Real-World Airborne Sound Analysis for Health Monitoring of Bearings in Railway Vehicles
Matthias Kreuzer, David Schmidt, Simon Wokusch, Walter Kellermann

TL;DR
This paper presents a method to detect railway bearing faults using airborne sound analysis, achieving reliable results with real-world data.
Contribution
The novel contribution is using MFCC features with an MLP classifier for bearing fault detection in real-world railway operations.
Findings
MFCCs are best suited for detecting bearing faults from airborne sound.
The MLP classifier reliably detects bearing damages not seen during training.
The method was validated using real-world commuter railway vehicle data.
Abstract
In this paper, the task of detecting bearing faults in railway vehicles during regular operation by analyzing acoustic (airborne sound) data is addressed. To that end, various features are studied, among which the Mel Frequency Cepstral Coefficients (MFCCs) are best suited for detecting bearing faults by analyzing airborne sound. The MFCCs are used to train a Multi-Layer Perceptron (MLP) classifier. The proposed method is evaluated with real-world data for a state-of-the-art commuter railway vehicle in a dedicated measurement campaign. Classification results demonstrate that the chosen MFCC features allow for reliable detection of bearing damages, even for damages that were not included in training.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1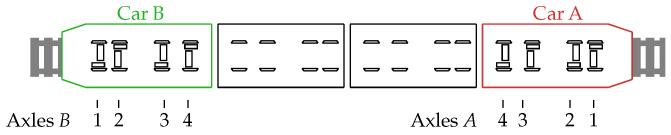 Figure 2
Figure 2 Figure 3
Figure 3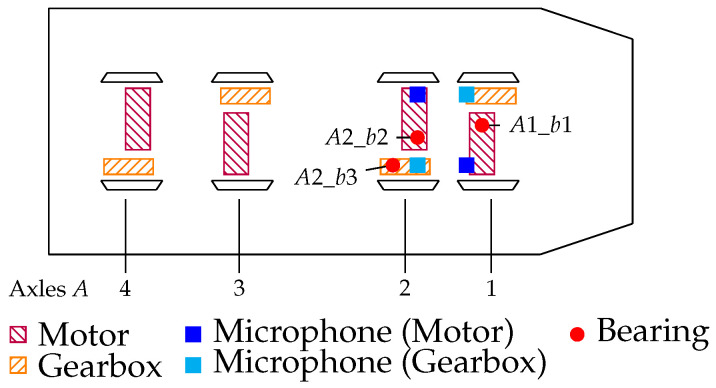 Figure 4
Figure 4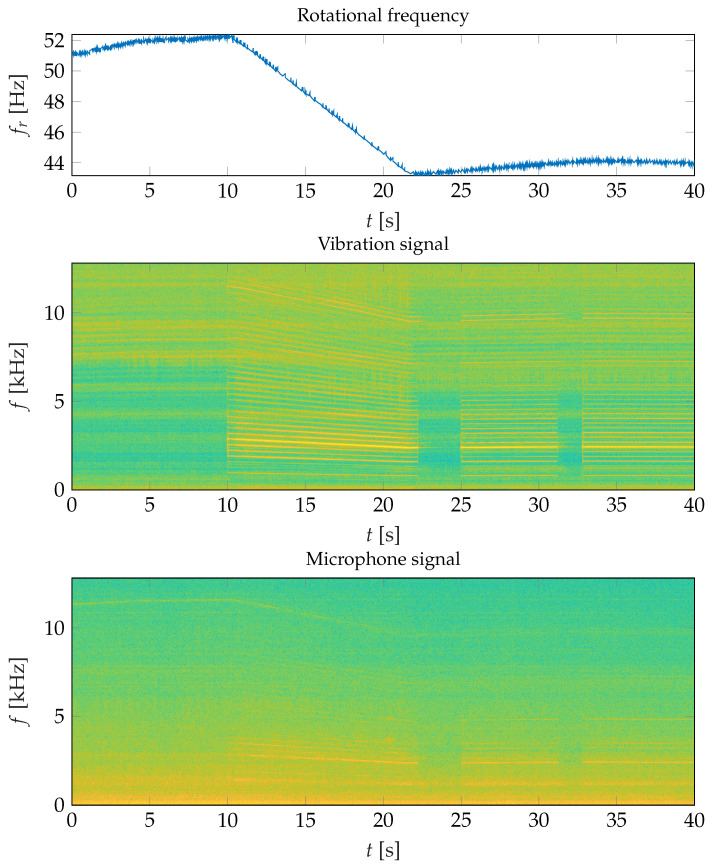 Figure 5
Figure 5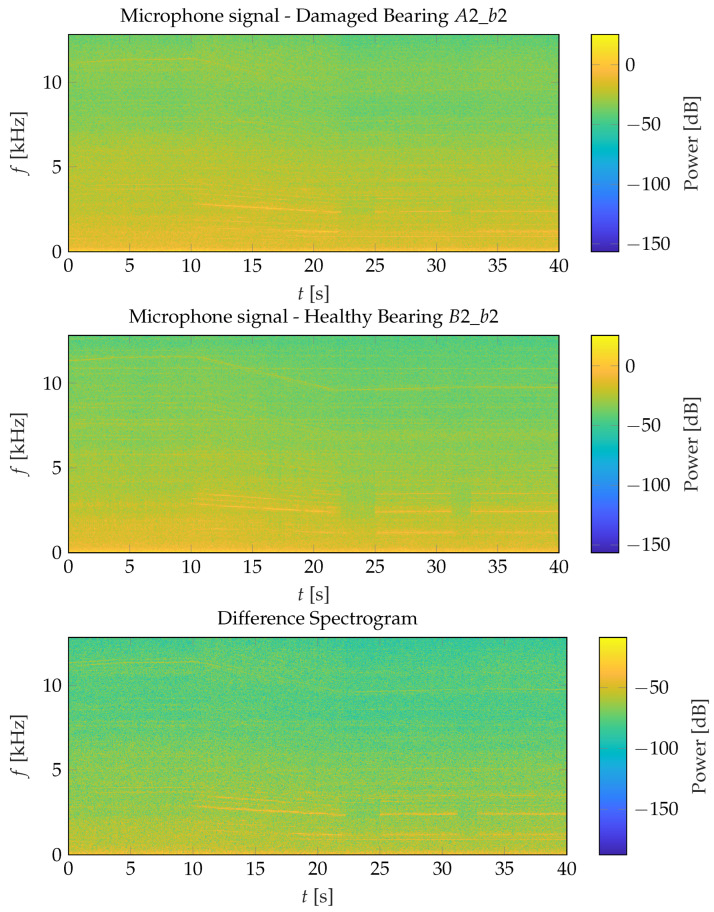 Figure 6
Figure 6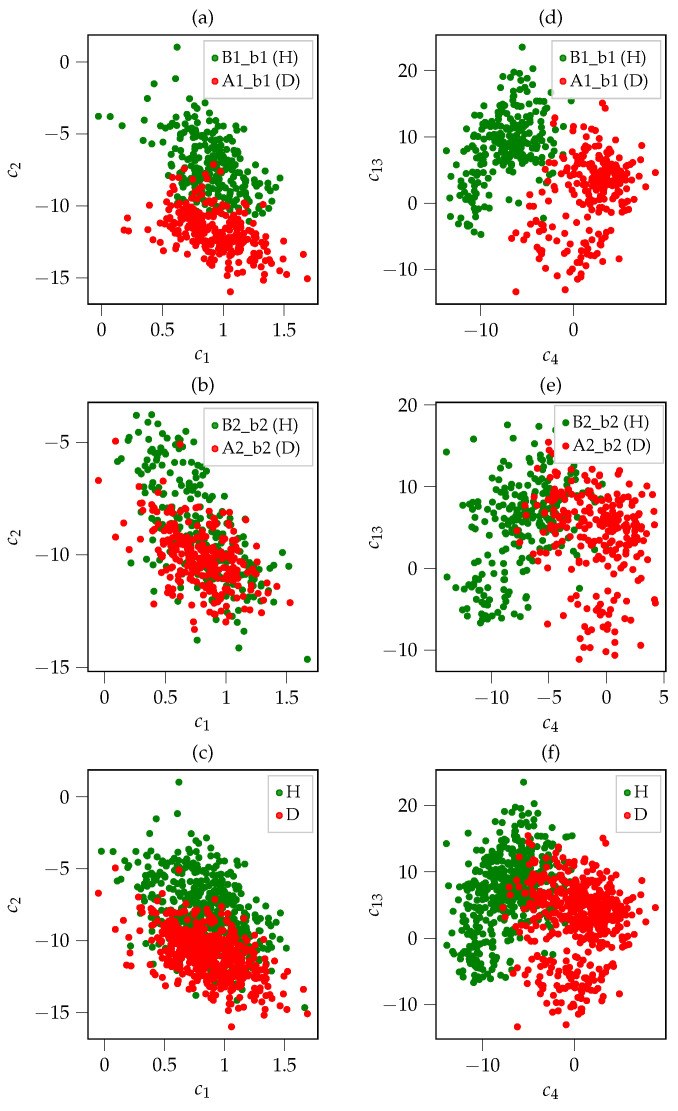 Figure 7
Figure 7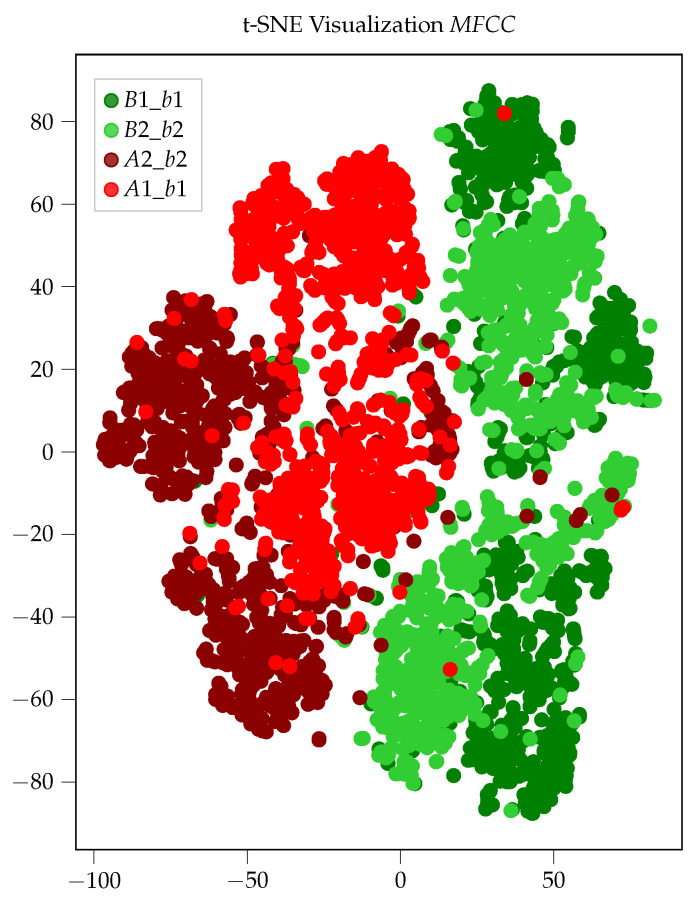 Figure 8
Figure 8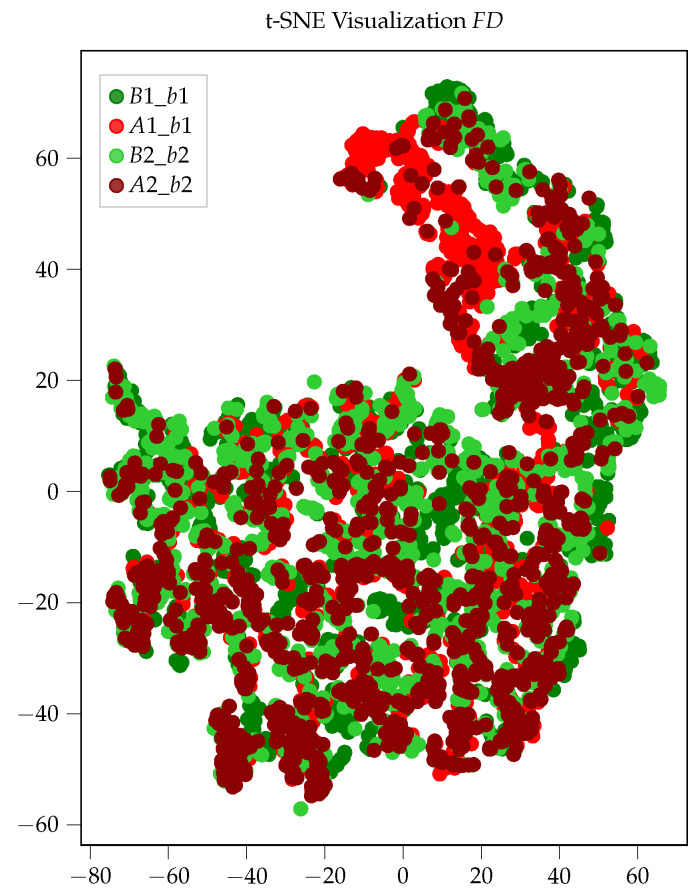 Figure 9
Figure 9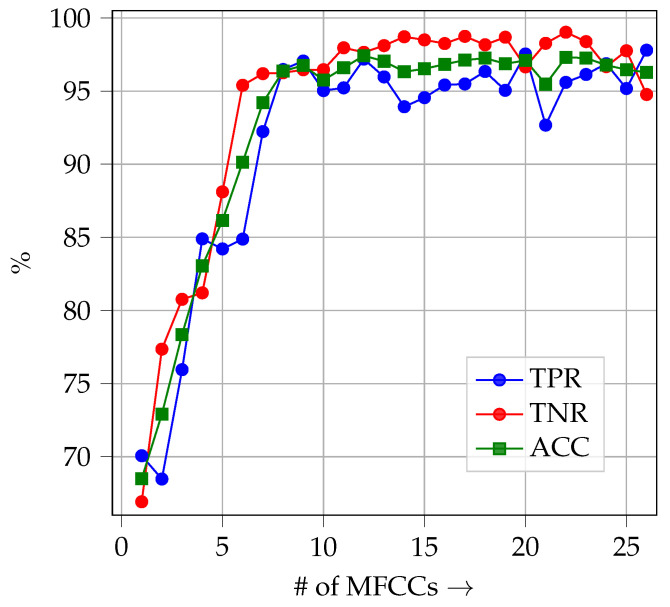 Figure 10
Figure 10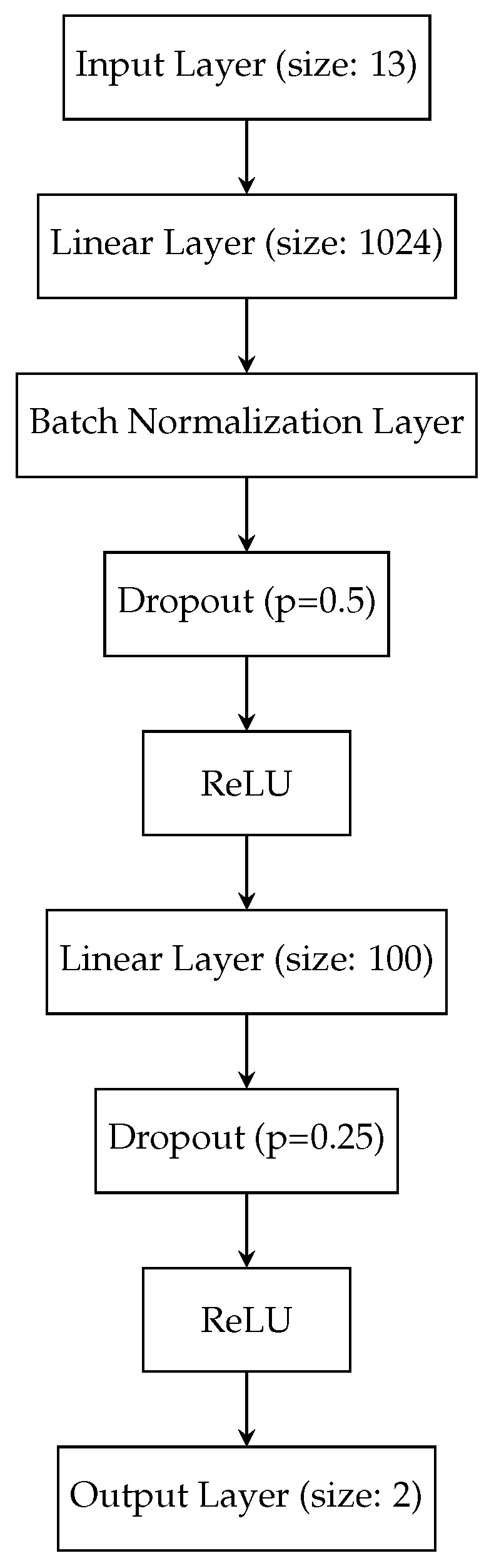 Figure 11
