Unsupervised Domain Adaptation Algorithm for Time Series Based on Adaptive Contrastive Learning
Huayong Liu, Peng Lin

TL;DR
This paper introduces a new algorithm for adapting time series models across domains using adaptive contrastive learning, improving accuracy and robustness.
Contribution
The novel ACLDA algorithm introduces adaptive feature enhancement and sample-level weights to improve domain adaptation for time series data.
Findings
ACLDA outperforms existing methods in average accuracy on multiple time-series datasets.
Adaptive augmentation and hard sample weighting enhance transferability and reduce overfitting.
Abstract
Time series data find extensive applications in finance, healthcare, and industrial monitoring domains. However, analytical models targeting such data are subject to notable constraints imposed by the rigid independent and identically distributed (IID) assumption and the high cost of data annotation. Unsupervised Domain Adaptation (UDA) offers an effective remedy for these challenges, and Contrastive Learning (CL) has been widely integrated into UDA frameworks, owing to its robust feature representation and clustering capabilities. Nonetheless, existing CL-based UDA methods suffer from two key limitations: (1) fixed data augmentation strategies result in imbalanced intensity—excessive augmentation erodes sample semantics, while insufficient augmentation induces model overfitting; (2) distribution alignment strategies neglect hard samples which are the core carriers of domain shift,…
Click any figure to enlarge with its caption.
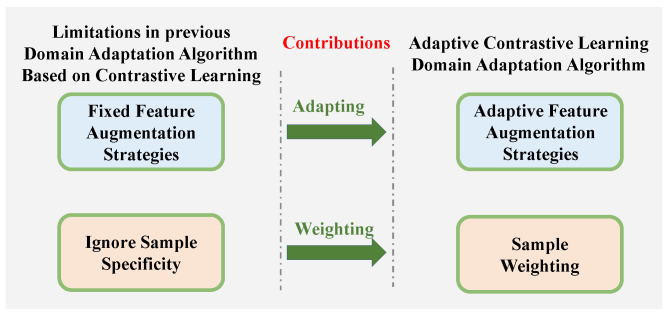 Figure 1
Figure 1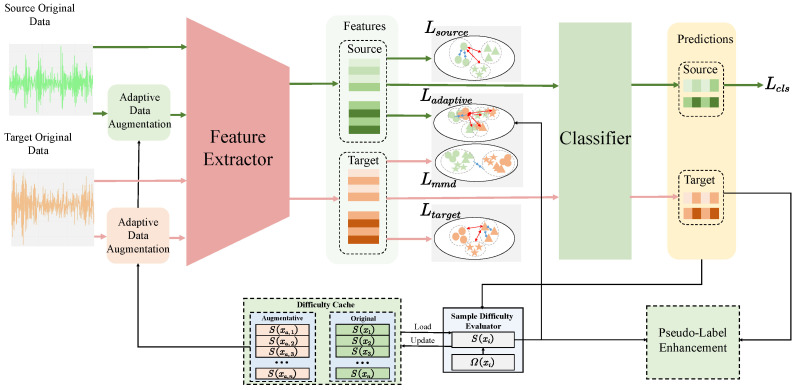 Figure 2
Figure 2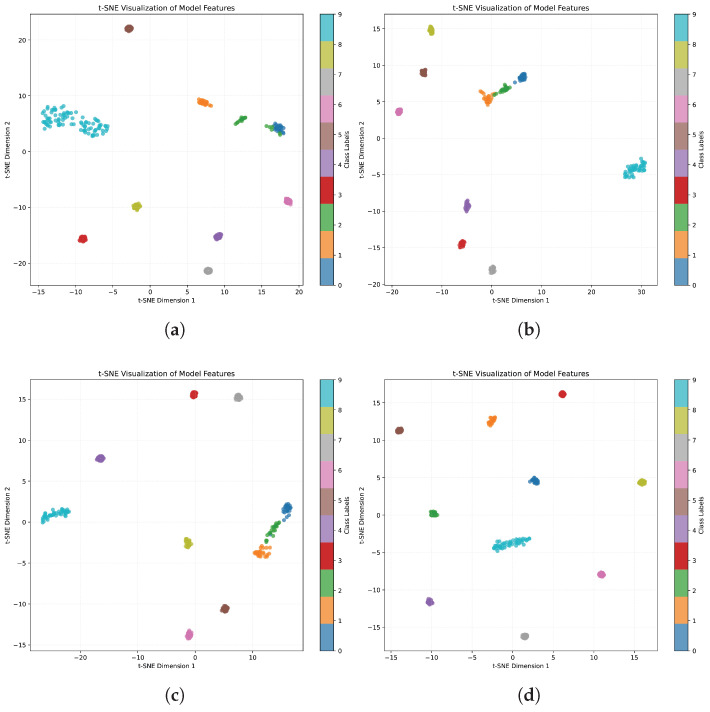 Figure 3
Figure 3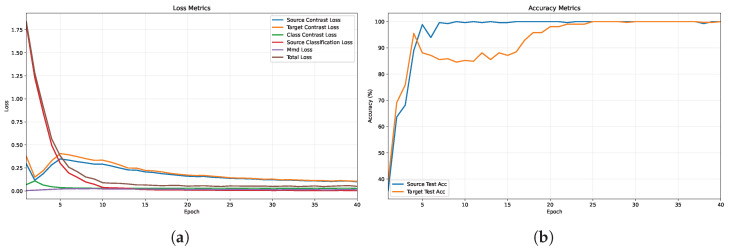 Figure 4
Figure 4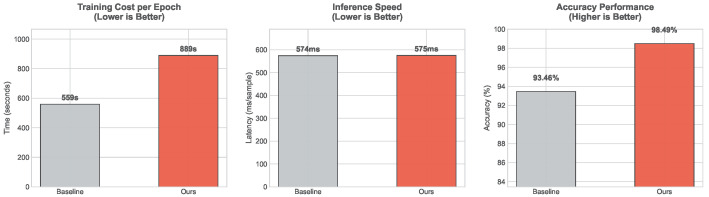 Figure 5
Figure 5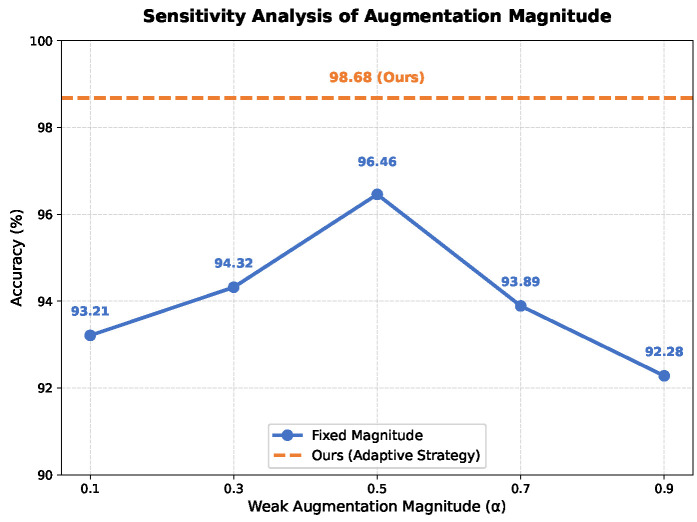 Figure 6
Figure 6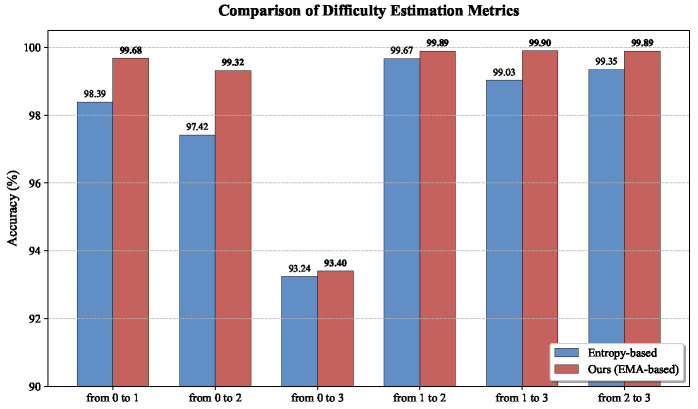 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Healthcare · Domain Adaptation and Few-Shot Learning · Time Series Analysis and Forecasting
1. Introduction
