Prediction of Cataract Severity Using Slit Lamp Images from a Portable Smartphone Device: A Pilot Study
David Z. Chen, Changshuo Liu, Junran Wu, Lei Zhu, Beng Chin Ooi

TL;DR
This pilot study explores using a smartphone-based slit lamp and deep learning to predict cataract severity without dilation, achieving promising accuracy.
Contribution
A portable smartphone-based slit lamp and deep learning model for predicting cataract severity without dilation is proposed and tested.
Findings
The model achieved 81.25% accuracy for undilated and 74.38% for dilated eyes.
Heat maps successfully identified anatomical areas of interest in some images.
The technique shows potential for estimating cataract density without dilation.
Abstract
Cataract diagnosis requires a comprehensive dilated examination by an ophthalmologist using a slit lamp; there is currently no effective means to objectively screen for cataracts in the community using portable devices without dilation. We hypothesized that it would be possible to predict cataract severity using deep learning on images taken using a portable smartphone-based slit lamp prototype, with and without dilation. In this prospective cross-sectional pilot study, slit lamp images were captured from eligible patients with cataracts in a tertiary clinic using a portable slit lamp prototype attached to a smartphone. The Pentacam nuclear staging score (PNS, Pentacam®, Oculus, Inc., Arlington, WA, USA) was taken from the dilated pupils and served as ground truth. A transformer prototypical network with the Swin transformer on the images was trained to assign the class label…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
