Stereo Gaussian Splatting with Adaptive Scene Depth Estimation for Semantic Mapping
Chenhui Fu, Jiangang Lu

TL;DR
This paper introduces StereoGS-SLAM, a new system for mapping environments using stereo cameras and 3D Gaussian Splatting, improving accuracy and efficiency in robotics and AR.
Contribution
The novel contribution is StereoGS-SLAM, which uses stereo inputs and adaptive depth estimation for real-time semantic mapping without active depth sensors.
Findings
StereoGS-SLAM achieves robust and scale-consistent reconstruction using passive RGB stereo inputs.
The hybrid keyframe selection strategy improves keyframe diversity and maintains real-time optimization.
Experiments show competitive performance in localization, rendering, and semantic reconstruction compared to existing systems.
Abstract
Simultaneous Localization and Mapping (SLAM) is a fundamental capability in robotics and augmented reality. However, achieving accurate geometric reconstruction and consistent semantic understanding in complex environments remains challenging. Although recent neural implicit representations have improved reconstruction quality, they often suffer from high computational cost and the forgetting phenomenon during online mapping. In this paper, we propose StereoGS-SLAM, a stereo semantic SLAM framework based on 3D Gaussian Splatting (3DGS) for explicit scene representation. Unlike existing approaches, StereoGS-SLAM operates on passive RGB stereo inputs without requiring active depth sensors. An adaptive depth estimation strategy is introduced to dynamically refine Gaussian scales based on real-time stereo depth estimates, ensuring robust and scale-consistent reconstruction. In addition, we…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
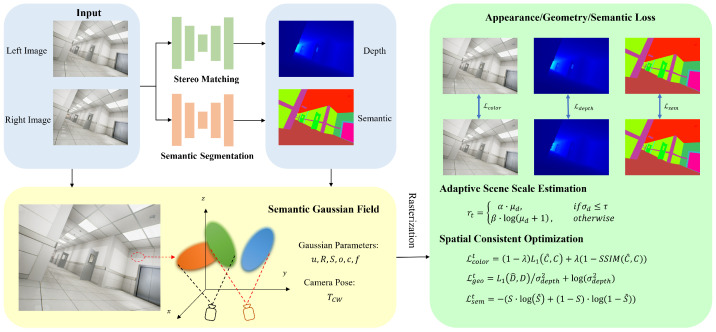 Figure 1
Figure 1 Figure 2
Figure 2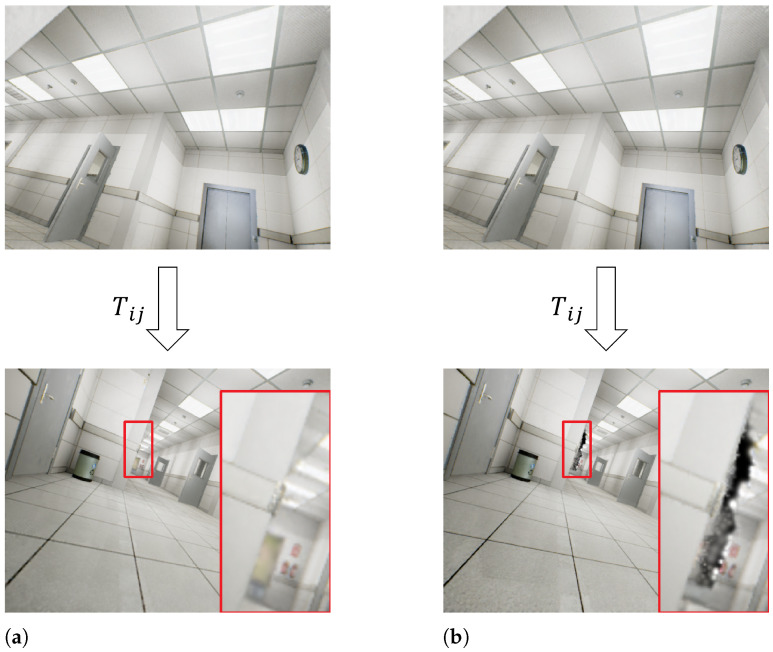 Figure 3
Figure 3 Figure 4
Figure 4- —National Natural Science Foundation of China
- —Zhejiang Province Science and Technology Plan Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Advanced Vision and Imaging · Robot Manipulation and Learning
1. Introduction
With the rapid development of robotics and augmented reality, SLAM systems have received increasing attention in recent years. Traditional SLAM methods [1,2,3] primarily rely on sparse feature points or geometric primitives to represent the environment. Although they offer high computational efficiency, these methods often struggle to provide rich semantic understanding and accurate geometric reconstruction in complex and dynamic environments. To overcome these limitations, researchers have explored the integration of semantic information into SLAM frameworks to enhance environmental perception and system robustness.
