A Multimodule Collaborative Framework for Unsupervised Visible–Infrared Person Re-Identification with Channel Enhancement Modality
Baoshan Sun, Yi Du, Liqing Gao

TL;DR
This paper introduces a new framework for matching people across visible and infrared images without supervision, improving accuracy and reducing modality gaps.
Contribution
The novel framework treats channel augmentation as an independent modality and combines four modules for enhanced cross-modal person re-identification.
Findings
The proposed method achieves Rank-1 accuracy of 93.34% on RegDB's visible-to-infrared setting.
It outperforms existing unsupervised and some supervised approaches in USL-VI-ReID.
The framework improves cluster consistency and reduces modality discrepancies effectively.
Abstract
Unsupervised visible–infrared person re-identification (USL-VI-ReID) plays a pivotal role in cross-modal computer vision applications for intelligent surveillance and public safety. However, the task remains hampered by large modality gaps and limited granularity in feature representations. In particular, channel augmentation (CA) is typically used only for data augmentation, and its potential as an independent input modality remains unexplored. To address these shortcomings, we present a multimodule collaborative USL-VI-ReID framework that explicitly treats CA as a separate input modality. The framework combines four complementary modules. The Person-ReID Adaptive Convolutional Block Attention Module (PA-CBAM) module extracts discriminative features using a two-level attention mechanism that refines salient spatial and channel cues. The Varied Regional Alignment (VRA) module performs…
Click any figure to enlarge with its caption.
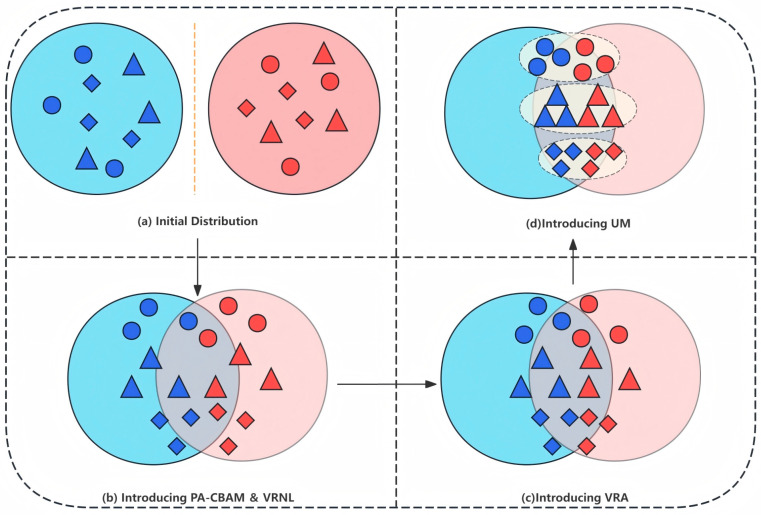 Figure 1
Figure 1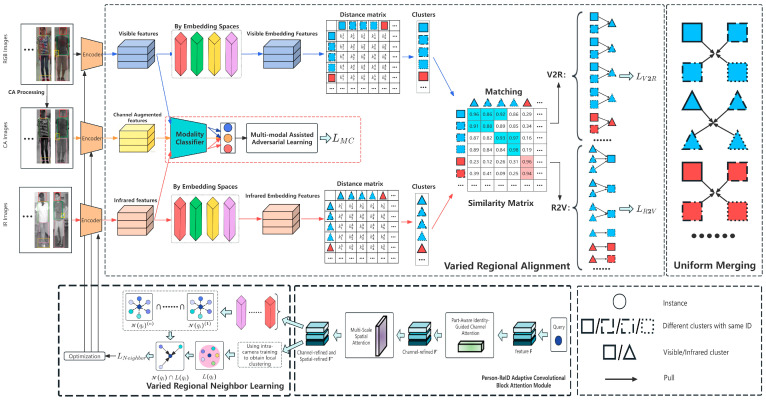 Figure 2
Figure 2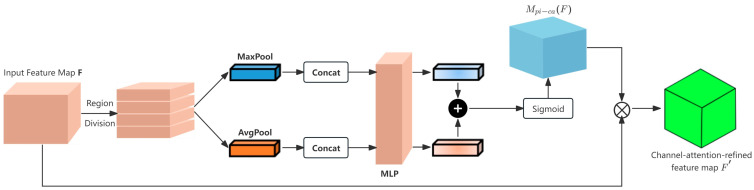 Figure 3
Figure 3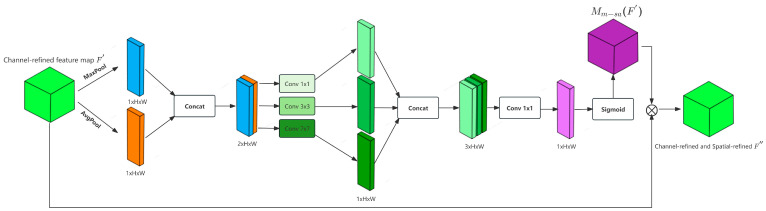 Figure 4
Figure 4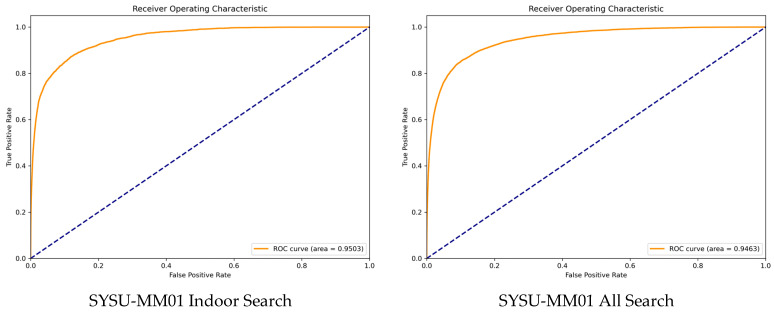 Figure 5
Figure 5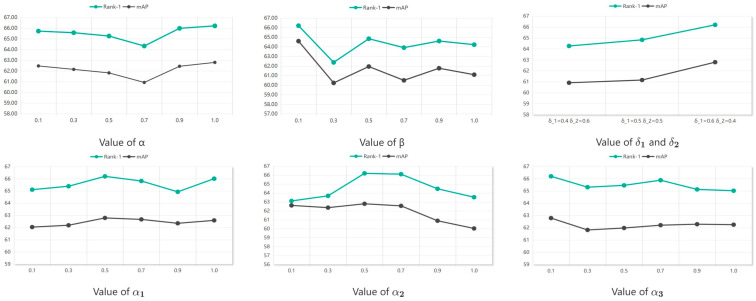 Figure 6
Figure 6 Figure 7
Figure 7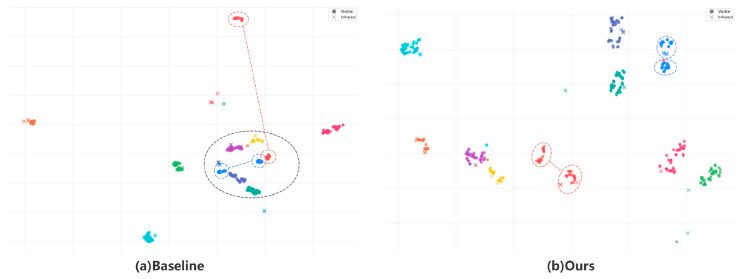 Figure 8
Figure 8- —Natural Science Foundation of Tianjin
- —National Undergraduate Training Program for Innovation and Entrepreneurship
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVideo Surveillance and Tracking Methods · Advanced Neural Network Applications · Gait Recognition and Analysis
1. Introduction
Person re-identification (ReID) aims to accurately match images of the same pedestrian captured from different camera angles and environmental conditions, providing essential support for intelligent surveillance and public safety [1,2,3,4]. As surveillance systems evolve to meet all weather operational demands, infrared (IR) functionality in devices is gaining popularity. This technology effectively addresses the challenges of blurred visible light imaging in nighttime or low-light conditions. Given the higher incidence of security incidents at night, visible–infrared person re-identification (VI-ReID) has emerged as a key research area in cross-modal computer vision. This focus aims to enable effective matching between visible light and infrared images [5,6,7,8].
