UMLoc: Uncertainty-Aware Map-Constrained Inertial Localization with Quantified Bounds
Mohammed S. Alharbi, Shinkyu Park

TL;DR
UMLoc is a new system that improves indoor localization by combining sensor data with maps and accounting for uncertainty.
Contribution
UMLoc introduces a novel framework that jointly models IMU uncertainty and map constraints for drift-resilient positioning.
Findings
UMLoc achieves a mean drift ratio of 5.9% over a 70m travel distance.
The system maintains calibrated prediction bounds with an average ATE of 1.36m.
Abstract
Inertial localization is particularly valuable in GPS-denied environments such as indoors. However, localization using only Inertial Measurement Units (IMUs) suffers from drift caused by motion-process noise and sensor biases. This paper introduces Uncertainty-aware Map-constrained Inertial Localization (UMLoc), an end-to-end framework that jointly models IMU uncertainty and map constraints to achieve drift-resilient positioning. UMLoc integrates two coupled modules: (1) a Long Short-Term Memory (LSTM) quantile regressor, which estimates the specific quantiles needed to define 68%, 90% and 95% prediction intervals serving as a measure of localization uncertainty and (2) a Conditioned Generative Adversarial Network (CGAN) with cross-attention that fuses IMU dynamic data with distance-based floor-plan maps to generate geometrically feasible trajectories. The modules are trained jointly,…
