Compact Dual-Quaternion-Based Visual Servoing for Perpendicular Alignment with Surface Normal Constraints
Sheng Li, Chao Ye, Chenlu Liu, Weiyang Lin

TL;DR
This paper introduces a new visual servoing method using dual quaternions to improve robotic button-pressing accuracy by ensuring perpendicular alignment.
Contribution
A novel dual-quaternion-based visual servoing method is proposed for accurate and efficient robotic pressing with surface normal constraints.
Findings
The method ensures perpendicular alignment between the end-effector and target surface during pressing.
Experimental results show improved positioning accuracy and computational efficiency compared to conventional methods.
Abstract
The ability to reliably press physical buttons is a common requirement in robotics. Conventional vision-based methods often suffer from positional errors during execution if the end-effector’s approach is not perpendicular to the target surface. This paper proposes a novel dual-quaternion-based visual servoing method that enables robots to reach desired poses and enhances accuracy in robotic button-pressing. Our method acquires target pose information (position, depth and surface normal direction) from the RGB-D camera and converts it into dual quaternion representation to construct the visual servoing control system. The image Jacobian matrix for the dual quaternion pose is then computed. The dual-quaternion-based visual servoing ensures that the pressing direction and the optical axis of the coaxially mounted camera remain perpendicular throughout the pressing motion, thereby…
Click any figure to enlarge with its caption.
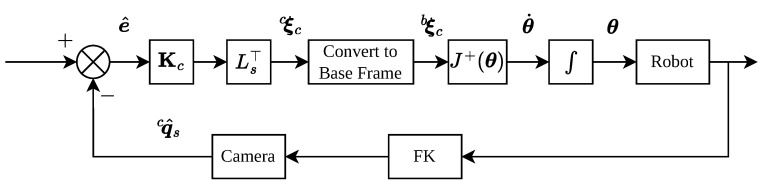 Figure 1
Figure 1 Figure 2
Figure 2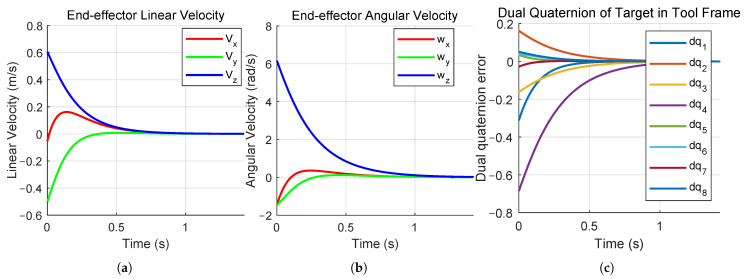 Figure 3
Figure 3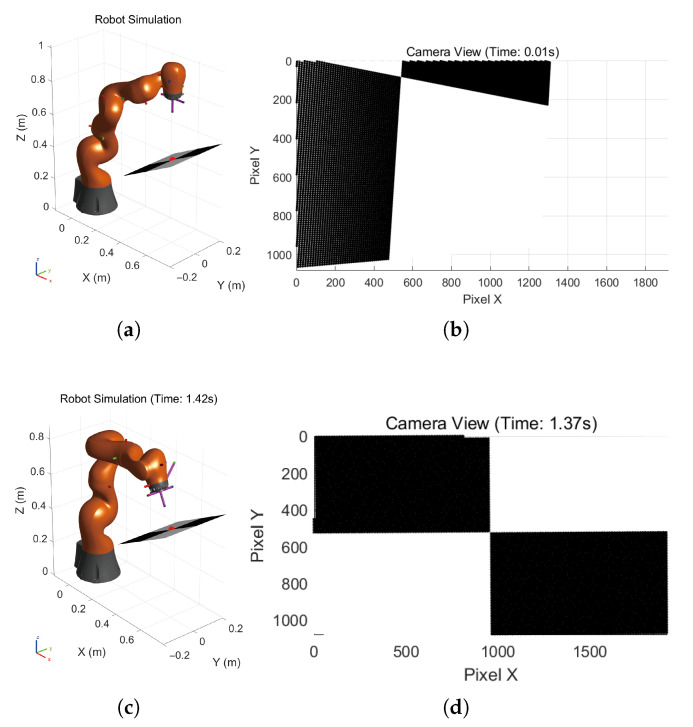 Figure 4
Figure 4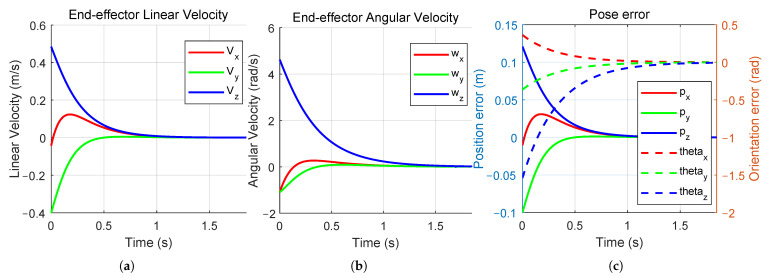 Figure 5
Figure 5- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Vision and Imaging · Soft Robotics and Applications · Optical measurement and interference techniques
1. Introduction
The need to reliably locate and press physical buttons represents a pervasive need in numerous robotic application domains. A widely adopted and effective solution in practice employs robots fitted with visual sensors, utilizing advanced computer vision and image recognition algorithms to successfully complete this operation. During the translational movement of the end-effector toward the specific button, if the orientation of the tool is not perpendicular to the plane where the button is located, a positional error will arise between the actual actuation point and the target position identified by image recognition—that is, pressing at an oblique angle will result in a lateral deviation. Therefore, it is necessary to adjust the robot to a pose where the end-effector is positioned straightly above the button and its orientation is orthogonal to the button plane before the execution of the pressing operation.