While existing VI-ReID research has progressed [9,10,11,12], many methods achieve high recognition accuracy using complex feature alignment strategies. However, these methods often depend on large-scale labeled cross-modal datasets [6,13,14,15]. Manually labeling such data is resource-intensive and fails to adequately represent complex, dynamic real-world scenarios, limiting industrial applications. In real-world intelligent surveillance, unsupervised methods play a crucial role in visible–infrared person re-identification (VI-ReID) when annotation resources are limited. Surveillance systems continuously produce vast amounts of cross-modal visual data (visible and infrared), making it infeasible to label every pedestrian image because of the substantial time and labor required. Moreover, surveillance environments change frequently—pedestrian flow, lighting, and camera placements all vary—so labeled datasets collected in one scene often fail to generalize to new, unlabeled deployments. By contrast, unsupervised VI-ReID directly learns discriminative cross-modal features from unlabeled data, eliminates heavy dependence on manual annotation, and adapts to the evolving characteristics of operational surveillance. These properties make unsupervised VI-ReID essential for deploying VI-ReID technology in practical intelligent surveillance systems. To address this, unsupervised visible–infrared person re-identification (USL-VI-ReID) has emerged. This approach generates pseudo-identity labels through clustering, reducing the need for manual annotation, and is now a key focus in VI-ReID research [16,17,18,19,20].
Despite these advancements and the clear practical demand, existing USL-VI-ReID methods still suffer from three critical limitations that hinder their performance, which our framework is specifically designed to address:
- Imperfect Cross-Modal Alignment: Visible light and infrared images differ fundamentally in their imaging principles, leading to significant disparities in their feature distributions that are difficult to reconcile.
- Insufficient Local Feature Representation: Most existing studies rely on a single global feature for matching, which struggles to capture fine-grained discriminative details (e.g., clothing textures and body parts). This approach is vulnerable to pose changes, occlusions, and illumination fluctuations, reducing the reliability of cross-modal similarity calculations and ultimately decreasing recognition accuracy [18,19,21].
- Underutilization of Channel Augmentation (CA): Traditional methods treat CA merely as a simple data augmentation tool, overlooking its potential as an independent input modality. They fail to leverage CA images effectively to bridge the gap between visible light and infrared modalities, further exacerbating the inconsistency in feature distributions between these modalities.
To comprehensively tackle the three aforementioned limitations, this paper introduces the USL-VI-ReID framework, which integrates multimodule collaborative optimization. As depicted in Figure 1, Channel Augmentation (CA) is treated as input data rather than just a data augmentation technique. By employing refined feature extraction, cross-modal regional alignment, and clustering integration, the framework enhances the discriminability and consistency of cross-modal pedestrian features. The framework comprises four core modules: First, the Person-ReID Adaptive Convolutional Block Attention Module (PA-CBAM) combines channel attention with multi-scale spatial attention to boost the channel discriminability of local pedestrian identity features and accurately capture key region information across scales, as shown in Figure 1b. Second, the Varied Regional Alignment (VRA) module incorporates the Multimodal Assisted Adversarial Learning (MAAL) module. This assists in identifying and matching diverse regional features across different modalities, utilizing channel augmentation technology to minimize modal differences and facilitate cross-modal association, as shown in Figure 1c. Third, the Varied Regional Neighbor Learning (VRNL) module ensures reliable neighbor learning through multi-region spatial association, as shown in Figure 1b. Fourth, the Uniform Merging (UM) module consolidates split clusters of the same ID, suppresses noise interference, and enhances the robustness of feature representation, as shown in Figure 1d.
The main contributions of this paper can be summarized into the following four points, which directly address the critical limitations of previous methods in local feature representation, cross-modal alignment, and channel augmentation utilization:
- The PA-CBAM module is designed to tackle the limitation of insufficient local feature representation. It uses a two-stage attention strategy—first optimizing channel responses, then refining spatial activations—to strengthen the discriminative representation of pedestrian identities. By producing more granular and locally informative features, PA-CBAM creates a robust foundation for subsequent cross-modal alignment and neighborhood learning and remedy shortcomings of traditional single global descriptors.
- The VRA module is proposed to achieve precise cross-modal alignment while fully exploiting the potential of channel augmentation. It incorporates the MAAL component and applies channel enhancement techniques to reduce modal discrepancies and enable cross-modal regional feature matching. In doing so, VRA moves beyond conventional channel enhancement approaches that serve merely as data augmentation and thus cannot fully bridge the modal gap.
- The VRNL module combines multi-region spatial association with multimodal adversarial learning and imposes parameter constraints to prevent excessive cross-modal matching. This design improves the reliability of neighborhood learning and enforces modal consistency, addressing the tendency of neighborhood learning to suffer from modal differences and the risk that overmatching will induce identity confusion.
- The UM module performs alternating contrastive learning to merge split clusters that correspond to the same identity, thereby reducing intra-modal variance and increasing robustness to noise. This mechanism counters problems encountered during preprocessing, including identity clustering fragmentation, large within-modal feature disparities, and interference from noisy samples.
2. Related Work
This section examines key research directions in visible–infrared person re-identification. It reviews the current state of supervised visible–infrared re-identification, unsupervised single-modality re-identification, and unsupervised visible–infrared re-identification. The analysis highlights the strengths and limitations of existing methods, providing a foundation for the proposed approach in this paper.