Time series data are widely prevalent in various fields, including financial markets, healthcare, industrial monitoring, and climate forecasting [1,2,3,4]. In industrial scenarios, fault diagnosis of rotating machinery vibration time-series signals can avoid equipment downtime losses in advance [5]. In the medical field, anomaly detection of time-series signals such as electrocardiogram (ECG) and electroencephalogram (EEG) is an important means for the early diagnosis of cardiovascular diseases and epilepsy [6]. However, time-series analysis models in these scenarios generally rely on the strong assumption that the distribution of training data (source domain) is consistent with test data (target domain). When there are domain shift scenarios between the source domain and the target domain, such as working condition fluctuations, environmental interference, or differences in data collection conditions, the inter-domain distribution shift will lead to a sharp decline in the generalization ability of the model, or even complete failure [7,8]. Secondly, the time cost and monetary cost of data annotation, as well as the subjectivity of manual annotation, are also important factors that cannot be ignored [9,10,11]. Unsupervised domain adaptation (UDA) technology for time series does not require labeled data in the target domain. It achieves model transfer by reducing the difference in domain distribution, which well solves the problems of domain difference and difficulty in obtaining labeled data, and has become a research hotspot and difficulty in the field of time series analysis [12,13,14].
Contrastive learning (CL) has demonstrated strong capabilities in enhancing feature extraction for UDA by constructing positive and negative sample pairs [15]. However, despite its success, existing CL-based UDA approaches face two critical limitations shown in Figure 1. First, regarding feature enhancement, most methods rely on fixed data augmentation strategies [2,12,16,17]. This lack of adaptability often leads to either excessive augmentation (destroying semantic information) or insufficient augmentation (causing overfitting to surface features), both of which degrade generalization ability. Second, regarding distribution alignment, previous studies typically treat all samples with equal importance during the contrastive process [18,19,20,21]. This uniform weighting overlooks “hard samples”—data points that deviate from cluster centers and often carry the most significant domain shift information. If these hard samples are weighted equally with easy samples, the crucial domain adaptation signals they carry will be masked by the majority of normal features, preventing the model from capturing the core cues necessary for effective cross-domain alignment.
