SemOD: Semantic-Enabled Object Detection Network Under Various Weather Conditions
Aiyinsi Zuo, Zhaoliang Zheng

TL;DR
This paper introduces a new object detection network that uses semantic information to improve performance in various weather conditions for autonomous driving.
Contribution
The novel contribution is a semantic-enabled network that enhances object detection by integrating semantic guidance into image restoration and detection.
Findings
The proposed method achieves mAP improvements of 1.49% to 8.78% over existing approaches.
Semantic information improves visual coherence and object boundary delineation in degraded images.
The network includes a preprocessing unit and detection unit for robust performance in diverse weather.
Abstract
In the field of autonomous driving, camera-based perception models are mostly trained on clear weather data. Models designed to handle specific weather conditions often lack generalization to dynamically changing environments and primarily focus on weather removal rather than robust perception. This paper proposes a semantic-enabled network for object detection under diverse weather conditions. Semantic information enables the model to generate plausible content in missing regions and accurately delineate object boundaries. It also preserves visual coherence and realism across both restored and original image areas, thereby facilitating image transformation and object recognition. Specifically, our architecture consists of a Preprocessing Unit (PPU) and a Detection Unit (DTU), where the PPU utilizes a U-shaped network enriched with semantics to refine degraded images, and the DTU…
Click any figure to enlarge with its caption.
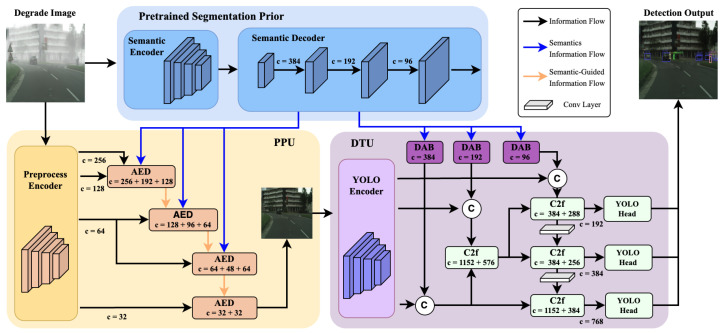 Figure 1
Figure 1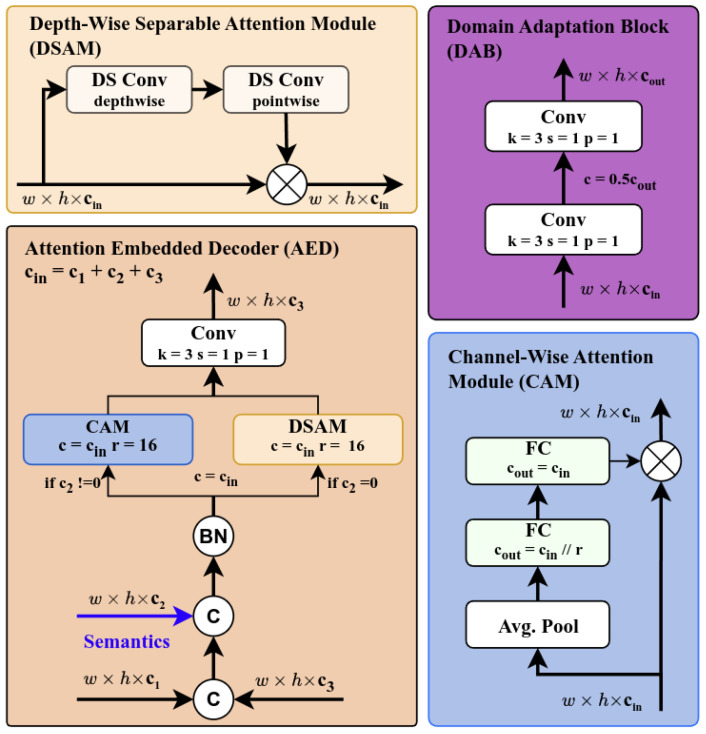 Figure 2
Figure 2 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsImage Enhancement Techniques · Advanced Neural Network Applications · Generative Adversarial Networks and Image Synthesis
1. Introduction
In the burgeoning field of autonomous vehicles, camera-based perception is of paramount significance, not only for their ability to provide high-resolution spatial details, but also for the critical color information they capture [1]. Despite significant strides in autonomous vision and tools [2,3,4], there is a prevalent trend of models being trained and tested on datasets heavily skewed towards clear weather images [5,6,7]. This bias, unfortunately, leaves them vulnerable to performance degradation under unfavorable weather conditions, such as fog, rain, or snow [8]. As the field continues to innovate, generating comprehensive models that cover a broad spectrum of computer vision tasks [9], it is imperative that the gap in performance under these severe conditions is systematically addressed, ensuring the safety and reliability of autonomous vehicles irrespective of environmental conditions, thereby paving the way for truly universal applicability.