3DGS has recently emerged as an explicit and differentiable scene representation technique in the SLAM domain [4]. Compared with traditional implicit methods, 3DGS enables faster rendering and higher reconstruction accuracy by allowing gradients to flow directly to the parameters of each Gaussian [5], establishing an almost linear relationship between photometric loss and Gaussian parameters during optimization. However, existing 3DGS-based SLAM systems predominantly depend on RGB-D sensors for depth acquisition, which limits their deployment in scenarios where active depth sensors are unavailable. Additionally, while recent studies have attempted to incorporate semantic information into the 3DGS framework, challenges remain in maintaining semantic consistency and spatial alignment, particularly in scenes with large depth variations.
To address these issues, this paper proposes StereoGS-SLAM, a stereo semantic 3DGS SLAM system. Our method utilizes a deep stereo matching network to predict dense depth maps from passive stereo RGB inputs, eliminating the need for active depth sensing. An adaptive scene depth estimation strategy dynamically adjusts the Gaussian scales based on real-time stereo depth estimates, enhancing reconstruction quality and robustness across diverse depth ranges. Furthermore, semantic information is integrated into the Gaussian optimization process to improve both semantic consistency and spatial alignment accuracy. The main contributions of this work are summarized as follows:
- We present StereoGS-SLAM, a system-level integration of stereo depth, 3DGS mapping, and semantic optimization that operates exclusively on passive stereo pairs without requiring active depth sensing;
- We design an adaptive scene depth estimation strategy that refines Gaussian scales and improves robustness under large depth variations, emphasizing scale stability within the existing rendering pipeline;
- We develop a hybrid keyframe selection mechanism that combines motion-triggered and fixed-interval policies with stochastic keyframe sampling to improve keyframe diversity and reduce optimization bias.
2. Related Work
2.1. Traditional Dense Semantic SLAM
Traditional dense semantic SLAM systems typically adopt explicit 3D structures (e.g., voxels, surfels, point clouds, or signed distance fields) to fuse geometry and semantics over time. SLAM++ [3] represents scenes with object-level models, while Co-Fusion [6] and SemanticFusion [7] maintain dense maps with object segmentation and CNN-based semantics. VSO [8] exploits semantics to improve robustness, and QuadricSLAM [9] introduces compact quadric landmarks. Despite their interpretability and mature fusion pipelines, these methods often rely on memory-intensive map representations and careful engineering to maintain real-time performance at high resolution. Moreover, many dense pipelines benefit strongly from direct depth measurements (RGB-D or depth sensing) to stabilize reconstruction; when depth is unavailable or unreliable, maintaining globally consistent dense geometry becomes substantially harder. As a result, extending such systems to passive stereo settings while preserving both geometric fidelity and semantic consistency remains non-trivial.
2.2. Neural Implicit and 3DGS SLAM
Neural implicit methods, particularly NeRF, model scenes continuously with MLPs but typically require expensive ray-based rendering and optimization, which limits real-time dense mapping and exacerbates online failure modes such as catastrophic forgetting [10]. Systems such as iMAP [11], NICE-SLAM [12], ESLAM [13], Vox-Fusion [14], and GO-SLAM [15] improve scalability, yet their performance is still often bounded by the computational cost of implicit rendering and the sensitivity of incremental optimization.
3D Gaussian Splatting (3DGS) provides an explicit, differentiable representation with efficient splatting-based rendering [4], making it attractive for SLAM. Compared with NeRF-style implicit models, 3DGS avoids costly volumetric rendering and enables faster optimization with explicit primitives; compared with voxel-based methods, it offers a more compact continuous representation without dense voxel grids, while still supporting efficient rendering. MonoGS [16] leverages monocular depth priors, SplaTAM [5] adopts parallel tracking/mapping for efficiency, and GS-SLAM [17] incorporates monocular depth for scale-related initialization. Semantic extensions such as GS3LAM [18], NEDS-SLAM [19], SDD-SLAM [20], and GSORB-SLAM [21] further integrate semantic cues into Gaussian maps. However, existing Gaussian-based SLAM pipelines still depend on RGB-D inputs or learned monocular depth, which restricts deployment in scenarios without active depth sensors or with poor depth generalization. In addition, 3DGS optimization is sensitive to scale initialization: large depth-range variations across frames can lead to over- or undersized Gaussians, degrading convergence stability and reconstruction fidelity, yet scale-consistent mapping under such variations is less explored in prior work.