To address these challenges, this paper proposes a domain adaptation algorithm based on adaptive contrastive learning (ACLDA). The main contributions are summarized as follows:
- We propose an adaptive data augmentation strategy for feature enhancement. Unlike fixed methods, this approach dynamically adjusts augmentation intensity based on data characteristics. It effectively prevents semantic destruction caused by over-augmentation and superficial learning caused by under-augmentation, ensuring the extraction of robust transferable features.
- We introduce an adaptive weighted supervised contrastive learning loss. By automatically assigning higher weights to hard samples, this mechanism prevents critical domain-shift cues from being masked by easy samples. This significantly improves the model’s adaptability to complex cross-domain scenarios.
- Extensive experiments demonstrate the superiority of ACLDA. Through the synergistic effect of adaptive augmentation and weighted contrastive learning, our method achieves refined class-level distribution alignment, characterized by high intra-class compactness and clear inter-class separability.
The remaining parts of this paper are organized as follows: Section 2 reviews related work; Section 3 details the proposed ACLDA algorithm; Section 4 presents the experimental results; and Section 5 concludes the paper.
2. Related Work
2.1. Unsupervised Domain Adaptation
Unsupervised domain adaptation alleviates the distribution discrepancy between the source and target domains by transferring knowledge learned from the labeled source domain to the unlabeled target domain [22]. Maximum Mean Discrepancy (MMD) is a classic distribution-based domain adaptation method that performs marginal distribution alignment by minimizing the distribution difference of features from the source and target domains in the Reproducing Kernel Hilbert Space (RKHS) [23]. However, MMD only focuses on the first-order statistical information of the distribution and cannot fully characterize complex data distributions. Maximum Mean Covariance Discrepancy (MMCD) combines MMD with Maximum Classifier Discrepancy (MCD) to construct a maximum mean covariance discrepancy metric [24]. Compared with MMD, MMCD captures more distribution information. Nevertheless, the aforementioned methods ignore the problem of intra-class data compactness. Chen et al. corrected the intrinsic graph and introduced a penalty graph to reduce the inter-domain distribution difference while ensuring the compactness of intra-class data, making features more discriminative [25]. Ganin et al. implemented adversarial-based unsupervised domain adaptation by introducing a Gradient Reversal Layer (GRL) into the model [26]. However, this method only aligns marginal distribution features and ignores class-level distribution alignment. The model proposed by Jiao et al. consists of a shared feature extractor and two task-specific classifiers. Through the adversarial training game among the three, the model can learn fault features with both class separability and domain invariance to adapt to cross-domain diagnosis requirements [27]. On the basis of marginal distribution alignment, Kuang et al. introduced conditional distribution adversariality to form a two-layer adversarial transfer learning framework, enabling the learning of class-separable diagnostic knowledge under imbalanced data [28]. Domain adaptation based on feature reconstruction is a type of technology that achieves cross-domain transfer through data reconstruction constraints, but there is often a natural conflict between reconstruction accuracy and class discriminability. Xu et al. adopted an iterative strategy with two reconstruction matrices to cyclically reconstruct the data matrix and update the common subspace for invariant feature learning [29]. Guo et al. proposed a Reconstruction-based Domain Adaptive Transfer Network (RDATN) and introduced class-level weights and sample-level weights into the loss function to mitigate the negative impact of anomalous classes in partial transfer learning [30].
2.2. Contrastive Learning in UDA
Contrastive learning aims to learn discriminative representations by pulling positive pairs closer and pushing negative pairs apart [15]. In the context of UDA, it has been widely adopted to enhance feature transferability. However, current research faces challenges in two aspects: data augmentation strategies and sample weighting mechanisms.
Data augmentation is crucial for constructing contrastive views. Chen et al. verified that data augmentation compels models to discard superficial redundant features and focus on core semantic characteristics [15]. Li et al. proposed masking rectangular regions to simulate missing information, enhancing intra-domain feature separability [31]. Pan et al. utilized random augmentation for self-supervised contrastive learning to perceive domain-invariant features [32]. Despite these advances, most existing UDA methods rely on pre-defined, fixed augmentation strategies. For instance, Eldele et al. mixed source and target data in a fixed proportion [16]. Wu et al. sequentially adopted four fixed augmentation methods (e.g., jittering, scaling) to obtain different views [2,17]. Darban et al. injected fixed anomaly patterns into normal samples to generate negative pairs for triplet learning [12]. While effective in specific settings, fixed augmentation lacks flexibility: insufficient intensity fails to drive the model to learn essential characteristics, while excessive intensity destroys original semantic features. Since the model evolves during training, fixed strategies often lead to mismatched augmentation.
Beyond augmentation, how to effectively utilize samples for alignment is another key challenge. Standard contrastive learning treats all samples equally. To address domain shift, recent works have incorporated pseudo-labels or instance-level mixing. Pang et al. selected reliable pseudo-labels of target data to construct positive/negative pairs for supervised contrastive learning [18,19]. Yu et al. generated virtual target data by mixing source data with target styles for instance contrastive learning [20]. Wang et al. performed alignment between samples with target statistical features and original samples to retain class discriminability [21]. However, these methods generally assign uniform importance to all samples, ignoring the critical role of “hard samples”—those deviating from cluster centers. In cross-domain tasks, hard samples are often the core carriers of domain shift. If weighted equally with easy samples, the adaptation signals from hard samples are easily masked by the large volume of easy samples, limiting the model’s ability to achieve refined alignment in complex scenarios.