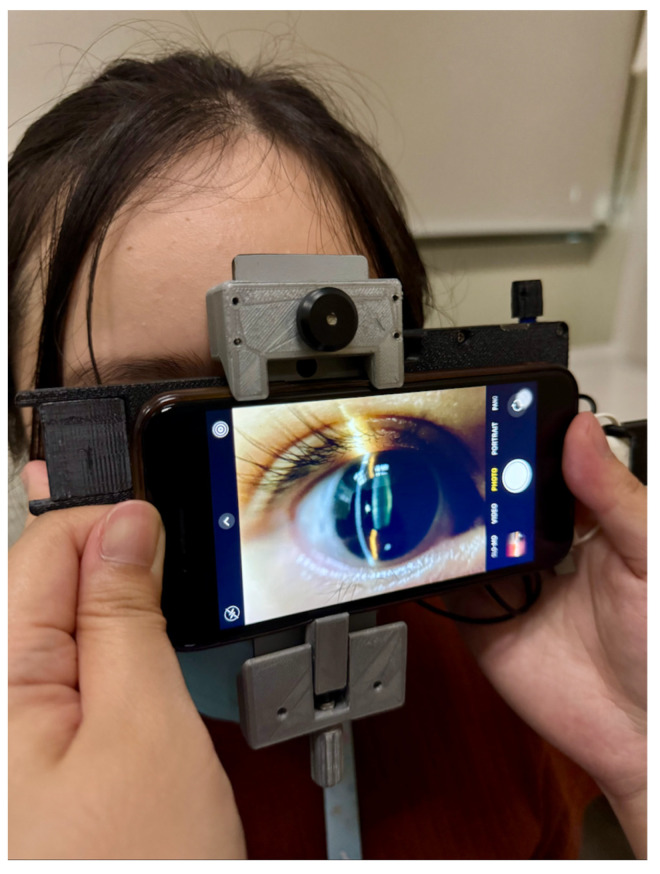 Figure 1
Figure 1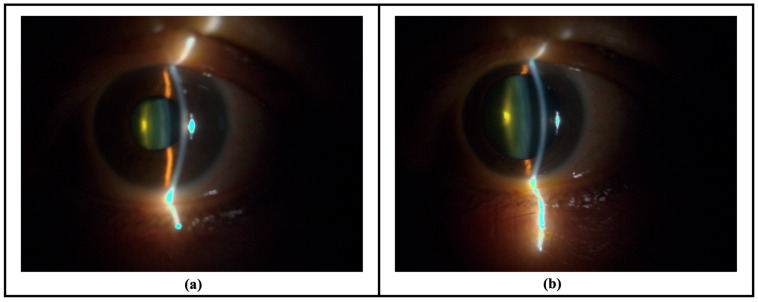 Figure 2
Figure 2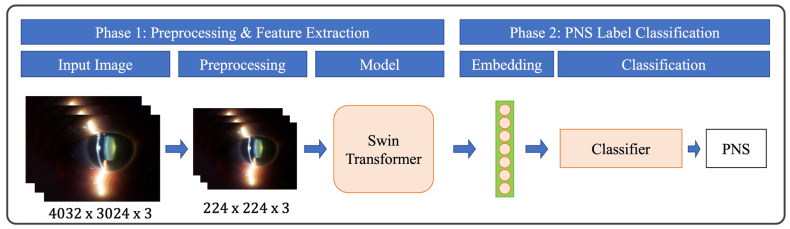 Figure 3
Figure 3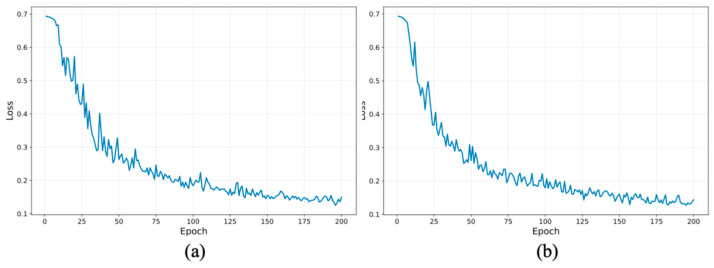 Figure 4
Figure 4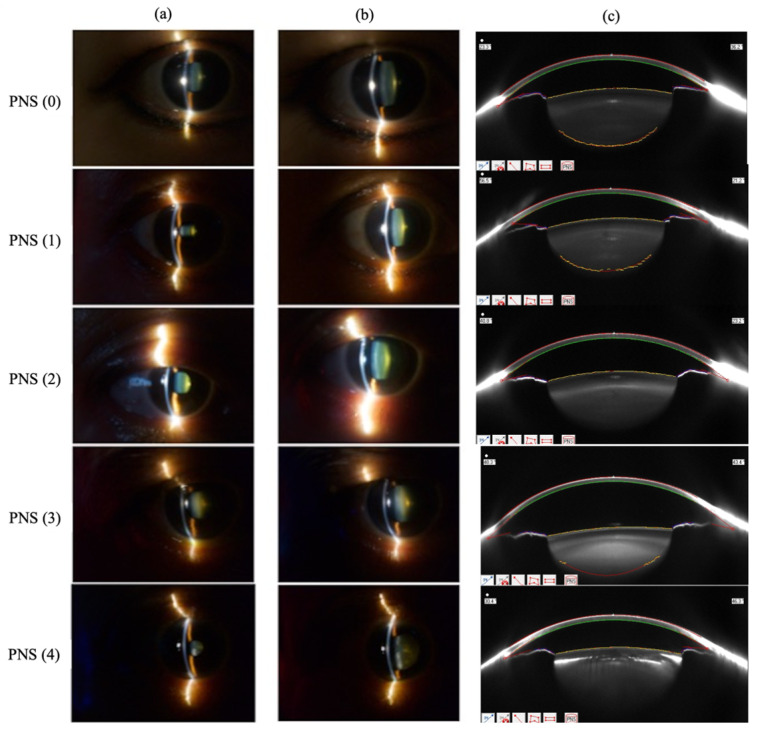 Figure 5
Figure 5 Figure 6
Figure 6- —NUHS Summit Programme in Innovation
- —National University Hospital, Singapore
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsOphthalmology and Visual Impairment Studies · Retinal Imaging and Analysis · Ocular Diseases and Behçet’s Syndrome
1. Introduction
A cataract is the result of age-related degeneration of the human crystalline lens. It is the leading cause of reversible blindness worldwide, affecting 35 million people [1]. The current gold standard of cataract assessment is through a slit lamp by an ophthalmologist. There have been several clinical grading scales created for the standardization of this grading, including the Lens Opacities Classification System II (LOCS II) [2], the Lens Opacities Classification System III (LOCS III) [3], the photographic Wisconsin Cataract Grading System [4], and the Oxford Clinical Grading System [5]. Of these, the LOCS III is by far the most popular clinical grading system used in population studies [6].
