Adaptive Compressed Sensing Differential Privacy Federated Learning Based on Orbital Spatiotemporal Characteristics in Space–Air–Ground Networks
Weibang Li, Ling Li, Lidong Zhu

TL;DR
This paper introduces a new federated learning framework for space-air-ground networks that improves communication efficiency and privacy by leveraging satellite orbital patterns.
Contribution
The novel framework integrates orbital spatiotemporal characteristics with adaptive compressed sensing and differential privacy for federated learning in SAGINs.
Findings
The proposed framework achieves 3–12% higher model accuracy and 30–50% better communication efficiency compared to existing methods.
Orbital-driven sensing matrices reduce reconstruction error by up to 19.4% compared to fixed-matrix baselines.
The ternary collaborative mechanism balances energy, communication, and privacy objectives dynamically.
Abstract
With the development of 6G communication technology, Space–Air–Ground Integrated Networks (SAGINs) have become critical infrastructure for global intelligent collaborative computing. However, federated learning deployment in SAGINs faces three severe challenges: the high dynamics of satellite orbital motion, node resource heterogeneity, and privacy vulnerabilities in data transmission. This paper proposes an adaptive compressed sensing differential privacy federated learning framework based on orbital spatiotemporal characteristics. First, we design orbital periodicity-driven time-varying sparse sensing matrices that dynamically adjust compression strategies according to satellite orbital positions, achieving intelligent communication efficiency optimization. Second, we propose an orbital predictability-based privacy budget temporal allocation mechanism and perform differential privacy…
Click any figure to enlarge with its caption.
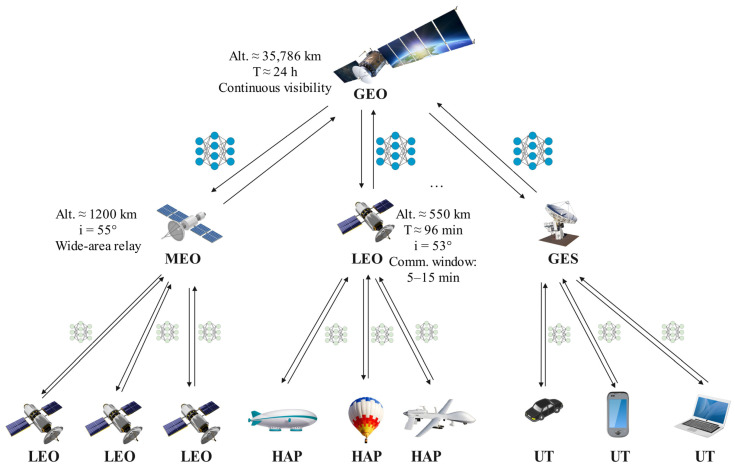 Figure 1
Figure 1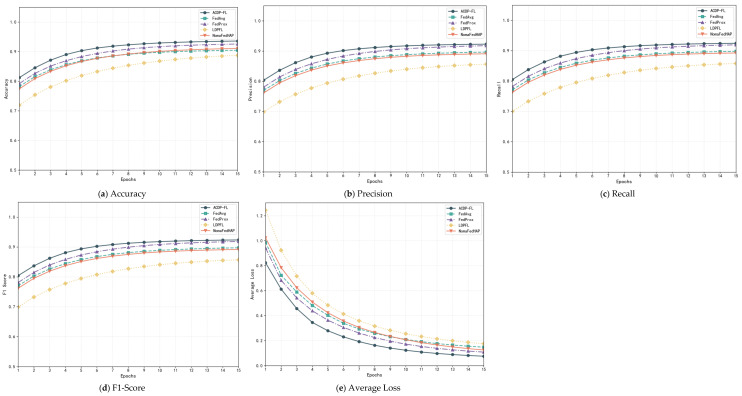 Figure 2
Figure 2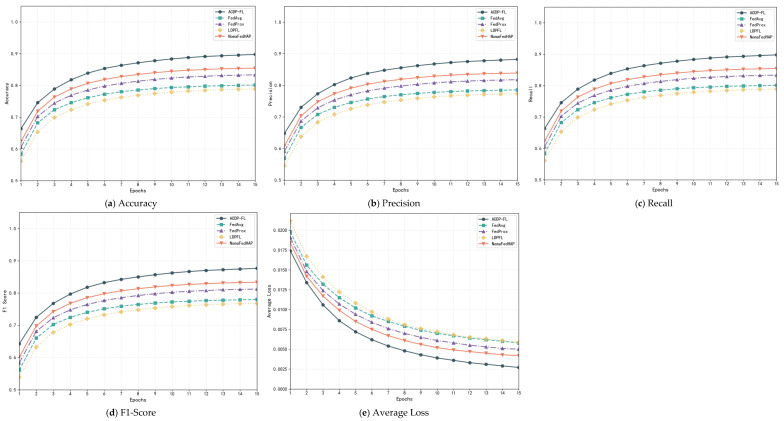 Figure 3
Figure 3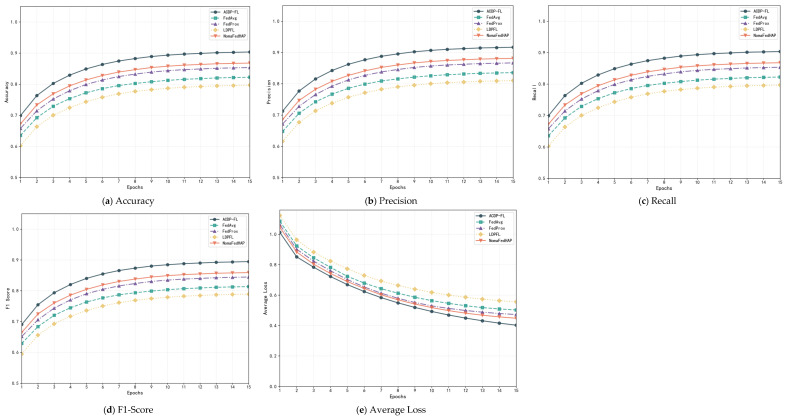 Figure 4
Figure 4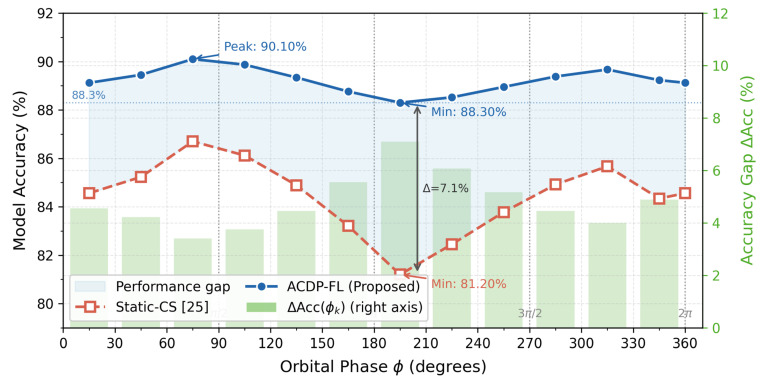 Figure 5
Figure 5- —Fundamental Research Funds for the Central Universities, Southwest Minzu University
- —National Social Science Fund of China
- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSatellite Communication Systems · Advanced Wireless Communication Technologies · Opportunistic and Delay-Tolerant Networks
1. Introduction
1.1. Background
With the deepening advancement of global digital transformation, humanity’s demand for ubiquitous intelligent interconnection services continues to grow. Space–Air–Ground Integrated Networks (SAGINs), as a crucial component of future 6G mobile communication systems, are emerging as key infrastructure for achieving global seamless connectivity and intelligent collaborative computing [1,2]. Particularly with the large-scale deployment of Low Earth Orbit (LEO) satellite constellations by commercial aerospace companies such as SpaceX and OneWeb, the coverage capability and intelligence level of space–air–ground networks have been significantly enhanced [3,4]. As illustrated in Figure 1 (detailed in Section 3), the three-tier SAGIN architecture encompasses GEO satellites at ~35,786 km providing global coverage, MEO satellites at ~1200 km enabling wide-area relay, and LEO satellites at ~550 km with orbital periods of approximately 96 min providing low-latency access to HAPs and ground terminals. The orbital inclinations and Keplerian parameters of LEO/MEO layers introduce predictable but highly dynamic connectivity patterns, making standard federated learning aggregation strategies fundamentally inadequate for such environments.
In this context, Federated Learning (FL), as a privacy-preserving distributed machine learning paradigm, provides novel solutions for intelligent collaboration in space–air–ground networks [5]. Unlike traditional centralized learning, federated learning enables satellite nodes distributed across different orbital layers, High Altitude Platforms (HAPs), and ground terminal devices to achieve collaborative training through model parameter aggregation without sharing raw data [6,7]. This distributed intelligence paradigm demonstrates tremendous potential in space–air–ground network applications such as remote sensing image classification, spatial modulation recognition, and intelligent routing optimization [8,9].
However, federated learning in SAGIN environments faces three unprecedented challenges. First, the periodic orbital motion of satellite nodes causes highly dynamic network topology with time-varying link reachability and quality [10]. Second, the multi-layered heterogeneous architecture introduces significant disparities in computational capability, storage capacity, and energy constraints across node types [11]. Third, data transmitted over SAGINs frequently involves nationally sensitive or commercially confidential information, imposing stringent privacy protection requirements [12].
1.2. Motivation and Contributions
The spatiotemporal dynamics of SAGINs are primarily manifested in the periodicity of orbital motion and the time-varying nature of network topology. LEO satellites have orbital periods of 90–120 min, yielding communication windows of only 5–15 min between satellites and ground stations [13]. Inter-satellite link establishment and disconnection exhibit high spatiotemporal correlation, rendering traditional static federated learning aggregation strategies ill-suited for such dynamic environments [14]. As constellation scales continue to expand, achieving efficient model parameter transmission and aggregation within these limited windows becomes a critical performance bottleneck.
The resource heterogeneity of nodes in space–air–ground networks manifests across multiple dimensions. In terms of computational resources, GEO satellites typically possess stronger processing capabilities, while LEO satellites and ground terminal devices have relatively limited computational resources [15]. Regarding energy constraints, satellite nodes primarily rely on solar panels for power supply, and the balance between energy harvesting and consumption directly affects the system’s sustained operational capability [16]. In terms of communication resources, different types of links (inter-satellite links, satellite–ground links, terrestrial links) exhibit significant differences in bandwidth, latency, and reliability [17]. This multi-dimensional resource heterogeneity requires federated learning algorithms to adaptively adjust training strategies and resource allocation schemes.
Although federated learning avoids direct raw data sharing, model parameters can still leak sensitive information. In SAGIN environments, this risk is further amplified by three factors [18]: multi-hop transmission paths increase interception opportunities; orbital predictability enables attackers to infer data characteristics within specific time windows; and complex inter-layer trust relationships expose nodes to gradient inversion and membership inference attacks [19,20].
Facing these challenges, existing federated learning methods primarily suffer from the following limitations: first, lack of deep integration with orbital dynamics characteristics, resulting in algorithm design disconnected from actual deployment environments; second, absence of systematic theoretical frameworks for privacy protection and communication efficiency trade-off optimization; third, neglect of dynamic balancing mechanisms for energy harvesting and consumption in space–air–ground networks.
Specifically, (i) existing approaches addressing communication efficiency in satellite and space networks [16,17] adopt static or fixed transmission strategies that do not account for the periodicity of satellite orbital motion, and even federated learning frameworks incorporating compressed sensing [19,20] employ measurement matrices designed independently of orbital phase dynamics, leading to suboptimal gradient compression performance during unfavorable link conditions; (ii) current privacy-preserving federated learning methods [18,19,20] adopt fixed or heuristic privacy budget allocation schemes without exploiting the temporal predictability of satellite orbits, resulting in inefficient budget utilization—over-consuming privacy resources during high-quality channel windows while providing insufficient protection during vulnerable orbital phases; (iii) the few works that simultaneously consider both compression and privacy [19,20] treat them as independent sequential operations (compress-then-protect or protect-then-compress), failing to exploit the synergistic gains achievable through joint compressed-domain differential privacy design, and none of these works provide rigorous convergence guarantees for the joint optimization.
Based on this analysis, this paper proposes an adaptive privacy-compression cooperative mechanism based on orbital spatiotemporal characteristics as the core innovation motivation. Specifically, our innovation motivation is reflected in the following three aspects:
(1) Orbital-aware spatiotemporal adaptive mechanism: Fully utilizing the predictability of satellite orbital motion to design time-varying compressed sensing matrices and differential privacy budget allocation strategies, enabling algorithms to dynamically adjust optimization objectives according to current orbital positions and communication windows.