Figure 11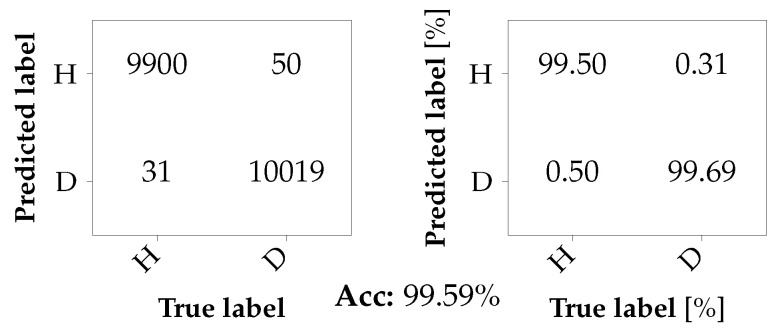 Figure 12
Figure 12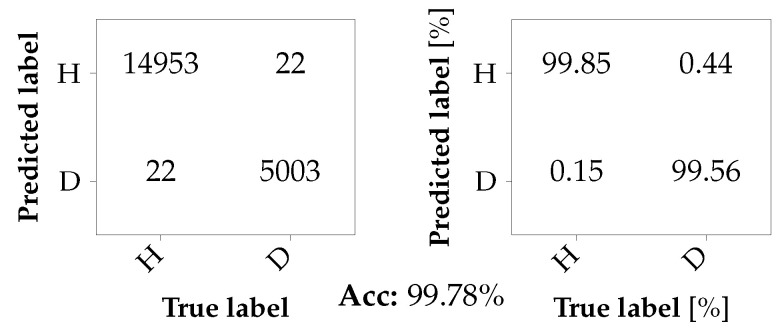 Figure 13
Figure 13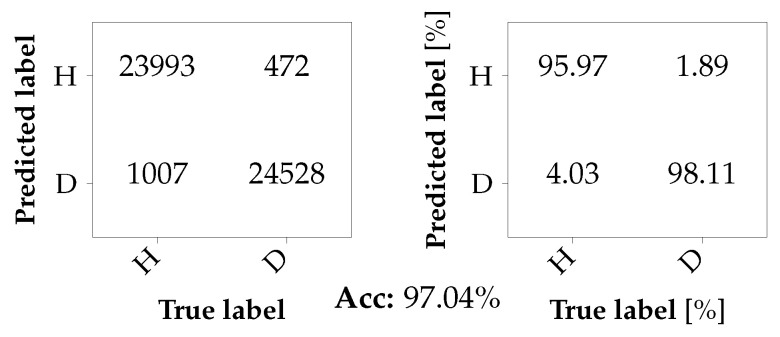 Figure 14
Figure 14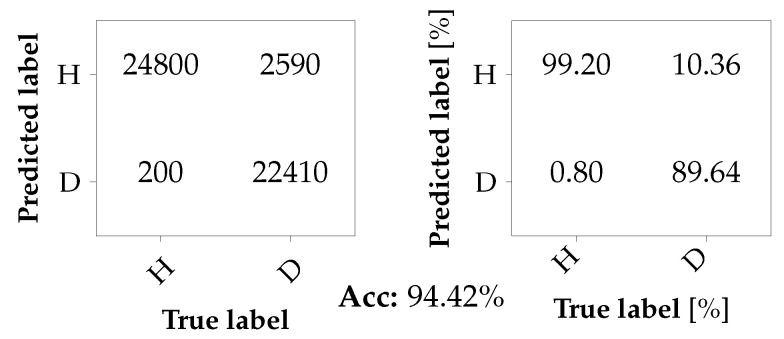 Figure 15
Figure 15- —Siemens Mobility GmbH
- —Friedrich-Alexander-Universität Erlangen–Nürnberg
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRailway Engineering and Dynamics · Machine Fault Diagnosis Techniques · Railway Systems and Energy Efficiency
1. Introduction
Bearings are vital components in rotating machinery, e.g., the induction motors of trains. Bearing damages can have severe consequences as they may cause a complete failure of the machine and thus cause undesired costs and downtime. Hence, the early and reliable detection of bearing damages is of great importance. Since the manual inspection of bearings is often an intricate and cumbersome task due to their difficult accessibility, non-invasive condition monitoring techniques are preferred.
