Enhancing ECG Classification Generalization Through Unified Multi-Dataset Training
Minchan Kim, Miyoung Shin

TL;DR
This paper introduces a new ECG classification framework that improves performance across different datasets, helping detect atrial fibrillation more reliably in various clinical settings.
Contribution
A novel multi-dataset ECG classification framework using supervised contrastive learning and layer-wise normalization to enhance generalization.
Findings
The model achieved 97.5% average accuracy and 89.3% F1-score in cross-dataset evaluations.
It outperformed single-dataset training and naïve multi-dataset aggregation methods.
The approach improves robustness against dataset-specific biases and distributional shifts.
Abstract
Atrial fibrillation (AF) is one of the most prevalent and clinically significant cardiac arrhythmias, and electrocardiography (ECG) is widely used for its detection. However, existing models often exhibit performance degradation when applied to unseen data due to dataset-specific biases and distributional shifts. This limited generalization remains a major obstacle to reliable clinical deployment. To address this, we propose a multi-dataset ECG classification framework designed to improve cross-dataset robustness. The model employs supervised contrastive learning and layer-wise normalization to stabilize training and mitigate the influence of domain-specific variations. The proposed approach was evaluated under a Leave-One-Dataset-Out setting, achieving an average accuracy of 97.5% and an F1-score of 89.3%. It consistently demonstrated superior performance compared with single-dataset…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
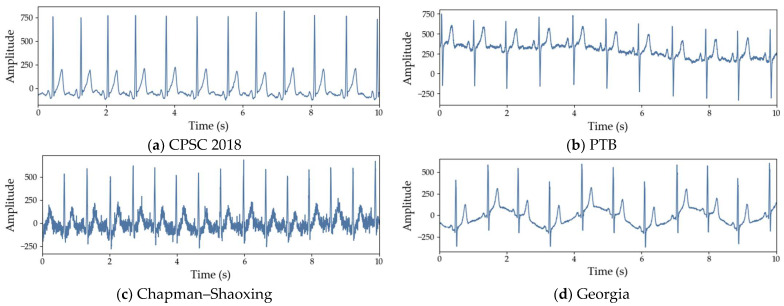 Figure 1
Figure 1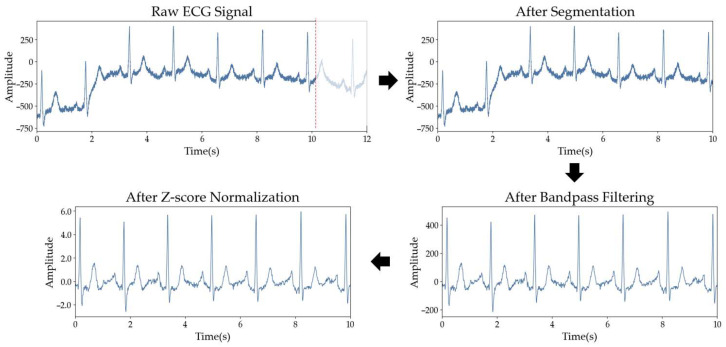 Figure 2
Figure 2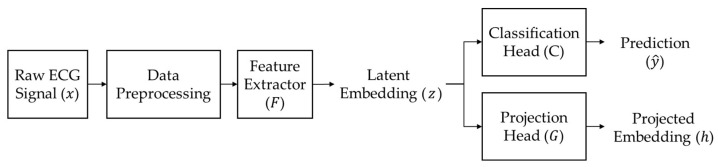 Figure 3
Figure 3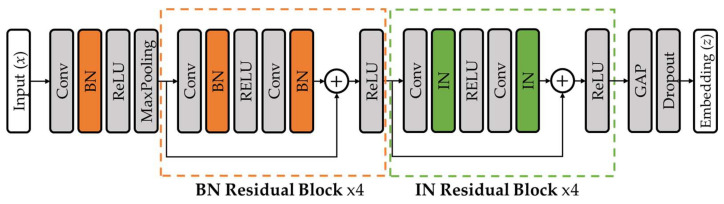 Figure 4
Figure 4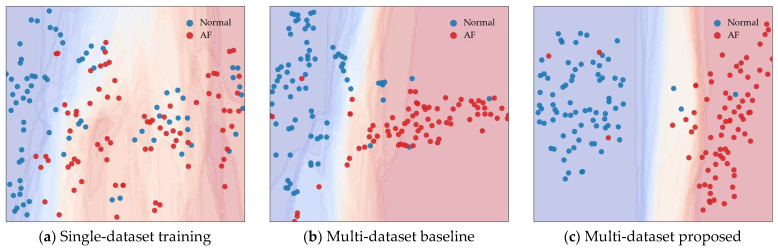 Figure 5
Figure 5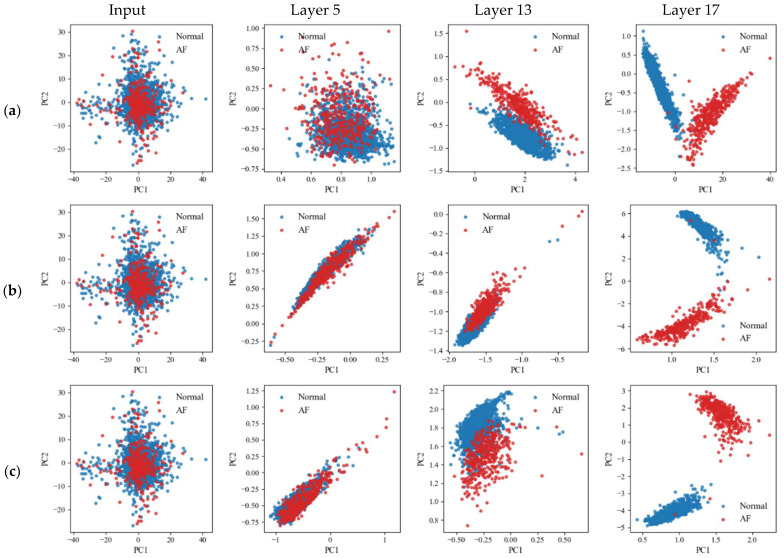 Figure 6
Figure 6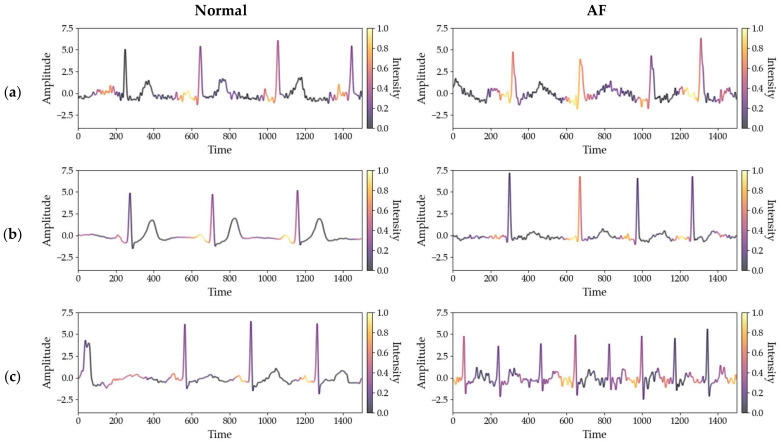 Figure 7
Figure 7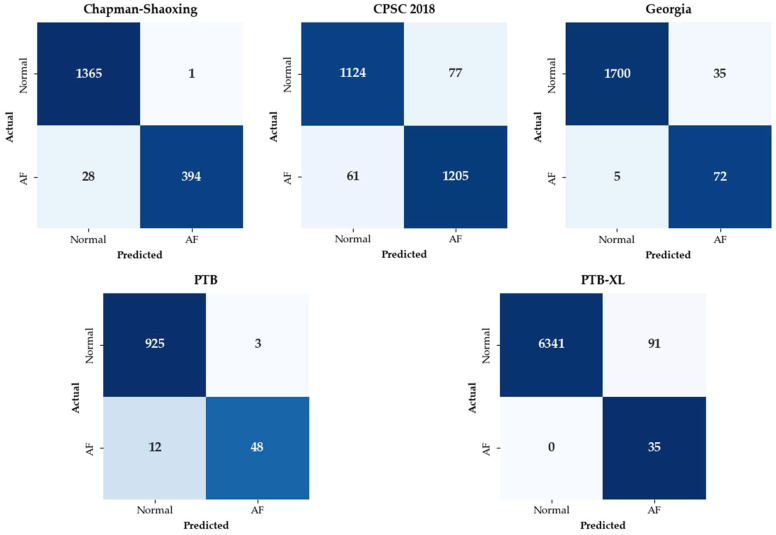 Figure 8
Figure 8- —National Research Foundation of Korea (NRF)
- —Ministry of Education
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsECG Monitoring and Analysis · Atrial Fibrillation Management and Outcomes · Cardiac electrophysiology and arrhythmias
1. Introduction
Atrial fibrillation (AF) is a cardiac arrhythmia characterized by rapid and irregular electrical activity in the atria, leading to irregular heart rhythms. It is one of the most common cardiovascular disorders and is closely associated with serious complications such as stroke and heart failure [1,2]. Patients with AF have been reported to have a substantially higher risk of stroke compared with the individuals without AF [3]. Therefore, the accurate identification of AF has become increasingly important in clinical practice.