3. Proposed Method: ACLDA
The proposed ACLDA framework aims to bridge the domain gap by learning higher-quality feature representations through adaptive contrastive learning. As depicted in Figure 2, the architecture consists of four key modules. The Sample Difficulty Perception module dynamically evaluates and caches the classification difficulty of samples. Based on these scores, the Feature Enhancement module applies adaptive data augmentation, ensuring that the feature extractor learns robust representations from samples. The Distribution Alignment Module achieves more precise distribution alignment through the synergy of MMD and weighted contrastive learning. The Pseudo-label Enhancement Module enhances the confidence of the prediction results for samples in the target domain.
The training workflow proceeds as follows: First, difficulty scores are retrieved to guide the generation of augmented views for both source and target batches. Then, these inputs are fed into the feature extractor to generate higher-quality feature representations via supervised contrastive learning on the source domain and self-supervised contrastive learning on the target domain. Crucially, we introduce a hybrid alignment strategy to align domain distributions. Global alignment is achieved via Maximum Mean Discrepancy (MMD). Meanwhile, weighted supervised contrastive learning is employed for fine-grained alignment, which leverages difficulty scores to prioritize hard samples during the alignment of source labels and target pseudo-labels. Finally, the classifier is optimized using source cross-entropy and target pseudo-label enhancement losses, with difficulty scores iteratively updated to reflect the model’s evolving state.
3.1. Sample Difficulty Perception
Mainstream difficulty-driven methods only use entropy as a direct metric for sample hardness, assuming that samples with higher entropy are more difficult to classify. Although such methods have been proven effective in other unsupervised or supervised classification scenarios, the model’s predictions on samples fluctuate significantly during training. If there are transient high-entropy samples, the model will treat them as hard samples, which will interfere with the model optimization direction. To address this issue, a sample difficulty evaluator is introduced to emphasize the impact of recent data while retaining long-term trends, thereby eliminating the interference of transient high-entropy samples on the training process.
3.1.1. Instantaneous Classification Difficulty Evaluation
The sample difficulty evaluator first calculates the instantaneous classification difficulty score of a sample. For a source or target domain sample and its corresponding prediction (where denotes an augmented sample and denotes an original sample), the instantaneous classification difficulty score is defined as follows:
where K denotes the number of classification categories, k represents the ground-truth label of the sample, and denotes the pseudo-label of the sample (the pseudo-label is set to the category with the maximum prediction probability).
3.1.2. Stable Classification Difficulty Evaluation
The instantaneous classification difficulty evaluation can only assess the sample classification difficulty in the current training iteration, which is prone to random fluctuations and thus lacks sufficient stability. The Exponential Moving Average (EMA) can effectively address this issue [33]. For a given instantaneous classification difficulty score , the method to calculate its stable classification difficulty score is as follows:
where denotes the stable classification difficulty score of the sample calculated in the previous mini-batch (retrieved from the Difficulty Cache). A larger weight indicates greater emphasis on the previously calculated stable classification difficulty score of the sample, with less influence from the instantaneous classification difficulty score of the current sample.
3.1.3. Difficulty Cache
The calculation of the stable classification difficulty score requires retrieving the stable classification difficulty score obtained from the previous mini-batch; thus, it is necessary to cache the stable classification difficulty score computed in each iteration. The stable classification difficulty score is also required in both the feature enhancement component and the distribution alignment component, but only the stable classification difficulty scores corresponding to augmented samples are used in the feature enhancement component. To facilitate the reading and writing of difficulty cache data, the difficulty cache is composed of two parts: the Augmentative Difficulty Cache (ADC) and the Original Difficulty Cache (ODC), which are responsible for storing the stable classification difficulty scores of original samples and augmented samples, respectively. For a sample with index idx, the stable classification difficulty score of the original sample can be retrieved from the ODC as , and the stable classification difficulty score of the augmented sample can be retrieved from the ADC as .
3.2. Feature Enhancement Module
To fully leverage the label information of the source domain and the unlabeled information of the target domain, while exploring the intrinsic value of samples through adaptive data augmentation to enhance the model’s robustness against domain discrepancies, this paper first dynamically generates adaptively augmented samples based on sample difficulty. Subsequently, supervised and self-supervised contrastive learning mechanisms are employed respectively according to the characteristics of the dual-domain data.
3.2.1. Adaptive Data Augmentation
Traditional fixed data augmentation methods suffer from either insufficient augmentation or excessive distortion. Insufficient augmentation results in negligible differences between augmented samples and original samples, failing to provide the model with adequate effective perturbations. Excessive distortion causes augmented samples to lose the core semantic features of the original samples (e.g., fault types, structural patterns) and become meaningless noisy samples. To avoid the aforementioned issues, this paper adopts an adaptive data augmentation method. For a given sample , its corresponding positively augmented sample via adaptive data augmentation is defined as follows:
where denotes weak augmentation, such as small-scale time-step shifting and slight amplitude scaling; denotes strong augmentation, such as time stretching/compression, adding high-intensity mixed noise, and local signal replacement. represents the stable classification difficulty score of the previous iteration . A larger value of indicates higher classification uncertainty of the augmented version of the sample, which leads to a larger proportion of weak augmentation and a smaller proportion of strong augmentation applied to the sample.
