Efficient Thermal Pose Estimation: Balancing Accuracy and Edge Deployment for Smart Home Activity Recognition
Gabriela Vdoviak, Tomyslav Sledevič, Vytautas Abromavičius, Dalius Navakauskas, Artūras Kaklauskas

TL;DR
This paper explores efficient thermal-image pose estimation for smart homes, finding that FP16 precision balances accuracy and performance on edge devices.
Contribution
The study introduces a thermal dataset and evaluates model scales and precision formats for edge deployment in activity recognition.
Findings
TensorRT FP16 maintains pose accuracy while reducing latency and power consumption compared to FP32.
INT8 further reduces power but causes accuracy losses in some configurations.
FP16 is recommended for the best accuracy-efficiency balance on edge devices.
Abstract
This study investigates efficient thermal-image human pose estimation under edge deployment constraints for smart home activity recognition. A single-person thermal dataset of 2500 images was collected and annotated with 17 body keypoints. YOLO11-pose and YOLOv8-pose models were trained and evaluated across all five model scales (n–x) at three input resolutions 640 × 512, 320 × 256, and 160 × 128 px. The accuracy was evaluated using box mean Average Precision (mAP50–95), pose mAP50–95, and Object Keypoint Similarity (OKS) metrics. Runtime performance was assessed using per-image latency and power measurements on three NVIDIA Jetson platforms: Orin Nano 4 GB, Orin Nano 8 GB and AGX Orin 64 GB, using PyTorch and TensorRT at FP32, FP16, INT8 precision. Human detection remained consistently high across model variants, whereas pose accuracy decreased as the input resolution was reduced.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2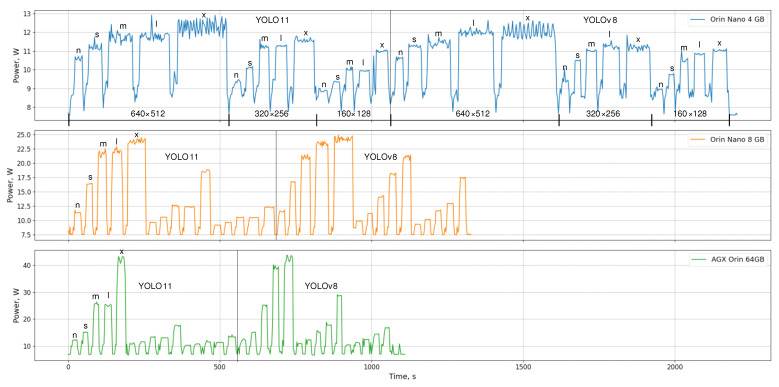 Figure 3
Figure 3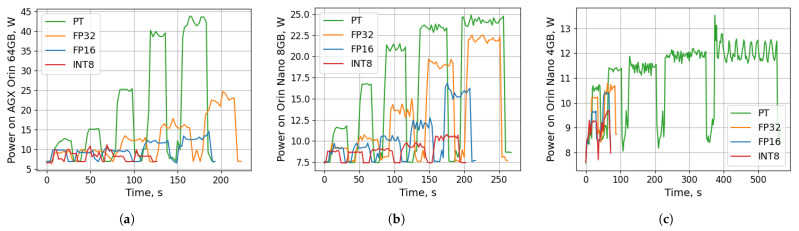 Figure 4
Figure 4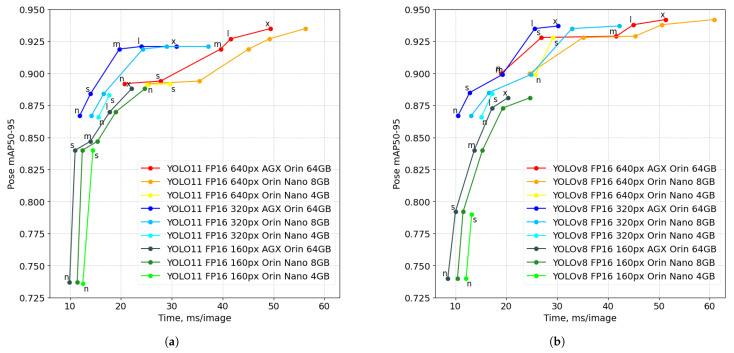 Figure 5
Figure 5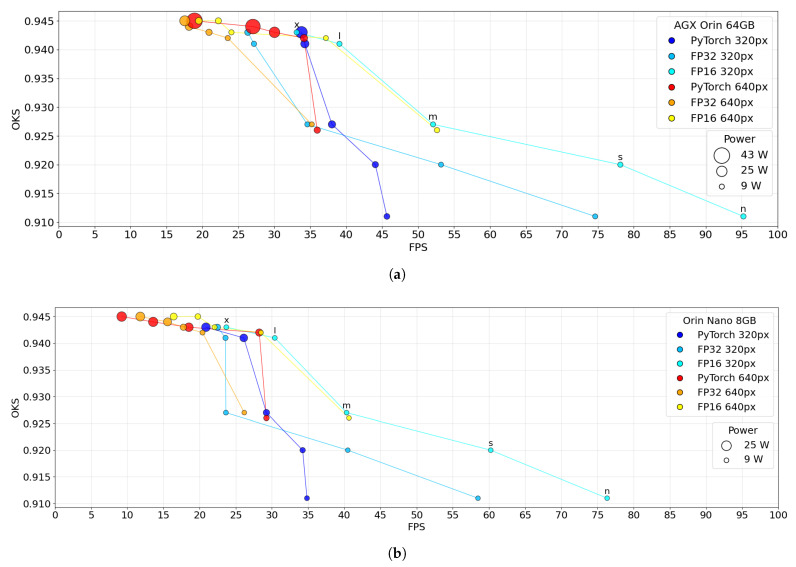 Figure 6
Figure 6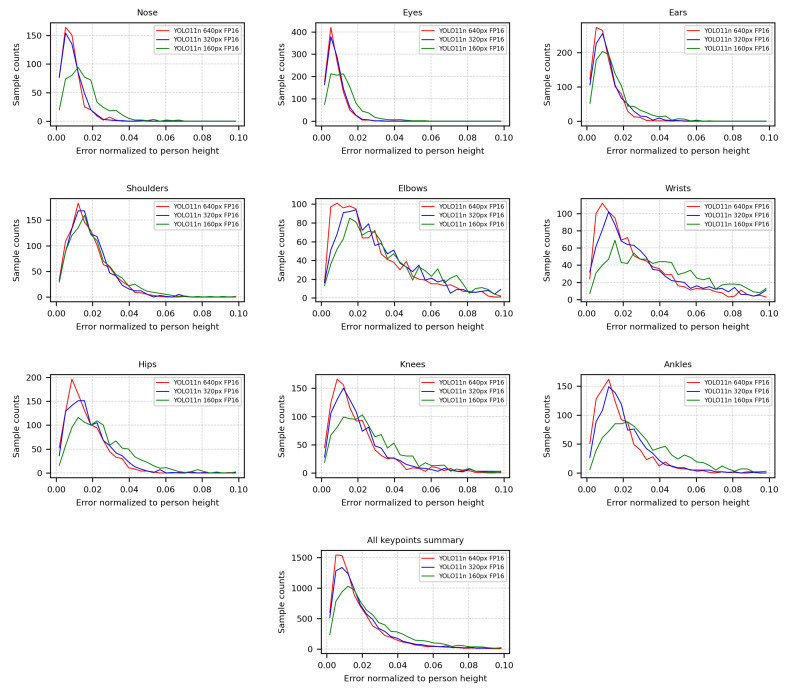 Figure 7
Figure 7 Figure 8
Figure 8- —European Union
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHuman Pose and Action Recognition · Context-Aware Activity Recognition Systems · Emotion and Mood Recognition
1. Introduction
Human pose estimation represents the structure of the human body by identifying anatomical keypoints and is widely used for analyzing human behavior in visual data. Pose-based representations have been widely applied across diverse domains, including sports analysis, human–computer interaction, surveillance, and healthcare, enabling quantitative analysis of human motion and automated assessment of body movements. A prominent example in the healthcare domain is home physiotherapy and telerehabilitation, where pose estimation enables remote monitoring of therapeutic exercises and functional recovery, supporting clinical supervision outside traditional care settings [1,2,3]. In smart home environments, pose-based representations provide a concise description of posture and movement without reliance on detailed appearance information. Consequently, pose-based cues support tasks such as activity recognition [4], fall-risk assessment [5], and long-term monitoring of behavioral patterns [6]. However, deploying such systems in residential settings requires reliable, continuous operation under practical constraints, motivating systematic consideration of sensing and deployment choices [4,5].
In the context of smart home monitoring, thermal imaging has emerged as a privacy-preserving alternative to RGB cameras, which capture identity-revealing appearance information and are sensitive to illumination conditions [7,8]. By encoding human presence through temperature patterns rather than visual texture, thermal data supports behavioral analysis and reliable operation in low-light or dark environments. Concurrently, thermal imagery introduces specific considerations for pose estimation such as reduced spatial detail, thermal noise, and lower contrast between adjacent body regions [9]. These factors can influence joint separability, particularly for small or partially occluded body parts, and motivate the development and optimization of pose estimation approaches that remain robust under practical sensing and edge deployment conditions.
Pose estimation models can be deployed across a variety of computing platforms, including workstation- or server-based GPU systems and embedded devices with limited computational resources. Compared with server- or cloud-based processing, on-device inference reduces latency, avoids continuous video transmission, and improves robustness to network interruptions, while better aligning with privacy-preserving principles [10,11]. Embedded GPU platforms such as the NVIDIA Jetson support always-on operation due to their smaller footprint and lower power consumption compared to workstation-class systems. However, tight constraints on compute capability, memory, and energy mean that real-time performance depends strongly on model scale, input resolution, and numerical precision, underscoring the importance of hardware-aware optimization and on-device profiling [12].