Electrocardiography (ECG) is a primary diagnostic tool for the detection and monitoring of AF [4]. ECG is widely used not only in hospital environments but also in wearable devices because of its non-invasive nature and cost-effectiveness. In recent years, this widespread use has motivated extensive studies on automated ECG-based rhythm classification using machine learning [5,6] and deep learning approaches [7,8,9,10].
Despite growing research efforts in ECG classification, several challenges remain in real-world clinical settings. Deep learning approaches typically require large-scale and accurately annotated ECG datasets [11], as ECG annotation is time-consuming, labor-intensive, and requires expert knowledge [12,13]. Publicly available ECG datasets, therefore, are often limited in both size and diversity, with individual datasets representing only a restricted range of clinical conditions and patient populations. This limitation has motivated increasing interest in utilizing multiple ECG datasets [11].
However, effectively utilizing multiple ECG datasets is non-trivial [14]. ECG signals inherently exhibit high variability due to differences in recording devices, acquisition environments, and patient characteristics [15]. As illustrated in Figure 1, even ECG signals corresponding to the same normal rhythm can differ markedly when drawn from different datasets. Such inter-dataset differences may lead models to overfit dataset-specific characteristics, thereby degrading performance on unseen datasets [16,17].
To mitigate inter-dataset variability, domain adaptation approaches incorporate information from the target dataset during training to reduce discrepancies between source and target data distributions. Among these approaches, adversarial learning has been widely used to suppress dataset-dependent information in learned representations [18,19,20]. Some approaches additionally model both dataset-specific and invariant features to better capture heterogeneous characteristics across datasets [21].
In practice, data from the target dataset are often unavailable during training. Domain generalization addresses this setting by learning representations that generalize across source datasets without access to target-dataset information. Adversarial learning combined with feature synthesis has been explored to introduce artificial distributional variations during training [22]. Multi-level representation learning has also been investigated, aggregating features from different network depths to capture ECG characteristics at multiple abstraction levels [23]. In addition, progressive deep learning frameworks combine time–frequency representations with complementary hand-crafted features to improve robustness and efficiency [24].
However, learning dataset-invariant ECG representations still remains challenging. Dataset-specific biases often distort rhythm patterns, making it difficult for models to capture consistent features across different data sources. Therefore, a learning strategy is required to explicitly align representations of the same rhythm class while suppressing irrelevant variations. To this end, we employ supervised contrastive learning to encourage ECG signals from the same rhythm class to form consistent representations in the feature space. This learning strategy guides the model to focus on rhythm-relevant characteristics instead of dataset-specific statistical patterns.
To jointly support representation learning and rhythm classification, we employ a dual-head architecture composed of a projection head and a classification head. Both heads share a common feature extractor and are optimized using supervised contrastive loss and classification loss, respectively. This design enables the model to learn representations that balance class-level alignment and discriminative capability within a unified feature space.
In addition, a layer-wise normalization strategy is incorporated into the feature extractor to reduce sensitivity to inter-dataset distribution differences. Batch normalization is applied in the early layers, while instance normalization is used in deeper layers. This configuration helps suppress dataset-dependent variations while preserving essential information for rhythm classification.
The objective of this study is to improve ECG classification across diverse datasets. We focus on capturing consistent rhythm features regardless of data variations.
The main contributions of our work are summarized as follows:
- We introduce a supervised contrastive learning framework specifically designed for multi-dataset ECG classification. This approach ensures that the model captures consistent rhythm features across different databases by learning a feature representation.
- We propose a dual-head architecture that effectively balances representation learning with arrhythmia classification. This design enables the feature extractor to learn a discriminative and well-structured feature space without the need for complex or heavy model architectures.
- We implement a layer-wise normalization strategy using instance normalization and batch normalization to stabilize the feature distribution across diverse data conditions. This strategy suppresses dataset-specific biases in the feature space, ensuring that the learned representations remain robust to inter-dataset distribution shifts.
- We demonstrate that our framework achieves robust generalization with significantly higher stability across unseen datasets. By minimizing the performance variance between different datasets, we confirm that the learned feature representations provide a more reliable foundation for deployment in realistic clinical scenarios.
2. Materials and Methods
2.1. Datasets
To evaluate the generalization performance of the proposed model, five publicly available ECG datasets were used in this study: the Chapman University–Shaoxing People’s Hospital ECG Database (Chapman–Shaoxing) [25], the Georgia 12-Lead ECG Challenge Database (Georgia), the China Physiological Signal Challenge 2018 Database (CPSC 2018) [26], the Physikalisch-Technische Bundesanstalt Diagnostic ECG Database (PTB) [27], and PTB-XL [28]. These datasets were selected to reflect diverse acquisition conditions, recording protocols, and patient populations.