In principle, structure-borne sound (vibration) and airborne sound are suitable for non-invasive condition monitoring of bearings. Over the past decades, mainly structure-borne sound that can be captured by acceleration sensors on the housing of the machine under inspection has been investigated. This is due to the fact that localized faults at one of the four main bearing components, i.e., the inner race, the outer race, the cage, and the rolling elements, lead to periodic excitations that alter the typical vibration signature of the machine. For detecting these alterations, structure-borne sound has been analyzed by employing envelope analysis, signal decomposition, and filtering techniques [1,2]. More recently, there has been a surge in the popularity of end-to-end Deep Neural Network (DNN)-based methods for vibration fault detection [3,4,5], particularly in the realm of bearing fault detection.
Although the analysis of structure-borne sound has been well-studied and has proven to be very effective for the detection and classification of bearing damages, this approach has certain drawbacks. For one, the acceleration sensors need to be mounted in close proximity to the bearing that is to be monitored. While this can be rather easily ensured in laboratory setups, it proves to be much more difficult in practical scenarios, e.g., the monitoring of bearings in the induction motors of railway vehicles. In such a scenario, the sensors need to be mounted on the bogie of the train, where space is limited, and safety regulations have to be met. This makes the retrofitting of sensor equipment for already existing vehicle platforms especially challenging. For such applications, less intrusive methods are preferable.
Methods for detection and classification of bearing faults using airborne sound have the potential to overcome some of the drawbacks of structure-borne sound-based monitoring. Microphones are less intrusive than acceleration sensors since they do not have to be placed directly on the component that is to be monitored but only in its vicinity. Therefore, the specifications regarding the placement of sensors are less strict, and microphones can also potentially be used to monitor multiple components simultaneously. Further, the sensing cost for microphones is usually significantly lower [6]. Finally, a multi-modal classification, i.e., the combination of airborne sound data and structure-borne sound data, can lead to more reliable classification results.
The classification of bearing faults by analyzing airborne sound data has already been addressed in [7], where a bearing fault feature extraction approach is proposed that combines Adaptive Variational Mode Decomposition (AVMD), an Improved Multiverse Optimization (IMVO) algorithm, and Maximum Correlated Kurtosis Deconvolution (MCKD) to subsequently identify fault features in the envelope spectrum of airborne sound. For a related application, the Variational Mode Decomposition (VMD) is used for denoising in [8]. In [8], which aims at the detection of cylinder misfires or blocked air inlets in a diesel engine, MFCCs are extracted from the denoised signals, which are then used to train a long short-term memory (LSTM) network, which acts as the classifier. Another signal decomposition technique, the Fourier decomposition method (FMD), is applied in [9] for the task of classifying bearing faults. The kurtosis of both the time-domain signal and its envelope are then extracted from the decomposed signals and used as features for training a random forest classification algorithm. Whereas the approaches in [7,8] rely on extracting hand-crafted features, the task of identifying discriminant features was handed to a Stacked Auto-Encoder (SAE), which operates on the raw spectrograms of sound signals. Moreover, in [10,11,12,13,14], features are extracted from the frequency-domain representations of sound signals, which are then fed into machine learning (ML)-based classifiers, e.g., k-Nearest Neighbors (k-NN), Support Vector Machine (SVM), and MLP, to classify bearing faults. The task of classifying bearing faults by analyzing sound signals and applying DNN-based methods is addressed in [9,15,16].
To the authors’ knowledge, all the above methods have only been evaluated in controlled laboratory settings using test benches in the absence of strong interferers. Furthermore, the proposed classifiers were not assessed with unfamiliar fault conditions, which are likely to occur in real-world situations. In contrast, this study, which expands upon our work in [17], analyzes the potential of analyzing airborne sound for the detection and classification of bearing faults in induction motors and gearboxes in a very challenging measurement environment: a modern commuter railway vehicle during regular operation. Although end-to-end DNN-based classification approaches have proven to be very effective for a variety of classification tasks, they exhibit certain drawbacks. Especially in practical scenarios in which you want to perform on-board condition monitoring, DNN-based approaches are not feasible due to memory and processing limitations. Further, in order to properly train DNNs, large amounts of training data are usually required. Otherwise, DNNs are prone to overfit. Consequently, feature-based approaches are still sought after as they require less processing power, consume less memory and allow for an easier interpretation.
To that end, various features from the time domain and the frequency domain as well as features for acoustic scene classification tasks are evaluated in an experimental study. Further, various classifiers will be evaluated using the best-performing feature set to determine the optimal bearing fault detection approach for the evaluated scenario. In the end, it will be demonstrated that MFCCs are highly effective features, and when they are combined with a relatively simple MLP, they enable the detection of bearing faults in a practical condition monitoring setup, even when encountering unseen fault conditions.
The remainder of this paper is structured as follows. In Section 2, the considered scenario is described diligently. Specifically, the railway vehicle is described in Section 2.1, the placement of the sensors is addressed in Section 2.2, the investigated bearing damages are described in Section 2.3, and the data acquisition process is presented in Section 2.4. Thereafter, the proposed bearing fault classification approach is discussed. First, the suitability of airborne sound for the classification of bearing faults is shown in Section 3.1. After this, the feature selection process and the choice of classifier are discussed in Section 3.2 and Section 3.3, respectively. The presented bearing fault classification approach is then evaluated on seen and unseen damages in Section 3.4. Lastly, conclusions are drawn in Section 4.
2. Scenario: Experimental Setup and Field Measurements
First, descriptions of the railway vehicle, the placement of the sensors, the bearing damages and the data acquisition process are given as background for our subsequent analysis.
