FLF-RCNN: A Fine-Tuned Lightweight Faster RCNN for Precise and Efficient Industrial Quality Inspection
Ningli An, Zhichao Yang, Liangliang Wan, Jianan Li, Yiming Wang

TL;DR
This paper introduces FLF-RCNN, a lightweight and efficient deep learning framework for industrial quality inspection that balances accuracy and computational efficiency.
Contribution
The novel FLF-RCNN framework introduces a lightweight backbone and adaptive anchor box adjustment for improved industrial defect detection.
Findings
FLF-RCNN achieves a mAP50 of 43.6% on the Tianchi dataset, outperforming models with MobileNet and EfficientNet backbones.
The proposed method reduces computational complexity by 40% and parameter count by 30% compared to the baseline Faster R-CNN.
The Adaptive Anchor Box-Adjustment Module improves detection across varied defect scales using K-means clustering.
Abstract
Industrial Quality Inspection (IQI) is a pivotal part of intelligent manufacturing, critical to ensuring product quality. Deep learning-based methods have attracted growing attention for their excellent feature extraction ability, outperforming traditional detection approaches. However, existing methods still face issues of insufficient efficiency and poor transferability, and this paper proposes a Fine-tuned Lightweight Faster RCNN (FLF-RCNN) framework designed to address key challenges in IQI, including the trade-off between accuracy and computational efficiency, and the insufficient adaptability of preset anchor box ratios. FLF-RCNN introduces a lightweight backbone network, LSNet, which enhances the receptive field through architectural optimization. Specifically, it uses a collaborative mechanism that combines large kernel convolutions for extracting contextual information and…
Click any figure to enlarge with its caption.
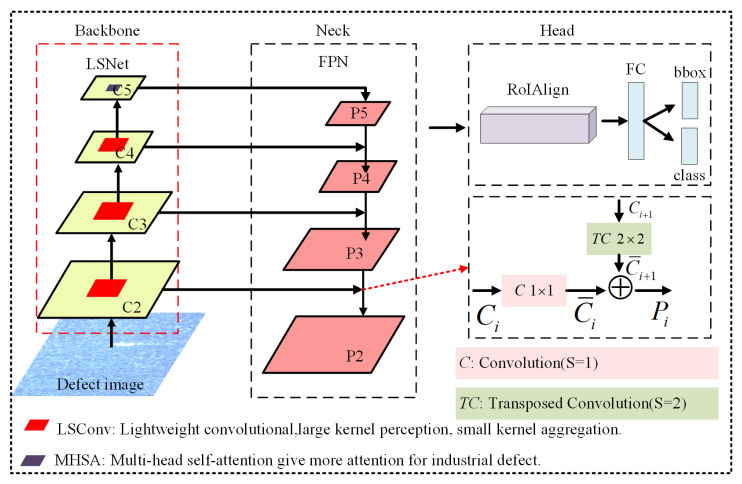 Figure 1
Figure 1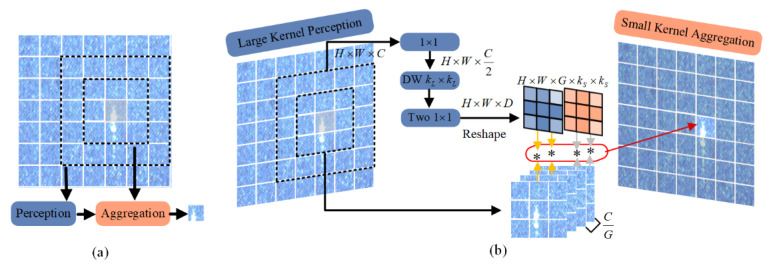 Figure 2
Figure 2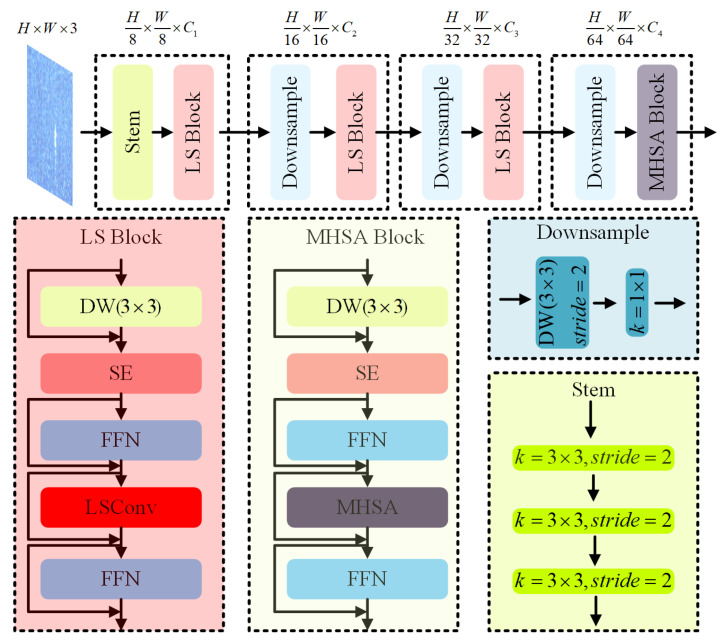 Figure 3
Figure 3 Figure 4
Figure 4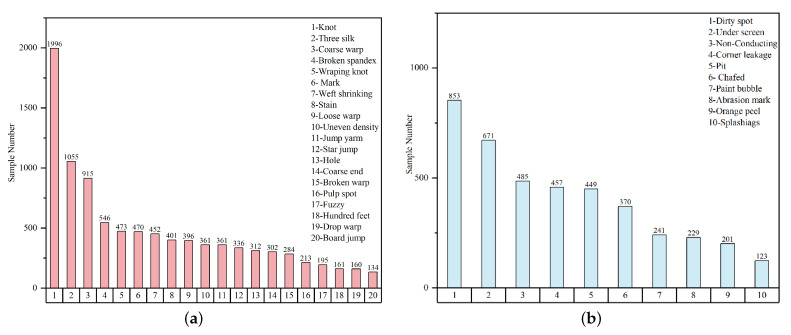 Figure 5