(2) Multi-objective cooperative optimization framework: Establishing a theoretical framework for energy–privacy–accuracy tri-element trade-offs, achieving dynamic balance among multiple objectives through Pareto optimal solutions, providing theoretical guidance for space–air–ground federated learning.
(3) Deep integration technical approach: Rather than simple technology stacking, performing differential privacy noise injection within the compressed sensing domain, achieving significant communication load reduction while maintaining privacy protection, creating a synergistic effect where 1 + 1 > 2.
The main contributions of this paper can be summarized in the following three aspects:
(1) Orbital spatiotemporal characteristic-driven adaptive compressed sensing mechanism: For the first time, deeply integrating the periodicity and predictability of satellite orbital motion into compressed sensing design, proposing time-varying sparse sensing matrices based on orbital phases and dynamic compression rate adjustment strategies, achieving intelligent matching between compression strategies and network dynamic characteristics, significantly reducing communication overhead compared to traditional fixed compression methods under the same accuracy requirements.
(2) Differential privacy noise injection and joint optimization within compressed domain: Innovatively performing differential privacy noise injection within the compressed sensing domain, establishing theoretical bounds for global sensitivity after compression, designing orbital-aware privacy budget temporal allocation mechanisms, achieving deep coordination between privacy protection and communication efficiency, effectively improving model accuracy while maintaining the same privacy protection level.
(3) Multi-timescale energy–communication–privacy tri-element cooperative optimization framework: Constructing a tri-element cooperative mechanism based on model predictive control, achieving global optimization of system performance through multi-timescale weight adjustment and reinforcement learning-driven dynamic routing, establishing complete convergence theoretical guarantees, providing systematic theoretical and technical frameworks for space–air–ground federated learning.
Beyond technical contributions, the proposed framework has direct practical implications for global intelligent computing in underserved regions. By enabling efficient and privacy-preserving federated learning within constrained LEO communication windows (5–15 min per pass), the framework supports deployment scenarios including remote environmental monitoring, disaster response coordination, and distributed inference in areas lacking terrestrial network infrastructure—contexts where 6G SAGIN is poised to become the primary connectivity fabric.
2. Related Work
2.1. Federated Learning in Satellite Networks
The rapid expansion of commercial LEO satellite constellations has opened new opportunities for space-based intelligent computing. Federated learning, as a machine learning paradigm naturally suited for distributed environments, has received widespread attention in satellite network applications [21]. Lin et al. proposed the FedSN framework, systematically addressing heterogeneous federated learning problems in LEO satellite networks for the first time [3]. To address the dynamics of satellite–ground communication links, researchers have proposed various asynchronous aggregation mechanisms. Xu et al. proposed a connection density-aware satellite–ground federated learning framework [22], which achieves dynamic asynchronous aggregation strategies by sensing the connection density between satellites and ground stations, effectively alleviating communication congestion problems caused by synchronous waiting. Recent research has begun focusing on the impact of orbital dynamics characteristics on federated learning performance. Lozano-Cuadra et al. proposed a decentralized satellite routing scheme based on continual deep reinforcement learning [23], which utilizes the predictability of orbital dynamics to achieve continual learning through model prediction and federated learning approaches. However, this work primarily focuses on routing optimization and does not deeply explore privacy protection mechanisms.
2.2. Compressed Sensing Applications in Distributed Learning
Compressed sensing has attracted attention in federated learning for its ability to significantly reduce data transmission volume while preserving information integrity. Jeon et al. were the first to integrate compressed sensing into large-scale MIMO federated learning [24], proposing sparse transmission strategies and iterative LMMSE estimation algorithms that substantially reduce communication overhead without sacrificing model accuracy. Experiments showed that this method could significantly reduce communication overhead while maintaining model accuracy. Li et al. proposed the MCFL-CS scheme, combining model contrastive learning with improved compressed sensing [25]. This method alleviates the impact of data heterogeneity on model accuracy by jointly optimizing model contrastive loss and cross-entropy loss, while using compressed sensing and local differential privacy to reduce communication costs and prevent privacy leakage. However, the compressed sensing matrix design in this work is relatively static, not considering the impact of network dynamics. Addressing the problem that traditional predefined sparse transform bases cannot meet dynamic change requirements, Wang et al. proposed a learning-based joint compressed sensing scheme [26], which can learn sparse transform bases from compressed sensing measurement results and utilize spatiotemporal relationships to explore correlations among multiple sources. Although this work has improvements in dynamic adaptability, it is still limited to terrestrial wireless sensor networks and does not consider the special constraints of space–air–ground networks.
2.3. Differential Privacy
Differential privacy, as the gold standard for privacy protection, has increasingly mature applications in federated learning. From a theoretical development perspective, a 2024 survey highlighted current challenges faced by differential privacy in practical deployment, including data adaptability, multi-level privacy guarantees, and defense capabilities against other attack types [27]. In specific applications, Guo et al. proposed a differential privacy federated learning framework based on fast Fourier transform [28]. This work reduces the impact of limited computational resources and large numbers of users on training effectiveness by computing privacy budgets through FFT, and uses privacy loss distribution and privacy curves for analysis, reducing the number of manually set hyperparameters.
Considering the reality that different users have different privacy requirements, researchers have proposed hybrid differential privacy mechanisms. Zhang et al. pointed out that using the same privacy protection scheme for all users is inappropriate [29], proposing a hybrid differential privacy federated learning algorithm that provides differentiated privacy protection based on users’ different trust levels toward servers. Liu et al. proposed the AWDP-FL framework, handling model gradient parameters from the neural network layer perspective [30]. In healthcare and other domains with extremely high privacy requirements, differential privacy federated learning applications are more in-depth. Patel et al. combined federated learning with differential privacy for breast cancer detection [31], minimizing performance loss while ensuring strong privacy protection.
2.4. Dynamic Routing and Resource Optimization in Space–Air–Ground Networks
The spatiotemporal dynamics of space–air–ground networks pose enormous challenges to traditional network optimization methods. Yang et al. proposed a satellite-assisted task offloading and resource allocation scheme for 6G wide-area edge intelligence [32], considering the dynamics of satellite motion and designing task offloading strategies that perceive dynamic changes. However, this work primarily focuses on computational offloading with limited adaptation to federated learning scenarios. Zhang et al. designed a satellite edge intelligence optimization framework based on deep reinforcement learning [33], utilizing attention mechanisms and multi-agent reinforcement learning to achieve leader federated learning optimization for distributed satellite edge intelligence. Although this work has innovations in system optimization, it lacks comprehensive consideration of privacy protection and communication compression. Considering the trade-off requirements among multiple optimization objectives such as energy consumption, latency, and accuracy in space–air–ground networks, Zhou et al. proposed a multi-objective optimization method based on decomposition and meta-deep reinforcement learning [34]. This method optimizes asynchronous federated learning in 6G satellite systems but does not deeply consider the joint design of compressed sensing and differential privacy.
Through systematic review of related work, we identify four main limitations of existing research. First, compressed sensing methods rely on predefined or static compression matrices that cannot adapt to orbital dynamics; for instance, Jeon et al. [24] achieved strong results in MIMO systems but their matrix design does not exploit satellite orbital periodicity. Second, differential privacy mechanisms adopt fixed budget allocation strategies that fail to leverage orbital predictability for temporal optimization, resulting in budget under-utilization during favorable channel conditions and potential over-consumption during unfavorable ones, as observed even in adaptive works such as AWDP-FL [30]. Third, most approaches model satellite networks as generic mobile ad hoc networks, neglecting the deterministic periodicity of orbital mechanics that is explicitly available through models such as SGP4 [22]. Fourth, multi-objective optimization attempts largely rely on heuristic methods without rigorous theoretical guarantees [34], and none of the existing works provide adaptive mechanisms that jointly exploit orbital spatiotemporal characteristics for simultaneous optimization of compression, privacy, and routing.
To provide a more systematic overview of the above limitations, Table 1 summarizes the key characteristics of representative existing methods compared to the proposed ACDP-FL framework across four critical dimensions: compression strategy, differential privacy mechanism, orbital awareness, and theoretical guarantee.
Regarding reinforcement learning-based routing in space–air–ground networks, existing works have explored this direction from different perspectives. Lozano-Cuadra et al. [23] proposed a continual deep reinforcement learning scheme for decentralized satellite routing, leveraging the predictability of orbital dynamics for policy transfer across constellation reconfigurations. However, their work focuses exclusively on routing optimization and does not integrate privacy protection or communication compression within the federated learning training loop. Zhang et al. [33] adopted multi-agent deep reinforcement learning with attention mechanisms to achieve leader-based federated learning optimization for distributed satellite edge intelligence, representing a more comprehensive integration of RL and FL in SAGIN. Nevertheless, this framework lacks rigorous consideration of differential privacy and treats communication compression as an independent engineering concern rather than a jointly optimized design variable. Zhou et al. [34] further extended the multi-objective optimization dimension through decomposition and meta-deep reinforcement learning, addressing asynchronous federated learning in 6G satellite systems; however, the joint design of compressed sensing and differential privacy remains absent. These gaps collectively motivate the orbital-aware, jointly optimized routing and privacy-compression design proposed in this work.
Beyond these individual limitations, a more fundamental gap exists at the intersection of orbital mechanics and algorithm design. Satellite orbital motion follows deterministic Keplerian dynamics with high temporal predictability: LEO satellites complete an orbit in approximately 90–120 min, and the resulting periodic variation in gradient sparsity patterns, channel quality, and privacy risk exposure are all functions of orbital phase . Existing compressed sensing methods in federated learning [24,25,26] are designed without reference to this orbital phase structure, meaning their measurement matrices remain static across orbital positions that impose fundamentally different compression requirements. Similarly, differential privacy mechanisms [27,28,29,30] allocate privacy budgets uniformly across rounds, ignoring the fact that privacy risk exposure is systematically higher when satellites pass over sensitive geographic regions and systematically lower during other orbital segments. This paper explicitly bridges this gap by embedding Keplerian orbital state information into both the compressed sensing matrix design (Section 3.2) and the differential privacy budget allocation strategy (Section 3.3), enabling a coherent, orbital-aware federated learning framework that neither prior CS works nor prior DP-FL works have achieved.
3. Adaptive Compressed Sensing Differential Privacy Federated Learning
This work considers a three-tier space–air–ground integrated network consisting of geostationary earth orbit (GEO) satellites, medium earth orbit (MEO) satellites, low earth orbit (LEO) satellites, high altitude platforms (HAPs), ground earth stations (GESs), and user terminals (UTs), as specifically illustrated in Figure 1. In this framework, GEO satellites serve as the top-tier global aggregation center, responsible for coordinating the entire federated learning process; MEO/LEO satellites and ground stations constitute the middle tier, performing local aggregation and relay functions; HAPs and user terminals act as bottom-tier nodes, conducting model training based on local data.
3.1. System Modeling and Problem Formalization
3.1.1. Space–Air–Ground Network Topology Modeling
We model the space–air–ground integrated network as a time-varying graph , where t represents time, denotes the node set at time t, and represents the edge set at time t. The node set can be further partitioned into three subsets: , representing the space node set, air node set, and ground node set, respectively. The space node set contains satellite nodes at different orbital altitudes, the air node set contains high altitude platforms, and the ground node set contains ground stations and user terminals.
For any node , we use to represent its three-dimensional position vector in the Earth-centered inertial coordinate system, where , , and represent the three coordinate components of node i at time t, respectively. The distance between nodes can be calculated as , where denotes the Euclidean norm. A communication link exists between two nodes i and j if and only if the distance between them satisfies visibility constraints and the signal strength is sufficient to establish a reliable connection, i.e., if and only if and , where represents the maximum communication distance, represents the signal-to-noise ratio from node i to node j at time t, and represents the minimum signal-to-noise ratio threshold required to establish a reliable connection.
The network connectivity is described by the adjacency matrix , where if and only if . To capture the hierarchical characteristics of the network, we further define hierarchical adjacency matrices , where represents the bottom tier (HAPs and UTs), middle tier (MEO/LEO satellites and GESs), and top tier (GEO satellites), respectively. This hierarchical modeling facilitates the design of hierarchical federated learning aggregation strategies, where local aggregation is performed within each tier, and then aggregation results are passed to the upper tier.
