Validation of a Diabetes Subtype Classification Model Using Data from U.S. Adults Before and After the COVID-19 Pandemic
Brian Lu, Peng Li, Andrew B. Crouse, Tiffany Grimes, Ava N. Smith, Matthew Might, Fernando Ovalle, Anath Shalev

TL;DR
This study validates a model for classifying diabetes subtypes and finds that severe diabetes subtypes increased after the pandemic.
Contribution
A validated diabetes subtype classification model and evidence of changing subtype distribution post-pandemic.
Findings
The model achieved 98% specificity and 93% sensitivity in classifying diabetes subtypes.
Severe insulin-dependent diabetes increased from 42% to 61% at UAB post-pandemic.
Similar increases in severe diabetes subtypes were observed in NHANES data.
Abstract
Background: We (and others) have previously identified five clinically distinct diabetes subtypes. Currently, few models to identify diabetes subtypes are readily accessible. Further, while COVID-19 has been associated with increased risk of new-onset diabetes, it remains unknown whether the pandemic is also associated with changes in diabetes subtype distribution. Methods: We used the electronic health records of patients diagnosed with diabetes from 2010 to 2019 at the Kirklin Clinic of the University of Alabama at Birmingham (UAB) to train models to assign diabetes subtypes previously identified by hierarchical clustering. We then applied the trained model to conduct a retrospective cluster analysis of electronic health records of patients diagnosed with diabetes from 2020 to 2024 at UAB. We further validated our findings using data from the 2015–2023 National Health and Nutrition…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
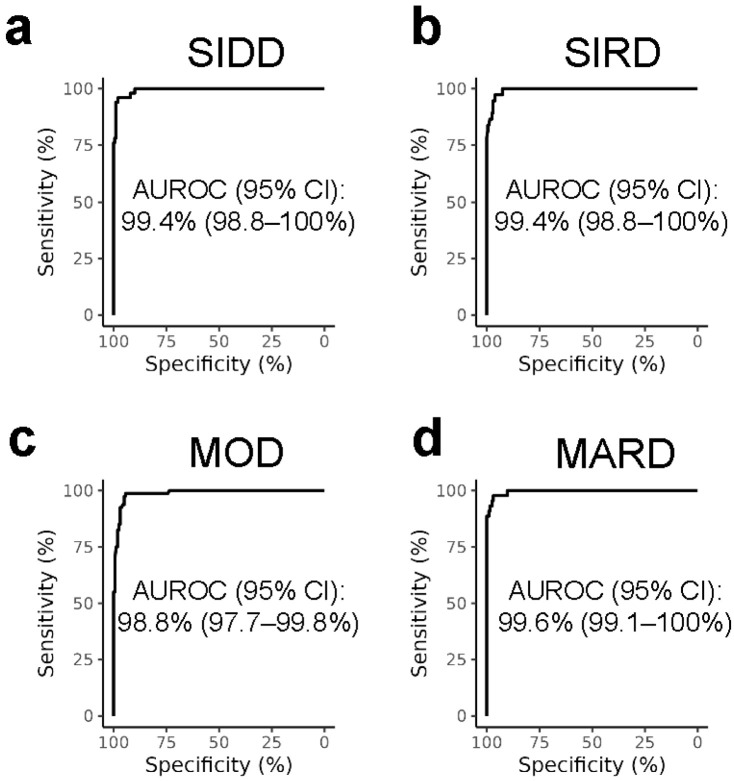 Figure 1
Figure 1- —National Center for Advancing Translational Sciences of the National Institutes of Health
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDiabetes and associated disorders · Diabetes, Cardiovascular Risks, and Lipoproteins · Hyperglycemia and glycemic control in critically ill and hospitalized patients
1. Introduction
Diabetes has been shown to cluster into five clinically distinct subtypes: severe autoimmune diabetes (SAID), severe insulin-deficient diabetes (SIDD), severe insulin-resistant diabetes (SIRD), mild obesity-related diabetes (MOD), and mild age-related diabetes (MARD) [1,2,3]. Corresponding to their different clinical characterizations, each subtype also has different risks of secondary complications. In particular, the severe diabetes subtypes SIDD and SIRD are associated with higher risks of cardiovascular complications and chronic kidney disease [1,2,4,5]. In contrast, the mild diabetes subtypes, MOD and MARD, come with lower risks of diabetic neuropathy [2,4,5]. As such, identifying these subtypes will allow for adjustments in treatment strategies and subsequent improvements in diabetes control. However, despite the increasing recognition of these subtypes in research and the potential for improved diabetes control, adoption of diabetes subtypes in the clinic has been slow. Furthermore, there is a lack of readily available tools to identify a patient’s particular diabetes subtype.