In this study, a binary classification task distinguishing normal and AF rhythms was considered. These two classes were selected because they are consistently represented across all five datasets, providing sufficient samples for a robust evaluation of cross-database generalization. Following the standardized labeling conventions of the PhysioNet challenges, recordings were categorized based on their assigned SNOMED CT codes [29]. To ensure label consistency, only records with a single rhythm annotation were included, while other arrhythmia types and multi-labeled records were excluded.
The main characteristics of each dataset are summarized below:
- Chapman–Shaoxing was jointly developed by Chapman University and Shaoxing People’s Hospital in China. It includes 45,152 ECG recordings, all of which are 10 s in duration and sampled at 500 Hz.
- CPSC 2018 was released as part of the China Physiological Signal Challenge held in Nanjing, China. It contains 13,256 ECG recordings with durations ranging from 6 s to 144 s, all recorded at a sampling frequency of 500 Hz.
- Georgia was constructed primarily at Emory University and represents ECG data from a population in the southeastern United States. It contains 20,672 ECG recordings with durations between 5 s and 10 s, recorded at a sampling frequency of 500 Hz. The data were collected under conditions representative of routine clinical practice.
- PTB is a clinical ECG dataset collected in Germany and includes 549 recordings from 290 subjects. Each recording consists of 15 signals, including the standard 12-lead ECG and Frank leads, with a baseline sampling frequency of 1000 Hz. The dataset also provides detailed clinical metadata such as age, sex, and diagnostic information.
- PTB-XL is a large-scale clinical ECG dataset comprising 21,837 12-lead recordings collected from 18,885 patients. All recordings are 10 s in duration and sampled at 500 Hz. Each record includes diagnostic, form, and rhythm information following the SCP-ECG standard.
An overview of the datasets, including their sources, number of subjects, number of records, recording lengths, and sampling frequencies, is provided in Table 1.
2.2. Data Preprocessing
In this study, lead I was used for all experiments. Lead I is commonly available in wearable devices and provides sufficient information for rhythm classification [30,31].
All ECG signals were resampled to 500 Hz for consistency. These signals were then divided into non-overlapping 10 s segments, resulting in a fixed length of 5000 time points per segment [32,33]. This duration was chosen to provide a sufficient number of heartbeats to reliably analyze beat-to-beat intervals while ensuring a consistent input dimension. Recordings shorter than 10 s were excluded to maintain data integrity. After segmentation, the numbers of normal and AF samples used in the experiments for each dataset are summarized in Table 2.
To eliminate artifacts while preserving clinical features, a fourth-order Butterworth bandpass filter with a passband of 1–45 Hz was applied [34]. This range was selected to effectively suppress low-frequency baseline wander caused by respiration and high-frequency powerline interference, without distorting the essential QRS complex morphology. Score normalization was applied to each ECG segment to standardize signal amplitudes by centering the data at a zero mean with unit variance. This normalization prevents the model from being biased by extreme amplitude peaks, ensuring that the overall morphological patterns are preserved regardless of fluctuations or signal outliers. Figure 2 depicts the overall ECG preprocessing pipeline.
2.3. Model Architecture
Figure 3 illustrates the overall architecture and processing flow of the proposed model. The model takes a preprocessed single-lead ECG signal of 10 s, denoted as , as input. The feature extractor extracts a latent embedding from the input ECG signal. The extractor is designed with a layer-wise normalization strategy, where different normalization schemes are applied at different network depths.
The extracted latent embedding is subsequently fed into two heads. The classification head produces the final rhythm prediction between normal and AF based on the latent representation. The projection head maps the latent embedding into a separate feature space used for supervised contrastive learning.
The feature extractor and both heads are jointly optimized using the classification and contrastive objectives during training. During inference, only the feature extractor and the classification head are used to generate the final prediction for an input ECG signal.
2.3.1. ECG Feature Extractor with Layer-Wise Normalization
The feature extractor is designed to learn discriminative and generalizable representations for rhythm classification across heterogeneous ECG datasets. It takes a single-lead ECG signal of 10 s, represented as as input. The input signal first passes through an initial convolutional layer, followed by batch normalization, a ReLU activation function, and a max pooling layer. The network then consists of a total of eight residual blocks.
The feature extractor follows a ResNet-based architecture with layer-wise normalization applied across different depths. Unlike standard ResNet configurations that apply a single normalization strategy throughout the network, different normalization schemes are applied at different network depths to better handle inter-dataset variability.