Figure 5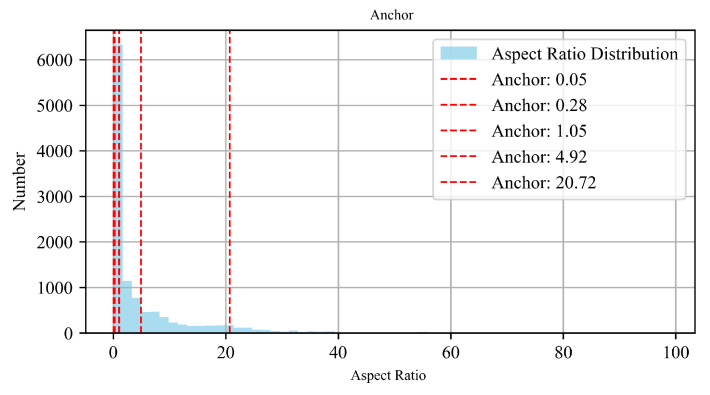 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8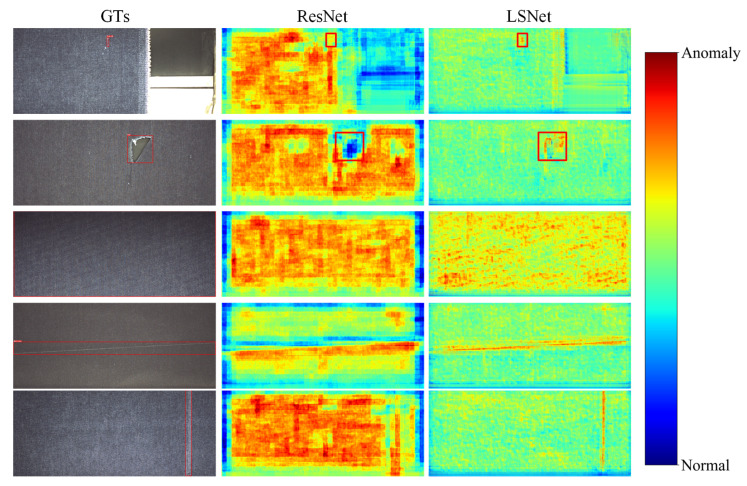 Figure 9
Figure 9- —Shaanxi Provincial Key R&D Program
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Industrial Vision Systems and Defect Detection · Infrastructure Maintenance and Monitoring
1. Introduction
Industrial Quality Inspection (IQI) plays a vital role in ensuring product consistency, enhancing production efficiency, and reducing scrap rates. With the manufacturing industry advancing toward high precision and automation, inspection systems are required to achieve high accuracy, robustness, and computational efficiency [1]. However, existing Deep Learning (DL) methods still struggle to balance accuracy and efficiency in practical industrial deployments [2]. Therefore, improving inference efficiency and deployment efficiency while maintaining detection performance has become a key research challenge.
IQI methods can generally be classified into two categories: traditional image processing techniques (such as edge detection [3], histogram analysis [4], and wavelet transform [5]) and DL-based approaches. Traditional techniques have played a vital role in early IQI tasks, such as the widely adopted Canny edge detection method, known for its high detection accuracy and strong noise resistance [6,7,8]. However, these approaches are heavily reliant on image quality and handcrafted feature design. Consequently, they often lack robustness and generalization capability, making them unsuitable for complex and variable industrial environments. With the rapid advancement of intelligent manufacturing, DL has made remarkable progress in IQI and has been widely applied in various industrial scenarios, such as metal surfaces [9,10], railway tracks [11,12], fabrics [13,14], PCBs [15,16] and engine blades [17,18]. Compared with traditional image processing methods, DL-based end-to-end methods eliminate handcrafted features, enabling better generalization and adaptability across domains.
