Memory-Augmented Spatio-Temporal Transformer for Robust Traffic Flow Forecasting
Puqing Hu, Chunjiang Wu, Chen Wang, Xin Yang, Zhibin Li, Tinghui Chen, Shijie Zhou

TL;DR
This paper introduces a new model for predicting traffic flow that uses memory to better capture long-term patterns and outperforms existing methods.
Contribution
The novel contribution is integrating a learnable memory tensor into an attention-based framework for traffic flow forecasting.
Findings
The proposed model achieves superior prediction accuracy on real-world traffic datasets.
The memory mechanism enables efficient and dynamic spatio-temporal representation learning.
The model offers robustness and a lightweight architecture compared to existing baselines.
Abstract
Accurate traffic flow prediction plays a critical role in intelligent transportation systems, supporting traffic management, congestion mitigation, and efficient utilization of road resources. Advances in neural network-based methods, particularly graph neural networks (GNNs) and attention-based models, have demonstrated strong capability in modeling spatio-temporal traffic dynamics. However, existing approaches still face notable challenges: GNN-based models often rely on static adjacency matrices, limiting their ability to capture dynamic and long-range spatial dependencies, while attention-based models usually involve complex architectures and heavy reliance on large-scale pre-training data. To address these limitations, this study proposes a novel traffic flow prediction model that integrates a learnable memory tensor into an attention-based framework. The introduced memory…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
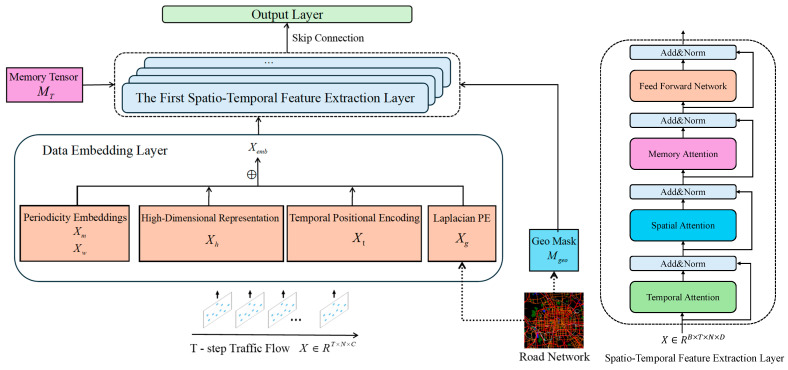 Figure 1
Figure 1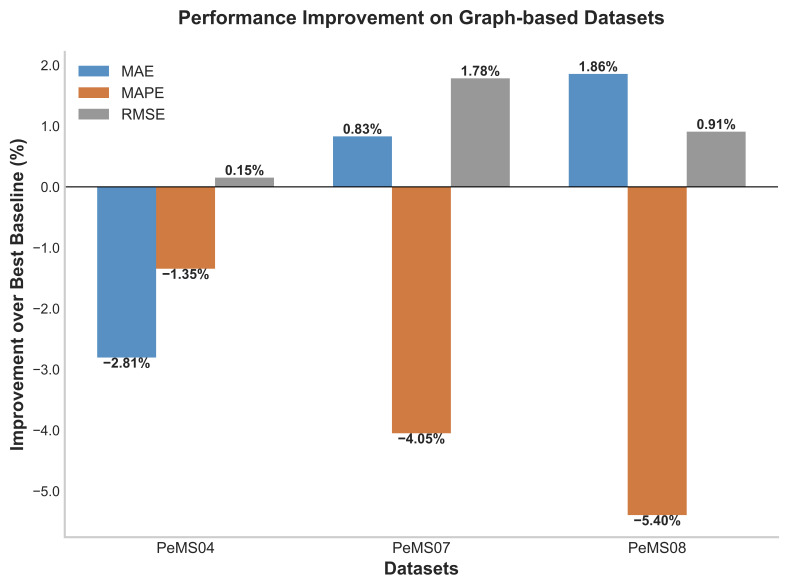 Figure 2
Figure 2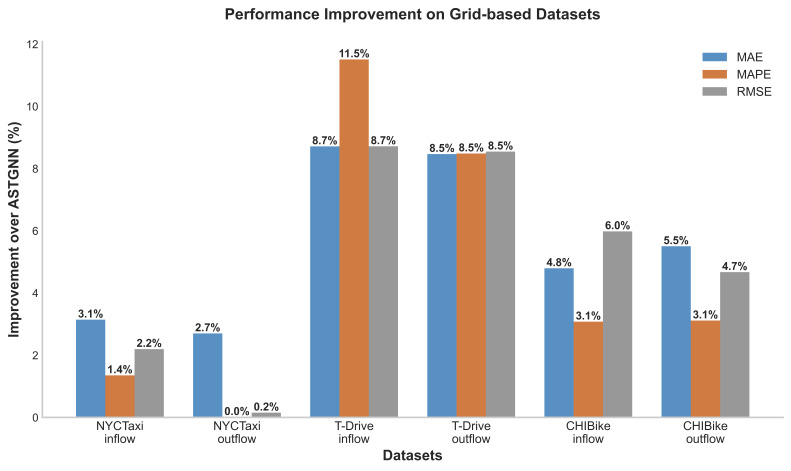 Figure 3
Figure 3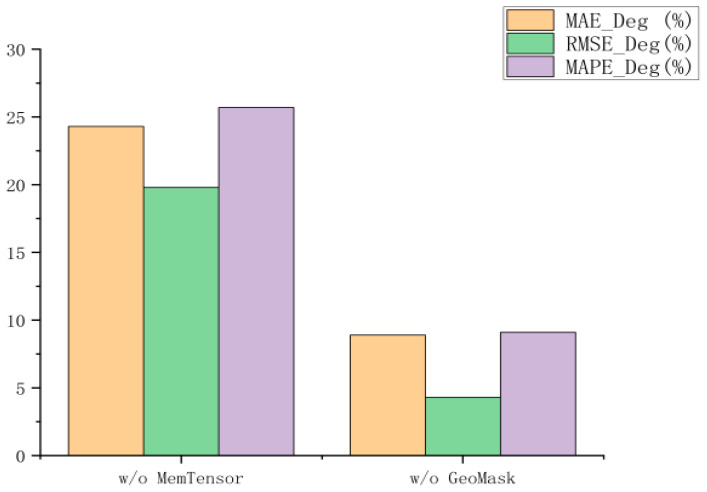 Figure 4
Figure 4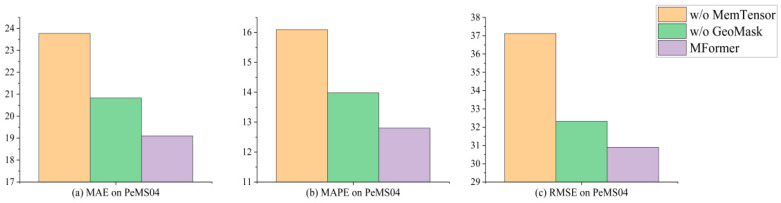 Figure 5
Figure 5| Dataset | Average Best Epoch | Heads | Mem Size | Embedding | Enc Depth | Hidden | LapE Dim | Drop Path | Attn Drop | Batch |
|---|---|---|---|---|---|---|---|---|---|---|
| PeMS04 | 99 | 8 | 32 | 16 | 8 | 2 | 16 | 0.05 | 0.2 | 4 |
| PeMS07 | 154 | 8 | 16 | 32 | 4 | 4 | 8 | 0.2 | 0.2 | 3 |
| PeMS08 | 255 | 8 | 32 | 16 | 4 | 2 | 16 | 0.1 | 0.2 | 4 |
| NYCTaxi | 241 | 8 | 32 | 32 | 6 | 4 | 8 | 0.3 | 0.1 | 8 |