Overall, these limitations motivate a stereo-only 3DGS semantic SLAM framework that avoids reliance on active depth sensing and enforces scale consistency via adaptive depth-driven Gaussian scaling under large depth-range variations. This work aims to advance recent 3DGS-based SLAM pipelines by addressing specific practical limitations in stereo-only deployment and scale stability.
3. Method
The overview of our proposed StereoGS-SLAM system is illustrated in Figure 1, and the algorithmic formulation is summarized in Algorithm 1. Given a set of stereo images, we first employ a pre-trained stereo network [22] to estimate dense disparity images. The network is pre-trained on the SceneFlow dataset and further fine-tuned on target datasets. During SLAM operation, the network parameters are kept frozen to ensure real-time performance while providing robust depth estimates. Based on the estimated disparity images and the camera intrinsic parameters, dense depth maps are subsequently computed. These maps offer rich geometric guidance for the 3DGS optimization process, benefiting from their high spatial density and more complete scene coverage. Algorithm 1 StereoGS-SLAM Overview
- Require: Stereo image stream , camera intrinsics, pre-trained stereo and semantic networks
- Ensure: Camera poses and Gaussian map
- 1:Initialize , set , select initial keyframe set
- 2:for each time step t do
- 3: Estimate disparity and depth; compute depth statistics
- 4: Initialize Gaussians from depth and colors
- 5: Render from and
- 6: Tracking: optimize by minimizing
- 7: Update keyframe set using the hybrid selection strategy
- 8: Mapping: sample and optimize via
- 9: Update semantic decoder and semantic features
- 10: Apply adaptive scene depth estimation to refine Gaussian scales
- 11:end for
3.1. 3D Gaussian Scene Representation
We generate the dense Gaussian scene representation following the method in [4],
where N is the number of Gaussians. Each Gaussian is defined by its 3D position in the world coordinate system, 3D covariance matrix , opacity , RGB color , and semantic feature ( denotes the number of objects in the scene).
With the 3D Gaussian scene representation parameters, we render multiple modalities at each pixel using the differentiable Gaussian splatting technique [4], including color, depth, and semantic features. Given the camera pose , the i-th 3D Gaussian is projected onto the 2D image plane for rendering, with
where is the Jacobian matrix of the projection function of the i-th Gaussian, and is the rotation part of the camera pose . After projection, the color of a single pixel is rendered by sorting the Gaussians in depth order and performing front-to-back -blending,
where represents the color of the i-th Gaussian, is the density computed by the opacity and the 2D covariance matrix as,
where is the offset vector from the pixel center to the projected mean of the i-th Gaussian. Similarly, the depth at each pixel is rendered as,
where denotes the depth of the i-th Gaussian centroid in the camera coordinate system.
Compared with 3D semantic information, the 2D semantic label is more accessible prior. Additionally, it is memory-inefficient to directly store a high-dimensional semantic feature vector in each Gaussian. Instead, we follow the same procedure as color and depth rendering. The semantic feature at each pixel is computed as,
where represents the semantic feature vector for the i-th Gaussian, with denoting the number of semantic classes. The semantic features are initialized from semantic segmentation predictions produced by the segmentation network [23] on RGB images, which provide the semantic signals used during online operation.
To decode the semantic label at each pixel, we utilize a lightweight CNN decoder to map the aggregated semantic features to semantic predictions,
where the semantic decoder is implemented as a single convolutional layer that transforms the input semantic feature dimension to the number of semantic classes. The decoder is trained end-to-end with the Gaussian optimization process. Specifically, the decoder weights are initialized randomly and updated jointly with Gaussian semantic features using the Adam optimizer. The semantic decoder and Gaussian semantic features are optimized simultaneously to ensure consistency between the 3D scene representation and semantic understanding. This joint optimization strategy allows the system to refine initial SAM-based semantic predictions based on the reconstructed 3D scene geometry and photometric consistency, leading to more accurate and spatially coherent semantic segmentation results.
We encode semantic information directly in the Gaussian primitives via the learnable features , which are initialized from 2D semantic predictions and then optimized jointly with geometry. During rendering, the semantic features are splatted and composited using the same opacity-aware accumulation as color and depth, so each pixel receives a weighted mixture of nearby Gaussians along the ray. This effectively spreads semantic cues across neighboring primitives while preserving spatial coherence through the Gaussian support and the visibility weights. The subsequent decoder maps the aggregated feature to class probabilities, and the semantic loss provides feedback that updates both and the decoder, encouraging consistent semantic labels across the map.