Click any figure to enlarge with its caption.
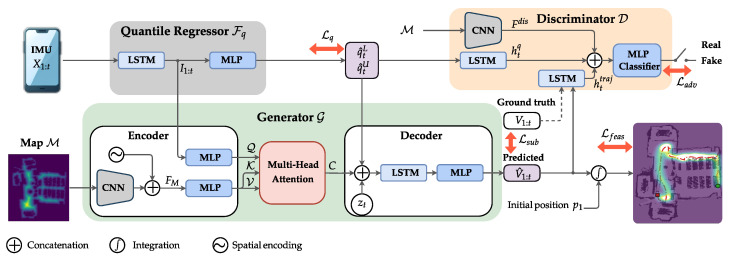 Figure 1
Figure 1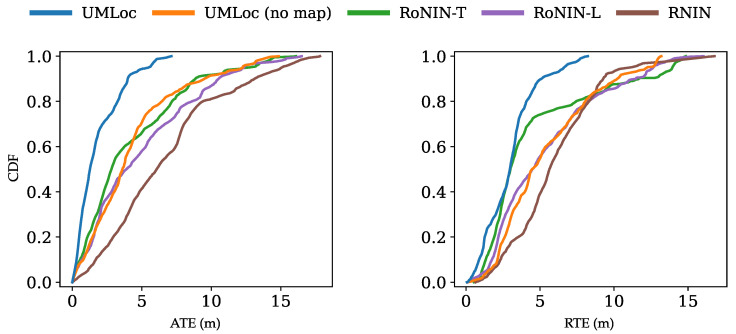 Figure 2
Figure 2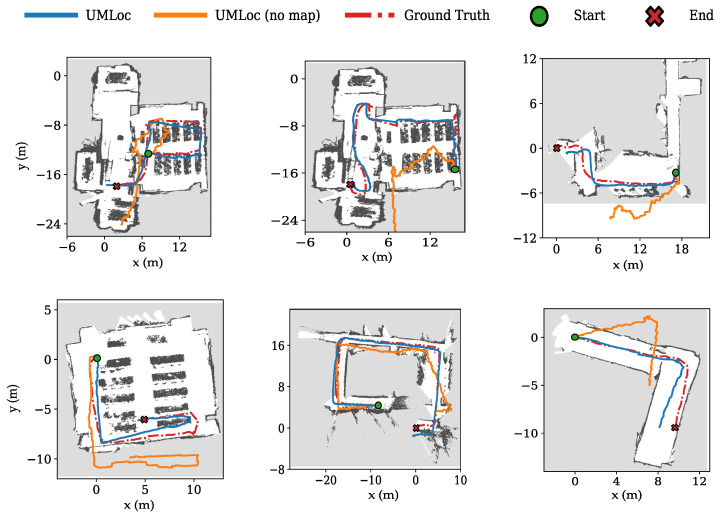 Figure 3
Figure 3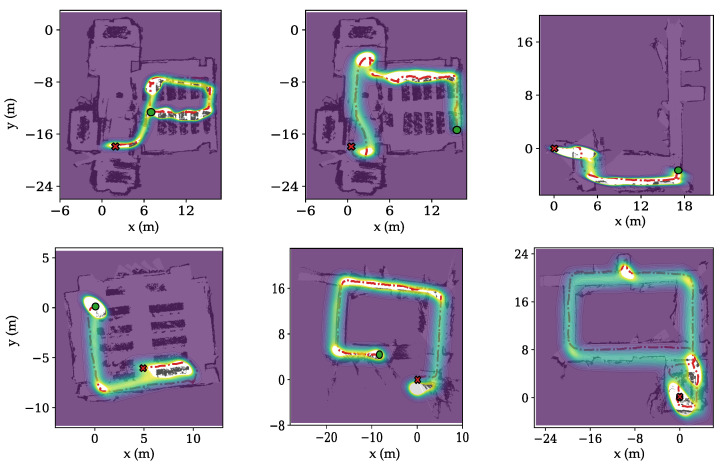 Figure 4
Figure 4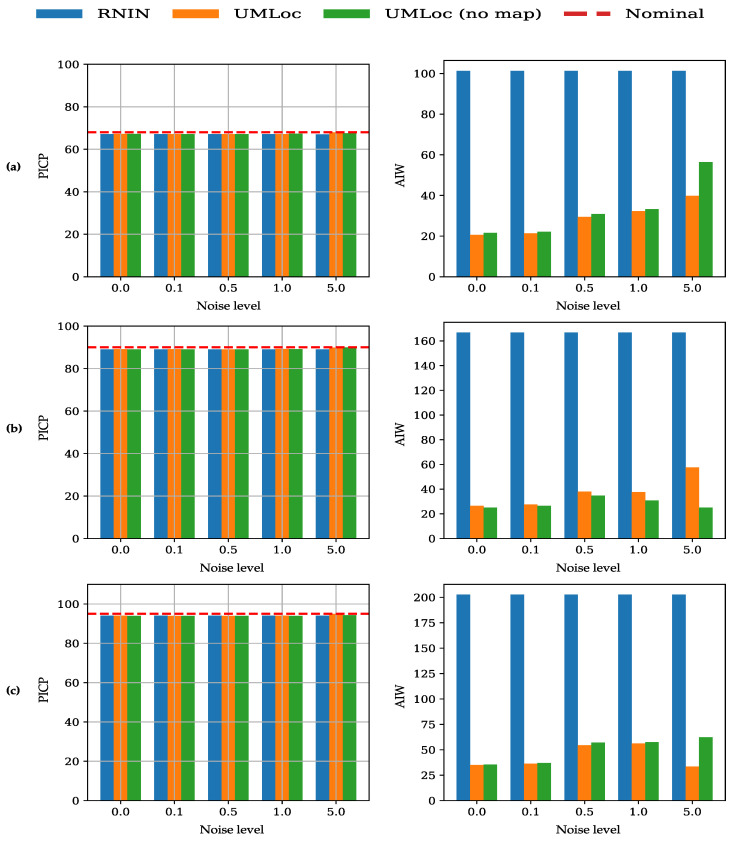 Figure 5
Figure 5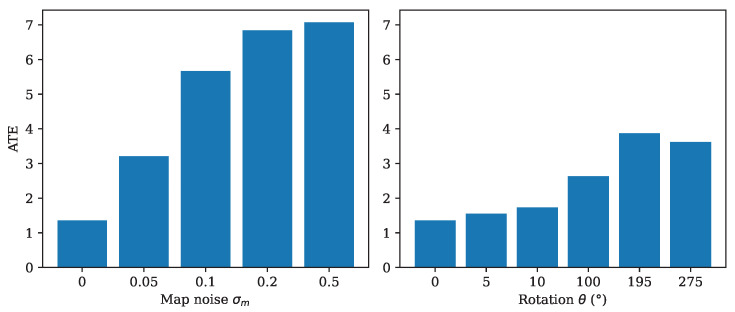 Figure 6
Figure 6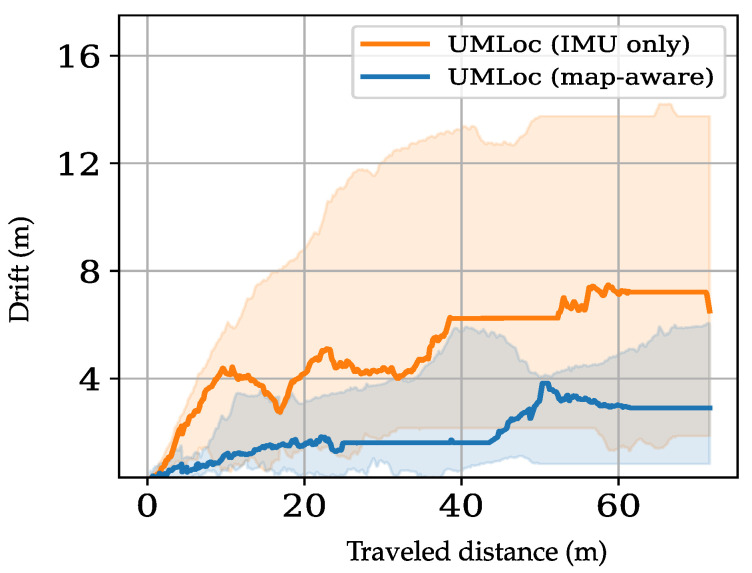 Figure 7
Figure 7- —King Abdullah University of Science and Technology (KAUST)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Indoor and Outdoor Localization Technologies · Inertial Sensor and Navigation
1. Introduction
Indoor localization has gained significant attention in recent years due to its wide range of applications in navigation, healthcare monitoring, emergency response and robotics [1]. Existing methods primarily depend on WiFi and Bluetooth, necessitating dense infrastructure, or on LiDAR and camera-based sensors, which require well-lit, feature-rich environments. These methods can achieve high accuracy but are costly, difficult to scale in real-world deployments [2,3], power-hungry and may interfere with human activity or raise privacy concerns [4,5,6,7]. A promising alternative is Inertial Measurement Units (IMUs). They are widely available on smartphones, require no line-of-sight, operate reliably across diverse environments and are both energy and computation-efficient.
