LRCFuse: Infrared and Visible Image Fusion Based on Low-Rank Representation and Convolutional Sparse Learning
Jingjing Liu, Yujie Zhu, Yuhao Zhang, Aiying Guo, Mengjiao Li, Jianhua Zhang

TL;DR
This paper introduces LRCFuse, a new method for fusing infrared and visible images using low-rank representation and convolutional sparse learning to better preserve and extract image features.
Contribution
The novel LRCFuse method combines low-rank representation with a common feature preservation module to enhance cross-modal image fusion.
Findings
LRCFuse preserves more detailed features from source images compared to existing methods.
The proposed multi-level optimization strategy improves fusion results for downstream tasks.
Quantitative evaluations show LRCFuse outperforms other techniques in detecting infrared targets and preserving visible image details.
Abstract
With the development of cross-modal image fusion in multi-sensor systems, current fusion technologies have made significant progress in feature extraction, facilitating more effective image analysis. However, insufficient fusion information may degrade the correlation between the source and fused images, often resulting in the omission of critical features from the original modalities. Therefore, in order to preserve as much information as possible, especially for the complete extraction of effective feature information in source images, this paper proposes a new cross-modal image fusion method based on low-rank representation and convolutional sparse learning named LRCFuse. Firstly, the learned low-rank representation (LLRR) blocks are employed to perform dimensionality reduction on the source images while simultaneously extracting their low-rank and sparse feature components.…
Click any figure to enlarge with its caption.
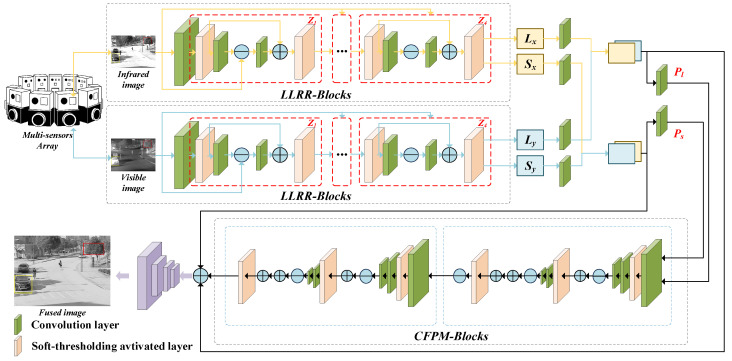 Figure 1
Figure 1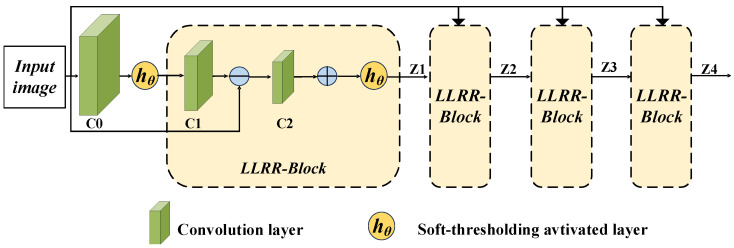 Figure 2
Figure 2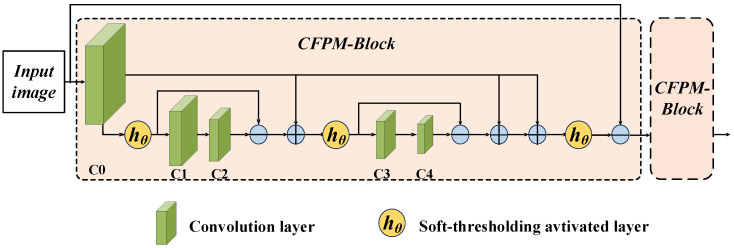 Figure 3
Figure 3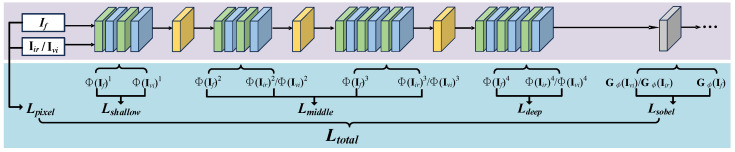 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15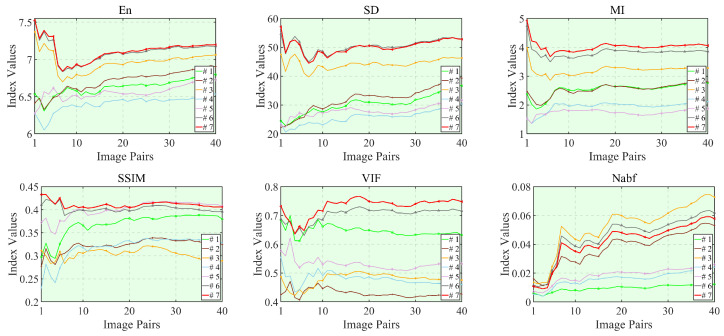 Figure 16
Figure 16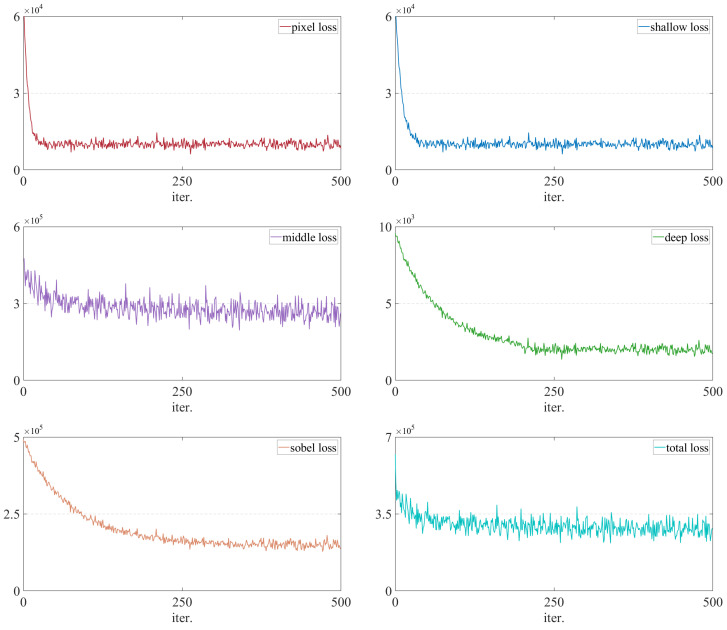 Figure 17
Figure 17- —National Key Research and Development (R&D) Program from Ministry of Science and Technology
- —National Natural Science Foundation of China
- —Shanghai Science and Technology Innovation Action Project
- —Shanghai Collaborative Innovation Center for Intelligent Perception Chip Technology
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image Fusion Techniques · Image Enhancement Techniques · Infrared Target Detection Methodologies
1. Introduction
Image fusion is a technique that integrates information from multi-modal sensors to generate a more comprehensive feature representation. Its core objective is to overcome the limitations of a single sensor in terms of accuracy, resolution, dynamic range, and noise resistance, thereby providing more reliable input for high-level visual analysis and decision making. Fused images can typically retain the complementary features of multiple sources of data, and thus play an irreplaceable role in various fields such as military monitoring [1], medical imaging [2], and environmental perception [3].
