Hierarchical Multi-Scale Feature Fusion Network with Implicit Neural Representation and Mamba for Cross-Modality MRI Synthesis
Zhihao Luo, Jun Lyu

TL;DR
This paper introduces a new AI model for generating missing MRI scans from available ones, improving accuracy and usefulness in medical diagnostics.
Contribution
The novel HMF-MambaINR model combines Mamba-based SSM and INR for superior cross-modality MRI synthesis.
Findings
HMF-MambaINR outperforms existing CNN, Transformer, and Mamba-based methods in MRI synthesis.
Synthesized images were positively evaluated by radiologists for quality and structural accuracy.
Abstract
Magnetic resonance imaging (MRI), a widely adopted modality in clinical practice, enables the acquisition of multi-contrast images from the same anatomical structure, commonly referred to as multimodal images. Integrating these diverse modalities is crucial for enhancing model performance across a variety of medical image analysis tasks. However, in real-world clinical scenarios, it is often impractical to acquire all MRI modalities simultaneously due to factors such as patient discomfort, time constraints, and scanning costs. As a result, synthesizing missing modalities from available ones has emerged as an effective solution. To address these challenges, we propose HMF-MambaINR, a hierarchical multi-scale feature fusion network for cross-modality MRI synthesis. The model integrates Mamba-based Selective State Space Modeling (SSM) and implicit neural representation (INR) to capture…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
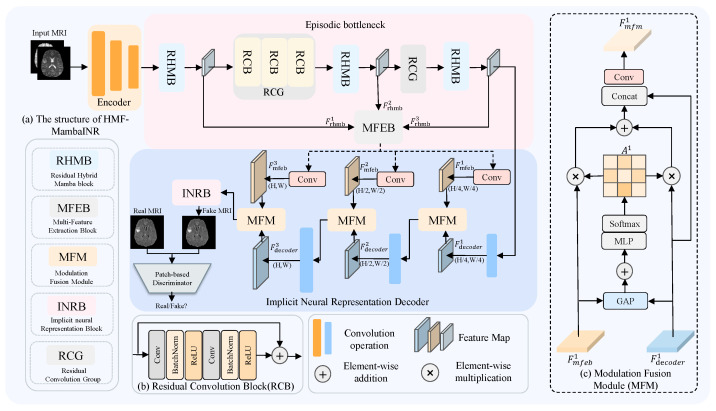 Figure 1
Figure 1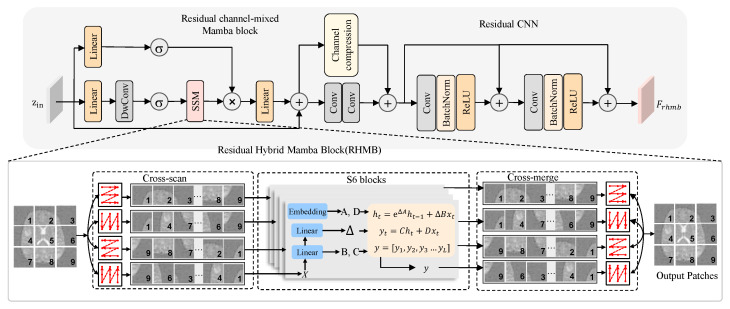 Figure 2
Figure 2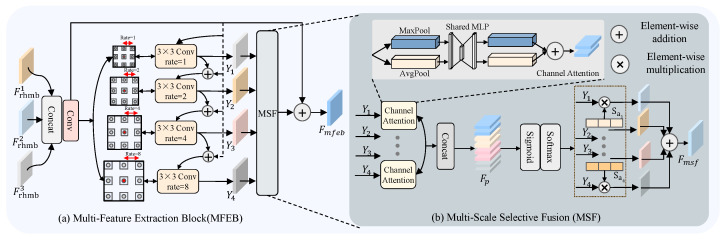 Figure 3
Figure 3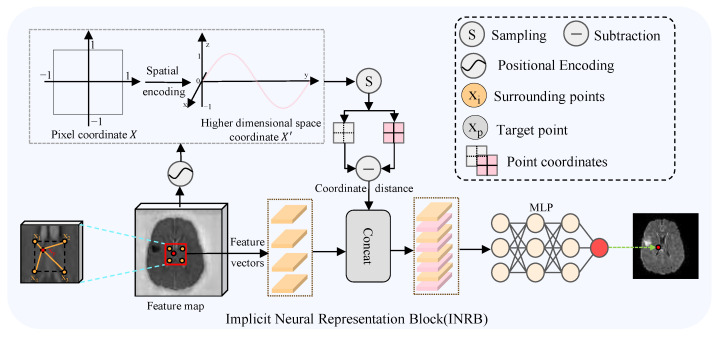 Figure 4
Figure 4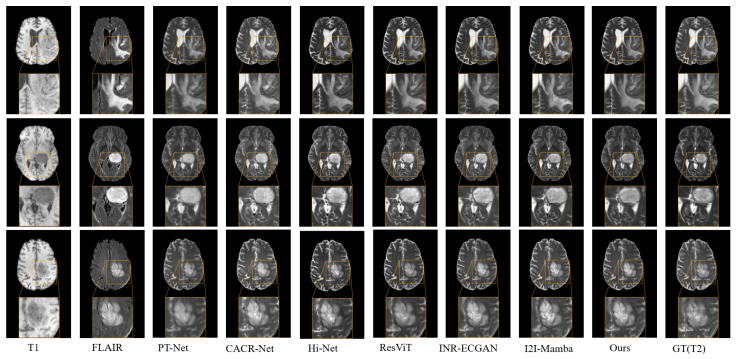 Figure 5
Figure 5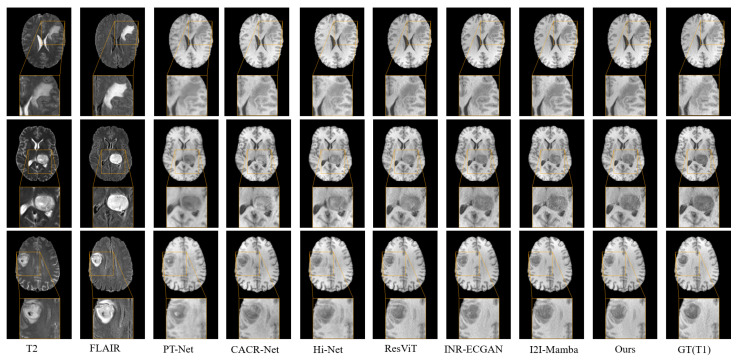 Figure 6