However, industrial inspection scenarios often involve complex backgrounds, diverse object shapes, and dense small targets, which impose higher demands on the accuracy and robustness of object detection algorithms. Two-stage detectors(such as Faster RCNN [19] and Mask RCNN [20]) incorporate a Region Proposal Network (RPN) and a Region of Interest (RoI) head for refined classification and localization, offering superior accuracy, robustness, and adaptability to challenging backgrounds, often yielding performance that exceeds one-stage methods(such as YOLO [21] and RetinaNet [22]). Nevertheless, their increased structural complexity, larger parameter sizes, and longer inference times hinder efficient deployment in efficiency-constrained industrial systems [23,24]. Although researchers have proposed lightweight backbone networks such as MobileNet [25] and EfficientNet [26] to improve deployment efficiency, these methods often compromise detection accuracy.
Another significant challenge in the industrial domain is the scarcity of high-quality annotated defect datasets. Due to proprietary restrictions and industry competition, publicly available datasets remain extremely limited. Furthermore, the high cost of data annotation and model training has constrained the adoption of DL methods among small- and medium-sized enterprises. These limitations hinder the generalization of models across diverse industrial environments. Consequently, Transfer Learning (TL) based on pretrained models has emerged as a promising solution [27,28,29,30]. By fine-tuning networks that have been pretrained on large-scale general-purpose datasets, it is possible to effectively adapt models to specific industrial tasks, thereby enhancing detection performance while reducing the reliance on extensive labeled data and lowering training costs.
Moreover, the anchor-based mechanisms widely adopted in existing two-stage detection frameworks also current notable limitations [31,32]. These predefined anchors are typically designed based on generic datasets, with fixed scales and aspect ratios that may differ significantly from the geometrical characteristics of industrial defects, such as scratches or cracks. This mismatch can lead to suboptimal candidate region proposals, thereby degrading the overall detection performance, particularly in multi-scale and small object scenarios. Designing more adaptive anchor generation strategies tailored to the geometry of industrial defects is, therefore, a critical direction for improving detection accuracy.
To address the challenges of efficiency optimization and transferability in two-stage detectors, this paper proposes a Fine-tuned Lightweight Faster RCNN (FLF-RCNN). In this context, our efficiency optimization focuses on the two-stage detection paradigm; while not achieving the extreme compactness of single-stage models, FLF-RCNN significantly reduces the computational burden typical of two-stage architectures. We first analyze the variations in defect aspect ratios in real industrial scenarios and design an Adaptive Anchor Box-Adjustment Module (AAB-AM) based on the K-means [33] clustering method. Extensive experiments are conducted on fabric and aluminum datasets released by Tianchi to validate the effectiveness of the proposed method. The main contributions are summarized as follows:
- 1.We propose the FLF-RCNN computationally optimized framework, which retains the high precision characteristics of two-stage detectors while reducing the overall computation of baseline Faster RCNN from 161.96 Giga Floating-Point Operations Per Second (GFLOPs) to 98.65 GFLOPs, a reduction of approximately 40%. Meanwhile, the number of model parameters is reduced from 41.24 Million (M) to 28.2 M, a decrease of about 30%.
- 2.To tackle the efficiency bottleneck of two-stage models, we introduce the LSNet backbone, which combines large-kernel convolutions for contextual information extraction and small-kernel convolutions for fine-grained feature extraction, enabling efficient and accurate defect representation within the Faster R-CNN framework.
- 3.To overcome the difficulty of preset anchor boxes matching the geometric characteristics of industrial defects, an AAB-AM is designed. Compared to the baseline model, this module improves the mAP50 metric by 13.2%. Results on Tianchi dataset demonstrate that FLF-RCNN offers a practical and deployable solution for IQI, balancing detection accuracy with computational efficiency.
The remainder of this paper is organized as follows: Section 2 reviews the related work. Section 3 resents the proposed FLF-RCNN architecture in detail. Section 4 reports and analyzes the experimental results. Finally, Section 5 concludes the paper.
2. Related Works
2.1. Lightweight Models
To meet the dual requirements of accuracy and efficiency in industrial inspection, researchers have extensively explored lightweight detection networks. These models significantly reduce computational complexity and memory overhead through techniques such as parameter compression [34], structural pruning [35], model quantization [36] and efficient module design [37], thereby achieving strong real-time capabilities. For example, Guan et al. [38] designed a lightweight version of YOLOv7 by integrating techniques such as sparse training, model pruning, and knowledge distillation. This approach reduced the number of parameters by 56.9% while preserving detection accuracy, it achieved an inference speed of 122.7 FPS, which marks an 85% improvement over the original YOLOv7. Song et al. [39] proposed YGNet, which integrates dynamic sparse convolution and a multi-scale feature fusion mechanism. This approach reduces computational cost by approximately 23% in remote sensing object detection tasks, while maintaining a high mAP of 96.2% on the Remote Sensing Object Detection Dataset (RSOD) and achieving an inference speed of 62 Frames Per Second (FPS), demonstrating its potential for deployment in high real-time scenarios. Huang et al. [10] developed a lightweight variant of YOLOv8, named YOLOv8-BVC, in which the original backbone was replaced with VanillaNet. As a result, the model size was reduced by 60 M, the computational cost decreased to 6 GFLOPs, and the inference speed increased to 263 FPS.