The current fusion methods can be classified into two categories: traditional methods [4,5,6] and deep learning methods [7,8,9]. Traditional methods, such sparse representation (SR), can extract sparse feature representations from the original data, which can reveal the structure and patterns of the data and have better mathematical interpretability. Dalal et al. [10] and Wright et al. [11] laid the foundation for feature representation learning by formulating images as sparse linear combinations and minimizing reconstruction error. Yao et al. [12] further proposed a joint sparse representation (JSR) model using a shared dictionary to achieve the collaborative fusion of multi-source images. Although SR can effectively capture local details, it has obvious limitations in modeling the global structure. To solve this problem, Candes et al. [13] introduced the robust principal component analysis (RPCA) method, which decomposes the data into low-rank components and sparse components, thereby capturing the global structure and local anomalies. Li et al. [14] adopted low-rank representation (LRR) instead of sparse representation (SR) and represented the data in the form of a low-rank matrix, which is suitable for noise data removal. To address the limitations of image reconstruction (SR) in capturing the global structure, Wu et al. [15] introduced a new representation learning technique using latent LRR (LatLRR), which can extract global and local structure information from the source images. Zhang et al. [16] proposed tensor low-rank representation (TLRR), which imposes low-rank constraints in a higher-order tensor domain to maintain cross-modal consistency. Although these methods have clear mathematical models, they usually rely on artificial prior knowledge and iterative optimization. Their computational complexity is high and their generalization ability for complex scenarios is also limited.
In contrast, the deep learning method, with its powerful end-to-end feature learning capability, significantly improves the performance of image fusion [17]. Li et al. [18] utilized dense connection architecture (DenseFuse) to enhance feature flow. Zhang et al. [19] provide a universal and efficient convolutional neural network (CNN) fusion framework (IFCNN). Its success essentially lies in the replacement of model-driven approaches by data-driven approaches, integrating the processes of feature extraction, activation and fusion into an efficient forward propagation network through extensive supervised or unsupervised training. Zhou et al. [20] used an M-SSIM- and TV-based hybrid loss to adaptively fuse infrared thermal features with visible textural, eliminating the need for manual fusion rules. Li et al. [21] combined a dual-stream feature interaction architecture with a color transformation network to preserve thermal target information while enhancing background texture and color fidelity. However, CNNs are inherently limited by their local receptive fields, making it difficult to effectively model long-range dependencies and global contextual information. To overcome this limitation, generative adversarial networks (GANs) has been introduced into fusion tasks. Ma et al. [22] pioneered the integration of adversarial training of FusionGAN into fusion tasks, generating high-quality fusion results through the interaction between the generator and the discriminator. Subsequently, Xu et al. [23] proposed a unified unsupervised framework (U2Fusion) that adaptively retains the salient information from the source images. Li et al. [24] utilized the adversarial learning between the generator and the discriminator to enhance the perceptual realism of the fused images. Meanwhile, the Transformer architecture and its core self-attention mechanism have also been introduced into this field. Ma et al. [25] presented the Swin Transformer image fusion network (Swin Fusion), which explicitly models global relationships through self-attention mechanisms, significantly improving contextual awareness, albeit at the cost of substantially increased computational complexity and parameter volume. To balance global modeling and multi-scale feature extraction, Shen et al. [26] designed a multi-scale cross-modal attention mechanism to enhance the extraction of significantly complementary features between different modalities. Zhang et al. [27] proposed a dual-branch frequency–spatial joint perception cross-modality network, specifically for improving the fusion quality of significant regions. Cheng et al. [28] integrated a joint low-light enhancement and image fusion network with channel attention to enhance fusion performance under low-light conditions. Li et al. [29] proposed a fusion method based on Knowledge Distillation and the Kansformer architecture, which achieves efficient multi-modal feature modeling under a dynamic sparse attention mechanism through a “Passive–Active” distillation learning scheme. Although these methods have significantly improved performance, they have poor mathematical interpretability and face bottlenecks in terms of credibility and reliability in critical applications.
To address the dual challenges of insufficient interpretability in deep learning and the limited generalizability of traditional methods, researchers have begun to explore a hybrid paradigm that combines traditional sparse priors with deep learning architectures, aiming to maintain the powerful feature learning capabilities of deep networks while preserving the mathematical transparency of traditional models. Li et al. [30] proposed RFN-Nest, which optimizes the information flow through residual fusion networks and nested connection structures. This method introduces dense skip connections and nested residual paths in the encoder–decoder architecture, effectively enhancing the integration and transmission of multi-scale features, significantly improving the detail restoration ability, and simultaneously alleviating the gradient vanishing problem in deep networks. On this basis, Li et al. [31] presented a lightweight dual-branch hybrid architecture. This architecture utilizes CNN and Transformer modules in parallel to extract local features and global dependencies respectively, and introduces an adaptive gating mechanism to achieve feature selection and fusion. It significantly reduces computational complexity while maintaining excellent fusion performance. On the other hand, in order to better fuse the complementary information in infrared and visible light images, Wang et al. [32] proposed an adaptive interactive Transformer and can effectively highlight infrared targets (AITFuse), while retaining the visible light background texture through cross-modal feature interaction and adaptive weight learning. Liu et al. [33] developed MATCNN technique, which combines multi-scale adaptive transform convolution and efficient attention mechanisms, embedding deformable convolution and spatial attention in the convolution structure to achieve cross-scale feature fusion and robust adaptation to geometric changes with lower parameter quantities. These hybrid methods not only enhance performance but also provide new avenues for understanding the decision-making mechanism of deep networks by introducing mathematical constraints from traditional priors.