However, the manual grading of cataracts by trained ophthalmologists is costly and subjective. Multiple studies in the past have attempted to incorporate the use of machine learning to automate nuclear cataract grading [7,8,9,10], including the use of an AI-powered mobile app [11]. In 2015, Gao et al. described a method using a convolutional–recursive neural network to grade nuclear cataracts from standardized images [12]. This method was validated on a population-based dataset of 5378 slit lamp images, achieving a 99.0% decimal grading error of ≤ 1.0. Despite these impressive results, the dataset required dilation, the use of standardized lighting conditions, and photography using a specialized digital slit lamp camera [13]—conditions that are not always available outside of a tertiary setting. Specifically, the need for a bulky photographic device and standardized photographic conditions limit the practical ability of community-based eye screening, especially in rural areas. In addition, ocular dilation is time-consuming and carries a remote risk of precipitating acute angle closure attack, especially in eyes with pre-existing narrow angles. For community-based automated nuclear cataract grading to be scalable and accessible, it should be performed with portable devices under physiologic conditions. However, the ability to autonomously grade nuclear cataracts without dilation and under heterogeneous conditions is still wanting.
In this pilot study, we describe the results of using deep learning to grade nuclear cataracts using a portable smartphone-based portable slit lamp (Figure 1), with and without dilation. We aim to determine the feasibility of grading nuclear cataracts in undilated eyes, which may serve as the basis to facilitate large-scale population-based screening.
2. Materials and Methods
2.1. Patient Recruitment and Image Capture
This was a prospective, single-institution, cross-sectional study conducted between 28 April 2022 and 11 July 2023 (both dates inclusive). Consecutive eligible patients were recruited from the tertiary eye clinic of the National University Hospital, Singapore. The inclusion criteria were as follows:
- Willing and able to participate in study, with mental capacity to consent;
- At least 40 years old;
- Having not had prior intraocular surgery or laser procedures to the eye, including laser refractive surgery;
- Fit enough to keep the eyes open for adequate image acquisition;
- No evidence of active intraocular inflammation;
- Not having concurrent external or anterior segment pathologies (e.g., corneal opacities, significant blepharoptosis), which would obscure photo-taking of the eye.
The research followed the tenets of the Declaration of Helsinki and was approved by the institutional domain-specific review board. Informed consent was obtained from all subjects after an explanation of the purpose and possible consequences of the study. If both eyes were eligible, both were included in the study.
2.2. Image Capture Protocol
After informed consent, all patients underwent a comprehensive ophthalmic examination by a single ophthalmologist (D.C.). Slit lamp photos were then captured with a portable device (the ‘Device’, Figure 1, also described previously elsewhere [14]). The technique for image capture was modified from a previous publication [15]. Briefly, a second-generation iPhone SE (Apple, Cupertino, CA, USA) with the Device was used for anterior segment photos in a dimmed room to simulate mesopic conditions. The Device comprises a light-emitting diode (LED) module fitted behind an optical slit and achromatic condensing lenses to produce an incident light of 45°, with the beam measuring 1 mm wide by 15 mm tall. The Device is held ‘en face’ at a working distance of approximately 2 cm from the eye, with the slit beam originating temporally and was aimed at the pupil center to produce a cross-sectional image of the crystalline lens (Figure 2). Five images were captured of each eye. The same slit lamp photo capture sequence was repeated after pharmacological dilation with one drop of tropicamide 1% (1% Mydriacyl^®^, Alcon Inc., Fort Worth, TX, USA) into the inferior fornix.
