Source-Free Active Domain Adaptation for Brain Tumor Segmentation via Mamba and Region-Level Uncertainty
Haowen Zheng, Che Wang, Yudan Zhou, Congbo Cai, Zhong Chen

TL;DR
This paper introduces a new method for brain tumor segmentation in MRI scans that adapts to different medical centers with minimal annotations and maintains data privacy.
Contribution
A novel SFADA framework with region-level uncertainty-guided sample selection and a Mamba-driven segmentation model for brain tumor segmentation.
Findings
The proposed method outperforms state-of-the-art methods with only 5% annotation budget.
It achieves robust segmentation accuracy across diverse domains and approaches fully supervised learning performance.
The framework effectively mitigates domain shift and complies with data privacy regulations.
Abstract
Background/Objectives: Accurate brain tumor segmentation from MRI is crucial for diagnosis but faces challenges like domain shifts across medical centers, data privacy constraints, and high annotation costs. While source-free active domain adaptation (SFADA) emerges as a promising solution to these issues, existing approaches often overlook the inherent structural complexity in tumor regions. Methods: We propose a novel SFADA framework composed of two major contributions. First, we introduce a Region-level Uncertainty-Guided Sample Selection (RUGS) strategy, enabling the identification of the most informative target-domain samples in a single inference pass. Second, we present the