Despite the success of these hybrid approaches in balancing interpretability and performance, the rapid evolution of deep learning has witnessed the emergence of entirely new architectural paradigms that operate through fundamentally different mechanisms. In recent years, Diffusion models and Mamba architectures have achieved remarkable progress in computer vision. Diffusion models generate high-quality images through iterative denoising processes, demonstrating exceptional performance in generative tasks such as super-resolution and image inpainting. Ma et al. [34] introduced the Diffusion model to the infrared and visible light fusion task, by combining the fusion prior with the iterative denoising process through the conditional diffusion framework, and using the reverse process to generate high-quality fused images, this effectively alleviated the instability problem in GAN training and enhances the ability to retain details. Mamba architectures, based on selective state space modeling, efficiently capture long-range dependencies with linear complexity, showing superior performance in classification and segmentation tasks. Xie et al. [35] proposed a dynamic feature enhancement network based on Mamba, which utilized the linear complexity selective scanning mechanism of the state space model to capture long-range dependencies, combined reversible neural network blocks to achieve lossless information transmission, and achieved efficient global modeling and local detail preservation in infrared–visible light fusion and medical image fusion tasks. However, these methods primarily focus on data-driven implicit feature learning, making it difficult to explicitly model the low-rank structure and sparse characteristics of multi-modal images. Consequently, they lack interpretability and deterministic guarantees for infrared and visible image fusion tasks. While these emerging paradigms push the boundaries of representational capacity, they also reveal a critical gap in explicit structural priors that could bridge interpretability and performance. This limitation motivates a reconsideration of classical model-driven approaches that enforce sparsity and low-rank constraints through principled mathematical formulations.
Convolutional sparse coding (CSC), as the theoretical foundation of CNNs, formulates image generation as a convolution of filter dictionaries and sparse feature maps, where the sparsity constraint can be regarded as a form of hard attention. In contrast, self-attention mechanisms can be interpreted as a soft, data-driven sparsification process. This theoretical link offers new perspectives for combining model interpretability with data-driven representational power. In recent years, researchers have attempted to integrate traditional priors with deep learning. For instance, Huang et al. [36] designed a two-stage fusion strategy based on CSC, which combines feature transfer and supplementation to enhance modal alignment. Yang et al. [37] proposed the LatLRR-CNN framework combining low-rank representation and CNNs, which combines feature transfer and supplementation to enhance modal alignment. By combining low-rank representation with CNNs, the trade-off between fusion quality and model complexity is effectively achieved. On this basis, Li et al. [38] further designed LRRNet, which combines the traditional low-rank representation theory with deep learning models. By introducing a low-rank regularization term to constrain the feature learning process, it can maintain the consistency of image structure while improving the detail retention ability and enhancing the visual naturalness and structural integrity of the fusion results. Yu et al. [39] incorporated CSC and attention mechanisms to enhance multi-modal feature integration. Cao et al. [40] proposed a cross-domain perception attention mechanism. By constructing a unified cross-domain feature representation and projecting it into the spatial and spectral subspaces, it effectively captures the intrinsic dependency relationship between space and spectrum. On this basis, a frequency-domain perception module is further introduced to fully utilize the low-level statistical features and high-level semantic features, thereby enhancing the comprehensive ability of structural and semantic representations. Based on this, Liu et al. [41] employed plug-and-play (PnP) low-rank priors for efficient dictionary learning, which learns effective feature maps through plug-and-play low-rank prior learning, and requires all sparse feature maps to be highly correlated at the global dimension, which precisely mimics the global context perception ability pursued by the self-attention mechanism. These works show that a hybrid approach, leveraging both interpretable traditional priors and deep learning, effectively constructs image fusion results of high performance.
Inspired by this, we propose an end-to-end image fusion framework base on low-rank representation and CSC named LRCFuse, whose structure is illustrated in Figure 1. The method first employs a low-rank representation learning module to extract low-rank and sparse components ( , , , and ) from the input images. Z represents the output of the LLRR-Block, while and represent the low-rank and sparse feature parts extracted from the two source images. Simultaneously, a common feature preservation module (CFPM) is introduced to extract cross-modal common features . Finally, the three types of features are aggregated to reconstruct the fused image. Furthermore, a multi-level optimization strategy is designed to comprehensively enhance fusion quality, ensuring that the output closely aligns with the source images in both structure and details.
The main innovations of this paper can be summarized as follows:
- Novel Fusion Method. This paper introduces a new cross-modal image fusion method, named LRCFuse, utilizing common feature preservation module (CFPM) to retain common features, and it employs learned low-rank representation (LLRR) to extract useful low-rank and sparse features, which is highly memory efficient for deployment.
- Multi-level Optimization. This work introduces a new multi-level optimization containing five loss terms, including pixel loss, shallow, middle, deep loss, and sobel loss, to improve model performance at multiple scales through image details, feature levels, and edge information.
- Applications. Experiments are conducted on accessible visible and infrared image datasets and compared with the latest approaches, show that the proposed LRCFuse achieves better information retention and image contrast.
The rest of this paper is organized as follows. Section 2 provides a brief overview of relevant works related to the topic of this paper. A detailed illustration of LRCFuse is presented in Section 3. The experimental results and analysis of LRCFuse are presented in Section 4. Section 5 summarizes the work of the paper and provides future research directions.
2. Related Work
Given an input data matrix , where and represent the dimensions of each pattern, the objective of RPCA is to decompose X into a low-rank matrix L and a sparse matrix S by solving a convex optimization problem that minimizes a weighted combination of the nuclear norm of L and the -norm of S.
where and represent the nuclear norm and the -norm, facilitating the low-rank and sparse recovery, respectively. While the minimization of these norms enables RPCA to successfully decompose the data into a low-rank background and a sparse anomaly component, a well-known limitation of this framework is its inability to efficiently model local spatial dependencies.
To address these limitations, the low-rank representation (LRR) model seeks to represent the data within a unified low-rank subspace. This framework retains the strength of global low-rank modeling inherent to RPCA but demonstrates superior efficacy in processing high-dimensional data and revealing latent structures, which are particularly vital in applications like image fusion. This can be formally expressed by the following optimization problem:
where ∗ denotes the convolution operator, D represents the dictionary matrix, and Z is globally constrained by the nuclear norm , and is decomposed into the low-rank matrix L and the sparse matrix S. Under this decomposition, the problem Equation (2) is transformed into
where denotes the Frobenius norm. Although LRR demonstrates competent performance in capturing low-rank and sparse components, they operate inherently within the matrix framework, thereby failing to fully preserve the high-order structural and multimodal correlations present in real-world data. To address this limitation, Zhou et al. [42] proposed the tensor LRR (TLRR) model, which extends the low-rank constraint from the matrix to the tensor domain, where denotes the nuclear norm based on the tensor singular value decomposition (t-SVD). However, the tensor nuclear norm based on t-SVD usually suffers from high computational cost and complex iterative optimization.
