Deep Robust Moving Horizon Estimation for Nonlinear Multi-Rate Systems
Rusheng Wang, Songtao Wen, Bo Chen

TL;DR
This paper introduces a deep learning method to improve state estimation in complex, asynchronous systems using a robust moving horizon estimation approach.
Contribution
The novelty lies in combining deep learning with MHE to handle model mismatch and enforce stability constraints in multi-rate nonlinear systems.
Findings
A synchronization method transforms asynchronous systems into synchronous ones for estimation.
A deep learning framework learns MHE weights while ensuring stability via barrier-function regularization.
The proposed method is validated through a target tracking example.
Abstract
In this paper, a moving horizon estimation (MHE)-based state estimation problem is studied for asynchronous multi-rate nonlinear systems. First, the asynchronous multi-rate system is transformed into a synchronous system at measurement sampling points through pseudo-measurement synchronization modeling. Secondly, a MHE strategy with a time-discounted quadratic objective is proposed. Under the detectability assumption, the exponential stability of the proposed MHE is established via the Lyapunov method, and the corresponding linear matrix inequality (LMI) constraints are derived. Moreover, to address the model mismatch after synchronization, a deep learning-based framework is proposed to approximate and learn the weighting parameters of the MHE. Then, barrier-function regularization is introduced to enforce the aforementioned LMI feasibility conditions, keeping the learned weights within…
Click any figure to enlarge with its caption.
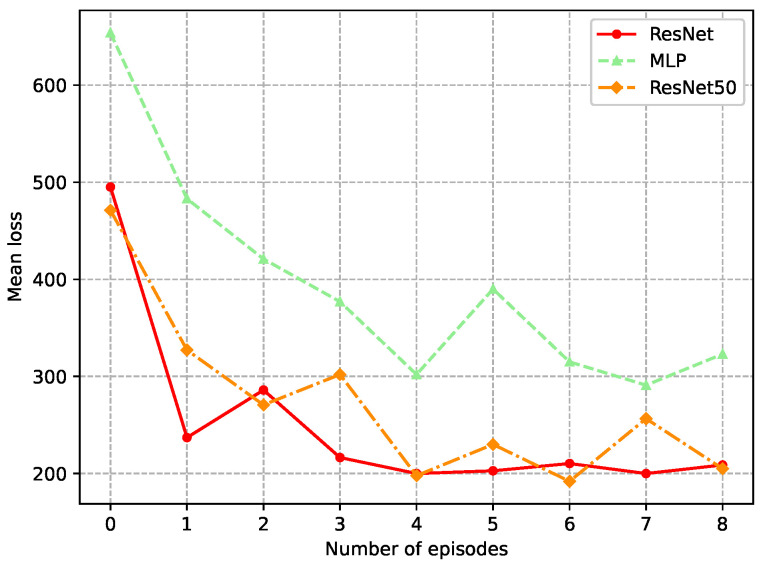 Figure 1
Figure 1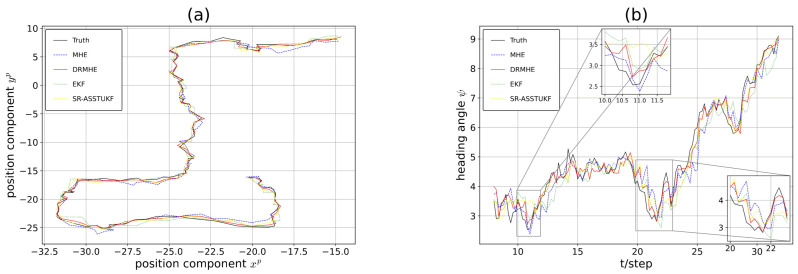 Figure 2
Figure 2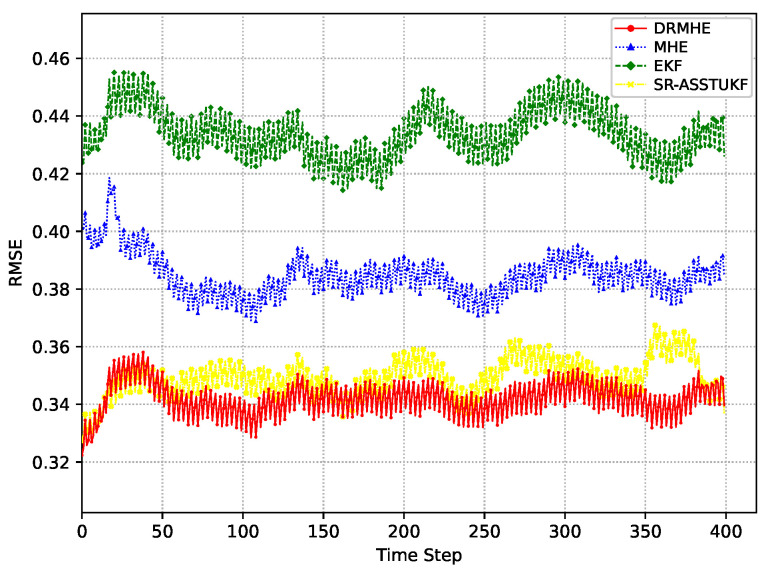 Figure 3
Figure 3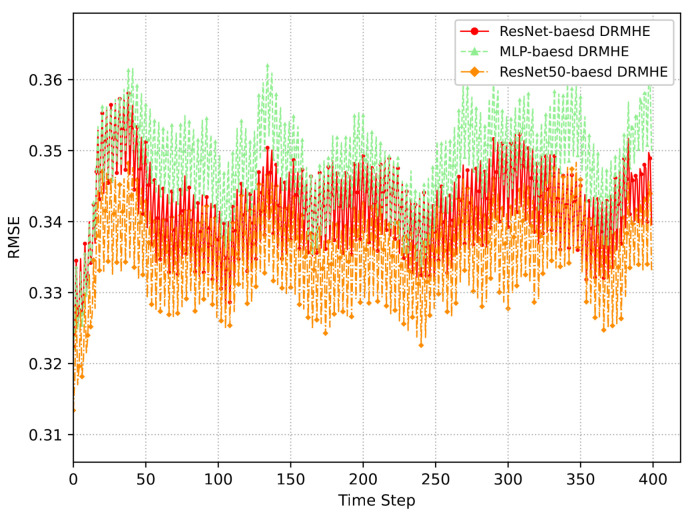 Figure 4
Figure 4- —Science and Technology Innovation 2025 Major Project of Ningbo
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsControl Systems and Identification · Advanced Adaptive Filtering Techniques · Stability and Control of Uncertain Systems
1. Introduction