3.2.2. Supervised Contrastive Learning for Source Domain
For the source domain features and , since the source domain data are accompanied by labels, the labels corresponding to the augmented source domain samples are identical to those of the original samples. For the convenience of loss function representation, we define , and the corresponding supervised contrastive learning loss for the source domain is given as follows:
where denotes the cosine similarity between features and ; represents a temperature parameter that adjusts the smoothness of similarity measurement, thereby affecting the sensitivity of the loss function to the similarity between data samples; denotes the positive sample set, which includes data belonging to the same fault type as feature ; denotes the negative sample set, which includes data belonging to different fault types from feature ; denotes the total number of samples in the class to which the negative sample q belongs; hyper-parameter modulate the intensity of class re-weighting.
3.2.3. Self-Supervised Contrastive Learning for Target Domain
For the target domain features and , since the fault types of the target domain data are unknown, self-supervised contrastive learning is adopted for the target domain data. An original sample and its corresponding augmented sample are mutual positive samples, while all other samples in the target domain are negative samples. The corresponding self-supervised contrastive learning loss for the target domain is given as follows:
where denotes all samples except the augmented sample corresponding to the target sample and the target sample itself; denotes the total number of samples in the class to which the negative sample q belongs; hyper-parameter modulate the intensity of class re-weighting.
3.2.4. Feature Enhancement Loss
In the feature enhancement component, this paper adopts adaptive data augmentation to avoid the problems of insufficient augmentation and over-augmentation. Moreover, leveraging the data characteristics of different domains, contrastive learning is introduced to improve the quality of features learned by the model and enhance the model’s robustness against cross-domain discrepancies. The feature enhancement loss is denoted as :
3.3. Distribution Alignment Module
The core challenge of unsupervised domain adaptation lies in the data distribution shift between the source domain and the target domain. Even though the representations are optimized through preliminary difficulty-aware adaptive augmentation and dual-domain contrastive learning, the source domain features may still retain domain-specific information, and the intra-class consistency and cross-domain compatibility of the target domain features have not yet been fully established. This paper uses the Maximum Mean Discrepancy (MMD) for global distribution alignment, optimizing the overall distribution distance between the source and target domains in the feature space to achieve macro-alignment of dual-domain features. Meanwhile, considering the importance of more refined distribution alignment strategies in the field of domain adaptation and the significance of hard samples for improving classification performance, the supervised contrastive loss is weighted to assign greater weights to hard-to-classify samples, thereby achieving sample-level class distribution alignment.
3.3.1. MMD Distribution Alignment
The core idea of MMD is as follows: by mapping dual-domain samples to the Reproducing Kernel Hilbert Space (RKHS), the distance between the sample means of the two domains is calculated. The smaller this distance, the closer the distributions of the two domains are. For the source domain features and target domain features , the MMD is defined as:
where denotes the mapping from the feature space to the RKHS; represents the Reproducing Kernel Hilbert Space, and denotes the norm of this space.
3.3.2. Weighted Supervised Contrastive Learning
Supervised contrastive learning takes each sample as an anchor, regards data of the same fault type as positive samples, and data of different fault types as negative samples. This is equivalent to assuming that each sample has the same weight, which leads to the problem of easy samples dominating the training process and insufficient learning of hard samples. To address this issue, this paper adopts weighted supervised contrastive learning, assigning larger weights to hard samples and smaller weights to easy samples. The category of target domain data is determined by its corresponding prediction result : the class with the maximum prediction probability is selected, provided that the probability of this class is greater than the threshold . For the source domain features and target domain features , after filtering the target domain features according to the threshold, all features are merged and denoted as . The category of each feature is denoted as , and the corresponding samples are denoted as . For a sample , its corresponding weight is given as follows:
where denotes the indicator function.
Once the weight of each sample is obtained, the weighted supervised contrastive learning loss can be formulated as follows:
where denotes the data belonging to the same fault type as , denotes the data belonging to different fault types from , and represents a temperature parameter that adjusts the smoothness of similarity measurement, thereby affecting the sensitivity of the loss function to the similarity between data samples; denotes the total number of samples in the class to which the negative sample q belongs; hyper-parameter modulate the intensity of class re-weighting.
3.3.3. Distribution Alignment Loss
To achieve more accurate distribution alignment, this paper simultaneously considers global MMD-based distribution alignment and class distribution alignment implemented via weighted supervised contrastive learning in the distribution alignment component. The total distribution alignment loss is given as follows:
3.4. Pseudo-Label Enhancement Module
In the pseudo-label enhancement module, the categories of source domain data can be explicitly determined, and the accurate prediction of source domain data is achieved by minimizing the cross-entropy loss. For target domain data, since the effectiveness of the domain alignment stage is affected by the quality of sample pseudo-labels, the reliability of target domain samples is improved by introducing pseudo-label enhancement for the target domain.
3.4.1. Classifier Optimization
For the predicted labels of augmented source domain samples , the predicted labels of original source domain samples , the ground-truth labels of augmented source domain samples , and the ground-truth labels of original source domain samples , the corresponding cross-entropy loss is given as follows:
where C denotes the total number of classes.