2.1. Description of the Railway Vehicle
For our investigations, a state-of-the-art commuter railway vehicle of the type Desiro HC RRX (Rhein-Ruhr-Express) [18] as depicted in Figure 1 is considered. For acquiring a sufficient amount of realistic bearing fault data, the railway vehicle was equipped with damaged bearings and a multitude of sensors. For the measurement campaign, two cars were monitored on two separate test trips between two cities on regular railway tracks with a duration of approximately 4 h each, conducted on public railway infrastructure under real operating conditions. Two of the four train cars, i.e., Car A and Car B (cf. Figure 2), were equipped with sensors, i.e., acceleration sensors, temperature sensors, microphones, etc., but in the following only the microphone data is considered. A drivetrain consisting of a motor and a gearbox is positioned at each of the four axles (cf. Figure 4). The axles are referred to as and with for Car B and Car A, respectively. The measurements of Car B serve as reference for the healthy state of a bearing since this car exhibits only healthy bearings, whereas Car A was equipped with damaged bearings. The damaged bearings will be described in more detail in Section 2.3.
2.2. Placement of the Microphones on the Railway Vehicle
As depicted in Figure 3, microphones were installed above every drivetrain component by attaching them to the bottom of the railway car. Consequently, the distance between the monitored component and the microphone is approximately . This was done for the first two axles of Car A and Car B. The locations of the microphones can be seen in Figure 4. In Figure 4, the microphone locations are marked by ■ and ■. The microphones marked by ■ are considered for classification tasks at the motor and the microphones marked by ■ are considered for classification tasks at the gearbox. Note that the microphones do not only capture the sounds that are caused by the bearings but also noise that is emitted from other components in the train bogie, e.g., brakes, dampeners, etc., or noise caused by the railway tracks.
2.3. Description of the Bearing Damages
As pointed out in Section 2, all of the investigated damaged bearings are installed in Car A. These bearing damages are summarized in Table 1 and are denoted by , and . The notation is explained as follows: the first identifier in refers to the axle, i.e., Axle 1 in Car A, and the second identifier refers to bearing (cf. Figure 4 and Table 1). Hence, the corresponding healthy bearings in Car B are denoted as , and , respectively. Bearing represents a bearing fault in a very early stage, whereas represents a bearing with a fault in a slightly more developed stage. Bearing is in the gearbox (G) and represents a fault at a developed stage. The locations of the bearings and the fault types can be inferred from Table 1. Note that the considered bearing damages did not develop naturally but were introduced artificially.
2.4. Data Acquisition
Omni-directional electret microphones of the type ‘M 370’ [19] were employed to capture signals at a sampling frequency of . The signals were segmented into non-overlapping frames, each containing 2048 samples ( ). For the evaluation, only frames with a mean rotational frequency of the axle within the range of are considered, as this frequency range was most commonly observed during the measurements. Notably, there were no restrictions imposed regarding the applied torque, the mode of the power converter, or the driving direction. Consequently, approximately 28,000 frames were obtained for each microphone.
3. Bearing Fault Classification Approach
Now that the considered scenario has been introduced, the bearing fault detection approach based on the analysis of airborne sound is presented next. At first, the use of airborne sound data for fault diagnosis is motivated by highlighting the similarities between spectrograms obtained for airborne sound data and spectrograms obtained for structure-borne sound data in Section 3.1. In this paper, a two-stage procedure is followed to find the optimal approach for the classification of bearing faults by analyzing airborne sound data. In the first stage, the most suitable features for bearing fault classification using airborne sound are identified in Section 3.2 by benchmarking the different features using the same classifier. In the second stage, the performance is optimized further by finding the best-performing classifier for the previously selected feature set in Section 3.3. Finally, the proposed bearing fault classification approach is evaluated for different scenarios in Section 3.4.
3.1. Airborne Sound vs. Structure-Borne Sound
To motivate the use of airborne sound data for bearing fault detection, we take a look at the following spectrograms: Figure 5 shows a rotational frequency curve (top figure) and the corresponding spectrograms for the structure-borne sound measured directly on the housing of the motor of Axle in Car B (center figure) and the spectrogram for the airborne sound (bottom figure) that was captured by the microphone located at the motor at the same axle and on the same car, i.e., . The rotational frequency curve exhibits a period of almost constant rotational speed, which is followed by a second period of constant rotational speed after a deceleration phase of approximately . It can be observed that the spectrogram of the vibration signal is dominated by harmonics of the rotational frequency. These harmonics can be clearly observed in the spectrum over the entire frequency range for time periods when torque is applied. The spectrogram of the microphone signal reveals a similar structure, although it is less prominent compared to the vibration signal. While the vibration signal exhibits sharp horizontal lines representing harmonics of the rotational frequency across the entire frequency spectrum, only a few faint harmonics are discernible in the microphone signal, predominantly below . Thus, it can be concluded that spectrograms generated for airborne sound signals share a resemblance with those for structure-borne sound signals, albeit with incomplete and less pronounced representation of components associated with periodic events in the motor.
Figure 6 shows the power spectrograms of bearing damage (top) and the corresponding healthy reference microphone at Axle 1 in Car B, for the same time interval as in Figure 5. The spectrogram of appears as a noisier version of the healthy reference. In both cases, the dominant spectral component is located at . For instance, between and it occurs at approximately , which coincides with the stator slot number of the motor. Compared to the healthy signal, the damaged spectrogram exhibits increased noise, particularly in the to range. The bottom subfigure of Figure 6 presents the difference power spectrogram between the healthy and damaged signals. Prior to subtraction, both spectrogram magnitudes were normalized to the average power of the healthy reference. The difference spectrogram indicates that the bearing damage does not introduce new distinct spectral components. Instead, it alters the signal power at the dominant harmonics of the rotational frequency.
Consequently, harmonics from bearings are recognizable in the sound signal that is captured in its proximity, and thus, changes w.r.t the condition of bearings should be detectable using adequate features.
3.2. Feature Evaluation and Selection
Following the above, we now investigate which features are best suited for measuring these alterations and thus identifying bearing faults successfully. To this end, we consider various statistical features from the time and the frequency domains. The selection of features is based on two criteria: (i) their ability to capture amplitude variations, impulsiveness and spectral energy redistribution caused by bearing damage, and (ii) their established use in audio signal analysis and bearing fault diagnostics reported in the literature. This grouping serves as a structured and interpretable comparison of conceptually different feature types. However, it does not restrict the final feature selection, as in a subsequent step all features are jointly evaluated using established feature-ranking techniques to determine the most informative subset independent of the initial grouping.
From the time domain we consider a set of well-known statistical features that are summarized in Table 2, where denotes the time-domain microphone signal at time instant k, which is obtained after sampling the continuous-time microphone signal with sampling frequency . This sampling frequency was not chosen for a specific reason, and the decision was made by our industry partner. The features listed in Table 2 form the first feature set, which is referred to as TD in the following. These features were applied for the classification of bearing fault damages, for example, in [10,20,21,22].