Prior studies have investigated human pose estimation from thermal imagery, primarily by adapting existing pose estimation models to the characteristics of infrared data. Common strategies include supervision transfer from RGB-trained pose estimators [13], domain adaptation techniques [14], and the use of lightweight backbones with resolution-robust training procedures [15,16]. Additional robustness is often obtained through data augmentation [17], multi-modal or multi-view configurations [18]. Despite these advances, publicly available thermal datasets with reliable keypoint annotations remain limited compared to the RGB domain, particularly for data captured under realistic residential conditions [17]. This limitation complicates the systematic evaluation of pose estimation robustness and efficiency under deployment-oriented constraints relevant to smart home applications. Concurrently, several studies have examined the deployment of pose-based methods across different computing platforms, most commonly targeting low-cost CPU devices such as the Raspberry Pi or workstation- and server-class GPU systems [19,20,21]. Embedded GPU platforms such as NVIDIA Jetson have been explored more recently as energy-efficient edge deployment solutions [22,23]. However, existing studies often evaluate model performance on a single hardware platform or configuration and tend to emphasize either pose estimation accuracy or inference speed in isolation. As a result, there is limited evidence jointly characterizing pose accuracy and keypoint consistency alongside inference latency and power consumption across multiple embedded platforms using a unified thermal pose estimation pipeline.
The main aim of this study was to investigate efficient thermal pose estimation for smart home applications by systematically analyzing trade-offs between pose accuracy, inference speed, and energy consumption under deployment-realistic constraints. Compared to most existing studies that evaluate pose estimation performance or deployment efficiency in isolation, this study provides a unified analysis that combines a newly annotated thermal pose dataset with multi-platform edge deployment experiments. This analysis demonstrates how model scale, input resolution, and numerical precision affect both pose quality and real-time feasibility on embedded systems. The main contributions of this study are as follows:
- collected and annotated a single-person thermal pose dataset consisting of 2500 thermal images;
- conducted a systematic evaluation of thermal pose estimation models (YOLO-pose) under varying model scales and input resolutions;
- deployed trained models on three NVIDIA Jetson platforms, examining accuracy–efficiency trade-offs, inference speed, and power consumption.
2. Related Works
Recent work in human activity recognition has focused on privacy-preserving sensing modalities and on-device inference strategies. Thermal imaging and pose-based representations have been investigated as alternatives to RGB data for enabling activity analysis under privacy and illumination constraints [24,25]. Consequently, efficient deployment of human pose estimation models on embedded platforms has become an important consideration, as computational and power limitations influence real-time feasibility [26]. This section reviews prior contributions related to our work, focusing first on thermal-domain pose estimation and then on deployment of pose estimation methods on embedded platforms.
2.1. Thermal-Domain Pose Estimation for Privacy-Preserving Activity Analysis
Thermal pose estimation aims to extract human anatomical keypoints from infrared imagery, where appearance cues are limited and contrast is primarily determined by temperature differences. Although well suited to privacy-preserving smart home monitoring, thermal data presents challenges such as low resolution, sensor noise, and reduced joint separability under weak thermal contrast [9,27]. Some studies have also explored deep learning methods for enhancing perception and feature extraction from sensor data across different sensing modalities [28,29]. Such approaches highlight the growing role of learning-based techniques in improving robustness when sensor observations are noisy or contain limited structural information.