To reflect real-world usage of smartphone applications, we captured the images using the default camera application (“Camera”) on the smartphone on automatic settings. We saved the images as digital negative (DNG) files, with 4032 × 3024 resolution, to preserve maximum image fidelity and minimize software post processing. The full uncompressed DNG images were used for automatic cataract analysis.
Scheimpflug imaging with Pentacam^®^ (Oculus, Inc., Arlington, WA, USA) was performed on the dilated eye. Pentacam grading was performed using Pentacam Nuclear Staging (PNS) software (Version 1.21r24). The PNS classification evaluates the optical density of a central, 4 mm three-dimensional reference block of the lens by analyzing the backward scatter when the eye is dilated, grading it from 0 to 5 [16]. PNS classification has been demonstrated to accurately estimate nuclear cataracts [17,18,19]; higher PNS scores are associated with the increased energy used during cataract surgery [20,21]. As a pilot study to explore the feasibility of using a portable device to identify cataracts that may be visually significant, we classified the attained PNS scores into two groups: Group 1 (PNS < 2), and Group 2 (PNS ≥ 2). The latter is correlated with significantly greater cataract density and energy used during phacoemulsification [20].
2.3. Deep Learning Technique
With our preliminary dataset, we have implemented a transformer-based network [22] for automated cataract analysis (Figure 3). The Swin transformer [23] represents a cutting-edge architecture, employing hierarchical self-attention mechanisms that efficiently capture both local and global features. We selected Swin transformer as the primary backbone because it is a widely validated state-of-the-art architecture for image classification and medical image analysis. By partitioning the input image into non-overlapping patches and progressively merging neighboring patches, the network performs multi-scale feature extraction, making it well-suited for the nuanced demands of medical image analysis, where both fine-grained details and broader structural patterns are critical [24,25]. Unlike traditional convolutional networks that depend on fixed-size kernels, the transformer-based approach adaptively models relationships between image patches. This flexibility allows the network to effectively capture varying degrees of cataract severity through both local and global image features, providing a promising tool for analyzing ocular images from portable smartphone-based slit lamp prototypes.
In this study, we trained the Swin transformer (Swin small variant pretrained on ImageNet-1K) to project images into a high-dimensional embedding space, leveraging the output from the global average pooling layer following the stacked self-attention blocks as the feature representation for each image. The model was optimized using cross-entropy loss, where prediction probabilities were computed via a SoftMax function applied to the class logits. Stochastic gradient descent was employed for optimization. An L2 regularization term (weight decay) was applied during optimization to improve generalization and prevent overfitting. The model was trained end-to-end without freezing backbone layers.
During inference, image labels were predicted by projecting the input into the embedding space and assigning the class label corresponding to the highest predicted probability. All models were implemented using the Apache SINGA platform [26], which integrates with the PyTorch 1.8 backend for model training and distributed optimization, while MLCask [27], an efficient pipeline management system, was employed to handle versioning and management of our deep learning pipelines.