In addition to the time-domain features listed above, we also consider various features from the frequency domain, e.g., spectral centroid and spectral kurtosis, which are computed from the frequency-domain representation of , i.e., . For the discrete-time signal with K samples of length M, Discrete Fourier Transform (DFT) can be defined as follows:
where and M denote the frequency bin index and the length of the DFT, respectively [23]. The considered features derived from the frequency-domain representation are listed in Table 3. These features form the second feature set, which is referred to as FD. In the literature, these features were applied for the task of classifying bearing faults, for example, in [10,24,25].
Localized bearing faults lead to periodic excitations which are caused by rolling elements every time they roll over a defect. Consequently, localized faults can be linked to characteristic frequencies [1] that are solely determined by the rotational frequency and the geometry of the bearing. Therefore, the amplitudes at multiples of the characteristic fault frequencies in the envelope magnitude spectrum of the microphone signals are also considered as features. These features are computed as amplitudes at multiples of the characteristic fault frequencies as follows:
where denotes the envelope spectrum (cf. [1]), which is obtained by applying the Hilbert transform [23], and is the frequency bin index corresponding to the characteristic fault frequencies , , and for a localized fault in the outer race, the inner race, the rolling cage and the rolling elements, respectively. To determine the characteristic fault frequencies, we refer to [1]. Typically, these fault-frequency-based features are used in the context of structure-borne sound analysis. According to Equation (2), a four-dimensional feature vector is formed, which is referred to as ENV in the following. In [26] it was shown that bearing faults could be reliably detected with state-of-the-art features for acoustic scene classification tasks that were extracted from structure-borne sound data. More specifically, the first 13 MFCCs were computed for vibration signals and were used as features to train a One-Class SVM where accuracies above could be obtained for laboratory data. MFCCs are state-of-the-art features for acoustic scene classification and speaker recognition tasks [27,28,29,30,31,32], as they allow for a compact representation of the spectrum of a signal by combining the cepstrum with a scaling of the frequency on the Mel scale [33]. The MFCCs for time frame n are computed as
where denotes the spectral energies of time frame n with , which are computed as
where are the time-domain input samples, is a window function and are the samples of a triangular window sequence for weighting the -th frequency bin for the i-th channel of the Mel filterbank output, denoted by . For a more detailed description of the computational steps that are required for computing the Mel Frequency Cepstral Coefficients (MFCCs), refer to [33]. Further, for the remainder of this paper, the first 13 MFCCs with are used as features if not explicitly stated otherwise.
An indication of their appropriateness is provided by the following example: Figure 7 shows two-dimensional scatter plots for two exemplary combinations of MFCCs. Figure 7a–c depicts scatter plots in which the values of the first MFCC, i.e., , are shown along the x-axis and the values for the second MFCC, i.e., , are shown on the y-axis. Figure 7a shows the data points for the healthy bearing and the damaged bearing , respectively, whereas Figure 7b shows the data points for and . and denote the data that was obtained from the microphones above the motors at Axle and Axle of Car B, respectively (cf. Figure 2). For Figure 7c, the data points for and and and are combined for the labels H (healthy) and D (damaged), respectively. For Figure 7d–f, a different combination of MFCCs is used: the values for the fourth MFCC, i.e., , are given along the x-axis and the values of the thirteenth MFCC, i.e., , are plotted on the y-axis. Again, the data points for and and and are combined for the labels H and D, respectively, in Figure 7f.
Figure 7a–f shows that the point clouds for the two classes, healthy (H) and damaged (D), only overlap to a small extent in these two exemplary two-dimensional subspaces. Hence, it is already possible to roughly discriminate between healthy and damaged samples in these two-dimensional subspaces. This is a clear indication that the MFCCs are well-suited for the classification of bearing faults using airborne sound. Since we cannot visualize the 13-dimensional subspace, we use the t-Stochastic Neighborhood Embedding (t-SNE) [34] technique for visualization purposes. t-SNE is a dimensionality reduction technique that allows the visualization of high-dimensional data in a lower-dimensional space, e.g., two-dimensional. The resulting scatter plot for the two-dimensional t-SNE visualization is shown in Figure 8. Here, the features for the healthy bearings and are depicted in dark and light green, whereas the features for the damaged bearings and are depicted in dark and light red. From Figure 8, we can see that the green and red scatter points form distinct clusters with only a few outliers. This further emphasizes the appropriateness of MFCCs as features for the detection of bearing faults by analyzing airborne sound. The situation is quite different for the other considered feature sets, i.e., TD, FD and ENV, as no distinct point clouds can be observed for healthy and damaged bearings as is the case in Figure 8. The t-SNE visualization for the FD feature set that is shown in Figure 9 serves as a representative example. After observing Figure 9, it becomes apparent that the data points for the healthy bearings and and the damaged bearings and do not lie separated from each other in the two-dimensional subspace but overlap and form one big point cloud. Similar pictures were obtained for the other two feature sets, i.e., TD and ENV. This indicates that in comparison to MFCCs, the statistical features from the time domain (TD) and the frequency domain (FD) as well as the bearing-fault-frequency-based features (ENV) are not equally well suited for the detection of bearing faults in the motors of railway vehicles using airborne sound.
Figure 7, Figure 8 and Figure 9 already hinted at the superiority of MFCCs as features, but this is further evidenced by the following classification results. The introduced feature sets are used to train an SVM [35] and are evaluated in a challenging scenario with unseen data. In particular, the data from the first axles of Car A and Car B are used for training, whereas the data from the second axles of Car A and Car B are used for testing. Consequently, serves as reference for the healthy class (H) and serves as reference for the damaged class (D) in the training set, and and (cf. Figure 3 and Figure 4) represent the healthy and damaged class in the test set, respectively. This scenario is challenging, as the classifier is confronted with data from bearings that were not included in the training. Further, the fact that the bearing fault in the test, i.e., , is an outer race fault whereas the bearing damage in the training set, i.e., , is an inner race fault further adds to the difficulty of the classification task.