3.4.2. Pseudo-Label Enhancement
Hard samples are adaptively selected based on the results of sample classification difficulty scores. Fine-grained alignment within the target domain is achieved by constructing a Pseudo-Contrastive Matrix (PCM), which corrects erroneous pseudo-labels and enhances the compactness of feature clustering. For target domain samples , their corresponding classification difficulty-aware scores are denoted as . According to the magnitude of the classification difficulty scores, target domain samples are filtered, and the top proportion of target domain samples are selected for pseudo-label enhancement. The predicted values corresponding to the filtered samples are denoted as , which are further represented as after one-hot encoding. A Pseudo-Label Matrix (PLM) is constructed, where . The Pseudo-Contrastive Matrix (PCM) is constructed as follows:
where is used to obtain the value of each element in the PCM. The loss function of pseudo-label enhancement is defined as the mean of the L1 distance between the PLM and the PCM, which aims to align the feature similarity between samples with the category relationship of pseudo-labels, thereby improving the confidence level of pseudo-labels in the target domain. The pseudo-label enhancement loss is given as follows:
where PLM denotes the Pseudo-Label Matrix, and PCM denotes the Pseudo-Contrastive Matrix.
3.5. Total Model Loss
The total model loss consists of four components: the classification loss , the pseudo-label enhancement loss , the feature enhancement loss , and the alignment loss . The total loss L is given as follows:
where , , , and denote the weights of the respective losses in the total loss.
3.6. Algorithm Implementation Details
To better describe the algorithm proposed in this paper, the training process of the model is presented in Algorithm 1. Algorithm 1 Training Algorithm of ACLDA
-
Input: Source domain samples and labels , target domain samples ; hyperparameter , , , , , and ; the total epoch number N, Augmentative difficulty cache (ADC) and Original difficulty cache (ODC).
-
Output: The parameters , of feature extractor F and classifier C.
-
1:set the values of and .
-
2:Randomly initialize
-
3:Initialize ADC, ODC
-
4:for do
-
5:
-
6:
-
7:
-
8: for do
-
9:
-
10:
-
11:
-
12:
-
13:
-
14:
-
15:
-
16:
-
17:
-
18:
-
19:
-
20: end for
-
21:
-
22:end for
4. Experimental Evaluation
To verify the performance of the algorithm proposed in this paper, multiple unsupervised domain adaptation algorithms are evaluated on several datasets. The results of these algorithms are compared to demonstrate the superiority of the proposed algorithm. Meanwhile, to further validate the effectiveness of the improvements proposed in this paper, ablation experiments are designed to illustrate the contribution of each improvement to the performance enhancement of the algorithm.
4.1. Experimental Simulation Environment
The hardware environment for the experiments in this paper is as follows: a central processing unit (CPU) of Intel(R) Xeon(R) Platinum 8470Q, and a graphics card of NVIDIA RTX 5090 (32GB). The software environment includes: the Ubuntu 22.04 LTS operating system, the CUDA 12.8 computing acceleration toolkit, and the deep learning framework with Python 3.12 as the programming language and PyTorch 2.8.0 as the core library.
4.2. Data Description
As shown in Table 1, five datasets are selected as experimental datasets in this paper. Among them, four datasets (UCIHAR, HHAR, SSC and MFD) are used for comparative experiments, where the standard unsupervised domain adaptation benchmark framework ADATIME proposed in [34] is adopted to compare the proposed method with other competing methods. The CWRU dataset is selected as the ablation study dataset to analyze the impact of the proposed improvements on the model performance.
4.2.1. UCIHAR Dataset
The UCIHAR dataset contains data from three types of sensors, namely accelerometers, gyroscopes, and body sensors, which were collected from 30 subjects. Each subject performed six activities: walking, walking upstairs, walking downstairs, standing, sitting, and lying down. Due to individual differences among the aforementioned subjects, each subject is regarded as an independent domain [35].
4.2.2. HHAR Dataset
The Heterogeneous Human Activity Recognition (HHAR) dataset collects raw data from 9 subjects via sensor readings of smartphones and smartwatches. To reduce data heterogeneity, the sensor data of all selected subjects were obtained from the same model of smartphone. Each subject is regarded as an independent domain [36].
4.2.3. SSC Dataset
The sleep stage classification task aims to divide electroencephalogram (EEG) signals into five sleep stages, namely wakefulness (W), non-rapid eye movement (NREM) sleep (N1, N2, N3), and rapid eye movement (REM) sleep [37]. This dataset contains electroencephalogram readings from 20 healthy subjects.
4.2.4. MFD Dataset
The Mechanical Fault Diagnosis (MFD) dataset was collected by the University of Paderborn, which aims to identify various early faults through vibration signals. This dataset was acquired under four different operating conditions, and each condition is regarded as an independent domain in the experiments of this study [38].
4.2.5. CWRU Dataset
The rolling bearing dataset is provided by Case Western Reserve University (CWRU). As a universally recognized benchmark dataset for evaluating and testing fault diagnosis methods, it includes four distinct health states: normal state, ball fault, inner race fault, and outer race fault. Each fault state is further subdivided into three different damage levels: 0.007 inches, 0.014 inches, and 0.021 inches. In addition, the experiments were conducted under four different load conditions, namely 0 horsepower, 1 horsepower, 2 horsepower, and 3 horsepower, with each load condition regarded as an independent domain [39].
