A Dual-Stream Transformer with Self-Supervised Contrastive Training for fMRI-Based Autism Spectrum Disorder Classification
Zirui Li, Lei Wang

TL;DR
This paper introduces a dual-stream Transformer model that improves autism classification by combining dynamic and global brain connectivity features using self-supervised learning.
Contribution
The novel TwoTST model integrates ROI time series and PCC matrices with self-supervised pre-training and contrastive learning for better ASD classification.
Findings
Contrastive learning, pre-training, and dual-stream structure improved mean AUC by 3–6%, 3–7%, and 3–4% respectively.
Attention Pooling was identified as the optimal fusion strategy for combining dual-stream features.
Relative parameter changes were higher in contrastive projection heads compared to TST modules during fine-tuning.
Abstract
Background/Objectives: Autism Spectrum Disorder (ASD) diagnosis is difficult due to heterogeneity. Current Time-series Transformer (TST) methods cannot capture both dynamic and global brain connectivity simultaneously, which limits ASD classification performance. Methods: We propose TwoTST, a dual-stream Transformer that combines raw Region of Interest(ROI) time series and Pearson correlation matrices(PCC).We pre-train the two TST branches via self-supervised learning by randomly masking ROIs and PCC, use contrastive learning and fine-tuning for feature alignment, evaluate five fusion strategies, and analyze relative parameter changes during fine-tuning. Results: Experiments were conducted on the ABIDE I dataset using the CC200 atlas. Contrastive learning, pre-training, and the dual-stream structure improve mean AUC by 3–6%, 3–7%, and 3–4% respectively. Attention Pooling is the optimal…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