Figure 6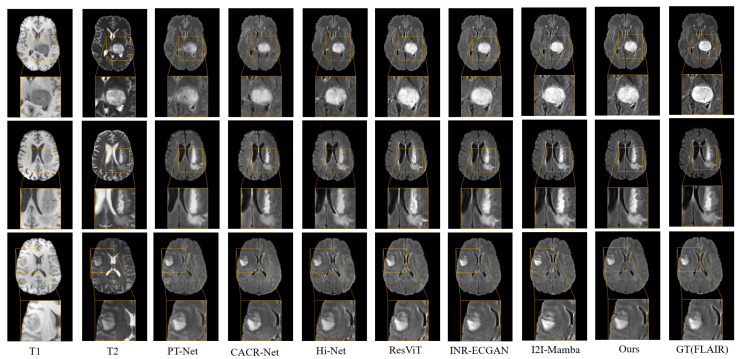 Figure 7
Figure 7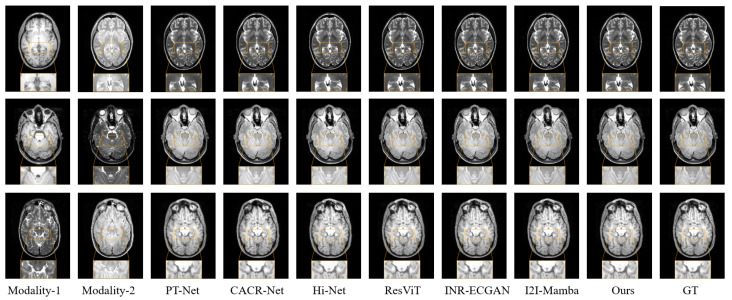 Figure 8
Figure 8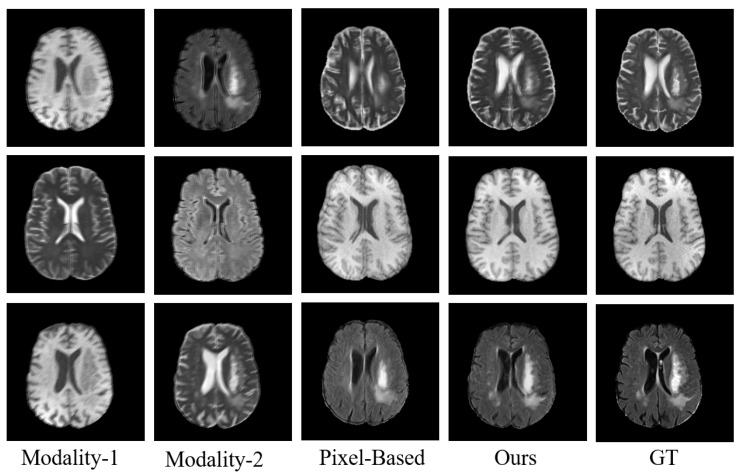 Figure 9
Figure 9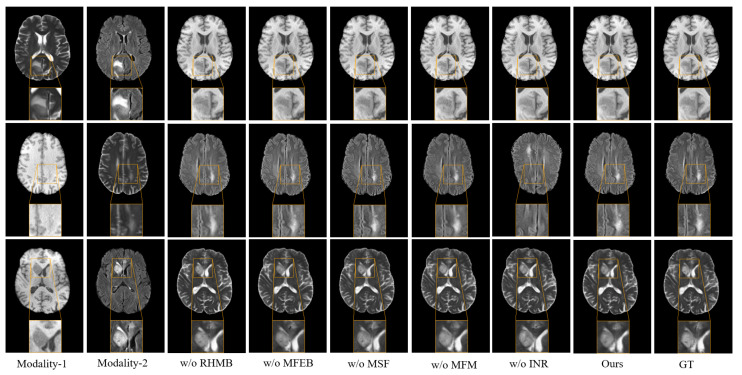 Figure 10
Figure 10- —National Natural Science Foundation of China
- —Yantai Basic Research Key Project
- —Youth Innovation Science and Technology Support Program of Shandong Province
- —Youth Program of the Natural Science Foundation of Shandong Province
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenerative Adversarial Networks and Image Synthesis · Advanced Image Fusion Techniques · Advanced Neural Network Applications
1. Introduction
Magnetic resonance imaging (MRI) has become an indispensable tool in clinical disease diagnosis, offering high-resolution structural and functional information without the risks associated with ionizing radiation. In clinical practice, multiple MRI modalities are typically acquired by configuring task-specific scanning parameters, such as T1-weighted (T1), contrast-enhanced T1-weighted (T1c), T2-weighted (T2), and T2 fluid-attenuated inversion recovery (FLAIR) images. Owing to the distinctive soft tissue contrast and feature representation of different modalities, which allow for the reflection of tissue anatomy and pathological changes from multiple perspectives, integrating the supplementary data obtained from different MRI sequences facilitates more effective medical image analysis [1,2]. However, in practical clinical settings, obtaining all required imaging modalities is frequently hindered by variations in scanning protocols, patient discomfort, and the substantial costs associated with imaging procedures. Therefore, the problem of cross-modality MRI image synthesis for missing modalities has attracted considerable interest across clinical and academic domains in recent years.