State estimation plays a vital role in modern control and perception systems, providing accurate estimates and unknown state of the system in applications such as cyber–physical security [1], unmanned systems [2], and robotics [3]. At present, most state estimation problems consider the situation of synchronous sampling of sensors. However, heterogeneous sensors tend to operate at different sampling frequencies, which makes the system have multi-rate characteristics. In particular, the actual system is mostly nonlinear, which further increases the complexity and challenge of the multi-rate system estimation.
1.1. Related Works
For the estimation problem in multi-rate systems, it is difficult to directly apply single-rate state estimation methods to solve estimation problems under asynchronous measurement models. Therefore, it is crucial to convert the asynchronous multi-rate systems into synchronous single-rate systems. At present, one of the main approaches to solving asynchronous estimation problems is to combine wavelet theory [4] with recursive multiscale modeling [5]. The core idea of this approach is to decompose signals into orthogonal components at different resolutions, enabling the modeling of stochastic phenomena across multiple scales. On this basis, for multiresolution multisensor systems with unknown sensor structures, an online projection operator estimation using generalized compactly supported wavelets and a recursive least-squares algorithm was proposed in [6]. In [7], sensor allocation in discrete-time teleoperation systems was investigated using a multi-rate sampling architecture and Krasovskii-based stability conditions. Moreover, the lifting technique has been employed to address various multi-rate estimation challenges. In [8], an – filtering was proposed to solve the multi-rate estimation problem by using lifting technique. In [9], an optimal state estimation algorithm was proposed in the sense of linear minimum mean square error for a single-sensor multi-rate system. However, the augmented manner of lifting technique makes a high computational cost and weak real-time ability.