Traditional inertial localization methods are typically divided into two categories: Strapdown Inertial Navigation Systems (SINS) and step-based approaches. SINS employ physics-based models to estimate device orientation and integrate linear acceleration to infer position [8]. Step-based methods exploit the periodic structure of human gait, relying on hand-crafted features or biomechanical models to approximate pedestrian motion through step detection, heading estimation and step length modeling [9,10]. While conceptually straightforward, these methods are highly susceptible to drift due to the accumulation of integration errors over time. Nonetheless, achieving accurate localization using only IMUs remains fundamentally challenging because of uncertainties in measurement and process, including unmodeled dynamics, sensor biases and the lack of absolute references, e.g., GPS.
In recent years, deep learning models have shown significant potential in mitigating drift in inertial positioning problems [11]. For instance, the Robust IMU Double Integration (RIDI) framework adopts a two-stage pipeline, employing a Support Vector Machine (SVM) to estimate device orientation and a Support Vector Regressor (SVR) to predict velocity vectors in the device frame [12]. Similarly, the Inertial Odometry Network (IONet), a Bidirectional Long Short-Term Memory (LSTM) model, addresses drift by estimating changes in velocity magnitude and direction from accelerometer and gyroscope data, thereby eliminating one level of integration and reducing cumulative error [13]. Extending this line of work, Robust Neural Inertial Navigation (RoNIN) introduces a robust velocity loss function. It investigates multiple network architectures, including LSTM, Temporal Convolutional Network (TCN) and ResNet, to more accurately capture ground-plane motion [14]. Nevertheless, unmodeled uncertainties can limit the model’s performance and accumulate errors, leading to trajectory drift.
Tight Learned Inertial Odometry (TLIO) pushes the boundaries of the field by utilizing a ResNet18 model and integrating it with a stochastic-cloning Extended Kalman Filter (EKF). This approach enables the simultaneous estimation of position, orientation, and sensor biases [15]. Similarly, Inertial Deep Orientation-Estimation and Localization (IDOL) combines LSTM with an EKF, enabling the model to learn velocity changes while using the filter to potentially rectify inaccurate orientation estimates [16]. Complementing this, Robust Neural Inertial Navigation Aided Visual-Inertial Odometry (RNIN-VIO) tightly couples an EKF-based VIO with a ResNet–LSTM that regresses displacements and their covariance to maintain robustness in weak-texture and motion-blurred scenes [17]. However, these methods modeled uncertainty by imposing a Gaussian distribution rather than providing calibrated prediction intervals. Although prior data-driven methods have achieved promising results, they lack explicit mechanisms to enforce spatial feasibility, often producing trajectories that intersect with obstacles, thus compromising realism and limiting practical deployment.
Despite these advances, existing inertial localization methods still suffer from inevitable drift over time. This limitation motivates exploring auxiliary information, such as map-based constraints, to provide absolute references for correcting drift and improving localization accuracy. Particle filters are widely known for integrating positional estimates with environmental constraints [18]. These filters propagate multiple hypotheses of location based on odometry, retaining or discarding particles based on their consistency with the map and sensor observations. While they are effective in practical applications [19,20], particle filters are highly sensitive to odometry noise, leading to premature removal of valid hypotheses. To address this issue, ref. [21] introduced learnable map embeddings that adaptively reweight particle distributions, enhancing robustness against noisy motion estimates. Yet, this method cannot propagate map consistency violations back into the feature learning process, hence limiting further improvements in localization accuracy.
The lack of an accurate inertial localization model that explicitly incorporates the spatial constraints and uncertainty bounds into position estimation motivates the design of an end-to-end localization framework to address these limitations. In this work, we introduce UMLoc, an Uncertainty-aware Map-constrained inertial Localization framework that aims to generate spatially feasible trajectories with quantified bounds. Thus, it elevates the task from unconstrained inertial tracking to map-compliant localization with probabilistic guarantees. The proposed architecture consists of two main components: (1) a quantile regression module based on an LSTM network, which estimates prediction intervals for velocity uncertainty; and (2) a Conditional Generative Adversarial Network (CGAN) with a cross-attention mechanism, which unifies quantile-derived uncertainty and distance-based map feasibility for trajectory generation. The key innovation lies in its structured conditioning via a cross-attention mechanism. It enables the model to simultaneously generate spatially consistent pedestrian positions within a global reference frame while providing a confidence measure that is both robust and interpretable. To achieve our objectives, curriculum learning is used to optimize the multitasking framework, starting with an adapted pinball loss to obtain predictive bounds. Then, an adversarial loss and a supervised trajectory loss with a map-compliance penalty are used to train the CGAN for map-compliant trajectory prediction. The proposed UMLoc is extensively evaluated across three datasets, our own dataset and two publicly available datasets. Furthermore, UMLoc is compared against strong baselines, including RoNIN-TCN, RoNIN Bi-LSTM [14] and RNIN [17], demonstrating superior accuracy, robustness and generalization. The main contributions of this work are as follows:
- We introduce an LSTM-based quantile prediction module that estimates prediction intervals for velocity, which are integrated to form a positional bound for position estimates.
- We design a CGAN with a cross-attention mechanism to generate trajectories that are consistent with both the learned uncertainty bounds and a 2D environmental map, thereby ensuring map-compliant localization.