2.1. Supervised Visible–Infrared Person Re-Identification
Supervised visible–infrared person re-identification (SVI-ReID) depends on extensive annotated cross-modal datasets. The primary goal is to bridge the inherent gap between visible and infrared modalities through an effective feature learning mechanism, ensuring precise cross-modal matching. Two main technical approaches have emerged: subspace learning and generative transformation. Subspace learning methods aim to create a shared feature space across modalities and enhance discriminability by adjusting feature distribution. MCLNet [22] employs a multi-branch network to emphasize identity-related features within this common subspace. DART enhances the feature subspace using a dynamic attention mechanism, significantly improving cross-modal feature consistency. Furthermore, MAUM [23] introduces a multi-scale alignment module to reduce the modality gap, showcasing strong feature alignment capabilities. FMCNet [24] employs a generative network to create cross-modal intermediate features. Despite their benefits, generative methods often incur high computational costs and may introduce image noise. For instance, GAN-based methods [25,26,27,28,29,30] can convert modalities but struggle to balance real-time performance with feature purity, limiting their industrial application.
The SVI-ReID method has achieved high recognition accuracy; however, its reliance on manual annotation limits its effectiveness in complex and dynamic real-world scenarios. The costs associated with annotation and the method’s adaptability to various scenes have become significant bottlenecks in advancing this research area.
2.2. Unsupervised Single-Modal Person Re-Identification
Unsupervised single-modal person re-identification (USL-ReID) focuses on extracting distinct features from unlabeled single-modal data, primarily visible light. The main approach involves generating pseudo-labels via clustering and employing contrastive learning strategies to enhance feature representation. This method significantly minimizes reliance on labeled data. Clustering and pseudo-label optimization are central to USL-ReID. Cluster-Contrast [20] creates a cluster-level memory dictionary and employs a momentum update strategy to reduce noisy pseudo-label propagation. ICE [31] enhances feature discrimination through inter-instance contrastive coding and pairwise similarity scores. Additionally, CAP [3] introduces a novel approach by dividing each cluster into multiple camera proxies. This method addresses intra-class differences for the same identity, offering a fresh perspective on improving pseudo-label quality. The advancement of contrastive learning strategies has significantly propelled the development of USL-ReID. For instance, IICS [32] improves local features using cross-image patch contrastive learning, while PPLR [33] introduces a progressive pseudo-label refinement mechanism to enhance feature discriminability. When applied to cross-modal scenarios, they fail to address the inherent feature distribution disparities between visible and infrared images. This oversight results in limited modal adaptability and a notable drop in performance.
2.3. Unsupervised Visible–Infrared Person Re-Identification
Unsupervised visible–infrared person re-identification (USL-VI-ReID) is a prominent research area. It aims to accurately match visible and infrared images in scenarios involving unlabeled cross-modal data. This is achieved through modal difference suppression, pseudo-label generation, and cross-modal association construction. The research primarily focuses on two areas: modal alignment and cross-modal clustering association.
Modal difference suppression often employs multimodal adversarial learning and feature enhancement techniques. ADCA [34] introduces a dual contrastive learning framework that narrows the modal gap by aggregating instances and memory features. Similarly, PGMAL [18] incorporates a graph matching mechanism with adversarial learning to optimize cross-modal feature distribution, enhancing feature consistency. Despite these advancements, many adversarial learning methods primarily target global feature alignment and fall short in addressing discrepancies in local key features, such as clothing textures and body part details. This limitation reduces the reliability of cross-modal similarity calculations. Developing cross-modal clustering associations is a key focus in USL-VI-ReID. Techniques like OTLA [19] and DOTLA [16] employ the optimal transport algorithm for cross-modal clustering matching. Meanwhile, MBCCM [35] enhances label assignment using multi-branch clustering associations. However, many of these approaches match clusters directly without adequate modal alignment, leading to potential errors in label assignment due to modal bias. This issue becomes more pronounced when there is an imbalance in the number of visible light and infrared clusters, significantly increasing the error rate.
Another representative multimodule collaborative approach is ReID-DeePNet [36], which addresses background clutter interference through a hybrid deep learning framework: it first fuses Mask R-CNN and GrabCut for precise pedestrian segmentation to suppress background noise, then extracts discriminative features via dual models (CNN and Deep Belief Network, DBN) and fuses their matching scores to improve re-identification accuracy. This work highlights the effectiveness of “background suppression + multi-model feature fusion” in enhancing feature discriminability, which aligns with our framework’s design philosophy of leveraging multimodule synergy (e.g., PA-CBAM for feature refinement, VRA for cross-modal alignment) to mitigate modal gaps and background interference. Notably, ReID-DeePNet verifies that integrating specialized preprocessing modules (e.g., segmentation) with multi-model feature learning can significantly improve ReID performance, providing valuable insights for our adoption of CA as an independent modality to bridge cross-modal feature discrepancies.
Existing methods often struggle with insufficient granularity in feature representation. Typically, they depend on a single global feature for matching, which fails to capture local key details of pedestrians and is susceptible to pose changes, occlusions, and lighting variations. Additionally, channel augmentation (CA) technology is primarily used for data augmentation. Its potential as an independent input modality to bridge modality gaps remains underexplored. This oversight exacerbates feature distribution inconsistencies between modalities, limiting performance improvements in USL-VI-ReID.
3. Methods
The framework of the proposed method is illustrated in Figure 2. Initially, we employ the Varied Regional Neighbor Learning (VRNL) module to harness associations among multiple regional spaces, enhancing neighbor learning reliability. Concurrently, the PA-CBAM module is integrated into VRNL for more precise feature extraction. Building on VRNL, we introduce the Varied Regional Alignment (VRA) module, designed to effectively identify and match diverse regional features across different modalities. The MAAL module supports the VRA module by utilizing channel enhancement technology to reduce modal differences, aiding subsequent cross-modal associations. Lastly, the Uniform Merging (UM) module integrates different clusters with the same identifier (ID) identified and matched by VRNL. This integration aims to reduce intra-modal gaps, minimize noise impact, and enhance the robustness and accuracy of feature representation.
3.1. The Baseline Re-ID Mode
In USL-VI-ReID, the training data includes visible light data and infrared data , represented as and , respectively, indicating their sample sizes. Existing studies [18,34,37] highlight that channel augmentation (CA) images significantly help bridge the gap between visible and infrared modalities. Consequently, we incorporated CA modality images into the input data to enhance the generalization ability of the visible modality. The CA data is represented as .
We adopt the momentum update strategy of Yang [1] to refresh the memories for all three modalities.
