DDAF-Net: Decoupled and Differentiated Attention Fusion Network for Object Detection
Bo Yu, Guanghui Zhang, Qun Wang, Lei Wang

TL;DR
DDAF-Net is a new network for object detection that improves performance by combining RGB and infrared data more effectively.
Contribution
The paper introduces a decoupled and differentiated attention fusion framework for RGB–IR object detection.
Findings
DDAF-Net achieves state-of-the-art performance on the LLVIP and M3FD datasets.
The decoupling–enhancement–fusion paradigm effectively addresses modality redundancy and noise interference.
Differentiated attention mechanisms improve cross-modal alignment and suppress noise.
Abstract
What are the main findings? A decoupled RGB–IR framework explicitly separates modality-common and -specific features, minimizing redundancy while retaining complementary details.A differentiated attention strategy robustly aligns cross-modal semantics and suppresses noise, achieving state-of-the-art performance on LLVIP and M3FD datasets. A decoupled RGB–IR framework explicitly separates modality-common and -specific features, minimizing redundancy while retaining complementary details. A differentiated attention strategy robustly aligns cross-modal semantics and suppresses noise, achieving state-of-the-art performance on LLVIP and M3FD datasets. What are the implications of the main findings? The proposed “decoupling–enhancement–fusion” paradigm offers a robust solution to modality redundancy, spatial misalignment, and noise interference.Its lightweight attention and adaptive gating…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1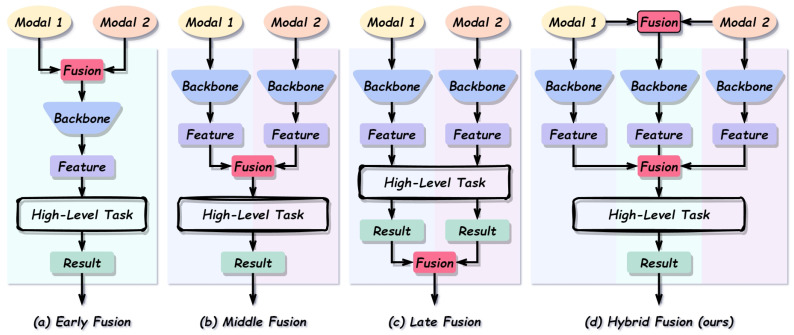 Figure 2
Figure 2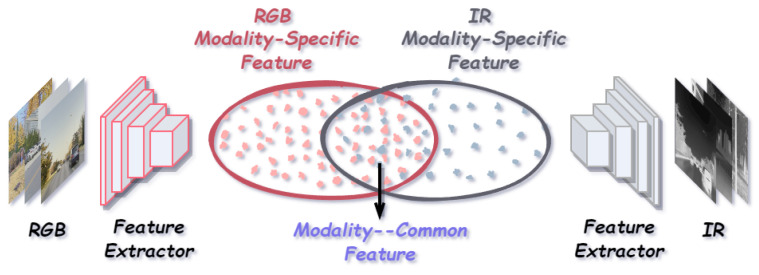 Figure 3
Figure 3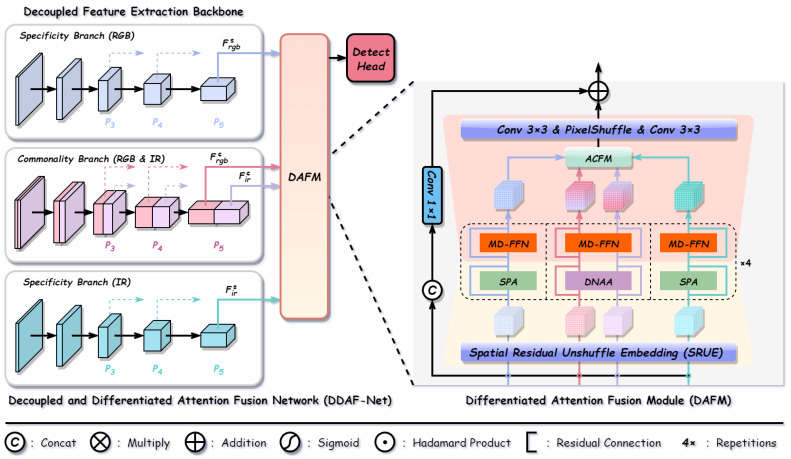 Figure 4