| CHIBike | 97 | 4 | 32 | 64 | 4 | 4 | 8 | 0.3 | 0.1 | 16 |
| T-Drive | 241 | 8 | 16 | 32 | 4 | 4 | 8 | 0.2 | 0.1 | 2 |
| Models | PeMS04 | PeMS07 | PeMS08 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | MAPE(%) | RMSE | MAE | MAPE(%) | RMSE | MAE | MAPE(%) | RMSE | |
| VAR | 23.750 | 18.090 | 36.660 | 101.200 | 39.690 | 155.140 | 22.320 | 14.470 | 33.830 |
| SVR | 28.660 | 19.150 | 44.590 | 32.970 | 15.430 | 50.150 | 23.250 | 14.710 | 36.150 |
| DCRNN | 22.737 | 14.751 | 36.575 | 23.634 | 12.281 | 36.514 | 18.185 | 11.235 | 28.176 |
| STGCN | 21.758 | 13.874 | 34.769 | 22.898 | 11.983 | 35.440 | 17.838 | 11.211 | 27.122 |
| GWNET | 19.358 | 13.301 | 31.719 | 21.221 | 9.075 | 34.117 | 15.063 | 9.514 | 24.855 |
| MTGNN | 19.076 | 12.961 | 31.564 | 20.824 | 9.032 | 34.087 | 15.396 | 10.170 | 24.934 |
| STSGCN | 21.185 | 13.882 | 33.649 | 24.264 | 10.204 | 39.034 | 17.133 | 10.961 | 26.785 |
| STFGNN | 19.830 | 13.021 | 31.870 | 22.072 | 9.212 | 35.805 | 16.636 | 10.547 | 26.206 |
| STGODE | 20.849 | 13.781 | 32.825 | 22.976 | 10.142 | 36.190 | 16.819 | 10.623 | 26.240 |
| STGNCDE | 19.211 | 12.772 | 31.088 | 20.620 |
| 34.036 | 15.455 |
| 24.813 |
| STTN | 19.478 | 13.631 | 31.910 | 21.344 | 9.932 | 34.588 | 15.482 | 10.341 | 24.965 |
| GMAN | 19.139 | 13.192 | 31.601 | 20.967 | 9.052 | 34.097 | 15.307 | 10.134 | 24.915 |
| TFormer |
|
| 31.349 | 20.754 | 8.972 | 34.062 | 15.192 | 9.925 | 24.883 |
| ASTGNN |
|
|
|
|
|
|
|
|
|
| MFormer | 19.123 | 12.800 |
|
| 9.220 |
|
| 10.001 |
|
- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTraffic Prediction and Management Techniques · Traffic control and management · Transportation Planning and Optimization
1. Introduction
With the acceleration of urbanization and the advancement of intelligent transportation systems, accurately predicting traffic flow has become one of the key technologies for alleviating traffic congestion, optimizing travel routes, and enhancing road resource utilization [1,2,3,4]. High-quality traffic forecasting not only provides real-time decision support for urban traffic management but also holds significant application value in smart mobility, logistics distribution, energy scheduling, and other fields [5,6,7,8,9]. Consequently, researching predictive models capable of fully capturing the spatio-temporal dependency features of traffic has emerged as a hot topic in the field of transportation computing and intelligent systems [10].