At the start of each training round, we build modality-specific clustering memory using the following formula:
In this context, denotes the number of instances in the k-th clustering set, while also refers to the instance features concatenated with each Regional Space. The variable m can assume three values: {v, r, c}, corresponding to the visible light modality, the infrared modality, and the CA modality, respectively.
In this paper, the Vision Transformer network extracts query features from visible light, infrared, and CA data, denoted as , , and , respectively.
For the loss function, using the visible and infrared query features and , the contrastive loss is calculated with the following formula:
In this context, and represent the positive clustering for visible-light and infrared memory, respectively, corresponding to the pseudo-label of the query feature F. represents the features of the k-th cluster in the visible light modality clustering memory and represents the features of the k-th cluster in the infrared light modality clustering memory. Additionally, τ denotes the temperature coefficient.
3.2. Person-ReID Adaptive Convolutional Block Attention Module
In feature extraction, we utilize the CBAM module concept [38] to develop the Person-ReID Adaptive CBAM (PA-CBAM) module. This module comprises two enhancement sub-modules: Part-Aware Identity-Guided Channel Attention (PI-CA) and Multi-Scale Spatial Attention (M-SA). Initially, PI-CA optimizes the input feature map in the channel dimension. Subsequently, M-SA refines it in the spatial dimension, resulting in a highly discriminative feature map.
PI-CA strengthens the model’s ability to discern local features and heightens its attention to identity-related characteristics, as shown in Figure 3. We segment the input feature map into K distinct horizontal region blocks . For each block, we apply average pooling and max pooling to retain the spatial context of each segment, producing two sets of part-level descriptors:
In this context, Concat(·) refers to the concatenation operation along the channel dimension. This operation integrates part-level contextual information into a global descriptor, maintaining the distinctiveness of each identity part.
This paper presents an identity-guided regularization term in the multi-layer perceptron (MLP) of channel attention to suppress background-related channels and enhance identity-related ones. This regularization uses identity pseudo-labels to maintain consistent channel weights for samples with the same identity while increasing differences in channel weights among samples with different identities. The modified MLP calculation formula incorporating this regularization is as follows:
In this context, denotes the part-level descriptor. The weight parameters of the MLP are represented by and , with r serving as the dimensionality reduction coefficient. The sample’s identity pseudo-label is indicated by y. Additionally, refers to the identity consistency regularization term, while λ stands for the regularization weight. Specifically, λ is used to adjust the strength of the identity-guided regularization constraint: a larger λ enhances the suppression of background-related channels and the emphasis on identity-related channels, while an overly large λ may lead to over-fitting of pseudo-labels. A moderate λ ensures the module refines identity-discriminative features without being affected by noisy pseudo-labels.
The channel attention map is calculated by integrating part-level descriptors with the identity-guided MLP. The formula is as follows:
Among these, represents the sigmoid function, which normalizes channel weights to the [0, 1] interval. The feature map, enhanced by channel attention, is derived through element-wise multiplication:
M-SA introduces a multi-scale convolution block to tackle the challenge of varying sizes of discriminative regions in person re-identification tasks, as shown in Figure 4. This block incorporates three convolution kernel sizes: 1 × 1, 3 × 3, and 7× 7. The 1 × 1 kernel captures global spatial dependencies, the 3 × 3 kernel targets local regions, and the 7 × 7 kernel models large-scale structural features. Initially, for the input feature map optimized by PI-CA, average and max pooling are applied along the channel dimension to aggregate channel information.
Among these operations, denotes average pooling, and signifies maximum pooling along the channel axis. The concatenated descriptor is then fed into the multi-scale convolution block.
In this context, denotes a convolution operation with a kernel size of k × k. Following this, the multi-scale features are combined into a single-channel feature map using a 1 × 1 convolution.
The spatial attention map is obtained through the sigmoid function:
The final feature map optimized by PA-CBAM is as follows:
3.3. Varied Regional Alignment
Current research methods often use channel enhancement techniques to improve intra-modal learning and clustering in visible light images. However, these approaches frequently neglect the alignment of distributions among channel-enhanced, visible light, and infrared images, treating enhancement merely as data augmentation. Inspired by MCLNet [22], CmGAN [39], and PCAL [40], we propose Multimodal Assisted Adversarial Learning (MAAL). MAAL aims to optimize the use of each modality, bridging the feature distribution gap across different modalities, thereby enhancing the model’s adaptability to cross-modal data and improving feature alignment. By employing an adversarial learning strategy, we leverage data from all three modalities to boost the model’s generalization, minimize modal discrepancies, and support model training. The modal classification loss is defined as follows:
Among these, can assume values of , , and , representing features of visible light, infrared, and channel-enhanced query samples, respectively. Similarly, can take values of , , and , indicating labels for the three modalities: visible light, infrared, and channel enhancement. The symbol denotes the modality classifier, while E signifies its parameters. CE stands for cross-entropy loss.
Building on this foundation, we introduced an additional modal classification loss. This loss aims to categorize the features of all three modalities into the channel-enhanced modality. The formula is as follows:
In this context, denotes the query sample features across three modalities: visible light, infrared, and channel enhancement. Additionally, θ signifies the parameters of the backbone network.
The total loss in the three-modal adversarial learning module can be expressed as
Here, and are the weight hyperparameters of the modal classification loss and the channel-augmented modal classification loss , respectively. regulates the intensity of the modality discrimination constraint for the three modalities (visible, infrared, CA), ensuring the model can distinguish different modal features; controls the strength of the constraint that maps all modal features to the CA modal space, which is the core to realize cross-modal feature alignment with CA as the bridge modality. The collaborative adjustment of and balances the dual objectives of “modal discrimination” and “cross-modal alignment” in adversarial learning. An alternating optimization approach is employed: the modality classifier is optimized using , while the backbone network is optimized using . Treating channel enhancement as an additional modality and integrating it into the training process ensures better distribution alignment of features across the three modalities—visible light, infrared, and channel enhancement—within the same probability space. This method is more effective than using channel enhancement solely for data augmentation.
Next, in the regional space, we calculated the distances between various features of visible light and infrared. We then constructed a distance matrix for these two modalities and clustered the features based on this matrix.
After obtaining the clusters for the visible light and infrared modalities, we denote the similarity matrix as The calculation method for this similarity matrix is as follows:
In this context, S(i,j) denotes the similarity within cluster and , while n indicates the nth regional space. Additionally, represents the Lth instance feature within this regional space, with the same notation applying to . Furthermore, signifies the number of instances in the kth cluster within the visible light modality, and this notation is consistent for .
After obtaining the similarity matrix, we aim to ensure that clusters with the same ID maintain consistent cross-modal labels. In each cycle, we select the pair of cross-modal clusters with the highest similarity from this matrix. The screening formula is as follows:
Arg max identifies the row and column numbers, i and j, where the maximum value in the similarity matrix occurs. These indices correspond to the pair of clusters with the highest similarity.