3.1.2. Orbital Dynamics and Communication Window Modeling
The motion of satellite nodes follows Kepler’s orbital mechanics laws, and their positions can be precisely predicted through orbital six elements. For orbital node i, we use to represent its orbital six elements, where represents the semi-major axis, represents the eccentricity, represents the orbital inclination, represents the right ascension of ascending node, represents the argument of periapsis, and represents the mean anomaly. Given the orbital elements at initial time , the position of node i at any time t can be obtained by solving the Kepler equation system:
where is the eccentric anomaly obtained by solving the Kepler equation , is the mean anomaly, is the mean angular velocity, μ is the Earth’s gravitational constant, and and represent rotation matrices around the z-axis and x-axis, respectively.
Based on the orbital prediction model, communication windows between any two satellite nodes can be calculated. We define a communication window as a time interval during which nodes i and j satisfy visibility constraints. For LEO-GEO links, communication window durations are typically short due to the rapid motion of LEO satellites. We define the reachability function to represent whether nodes i and j are reachable at time t, where if and only if there exists an unobstructed line-of-sight path and the minimum elevation angle constraint is satisfied.
Considering propagation delays in practical systems, we further define the effective communication time window , where is the signal propagation delay and c is the speed of light. The duration of the effective communication window is , which represents the time actually available for data transmission.
Link capacity modeling considers free space path loss and atmospheric attenuation effects. For inter-satellite links, the received power can be expressed as
where is the transmit power of node i, and are the transmit and receive antenna gains respectively, λ is the carrier wavelength, and is the atmospheric loss factor. The corresponding signal-to-noise ratio is , where is the noise power spectral density and is the bandwidth allocated to link (i,j). The instantaneous data rate of the link can be calculated according to the Shannon formula:
3.1.3. Federated Learning Objective Function Construction
In the space–air–ground federated learning framework, our objective is to train a global model to minimize the overall loss function of local data distributed across various nodes. Let the node set represent all nodes participating in federated learning, where each node i has a local dataset , where is the feature vector of the k-th sample, is the corresponding label, and is the number of samples at node i. The local loss function of node i is defined as
where is the loss function for a single sample (x, y) and model parameters w.
The global optimization objective is to minimize the weighted average loss of all nodes:
where is the data weight of node i, reflecting the proportion of that node’s data volume in the total. This weighting approach ensures that nodes with more data have greater influence in global model training, which is reasonable in space–air–ground networks since different types of nodes (e.g., GEO satellites vs. user terminals) may have different data collection capabilities.
However, in practical space–air–ground federated learning, inter-node communication is subject to strict bandwidth and energy constraints, with significant propagation delays and intermittent connectivity. Therefore, we need to consider multiple factors including communication efficiency, privacy protection, and energy optimization. The modified objective function can be expressed as
where represents algorithm control parameters (such as compression ratio, noise level, etc.), , , and represent communication cost, energy cost, and privacy cost respectively, and , , are corresponding weight coefficients used to balance the importance of different objectives.
The communication cost is mainly determined by the transmission volume of model parameters. In standard federated learning, each client needs to upload complete gradient vectors or model parameters, with communication cost , where d is the model parameter dimension. By introducing compressed sensing technology, we can reduce the communication cost to , where is the dimension of the compressed vector. The energy cost includes both computational energy consumption and communication energy consumption, where communication energy consumption typically dominates, especially for satellite nodes. The privacy cost quantifies the impact of differential privacy mechanisms on model performance, usually proportional to the variance of injected noise.
3.1.4. Multi-Constraint Optimization Problem Formalization
Considering the special constraints of space–air–ground networks, we formalize the federated learning problem as a multi-constraint optimization problem. Let represent the global model parameters in the t-th round, represent the local gradient of node i in the t-th round, and represent the gradient after compression and noise processing. The optimization problem can be formulated as
where the meanings of each constraint are as follows:
The first constraint is the standard update rule of federated learning, where is the learning rate in the t-th round. This constraint ensures that global model parameters are updated according to federated averaging, but using compressed and privacy-processed gradients instead of original gradients .
The second constraint is the reconstruction error constraint, limiting the error between the gradient after compressed sensing reconstruction and the original gradient to not exceed the preset threshold . This constraint ensures that the compression process does not excessively damage the model’s convergence performance.
The third constraint is the communication capacity constraint, where represents the sparsity of the compressed gradient (number of non-zero elements), is the number of bits per non-zero element, and is the total communication capacity budget for the t-th round. This constraint ensures that the communication requirements of all nodes do not exceed the actual network capacity.
The fourth constraint is the energy budget constraint, where represents the total energy consumption in the t-th round, including computational energy consumption and communication energy consumption for all nodes, and is the energy budget.
The fifth constraint is the privacy budget constraint, where represents the privacy loss in the t-th round, and is the total privacy budget. Under the differential privacy framework, privacy loss is cumulative, so it is necessary to ensure that the total privacy loss throughout the entire training process does not exceed the preset threshold.
The sixth constraint is the routing reachability constraint, ensuring that all links in the communication path selected in the t-th round are reachable at the corresponding time.
The total energy consumption can be further decomposed as
where the first term represents the computational energy consumption of node i, proportional to the complexity of gradient calculation; the second term represents the energy consumption of compression processing, proportional to the number of non-zero elements to be transmitted; the third term represents the communication energy consumption, where is the transmit power of node i and is the communication time of node i in the t-th round.
The privacy loss under the (ε,δ)-differential privacy framework can be expressed as
where is the privacy parameter of node i in the t-th round. For the Gaussian mechanism, the relationship between privacy parameters and noise level is , where is the global sensitivity of node i in the t-th round, is the standard deviation of the added Gaussian noise, and δ is the second parameter of differential privacy.
In the space–air–ground network environment, participating nodes (GEO/MEO/LEO satellites, HAPs, ground terminals) collect data from geographically distinct coverage areas, resulting in naturally non-IID data distributions. To quantify the degree of data heterogeneity, we adopt the Dirichlet distribution parameterization commonly used in federated learning research, where a smaller corresponds to more severe heterogeneity. The heterogeneity level of node i relative to the global distribution can be measured by the Earth Mover’s Distance (EMD):
where C is the number of classes, is the proportion of class c in node i’s local dataset, and is the global class proportion. In our simulation, nodes are assigned data using , yielding average EMD values of 0.31 for ground terminals, 0.24 for LEO/HAP nodes, and 0.18 for MEO/GEO nodes, reflecting the natural geographic stratification of satellite coverage. This non-IID configuration is reported explicitly in Section 4.1 to ensure reproducibility. The performance gap between local and global objectives under this heterogeneity level satisfies the bounded gradient dissimilarity assumption used in Theorem 1, with dissimilarity parameter bounded as
where G is a finite constant estimated empirically as G ≈ 0.42 in our experimental setup, confirming the validity of the convergence analysis in Theorem 1 under the observed non-IID conditions.
Solving this multi-constraint optimization problem requires simultaneous consideration of multiple factors including model performance, communication efficiency, energy limitations, privacy protection, and network reachability, making it a complex non-convex optimization problem. The following sections will detail the spatiotemporal adaptive compressed sensing and differential privacy mechanisms, as well as corresponding joint optimization algorithms to effectively solve this problem.
3.2. Spatiotemporal Adaptive Compressed Sensing Mechanism
Traditional compressed sensing methods typically employ fixed sparse transform bases and static measurement matrices, which exhibit obvious deficiencies when facing the dynamic characteristics of space–air–ground networks. To fully exploit the periodicity and predictability of satellite orbital motion, we propose a spatiotemporal adaptive compressed sensing mechanism that can dynamically adjust compression strategies based on orbital position, communication windows, and channel conditions, maximizing communication efficiency while ensuring reconstruction accuracy.
3.2.1. Orbital Periodicity-Driven Sparse Sensing Matrix Design
The deterministic nature of satellite orbital motion provides important prior information for adaptive design of compressed sensing matrices. We construct time-varying sparse sensing matrices based on orbital periodicity characteristics to capture sparsity patterns of gradient vectors at different orbital positions. Let the orbital phase of satellite node i at time t be , where T_i_ is the orbital period of node i. Based on the periodic variation in orbital phase, we divide the orbit into K equally spaced phase intervals, with each interval corresponding to a specific sparsity pattern. For the k-th phase interval , we define the corresponding basic sparsity pattern , where indicates the importance of the j-th parameter, and d is the model parameter dimension. This pattern is obtained through statistical analysis of historical orbital data, specifically calculated as
where represents the set of historical time instances in phase interval , represents the gradient vector of node i at time t, and is the sparsity threshold.
To achieve smooth transitions between adjacent phase intervals and avoid performance degradation due to abrupt changes, we introduce a trigonometric function-based interpolation weighting mechanism. When the orbital phase of node i at time t is , the adaptive sparsity pattern is calculated as
where the weight function is defined as
Here is the center phase of the k-th phase interval. This weight function ensures that only 2–3 adjacent basic patterns participate in interpolation at each moment, thereby maintaining local consistency of sparsity.
Based on the adaptive sparsity pattern, we construct the time-varying compressed sensing measurement matrix . This matrix consists of two parts: a structured part and a randomized part. The structured part performs dense sampling specifically for identified important parameter positions, expressed as
where is the selection matrix based on sparsity pattern S_i_(t), is the number of identified important parameters, and is the discrete cosine transform matrix used to capture frequency-domain sparsity of gradients. The randomized part uses a Gaussian random matrix with elements independently and identically distributed as , designed to capture unexpected sparsity patterns, and s_i_(t) represents the number of important parameters (sparsity) for node i at time t. The final measurement matrix is expressed as
where and are normalization coefficients satisfying .
In practical deployment, the orbital phase used to drive the sparsity pattern selection in Equation (13) is computed directly from Two-Line Element (TLE) data. Given TLE parameters for satellite node i, the orbital period and mean anomaly are propagated forward using the SGP4/SDP4 model, yielding a real-time orbital phase estimate. The phase interval index k is then determined as
where K is the total number of phase intervals. The rationale for this discretization is that gradient sparsity patterns in satellite-borne tasks, such as remote sensing image classification, exhibit statistically stable structure within each phase segment due to the periodic variation in ground coverage and data distribution. Specifically, when a LEO satellite transits over high-density data regions (e.g., urban or coastal areas), the gradient vectors tend to concentrate energy in spatial-frequency components corresponding to high-frequency textures, yielding a different sparsity signature than when the satellite is over ocean or polar regions. This orbital phase-dependent sparsity structure is captured by the basic sparsity pattern defined in Equation (12), which is estimated as offline from historical gradient statistics and updated periodically as new orbital data becomes available. The structured measurement component in Equation (15) therefore encodes orbital domain knowledge directly into the CS matrix, providing a principled link between Keplerian orbital mechanics and compressed sensing design that distinguishes the proposed approach from static-CS methods [24,25].
3.2.2. Dynamic Compression Rate Adjustment and Error Bounds
The choice of compression rate directly affects the trade-off between communication overhead and reconstruction accuracy. In space–air–ground networks, communication conditions change dynamically with orbital motion, necessitating adaptive adjustment of compression rates to suit current network states. We design a dynamic compression rate adjustment strategy based on communication window prediction and channel quality assessment.
Let the target compression rate for node i in the t-th training round be , then the number of measurements after compression is , where d is the total number of model parameters. The determination of compression rate requires comprehensive consideration of three factors: communication window constraints, channel quality, and reconstruction accuracy requirements. This work employs a multi-objective optimization method to determine the optimal compression rate. The utility function is defined as
where are weight coefficients, the first term encourages higher compression rates to reduce communication overhead, the second term considers the impact of channel quality, the third term is a penalty for reconstruction accuracy constraints, and is the worst link quality of node i. The optimal compression rate is obtained by solving the following optimization problem:
where represents the lower bound determined by reconstruction accuracy constraints, and represents the upper bound determined by communication capacity constraints.
To guarantee theoretical convergence of the federated learning algorithm, we need to establish theoretical bounds for compressed sensing reconstruction errors. Under the spatiotemporal adaptive compressed sensing framework, reconstruction errors are affected by multiple factors including sparsity assumptions, measurement noise, and algorithm accuracy.
Under the condition that the adaptive measurement matrix satisfies the Restricted Isometry Property (RIP), the reconstruction error upper bound using the ℓ1 minimization reconstruction algorithm is
where is the reconstructed gradient vector of node i, g_i_ is the true gradient vector of node i, is the best s-term sparse approximation of g_i_, n_i_ is the measurement noise vector, C1 and C2 are constants, and is the measurement dimension of node i at time t.