Figure 4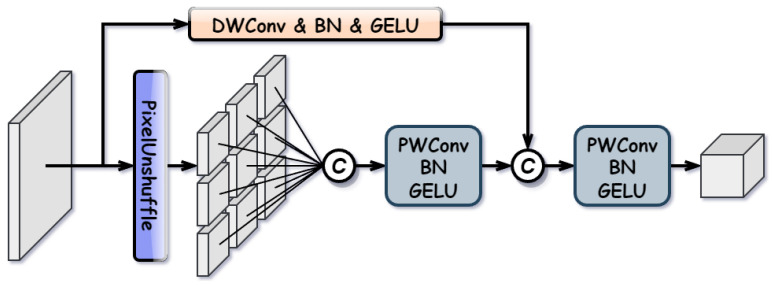 Figure 5
Figure 5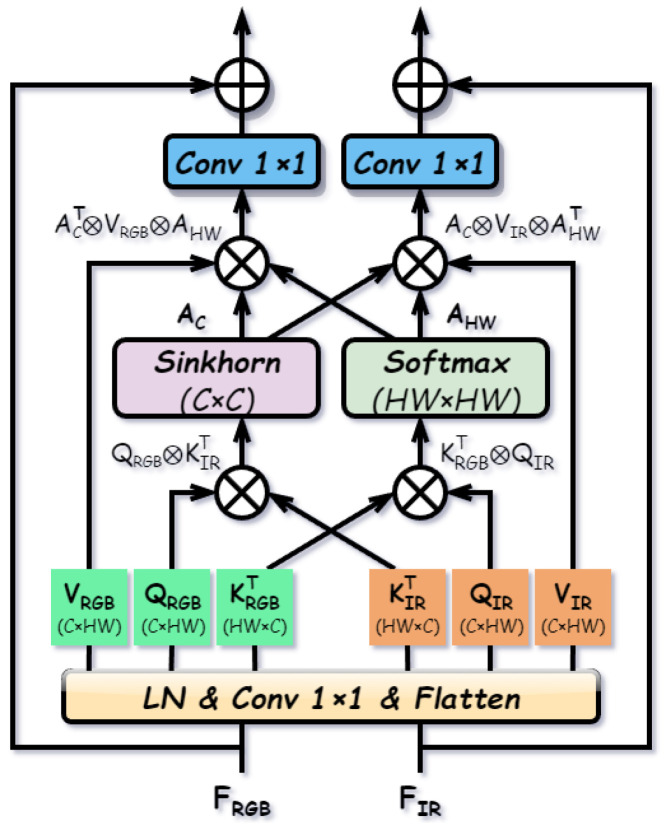 Figure 6
Figure 6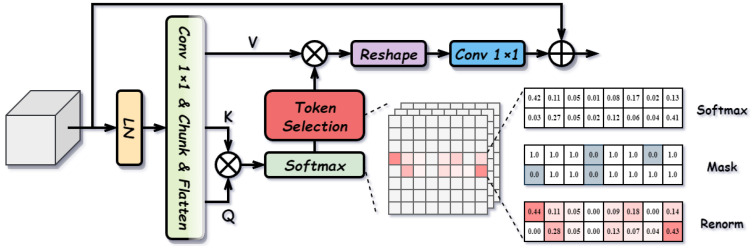 Figure 7
Figure 7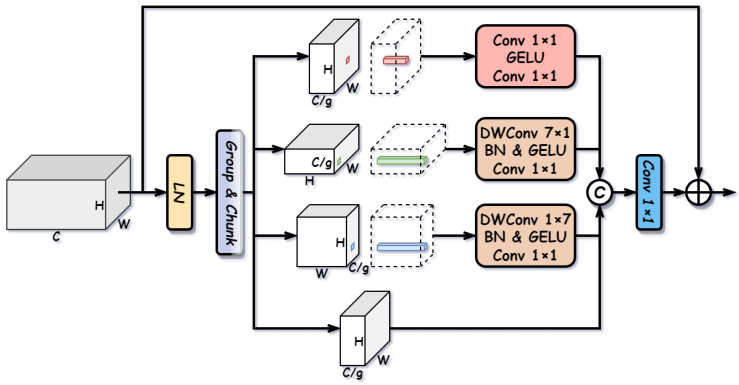 Figure 8
Figure 8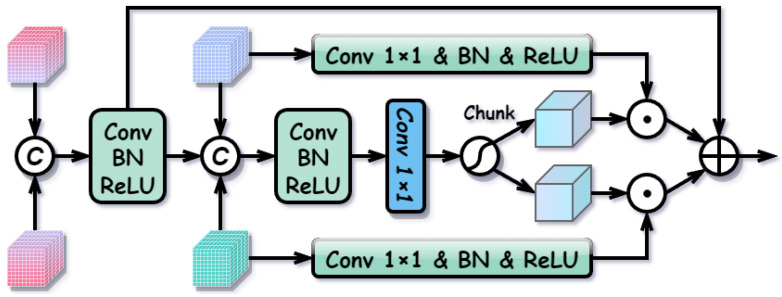 Figure 9
Figure 9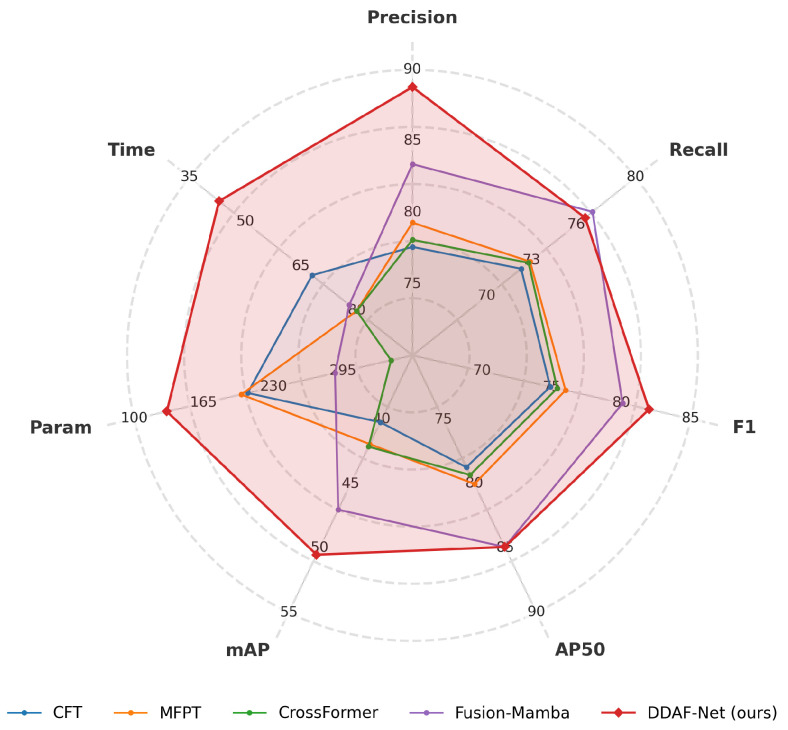 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12- —Liaoning Provincial Key R&D Programme “R&D of Multiscenario Intelligent Robot Crowd Collaborative Command and Dispatch System”
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Infrared Target Detection Methodologies · Advanced Image Fusion Techniques
1. Introduction
Multimodal fusion aims to integrate information from diverse sensors to achieve environmental perception capabilities that are more comprehensive and robust than those of single-modality systems. This technology has demonstrated significant advantages in various fields, including autonomous driving [1], industrial defect inspection [2], medical image analysis [3], and emotion recognition [4]. In object detection tasks, a single sensor often struggles to maintain stable performance within complex and dynamic environments. Visible (RGB) images provide rich color and texture information, facilitating precise object localization and category discrimination; however, their performance deteriorates significantly under low-light, high-glare, or adverse weather conditions. In contrast, infrared (IR) images provide stable thermal radiation contours in low light or total darkness but typically lack fine-grained textural details and high-level semantic representation. Consequently, fusing RGB and IR images—two heterogeneous modalities with significant complementarity—is widely regarded as an effective approach for achieving robust all-day and all-weather object detection.