Source-Free Active Domain Adaptation Network (SFADA-Net), a Mamba-driven segmentation model equipped with a dual-path multi-kernel convolution module for enhanced local feature interaction and a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
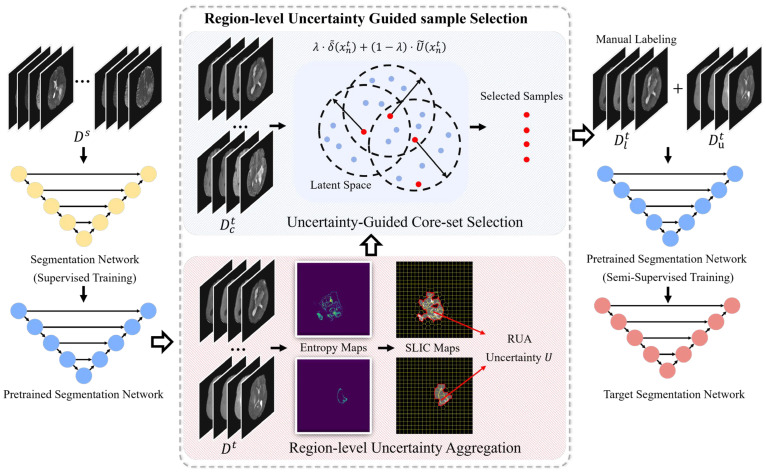 Figure 1
Figure 1 Figure 2
Figure 2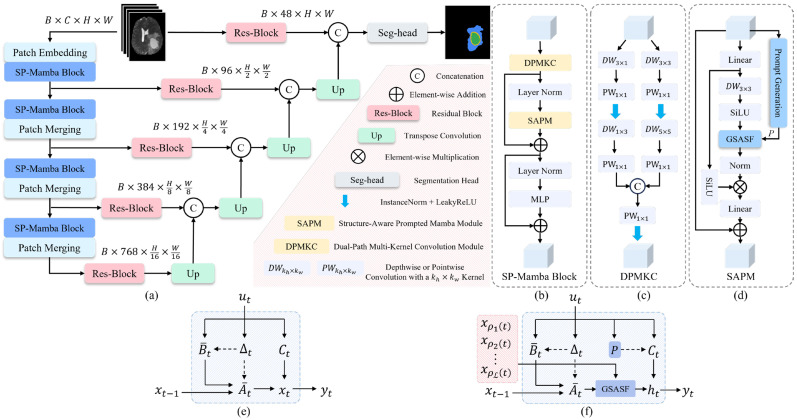 Figure 3
Figure 3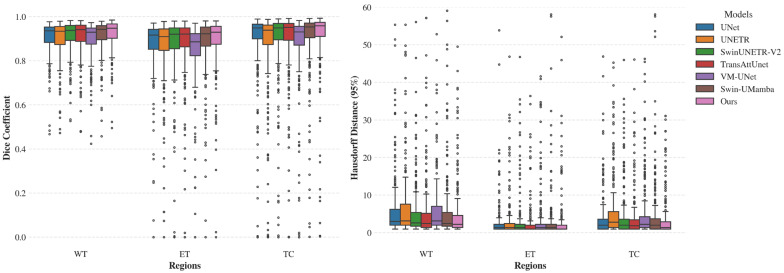 Figure 4
Figure 4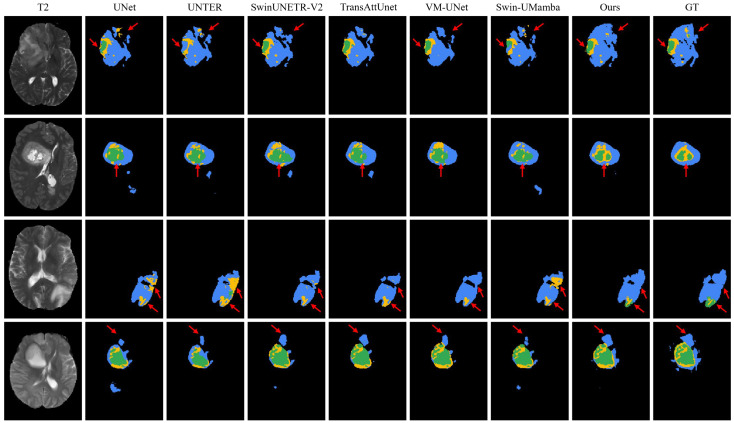 Figure 5
Figure 5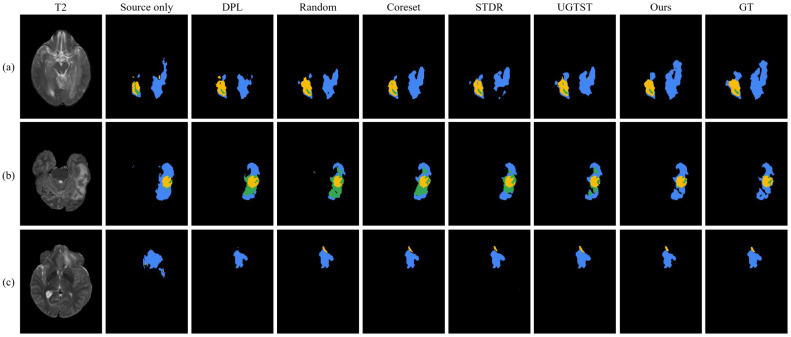 Figure 6
Figure 6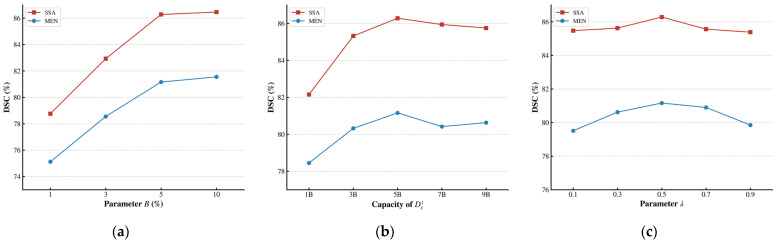 Figure 7
Figure 7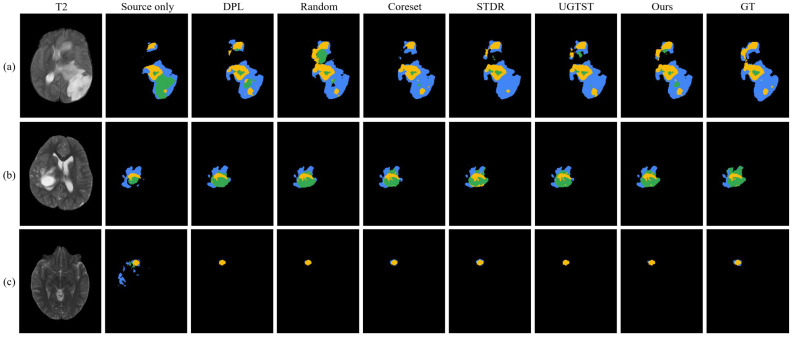 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Brain Tumor Detection and Classification · Advanced Neural Network Applications
1. Introduction
Gliomas are one of the most common primary brain tumors and pose a serious threat to human health [1]. Magnetic resonance imaging (MRI), with its advantages of non-invasiveness, high-quality imaging, and absence of skull artifacts, has become the central tool in the diagnosis of brain tumors [2,3,4,5]. However, in clinical practice, radiologists mainly delineate tumor regions manually on MRI, which is time-consuming, labor-intensive, and prone to error and inter-observer variability, particularly in resource-limited settings [6]. These limitations may compromise delineation accuracy and even lead to treatment failure, underscoring the urgent need for efficient and robust automated solutions [7].
