Accelerated Full Waveform Inversion by Deep Compressed Learning
Maayan Gelboim, Amir Adler, Mauricio Araya-Polo

TL;DR
This paper introduces a deep learning method to reduce the computational cost of Full Waveform Inversion by selecting the most relevant seismic data.
Contribution
The novel approach uses a deep neural network with compressed learning to efficiently select seismic data for inversion.
Findings
The proposed method outperforms random sampling in 2D FWI using only 10% of the data.
The approach enables efficient hierarchical selection of relevant seismic data for inversion.
Results suggest potential for accelerating large-scale 3D FWI.
Abstract
We propose and test a method to reduce the dimensionality of Full Waveform Inversion (FWI) inputs as a computational cost mitigation approach. Given modern seismic acquisition systems, the data (as an input for FWI) required for an industrial-strength case is in the teraflop level of storage; therefore, solving complex subsurface cases or exploring multiple scenarios with FWI becomes prohibitive. The proposed method utilizes a deep neural network with a binarized sensing layer that learns by compressed learning seismic acquisition layouts from a large corpus of subsurface models. Thus, given a large seismic data set to invert, the trained network selects a smaller subset of the data, then by using representation learning, an autoencoder computes latent representations of the shot gathers, followed by K-means clustering of the latent representations to further select the most relevant…
Click any figure to enlarge with its caption.
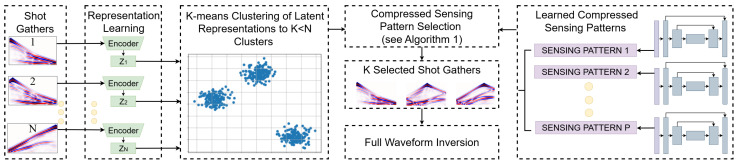 Figure 1
Figure 1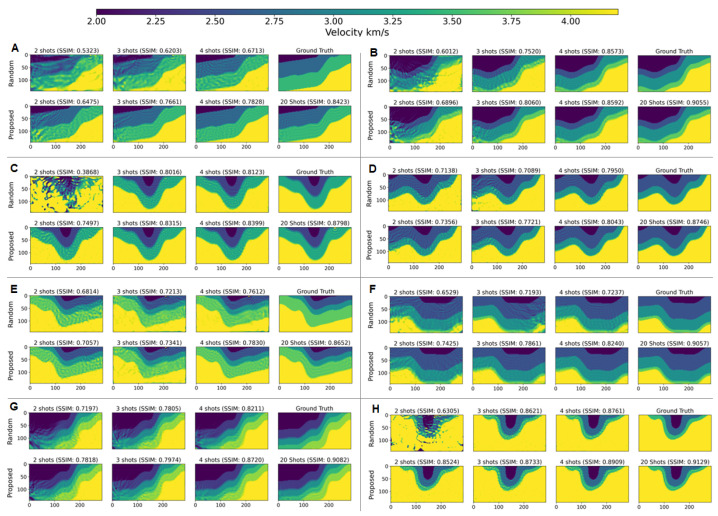 Figure 2
Figure 2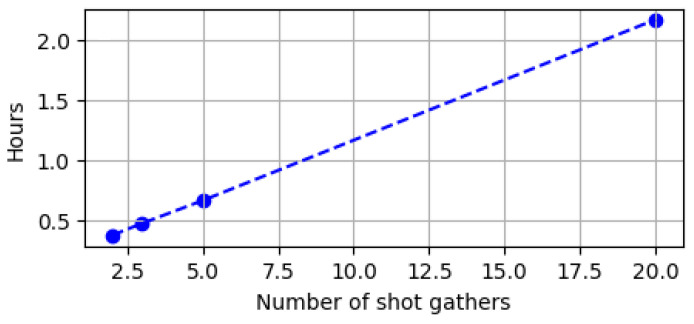 Figure 3
Figure 3 Figure 4
Figure 4- —TotalEnergies EP R&T US
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSeismic Imaging and Inversion Techniques · Seismic Waves and Analysis · Seismology and Earthquake Studies
1. Introduction
Seismic inversion is a fundamental tool in geophysical analysis, involving the estimation of subsurface properties such as velocity, density, and impedance from recorded seismic data. Full Waveform Inversion (FWI) [1] is a widely-used seismic inversion tool, and it has become the industry standard for model building/reconstruction in subsurface characterization workflows. It is utilized for hydrocarbon exploration, sequestration, and shallow hazard assessment, among others. FWI has all the challenges of an inversion process: non-linear, non-convex, ill-posed, and it is computationally demanding [1], in particular for 3D inversion and when more complete physics beyond the acoustic approximation are targeted (i.e., elastic, viscoelastic).