One strategy to address these challenges is supervision transfer from RGB data, enabling thermal pose learning without extensive manual annotation. Chen et al. [15] proposed ThermalPose, a bottom-up multi-person pose estimation framework trained using supervision transferred from paired visible imagery. The method achieved pose accuracy comparable to RGB baselines in well-contrasted scenes while remaining functional in dark environments. The authors further demonstrated that this lightweight model reduced computational complexity relative to standard OpenPose variants, although its performance decreased under occlusion and crowding. Similarly, Smith et al. [14] evaluated multiple pose estimation architectures adapted to thermal imagery and showed that top-down methods, particularly ViTPose, achieved higher accuracy than bottom-up approaches, but reduced throughput in multi-person scenarios. Beyond supervision transfer, lightweight and efficiency-oriented model design has also been explored to support practical deployment on embedded systems. Zang et al. [16] introduced LMANet, a lightweight multi-stage attention network for single-person keypoint detection in far-infrared imagery. By combining a MobileNetV3 backbone with channel and spatial attention, the model achieves a favorable accuracy–efficiency trade-off while maintaining real-time performance. These findings highlight the importance of architectural choices when thermal imagery resolution and contrast are limited.
Other studies explored extended sensing configurations to improve robustness under occlusion and ambiguous thermal signatures. Zhu et al. [6] proposed a two-stage framework for in-bed health monitoring that estimates 2D pose from thermal sequences and fuses aligned depth information to recover 3D joint positions. While the approach improves robustness under darkness and partial occlusions, occlusion from bedding and depth ambiguity remain challenging. In their study, Zhu et al. [30] introduced a dual-channel cascaded network for 3D pose estimation from a single infrared video, leveraging temporal context and thermal intensity cues to regress joint depth, achieving a mean 3D joint error below 21 mm, with mean joint estimation error of 18.9 mm.
Multi-view thermal camera setups have also been explored to improve robustness of pose estimation under occlusion and viewpoint ambiguity. Lupión et al. [18] proposed a privacy-preserving multi-view infrared framework for 3D pose estimation in smart home environments, transferring annotations from paired RGB images to train thermal-specific detection and pose models. On a dataset collected with three low-cost thermal cameras, the proposed detector achieved 99.58% detection accuracy, outperforming baseline YOLO on thermal images. However, the approach relies on multiple synchronized cameras, which may limit deployment flexibility in residential settings.
Chen et al. [31] examined recognition from ultra-low-resolution infrared thermopile imagery and observed that limited spatial resolution and small human–environment temperature differences can blur or erase hand contour details, making recognition difficult. Although the task focuses on hand gesture recognition rather than full-body pose estimation, the findings remain relevant for thermal-based human analysis. While reconstruction-based enhancement can improve recognition accuracy, it introduces substantial computational overhead, underscoring the trade-off between accuracy and efficiency when low-cost thermal sensing hardware is used.
2.2. Edge Deployment of Pose Estimation Models
Edge deployment of pose estimation models requires balancing pose detection accuracy with inference latency, throughput, and energy consumption under tight computational constraints. Prior studies highlight that hardware-aware optimization and on-device profiling are essential to sustain real-time performance in smart home systems [26].
Several studies have focused on optimizing pose estimation models for embedded GPU platforms, particularly NVIDIA Jetson devices. Kuzdeuov et al. [23] evaluated YOLO11-pose variants by converting PyTorch models to TensorRT on a Jetson AGX Orin 64 GB platform and comparing FP32, FP16, and INT8 precision. The results show that TensorRT significantly reduces inference latency, for instance reducing YOLO11n from 21.3 ms in PyTorch to 3.2 ms in FP16 TensorRT, while preserving pose accuracy. Although INT8 inference achieves the lowest latency, it introduces noticeable accuracy degradation, leading the authors to identify FP16 TensorRT as the most practical configuration for real-time thermal pose estimation on Jetson devices. Similarly, Wang et al. [22] proposed a lightweight skeletal temporal model for real-time activity recognition intended for deployment on resource-constrained platforms. The pipeline combines lightweight pose estimators with a compact LSTM-based temporal model. The authors report real-time performance on a workstation-class GPU (31.4 FPS) and CPU (25.3 FPS), while deployment on an NVIDIA Jetson Orin Nano achieves approximately 11.18 FPS in a multi-person setting.
Other works focused on CPU-based embedded platforms. Analia et al. [21] proposed a privacy-preserving long-lie detection system deployed on a Raspberry Pi 5 using low-resolution thermal imagery and pose-derived features. By extracting a reduced set of reliable keypoints using a lightweight MediaPipe Pose variant and applying temporal logic-based classification, the system achieves real-time operation with high detection performance. Wang et al. [32] presented an edge-oriented pose-based activity recognition system for Raspberry Pi 4B, incorporating lightweight YOLO-Pose models, temporal convolutional networks, and hardware-aware optimizations such as adaptive frame sampling and INT8 quantization. Experimental results showed that these optimizations increased throughput from 6.1 FPS to 8.5 FPS, while improving the F1-score for abnormal behavior detection from 0.86 to 0.88. At a higher system level, Zeng et al. [13] introduced ThermiKit, an edge-optimized LWIR analytics framework for privacy-preserving smart home and eldercare monitoring. The framework integrates lightweight modules for detection, pose estimation, and tracking under a shared backbone adapted through RGB-to-thermal supervision transfer. Designed to operate under a sub-1 TOPS compute budget, the system achieved real-time performance while improving detection by up to 6.42% mAP over baseline YOLO models across multiple thermal sensors.
Existing research demonstrates that thermal pose estimation enables privacy-preserving human activity analysis, but remains challenged by factors such as low spatial resolution, thermal noise, occlusion, and limited joint separability. Prior studies have proposed a variety of approaches to enhance robustness, such as supervision transfer, lightweight architectures, and multi-view or depth-assisted designs, often at the cost of increased computational complexity or reliance on constrained sensing setups. In regard to deployment, recent studies show that pose estimation can be executed on embedded platforms such as Raspberry Pi and NVIDIA Jetson through model compression, quantization, and hardware-aware optimization. However, existing implementations differ substantially in sensing modality, pose representation, optimization strategy, and evaluation metrics, which complicates direct comparison of practical performance limits. In particular, few works systematically evaluate inference speed, power consumption, or pose accuracy across multiple edge platforms using a consistent thermal pose estimation pipeline, motivating further investigation under realistic smart home constraints.