The application of computer vision provides a viable approach for the autonomous detection, precise localization, and accurate identification of physical buttons, enabling vision-guided robotic interaction and control. Early research primarily relied on traditional image processing techniques. Methods such as edge detection (e.g., Canny operator) [1], shape analysis (e.g., Hough transform), and template matching were widely used for button detection. While effective in structured environments, these approaches were often sensitive to lighting variations, occlusions, and complex backgrounds. Subsequent work integrated feature engineering methods (e.g., SIFT, HOG features) [2,3] with machine learning classifiers (e.g., Support Vector Machines, Random Forests), which improved generalization but still depended on hand-crafted features. In recent years, deep learning-based detection and recognition methods have become the mainstream. Convolutional Neural Networks (CNNs) can automatically learn more discriminative feature representations, significantly enhancing recognition accuracy in complex scenes. Region proposal-based object detection architectures (e.g., Faster R-CNN, YOLO series) [4,5] and instance segmentation models (e.g., Mask R-CNN) [6] have enabled simultaneous button localization, classification, and pixel-level segmentation. Al-Shanoon and Lang [7] demonstrated that CNN-based 3D visual servoing can achieve robust manipulation without requiring precise camera calibration. Ribeiro et al. [8] proposed an end-to-end deep learning approach that directly maps images to robot velocities, achieving real-time performance at 30 fps. Moreover, the introduction of attention mechanisms and Transformer architectures has further improved the model’s ability to focus on critical regions and model long-range dependencies. Wu et al. [9] proposed a hierarchical data-driven predictive control framework for image-based visual servoing systems with unknown dynamics, demonstrating that online learning combined with predictive control can significantly improve tracking accuracy and robustness compared to conventional methods.
Dual quaternions constitute a more advantageous representation for rigid-body motion across multiple dimensions [10]. As a concise and computationally efficient mathematical formalism, dual quaternions enable a unified characterization of spatial transformations—including line geometry mappings—with lower memory requirements and reduced operational costs [11,12,13]. In contrast to traditional methodologies that employ independent control loops for translational and rotational components, dual-quaternion-based techniques naturally incorporate the interdependence between these motions, leading to more physically consistent and intuitive trajectory generation [14]. Furthermore, the combination of screw theory with dual quaternions inherently ensures frame invariance, yielding considerable savings in computational overhead while demanding fewer arithmetic operations for standard tasks such as kinematic composition and exponential calculations. This enhances the performance of both forward and inverse kinematic computations [15]. These beneficial attributes have stimulated growing interest in adopting unit dual quaternions within robot motion planning and control. For example, Wang et al. [16] utilized unit dual quaternion kinematics to formulate a distributed control architecture for networked multi-body systems. Similarly, Daniilidis [17] exploited a dual-quaternion parameterization to concurrently resolve hand-eye rotation and translation via singular value decomposition. Abaunza et al. [18] conducted a systematic comparison of kinematic screw and dual-quaternion-based motion controllers, demonstrating the superior numerical stability of dual quaternion formulations.