Cross-modality medical image synthesis aims to generate missing target modalities by learning a mapping from the available source modality to the desired one. Owing to the high dimensionality of medical images, their complex anatomical structures, and the nonlinear contrast variations across modalities, cross-modality synthesis becomes particularly challenging when the target modality is unavailable during inference [3]. In recent times, deep learning has grown to become the prevailing approach for medical image synthesis, largely due to its powerful capacity for approximating complex nonlinear functions. By performing nonlinear transformations in intermediate feature spaces, neural networks learn to map source modality images to their corresponding target modalities [4,5], effectively addressing many of the challenges inherent in this task. Early works primarily leveraged convolutional neural networks (CNNs), which apply local, spatially invariant filters to extract features, demonstrating superior representational power over traditional methods [6]. Subsequent advancements introduced generative adversarial networks (GANs), which incorporate adversarial loss to better model complex anatomical structures, leading to further performance improvements [7]. However, convolutional architectures inherently possess limited receptive fields, restricting their capacity to capture long-range dependencies and global contextual relationships [8]. To overcome these challenges, recent methods have adopted Transformer-based architectures that utilize self-attention mechanisms to dynamically model global context by computing attention weights among all token pairs [9]. This approach significantly improves the network’s capacity to capture long-range dependencies, enhancing performance on high-level tasks such as medical image synthesis [10]. Nevertheless, the self-attention mechanism incurs quadratic complexity with respect to the input size, which hinders the scalability of Transformers to high-resolution image data. Recently, the emergence of the improved selective structured state space model (Mamba) [11] provides a new solution to the above problem. Mamba achieves selective attention to key positions while maintaining linear computational complexity, combining local modeling efficiency with global modeling capabilities. This architecture decreases computational demands and boosts inference efficiency.
Current research efforts have started investigating the implementation of Mamba in multi-modal image fusion tasks [12,13]. Atli et al. [14] proposed a Mamba-based medical image synthesis model that integrates hybrid-channel Mamba blocks with CNNs, effectively capturing both short-range and long-range contextual information in medical images. However, the results generated by existing methods still suffer from issues such as blurred local textures and insufficient detail restoration. The reason is that existing methods fail to fully leverage multi-scale semantic information in multimodal medical images, which hinders the model’s capacity to accurately represent critical structures. Indeed, multi-scale feature fusion has been widely adopted in various vision tasks to enhance both contextual understanding and fine-grained detail modeling. Examples include multi-scale context modules with atrous mechanisms for RGB-T salient object detection [15], hierarchical multi-scale learning in brain tumor segmentation [16], and dynamic multi-scale fusion for improved medical image assessment [17]. In addition, existing Mamba-based synthesis models typically rely on discrete pixel-level or voxel-level representations, which inherently limit their ability to recover fine-grained details [18]. Given the recent excellent performance of implicit neural representation (INR) in encoding images into continuous functional representations [19,20,21], we propose to combine Mamba’s global sequence modeling capabilities with INR’s high-fidelity reconstruction capabilities in continuous space, and further introduce a multi-stage, multi-scale feature fusion mechanism to gradually guide the image synthesis process from coarse to fine. Unlike hybrid Transformer-CNN architectures that operate on fixed discrete grids, the combination of Mamba and implicit neural representations offers complementary advantages. Mamba excels at efficient global sequence modeling and long-range dependency capture, while implicit neural representations encode images as continuous functions, enabling more accurate reconstruction of fine structures and boundaries. This synergy forms a more effective representation framework and directly addresses the limitations of discrete pixel-level representations in current Mamba-based synthesis models. This design effectively solves the problem that existing methods are difficult to balance between structure and detail modeling, and provides a novel and promising solution for synthesizing multimodal medical images, which can be used not only to augment datasets for research but also to support downstream clinical tasks such as segmentation, registration, and diagnostic decision-making.
Building on these foundations, we propose a hierarchical multi-scale feature fusion network with Mamba and implicit neural representation (HMF-MambaINR). HMF-MambaINR selectively inserts the residual hybrid mamba block(RHMB) module to capture spatial contextual information and employs channel mixing layers for deep feature interaction across channels. Subsequently, a Multi-Feature Extraction Block (MFEB) is introduced to capture both fine-grained local textures and high-level global semantics by integrating multi-scale contextual representations across different feature hierarchies, and leverage the Modulation Fusion Module (MFM) module fine-grained integration of features across multiple scales, facilitating the fusion of spatially diverse structural and contextual information. Finally, an implicit neural representation block (INRB) maps the fused features into a continuous image generation function, enabling the synthesis of medical images with enhanced structural detail and rich tissue textures.
The primary contributions can be summarized as follows:
- We propose a novel cross-modality MRI synthesis model (HMF-MambaINR) based on Mamba and INR to synthesize missing target domain images.
- We design an innovative MFEB, which captures multi-scale features through multi-scale receptive fields and adaptively adjusts the weights of features at each scale based on their content, learning and understanding the complementary information between multiple features.
- We introduce the MFM, which effectively facilitates multi-scale feature integration, alleviates feature sparsity issues encountered during the decoding stages, and thereby enhances the overall network performance.
- We incorporate INR to model the continuous mapping between multi-modal feature and the image space, significantly enhancing the model’s representational capacity and its ability to synthesize fine-grained anatomical structures.
2. Related Works
2.1. Medical Image Synthesis
The objective of cross-modality medical image synthesis is to transform source modality images into corresponding missing target modalities. Several approaches have been introduced recently to overcome this problem. For example, Nie et al. [22] trained a fully convolutional network using an adversarial learning strategy to predict CT images from corresponding MR images. Similarly, Wei et al. [23] proposed a three-dimensional fully convolutional architecture was introduced for FLAIR image synthesis by learning mappings from other available MR modalities. Dar et al. [6] presented an approach powered by a conditional GAN architecture, utilizing pixel-level and cyclic consistency loss functions for multi-modal MRI image synthesis. However, these approaches predominantly concentrate on synthesizing medical images from a single source modality. To enhance synthesis performance using multiple modalities, numerous techniques for synthesizing images across multiple modalities have emerged. Zhou et al. [24] designed modality-specific networks to capture features of individual modalities and employed a layer-wise fusion strategy, further boosting the model’s effectiveness in multimodal image synthesis. Peng et al. [25] proposed a reliability-aware integration and inter-modal enhancement framework, which effectively utilized synergistic features across distinct data sources to generate high-quality target modality images. Li et al. [26] further incorporated boundary-sensitive pretraining combined with multi-scale fine-tuning strategies, enabling their model to generalize across both paired and unpaired MRI synthesis tasks.