Modern seismic acquisition configurations with a large number of seismic sources (i.e., shots) significantly increase the computational burden and complicate data manipulation. Several research directions aim to optimize seismic configurations and subsequent data manipulation to address these challenges. For example, using diffusion models for reconstruction and importance weighting of sources [2] or creating a sampling pattern based upon the changing complexity of the sampling area [3]. Some studies such as [4] have explored the integration of Compressed Sensing (CS)-based methods, where for instance, random sampling of sources is performed, then other sources are added to the sampling space, controlling the maximum distance between sources as a parameter. In [5] a greedy algorithm is conditioned by computing illumination maps from virtual sources towards selecting an optimal subset of the data. A combined deep learning (DL) network and a straight-through estimator (STE) [6] to limit the number of sources and receivers when sampling shot gathers was suggested in [7]. Thus, balancing between limiting the number of sources, but still optimizing the selection of sources for the reconstruction of shot gathers. A combination of generative adversarial network (GAN) and CS was proposed in [8] that introduced shot gather reconstruction based on conditional-GAN combined with a repeated creation of sampling schemes to optimize the placement of sources near surface obstacles. In the same context, Jiang et al. [9] utilized GAN to create a transformed domain that connects a CS-based sampling of the seismic data to the original, non-sampled data. Nevertheless, all the above works focus on seismic data reconstructing, rather than inversion. Improving FWI with DL is a developing field of research, including the improvement of initial models [10] or combining DL network with FWI principles to improve reconstruction’s results, like using an iterative approach for a reconstruction [11] and using the wave equation [10,12]. Random shot selection for FWI, which is industry standard for reducing FWI computational load, was proposed in [13]. Methods for improving the calculation of the gradient generated by this selection approach were presented in [14,15].
In previous work, we utilized Compressed Learning (CL) [16], which is a framework for machine learning in the CS domain, for DL-based 3D seismic inversion [17]. In this paper we leverage this approach, and augment it with representation learning to reduce the FWI computational load; by choosing only a small subset of the available seismic data, this step is essential in realistic scenarios where very large volumes of seismic data, on the order of Terabytes, are typically utilized to reconstruct subsurface models.
The contributions to this paper are two-fold: (i) we present a deep learning workflow that first learns candidate compressed sensing layouts, then selects online the best layout for specific data to invert by FWI; and (ii) we introduce the first utilization of representation learning [18] for feature extraction and clustering [19,20] of seismic shot gathers in learned latent space for inversion. The rest of this paper is organized as follows: Section 2 presents theoretical background on FWI and the main ingredients of the proposed solution: compressed learning and sensing, and representation learning. Section 3 presents the two-stage solution, including deep compressed learning and shot gathers clustering by representation learning. Performance evaluation is presented in Section 4, and conclusions are discussed in Section 5.
2. Theoretical Background
FWI is a seismic imaging technique that uses the full seismic wavefield to create high-resolution subsurface models. It works by iteratively adjusting a subsurface model until synthetic data generated from the forward operator matches the observed seismic data . FWI minimizes the following loss function:
where is the number of shots (i.e., seismic sources). Therefore, the complexity of minimizing is linear in , which motivates FWI running time reduction by selecting only a small subset of the shots that are the most relevant for the inversion process. is a forward operator, which numerically solves seismic waves propagation through the mechanical medium ( ). In this work, we simulated seismic waves using the acoustic approximation [21], represented by the following wave equation:
where is the seismic wave displacement, is the P-wave velocity model and is the perturbation source (i.e., shot) function. The relationship between the forward operator and the wave displacement can be described as: where is a detection operator, responsible for obtaining the values calculated by the propagation simulation.