Therefore, model lightweighting has significant advantages in reducing computational complexity and improving real-time performance. However, traditional lightweighting methods such as parameter compression, structural pruning, and model quantization often come at the cost of model accuracy: pruning and compression simplify the model by removing redundant structures, which can lead to a decrease in representational capacity; quantization reduces computational overhead by lowering numerical precision, but often introduces noticeable accuracy loss; while knowledge distillation can mitigate performance degradation to some extent, it still struggles to completely avoid accuracy loss. In contrast, designing lightweight networks from scratch allows for the joint optimization of efficiency and accuracy, balancing computational efficiency and feature representation ability during the model construction phase. To this end, this paper introduces LSNet [40], a lightweight backbone network based on efficient convolution design. Through native optimization at the structural level, it significantly reduces computational burden while effectively maintaining high detection accuracy, overcoming the inherent limitations of traditional post-processing lightweighting methods.
2.2. Fine-Tuning Methods
To address challenges such as data scarcity and poor task adaptability in IQI, fine-tuned strategies based on pretrained models have attracted significant attention from researchers. These strategies leverage models pretrained on large scale generic datasets and adapt them to specific target tasks through Fine-tuning (FT), effectively enhancing performance in the target domain. For instance, Praveen et al. [27] employed a U-Net architecture combined with a ResNet [41] backbone pretrained on ImageNet for steel surface defect segmentation. This TL approach significantly improved classification accuracy by 5% and segmentation precision by 26%, with especially notable gains in low-data scenarios. Cheng et al. [28] proposed a two-stage training process along with a “metric reweighting module” to tackle class imbalance, achieving a substantial performance boost of up to 11.98% in detecting rare aluminum defect categories. Seungmi et al. [29] designed an anomaly detection system that estimates the density of normal data by FT a feature extractor, enabling effective domain distribution learning and improved anomaly detection performance without additional computational overhead. Woo-Kyun et al. [30] developed a fine-tuned MobileNet1-SC model that achieved superior detection results on the StitchingNet dataset. These examples demonstrate that TL-based FT method not only alleviates the data insufficiency commonly faced in industrial inspection tasks but also shortens training cycles and enhances model robustness and generalization capabilities. As a result, FT has become a critical technical route in intelligent industrial inspection. Inspired by these methods, this paper uses fine-tuned strategies into a lightweight detection framework and adapts it to the characteristics of industrial tasks for further evaluation.
2.3. Anchor-Based Detection Method
Anchor-based detection methods have been widely adopted in object detection frameworks such as Faster RCNN [19] and RetinaNet [22], owing to their stable training and reliable performance, where the Faster RCNN uses anchors for prediction proposals, while the RetinaNet is used for dense prediction. The two-stage method maintains high performance in complex scenarios due to its anchor prediction proposal-based feature. However, in industrial scenarios where defects often exhibit irregular shapes, small sizes, or extreme aspect ratios, the fixed anchor configurations, often optimized for general-purpose datasets like COCO, may poorly align with the geometric characteristics of industrial defects may not provide adequate coverage. This mismatch can result in low recall rates and poor localization, especially for small or elongated targets. To address this, some studies have introduced K-means clustering to optimize anchor ratios, while others propose data-driven or dynamic anchor mechanisms such as Meta Anchor and Guided Anchoring [31,32].
Nevertheless, these improvements may increase training complexity or remain insufficient under highly variable industrial conditions. In this work, we retain the anchor-based paradigm and enhance anchor adaptability through a K-means-based adjustment strategy tailored to defect geometries, thereby enhancing multi-scale defect detection without introducing additional structural complexity.
3. Methodology
3.1. FLF-Framework
This paper proposes FLF-RCNN, a lightweight object detection framework based on Faster RCNN that is specifically designed for industrial quality inspection (IQI) tasks. As illustrated in Figure 1, the architecture consists of backbone, neck and head. To achieve model lightweight, the traditional feature extraction backbone is replaced by a lightweight network, which is LSNet. LSNet adopts LSConv as its fundamental building block, which optimizes the receptive field of convolutional kernels by leveraging a collaborative mechanism of large kernel convolutions for contextual information and small kernel convolutions for fine-grained details. This design enables efficient and accurate defect feature modeling. In contrast to traditional lightweight methods that focus on pruning, parameter compression, or sparsification, LSNet achieves reduced computational complexity and model size by introducing a streamlined and optimized network architecture. It achieves superior inference efficiency without compromising detection performance, making it particularly suitable for IQI scenarios where deployment efficiency is critical. Moreover, this work incorporates a fine-tuned strategy by adapting the pretrained backbone from large-scale generic datasets to the target industrial task. This TL approach enhances the model’s generalization ability and practical applicability in diverse industrial inspection environments.