Traditional research in the field has primarily focused on models that excel in mitigating single-domain adverse conditions such as fog, rain, or snow [10,11,12,13]. While these models have been instrumental in deepening our understanding of specific weather-related challenges, their narrow focus has hindered their applicability to the broader spectrum of weather conditions that are commonly encountered in real-world driving scenarios. To address this limitation, more recent studies have pivoted towards developing models capable of handling multiple weather conditions [14,15,16]. However, these models often prioritize weather removal performance, measured by metrics such as Peak Signal-to-Noise Ratio (PSNR), over the critical goal of object detection in autonomous vehicles. Concurrently, there has been a surge in holistic approaches aimed at improving object detection in inclement weather [17,18,19]. These methods generally involve augmenting the model with additional degraded images or tweaking the detection unit to better capture objects in harsh weather conditions. Despite these advancements, these solutions frequently suffer from limitations such as a confined focus on similar weather domains (e.g., foggy and light rain conditions) or subpar performance across diverse weather conditions.
In order to tackle the dual challenges of domain adaptation and performance excellence, we proposed a Semantic-enabled Object Detection network (SemOD) for diverse weather conditions. In this network, prior knowledge of semantic segmentation provides pixel-level explanations for understanding complex environments, transforming the network from a black-box model under different weather conditions into an enhanced model structure based on semantic feature maps. Specifically, the architecture employs a two-tiered network consisting of a Pre-processing Unit (PPU) and an Object Detection Unit (DTU). The PPU adopts a semantic-enhanced U-shaped net [20]: its encoder decodes feature variances in a degraded image, and it applies appropriate transformations at different scales of the feature maps to remove ambiguity or smudges based on the areas’ corresponding semantic information refined by an Attention-Embedded Decoder (AED). Following this, the enhanced image, along with the acquired semantic information, is connected to the downstream DTU. DTU incorporates a modified version of the YOLO network, adept at integrating semantic features in parallel with the original backbone output within its “Neck” block, during which a dedicated Domain Adaptation Block (DAB) facilitates the seamless transition from the domain of semantic segmentation to object detection. This innovative orchestration of semantic information acts as an advanced attention mechanism, steering both the PPU and DTU toward enhanced performance. Notably, it delivers a superior performance increase of up to 8.78% in mAP value under snowy weather conditions compared with the next-best contemporary methodologies.
To our knowledge, our work is the inaugural application of semantic information in all-weather image transformation and object detection. The contributions of this paper are as follows:
- (1)This paper proposes a novel semantic enhancement framework designed for object detection under various weather conditions, utilizing semantic information to improve image quality and guide the detection process.
- (2)This paper introduces a dual-use strategy with adaptation modules, including the AED in the PPU and the DAB in the DTU, to maximize the benefits of semantic module prior knowledge and significantly enhance model performance in diverse weather conditions.
- (3)This paper comprehensively evaluates the proposed model on multiple datasets and conducts a detailed study on out-of-domain datasets to demonstrate the model’s adaptability to domain gaps and performance improvements.
- (4)This paper customized a more comprehensive dataset for verification under different weather conditions, and, to benefit the community, all the datasets and code are open-sourced.