Diabetes has emerged as one of the comorbidities of coronavirus disease-2019 (COVID-19) [6,7]. Additionally, while it is primarily a respiratory disease caused by the severe acute respiratory syndrome-coronavirus-2 (SARS-CoV-2), COVID-19 has also been associated with increased risks of new-onset diabetes [8,9,10]. However, it remains unknown whether the pandemic has also been associated with changes in diabetes subtype distribution.
In the current study, we trained a multiclass random forest classification model to identify diabetes subtypes based on previously established subtype parameters. We then applied the model in a cross-sectional study and evaluated diabetes subtype distributions before and after the COVID-19 pandemic among two distinct cohorts of U.S. adults.
2. Materials and Methods
2.1. University of Alabama at Birmingham Cohort
We conducted a retrospective analysis of the electronic health records of adult patients with diabetes at the Kirklin Clinic of the University of Alabama at Birmingham (UAB). All human studies were approved by the UAB Institutional Review Board. Informed consent for participation was not required, as the UAB Institutional Review Board granted a waiver of HIPAA authorization. Patients with diabetes between 2010 and 2019 were selected and assigned diabetes subtypes as previously described [2]. Briefly, we screened the electronic health records of 89,875 patients diagnosed with diabetes between 1 January 2010 and 31 December 2019. Adult patients with International Classification of Diseases (ICD) diabetes codes were selected based on the availability of data for 6 established clustering parameters (GAD autoantibody, HbA1c, BMI, diagnosis age, HOMA-B, and HOMA-IR), resulting in 1194 patients being selected for subtype assignment by hierarchical clustering (Figure S1). For patients with diabetes between 2020 and 2024, 51,858 patients diagnosed with diabetes between 1 January 2020 and 23 May 2024 at the Kirklin Clinic of UAB were similarly screened and selected, resulting in 165 patients being selected for subtype assignment (Figure S2). Identical International Classification of Diseases and Logical Observation Identifiers Names and Codes (LOINC) codes were used for diagnoses and laboratory results, respectively. Diabetes subtypes for the 165 patients from 2020 to 2024 were identified using the diabetes subtype model described below. Due to the focus on type 2 diabetes, patients with severe autoimmune diabetes (SAID) were excluded, resulting in 1084 patients from 2010 to 2019 and 155 patients from 2020 to 2024 being selected for analysis.
2.2. National Health and Nutrition Examination Surveys Cohort
To validate our findings, we repeated the above analysis using National Health and Nutrition Examination Surveys (NHANES) data from the 2015–2023 cycles with minor modifications. Data were obtained from the 2015–2016, 2017–2020, and 2021–2023 Continuous National Health and Nutrition Examination Surveys (NHANES, unweighted n = 37,464) using nhanesA [11]. NHANES cycles prior to 2015 were not used because they included different methodologies for insulin and glucose measurements. Adult participants with medically diagnosed diabetes and adult participants with HbA1c ≥ 6.5% or fasting plasma glucose ≥ 7 mmol/L from the 2015–2016, 2017–2020, and 2021–2023 cycles and with available values for HbA1c, BMI, age, HOMA-B, and HOMA-IR (unweighted n = 1709) were selected (Figure S3). Diabetes subtypes were identified using the diabetes subtype model described below and de novo hierarchical clustering as previously described, with minor modifications [2]. GAD autoantibody measurements were not available in NHANES and were imputed as negative. The lack of GAD autoantibody measurements in NHANES precluded the identification of the SAID subtype. However, since SAID generally only accounts for a very small percentage of diabetes diagnoses [1,2], and largely represents type 1 diabetes, it was not relevant for this type 2 diabetes-focused analysis. Also, as c-peptide values were not available, and insulin-derived HOMA1 estimates are not directly interchangeable with c-peptide-derived HOMA1 estimates, insulin values were used for HOMA-B and HOMA-IR calculations then scaled using the HOMA1 mixed-effect model described below. Age at time of survey was used instead of age at time of initial diabetes diagnosis due to the large time gap between the initial diabetes diagnosis and the survey and is a limitation that may affect subtype assignment. However, as a person’s diabetes subtype may change over time [12], age at time of survey, when the other clinical parameters were measured, should provide a better reflection of the participant’s diabetes subtype at the time of the survey. Participants with zero adjusted weights were removed, resulting in 1132 participants from 2015 to 2020 and 470 participants from 2021 to 2023 being selected for analysis.