Our contribution is to introduce a dual-quaternion-based visual servoing control system designed specifically for tasks requiring precise perpendicular alignment with a surface, such as button pressing. The control system uniquely obtains the target’s pose—including its position, depth, and surface normal direction—from an RGB-D camera and integrates this information into a compact dual quaternion representation. And the corresponding image Jacobian matrix for the dual quaternion pose representation is computed. The dual-quaternion-based visual servoing ensures that the pressing direction coaxial with the optical axis of the end-effector-mounted camera remains perpendicular to the target plane throughout the entire motion, which effectively reduces misalignment between the actual contact point and the visually identified target. By leveraging the mathematical properties of dual quaternions for representing poses in SE(3), our method offers a more compact, concise, and computationally efficient way to construct the visual servoing control system compared to traditional approaches. Unlike image-based pointing systems that explicitly address sensing delays through inertial augmentation [19] or multi-layer controllers that compensate for both sensing dynamics and robot dynamics [20], our method leverages the compact algebraic structure of dual quaternions to achieve computational efficiency with a single-layer geometric control law. While the proposed method does not explicitly incorporate delay compensation or actuator saturation handling, its geometric consistency and reduced computational complexity provide measurable efficiency gains suitable for implementation on various platforms.
This paper is organized as follows: Section 2 provides an overview of the fundamental mathematical framework and operational rules related to dual quaternions. Section 3 proposes the novel method based on unit dual quaternions for robot trajectory planning that yields enhanced accuracy in button-pressing tasks. Section 4 presents the simulation and experimental results to demonstrate the effectiveness and superiority of the proposed method. Section 5 summarized the conclusion.
2. Mathematical Background
2.1. Quaternion
Several equivalent mathematical forms can represent quaternions. A fundamental form is given by the following definition:
where and the imaginary units are governed by the following rules:
Quaternions extend the concept of complex numbers from a two-dimensional plane to a four-dimensional space. It is also defined as a pair
where is the scalar component, is the vector component and .
The scalar multiplication of quaternions is
where is an arbitrary scalar.
The conjugate of the quaternion can be defined as
Let two quaternions be defined as . The addition and multiplication operations are then given by
Quaternion multiplication can be represented in matrix form as
The norm of a quaternion is defined as
If , the inverse of a quaternion is given by
Specifically, a quaternion is termed a unit quaternion if its norm is equal to 1. For such a quaternion, its inverse is directly given by the conjugate
Furthermore, a unit quaternion that represents a rotation by an angle about the rotation axis can be expressed in the form:
2.2. Dual Quaternion
The dual number, which is invented by Clifford and developed by Study, is defined as
where is called the real part, is called the dual part and is the dual element.
The dual quaternion is constructed by applying the principles of dual numbers to quaternion algebra. Specifically, it can be represented as a quaternion whose components are themselves dual numbers, or equivalently, as a dual number whose two components are quaternions. This leads to the following standard notation:
where and are quaternions.
The conjugate of a dual quaternion is given by:
Let and be two dual quaternions. The addition and multiplication operations are then given by
If , the norm of the dual quaternion is defined as , and we can obtain
If , the dual quaternion is called unit dual quaternion, where the necessary and sufficient conditions are as follows.
A dual quaternion is a unit dual quaternion, defined by , if and only if the following conditions hold:
And the inverse of a unit dual quaternion is
3. Dual Quaternion Visual Servoing
To ensure actuation accuracy when pressing the target button, the tool’s Z-axis must be aligned perpendicular to the button plane before the pressing motion. A misalignment between the tool axis and the surface normal vector will introduce a lateral positional error during the downward motion, causing the actual press point to deviate from the the image recognition results. Therefore, the end-effector must first be moved to a pose where its orientation is normal to the button plane and its position is directly above the target point along the surface normal vector.
3.1. Desired Dual Quaternion Pose
Given a plane specified by its unit normal vector and the Cartesian position coordinate of a target button, the set of rigid body poses restricted to lie on the normal line through and to have their orientations aligned with constitutes a subgroup of . This subgroup can be parameterized by the unit dual quaternion .
In terms of the task, a pose satisfies the task requirements if its position is obtained by translating the target position along the unit normal vector by an arbitrary distance d, and its orientation coincides with the unit normal vector while allowing arbitrary rotation about .