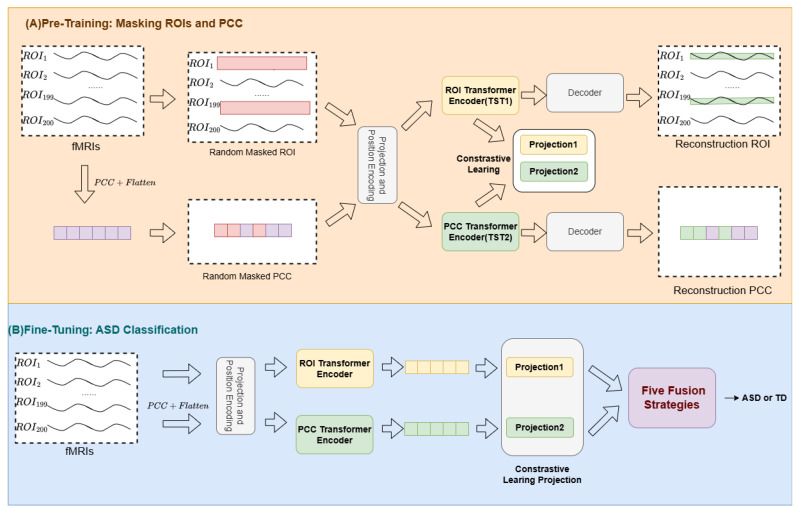 Figure 1
Figure 1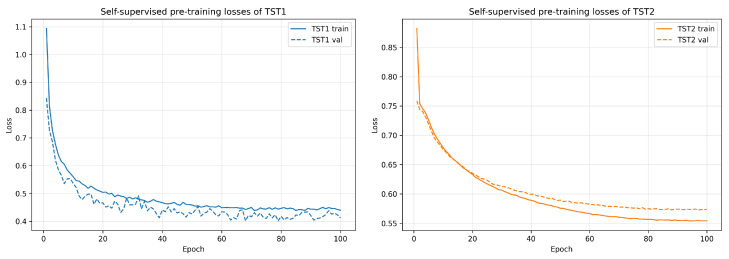 Figure 2
Figure 2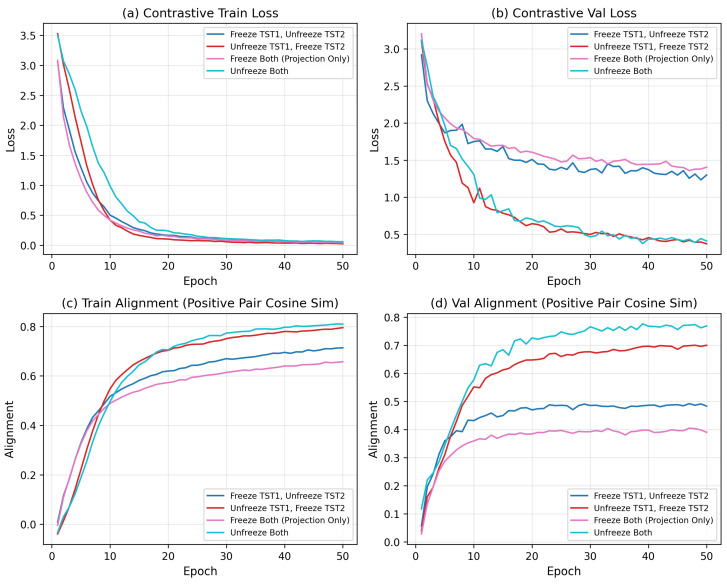 Figure 3
Figure 3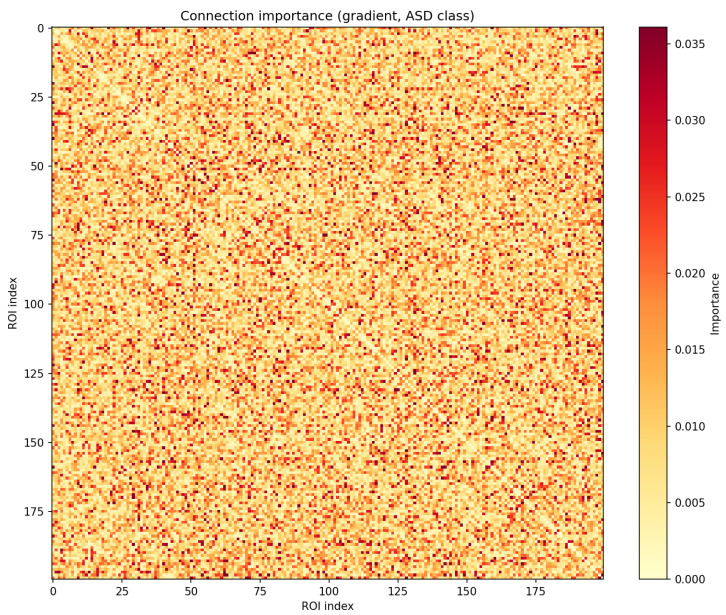 Figure 4
Figure 4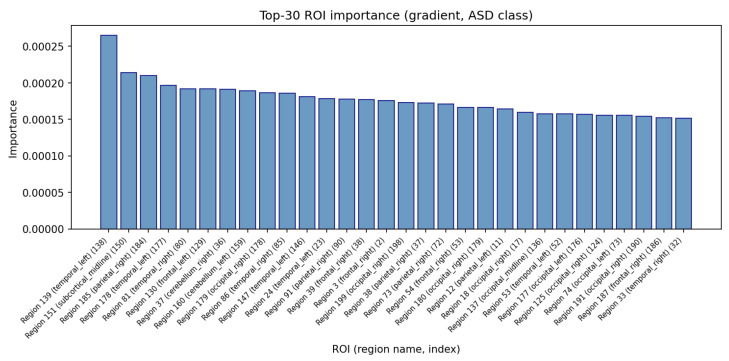 Figure 5
Figure 5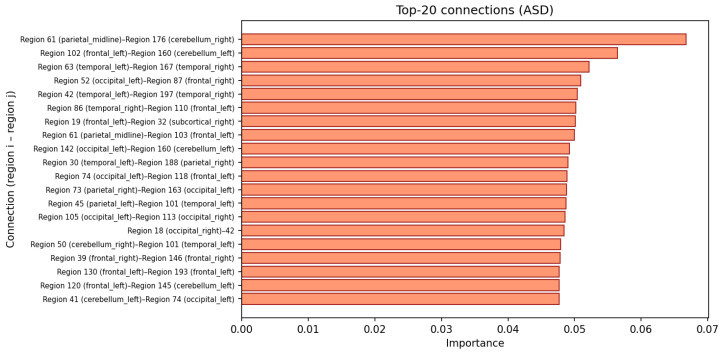 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAutism Spectrum Disorder Research · Functional Brain Connectivity Studies · EEG and Brain-Computer Interfaces
1. Introduction
Autism Spectrum Disorder (ASD) is a neurodevelopmental disorder characterized by persistent deficits in social communication and interaction, along with restricted and repetitive patterns of behavior, interests, or activities [1]. ASD affects approximately 1 in 100 children globally [2], yet diagnosis remains challenging due to extensive phenotypic heterogeneity. Current diagnostic practices predominantly rely on behavioral assessments, which may be subjective and prone to observer bias [3], necessitating objective biomarkers for accurate and early diagnosis.
Functional magnetic resonance imaging (fMRI) has emerged as a powerful non-invasive tool for investigating brain function and connectivity patterns in ASD [4]. Resting-state fMRI (rs-fMRI) has shown promise for identifying neuroimaging biomarkers associated with ASD [5,6]. Previous studies have demonstrated the potential of using Pearson correlation coefficients computed from time series of regions of interest for classifying autism spectrum disorder via machine learning approaches [7,8,9]. However, these methods primarily focus on static functional connectivity patterns, treating correlation matrices as fixed representations of brain network topology, thereby neglecting the temporal dynamics inherent in fMRI data [10,11,12].