In recent years, leveraging advancements in deep learning, neural network-based traffic forecasting methods have demonstrated significant advantages in modeling complex nonlinear relationships. Early works employed convolutional neural networks (CNNs) for traffic flow prediction, such as STResNet [11], which utilized 2D CNNs to model the spatial dependencies and residual structures of traffic networks, capturing long-term dependencies. Research predominantly employs graph neural networks (GNNs) to model traffic topology. For instance, STGCN [12] achieves joint modeling of spatial and temporal features by combining graph convolution with sequence modeling. Subsequently, ASTGCN [13] introduced an attention mechanism to enhance the model’s ability to represent spatio-temporal structures.
Although existing methods have achieved certain performance improvements, the aforementioned work and other related studies highlight the following issues:
- (a)CNN-based approaches typically employ regular grids or fixed convolutional kernels, assuming fixed neighborhood relationships. This approach is ill-suited for the irregular topology of road networks and lacks sufficient modeling capability for long-range dependencies, making it difficult to adapt to complex dynamic traffic changes [11].
- (b)GNN-based methods tend to rely heavily on static adjacency matrices, capturing only local spatial dependencies within fixed structures. They struggle to model interactions between distant or dynamically changing nodes [12].
- (c)Many current models rely on large-scale data for training or pre-training. Under constrained conditions such as small cities or newly deployed sensor sections, data is often limited or sparse, significantly degrading the performance of data-hungry models [14].
From a biomimetics perspective, robust prediction in dynamic environments is a hallmark of biological intelligence: living systems continuously integrate noisy sensory inputs with accumulated experience and selectively deploy attention mechanisms to anticipate forthcoming states. Motivated by this principle, we view traffic flow forecasting as a bio-inspired information-processing task and design MFormer to leverage an adaptive attention mechanism enhanced by a learnable memory tensor, enabling persistent contextual recall during spatio-temporal prediction.
Specifically, this work introduces a learnable, node-wise Memory Tensor that serves as a compact external memory bank shared across all encoder layers. Each node is associated with a memory vector that is optimized end-to-end together with the forecasting network. Instead of relying on expensive pre-training or very deep temporal stacks, the Memory Tensor provides a persistent global context that can be injected into the attention computation, enabling the model to recall long-term patterns and stabilize predictions under sparse or noisy observations. This design is lightweight (the memory size is a tunable hyperparameter) and can be trained directly on target datasets without any additional self-supervised objectives. Unlike conventional methods that rely heavily on pre-training or static graph structures, the proposed model can accurately and efficiently predict dynamic traffic flow in complex urban environments. By integrating a learnable memory tensor within an attention-based framework, the model captures both short-term temporal fluctuations and long-term spatial correlations, enabling it to adapt to time-varying traffic propagation patterns and heterogeneous road network interactions. The main contributions of this paper are summarized as follows:
- •Adaptive Memory Tensor Integration: This study designs a novel memory tensor module that adaptively encodes spatial and temporal dependencies in traffic data. This component enhances the attention mechanism by dynamically updating context representations according to evolving traffic conditions.
- •Attention-based Architecture for Spatiotemporal Learning: This study constructs an attention-driven prediction framework that efficiently fuses spatial correlations among road segments with temporal dynamics, enabling the model to focus on critical patterns relevant to future traffic states.
- •Pre-training-free Prediction Framework: The proposed model eliminates the need for pre-training, achieving competitive or superior prediction performance through end-to-end training directly on traffic datasets.
- •Comprehensive Experimental Validation: Extensive experiments on multiple real-world traffic datasets demonstrate that the proposed model outperforms several existing baselines in terms of prediction accuracy and generalization ability, particularly under time-varying traffic scenarios.
The remainder of this paper is organized as follows. Section 2 reviews related work on traffic flow forecasting and Transformer-based spatio-temporal modeling. Section 3 formally defines the traffic forecasting problem and introduces the notation used throughout the paper. Section 4 presents the proposed MFormer model in detail, including the data embedding strategy, spatio-temporal encoder design, and the memory-augmented attention mechanism. Section 5 reports extensive experimental results on multiple real-world datasets and provides comparative evaluations and ablation studies to demonstrate the effectiveness of the proposed approach. Finally, Section 6 concludes the paper and discusses potential directions for future research.