2. Related Work
2.1. Degraded Image Transformation
Significant strides have been made in the academic field in removing weather distortion from images, initially focusing on individual weather phenomena such as fog, rain, and snow. Innovations include the application of Convolutional Neural Networks (CNNs) leveraging atmospheric luminosity and transmission maps for dehazing [10] and advancements in color aberration control through multiple input generation [21]. Moreover, the integration of pyramid CNNs and vision transformers [22,23] has enriched the methodology for rain and snow removal, utilizing techniques from temporal data analysis, attention mechanisms, and advanced CNN architectures [13,24,25,26,27]. Recent studies adopt a holistic strategy for weather distortion removal. For example, URIE replaces conventional convolutional layers in U-Net architectures with more complex modules [28], while TransWeather employs a single encoder–decoder framework with specialized units for handling minor distortions [16]. Li et al. further extend this line of research by introducing multiple task-specific encoders and physics-inspired tensor operations, combined with adversarial learning [15]. Although these methods generally perform holistic weather removal, our approach enhances the process by incorporating semantic information, thereby preserving more of the original content after removing various weather effects.
2.2. Object Detection with Degraded Images
In response to the critical need to integrate image transformation into downstream tasks to enhance efficacy, several innovative methodologies have emerged. One pioneering approach employs an end-to-end, deep learning-oriented framework, capable of addressing myriad weather conditions concurrently. These methodologies augment image clarity for the perception network, thereby potentiating enhanced perceptual outcomes [19,29]. Another end-to-end framework addresses domain adaptation in detection and solves this problem under Foggy and Rainy Weather [30]. An alternative technique progressively adapts images originally captured under benign weather conditions to adverse climatic scenarios. This effective interpolation bridges the chasm between two disparate domains, thereby bolstering the resilience of object detection models [17]. Additionally, an inventive image-adaptive framework enables individual image enhancement to improve detection performance, demonstrating its efficacy under both fog-laden and dimly lit conditions [31]. Despite these advancements, several challenges persist: these techniques either treat image transformation and object recognition as a singular, cohesive task and train accordingly, or they solely modify the object detectors. Consequently, despite their innovative undertones, such methods often result in a constrained focus on analogous weather domains (e.g., foggy and light rain conditions) or manifest suboptimal performance when encountering diverse domains.
2.3. Semantic-Based Models
Semantic segmentation, a pivotal subject in computer vision, is critical for advanced scene understanding. The advent of deep learning ushered in an era of accurate pixel-level segmentation, pioneered by Fully Convolutional Networks (FCNs) [32] and U-Net [20]. Building on these foundations, recent advancements in large language models and transformers have further expanded the scope of vision research, leading to the development of universal segmentation networks [7,33,34,35]. Following these successes, the integration of semantic prior information has been actively explored to enhance related tasks, such as image transformation and object detection. In particular, effective inpainting methods, supported by coherence priors among semantics, textures, or classes, have refined image reconstruction and contextual consistency [36,37]. Through multi-scale and joint optimization strategies, a tighter synergy between image restoration and semantic segmentation has been established, enabling semantically informed refinements. In the parallel domain of video super-resolution, semantic prior-based models—most notably the generative adversarial network (GAN) framework proposed by [38]—demonstrated significant improvements by leveraging diverse texture styles across semantic classes, thereby reducing noise and recovering realistic textures through spatial feature transformation. Motivated by these insights, this paper incorporates semantic information into both the degraded pre-processing stage and the object detection stage. Such integration allows for improved restoration of meaningful content in degraded images, ultimately enhancing detection accuracy and denoising effectiveness.
3. Methodology
3.1. Network Architecture
To derive sturdy objects’ bounding boxes, denoted as , from a visually impaired image I, we adopted an integrated methodology, uniting the knowledge from the spheres of image transformation and object detection. Represented in Figure 1, initially, the impaired image was transformed into a weather-neutral image through the Pre-Process Unit (PPU), inherently enhancing visibility by eradicating visually distracting weather artifacts. Subsequently, object detection techniques were employed through the Detection Unit (DTU) to extract from the resultant images.