- We couple these two modules into a novel end-to-end learning framework for inertial localization that: (1) Effectively propagates IMU uncertainty through to the final trajectories; (2) Yields reliable, drift-reduced position predictions.
Beyond these technical contributions, we also establish an indoor localization benchmark dataset consisting of synchronized IMU data, ground-truth poses and floor plan maps.
This paper is organized as follows: Section 2 describes the formulation of the localization problem. Section 3 introduces the proposed UMLoc with its data preparation and training process. Then, the inertial localization results and the ablation study are presented in Section 4. Finally, concluding remarks on the proposed methods are presented in Section 5.
2. Problem Description
We formulate the inertial localization problem as a learning task. It exploits IMU data from a handheld device (e.g., a smartphone) and a corresponding 2D map of the environment to predict the pedestrian’s position. Let denote IMU measurements from the initial time to the current time t, where each vector at time contains three-axis linear acceleration and three-axis angular velocity .
The goal is to estimate the corresponding sequence of positions within a time window while accounting for drift and spatial constraints. To facilitate this, we define the velocity sequence as , where each velocity vector represents motion in the 2D plane. The corresponding position at time is denoted by , lying in a global 2D coordinate frame that is aligned with the environmental map . We assume that the vertical position remains constant and that the map is known a priori. To address the problem, we decompose the localization task into two interconnected sub-tasks.
2.1. Uncertainty Estimation via Quantile Regression
Let denote a random variable representing the ground-truth velocity at time t. For each time step t, the probability that falls within the conditional lower and upper quantiles, given IMU observation , is defined as
where the inequality in (1) is applied element-wise, and represent the conditional lower and upper quantiles of conditioned on the initial velocity and IMU data , with denoting the tail probability. These quantiles define the prediction interval at confidence level , expressed as .
To estimate these quantiles, we train a quantile regression network:
where denotes a quantile regression network parameterized by , trained using the adapted pinball loss described in Section 3.2. The predicted quantiles define a prediction interval such that . These quantiles capture both model uncertainty and intrinsic data variability, serving as constraints for subsequent trajectory generation. By providing statistically grounded uncertainty margins, the learned bounds improve the reliability and robustness of inertial localization.
2.2. Map-Constrained Trajectory Generation
A generative neural network model is designed to generate realistic velocity trajectories by sampling from the learned distribution :
where is the condition, represents IMU features from the initial time to current time t and encodes the environmental map. The prediction interval and act as quantile-based quantified uncertainty bounds that guide trajectory generation. Subsequently, multihead cross-attention is employed to fuse the IMU dynamics and distance-based map feasibility.
3. Uncertainty-Aware Map-Constrained Inertial Localization
UMLoc is a two-stage framework that (1) estimates predictive uncertainty bounds using an LSTM-based quantile regression module and (2) generates spatially feasible velocity trajectories via a CGAN conditioned on an environmental map. Figure 1 illustrates the end-to-end pipeline of the proposed UMLoc framework.
We begin by introducing the quantile prediction module, followed by the map-constrained CGAN, which employs a cross-attention mechanism to generate trajectories consistent with both the predicted uncertainty intervals and the environmental map. We then describe the data-collection process used for training and present the progressive training curriculum designed to optimize the model end-to-end.
3.1. LSTM-Based Quantile Regression Module
Localization drift primarily stems from propagated modeling uncertainties, IMU sensor biases and variability in human motion patterns. Instead of relying on deterministic velocity estimates, as in prior work [13,14,16], we employed a quantile regression approach to estimate prediction intervals, providing interpretable measures of uncertainty.
Formally, given an IMU sequence , the quantile regression module computes the lower and upper quantiles, and , of the ground-truth . It is conditioned on the initial velocity and the IMU data , at each time t. To compute these quantiles, the module is trained using an adapted pinball loss. The loss extends the classic formulation [22] by the cumulative sum of the predicted velocity quantiles to estimate positional displacement over the interval :
where T is the trajectory length, and .
In inertial navigation, positions are obtained by integrating velocities; thus, the dominant failure mode is drift, where small systematic velocity errors accumulate over time. To align the training objective with this property, we apply the pinball loss to the cumulative velocity residuals. Therefore, minimizing (4) encourages the predicted quantiles to provide calibrated bounds not only on instantaneous velocity but also on the integrated displacement, which directly governs long-horizon position error.
We stacked two layers of unidirectional LSTM layers with 64 units each to extract sequential features . The resulting features are passed through two linear layers with shared weights of size , producing four scalar outputs at each time step. These scalars correspond to the predicted lower and upper quantiles for the two velocity components, and . Together, these components constitute the quantile regressor shown in Figure 1. In this work, we experimented with different values of , corresponding to prediction intervals, respectively. The resulting interval serves as an uncertainty-aware constraint, which conditions the trajectory generation module in the second stage of UMLoc.
3.2. Conditional Generative Adversarial Network (CGAN)
The CGAN module consists of two components: a generator network and a discriminator network , as illustrated in Figure 1. The generator learns to produce realistic velocity trajectories by sampling from the learned distribution as in (3). The discriminator learns to classify real and generated velocity trajectories. The overall CGAN objective integrates an adversarial loss and a supervised estimation loss with a map feasibility penalty to jointly improve localization accuracy, spatial feasibility and drift resilience.