3. Materials and Methods
The keypoint detection accuracy is evaluated using a newly collected single-person thermal image dataset. The dataset contains 2500 annotated thermal images with a spatial resolution of px, acquired using a Lynx L15 thermal monocular (HIKMICRO, Hangzhou, China). Raw thermal video sequences were recorded in MP4 format at 25 fps. To reduce temporal redundancy, every fifth frame was extracted from the recordings and manually annotated. Each selected frame was labeled with a single-person bounding box and 17 body keypoints (Figure 1), following the standard human pose estimation annotation protocol.
To quantify the similarity between predicted and ground-truth keypoints, the keypoint similarity metric is defined as:
where denotes the Euclidean distance between the predicted and ground-truth location of the i-th keypoint, with . The parameter represents the per-keypoint standard deviation, accounting for localization uncertainty, and s denotes the segmented area of the ground-truth object. In pose detection scenarios where only the bounding box width w and height h are available, the segmented area is approximated using a scaling factor of 0.53, i.e., .
The object keypoint similarity ( ) score aggregates the similarity of all visible keypoints and is computed as:
where is the keypoint similarity of the i-th keypoint, denotes the indicator function that evaluates to 1 if the condition is satisfied and 0 otherwise, and is the ground-truth visibility flag for the i-th keypoint. Only keypoints labeled as visible or occluded are included in the computation.
The standard deviation parameter varies significantly across different body joints. Head-related keypoints (nose, eyes, and ears) are associated with smaller values, reflecting their higher localization precision, whereas body and limb keypoints (shoulders, hips, knees, and ankles) exhibit larger values due to increased positional variability:
Three NVIDIA Jetson platforms were employed to investigate inference speed, power consumption, and numerical precision effects (PyTorch, FP32, FP16, and INT8): Jetson Orin Nano 4 GB, Jetson Orin Nano 8 GB, and Jetson AGX Orin 64 GB (Figure 2). These devices span a wide range of edge AI performance classes, enabling a systematic evaluation of efficiency-accuracy trade-offs. The Jetson Orin Nano modules feature an NVIDIA Ampere GPU with 512 CUDA cores and support configurable power modes of 10 W and 15 W, delivering up to approximately 20 TOPS (4 GB) and 40 TOPS (8 GB) of AI performance. The Jetson AGX Orin 64 GB integrates a significantly larger Ampere GPU with 2048 CUDA cores and 64 Tensor Cores, operating in configurable 30 W to 60 W power modes and providing up to 275 TOPS of peak AI performance. All platforms support hardware-accelerated mixed-precision and INT8 inference via Tensor Cores, allowing a consistent comparison of model latency, throughput, energy consumption and pose estimation accuracy across devices with substantially different computational resources.
Both YOLO11-pose and YOLOv8-pose models follow the single-stage detection paradigm of the YOLO family, in which object detection and keypoint localization are predicted directly from convolutional feature maps in a unified network. The architecture consists of a backbone for feature extraction, a neck that aggregates multi-scale features, and a task-specific head that jointly predicts bounding boxes and human pose keypoints. For pose estimation, the detection head is extended to regress the coordinates and confidence of 17 body keypoints in addition to the person bounding box. The YOLO11 and YOLOv8 pose variants mainly differ in architectural refinements and scaling strategies across model sizes (n–x), but follow the same overall design principle of pose prediction.
All YOLO-based pose estimation models were trained using an NVIDIA GeForce RTX 4080 Super GPU equipped with 16 GB of VRAM. The training environment consisted of Ultralytics v8.3.80, Python 3.12.9, PyTorch 2.5.1 and CUDA 12.6. Model training was performed at three fixed input resolutions: px, px, and px. The dataset was partitioned into 80% for training and 20% for validation and testing, with an identical data split applied to all experiments to ensure comparability. To support reproducibility, a fixed random seed was used across all training runs, ensuring consistent data shuffling, weight initialization and augmentation behavior. Data augmentation included random image translation of up to of the image width, scaling with a gain of and horizontal flipping with a probability of 0.5. Mosaic augmentation was disabled during the final 10 training epochs to promote training stability.
Model optimization was performed using the AdamW optimizer with a learning rate of momentum of 0.9 and weight decay regularization. The maximum number of training epochs was set to 1000, with model checkpoints saved every 10 epochs. Early stopping was enabled with a patience of 100 epochs, terminating training if no validation improvement was observed to prevent overfitting and reduce unnecessary computation. The batch size was dynamically adjusted between 4 and 96, depending on the input resolution and model complexity, to efficiently utilize available GPU memory. In practice, most models converged to their minimum validation loss within 200–400 epochs.
4. Results
This section presents the runtime and accuracy results of deploying YOLO11-pose and YOLOv8-pose models on three NVIDIA Jetson platforms. The results include inference time and power consumption measured across various model sizes, input resolutions, and numerical precisions. The object detection and pose estimation accuracy of the models is evaluated using mean Average Precision (mAP) and Object Keypoint Similarity (OKS).
4.1. Power Consumption and Inference Speed
This subsection reports inference-time power consumption and latency across model scales, input resolutions, precision modes and Jetson platforms.
Figure 3 presents the power consumption measured during inference on the test split for the three Jetson platforms while executing all YOLO11-pose and YOLOv8-pose PyTorch models. For each device, inference was performed sequentially across the five model sizes (n, s, m, l, x) at three input resolutions ( px, px and px), first for YOLO11 and subsequently for YOLOv8 models. To ensure stable and repeatable measurements, a 10 s idle pause was inserted between consecutive inference runs, which is visible in the power traces as low-consumption intervals.
On the Orin Nano 4 GB, power consumption remained relatively stable, typically ranging between approximately 9–13 W, with modest stepwise increases for larger models and higher input resolutions. The Orin Nano 8 GB exhibited a wider dynamic range, reaching peak values of approximately 25 W for the largest models at the highest resolution. In contrast, the AGX Orin 64 GB showed the highest power variability and peak consumption, exceeding 43 W for the largest (x) models, reflecting its substantially higher computational capacity. Across all platforms, increasing model size and input resolution resulted in longer processing times and higher sustained power consumption, while smaller models and lower resolutions produced shorter inference durations with reduced power peaks.