To overcome the limitation of lifting technique, the pseudo measurement method was developed to achieve synchronization in multi-rate systems. Based on this approach, a distributed matrix-weighted fusion estimation algorithm was proposed in [10], and a optimal sequential fusion filter with unreliable measurements and correlated noises was investigated in [11]. Consider the networked multi-rate systems, the variance-constrained state estimation problem was investigated in the presence of network-induced probabilistic sensor failures and measurement quantization [12], and a multi-rate filter was proposed for networked multisensor fusion systems with packet dropouts [13]. More recently, Sequential Student’s t-based UKF Fusion (SR-ASSTUKF) was proposed in [14] for nonlinear multi-rate multisensor systems with heavy-tailed noise and missing measurements, and it incorporated a t-test-driven adaptive mechanism to cope with nonstationary measurement uncertainty. However, it remains a one-step recursive fusion filter and does not explicitly optimize over a moving horizon to compensate for pseudo-measurement-induced model mismatch. Note that the above methods have not considered model mismatch in the synchronous modeling process, nor the need for adaptive weighting under time-varying noise conditions.
Different from conventional nonlinear filter that rely on one-step updates, such as extended Kalman filter (EKF) and unscented Kalman filter (UKF) [15], moving horizon estimation (MHE) optimizes state estimates over a finite moving window. Noted that the moving time window can better handle the asynchronous multi-rate measurements. In [16], the deviation from past estimates was penalized based on confidence weighting, where the arrival cost term in the MHE objective function was approximated by using an EKF-based covariance update. In [17], a suboptimal MHE was proposed that achieves robust stability not through optimization, but by constructing a feasible candidate solution. Additionally, a moving horizon estimator with robust global asymptotic stability was proposed in [18] under bounded disturbances. However, conventional MHE schemes generally neglect the effect of model mismatch, which undermines their robustness under strong nonlinearities and asynchronous measurements.
To improve estimation robustness, recent studies have incorporated deep learning into the MHE framework to compensate for the deficiencies of observation model under multi-rate conditions. In [19], a neural network-based nonlinear approximation function was introduced to improve estimation accuracy during the cost minimization process. Moreover, an autotuning NeuroMHE scheme was proposed in [20], where a multi-layer perceptron dynamically adjusts the weighting parameters of the estimation window. In [21], variational-Bayes adaptive MHE was proposed to guarantee mean-square boundedness under stochastic formulations. In [22], Gaussian-process-based MHE learned unknown dynamics with Gaussian-process regression and proved practical robust exponential stability with convergence to an error neighborhood. Furthermore, a recent systematic review was presented in [23], it shows that Neural MHE research covers model learning, cost learning, and optimization approximation, but rigorous stability guarantees beyond empirical validation are still widely missing. Noted that the above learning-based MHE studies typically establish theoretical guarantees in weaker senses, rather than in the robust global exponential stability (RGES) sense required for bounded-disturbance nonlinear systems. Obviously, the latter is more suitable for systems that contain time-varying learning-based components.
1.2. Motivations and Contributions
When the MHE weights are learned in a data-driven manner, the estimator is no longer a time-invariant optimization-based mapping. As a result, classical RGES analyses, which rely on uniform detectability/contractivity and uniformly positive bounded weights, do not apply directly. Without an explicit mechanism that constrains the learned weights to a stability-preserving region, learning may induce extreme or fast-varying weights, thereby violating these conditions under bounded disturbances and nonlinear dynamics. Recently, a proportional–integral filter has been proposed in [24] to handle the bounded disturbance under linear single-rate framework, and the boundedness of the Lyapunov–Krasovskii functional was also derived. On this basis, the nonfragile extended dissipativity state estimator was designed in [25] for discrete-time neural networks to ensure estimation performance under time-varying delays. In this case, how to effectively compensate for multi-rate observation errors using deep learning while preserving the robust stability structure of MHE remains a challenging problem.
Motivated by the above analysis, this work will investigate the deep learning-based robust MHE framework for addressing the estimation problem of nonlinear multi-rate systems. The main contributions are summarized as follows:
- A robust MHE is developed for nonlinear multi-rate systems, where the linear matrix inequality (LMI) constraints are derived to ensure the boundedness and exponential convergence of the estimation error under bounded disturbances.