As the classifier, an SVM with Radial Basis Function (RBF) kernel [35] is utilized whose parameters are optimized following a 5-fold cross-validation approach on the training data. The training and test sets each consist of 50,000 frames of length 2048. The results are summarized in Table 4. In Table 4, the True Positive Rate (TPR) indicates how well the healthy class is predicted, whereas the True Negative Rate (TNR) indicates how well the damaged class is predicted by the classifier. ACC denotes the overall accuracy. A good classifier exhibits both a high TPR and a high TNR as this shows that the classifier is able to predict both classes equally well and is not biased towards a single class. From Table 4 it can be inferred that the three feature sets TD, FD and ENV do not allow for a reliable classification of unseen damages at all, as the overall accuracies are , and , respectively. The obtained accuracy values demonstrate that these features cannot reliably classify bearing faults if they are extracted from raw microphone signals. The combination of TD, FD and ENV to a single feature vector of length 21 yields an improved overall accuracy of . Thus, it has been demonstrated that these feature sets are not well-suited for the classification of unseen bearing damages. However, with an overall accuracy of , the MFCC feature set is by far the best-performing feature set. The bearing damage can be accurately predicted as the TNR is . With a TPR of , the accuracy for the healthy class is slightly worse, yet the healthy class can still be very well predicted. The classification performance depending on the number of MFCCs that are considered for classification for the same scenario is illustrated in Figure 10. From Figure 10 it can be gathered that already accuracies above 95% can be gathered with the first six MFCCs [36]. Yet, the classification performance does not improve by considering more than 13 MFCCs for decision making, which coincides with empirical findings for speaker recognition tasks [36]. Thus, choosing the first 13 MFCCs as a feature set is a reasonable choice.
Evidently, the performance of the MFCC feature set is far superior to all other feature sets. Due to this large difference, there is no reason to assume that any of the other feature sets would outperform the MFCC if another classifier was chosen.
To corroborate our feature selection even further, we also consider the following feature-ranking methods:
- Relief: A feature ranking method that estimates the importance of each feature based on how well it discriminates between instances that are similar and those that are different. This is achieved by computing the difference of feature values between the nearest instances of the same class (near-hit) and the nearest instances of the other class (near-miss). Features are deemed to be more important if the difference for the near-miss is larger than for the near-hit [37].
- Minimal-Redundancy-maximal-Relevance (mRMR): Features are ranked by evaluating their relevance to the target variable, i.e., the class label, and their redundancy with other features. Relevance and redundancy are measured based on mutual information. Features are then selected to maximize relevance while minimizing redundancy. The result is a ranked list of features [38].
- Decision trees (DTs): The importance of features can also be estimated with decision trees. How much each feature contributes to the overall predictive accuracy of the decision tree is evaluated. Features with higher importance values are deemed more influential in making predictions.
- Sequential feature selection (SFS): This method systematically evaluates different combinations of features by iteratively adding a feature to the feature set based on how the addition of this specific feature affects a defined criterion, e.g., the overall accuracy.
The feature ranking results that were obtained for the feature ranking techniques listed above are summarized in Table 5. Every column lists the 13 best features as they were identified by the respective feature ranking method. The last row in Table 5 lists the accuracy values that were obtained for the mixed feature sets for the same scenario that was already considered in Table 4. After studying Table 5, it becomes evident that all four feature-ranking techniques clearly identify the MFCCs, which are denoted as , as the most important features for the reliable classification of unseen damages, since each feature set consists mainly of MFCCs. Remarkably, the mixed feature sets are not able to outperform the pure MFCC feature vector, as evidenced by the results in Table 5 and Table 4, although data from all bearings was considered for each feature-ranking technique. Thus, after considering all the investigations above, it can be clearly stated that the MFCCs are the best suited features for the task at hand. Note that with the data used, the feature ranking methods should ideally yield the set of 13 MFCCs as optimum features or produce a feature vector that outperforms the MFCC feature vector. The reason for the given results remains to be investigated.
3.3. Classification
Since it has been demonstrated that the MFCCs are the best-performing features with a commonly used classifier, it is now investigated in the next step whether the classification performance can be improved even further by pairing the MFCCs with another classifier. To this end, various supervised machine learning classifiers are evaluated for the scenario that was already evaluated in Section 3.2. For our comparative study, we consider the following classifiers: k-NN [39], SVMs [40] with both linear and polynomial kernels, Decision Tree [20], Random Forest [41], AdaBoost [42], Naive Bayes [43,44], Linear Discriminant Analysis (LDA) [45], Quadratic Discriminant Analysis (QDA) [46] and MLPs [21]. At this point, we forego the introduction of each classifier as it would exceed the scope of this paper, but refer to [35] for a more detailed description and to [47] for implementation details. For the k-NN classifier, we consider two different values, i.e., and . Just like in Table 4, we include the SVM in our evaluation but now consider an SVM with a linear kernel and an SVM with a polynomial kernel with a degree of 3 instead of the RBF kernel. We also consider a simple MLP classifier, i.e., MLP (baseline), which consists of one hidden layer with 100 neurons, and our proposed MLP classifier whose architecture is shown in Figure 11. The proposed MLP architecture consists of two hidden layers with 1024 and 100 neurons, respectively. The first hidden layer is followed by a batch normalization layer, a dropout layer with dropout probability to decrease the risk of overfitting and a Rectified Linear Unit (ReLU) activation function. A second dropout layer with dropout probability with is added after the second hidden layer of size 100. Then, another ReLU is added before the output layer of size 2. The classification results for all considered classifiers are summarized in Table 6. Again, the TPR, the TNR and the overall accuracy (ACC) are considered in our evaluation. Considering Table 6, it can be stated that MFCCs are well-suited features independent of the classifier, as the overall accuracy for 9 of the 12 considered classifiers is above and the lowest accuracy is still above for the rather simple Naive Bayes classifier. With the k-NN classifier, which is a popular choice due to its simplicity, accuracies of and can be obtained for and , respectively. Although the accuracy could be improved by increasing the value for k from 5 to 10, choosing did not improve the accuracy any further. After comparing the three different SVMs—SVM (RBF Kernel) (cf. Table 4), SVM (lin. Kernel) and SVM (poly. Kernel)—it can be stated that the highest accuracy is achieved by SVM (lin. Kernel) with an accuracy value of . However, when inspecting TPR and TNR, it can be noticed that the classifier is biased towards TNR, which is obvious from the 6 percentage point difference relative to TPR. While the overall accuracy for SVM with RBF kernel is percentage points lower, the difference between TPR and TNR is not as significant, i.e., vs. , which is preferable. However, the polynomial kernel with a degree of 3 is the worst-performing kernel choice, as the overall accuracy is . For the decision-tree-based classifiers—Decision Tree, Random Forest and AdaBoost—accuracies of , and are achieved. As Random Forest and AdaBoost are ensemble learning methods that combine more than one decision tree for decision making, it is natural that better accuracies are obtained. Very good results can also be obtained by the discriminant analysis classifiers, LDA and QDA, as accuracy values of and can be observed, respectively. With the MLP (baseline) classifier, an accuracy of is also achieved. Yet, with our proposed MLP classifier, i.e., MLP (proposed), the accuracy can be increased by over 2 percentage points to . Therefore it can be stated that by using the MFCCs as features, good classification results can be obtained with a variety of classifiers, which further supports their aptitude. In conclusion, it can be stated that leveraging MFCCs as features yields consistently superior classification results across various classifiers, which underscores their efficacy and suitability for the task. Since our proposed classifier yielded the best results for the considered scenario, our further investigations are based on MLP (proposed) and the MFCCs as features. Please note that end-to-end DNN-based approaches have not been completely excluded from our investigation, as Convolutional Neural Networks (CNNs) were also considered. In particular, ResNet [48] models of varying model complexity were trained to automatically extract features from the raw microphone data. However, the considered models did not outperform the feature-based approach.