2.2. Transformers and SSM Models in Medical Imaging
In recent years, Transformer-based approaches have gained significant traction in computer vision tasks [9], demonstrating strong potential in medical image segmentation, reconstruction, and synthesis. Dalmaz et al. [10], who integrated adversarial training with a Transformer-based generator for cross-modality synthesis; Yan et al. [27], who proposed a Swin Transformer architecture to alleviate boundary artifacts from small patch sizes; Liu et al. [28] developed a hierarchical, cross-contrast attention framework that models contrastive relationships for high-quality synthesis, while Zhang et al. [29] extracted modality-invariant and modality-specific representations to generate anatomically consistent images. Despite these advances in context modeling and image quality, the high computational cost of global interactions limits their clinical application.
As a promising alternative, selective state space models (SSMs) offer long-range dependency capture with low complexity. Recent applications in medical imaging include segmentation [30,31], classification [32], and synthesis [14]. For instance, Ma et al. [33] introduced a CNN-SSM hybrid for robust heterogeneous image processing, Yue et al. [32] proposed a Conv-SSM dual-branch module for multi-level feature extraction and improved classification, and Xing et al. [34] developed a tri-directional Mamba module for sequential and multi-scale modeling in 3D volumes. Atli et al. [14] pioneered SSM for modality translation, enabling efficient cross-modal synthesis. However, further enhancements can be achieved by integrating multi-stage and multi-scale features most relevant to target modality synthesis.
2.3. Implicit Neural Representation
INR is an emerging coordinate-based technique that leverages multilayer perceptrons (MLPs) to model continuous-domain signals. Unlike traditional methods that explicitly store signal values at each pixel or voxel, INR learns a continuous mapping from spatial coordinates to signal intensities, thereby achieving a compact and implicit encoding of visual data [35]. Originally developed for 3D vision applications, INR has recently garnered increasing attention in 2D image tasks. Li et al. [36] introduced a reference-aware attention module based on INR to achieve super-resolution of any scale. Gu et al. [37] introduced a self-distillation-based INR method that amplifies capillary details to facilitate retinal vessel segmentation for ophthalmic disease diagnosis. Wei et al. [38] combined uncertainty-guided sampling with INR to learn a mapping from feature–coordinate pairs to segmentation outputs. Recently, Feng et al. [39] first attempted to establish a continuous mapping of synthetic aperture radar (SAR) features to optical images through INR. However, their method is built upon CNN architectures, which are limited by the local receptive field and limited modeling capabilities of convolution and are difficult for capturing global contextual relationships and complex cross-modal nonlinear mapping relationships.
3. Methodology
3.1. Overview
As illustrated in Figure 1a, the proposed HMF-MambaINR architecture consists of an encoder, an episodic bottleneck, and a decoder, which together synthesize target-modality images from input source-modality images. The encoder comprises three stages, each based on a standard CNN block, consisting of a convolutional layer, batch normalization, and a ReLU activation function. The bottleneck module is primarily composed of three subcomponents: RHMB, CRG, and MFEB. The RHMB intermittently inserted at three critical positions: the beginning, middle, and end, to enhance the modeling of deep semantic features. The key features extracted from the three RHMB stages are fed into the MFEB, which is used to extract complementary information of features at different stages. Residual convolution group(RCG) uses a standard residual CNN module as its basic structure. The decoder module mainly consists of MFM and INRB. MFM is used to dynamically fuse features of different scales and enhance the expression of key features. INRB module uses continuous space mapping mechanism for image synthesis. The rest of the module retains the same CNN block structure as the encoder. The detailed architectural designs and implementation specifics of each key module are further elaborated in the subsequent sections.
3.2. Residual Hybrid Mamba Block
The RHMB effectively exploits the sensitivity of SSM to long-range contextual dependencies, while leveraging the local accuracy advantages of CNN, significantly enhancing overall performance without introducing additional computational overhead. As shown in Figure 2, the RHMB consists of three key components: First, the SSM layer for capturing long-range contextual information; second, the channel mixing layer for modeling dependencies between feature map channels; and third, the convolutional layer for extracting local features. In the RHMB block, the input feature map is first tokenized into disjoint blocks with dimensions , resulting in a sequence . In the first branch, the sequence is linearly embedded for the calculation of the gating variable G:
where denotes an activation function. In the second branch, the input sequence is first linearly embedded, then undergoes feature mixing via depthwise separable convolution, and finally, it is projected through the SSM layer:
The SSM layer in the equation is built upon the selective state space sequence model. Specifically, the sequence of patches is first extended by performing selective scanning in multiple directions of the 2D feature map. Then, the resulting sequence is processed using state space modeling, and finally, the processed sequence is merged back. In this process, we construct a discretized state space model:
In this context, h denotes the hidden state, z represents the source sequence, and refers to the target sequence, where n stands for the sequence index, while , , , and are the learnable SSM parameters. N is the dimensionality of the state representation.
After applying the Hadamard product for gating M, a linear projection is performed, followed by a residual addition with the input sequence:
To further capture the context between different feature channels, will pass through the channel mixing layer:
The channel mixing layer is implemented using a convolution. Finally, a residual CNN block takes the processed features and generates the output:
The RCNN module is composed of two repeated CNN blocks, each containing a convolutional layer followed by batch normalization and a ReLU activation.