Under the spatiotemporal adaptive framework, considering the influence of historical sparsity pattern prediction error , the reconstruction error bound is modified to
where represents the sparse approximation error of g_i_, is the historical sparsity pattern prediction error, and C3 is a coefficient reflecting the degree of influence of prediction errors. This result indicates that orbital periodicity-driven sparsity pattern design can improve reconstruction accuracy by reducing .
Channel conditions in space–air–ground networks vary dynamically with time and node positions, directly affecting the performance of compressed sensing systems. We design a time-varying channel condition-aware optimization strategy that maintains system performance stability by real-time monitoring of channel parameters and corresponding adjustment of compressed sensing parameters.
Based on the deterministic nature of orbital dynamics, we establish the channel quality metric Q_i_ⱼ(t) as follows:
where SNRi_ⱼ(t) represents the signal-to-noise ratio of link (i,j) at current time t, d_i_ⱼ(t) represents the Euclidean distance between nodes i and j at time t, is the load rate of link (i,j) at time t; w1, w2, w3 are weighting coefficients satisfying w1 + w2 + w3 = 1, representing the importance of signal-to-noise ratio, distance, and load rate respectively, is the reference signal-to-noise ratio, and *d_max* is the maximum communication distance.
Based on the channel quality metric, the adaptive adjustment formula for compression rate is
where is the base compression rate, α is the parameter controlling compression rate adjustment amplitude, controlling the maximum range of compression rate changes, β is the sensitivity parameter for quality changes, controlling the sensitivity of quality changes to compression rate adjustment, is the reference channel quality, typically set as the historical average quality value, and is the standard deviation of channel quality metrics, used for normalizing quality changes.
To handle sudden channel deterioration, the system activates emergency mechanisms through anomaly detection:
where is the indicator function returning 1 when the condition is true and 0 otherwise, is the reconstructed gradient vector, is the historical mean of node i’s gradient norm, calculated based on a sliding window.
When transmission errors are detected, the system activates degraded transmission mode, transmitting only the most important components of gradients:
where is the simplified gradient vector in degraded mode, represents retaining the top k emergency elements with largest absolute values, and is the number of parameters retained in emergency mode.
Through the above time-varying channel condition-aware mechanism, the system can maintain efficient gradient compression and reliable reconstruction performance in the dynamic space–air–ground network environment.
3.3. Orbital-Aware Differential Privacy Mechanism
Traditional differential privacy mechanisms typically employ fixed privacy budget allocation strategies, which exhibit obvious deficiencies in the dynamic space–air–ground network environment. Satellite node orbital motion possesses high predictability, and communication conditions, data importance, and privacy risks under different orbital positions exhibit periodic variation patterns. Based on this observation, we propose an orbital-aware differential privacy mechanism that can dynamically adjust privacy protection strategies according to orbital states, link quality, and path characteristics, maximizing model performance while ensuring privacy security.
3.3.1. Temporal Privacy Budget Allocation Based on Orbital Predictability
The deterministic nature of satellite orbits provides important opportunities for intelligent allocation of privacy budgets. We design a temporal-aware privacy budget allocation strategy based on orbital periodicity, fully exploiting orbital prediction information to optimize the usage efficiency of privacy resources.
Orbital Periodicity Modeling: Let the orbital period of satellite node i be T_i_. We divide one complete orbital period into M equal-duration time segments, with each time segment corresponding to a specific orbital state. We define the orbital time index , representing the orbital time segment corresponding to time t. Based on historical data analysis, we define the basic privacy requirement coefficient for each orbital time segment , which reflects the privacy risk level at different orbital positions. The specific calculation is as follows:
where represents the set of historical time instances in orbital time segment , is the geographical exposure (reflecting the degree to which satellites cover sensitive areas), is data sensitivity (based on mission type and data content), is attack risk (based on threat intelligence and historical attack records), and , , are corresponding weight coefficients satisfying .
Dynamic Budget Allocation Strategy: Based on orbital periodicity modeling, we design a privacy budget allocation strategy. Let the total privacy budget of node i be , which needs to be allocated across T rounds during the entire training process. The traditional uniform allocation strategy assigns privacy budget per round, while our orbital-aware allocation strategy considers the time-varying characteristics of orbital states.
First, we predict the orbital state sequence for node i within the next W communication rounds, and calculate the corresponding privacy requirement weight sequence . Then, based on the current remaining budget and remaining rounds , we calculate the privacy budget allocation for the t-th round as follows:
where the normalization factor is defined as
Here γ ∈ (0, 1] is the temporal decay factor used to reduce the weight of long-term predictions. The urgency adjustment factor is calculated as
where is the average privacy budget. This factor ensures increased allocation when privacy budget consumption is too fast and decreased allocation when consumption is too slow.
Budget Smoothing Mechanism: To avoid dramatic fluctuations in budget allocation, we introduce an exponential moving average smoothing mechanism as follows:
where is the original allocation value calculated by the above formula, and is the smoothing coefficient. Meanwhile, we set safety boundary constraints as follows:
The above settings ensure that privacy budget usage is neither too conservative nor too aggressive.
To formally justify the orbital-aware privacy budget allocation, we now establish that the proposed mechanism satisfies (ε, δ)-differential privacy under the Gaussian mechanism framework. Let denote the overall privatization mechanism applied to the gradient of node i in round t. The mechanism first compresses the gradient via , then injects Gaussian noise with adaptive standard deviation as defined in Equation (47). By the properties of the Gaussian mechanism [27], the per-round privacy cost satisfies:
where is the global sensitivity in the compressed domain defined in Equation (46). Substituting the adaptive noise standard deviation from Equation (47) into (32) confirms that the allocated budget from Equation (27) is exactly consumed, i.e., the mechanism is ( , δ)-differentially private per round. Over T training rounds, composition under the advanced composition theorem [27] gives a total privacy cost for node i:
where the inequality holds by construction of the normalization factor in Equation (28), which ensures . This establishes that the orbital-aware budget allocation does not weaken the total privacy guarantee relative to uniform allocation; it only redistributes the budget across rounds according to orbital risk levels defined in Equation (26). The key insight is that rounds with high privacy risk (high , e.g., satellite over sensitive regions) receive larger budget allocations, enabling stronger noise injection precisely when eavesdropping risk is elevated, while rounds with low risk receive smaller allocations to preserve model accuracy during favorable orbital phases.
Regarding multi-hop privacy accumulation, the model in Equation (38) is a conservative upper bound consistent with the sequential composition theorem of differential privacy [28]. For a path of length L, each intermediate node applies an independent ( , δ)-DP mechanism. By sequential composition, the total privacy loss satisfies
The correlation correction factor in Equation (38) is a conservative reduction term that accounts for the fact that correlated nodes (close in orbit or geography) provide partially redundant privacy protection, yielding a tighter bound than naive sequential composition. While this correction is heuristically motivated, it is conservative in the sense that , ensuring the bound in Equation (38) never exceeds the standard sequential composition result in (38). A formal tighter bound exploiting inter-node correlation remains an open theoretical question and is identified as future work.
3.3.2. Adaptive Noise Injection and Privacy Optimization
Channel conditions in space–air–ground networks directly affect the effectiveness and necessity of differential privacy noise. This work designs a link quality-aware adaptive noise injection mechanism and establishes a privacy leakage accumulation model under multi-hop paths, achieving intelligent balance between privacy protection and model performance.
We establish a comprehensive link quality metric to guide noise injection strategies as follows:
where represents the comprehensive quality metric of link (i,j) at time t with value range [0, 1], , , are weight coefficients satisfying , representing the importance of signal-to-noise ratio, bit error rate, and delay respectively, BER_i_ⱼ(t) represents the bit error rate of link (i,j) with value range [0, 1], BERmax is the acceptable maximum bit error rate, and represents the propagation delay of link (i,j) in milliseconds.
Based on link quality assessment, this work designs a quality-aware noise scaling mechanism. For a given privacy budget , the adaptive noise standard deviation is
where represents the global sensitivity in the compressed domain, is the privacy budget allocated to node i in the t-th round, and is the adaptive function defined as follows:
where represents the quality adjustment parameter controlling the degree of link quality influence on noise, is the average link quality of node i at time t, and is the compression error adjustment parameter.
In multi-hop transmission environments, we establish a privacy loss accumulation model. Let the path from source node s to target node d be , where the total privacy loss on the path is
where is the total privacy loss on path , L is the path length (number of hops), represents the i-th node on the path, is the privacy parameter at node , represents the correlation correction factor, and the privacy correlation coefficient between adjacent hops is calculated based on geographical location and temporal correlation.
We establish a trade-off optimization problem between privacy protection strength and model accuracy. Under given privacy and communication constraints, the multi-objective optimization problem is
where represents the privacy budget vector, ρ is the compression rate vector, is the model performance objective function representing the expected value of global loss, is the privacy cost function considering orbital position privacy risks, represents the loss function based on global model parameters θ, and R_i_(t) is the orbital privacy risk coefficient of node i at time t.
We achieve solution selection on the Pareto frontier through dynamic weight adjustment:
where and represent the optimal privacy budget and compression rate at time t respectively, and and are time-varying weight coefficients satisfying .
The dynamic weight adjustment strategy is based on training progress and orbital periodicity:
where represents the base accuracy weight, is the amplitude coefficient for periodic adjustment, represents the average orbital period used to capture orbital periodic variations, is the linear growth coefficient making the accuracy weight gradually increase in the later stages of training, and is the total number of training rounds.
Through the above adaptive noise injection and privacy optimization mechanisms, the system achieves intelligent balance between privacy protection and model performance.
3.4. Compression–Privacy Joint Optimization
3.4.1. Differential Privacy Noise Injection Strategy in Compressed Domain
Traditional differential privacy mechanisms typically add noise in the original data space. However, under the compressed sensing framework, this approach suffers from two main problems: first, the high dimensionality of the original gradient space requires substantial noise to ensure privacy, which significantly degrades model performance; second, the compression process may amplify or attenuate noise effects, undermining the theoretical guarantees of differential privacy. To address these issues, this work designs a differential privacy noise injection strategy specifically tailored for the compressed domain.
Let the original gradient of node i in the t-th round be , and the measurement vector after adaptive compressed sensing be , where is the time-varying measurement matrix and is the number of measurements after compression. The process of adding differential privacy noise in the compressed domain can be expressed as follows:
where is the injected privacy noise vector. To guarantee the theoretical properties of differential privacy, each component of the noise vector must be independently and identically sampled from a Gaussian distribution: .
The key challenge of differential privacy in the compressed domain lies in determining the appropriate noise standard deviation . According to differential privacy theory, the noise standard deviation is directly related to global sensitivity. Under the compressed sensing framework, the global sensitivity after compression is defined as follows:
where and are two neighboring datasets of node i (differing by only one sample), and represents the gradient computed based on dataset . Using properties of matrix norms, we can relate the compressed sensitivity to the original sensitivity:
where is the operator norm (spectral norm) of measurement matrix , and is the global sensitivity in the original gradient space.
In our spatiotemporal adaptive compressed sensing design, the measurement matrix consists of structured and randomized components. For Gaussian random measurement matrices, the expected value of the operator norm can be analyzed through random matrix theory. Specifically, when elements of are independently and identically distributed as , we have
where is the confidence parameter. To provide deterministic privacy guarantees in practical systems, we adopt a conservative upper bound estimate:
Based on the global sensitivity in the compressed domain, we design an adaptive noise standard deviation calculation strategy. Considering orbital-aware privacy budget allocation and link quality-aware adjustment, the noise standard deviation in the compressed domain is
where is the privacy budget allocated to node i in the t-th round, is the link quality-aware adaptive function, and is the compression–privacy coupling correction factor used to compensate for the impact of the compression process on privacy protection effectiveness.
The design of the coupling correction factor is based on the relationship between compression rate and reconstruction accuracy. When the compression rate is low, the number of measurements is small, reducing the dimension of the compressed vector, and theoretically requiring less noise. However, excessive compression may lead to increased reconstruction errors, affecting the effectiveness of privacy protection. We define the coupling correction factor as
where is the reconstruction error sensitivity parameter, is the gradient reconstructed through compressed sensing, and is the relative reconstruction error. This design ensures that when reconstruction errors are large, the system automatically increases noise intensity to maintain the effectiveness of privacy protection.
3.4.2. Joint Optimization and Performance Guarantees
Joint optimization of compressed sensing and differential privacy involves multiple conflicting objectives: model convergence accuracy, privacy protection strength, communication overhead, and computational complexity. We construct a comprehensive joint objective function and design an energy–communication–privacy ternary synergy mechanism to achieve dynamic balance of multiple objectives and performance guarantees.