To ensure stability during matching and reduce computational demands, we set a parameter, μ, to limit the number of matches between modalities. This helps prevent excessive matching and identity confusion. The parameter μ can restrict matches for either visible light or infrared clusters. In this study, we applied μ specifically to limit matches for each infrared cluster.
We employed the TokenMatcher method [37] to learn cross-modal features through modal shared contrast. This process involves two components: visible-to-infrared modal learning and infrared-to-visible modal learning. The corresponding loss functions are expressed as follows:
In this context, and denote the modality-specific shared memories for the visible-light and infrared modalities, respectively. Additionally, and refer to the cross-modality labels for the visible-light query sample and the infrared query sample , respectively. Furthermore, and represent the set of infrared cluster instances corresponding to the k-th visible-light cluster, or the set of visible-light cluster instances corresponding to the k-th infrared cluster, respectively. represents the set of instances contained in the k-th cluster in the visible light modality. represents the set of instances contained in the k-th cluster in the infrared light modality. denotes the temperature coefficient.
The total loss function for modal shared contrastive learning is expressed as . This function aids in the reconstruction process.
3.4. Varied Regional Neighbor Learning
After completing cross-modal regional alignment and feature distribution optimization in the VRA module, we introduce the VRNL module to further improve neighbor-learning reliability and cross-modal feature consistency. VRNL combines multi-region spatial association with parameter constraints to perform efficient neighbor mining. For the query samples and , we define the intra-modal neighbor set as follows:
In this context, represents the intra-modal neighbor set derived from the k-th domain space of . The variable m can be either v or r. The definition of is as follows:
Among them, ρ represents the size of the range that neighbors can choose from.
For the query samples and , the inter-modal neighbor sets are defined as follows:
For , the inter-modal neighbor set is derived from the k-th domain space of . The same principle applies to . The definitions of and are as follows:
In this way, we obtain the neighbor sets , , , .
We sequentially optimize the obtained neighbor sets , , , . Inspired by CALR [41], we developed an optimization method specifically for these neighbor sets. For a given query sample , we derive the neighbor set , the corresponding local cluster formed within the camera, and multiple sub-clusters segmented from . Thus, the optimization process for the neighbor set is expressed as follows:
In this study, denotes the sample set remaining after excluding samples captured by camera c from the neighbor set . This method effectively removes noisy samples from the same camera, thereby enhancing the reliability of the neighbor set results. The same approach is applied to optimize , , and .
For the given query sample , the neighbor learning loss from visible light to visible light is determined using the following formula:
In this context, denotes the batch size of the query sample . signifies the similarity contribution of the positive samples and indicates the cumulative similarity contributions between the query samples and all visible-light samples. Additionally, indicates the loss of a single query–neighbor pair. implies the total neighbor learning loss from visible light to visible light. Similarly, we calculate the neighbor learning losses for transitions from visible light to infrared, infrared to infrared, and infrared to visible light, represented as , , and , respectively. Ultimately, the final optimization objective of Varied Regional Neighbor Learning is defined by the following formula:
3.5. Uniform Merging
Following the above processing, there is a significant similarity among multiple visible light clusters linked to the same infrared cluster, and vice versa. These clusters likely originate from the same ID split. Thus, we apply Uniform Merging to combine different clusters of the same identity in both visible light and infrared modalities, further minimizing intra-modal differences.
To retrieve infrared clusters corresponding to a visible-light query feature , first identify the infrared clusters linked to . Next, find all visible-light clusters associated with these infrared clusters. This process yields a set of visible-light clusters that share the same pedestrian identity as the visible-light query feature . We denote the number of clusters in this group as . Thus, multiple distinct visible-light clusters are represented by the same cross-modal label, .
The alternating contrastive learning strategy [18] facilitates the Uniform Merging process using the visible-light modality-specific memory .
For the infrared modality, consider an infrared query feature denoted as . We assume the number of clusters in the infrared group, associated with the same pedestrian identity as , equals . These clusters are represented with the same cross-modal label as .
Similarly, we can obtain
To balance the contributions of the two modality fusion losses, we introduce hyperparameters and . The total loss for Uniform Merging is defined as
Among these, and serve as adjustable parameters to control the proportions of visible light fusion loss and infrared fusion loss within the total loss.
The final total training loss can be expressed as
4. Experiments
4.1. Datasets
This study evaluated the proposed method’s performance using two well-known benchmark datasets in visible–infrared person re-identification (VI-ReID): SYSU-MM01 [42] and RegDB [43]. The experiments adhered to established protocols in the field.
SYSU-MM01 is a comprehensive cross-modal pedestrian dataset, gathered from various indoor and outdoor environments using a multi-camera system. This system includes four visible light (RGB) cameras and two near-infrared (IR) cameras. The dataset comprises 303,420 pedestrian images representing 491 unique identities, with 287,628 images in the visible light modality and 15,792 in the infrared modality. Significant intra-class variations exist in the images for each identity, due to real-world factors such as changes in view angles, pedestrian poses, lighting conditions, and occlusions. These variations effectively simulate the challenges encountered in the VI-ReID task.
SYSU-MM01 is structured into distinct training and test sets for model training and evaluation. The training set comprises 395 identities, including 22,258 visible light images and 11,909 infrared images in certain protocol settings. The test set consists of 96 identities. During inference, the query set includes 3803 infrared images from the test set, while the gallery set contains 301 randomly selected visible light images. Two standard evaluation modes are used: (1) All-Search mode, where the gallery set is randomly sampled from visible light images taken by both indoor and outdoor cameras; (2) Indoor-Search mode, where the gallery set consists solely of visible light images captured by indoor cameras.
RegDB is a compact yet representative cross-modal pedestrian dataset captured using a dual-camera system comprising a visible light (RGB) camera and an infrared (IR) camera. The dataset includes 8240 images representing 412 unique identities, with each identity having 10 visible light images and 10 infrared images, totaling 4120 images for each modality. Like SYSU-MM01, RegDB exhibits significant intra-class variations due to real-world factors such as pose, illumination, and viewing angle.
RegDB was randomly split into two non-overlapping subsets for training and testing, each with 206 identities. Following established studies, we employed two standard cross-modal evaluation modes: (1) Visible-to-Infrared/Visible–Thermal mode, which involves retrieving matching infrared images using visible-light images as queries, and (2) Infrared-to-Visible/Thermal–Visible mode, which involves retrieving matching visible-light images using infrared images as queries.