To address this issue, Yang et al. [37] proposed an infrared and visible image fusion method, termed LatLRR-CNN, which combines latent low-rank representation (LatLRR) with convolutional neural networks (CNN). In this method, LatLRR is employed to decompose the source images into low-rank parts and salient parts, as shown in Equation (4), which are then fused separately by CNNs. By introducing the self-representation term and the latent low-rank component , LatLRR avoids heavy tensor decomposition while still effectively capturing the low-rank structure of the data, leading to the formulation in Equation (4).
However, the LatLRR model in Equation (4) still relies on the conventional nuclear norm to enforce low-rankness, which limits its efficiency and representation capability. To overcome this issue, Liu et al. [41] employed the plug-and-play tensor low-rank approximation (PnP-TLRA) framework in Equation (5). In this framework, the standard nuclear norm is replaced with a plug-and-play (PnP) prior based on deep learning, enabling more efficient and flexible low-rank representation.
where the strategy incorporates deep learning-based PnP priors to guide and constrain the low-rank estimation.
Although the PnP-TLRA framework has shown strong performance, it still suffers from several inherent limitations. Specifically, the model heavily relies on global low-rank constraints, which are often inadequate for capturing fine-grained local structures. The optimization process tends to emphasize global correlations at the expense of localized fidelity, potentially leading to oversmoothed outputs.
3. The Proposed Method
To overcome the limitations of existing cross-modal fusion approaches, we propose a novel framework named LRCFuse. The architecture of LRCFuse is organized into three parts. First, the LLRR module decomposes the source images into low-rank and sparse components through a decomposition model and its corresponding LLRR-Blocks. Next, the CFPM module, based on convolutional sparse coding, is introduced to recover common features shared across modalities, thereby compensating for the insufficient modeling ability of low-rank representation alone. Finally, a multi-level loss function is designed, incorporating pixel, shallow, middle, deep, and sobel constraints, in order to hierarchically supervise and refine the fused representation. The details of the LLRR, the CFPM, and the loss formulation are described in the following subsections.
3.1. LLRR
3.1.1. The Decomposition Model
Benefiting from the strengths of the above three formulations (Equations (1)–(5)) in terms of low-rank modeling, foreground preservation, and computational efficiency, we further propose a multi-dictionary low-rank and sparse decomposition model in Equation (6), where the input X is decomposed as , with L representing the low-rank matrix, S denoting the sparse matrix, and denoting the dictionaries for the low-rank and sparse components, and E reinterpreted as a noise. This formulation jointly imposes refined constraints on the low-rank term, sparse structure, and noise residuals, while employing independent dictionaries to decouple different components. As a result, it enhances the interpretability and structural modeling capacity of the fused features.
Here, (with ) denotes a joint sparse norm promoting structured sparsity. Unlike the standard -norm, which induces element-wise sparsity, the -norm encourages group-wise sparsity by combining the -norm of rows within the matrix. This construction drives entire rows to zero when their collective energy is small, making it particularly effective for tasks such as joint feature selection or image fusion, while preserving the internal relationships among coefficients in non-zero rows, as shown in Equation (7).
We incorporate the PnP prior and adopt the DDLCN [43] architecture to learn two discriminative dictionaries, and . These dictionaries are used to project the low-rank structure L and the sparse structure S into a shared representation space. In this model, the term captures the essential image content, encompassing both global structures and latent mappings. To regularize the noise term E, we employ the generalized norm, which promotes structured sparsity and offers flexibly in adapting to deiverse foreground patterns. This idea is motivated by the weighted schatten minimization method proposed by Xu et al. [44], which has demonstrated exceptional performance in image denoising. In their study, when , the model is able to better approximate the original low-rank assumption and effectively remove noise. Motivated by LRR-based formulations, Equation (7) can be rewritten into a unified optimization form as
To quickly optimize Equation (8), the optimization methods for the nuclear norm and Frobenius norm [45] are employed here to avoid time-consuming matrix decomposition calculations. The mapping formula is given as
By integrating Equations (8) and (9), the issue can be rephrased as follows:
Finally, the model can be stated in a general concise form as
where , , and denote the regularization term combining nuclear norm approximation and sparse error. Then, in order to solve Equation (11), we propose the optimization algorithm for LRCFuse method (see Algorithm 1).
In Algorithm 1, denotes the encoding matrix, which projects the input into the coefficient space. U denotes the constant term obtained by projecting the input through the encoding matrix , which serves as the driving signal for the iterative update. In the formula , V denotes the identity matrix, and H represents the linear recurrence/contraction matrix to enhance stability. is the step size, set as . The and are then reconstructed with the learned dictionary and . Algorithm 1 Optimization algorithm for LRCFuse with and .Input: Output: Define 1: Define 2:
- 1:Initialize
- 2:for to T do
- 3:
- 4:
- 5:end for
- 6:Let and split , where is the low-rank matrix and S is the sparse matrix.
- 7:Output and .
Consequently, the iterative optimization in Algorithm 1 can be reformulated as
where ∗ indicates the convolution operation, and are learnable convolutional layers, and refers to the soft thresholding (shrinkage) function [46]. Here is an activation function, which is defined as follows:
where indicates the sign function. The output of a stack of LLRR blocks produces the final features Z (steps in LISTA [47]). The low-rank feature and the sparse feature can be computed with the proper convolutional layers ( and ). Here, convolutional layers can be regarded as a practical implementation of dictionaries, namely convolutional dictionaries. Therefore, and are mathematically equivalent, with the former being more common in theoretical formulations and the latter more suitable for describing network implementations.
Next, the common features C will be obtained by solving the following optimization formula:
where , and represent the four convolution layers. X and Y represent the visible light and infrared images respectively. Equation (14) is solved by updating each variable alternately while fixing the other variables, and the iterative solution process can be referred to in the literature [9]. Then, the proposed common feature part can be obtained. Finally, the , and obtained through Equation (14) are summed pixel by pixel and averaged to obtain the final fused feature values. Then, three layers of deconvolution are applied to obtain the final fused image.
3.1.2. LLRR-Blocks
After applying the LLRR decomposition model to a single-channel image to extract its low-rank and sparse features, multiple LLRR layers are cascaded to construct deep representations. The structure of the LLRR-Block is shown in Figure 2, where the output feature Z is obtained via optimization using the LISTA algorithm. The core of LISTA is the soft thresholding operation, which updates the low-rank and sparse coefficients in each iteration.