2. Related Work
2.1. Traffic Flow Forecasting
Early traffic flow forecasting primarily relied on statistical modeling and classical machine-learning methods. Time-series models such as the Autoregressive Integrated Moving Average (ARIMA) and vector autoregression (VAR) were used to capture trends and periodicity and to jointly model multiple sensors [15,16]. Meanwhile, the Kalman Filter was shown to be effective for real-time forecasting under noisy measurements [17]. State-space neural network formulations were also explored to combine dynamical system modeling with nonlinear function approximation for prediction in traffic systems [18]. Traditional machine learning baselines such as Support Vector Regression (SVR) and Random Forest (RF) can be competitive, particularly for short-horizon prediction or when training data are limited [16]. However, these approaches usually struggle to capture nonlinear spatio-temporal interactions and non-Euclidean spatial correlations in large-scale road networks.
In recent years, deep learning has gained widespread adoption in traffic flow forecasting due to its powerful nonlinear modeling capability. Convolutional neural networks (CNNs) were first introduced to process rasterized traffic representations and capture local spatial patterns, and graph neural networks (GNNs) later became a mainstream choice by explicitly modeling road-network topology and non-Euclidean spatial relations. More recently, attention mechanisms and transformer-style architectures have shown strong performance because they can flexibly capture dynamic, long-range spatio-temporal dependencies. To better model complex spatio-temporal interactions, many works emphasize learned (rather than fixed) graph structures and heterogeneity, including adaptive graph generation [19], dynamic graph convolution/recurrent frameworks [20,21], and heterogeneity/non-stationarity-aware modeling [22,23]. Recent surveys and benchmarks further summarize these trends and highlight open challenges such as generalization, robustness, and scalability [24,25]. In parallel, transformer-based traffic predictors continue to evolve from early multi-attention designs toward hierarchical and delay-aware attention [26,27] and mixed attention/convolution designs for efficiency [28]. Pre-training and multi-source fusion are also being explored to improve transferability across cities and sensor layouts [29,30]. Beyond traffic-specific models, progress on long-horizon sequence modeling suggests that learnable memory and interpretable attention can be beneficial for forecasting [31,32].
Building upon these works, this study proposes an adaptive, learnable memory tensor that captures global spatio-temporal dependencies to enhance learning in the model’s self-attention layer.
2.2. Transformer
The Transformer model was initially proposed to address sequence modeling and machine translation problems in Natural Language Processing (NLP) [33]. By abandoning traditional recurrent neural networks, it resolved issues of vanishing gradients and computational inefficiency in modeling long sequences, becoming the first model to fully leverage attention mechanisms for sequence data. Its core advantages include modeling global dependencies, strong parallel computing capabilities, and stable parameter updates, significantly enhancing performance in tasks like text translation and semantic modeling. The Transformer’s structure is highly modular, primarily composed of multi-head self-attention mechanisms stacked with feedforward neural networks, enabling efficient capture of complex dynamic relationships within sequences. This structural versatility has rapidly extended the Transformer’s application from NLP to image recognition, speech recognition, and even spatio-temporal sequence tasks like traffic flow prediction in recent years. Research indicates that while traditional CNN and GNN models excel at modeling spatial dependencies, they are often constrained by local window limitations in temporal modeling. In contrast, Transformers can flexibly model dependencies across arbitrary time scales [34]. The emerging wave of Transformer-based traffic flow prediction models demonstrates leading performance and stability on public datasets, establishing Transformers as an indispensable modeling paradigm in modern traffic forecasting.
3. Problem Definition
3.1. Definition of the Road Network
The road network is represented as a graph , where denotes the set of N nodes, is the set of edges, and ∈ is the adjacency matrix encoding the structural connectivity between nodes in the network.
3.2. Definition of the Traffic Flow Tensor
Let denote the traffic flow at time t of N nodes in the road network, where C denotes the number of traffic-related features per node, for example, C = 2 when the data includes inflow and outflow. The complete historical record over time steps is denoted by a traffic tensor .
3.3. Problem Formalization
The objective of traffic flow prediction is to estimate future traffic conditions based on past observations. Given the historical traffic tensor over the previous time steps and the underlying network topology , the task is to learn a predictive mapping that forecasts traffic states for the next timesteps: .
4. Methods
Figure 1 shows the framework of MFormer, which consists of a data embedding layer, stacked L spatial-temporal encoder layers, and an output layer. The following subsections describe each module in detail.
4.1. Data Embedding Layer
The data embedding layer converts the input into a high-dimensional representation. First, the raw traffic flow is transformed into through one fully connected layer, where is the input dimension and is the embedding dimension.
To enhance the model’s ability to perceive periodic features, we introduce two embeddings to cover the daily periodicity and weekly periodicity . In this way, two periodicity embeddings are obtained, and .