We employed standard experimental settings to assess the proposed method on the two benchmark datasets [44], and three core performance metrics, Cumulative Matching Characteristics (CMCs, quantified by Rank-1 accuracy), mean Average Precision (mAP), and mean Inverse Negative Penalty (mINP [2]), were adopted for comprehensive evaluation. These metrics are the de facto standards in the VI-ReID field, ensuring a fair and rigorous comparison with existing state-of-the-art methods.
To quantitatively evaluate the cross-modal retrieval performance of the proposed method, three widely adopted and standard metrics in the person re-identification community are employed: Rank-1 accuracy, mean Average Precision (mAP) and mean Inverse Negative Penalty (mINP). Their specific definitions in unsupervised visible–infrared person re-identification (USL-VI-ReID) are elaborated as follows.
Rank-1 accuracy: It is the most intuitive retrieval metric, representing the percentage of queries for which the top-1 retrieved gallery sample is the correct match (the same identity as the query).
mean Average Precision (mAP): It is the mean value of Average Precision (AP) across all query samples, where AP measures the precision of all correct retrievals for a single query at all recall levels. Mathematically, AP is calculated as the area under the precision–recall curve for each query, and mAP further averages this metric over the entire query set.
mean Inverse Negative Penalty (mINP): It is a challenging metric designed to evaluate the model’s retrieval performance on hard samples (e.g., pedestrians with severe occlusions, large pose changes or low image quality). mINP is defined as the mean value of the inverse of the negative penalty for each query, where the negative penalty is determined by the ratio of the number of incorrect samples ranked higher than the first correct sample to the total number of gallery samples.
To further evaluate the robustness of the proposed method under different similarity thresholds, we also supplement the Receiver Operating Characteristic (ROC) curve, which plots the True Positive Rate (TPR) against the False Positive Rate (FPR) to reflect the trade-off between retrieval accuracy and false positive risk.
4.2. Implementation Details
This method utilizes the PyTorch framework and was trained on four NVIDIA GeForce RTX 4090 graphics cards (GPU Part Number: 2684-301-A1; max boost clock: 3105 MHz; memory: 24,564 MiB GDDR6X). We employed the Visual Transformer (Vit) [45] as the backbone network. Unlike CNNs, which expand local receptive fields, the ViT self-attention mechanism directly models long-range dependencies across the entire image [45]. This capability is essential for capturing both global pedestrian structure (for example, body size) and local discriminative features (for example, clothing texture), thereby addressing the core problem of insufficient feature granularity in USL-VI-ReID.
During the training phase, we selected four identities, each with 16 instances. We applied preprocessing techniques including random horizontal flipping, cropping, occlusion, color jittering, and channel erasing. All pedestrian images for training and testing were resized to the specified size of 384 × 128.
The initial learning rate is set to . It decreases by a factor of 0.1 every 20 epochs. The training process adopts a two-stage progressive optimization strategy to balance feature extraction, modal alignment, and cluster refinement. We adopt the Stochastic Gradient Descent (SGD) optimizer for model training, which is widely used in person re-identification tasks for stable convergence. The training process uses different learning rates and fixed weight decay for the two phases. The detailed design logic and implementation steps are as follows:
Phase 1 (Epoch 1–50): The initial learning rate is set to , with momentum = 0.9 and weight decay = . This phase focuses on feature initialization and modal gap mitigation. Only PA-CBAM and MAAL modules are enabled. PA-CBAM is used to extract fine-grained identity features, while MAAL performs three-modal adversarial learning to align the feature distributions of visible, infrared, and CA modalities. This phase lays a foundation for subsequent cross-modal association by reducing inherent modal discrepancies.
Phase 2 (Epoch 51–100): The learning rate is reduced to , while momentum and weight decay remain unchanged. The momentum parameter accelerates the convergence of SGD in flat regions of the loss function, and the fixed weight decay suppresses over-fitting caused by pseudo-label noise in unsupervised learning, which is critical for the stability of the multimodule collaborative framework. This phase focuses on cross-modal alignment and cluster optimization. On the basis of Phase 1, VRA, VRNL, and UM modules are added. VRA realizes regional-level cross-modal feature matching, VRNL enhances the reliability of neighbor learning and stabilizes pseudo-labels, and UM merges split clusters of the same identity. This progressive module activation strategy avoids training instability caused by excessively complex constraints at the initial stage.
We set the batch size to 64, organized as four identities per batch with 16 instances for each identity. Input images have a height of 384 and a width of 128. For data augmentation, we apply random horizontal flipping with probability 0.5, random cropping to a target size of 384 × 128, color jittering (brightness = 0.5, contrast = 0.5, saturation = 0.5), and channel erasing with probability 0.5. The hyperparameters α and β are set to 1.0 and 0.1, respectively. Similarly, δ_1_ and δ_2_ are assigned values of 0.6 and 0.4. For α_1_, α_2_, and α_3_, the values are 0.4, 0.5, and 0.03. According to [18,34], for intra-modal clustering on two datasets, the hyperparameters and are both set to 30 and 6. In inter-modal clustering, to thoroughly explore inter-modal associations, and are set to 40 and 32 on the SYSU-MM01 dataset, while on the RegDB dataset, they are set to 38 and 18. The parameter μ, which limits the number of matches, is set to 3. This prevents excessive inter-modal matching while maximizing its potential. The number of regions N is dataset-specific: four for SYSU-MM01 and six for RegDB. The neighborhood radius for DBSCAN is consistently set to 0.6 across both datasets.
4.3. Comparison with State-of-the-Art Methods
In this subsection, we compare our proposed method with the current state-of-the-art techniques. These include 11 supervised visible–infrared person re-identification (SVI-ReID) methods, 6sixunsupervised single-modal person re-identification (USL-ReID) methods, and 15 unsupervised visible–infrared person re-identification (USL-VI-ReID) methods. Table 1 presents the comparison results.
4.3.1. Performance Comparison on the SYSU-MM01 Dataset
Our method significantly surpasses existing unsupervised single-modal person re-identification (USL-ReID) techniques. USL-ReID methods, while excelling in single-modal tasks [3,20,33,58], fail to account for inter-modal differences, resulting in poor performance in cross-modal person re-identification. Consequently, USL-ReID is unsuitable for cross-modal applications.
Our method surpasses current state-of-the-art unsupervised methods. On the SYSU-MM01 dataset’s “all search” mode, it achieves a Rank-1 accuracy of 66.20%, a mean Average Precision (mAP) of 62.79%, and a mean Inverse Negative Penalty (mINP) of 49.42%. In “Indoor Search” mode, these metrics improve to 69.36%, 74.72%, and 70.84%, respectively. Compared to the leading unsupervised method, DMDL [68], our approach shows superior performance on the RegDB dataset.
Our method surpasses some supervised cross-modal person re-identification (SVI-ReID) techniques. This improvement stems from effectively leveraging information across different region labels. However, it still lags behind the current state-of-the-art fully supervised methods. This performance gap is primarily due to the absence of annotation information in the unsupervised approach.