2.4. Experiment Setup for Deep Learning Model
The input images were captured with a native resolution of 4032 × 3024. Before being fed into the model, all images were resized to 224 × 224 pixels using bicubic interpolation to maintain consistent input dimensions and manageable computational cost. Although the model operates on the resized inputs, acquiring images at a high resolution remains beneficial during data collection, as it helps preserve overall image quality, reduces the impact of sensor noise, and provides reliable source images for subsequent preprocessing, and annotation. The resized images were then normalized using the standard ImageNet mean and standard deviation to match the input distribution expected by the pretrained model. During training, we adopted a comprehensive data augmentation pipeline via the create_transform function from the TIMM package. Input images were resized to 224 × 224 pixels and subjected to color jittering with a factor of 0.4, the ‘rand-m9-mstd0.5-inc1’ AutoAugment policy to enhance sample diversity, and random erasing (pixel-level mode, probability 0.25, with a single erasing count) to improve generalization. Bicubic interpolation was consistently used for image rescaling. The model was trained for 200 epochs using the AdamW optimizer (weight decay = 0.05) with an initial learning rate of 9.735 × 10^−5^ (cosine learning rate scheduling was applied). Training was performed using distributed data parallelism across three NVIDIA RTX 2080 Ti GPUs, with a batch size of 32 per GPU and gradient accumulation over 2 steps, resulting in an effective global batch size of 192. Early convergence was observed before completion of 200 epochs. All experiments were conducted on a workstation equipped with 64 GB RAM and an Intel^®^ Xeon^®^ W-2133 CPU @ 3.60 GHz, with a total training time of approximately 30 min. Training loss curves (Figure 4) demonstrate that convergence was achieved before completion of 200 epochs, supporting the adequacy of this training schedule.
3. Results
3.1. Patient Characteristics
In total, 198 eyes of 99 subjects were included in this study. The mean age of included subjects was 65.3 ± 10.4 years (range, 41.0 to 88.0 years). Of the 198 eyes included in the study, the average PNS score was 1.57 ± 0.81 (range, 0 to 4). Figure 5 illustrates the clinical slit lamp photographs and corresponding PNS scores.
3.2. Deep Learning Model on Automated Cataract Analysis
After excluding 80 images (4.0%) deemed of poor quality, a total of 1900 images (950 dilated, 950 undilated) of 198 eyes were included. Table 1 shows the detailed data statistics (note the undilated images and dilated images share the same PNS statistics). We randomly split the dataset at the patient level into a ratio at around 9:1:2 for training, validation, and testing, respectively, following standard machine learning practice. The split ratio was applied to the overall dataset rather than enforced separately for each class. Because the numbers of Group 1 and Group 2 samples were not equal and patient-level partitioning was preserved to prevent data leakage, per class sample counts in each subset do not exactly follow the 9:1:2 proportion. We used the training set for learning the model and validation set to select the hyper-parameters of our deep learning method. Finally, we report the performance of our model on the test set.
Table 2 and Table 3 show the experiment results of our developed deep learning model on automated cataract analysis in undilated and dilated eyes, respectively. For evaluation, we used class average accuracy to measure the performance of the deep learning model. With the preliminary dataset, the deep learning model achieved an average accuracy of 81.25% for undilated images and 74.38% for dilated images. Although the overall accuracy was moderate, it is important to note that images were acquired using a portable smartphone-based slit lamp under heterogeneous real-world conditions, including undilated eyes. This setting is substantially more challenging than standardized, clinic-based imaging protocols. As a pilot feasibility study, these results demonstrate the practical potential of AI-assisted cataract grading in portable screening scenarios. The confusion matrices also reveal asymmetric error patterns. In both undilated and dilated eye experiments, false positives (i.e., Group 1 predicted as Group 2) occurred more frequently than false negatives. Consequently, the model demonstrates high sensitivity but relatively lower specificity. From a clinical screening perspective, this asymmetry may be acceptable because missing clinically significant cataracts (false negatives) may delay diagnosis and referral, whereas false positives mainly result in additional confirmatory examination.
In particular, performance was slightly lower in dilated eyes compared to undilated eyes. While this may initially seem counterintuitive given that clinical ground truth is established using dilated examinations, it likely stems from differences in how deep learning models process visual information compared to human clinicians. Clinicians rely on dilation to evaluate the entire crystalline lens, particularly peripheral cortical features. For the Swin transformer, however, the undilated pupil effectively acts as a natural anatomical crop. The constricted iris masks out peripheral regions, inadvertently guiding the model’s attention directly to the central lens, which contains consistent, high-yield diagnostic features of opacity. Conversely, pharmacological dilation exposes a significantly larger area of the anterior segment. This introduces complex peripheral light scattering, iris shadows, and a wider surface area for specular reflections. Because the model was trained on whole-image classification without explicit pixel-level segmentation to restrict its focus, this newly exposed peripheral area acts as visual noise. The model may become distracted by these peripheral optical artifacts in dilated images, leading to greater feature variability and slightly lower classification accuracy compared to the naturally constrained field of view in undilated eyes.