3.2. LSConv
The LSConv is designed to overcome the limitations of traditional convolution operations such as fixed kernel weights and the computational redundancy associated with self-attention mechanisms. By employing large convolutional kernels to capture broader contextual information and small kernels for localized feature aggregation, LSConv facilitates efficient information fusion. This approach allows computational resources to be focused on defect regions, thereby achieving model lightweight without sacrificing performance. Where represents the output of this region. By adjusting the positions of perception and aggregation, the model enables contextual representation across varying receptive fields, denoted as and . This mechanism allows for capturing both global contextual information and fine-grained local details at different scales, thereby enhancing the representation of defect features. For regions requiring only limited contextual aggregation, an adaptive weighted feature summation strategy is employed to reduce computational overhead. As illustrated in Figure 2a, the core idea involves using large kernels for broad contextual perception and small kernels for localized aggregation. This “see large, focus small” design effectively balances accuracy and efficiency. In the following paragraph, we provide a detailed formulation of computation process.
Large Kernel Perception (LKP): The LKP adopts the design of large kernel bottleneck block. As shown on the left side of Figure 2b, the token is first projected to a lower channel dimension through point-wise convolution (PW) to achieve lightweight. By adopting large kernel Depth-Wise convolution (DW) with a kernel size of , the large field of view spatial contextual information of is effectively captured. Where represents the convolution calculation area of size centered on . This method can improve the expression ability of context at the lowest cost and generate contextual adaptive weights for the feature aggregation process. This process can be expressed as:
where is the generation weight of .
Small Kernel Aggregation (SKA): The SKA adopts the design of grouped dynamic convolution, as shown on the right side of Figure 2b. By dividing the channels into G groups, each group containing channels and the channels in the same group share the aggregation weights to reduce the memory overhead and computational cost of the lightweight model. Then the weight of obtained by perception also needs to be processed to obtain , where is the size of the aggregated convolution kernel. The context is aggregated through , where represents the neighborhood of size centered on . Thus, the aggregated feature is obtained . This process can be expressed as:
3.3. LSNet
LSNet consists of four components: Stem, LS Block, Down-sample, and MHSA Block. Its structure is shown in Figure 3. Among them, LS Block uses LSConv as the core building unit, combines the feedforward network (FFN) to enhance the nonlinear expression ability, and introduces an SE module to adaptively adjust channel-wise weight. It is worth noting that the spatial-contextual weights generated by LKP within LSConv and the channel-wise attention weights from the SE module operate at distinct levels—spatial perception versus channel recalibration—and are applied sequentially to complementarily enhance feature representation. The network accelerates convergence and optimization through residual connections. LSNet is divided into four stages: In the first stage, the Stem module performs preliminary downsampling to reduce feature map size and extract basic semantic information. Subsequently, LS Blocks are introduced for feature extraction, combining depthwise separable convolution and pointwise convolution to achieve spatial downsampling and channel compression. The second and third stages repeat this combination of downsampling and LS Blocks to further deepen the network. To enhance the modeling of long-range dependencies in low-resolution feature maps, a Multi-Head Self-Attention (MHSA) module is introduced in the fourth stage, enabling more effective global context aggregation.
3.4. Fine-Tuning
In practical DL applications, training a deep neural network from scratch typically requires a large amount of labeled data and considerable computational resources, which poses significant challenges in industrial visual inspection tasks. To address this, FT has emerged as an efficient TL strategy and is widely adopted for model adaptation. The core idea of FT is to initialize the model with weights pretrained on large-scale general-purpose datasets, and then update all or part of the parameters to align with the specific characteristics of the target domain. This process enables the model to quickly adapt to new dataset distributions and task requirements, thereby improving convergence speed and generalization ability.
Specifically, let the parameters of the pretrained model be denoted as , which has already acquired strong feature representation capabilities on a large-scale source dataset . When adapting the model to a new target dataset , we initialize the model with and define the FT objective as minimizing the loss function over , formulated as:
where denotes the task specific loss function on the target domain. The FT process is equivalent to starting from a well-trained initialization point in the parameter space and making slight adjustments to the model parameters using data from the target task. This strategy supports knowledge transfer and task-specific adaptation, effectively addressing the limitations of data scarcity and insufficient generalization faced by models trained from scratch.
In this study, we incorporate the LSNet, pretrained on a general object detection dataset, as the backbone feature extractor of the Faster RCNN framework. A staged unfreezing strategy is adopted for FT, where LSNet is divided into four stages. The parameters are progressively unfrozen, beginning with the feature extraction layers and ultimately FT the entire network, thereby enabling a systematic analysis of the impact of various FT strategies on model performance.