In the LRCFuse framework, four LLRR blocks are employed to decompose the source images (infrared image and visible image , as shown in Figure 1). Specifically, and denote the low-rank and sparse coefficients of the visible image, respectively, while and represent the corresponding coefficients for the infrared image. Each LLRR block progressively extracts residual information from the source features, ensuring that subsequent modules capture characteristics not identified in previous layers, thereby retaining more details and critical information step by step.
The separation of sparse features is primarily achieved through the soft thresholding function , which operates on the feature map in each iteration of LISTA. This function thresholds the features by setting values below to zero, while shrinking significant features, thereby suppressing noise and non-significant components and enhancing the sparsity of the features.
After obtaining the low-rank and sparse , , , and , four convolutional layers , , , and are used to further extract their respective feature representations. These are then fused through concatenation and two additional convolutional layers, ultimately yielding the fused low-rank feature and sparse feature .
3.2. CFPM-Blocks
In the above work, the LLRR-Blocks first decompose the features into a low-rank component and a sparse component . Subsequently, the CFPM-Blocks formulate the set of common feature coefficients as the optimization variables and conduct a joint regularized reconstruction of both modalities under a sparsity prior, as specified in Equation (15).
where the convolution kernels and are used to capture cross-modal structural patterns, while and are convolved with the known low-rank and sparsity , respectively, to incorporate modality-specific decomposable elements. In addition, represents a set of shared feature coefficient maps, where each convolutional kernel and corresponds to the k-th coefficient and is convolved respectively with , , , and , during the reconstruction of the two modalities. Here, and represent the and aligned with the channel or sub-band associated with the k-th kernel. The parameter controls the strength of the regularization term.
Given that and have been derived from the LLRR-Block module, the CFPM module first treats them as known priors to strip away the explainable components of each modality, resulting in two residuals signals for the subsequent shared convolutional fitting. These residuals are then jointly represented under convolutional kernel sets and via CSC, and the shared coefficients are estimated with an additional sparsity regularization constraint. This process directly yields by minimizing the objective function. This strategy explicitly decouples modality-specific low-rank and sparse information from cross-modal shared representations by first separating the unique components and then encoding the residuals with shared convolutional sparse coding, thereby enhancing the interpretability and robustness of the common features. To ensure the reproducibility of the proposed method and clarify the alternate updating process of the CFPM-Blocks, the detailed step-by-step optimization procedure is summarized in Figure 3 and Algorithm 2. Algorithm 2 Optimization process for CFPM-Blocks
- 1:Input: , , X and Y.
- 2:Output: .
- 3:Initialize: , learning rate , regularization parameter .
- 4:Step 1: Residual Extraction (Pre-processing)
- 5: {Extract residuals from modality X}
- 6: {Extract residuals from modality Y}
- 7:Step 2: Iterative Optimization (Unfolded intoTStages)
- 8:for toTdo
- 9: {Gradient Descent Step for Fidelity Terms in Equation (15)}
- 10:
- 11: {Implemented by Convolution Layers }
- 12: {Proximal Mapping for Sparsity Regularization}
- 13: {Implemented by Layer}
- 14:end for
- 15: {Assign the final iterated value to }
- 16:return
3.3. The Loss Functions of LRCFuse
To ensure that the fused image preserves complementary information from both infrared and visible source images, the generated fused image , the visible image , and the infrared image are fed into a pre-trained VGG-16 [48] network. By extracting feature representations at different convolutional layers, we obtain low-level texture and edge information, mid-level semantic structures, and high-level abstract representations. Based on these hierarchical features, the corresponding loss functions are constructed to guide the training process, ensuring that the fused image remains consistent with the source images at the pixel, structural, and semantic levels. The loss function architecture is shown in Figure 4. The definition of the total loss function is as follows:
where , , , and represent the weight of the loss function for each part. For the description of the losses for each part, it is as follows.
measures the per-pixel difference between the fused and visible images, encouraging the fused image to remain close to the source and preserve visible details.
where represents the fused image and represents the visible image. uses low-level features to enforce local structural similarity between the fused and visible images, such as edges and textures.
where (·) represents the features that the loss network extracts from (·), and represents the output of the first convolution block. guides the fusion process to retain critical infrared information and enhance the semantic content of the fused image.
where K represents the number of convolutional blocks, and represents the weight of each item. The balancing parameters and regulate the trade-off between features in visible and infrared images. In particular, ought to be substantially less than . constrains the fused image by matching gram-based correlations [49], thereby enforcing high-level semantic consistency with the infrared source.
where represents a gram matrix, which is a covariance matrix with no whitening operations. drives the fused image to retain sharper infrared edges and finer structural details.
Here denotes the gradient feature map obtained by the sobel operator, defined as
where and denote the horizontal and vertical sobel gradients of fused image , respectively.
In conclusion, the fused image generated by LRCFuse can more comprehensively retain the detailed information in the visible light image. At the same time, by introducing a composite loss function composed of five components and its carefully configured weights, it effectively enhances the saliency of infrared target features.
4. Experiments and Analysis
To comprehensively evaluate the performance of LRCFuse, nine state-of-the-art fusion methods are selected for experimental comparison, such as DenseFuse [18], FusionGAN [22], IFCNN [19], U2Fusion [23], RFN-Nest [30], SwinFusion [25], LRRNet [38], AITFuse [32] and MATCNN [33]. Additionally, experiments are conducted on three publicly available datasets: TNO (https://github.com/yanyanchun/TNO_Image_Fusion_Dataset, accessed on 5 March 2026); Roadscene (https://github.com/hanna-xu/RoadScene, accessed on 5 March 2026); and M3FD (https://github.com/JinyuanLiu-CV/TarDAL, accessed on 5 March 2026), as shown in Figure 5, to ensure a robust assessment of the proposed method.
•The TNO dataset, commonly used for visible and infrared image fusion research, contains 60 pairs of cross-modal images captured in military settings. These images cover various environments, including indoor and outdoor scenes, nighttime visual scenarios, challenging lighting conditions, adverse weather conditions, and other diverse scene settings.•The RoadScene dataset, collected from FLIR videos, is more focused on civilian scenarios, particularly for autonomous driving and intelligent transportation systems. It contains a large number of common road scene elements, such as roads, cars, pedestrians, and other characteristic scenes.•The M3FD dataset, designed for infrared and visible light image fusion and cross-modal target detection research, is a multispectral dataset. The dataset comprises 15,000 images covering various complex scenes, including six categories of targets such as people, cars, buses, motorcycles, lamps, and trucks.