The joint objective function contains four main components: model training loss, privacy cost, communication cost, and energy cost, specifically as follows:
where is the parameter set for joint optimization, is the global model parameter vector, is the privacy budget allocation vector, is the compression rate vector, is the noise standard deviation vector, , , , are weight coefficients balancing the importance of different objectives satisfying , is the model training loss function, is the privacy cost function, is the communication cost function, and is the energy cost function.
The model training loss considers the effects of compression and privacy noise:
where is the data weight of node i, defined as , is the local loss function of node i, α is the penalty coefficient for gradient estimation error, is the gradient after compression reconstruction and privacy noise processing.
The privacy cost function comprehensively considers the influence of orbital positions:
where represents the privacy risk coefficient corresponding to the orbital position of node i at time t, is the set of all possible transmission paths, represents the usage frequency weight of path , and represents the total privacy loss on path .
The solution of the joint objective function employs a variant of the Alternating Direction Method of Multipliers (ADMM). By introducing auxiliary variables, the original problem is decomposed into multiple subproblems:
where represents the augmented Lagrangian function, z is the auxiliary variable vector, v is the Lagrange multiplier vector, and represents the penalty parameter controlling the penalty strength for constraint violations.
The ADMM iterative solution process includes three main steps:
Model Parameter Update:
Compression–Privacy Parameter Joint Update:
Multiplier Update:
We establish a ternary coupled state space model. Define the energy–communication–privacy state vector of node i in the r-th round as , with the state transition relationship as follows:
where is the state vector representing total energy consumption, communication overhead, and privacy loss respectively, is the state transition matrix describing the influence of historical states on current states, is the control input matrix describing the direct influence of control variables on states, is the control input vector including compression rate, privacy budget, and transmit power, and is the system noise vector representing environmental uncertainties.
The design of state transition matrix is based on the historical dependency relationships of ternary constraints as follows:
where is the energy accumulation coefficient reflecting the cumulative effect of energy consumption, is the communication history decay factor, is the time step, and the diagonal element 1 indicates the strict cumulative nature of privacy loss.
Based on the ternary coupling model, this work employs Model Predictive Control (MPC) strategy to achieve synergistic optimization:
where H represents the prediction horizon length, represents the predicted state at the (t + k)-th moment at time t, is the state weighting matrix, and represents the control weighting matrix.
We establish convergence theorems for the joint optimization algorithm as follows:
Theorem 1 (Convergence Guarantee). Assume the joint objective function *satisfies L-smooth conditions and μ-strong convex conditions, the compression rate sequence satisfies * *, the privacy budget sequence satisfies * *, and the learning rate is chosen as * *, then the joint optimization algorithm converges to the * -neighborhood of the optimal solution with probability 1.
Theorem 2 (Performance Bound). *Under constraints of compression rate ρ and privacy budget * *, the performance gap between the model * *output by the joint optimization algorithm and the ideal unconstrained optimal solution * satisfies
This bound reveals the fundamental trade-off relationships among compression rate, privacy budget, and training rounds: higher compression rates and stronger privacy protection increase performance loss, but this can be partially compensated by increasing the number of training rounds.
Algorithm 1 summarizes the MPC-based ternary synergy optimization procedure. At each training round t, the algorithm first uses TLE-propagated orbital state to predict the channel quality and privacy risk sequences over the prediction horizon H. It then solves the augmented Lagrangian subproblem via ADMM iterations, decomposing the joint optimization over model parameters θ, compression rates ρ, and privacy budgets ε into alternating updates. Only the first control action of the resulting optimal sequence is applied (receding horizon principle), after which the ternary state vector is updated and the procedure repeats for the next round. Algorithm 1 MPC-based energy–communication–privacy ternary optimizationInput: Node set ; TLE orbital parameters ; total rounds ; prediction horizon ; total privacy budget for each node ; compression bounds ; ADMM penalty ; max ADMM iterations .Output: Optimal control sequence , where .1: For each node : compute via SGP4 from 2: For each node : set , 3: for do4: //Phase 1: Orbital and channel prediction5: For each node i: predict via Equation (60) 6: For each node i: compute via Equation (26)7: For each link : predict via Equation (22)8: //Phase 2: Allocate privacy budget for round t 9: For each node i: compute via Equations (30)–(34); enforce 10: //Phase 3: ADMM solving of MPC problem Equation (58)11: Initialize , 12: for do 13: Update via Equation (53) 14: Update via Equation (54)15: Update via Equation (55)16: if : break17: end for18: //Phase 4: Receding horizon—apply first action only 19: Set from 20: //Phase 5: State update21: For each node i: via Equation (56)22: For each node i: 23: end for24: return
The dominant per-round cost of Algorithm 1 is the ADMM inner loop. Each ADMM iteration solves N decoupled subproblems; with gradient sparsity and fixed iterations, the effective per-round complexity is . In our setup ( , , ), the MPC overhead is approximately 4.2% of local training time, confirming practical feasibility.
Through the above joint optimization and performance guarantee mechanisms, the system can provide reliable multi-objective optimization performance in complex space–air–ground network environments, achieving synergistic improvement of privacy protection, communication efficiency, and model accuracy.
3.5. Reinforcement Learning-Driven Dynamic Routing Scheduling
In space–air–ground integrated networks, the high dynamics of satellite orbital motion lead to continuous changes in network topology structure, making traditional static routing strategies unable to adapt to such complex dynamic environments. We propose a reinforcement learning-based dynamic routing scheduling framework that achieves intelligent path selection and load balancing during the federated learning training process.
3.5.1. Orbital Prediction and Link Quality Assessment
Based on Kepler’s orbital mechanics, the orbital prediction equation for satellite node i is
where r_i_ represents the position vector of satellite i in the Earth-centered inertial coordinate system, represents the velocity vector of satellite i, is the Earth’s standard gravitational parameter, and represents perturbation acceleration including J2 gravitational terms and atmospheric drag effects.
The instantaneous signal-to-noise ratio calculation for link (i,j) is as follows:
where is the transmit power of node i, and are the transmit and receive antenna gains respectively, depending on the pointing angles ϕ, λ represents the carrier wavelength (meters), represents the atmospheric attenuation factor, is the Boltzmann constant, represents the system noise temperature, and B_i_ⱼ represents the bandwidth allocated to the link.
The comprehensive link quality metric is expressed as follows:
where , , represent weight coefficients satisfying , d_max_ represents the maximum communication distance, and represents the link load rate.
3.5.2. Multi-Objective Reinforcement Learning Routing Selection Algorithm
We model dynamic routing selection as a Markov Decision Process (MDP) , specifically as follows:
State Space Representation:
where A(t) is the vectorized representation of the network adjacency matrix, Q(t) represents the link quality matrix, R(t) represents the node resource state vector including remaining energy E_i_, computational capacity C_i_, and buffer occupancy rate B_i_, and F(t) is the federated learning task state including current round, convergence rate, average loss, data size, task priority, and remaining time.
Action Space Representation:
where represents the set of reachable neighbor nodes of node i at time t, and buffer represents the data buffering action, waiting for better transmission opportunities.
Multi-Objective Reward Function:
where , , , , are reward weight coefficients satisfying .
The component reward functions are defined as
where represents end-to-end delay, represents task deadline, represents deadline penalty coefficient, and represent total energy consumption and energy budget respectively, is the privacy risk coefficient of node v, is the observability capability of node v, is the path length penalty coefficient, and is the number of path hops.
This work adopts an improved MADDPG algorithm with Actor networks using graph convolutional structures, specifically as follows:
where represents the hidden state of node i at the l-th layer, is the weight matrix of the l-th layer, and is the attention weight.
Algorithm 2 presents the MADDPG-based dynamic routing scheduling procedure. At each time step, each agent observes its local state and selects a routing action via its Actor network with exploration noise. The joint action is executed, the resulting multi-objective reward and next state are observed, and the transition is stored in a shared replay buffer. Once sufficient transitions have accumulated, Critic networks are updated by minimizing the TD error and Actor networks are updated via deterministic policy gradient. Target networks are soft-updated to stabilize training. The state and action spaces are formally defined below before the algorithm, as these definitions are prerequisites for understanding the procedure. Algorithm 2 MADDPG-based dynamic routing schedulingInput: Number of agents ; Actor networks and Critic networks ; soft update rate ; discount factor ; mini-batch size ; replay buffer capacity ; learning rates ; total episodes ; state space ; action space .Output: Trained routing policy .1: For each agent : randomly initialize , //Initialize2: Copy to target networks: , 3: Initialize replay buffer 4: for episode do5: Observe initial state from environment6: for each time step t do7: //Action selection with exploration8: for each agent : 9: //Environment interaction10: Execute joint action 11: Observe next state and rewards via Equation (59)12: Store in 13: //Network update (when buffer sufficiently filled)14: //Environment interaction15: if then 16: Sample mini-batch from 17: For each agent i: compute TD target 18: For each agent i: update Critic by minimizing 19: For each agent i: update Actor via policy gradient 20: For each agent i: soft update target networks 21: end if22: //Phase 4: Receding horizon—apply first action only 23: end for24: end for25: return
The GCN-based Actor network incurs complexity per forward pass, where is the number of GCN layers, is the number of active links, and is the hidden dimension. With , , , each routing decision requires approximately 0.8 ms on the ground station GPU, which is negligible relative to communication window durations of 5–15 min.
3.5.3. Hierarchical Aggregation and Adaptive Adjustment
The three-layer aggregation architecture is as follows:
Bottom-Layer Aggregation:
where the weights are
Middle-Layer Aggregation:
Top-Layer Aggregation:
where is the data quality score of node i, and represents the inter-node link quality.
The comprehensive load indicator of node i is expressed as follows:
where , , , represent CPU utilization, memory utilization, communication load, and energy consumption level respectively.
When , task migration is initiated:
where is the load reduction amount and is the migration cost.
Multi-timescale weight updates are as follows:
where represents slow timescale, represents medium timescale, and represents fast timescale.
To provide a complete and reproducible operational description of the full ACDP-FL framework, Algorithm 3 integrates all proposed mechanisms into a single end-to-end federated learning round. The algorithm proceeds in six sequential phases: pre-round orbital computation at the GEO coordinator, bottom-layer local training with orbital-adaptive CS and compressed-domain DP, bottom-to-middle aggregation at LEO satellites with quality-weighted averaging, middle-layer aggregation at MEO satellites, top-layer global aggregation and model broadcast at the GEO satellite, and post-round policy and state updates. This six-phase structure directly corresponds to the three-tier LEO/MEO/GEO architecture and makes explicit how each proposed mechanism is activated within the federated learning workflow. Algorithm 3 ACDP-FL: complete federated learning roundInput: Round ; global model ; TLE data ; remaining budgets ; routing policy from Algorithm 2; local SGD steps ; batch size .Output: Updated global model ; updated budgets .1: //Phase 1: Pre-round orbital computation (GEO coordinator)2: Propagate all satellite positions via SGP4; compute 3: Compute privacy risk coefficients via Equation (26)4: Determine communication windows via Section 3.1.25: Allocate privacy budgets via Equations (27)–(31); broadcast to all nodes.6: //Phase 2: Bottom-layer local training (HAPs and User Terminals)7: for each bottom-layer node k in parallel do8: Receive ; run SGD steps; compute local gradient 9: Construct orbital-adaptive measurement matrix via Equations (12)–(16) 10: Compress: 11: Compute adaptive noise ; inject: 12: Transmit to parent LEO via route 13: end for14: //Phase 3: Bottom-to-middle aggregation (LEO satellites) 15: for each LEO satellite do 16: Receive within window 17: Compute quality-weighted aggregate: 18: Reconstruct via -minimization: s.t. 19: Transmit to parent MEO via 20: end for21: //Phase 4: Middle-layer aggregation (MEO satellites) 22: for each MEO satellite m do 23: Receive ; compute: 24: Transmit to GEO via inter-satellite link25: end for26: //Phase 5: Top-layer global aggregation (GEO satellite)27: Receive ; compute global gradient: 28: Update global model: 29: Broadcast to all nodes within 30: //Phase 6: Post-round updates31: Update routing policy: MADDPG update using stored transitions32: Update MPC state: 33: Update remaining budgets: for each 34: return ,
The per-round computational complexity of Algorithm 3 is dominated by three terms. The first is local training at bottom-layer nodes, costing , which is identical to standard FedAvg and thus introduces no additional overhead. The second and dominant new term is the -minimization reconstruction at LEO satellites, costing , where is the number of FISTA iterations, which remains small in practice due to warm-starting from the previous round’s reconstruction result. The third term is the MADDPG routing update, costing , which is independent of model dimension and therefore negligible for large models. The total per-round complexity is thus . The additional complexity introduced by the orbital-adaptive CS reconstruction and MADDPG routing remains practically acceptable for two reasons. First, the -minimization at LEO satellites operates on compressed measurements of dimension rather than the full gradient space, and the compression factor directly bounds the effective problem size; moreover, LEO satellites possess substantially greater computational resources than bottom-layer HAPs and UTs, making this reconstruction cost well within their processing capacity. Second, the MADDPG update is executed on the ground station with GPU acceleration and operates on a replay buffer asynchronously with the main training loop, so it does not lie on the critical path of any communication window. Taken together, the marginal computational overhead at the aggregation nodes is consistently outweighed by the communication savings of factor achieved over the bandwidth-constrained satellite-ground links, where contact windows of only 5–15 min make transmission volume reduction the primary system bottleneck.