3.3. Multi-Feature Extraction Block
As illustrated in Figure 3a, we introduce a Multi-Feature Extraction Block (MFEB) designed to capture multi-scale features more effectively and enhance the model’s capacity to represent both semantic and structural information. This structure fully leverages feature information from different stages while capturing multi-scale feature representations, enabling the fusion of shallow local textures and deep semantic features, consequently strengthening the model’s competence for multi-level understanding and representation of image content.
First, we concatenate the feature outputs from the three stages of the RHMB module to serve as the input for subsequent multi-scale extraction process. The features from the three stages are specifically represented as , , and . These features are stacked along the channel dimension, and the resulting concatenated feature map is then passed through a convolution operation for dimensionality reduction, producing an intermediate feature map .
The input feature map undergoes a series of four dilated convolutions with distinct dilation factors to extract features across multiple scales · .
In this design, i denotes the number of dilated convolutions, which is set to 4 based on experimental configuration. This design preserves the network’s depth while expanding its width, thereby enabling the extraction of fine-grained structural details as well as abstract contextual representations. Following feature extraction, we employ a Multi-scale selective fusion (MSF) module to integrate the multi-scale features . The details of MSF are shown in Figure 3b. First, global average pooling and global max pooling are performed on the four features from the previous stage to obtain their respective average channel weights. The results of pooling are represented as and . Then, a convolution operation is applied, and the outputs from max pooling and average pooling are individually summed:
Here, represents the fused feature of the i-th multi-scale feature extracted in the preceding stage, and the index corresponds to the four multi-scale features. Than, the results are concatenated into . The weights are then mapped to the range of 0 to 1 using the sigmoid activation function, followed by a softmax operation applied to normalize the values at the same position across the multi-scale average channel weights, thereby achieving consistency modeling across scales:
Here, represents the j-th element within the channel attention map, with the sum of all elements equal to 1. denotes the j-th element of . Subsequently, the features are weighted by their corresponding normalized coefficients and then summed to produce the updated multi-scale features:
where denotes the fused feature map. Finally, the processed features are added to the initial features, and the resulting sum is used as the input to the subsequent model.
3.4. Modulation Fusion Module
To effectively mitigate feature sparsity encountered during the decoding stages, we propose the MFM (Figure 1c). This module progressively integrates features extracted by the MFEB, while employing a dynamic weighting mechanism to adaptively emphasize and enhance critical feature representations. Specifically, the MFM module at the i-th stage receives feature inputs from two distinct sources: , extracted from the convolution operation after MFEB, and , produced by the decoder at the corresponding stage. Here, i denotes the index of the current MFM module within the multi-stage fusion process. The fusion network comprises three such MFM modules. Both feature maps are first processed by a global pooling operation, yielding intermediate representations and . Subsequently, the features are merged via element-wise addition. The combined features are subsequently fed into an MLP for nonlinear transformation and dimensionality reduction, followed by channel-wise softmax normalization to generate adaptive fusion weights.
The values in represent the relative importance of and within the synthetic network. These weights are applied to the input features through an element-wise multiplication, enabling feature modulation. This modulation process effectively highlights critical representations and helps preserve fine-grained structural details.
The modulated features are then concatenated with the original input , then passed through a convolutional layer to generate the final output feature map .
3.5. Implicit Neural Representation Block
Figure 4 depicts the architecture of the INRB, which learns the implicit transformation from source modality features to the target image. Specifically, each predicted pixel is continuously described by the surrounding four locally related points ( ). These pixel points are recorded in the relative coordinate set , where the “2” denotes the horizontal and vertical coordinates. Additionally, we employ periodic spatial encoding to project these coordinates X are mapped into a higher-dimensional space to enhance the recovery of high-frequency details. The encoding procedure can be expressed as:
The function denotes the coordinate mapping mechanism. x represents the coordinate values of X, which are normalized to the range . The hyperparameter L determines the dimensionality of the encoding, and in our experiments, we set . Then, based on nearest-neighbor interpolation, four local related points ( ) are used as input features for the target point . Simultaneously, by calculating the positional offsets between the target point and the local related points, we obtain the corresponding relative position encoding. Subsequently, we combine the local feature vectors and their corresponding position encodings to form the intermediate features .
Finally, these are input into the decoder , where the weighted average of predictions from neighboring grids is computed to achieve a continuous translation. This process can be regarded as implicit neural interpolation. This procedure can be formulated as:
Here, represents the final pixel value at point . Let denote the area of the region between the target point and a local related point . denotes the local integration weight, which satisfies the condition that the sum of all equals 1. represents the MLP layer.
3.6. Loss Function
Here, we design the HMF-MambaINR as part of an adversarial framework, a conditional discriminator D operating on image patches is employed [40]. This discriminator is used to distinguish between the actual target images and the synthetic target images generated by the generator G. Assuming that the training set contains pairs of source and target images for each example, we train the generator G using a composite objective function that accounts for both pixel-level reconstruction error and adversarial feedback:
Here, represents the expectation, and denotes the synthetic image generated by the generator G from the source image X. and are the weight coefficients of the pixel-by-pixel loss term and the adversarial loss term, which are 1 and 100 respectively. Meanwhile, the discriminator D is trained using adversarial loss to optimize its ability to to differentiate authentic target images from synthetically generated ones:
4. Experiments
4.1. Dataset
To demonstrate the effectiveness of our approach, experiments were conducted on two commonly used brain MRI datasets: the BraTS 2020 dataset [41,42,43] and the IXI dataset [44].
BraTS Dataset [41,42,43]. We used the BraTS 2020 dataset, which selected multi-parametric magnetic resonance imaging (mpMRI) scans collected from 240 patients with confirmed diffuse glioma. Four distinct MRI modalities constitute the dataset: T1-weighted (T1), T1c (contrast-enhanced T1), T2-weighted (T2), and FLAIR. In this study, we utilize the T1, T2, and FLAIR modalities to evaluate the effectiveness of the proposed method. Each modality volume has a spatial resolution of voxels. For each subject, we extract 60 axial 2D slices containing brain tissue for subsequent analysis.Each axial slice was cropped to a pixel image from the central region, then resized to pixels. For the purposes of training and evaluating the model, we divided the data from the 240 subjects into training (70%), validation (10%), and testing (20%) sets. All images were linearly scaled to ensure their intensity values fell within the range.