- A stability-preserving neural framework is developed by embedding the LMI feasibility conditions into the learning process. This design keeps the adaptive weights within a feasible set and prevents learning-induced variations from undermining the required RGES conditions.
Notation: Let denote the positive real numbers and denote the set of non-negative integers. The identity matrix is denoted by . For a vector , its Euclidean norm is denoted by . The notation denotes the determinant of a square matrix. Moreover, for any positive definite matrix , the quadratic norm is defined by . Let denote the maximum generalized eigenvalue of positive definite matrices A and B. A function is of class if it is continuous, strictly increasing, and satisfies . In addition, if is unbounded, then . A function is of class if for each fixed and for each fixed . The term denotes a quantity such that i.e., is of higher order than as .
2. Problem Formulation
2.1. System Model
Consider the following asynchronous multi-rate nonlinear system with m sensors
where is the system state, is the measurement collected by the i-th sensor. The disturbance input signal and measurement noise are locally essentially bounded functions taking values in set and , respectively. The nonlinear mappings and , which describe the system dynamics and output equation, are assumed to be jointly continuous. Meanwhile, and are closed.
Assume that the i-th sensor provides measurement every time unit, where is a positive integer multiple of the state updating period T. In this case, the asynchronous of the measurments will increase the design difficulty of the estimator. To synchronize the system state equation and measurement equation, a pseudo-measurement modeling approach [10] is adopted. Specifically, define a binary function:
where denotes that a new measurement is available at time t; otherwise, the sensor is not sampled.
Subsequently, the predicted value is used as the pseudo-measurement for compensating sensor information at the unsampled moment, yielding the following reconstructed measurement model:
where is the predicted value of . Let
From (2)–(8), the reconstructed synchronous measurement model can be given by:
In this paper, the initial estimate is used to moving estimate the state at time t, where is unknown but belong to a known compact set . Generally, MHE formulates state estimation as a finite-horizon optimization, where an arrival cost encodes past information, while a running cost penalizes process and measurement residuals. Thereby, based on the input–output history of system (1) and (9) over a sliding window with length at time t, the window-initial state and disturbance sequence can be obtained by the MHE, and the corresponding estimate over the N-step horizon is generated by recursing system dynamic (1) and (9). It is concluded that the MHE formulates the following optimization problem:
where , Q, R and are corresponding optimization parameters. Note that denotes the arrival state estimate at the beginning of the current horizon, which is derived from the previous estimation result.
Denote and as the optimal values of Problem (10), and the estimate at time t can be obtained by propagating the optimal window-initial estimate:
It should be pointed out that the updated measurement sequence is used to resolve the optimization problem (10) at time , and then yielding a new estimate . This shift-and-update procedure is iteratively performed for all , thereby implementing the moving horizon estimation process in a receding-horizon manner.
2.2. Problem of Interest
Note that model synchronization renders the measurement information from (4) non-stationary, while traditional MHE with fixed weights is sensitive to this non-stationarity, and thus requiring frequent adjustment of the weights. To overcome this limitation, we will design an adaptive deep robust MHE (DRMHE).
To construct that the robust stability of the proposed DRMHE, an appropriate detectability assumption is required. Particularly, a suitable nonlinear detectability concept is incremental input/output-to-state stability (i-IOSS) [26]. In this case, the i-IOSS Lyapunov function has become a standard framework for describing nonlinear detectability [27,28,29].
Definition 1(i-IOSS Lyapunov function [28]). A function is an i-IOSS Lyapunov function for the system (1) and (9) if it is continuous, and there exist functions , and a constant such that the following dissipation inequalities hold:
where , , , and the nonlinear mapping relationship between and is derived from (9).
Definition 2(RGES [30]). A state estimator for system (1) and (9) is RGES if there exist functions , and such that for all , , and the estimated state satisfies
Detectability ensures the linear convergence of estimation errors within a finite horizon [30], which is a standard requirement for the robust exponential stability of MHE. Under the above definitions, the detectability assumption and regularity conditions are presented as follows.