While numerous automated approaches, particularly convolutional neural networks (CNNs) and Transformers, have achieved remarkable progress in brain tumor segmentation, they are limited by insufficient global representation and high computational costs, respectively [8,9,10]. In this context, the emerging Mamba architecture has attracted wide attention, showing strong performance in image segmentation tasks. VM-UNet [11] first integrated Vision Mamba into the U-Net [12] architecture, while Swin-UMamba [13] combined Mamba with the Swin Transformer. Both approaches improve segmentation accuracy. However, brain tumor MRI images often have complex textures, irregular shapes, and low contrast with surrounding tissues. These characteristics make feature segmentation and boundary delineation challenging, placing higher demands on the robustness and fine feature perception ability of Mamba in real-world applications [14,15].
Although deep learning has achieved remarkable progress in brain tumor segmentation, its clinical application is still limited by several factors, including the high cost of obtaining annotated data, significant cross-center domain shifts, data scarcity in low-resource regions, and strict constraints on data security privacy [16,17,18]. To address these challenges, a variety of domain adaptation strategies have been proposed. Unsupervised domain adaptation (UDA) [19] uses labeled source data but remains source-dependent. Source-free domain adaptation (SFDA) [20] eliminates source data access during training but faces performance gaps compared to supervised models [21,22]. Semi-supervised domain adaptation (SSDA) enhances generalization by labeling limited target samples, yet its random selection ignores variations in sample information and difficulty [23,24]. Source-free active domain adaptation (SFADA) extends the SFDA framework by incorporating active learning. It actively selects a small set of target-domain samples for manual annotation and then fine-tunes the model in a semi-supervised way, without accessing source-domain data [25]. This strategy reduces annotation costs while maintaining data privacy.
Despite its potential, current methods present notable gaps in effectively bridging source and target domains. Current SFADA methods often select target samples based on model uncertainty or feature distribution [25,26,27]. They do not adequately reflect the differences in structural complexity and discriminative difficulty among brain tumor regions. In addition, these methods tend to depend strongly on the performance of the initial segmentation model, which limits further improvements in domain adaptation effectiveness.
To address the above issues, we propose a novel uncertainty-based SFADA framework designed to handle the structural complexity of brain tumors. Specifically, we propose a Region-level Uncertainty-Guided Sample Selection (RUGS) strategy. It includes Region-level Uncertainty Aggregation (RUA) and Uncertainty-Guided Core-set Selection (UGCS). The former aggregates high-uncertainty regions in slices. The latter ensures sample diversity while prioritizing samples that the model finds most uncertain. RUGS requires no source domain data and completes sample selection in one inference pass. To further address the limitations of backbones in segmentation performance, we introduce Source-Free Active Domain Adaptation Network (SFADA-Net), a Mamba-based backbone model. The core components of SFADA-Net are the Dual-Path Multi-Kernel Convolution (DPMKC) module and the Structure-Aware Prompted Mamba (SAPM) module. DPMKC uses dual-path cascaded convolutions to enhance local feature extraction. SAPM applies grouped structure-aware processing and adds prompts to improve Mamba’s ability to capture spatial structures and handle anti-causal modeling. Overall, the combination of RUGS and SFADA-Net effectively narrows the performance gap between source-free adaptation and supervised learning under very low annotation budgets.
The main contributions of this work are as follows:
- To our knowledge, this is the first work to apply SFADA to cross-center brain tumor segmentation. It explores a new solution and improves domain adaptation accuracy.
- We introduce the RUGS strategy, which identifies the most informative target-domain samples for annotation without requiring any source data, thereby significantly reducing labeling cost.
- We propose SFADA-Net, a Mamba-based segmentation model, and train it in a semi-supervised setting using samples selected by RUGS, which enhances domain adaptation performance.
- We conducted extensive experiments on three target-domain datasets and demonstrated that our framework achieved more accurate segmentation and better generalization than related state-of-the-art domain adaptation methods.