In addition, Table 4 presents the model performance on both undilated and dilated eye images, reporting predictive uncertainty (measured via entropy) alongside standard classification metrics for each class label. For undilated eyes, the model achieved a high overall accuracy of 81.25%. Specifically, for Group 2, it attained perfect recall (100%) and a precision of 72.73%, yielding an F1 score of 84.21%. For Group 1, the model demonstrated 100% precision, 62.50% recall, and an F1 score of 76.92%. In the case of dilated eyes, performance declined moderately, with an overall accuracy of 74.38%. Notably, the predictive entropy was 0.3163 for undilated and 0.3376 for dilated eyes, indicating generally low uncertainty in both cases, although slightly higher ambiguity in the dilated condition, which is consistent with its comparatively reduced predictive performance. However, entropy was not used for threshold-based rejection or selective prediction in this pilot study, and, therefore, should be interpreted as a descriptive confidence measure rather than a validated reliability guarantee. Future work will investigate uncertainty calibration and selective prediction strategies to enhance clinical robustness.
Beyond overall accuracy, Table 5 presents the sensitivity, specificity, receiver operating characteristic–area under the curve (ROC–AUC), and calibration metrics (Brier score and expected calibration error with 10 bins). The ROC–AUC was 84.30% (undilated) and 76.55% (dilated), indicating good discriminative ability. Calibration performance was assessed using the Brier score (16.39 and 20.15) and expected calibration error (ECE-BIN10: 15.81 and 17.78), demonstrating reasonable probability calibration in this pilot setting.
3.3. Comparison with Other Baseline Architectures
To strengthen the validity of our findings, in Table 6, we compared the Swin transformer backbone with three widely used image classification architectures: ResNet50 [28], EfficientNet [29], and Vision Transformer (ViT-B/16) [30]. All baseline models were trained and evaluated under the same data split, preprocessing pipeline, and optimization settings to ensure fair comparison.
For undilated eyes, ViT-B/16 achieved the highest overall accuracy (80.26%), followed by EfficientNet (79.65%) and ResNet50 (78.60%). Notably, ViT demonstrated a more balanced performance between the two classes, achieving a Group 2 F1 score of 58.82%, compared to 34.09% for EfficientNet and 32.97% for ResNet50. Both EfficientNet and ResNet50 showed high recall for Group 1 (>92%), but substantially lower recall for Group 2 (25%), indicating a bias toward the majority class.
For dilated eyes, ViT-B/16 again achieved the highest overall accuracy (82.11%), followed by ResNet50 (72.42%) and EfficientNet (69.82%). ResNet50 showed relatively strong performance for Group 2 in dilated eyes (F1 = 65.26%), while EfficientNet demonstrated lower precision for Group 2 (34.88%). ViT achieved high Group 1 recall (97.33%) but comparatively lower recall for Group 2 (25%), suggesting potential class imbalance sensitivity.
Overall, transformer-based architectures (ViT and Swin transformer) demonstrated competitive or superior performance compared with conventional convolutional networks (EfficientNet and ResNet50), particularly in maintaining better balance across class-specific metrics. These results support the suitability of transformer-based backbones for cataract severity classification in portable slit lamp imaging scenarios.
3.4. Heat Maps
Based on the transformer prototypical network, heat maps were generated to visualize regions contributing to cataract severity prediction. The integrated gradients method [31] was adopted for visualization, which is an attribution method for deep networks. As shown in Figure 6, in correctly predicted cases, the attribution maps generally highlight the central crystalline lens region corresponding to cataract opacity. In contrast, misclassified examples tend to exhibit more diffuse or misplaced attention patterns, often associated with specular reflections or peripheral illumination artifacts.