Assumption 1(Detectability [28]). For each , system (1) and (9) admits a i-IOSS Lyapunov function V according to Definition 1 with quadratic bounds and supply rates, i.e., there exist and such that
for all , , and .
Assumption 2. The function f is continuously differentiable in all of its arguments, h is affine in , and the sets and are convex.
In conclusion, the problems to be solved in this paper are summarized as follows:
- 1.Under Assumption 1 and sensor asynchronous sampling, how may we prove the robust exponential stability of the proposed MHE and derive the corresponding LMI conditions?
- 2.Under Assumption 2, how may we employ deep learning to select time-varying weights within the admissible feasibility set without violating the LMI constraints?
3. Stability Analysis of Designed MHE
In order to establish RGES of the proposed moving horizon estimation, the following lemma is introduced. It indicates that the function V in Assumption 1 can be regarded as the N-step Lyapunov function of MHE.
Lemma 1. When Assumption 1 holds, the Lyapunov function V with respect to optimal state estimate satisfies
for all , , , and .
Proof of Lemma **1.**By solving optimization problem (10), the optimal solutions and at time t can be obtained. By iterating inequality (16) N times and combining it with the Lyapunov-function upper bound (15) in Assumption 1, one obtains
Next, by applying the Cauchy–Schwarz inequality to the term , and the triangle inequality to the term , we obtain
Similarly, for the first term in (18), one has
By substituting (19)–(21) into (18), and combining the cost function (10) which lead to
Since is the minimum of (10), for any feasible and it holds that
Substituting this bound into the previous inequality (22) yields the desired estimate. Evidently, the true state and disturbance sequences, as a feasible solution to the MHE problem, also satisfy the above relationship. Hence, we obtain
Then, by utilizing the properties of the maximum generalized eigenvalue to reformulate the arrival cost, one has
where denotes the maximum generalized eigenvalue of and . By substituting (25) into (24), the relationship between the Lyapunov function at the initial time step and the current time step of the receding horizon is obtained. □
Based on the N-step Lyapunov inequality (17) under Assumption 1, the RGES of the MHE will be analyzed below, with
Theorem 1. When the Assumption 1 holds, there exists a horizon that is selected to satisfy , such that the proposed MHE estimator is RGES in the sense of Definition 2 for all .
Proof of Theorem **1.**Define and for all , such that t can be expressed as . Then, the Lyapunov relationship under full information for can be derived from (24):
When , applying the lower bound mentioned in Lemma 1 k times yields
Using the bound
together with , inequality (28) can be derived as
From (30), taking the square root of the lower bound in (15), we have
where , , , and . It is concluded from (31) that the estimation error satisfies (14) and the RGES of proposed MHE has been established. □
On the basis of Theorem 1, the existence condition of i-IOSS Lyapunov function is provided in the following Theorem. In particular, the quadratic i-IOSS Lyapunov function can be certified via contraction/Riemannian methods [28].
Define the Jacobian linearizations of (1) and (9) at the operating point as
Theorem 2. When the Assumption 2 holds, if there exist symmetric matrices , and a constant such that
for all . Then, is a i-IOSS Lyapunov function and satisfies Assumption 1 with .
Proof of Theorem **2.**See ([28], Theorem 2), the detailed proof is omitted. □
Therefore, the LMI constraints are expressed as matrix inequalities in (33), which are crucial for ensuring the robustness and convergence of the MHE. In particular, they provide a verifiable sufficient condition that enforces the i-IOSS-based dissipation/contraction structure required by the RGES-type analysis.
Remark 1. Notice that the cost function J of MHE can be parameterized by any positive definite matrices P, Q, R and any when Assumption 2 holds. Moreover, if the uniform boundary is known a priori, the time-varying weights , , can be determined by (10), and the detailed selection strategy will be presented in Section 4.
4. Deep Robust MHE Based on Barrier Function
4.1. Architecture
Generally, the arrival cost covariance P is approximated via the EKF, which depends on the Jacobian matrices (32). However, the accuracy of the Jacobian matrices is affected by the pseudo measurement (4), and observation errors make the choice of R is crucial. To address this, a deep neural network [20] is adopted to regress the time-varying matrices .