Batch normalization is applied to the initial convolutional layer and the first four residual blocks. This design stabilizes mini-batch activation distributions in early layers, facilitating robust low-level feature extraction under multi-dataset training. Instance normalization is applied to the remaining four residual blocks. By normalizing activation statistics independently for each sample, this strategy reduces the influence of dataset-specific distributional differences on higher-level representations. The transition point was determined empirically to achieve an optimal trade-off between preserving low-level structural features and maintaining high-level style invariance. This approach filters out dataset-specific stylistic noise while preserving the essential morphology of the signals, which has been shown to improve generalization performance [35]. Figure 4 illustrates the overall architecture of the proposed ECG feature extractor.
2.3.2. Dual-Head Architecture
A dual-head architecture, consisting of a projection head and a classification head, is designed to jointly perform supervised contrastive learning and rhythm classification. The latent embedding z extracted by the feature extractor is fed into two parallel heads, each optimized for a different learning objective.
The classification head produces the final prediction for binary rhythm classification. It consists of two fully connected layers and outputs logits for rhythm classification, which are optimized with a binary cross-entropy loss. The projection head maps the latent embedding into a lower-dimensional embedding space. It is also implemented using two fully connected layers and outputs embeddings for supervised contrastive loss computation.
By adopting this dual-head design, the feature extractor is encouraged to learn representations that are simultaneously discriminative for rhythm classification and well-structured for contrastive representation learning.
The complete specifications of the integrated architecture, covering the entire pipeline from the feature extractor to both heads, are provided in Appendix A.
2.4. Training Strategy
To increase the diversity of sample relationships for supervised contrastive learning, each training mini-batch is constructed using ECG samples drawn from multiple datasets. Let a mini-batch be defined as
where denotes an input ECG segment, is the corresponding rhythm label, and indicates the dataset from which the sample is drawn. To ensure robust cross-dataset representation learning, each mini-batch is constructed such that at least one Normal and one AF sample are included. This batch composition allows samples with the same or different rhythm labels to be compared across datasets.
Each input ECG signal is first mapped to a latent embedding through the feature extractor as
The resulting latent embedding is then forwarded to two heads for rhythm classification and supervised contrastive learning.
The classification head takes as input and produces a prediction for the rhythm label. The output is converted into a probability for the AF class, and the classification loss is defined using the binary cross-entropy loss,
where . This loss promotes discriminative feature learning for binary rhythm classification.
The projection head maps the latent embedding into a lower-dimensional feature space for contrastive learning,
Samples sharing the same rhythm label are treated as positive pairs, while samples with different labels are treated as negative pairs. The supervised contrastive loss is defined as
where denotes the set of positive samples sharing the same label as sample , represents all samples within the mini-batch, and τ is a temperature parameter.
The overall training objective is defined as a weighted combination of the classification loss and the supervised contrastive loss,
where controls the relative contribution of the two loss terms.
The training process is summarized in Algorithm 1. Algorithm 1: Supervised contrastive training for ECG arrhythmia classification1:This algorithm outlines the training procedure for multi-dataset ECG classification using supervised contrastive learning. Input: Multi-dataset ECG samples from, feature extractor , classification head , projection head , loss weight temperature parameter τ, training epochs
Output: Trained parameters 2:Initialize parameters 3:for epoch = 1 to E do4: for each min-batch do5: Sample a mini-batch6: from multiple datasets7: Subject to 8: for each do9: Compute latent embedding10: 11: Compute projection embedding12: 13: Compute classification prediction14: 15: end for 16: Compute binary cross-entropy loss using Equation (3)17: Compute supervised contrastive loss using Equation (5)18: Compute total loss19: 20: Update by backpropagation21: end for 22:end for
3. Results
3.1. Experimental Setup
The overall training objective for ECG classification was a combination of two loss terms, and . The balancing weight α between the two losses was set to 0.5 for all experiments. The temperature parameter τ used in supervised contrastive learning was fixed to 0.07. The batch size was set to 64. The dimensions for the latent and projected embeddings were set to 512 and 32, respectively. The rationale for selecting these specific parameter values is further analyzed in Section 3.5.2 and the Appendix B.
Model training was conducted under a Leave-One-Dataset-Out (LODO) evaluation protocol [36]. In each experiment, one dataset was held out as the test set, while the remaining datasets were used for training and validation. This setting was adopted to evaluate the ability of the model to generalize to unseen ECG dataset.