3.2. Pre-Process Unit (PPU)
3.2.1. Architecture of the PPU
In the Pre-Process Unit, we aim to transform from I to under diverse weather conditions of fog, rain, and snow. To make the transformed images closely mimic a clear-weather counterpart of I, we undertook meticulous examination of images under these weather conditions. We recognized that weather effects could be dichotomized into two principal categories: visual impediments created by weather elements of varying sizes (rain, fog, snow particles) situated at diverse distances from the viewing stand, and the ubiquitous obscurity and ambiguity as a result of light’s inability to penetrate the particle walls. This could be encapsulated with a refined version of equations proposed in [39]:
where x signifies the pixel index of the image, and denote the visually impaired input and the clear output, respectively, models the scattering effect induced by diverse particles (e.g., water droplets, dust) within the medium (e.g., fog, haze). Here, corresponds to the scattering effect due to the i-th particle at location x, and , the medium transmission map, serves as a weighting factor determining the impact of scattering on the observed intensity. A characterizes the lighting conditions of this environment, and together with the latter coefficient that quantifies the portion of light that is not directly transmitted but reaches the camera after atmospheric scattering, the term encapsulates the ambiguity enveloping the entire image induced by the weather.
After the analysis of the constitution of degraded images , the objective becomes generating, through pre-processing, enhanced images that approximate the clean images B as closely as possible. Many studies resorted to a U-shaped architectural framework to accomplish this, and upon scrutinizing this structure, it was evident that U-Net [20] performed outstandingly in removing the global atmospheric scattering effect in the weather degradation model, attributable to its symmetric contracting and expanding form. Consequently, it effectively ascertained the mapping U such that
Here, U-Net utilizes both global (via the contracting path) and local (via the expanding path) features to minimize the ambiguity , delivering a less noisy image . This led us to construct our Preprocess Encoder, which generates encoded feature maps at various stages, denoted as , for skip connection, thus enriching the decoded feature maps for the image-wise obscureness removal using decoders.
Nonetheless, the elimination of from the degraded image posed a significant challenge; it was not merely a reconstruction task but rather an inpainting task for regions originally occluded by weather particles, where the U-Net’s performance fell short. This suboptimal performance arose from the characteristics of convolutions in the U-Net, which primarily aggregated local and global information during reconstruction. However, these convolutions might lack sufficient context when significant portions of the image were heavily degraded (e.g., during a rainstorm) or if they concentrated on irrelevant sections of an image (e.g., focusing on road surfaces while attempting to remove snow on a car edge), preventing the model from generating novel, contextually appropriate content.
To address this issue, we incorporated semantic priors, which provided high-level contextual information, enabling the model to generate plausible content for missing areas. The model then had an understanding of object boundaries and potential interactions with other items, with which a transformation could thus be applied to remove the scattering effects and mathematically expressed as follows:
Here, f represents a stack of our Attention-Embedded Decoders, with semantic information supplied by a pre-trained HRNet [40] that offers a semantic feature map as input. HRNet is selected for its exceptional performance across various benchmark datasets. The model’s understanding of the overall scene (via semantics) helped it preserve visual coherence and realism across both the filled-in and existing portions of the image.
3.2.2. Attention-Embedded Decoder
Our design incorporated a decoder that accepted two feature maps and semantic data , and, in return, dispensed a decoded feature map as input for the subsequent decoder. Specifically, after rudimentary upsampling and concatenation of the feature maps with a normalized input, attention modules are instigated contingent on the presence of semantic information. Should semantic data be available, the feature maps traverse a channel-wise attention module (CAM) that incorporates the principles of squeeze-and-excitation [41]:
This equation, as figuratively represented in Figure 2, includes squeeze and excitation layers and to recalibrate the original feature maps adaptively. The squeeze linear function , along with the average pooling layer, aggregates the input feature map across spatial dimensions (height and width) to produce a channel descriptor. This operation generates a global understanding of the input feature map for each channel. The excitation function then takes the squeezed feature vector (output of ); processes it through a self-gating mechanism that involves two fully-connected layers (a dimensionality-reduction layer followed by a dimensionality-increasing layer), a non-linear activation function in between, and a sigmoid activation at the end; and applies the output to the original feature map. Upon attention completion, a final convolution is invoked to reconstruct from the semantic prior-weighted feature map.