Let denote the output of a residual network (ResNet) [31], and defining as the ResNet with parameters , DRMHE assigns the weights via
where is the predicted state.
The estimated state implicitly depends on , and thus on the network parameters . Specifically, this implicit dependence allows for the end-to-end learning of the parameters through gradient-based optimization.
Then, in order to obtain the process of learning the optimal parameter with respect to ResNet-based DRMHE, we formulate the following optimization problem:
It is noted that the loss in terms of estimation error over the horizon N is proposed in this paper, rather than the error between the neural network outputs and the ideal covariance. This is because the ideal covariance cannot be accurate determined using the model (1) and (9). In this case, the loss function is set to
where the gradient of the loss (36) with respect to the ResNet parameters is computed by backpropagation [32], and the chain rule is given by:
In fact, the training structure of is a bi-level optimization scheme. In the outer forward pass, the MHE optimizer receives and generates the optimal solution , yielding the loss In the backward pass, the gradient components are computed and fed back to the network. Note that the gradient is recursively computed using a Kalman filter-based gradient solver [33]. The inner optimization computes by standard machine learning tools, enabling the neural network to update accordingly. In particular, the loss used for updating the neural network parameters is not the tracking error loss itself, but rather its projected form:
It reflects the dependency of the final loss on the neural network parameters through the weighting map .
4.2. Conflict Between Learning and RGES Guarantees
In learning-based weight adaptation, the weights are generated by
where is fixed after offline training while the input varies over time, so the LMI constraints become time-varying through . This reveals a structural conflict between RGES and unconstrained learning. RGES relies on the LMI/i-IOSS inequalities (33) holding for all time instants with time-uniform margins, so that time-uniform contraction constants and i-IOSS Lyapunov function exist. By contrast, optimizes an average data-fitting objective and does not enforce (33). Therefore, the learned weights may violate the LMI constraints at some t, which breaks the uniform contraction argument and prevents concluding RGES.
To formalize this point, we model the time-varying LMI constraints as a scalar-valued constraint function
where represents the satisfaction of the LMI constraints induced by the learned weights . For instance, may be chosen as the maximum eigenvalue of the symmetric matrix defining the LMI residual at time t, but the following discussion only requires continuity and differentiability.
Define the LMI-constraints violation set at time t as
If is continuous in , then is open in .
Assumption 3. Assume that, for each time t, the scalar-valued constraint function is continuous and differentiable with respect to ω. Moreover, there exist a time such that
where is a boundary point of the feasible set.
Corollary 1. Consider an offline-trained parameter update driven by the neuro loss :
with step size . Suppose Assumption 3 holds. If exist some time t and a boundary point satisfying
and the loss descent direction is misaligned with the LMI-feasible direction at , i.e.,
Then, there exists such that for all the unconstrained update (43) violates the time-t LMI constraints, i.e., .
Proof. When Assumption 3 holds, a first-order Taylor expansion of at time along the update direction in (43) gives
Using (44) and (45), the leading term satisfies
Hence, there exists some time t and such that for all , which is equivalent to by the definition of . □
Remark 2. Corollary 1 implies that once an unconstrained learning update yields a parameter ω such that for some time t, the LMI constraints used to derive the N-step Lyapunov recursion may fail at that instant. As a consequence, the key inequality required to propagate a time-uniform contraction factor can no longer be guaranteed, and and the estimator may fail to satisfy RGES. This observation directly motivates the next subsection: we enforce during training via barrier-based constrained optimization, so that the LMI constraints remain satisfied for all relevant t and the RGES proof chain can be closed.
4.3. Barrier-Based Optimization for Deep Robust MHE
This section addresses a critical challenge in DRMHE: enforcing strict satisfaction of LMI constraints during neural network training. However, the LMI constraints represent hard constraints incompatible with standard backpropagation. In this case, a barrier-based optimization method is proposed, which integrates barrier regularization with the tracking error loss to ensure neural network weights satisfy i-IOSS conditions.
According to the negative semi-definiteness of matrix inequalities, an equivalent Schur complement form of (33) is derived:
The hard constraint (48) and (49) are incorporated into the loss function via a barrier function:
with a small margin .