The generator architecture is shown in Figure 1 and consists of a CNN–attention encoder and an LSTM-based decoder. The encoder processes the 2D environmental map to generate a feature map. We encode this map using a lightweight CNN consisting of two blocks (32 and 64 channels) of Convolution, batch normalization and Rectified Linear Unit (ReLU), each followed by max-pooling. Then a depthwise convolution and a final pointwise convolution that projects features to the context feature dimension. Then, it is augmented by the 2D coordinates (spatial encoding) to provide spatial awareness as .
The feature map is reshaped into a sequence of tokens and linearly projected by the MLP to obtain the keys and values . In parallel, the temporal IMU features are projected to the same attention dimension d via an MLP to form the temporal queries . Then, we apply multi-head cross-attention with heads, where each head attends from the temporal queries to the spatial tokens. The head outputs are concatenated and projected to produce the fused context sequence as follows:
where , , and are learnable projection matrices. The resulting context vector aggregates map information relevant to the current IMU state, allowing the model to selectively emphasize spatial regions (e.g., high-clearance corridors vs. near-obstacle areas) when generating the trajectory.
Overall, this design grounds the IMU sequence in the environment’s spatial context while enforcing feasibility constraints that prevent information leakage from invalid areas. To introduce controlled stochasticity and enhance diversity, the cross-attention context vector at time step t is concatenated with latent Gaussian noise ∼ . At each step, we form the decoder input by concatenating the cross-attention context , the latent Gaussian noise and embedded uncertainty bounds . The decoder is a recurrent predictor parametrized by comprising a single-layer LSTM with 64 units. The LSTM hidden state is then mapped through a linear layer to generate the velocity estimate conditioned on the predicted quantiles and cross-attention context vector, ensuring that the generated trajectories remain within the learned quantile-based uncertainty bounds as follows:
Thus, the positions follow discrete integration: , where is the sampling period which corresponds to in our experiments.
To differentiate between real velocity trajectory and generated trajectory , the discriminator is conditioned on . We used 2 LSTM encoders with 32 units to process the trajectory and the corresponding quantile bounds, respectively, and use their final hidden states, denoted by and . In addition, a CNN extracts a feature vector from the 2D map . The MLP classifier then takes the concatenation of these features and hidden states to distinguish between real and generated velocity trajectories.
where denotes the discriminator’s predicted label, indicating whether the selected trajectory sample corresponds to a ground truth (real) or generated (fake) data.
Empirically, adding to reduced stability and did not improve the framework’s performance. The discriminator is trained to minimize the following adversarial loss :
We train the generator to encourage the production of trajectories with low final displacement error (FDE). Specifically, we generate samples and select the trajectory with the lowest FDE. The generator is optimized with a composite weighted objective that combines adversarial loss and a supervised velocity and position loss with a map feasibility penalty, , where
Here, penalizes trajectories that are close to or intersect with obstacles in the map. This penalty uses a safety margin, , which is applied when the trajectories are within distance of any obstacles. is chosen empirically to be . The supervised loss enforces supervision, with chosen to balance the velocity and position contribution. The weights are empirically chosen to balance each learning task and stabilize training, with and linearly ramped over training iterations i to gradually enforce spatial feasibility .
3.3. Data Preparation for Training and Evaluation
Each data sample comprises 6-DoF IMU readings collected from an Android smartphone (Samsung Galaxy S23 Ultra, Vietnam) placed in the pedestrian’s pants pocket. It consists of 3-axis linear accelerations and 3-axis angular velocities, in addition to ground-truth position data and a 2D map generated using the SLAM API of the Stereolabs (Paris, France) ZED 2i camera system, which is fixed to the pedestrian’s chest. The IMU measurements are reported in the device body frame , which changes dynamically as the device moves. In contrast, both the ground-truth positions and the 2D map are represented in a fixed global frame . It is defined by a right-handed z-up coordinate system with the z-axis aligned with the gravity. Hence, the Android Game Rotation Vector (GRV) [23] is used to estimate the smartphone’s orientation in quaternion form. It is then applied to transform the IMU measurement from the body frame to the global frame : where denotes the quaternion conjugate of .
During training, both IMU data and ground-truth velocities are randomly rotated by an angle on the horizontal plane [14]. This augmentation compels the model to learn heading-invariant motion patterns such as steps, turns and lateral movements. As a result, the trajectory direction naturally emerges from successive velocity predictions, leading to better generalization at inference. During testing, the GRV is used to estimate the smartphone’s orientation to ensure that the z-axis of the output frame remains aligned with gravity.
In addition, a 2D map is constructed as a binary occupancy grid , where static structures such as walls, doors and offices are represented as obstacles. Hence, takes the value 1 if cell is free and 0 otherwise. To enable differentiability and capture rich spatial context, a Euclidean distance transform is applied to the occupancy grid, producing a smoothed representation. In , each cell stores the shortest Euclidean distance to the nearest obstacle.
The resulting distance values are converted to metric units using the map resolution r (in meters per pixel), yielding the final map representation . This continuous map-aware encoding promotes numerical stability, embeds spatial proximity to obstacles and supports gradient-based learning.
3.4. Training Process
We adopted a curriculum-based learning strategy to meet our objectives of predictive bounds, feasible trajectory generation and reduced drift in inertial localization. The training is conducted in three successive phases to stabilize adversarial learning and propagate uncertainty from quantile bounds into the map-conditioned generator.