From the training data, 10% of the samples were randomly selected as a validation set. Early stopping was applied based on the validation loss, and training was terminated if no improvement was observed for five consecutive epochs. The maximum number of training epochs was set to 50. The Adam optimizer was used for all experiments with parameters β_1_ = 0.9 and β_2_ = 0.999. The initial learning rate was set to 1 × 10^−3^. We employed an early stopping mechanism with a patience of five epochs and a ReduceLROnPlateau scheduler, which halved the learning rate if validation loss stagnated for two consecutive epochs.
All experiments were implemented using PyTorch 2.5 and executed on an NVIDIA GeForce RTX 4060 Ti GPU environment with CUDA 12.1. Detailed computational requirements are provided in Table A3 of Appendix A.
3.2. Evaluation Metrics
The classification performance of the proposed model was evaluated using accuracy, precision, recall, specificity, F1-score, AUC- ROC and PR-AUC.
Accuracy measures the proportion of correctly classified samples among all samples and is defined as
where T**P and T**N denote the numbers of correctly classified normal and AF samples, respectively, and F**P and F**N represent false positives and false negatives.
Precision is the proportion of positive identifications that were actually correct, reflecting the model’s predictive accuracy for the positive class:
Recall, also referred to as sensitivity, measures the proportion of actual positives that were correctly identified, indicating the model’s ability to detect the positive class:
Specificity was employed to evaluate the model’s ability to correctly identify the negative class. It is defined as the proportion of actual negatives that are correctly identified as such:
To account for class imbalance, the F1-score was also used. The F1-score is defined as the harmonic mean of precision and recall,
The ROC-AUC represents the area under the receiver operating characteristic curve, which illustrates the relationship between the true positive rate and the false positive rate across different decision thresholds. It reflects the overall discriminative capability of the model.
The PR-AUC, defined as the area under the precision–recall curve, was additionally considered. This metric is particularly informative in imbalanced classification settings, as it more sensitively captures the detection performance for the positive class.
3.3. Generalization Performance for ECG Classification
Table 3 compares the generalization performance of the proposed method with single-dataset training and a multi-dataset baseline. The baseline is trained by naively aggregating multiple datasets without explicitly addressing inter-dataset variability.
The proposed method for multi-dataset training consistently outperformed both single-dataset training and the multi-dataset baseline on each test dataset, achieving an average accuracy of 97.5% and an F1-score of 89.3%. In addition, the proposed method yielded strong performance in terms of specificity and PR-AUC, with average values of 96.2% and 92.8%, respectively.
When Chapman–Shaoxing was used as the test dataset, the proposed method achieved an F1-score of 97.7%, which corresponds to an improvement of 25.9% compared to single-dataset training and 31.4% compared to the baseline. On the PTB-XL test dataset, the proposed method recorded an F1-score of 72.9%, surpassing both single-dataset training (F1-score: 67.2%) and the baseline (F1-score: 58.0%).
The proposed method also substantially reduced performance variability across test datasets. This indicates that the proposed framework not only improves overall classification performance but also provides more consistent generalization across heterogeneous ECG datasets.
3.4. Characterization of Learned Representation Space
Figure 5 illustrates the learned representation space formed under different training strategies. The decision boundaries are defined by classifiers trained on the corresponding training data, while the test samples are projected onto the same feature space. Each point represents an individual test sample, and the background color indicates the class-specific decision regions.
As shown in Figure 5a, when the model is trained on a single dataset, normal and AF samples are widely scattered and heavily overlapping in the representation space. As a result, the decision boundary between the two classes is poorly defined.
As shown in Figure 5b, the multi-dataset baseline achieves partial improvement in class separation compared to single-dataset training. However, a substantial number of test samples remain close to the decision boundary, indicating unstable class separation in the learned representation space.
In contrast, Figure 5c shows that the proposed method produces a more structured representation space. Samples belonging to the same rhythm class form more compact clusters and are separated by a clearer decision boundary. This separation is preserved for test samples collected from a different dataset, suggesting that the learned representations emphasize rhythm-relevant characteristics rather than dataset-specific variations.
3.5. Ablation Studies
3.5.1. Effect of Layer-Wise Normalization
Table 4 presents a comparison of classification performance obtained by applying different normalization strategies within the feature extractor. Compared to configurations applying uniform batch or instance normalization across all layers, the proposed layer-wise normalization strategy achieved superior performance, reaching an accuracy of 97.5% and an F1-score of 89.3%.
Figure 6 presents the class distributions in the learned feature space at different network depths for each normalization strategy. With batch normalization applied across all layers, Normal and AF samples remain closely distributed even at the final layer (layer 17), showing limited class separation. When instance normalization is applied across all layers, separation between the two classes emerges only in deeper layers and remains relatively weak in early and intermediate layers.