The advent of Transformer architectures has revolutionized time series analysis, thanks to their capacity to capture long-range temporal dependencies via self-attention mechanisms [13,14]. In neuroimaging, self-supervised pre-training has proven effective for Transformers to extract meaningful representations from fMRI data. Zhou et al. proposed masking entire ROIs in raw fMRI time series and reconstructing masked segments [15], while Mahler et al. developed pre-training by masking values in Pearson correlation coefficient matrices [16]. Both approaches demonstrated improved classification performance.
Despite these advances, existing Transformer-based fMRI analysis approaches face three key challenges: Modality isolation: most studies rely on a dichotomous approach, focusing either on temporal dynamics (raw ROI time series) or static functional connectivity (PCC matrices)—yet few have attempted to jointly model these two complementary modalities within a unified framework. Feature misalignment: though self-supervised pre-training has been explored to boost model generalization, few studies have designed pre-training objectives that explicitly align temporal and connectivity features in a shared representation space. Even when both modalities are integrated, their feature embeddings tend to remain isolated, leaving the inherent correlations between dynamic neural activity and stable functional connectivity unaccounted for.
To address these limitations, we propose TwoTST, a dual-stream Transformer framework that simultaneously captures dynamic temporal patterns and global functional connectivity from rs-fMRI data for ASD classification. To address modality isolation, we employ two specialized Transformer encoders: TST1 processes raw ROI time series for temporal dynamics, while TST2 processes PCC matrices for static connectivity. To address feature misalignment, we employ contrastive learning during the self-supervised pre-training stage to explicitly align the feature representations of the two Transformers, and evaluate five distinct fusion strategies in the fine-tuning phase to determine the optimal integration scheme. We further calculate the parameter change rate for both the dual-stream Transformer and the contrastive pre-trained model under the unfrozen fine-tuning setting, which validates the effectiveness of our pre-training strategy and the sensitivity of the proposed architecture. A comprehensive series of ablation experiments is conducted to verify the reliable classification performance of our framework. To assess the generalization capability of our model, we perform leave-one-site-out (LOSO) cross-validation across 19 sites on the dataset, demonstrate that our model possesses a certain degree of generalization ability across different fMRI acquisition sites. In addition, our model enables interpretability by identifying abnormal functional connections and atypical brain regions associated with ASD. Based on five independent runs with different random seeds, the optimal fusion strategy achieves a mean AUC of 0.74 ± 0.04. The code is available at https://github.com/Leezy-Ray/twoTST.
2. Related Work
2.1. fMRI-Based ASD Classification
Early approaches to ASD classification using fMRI data primarily relied on static functional connectivity measures, computing Pearson correlation coefficients between time series of different brain regions over entire scan durations [7,8]. Traditional machine learning classifiers, including support vector machines and random forests, have been applied to these static connectivity features with reasonable success [17,18]. However, these approaches fundamentally ignore the temporal dynamics inherent in fMRI data. The recognition that functional connectivity is inherently dynamic has led to the development of dynamic functional connectivity (dFC) methods [10,11,12], which employ sliding window techniques to compute connectivity matrices at different time points. While dFC methods have shown promise, they introduce challenges including the need for the careful selection of window parameters and increased dimensionality, which can exacerbate overfitting in small datasets [19].
Deep learning approaches have demonstrated potential for capturing complex patterns from high-dimensional brain data. Convolutional neural networks have been applied to functional connectivity matrices by treating them as images [20], while graph neural networks have been used to model the non-Euclidean structure of brain networks [21]. More recently, Transformer architectures have been adapted for neuroimaging applications, with hierarchical transformers proposed to learn inter-community relationships among brain regions [15]. However, most existing approaches focus on either temporal dynamics or static connectivity, rarely integrating both modalities effectively within a unified framework.
2.2. Self-Supervised Contrastive Learning and Multimodal Fusion
Self-supervised learning has emerged as a valuable paradigm for learning representations from limited labeled data in medical imaging [22]. Among self-supervised approaches, contrastive learning provides an effective way to align multimodal features by maximizing the similarity of consistent representations in a shared embedding space [23,24]. In fMRI analysis, masking-based pre-training strategies have demonstrated significant effectiveness. Zhou et al. proposed a framework that randomly masks entire ROIs in raw fMRI time series and reconstructs the masked segments [15], while Mahler et al. developed a multi-atlas enhanced Transformer framework that employs self-supervised pre-training by masking values in PCC matrices [16]. However, these approaches focus on single-modal pre-training, leaving the alignment between different modalities largely unexplored.
The integration of multiple data modalities has shown promise in improving classification performance in neuroimaging [25]. Different fusion strategies have been explored, including early fusion, late fusion, and intermediate fusion [26], with attention-based fusion mechanisms proving particularly effective [27]. However, most existing fusion approaches treat different modalities as relatively independent sources of information, without explicitly modeling the interactions and correlations between them. The development of fusion mechanisms that enable mutual interaction between different feature streams, particularly at the Transformer level, remains an underexplored area.