Despite the immense potential of RGB-IR multimodal fusion in object detection, existing methods still face several key challenges during the modeling process. First, modality redundancy is prevalent. Different sensors often contain substantial semantically overlapping common information [5] (e.g., geometric structures and contour shapes) when describing the same object. Without explicit constraints during the feature extraction or fusion stage, this redundancy leads to repetitive modeling, which not only increases computational overhead but may also weaken discriminative semantic expression. Second, modality-specific information, while complementary, inevitably introduces noise interference. As illustrated in Figure 1, in nighttime scenarios, the RGB modality often contains significant background noise due to poor illumination or occlusion, whereas the IR modality preserves clear object contours. If such modality-specific noise is not effectively suppressed during fusion, unreliable RGB responses may be erroneously amplified and introduced into the fused features, thereby interfering with discriminative representation and degrading detection robustness. Third, modality misalignment remains a prominent issue. Due to differences in sensor imaging mechanisms, viewpoint offsets, and resolutions, RGB and IR features often exhibit deviations in spatial layout and semantic response, hindering the establishment of cross-modal semantic consistency. Finally, fusion strategy designs remain relatively coarse. A significant number of existing methods rely on simple feature concatenation or element-wise addition, lacking explicit fusion guidance mechanisms. This makes it difficult to model complex cross-modal dependencies, often leading to modality dominance or information suppression.
To address these issues, we propose the Decoupled and Differentiated Attention Fusion Network (DDAF-Net), which resolves these challenges through a targeted modular design. To tackle modality redundancy, DDAF-Net introduces a Siamese weight-sharing strategy [6,7] at the backbone level, explicitly decoupling RGB and IR features into modality-common features and modality-specific features. The weight-sharing branch learns cross-modal invariant semantics by enforcing parameter consistency, effectively avoiding repetitive modeling of common information, while parallel modality-specific branches retain the discriminative expression capabilities of each modality. On this basis, we design the Differentiated Attention Fusion Module (DAFM) to further achieve feature enhancement and cross-modal alignment. First, the Spatial Residual Unshuffle Embedding (SRUE) is introduced to perform lossless downsampling while effectively preserving global contextual semantics. Subsequently, to address noise interference in modality-specific features, we introduce Sparse Purification Attention (SPA). By utilizing a sparse attention mechanism to suppress non-salient responses and focus on key regions, SPA enables the selective utilization of complementary information, thereby improving feature robustness. Regarding modality misalignment, we propose Dual-Norm Alignment Attention (DNAA), which utilizes Sinkhorn iterations to explicitly establish correspondences between RGB and IR features at both channel and spatial levels, promoting semantic consistency modeling of modality-common features. Finally, to overcome the lack of effective guidance in fusion strategies, we propose the Adaptive Complementary Fusion Module (ACFM). This module uses the aligned modality-common features as a semantic anchor, dynamically generating gating weights to adaptively regulate the fusion ratio of modality-specific information, thus achieving stable and complementary cross-modal feature integration.
Based on the above design, the main contributions of this paper are summarized as follows:
- We propose an RGB-IR fusion framework with explicit specificity–commonality decoupling, effectively mitigating modality redundancy and cross-modal interference through a Siamese weight-sharing strategy.
- We design the DAFM, which combines DNAA and SPA to achieve semantic alignment of modality-common features and noise suppression of modality-specific features, respectively.
- We propose the ACFM, which establishes a dynamic weighting mechanism using modality-common features as a semantic anchor, effectively balancing the fusion of cross-modal complementary information across varying scenarios.
- Extensive experiments on public datasets such as LLVIP and M^3^FD demonstrate that the proposed DDAF-Net achieves performance superior to existing methods in RGB-IR object detection tasks.
The remainder of this paper is organized as follows. Section 2 reviews related work. Section 3 presents the overall architecture and core modules of DDAF-Net. Section 4 provides experimental results and a detailed analysis. Finally, Section 5 concludes the paper and discusses future research directions.
2. Related Work
Research on multimodal fusion can generally be categorized along two dimensions: fusion stage and fusion mechanism. The fusion stage focuses on where multimodal interactions occur within a network, while the fusion mechanism concerns how these interactions and integrations are realized. This section reviews representative studies from both perspectives.
2.1. Fusion Stages
According to the position at which multimodal information is integrated, existing methods are commonly divided into early fusion, middle fusion, late fusion, and hybrid fusion paradigms [8], as illustrated in Figure 2.
Early fusion integrates multimodal information directly at the data or shallow feature level [9]. This paradigm is simple and preserves fine-grained raw information; however, it is highly sensitive to modality noise or missing data, and naive feature concatenation often leads to the curse of dimensionality. Middle fusion performs cross-modality interaction at intermediate layers [10], enabling semantic alignment and complementarity between modalities. However, its effectiveness heavily depends on the choice of fusion layer(s) and the overall network design. Late fusion processes each modality independently and combines the predictions at the decision stage using strategies such as voting, weighted averaging, or ensemble methods [11]. Although this paradigm offers strong modularity and robustness, the absence of intermediate feature interaction prevents the effective exploitation of complementary mid-level representations. Hybrid fusion combines multiple fusion stages by introducing cross-modal interactions at different network depths [12]. While this paradigm achieves greater flexibility and often superior performance, it also increases model complexity and computational overhead, and may still suffer from redundant feature modeling or insufficient guidance for selectively utilizing modality-specific complementary information.