IXI Dataset [44]. The IXI dataset consists of brain images acquired using T1, T2, and PD weighting protocols, collected from healthy subjects using multiple scanners with varying magnetic field strengths. We selected a subset containing 6000 paired 2D slices across the three modalities. All slices were center-cropped and resized to pixels, and intensities were normalized to . The data distribution involves a random split, comprising a training set (70%), a validation set (10%), and a test set (20%).
4.2. Comparison Methods
To thoroughly assess the performance of the proposed HMF-MambaINR model, we selected representative methods from the current field of multi-modal medical image synthesis as baseline comparisons, including HiNet [24], PTNet [45], CACR-Net [25], ResVIT [10], INR-ECGAN [39] and IxI-Mamba [14]. These methods can be broadly summarized as follows:
HiNet [24] employs modality-specific subnetworks to learn representations and integrates a fusion network to derive a shared feature representation across different modalities, facilitating target image synthesis. PTNet [45] adopts a multi-scale pyramid Transformer, emphasizing cross-scale context modeling to enhance image synthesis performance. CACR-Net [25] proposes a confidence-guided fusion and cross-modal refinement network, further refining the target modality image. ResVIT [10] employs a hybrid CNN-Transformer framework, combining residual Transformer blocks and a channel compression module for multi-modal medical image synthesis. INR-ECGAN [39] is the first to explore implicit neural representations for modeling a continuous mapping from SAR features to optical images. IxI-Mamba [14] is based on selective state space modeling, effectively capturing long-range contextual dependencies while preserving local structural accuracy, balancing global consistency and detail representation.
4.3. Experimental Results
We conducted three multi-modal image synthesis experiments using the BraTS 2020 dataset: T2 was synthesized from T1 and FLAIR ( ), T1 from T2 and FLAIR ( ), and synthesizing FLAIR from T1 and T2 ( ). For each synthesis task, we presente’d quantitative analyses alongside qualitative illustrations in the following sections.
Using the T2 synthesis task as a representative example, we presented both quantitative evaluations and visual comparison results of different methods in Figure 5 and Table 1, respectively. Compared to the I2I-Mamba, our proposed method achieved improvements of 0.47 in PSNR, 0.014 in SSIM, and 0.015 in NMSE. Furthermore, as illustrated in Figure 5, HMF-MambaINR not only preserved the structural integrity of the synthesized T2 images but also produced more accurate pixel distributions and sharper visual details, clearly outperforming other methods in both perceptual quality and structural fidelity.
For the T1 synthesis task, Table 1 presents the quantitative results for this task. Our HMF-MambaINR model markedly surpassed existing methods across key metrics, including PSNR, SSIM, and NMSE. These results demonstrated that our model effectively integrated information from different stages and scales, thereby enhancing synthesis performance. Figure 6 provided visual comparisons of T1 images synthesized by our method and by representative baselines. The T1 modality images synthesized by the HMF-MambaINR model exhibited higher quality than those synthesized by the other methods. These improvements included clearer tissue delineation and fewer artifacts, producing visually superior high-quality outputs.
In the final T1, T2 → FLAIR synthesis task, we presented quantitative comparisons with baseline methods in Table 1 and provided qualitative visualizations in Figure 7 to illustrate the perceptual fidelity of the synthesized results. Clearly, CACR-Net and Hi-Net performed poorly in this task, whereas the proposed method demonstrated substantial gains across all three evaluation metrics. Furthermore, compared to I2I-Mamba, HMF-MambaINR demonstrated improvements of 0.51, 0.013, and 0.008 in PSNR, SSIM, and NMSE, respectively. In the yellow box region of Figure 7, the FLAIR modality images synthesized using our method exhibited more precise pixel details, further confirming the advantages of our approach in cross-modality MRI synthesis.
In addition, we conducted complementary experiments on the IXI dataset to further evaluated the generalizability of our method on healthy brain MRI data. Specifically, we designed three synthesis tasks: synthesizing T2 using T1 and PD as inputs ( ), synthesizing PD using T1 and T2 as inputs ( ), and synthesizing T1 using T2 and PD as inputs ( ). These tasks covered diverse modality combinations, offering a thorough evaluation of the model’s performance across both pathological and non-pathological conditions.
Table 2 presented the PSNR, SSIM, and NMSE scores for the multi-input single-output synthesis tasks. Our proposed MFE-MambaINR model consistently achieved the highest performance across all tasks. It outperformed convolution-based models, Transformer-based architectures, and the original Mamba-based baseline. Averaged across the three benchmark tasks, our method consistently outperformed INR-ECGAN, delivering a PSNR improvement of 0.89, a 0.010 increase in SSIM, and a 0.02 reduction in NMSE. Furthermore, it surpassed ResViT, with gains of 0.43 in PSNR, 0.050 in SSIM, and a 0.002 decrease in NMSE. Compared to I2I-Mamba, our approach achieved comparable improvements—0.41 higher PSNR, 0.006 higher SSIM, and a 0.002 lower NMSE. Figure 8 illustrated the qualitative comparison of synthesized results for three tasks: T1, PD → T2 (first row), T1, T2 → PD (second row), and T2, PD → T1 (third row). As shown, MFE-MambaINR generated images with fewer artifacts and clearer tissue structures compared to convolution-, Transformer-, and Mamba-based models, further demonstrating its effectiveness in high-fidelity modality synthesis.