Furthermore, a comprehensive evaluation of the comparative results is conducted through both qualitative and quantitative assessments. Qualitative evaluation provides intuitive visual comparisons in terms of contrast and structural preservation, yet it is inherently subjective. Quantitative evaluation, on the other hand, employs a set of numerical metrics to characterize fusion performance from multiple perspectives, enabling an objective and multi-faceted analysis. To thoroughly assess the performance of LRCFuse, six evaluation metrics are selected, covering five fundamental aspects of fused image quality: the information-theoretic evaluation metrics En, MI, structural similarity-based evaluation metric SSIM, image feature-based evaluation metric SD, human visual perception-based evaluation metric VIF, and evaluation metric Nabf based on the source image and generated image. For all metrics except Nabf, higher numerical values indicate improved fusion performance.
(1) En: Entropy quantifies the information content within an image, with higher values reflecting greater informational richness and uncertainty.
(2) MI: Mutual information quantifies the similarity between two images by measuring how much information is shared between them. Higher mutual information indicates a greater degree of similarity.
(3) SSIM: The Structural Similarity Index is a widely adopted metric for evaluating image distortion, as it jointly considers luminance, contrast, and structural information. A higher SSIM score indicates improved structural preservation and contrast consistency between the compared images.
(4) SD: Standard deviation measures the dispersion of pixel values within an image. A higher standard deviation signifies greater variation in pixel values, making it a useful metric for evaluating image sharpness.
(5) VIF: Visual Information Fidelity assesses image quality by considering brightness, contrast, and structural information. A higher Visual Information Fidelity (VIF) score suggests that attributes like brightness and contrast in the fused image are more perceptually aligned with the human visual system.
(6) Nabf: Normalized absolute barycenter deviation calculates the average difference between the generated and original images. A lower normalized absolute barycenter deviation indicates that the generated image contains less noise and is closer to the original image.
Finally, the PyTorch 1.13.1 framework is employed to train and test the model on a server running the Ubuntu operating system, equipped with an Intel Core i7-3770k CPU and an NVIDIA GeForce RTX 4090 GPU.
4.1. Parameter Settings
4.1.1. Training Details
The proposed model is trained on the MSRS (https://github.com/Linfeng-Tang/MSRS, accessed on 5 March 2026), multispectral dataset. The MSRS dataset is a public benchmark for multi-modal image fusion, consisting of registered pairs of visible and infrared images, and is widely used for training and evaluating cross-modal fusion methods. To generate more training samples, 1444 pairs of infrared and visible image pairs from the MSRS dataset are further processed and divided into 41,703 pairs of patches, each with a resolution of 128 × 128 pixels. From these, 20,000 pairs of IR-VI images are randomly selected for training. The model is trained for 30 epochs with batch size of eight. All training images are converted to grayscale, and the learning rate is set to . Following the work of [38], is set to 0.005, is set to 0.5, to 0.05, and both and to 0.005.
4.1.2. The Impact of Lshallow and Lmiddle
During the training phase, and are set to 0.01 and 0.5, respectively, as the value of is significantly larger than the other losses. To maintain more details, is set to ten. The is set to 0.5 in , ensuring it is substantially smaller than . The number of LLRR-Blocks is fixed at four, with is set to 700 in the initial analysis. The influence of parameters ( in ; in ) can be examined under these conditions. Their values are specified as follows: ; . The fusion results for different value of and are illustrated in Figure 6.
In the proposed loss function, is utilized to control , which represents the shallow information in the image. A larger value of leads to more prominent details from the visible light image being fused into the composite image. Meanwhile, the magnitude of affects the prominence of infrared features in the fused image. A larger results in more prominent infrared features in the fused image. From Figure 6, it is evident that the fused image tends to resemble the visible image more when decreases and increases, while it resembles the infrared image more when increases and decreases. Based on Figure 6, a set of combinations can be identified: and . The average values of the six metrics for different parameter combinations are shown in Table 1.
In Table 1, when = 1.9 and = 1.0, LRCFuse obtains four optimal values (e.g., En, SD, MI and VIF) and one suboptimal value (SSIM). The four optimal values indicate that LRCFuse retains more detailed information while preserving the salient features of the infrared image. In constrast, the fusion image produced by the other three sets of parameters is not as close to the performance of the original image as those generated by the suboptimal values. Therefore, and are set to 1.9 and 1.0, respectively. In Table 2, when = 0.5, LRCFuse obtains five optimal values (En, SD, MI, SSIM and VIF). It can be concluded that in subsequent experiments, is fixed at 0.5.
4.1.3. The Impact of Lpixel and Ldeep
Next, the effects of on and on are analyzed. The optimal value of is defined within the interval . The objective evaluation of different values of is presented in Table 3.
When , the proposed fusion method obtains four optimal quality metrics, indicating that LRCFuse preserves both infrared features and details. Therefore, is set to ten in the subsequent experiments. The ideal value of is determined by sampling several values from the interval . The objective evaluations for different values of are presented in Table 4. The fusion method identifies five optimal values and one suboptimal value when . Therefore, 700 is established as the optimal value for in .
4.1.4. The Impact of γ5 on LSobel
The optimal value of is defined by sampling different values within the interval . The objective evaluations for different values of are presented in Table 5. When , the fusion method obtains three optimal values and two suboptimal values. Therefore, in is set to 1000.
4.2. Fusion Result Analysis
4.2.1. Experiments on the TNO Dataset
Three pairs of representative images from the TNO dataset (named “Helicopter”, “Kaptein_1654”, and “Soldier_behind_smoke_1”) are chosen for qualitative assessment to visually illustrate the variations in fusion performance between LRCFuse and other methods. The fusion results are shown in Figure 7, in which the proposed method outperforms the other methods. For clear comparison, red boxes are used to select regions rich in textural information and yellow boxes are used to highlight areas with significant information in the images.
It can be observed from Figure 7 that the visible image detail information is partially injected into the fused image through DenseFuse, FusionGAN, and RFN-Nest, while the infrared target’s intensity is diminished. IFCNN, U2Fusion and MATCNN successfully maintain the salient objects in infrared images, although some textural are lost. SwinFusion, LRRNet, and AITFuse combine the complementary information from the original image, resulting in the blurred and unclear images. In contrast, the proposed LRCFuse effectively retains the rich textural details of visible images while maintaining the significant intensity of the targets.