2. Methods
This section presents the proposed framework for SFADA. Section 2.1 formulates the problem setting, and Section 2.2 introduces the RUGS strategy. Subsequently, Section 2.3 and Section 2.4 detail the SFADA-Net architecture and the semi-supervised training objectives.
2.1. Problem Setting and Notation
We consider SFADA setting for brain tumor segmentation. Let denote the source-domain dataset consisting of labeled samples, where is the image and is the corresponding pixel-wise label from the label space . In the adaptation phase, we are given a target domain dataset with unlabeled samples. We assume a domain shift exists between the source and target distributions, i.e., . Crucially, the source dataset is inaccessible due to privacy concerns; only the source-pretrained model and the unlabeled target data are available.
We aim to select a small yet informative subset of target samples, denoted as , for manually annotated under an annotation budget . The remaining samples constitute the unlabeled set . Using the labeled set and the unlabeled set , we adapt the pretrained model to optimize segmentation performance on the target domain.
2.2. Region-Level Uncertainty-Guided Sample Selection Strategy
To select the most valuable samples for annotation, we propose the RUGS strategy, which consists of two sequential components: RUA and UGCS, as illustrated in Figure 1. RUA first filters the model predictions to identify target-domain samples with high regional uncertainty. From this pool, UGCS selects a refined subset that balances uncertainty and diversity. Once annotated by experts, we incorporate these chosen samples into SFADA-Net for semi-supervised training.
2.2.1. Region-Level Uncertainty Aggregation
Given an unlabeled input image , the pretrained segmentation network outputs the logits for each pixel. For a specific pixel in the image spatial domain , the entropy at that pixel is computed based on the logits via the softmax function as follows [28]:
where denotes the softmax output for class , denotes the logit for class at pixel .
To aggregate pixel-wise uncertainty into region-level representations, we propose RUA method. This method includes the following steps. First, we apply the Simple Linear Iterative Clustering (SLIC) algorithm [29] to partition the entropy map into superpixel regions , satisfying and for . Compared with other superpixel methods, we choose SLIC because of its fast computation speed, good boundary adherence, and controllable number of segmented regions. This is particularly important for capturing complex tumor boundaries in medical images. We set the number of superpixel regions to 400 and the compactness parameter to 0.05, which achieves finer-grained segmentation and better adherence to weak and complex boundaries in medical images. For the -th superpixel region , the region-level uncertainty is computed as:
where denotes the indicator function.
Next, to reduce the influence of large low-entropy background regions, we filter the entropy values of the superpixel regions and extract regions associated with higher prediction uncertainty, which are typically concentrated in foreground and boundary areas. Specifically, we apply K-means++ [30] to adaptively partition the region-level uncertainties into clusters by minimizing the following objective. By setting , we divide the region-level uncertainties into two distinct clusters. The first is a high-uncertainty cluster, usually capturing challenging tumor boundaries or foregrounds. The second is a low-uncertainty cluster representing normal brain tissue and clear background. This clear division effectively isolates the most informative superpixel regions. The K-Means++ clustering is formulated as follows:
where is the squared Euclidean distance, is the cluster centroid, is the number of regions assigned to cluster . The cluster with the higher centroid value is designated as the high-uncertainty set . We enforce to ensure sufficient foreground coverage. The parameter , set to 0.1 in our experiments, serves as a safety threshold to guarantee the minimum required ratio of foreground coverage. Finally, RUA uncertainty is derived by a conditional aggregation:
where is a smoothing factor. Based on , we rank all unlabeled samples and select the top samples to form the candidate set for the subsequent fine-grained selection. We set the size of the candidate set to 5 times the annotation budget . This setting not only effectively filters out a large number of low-informative samples, but also reserves sufficient headroom for optimization in the UGCS.
2.2.2. Uncertainty-Guided Core-Set Selection
Following the coarse-grained screening via RUA, may still contain adjacent slices with high semantic similarity, leading to information redundancy. To mitigate this and optimize the annotation budget, we propose UGCS. Adapted from the Core-set framework [31], UGCS formulates sample selection as a greedy optimization problem that balances diversity and uncertainty of the samples.
Let denote the set of currently selected samples, and represent the deep feature vector of a candidate sample in the latent space, where is the encoder of the network. To quantify diversity, we define a distance metric , which computes the minimum Euclidean distance from to the manifold of selected samples:
A lower indicates that lies in a high-density region already covered by (i.e., information redundancy). Conversely, a higher value implies that the sample occupies a sparse region in the latent feature space.