First, the quantile module was pretrained for 150 epochs by minimizing . Next, CGAN was trained for 50,000 iterations to generate global velocity sequences, while optimizing with the quantile module frozen, starting with a warm-up supervised learning to minimize . After that, we annealed the adversarial term to shape realistic and multimodal motion once predictions were reasonable. Then, we ramped the feasibility loss to enforce map compliance. Finally, both modules were fine-tuned jointly in an end-to-end manner.
We implemented the proposed model using PyTorch and ran it on an NVIDIA RTX 2080 Ti GPU (12 GB). In this work, we tuned the hyperparameters using optuna [24] for hyperparameter optimization. For training, the Adam optimizer was used, with learning rates of for the quantile module, generator and discriminator, respectively. We used the two-time-scale update rule [25], training the discriminator with a larger learning rate and multiple updates per generator step, which empirically stabilizes CGAN training and improves convergence. A batch size of 16 and a window of size 120, corresponding to , is employed to train the proposed model. A scheduler is used to adjust the learning rate of the quantile module, reducing it by a factor of if the validation loss does not decrease for 15 epochs.
The end-to-end model required approximately 14 h of training. Regarding the inference time, UMLoc requires an average of per full trajectory. For streaming operations, the average latency is per prediction window, using CGAN samples per instance. It corresponds to an effective inference rate of approximately 200 Hz, which supports real-time deployment at 60–100 Hz (i.e., – budget per step), providing a – × computational margin, given access to the 2D map.
4. Results
4.1. Experimental Setup
4.1.1. Datasets
We evaluated the proposed UMLoc model on three inertial localization datasets to assess its performance, generalization and robustness. RoNIN [14] and RNIN [17] are two publicly available datasets for inertial localization (see Table 1). To complement these benchmarks, we introduce a new dataset comprising over 2 h of indoor pedestrian trajectory data collected across 5 buildings with 12 different map layouts. We recorded IMU and camera data at a sampling rate of 60 Hz, with each trajectory lasting no longer than 10 min. We developed a custom Android application to log all sensor streams. This dataset establishes a new benchmark for map-aware inertial localization in indoor environments.
4.1.2. Baselines and Metrics Definitions
To evaluate the proposed inertial localization model UMLoc, we compared its performance against three state-of-the-art baselines:
- RoNIN LSTM [14]: A recurrent model that employs LSTM layers with bilinear layers to regress velocity directly from IMU data.
- RoNIN TCN [14]: A convolution-based alternative that utilizes a Temporal Convolutional Network (TCN) for velocity prediction from IMU data.
- RNIN-VIO [17]: An uncertainty-aware deep learning model that explicitly predicts displacement along with its associated covariance from IMU data.
By benchmarking against diverse architectures and datasets, we aim to comprehensively demonstrate the effectiveness and robustness of UMLoc across different environments, people, devices and multiple levels of sensor noise captured in the datasets.
For systematic evaluation, we employ multiple quantitative metrics for each position trajectory of length T:
- Absolute Trajectory Error (ATE): The Root Mean Square Error (RMSE) between estimated and ground-truth positions is given as . It reflects global trajectory consistency and accumulates over time due to drift.
- Relative Trajectory Error (RTE): The RMSE of position differences over a fixed time interval ( min) is calculated as
It captures local trajectory consistency.
- FDE: The final displacement error is normalized by the total trajectory distance L, . It quantifies long-term drift relative to the path distance.
4.1.3. Smartphone Orientation Handling
RoNIN performs pre-alignment of the tracking and IMU devices at the start and end of each recording session [14]. Specifically, it employs two smartphones, one dedicated to collecting ground-truth trajectories and the other to capturing the pedestrian’s actual motion data. In addition, orientation supervision is applied during training using ground-truth device orientations. However, at test time, the model relies on device orientation, making orientation errors a dominant source of drift. RNIN, by contrast, employs controlled setups (e.g., VICON motion capture systems or rigid camera–IMU assemblies) and leverages ground-truth orientations, thereby bypassing orientation noise inherent in free-hand use. However, in real-world scenarios, ground-truth orientations are unavailable. To address this, UMLoc is trained and evaluated exclusively using GRV, which reflects realistic deployment conditions. This design makes our experiments particularly challenging, as no ground-truth orientations are assumed.
4.2. Experiment Results
For each dataset (RoNIN, RNIN, ours), we adopted a zero-shot protocol by holding out entire sequences from unseen users, devices and buildings for testing. The zero-shot testing demonstrates performance and generalization to unseen data. Also, in all experiments, we used the prediction interval for the UMLoc model, as it provided more robust and accurate localization than the and intervals, unless stated otherwise. Table 2 reports the evaluation metrics for all the datasets on UMLoc against baseline models to summarize their performance. Across these splits, UMLoc transfers without fine-tuning, maintaining competitive accuracy on new people and phones (a capability particularly demonstrated by the results on the RoNIN and RNIN datasets). Furthermore, cross-building testing in our dataset demonstrates that UMLoc maintains competitive accuracy in diverse layouts.
4.2.1. Evaluation on RoNIN and RNIN Datasets
RoNIN and RNIN are two widely used indoor inertial benchmark datasets containing diverse pedestrian trajectories [14,17]. These datasets are collected from different devices and by different people. The RoNIN dataset comprises over 40 h of recordings and uses a 85/15 train–test split, whereas RNIN includes 7 h of data with a 90/10 split, following the original papers’ setup. Since neither dataset provides map information, we supplied UMLoc’s CNN branch with a uniform feasibility map to maintain identical model capacity and ensure a fair comparison that quantifies IMU-only performance.