4.3. Experimental Content
The experiments in this paper are divided into two parts: comparative experiments and ablation experiments. Comparative experiments compare the algorithm proposed in this paper with mainstream unsupervised domain adaptation algorithms to demonstrate the superiority of the proposed algorithm. To further verify the performance improvement of the proposed method on unsupervised domain adaptation algorithms, the ablation experiments compare the performance of a baseline model without the proposed modules with that of the algorithm integrated with the corresponding modules, thereby illustrating the impact of the proposed modules on unsupervised domain adaptation algorithms.
The comparative experiments adopted in this paper draw on the AdaTIME framework, where 12 unsupervised domain adaptation algorithms are implemented on four datasets for comparison with the proposed algorithm. To eliminate the impact of irrelevant variables on the results of comparative experiments, all algorithms in this experiment use the same feature extraction network and classifier. For each dataset, the hyperparameters of each algorithm are set to the optimal values for that dataset. Ten transfer scenarios are selected for each dataset to evaluate model performance. To address the impact of randomness in a single experiment on the credibility of results, each algorithm is run five times under each transfer scenario, and the average accuracy of the five runs is calculated to measure the performance of the algorithm on the corresponding transfer task for that dataset.
Ablation experiments are conducted on the CWRU dataset to analyze the role of key components in the model. These ablation experiments start with a baseline model without domain adaptation, which is obtained only by fine-tuning the feature extractor. In addition, MMDA is used as the second control model to verify the functions of the “Adaptive Data Augmentation (ADA) module” and the “Adaptive Weighted Contrastive Learning (AWCL) module” in the proposed algorithm. To verify the role of the ADA module in the model, the AWCL module is removed from the proposed model (w/o AWCL); to verify the role of the AWCL module, the ADA module is removed from the proposed model (w/o ADA). Since the proposed model is modified based on the MMDA model, the MMDA model can be regarded as the proposed method with both the ADA and AWCL modules removed (w/o AWCL + w/o ADA). Finally, the performance of the complete model is evaluated.
4.4. Analysis and Discussion of Comparative Experimental Results
The results of the comparative experiments are presented in Table 2, Table 3, Table 4 and Table 5, where each table shows the accuracy comparison between the algorithm proposed in this paper and other mainstream algorithms across 10 transfer scenarios on the corresponding dataset. It can be clearly observed from the data that, compared with other algorithms, the proposed algorithm does not show a significant advantage in accuracy on a single transfer task scenario. However, on average, the proposed algorithm achieves the best performance across all four datasets, indicating that it has better robustness. This benefit stems from the adaptive feature enhancement module proposed in this paper: on the one hand, adaptive data augmentation expands the number of dataset samples; on the other hand, it aligns data augmentation operations with the classification capability of the model. Through contrastive learning, the model can more easily extract important features of samples, which greatly improves feature quality. The combination of adaptive data augmentation and contrastive learning significantly enhances the generalization ability of the model.
The EEG dataset exhibits a significant class imbalance problem, where the number of minority class samples is much smaller than that of majority class samples. Compared with other datasets, the proposed algorithm achieves a more substantial performance improvement on the EEG dataset, demonstrating that it can still obtain favorable accuracy in class-imbalanced scenarios. This is attributed to the adaptive weighted contrastive learning module proposed in this paper. When the dataset is imbalanced, the model tends to perform poorly in classifying minority samples; the module assigns larger weights to minority samples, thereby mitigating the bias of model training toward majority samples caused by class imbalance.
4.5. Results and Discussion of Ablation Experiments
The results of the ablation experiments are presented in Table 6. When the adaptive feature enhancement module is applied independently, the model performance outperforms that of the baseline model. When the adaptive weighted contrastive learning module is applied alone, the model performance also exceeds that of the baseline model. When the adaptive data augmentation module and the adaptive weighted contrastive learning module work jointly, the model achieves better performance than either module applied individually, and its performance is significantly superior to that of the baseline model. This result further demonstrates that the proposed improvements are beneficial to the model performance.
To intuitively evaluate the contribution of each component in the proposed ACLDA framework, we visualize the learned feature representations using t-SNE embeddings on the CWRU dataset. Figure 3 illustrates the feature distributions under four different settings: (a) Description of baseline model, (b) Description of our model(w/o afa), (c) Description of our model(w/o wacl), and (d) Description of our model. In these plots, different colors represent different classes (or domains), where points from the target domains are projected into the same 2D space. As depicted in Figure 3d, the result demonstrates the effectiveness of the complete ACLDA framework. It is evident that the feature distributions of the source and target domains are well-aligned, showing a high degree of overlap. Moreover, the features exhibit clear cluster structures with high intra-class compactness and large inter-class separability. This superior visualization result confirms that the synergistic interaction between the difficulty perception mechanism and the weighted alignment strategy enables the model to learn highly discriminative representations, significantly boosting classification performance on the target domain.
Through the analysis of the ablation experiment results, it can be concluded that the feature enhancement module is beneficial for improving intra-class compactness and reducing domain discrepancies. The adaptive weighted contrastive learning module contributes to intra-class compactness and inter-class discriminability. By combining these two modules, the intra-class compactness is enhanced and the inter-class decision boundaries are more distinct, which is favorable for improving the classification performance of the model. Meanwhile, the reduction in the feature distribution discrepancy between the source and target domains indicates that the proposed model has stronger robustness.