Because pixel-level annotations of cataract regions were not available in this pilot dataset, automated spatial localization metrics could not be computed. To account for this quantitatively, we conducted a manual review of the attribution maps for the test set. Among correctly predicted cases, all the attribution maps accurately localized the primary attention on the central crystalline lens. Conversely, in misclassified examples, the model’s attention was frequently misplaced: a total of 57.75% of these errors were driven by heavy focus on specular corneal reflections, 35.21% were misdirected by peripheral illumination artifacts, and 7.04% exhibited a highly diffuse attention pattern lacking any distinct focal region. Therefore, while the attribution maps are presented primarily as qualitative visualizations, this semi-quantitative breakdown illustrates that the model generally learns the correct anatomical features for accurate prediction, whereas misclassifications are strongly linked to identifiable imaging artifacts.
4. Discussion
In this pilot study, we describe a novel method to grade nuclear cataracts using slit lamp images taken from a smartphone-based portable slit lamp device in undilated eyes. Our preliminary results suggest that AI was able to grade cataracts in both dilated and undilated eyes, although the accuracy of AI on the undilated eyes was higher. The heat maps generated based on attribution masks provide preliminary evidence that the integrated gradient could correctly identify the anatomical areas of concern.
The benefit of having an automated digital grading for cataracts is clear. Cataracts are a universal age-related opacification of the crystalline lens that affect everyone from around 60 years old. A digital cataract grading system was shown to be more cost-effective than human grading as early as 1999 [32]. However, it is not fully implemented; some challenges include the routine need for dilation and the strict requirements for image standardization. While severe cataracts could be diagnosed with low-cost screening methods with a penlight and crude visual acuity assessment, a cost-effective solution to identify moderate yet visually significant cataracts is still lacking.
Over the past decade, there has been increasing interest in using deep learning to grade nuclear cataracts automatically (Table 7). These studies utilized standardized slit lamp images from existing databases, such as the Singapore Malay Eye Study [13], the Age-Related Eye Disease Study (AREDS) [33], or retrospective datasets of clinical slit lamp images compared against different clinical standards. However, while these studies report impressive performances, they were all trained on existing databases of dilated slit lamp photographs taken under strict lighting conditions, which significantly limit their applicability for use as a community-based screening tool where dedicated slit lamp cameras and exacting lighting requirements are not possible. This set-up—in particular, ocular dilation—is not routinely performed outside of eye clinics. Conversely, alternative approaches for community-based smartphone cataract screening using AI do not yet incorporate slit lamp imaging [34,35,36], even though slit lamp-based photographs are widely regarded as the superior method for assessing nuclear cataracts [37].
To bridge this gap, our work is the first to report automated cataract grading using a portable smartphone slit lamp set-up. In addition, our study was performed on undilated eyes under real-world, pragmatic, imaging conditions. While the deep learning backbone itself is not novel, the innovation of this study lies in translating state-of-the-art AI methods into a portable, smartphone-based slit lamp platform and evaluating its feasibility in a non-standardized, undilated clinical setting. If fully deployed, this approach could help to overcome key practical barriers to community-based cataract screening and expand access to early detection. Another strength of our study is that a standardized protocol was used for image capture; the ground truth used in this study (PNS) was shown to be an objective and reproducible way to grade cataracts [18]. Standardized grading scales, such as the LOCS III, on the other hand, have been reported to have suboptimal reproducibility [33,43,44]. A strength of our AI approach lies in its enhanced representation capability, derived from the attention mechanism to effectively model complex patterns specific to the medical domain [24,25]. Recent studies [45,46] have further demonstrated the effectiveness of transformer-based architectures and deep learning models in ophthalmic imaging and medical image classification tasks under real-world conditions, supporting the methodological choice and performance level observed in our work.