3. Materials and Methods
3.1. Framework Overview
We propose TwoTST, a dual-stream Transformer framework for ASD classification that integrates both dynamic temporal patterns and static functional connectivity from rs-fMRI data. As illustrated in Figure 1, our framework consists of two main phases: self-supervised pre-training and supervised fine-tuning.
In the pre-training phase (Figure 1A), both TST encoders are pre-trained independently using masked reconstruction. Given raw fMRI time series from ROIs, TST1 reconstructs masked ROI time series segments, while TST2 reconstructs masked PCC values computed from the time series. We then employ contrastive learning to train two linear projection heads. After pre-training, the TST encoders and the two linear projection layers are utilized for fine-tuning, during which we evaluate five fusion strategies and diverse parameter freezing settings for the pre-trained modules to identify the optimal configuration that yields the highest AUC.
In the fine-tuning phase (Figure 1B), the TST encoders extract features from ROI time series and PCC matrices, respectively. These extracted features go through the linear projection layers trained via contrastive learning and are then fused using five connection methods, namely Concat, Gated, Cross-Attention, Bilinear, and Attention Pooling (see Table 1).
3.2. Model Architecture
3.2.1. ROI Transformer Encoder (TST1)
The ROI Transformer Encoder processes raw fMRI time series to capture temporal dynamics across brain regions. The input fMRI volumes are parcellated using the CC200 atlas into regions of interest (ROIs), resulting in a 2D matrix representation , where T denotes the number of time points. Each time point is projected to a hidden dimension through a linear projection layer, and sinusoidal positional encodings are added to encode temporal order. A learnable [CLS] token is prepended to the sequence, which is then processed through Transformer encoder layers with multi-head self-attention, feed-forward networks, residual connections, and layer normalization. The final representation is extracted from the [CLS] token output. During self-supervised pre-training, TST1 learns to reconstruct masked ROI time points. Specifically, we randomly mask of time points and train the encoder–decoder to reconstruct the masked values:
where denotes the set of masked time points, is the original ROI value, and is the reconstructed value. This enables the encoder to capture dynamic temporal patterns from the raw time series.
3.2.2. PCC Transformer Encoder (TST2)
The PCC Transformer Encoder processes functional connectivity matrices to capture global static patterns. Given the preprocessed fMRI time series , we compute the Pearson correlation coefficient matrix :
The upper triangular elements (excluding the diagonal) are extracted and flattened into a vector , where 19,900. The flattened vector is segmented into N patches, each embedded through a linear projection to dimension . After adding positional encodings, the patches are processed through Transformer encoder layers with the same architecture as TST1. The final representation is obtained via mean pooling and layer normalization across the patch dimension. During self-supervised pre-training, TST2 learns to reconstruct masked elements in the flattened PCC vector. Specifically, we randomly mask of elements in and reconstruct them:
where denotes the set of masked positions, is the original PCC value, and is the reconstructed value. This enables the encoder to capture global connectivity structures from the correlation matrix.
3.2.3. Self-Supervised Pre-Training
Both encoders are pre-trained using a masked reconstruction objective. For TST1, we randomly mask of time points in the ROI sequences and train the encoder–decoder architecture to reconstruct the masked values. For TST2, we randomly mask of the PCC vector elements and reconstruct them. The pre-training loss is
where denotes mean squared error and is a balancing coefficient.
3.3. Contrastive Learning for Feature Alignment
To address the issue of feature misalignment between temporal and connectivity modalities, we introduce a contrastive learning strategy to align the feature representations from the two TST encoders in a shared embedding space. Let denote the feature vector extracted by TST1 from ROI time series, and denote the feature vector extracted by TST2 from the corresponding PCC matrix. These features are projected into a contrastive latent space via a shared linear projection head:
where denotes the linear projection head (implemented as a two-layer MLP) and are the normalized projected features ( ). The InfoNCE contrastive loss is then minimized to pull positive pairs (features from the same subject) closer and push negative pairs (features from different subjects) apart:
where is the cosine similarity, is the temperature parameter, and N is the number of negative samples in the batch.
3.4. Five Transformer-Level Fusion Strategies
To effectively integrate the complementary information from temporal dynamics (TST1) and functional connectivity (TST2), we evaluate five connect fusion methods. All methods first align features to a common dimension through linear projection:
where and .
3.4.1. Concat
The simplest approach directly concatenates the aligned features:
3.4.2. Gated
This method employs learnable gating weights for adaptive fusion:
where is the sigmoid function and ⊙ denotes element-wise multiplication.
3.4.3. Cross-Attention
Bidirectional Cross-Attention with residual connections enables mutual information exchange:
where .