To reduce the number of utilized shots we designed a compressed learning [16] deep network, detailed in Section 3, that performed compressed sensing of the shots. Compressed Sensing (CS) enables reconstruction of a signal from a small number of linear projections (i.e., measurements) measurements, under certain assumptions as detailed in the following. Given a signal an sensing matrix (such that ) and a measurements vector , the goal of CS is to recover the signal from its measurements. According to CS theory [22], signals that have a sparse representation in the domain of some linear transform can be exactly recovered with high probability from their measurements. While CS was originally developed for general sensing matrices, it was extended [23] to binary sensing matrices. Compressed Learning (CL) is the extension of CS to solve machine learning problems in the CS domain. CL was introduced in [16], which proved that direct inference from the compressive measurements is possible with high accuracy in Support Vector Machines. CL extensions to deep learning were introduced by [24,25].
In this work, we employed for the first time representation learning (RL) [26] to analyze seismic traces in latent space. RL is utilized for automatic discovery of useful features from raw data, without relying on manual feature engineering. For RL we utilized an autoencoder, composed by a cascade of encoder and decoder sub-networks. The encoder maps a seismic signal to a reduced dimension latent representation , namely . The decoder reconstructs the signal from the latent representation, namely . The latent representation retains essential information, enabling tasks such as denoising, compression, anomaly detection and inference, among others, to be performed [18,19].
3. Deep Compressed Learning and Representation Learning in FWI
We designed a 2D Deep Compressed Learning (DCL) architecture (Table 1) that jointly optimizes shots selection and the inversion of the selected shots. A sensing layer for shot selection was designed using a straight-through estimator [6] to create learnable binary weights for all available shots (i.e., ‘1’ indicates a selected shot and ‘0’ non-selected shot). This layer utilizes a binarization function, , returning ‘1’ if and ‘0’ otherwise, where is a learnable weight. The binarization function’s derivative is discontinuous and has an indefinite value, making it unsuitable for back-propagation. As a result, we employ the binarization function for the forward-pass but substitute the hard-sigmoid function [6] for the backward-pass. This architecture was trained by minimizing the following mixed loss function:
where MAE is mean absolute error, represent the ground-truth and predicted velocity models, respectively. Here, the reconstructed velocity model can be written as . Where represents the shot gathers of and ⊙ is the element-wise multiplication operator. serves as DL reconstruction operator. are the target and learned sensing rates, respectively, and controls the trade-off between the two misfit terms. The learned sensing rate is defined as , where is the i-th binarized coefficient of the sensing layer. The binarized coefficient’s gradient is estimated using a STE. The loss function measures two misfit terms: the mean absolute error (MAE) between the ground-truth velocity model and the reconstructed one , provided by the DL reconstruction operator, whose input is the compressive sensed subset of shot gathers, denoted by ; and the squared error between the target sensing rate and the learned sensing rate . Thus, the optimization of is based on these two misfit terms. Training the DCL model yields two outputs: a set of selected shot gathers (i.e., learned sensing pattern) and a reconstructed velocity model, not used in this work.
We observed that training the DCL multiple times resulted in different sensing patterns for velocity model reconstruction with comparable high quality (SSIM ). This variability, namely having several equally good sensing patterns, is reasonable and was also reported by [4] in the context of CS for shot gather reconstruction. Therefore, for all the velocity models in the training data, we can learn multiple sensing patterns of shot gathers, by multiple training of the DCL network. However, applying each one of the learned patterns on new unseen data (i.e., selecting different subsets of shots), will not necessarily provide equally good results, and requires identifying the best sensing pattern for the specific data to invert by an additional selection step.