Table 2 shows that UMLoc without map conditioning achieves an ATE of and FDE of over the traveled distance on the RoNIN dataset. For RNIN, it attains ATE of and RTE around over a period of . These results show marginal improvements across all metrics relative to the strongest baselines (see the ”Improvement” rows).
4.2.2. Evaluation on Our Dataset
We split the trajectories into an split for training and testing. The testing split includes a mix of unseen layouts and trajectories. All baseline models were retrained using identical splits to ensure a fair comparison. On our dataset, UMLoc with map conditioning outperforms all baselines, as well as its IMU-only variant, achieving over improvement over the strongest baseline. UMLoc achieved an average drift of over an average travel distance of , corresponding to a total combined travel distance over for testing trajectories (see Table 2). Also, the cumulative distribution functions (CDFs) of ATE and RTE show that UMLoc is the first to reach its maximum error, as illustrated in Figure 2. Figure 3 provides a visualization of selected unseen trajectories on their maps to compare the UMLoc with its IMU-only variant. The UMLoc accurately predicts map-compliant trajectories and effectively avoids obstacle areas.
To test the model’s ability to generate multiple trajectories that follow the map constraints and to assess its uncertainty estimation, we draw 20 trajectory samples from the CGAN. In Figure 4, the density is demonstrated over the 2D map with the ground truth trajectory. The resulting high-density ridge closely follows the ground-truth path while remaining within free space, indicating slight bias and good adherence to map constraints.
4.2.3. Robustness Test
To evaluate the resilience of the proposed UMLoc pipeline under realistic operating conditions, we introduced two common sensor degradations only at the testing time:
(i) Additive Gaussian noise. Each accelerometer and gyroscope reading was corrupted with zero-mean and standard deviations , where is the captured IMU standard deviation. This perturbation mimics thermal noise in low-cost MEMS units, human-induced vibrations, electromagnetic interference and the gradual increase in noise power caused by sensor aging.
(ii) Random sample dropout. A total of of IMU frames were randomly replaced with 0. This scenario reflects real-world issues such as packet loss on wireless links and power-saving modes.
For the above two settings, we computed the Prediction-Interval Coverage Probability (PICP) and Average Interval Width (AIW) to evaluate the quantile calibration:
where the inequality in (8) is applied element-wise. Since RoNIN does not natively provide uncertainty measures for a fair comparison, we used RNIN as the baseline for the robustness test. We derived the component-wise prediction intervals of , and (corresponding to ) by using multiples of the predicted standard deviation , specifically , and (detailed in Appendix A). For example, the interval bounds were calculated as
The evaluation of the prediction interval is shown in Figure 5, which reports PICP and AIW for the 3 intervals . The figure highlights how well the intervals are maintained against different operating conditions. UMLoc consistently maintains its coverage probability close to the nominal target and exhibits the most adaptive increase in interval width, even at high noise levels. In contrast, RNIN maintains coverage, but the intervals are unrealistically wide. Overall, UMLoc provides the best balance, effectively maintaining high coverage while keeping a reasonable interval width under noisy conditions and clearly outperforms RNIN in terms of robustness and calibration. These results demonstrate that our method’s explicit uncertainty quantification is robust against the inevitable noise, interference and data gaps encountered in practical deployments.
4.2.4. Map Sensitivity Test
We further expand the quantitative performance analysis by conducting two inference-time sensitivity tests that perturb the map while keeping the IMU stream and the ground-truth trajectory fixed. The resulting degradation is reported in ATE. First, we inject Gaussian map noise to emulate map extraction and discretization errors:
where is specified in meters. Second, we evaluate map-trajectory misregistration by applying a rigid 2D transformation to the distance map only:
where R is a planar rotation by degrees, and is a translation (converted from meters to pixels using the map resolution).
Figure 6 presents the ATE as a function of map noise and misalignment. The results illustrate performance degradation and clearly delineate UMLoc’s sensitivity boundaries with respect to map quality and map trajectory misregistration.
4.2.5. Ablation Study
We conducted an ablation study to explicitly evaluate the contribution of key components of UMLoc, focusing on (i) multi-head cross-attention, (ii) generator loss and (iii) the impact of map conditioning. Table 3 reports the ATE results of the ablation study on our dataset.
(i) Multi-head cross-attention. To evaluate the effectiveness of the cross-attention module, we replaced it with a simple MLP that takes the concatenated IMU feature and map feature as input. With this modification, ATE increases compared to the proposed model with the cross-attention module. This confirms that multi-head cross-attention more effectively fuses IMU and map information, leading to improved localization performance.
(ii) Generator loss . To evaluate the contribution of each component in the generator loss, we removed individual terms one at a time. Specifically, we ablated the feasibility loss , the position term in the supervised loss and the velocity term in the supervised loss. In all cases, performance degrades to some extent. Overall, combining these three loss components provides a balanced objective that constrains velocity prediction, trajectory accuracy, and feasibility, resulting in the best performance.