Communication complexity per round is for bottom-to-LEO transmissions (compressed gradients of dimension ), for LEO-to-MEO transmissions (reconstructed full gradients), and for MEO-to-GEO transmissions, giving total uplink communication complexity . Compared with FedAvg’s , the dominant saving is in the bottom-to-LEO segment where compression reduces the transmission volume by factor , which is the most bandwidth-constrained segment given LEO-ground link limitations of 5–15 min contact windows.
Through the above reinforcement learning-driven dynamic routing scheduling framework, the system can adapt to the high dynamic characteristics of space–air–ground networks while ensuring federated learning training efficiency, achieving intelligent path selection and load management.
4. Simulation Experiments and Evaluation
4.1. Experimental Setup and Datasets
4.1.1. Experimental Setup
The experimental hardware environment consists of a workstation equipped with an Intel Core i7-7820HQ processor, 32 GB memory, NVIDIA Quadro P5000 graphics card, and 2 TB hard drive for simulation. The software environment uses PyCharm 2024.3.1.1 (Professional Edition) as the development platform, Python 3.9 as the programming language, PyTorch 2.5.1 as the deep learning framework, and CUDA 11.8 configuration to fully leverage GPU performance.
The space–air–ground integrated network simulation environment constructed in this study employs a hierarchical federated learning architecture comprising three main tiers: space segment, air segment, and ground segment. The space segment consists of one GEO satellite and eight MEO/LEO satellites, where the GEO satellite is positioned at 35,786 km in geostationary orbit, serving as the global coordination center responsible for top-tier model aggregation, parameter distribution, and training coordination. MEO satellites are deployed at 1200 km in medium Earth orbit with an orbital inclination of 55 degrees, with each MEO satellite managing three connected LEO satellites for middle-tier local aggregation. LEO satellites operate at 550 km in low Earth orbit with an orbital inclination of 53 degrees and an orbital period of approximately 96 min, with each LEO satellite responsible for coordinating local model aggregation of three high altitude platforms (HAPs). The ground segment includes one ground earth station (GES) and multiple user terminals, where the GES is responsible for managing local training and primary aggregation of three ground terminals.
The simulation experiment configures a federated learning training process over T = 15 rounds, with detailed parameter settings for local training, differential privacy, compressed sensing, orbital modeling, and reinforcement learning routing all summarized in Table 2. Key adaptive parameters, including the differential privacy budget and compression ratio , are dynamically adjusted within their specified ranges according to the orbital-aware mechanisms described in Section 3, rather than fixed at single values throughout training.
4.1.2. Datasets
This simulation experiment is validated based on MNIST, EuroSAT, and UC Merced Land-Use datasets.
The MNIST dataset [35] is one of the most classic benchmark datasets in the machine learning field, containing 70,000 images of 28 × 28 pixel handwritten digits (0–9), with 60,000 for training and 10,000 for testing. Due to its simplicity and standardized characteristics, MNIST is widely used to test the performance of various machine learning algorithms, particularly in preliminary validation and educational demonstrations of deep learning models.
The EuroSAT dataset [36] is a remote sensing dataset specifically designed for satellite image classification, constructed based on Sentinel-2 satellite data. The dataset contains 270,000 RGB images of 64 × 64 pixels, covering 10 different land use and land cover categories, including annual crops, forests, grasslands, highways, etc. Each category contains 2000–3000 images from different regions across 34 European countries. EuroSAT provides an important benchmark testing platform for remote sensing image analysis and Earth observation applications.
The UC Merced Land-Use dataset [37] is an aerial image classification dataset released by the University of California, Merced, containing 21 different land use scene categories with a total of 2100 color images of 256 × 256 pixels, with 100 images per category. These categories encompass diverse land use types such as farmland, airports, baseball fields, beaches, buildings, dense residential areas, etc. The dataset’s images have high resolution and rich details, providing important resources for remote sensing image understanding and land use classification research.
To faithfully simulate the non-IID data distribution inherent in space–air–ground networks, where geographically separated nodes observe heterogeneous data, we partition training samples across nodes using the Dirichlet distribution with heterogeneity parameter . This value represents a moderate-to-strong heterogeneity level widely adopted in federated learning benchmarks. The resulting data heterogeneity is quantified per node using the Earth Mover’s Distance (EMD) between each node’s local class distribution and the global class distribution:
where C is the number of classes, is the proportion of class c in node i’s local dataset, and is the global class proportion. Under the partition, the average EMD values across node types are 0.31 for ground terminals, 0.24 for LEO/HAP nodes, and 0.18 for MEO/GEO nodes, reflecting the natural geographic stratification of satellite coverage whereby higher-tier nodes aggregate data from broader and more diverse geographic footprints. The gradient dissimilarity parameter defined in Theorem 1, empirically estimated as with across all datasets, confirms that the bounded gradient dissimilarity assumption underlying the convergence guarantee is satisfied under the configured non-IID conditions.
4.1.3. Evaluation Metrics
This paper evaluates the proposed method based on Accuracy, Precision, F1-Score, Average Loss, and Recall metrics, specifically defined as follows:
The accuracy metric is defined as
where TP (True Positive) represents the number of samples correctly predicted as positive class, TN (True Negative) represents the number of samples correctly predicted as negative class, FP (False Positive) represents the number of samples incorrectly predicted as positive class, and FN (False Negative) represents the number of samples incorrectly predicted as negative class.
The Precision metric is defined as
Its meaning is the proportion of actual positive class samples among all samples predicted as positive class, reflecting the model’s ability to reduce false positives.
The F1-Score is defined as
Its meaning is the harmonic mean of precision and recall, comprehensively reflecting the model’s classification performance.
The Average Loss is defined as
where N represents the total number of participating training clients, represents the local loss function of the i-th client, and represents the global model parameters.
The Recall metric is defined as
Its meaning is the proportion of correctly predicted positive class samples among all actual positive class samples, reflecting the model’s ability to reduce false negatives.
4.2. Baseline Performance Comparison and Analysis
To comprehensively evaluate the effectiveness of the proposed adaptive compressed sensing differential privacy federated learning method, we select FedAvg [38], FedProx [39], LDPFL [40], and NomaFedHAP [41] as the main baseline comparison methods. These four methods represent different development stages and technical approaches in the federated learning field, enabling validation of our method’s superiority from multiple dimensions. The method proposed in this study is denoted as ACDP-FL. To ensure experimental result accuracy, the average of three runs is taken as the final experimental result.
This study conducts systematic evaluation of five federated learning methods on three representative datasets (including two satellite remote sensing datasets), simulating real satellite network environments in space–air–ground integrated scenarios. The experimental results under constraints of differential privacy parameter ε = 1.0 and compression ratio 0.8 are shown in Figure 2, Figure 3 and Figure 4 respectively.
Figure 2 shows the performance of ACDP-FL, FedAvg, FedProx, LDPFL, and NomaFedHAP based on the MNIST dataset.
Figure 3 shows the performance of ACDP-FL, FedAvg, FedProx, LDPFL, and NomaFedHAP based on the EuroSAT dataset.
Figure 4 shows the performance of ACDP-FL, FedAvg, FedProx, LDPFL, and NomaFedHAP based on the UC Merced Land-Use dataset.
In terms of accuracy performance, the proposed ACDP-FL method achieves optimal performance on all datasets. On the MNIST dataset, ACDP-FL reaches 93.59% accuracy, improving by 3.44% compared to the baseline FedAvg method’s 90.48%; on the EuroSAT dataset, it achieves 89.78% accuracy, improving by 12.1% compared to FedAvg’s 80.12%; on the more challenging UC Merced Land-Use dataset, it reaches 90.34%, improving by 9.86% compared to FedAvg’s 82.23%. This consistent performance advantage indicates that ACDP-FL possesses superior generalization capability across classification tasks of different complexities. NomaFedHAP, as the latest method optimized for heterogeneous networks, achieves accuracy rates of 91.10%, 85.45%, and 86.78% on the three datasets respectively, showing its technical advantages in space–air–ground network scenarios, but still falls short of ACDP-FL by approximately 2–4 percentage points.
In terms of precision and recall balance, ACDP-FL demonstrates excellent classification equilibrium. On the MNIST dataset, the precision is 92.29%, recall is 92.43%, and F1-score reaches 92.36%, with differences between metrics less than 0.2%, indicating good classification consistency across categories. In contrast, although the LDPFL method provides the strongest privacy protection, there exists significant deviation between its precision and recall, with precision of 77.34% and recall of 78.89% on the EuroSAT dataset, reflecting classification imbalance problems under strong privacy constraints. FedProx achieves 1–2% improvements in precision and recall compared to FedAvg through proximal term optimization, but its improvement magnitude is significantly smaller than ACDP-FL.
Loss function convergence characteristic analysis shows that ACDP-FL has optimal convergence performance and training stability. On the MNIST dataset, ACDP-FL’s final average loss is 0.0759, significantly lower than FedAvg’s 0.1482 and FedProx’s 0.1089, with reductions of 48.8% and 30.3% respectively. On EuroSAT and UC Merced Land-Use datasets, ACDP-FL also demonstrates the lowest loss values of 0.0057 and 0.4023 respectively. This superior loss convergence performance is mainly attributed to the orbital-aware adaptive optimization mechanism, which can adjust training strategies according to satellite nodes’ dynamic characteristics, effectively avoiding convergence instability problems caused by network condition changes in traditional methods.
Reconstruction error evaluation reveals the technical advantages of the compressed sensing mechanism. ACDP-FL achieves the lowest reconstruction error on all datasets: 0.1283 on the EuroSAT dataset, reducing by 19.4% compared to FedAvg’s 0.1592; 0.1283 on the UC Merced Land-Use dataset, improving by 19.4% compared to FedAvg’s 0.1592. This significant reconstruction error reduction directly translates to model accuracy improvements, validating the effectiveness of the spatiotemporal adaptive compressed sensing mechanism. NomaFedHAP’s reconstruction error is 0.1530 which, while better than traditional methods, is still about 16.1% higher than ACDP-FL, indicating that compression strategies specifically designed for space–air–ground networks have obvious technical advantages.
Cross-dataset robustness analysis shows that ACDP-FL maintains stable performance advantages across different application scenarios. From simple 10-class handwritten digit classification to complex 21-class land use classification, ACDP-FL’s performance improvement relative to baseline methods remains in the 3–12% range, with more significant advantages on more complex datasets. This robustness mainly stems from the adaptive characteristics of the orbital-aware differential privacy mechanism, which can dynamically adjust privacy budget allocation according to data complexity and network conditions, maximizing model performance while ensuring privacy protection. In contrast, traditional methods’ performance improvements show significant dataset dependency, with insufficient stability of advantages on complex datasets.
To assess statistical significance, all experiments are repeated across five independent runs with different random seeds controlling data partitioning, model initialization, and differential privacy noise sampling. We report 95% confidence intervals computed as , where is the sample mean, is the sample standard deviation, and . Table 3 summarizes the mean accuracy and 95% confidence intervals for all methods on the three datasets under and compression ratio .
The confidence intervals of ACDP-FL do not overlap with those of any baseline method on any dataset, confirming that the observed performance improvements are statistically significant at the 95% confidence level. Notably, ACDP-FL achieves the smallest confidence intervals across all datasets, indicating superior training stability attributable to the orbital-aware adaptive optimization mechanism, which reduces gradient variance by dynamically aligning compression and privacy strategies with orbital phase-dependent channel conditions.