A clear distinction across platforms is that the devices operate in different power regimes as workload increases. The Orin Nano 4 GB remains within a narrow power band, indicating limited headroom to raise instantaneous power with increasing model scale and input resolution. Consequently, higher workloads are expressed primarily as longer execution time rather than substantially higher peaks. In contrast, the Orin Nano 8 GB, and particularly the AGX Orin 64 GB, exhibit larger increases in power draw for heavier configurations, which reduces total completion time at the expense of higher power demand. These trends highlight that deployment decisions should consider power and runtime jointly, because energy per inference is determined by the combined effect of power draw and execution duration rather than by peak power alone.
Figure 4 summarizes the temporal power behavior of all YOLOv8-pose model variants during repeated inference on three Jetson platforms. Each model is executed sequentially with a 10 s idle interval to clearly distinguish individual runs. On the AGX Orin 64 GB (Figure 4a), the larger models (l and x) exhibit pronounced peaks approaching 40–44 W, while the smaller variants maintain substantially lower and more stable power envelopes. The separation between precision modes is most evident for the larger variants, where PyTorch produces the highest peaks, whereas FP16 and INT8 remain substantially lower. The Orin Nano 8 GB (Figure 4b) follows the same trend but with reduced magnitude, typically operating within 8–25 W depending on model size and precision mode, demonstrating a more constrained but still scalable power profile. For the largest variants, FP32 rises toward the upper end of the observed range, while FP16 and INT8 remain lower and exhibit reduced short-term fluctuations. The most resource-limited device, Orin Nano 4 GB (Figure 4c), can only deploy the n and s models due to insufficient memory for compiling the m, l and x engines. Despite this, it sustains comparatively modest power levels around 8–13 W with short, well-defined execution bursts separated by idle periods. For the supported n and s variants, PyTorch consistently draws the most power and shows the greatest temporal fluctuation. FP32 lowers the peak demand but remains noticeably above baseline. In contrast, FP16 and INT8 operate near the device baseline, with INT8 generally producing the lowest and smoothest power trace. Across all platforms, the precision mode has a visible effect: PyTorch and FP32 consistently draw the highest and most fluctuating power, whereas FP16 and particularly INT8 deliver more energy-efficient inference, underscoring the benefit of reduced numerical precision for edge deployment.
Table 1 reports per-image latency and power consumption for YOLO11-pose and YOLOv8-pose models on the Jetson AGX Orin 64 GB across three input resolutions and four precision modes. For both architectures, per-image time increases with model scale and decreases with input resolution. For instance, under FP16 precision mode, YOLOv8 latency ranges from 19.0–51.3 ms at px, 10.5–30.2 ms at px, and 8.5–20.3 ms at px (from n to x). At px, the n and s variants remain below 30 ms in FP16 and INT8, whereas the l and x variants increase to approximately 40–57 ms depending on precision. Across resolutions, YOLO11 and YOLOv8 exhibit comparable latency trends, with differences becoming most apparent for the larger model scales. The power measurements show a strong dependence on both model size and precision mode. PyTorch execution shows the highest power draw and the largest variation with model scale, reaching up to 42–43 W for the largest variants at px. In contrast, the lower-precision TensorRT engines operate in a substantially lower power band. FP16 typically draws about 9–13 W, and at resolution of px its power increases gradually with model scale. INT8 precision mode is the most stable, remaining close to approximately 8–10 W across model sizes and resolutions. Lower power does not always translate into the lowest latency. While INT8 generally minimizes power, FP16 is faster for several model–resolution pairs, with only a small increase in power draw. At px, FP32 does not reliably improve latency for the larger models and can be slower than PyTorch.
In Table 2, the Jetson Orin Nano 8 GB results show clear latency scaling with both input resolution and model size for YOLO11-pose and YOLOv8-pose models. At px resolution, FP16 precision mode latency ranges from 25.4–56.3 ms for YOLO11 and 24.6–60.9 ms for YOLOv8 (from n to x), while INT8 precision mode reduces this to 23.2–52.7 ms and 22.3–54.2 ms, respectively. At px resolution, FP16 precision mode spans 14.2–37.2 ms (YOLO11) and 13.1–42.2 ms (YOLOv8), with INT8 precision mode reaching 13.0–31.8 ms and 9.4–26.5 ms. At the lowest resolution, INT8 achieves the smallest latencies overall, down to 6.5 ms for YOLOv8-n, while remaining below 20 ms for both architectures up to the largest variant. Power consumption on the Orin Nano 8 GB remains comparatively constrained. At px resolution, PyTorch draws the highest power and increases with model scale, reaching 23.9–24.5 W for the x variants, whereas FP16 typically remains within 9–16 W and INT8 stays near 8.7–10.3 W. At and px resolutions, FP16 and INT8 power consumption becomes nearly flat across model scales, remaining close to the device baseline while maintaining reduced latency relative to PyTorch and FP32.
Table 3 highlights the limitations and efficiency characteristics of the Jetson Orin Nano 4 GB for YOLO11-pose and YOLOv8-pose models. The missing entries indicate configurations where FP32, FP16, INT8 engines could not be generated, so only the n and s variants are available in optimized precision modes, whereas larger variants (m, l, x) are reported only for PyTorch execution. Within the supported variants, reduced-precision execution substantially lowers latency compared with PyTorch. For example, at resolution of px, YOLOv8-n decreases from 43.2 ms (PyTorch) to 25.7 ms (FP16) and 22.5 ms (INT8), and YOLOv8-s decreases from 70.1 ms (PyTorch) to 29.2 ms (FP16) and 25.6 ms (INT8). Reducing the input resolution further lowers latency, with YOLOv8-n reaching 14.8 ms at px and 8.8 ms at px in INT8. Power consumption on the Orin Nano 4 GB remains comparatively stable. At resolution of px, PyTorch reaches approximately 10.5–12.2 W depending on the model variant, while FP16 and INT8 operate in a narrower band around 9.1–9.6 W for the supported n and s configurations. At and px resolutions, FP16 and INT8 power draw remains close to the device baseline (approximately 8.5–9.0 W), with only minor variation between n and s. Overall, the table shows that lower-precision modes reduce latency while keeping power consumption low and stable on the 4 GB platform for the configurations that fit in memory.