2.3. Diabetes Subtype Classification Model
To identify diabetes subtypes, we trained and evaluated multiple multiclass classification models using UAB patients with diabetes from 2010 to 2019 with diabetes subtypes previously identified using hierarchical clustering [2]. Model subtype assignment was based on the 6 clustering parameters described above (Supplemental Methods). Models were trained using the scikit-learn Python machine learning library version 1.5.2 with 80% of the UAB patients from 2010 to 2019 for training and 20% of the UAB patients from 2010 to 2019 for testing. The optimal hyper-parameters were selected using grid search with 5-fold rotation estimation repeated 5 times. The final model was chosen based on average rotation estimation performance metrics during training. Final model metrics were evaluated on the holdout 20% testing set of UAB patients from 2010 to 2019.
2.4. HOMA1 Mixed-Effect Model
As the HOMA1_c-peptide_ values we used for classification were not directly comparable to HOMA1_insulin_ values, we constructed a linear mixed-effect model to scale HOMA1_insulin_ values to comparable HOMA1_c-peptide_ values. HOMA1_insulin_ values were calculated as originally described by Matthews et al. [13]. The mixed-effect model was constructed using records from UAB (n = 2720) and from the 1999–2004 NHANES cycles (unweighted n = 6331) where patients/survey participants had their insulin, c-peptide, and glucose measured simultaneously (3003 and 6510 HOMA1_insulin_/HOMA1_c-peptide_ pairs from UAB and NHANES, respectively). Data from 80% of the patients/survey participants were used for training and data from 20% of the patients/survey participants were used for testing. Self-reported sex and race were included as fixed effects, as both have previously been reported to contribute to differences in insulin clearance rates [14,15]. The model included random intercepts for patients/survey participants to account for repeated measures. To obtain the population average, only fixed effects were used to scale HOMA1_insulin_ values to HOMA1_c-peptide_ values.
2.5. Statistical Analysis
Statistical analyses were performed using the R software version 4.4.0 (R Foundation). Differences between continuous parameters were analyzed using Student’s t test. Differences in categorical variables were analyzed using Pearson’s Chi-squared test. The association between time periods and diabetes severity within each cohort were also assessed using multivariable logistic regression to adjust for sex, race, age, BMI, and diabetes diagnosis status as appropriate. NHANES data was analyzed with adjusted fasting subsample 2 year mobile exam center (MEC) weights according to the NHANES analytic guidelines to account for the complex survey design. Confidence intervals for area under the receiver operator characteristics curves were generated by bootstrapping.
2.6. Code Availability
Our diabetes subtype classification application, DiaClue, is accessible at https://diaclue.com/ (accessed on 12 March 2026). The code for DiaClue is available at https://github.com/avasmith98/diabetes-cluster-app (accessed on 23 February 2026). The codes for model training and data analysis are available at https://github.com/brianluhd/cluster_prediction (accessed on 13 November 2025) and https://github.com/brianluhd/COVID19_clusters (accessed on 29 January 2026), respectively.