4.4. Model Complexity
We assessed the model complexity of our approach alongside several state-of-the-art methods by measuring FLOPs, parameter counts, and inference times, as summarized in Table 3. Although MFE-MambaINR incurred slightly higher FLOPs and parameters than I2I-Mamba, it improved image synthesis performance, especially in preserving fine details and structural fidelity. This gain underscored the efficacy of integrating Multi-Scale Feature Enhancement and INR modules to boost performance while maintaining controlled complexity. In terms of inference efficiency, MFE-MambaINR requires slightly longer inference time compared to I2I-Mamba, but the increase is modest and acceptable given the notable improvements in synthesis quality. In contrast to ResViT, MFE-MambaINR achieved better synthesis quality with fewer parameters and reduced FLOPs. These results demonstrated that our model struck a favorable balance between synthesis accuracy and computational efficiency, enhancing performance while minimizing resource demands. This rendered our model better suited for practical medical image processing tasks in clinical settings.
4.5. Radiology Evaluation and Error Analysis
To more comprehensively assess the quality of the synthesized images produced by the proposed method, we designed and conducted a subjective evaluation experiment involving three experienced radiologists. The experts independently evaluated the generated images using multiple criteria. The images were anonymized and arranged randomly, and the radiologists were blinded to the source of each image to prevent potential bias throughout the evaluation. This study evaluated three tasks on the BraTS dataset, with 12 images per task, for a total of 36 images.
The evaluation focused on three key assessment criteria: overall visual fidelity, contrast characteristics, and structural edge clarity. A five-level Likert scale was employed to assess both overall visual fidelity and contrast characteristics, with ratings defined as: 1 for “unacceptable,” 2 for “poor,” 3 for “acceptable,” 4 for “good,” and 5 for “excellent”. Structural edge clarity was assessed using a three-point scale, where 1 indicated “unclear edges”, 2 indicated “discernible edges”, and 3 indicated “clear edges”. As shown in Table 4, our model achieved scores of 4.75, 4.53, and 2.65 in image quality, image contrast, and structural contour, respectively, significantly outperforming other methods. These results indicated that our approach can more accurately capture fine anatomical structures and demonstrated higher clinical value.
To further evaluate the robustness of our model, we conducted additional experiments on the BraTS 2020 dataset by introducing simulated motion artifacts, aiming to mimic realistic and imperfect clinical acquisition conditions. Under motion corruption, the source modality was deliberately subjected to spatially varying motion-induced ghosting and blurring effects, which are commonly observed in routine MRI scans due to patient movement. The proposed model was then evaluated without any additional fine-tuning to assess its generalization capability under such challenging conditions. As shown in Table 5, we compared the performance of our model under normal conditions and in the presence of motion artifacts. The results indicated that our model exhibited only a limited performance drop when motion corruption was introduced. As illustrated in Figure 9, we visualized the outputs of our model on different MRI modalities. The results demonstrated that, despite some degradation caused by motion artifacts, our model successfully recovered fine structural details and maintained contrast consistent with the ground truth. To further investigate the contribution of the INR module, we replaced it with a parameter-matched Pixel-Based decoder and generated the corresponding outputs. We observed that the Pixel-Based decoder produced noticeable blurring, loss of structural details, and visible boundary ghosting, indicating that the INR-based model better preserved anatomical fidelity and fine-grained features.
4.6. Ablation Study
To verify the contribution of each constituent part of the proposed network, comprehensive ablation studies were performed on the BraTS 2020 dataset. Qualitative and quantitative assessments of the experimental data are detailed in Figure 10 and Table 6.
The Role of the RHMB Module. To assess the effectiveness of the RHMB module in extracting deep semantic features and local texture information from images, as well as its contribution to enhancing the quality of synthesized images for missing modalities, ablation experiments were designed. Specifically, a variant model, named w/o RHMB, was created by replacing the RHMB module with a convolutional layer of comparable parameter count. This model performed only basic convolution operations on the features, lacking the context-enhancing mechanism. The experimental results indicated a significant degradation in the structural integrity and detail representation of the synthesized images when the RHMB module was removed, demonstrating the importance and effectiveness of RHMB in multi-modal medical image synthesis tasks.The Impact of the MFEB Module. To assess the contribution of the MFEB to the overall model performance, we performed an ablation analysis by retaining only the connection and convolution operations in the MFEB module, referred to as w/o MFEB. The experiment was designed to quantify the effect of multi-stage and multi-scale feature extraction on the quality of modality synthesis. As reported in the results Table 6, eliminating the MFEB module led to a significant performance drop. This finding highlighted the critical importance of jointly leveraging complementary features extracted across different stages and scales—particularly those closely aligned with the target modality—in improving the fidelity and perceptual quality of the synthesized images.The Impact of the MSF Module. To validate the performance impact of the multi-scale feature fusion module in the MFEB module, relevant ablation experiments were designed. Specifically, a baseline model was constructed without the MSF module, named w/o MSF, and was replaced with standard convolution operations for comparison. Experimental evidence supported the conclusion that after removing the MSF module, the model performed poorly in the multimodal feature fusion task, highlighting the key role of this module in improving the quality of image synthesis.The Impact of the MFM Module. In order to better study the effectiveness of the MFM module in enhancing the feature representation capability of the network, we constructed a variant model, named w/o MFM, in which the MFM module was replaced by a feature addition module. As shown in Table 6 and Figure 10, the MFM module was able to effectively alleviate the feature sparsity problem in the encoding process and significantly enhanced the overall performance of the model.The Importance of the INR Module. To explore the contribution of INRB to image synthesis tasks, corresponding ablation experiments were conducted. Specifically, the INR module in the original model was replaced with a parameter-matched standard MLP layer without coordinate embedding to form a comparison model, named w/o INR. This experiment was designed to analyze the specific contributions of continuous implicit representations in preserving image details, structural restoration, and texture reconstruction. The experimental results confirmed that the INR decoder significantly enhanced the continuity and detail retention of the synthesized images, thereby verifying the effectiveness and potential of modeling medical images using continuous functions.