On the other hand, with the proposed layer-wise normalization strategy, class separation becomes progressively clearer across network depth. The final layer demonstrates the most distinct separation compared with other normalization strategies. These observations support that the proposed normalization strategy promotes stable representation learning across network depth and yields more discriminative features for rhythm classification.
3.5.2. Effect of Loss Function Configuration
Table 5 summarizes the classification performance under different loss function configurations. When the model was trained using only the supervised contrastive loss ( ), the F1-score was limited to 39.1% and the accuracy dropped to 63.9%. Training with only the binary cross-entropy loss ( ) resulted in an F1-score of 75.2% and an accuracy of 88.1%, but performance gains remained constrained under the multi-dataset setting.
In contrast, the proposed loss formulation combining and consistently achieved superior performance across evaluation metrics. With α = 0.25, the highest specificity of 98.7% was obtained, along with an accuracy of 92.9%. When α was set to 0.5, the model achieved an accuracy of 97.5% and a F1-score of 89.3%.
These results suggest that the two loss functions play complementary roles. While supports effective rhythm discrimination, helps reduce inter-dataset variability by encouraging consistent representations across datasets.
3.6. Comparison with Existing Methods
Comparative experiments were conducted to evaluate the performance of the proposed method against existing approaches designed for multi-dataset learning. In addition to the naïve baseline model, representative methods were considered:
- DANN (domain adversarial neural network) combines a rhythm classifier and a dataset discriminator within a shared feature extractor [18]. During training, the two objectives are optimized in an adversarial manner to encourage dataset-invariant feature representations.
- DSBN (domain-specific batch normalization) shares convolutional layer weights across datasets while maintaining separate batch normalization statistics for each dataset, allowing dataset-dependent feature normalization [37].
- MS-DANN (multi-scale domain adversarial neural network) is a modified architecture inspired by [38], which combines multi-scaled residual blocks for temporal feature extraction with a domain adversarial training strategy to enhance generalization.
As shown in Table 6, the adversarial domain adaptation method, DANN, achieved an F1-score of 75.5% and a PR-AUC of 91.4%. The DSBN approach improved performance over the baseline on several metrics, achieving an F1-score of 86.3% and a PR-AUC of 92.9%, which was the highest among the comparison methods. Additionally, MS-DANN reached an F1-score of 85.0% and a PR-AUC of 92.5%.
The proposed method achieved the best overall performance, with an accuracy of 97.5% and an F1-score of 89.3%. It outperformed all comparison methods in terms of accuracy and F1-score, while achieving a PR-AUC (92.8%) comparable to that of DSBN.
Table 7 compares the proposed framework with existing studies on AF classification using multiple ECG datasets. The proposed approach demonstrates competitive performance and stable generalization across diverse datasets using a unified training strategy with a single-lead ECG input.
3.7. Analysis of Class-Discriminative Activation Regions
Figure 7 presents Grad-CAM visualizations to analyze whether the model consistently attends to rhythm-relevant ECG regions across different datasets. For normal rhythms, the model primarily attends to regions around the P-wave.
For AF rhythms, attention is mainly concentrated around the R-peaks and regions exhibiting abnormalities in the P-wave. These attention patterns are consistent with ECG features that are clinically used for AF detection [44].
Similar attention patterns are observed across datasets despite differences in signal characteristics and acquisition conditions. This indicates that the model relies on rhythm-relevant features rather than dataset-specific characteristics.
4. Discussion
In this study, we addressed the generalization problem from two perspectives: model architecture and normalization strategy. Our goal was to ensure the network extracts features that capture essential rhythm patterns rather than dataset-specific characteristics.
To achieve this, we first utilized supervised contrastive learning. The objective was to encourage ECG segments with the same rhythm to form consistent representations in the feature space, regardless of their origin. This approach allows the feature extractor to prioritize rhythm-related information over variations between different datasets.
Next, we implemented a layer-wise normalization strategy to address the limitations of standard methods. We observed that using only batch normalization often results in features where sample differences are heavily influenced by the specific dataset. To suppress these variations, we integrated instance normalization with batch normalization. This hybrid approach enables the model to reduce the influence of dataset-specific traits and focus on invariant rhythm patterns.
Overall, our results showed that the proposed framework achieved consistent performance improvements across all test datasets, regardless of the origin of the data. This stability across different test sets is a key outcome of our study. In particular, we observed significant gains in AF detection. AF is characterized by irregular rhythms, which typically leads to large performance variances between different datasets. Our framework effectively reduced this gap by capturing more robust features that are less sensitive to these variations.