Hence, we modify to
where is a regularization coefficient and is a penalty factor. Minimize the loss metric (52) by training the weights to enhance the robustness of MHE, thereby improving the state estimation performance.
The resulting procedure of bi-level optimization is summarized as Algorithm 1. Algorithm 1 Bi-level Optimization for Deep Robust MHE
- Input: Predicted state ;
- Initialization: Initial tuning parameter ;
- for to do
- for to T do
- Outer Optimization (Forward Pass):
- Solve the MHE problem (10) by substituting to obtain ;
- Compute batch loss using (36);
- Outer Optimization (Backward Pass):
- Compute gradient components , ;
- Inner Optimization (neural network):
- Compute using machine learning tool;
- Update using gradient-based optimization;
- Update adaptive weightings using (34);
- end for
- end for
- return .
5. Numerical Example
Consider a vehicle localization system in a two-dimensional horizontal space, where three sensors are used to track the state of the target. The nonlinear vehicle motion model can be given by [34]:
where and are the positions of the vehicle along the X-axes and Y-axes, respectively, denotes the heading angle, is the constant speed. The parameter denotes the sampling time, and denote the distances to the rear and front axles, respectively. The side-slip angle is determined by the control input . According to (53), the nonlinear state equation can be expressed by
Moreover, three sensors indexed by observe the target, providing heading angle and planar position components . Meanwhile, the measurement equations are same as (2). In detail, the simulation setup of initial state is set to , constant speed , front/rear axle lengths , and control input . The sampling time is , and sensor update intervals are 0.2, 0.3, and 0.6, respectively. The MHE horizon and discount factor are and . Moreover, the process and measurement noise variances are and .
The neural network is implemented as a ResNet with a block configuration of [2, 3, 4, 2] and Rectified Linear Unit (ReLU) activations. It takes the predicted state as input, and employs residual connections to alleviate the vanishing-gradient problem. The training set consists of time steps 100–5000, and testing is performed on a separate trajectory generated under different initial conditions and noise. This multi-rate simulation with bounded noise and bounded disturbances is adopted to ensure controlled and repeatable evaluation, and it is consistent with the assumptions required for the RGES guarantee. The Adam optimizer is adopted for training, and the mean loss is compared in Figure 1 across different network architectures, including a standard ResNet, ResNet50 with deeper residual block configurations, and a multilayer perceptron (MLP). It can be observed that the ResNet network achieves a lower mean loss than the MLP and reaches a stable level more rapidly. In contrast, ResNet50 shows less smooth training loss and overfitting, which is caused by its excessively deep network structure. Based on the definition of the loss function (52), it is indicated that the DRMHE framework using ResNet exhibits excellent convergence and training efficiency.
The true trajectory and the tracking trajectories of DRMHE, MHE, EKF, and SR-ASSTUKF [14] are plotted in Figure 2. The inset in Figure 2b shows the estimated heading angle at the moment of fastest change. EKF and MHE exhibit limited robustness, whereas SR-ASSTUKF achieves improved tracking via Student’s t-based sequential fusion. Nevertheless, because the yaw angle is measured at the lowest rate and experiences the most frequent dropouts, the robustness of SR-ASSTUKF decreases as measurement missingness becomes more severe. It demonstrates that DRMHE reacts more quickly, exhibits lower latency, and has smaller error spikes, enabling it to return to the normal trend faster than other methods.
Meanwhile, the root mean square error (RMSE) is adopted to evaluate the estimation performance of multisensor multi-rate estimators. In particular, to mitigate occasional outcomes caused by random noise in a single run, 200 Monte Carlo simulation runs are conducted. The RMSE of these estimator are reported to ensure statistical significance in Figure 3. It can be observed that the RMSE of the proposed DRMHE is lower than those of EKF [15], MHE [28], and SR-ASSTUKF [14], indicating superior estimation accuracy of DRMHE. It shows the DRMHE exhibits only slight fluctuations while maintaining a low estimation error, and indicates superior robustness and stability of proposed DRMHE under interference and asynchronous sampling. It can be further observed that the RMSE of DRMHE decays more rapidly and reaches its steady level earlier. Moreover, a numerical table of RMSEs of different methods is presented in Table 1, which shows DRMHE has a lower tracking error intuitively.