We also render a silhouette image to determine the cumulative opacity for each pixel,
3.2. Adaptive Scene Depth Estimation
The variations in depth range across different frames result in significant variance in the 3D Gaussian scales corresponding to these frames, leading to overly large or small Gaussian spheres that degrade reconstruction quality and system robustness. To address this limitation, we propose a novel adaptive scene depth estimation strategy. This strategy dynamically estimates and updates the scene depth, enabling more accurate Gaussian initialization and optimization.
For each incoming frame, we derive robust geometric characteristics from the depth distribution to characterize the scene properties. Based on these depth characteristics, we formulate an adaptive scene radius computation that accounts for both local scene characteristics and global scale variations. The adaptive scaling mechanism employs different strategies for uniform and complex scenes: for relatively uniform depth distributions, we use linear scaling of central depth values, while for scenes with significant depth variations, we apply logarithmic transformation to balance the scale estimation for both near and far objects. The adaptive scene radius computation is defined as,
where is the median depth, is the depth standard deviation, is a scene depth threshold, and are scaling parameters.
To ensure temporal consistency and prevent abrupt scale variations that could destabilize the system, we apply a temporal smoothing mechanism based on an exponential moving average with a smoothing factor , which balances responsiveness and stability. The resulting adaptive scene depth estimate is then integrated into the Gaussian mapping pipeline. Specifically, during Gaussian scale initialization, the mean squared distances are modulated using the estimated scene depth. This strategy allows the system to effectively handle scenes with varying depth ranges and remain robust under sparse or noisy depth measurements. As the scene depth range evolves over time, the mean Gaussian scale is designed to adapt accordingly rather than strictly converge, reflecting the intended response to changing scene geometry.
3.3. Spatial Consistency Mapping
Initial Gaussians are generated from all pixels, as the rendered silhouette map is initially empty. Each Gaussian is initialized with the following properties: color sampled from the corresponding pixel, center position determined by unprojecting the stereo-estimated depth, opacity fixed at 0.5, semantic features randomly initialized using spherical harmonics representation, and radius initialized based on the adaptive scene depth estimation to maintain appropriate projection size in the image plane.
After tracking a frame, we enforce spatial consistency in the Gaussian representation through an adaptive expansion strategy. New Gaussians are selectively introduced only in spatial regions that are inadequately represented by existing elements, ensuring comprehensive yet efficient scene coverage. Spatial consistency is maintained by utilizing cumulative opacity and depth information to construct an unobservable region mask ,
where denotes the indicator function, represents the cumulative opacity threshold for unobservable regions, indicates the -norm, and corresponds to the median -norm error between rendered and stereo-estimated depth.
The mapping objective aims to produce a spatially coherent and detailed 3D representation consistent across all observed frames. This is achieved through joint optimization of all Gaussian parameters by minimizing a comprehensive rendering-based objective function. To reduce optimization bias and enhance global map consistency, we employ a random keyframe sampling strategy during mapping. Instead of optimizing all keyframes in each iteration, we randomly sample a subset of keyframes, which discourages overfitting to recent observations and maintains a more balanced representation of the scene. The color loss combines -norm with structural similarity (SSIM) between rendered and observed colors,
where and C represent rendered and ground truth colors, respectively, with as the balancing factor.
The geometric loss incorporates depth uncertainty to enhance the geometric accuracy of the reconstructed scene,
where and D denote the rendered and estimated depth, respectively, and represents the depth uncertainty estimated from the stereo matching process. The depth uncertainty is computed based on the reliability of stereo depth estimation, with higher uncertainty assigned to regions where depth estimation is less reliable, derived from both local disparity gradient consistency and image gradient information to provide robust depth estimates across different scene regions. Specifically, the depth uncertainty is formulated as,
where denotes the 2D pixel coordinate in the image plane, denotes the Euclidean norm of the disparity gradient measuring local disparity variation, denotes the 90th percentile of disparity gradient magnitudes over the entire image used as a normalization factor, denotes the Euclidean distance from pixel to the nearest image edge extracted using the Canny operator, and denotes a normalization constant controlling the influence range of image edges on the confidence value.
The semantic consistency loss is formulated as a multi-class cross-entropy (softmax + CE),
where S is a one-hot semantic label and is the decoded class-probability vector at each pixel.
The composite mapping loss incorporates awareness of unobservable regions while jointly optimizing color, geometric, and semantic consistency,
where , , and are the color, geometric, and semantic consistency loss weights, respectively.
3.4. Tracking and Keyframe Selection
Given a Gaussian scene representation , the camera pose initialization follows a constant-velocity model in [24],
In implementation, this is approximated as first-order extrapolation of rotation and translation parameters:
where q is the camera quaternion and is translation. To ensure accurate camera pose estimation, only those rendered pixels with reliable depth information are factored into the tracking loss function. Then the camera pose is updated iteratively by gradient descent optimization through differentiably rendering color, depth, and semantic maps, minimizing the following loss function,
where simply employs the -norm between the rendered image and the ground truth, , , and are the weights for each term.