Comparing across all evaluated platforms, power consumption and latency scale consistently with computational performance. The AGX Orin 64 GB exhibits the highest power usage but also the best inference speed, making it suitable where maximum throughput is required. The Orin Nano 8 GB operates in a mid-range regime, consuming noticeably less power while still delivering reasonable latency across a wider range of models. The Orin Nano 4 GB shows the lowest overall power levels, but it is also the most constrained platform. Optimized FP32, FP16, and INT8 engines are available only for the n and s variants. Across all tested devices, reduced precision (especially INT8) generally lowers power consumption relative to PyTorch and FP32, while FP16 and INT8 typically provide substantial latency reductions compared with full precision. However, latency gains are not strictly monotonic across all configurations, and FP16 can be faster than INT8 for certain model-resolution combinations. These findings show the importance of reduced-precision inference for efficient deployment on edge hardware.
4.2. Precision and Keypoint Similarity
This subsection examines how numerical precision and input resolution influence thermal pose estimation quality, with emphasis on keypoint consistency under edge-deployment constraints. It is important to note that detection and keypoint localization respond differently to reduced precision and spatial downsampling. Therefore, both detection-oriented and pose-oriented metrics are considered in order to differentiate between missed detections and localization errors.
Table 4 shows detection and pose estimation accuracy for YOLO11-pose and YOLOv8-pose across five model scales (n–x), three input resolutions, and four numerical precision modes. For PyTorch, TensorRT FP32, and TensorRT FP16, box mAP50–95 remains high across all configurations, with only modest reductions at the lowest resolution. In contrast, pose accuracy exhibits a stronger dependence on spatial resolution: both pose mAP50–95 and mean OKS decrease as the input is downsampled, reflecting the loss of fine-grained thermal detail needed for reliable keypoint localization. Across both model families, FP16 closely matches PyTorch and FP32, with differences typically confined to the third decimal place, indicating that mixed-precision inference preserves both detection and pose accuracy.
INT8 precision mode shows a different behavior. While box mAP50–95 generally remains relatively high, pose quality can degrade substantially and the extent of degradation depends on the specific configuration. At px resolution, FP16 pose mAP50–95 ranges from 0.892–0.935 for YOLO11 and 0.900–0.942 for YOLOv8, whereas INT8 drops to 0.136–0.331 and 0.279–0.430, respectively. The same pattern is reflected in mean OKS, which remains high for FP16, up to 0.940 for YOLO11-x and 0.945 for YOLOv8 at px, but decreases markedly for INT8 in several model variants. Notably, INT8 pose metrics do not follow a strictly monotonic trend with resolution, suggesting that quantized pose accuracy is sensitive to the interaction between model capacity, input resolution, and calibration. The results identify FP16 as a robust deployment setting for preserving pose accuracy, whereas INT8 should be applied selectively when efficiency constraints dominate and the resulting keypoint quality is acceptable for the downstream task.
Pose accuracy stability under reduced precision is summarized in Table 5 using the mean and standard deviation of the accuracy degradation relative to PyTorch, averaged across five model scales at each input resolution. Across both YOLO11 and YOLOv8, FP32 and FP16 produce near-zero changes in both ΔOKS and ΔPose mAP50–95, with deviations on the order of and standard deviations of approximately 0.001–0.002. This indicates that the TensorRT FP32, FP16 engines preserve pose accuracy consistently across model scales and resolutions, with no practically meaningful loss relative to PyTorch.
In contrast, INT8 precision mode introduces a substantial and resolution-dependent degradation in both metrics. For YOLO11, the mean ΔOKS decreases from at px to at px and at px. The corresponding ΔPose mAP50–95 follows the same trend ( to and ). YOLOv8 exhibits closely matching behavior, with slightly smaller but comparable INT8 losses. The larger INT8 standard deviations relative to FP16 and FP32 suggest increased variability across model scales, consistent with quantization sensitivity to network capacity and configuration. These results confirm that FP16 offers a robust and architecture-independent optimization for edge deployment, whereas INT8 accuracy degradation is both model- and resolution-dependent and should be applied selectively.
Figure 5 illustrates the relationship between inference latency (time per image) and pose mAP50–95 accuracy for YOLO11 and YOLOv8 FP16 engines across three Jetson platforms and three input resolutions. Each polyline corresponds to a fixed platform and resolution, with markers annotated by model scale (n–x). A consistent trade-off is observed: higher resolutions and larger models increase pose accuracy but also increase per-image time, whereas lower resolutions reduce latency at the expense of keypoint precision. The resolution setting primarily shifts the operating point range along both axes. At px, most configurations cluster at low latency (roughly ∼10–20 ms/image) with lower pose mAP50–95 (approximately ∼0.74–0.89). At px, latency increases (about ∼12–40 ms/image), while accuracy rises into the ∼0.87–0.94 range depending on model size. At px, the highest accuracies are achieved (up to ∼0.94–0.95), but latencies extend to the upper end of the plotted range (up to ∼60 ms/image). Across all resolutions, the Jetson AGX Orin 64 GB occupies the leftmost region, indicating the lowest latency at comparable accuracy. The Orin Nano 8 GB follows the same accuracy trend but at higher per-image times, and the Orin Nano 4 GB is further constrained, with points concentrated on the smaller variants visible in the plot. For both architectures, accuracy gains tend to diminish for the largest scales: moving from mid-sized to large models increases latency more than it increases pose mAP50–95, particularly at the highest resolution.
Figure 6 shows the trade-off between pose estimation accuracy (OKS) and throughput (FPS) for YOLOv8 models evaluated on the Jetson AGX Orin 64 GB and Orin Nano 8 GB platforms. On both devices, larger model variants and higher input resolutions cluster toward higher OKS values but achieve lower FPS, indicating that improved keypoint localization accuracy is obtained at the expense of reduced throughput. These high-accuracy operating points are also associated with increased power demand, particularly on the AGX Orin 64 GB, where larger models at high resolution reach the upper range of the device’s power envelope. Conversely, smaller network variants and lower input resolutions achieve higher FPS with lower power consumption, but at the cost of reduced OKS, reflecting decreased localization precision under limited spatial detail. The AGX Orin 64 GB attains higher FPS than the Orin Nano 8 GB at comparable OKS levels, but with higher peak power usage, whereas the Orin Nano 8 GB provides a balanced compromise between accuracy, throughput, and power. Across both platforms, FP16 points generally lie to the right of FP32 and PyTorch at comparable OKS, indicating higher FPS for similar keypoint similarity. At px resolution, OKS values are tightly clustered near the top of the axis across precision modes, while FPS varies more strongly, so differences are dominated by throughput and power rather than accuracy. At px resolution, the smallest variants achieve the highest FPS, whereas moving toward larger variants increases OKS only slightly but shifts operating points leftward, reflecting diminishing accuracy returns for a substantial loss in throughput. Marker sizes increase for lower-FPS, high-resolution configurations, indicating higher power consumption. This effect is more pronounced on the AGX Orin 64 GB, where the marker-size range is wider and the highest-power points coincide with the largest models at px resolution.