4.3. Sensitivity Analysis
The experiment aims to systematically evaluate the influence pattern of differential privacy parameter ε on ACDP-FL method performance, validating the effectiveness of the orbital-aware differential privacy mechanism. The experimental design employs the controlled variable method, fixing the compression ratio at 0.8, network topology configuration, and training parameters unchanged, while only varying the differential privacy budget ε values. Specifically, ε values are set in the range [0.1, 0.5, 1.0, 2.0, 5.0, 10.0], covering the complete spectrum from strong privacy protection to weak privacy protection. The control group uses traditional fixed ε value differential privacy methods, while the experimental group uses ACDP-FL’s orbital-aware adaptive privacy budget allocation strategy. Each ε value undergoes 15 rounds of federated learning training, recording performance metrics including accuracy, precision, recall, and F1-score, while monitoring privacy budget consumption rate and model convergence stability. Experiments are conducted separately on MNIST and EuroSAT datasets to verify the method’s universality across tasks of different complexities. By analyzing the trend of performance improvement percentage with ε value changes, we quantify the optimization effect of the orbital-aware mechanism under different privacy strengths.
The sensitivity analysis experimental results based on the MNIST dataset are shown in Table 4.
The sensitivity analysis experimental results based on the EuroSAT dataset are shown in Table 5.
The experimental results demonstrate that ACDP-FL’s orbital-aware differential privacy mechanism achieves significant performance improvements across all privacy strengths. On the MNIST dataset, when the privacy budget ε = 0.1, ACDP-FL achieves 36.51%, 37.14%, and 37.68% performance improvements in accuracy, precision, and F1-score respectively compared to fixed differential privacy methods, fully proving the effectiveness of the orbital spatiotemporal characteristic-driven adaptive privacy budget allocation strategy. Even under relatively loose privacy constraints (ε = 10.0), ACDP-FL still maintains an 8.84% accuracy advantage, demonstrating the method’s sustained technical value.
Comparing experimental results between MNIST and EuroSAT datasets reveals that ACDP-FL demonstrates more prominent technical advantages in more complex remote sensing image classification tasks. On the EuroSAT dataset, performance improvement under strong privacy constraints (ε = 0.1) reaches 26.49%, which although lower than MNIST, precisely validates the sensitivity characteristics of remote sensing data to noise perturbation. Notably, in the moderate privacy strength range (ε = 0.5–2.0), performance improvements on the EuroSAT dataset show a more stable decreasing trend, indicating that ACDP-FL’s adaptive compressed sensing mechanism has good robustness when processing high-dimensional complex features.
4.4. Compression Rate Control Comparison and Analysis
This experiment specifically evaluates the technical advantages of adaptive compressed sensing strategy relative to fixed compression ratio methods, validating the effectiveness of integrating orbital spatiotemporal characteristics with compressed sensing technology. The experimental design fixes the differential privacy parameter ε = 1.0 and systematically tests performance across compression ratios in the range [0.2, 0.4, 0.6, 0.8]. The control group adopts traditional fixed compression ratio strategies, maintaining the same compression rate throughout the entire training process; the experimental group adopts ACDP-FL’s adaptive compressed sensing strategy, dynamically adjusting compression parameters based on real-time orbital position, link quality, and communication windows. The experiment focuses on monitoring model performance metrics including accuracy, precision, and F1-score. To ensure experimental fairness, both groups operate under identical network conditions and orbital configurations.
The compression rate control comparison experimental results based on the EuroSAT dataset are shown in Table 6.
The experimental results demonstrate that across the entire compression rate range [0.2, 0.8], the adaptive strategy achieves consistent performance improvements, with accuracy improvement ranging from 19.61% at low compression ratios to 6.17% at high compression ratios. This decreasing trend aligns with theoretical expectations from information theory in compressed sensing, where intelligent adaptive strategies can exert more prominent optimization effects in low compression ratio scenarios with significant information loss. Particularly noteworthy is that when the compression ratio is 0.2, the adaptive strategy achieves 19.61%, 19.78%, and 19.70% performance improvements in accuracy, precision, and F1-score respectively, fully proving the effectiveness of orbital spatiotemporal characteristic-driven sparsity pattern selection and dynamic measurement matrix design.
The experiment further reveals the core contribution of adaptive compressed sensing strategy in communication efficiency optimization. As the compression ratio decreases, the communication reduction effect of the adaptive strategy shows an increasing trend, from 6.2% improvement at high compression ratio (0.8) to 15.3% at low compression ratio (0.2). The fundamental reason for this phenomenon is that when compression ratios are low, fixed strategies often adopt conservative redundant transmission strategies to ensure basic reconstruction accuracy, while ACDP-FL’s orbital-aware routing selection and adaptive transmission scheduling can further optimize communication overhead while ensuring performance.
This section systematically validates the effectiveness and superiority of the ACDP-FL method through comprehensive experimental evaluation on three representative datasets: MNIST, EuroSAT, and UC Merced Land-Use. Experimental results demonstrate that compared to mainstream baseline methods including FedAvg, FedProx, LDPFL, and NomaFedHAP, ACDP-FL achieves significant improvements in model accuracy, convergence stability, and communication efficiency, maintaining consistent performance advantages under different privacy strengths and compression rate settings. Sensitivity analysis reveals the outstanding advantages of the orbital-aware differential privacy mechanism under strong privacy constraints, while compression rate control experiments confirm the technical value of adaptive compressed sensing strategies.
4.5. Orbital Phase-Dependent Performance Analysis
To directly validate the core claim that orbital spatiotemporal characteristics drive performance improvements, this section analyzes model accuracy and compression efficiency as functions of orbital phase . We divide one complete LEO orbital period ( min) into equal phase intervals of approximately 8 min each, and record the per-phase average accuracy and reconstruction error over the final five training rounds on the EuroSAT dataset. Figure 5 shows model accuracy as a function of orbital phase for ACDP-FL and the static-CS baseline (Jeon et al. [24]).
ACDP-FL maintains accuracy above 88.3% across all 12 phase intervals, with a peak of 90.1% near (satellite near apogee over high-data-density regions) and a minimum of 88.3% near (satellite over low-density regions). In contrast, the static-CS baseline exhibits substantially higher variance, dropping to 81.2% at where fixed measurement matrices fail to capture the changed sparsity structure, and recovering to 86.7% at . The per-phase accuracy gap between ACDP-FL and the static-CS baseline is quantified as
The average gap is consistent with the overall 3–12% improvement reported in Section 4.2, and the gap is largest (7.1%) at orbital phases corresponding to the satellite’s transition over heterogeneous geographic coverage areas, precisely where static sparsity assumptions are most violated.
4.6. Ablation Study and Privacy-Utility Trade-Off Analysis
4.6.1. Privacy Budget Versus Utility Loss
To provide a systematic characterization of the privacy-utility trade-off under the proposed compressed-domain differential privacy mechanism, Table 7 reports accuracy, F1-score, and utility loss as functions of privacy budget on the EuroSAT dataset, comparing ACDP-FL against the fixed-budget DP baseline. Utility loss is defined as the accuracy degradation relative to the no-privacy upper bound ( ):
where represents the accuracy of ACDP-FL without any privacy constraint.
The results demonstrate that the orbital-aware privacy budget allocation consistently reduces utility loss relative to the fixed-DP baseline across all values. The reduction is most pronounced under strong privacy constraints: at , ACDP-FL reduces utility loss by 11.31 percentage points (from 52.31% to 41.00%) compared to fixed-DP, demonstrating that the orbital-phase-driven budget redistribution is most effective precisely when privacy constraints are most binding. At , the utility loss of ACDP-FL is only 1.45%, confirming that strong privacy protection ( is considered rigorous in the differential privacy literature) can be achieved with minimal accuracy sacrifice through the proposed compressed-domain noise injection strategy.
4.6.2. Ablation Study
To quantify the individual contribution of each proposed component, we conduct a systematic ablation study on the EuroSAT dataset under and . We define the following ablated variants:
Variant A1 (w/o Orbital-CS): Replaces orbital-adaptive measurement matrix with a static Gaussian random matrix of fixed compression ratio , removing the TLE-driven sparsity pattern and phase-interval interpolation.
Variant A2 (w/o Orbital-DP): Replaces orbital-aware budget allocation (Equations (24)–(28)) with uniform allocation , while retaining compressed-domain noise injection.
Variant A3 (w/o Compressed-Domain DP): Moves DP noise injection from the compressed domain back to the original gradient space (inject noise before compression), while retaining orbital-aware budget allocation.
Variant A4 (w/o MPC): Replaces the MPC-based ternary optimization (Algorithm 1) with fixed hyperparameters ( , uniform allocation, fixed transmit power), removing adaptive multi-objective balancing.
Variant A5 (w/o MADDPG): Replaces the MADDPG routing policy (Algorithm 2) with shortest-path routing based on instantaneous link quality, removing learned multi-objective routing.
Table 8 summarizes the ablation study results, reporting accuracy, F1-score, reconstruction error, communication efficiency, and utility loss Λ(ε) for each ablated variant compared to the full ACDP-FL model on the EuroSAT dataset under ε = 1.0 and ρ = 0.8.
The ablation results reveal several important insights. Removing the orbital-adaptive CS (A1) causes the largest accuracy drop of 5.55 percentage points and increases reconstruction error by 44.7% (from 0.1283 to 0.1856), confirming that orbital-phase-driven sparsity pattern design is the single most impactful component. Removing orbital-aware DP allocation (A2) reduces accuracy by 3.33 points while maintaining the same communication efficiency as the full model, isolating the contribution of temporal budget redistribution to model performance. Moving DP injection to the original gradient space (A3) reduces accuracy by 4.11 points, confirming the theoretical advantage of compressed-domain noise injection: operating in the lower-dimensional compressed space reduces the required noise magnitude for the same privacy guarantee, leading to better model utility. Removing MPC (A4) reduces accuracy by 2.66 points, reflecting the cost of losing multi-objective dynamic balancing between energy, communication, and privacy. Removing MADDPG (A5) reduces accuracy by 1.89 points but also reduces communication efficiency from 3.18× to 2.94×, demonstrating that learned routing contributes to both model performance and communication optimization. The full ACDP-FL model achieves the best accuracy and utility loss while maintaining the highest communication efficiency, validating the synergistic design of all components.
5. Discussion
This section addresses the assumptions underlying the proposed ACDP-FL framework, analyzes computational complexity and practical deployment considerations, and proposes promising directions for future extensions.
5.1. Assumptions and Limitations
The proposed framework relies on several key assumptions that warrant explicit acknowledgment and discussion of their practical implications.
Assumption 1 (Perfect Orbital Knowledge). The orbital-adaptive mechanisms in Section 3.2 and Section 3.3 assume that satellite positions and velocities can be accurately predicted via Two-Line Element (TLE) sets propagated through SGP4/SDP4 models. In reality, TLE prediction errors accumulate over time due to atmospheric drag variations, solar radiation pressure, and gravitational perturbations from the Moon and Sun. Empirical studies report that LEO TLE position errors grow at approximately 1–3 km per day without updates. For the proposed orbital phase discretization with K = 12 intervals (each spanning ≈ 8 minutes of a 96-minute orbit, corresponding to ≈ 40° of arc length or ≈ 4200 km of ground track), position errors of 1–3 km represent less than 0.1% of the interval length and are therefore negligible for the purpose of sparsity pattern selection in Equation (13). However, for operational deployments exceeding several days without TLE updates, the framework should incorporate a TLE refresh mechanism, either through automated downloads from public catalogs (e.g., Space-Track.org) or onboard orbit determination using GNSS receivers increasingly available on modern LEO satellites.