To address the limitations of fixed-interval keyframe selection, we propose a hybrid keyframe selection strategy that combines adaptive motion-based selection with a fixed-interval fallback mechanism. The motion-aware selection computes the relative transformation between the current frame and the most recently selected keyframe, estimating rotation angle and translation distance d,
where and are the rotation matrix and translation vector of the relative transformation, respectively. If either or 0.1 m, the current frame is selected as a keyframe. Otherwise, the method defaults to fixed-interval selection for temporal regularity.
Additionally, special handling ensures robust initialization and completion: the first and final frames are always selected as keyframes. We implement random keyframe sampling during optimization, selecting a subset of keyframes each iteration to reduce computational load while maintaining global map consistency.
4. Experiment
4.1. Experimental Setup
Datasets. To compare with other neural explicit SLAM methods, we evaluate our method on both the synthetic dataset (TartanAir [25]) and the real-world dataset (EuRoC [26]). Both datasets provide stereo image sequences along with ground truth camera poses. Due to memory constraints, each sequence runs a fixed number of frames to ensure a comprehensive evaluation.
Evaluation Metrics. Following [5,18,19], we use ATE for pose evaluation, PSNR/ SSIM [27]/LPIPS [28] for rendering quality, and mIoU for semantic accuracy (from dataset-provided annotations used only for evaluation). We also report Depth L1 between rendered depth and stereo-estimated depth as an internal geometric-consistency indicator, not as an independent depth benchmark.
Baseline. For tracking and mapping, we compare with classical stereo visual odometry such as SDSO [29], VINS-Fusion [30] and ORB-SLAM3 [31], as well as several recent representative 3DGS-based methods, including MonoGS [16], Photo-SLAM [32], SplaTAM [5] and GS3LAM [18]. For semantic reconstruction, our method is compared with NICE-SLAM [12], GS3LAM [18], and SGS-SLAM [33]. We explicitly distinguish baseline result sources as: R (re-run by us on the RTX 4090 platform under matched input settings) and P (numbers reported in the original papers when full reproducibility assets are unavailable). R: {SGS-SLAM, SplaTAM, GS3LAM, MonoGS, NICE-SLAM, SDSO, ORB-SLAM3, VINS-Fusion}; P: {Photo-SLAM not re-run due to reproducibility-asset limitations}.
Implementation Details. Experiments are run on an NVIDIA RTX 4090 GPU (24 GB) and a 16-core Intel Xeon(R) Gold 6430 CPU. The stereo network is pre-trained on SceneFlow [34] and fine-tuned only on designated training splits (evaluation sequences excluded), then kept frozen during SLAM inference; the semantic network is pre-trained on SA-1B [23]. Unless stated otherwise, StereoGS-SLAM results are averaged over 10 random seeds and reported as mean ± standard deviation, with 95% CI ( ) provided in supplementary statistics. Runtime is profiled as ms/frame and FPS at 640 × 480 (TartanAir) and 752 × 480 (EuRoC). Tracking uses learning rates for camera rotation/translation and 0 for Gaussian parameters; mapping uses 0.0001 (means3D), 0.0025 (RGB/semantic), 0.001 (rotation/log-scales), and 0.05 (opacity), with semantic-decoder Adam LR . Pruning is enabled every 20 iterations with an opacity threshold of 0.005. Full execution order, trigger conditions, pseudocode, and default parameters are provided in Appendix A (Algorithm A1, Table A1).
4.2. Rendering Evaluation
Table 1 compares rendering performance on TartanAir. Although competing methods leverage ground-truth depth, our stereo method achieves the best overall performance across sequences. These gains are attributed to adaptive scale refinement and semantic-aware optimization. Figure 2 provides a qualitative comparison, where StereoGS-SLAM yields sharper boundaries and fewer artifacts under large depth variations.
Table 2 reports the quantitative evaluation of reconstruction quality on the EuRoC dataset. The proposed method shows consistent improvements across most sequences, demonstrating strong robustness and generalization in real-world scenarios. Since Photo-SLAM provides results for only four sequences, our evaluation is restricted to those subsets. These results indicate that our system handles challenging real-world conditions, including dynamic environments and textureless surfaces frequently encountered in practical robotic applications.