In the singular scenario where semantic information was absent and when the last decoding takes place to transform to , we deployed a strategy predicated on the depth-wise separable attention module (DSAM) [42], shown in Figure 2, to capture spatial and inter-channel data for the final image output as follows:
where is the product of two depth-wise separable convolutions with the original input x and ∘ denotes element-wise multiplication. Hitherto, we have developed a decoder sequence that employs a semantic prior to guide the reconstruction process, particularly in the preliminary stages when data is scarce yet the cascading effect is profound.
Ultimately, the efficacy of this module lies in its capacity to prioritize areas necessitating meticulous restoration and abundant guidance from the semantic maps, whilst reducing focus on regions where degradation is either uniform or negligible. This mechanism empowers the model to generate precise reconstructions, thereby considerably enhancing overall image quality.
3.3. Detection Unit
3.3.1. Detection Unit Architecture
Subsequently, after the image transformation, we extract the objects’ bounding boxes from the enhanced image through non-maximum suppression P output of a typical YOLO [6] detector, delineated as follows:
In this equation, P represents the prediction tensor outputted by the detector, K illustrates the maximum number of possible bounding boxes, and refers to the confidence scores for the ith bounding box belonging to each of the c classes that the model is trained to predict.
Our methodology leveraged a semantic-augmented YOLO framework to achieve this P, based on the YOLOv11 [43] architecture shown in Figure 1. The detection component incorporates both the refined images and the contextually-adapted semantic data to yield a prediction tensor, . Despite the robust pre-processing unit, the polished images may still contain residual noise or distortions relative to the pristine images, denoted as . By furnishing the prediction function, Y, with , the model attains heightened resilience to noise N. Illustratively, discerning a roadway in bolsters Y’s confidence in detecting a car or stipulating a more precise bounding box when borders appear ambiguous by leveraging the spatial contours informed by , even if the image contains minor aberrations.
For realization, we incorporated the same HRNet [40] for semantic segmentation, a backbone network for feature disentanglement, a domain adapter for harmonizing semantic and detection features, and a composite neck-head network for feature orchestration and prediction articulation. During the forward pass, multi-scale features are initially extracted by the backbone, followed by semantic segmentation of the input. The results of backbone and semantic segmentation outputs are aggregated along the channel dimension to pass through the C2f layers presented in the original YOLOv11 network [44], thereby weaving semantic and detection features into a unified canvas for efficient detection.
3.3.2. Domain Adaptation Block
The Domain Adaptation Block (DAB) bridges the gap from the segmentation prior trained for semantic segmentation to cross-weather domain object detection. Here, the DAB conducts transformations of the semantic features to align them with the detection attributes and thus adapts the domains of semantic segmentation and object detection—it is an interim step that we leverage to ensure that the domain of semantic segmentation effectively informs and enhances the domain of object detection, regardless of the weather, for the eventual goal of robust detection.
Shown in Figure 2, upon initialization, the module creates a dual convolution that consists of a convolution2d, batch normalization, and SiLu activation. These layers were designed to acclimate the input features derived from the semantic segmentation model , which are intrinsically dense and pixel-specific, to the object-oriented, sparse realm of object detection , thereby bolstering the prediction function Y.
This domain transformation process helps in consolidating the local and global context of the image, which leads to a robust and verifiably improved efficacy of the detection subsystem and, consequently, the holistic model.
3.4. Training
Our model’s training follows a sequential multi-task optimization approach, where the PPU learns to transform the degraded images first, followed by the DTU acquiring the ability to detect from the enhanced images. In PPU, we transformed the degraded images to ( ) where the degraded images encompass all domains of adverse weather; we then employed the Charbonnier loss [45] as the training loss to minimize the influence of extreme outliers, as encapsulated by the equations below:
where symbolizes the pixel intensity of the input image, signifies the pixel intensity of the optimized image, represents a minimal constant, and N equates to the total pixel count in the image. The summation extends across all pixels within the image.
Subsequent to the formulation of a stable , we train the detection unit employing the YOLO loss function [46]:
where, . For the detection unit, we also enlarged the image to ( ) to keep the objects’ ratio uniform with the original images.
4. Experiments
In the following sections, we will introduce the dataset used to test our experiments, the experimental settings, the evaluation metrics, the comparison methods, the quantitative results, and the qualitative results.