(iii) Map conditioning. To study the effect of map conditioning, we repeated the experiments using a uniform feasibility map instead of the true map. Figure 7 presents the drift-error analysis, defined as the position estimation error aggregated over trajectories and reported as a function of traveled distance up to a common horizon of . Each trajectory’s drift-versus-distance curve is linearly interpolated onto a shared grid before computing statistics.
The results reveal a substantial reduction in drift, validating the synergy between uncertainty bounds and spatial feasibility constraints. Notably, UMLoc with map conditioning consistently achieves lower cumulative drift than its IMU-only variant, effectively suppressing drift growth over distance. These findings underscore the critical role of map conditioning in improving localization accuracy, reducing positional uncertainty, and enhancing reliability during long-duration deployments.
4.2.6. Generalization
Generalization is assessed along two dimensions: environment generalization and trajectory behavior generalization. Environment generalization examines whether a model trained on certain areas can transfer to unseen floor-plan geometries (e.g., different corridor topologies, room connectivity, and obstacle configurations). Trajectory behavior generalization evaluates whether the model can handle diverse pedestrian motion patterns within and across environments (e.g., changes in walking speed, stops and turns, long straight segments versus frequent direction changes), which directly affect IMU drift accumulation. Table 2 reports the evaluation of our model using held-out layouts and trajectories in a zero-shot setting. This protocol explicitly evaluates both cross-building (layout) transfer and cross-trajectory (behavior) transfer. Notably, in the cross-building evaluation, UMLoc maintains competitive accuracy across diverse layouts in our dataset In contrast, the model in [16] exhibits clear performance degradation under similar cross-building conditions, as discussed in the original reference.
In addition, we conduct a second generalization study comparing building-specific training with a universal model. For each building in our dataset, we trained an independent UMLoc model using only trajectories collected in that building and evaluated it on a held-out set of previously unseen trajectories from the same building, reporting the resulting ATE. We then averaged the ATE across all buildings. In parallel, we trained a single universal UMLoc model on the combined training data from multiple buildings and evaluated it on unseen trajectories using the same protocol. The comparison, summarized in Table 4, directly examined whether a single globally trained model can match the performance of specialized per-building models, thereby demonstrating generalization across both layout diversity and motion variability.
We attribute the strong generalizability of the single UMLoc model to three main factors: (i) the IMU encoder learns kinematic patterns that are agnostic primarily to the users and environments; (ii) device differences are mitigated through noise augmentation and the use of the quantile objective, which encourages calibrated and less over-confident predictions under data shifts; and (iii) the map-aware feasibility prior effectively constrains drift even in unfamiliar spaces, provided the floor plan is well-aligned with the global frame.
5. Conclusions
In this paper, we propose UMLoc, a novel localization framework that integrates an LSTM-based quantile-regression module with a map-conditioned CGAN to reduce drift and provide explicit prediction intervals. Through comprehensive experiments across our dataset and benchmark datasets, UMLoc consistently outperforms state-of-the-art approaches. The results demonstrate substantial improvements in accuracy, robustness and generalization capabilities. This work opens new avenues for researchers to explore more sophisticated integration techniques, extend the concept to various sensor modalities and address real-world localization challenges.
Future research directions include extending UMLoc to three-dimensional localization and addressing deployment challenges in real-world indoor navigation (i.e., shopping malls, airports, office buildings, hospitals and industrial facilities) and robotic applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Arnold M. Schaich F. Indoor positioning systems: Smart fusion of a variety of sensor readings Proceedings of the 2021 IEEE 22nd International Workshop on Signal Processing Advances in Wireless Communications (SPAWC)Lucca, Italy 27–30 September 20211510.1109/SPAWC 51858.2021.9593158 · doi ↗
- 2Ahmetovic D. Gleason C. Ruan C. Kitani K. Takagi H. Asakawa C. Nav Cog: A navigational cognitive assistant for the blind Proceedings of the 18th International Conference on Human-Computer Interaction with Mobile Devices and Services Florence, Italy 6–9 September 20169099
- 3Onkar Pathak P.P. Palkar R. Tawari M. Wi-Fi indoor positioning system based on RSSI measurements from Wi-Fi access points–A trilateration approach Int. J. Sci. Eng. Res.2014512341238
- 4Zhang J. Singh S. LOAM: Lidar odometry and mapping in real-time Proceedings of the Robotics: Science and Systems Berkeley, CA, USA 12–16 July 2014 Volume 219
- 5Zhang J. Singh S. Visual-lidar odometry and mapping: Low-drift, robust, and fast Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA)Seattle, WA, USA 26–30 May 201521742181
- 6Xu W. Zhang F. Fast-lio: A fast, robust lidar-inertial odometry package by tightly-coupled iterated kalman filter IEEE Robot. Autom. Lett.202163317332410.1109/LRA.2021.3064227 · doi ↗
- 7Zhao C. Yen G.G. Sun Q. Zhang C. Tang Y. Masked GAN for unsupervised depth and pose prediction with scale consistency IEEE Trans. Neural Netw. Learn. Syst.2020325392540310.1109/TNNLS.2020.304418133361009 · doi ↗ · pubmed ↗
- 8Jiménez A.R. Seco F. Prieto J.C. Guevara J. Indoor pedestrian navigation using an INS/EKF framework for yaw drift reduction and a foot-mounted IMU Proceedings of the 2010 7th Workshop on Positioning, Navigation and Communication Dresden, Germany 11–12 March 2010135143