2.2. Fusion Mechanisms
Fusion mechanisms determine how multimodal features interact and are integrated within a network, thereby directly influencing both representational capacity and computational efficiency. Based on their underlying principles, existing fusion mechanisms can be broadly categorized as follows.
Operator-based fusion combines multimodal features using simple mathematical operations such as concatenation, weighted summation, or element-wise multiplication [13]. These approaches are computationally efficient and easy to implement; however, their limited modeling capacity makes it difficult to capture complex cross-modal dependencies.
Attention-based fusion has been widely adopted to model both intra-modal contextual relationships and inter-modal interactions [14,15]. Self-attention enhances contextual representation within each modality [16,17], while cross-attention facilitates feature alignment and information aggregation across modalities [18,19]. Despite their effectiveness, attention-based methods often incur substantial computational and memory costs when applied to high-resolution feature maps. Moreover, many existing approaches adopt homogeneous attention designs, lacking differentiated mechanisms to separately address modality-common alignment and modality-specific noise suppression.
Gating-based fusion employs learnable gating units to dynamically regulate the contribution of multimodal features [20,21]. By adaptively adjusting feature weights according to modality reliability or relevance, gating mechanisms alleviate modality imbalance and dominance issues. Owing to their low parameter count and computational efficiency, gating-based fusion methods are particularly suitable for adaptive multimodal integration in scenarios with varying modality quality.
Beyond these mainstream categories, several more advanced fusion mechanisms have also been explored. Tensor- or bilinear-pooling-based fusion captures high-order cross-modal interactions [22], but suffers from high computational and memory costs. Graph neural network (GNN)-based fusion leverages graph structures to facilitate cross-modality information propagation [23], but its performance heavily depends on graph construction and suffers from low efficiency in large-scale inference. Contrastive learning-based fusion aligns modalities by maximizing cross-modal consistency among positive samples while separating negative samples [24], showing strong performance in representation learning but requiring careful negative sampling and loss design. Generative model-based fusion explicitly models joint multimodal distributions [25], enabling cross-modal completion and generalization, yet often encounters training instability and high computational overhead.
2.3. Motivation
Existing RGB–IR multimodal fusion methods mainly explore the problem from two perspectives: fusion stage and fusion mechanism. Most approaches tend to treat features from different modalities as a whole and perform unified modeling and fusion. However, in real-world complex scenarios, modality-complementarity and noise interference often coexist, where noise primarily originates from unstable responses of modality-specific information under illumination variations, occlusions, or imaging discrepancies. Without explicitly distinguishing the intrinsic attributes of multimodal features, unreliable modality-specific characteristics may be indiscriminately introduced into the fused representations, regardless of the fusion stage or the fusion operator employed, thereby degrading discriminative performance.
Motivated by this observation, we argue that multimodal features should first be structurally decoupled into modality-common features and modality-specific features. The former capture cross-modal consistent and semantically stable shared information, while the latter encode modality-exclusive cues with complementary potential but uneven reliability. A conceptual illustration of this feature decoupling paradigm is presented in Figure 3. On this basis, differentiated enhancement strategies are required: modality-common features should be reinforced through cross-modal alignment and consistency modeling, whereas noise interference within modality-specific features should be suppressed to enable the selective utilization of complementary information. Finally, the enhanced modality-common features can serve as a semantic foundation to guide the adaptive fusion of modality-specific information, thereby achieving robust and effective cross-modal feature integration across diverse scenarios.
3. Proposed Method
This section presents the proposed DDAF-Net. We first introduce the overall network architecture. Subsequently, we provide a detailed description of the DAFM, which serves as the core component of our framework. Finally, the loss functions utilized for training are formulated.
3.1. Overview of DDAF-Net
Problem Definition. The goal of this study is to design an efficient multimodal fusion function for object detection, enabling optimal integration of complementary information from heterogeneous modalities.
Given a pair of registered RGB and IR images, and , the task aims to predict a set of bounding boxes and their corresponding class labels . DDAF-Net learns a robust fused representation that effectively combines complementary cues while suppressing modality-specific noise. This process can be formalized as:
where , denotes the detection head, and represents the decoding prediction module.
Formulation of Decoupled Representation. Motivated by the analysis in Section 2.3, we formulate the intermediate feature representations of RGB and IR modalities as the superposition of modality-common features, modality-specific features, and modality-dependent noise:
where denotes modality-common features shared across modalities, capturing semantically consistent information, represents modality-specific features with complementary potential, and corresponds to modality-dependent noise.
This formulation explicitly distinguishes cross-modal consistent semantics from modality-specific information, providing a principled basis for differentiated feature enhancement and guided fusion in the proposed framework.
Network Architecture. As illustrated in Figure 4, the proposed DDAF-Net consists of two key components: the Decoupled Feature Extraction Backbone and the DAFM.
Following the decoupled representation formulation, the backbone adopts a three-branch structure based on a Siamese network architecture, extracting features at multi-scale pyramid levels (P3, P4, and P5). Specifically, two independent modality-specific branches are employed to capture the unique characteristics of each modality ( and ). Simultaneously, a parallel modality-common branch adopts a weight-sharing strategy to jointly model RGB and IR inputs, extracting cross-modal invariant common features ( and ). Consequently, at each scale, the backbone generates a decoupled feature quadruple , serving as the input for the subsequent fusion stage.
The core fusion process is executed by the DAFM. Its structure is illustrated in the zoomed-in view of Figure 4. Upon entering this module, the four feature maps are first projected via SRUE, which achieves lossless downsampling while preserving global semantic context. Subsequently, differentiated attention mechanisms are applied for feature processing: modality-specific features ( , ) are refined by SPA to suppress noise and highlight complementary details, whereas modality-common features ( , ) are modeled by the DNAA to facilitate effective modal alignment and enhance semantic consistency. Following this differentiated processing, all features are further enhanced by the MD-FFN, which reinforces local representations and information interaction across the channel, height, and width dimensions. Next, the enhanced features are aggregated via the ACFM, which utilizes modality-common features as a semantic anchor to dynamically weight and fuse complementary information from modality-specific features. Finally, the fused features undergo spatial upsampling to restore the original resolution and are element-wise added to the residual branch to generate the final module output. To promote deep feature interaction, the DAFM is stacked N times (default ) with residual connections.