4.3.2. Performance Comparison on the RegDB Dataset
Our method not only surpasses unsupervised single-modal person re-identification (USL-ReID) techniques but also achieves state-of-the-art performance in unsupervised cross-modal person re-identification (USL-VI-ReID). Specifically, for the visible-to-infrared and infrared-to-visible conversion modes, it recorded 93.34% and 91.89% on Rank-1, 87.55% and 86.58% on mAP, and 76.08% and 73.60% on mINP, respectively. When compared to the current leading unsupervised method, DMDL [70], on the RegDB dataset, our approach shows superior performance. Notably, in the visible-to-infrared mode, it improves by 2.71% on Rank-1, 2.22% on mAP, and 2.29% on mINP.
Furthermore, our method outperforms certain supervised cross-modal person re-identification (SVI-ReID) methods on the RegDB dataset. This result further confirms the effectiveness of our proposed approach.
We evaluate the computing time on a NVIDIA GeForce RTX 4090. Our input size measures 384 × 128, and our method contains approximately 91.5 million parameters, which is about 5 million more than the standard ViT-Base model. The model achieves 31.6 GFLOPs on FLOPs parameters. Table 2 indicates that there is still potential for improving FPS, and we will explore further lightweight options for the model in the future.
Compared with clustering-based USL-VI-ReID methods such as RULN [66], our approach incurs a higher computational cost. Clustering-only methods typically optimize a simple contrastive loss and omit complex adversarial training or multi-region feature alignment; therefore, their overhead remains low, comparable to the ResNet-50 baseline reported in Table 2. This lower cost, however, comes at the expense of cross-modal alignment: clustering-only pipelines frequently fail to bridge severe modality gaps, whereas the extra computation of our method delivers substantially better cross-modal alignment and downstream discriminability.
Relative to adversarial-based USL-VI-ReID approaches, our hybrid framework offers clear efficiency advantages. Conventional GAN-based solutions commonly train multiple generators and discriminators, which markedly increases computational demand; by contrast, our lightweight MAAL module achieves similar alignment objectives with a much lower cost. Although multimodule collaboration reduces our FPS compared with the basic ViT-Base, it does not produce the exponential FLOPs growth characteristic of heavy adversarial models. Thus, our method attains a pragmatic trade-off, preserving much of the discriminative power associated with adversarial learning while maintaining efficiency closer to clustering-based approaches.
Figure 5 presents the ROC curves of our method on SYSU-MM01 datasets, with the dashed line representing the random guess baseline. It can be observed that our method’s curves are significantly above the baseline across all scenarios, indicating strong discriminative ability to distinguish positive cross-modal pairs from negative ones. Specifically, the Area Under the Curve (AUC) values reach 95.03% (SYSU-MM01 Indoor Search) and 94.63% (SYSU-MM01 All Search), which verifies the superior robustness of our method under different similarity thresholds. This performance gain benefits from the multimodule collaborative optimization, which enhances the model’s ability to capture consistent cross-modal cues while suppressing false matches.
4.4. Ablation Study
In this subsection, we verify the effectiveness of each component of the proposed method through rigorous ablation experiments. Table 3 presents the experimental results.
4.4.1. Validation of the Effectiveness of PA-CBAM
Comparing the results of No. 2 and No. 1 reveals that introducing PA-CBAM to the baseline model improved its Rank-1 accuracy by over 1 percentage point. PA-CBAM’s primary function is to enhance pedestrian feature discriminability and accuracy. It achieves this through a two-level attention mechanism involving “channel dimension optimization and spatial dimension adjustment”. This mechanism provides a high-quality feature foundation for subsequent modules like cross-modality alignment and neighbor learning.
4.4.2. Validation of the Effectiveness of VRA
Comparing the results of No. 5 and No. 1 reveals that introducing the VRA improved model performance by over 10% on the SYSU-MM01 dataset and over 37% on the RegDB dataset. This improvement primarily stems from the MAAL module’s role as an auxiliary component. The MAAL module reduces interference from inherent modal differences by enhancing crucial identity-discriminating feature channels and suppressing redundant noise channels. Consequently, the VRA module more effectively captures “essentially consistent regional features” across modalities. It also identifies and matches diverse regional features between different modalities, ultimately reducing modal differences and laying the groundwork for subsequent cross-modal association tasks.
4.4.3. Validation of the Effectiveness of VRNL
Comparing No. 4 with No. 1 reveals that using VRNL alone significantly enhances performance. Furthermore, as indicated by No. 6, incorporating VRNL with VRA further boosts performance. The model’s ability to learn from neighbors improves by leveraging multi-region spatial correlation. Additionally, the integration of the PA-CBAM module within the VRNL module ensures that multi-region features are not affected by low-quality features, thereby enhancing the accuracy of neighbor learning.
4.4.4. Validation of the Effectiveness of UM
Serial numbers 3 and 7 demonstrate that incorporating UM into the baseline model, either alone or alongside VRA and VRNL, enhances model performance. This improvement occurs because UM consolidates scattered clustering of identical IDs, reduces noise, and offers a unified ID feature representation. Consequently, it addresses the fragmentation of identical ID features left by previous modules, thereby boosting the model’s performance, quality, and robustness.
To further clarify the core functions and unique contributions of each module and the CA modality in the proposed framework, their respective design objectives, solved challenges and key contributions are summarized in Table 4.
4.5. Hyperparameter Analysis
The hyperparameters α and β in formula (17) regulate the adversarial intensity between the “backbone network” and the “modality classifier.” In the UM module, the hyperparameters and in formula (44) balance the fusion loss of the two modalities. Additionally, the hyperparameters α_1_, α_2_, and α_3_ in formula (45) adjust the weight parameters of VRA, VRNL, and UM. As illustrated in Figure 6, we evaluated the model’s performance across various parameter values.
In addition to the hyperparameters analyzed above, the regularization weight λ in the PA-CBAM module is another key hyperparameter affecting model performance, and its optimal value is determined through grid search experiments combined with performance convergence verification, the representative dataset for USL-VI-ReID. Specifically, for λ, we search the grid range of [0.001, 0.01, 0.1, 1.0, 10.0] and select the value with the highest Rank-1 accuracy of the cross-modal retrieval; the optimal value of λ = 0.1 is finally determined. Initially, the value of α was set to 1.0. We then adjusted β to 0.1, 0.3, 0.5, 0.9, and 1.0. The results indicated that decreasing β improved model performance. However, when β reached 0.1, the performance gains plateaued, making the model performance relatively insensitive to further changes in α. Consequently, α was set to 1.0.