3.4. Experiments
To complete our experimental study, we investigate some more classification scenarios with real-world data. In our evaluation, we distinguish between scenarios with seen bearing damages and unseen bearing damages. In Section 3.2 and Section 3.3, we already considered a challenging scenario with unseen damages. Although scenarios with unseen damages are highly relevant for practical applications, scenarios involving seen damages are predominant in the literature. In these scenarios a random split is performed on the available data to generate the training and test data. Thus, the classifier has “seen” all bearings in some capacity in training.
3.4.1. Classification with Seen Damages
For the first classification task, a binary classification at the engine is considered. The classifier is trained with data from the first two axles of Car A, i.e., and , and Car B, i.e., and . The data from Car A is labeled as damaged (D), whereas the data recorded in Car B is labeled as healthy (H). For training and testing, the data was split randomly into datasets of sizes 80,000 and 20,000 samples, respectively. The results are summarized in the form of confusion matrices in Figure 12. While the confusion matrix on the left summarizes the classifications in absolute numbers, the confusion matrix on the right gives the according percentages. It can be observed that the bearing faults can be very well detected with a TNR of , while the probability of correctly predicting the healthy bearings is almost as high with . Thus, the number of false alarms is negligibly small.
A similar experiment is conducted for the gearbox. Since only a single instance of bearing damage, i.e., , is available for the gearbox, the data obtained from the healthy gearboxes at the three remaining axles, i.e., , , and , are labeled as healthy (H). The sizes of the test and training sets are identical to those in the previous experiment. The resulting confusion matrices are shown in Figure 13. Once again, an almost perfect classification result is achieved, with an accuracy of However, it has to be noted that it cannot be ruled out that the damaged bearing at the motor, i.e., , also affects the microphone signal at the gearbox on the same axle and, thus, the classification result. Yet the fact that the classifier is able to correctly classify the data obtained from the healthy gearbox of the first axle of Car A as healthy speaks against this concern.
3.4.2. Classification with Unseen Damages
For the classification with unseen damages, the following scenarios are considered: the classifier is trained with data from one of the two damaged bearings at the motor, either or , and data from the corresponding axle of Car B, i.e., or . The classifier is then tested with data from the remaining damaged bearing and its corresponding healthy reference. Thus, if the classifier is trained with and , it is tested with and , and vice versa. Again, the training set and the test set consist of 50,000 samples each. Although the scenario in which and form the test set was already briefly discussed in Section 3.3 (cf. Table 6), the complete confusion matrix is now shown in Figure 14. The results for the second scenario where and are used for testing instead of for training are shown in Figure 15. Here, the overall accuracy slightly drops to . Noticeably, the TNR has dropped below , which leads to an increased number of missed detections. A plausible explanation for this behavior is the following: while bearing represents a bearing fault in a more advanced stage, bearing represents a fault in a rather early stage. Therefore, it is plausible that when the classifier has only been trained on advanced faults, it has difficulty detecting less severe faults, leading to an increased number of undetected faults.
The experiments with unseen data support the claim that the features are genuinely fault-related rather than axle-related, as the bearing faults at the motor were reliably detected even when positioned on different axles.
In summary, bearing faults can be effectively detected using acoustic data and a feature-based classification approach. However, it is important to note that the available datasets contained only a limited number of bearing faults, which requires careful classifier design to minimize the risk of overfitting.
4. Conclusions
In this paper, it is demonstrated that classifying bearing faults in railway vehicles using airborne sound data is feasible even in challenging real-world scenarios. In an experimental study, various features from the time domain and the frequency domain were extracted from sound signals recorded not on a test bench but on a railway vehicle during regular operation and then compared with respect to their performance with various classifiers. This study showed that the Mel Frequency Cepstral Coefficients (MFCCs) clearly outperform all of the other features. In order to optimize the classification performance, the MFCCs were used to train various classifiers. The experiments showed that with our proposed MLP, near-perfect classification results were achieved for scenarios with seen damages, and for unseen data, accuracies exceeded 94%. In conclusion, airborne sound data is well-suited for detecting and classifying bearing faults in the considered scenario. Consequently, microphones can be a valuable addition to acceleration sensors and warrant further investigation. In future work, these promising results should be validated in other scenarios, such as detecting rotor imbalance, and in more complex tasks, like multi-class classification involving various bearing damages, which would require more recorded data. Additionally, exploring a bi-modal approach that combines structure-borne and airborne sound for classification could potentially yield even better results.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Randall R.B. Antoni J. Rolling element bearing diagnostics—A tutorial Mech. Syst. Signal Process.20112548552010.1016/j.ymssp.2010.07.017 · doi ↗
- 2Peng B. Bi Y. Xue B. Zhang M. Wan S. A survey on fault diagnosis of rolling bearings Algorithms 20221534710.3390/a 15100347 · doi ↗
- 3Neupane D. Seok J. Bearing fault detection and diagnosis using case western reserve university dataset with deep learning approaches: A review IEEE Access 20208931559317810.1109/ACCESS.2020.2990528 · doi ↗
- 4Hamadache M. Jung J.H. Park J. Youn B.D. A comprehensive review of artificial intelligence-based approaches for rolling element bearing PHM: Shallow and deep learning JMST Adv.2019112515110.1007/s 42791-019-0016-y · doi ↗
- 5Zhang S. Zhang S. Wang B. Habetler T.G. Deep learning algorithms for bearing fault diagnostics—A comprehensive review IEEE Access 20208298572988110.1109/ACCESS.2020.2972859 · doi ↗
- 6Yun H. Kim H. Kim E. Jun M.B.G. Development of internal sound sensor using stethoscope and its applications for machine monitoring Procedia Manuf.2020481072107810.1016/j.promfg.2020.05.147 · doi ↗
- 7Wu S. Zhou J. Liu T. Compound fault feature extraction of rolling bearing acoustic signals based on AVMD-IMVO-MCKD Sensors 202222676910.3390/s 2218676936146118 PMC 9502951 · doi ↗ · pubmed ↗
- 8Yan H. Bai H. Zhan X. Wu Z. Wen L. Jia X. Combination of VMD mapping MFCC and LSTM: A new acoustic fault diagnosis method of diesel engine Sensors 202222832510.3390/s 2221832536366023 PMC 9657700 · doi ↗ · pubmed ↗