Let denote a set of P vectors, where each represents a sensing pattern for selecting K shot gathers from a total of N sources, aimed at achieving high-quality reconstruction of the velocity model . Let denote a set of N shot gathers, here each , where are the number of receivers and time-samples, respectively.
Representation learning: we employed a convolutional auto-encoder (CAE) for mapping shot gathers to compact latent representations. The encoder sub-network E projects the shot gather into a low-dimensional latent representation , where and . The decoder sub-network (including the bottleneck) D, reconstructs the CAE input as .
We further applied K-means, denoted by , using the latent representations as feature vectors, to create K clusters [20,27]. The clustering process results in N labels (one per shot): where . Let us denote a set as a subset of shot gathers that belong to class . The subset includes only the labels associated with the shot gathers specified by , defined by
The underlying assumption is that a highly informative sensing pattern would include shot gathers from as many clusters as possible. To quantify this, we assign a diversity score to each recommendation vector , calculated as the number of unique elements in : , and selected the sensing pattern vector with the highest diversity score. In cases where multiple vectors achieve the same maximum value of , we introduce a distance score , defined as the sum of pairwise Euclidean distances between the latent representations of the shot gathers within :
The underlying assumption is that higher average distance between shot gathers in the latent space, namely a higher score, indicates that more unique information is carried by these shots, and therefore more relevant for inversion. The complete solution is summarized in Figure 1 and Algorithm 1. Algorithm 1: Shots Sensing Pattern Selection.
3.1. Dataset Preparation
We created a dataset of 5800 layered 2D velocity models with 5–8 layers using GemPy [28], with velocity ranging between 2 to 4.5 km/s. The dataset was split into the following disjoint sets; deep learning models (DCL and autoencoder) training and validation 5500 and 250 models, respectively, and 50 testing models for FWI evaluation. Each velocity model represented an area of 2 km × 1 km (width × depth) discretized to a grid of 288 × 144 points. The spacing between grid points was set at 6.99 m. Receivers were placed at every other grid point along the lateral dimension. Each shot gather was recorded for a period of one second. For each velocity model, 20 shot gathers were generated, with shots positioned uniformly along the 2 km lateral dimension.
3.2. Deep Learning Architectures and Training
Table 1 and Table 2 present the two deep learning architectures used in our experiments. Table 1 describes our proposed DCL architecture, where all convolution layers include ReLU activations. IN* denotes instance normalization layer, and Enc1* denotes an encoder layer without max pooling. For the STE, we initialized the model randomly while ensuring that the number of initially selected shot gathers matched the target value. This design enables monitoring of how far the STE deviated from its initial configuration during training. The initial weight for a binary ‘1’ was set to 0.25, and for a binary ‘0’ to −0.25. Table 2 presents the autoencoder architecture used to encode shot gathers (output of Enc5) for K-means clustering. Prior to training the autoencoder, all shot gathers were normalized to [−1, 1] for consistent input scaling. ADAM optimizer was used for training all deep learning models, experiments were conducted on NVIDIA GraceHopper GH200 GPUs.
4. Performance Evaluation
As a reference for all experiments, FWI experiments were conducted using the complete set of 20 shot gathers on the 50 test velocity models (not used during training or validation of the deep learning models). Following standard practice, we initialized the FWI executions with smoothed version of the ground-truth velocity model. We then repeated the FWI experiments on the same testset of velocity models, but using randomly selected subsets of 2, 3, 4, and 5 shot gathers. For each of these configurations, the shot gathers were randomly chosen prior starting FWI. To ensure statistical robustness, we repeated the random selection experiments three times for each velocity model.