3.4.4. Bilinear
Bilinear transformation captures feature interactions with residual connection:
3.4.5. Attention Pooling
Attention-weighted aggregation of the two features:
3.4.6. Classification Head and Training Strategy
The fused features from all methods are passed through a three-layer MLP classifier with hidden dimensions [256, 64, 2] to produce the final classification output. During fine-tuning, both TST1 and TST2 encoders are frozen, and only the projection layers, fusion module, and classifier are trained. This strategy significantly reduces the number of trainable parameters, mitigating overfitting on the limited ASD dataset. The training objective is cross-entropy loss:
where is the ground truth label, and is the predicted probability for class i.
4. Experiments
4.1. Datasets and Preprocessing
4.1.1. ABIDE I Dataset
We evaluate our proposed TwoTST framework on the Autism Brain Imaging Data Exchange (ABIDE) I dataset [5], a large-scale multi-site public repository that aggregates resting-state functional magnetic resonance imaging (rs-fMRI) data from 17 international imaging sites. The dataset comprises 1112 subjects (age: years; 948 males and 164 females), including individuals diagnosed with Autism Spectrum Disorder (ASD) and typically developing (TD) controls.
4.1.2. Data Preprocessing
We utilized the preprocessed rs-fMRI data processed via the Configurable Pipeline for the Analysis of Connectomes (CPAC) [28], downloaded from the Preprocessed Connectomes Project. The preprocessing pipeline included slice timing correction, motion correction, nuisance regression (including motion parameters, white matter, and cerebrospinal fluid signals), band-pass filtering (0.01–0.1 Hz), and registration to MNI152 standard space.
The rs-fMRI data were parcellated using the Craddock 200 (CC200) atlas [28], which divides the brain into spatially coherent and functionally homogeneous regions of interest (ROIs). For each subject, the mean time series within each ROI was extracted, yielding a 2D matrix representation , where T denotes the number of time points (100 in the ABIDE dataset) and represents the number of ROIs.
4.1.3. Quality Control
After quality control to remove subjects with excessive head motion or incomplete data coverage, we performed additional data cleaning to exclude subjects with any ROI containing all-zero values (indicating missing or corrupted data). This resulted in a final cohort of 963 subjects (493 with ASD, 470 TD controls) for model training and evaluation. The processed data were formatted as a tensor with dimensions (963 subjects, 100 time points, 200 ROIs).
4.2. Experimental Settings
4.2.1. Implementation Details
All experiments were implemented in PyTorch 2.5.1+cu124 and conducted on NVIDIA RTX 4090D GPUs. The dataset was split into training (70%), validation (10%), and test (20%) sets with stratified sampling to maintain class balance.The model and training configurations are shown in Table 2.
4.2.2. Model Evaluation
We evaluated model performance using five metrics: Area Under the ROC Curve (AUC), Accuracy (ACC), Sensitivity (True Positive Rate), Specificity (True Negative Rate), and F1 Score. AUC was used as the primary metric for model selection during training.
4.3. Results
4.3.1. Self-Supervised Pre-Training Loss
Figure 2 shows self-supervised pre-training reconstruction loss curves of the two temporal transformers. The left panel shows the training and validation reconstruction losses of TST1 across epochs, and the right panel shows the corresponding losses of TST2. Both models exhibit stable convergence under the self-supervised objective, indicating that the pre-training stage successfully learns meaningful temporal representations.
4.3.2. Effect of Freezing Strategies for Contrastive Learning
As shown in Figure 3, to quantify how much of the downstream performance comes from updating the backbone encoders versus the projection heads, we compare four freezing strategies during contrastive learning: (i) freeze both TST1 and TST2, (ii) freeze TST1 only, (iii) freeze TST2 only, and (iv)unfreeze both encoders while always training the projection heads. Across all fusion variants, we consistently observe the ordering
showing that allowing both temporal and connectivity encoders to adapt to the contrastive objective yields the most discriminative joint representation. However, the performance gap between unfreeze both and freeze TST1 is smaller than the gap to the other two settings, suggesting that the PCC encoder (TST2) is more sensitive to task-specific adaptation.
4.3.3. Comparison of Fusion Strategies
After fixing the best pre-training and contrastive-learning strategy (pre-train TST1/TST2, enable contrastive learning with frozen projection heads at fine-tuning, and unfreeze both encoders), we systematically compare five fusion mechanisms between temporal dynamics (TST1) and functional connectivity (TST2): Concat, Gated fusion, Cross-Attention, Bilinear pooling, and Attention Pooling. For each fusion method, we run five experiments with different random seeds and report the mean and standard deviation of performance on the subject-level test set.
Table 3 summarizes the results (Mean ± Std over 5 runs). Overall, Gated and Concat fusion provide strong baselines, while Attention Pooling achieves competitive performance and is selected as our default fusion in the final configuration due to its simplicity and stability.