Let denote the desired orientation of the end-effector for pressing the button in the world frame. Therefore, the orientation can be described in the form of a unit dual quaternion constructed with :
Similarly, given a translation vector and a pure quaternion , a translation motion can be described as a unit dual quaternion constructed with :
If the current Cartesian position coordinate of the end-effector is expressed as , the closest position in the subgroup from the current end-effector position is the projection of onto the line through point with the unit direction vector . And this closest position can be written as
According to Equation (25), we can consider as a translation vector and construct a corresponding pure quaternion . The closest and feasible translation dual quaternion in the world frame can be derived:
Therefore, combining the rotation and translation parts above, a desired pose with closest position and feasible orientation can be described in the form of unit dual quaternions as
The obtained target pose guarantees that the end-effector is positioned directly above the button and oriented orthogonally to the target plane. Initiating the pressing motion from this pose ensures that the end-effector’s movement direction and the optical axis of the coaxially mounted camera remain orthogonal to the button plane, thereby eliminating any lateral displacement error between the actual and visually identified contact points.
3.2. Dual Quaternion Error and Control Law
Our approach is based on eye-in-hand position-based visual servoing. This error is defined in a general form as
where s is a mapping function of current image features (e.g., point, shape, pose, or frequency-domain features) obtained by the camera, and represents the mapping function of the desired image features. The system is considered to have reached a stable convergence point when this image error is driven to zero.
If a camera mounted on the end-effector is used for visual recognition of a fixed target object, the relative pose between the camera and the object can be utilized as the image feature s. For notational clarity, we define the current camera frame as frame c, the desired camera frame be frame , and the target object frame be frame s. The pose transformation of the target object frame with respect to frame c and frame , denoted as and respectively, is represented using dual quaternions.
For a unit quaternion , both and represent the same physical rotation. To ensure uniqueness in the additive error computation, we enforce the convention that the scalar part satisfies . This is achieved by the mapping: To ensure uniqueness in error computation, we adopt the convention that the scalar part of the quaternion satisfies . This is implemented as follows: if the scalar part , the quaternion is used directly; if , we take its negative. This mapping yields a normalized quaternion with a non-negative scalar part.
For a unit dual quaternion , the sign ambiguity is resolved by applying the above sign convention to select . This guarantees a unique representation.
Therefore, we can define the dual quaternion error as the difference between the actual and expected target poses in the camera frame. And the error can be expressed as
The objective of visual servoing control is to move the robot’s end-effector with the camera and minimize the image error .
Limited by the camera’s field of view, the visual servoing task operates in a neighborhood of the desired pose where the rotation angle error . This ensures that the error remains valid and the system avoids the related singularity. The additive form avoids the quaternion multiplication and logarithm computation required for the relative error, reducing the control loop latency facilitating straightforward proportional control without the need for nonlinear error projection. For the usual task with typical initial poses within 90° of the target and limitation of the camera’s field of view, the additive error provides an feasible approximation.
Let and denote the instantaneous linear and angular velocities of the camera expressed in the camera coordinate frame respectively. If the camera’s pose change rate is compactly represented as a vector , the rate of change in the image features , can be expressed as a function of the camera velocity as follows:
where is the image Jacobian matrix.
Differentiating Equation (32) and substituting Equation (33) into the result, we obtain
If we choose the velocity of the camera as
where is a positive definite diagonal gain matrix that is manually designed. The choice leads to a linear system.
In the following, we provide a proof of stability for the control system constructed as described above. We define the following Lyapunov function candidate which is a positive definite quadratic function:
Differentiating Equation (36) and substituting Equation (34) into the result, we can obtain
Since is a diagonal matrix and we choose , substituting Equation (35) into Equation (37) derives
Therefore, if is a positive definite matrix, the derivative of the Lyapunov function of the system is negative. The system is asymptotically stable.
3.3. Image Jacobian Matrix Derivation
We now calculate the image Jacobian matrix . Let the position of the image target expressed in the camera coordinate frame be denoted as a position vector and a position quaternion and the orientation be denoted as a quaternion . The pose of the image target described as a unit dual quaternion can be expressed as
We begin by considering the real part of the dual quaternion. Its derivative is computed as follows. The orientation at time t and is given by the quaternions and , respectively. If we denote the instantaneous angular velocity of the image target expressed in the camera frame as , the rotational change during corresponds to a rotation by an angle about the instantaneous axis , and is described by
It follows that . If we consider as the original orientation, we can calculate the quaternion derivative through the difference between and as
Therefore, the time-derivative of the quaternions can be obtained
Finally, we consider the derivative of the pose represented by the unit dual quaternion. Differentiating Equation (39) with respect to time t, we can obtain
By substituting the quaternion product given in Equation (9) into Equation (43) and simplifying the result to the matrix form, we can obtain
Based on the geometric relationship, the velocity of the target object in the camera frame is related to the camera’s velocity as follows:
where and are the linear velocity and angular velocity of the camera in the camera frame respectively.