Figure 8 presents the visualization results, which may be broadly classified into two groups. The first type of results tend to be visible images, such as DenseFuse, IFCNN, U2Fusion, SwinFusion, and LRRNet. In particular, their fusion methods lose a considerable amount of the contrast information contained in infrared images, even as they retain certain textural features. The second type of images are closer to infrared images, including FusionGAN, RFN-Nest, AITFuse, and MATCNN. These methods effectively maintain significant contrast, but sacrifice depth in the textural details, resulting in images that resemble sharpened infrared images. In contrast, LRCFuse resembles more closely a hybrid of these two classifications, successfully highlighting the subject while preserving a sizable contrast and retaining rich texture structures in the fusion results.
For Figure 9, it can be observed that FusionGAN and AITFuse exhibit limitation in preserving textural and image clarity in their fusion results. IFCNN, U2Fusion, and SwinFusion appear blurry due to insufficient brightness to highlight the targets. Although DenseFuse, RFN-Nest and MATCNN can enhance the textural details of the targets, they are compromised by significant noise and a lack clarity in the fusion images. As opposed to the previously mentioned methods, LRCFuse effectively maintains the textural information apparent in visible images while also preserving sparse features from infrared images. Specifically, in the above images, the fuselage of the Helicopter achieves satisfactory infrared display without generating high-brightness highlights. In addition, the infrared features effectively contribute to the preservation and enhancement of the textural details of the targets.
Table 6 presents the average values of these metrics. Based on the average results, LRCFuse obtained the four optimal values (En, SD, MI, and VIF) with an increase of 1.12% for En, 4.01% for SD, 26.53% for MI, and 0.02% for VIF compared to the suboptimal values, while its Nabf dropped by 22.49%. Furthermore, according to the average ranking statistical analysis, our proposed model achieves the highest average ranking (Avg. Rank). Therefore, we can conclude that our method demonstrates a substantially superior comprehensive performance compared to the other approaches. This result indicates that the performance differences among the compared methods are statistically significant.
4.2.2. Experiments on the RoadScene Dataset
Three pairs of representative images from the RoadScene dataset are selected for qualitative assessment (FLIR_00211, FLIR_00288 and FLIR_04688) (Figure 10, Figure 11 and Figure 12).
From the red box, it can be observed that the six models, except for SwinFusion, LRRNet, and MATCNN, exhibit relatively blurry textures on the tree branches and less clear car appearances due to high brightness levels. In contrast, the proposed LRCFuse provides clearer details in the tree branches and a more distinct car outline and surface compared to SwinFusion, LRRNet, and MATCNN. Additionally, Table 7 demonstrates that the fused images produced by LRCFuse are more consistent with human subjective perception and contain more detailed information.
On the RoadScene dataset, LRCFuse achieves four optimal values (En, SD, MI, and VIF), with increases of 1.11% for En, 29.12% for SD, 35.39% for MI, and 15.12% for VIF compared with the suboptimal results. Combined with the fact that LRCFuse obtained the highest Avg. Rank, the evidence strongly supports that our model provides a more effective and stable fusion strategy compared with other baselines. While LRCFuse leads in En, SD, MI, and VIF, its relatively higher and lower reflect a calculated sharpness–contrast trade-off. Our deep unfolding mechanism intentionally intensifies edge gradients and local contrast to maximize information retention and thermal saliency (evidenced by the superior SD). However, because and are sensitive to substantial deviations from source image brightness and structural distributions, they numerically penalize these enhancements as artifacts or structural shifts.
4.2.3. Experiments on the M3FD Dataset
Three pairs of representative images from the M3FD dataset (00818, 02440 and 03708) are selected for qualitative assessment.
From Figure 13, Figure 14 and Figure 15, it can be observed that DenseFuse and IFCNN preserve some details, especially the contours of the targets, but the overall contrast of the images is relatively low. FusionGAN, U2Fusion, AITFuse, and MATCNN generate images that are overall clearer, but some regions have lower contrast. RFN-Nest, SwinFusion, and LRRNet produce images with good overall quality, but artifacts or distortions appear in certain areas. In comparison, the proposed LRCFuse performs exceptionally well in preserving the contours and textures of targets. It also handles detail retention, contrast, and noise processing effectively, resulting in clearer and more contrast-rich images.
From Table 8, it can be concluded that in the M3FD dataset, LRCFuse achieves the best values for En, SD, MI, and VIF, with increases of 1.41% for En, 22.63% for SD, 15.42% for MI, and 1.19% for VIF compared with the suboptimal results. The lower scores in and SSIM highlight a clear trade-off between aggressive contrast enhancement and structural mimicry. To maximize target saliency, LRCFuse intentionally intensifies edge gradients and shifts local luminance distributions. While these modifications significantly improve visual clarity and downstream interpretability, they are numerically penalized by as artifacts and by SSIM as structural deviations from the source images. This confirms that LRCFuse prioritizes informative feature recovery over conservative pixel-level similarity. Given that LRCFuse consistently secures the highest Avg. Rank, we can conclude that it offers the most competitive overall performance across the M3FD dataset. In addition, the proposed approach successfully maintains image quality while ensuring authenticity and naturalness.
4.3. Analysis of Computational Complexity
Table 9 presents a comprehensive comparison of various image fusion methods, including the proposed LRCFuse, in terms of model parameters, runtime, and computational complexity (FLOPs). To ensure a fair comparison, all the models were evaluated on the same hardware platform equipped with an Intel Core i7-3770K CPU, 32 GB of RAM, and an NVIDIA GeForce RTX 4090 GPU. Traditional lightweight CNN-based models such as DenseFuse and IFCNN maintain low parameter counts and FLOPs, yet still suffer from relatively long inference times. On the other hand, more complex networks like FusionGAN, U2Fusion, and RFN-Nest offer stronger representational power but exhibit significantly larger model sizes and computational overhead, which hinders their applicability in resource-constrained environments.
In contrast, LRCFuse achieves an optimal balance by requiring only 0.18 M parameters, with an inference time of 0.06 s and 171.64 GFLOPs. This demonstrates its exceptional memory efficiency with a compact architecture. While the FLOPs are relatively higher due to the iterative unfolding design, the minimal parameter count significantly reduces memory access costs, making the model particularly advantageous for memory-constrained deployment in real-time applications. Furthermore, in terms of training efficiency, LRCFuse requires only 0.74 h for convergence, achieving the second-best performance among all compared methods. Compared to heavy-duty models such as AITFuse (17.82 h), RFN-Nest (11.77 h), and MATCNN (10.76 h), which demand substantial temporal resources, LRCFuse significantly reduces the training overhead. The relatively short training duration, alongside its low inference latency, further validates the practical deployability and optimization efficiency of the proposed framework.