4.6. Convergence and Stability Analysis
To validate the effectiveness and robustness of the proposed method, we monitored the descending trends of various loss functions and the accuracy variations throughout the training process, which spanned 40 epochs. Figure 4a,b illustrate training loss curves and the test accuracy curves, respectively.
The model exhibits high learning efficiency, with source accuracy saturating near 100% by epoch 10 and target accuracy stabilizing by epoch 25, indicating effective cross-domain knowledge transfer. This is corroborated by the loss curves, where the total loss drops sharply in the initial phase, driven by the classification loss, while contrastive losses decrease smoothly to optimize feature discriminability. Post-convergence behavior (after epoch 20) is characterized by minimal fluctuation in accuracy and consistently low MMD loss. This sustained stability through epoch 40 confirms the method’s resilience against overfitting and negative transfer.
4.7. Complexity and Efficiency Analysis
To assess the scalability and practical applicability of the proposed framework, we analyzed its computational complexity and runtime performance.
Empirically, we compared the training time, inference latency, and accuracy of our method against the baseline on the target dataset. As shown in Figure 5, our method requires 889 s per epoch for training, compared to 559 s for the baseline. This increase is primarily attributed to the additional gradient computations required for the contrastive loss. However, this training overhead is a worthwhile trade-off for the significant performance gain, with accuracy improving from 93.46% to 98.49%. Crucially, for real-world deployment, the inference speed remains virtually unaffected. Since the difficulty-aware weighting and augmentation modules are training-time regularization techniques, they are detached during inference. Consequently, our model achieves a total inference time of 575 ms for the entire test set, comparable to the baseline’s 574 ms. This demonstrates that our method enhances generalization without compromising real-time processing efficiency.
4.8. Sensitivity Analysis on Augmentation Magnitude
As shown in Figure 6, when employing fixed data augmentation strategies, weak augmentation fails to guarantee sample diversity, while overly strong augmentation compromises sample semantics. Both scenarios lead to performance degradation. To address this, the adaptive data augmentation method proposed in this paper effectively operates within a “safe” semantic boundary.
4.9. Comparison of Difficulty Estimation Metrics
To address the concern about the stability of our difficulty estimation mechanism, we have conducted comparative experiments with the standard Entropy-based difficulty metric. As shown in Figure 7, our EMA-based method consistently outperforms the Entropy-based baseline in all scenarios.
5. Conclusions
In this paper, we integrate the unsupervised domain adaptation (UDA) algorithm with contrastive learning (CL), and propose a novel unsupervised domain adaptation algorithm based on adaptive contrastive learning. Different from existing methods, our contributions are twofold: first, we introduce an adaptive intra-domain contrastive learning strategy, which enables the model to perform adaptive data augmentation on raw samples according to its own learning capability, and then leverages both augmented and raw samples for contrastive learning, thereby enhancing the quality of features extracted by the model. Second, unlike traditional distribution alignment schemes, we adopt adaptive weighted supervised contrastive learning for class-level alignment; this method allows the model to focus on samples that are conducive to improving its prediction accuracy, while also facilitating the enlargement of inter-class differences and the enhancement of intra-class compactness. In the comparative experiments, the proposed algorithm achieves state-of-the-art performance on four benchmark datasets, which verifies its superiority and favorable robustness. Moreover, the results of ablation experiments demonstrate that the proposed method contributes to the performance improvement of domain adaptation algorithms, confirming its practical value.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Jin X.Y. Park Y. Maddix D. Wang H. Wang Y.Y. Domain adaptation for time series forecasting via attention sharing Proceedings of the 39th International Conference on Machine Learning (ICML 2022)Baltimore, MD, USA 17–23 July 20221028010297
- 2Ozyurt Y. Feuerriegel S. Zhang C. Contrastive learning for unsupervised domain adaptation of time seriesar Xiv 20222206.06243
- 3Zhang H.Y. Zhang Y.F. Liang J. Zhang Z. Wang L. Spectral decomposition and adaptation for non-stationary time series anomaly detection Neurocomputing 202566213197810.1016/j.neucom.2025.131978 · doi ↗
- 4Painblanc F. Chapel L. Courty N. Friguet C. Pelletier C. Tavenard R. Match-and-deform: Time series domain adaptation through optimal transport and temporal alignment Joint European Conference on Machine Learning and Knowledge Discovery in Databases Springer Berlin/Heidelberg, Germany 2023341356
- 5Cen J. Yang Z.H. Liu X. Xiong J.B. Chen H.H. A review of data-driven machinery fault diagnosis using machine learning algorithms J. Vib. Eng. Technol.2022102481250710.1007/s 42417-022-00498-9 · doi ↗
- 6Hassan A.R. Subasi A. Automatic identification of epileptic seizures from EEG signals using linear programming boosting Comput. Methods Programs Biomed.2016136657710.1016/j.cmpb.2016.08.01327686704 · doi ↗ · pubmed ↗
- 7Pan S.J. Yang Q. A survey on transfer learning IEEE Trans. Knowl. Data Eng.2009221345135910.1109/TKDE.2009.191 · doi ↗
- 8Zhang Y.S. A survey of unsupervised domain adaptation for visual recognitionar Xiv 202110.48550/ar Xiv.2112.067452112.06745 · doi ↗