4. Experiments
4.1. Datasets Description
To verify the effectiveness of the proposed FLF-RCNN model, we conducted a systematic evaluation on the Tianchi fabric dataset (Fabric) [42] and the aluminum surface defect dataset (Aluminum) [43]. Figure 4 shows representative defect samples from the two datasets (cropped to highlight the defect area). It can be observed that there are obvious differences between the two datasets in terms of target size and anchor box ratio. Specifically, the defects in the Fabric dataset are usually small in size, slender in shape, and have blurred edges, which makes them difficult to detect; while the defects in the Aluminum dataset are characterized by uneven size distribution and complex and diverse shapes. Thus, we explain the composition of the two datasets respectively, and perform parameter adjustment and model evaluation based on their characteristics in subsequent experiments.
Fabric: This dataset has a total of 5913 images, each with a resolution of , and a total of 20 types of defects. We counted each defect on each image, a total of 9523 defects, and the detailed statistical data set for each type of defect is shown in Figure 5a. Figure 5. Statistical results of Tianchi (a) fabric dataset and (b) aluminum dataset.Aluminum: This dataset contains 3005 images with a resolution of . There are 10 types of defects and 4079 labeled instances. The detailed statistics are shown in Figure 5b.
To improve the detection model’s adaptability to varying geometric characteristics of targets, we conducted a statistical analysis of the aspect ratios of all defect targets across two datasets, as shown in Figure 6, the results reveal significant variations in aspect ratios with a long-tail distribution. To address the insufficient adaptability of predefined anchor boxes, this study employs the K-means clustering algorithm to automatically generate anchor candidate ratios that better fit the real aspect ratios of targets. The specific procedure is as follows, let the set of all target aspect ratios be , to reduce clustering bias caused by scale differences, the natural logarithm of the aspect ratios is first computed, resulting in:
where represents the result of applying the logarithm to , forming a new set = {r1,r2,…rN}. Then, we perform K-means clustering on , partitioning the data into K clusters, which are defined as:
Among them, represents the point set of the number of k, and represents the center of the kth cluster. After clustering, an exponential inverse transformation is applied to the cluster centers to obtain the set of anchor box ratios used in practice:
Finally, we get a set of anchor box ratios . The red dashed lines in represent the adaptive anchor box ratios generated by the proposed method. This approach dynamically adjusts anchor parameters according to the target shapes in different datasets, thereby enhancing the detector’s adaptability to multi-scale defects.
4.2. Implementations Details
The network is implemented in Python 3.8 under the Pytorch framework. The experiment is built on a Linux system and uses an Nvidia GeForce RTX 2080Ti GPU. The hyperparameter settings used in the experiment are shown in Table 1, where including learning rate, batch size, number of training rounds, anchor box ratio generates by AAB-AM, the number of clusters K, large kernel and small kernel , all of which are obtained through manual tuning to ensure the stability and convergence of model performance. To ensure the fairness of the comparative experiments, all the comparative methods use the official implementation provided by the open source target detection tool library MMDetection [44] in the comparison of the whole methods, in order to fairly evaluate the contribution of the lightweight backbone LSNet introduced in this paper to the model performance, all the two-stage methods used for comparison are embedded with AAB-AM. The specific contribution of each component will be analyzed in detail in the ablation experiment.
4.3. Evaluation Metrics
To compare the model effects more fairly, two common indicators, precision and recall, were used in the experiments, which are defined as:
Among them, P represents precision, R represents recall, , , and represent the number of true positives, false positives, and false negatives, respectively. IoU is the core indicator for judging whether the predicted bounding box matches the ground truth bounding box, which directly determines the positive and negative sample division of the detection result. It is defined as:
where represents the predicted box and represents the ground truth bounding box. Whether the predicted bounding box is a positive sample needs to be determined based on the predetermined threshold of IoU. If the IoU threshold is 0.5, all bounding boxes with IoU greater than 0.5 are positive samples, and the rest are negative samples. In this case, the calculated AP value is defined as AP50, and AP75 and other indicators have similar definitions. We will not make too much quantitative description. Here, we give the definitions of mAP and mAR:
where i represents the average accuracy of a specific class and n represents the number of classes. In addition, since the defect scales of real industrial data vary, to compare the performance of the model at different defect scales, we briefly introduce mAP_s, mAP_m and mAP_l. Given the definition of defect area:
where represent the two horizontal coordinates of the ground truth, and represent the two vertical coordinates of the ground truth.
If , then:
If , then:
If , then:
4.4. Comparative Experiment
To comprehensively evaluate the lightweight performance and IQI capability of the proposed FLF-RCNN model, we conducted comparative experiments on the Tianchi dataset with some representative object detection models, encompassing both one-stage and two-stage approaches [45,46,47]. The experiments first assessed the parameter count (Param) and computational complexity (FLOPs) of each model on the fabric dataset, with detailed results shown in Table 2 and corresponding performance metrics presented in Table 3. Subsequently, detection accuracy and other performance indicators were evaluated on the aluminum dataset, as summarized in Table 4.