Finally, the fused features are fed into the detection head to predict object categories and regress bounding box coordinates.
3.2. Differentiated Attention Fusion Module (DAFM)
To effectively enhance and fuse decoupled modality-common and modality-specific features, we design the DAFM as the core fusion component of the network.
3.2.1. Spatial Residual Unshuffle Embedding (SRUE)
Standard downsampling operations, such as max pooling or strided convolution, are prone to losing fine-grained spatial information, whereas processing high-resolution features imposes significant computational burdens on attention mechanisms. To address this, we propose SRUE, which achieves lossless feature projection by preserving spatial details and global semantics during downsampling. The structure of SRUE is illustrated in Figure 5.
Specifically, the SRUE processes the input feature through two parallel branches. The main branch rearranges spatial pixels into the channel dimension and adjusts the channels via pointwise convolution to retain local spatial information, formulated as:
where denotes the pixel unshuffle operation with a downsampling factor s, which reshapes the tensor from to . , , and represent pointwise convolution, Batch Normalization, and the activation function, respectively.
The residual branch utilizes a depthwise convolution with stride s and kernel size to preserve contextual semantic information, formulated as:
where denotes depthwise convolution, and aligns the channel dimensions with when necessary.
Finally, the lossless features from the main branch and the context-aware features from the residual branch are concatenated and fused to generate the output embedding :
where denotes concatenation along the channel dimension.
3.2.2. Dual-Norm Alignment Attention (DNAA)
Although the Siamese backbone extracts modality-common features, inherent discrepancies in sensor imaging mechanisms and viewpoints inevitably lead to spatial and semantic misalignment between RGB and IR representations. To address this, we propose DNAA, which explicitly establishes cross-modal correspondences from both channel and spatial perspectives to enhance the semantic consistency of modality-common features. The structure of DNAA is illustrated in Figure 6.
Specifically, given the modality-common features , DNAA first applies Group Normalization and concatenates the features for joint projection. The query, key, and value matrices are generated via a unified linear projection and subsequent splitting, formulated as:
where denotes Group Normalization. The generated matrices are flattened to , where .
To align cross-modal semantic distributions, we introduce a channel alignment map . Leveraging the intrinsic semantic consistency of modality-common features, we employ Sinkhorn iterations to enforce a doubly stochastic constraint, establishing a strict bijective mapping for robust global alignment. Conversely, for the spatial alignment map , the underlying correspondence is inherently non-bijective due to occlusion and parallax. Enforcing a strict Sinkhorn constraint here would erroneously force matches for occluded regions and incur prohibitive quadratic computational costs ( ). Instead, we adopt Softmax normalization, which naturally accommodates asymmetric and multi-to-one relationships, allowing the suppression of irrelevant regions. This differentiated process is defined as:
where represents the iterative normalization process along both dimensions.
Finally, feature enhancement is achieved by jointly applying the channel and spatial alignment matrices to the value matrices. The aligned features are projected and added to the original inputs via residual connections:
The enhanced features are then reshaped back to . By aligning features specifically along both channel and spatial dimensions, DNAA effectively mitigates cross-modal discrepancies.
3.2.3. Sparse Purification Attention (SPA)
Modality-specific features, though rich in complementary information, are frequently contaminated by modality-dependent noise. Standard dense attention mechanisms, which aggregate features indiscriminately across all spatial positions, risk propagating or even amplifying this noise. To address this, we propose SPA. By leveraging sparsity constraints to filter out non-salient responses, SPA effectively suppresses noise while preserving critical complementary information. The structure of SPA is illustrated in Figure 7.
Specifically, for a given modality-specific feature (representing either or ), SPA first applies Group Normalization followed by linear projections to generate query (Q), key (K), and value (V) tensors. These are then reshaped for multi-head attention computation:
where represents the reshaping operation for h heads, is the head dimension, and is the initial attention map.
To eliminate noise interference, we introduce a Top-k Purification mechanism. For each query position, only the top-k most relevant keys are retained. The attention map is then renormalized to ensure the weights sum to one:
where is the binary mask derived from the top-k indices determined by a retention ratio r (i.e., ), and is a small constant for numerical stability.
Finally, the purified attention map aggregates the value features, and the output is projected back to the original dimension and added to the input via a residual connection:
where reshapes the multi-head output back to . SPA effectively purifies modality-specific features, ensuring that only robust and salient complementary information is propagated.
3.2.4. Multi-Dimensional Feed-Forward Network (MD-FFN)
Standard feed-forward networks typically perform pixel-wise operations, focusing solely on channel mixing while neglecting local spatial contexts. Although the preceding attention modules capture global or sparse dependencies, enhancing local feature interactions along different geometric dimensions is crucial for refining object boundaries and shapes. To achieve this efficiently, we propose the MD-FFN. By decoupling feature processing into channel, height, and width dimensions, the MD-FFN captures multi-scale anisotropic contexts with minimal computational overhead. The structure of the MD-FFN is illustrated in Figure 8.
Specifically, given an input feature , the MD-FFN first applies Layer Normalization and splits the feature into four parts along the channel dimension, , where each part has channels. These parts are processed by four parallel branches to extract complementary contextual information:
(1) Channel Mixing Branch: This branch follows the standard FFN design to model inter-channel dependencies using pointwise convolutions:
(2) Height and Width Mixing Branches: To capture anisotropic spatial contexts without the high cost of large dense kernels, we employ strip depthwise convolutions. The height branch uses a kernel to aggregate vertical context, while the width branch uses a kernel for horizontal context:
(3) Identity Branch: The fourth part remains unchanged to preserve original feature information.