Figure 4 compares the RMSEs of MLP-based DRMHE, ResNet-based DRMHE, and ResNet50-based DRMHE. Meanwhile, the computational time required for DRMHE using these different network structures under 40 simulation experiments is reported in Table 2. It can be seen that ResNet achieves superior estimation performance compared with MLP, while the deeper ResNet50 network results in less smooth convergence and increased computational cost. This performance pattern is mainly attributed to the fact that the learning algorithm in this study is applied to multi-sensor data with a relatively small dataset, indicating that the depth of ResNet should be adjusted to the amount of data required.
6. Conclusions
In this paper, a deep robust moving horizon estimation method for nonlinear multi-rate systems was proposed. In detail, a pseudo-measurement compensation mechanism was designed to establish a synchronization model for multi-rate systems. Under the detectability assumption, Lyapunov-based analysis was employed to derive the LMI constraints for ensuring RGES of the estimation framework. To reduce the impact of model mismatch caused by pseudo-measurements, ResNet was employed to approximate the weighting parameters, thereby improving estimation robustness and accuracy. Then, a barrier-regularized training strategy was designed to reconcile the structural conflict between neural weight learning and RGES guarantees, by restricting the learned weights to a feasible region throughout training. Finally, a simulation example was presented to show the effectiveness of the proposed algorithm.
This paper considered a multirate systems with sensor uniform sampling, while the complexity of the real environment leads to many non-uniform sampling situations for sensors. Meanwhile, MHE scheme essentially has an insufficiency in terms of computational efficiency. In this case, the non-uniform sampling of sensors will be studied, and the learning-based nonlinear fusion criterion will be further designed to adapt to the effective fusion of asynchronous multimodal information. To reduce computational burden, future work will study stability guarantees for suboptimal MHE under a fixed number of solver iterations or early-termination rules, while preserving RGES-type properties as much as possible. Moreover, how to extend the framework to networked systems with packet dropouts and limited communication resources also be our future work.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ierardi C. Orihuela L. Jurado I. Distributed estimation techniques for cyber-physical systems: A systematic review Sensors 201919472010.3390/s 1921472031671691 PMC 6864544 · doi ↗ · pubmed ↗
- 2Zhang L. Viktorovich P.A. Selezneva M.S. Neusypin K.A. Adaptive estimation algorithm for correcting Low-Cost MEMS-SINS errors of unmanned vehicles under the conditions of abnormal measurements Sensors 20212162310.3390/s 2102062333477362 PMC 7829826 · doi ↗ · pubmed ↗
- 3Yan C. Lyu M. Chen Y. Zhang J. An Adaptive External Torque Estimation Algorithm for Collision Detection in Robotic Arms Sensors 202525631510.3390/s 2520631541157369 PMC 12567444 · doi ↗ · pubmed ↗
- 4Graps A. An introduction to wavelets IEEE Comput. Sci. Eng.19952506110.1109/99.388960 · doi ↗
- 5Chou K.C. Willsky A. Benveniste A. Basseville M. Recursive and iterative estimation algorithms for multiresolution stochastic processes Proceedings of the 28th IEEE Conference on Decision and Control IEEE Piscataway, NJ, USA 198911841189
- 6Cui P. Pan Q. Zhao K. Wang G. Li J. Estimation of the projection operator in a multiresolution multisensor data fusion scheme IEEE Trans. Circuits Syst. II Express Briefs 2006531343134710.1109/TCSII.2006.883824 · doi ↗
- 7Ghavifekr A.A. De Fazio R. Velazquez R. Visconti P. Sensors allocation and observer design for discrete bilateral teleoperation systems with multi-rate sampling Sensors 202222267310.3390/s 2207267335408287 PMC 9002628 · doi ↗ · pubmed ↗
- 8Yu B. Shi Y. Huang H. l 2–l∞ filtering for multirate systems based on lifted models Circuits Syst. Signal Process.20082769971110.1007/s 00034-008-9058-3 · doi ↗