3. Results
To assign diabetes subtypes, we trained multiclass random forest, gradient boosting, histogram-based gradient boosting, and Gaussian Naive Bayes classification models using UAB patients with previously assigned diabetes subtypes from 2010 to 2019 [2]. All models, besides the Gaussian Naive Bayes models, achieved similar performances (Table S1). Model performances were comparable when trained on either the non-linear HOMA2 values or the linear approximation HOMA1_c-peptide_ values, but slightly worse when trained on glucose and c-peptide values directly (Table S1). The random forest model using HOMA1_c-peptide_ values was chosen for its simplicity and interpretability and comparable performance to the more complex, but less interpretable, models. The final random forest model had an average specificity of 98% and an average sensitivity of 93%. The area under the receiver operator characteristics curves were over 98% for each diabetes subtype (Figure 1).
As our HOMA1_c-peptide_ values used for classification were not directly comparable to HOMA1_insulin_ values, direct use of HOMA1_insulin_ values in the trained random forest model resulted in weak agreement with subtypes previously assigned by hierarchical clustering using the c-peptide-derived non-linear HOMA2 [2] (Table S2). Therefore, to allow the use of our diabetes subtype classification model on NHANES data with HOMA1_insulin_ values, we also constructed a linear mixed-effect model using HOMA1_insulin_ and HOMA1_c-peptide_ estimate pairs from UAB and NHANES (Figure S4). Diabetes subtype classification with the random forest model using scaled HOMA1_insulin_ showed strong agreement with subtypes previously assigned by hierarchical clustering [2] (Table S2), indicating that our mixed-effect model can effectively scale insulin-derived HOMA values for downstream diabetes subtype classification without having a substantial impact on model performance.
Using the trained random forest model, we assigned diabetes subtypes to patients with diabetes from UAB between 2020 and 2024. Interestingly, the distribution of diabetes subtypes was significantly different between 2010–2019 and 2020–2024 in the UAB cohort (p < 0.001), while cohort demographics did not change overall, and the proportions of males and Black/African Americans remained similar (Table 1). In particular, the proportion of patients with severe subtypes of diabetes (severe insulin-deficient diabetes and severe insulin-resistant diabetes) increased from 42% (455/1084) in 2010–2019 to 61% (94/155) in 2020–2024, while the proportion of patients with mild subtypes of diabetes (mild obesity-related diabetes and mild age-related diabetes) decreased from 58% (629/1084) to 39% (61/155) (p < 0.001). The increase in severe diabetes subtypes remained significant even after adjusting for sex, race, age, and BMI (adjusted odds ratio [AOR], 1.96; 95% CI 1.38–2.79; p < 0.001).
To validate our findings, we repeated the analysis using the 2015–2023 NHANES data (Table 2). The diabetes subtypes assigned by the trained random forest model were similar to those assigned by de novo hierarchical clustering (Figure S5). While NHANES had also similar proportions of males and Black/African American participants between 2015–2020 and 2021–2023, there was again a significant difference between the distribution of diabetes subtypes (p = 0.047). The proportion of survey participants with severe subtypes of diabetes increased from 31% (weighted, 354/1132) in 2015–2020 to 40% (weighted, 172/470) in 2021–2023, while the proportion of participants with mild subtypes of diabetes decreased from 69% (weighted, 778/1132) to 60% (weighted, 298/470) (p = 0.006). The increase in severe diabetes subtypes remained similarly significant after adjusting for sex, race, age, and BMI (AOR, 1.45; 95% CI, 1.08–1.95; p = 0.015). Similar increases in severe diabetes subtypes were again observed in NHANES using subtypes assigned by de novo hierarchical clustering (Table S3). Surprisingly, only a small fraction of people assigned the SIDD subtype were prescribed insulin in this cohort (weighted 27%, 35/98).
4. Discussion
In the current study, we trained a multiclass random forest classification model to identify diabetes subtypes using established clustering parameters. Using this model, our studies identified an increase in the proportions of patients with severe subtypes of diabetes in the more recent years following the pandemic. We also observed a surprisingly low rate of insulin usage in patients with SIDD in the NHANES cohort, suggesting that severe insulin deficiency in patients with diabetes may not be adequately recognized and managed and underlining the need for tools to facilitate better recognition and management. Since severe subtypes of diabetes have an increased lifetime risk of diabetes complications [1,2,4,5], recognizing and adequately adjusting treatment of these diabetes subtypes should help improve the outcome.