To further investigate how much each module adapts during fine-tuning, we measure the mean relative parameter change of TST1, TST2, and the two projection heads across the five seeds. The results are shown in Table 4.
We find that TST1 and TST2 exhibit relatively small changes around – , while the projection heads show much larger changes around – , especially under Gated and Attention Pooling fusion. In contrast, under Cross-Attention and Bilinear fusion, the projection heads change less, suggesting that the contrastive representations are already better aligned with the downstream task in these settings. These results support our design choice of using projection-based fusion with a light-weight classifier on top of the pre-trained encoders.
4.3.4. Leave-One-Site-Out (LOSO) Validation
Based on the optimal configuration (Attention Pooling fusion, self-supervised pre-training, contrastive learning, and unfrozen encoders), we conduct Leave-One-Site-Out (LOSO) cross-validation across 19 independent scanning sites to verify the cross-site generalization ability of our model. We adopt subject-level evaluation with majority voting to aggregate predictions from different sliding windows, and report AUC, Accuracy, Sensitivity, Specificity, and F1 Score for each site.
Table 5 details the LOSO performance on all 19 sites. The proposed model achieves stable and reliable classification performance across most heterogeneous sites, which demonstrates its strong generalization to multi-center fMRI data and practical clinical value.
Most sites achieve AUC , and UM_2 yields the best performance (AUC = 0.93, Accuracy = 0.88, F1 = 0.91). Sites including CMU, SDSU, and USM also obtain AUC above 0.80. These results confirm that the combination of self-supervised pre-training, contrastive feature alignment, and Attention Pooling fusion effectively alleviates multi-center data distribution shift, enabling robust and accurate ASD identification at a cross-site level.
4.3.5. Explanation Studies
To assess the model interpretability of the proposed TwoTST model, we analyze which functional connections and regions of interest (ROIs) the final classifier actually relies on when predicting ASD. Concretely, we work with the best-performing configuration, load the final checkpoint, and compute gradient-based importance scores with respect to the ASD logit.
Given an input sample x, let denote the logit of the ASD class. For the connectivity stream, we consider the vectorized upper triangle of the PCC matrix, i.e., one scalar per connection . For each sample we compute the gradient
take the absolute value, and then average over all analyzed samples:
The resulting importance matrix assigns one importance score to each functional connection. A large means that small perturbations of the connection between ROI i and ROI j cause strong changes in the ASD logit, so the model heavily relies on this edge when distinguishing ASD from typically developing controls (TC).
For the time-series stream, we take the 4D tensor of gradients of w.r.t. the BOLD time series . For each ROI k, we first aggregate gradients along the temporal dimension, and then average across samples:
This yields one scalar importance score per ROI. ROIs with larger are those whose temporal dynamics are most influential for the final ASD decision. All indices are defined in the CC200 atlas; during visualization, we map each ROI index to the corresponding anatomical label and lobe/hemisphere information.
Figure 4 shows the full connection-importance matrix as a heatmap, revealing a clearly non-uniform pattern: only a relatively sparse subset of connections exhibits high importance scores, while most are close to zero. This indicates that, although the model is trained on all possible pairwise connections, the final decision function effectively concentrates on a small set of discriminative edges, which can be interpreted as candidate abnormal connectionsassociated with ASD.
Figure 5 summarizes the ROI importance vector as a bar plot, sorted in descending order and annotated with CC200 region labels. The distribution is again strongly skewed: only a limited number of ROIs contribute substantially to the ASD logit, whereas many regions have negligible influence. From a neuroscientific perspective, these highly weighted ROIs can be viewed as key regions whose BOLD dynamics are most informative for ASD vs. TC discrimination, while the atlas mapping allows us to relate them to known systems in the ABIDE literature.
Finally, Figure 6 visualizes the top-ranked connections from as a bar chart of ROI–ROI pairs. Each bar corresponds to a pair together with its gradient-based importance score. In combination with group-level PCC differences (ASD vs. TC), these connections can be further characterized as potential under-connected or over-connected edges in ASD. Taken together, the connection-level heatmap, the ROI-level importance distribution, and the top-connection list demonstrate that the model does not behave as an opaque black box: it yields a coherent and spatially structured pattern of important regions and connections, which can be systematically related back to established neuroscientific findings on ASD.
4.3.6. Ablation Studies
We conduct a series of ablation experiments to disentangle the contributions of contrastive learning, pre-training, and fusion choices. All ablation experiments are independently repeated five times with distinct random seeds to ensure reproducibility. For statistical validation, we report the mean AUC (±standard deviation, SD) as the primary metric, and perform paired two-tailed t-tests to compare performance between experimental conditions; Bonferroni correction is applied for multiple comparisons to control Type I error. Statistical significance is denoted as: * , ** , *** .