Similarly, simplifying the result to the matrix form, we can derive
where is the skew-symmetric matrix of the vector .
By combining Equation (44) with Equation (47), the image Jacobian matrix in Equation (33) can be derived
The control system structure is shown in Figure 1 and the whole control process is shown in Algorithm 1. Algorithm 1 Dual-Quaternion-Based Visual Servoing with Normal AlignmentInput: Gain matrix , Convergence threshold Output: Robot reaches pose with end-effector perpendicular to target surface
- 1:Initialize: Robot current pose
- 2:while do
- 3: Perception:
- 4: Capture RGB image and depth image
- 5: Detect target position and estimate surface normal
- 6: Desired Pose Construction:
- 7: Compute closest point on normal line:
- 8: Construct translation dual quaternion: where
- 9: Construct rotation dual quaternion:
- 10: Desired pose:
- 11: Error Computation:
- 12: Ensure scalar part of is non-negative
- 13: Compute dual quaternion error:
- 14: Control Law:
- 15: Compute image Jacobian:
- 16: Camera velocity:
- 17: Execution:
- 18: Transform to robot joint velocities:
- 19: Send to robot controller and update pose
- 20:end while
- 21:return Robot reaches pose
4. Simulations and Experiments
The experiments were conducted using a KUKA LBR iiwa 14 R820 manipulator (KUKA Deutschland GmbH, Augsburg, Germany). A RealSense Depth D435i camera (Intel Corporation, Santa Clara, CA, USA) which is an RGB-D camera is chosen to be the simulation camera for 3D scene reconstruction, depth information extraction and the image recognition. The RGB-D camera is set on the end-effector, aligned parallel to it. The experimental platform is shown in Figure 2. It is used for image recognition of the target and responsible for acquiring depth information around the target and measuring the normal vector of the plane on which the target is located. The camera intrinsics are set as follows: the image resolution is 1920 × 1080 pixels, the principal point is located at (966, 532), and the focal lengths in the x and y directions are both 1395 pixels. By integrating the depth information and button position data obtained from the camera, the three-dimensional position vector of the target button in the camera coordinate system, along with the normal vector of its residing plane, can be accurately computed. The initial pose of the camera on the robot in the base frame is represented using dual quaternions as
And the target is selected as a 0.4 m by 0.4 m black and white checkerboard, with its center at , and its plane normal vector is .
The simulation results of the dual-quaternion-based visual servoing are presented in Figure 3 and Figure 4. Figure 3a,b illustrate the linear and angular velocities, respectively, of the robot’s end-effector expressed in its own coordinate frame. Both velocities can be seen to converge to zero as the camera and end-effector approach their desired poses. Figure 3c illustrates the pose error between the actual and expected target poses in the camera frame expressed as unit dual quaternions. Figure 4a,b show the initial pose of the robot and the initial camera view, respectively. Figure 4c,d show the final robot pose after task completion and the corresponding camera view. The robot finally moves to the desired pose directly above the target point on the black and white checkerboard, with the end-effector frame oriented perpendicularly to the target plane, indicating that the visual servoing task was accomplished. The pose error converges to , which means the actual robot pose coincides with the desired pose. By leveraging the mathematical properties of dual quaternions in SE(3), our method offers a compact and computationally efficient visual servoing formulation. Simulation results demonstrate that this approach not only simplifies the system construction but also achieves reliable convergence.
To quantitatively evaluate the advantages of the proposed dual-quaternion-based approach, we implemented a comparative experiment using the conventional homogeneous transformation matrix method. The same proportional control law with identical gain matrices is applied to ensure a fair comparison. Figure 5 presents the simulation results obtained using the homogeneous matrix method under identical experimental conditions. As shown in Figure 5a,b, the linear and angular velocities of the end-effector exhibit similar convergence trends. Figure 5c reveals the pose error achieved by the homogeneous matrix method are comparable in magnitude but require approximately 1.5 s to converge, whereas the proposed dual quaternion method achieves convergence within approximately 1.2 s.