4.4. Ablation Experiments
4.4.1. Effectiveness of LLRR-Blocks
To evaluate the effectiveness of the LLRR-Blocks, their quantity is incrementally increased from zero (no LLRR-Blocks) to four, and the resulting effects are demonstrated through objective evaluation presented in Table 10. The analysis reveals that with only one module, the model achieves a single optimal value for the Nabf. When three modules are employed, two optimal values for En and SD are obtianed. Furthermore, with four modules, the model achieves three optimal values for MI, SSIM, and VIF, with MI increasing by 10.96%, SSIM by 0.55%, and VIF by 10.11%. At this configuration, the model effectively leverages the rich information present in the original images.
4.4.2. Effectiveness of CFPM-Blocks
Subsequently, in order to determine the validity of the modules adopted in the network architecture, an ablation experiment of the modules by removing or deleting some of them is conducted. As illustrated in Table 11, the introduction of CFPM-Blocks leads to improvements in four key metrics. The SD increases by 5.10%, MI rises by 42.98%, SSIM improves by 14.29%, and VIF enhances by 41.53%. Notably, MI and VIF exhibit the most significant gains. These findings demonstrate that the CFPM-Blocks clearly improve the contrast of fusion results, enhance retention of information from the original images, and contribute to more realistic outcomes.
4.4.3. Effectiveness of the Loss Function
influences whether the fused image can retain more detailed information, while , , and control the shallow, middle, and deep features of the fused image, respectively. Additionally, emphasizes the prominent infrared features in the fused image. Each component is individually set to zero to eliminate its impact, allowing for an analysis of effectiveness through the observation of changes in objective indicators. The specific objective evaluations are presented in Table 12. From Table 12, it can be observed that when only and are included in the loss function, the fusion result obtains the lowest Nabf, suggesting that the model introduces the least artifacts during the fusion process. When the loss function is composed of , , and , LRCFuse obtains the optimal values for En and SD, indicating that the spatial structure of the fusion result generated is the most consistent with the original image. Finally, when the loss function is fully composed of the five proposed terms, the best three indicators (MI, SSIM, and VIF) are obtained. Compared to the suboptimal value, the MI increases by 11.68%, SSIM by 1.24% and VIF by 11.05%. The same result is shown in Figure 16. This demonstrates that the fused images significantly enhance richness of the original images. In conclusion, the effectiveness of the proposed multi-level optimization is substantiated by the aforementioned results.
Based on the previous discussion, the loss values for each part and the total loss are shown in Figure 17. As illustrated in Figure 17, and exhibit near-instantaneous convergence within 200 iterations, enabling the model to rapidly prioritize low-level textural details. While displays inherent fluctuations—stemming from the competitive balancing between visible spatial information and infrared salient features—it reaches a steady state alongside the smooth, monotonic descent of and . Overall, the network achieves a robust equilibrium, ensuring a harmonious trade-off between structural preservation and multi-modal feature enhancement.
5. Conclusions
This paper introduces a novel cross-modal image fusion approach, termed LRCFuse, which integrates LLRR-Blocks with CFPM. The LLRR module employs four convolutional layers to separately extract low-rank and sparse features from visible and infrared images. These features are concatenated and further processed through two additional convolution operations to produce the corresponding fused representations. In the CFPM module, an iterative algorithm is utilized to identify the shared features between the two modalities. The three resulting feature sets are then fused to generate the final output image. Moreover, a multi-level optimization is proposed to supervise the training process, enabling the model to effectively learn and refine cross-modal feature representations. The experimental results on two widely used infrared and visible image datasets, TNO and RoadScene, demonstrate that LRCFuse achieves significant improvements in the MI index over existing fusion techniques, with gains of 26.53% on TNO, 35.39% on RoadScene, and 15.42% on the M3FD dataset. Benefiting from its ability to preserve complementary structures and extract modality-common information, LRCFuse exhibits potential in multi-sensor image fusion tasks.
For future work, we aim to further reduce the model size through architectural simplifications and compression techniques, enhancing the deployment capability of LRCFuse on edge devices. While recent advancements such as Diffusion models and Mamba-based architectures have shown great potential in generative modeling and long-range dependency capture, our LRCFuse offers a more lightweight and interpretable alternative. Future research will explore integrating the stochastic priors of Diffusion models or the efficient scaling of Mamba into our deep unfolding framework to further enhance fusion quality while maintaining deployment efficiency. Additionally, extending LRCFuse to multi-scenario computational imaging, such as daytime and nighttime intelligent perception, will further expand its applicability in real-world systems.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhao H. Zhang Y. Chen Y. Zhao H. Jiang Z. Cao M. Yang H. Ding Y. Li P. Comparative Study of Different Algorithms for Human Motion Direction Prediction Based on Multimodal Data Sensors 20262650110.3390/s 2602050141600297 PMC 12845797 · doi ↗ · pubmed ↗
- 2Li X. Sun H. Li T.Q. CHARMS: A CNN-Transformer Hybrid with Attention Regularization for MRI Super-Resolution Sensors 20262673810.3390/s 2602073841600530 PMC 12845672 · doi ↗ · pubmed ↗
- 3Wang H. Zhu R. Ye Z. Li Y. Robot Object Detection and Tracking Based on Image–Point Cloud Instance Matching Sensors 20262671810.3390/s 2602071841600511 PMC 12845642 · doi ↗ · pubmed ↗
- 4Simone G. Farina A. Morabito F.C. Serpico S.B. Bruzzone L. Image fusion techniques for remote sensing applications Inf. Fusion 2002331510.1016/S 1566-2535(01)00056-2 · doi ↗
- 5Metwalli M.R. Nasr A.H. Allah O.S.F. El-Rabaie S. El-Samie F.E.A. Satellite image fusion based on principal component analysis and high-pass filtering J. Opt. Soc. Am. A 2010271385139410.1364/JOSAA.27.00138520508708 · doi ↗ · pubmed ↗
- 6Mishra D. Palkar B. Image fusion techniques: A review Int. J. Comput. Appl.201513071310.5120/ijca 2015907084 · doi ↗
- 7Liu C. Qian J. Fang F. ISGM-Fus: Internal structure-guided model for multispectral and hyperspectral image fusion Neurocomputing 202565013077710.1016/j.neucom.2025.130777 · doi ↗
- 8Zhang L. Wang L. Wu Y. Chen M. Zheng D. Cai Y. ISCD Fuse: Interval sampling correlation driven visual state space models for multimodal image fusion Neurocomputing 202564013032910.1016/j.neucom.2025.130329 · doi ↗