Stereo vs. RGB-D Depth Quality. When comparing against RGB-D baselines, it is important to account for the sensing modality. RGB-D sensors provide direct depth measurements, but their depth accuracy and resolution typically degrade with increasing range [35]. Stereo depth is inferred from disparity; small disparity errors can induce depth errors that grow with distance, and matching is particularly difficult in textureless, occluded, or illumination-varying regions [36,37]. Consequently, RGB-D pipelines may benefit from higher-quality depth inputs under favorable conditions, while passive stereo methods can be disadvantaged in challenging scenes. Our results indicate that StereoGS-SLAM remains competitive despite operating under this more demanding stereo-depth setting.
4.3. Tracking Evaluation
Table 3 summarizes the tracking performance on the TartanAir dataset. We compare the proposed StereoGS-SLAM with widely used traditional SLAM methods and recent 3DGS-based SLAM systems. For re-running traditional SLAM baselines, loop closure detection is disabled to reduce pipeline-side advantages under different back-end settings. Both SDSO and VINS-Fusion experience tracking failures due to their high sensitivity to photometric variations within the scenes. Benefiting from the incorporation of spatial stereo constraints during the tracking stage, StereoGS-SLAM achieves higher tracking accuracy compared with other 3DGS-based methods on our tested sequences. jimaging-12-00105-t001_Table 1Table 1Qualitative Rendering Evaluation on TartanAir (mean ± std).MethodMetricHospitalCar WeldingOfficeAvg.P000P001P002P001P002P004P000P001P002 SplaTAM [5]PSNR ↑26.255 ± 0.14420.69 ± 0.09126.161 ± 0.22614.438 ± 0.00514.983 ± 0.19314.048 ± 0.22123.754 ± 0.10926.138 ± 0.27220.421 ± 0.27820.765 ± 0.171SSIM ↑0.907 ± 0.0080.861 ± 0.0090.956 ± 0.0080.581 ± 0.0040.77 ± 0.0110.505 ± 0.0100.884 ± 0.0100.944 ± 0.0110.824 ± 0.0060.804 ± 0.009LPIPS ↓0.147 ± 0.0110.277 ± 0.0160.072 ± 0.0170.482 ± 0.0120.241 ± 0.0070.478 ± 0.0150.215 ± 0.0140.115 ± 0.0190.226 ± 0.00130.250 ± 0.013MonoGS [16]PSNR ↑22.621 ± 0.28120.627 ± 0.12828.375 ± 0.28916.002 ± 0.25519.911 ± 0.19117.22 ± 0.20425.596 ± 0.00625.67 ± 0.17720.018 ± 0.08821.782 ± 0.180SSIM ↑0.835 ± 0.0120.688 ± 0.0180.841 ± 0.0120.488 ± 0.0110.641 ± 0.0080.411 ± 0.0170.876 ± 0.0190.869 ± 0.0070.712 ± 0.0050.707 ± 0.012LPIPS ↓0.363 ± 0.0130.497 ± 0.0150.162 ± 0.0110.53 ± 0.0120.423 ± 0.0220.37 ± 0.0140.244 ± 0.0150.222 ± 0.0130.382 ± 0.0150.355 ± 0.014SGS-SLAM [33]PSNR ↑26.714 ± 0.04420.998 ± 0.18926.124 ± 0.01213.348 ± 0.15715.097 ± 0.26714.168 ± 0.23823.248 ± 0.26126.158 ± 0.16519.982 ± 0.18820.649 ± 0.169SSIM ↑0.917 ± 0.0070.880 ± 0.0190.958 ± 0.0120.565 ± 0.0080.771 ± 0.0110.510 ± 0.0150.862 ± 0.0180.940 ± 0.0160.805 ± 0.0150.801 ± 0.013LPIPS ↓0.138 ± 0.0160.255 ± 0.0060.070 ± 0.0040.492 ± 0.0040.241 ± 0.0110.474 ± 0.0190.245 ± 0.0110.120 ± 0.0160.249 ± 0.0160.254 ± 0.011GS3LAM [18]PSNR ↑27.988 ± 0.13920.025 ± 0.16227.741 ± 0.24414.935 ± 0.21016.927 ± 0.22318.072 ± 0.05625.084 ± 0.13126.817 ± 0.25322.17 ± 0.16022.195 ± 0.175SSIM ↑0.939 ± 0.0130.849 ± 0.0070.953 ± 0.0080.565 ± 0.0050.837 ± 0.0180.743 ± 0.0130.915 ± 0.0070.948 ± 0.0040.859 ± 0.0040.845 ± 0.009LPIPS ↓0.116 ± 0.0060.28 ± 0.0030.067 ± 0.0040.494 ± 0.0170.188 ± 0.0170.276 ± 0.0050.171 ± 0.0030.108 ± 0.0120.185 ± 0.0150.209 ± 0.009OursPSNR ↑29.630 ± 0.28124.084 ± 0.16628.867 ± 0.19719.268 ± 0.04222.102 ± 0.18321.080 ± 0.05126.032 ± 0.06028.744 ± 0.10422.125 ± 0.11424.659 ± 0.102SSIM↑0.962 ± 0.0030.945 ± 0.0040.956 ± 0.0150.731 ± 0.0050.852 ± 0.0110.866 ± 0.0120.932 ± 0.0040.955 ± 0.0070.821 ± 0.0040.891 ± 0.007LPIPS ↓0.090 ± 0.0080.212 ± 0.0040.101 ± 0.0290.389 ± 0.0150.222 ± 0.0120.211 ± 0.0060.151 ± 0.0200.081 ± 0.0150.221 ± 0.0210.186 ± 0.014Note: Green highlighting indicates best performance. Yellow highlighting indicates second-best performance. ↑ denotes higher-is-better and ↓ denotes lower-is-better. SplaTAM, SGS-SLAM, GS3LAM run in RGB-D mode; MonoGS runs in stereo mode. The evaluation is conducted on three scenes: Hospital, Car Welding, and Office, with three different trajectory sequences (e.g., P000, P001, P002) selected from each scene. jimaging-12-00105-t002_Table 2Table 2Qualitative Rendering Evaluation on EuRoC (mean ± std).MethodMetricMH01MH02V101V201Avg.SplaTAM [5]PSNR ↑13.395 ± 0.25215.322 ± 0.01519.578 ± 0.19520.045 ± 0.27617.085 ± 0.185SSIM ↑0.575 ± 0.0180.635 ± 0.0110.800 ± 0.0120.858 ± 0.0090.717 ± 0.013LPIPS ↓0.347 ± 0.0260.345 ± 0.0150.161 ± 0.0160.126 ± 0.0280.245 ± 0.021Photo-SLAM [32]PSNR ↑13.95214.20117.06915.67715.225SSIM ↑0.4200.4300.6180.6220.523LPIPS ↓0.3660.3560.2660.3230.328MonoGS [16]PSNR ↑17.783 ± 0.02015.721 ± 0.00316.332 ± 0.28822.384 ± 0.24418.055 ± 0.139SSIM ↑0.709 ± 0.0080.709 ± 0.0200.767 ± 0.0110.893 ± 0.0030.770 ± 0.011LPIPS ↓0.281 ± 0.0240.227 ± 0.0100.281 ± 0.0250.210 ± 0.0140.250 ± 0.018GS3LAM [18]PSNR ↑16.870 ± 0.11318.002 ± 0.05219.186 ± 0.09320.749 ± 0.11818.702 ± 0.094SSIM ↑0.679 ± 0.0040.776 ± 0.0100.798 ± 0.0150.853 ± 0.0180.777 ± 0.012LPIPS ↓0.287 ± 0.0160.265 ± 0.0140.171 ± 0.0040.125 ± 0.0150.212 ± 0.012OursPSNR ↑18.722 ± 0.15919.154 ± 0.27020.298 ± 0.25822.505 ± 0.18320.170 ± 0.217SSIM ↑0.841 ± 0.0120.759 ± 0.0150.810 ± 0.0100.907 ± 0.0080.829 ± 0.011LPIPS ↓0.214 ± 0.0090.257 ± 0.0120.134 ± 0.0070.126 ± 0.0060.183 ± 0.009Note: Green highlighting indicates best performance. Yellow highlighting indicates second-best performance. ↑ denotes higher-is-better and ↓ denotes lower-is-better. SplaTAM, Photo-SLAM, and GS3LAM run in RGB-D mode, while MonoGS runs in stereo mode. Some baselines are re-run on our hardware while others are paper-reported due to reproducibility limitations.
4.4. Semantic Evaluation
Table 4 presents the quantitative semantic evaluation results in comparison with existing neural semantic SLAM approaches. StereoGS-SLAM achieves strong performance and improves over prior baselines by more than 2% on average. As shown in the table, 3DGS-based methods generally outperform NeRF-based approaches in semantic reconstruction. This is primarily because the explicit Gaussian representation can accurately delineate object boundaries, producing more precise and spatially consistent 3D semantic segmentation. Compared with other 3DGS-based approaches, StereoGS-SLAM further improves semantic reconstruction quality. This improvement arises from the proposed adaptive scene depth estimation mechanism, which dynamically adjusts Gaussian scales to better capture scene geometry. By reducing uncertainty at object surfaces and boundaries, the system achieves stronger geometric-semantic alignment. Additionally, the introduced random sampling-based keyframe mapping strategy reduces optimization bias and improves global semantic consistency.