All FWI experiments were undertaken following stopping conditions: (i) Early stopping after 10 iterations without decrease in the loss function ; or (ii) Early stopping upon reaching , a threshold beyond which we observed no significant improvements in velocity model reconstruction; or (iii) a limit of 500 iterations. All FWI experiments were performed on computing nodes supporting AMD Genoa-X multi-core. We trained three times each DCL architecture (i.e., for 2, 3, 4, and 5 shot gathers). This resulted in a total of twelve distinct shot gather sensing layers (three per sensing rate). Since we used 50 velocity models for testing, this lead to 150 FWI runs per sensing rate. Next, FWI experiments were carried out using each DCL-learned sensing layer, with standard smoothed initial velocity model. In the final stage, we applied the proposed solution (DCL-RL) to select the shots for FWI, and evaluated inversion quality. Figure 2 presents examples of FWI results under the different strategies for shot selection, and Figure 3 summarizes measured FWI running times for the different number of selected shots, clearly indicating the potential of accelerating FWI.
Table 3 summarizes the results of all experiments above with noiseless data. Inversion quality trends were observed as follows: (i) as expected, FWI utilizing a randomly selected subset of the available shots produced less accurate models as compared to using all 20 shots. (ii) DCL-based shot selection vs. random selection, is sometimes better but not for all sensing rates. (iii) the proposed DCL-RL solution consistently outperforms random shot selection in terms of mean absolute error (MAE, lower is better), structural similarity (SSIM, higher is better) and Peak Signal-to-Noise Ratio (PSNR, higher is better), for all sensing rates. Table 4 summarizes the results of all experiments above with noisy date (additive Gaussian noise at SNR = 10 dB), clearly demonstrating the advantage of DCL-RL as compared to random selection, also in the presence of noise.
5. Conclusions
We presented a novel solution for seismic sources (e.g., shots) selection in FWI by utilizing auxiliary compressed learning and representation learning deep neural networks. The proposed DCL-RL solution achieved consistent advantage in FWI model reconstruction quality as compared to random shot selection, which is often used in practice. Our study also reveals that the advantage of DCL-RL increases for the lower sensing rates (e.g., almost 3dB PSNR advantage at 10% sensing rate). These results pave the way for FWI acceleration in large scale surveys with very large numbers of shots gathers, especially (but not limited to) 3D surveys. Future work should evaluate this method on larger and more diverse 2D and 3D testsets.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Virieux J. Operto S. An overview of full-waveform inversion in exploration geophysics Geophysics 200974 WCC 1WCC 2610.1190/1.3238367 · doi ↗
- 2Wang X. Wang Z. Lei X. Zhu C. Gao J. Seis-PDDN: Seismic Undersampling Design and Reconstruction Using Prior Distribution and Diffusion Null-Space Iteration IEEE Trans. Geosci. Remote Sens.202462593231310.1109/TGRS.2024.3485579 · doi ↗
- 3Xu Y. Yu S. Active sampling design for seismic data based on dynamic matching distance Proceedings of the SEG International Exposition and Annual Meeting SEG Houston, TX, USA 2024 SEG-2024
- 4Titova A. Wakin M.B. Tura A.C. Achieving robust compressive sensing seismic acquisition with a two-step sampling approach Sensors 202323951910.3390/s 2323951938067893 PMC 10708780 · doi ↗ · pubmed ↗
- 5Verschuren M. Araya-Polo M. Directional Full-Wave Scatter Source Modelling and Dip-Sensitive Target-Oriented RTM Annu. Eage Meet. Proc.201720171510.3997/2214-4609.201700525 · doi ↗
- 6Hubara I. Courbariaux M. Soudry D. El-Yaniv R. Bengio Y. Binarized neural networks Adv. Neural Inf. Process. Syst.201629
- 7Hernandez-Rojas A. Arguello H. Design of Undersampled Seismic Acquisition Geometries via End-to-End Optimization IEEE Trans. Geosci. Remote Sens.202462590141310.1109/TGRS.2023.3339119 · doi ↗
- 8Zhang X. Zhang S. Lin J. Sun F. Zhu X. Yang Y. Tong X. Yang H. An Efficient Seismic Data Acquisition Based on Compressed Sensing Architecture with Generative Adversarial Networks IEEE Access 2019710594810596110.1109/ACCESS.2019.2932476 · doi ↗