However, this study has several limitations. To use rhythms that are commonly available across multiple diverse datasets, our scope was restricted to binary classification. This must be expanded to multi-class arrhythmia detection in the future.
Furthermore, performance remains suboptimal in certain cases. As shown in the confusion matrices in Appendix C, some normal waveforms are still misclassified as AF, likely because specific morphological features in those recordings are easily confused with arrhythmic patterns. There is also a concern regarding the segmentation process. While the original records are fully annotated, the process of cutting the entire record into segments might not have captured enough of the representative rhythm in some cases.
Finally, we observed that adding more datasets does not always yield significant improvements. In cases where performance is already high, merging additional data can sometimes have a limited impact on the learning process. This suggests that future work should explore more selective dataset integration strategies to ensure optimal learning.
5. Conclusions
This study addresses the cross-dataset generalization problem in multi-dataset ECG classification by reducing the model’s reliance on dataset-specific characteristics. Training deep learning models on multiple ECG datasets often leads to overfitting to dataset-specific patterns, resulting in degraded performance on unseen datasets. In contrast, the proposed framework emphasizes rhythm-discriminative representations that are less sensitive to dataset-specific variations.
Our experimental results demonstrate that a unified framework integrating of supervised contrastive learning, a dual-head architecture, and layer-wise normalization effectively enhances generalization across datasets. Supervised contrastive learning encourages ECG segments belonging to the same rhythm class to form compact and consistent groups in the feature space, regardless of their dataset origin. This property is particularly important in cross-dataset settings, where intra-class variability can otherwise dominate the learned representations. The dual-head architecture enables joint optimization of contrastive representation learning and rhythm classification, allowing the shared feature extractor to capture class-level relational structure while retaining discriminative power for binary rhythm classification. In addition, the layer-wise normalization strategy contributes to stabilizing cross-dataset performance by preserving global signal characteristics in early layers and reducing sensitivity to dataset-specific distribution shifts in deeper layers.
Overall, the proposed framework consistently outperformed single-dataset training and simple dataset-merging baselines under the LODO setting. The reduced performance variability across test datasets highlights the importance of learning dataset-invariant representations for reliable ECG classification in realistic deployment scenarios. These advancements support the development of more reliable AI tools that can maintain consistent performance in realistic clinical deployment scenarios.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Murtagh B. Smalling R.W. Cardioembolic stroke Curr. Atheroscler. Rep.2006831031610.1007/s 11883-006-0009-916822397 · doi ↗ · pubmed ↗
- 2Virani S.S. Alonso A. Benjamin E.J. Bittencourt M.S. Callaway C.W. Carson A.P. Chamberlain A.M. Chang A.R. Cheng S. Delling F.N. Heart disease and stroke statistics—2020 update: A report from the American Heart Association Circulation 2020141 e 139e 59610.1161/CIR.000000000000075731992061 · doi ↗ · pubmed ↗
- 3Healey J.S. Connolly S.J. Gold M.R. Israel C.W. Van Gelder I.C. Capucci A. Lau C.P. Fain E. Yang S. Bailleul C. Subclinical atrial fibrillation and the risk of stroke N. Engl. J. Med.201236612012910.1056/NEJ Moa 110557522236222 · doi ↗ · pubmed ↗
- 4Lankveld T.A.R. Zeemering S. Crijns H.J.G.M. Schotten U. The ECG as a tool to determine atrial fibrillation complexity Heart 20141001077108410.1136/heartjnl-2013-30514924837984 · doi ↗ · pubmed ↗
- 5Sahoo S. Kanungo B. Behera S. Sabut S. Multiresolution wavelet transform based feature extraction and ECG classification to detect cardiac abnormalities Measurement 2017108556610.1016/j.measurement.2017.05.022 · doi ↗
- 6Ganapathy N. Baumgaertel D. Deserno T.M. Automatic detection of atrial fibrillation in ECG using co-occurrence patterns of dynamic symbol assignment and machine learning Sensors 202121354210.3390/s 2110354234069717 PMC 8161329 · doi ↗ · pubmed ↗
- 7Hannun A.Y. Rajpurkar P. Haghpanahi M. Tison G.H. Bourn C. Turakhia M.P. Ng A.Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network Nat. Med.201925656910.1038/s 41591-018-0268-330617320 PMC 6784839 · doi ↗ · pubmed ↗
- 8Ramesh J. Solatidehkordi Z. Aburukba R. Sagahyroon A. Atrial fibrillation classification with smart wearables using short-term heart rate variability and deep convolutional neural networks Sensors 202121723310.3390/s 2121723334770543 PMC 8587743 · doi ↗ · pubmed ↗