As shown in Table 2, FLF-RCNN demonstrates significant advantages in model complexity compared to most two-stage detectors and some one-stage detectors such as YOLOv3, YOLOV5l and YOLOV7. While maintaining architectural integrity, FLF-RCNN achieves a notable reduction in both parameter count and computational cost, highlighting its lightweight characteristics. Although there remains a parameter gap compared to lightweight models such as MobileNet and EfficientNet. Table 3 reveals that FLF-RCNN significantly outperforms these models in detection accuracy, reflecting a superior balance between accuracy and efficiency. Notably, FLF-RCNN enhances detection performance while reducing model complexity, primarily through the optimized its perception and aggregation mechanisms. Specifically, compared to the baseline Faster RCNN, FLF-RCNN achieves a 7.9% improvement in mAP and a 13% gain in mAP50. It exhibits particularly strong performance in detecting large targets, with a 10% increase in mAP_l. In terms of model complexity, its computational cost is reduced from 161.96 GFLOPs to 98.65 GFLOPs (a reduction of approximately 40%), and parameter count decreases from 41.24M to 28.2M (around 30% reduction).
On the aluminum dataset, FLF-RCNN achieves the best overall performance. As shown in Table 4, it outperforms all compared models on most key evaluation metrics. Since most defect targets in this dataset are relatively large, the mAP_s is marked as “Nan,” which aligns with the data distribution characteristics.
Furthermore, we conducted a visual analysis of the detection results for selected models. Representative detection outputs are presented in Figure 7 and Figure 8. Figure 7 illustrates the detection performance of various models on five representative defect categories: Broken Spandex, Stain, Pulp Spot, Star jump, and Coarse End. The results reveal considerable performance variation across different models and defect types. Specifically, for Broken Spandex defects, both MobileNet and EfficientNet exhibit systematic missed detections. In the case of Stain defects, Swin-Transformer fails to detect any instances, whereas other models maintain stable performance, highlighting the Transformer-based architecture’s sensitivity to low-contrast anomalies. For Pulp spot, multiple methods have multiple overlapping bounding boxes, suggesting difficulties in precise localization under complex texture backgrounds. Regarding Coarse End detection, all models except PAFPN, MobileNet, and EfficientNet successfully identify the defects.
Overall, FLF-RCNN demonstrates superior perform on small scale (such as Broken Spandex and Stain), slender in shape (such as Jump Yarn and Coarse End), and blurred edges (such as Pulp Spot). This performance gain is primarily attributed to the LSConv in the feature extraction stage. The large kernel convolution component effectively expands the receptive fields and enhances the model’s ability to capture global contextual semantics, which is particularly beneficial for detecting slender structural defects. Meanwhile, the small kernel convolution component, equipped with an adaptive weighted feature fusion mechanism, strengthens the modeling of local texture and fine-grained details. The collaborative mechanism between these two components enable LSNet to achieve accurate localization and identification, even in challenging industrial scenarios involving complex textures, small targets, or severely deformed defects.
On the aluminum dataset, FLF-RCNN also performed well, with accurate detection frames, less redundancy, and fine adaptability to defects of different sizes, further verifying the feasibility and practical value of this method in complex industrial scenarios.
4.5. Ablation Experiment
To verify the practical effects of the key components in the proposed model, we designed and conducted a systematic ablation experiment on the Tianchi fabric dataset. The specific results are shown in Table 5 and Table 6.
As shown in Table 5, first, we evaluated the impact of the AAB-AM on detection performance. Experimental results indicate that the application of the K-means-based AAB-AM leads to a notable 3.0 percentage point improvement in the mAP_l metric (from 9.1% to 12.1%), with additional performance gains observed across other evaluation metrics. This demonstrates that reconstructing anchor box ratios according to the scale diversity of defects effectively enhances the model’s ability to match multi-scale targets, thereby improving overall detection accuracy. Subsequently, we assessed the effectiveness of the incorporated computationally optimized backbone network, LSNet [38]. By replacing the conventional ResNet backbone with LSNet, we observed that the model achieved the highest scores across all metrics except mAP_m (medium object). These improvements are attributed to LSNet’s optimized receptive field and feature aggregation strategies, which enable more comprehensive extraction of multi-scale defect features and more accurate representation and localization of defects.
To further evaluate the effectiveness of the fine-tuned strategy, we conducted a stage-wise unfreezing experiment, as shown in Table 6. Based on the LSNet backbone, two training strategies were evaluated: random initialization and transfer learning with fine-tuning. Specifically, the stage-wise unfreezing strategy progressively unlocks backbone layers from deeper stages (Stage 4) to shallower stages (Stage 1), while maintaining a uniform learning rate (0.0001) across all layers to ensure stability. The results reveal that models trained from random initialization exhibit significantly lower detection accuracy. In contrast, under the TL setting, progressively unfreezing the backbone network led to a steady improvement in model accuracy as more layers were unlocked. The model achieved optimal performance under the full fine-tuning configuration (no frozen layers). These results demonstrate that the fine-tuned strategy based on a pretrained model not only effectively retains general visual representations but also allows the model to gradually adapt to the specific patterns of industrial inspection tasks. This facilitates faster convergence and improves training stability, which is critical for data-scarce industrial scenarios.