First, we compare configurations with and without contrastive learning under the same fusion and freezing strategy. For the “without” contrastive learning group, we do not utilize the two pre-trained Proj. Head 1 and Proj. Head 2 in the model architecture.
As shown in Table 6, with the exception of Bilinear fusion (non-significant change, ), all other fusion methods (Concat, Gated, Cross-Attention, and Attention Pooling) achieved a statistically significant AUC improvement when contrastive learning and projection heads were enabled (all after Bonferroni correction). Concat fusion yielded a notably larger and highly significant gain of (*** ), indicating that contrastive alignment is particularly helpful for more expressive fusion modules.
Second, we perform a “no pre-training” ablation where TST1 and TST2 are randomly initialized and trained end-to-end together with the fusion module. The results are shown in Table 7.
Across multiple fusion types, pre-training consistently improved or preserved performance, with statistically significant gains observed for Gated ( , * ), Cross-Attention ( , *** ), Bilinear ( , ** ), and Attention Pooling ( , * ) after Bonferroni correction. Only Concat fusion showed a non-significant small improvement ( , ). Combined with the parameter-change analysis, these statistically validated results demonstrate that self-supervised pre-training followed by contrastive projection and light-weight fine-tuning is a more effective strategy than purely supervised training from scratch.
Third, we perform a “single-backbone” ablation where we only keep one of the two temporal transformers. Concretely, we consider (i) TST1-only: we pre-train TST1, attach a task-specific prediction head, and fine-tune the whole model end-to-end; and (ii) TST2-only: we pre-train TST2, attach the same prediction head, and fine-tune it in the same way. We then compare these single-backbone models against the full TwoTST model (TST1 + TST2 with Attention Pooling fusion) under identical training and evaluation protocols, using one-way ANOVA with post hoc Bonferroni correction for multiple comparisons. The results are shown in Table 8.
One-way ANOVA reveals a significant main effect of model architecture on AUC ( , ). Post hoc Bonferroni-corrected comparisons confirmed that the full TwoTST model achieved significantly higher AUC than TST1-only ( , ** ) and TST2-only ( , * ). While single pre-trained backbones yielded competitive performance, the statistically validated improvement of TwoTST over the best single-backbone variant (TST2-only) by absolute AUC (from to ) confirms that jointly leveraging two complementary temporal representations is more effective than relying on a single pre-trained TST. Combined with the pre-training ablations above, this result further supports our design choice of using two pre-trained temporal transformers followed by lightweight fusion and task-specific fine-tuning.
5. Discussion
5.1. Comparison with Existing Methods
To ensure the rigor and reproducibility of our comparative experiments (addressing generalization and fair comparison concerns), we (1) downloaded the official source code of all baseline methods from their respective paper repositories; (2) re-ran all methods on the identical ABIDE I (CC200) sample split (same training/validation/test sets) to eliminate dataset bias; (3) independently repeated each experiment for five distinct random seeds to quantify performance variability; (4) adopted AUC ± standard deviation (SD) as the core evaluation metric (supplemented with ACC, Sensitivity, Specificity ± SD for comprehensive comparison). Table 9 presents a rigorous comparison with traditional machine learning approaches (SVM and Random Forest), deep learning methods (DAE), and graph-based neural networks (MVS-GCN, FBNET, and WL-DEEPGCN), while Table 10 details the consistent implementation settings across all methods.
Our proposed TwoTST framework achieves substantial improvements over all baseline methods. Traditional machine learning methods (SVM and Random Forest) and early deep learning approaches (DAE) achieve relatively modest performance (accuracy around 67–68%), primarily because they rely on handcrafted features or shallow representations that fail to capture the complex temporal dynamics and connectivity patterns in fMRI data. Graph-based methods (MVS-GCN and FBNET) show improved performance by explicitly modeling brain network topology, but they typically focus on static connectivity matrices and do not fully exploit the temporal information inherent in fMRI time series.
Computational Complexity, Training Time, and Scalability. To provide a complete comparison, we report model size, approximate training time, and scalability characteristics in Table 11. TwoTST consists of two Transformer encoders (TST1 for time series, TST2 for connectivity), projection heads for contrastive learning, and an Attention Pooling fusion module, yielding approximately 36.5 M parameters. Traditional methods (SVM and Random Forest) have negligible parameters and train in minutes but rely on handcrafted features. DAE and graph-based methods (MVS-GCN and FBNET) use 1–3 M parameters and typically require 5–10 min of GPU training on ABIDE. TwoTST involves a multi-stage pipeline: pre-training TST1 and TST2, contrastive learning, and fine-tuning, totaling approximately 20–30 min on a single GPU (e.g., NVIDIA RTX 4090D) for the full workflow on ABIDE I. Despite a higher parameter count and longer training time, TwoTST achieves the best performance and offers favorable scalability: (i) inference is linear in the number of samples and sequence length; (ii) the dual-stream design allows independent scaling of temporal (TST1) and connectivity (TST2) capacities; (iii) the architecture generalizes to other atlases by adjusting n_rois and pcc_dim, with complexity scaling as for the connectivity stream. For deployment, only the fine-tuned model is required; pre-training needs to be performed once per dataset.