Graph Laplacian eigenvectors [35] are utilized for global road network modeling. First, the normalized Laplacian matrix is computed as:
where is the adjacency matrix, is the degree matrix, and is the identity matrix. Second, the eigenvalue matrix and the eigenvector matrix are obtained by . Third, a fully connected layer is applied to the smallest nontrivial eigenvectors to generate the global road network embedding .
Following the original Transformer [33], a temporal positional encoding is employed to introduce position information of the input sequence.
Finally, the output of the data embedding layer is obtained by summing the above embedding vectors as:
4.2. Spatial-Temporal Encoder Layer
The spatio-temporal encoder layer converts the input into complex and dynamic spatio-temporal features. The core of the encoder layer includes three components:
4.2.1. Temporal Attention (TA)
A temporal attention mechanism is designed to capture dynamic global temporal dependencies in traffic data. Formally, for node n, the query, key, and value matrices are computed as:
Here is the input to the i-th layer of the encoder, and are learnable parameters. Then, attention is applied along the temporal dimension to obtain the temporal dependencies between all time steps for node n as:
Due to the inclusion of learnable query and key parameters, the global temporal dependencies is dynamic. Thus, the TA model can be adapted to capture the dynamic global temporal dependencies. Finally, the TA output is computed by multiplying the attention scores with the value matrix as:
In this way, through the temporal attention in Equations (3)–(5), each time step interacts with all the time steps, and the dynamic global temporal dependencies can be obtained.
4.2.2. Spatial Attention (SA)
We design a spatial mask attention mechanism to capture dynamic geographic dependencies in traffic data. Formally, for time step t, the query, key, and value matrices are computed as:
where is the input to the i-th layer of the encoder, and are learnable parameters. Then, attention is applied along the spatial dimension to obtain the spatial dependencies among all nodes at time step t as:
Due to the inclusion of the learnable parameters of query and key, the global spatial dependencies is dynamic. Thus, the SA model can be adapted to capture the dynamic global spatial dependencies. Finally, the output of the SA module can be obtained by the attention scores with the value matrix as:
For the simple spatial attention in Equation (8), each node interacts with all nodes, which means that each node will interact with nodes that are not connected in the road network. As a result, the model is unable to accurately model the global information of the road network. Thus, a graph masking matrix is required to help the model accurately model the global information of the road network.
where is the hop count between node i and node j, which is calculated by the adjacency matrix, and is a manually set threshold of hop count. Based on the value of in Equation (9), a spatial masking mechanism is introduced as follows:
In this way, through the spatial attention in Equation (10), each node interacts with adjacent nodes and itself, and the dynamic geographic spatial dependencies can be obtained.
4.2.3. Memory Attention(MA)
A global temporal attention mechanism is designed to enhance the model’s ability to perceive long-term temporal features. Formally, for node n, the query, key, and value matrices are computed as:
Then, to extract long-term temporal features, an adaptive memory tensor is introduced. Next, fully connected layers are used to transform the memory tensor into two new tensors , respectively. These two tensors are then used to update the key and value matrices in Equation (12):
As the memory tensor continuously learns global temporal features, both the key and value matrices also acquire the ability to perceive global features. Based on Equations (4) and (5), dynamic long-term temporal features are obtained.
4.3. Output Layer
The output layer consists of three 1 × 1 convolutions:
where is the output of the i-th layer of the encoder, is the convolution operation, are the convolution kernel, and are the bias corresponding to the convolution kernel.
The first 1 × 1 convolution maps the features to a higher dimension to enhance the model’s ability to represent traffic flow features. The second 1 × 1 convolution maps the features from the input length to the output length . And the third 1 × 1 convolution maps the features from dimension to output dimension 1.
Algorithm 1 summarizes the overall workflow of MFormer. Algorithm 1: MFormer for Traffic Flow ForecastingInput: Historical traffic tensor , time indices , adjacency matrix (or grid coordinates), input length , output length , encoder depth .Operation/* Initialization /1.Initialize learnable parameters (embeddings, attention projections, nonlinear feature transformation, and output head) and the Memory Tensor .2.Compute Laplacian positional encoding and periodic embeddings; obtain embedded input using Equation (2).3.Construct the geographic masking matrix G using Equation (9) geo mask./ Spatial-Temporal Encoder (× L) /4.Set skip <-- 0.5.for l = 1 to L do6. Compute temporal attention using Equations (3)–(5) to obtain .7. Compute spatial masked attention using Equations (6)–(10) with mask G to obtain .8. Compute memory attention using Equations (11) and (12) and Equations (4) and (5) to obtain (long-term temporal features).9. Apply nonlinear feature transformation + residual connection + normalization to obtain .10. Update skip <-- skip + Conv1 × 1( ).11.end for/ Output Head /12.Generate prediction using the output layer in Equation (13).13.Return / Operation Ending */Output: Predicted traffic tensor over the next time steps.