Finally, the outputs from all branches are concatenated and fused via a linear projection, followed by a residual connection to the original input:
By explicitly modeling interactions along the channel, height, and width axes, the MD-FFN significantly enhances the local representation capability of the network.
3.2.5. Adaptive Complementary Fusion Module (ACFM)
After the differentiated enhancement, the network obtains aligned modality-common features and purified modality-specific features. Simple fusion strategies, such as element-wise addition or concatenation, treat these components indiscriminately, lacking flexibility to adapt to dynamic scene variations (e.g., RGB failure in total darkness). To address this, we propose the ACFM. The ACFM utilizes the stable modality-common features as a semantic anchor to dynamically regulate the incorporation of complementary modality-specific information. The structure of the ACFM is illustrated in Figure 9.
Specifically, the ACFM takes four feature maps as input: two aligned common features ( ) and two purified specific features ( ). First, we construct a robust semantic baseline by fusing the modality-common features, which contain consistent geometric and semantic cues:
Next, to determine the reliability of modality-specific information, we generate dynamic gating weights. The base feature is concatenated with both modality-specific features to form a comprehensive context representation, which is then processed by a gating network:
where GateNet consists of a convolution followed by a projection and a Sigmoid function, producing weights that represent the importance of RGB- and IR-specific details, respectively.
Finally, the modality-specific features are transformed to align with the baseline space and adaptively aggregated based on the generated weights:
where ⊙ denotes element-wise multiplication. By anchoring the fusion on stable common semantics and adaptively selecting complementary details, the ACFM ensures robust feature integration across varying environmental conditions.
3.3. Loss Function
The training of DDAF-Net is supervised by a composite objective function that simultaneously optimizes object detection performance and enforces the structural decoupling of multimodal features. The total loss is formulated as:
where represents the task-specific detection loss, and denotes the orthogonality constraint for feature decoupling. The hyperparameter balances the trade-off between detection accuracy and feature independence, which is set to in our experiments. Importantly, the orthogonality constraint is introduced as a soft regularization term rather than a primary optimization objective. It does not dominate the training process, but instead gently encourages feature independence without compromising the learning of the main detection task.
Detection Loss. Following standard object detection paradigms, the detection head is optimized using a weighted sum of classification, bounding box regression, and objectness losses:
where denotes the classification loss, represents the bounding box regression loss, and indicates the objectness loss for foreground-background confidence.
Orthogonality Loss. To validate the proposed decoupling paradigm, it is crucial to ensure that the modality-common features ( ) and modality-specific features ( ) encode distinct semantic information rather than redundant cues. To achieve this, we introduce an orthogonality constraint that minimizes the cosine similarity between the two representations. For each modality across all pyramid levels, the loss is defined as:
where flattens the feature map into a vector, and denotes the norm. By minimizing , the network is penalized for feature correlation, thereby forcing the specific branch to capture complementary details exclusive to the modality, separate from the shared semantics in the common branch.
4. Experiments
4.1. Datasets and Evaluation Metrics
To comprehensively evaluate the effectiveness of the proposed method, experiments were conducted on three representative and complementary multimodal datasets: FLIR [26], LLVIP [27], and M^3^FD [28].
The FLIR dataset is designed for multimodal object detection and covers both daytime and nighttime scenes. Since the original version suffers from significant misalignment between modalities, this study adopts the aligned FLIR-Aligned version, which contains 5142 pairs of RGB–IR images (4129 for training and 1013 for testing) with a resolution of 640 × 512. It includes classes such as Person, Car, Dog, and Bicycle. The major challenges of this dataset lie in the large domain gap between different time periods and the need for effective exploitation of infrared cues.
The LLVIP dataset focuses on pedestrian detection under low-light conditions. It contains 15,488 pairs of RGB–IR images (12,025 for training and 3463 for testing) with a resolution of 1280 × 1024. Its only annotated class is Person. The main difficulty lies in the severe degradation of the RGB modality under low illumination, which places higher demands on cross-modality complementarity.
The M^3^FD dataset consists of 4200 pairs of RGB–IR images (resolution 1024 × 768), annotated with over 34,000 instances across six classes (People, Car, Bus, Motorcycle, Truck, and Lamp). Since there is no official split, an 80%/20% division is adopted for training and testing, respectively. M^3^FD features diverse categories and scenes but suffers from certain misalignment issues, posing challenges for robust detection across modalities.
For evaluation, the mean Average Precision (mAP) following the COCO protocol is employed as the primary metric, including the following:
- [email protected] (AP_50_): average precision at IoU threshold 0.5.
- [email protected] (AP_75_): average precision at IoU threshold 0.75.
- [email protected]:0.95 (mAP): average precision averaged over IoU thresholds from 0.5 to 0.95, reflecting detection performance under varying strictness.
In addition, to assess practical efficiency, the inference time and model parameters are also reported, providing a balanced evaluation of accuracy and computational cost.
4.2. Implementation Details
The proposed DDAF-Net is implemented based on the Ultralytics YOLOv8 framework. During training, all images are resized to 640 × 640, and standard data augmentation techniques such as Mosaic and RandAugment are applied. The optimizer is AdamW with an initial learning rate of 0.001, momentum of 0.937, and weight decay of 0.0005. The total number of training epochs is 300, with a batch size of 16. To ensure reproducibility, the deterministic mode is enabled and random seeds are fixed.
Experiments are conducted on four NVIDIA A30 GPUs (24 GB each) using Python 3.8.20, PyTorch 2.3.1, and Ultralytics v8.3.146.
4.3. Quantitative Comparisons
To thoroughly evaluate the proposed DDAF-Net for multimodal sensor-based object detection, this section compares it with representative infrared–visible fusion detectors in terms of overall accuracy, computational efficiency, and per-class performance.
4.3.1. Comparison with Representative Methods
To validate the detection performance of DDAF-Net under different scenarios, we conduct systematic comparisons on the FLIR-Aligned and LLVIP datasets against multiple baseline single-modality detectors and state-of-the-art multimodal fusion approaches. Table 1 reports the results on AP_50_, AP_75_, and mAP metrics.