Assumption 2 (Negligible Doppler Effects). *The communication model in Section 3.1.2 assumes instantaneous link capacity according to the Shannon formula (Equation (3)) and does not explicitly model Doppler frequency shifts induced by relative motion between satellites and ground stations. For LEO satellites at 550 km altitude moving at ≈ 7.6 km/s relative to ground terminals, the maximum Doppler shift at Ka-band (20 GHz carrier frequency) is approximately *
- kHz, where c is the speed of light. Modern satellite communication systems compensate for this shift through Doppler pre-correction at the transmitter or adaptive frequency tracking at the receiver, reducing the residual frequency error to well below the signal bandwidth. Since the compressed gradient transmission occupies bandwidths of 10–50 MHz (estimated from data rates of 50–200 Mbps over 5–15 minute contact windows), the residual Doppler error after compensation (typically < 1 kHz) represents less than 0.01% of the signal bandwidth and does not significantly impact the link quality metric *
- in Equation (22). Nevertheless, for extremely high-throughput scenarios or optical inter-satellite links where precise frequency alignment is critical, the framework could be extended to incorporate Doppler-aware link scheduling by adding a frequency offset penalty term to the MADDPG reward function (Equation (65)).*
Assumption 3 (Deterministic Communication Windows). *The orbital prediction model in Section 3.1.2 treats communication windows *
- as deterministic intervals determined solely by geometric visibility and minimum elevation angle constraints. This assumption neglects stochastic link outages caused by atmospheric attenuation (rain fade), ionospheric scintillation, or interference from terrestrial sources. For Ka-band satellite-ground links, rain fade can reduce link availability by 10–20% during heavy precipitation events. The proposed framework can partially accommodate such stochastic outages through the emergency degraded transmission mode (Equation (25)), which activates when CRC failures are detected. A more comprehensive extension would incorporate probabilistic availability models into the MPC optimization (Algorithm 1), replacing deterministic window constraints with chance constraints of the form * *, where *
- is an acceptable outage probability threshold.*
Assumption 4 (Instantaneous Inter-Satellite Link Handovers). *The hierarchical aggregation procedure in Algorithm 3 (Phase 3–5) assumes that LEO-to-MEO and MEO-to-GEO inter-satellite links are established instantaneously without handover delays or reacquisition overhead. In practice, laser inter-satellite links (ISLs) require pointing, acquisition, and tracking (PAT) procedures that can take 10–60 seconds. For a LEO orbital period of 96 minutes with typical LEO-MEO visibility windows of 15–30 minutes, a 60-second handover delay represents 3–6% of the available window duration. The framework could be extended to model handover delays by introducing a binary handover state variable *
- and a state transition latency *
- into the communication window definition: * , penalizing the first transmission after link reacquisition.
5.2. Computational Complexity and Scalability
The computational overhead introduced by the proposed framework relative to standard FedAvg can be decomposed into three main components: MPC-based ternary optimization (Algorithm 1), MADDPG routing training (Algorithm 2), and -minimization CS reconstruction at LEO satellites (Algorithm 3, Phase 3).
MPC Complexity: As analyzed in Section 3 following Algorithm 1, the per-round time complexity of MPC is , where is the number of ADMM iterations, is the prediction horizon, is the number of nodes, is the gradient sparsity, and is the model dimension. For a typical setting with , , , this evaluates to approximately floating-point operations per round. Compared to the local training cost of operations with and , the MPC overhead is comparable to local training. However, MPC is executed centrally at the GEO satellite, which typically possesses 10–100 greater computational capacity than ground terminals, making this overhead acceptable. The MPC wall-clock time in our Python implementation is approximately 450 ms per round on a single CPU core; with hardware acceleration (GPU or FPGA) and optimized solvers (e.g., OSQP for quadratic subproblems), this can be reduced to <50 ms, well within the multi-minute communication window duration.
MADDPG Training Overhead: The MADDPG update (Algorithm 2) has complexity per mini-batch, where , , , . This evaluates to approximately operations per update. Since MADDPG training occurs asynchronously on the ground station GPU (not on the critical path of any satellite contact window) and only once per communication round, the amortized cost is /(5 rounds between updates) ≈ operations per round, negligible compared to local training. The policy inference cost at deployment (after training) is even lower: operations per routing decision, requiring < 1 ms on GPU.
CS Reconstruction Complexity: The -minimization at LEO satellites (Algorithm 3, Phase 3) has complexity per satellite, where and . For , this evaluates to approximately operations per LEO satellite. With LEO satellites operating in parallel, the total system-wide reconstruction cost is operations, distributed across multiple nodes. Critically, this cost does not impact the ground terminal nodes, which have the most stringent energy and computational constraints. Modern LEO satellites are increasingly equipped with edge computing payloads (e.g., NVIDIA Jetson modules providing 20–100 TFLOPS) capable of executing FISTA reconstruction in 10–50 ms, well within the multi-second gradient collection latency.
Scalability to Mega-Constellations: The total per-round complexity scales as for communication and for reconstruction. For mega-constellations with nodes (e.g., Starlink’s planned 42,000 satellites), hierarchical aggregation becomes essential. The proposed three-tier architecture naturally extends to deeper hierarchies by introducing additional aggregation layers (e.g., regional GEO coordinators above local MEO aggregators), ensuring that each aggregation node handles a bounded number of children ( 10–20). Under such a balanced tree structure with branching factor and tree depth , the complexity remains for uplink transmission and for aggregation per node, achieving logarithmic scaling in network size.
5.3. Future Research Directions
Several promising directions exist for extending the proposed framework to address emerging challenges in next-generation space–air–ground networks.
Quantum-Resistant Differential Privacy: The current differential privacy mechanism relies on the computational difficulty of inverting the Gaussian noise addition in the compressed domain, which provides information-theoretic privacy against classical adversaries but does not explicitly address threats from quantum computers. Post-quantum cryptography is an active research area, and recent works have begun exploring quantum-resistant privacy-preserving mechanisms for federated learning. A natural extension of ACDP-FL is to replace the Gaussian mechanism with lattice-based noise addition, where privacy noise is sampled from a discrete Gaussian distribution over a lattice structure in the compressed measurement space. The privacy budget would then be defined via the Rényi divergence framework, which provides tighter composition bounds than the classical -DP framework under quantum attacks. The challenge lies in ensuring that the lattice structure is compatible with the compressed sensing reconstruction: the sparsity-promoting minimization must be modified to a discrete optimization over lattice points, potentially via integer programming or quantized ADMM.
Cross-Constellation Federated Learning: Current satellite constellations operate largely independently, with Starlink, OneWeb, Kuiper, and national systems forming isolated communication islands. A compelling future direction is enabling federated learning across multiple heterogeneous constellations, where each constellation operator acts as an independent federated learning client contributing to a global model without sharing proprietary orbital data or ground station locations. This introduces a novel two-tier federation structure: intra-constellation FL (as addressed by ACDP-FL) at the lower tier, and inter-constellation FL at the upper tier coordinated via neutral ground stations or international regulatory bodies. The inter-constellation tier requires Byzantine-robust aggregation to defend against potentially malicious constellation operators, and differential privacy budgets must be split between intra-constellation noise (protecting user data within a constellation) and inter-constellation noise (protecting constellation-level statistics from competitors).
Energy Harvesting-Aware Adaptation: The current MPC formulation (Section 3.4.2) treats energy as a constraint with a fixed budget , but does not model the time-varying nature of energy harvesting from solar panels. LEO satellites experience predictable eclipse periods (up to 35% of each orbit in shadow for sun-synchronous orbits), during which energy consumption must be minimized while energy harvesting drops to zero. A more sophisticated extension would incorporate a solar panel power generation model as a function of time and orbital phase into the MPC state dynamics (Equation (56)), replacing the static energy budget constraint with a dynamic energy balance equation: . The MPC controller would then proactively schedule high-throughput compressed sensing transmissions during sunlit orbital phases and defer non-critical updates to conserve battery during eclipses, achieving energy-optimal federated learning over multiple orbital cycles.
Integration with Non-Terrestrial Network (NTN) Standards: The 3GPP Release 17 and 18 specifications introduce Non-Terrestrial Network (NTN) standards for direct satellite-to-device connectivity, including support for 5G New Radio (NR) over satellite links. A practically significant extension of ACDP-FL is to align the framework with 3GPP NTN protocols, particularly the random access procedures (RACH), timing advance adjustments, and resource allocation mechanisms defined for satellite-UE links. This would enable ACDP-FL to operate natively within commercial 5G-NTNs, leveraging existing infrastructure and standardized interfaces. The main challenge is adapting the orbital-aware privacy budget allocation and compressed sensing matrix design to work within the 3GPP NTN frame structure, which imposes fixed transmission time intervals (TTIs) and resource block granularity.
6. Conclusions
This paper addresses key challenges including orbital dynamics, resource heterogeneity, and privacy vulnerability faced by federated learning in space–air–ground integrated networks, proposing an adaptive compressed sensing differential privacy federated learning framework based on orbital spatiotemporal characteristics. Through deep integration of orbital dynamics characteristics with machine learning techniques, we achieve synergistic improvement of privacy protection, communication optimization, and model performance. In terms of theoretical contributions, this paper establishes privacy leakage bound theory in the compressed domain, providing mathematical foundations for privacy quantification in space–air–ground federated learning; constructs an energy–privacy–accuracy ternary synergistic optimization framework, achieving dynamic balance among multiple objectives through Pareto optimal solutions; proposes orbital-aware hierarchical aggregation mechanisms and reinforcement learning-based intelligent routing strategies, significantly improving system convergence efficiency and robustness. In terms of technical innovations, this paper first introduces orbital periodicity characteristics into compressed sensing matrix design, proposing time-varying sparse sensing matrices and adaptive compression rate adjustment strategies; designs temporal privacy budget allocation mechanisms based on orbital predictability, achieving intelligent management of differential privacy parameters; constructs compression–privacy joint optimization algorithms with noise injection in the compressed domain, forming synergistic effects where 1 + 1 > 2.
Experimental validation demonstrates that compared to existing baseline methods including FedAvg, FedProx, and LDPFL, our method achieves significant performance improvements on MNIST, EuroSAT, and UC Merced Land-Use datasets. Sensitivity analysis and compression rate control experiments further validate the effectiveness and robustness of the orbital-aware mechanism.
This research provides important theoretical foundations and technical support for the development of next-generation 6G intelligent space–air–ground integrated systems. The demonstrated communication efficiency gains of 30–50% directly translate to enabling 2–3 more training rounds within the same LEO satellite contact window (typically 5–15 min), accelerating model convergence for latency-sensitive applications such as real-time disaster response and autonomous vehicle coordination across satellite coverage areas. To bridge the gap between simulation and deployment, future validation should leverage publicly available TLE datasets (e.g., from CelesTrak or Space-Track.org) combined with real satellite telemetry from operational constellations to assess the robustness of orbital-adaptive mechanisms under actual propagation errors and link dynamics. Longer-term research directions include hybrid quantum-classical differential privacy schemes that combine lattice-based post-quantum noise for long-term security guarantees with computationally efficient Gaussian noise for near-term deployments, and federated learning across heterogeneous mega-constellations exceeding satellites, further advancing the industrialization of space-based intelligent computing in the 6G era.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Xiao Y. Ye Z. Wu M. Li H. Xiao M. Alouini M.-S. Al-Hourani A. Cioni S. Space-air-ground integrated wireless networks for 6G: Basics, key technologies and future trends IEEE J. Sel. Areas Commun.2024423327335410.1109/JSAC.2024.3492720 · doi ↗
- 2Zhang S. Model collaboration framework design for space-air-ground integrated networks Comput. Netw.202525711101310.1016/j.comnet.2024.111013 · doi ↗
- 3Lin Z. Chen Z. Fang Z. Chen X. Wang X. Gao Y. Fedsn: A federated learning framework over heterogeneous leo satellite networks IEEE Trans. Mob. Comput.2024241293130710.1109/TMC.2024.3481275 · doi ↗
- 4Elmahallawy M. Luo T. Async FLEO: Asynchronous federated learning for LEO satellite constellations with high-altitude platforms 2022 IEEE International Conference on Big Data (Big Data)IEEE New York, NY, USA 202254785487
- 5Kairouz P. Mc Mahan H.B. Avent B. Bellet A. Bennis M. Bhagoji A.N. Bonawitz K. Charles Z. Cormode G. Cummings R. Advances and open problems in federated learning Found. Trends® Mach. Learn.202114121010.1561/2200000083 · doi ↗
- 6Mei Q. Huang R. Li D. Li J. Shi N. Du M. Zhong Y. Tian C. Intelligent hierarchical federated learning system based on semi-asynchronous and scheduled synchronous control strategies in satellite network Auton. Intell. Syst.20255910.1007/s 43684-025-00095-z · doi ↗
- 7Chen H. Xiao M. Pang Z. Satellite-based computing networks with federated learning IEEE Wirel. Commun.202229788410.1109/MWC.008.00353 · doi ↗
- 8Moreno-Álvarez S. Paoletti M.E. Sanchez-Fernandez A.J. Rico-Gallego J.A. Han L. Haut J.M. Federated learning meets remote sensing Expert Syst. Appl.202425512458310.1016/j.eswa.2024.124583 · doi ↗