Table 1 provides a quantitative comparison of computational efficiency between the proposed dual quaternion method and the conventional homogeneous matrix method. The results demonstrate that the proposed method requires only 1.8628 ms per control cycle on average, achieving a 27.9% reduction in computation time compared to the homogeneous matrix method (2.5836 ms). Furthermore, the proposed method exhibits lower computational complexity with 45 FLOPs per control cycle on average versus 65 FLOPs for the homogeneous matrix approach. These gains stem from the compact algebraic structure of dual quaternions, which naturally couples rotational and translational components without requiring separate matrix operations for pose composition and error computation. The reduced computational overhead is particularly advantageous for real-time implementation on resource-constrained robotic platforms.
5. Conclusions and Future Work
In this paper, we have introduced a novel visual servoing method based on dual quaternions to fulfill the requirements of reaching poses guaranteeing perpendicular alignment in robotic button-pressing tasks. By formulating the pose representation and error minimization within the dual quaternion algebra, we achieve a compact and computationally efficient approach to conduct the visual servoing control. Our contribution lies in the derivation of the control law and the corresponding image Jacobian matrix for the dual quaternion pose representation, which simplifies the computation and ensures convergence. Although our method effectively decreases execution misalignment in the button-pressing progress, the framework itself is general and applicable to a broad range of precision manipulation tasks. Experimental results show that our dual-quaternion-based approach not only enhances positioning accuracy but also achieves superior computational efficiency compared to conventional methods.
While the proposed method demonstrates effective performance, several practical constraints should be acknowledged. In practice, RGB-D frame acquisition and target detection introduce latency that may affect stability at high speeds. Future work will incorporate delay-compensated control. Furthermore, surface normal estimation from depth data is sensitive to sensor noise, particularly on specular or textureless surfaces. This limits application to surfaces with particular reflecting properties. Robust filtering or learning-based methods could improve this. Moreover, the method assumes the target remains within the camera field of view during servoing. Large initial misalignments may cause target loss, necessitating visual tracking or exploratory motions. For larger workspaces, adjusting camera viewpoint with a proper algorithm would be necessary.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mahalle A.G. Shah A.M. An Efficient Design for Canny Edge Detection Algorithm Using Xilinx System Generator Proceedings of the 2018 International Conference on Research in Intelligent and Computing in Engineering (RICE)San Salvador, El Salvador 22–24 August 20181410.1109/RICE.2018.8509063 · doi ↗
- 2Zheng L. Yang Y. Tian Q. SIFT Meets CNN: A Decade Survey of Instance Retrieval IEEE Trans. Pattern Anal. Mach. Intell.2018401224124410.1109/TPAMI.2017.270974929610107 · doi ↗ · pubmed ↗
- 3Surasak T. Takahiro I. Cheng C.H. Wang C.E. Sheng P.Y. Histogram of oriented gradients for human detection in video Proceedings of the 2018 5th International Conference on Business and Industrial Research (ICBIR)Bangkok, Thailand 17–18 May 201817217610.1109/ICBIR.2018.8391187 · doi ↗
- 4Yang L. Zhong J. Zhang Y. Bai S. Li G. Yang Y. Zhang J. An Improving Faster-RCNN with Multi-Attention Res Net for Small Target Detection in Intelligent Autonomous Transport with 6GIEEE Trans. Intell. Transp. Syst.2023247717772510.1109/TITS.2022.3193909 · doi ↗
- 5Li J. Tang H. Li X. Dou H. Li R. LEF-YOLO: A Lightweight Method for Intelligent Detection of Four Extreme Wildfires Based on the YOLO Framework Int. J. Wildland Fire 202433 WF 2304410.1071/WF 23044 · doi ↗
- 6Hou M. Huo D. Yang Y. Yang S. Chen H. Using Mask R-CNN to Rapidly Detect the Gold Foil Shedding of Stone Cultural Heritage in Images Herit. Sci.2024124610.1186/s 40494-024-01158-9 · doi ↗
- 7Al-Shanoon A. Lang H. Robotic Manipulation Based on 3-D Visual Servoing and Deep Neural Networks Robot. Auton. Syst.202215210404110.1016/j.robot.2022.104041 · doi ↗
- 8Ribeiro E.G. de Queiroz Mendes R. Grassi V. Real-Time Deep Learning Approach to Visual Servo Control and Grasp Detection for Autonomous Robotic Manipulation Robot. Auton. Syst.202113910375710.1016/j.robot.2021.103757 · doi ↗