5. Experiments
5.1. Datasets
The proposed MFormer is evaluated on six widely used real-world traffic datasets, covering both sensor-based road networks and grid-based urban mobility scenarios. The PeMS04, PeMS07, and PeMS08 datasets are collected from the California Performance Measurement System (PeMS) and consist of traffic flow measurements recorded by loop detectors deployed on highway networks. These datasets represent graph-structured traffic networks with irregular topologies and strong spatial dependencies. In contrast, NYCTaxi, CHIBike, and T-Drive are grid-based urban mobility datasets constructed by partitioning urban areas into regular spatial grids, where each grid cell aggregates inflow and outflow volumes within fixed time intervals. Together, these datasets cover diverse traffic patterns, spatial structures, and temporal resolutions, providing a comprehensive benchmark to evaluate the accuracy, robustness, and generalization ability of traffic flow forecasting models. All datasets used in this study are longitudinal time-series datasets collected through repeated measurements over extended periods, rather than single time-point observations. Traffic states are continuously recorded at fixed sampling intervals, which reflect the dynamic and evolving nature of urban traffic systems.
Table 1 summarizes the key statistics of all datasets employed in our experiments, including the number of nodes, edges, timesteps, sampling interval, and overall time range.
5.2. Baselines
To evaluate the performance of MFormer under different spatial structures, representative baselines are selected, and experiments are conducted separately on graph-based and grid-based datasets according to the modeling assumptions of each method.
This experimental design ensures a fair and meaningful comparison by avoiding the inappropriate application of models to incompatible spatial structures. Specifically, the selected baselines are categorized into four major groups:
- Grid-based models. This group includes STResNet [11], DMVSTNet [36], and DSAN [37], which are specifically designed for grid-structured urban mobility data. These models mainly employ convolutional or attention-enhanced convolutional operations over regular spatial grids, making them particularly suitable for datasets such as NYCTaxi and CHIBike, where traffic states are aggregated over fixed spatial cells. However, due to their reliance on predefined and regular neighborhood structures, these approaches are not explicitly tailored to irregular graph-structured road networks. As a result, they are primarily used as reference baselines for grid-based datasets rather than direct competitors on graph-based traffic networks.
- Time series prediction models. Classical time series methods, including VAR and SVR, are included as traditional statistical and machine learning baselines. These models focus primarily on temporal correlations and do not explicitly model spatial dependencies. Although their expressive power is limited compared to deep spatio-temporal models, they provide a useful lower-bound reference and help quantify the performance gains achieved by advanced neural architectures.
- Graph neural network-based models. This category consists of STGCN [12], MTGNN [14], DCRNN [38], STSGCN [39], STFGNN [40], STGODE [41], STGNCDE [42] and GWNET [43]. These methods explicitly model road network topology using graph convolution, diffusion processes, or neural differential equations. They represent the mainstream direction in traffic forecasting research and serve as strong baselines for evaluating MFormer’s ability to capture spatial dependencies in graph-structured data.
- Self-attention-based models. In addition, representative attention-driven models are included, namely GMAN [44], ASTGNN [22], TFormer [26], and STTN [45],. These methods leverage self-attention mechanisms to capture long-range spatio-temporal dependencies and are particularly relevant for comparison, as MFormer also adopts an attention-based architecture. Evaluating against these models highlights the effectiveness of the proposed memory-enhanced attention mechanism.
5.3. Experiment Settings
Data Processing. Following common practice in traffic flow forecasting, all datasets are split into training, validation, and test sets to ensure fair evaluation and reproducibility. For grid-based datasets, the data are divided at a ratio of 7:1:2, and the inflow and outflow of the past six time steps are used to predict the traffic conditions in the subsequent time window. This setting is consistent with prior studies on urban mobility prediction and reflects short-term forecasting scenarios. For graph-based datasets, a 6:2:2 split ratio is adopted, which is widely used in graph-based traffic prediction benchmarks. The model takes traffic observations from the past twelve time steps as input and predicts traffic flow for the next twelve time steps, enabling the evaluation of medium-horizon forecasting performance under realistic traffic dynamics.
Model Settings. All experiments are conducted on a machine equipped with an NVIDIA GeForce 4090 GPU(NVIDIA Corporation, Santa Clara, CA, USA). The hidden layer size d of MFormer is searched over {16, 32, 64, 128}.
The depth of the spatio-temporal feature extraction block is searched over {2, 4, 6, 8}. The feature dimension of the Memory Tensor is searched within {16, 32}. During model training, the AdamW optimizer [46] is employed with a learning rate of 0.001. The batch size is varied across {2, 4, 8, 16}, and training is conducted for 500 epochs. An early stopping mechanism is triggered when the best validation loss fails to decrease for 50 consecutive epochs. The optimal model is determined based on validation set performance.
We select the final architectural and training configuration based on validation performance, and the best hyperparameters for each dataset are summarized in Table 2. Regarding convergence, with early stopping and a maximum of 500 epochs, the selected best checkpoints are consistently reached within 97–255 epochs across the six datasets, indicating stable convergence behavior under our training protocol.