The limitations of this study include the relatively low number of patients with diabetes and complete data in the UAB and NHANES cohorts. Our analysis was therefore also limited to the time periods before and after the COVID-19 pandemic instead of a more granular time scale. However, our findings were consistent across the two cohorts, and the weight adjustments methods applied to NHANES data produced nationally representative estimates. Our findings are also consistent with the increase in HbA_1c_ and decrease in glycemic control that were recently found in NHANES [16].
While HOMA estimates for the NHANES cohort were derived from fasting glucose, as it was part of the survey design, the glucose values used to calculate HOMA estimates for the UAB cohort were presumed to be non-fasting, as the fasting status was not specified in the UAB electronic health records, and this could theoretically affect classification. Nonetheless, our findings were still consistent across the two cohorts, which is in alignment with previous findings that fasting and non-fasting HOMA estimates are similar and correlate [17].
Also, the established diabetes classification model used in the present studies does not take into account the use of any glucose-lowering medications, which may affect subtype assignment and confound the underlying diabetes etiology.
With the current studies being observational, further studies are required to determine the causes of the increase in severe diabetes subtypes, but potential explanations may include direct biological effects from SARS-CoV-2 infection and indirect effects from the pandemic lockdowns and the resulting disruption of diabetes services. COVID-19 is associated with increased risk of new-onset diabetes [6,7], and SARS-CoV-2 has been shown to be able to directly infect pancreatic beta cells, impair beta cell function, and induce beta cell apoptosis [18]. The associated inflammation from SARS-CoV-2 infection can also induce beta cell pyroptosis [19]. Furthermore, although BMI remained unchanged in our study cohorts, SARS-CoV-2 can increase insulin resistance through direct infection of adipocytes [20]. Potential disruptions in health services and diabetes care during the pandemic include limited access to routine care and medications, increased use of telemedicine, and changes in patient care-seeking behavior [21]. Pandemic-associated disruptions in diabetes services may have also led to a delay in diabetes diagnosis, allowing diabetes to worsen prior to diagnosis. However, recent estimates did not identify any changes in the age-adjusted prevalence of total, diagnosed, and undiagnosed diabetes following the COVID-19 pandemic [16,22], making this possibility unlikely.
Previous studies have also studied the correlation between insulin-derived HOMA and c-peptide-derived HOMA values [23,24], and while it was not significant in people from Cameroon without diabetes [24], a significant correlation between insulin-derived HOMA-IR and c-peptide-derived HOMA-IR was found in people from India who have diabetes [23], which was consistent with our findings.
Although the diabetes subtypes initially described by Ahlqvist et al. have been well replicated across multiple populations and are generally similar across populations [25,26,27], cross-validation of clusters has shown varying results when cluster centers from one cohort were applied to other cohorts [27]. As such, while we were able to successfully apply our diabetes subtype classification model trained on the UAB cohort to the nationally representative NHANES cohort, no independent clinical validation was possible, and the performance of our model on populations outside of the United States that were not represented in the training cohort remains unknown and may be limited.
To facilitate the use of our model to identify subtypes of adult-onset, non-monogenic, non-gestational diabetes, we created DiaClue, which can be accessed as a web application and as a downloadable application on mobile devices. Users can directly input the six clinical parameters required for cluster assignment and DiaClue will output the most likely subtype assignment. Recognizing that a person with diabetes may have clinical features that overlap with multiple subtypes, DiaClue also outputs a percentage score for each subtype, along with a score breakdown using Shapley additive explanations for the most likely subtype [28], to aid users in making their independent and balanced subtype assignment. A few studies have previously described diabetes subtype classification models [12,29,30,31,32,33]. To our knowledge, no publicly accessible model trained on a recent U.S. cohort was previously available. The model described by Bello-Chavolla et al. was trained on NHANES III data from 1988 to 1994 [12], the model described by Mori et al. [31] used the All-New Diabetes in Scania (ANDIS) cluster centroids originally identified by Ahlqvist et al. [1], and the model described by Baskar et al. was trained on a cohort from India [33]. In comparison, our model was trained on the more recent 2010–2019 data from a multiracial patient cohort from the Kirklin Clinic at UAB, a large academic multispecialty clinic in the US Deep South [2].