Furthermore, to verify the feature representation capability of LSNet, we compared its feature response maps with those of ResNet at the first layer output of the FPN, as illustrated in Figure 9. Visualization of five representative defect samples-characterized by small size, slender shape and blurred edges, reveals that ResNet produces significant background noise and lacks precise focus on defect regions. In contrast, LSNet exhibits superior spatial selectivity, with strong activation in defect regions and significantly suppressed background interference, enabling accurate localization of the defects. Whether dealing with tiny, slender, or edge-blurred defects, LSNet consistently provides effective feature representations. The visual discrepancy between the two methods clearly demonstrates the advantage of LSNet in both feature perception and expression. This benefit stems from its cooperative large kernel and small kernel receptive field structure and efficient feature aggregation strategy.
In summary, FLF-RCNN achieves a well-balanced trade-off between accuracy and efficiency by integrating AAB-AM and a fine-tuned lightweight backbone. Without relying on destructive compression techniques such as pruning or quantization, the model achieves approximately a 40% reduction in computational cost and a 30% reduction in parameter count, while improving detection accuracy (mAP) by up to 7.9%. These results highlight the high deployment potential of the proposed model, especially in real-time industrial inspection scenarios with limited computing resources.
5. Conclusions
In this paper, a computationally efficient detection method, termed FLF-RCNN, is proposed for IQI. Built upon the Faster R-CNN architecture, FLF-RCNN is designed to maintain high detection accuracy while significantly reducing computational complexity and parameter size relative to standard two-stage detectors.
Specifically, a fine-tuned optimized backbone network, LSNet, is incorporated as the feature extractor. By leveraging large-kernel convolution for contextual information extraction and small-kernel convolution for efficient feature aggregation, LSNet achieves approximately 30% parameter reduction and approximately 40% FLOPs reduction without sacrificing representation capability. Additionally, an AAB-AM module based on K-means clustering is introduced, which improves the detection performance for large-scale defects (mAP_l) by 3%. Overall, the proposed FLF-RCNN outperforms the baseline Faster R-CNN by 7.9% in mAP. Compared with typical lightweight models, although FLF-RCNN still has a gap in parameter size compared to architectures such as MobileNet and EfficientNet, its superior mAP performance demonstrates its practical value in high-precision IQI scenarios where detection accuracy is prioritized over extreme model compactness.
Future work will focus on further validating the generalization capability of the proposed framework across more diverse industrial defect domains. In particular, we plan to extend our method to other surface defect benchmarks such as the SSGD dataset [52], and adapt the framework to better accommodate material-specific characteristics. We also intend to explore model compression and optimization strategies to further enhance deployment efficiency in resource-constrained industrial environments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ameri R. Hsu C.C. Band S.S. A systematic review of deep learning approaches for surface defect detection in industrial applications Eng. Appl. Artif. Intell.202413010771710.1016/j.engappai.2023.107717 · doi ↗
- 2Ramesh K. Indrajith M. Prasanna Y. Deshmukh S.S. Parimi C. Ray T. Comparison and assessment of machine learning approaches in manufacturing applications Ind. Artif. Intell.20253210.1007/s 44244-025-00023-3 · doi ↗
- 3Canny J. A computational approach to edge detection IEEE Trans. Pattern Anal. Mach. Intell.2009667969821869365 · pubmed ↗
- 4Otsu N. A threshold selection method from gray-level histograms Automatica 197511232710.1109/TSMC.1979.4310076 · doi ↗
- 5Tsai C.S. Hsieh C.T. Huang S.J. Enhancement of damage-detection of wind turbine blades via CWT-based approaches IEEE Trans. Energy Convers.20062177678110.1109/TEC.2006.875436 · doi ↗
- 6Mittal M. Verma A. Kaur I. Kaur B. Sharma M. Goyal L.M. Roy S. Kim T.H. An efficient edge detection approach to provide better edge connectivity for image analysis IEEE Access 20197332403325510.1109/ACCESS.2019.2902579 · doi ↗
- 7Mishra S. Thanh L.T. SAT Meas-object detection and measurement: Canny edge detection algorithm Proceedings of the International Conference on AI and Mobile Services Springer Berlin/Heidelberg, Germany 202291101
- 8Ma Q.D. Ma Z. Ji C. Yin K. Zhu T. Bian C. Artificial object edge detection based on enhanced Canny algorithm for high-speed railway apparatus identification Proceedings of the 2017 10th International Congress on Image and Signal Processing, Bio Medical Engineering and Informatics (CISP-BMEI)IEEE Piscataway, NJ, USA 201716