4.1. Dataset
4.1.1. Cityscapes Dataset
In our quest for robust object detection under challenging weather conditions, we turned to the Cityscapes [47] dataset, which is rich in its diversity across various climatic scenarios. From this collection, we sourced:
- 3475 pristine (sunny) images [47];
- 10,425 foggy captures, with visibilities of 150, 300, and 600 m, courtesy of [48]. Foggy Cityscapes is established by simulating the fog of different intensity levels on the Cityscapes images, which generates the simulated three levels of fog based on the depth map and a physical model;
- 1062 rainy images, which involve 36 variations of rain intensity on 295 selected images, as provided by [49].
Such datasets are widely adopted benchmarks in the community, providing standardized and reproducible evaluation protocols for fair comparison across different methods.
4.1.2. Customized Dataset
To achieve more comprehensive coverage of weather conditions, we performed data augmentation and data generation on existing datasets to enrich and create more diverse datasets under various weather conditions. Following Transweather [16], we incorporated the following:
- The RainDrop dataset, which consists of 1069 images [13];
- A subset of Snow100K [26], from which we selected 13,283 images to represent snowy conditions.
4.1.3. Dataset Classes
For the purpose of bounding box extraction across all these datasets, our primary focus was on core traffic participants. Our detection classes consisted of car, pedestrian, truck, bus, rider, bicycle, and motorcycle. To facilitate the extraction process, we employed [50], which efficiently generated 2D bounding boxes for the Cityscapes dataset. Meanwhile, for the Snow100K dataset, annotations were done manually. Additionally, we integrated clear weather images from Cityscapes into the enhanced datasets to act as a benchmark for detection under other weather conditions. Access links for the unified dataset and annotations are available at: https://github.com/EnisZuo/SemOD (accessed on 11 February 2026).
4.2. Experiment Settings
We merged data under the same weather conditions from the datasets mentioned above, and the training dataset was shuffled at random while preserving the individual test sets from each dataset. To assess model performance more fairly across distinct weather scenarios, we split the training and validation sets at a 4:1 ratio.
We resized each sample in the dataset to a size of as the input to the Pre-Process Unit (PPU). The transformed images from PPU are then resized to for the detection unit (DTU) to output detection bounding boxes, ensuring that object dimensions remain consistent with the original images. The same resizing and similar image flow are applied to other benchmark models in order to conduct a fair comparison.
Every model, including the SOTA methods used for comparison, was trained and assessed on a single Nvidia RTX 3090 GPU with a learning rate of 0.0005. The training was conducted with a train batch size of 12 and a test batch size of 16, using SGD as the optimizer and a weight decay of 0.0001. Training of all models in both processing steps commences with an initial duration of 50 epochs. Adhering to the manners used by Transweather [16] and Yolo-v11 [43], we report metric values on validation sets, where higher values signify superior performance.
To ensure training stability and fairness, all models were trained under identical experimental settings, including data splits, input resolutions, data augmentation strategies, optimizer configurations, learning rate schedules, and training epochs. YOLO-based detectors may exhibit performance fluctuations due to stochastic factors such as random initialization, data shuffling, and on-the-fly data augmentation. To mitigate such effects, the data splits were fixed across all experiments, and a unified training protocol was adopted for both the Yolov11 baseline and our proposed method. Under these controlled conditions, we observed that the performance variance of the YOLOv11 baseline is relatively limited, whereas the improvements achieved by our method consistently exceed typical baseline fluctuations across all weather conditions, particularly under adverse weather conditions. This indicates that the reported gains are attributable to the proposed semantic-enhanced architecture rather than incidental baseline variance.
4.3. Evaluation Metrics and Comparison Methods
We evaluate detection quality with COCO-style mean Average Precision [51], reporting (AP at IoU = 0.50), (AP at IoU = 0.75), and , the mean AP averaged over IoU thresholds . Our comparisons use YOLOv11 as detection baselines, and it cover weather-removal–plus–detector pipelines (DENet [29], UEMYolo [19], Urie + Yolo [28], and TransWeather + Yolo [16]), and domain-adaptive detectors (DA-Faster [52], UaDAN [53], and DA-detect [30]); for fairness, all methods use the same resizing scheme and validation splits.