This preliminary study is limited by the small sample size of the images tested; it is likely that the initial developed model has issues with overfitting. In addition, as this study adopts established backbone architectures without introducing new architectural modules, systematic ablation experiments were not performed in the current work. Such analyses will be incorporated in future studies to better quantify the contribution of different model components and training strategies. Likewise, due to the small sample size, the heat maps of typical images were overlaid on other images, leading to issues with attribution mask allocation (Figure 6, bottom row). Larger, multi-center studies with broader demographic representation will be necessary to confirm the robustness and external validity of these findings. Another limitation of our study is the relatively mild cataracts in the captured dataset—all the cataracts identified were less than PNS 5, with the majority being graded as 0 to 1 (88 of 198 eyes, 44.4%). The accuracy of our deep learning model is also lower compared to alternative algorithms published previously [40,47]. However, ours is an initial proof-of-concept study to establish the feasibility of evaluating cataract density in undilated eyes captured on mobile devices. Our initial results are encouraging.
In conclusion, we have demonstrated preliminary results indicating that deep learning could be used to grade cataracts with slit lamp images taken from undilated eyes. Further work is underway to validate this technique in a larger and more diverse group of eyes with cataracts.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Lee C.M. Afshari N.A. The Global State of Cataract Blindness Curr. Opin. Ophthalmol.2017289810310.1097/ICU.000000000000034027820750 · doi ↗ · pubmed ↗
- 2Chylack L.T. Leske M.C. Mc Carthy D. Khu P. Kashiwagi T. Sperduto R. Lens Opacities Classification System II (LOCS II)Arch. Ophthalmol.198910799199710.1001/archopht.1989.010700200530282751471 · doi ↗ · pubmed ↗
- 3Chylack L.T. Wolfe J.K. Singer D.M. Leske M.C. Bullimore M.A. Bailey I.L. Friend J. Mc Carthy D. Wu S.Y. The Lens Opacities Classification System III. The Longitudinal Study of Cataract Study Group Arch. Ophthalmol.199311183183610.1001/archopht.1993.010900601190358512486 · doi ↗ · pubmed ↗
- 4Klein B.E.K. Klein R. Linton K.L.P. Magli Y.L. Neider M.W. Assessment of Cataracts from Photographs in the Beaver Dam Eye Study Ophthalmology 1990971428143310.1016/S 0161-6420(90)32391-62255515 · doi ↗ · pubmed ↗
- 5Sparrow J.M. Bron A.J. Brown N.A. Ayliffe W. Hill A.R. The Oxford Clinical Cataract Classification and Grading System Int. Ophthalmol.1986920722510.1007/BF 001375343793374 · doi ↗ · pubmed ↗
- 6Wong W.L. Li X. Li J. Cheng C.-Y. Lamoureux E.L. Wang J.J. Cheung C.Y. Wong T.Y. Cataract Conversion Assessment Using Lens Opacity Classification System III and Wisconsin Cataract Grading System Investig. Ophthalmol. Vis. Sci.20135428028710.1167/iovs.12-1065723233255 · doi ↗ · pubmed ↗
- 7Xu Y. Gao X. Lin S. Wong D.W.K. Liu J. Xu D. Cheng C.-Y. Cheung C.Y. Wong T.Y. Automatic Grading of Nuclear Cataracts from Slit-Lamp Lens Images Using Group Sparsity Regression Med. Image Comput. Comput. Assist. Interv.20131646847510.1007/978-3-642-40763-5_5824579174 · doi ↗ · pubmed ↗
- 8Huang W. Chan K.L. Li H. Lim J.H. Liu J. Wong T.Y. A Computer Assisted Method for Nuclear Cataract Grading from Slit-Lamp Images Using Ranking IEEE Trans. Med. Imaging 2011309410710.1109/TMI.2010.206219720679026 · doi ↗ · pubmed ↗