These results indicate that single-modality detectors are limited by environmental conditions, whereas IR offers better stability than RGB. Multimodal fusion methods significantly enhance detection by leveraging complementary information. DDAF-Net achieves state-of-the-art performance on both datasets, recording 50.5% mAP on FLIR-Aligned and 68.7% mAP on LLVIP, outperforming the latest Fusion-Mamba (TMM’25). Notably, DDAF-Net exhibits a substantial lead in the stricter AP_75_ metric (52.6% and 78.2%, respectively), verifying its superior capability in precise object localization and feature discrimination.
4.3.2. Inference Time and Computational Efficiency
In real-world applications, balancing computational complexity with inference efficiency is crucial for model practicality. To assess this, we compare DDAF-Net against representative methods on the FLIR-Aligned dataset across accuracy metrics (precision, recall, F1, AP_50_, mAP) and efficiency indicators (parameters, time). The comprehensive results are illustrated in the radar chart in Figure 10.
DDAF-Net exhibits the most robust overall performance, covering the largest area in the radar chart. Regarding detection accuracy, it achieves the highest precision (88.78%), F1-score (81.98%), and mAP (50.53%), while matching the top performance in AP_50_ (84.89%). Crucially, in terms of efficiency, DDAF-Net demonstrates a significant advantage: it requires only 130.5 M parameters and 43 ms inference time, making it drastically lighter and faster than the state-of-the-art Fusion-Mamba (287.6 M, 78 ms) and CrossFormer (340.0 M, 80 ms). This comparison confirms that DDAF-Net offers an optimal trade-off between high-precision detection and low computational cost, validating its potential for efficient real-time deployment.
4.3.3. Per-Class Performance Analysis
To further evaluate DDAF-Net’s capability in complex multi-category scenes, we conduct comparisons with recent multimodal fusion detectors on the M^3^FD dataset. Table 2 summarizes the per-class detection results using different backbones.
The results demonstrate that DDAF-Net establishes new state-of-the-art performance. Equipped with the CSPDarknet53v8 backbone, it achieves 90.6% AP_50_ and 63.5% mAP, surpassing the latest Fusion-Mamba by 2.6% and 1.6%, respectively. Even with the lighter v5 backbone, DDAF-Net (88.1% AP_50_) remains competitive, outperforming all other methods using the same backbone architecture.
In terms of category-specific performance, DDAF-Net shows exceptional strength in detecting small and distinct targets. Notably, in the challenging People category, it reaches 88.5%, significantly outperforming Fusion-Mamba (84.3%) by 4.2%. Furthermore, it dominates large-scale vehicle detection, securing the best scores in Bus (96.8%) and Truck (90.7%), while maintaining top-tier performance in other categories like Motorcycle (86.0%) and Car (94.2%). This balanced performance across diverse categories validates the model’s strong inter-class consistency and its ability to effectively leverage cross-modality features for both fine-grained and large-scale objects.
4.4. Qualitative Analysis
To intuitively demonstrate the detection performance of DDAF-Net, representative samples were selected from the FLIR-Aligned (a, b), LLVIP (c, d), and M^3^FD (e, f) datasets for visualization, as illustrated in Figure 11. These samples cover various challenging scenarios, including low illumination, strong lighting, occlusion, dense crowds, and small objects. All visualizations were performed under a confidence threshold of 0.5.
DDAF-Net can accurately localize and recognize objects even under severe occlusion, dense scenes, or cases where targets are hardly visible in the RGB modality. In contrast, the CFT method tends to suffer from both missed and false detections under such conditions. Particularly in Figure 11b–d, DDAF-Net not only detects most ground-truth objects precisely but also identifies potential targets that other methods overlook, demonstrating its superiority in cross-modal feature complementarity. Moreover, DDAF-Net shows a clear advantage in boundary precision and small-object detection (see Figure 11e). These qualitative results further validate the robustness and generalization capability of the proposed model under diverse and complex scenes.
4.5. Ablation Studies
In this section, we perform comprehensive ablation studies on the M^3^FD dataset to validate the effectiveness of the proposed framework and the necessity of each specific component.
To investigate the validity of the proposed “decoupling–enhancement–fusion” paradigm, we constructed two control groups for comparison with our DDAF-Net:
- 1.Two-Stream: a standard uncoupled architecture where RGB and IR branches are independent (no weight sharing) and fused via simple concatenation and convolution.
- 2.Baseline: the proposed Decoupled Feature Extraction Backbone combined with naive fusion (concatenation + convolution), without the DAFM.
The results are reported in Table 3. Interestingly, the Baseline (54.7% mAP) performs slightly worse than the traditional Two-Stream architecture (56.1% mAP). This phenomenon supports our analysis in Section 1: simply decoupling features into modality-common and modality-specific parts forces them into distinct semantic subspaces. Without explicit alignment and enhancement mechanisms, naive concatenation fails to reconcile the spatial misalignment in common features or filter the noise in specific features, leading to suboptimal feature integration.
However, when the DAFM is introduced, the performance improves dramatically, jumping from 54.7% to 63.5% mAP. This substantial gain (+8.8% mAP) confirms that the decoupled features possess high potential, but their value can only be fully unlocked through differentiated processing—specifically, aligning the common semantics and purifying the specific details.
To verify that the performance gains stem from our specific differentiated designs (DNAA, SPA, ACFM) rather than the mere application of attention mechanisms, we conducted an internal ablation of the DAFM. We replaced each proposed module with its generic counterpart to observe the impact:
- w/o DNAA: replaces DNAA with standard cross-attention.
- w/o SPA: replaces SPA with standard dense self-attention.
- w/o ACFM: replaces ACFM with feature concatenation.
- Generic Attn: replaces all three modules with their generic counterparts simultaneously.