4.4. Quantitative Results
4.4.1. Pre-Process Unit Analysis
In gauging the efficacy of the Pre-Process Unit, we meticulously adhered to the benchmarks set by [16], deploying two prominent metrics: PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index Measure). PSNR quantifies the fidelity discrepancy between an original image and its modified counterpart, with superior fidelity indicated by a heightened PSNR. Conversely, SSIM assesses variances in structural nuances, luminosity, and texture, delivering a holistic, perceptually salient evaluation. Its values span from −1 to 1, with a perfect score of 1 denoting identical imagery.
Table 1 shows that our module surpasses state-of-the-art models, achieving at least 6.02% PSNR and 1.32% SSIM gains. This underscores the mastery of our semantic-enabled reconstruction. Additionally, beyond mere metric improvement, our Pre-Process Unit adeptly emphasizes regions identified as pivotal by semantic information, as further evidenced by subsequent object detection metrics and qualitative analyses.
4.4.2. Ablation Study
To study the contribution of each module in achieving such an object detection performance, we started from the plain Yolo-v11 network and added components one by one and thus identified four structures: (1) Yolo-v11 detection module (2) PPU + Yolo-v11, where PPU denote Pre-Process Unit (3) PPU + Yolo-v11 + Semantic module (Ours w/o domain adaption module) (4) SemOD (PPU + Yolo-v11 + Semantic module + DAB). All experiments are conducted with the same training parameters on four cross-domain datasets. The ablation study in Table 2 clearly justifies the positive effect of each proposed module across all datasets.
Our Pre-Process Unit (PPU), mirroring other image transformation components, led to a pronounced improvement in object detection performance. Subsequent incorporation of semantic information markedly improved detection robustness, especially in Snowy conditions where a domain gap exists. A simple domain-adaptation block further enhanced this performance, solidifying unmatched performance across datasets. Such outcomes attest that our module deployment is not merely theoretically cogent but also pragmatically pivotal in advancing the paradigm of semantic-enabled object detection.
4.4.3. Entire Model
The performance comparison of different models under various weather scenarios can be found in Table 3. In order to comprehensively assess the performance of SemOD, we compared it with two integrated solutions specifically designed for object detection under adverse weather conditions based on the YOLO framework [19,29]. Additionally, to evaluate our model’s performance in weather removal, we compared it against the current two best-performing image transformation methods [15,16], and integrated them with YOLOv11 for comparison across four different weather conditions.
As shown in Table 3, our method demonstrates significant improvements in mAP compared to the suboptimal methods across all adverse weather conditions, with increases of 5.10% for foggy, 2.68% for rainy, and 8.78% for snowy scenarios, respectively. It is noteworthy that the improvements are even more pronounced on the customized snowy-weather dataset, which is not based on Cityscapes, due to the larger and more distinct domain differences between this dataset and the Cityscapes-based dataset. Supported by our semantic module, our model not only exhibits the best enhancement performance but also reflects the greater ability of this approach to substantially reduce domain divergence effects. Furthermore, it is noteworthy that even in clear weather conditions without adverse weather interference, our model outperforms the YOLOv11 detection model (with a 1.49% improvement). This result indicates that with the enhanced support of the semantic module, the accuracy of detection has also been enhanced. Therefore, through quantitative comparisons across different weather datasets, the superiority of our approach is evident.
4.4.4. Inference Time
To address real-time applicability and computational cost, we report estimated end-to-end per-frame latency under the same setting as our accuracy experiments (single NVIDIA RTX 3090, batch = 1; PPU input , detector input ). As summarized in Table 4, relative to the plain detector, SemOD adds only ∼17–34 ms per frame while delivering the reported accuracy gains; the DAB alignment accounts for merely ∼1–3 ms of the total latency. These results indicate that our method is deployable in real time on commodity GPUs.