Figure 7 presents the normalized absolute localization error of individual keypoints relative to person height, shown as error distributions for each input resolution. The y-axis reports sample counts, indicating how frequently a given normalized error occurs across the evaluated test instances. Across keypoints, the distributions are right-skewed, with most samples concentrated at low errors and a decreasing tail toward larger deviations. As expected, higher input resolutions consistently yield tighter distributions and shorter tails, while the lowest resolution exhibits broader spreads and more frequent large-error outliers. The resolution effect is smallest for larger, centrally located joints (shoulders and hips), where the peaks remain close and the main change is a modest tail increase. In contrast, distal joints (wrists, knees, and ankles) show the most pronounced degradation at px, with visibly heavier tails extending toward 0.08–0.10 of person height. Head keypoints (nose, eyes, and ears) remain the most precisely localized in overall, with sharp peaks near small errors for px and px. The aggregated keypoints figure confirms the same ordering across resolutions, where px stays close to px, while px shifts probability mass toward higher errors. These findings reinforce the importance of selecting an appropriate input resolution depending on the targeted application. High-precision tasks benefit from increased resolution, whereas coarse pose estimation remains feasible under strong resolution constraints.
In Figure 8 we provide a qualitative visualization of pose estimation results on thermal images, using the mean OKS score as an overall similarity indicator. Ground-truth keypoints are shown in green and predictions in blue, and each keypoint is accompanied by two concentric similarity regions. The inner and outer circles correspond to OKS similarity levels of 0.95 and 0.75, respectively, and the annotated mean OKS value summarizes the per-frame agreement between the two skeletons. The six examples cover different viewpoints and subject scales within the scene, allowing visual inspection of model behavior under typical indoor conditions. Across the six examples, the reported mean OKS values range from 0.91 to 0.97, indicating consistently strong agreement between predictions and ground truth. Higher-scoring cases occur when the person occupies a larger image region and limb contours are clearly separated from the background, which reduces ambiguity during keypoint placement. The lower end of the range is observed in more challenging frames, such as smaller or more distant subjects and seated poses with self-occlusion or interaction with furniture, where distal joints are harder to resolve. In these cases, visible offsets most often appear at the wrists and ankles, while the torso and proximal joints remain comparatively stable. These findings show that the proposed models are capable of reliable and anatomically consistent pose reconstruction in thermal imagery, supporting their suitability for smart-home human activity recognition scenarios.
5. Discussion
This study provides a unified evaluation of thermal pose estimation accuracy and deployment efficiency by combining a newly annotated single-person thermal dataset with on-device latency and power measurements on three NVIDIA Jetson platforms. The results show that bounding-box detection in thermal data is consistently high across model scales and resolutions (Table 4). In contrast, pose estimation remains the limiting factor because keypoints require finer spatial localization, which is challenging in thermal imagery under limited spatial detail and weak joint separability [27]. This separation is important for smart-home activity recognition, where downstream performance is often constrained by keypoint stability rather than person detection [4].
For both YOLO11-pose and YOLOv8-pose models, FP16 inference achieves accuracy comparable to PyTorch and FP32, while offering substantial reductions in latency and power consumption (Table 4 and Table 5). The mean accuracy difference remains close to zero, and the standard deviations across model scales are minimal, indicating stable numerical behavior under mixed precision. These findings align with prior Jetson-focused studies that identify TensorRT FP16 as a strong operating point for real-time thermal pose estimation [23], and with broader evidence that hardware-aware optimization and on-device profiling are essential for embedded deployment feasibility [12]. From a deployment perspective, FP16 represents a reliable operating point, combining stable accuracy with reduced power consumption when TensorRT conversion is feasible.
Across devices and model scales, INT8 quantization reduces power consumption compared with PyTorch and FP32, and it often shortens per-image latency for the same model and resolution (Figure 3 and Figure 4, Table 1, Table 2 and Table 3). However, the accuracy results show that quantization can substantially lower pose mAP50–95 and OKS metrics, particularly at higher resolutions and for several model variants (Table 4). This behavior is consistent with prior Jetson thermal pose evaluations that report INT8 speedups accompanied by measurable accuracy loss [23], and with edge pipelines that treat quantization as a throughput lever that must be balanced against task requirements [32]. The mean INT8 accuracy difference also shows greater variability across model scales (Table 5), which suggests that quantization sensitivity depends on network capacity and internal activation statistics. Importantly, INT8 does not always achieve the lowest latency, implying that memory traffic and precision-specific scheduling can dominate performance for certain model–resolution pairs. For smart-home applications, INT8 is therefore best viewed as an energy-saving option that requires per-configuration validation, especially when the target activities depend on accurate joint localization. These findings suggest that simple post-training INT8 quantization may be insufficient for pose estimation tasks that require fine-grained joint localization. More advanced approaches such as quantization-aware training, improved calibration with representative thermal samples, or selective or mixed-precision deployment could help reduce accuracy loss while retaining most of the efficiency benefits. These directions were not explored in the present study but represent promising future work for improving INT8 viability on edge devices.
Beyond numerical precision, input resolution and model scale define a consistent accuracy–latency trade-off across devices and model families (Figure 5). Higher resolutions and larger models improve pose accuracy, but they also increase per-image processing time and typically power consumption. The keypoint error distributions (Figure 7) indicate that distal joints experience the largest loss of localization precision at px, which is consistent with weaker thermal boundaries and reduced discriminability for small structures under low spatial detail [31]. In contrast, central joints (shoulders and hips) remain comparatively stable across resolutions, suggesting that coarse posture cues can still be extracted reliably under strong downsampling. This supports a practical deployment guideline: low resolution can be sufficient for coarse activities (standing, sitting), while higher resolution is preferable when fine-grained motion cues or limb interactions are required.
While the Jetson AGX Orin 64 GB achieves the lowest per-image latency at comparable accuracy, it also reaches the highest peak power for larger variants at high resolution (Table 1, Figure 3 and Figure 4). The Orin Nano 8 GB provides a middle ground, maintaining moderate latency with a more constrained power profile (Table 2). On the Orin Nano 4 GB, memory limits prevented building optimized engines for several larger variants (Table 3), although PyTorch execution remained possible. This distinction matters for real deployment because the most efficient operating points often require TensorRT compilation and sufficient memory headroom, as also reflected in prior Jetson deployment studies that rely on TensorRT engines for real-time performance [23]. Therefore, hardware selection should consider not only achievable FPS, but also whether the intended model family and precision mode can be deployed reliably within the device memory budget.