The impact of identifying diabetes subtypes on treatment and outcome using our application and in general has yet to be evaluated in prospective, randomized clinical trials. However, our application can provide information relevant to pathophysiology and complication risks and thereby support clinicians in their tailoring of diabetes management strategies. Although current clinical guidelines do not include diabetes subtypes, strategies for subtype-specific management have been proposed [34,35,36]. A summary of these therapeutic considerations for subtype-specific diabetes management strategies according to prior reviews is provided in Table 3.
5. Conclusions
The model presented here can facilitate the identification of diabetes subtypes. Interestingly, we found that the proportions of patients with severe subtypes of diabetes increased in the more recent years following the pandemic. While further studies are required to examine the potential causes of this phenomenon, diagnosing these diabetes subtypes and identifying trends early will support better tailoring of diabetes management strategies and should improve diabetes control and outcomes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ahlqvist E. Storm P. Karajamaki A. Martinell M. Dorkhan M. Carlsson A. Vikman P. Prasad R.B. Aly D.M. Almgren P. Novel subgroups of adult-onset diabetes and their association with outcomes: A data-driven cluster analysis of six variables Lancet Diabetes Endocrinol.2018636136910.1016/S 2213-8587(18)30051-229503172 · doi ↗ · pubmed ↗
- 2Lu B. Li P. Crouse A.B. Grimes T. Might M. Ovalle F. Shalev A. Data-driven Cluster Analysis Reveals Increased Risk for Severe Insulin-deficient Diabetes in Black/African Americans J. Clin. Endocrinol. Metab.202511038739510.1210/clinem/dgae 51639078946 PMC 11747757 · doi ↗ · pubmed ↗
- 3Zou X. Zhou X. Zhu Z. Ji L. Novel subgroups of patients with adult-onset diabetes in Chinese and US populations Lancet Diabetes Endocrinol.2019791110.1016/S 2213-8587(18)30316-430577891 · doi ↗ · pubmed ↗
- 4Xing L. Peng F. Liang Q. Dai X. Ren J. Wu H. Yang S. Zhu Y. Jia L. Zhao S. Clinical Characteristics and Risk of Diabetic Complications in Data-Driven Clusters Among Type 2 Diabetes Front. Endocrinol.20211261762810.3389/fendo.2021.617628 PMC 828196934276555 · doi ↗ · pubmed ↗
- 5Asplund O. Thangam M. Prasad R.B. Lejonberg C. Ekstrom O. Hakaste L. Smith J.G. Rosengren A.H. Oscarsson J. Carlsson B. Comorbidities and mortality in subgroups of adults with diabetes with up to 14 years follow-up: A prospective cohort study in Sweden Lancet Diabetes Endocrinol.202614294010.1016/S 2213-8587(25)00283-941248671 · doi ↗ · pubmed ↗
- 6Singh A.K. Gillies C.L. Singh R. Singh A. Chudasama Y. Coles B. Seidu S. Zaccardi F. Davies M.J. Khunti K. Prevalence of co-morbidities and their association with mortality in patients with COVID-19: A systematic review and meta-analysis Diabetes Obes. Metab.2020221915192410.1111/dom.1412432573903 PMC 7361304 · doi ↗ · pubmed ↗
- 7Crouse A.B. Grimes T. Li P. Might M. Ovalle F. Shalev A. Metformin Use Is Associated with Reduced Mortality in a Diverse Population with COVID-19 and Diabetes Front. Endocrinol.20201160043910.3389/fendo.2020.600439 PMC 783849033519709 · doi ↗ · pubmed ↗
- 8Zhang T. Mei Q. Zhang Z. Walline J.H. Liu Y. Zhu H. Zhang S. Risk for newly diagnosed diabetes after COVID-19: A systematic review and meta-analysis BMC Med.20222044410.1186/s 12916-022-02656-y 36380329 PMC 9666960 · doi ↗ · pubmed ↗