Evaluation Metrics. To comprehensively assess prediction accuracy, three widely used evaluation metrics are adopted: Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Root Mean Square Error (RMSE). These metrics jointly reflect absolute deviation, relative error, and sensitivity to large prediction errors. For grid-based datasets, traffic values below 10 are excluded during evaluation, following DMVSTNet [30]. Given the lower traffic volume in the CHIBike dataset, the threshold is adjusted to 5, consistent with PDFormer [27], ensuring fair and meaningful metric computation. We repeat all experiments ten times and report the average results.
5.4. Performance Comparison
Comparison results with baselines on graph-based and grid-based datasets are shown in Table 3, Table 4 and Table 5 and Table 6. Bolded results indicate the best performance, while underlined results represent the second-best performance. Based on the data in these tables, the experimental results indicate that:
- (a)MFormer achieves the lowest MAE/MAPE/RMSE across all three grid-based datasets. Compared to the second-best model ASTGNN, MFormer achieves average improvements of 5.55%, 4.59%, and 5.04% in MAE, MAPE, and RMSE, respectively. Notably, MFormer significantly reduces prediction errors on the T-Drive and CHIBike datasets. Figure 2 and Figure 3 further illustrate the detailed improvement margins of MFormer relative to the best baseline. Within grid-based datasets, performance improvement varies by dataset characteristics: T-Drive shows the most significant gains, with MAE and RMSE exceeding 8%, and MAPE reaching 11.51% on inflow. This indicates that MFormer’s Memory Tensor mechanism offers superior modeling capabilities for trajectory data with high spatio-temporal sparsity, effectively learning long-term dependencies under sparse observations. Improvements on the NYCTaxi dataset range between 2% and 4%, while those on the CHIBike dataset range between 4% and 6%,demonstrating the model’s stability and universality across different urban transportation scenarios.
- (b)Across three graph-based datasets, MFormer consistently demonstrates superior predictive performance. While slightly trailing ASTGNN in MAE and MAPE metrics, it achieves comprehensive leadership in RMSE—a metric more reflective of prediction stability—with improvement rates of 0.15%, 1.78%, and 0.91% on the PeMS04, PeMS07, and PeMS08 datasets, respectively. This result indicates that MFormer’s predictions exhibit smaller squared error deviations, stronger suppression of large errors and outliers, and more stable and reliable results, demonstrating its outstanding robustness.
Compared with time-series baselines, MFormer explicitly models spatial dependencies via spatial attention, which explains the consistent gains on network-wide forecasting tasks. Compared with GNN-based predictors, whose information propagation is effectively constrained by fixed-hop message passing, MFormer uses global attention to directly capture long-range spatial-temporal interactions without requiring deep diffusion steps, alleviating long-range dependency loss. Compared with attention-based models without external memory, the proposed Memory Tensor injects persistent node-wise global context into the attention computation, which stabilizes long-horizon prediction and suppresses large deviations; this is consistent with MFormer’s stronger RMSE performance on graph datasets and its larger improvements on sparse mobility data such as T-Drive.
Due to the strong forecasting performance of attention-based models, we further compare the computational cost of MFormer with representative attention-based baselines on the PeMS04 and NYCTaxi datasets. Table 7 reports the average training and inference time per epoch measured under the same hardware and implementation environment in this work. GMAN [44] and ASTGNN [22] adopt an encoder–decoder architecture, whereas STTN [45] replaces the encoder–decoder pipeline with a forward procedure. TFormer [26] performs only spatial attention, resulting in reduced attention computation along the temporal dimension. In contrast, MFormer employs a forward prediction pipeline with a stacked spatio-temporal attention encoder augmented by an adaptive Memory Tensor, and Table 7 shows that it achieves competitive training and inference efficiency among attention-based baselines while maintaining strong forecasting accuracy.
5.5. Ablation Study
To validate the effectiveness of the Memory Tensor in MFormer, we created two variants using MFormer:
(1) w/o MemTensor: This variant removes the Memory Tensor, meaning the model’s attention module loses the spatio-temporal adaptive enhancement provided by the Memory Tensor. (2) w/o GeoMask: This variant removes the geographic masking matrix, meaning each node attends to all nodes rather than only those closer to it. MFormer is comprehensively compared with the two variants.
Figure 4 quantifies the performance degradation when removing each component. Figure 5 shows the comparison results between MFormer and the two variants on the PeMS04 dataset. The results indicate that:
(a) MFormer achieves significant improvements over w/o MemTensor across all three metrics: RMSE is reduced by 19.8%, MAE is reduced by 24.3%, and MAPE is reduced by 25.7%. This is because the proposed Memory Tensor possesses strong adaptive learning capabilities and effectively learns complex spatio-temporal relationships in real traffic scenarios, thereby enhancing traffic flow prediction accuracy.
(b) The prediction performance of w/o GeoMask deteriorates compared to MFormer: RMSE increases by 4.3%, MAE by 8.9%, and MAPE by 9.1%. Although the degradation is relatively minor, it still indicates that the geographic masking has a positive effect on the model’s prediction performance.