The results are summarized in Table 4. Replacing all proposed components with generic attention and naive fusion yields 58.5% mAP, which is higher than the baseline (54.7%) due to the global receptive field of attention, yet still significantly inferior to the full model (63.5%), indicating that performance gains do not stem from attention mechanisms alone. Specifically, substituting SPA with dense self-attention causes the largest degradation (−3.0% mAP), confirming that modality-specific features contain substantial noise that is amplified by indiscriminate global aggregation, whereas SPA effectively purifies these features via sparsity constraints. Replacing DNAA with standard cross-attention results in a 2.3% mAP drop, as cross-attention lacks the explicit bijective alignment enforced by the Sinkhorn-based dual-normalization design, which is crucial for maintaining semantic consistency in modality-common features. Finally, removing the adaptive fusion mechanism leads to a 1.6% mAP decline, demonstrating that simple concatenation fails to handle dynamic modality reliability, while the ACFM leverages aligned common features as a semantic anchor to robustly fuse complementary information.
To further provide a detailed computational complexity analysis and evaluate the module-wise overhead, we conducted a hyperparameter sensitivity study on the number of stacked DAFM blocks (N). Table 5 reports the detection accuracy along with comprehensive complexity metrics, including parameters, network Layers, FLOPs, and inference speed (FPS).
As shown in Table 5, the proposed DAFM is highly parameter- and computation-efficient. Increasing the number of stacked blocks from 2 to 4 brings a significant performance gain of +1.1% mAP while only introducing a marginal overhead of 0.8 M parameters and 2.78 G FLOPs. This indicates that the core components of the DAFM (DNAA, SPA, and ACFM) focus on efficient feature recalibration rather than heavy channel transformations. However, when the stack deepens to , the performance saturates (only a +0.2% mAP improvement), yet the inference speed drops drastically from 19.39 FPS to 8.82 FPS due to the sequential execution of over 3000 layers. Consequently, we adopt as the default setting to achieve the optimal trade-off between detection accuracy and computational efficiency.
As shown in Figure 12, we further visualize the feature-level heatmaps using EigenCAM [54] for the Baseline, Generic Attn, and DDAF-Net. The heatmaps reveal that the Baseline model focuses on many irrelevant regions, while Generic Attn introduces noise due to its global aggregation. In contrast, DDAF-Net achieves much more concentrated attention on the salient areas, confirming that our proposed design not only improves performance but also enhances feature discrimination by focusing on the most informative regions.
5. Conclusions and Future Work
In this paper, we proposed DDAF-Net to address the persistent challenges of modality redundancy, noise interference, and spatial misalignment in RGB-IR object detection. By establishing an explicit “decoupling–enhancement–fusion” paradigm, our method effectively decomposes multimodal inputs into modality-common and modality-specific representations. Within the proposed DAFM, DNAA ensures robust semantic consistency across modalities, while SPA successfully filters modality-dependent noise to retain distinct complementary details. Furthermore, the ACFM utilizes the aligned common semantics as an anchor to dynamically guide the integration of these features. Extensive experiments on the FLIR-Aligned, LLVIP, and M^3^FD datasets demonstrate that DDAF-Net achieves state-of-the-art performance in both detection accuracy and inference efficiency, validating the superiority of the proposed differentiated modeling strategy.
Despite these promising results, several avenues for future research remain. First, while DDAF-Net achieves a favorable trade-off between accuracy and speed, deployment on strictly resource-constrained edge devices (e.g., UAVs or IoT sensors) may require further optimization techniques such as network quantization or distillation. Second, although DNAA handles mild spatial misalignment effectively, evaluating the model’s performance boundaries under extreme RGB-IR misalignment (e.g., large viewpoint offsets or resolution mismatches) and severe single-modality occlusion remains a critical challenge. Furthermore, our current framework operates under the assumption of registered image pairs. In real-world deployments, dynamic scenes or sensor calibration errors frequently result in completely unregistered pairs, which can significantly degrade fusion efficacy. To address these limitations, future research will explore integrating lightweight registration preprocessing steps or flow-based dense feature matching networks directly into the pipeline, enabling robust end-to-end detection on unaligned sensor data. Finally, the proposed decoupling paradigm is theoretically generic and could be extended to other heterogeneous sensor combinations, such as LiDAR-Camera or Event-RGB fusion, to further broaden the applicability of robust multimodal perception systems.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bai X. Hu Z. Zhu X. Huang Q. Chen Y. Fu H. Tai C.L. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)New Orleans, LA, USA 19–24 June 202210901099
- 2Costanzino A. Ramirez P.Z. Lisanti G. Di Stefano L. Multimodal industrial anomaly detection by crossmodal feature mapping Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Seattle, WA, USA 17–21 June 20241723417243
- 3Ding Y. Yu X. Yang Y. RF Net: Region-aware fusion network for incomplete multi-modal brain tumor segmentation Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)Montreal, QC, Canada 10–17 October 202139753984
- 4Zhu L. Zhu Z. Zhang C. Xu Y. Kong X. Multimodal sentiment analysis based on fusion methods: A survey Inf. Fusion 20239530632510.1016/j.inffus.2023.02.028 · doi ↗
- 5Zhao Z. Bai H. Zhang J. Zhang Y. Xu S. Lin Z. Timofte R. Van Gool L. Cddfuse: Correlation-driven dual-branch feature decomposition for multi-modality image fusion Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Vancouver, BC, Canada 18–22 June 202359065916
- 6Zhang Y. Chen J. Huang D. Cat-det: Contrastively augmented transformer for multi-modal 3d object detection Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)New Orleans, LA, USA 19–24 June 2022908917
- 7Zhang X. Sun Y. Han Y. Li Y. Yin H. Xing Y. Zhang Y. SSML-Q Net: Scale-separative metric learning quadruplet network for multi-modal image patch matching Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI)Macao, China 19–25 August 202349534960
- 8Xu Z. So D.R. Dai A.M. Mufasa: Multimodal fusion architecture search for electronic health records Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)Virtual Event 2–9 February 2021 Volume 351053210540