218 · doi ↗