Regarding and , previous research has sometimes assigned equal contribution weights of 0.5 to the visible and infrared modalities; this practice has been recommended because balancing the weights can improve the extraction of infrared features when the visible-light dataset is substantially larger than the infrared dataset. In contrast, our experiments showed that weighting the visible and infrared modalities at 0.6 and 0.4, respectively, produced superior performance compared with the 0.5/0.5 split. We attribute this improvement to the greater amount of fine-grained feature information present in the visible-light modality relative to the infrared modality.
For the weighting parameters , , and , the model achieved optimal performance when equaled 0.5. Experimental observations indicated that the model was relatively insensitive to the values of and : setting = 0.5 and = 0.1 produced the best performance.
4.6. Analysis of Visualization
Visualization of retrieval results: Figure 7 compares the retrieval outcomes of our method with the baseline method. The baseline model demonstrates limited retrieval capabilities. In contrast, our method accurately retrieves data even in complex scenarios involving variations in color, texture, perspective, and environment.
T-SNE Feature Visualization: Figure 8 illustrates the t-SNE feature distribution of 10 randomly selected identity samples from the SYSU-MM01 dataset. In contrast to the baseline model, samples of the same identity are more closely clustered in the feature space, while samples of different identities show clearer and more distinct separation. This finding confirms our method’s effectiveness in cross-modal feature alignment and improving the identity discriminability of features.
5. Conclusions
This paper presents a multimodule collaborative optimization framework that addresses three principal challenges in unsupervised visible–infrared person re-identification (USL-VI-ReID): large modal discrepancies, limited feature granularity, and underutilization of channel augmentation (CA). Treating CA as an independent input modality, the framework achieves improvements through four complementary modules that interact synergistically. First, the PA-CBAM module implements a two-level attention strategy that initially locates pedestrian regions and then refines their representations, thereby extracting precise local identity cues. Second, the VRA module, together with the multimodal auxiliary adversarial learning (MAAL) module, mitigates modal gaps and promotes cross-spectral feature alignment. Third, the VRNL module based on the cross-modal aligned features enforces reliable neighborhood learning by exploiting multi-region spatial associations. Finally, the UM module increases robustness to interference by merging split clusters corresponding to the same identity. Extensive experiments on the SYSU-MM01 and RegDB datasets validate the approach: it substantially outperforms most unsupervised baselines and even exceeds the performance of several supervised methods.
Despite promising results, the method retains several important limitations that warrant further improvement. First, the framework degrades under extreme environmental conditions—for example, heavy rain, dense fog, or severe occlusion from objects such as umbrellas and backpacks. The PA-CBAM module’s multi-scale spatial attention depends on relatively clear regional features; when critical body parts (for instance, the head and torso) are heavily occluded, the VRA module struggles to align cross-modal information and to extract consistent local cues. Second, the model exhibits higher computational complexity than lightweight USL-VI-ReID approaches. Integrating four collaborative modules with a ViT backbone increases parameter count and floating-point operations (FLOPs), which constrains deployment on resource-limited edge devices (such as low-power surveillance cameras and drones) that require strict hardware budgets for real-time inference. Third, the framework’s hyperparameters are dataset-specific (for example, the number of regions N equals 4 for SYSU-MM01 and 6 for RegDB) and lack an adaptive tuning mechanism for unseen datasets. This dependence weakens generalization in practical settings, where dataset characteristics—image resolution, number of identities, and intra-class variation—may differ substantially.
Based on the identified limitations, we propose three promising directions for future work. First, we improve discriminative feature extraction under extreme conditions by integrating a deformable attention mechanism into the PA-CBAM module. This integration allows the model to adapt its receptive field dynamically to occlusion patterns and environmental noise and, when combined with part-aware self-supervised pretraining tasks (for example, pedestrian part segmentation), strengthens the robustness of local feature representations. Second, we investigate model-lightweighting strategies to increase deployment feasibility. Concretely, we replace the full ViT backbone with a hybrid architecture (for example, a CNN–ViT fusion) that preserves CNN strengths in local feature extraction while exploiting Transformer capabilities for global dependency modeling. We also adopt knowledge distillation to compress the multimodule framework, transferring discriminative knowledge from the current large model to a lightweight student network with minimal performance loss. Third, we develop an adaptive hyperparameter-optimization framework driven by dataset meta-features such as average image resolution, occlusion rate, and modal-difference intensity. A trained meta-regressor predicts optimal hyperparameters (for example, the number of regions N and the DBSCAN neighborhood radius) for new datasets, thereby improving the model’s generalization across diverse real-world scenarios.
Future research efforts not only address the current method’s limitations but also advance the practical deployment of USL-VI-ReID in more complex, resource-constrained intelligent surveillance scenarios.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Yang F. Weng J. Zhong Z. Liu H. Wang Z. Luo Z. Cao D. Li S. Satoh S. Sebe N. Towards robust person re-identification by defending against universal attackers IEEE Trans. Pattern Anal. Mach. Intell.2022455218523510.1109/TPAMI.2022.319901335969571 · doi ↗ · pubmed ↗
- 2Ye M. Shen J. Lin G. Xiang T. Shao L. Hoi S.C. Deep learning for person re-identification: A survey and outlook IEEE Trans. Pattern Anal. Mach. Intell.2021442872289310.1109/TPAMI.2021.305477533497329 · doi ↗ · pubmed ↗
- 3Wang M. Lai B. Huang J. Gong X. Hua X.-S. Camera-aware proxies for unsupervised person re-identification Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021 AAAI Press Palo Alto, CA, USA 2021 Volume 3527642772
- 4Lin Y. Dong X. Zheng L. Yan Y. Yang Y. A bottom-up clustering approach to unsupervised person re-identification Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, Hawaii, USA, 27 January–1 February 2019 AAAI Press Palo Alto, CA, USA 2019 Volume 3387388745
- 5Lu A. Zhang Z. Huang Y. Zhang Y. Li C. Tang J. Wang L. Illumination distillation framework for night-time person re-identification and a new benchmark IEEE Trans. Multimed.20232640641910.1109/TMM.2023.3266066 · doi ↗
- 6Wang G.-A. Zhang T. Yang Y. Cheng J. Chang J. Liang X. Hou Z.-G. Cross-modality paired-images generation for rgb-infrared person re-identification Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020 AAAI Press Palo Alto, CA, USA 2020 Volume 341214412151
- 7Wang S. Xu X. Liu L. Tian J. Multi-level feature fusion model-based real-time person re-identification for forensics J. Real-Time Image Process.202017738110.1007/s 11554-019-00908-4 · doi ↗
- 8Yan Z. Zheng Y. Fan D.-P. Li X. Li J. Yang J. Learnable differencing center for nighttime depth perception Vis. Intell.202421510.1007/s 44267-024-00048-9 · doi ↗