5. Discussion
This paper introduced a hierarchical multi-scale feature fusion network designed for multi-modal MRI synthesis. Existing CNN-based methods struggled to effectively model non-local dependencies between distant anatomical structures due to their limited receptive field, which restricted their performance in global structural modeling. While Transformer-based methods mitigated this issue to some extent by employing self-attention operators, they introduced quadratic computational complexity with respect to sequence length, thereby limiting inference efficiency. In contrast to these approaches, the proposed HMF-MambaINR model integrated the context-aware modeling capability of state space models (SSM) with the local precision of convolutional neural networks (CNN), enabling efficient modeling of long-range dependencies in medical images without increasing computational burden. Additionally, by incorporating a multi-stage, multi-scale feature extraction and fusion mechanism, the proposed method facilitated cross-layer information exchange by integrating multi-level features from different stages and scales. This design allowed the simultaneous aggregation of fine-grained texture details and high-level semantic representations, thereby enhancing both the richness and robustness of feature representations. Unlike traditional explicit decoders, an INR decoder was designed in the decoding stage. This decoder took image coordinates as input and performed continuous mapping of the fused features through a multi-layer MLP. Owing to its ability to model spatial continuity, this module demonstrated superior expressive power when handling complex boundary structures in medical images. From a clinical deployment perspective, the proposed HMF-MambaINR framework demonstrated favorable feasibility for real-world applications. The use of Mamba-based state space modeling enabled efficient long-range dependency modeling with linear computational complexity, which was well suited for high-resolution MRI data in routine clinical environments. Moreover, the proposed method operated on standard MRI modalities without requiring additional annotations or specialized acquisition protocols, facilitating seamless integration into existing clinical workflows. The implicit decoder further supported continuous and structurally consistent image synthesis, enhancing robustness across heterogeneous scanners and imaging settings.
6. Conclusions
In this paper, we proposed a novel learning-based model for cross-modality MRI synthesis. The proposed model, named HMF-MambaINR, employed residual mixed Mamba blocks to model both spatial and channel context, effectively capturing contextual information in medical imaging while avoiding the quadratic complexity inherent in self-attention mechanisms. To further enhance feature representation, we introduced a multi-feature, multi-scale feature extraction module (MFEB), which extended the network’s width while maintaining its depth. This design helped the model better extract shallow texture details and global semantic features. In addition, we developed a modulation fusion module (MFM) to dynamically integrate multi-scale features and effectively alleviate feature sparsity during the decoding stage. Finally, we designed an implicit decoder that continuously mapped the fused features back to the medical image, enabling more effective preservation of fine textures and structural details. Compared with current mainstream methods—including convolutional, Transformer-based, and Mamba-based models—our approach delivered consistently improved performance across all evaluated tasks.
7. Limitations and Future Work
Despite these promising properties, several limitations remain and should be addressed in future work. First, the current evaluation is primarily conducted on public benchmark datasets under controlled experimental settings, which may not fully capture the diversity and complexity of raw clinical data encountered in real-world practice. As a result, the generalization performance under diverse acquisition protocols, scanner vendors, and patient populations requires further investigation. Second, although image quality metrics and expert-based subjective evaluations indicate higher synthesis quality, these assessments do not directly reflect the clinical utility of the synthesized images in downstream tasks such as segmentation, registration, or diagnostic decision-making. Future research will focus on closing the gap between methodological validation and real-world clinical deployment. In particular, the proposed framework will be evaluated on real-world clinical datasets obtained under routine clinical settings to comprehensively examine robustness and generalizability in practical scenarios. In addition, task-driven evaluations will be conducted by incorporating synthesized images into downstream clinical pipelines to quantitatively measure their impact on clinically relevant tasks. Beyond evaluation, integrating uncertainty-aware modeling or diffusion-based probabilistic mechanisms [46] into the HMF-MambaINR framework could further enhance its ability to represent complex anatomical structures, blurred boundaries, and uncertain scenarios, thereby improving reliability in real-world clinical deployment.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhou T. Liu M. Fu H. Wang J. Shen J. Shao L. Shen D. Deep multi-modal latent representation learning for automated dementia diagnosis Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention Springer Berlin/Heidelberg, Germany 2019629638
- 2Fan J. Cao X. Wang Q. Yap P.T. Shen D. Adversarial learning for mono-or multi-modal registration Med. Image Anal.20195810154510.1016/j.media.2019.10154531557633 PMC 7455790 · doi ↗ · pubmed ↗
- 3Zhang P. Li T. Wang G. Wang D. Lai P. Zhang F. A multi-source information fusion model for outlier detection Inf. Fusion 20239319220810.1016/j.inffus.2022.12.027 · doi ↗
- 4Sevetlidis V. Giuffrida M.V. Tsaftaris S.A. Whole image synthesis using a deep encoder-decoder network Proceedings of the Simulation and Synthesis in Medical Imaging: First International Workshop, SASHIMI 2016, Held in Conjunction with MICCAI 2016, Athens, Greece, October 21, 2016, Proceedings 1Springer Berlin/Heidelberg, Germany 2016127137
- 5Chartsias A. Joyce T. Giuffrida M.V. Tsaftaris S.A. Multimodal MR synthesis via modality-invariant latent representation IEEE Trans. Med Imaging 20173780381410.1109/TMI.2017.276432629053447 PMC 5904017 · doi ↗ · pubmed ↗
- 6Dar S.U. Yurt M. Karacan L. Erdem A. Erdem E. Cukur T. Image synthesis in multi-contrast MRI with conditional generative adversarial networks IEEE Trans. Med. Imaging 2019382375238810.1109/TMI.2019.290175030835216 · doi ↗ · pubmed ↗
- 7Fu Y. Wu X.J. Durrani T. Image fusion based on generative adversarial network consistent with perception Inf. Fusion 20217211012510.1016/j.inffus.2021.02.019 · doi ↗
- 8Kodali N. Abernethy J. Hays J. Kira Z. On convergence and stability of gansar Xiv 201710.48550/ar Xiv.1705.072151705.07215 · doi ↗