5.2. Limitations and Future Directions
Despite the promising results, our study has several limitations that warrant further investigation:
Single Dataset Evaluation: Our experiments were conducted exclusively on the ABIDE I dataset. While this enables direct comparison with existing methods, the generalizability of our approach to other ASD datasets or different neurological conditions remains to be validated. Future work should evaluate TwoTST on additional datasets such as ABIDE II and other multi-site repositories.
Fixed Parcellation: We used the CC200 atlas with 200 ROIs throughout our experiments. Different parcellation schemes (e.g., AAL and Schaefer) or finer-grained parcellations may yield different results. Investigating the impact of parcellation choice on model performance is an important direction for future research.
Multi-modal Integration: Our current framework focuses solely on rs-fMRI data. Integrating structural MRI (sMRI), diffusion tensor imaging (DTI), or clinical phenotypic information could potentially improve diagnostic accuracy and provide a more comprehensive characterization of ASD.
In summary, TwoTST represents a significant advancement in fMRI-based ASD classification by effectively combining temporal dynamics and functional connectivity through a dual-stream Transformer architecture. The substantial performance improvements over existing methods demonstrate the potential of self-supervised contrastive learning and Attention Pooling fusion for neuroimaging analysis.
6. Conclusions
This paper presents TwoTST, a dual-stream Transformer framework for fMRI-based ASD classification that simultaneously captures temporal dynamics (via TST1 processing raw ROI time series) and global connectivity patterns (via TST2 processing PCC matrices). We perform masked reconstruction pre-training and contrastive learning to align dual-branch features. Fine-tuning experiments show that unfreezing both encoders with contrastive projection heads achieves optimal performance. Among five fusion methods over five random seeds, Attention Pooling performs best with an AUC of . LOSO cross-validation proves its strong cross-site generalization. The pre-trained encoders are updated moderately ( – ) in fine-tuning, supporting the effectiveness of pre-training. Gradient-based importance scores and connection-importance matrix offer interpretable ASD biomarkers. Comprehensive ablation experiments validate each key component and the whole TwoTST framework.
7. Patents
The authors declare that no patents resulted from the work reported in this manuscript.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1American Psychiatric Association Diagnostic and Statistical Manual of Mental Disorders (DSM-5)American Psychiatric Publishing Washington, DC, USA 2013 Volume 51947
- 2Zeidan J. Fombonne E. Scorah J. Ibrahim A. Durkin M.S. Saxena S. Yusuf A. Shih A. Elsabbagh M. Global prevalence of autism: A systematic review update Autism Res.20221577879010.1002/aur.269635238171 PMC 9310578 · doi ↗ · pubmed ↗
- 3Lord C. Elsabbagh M. Baird G. Veenstra-Vanderweele J. Autism spectrum disorder Lancet 201839250852010.1016/S 0140-6736(18)31129-230078460 PMC 7398158 · doi ↗ · pubmed ↗
- 4Ogawa S. Lee T.M. Kay A.R. Tank D.W. Brain magnetic resonance imaging with contrast dependent on blood oxygenation Proc. Natl. Acad. Sci. USA 1990879868987210.1073/pnas.87.24.98682124706 PMC 55275 · doi ↗ · pubmed ↗
- 5Martino A.D. Yan C.-G. Li Q. Denio E. Castellanos F.X. Alaerts K. Anderson J.S. Assaf M. Bookheimer S.Y. Dapretto M. The autism brain imaging data exchange: Towards a large-scale evaluation of the intrinsic brain architecture in autism Mol. Psychiatry 20141965966710.1038/mp.2013.7823774715 PMC 4162310 · doi ↗ · pubmed ↗
- 6Uddin L.Q. Supekar K. Menon V. Reconceptualizing functional brain connectivity in autism from a developmental perspective Front. Hum. Neurosci.2013745810.3389/fnhum.2013.0045823966925 PMC 3735986 · doi ↗ · pubmed ↗
- 7Plitt M. Barnes K.A. Martin A. Functional connectivity classification of autism identifies highly predictive brain features but falls short of biomarker standards Neuroimage Clin.2014735936610.1016/j.nicl.2014.12.01325685703 PMC 4309950 · doi ↗ · pubmed ↗
- 8Ronicko J.F.A. Thomas J. Thangavel P. Koneru V. Langs G. Dauwels J. Diagnostic classification of autism using resting-state f MRI data improves with full correlation functional brain connectivity compared to partial correlation J. Neurosci. Methods 202034510888410.1016/j.jneumeth.2020.10888432730918 · doi ↗ · pubmed ↗