4.5. Qualitative Results
In the qualitative assessment, we set our model against its next-best alternative, “Transweather + Yolo-v11”, across four distinct weather scenarios, as depicted in Figure 3. We not only compared the detection performance of the models but also assessed the effects after weather removal. By comparing the first rows of (b) and (c) at an enlarged scale, we observed that our approach achieves a higher level of scene restoration after weather removal. In particular, when comparing images such as roadside billboards and text, we found that clarity and sharpness were notably improved. Inspecting the bounding boxes of all classes, it’s evident that our model, SemOD, consistently delivers higher confidence, superior accuracy, and fewer false positives. Specifically, SemOD’s superiority increases as objects are farther from the camera. In fact, SemOD not only rectifies inaccurate or even false detection boxes but also captures several diminutive objects ignored by the alternative, spanning from pedestrians to bicycles to vehicles. For example, in the sunny-weather scenario, where adverse weather is no longer a distractor, our model can detect objects that are far away. This observation is a testament to our theoretical analysis that, without contextual information provided by semantics prior, traditional models are inferior at generating logical and meaningful content to replace weather effects and informed bounding boxes in areas heavily degraded by different weather conditions.
Additionally, this qualitative analysis corroborates our understanding that SemOD, incorporating semantics, is more robust to domain gaps across different datasets: the Sunny, foggy, and rainy datasets are all generated from the Cityscapes dataset. Snowy weather images are, on the other hand, selected from the Snow100K dataset and thus have different lighting, architecture, and traffic patterns, as shown in our visualization. Here, SemOD yields clearer weather-removal images and bounding boxes with higher confidence scores than the next-best alternative. However, other models sacrificed some environmental interpretability when handling different weather conditions, resulting in detection outcomes that did not meet our expectations, especially when there was a significant domain gap, which was more pronounced in such cases. SemOD captured common and crucial features in adverse weather images through the expanded interpretability provided by the semantic network.
5. Conclusions
In this study, we introduced “SemOD”, a semantic-enhanced object detection network tailored for robust performance in various weather conditions, including fog, rain, snow, and clear skies. Our network comprises a preprocessing unit and a detection unit. We not only elucidated the amplified benefits of semantic information at two critical model stages—image transformation and object detection—but also rigorously substantiated this synergy through extensive experimentation. This integration significantly enhances the mean Average Precision of object detection, surpassing the state-of-the-art (SOTA) across all comparisons, with improvements ranging from 1.49% in clear skies to 8.78% in snowy conditions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Vargas J. Alsweiss S. Toker O. Razdan R. Santos J. An overview of autonomous vehicles sensors and their vulnerability to weather conditions Sensors 202121539710.3390/s 2116539734450839 PMC 8400151 · doi ↗ · pubmed ↗
- 2Xia X. Meng Z. Han X. Li H. Tsukiji T. Xu R. Zheng Z. Ma J. An automated driving systems data acquisition and analytics platform Transp. Res. Part C Emerg. Technol.202315110412010.1016/j.trc.2023.104120 · doi ↗
- 3Zheng Z. Han X. Xia X. Gao L. Xiang H. Ma J. Open CDA-ROS: Enabling Seamless Integration of Simulation and Real-World Cooperative Driving Automation IEEE Trans. Intell. Veh.202383775378010.1109/TIV.2023.3298528 · doi ↗
- 4Xiang H. Xu R. Xia X. Zheng Z. Zhou B. Ma J. V 2xp-asg: Generating adversarial scenes for vehicle-to-everything perception 2023 IEEE International Conference on Robotics and Automation (ICRA)IEEE Piscataway, NJ, USA 202335843591
- 5Girshick R. Fast r-cnn 2015 IEEE International Conference on Computer Vision (ICCV)IEEE Piscataway, NJ, USA 201514401448
- 6Jiang P. Ergu D. Liu F. Cai Y. Ma B. A Review of Yolo Algorithm Developments Elsevier Amsterdam, The Netherlands 2022 Volume 19910661073
- 7Dosovitskiy A. Beyer L. Kolesnikov A. Weissenborn D. Zhai X. Unterthiner T. Dehghani M. Minderer M. Heigold G. Gelly S. An image is worth 16x 16 words: Transformers for image recognition at scalear Xiv 20202010.11929
- 8Pei Y. Huang Y. Zou Q. Zang H. Zhang X. Wang S. Effects of image degradations to cnn-based image classificationar Xiv 201810.48550/ar Xiv.1810.055521810.0555231689183 · doi ↗ · pubmed ↗