(c) Comparing the performance of variants without MemTensor, without GeoMask, and MFormer reveals that removing Memory Tensor causes an average performance degradation of 23.3%, while removing GeoMask results in an average degradation of 7.5%. This significant disparity clearly demonstrates that the Memory Tensor is the core component of MFormer, with its adaptive learning capability playing a decisive role in model prediction accuracy. In contrast, GeoMask serves as a supplementary prior constraint, complementing the optimization of model performance.
6. Conclusions
This study proposes a novel traffic flow prediction model, MFormer. This model adaptively captures complex spatiotemporal features in real traffic and continuously learns during training. This not only significantly enhances the model’s ability to model long-term time series dependencies but also enables it to more flexibly handle dynamic spatial relationships and nonlinear variations within road networks. By organically integrating temporal attention, spatial attention, and memory attention mechanisms, MFormer constructs an end-to-end unified prediction model. This architecture simultaneously captures local short-term fluctuation patterns and global long-term evolutionary trends, thereby providing a more comprehensive feature representation for traffic state prediction. Experimental results on six real-world traffic datasets demonstrate that MFormer significantly outperforms mainstream baseline models across multiple evaluation metrics, exhibiting higher prediction accuracy, stronger generalization capabilities, and improved robustness. From a practical perspective, improved traffic forecasting accuracy may translate into tangible economic benefits, including reduced congestion duration, lower fuel consumption, improved fleet dispatch efficiency, and enhanced infrastructure utilization. Even modest error reductions can contribute to significant cost savings in large-scale urban transportation systems. Although a full economic simulation is beyond the scope of this work, the proposed approach provides a promising foundation for real-world intelligent transportation deployment.
Despite MFormer’s strong predictive performance, the following limitations remain:
(a) The static design of the Memory Tensor struggles to dynamically adapt to varying traffic patterns and sudden events across different time periods, since it is globally shared and optimized during training without time-conditioned updates;
(b) Sequential computation of triple attention mechanisms creates efficiency bottlenecks in large-scale networks, due to the quadratic complexity of attention operations along temporal and spatial dimensions.
(c) Insufficient model interpretability hinders understanding of the spatio-temporal patterns learned by each component and their decision-making mechanisms. This limitation arises because the triple-attention mechanism and Memory Tensor learn highly distributed and implicitly encoded representations without explicit semantic or physically grounded constraints, making their internal decision logic difficult to disentangle.
Future work focuses on three directions. First, future work explores dynamic and context-aware memory mechanisms. While MFormer currently employs a static learnable Memory Tensor to encode long-term patterns, future designs incorporate time-conditioned updates and event-aware routing to better adapt to abrupt traffic changes while retaining stable long-term regularities. More efficient large-scale inference strategies are investigated, such as sparse or factorized attention, cluster-based spatial routing, and caching of structural encodings, to reduce computational overhead and support real-time deployment on city-scale networks. Model interpretability is enhanced by developing memory attention visualization and attribution techniques, enabling clearer analysis of how memory representations capture recurring traffic patterns and improving the transparency and reliability of model predictions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Shaygan M. Meese C. Li W. Zhao X. Nejad M. Traffic prediction using artificial intelligence: Review of recent advances and emerging opportunities Transp. Res. Part C Emerg. Technol.202214510392110.1016/j.trc.2022.103921 · doi ↗
- 2Liu X. Qin L. Xu M. Zhou Y. Wang B. Yu W. Xiong W. A comprehensive review of traffic flow forecasting based on deep learning Neurocomputing 202666813226910.1016/j.neucom.2025.132269 · doi ↗
- 3Weng W. Fan J. Wu H. Hu Y. Tian H. Zhu F. Wu J. A decomposition dynamic graph convolutional recurrent network for traffic forecasting Pattern Recognit.202314210967010.1016/j.patcog.2023.109670 · doi ↗
- 4Sun Y. Jiang X. Hu Y. Duan F. Guo K. Wang B. Gao J. Yin B. Dual dynamic spatial-temporal graph convolution network for traffic prediction IEEE Trans. Intell. Transp. Syst.202223236802369310.1109/TITS.2022.3208943 · doi ↗
- 5Guo X. Zhang Q. Jiang J. Peng M. Zhu M. Yang H.-F. Towards explainable traffic flow prediction with large language models Commun. Transp. Res.2024410015010.1016/j.commtr.2024.100150 · doi ↗
- 6Wang S. Chen A. Wang P. Zhuge C. Predicting electric vehicle charging demand using a heterogeneous spatio-temporal graph convolutional network Transp. Res. Part C Emerg. Technol.202315310420510.1016/j.trc.2023.104205 · doi ↗
- 7Li C. Geng M. Chen Y. Cai Z. Zhu Z. Chen X. Demand forecasting and predictability identification of ride-sourcing via bidirectional spatial-temporal transformer neural processes Transp. Res. Part C Emerg. Technol.202415810442710.1016/j.trc.2023.104427 · doi ↗
- 8Wei Y. Wang Y. Hu X. The two-echelon truck-unmanned ground vehicle routing problem with time-dependent travel times Transp. Res. Part E Logist. Transp. Rev.202519410395410.1016/j.tre.2024.103954 · doi ↗