4.5. Ablation Study
Adaptive Scene Depth Estimation. We isolate the effect of the adaptive scene depth estimation (ASDE) by disabling only this module while keeping all other components unchanged and compare the results with the full system. As illustrated in Figure 3, removing adaptive depth estimation leads to enlarged Gaussian scales near object boundaries, resulting in blurred contours and reduced geometric precision. Quantitative results in Table 5 further confirm this degradation: PSNR decreases by 2.199 dB, SSIM drops by 0.04, and LPIPS increases by 0.03. This indicates that the system becomes less capable of preserving high-frequency structural detail. Moreover, removing dynamic scale adaptation results in a 0.98 cm increase in ATE RMSE, highlighting its importance for stable camera pose estimation across different depth ranges.
Hybrid Keyframe Selection Ablation. We ablate the hybrid keyframe strategy to assess its impact on map consistency and tracking. As shown in Figure 4, removing the strategy yields uneven keyframe coverage and biased sampling, causing over-optimized local regions and under-updated areas. Table 5 shows clear degradations and a higher ATE RMSE, indicating reduced scene coherence and increased pose drift. These results confirm that the hybrid strategy mitigates optimization bias and improves long-term stability.
5. Conclusions
We propose StereoGS-SLAM, a stereo semantic SLAM system that leverages 3DGS for explicit scene representation. Unlike existing approaches, the proposed method operates solely on passive RGB stereo pairs without relying on active depth sensors, thereby improving its applicability in real-world robotic environments. The core technical contributions include an adaptive scene depth estimation strategy that dynamically adjusts Gaussian scales, and a hybrid keyframe selection mechanism that improves keyframe diversity while maintaining computational efficiency. Comprehensive evaluations on the TartanAir and EuRoC datasets show that StereoGS-SLAM achieves competitive performance in camera pose estimation, rendering fidelity, and semantic reconstruction compared with recent 3DGS-based SLAM systems. Our contributions extend the 3DGS-SLAM pipeline by incorporating stereo depth-driven scale adaptation and more stable keyframe optimization, thereby improving both geometric precision and semantic consistency.
6. Future Work
Future work can proceed along several directions. First, improving stereo depth reliability in low-texture or reflective regions could further stabilize mapping, for example, by incorporating uncertainty-aware weighting or temporal consistency in depth estimation. Second, long-term semantic consistency can be strengthened with lightweight temporal regularization and more effective keyframe management. Third, extending the system to additional sensing modalities may improve robustness under fast motion and challenging lighting. Finally, the overall cost still increases as the map expands over long trajectories due to the growth of ; more aggressive map compression and adaptive Gaussian pruning are promising for scalability while preserving rendering and semantic quality.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Davison A.J. Reid I.D. Molton N.D. Stasse O. Mono SLAM: Real-Time Single Camera SLAMIEEE Trans. Pattern Anal. Mach. Intell.2007291052106710.1109/TPAMI.2007.104917431302 · doi ↗ · pubmed ↗
- 2Newcombe R.A. Lovegrove S.J. Davison A.J. DTAM: Dense Tracking and Mapping in Real-Time Proceedings of the 2011 International Conference on Computer Vision Barcelona, Spain 6–13 November 201123202327
- 3Salas-Moreno R.F. Newcombe R.A. Strasdat H. Kelly P.H. Davison A.J. SLAM++: Simultaneous Localisation and Mapping at the Level of Objects Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Portland, OR, USA 23–28 June 201313521359
- 4Kerbl B. Kopanas G. Leimkühler T. Drettakis G. 3D Gaussian Splatting for Real-Time Radiance Field Renderingar Xiv 20232308.0407910.1145/3592433 · doi ↗
- 5Keetha N. Karhade J. Jatavallabhula K.M. Yang G. Scherer S. Ramanan D. Luiten J. Spla TAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLA Mar Xiv 20242312.02126
- 6Rünz M. Agapito L. Co-Fusion: Real-time Segmentation, Tracking and Fusion of Multiple Objects Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA)Singapore 29 May–3 June 201744714478
- 7Mc Cormac J. Handa A. Davison A. Leutenegger S. Semantic Fusion: Dense 3D Semantic Mapping with Convolutional Neural Networks Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA)Singapore 29 May–3 June 201746284635
- 8Lianos K.N. Schönberger J.L. Pollefeys M. Sattler T. VSO: Visual Semantic Odometry Proceedings of the Computer Vision—ECCV 2018: 15th European Conference Munich, Germany 8–14 September 2018246263