In highly memory-constrained edge environments such as the Jetson Orin Nano 4 GB, several strategies may help mitigate memory bottlenecks during deployment. For instance, selective layer partitioning or layer-wise execution strategies can distribute intermediate activations across available memory regions, reducing peak memory demand during inference. In heterogeneous edge systems, pipeline parallelism between CPU and GPU components may also be used to overlap computation and memory transfers, enabling more efficient utilization of limited device resources. Additionally, model compression techniques such as structured pruning, lightweight backbone substitutions, or reduced activation precision may further lower the memory footprint while preserving acceptable accuracy. Although these approaches were not explored in the present study, they represent promising directions for extending thermal pose estimation pipelines to devices with tighter memory constraints.
The qualitative examples confirm that the predicted poses remain anatomically plausible and consistent across typical indoor scenes, with mean OKS values in the 0.91–0.97 range (Figure 8). Residual errors are most visible at the wrists and ankles in more challenging cases, such as smaller subjects or seated poses with self-occlusion or interaction with furniture. This pattern is consistent with the known difficulty of localizing distal joints in low-detail thermal imagery. For activity recognition, these error patterns suggest that models can provide reliable global pose structure and limb connectivity, while the precise localization of hand- and foot-related joints remains a dominant source of uncertainty. This observation supports the use of pose-derived features that are robust to small distal-joint offsets, such as torso orientation, hip–knee angles, or temporal smoothing of limb trajectories, especially under low-resolution operation [21].
This study uses a single-person thermal dataset acquired under a specific thermal sensor and indoor setup, which may limit generalization to multi-person scenes, different room layouts, or sensors with different noise and contrast characteristics [17]. The frame extraction strategy reduces temporal redundancy, but the dataset can still contain correlated viewpoints and backgrounds, and the evaluation does not explicitly test cross-subject or cross-environment transfer. Therefore, the reported accuracy–efficiency trade-offs should be interpreted as deployment-oriented evidence under controlled residential conditions rather than as a claim of broad domain generalization.
6. Conclusions
This study investigated efficient thermal pose estimation for privacy-preserving smart home activity recognition by combining a newly annotated single-person thermal dataset with deployment on three NVIDIA Jetson platforms: Orin Nano 4 GB, Orin Nano 8 GB, and AGX Orin 64 GB. A comprehensive evaluation was conducted to assess the accuracy, latency, and power trade-offs of the YOLO11-pose and YOLOv8-pose models across a range of model sizes, input resolutions, and numerical precision modes. The findings indicate that person detection in thermal imagery shows consistent robustness, while pose accuracy remains a limiting factor and is primarily affected by the quality of keypoint localization.
Across the two model families examined, TensorRT FP16 was identified as the most reliable option for edge deployment. FP16 maintains pose accuracy comparable to that of PyTorch and FP32, while concurrently achieving a substantial reduction in per-image latency and power consumption across all evaluated devices. INT8 has been shown to reduce power consumption and improve latency. However, it introduces substantial degradations in pose mAP50–95 and OKS. Consequently, INT8 is only suitable when energy savings are a primary concern and the resulting keypoint quality is validated for the specific target task. Input resolution and model size define a consistent accuracy–efficiency trade-off. Higher resolutions improve keypoint localization, while a high degree of downsampling increases distal joint errors (wrists, knees, and ankles) and reduces fine-grained pose fidelity. In addition, the selection of the embedded device affects not only throughput and power consumption but also which optimized engines can be deployed in practice, as memory limitations on the Orin Nano 4 GB restrict TensorRT support for larger model variants.
Future research could investigate thermal pose estimation under more diverse and realistic conditions, including multi-person scenes and occlusions to better assess generalization and improve distal-joint stability. In parallel, edge deployment could be extended with quantization-aware training and improved INT8 calibration to reduce pose degradation, together with memory-aware optimization strategies that enable larger models and higher resolutions on resource-limited Jetson devices.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Latreche A. Kelaiaia R. Chemori A. Kerboua A. A new home-based upper-and lower-limb telerehabilitation platform with experimental validation Arab. J. Sci. Eng.202348108251084010.1007/s 13369-023-07720-0PMC 1003934337361467 · doi ↗ · pubmed ↗
- 2Clemente C. Chambel G. Silva D.C. Montes A.M. Pinto J.F. Silva H.P.D. Feasibility of 3D body tracking from monocular 2D video feeds in musculoskeletal telerehabilitation Sensors 20232420610.3390/s 2401020638203068 PMC 10781343 · doi ↗ · pubmed ↗
- 3Aguilar-Ortega R. Berral-Soler R. Jiménez-Velasco I. Romero-Ramírez F.J. García-Marín M. Zafra-Palma J. Muñoz-Salinas R. Medina-Carnicer R. Marín-Jiménez M.J. Uco physical rehabilitation: New dataset and study of human pose estimation methods on physical rehabilitation exercises Sensors 202323886210.3390/s 2321886237960561 PMC 10648737 · doi ↗ · pubmed ↗
- 4Gao Z. Chen J. Liu Y. Jin Y. Tian D. A systematic survey on human pose estimation: Upstream and downstream tasks, approaches, lightweight models, and prospects Artif. Intell. Rev.2025586810.1007/s 10462-024-11060-2 · doi ↗
- 5Sykes E.R. Next-generation fall detection: Harnessing human pose estimation and transformer technology Health Syst.2025148510310.1080/20476965.2024.239557440438315 PMC 12107650 · doi ↗ · pubmed ↗
- 6Zhu Y. Xiao M. Xie Y. Xiao Z. Jin G. Shuai L. In-bed human pose estimation using multi-source information fusion for health monitoring in real-world scenarios Inf. Fusion 202410510220910.1016/j.inffus.2023.102209 · doi ↗
- 7Bustos N. Mashhadi M. Lai-Yuen S.K. Sarkar S. Das T.K. A systematic literature review on object detection using near infrared and thermal images Neurocomputing 202356012680410.1016/j.neucom.2023.126804 · doi ↗
- 8Zhang W. Li J. Tien P. Calautit J.K. Vision-based Occupancy Detection in Indoor Environments: A Comparison of Standard RGB and Thermal Cameras J. Build. Eng.202511411421510.1016/j.jobe.2025.114215 · doi ↗