To integrate this diversity measure with RUA uncertainty , we normalize both scores to the range at each iteration:
where iterates over all samples in . Finally, the active selection is formulated as a greedy optimization problem.
For each iteration, the algorithm selects the next sample that maximizes the weighted combination of uncertainty and diversity:
where is a balancing coefficient, set to 0.5 in our experiments. It trades off sample uncertainty against diversity, preventing the algorithm from over-sampling redundant adjacent slices from the candidate pool. This selection process iterates until the size of reaches the predefined annotation budget . After the selection loop is completed, the final set is designated as the labeled set and submitted to medical experts for manual annotation.
2.3. Segmentation Network Architecture
We propose SFADA-Net for brain tumor segmentation in domain adaptation scenarios, and employ it as the core segmentation backbone of the entire SFADA framework. SFADA-Net not only performs the final segmentation task in the target domain, but also serves as a bridge between the active sample selection stage and the semi-supervised adaptation stage. During the selection phase (see Section 2.2), it provides pixel-wise predictive probability maps to the RUA module for uncertainty estimation and supplies deep latent representations to the UGCS module for diversity measurement. During the adaptation phase, SFADA-Net serves as the core model optimized under the semi-supervised learning (SSL) paradigm. A complete flowchart of the SFADA framework is shown in Figure 2.
SFADA-Net consists of three main components: a feature encoder composed of 4 SP-Mamba blocks, skip connections augmented with Residual Blocks, and a decoder based on transposed convolutions to predict the final segmentation mask. Each SP-Mamba block integrates the Dual-Path Multi-Kernel Convolution (DPMKC) and Structure-Aware Prompted Mamba (SAPM) modules, with channel numbers progressively increasing as 48, 96, 192, 384, and 768 to capture local details and long-range spatial dependencies at multiple scales. The overall architecture and key module designs are shown in Figure 2. Details of SFADA-Net are described below.
2.3.1. Dual-Path Multi-Kernel Convolution Module
The DPMKC is positioned before the designed SAPM module and is primarily responsible for extracting local detail information from features. As illustrated in Figure 3c, DPMKC uses a two-branch design that combines direction awareness and multi-scale aggregation. The first branch is the direction-aware path. It uses depth-wise separable convolutions with and kernels to model horizontal and vertical spatial dependencies. A point-wise convolution follows to fuse and interact features across scales. The second branch is the multi-scale aggregation path. It connects and convolutions in series to obtain local texture and wider contextual information. The output of the direction-aware path is computed as:
where denotes the input feature map, represents a depth-wise separable convolution with a kernel, followed by a point-wise convolution with a kernel, instance normalization, and a Leaky ReLU activation. denotes the output of the direction−aware pathway and is denotes the output of the multi-scale aggregation pathway.
The two branch outputs are concatenated channel-wise and fused by a convolution block. A residual connection reuses the input features. The final output is:
where is channel-wise concatenation and is a convolution followed by normalization and active function.
2.3.2. Structure-Aware Prompted Mamba Module
The standard Mamba [32] is based on a state space model (SSM) with the discrete state transition equation and observation equations:
where denotes the state variable, is the input sequence, and is the output sequence. Given a time step , the state transition matrix is , the input matrix is . is the output matrix, and is direct transmission matrix. In Mamba, , , , and are all functions of the input sequence .
Although the standard Mamba effectively captures long-range dependencies in 1D sequential data, its application to 2D vision tasks introduces two critical limitations: First, flattening images via directional scanning inherently disrupts spatial adjacency and degrades local structural continuity [33]. Second, Mamba’s strictly causal formulation restricts pixels to attending only to preceding tokens, blinding the model to subsequent context and hindering global perception.
To mitigate the first issue, we adapt the Structure-Aware State Fusion (SASF) mechanism from Spatial-Mamba [34]. By integrating SASF between the state transition and observation equations, we establish neighborhood connectivity within the state space. SASF calculates a new structure-aware state variable by aggregating neighboring state variables in a 2D neighborhood:
where denotes the 2D neighborhood set consisting of state variables, represents the learnable weight, and is the index of the -th neighboring state corresponding to position . By fusing local neighborhood states, the structure-aware state variable incorporates both the global information from the standard Mamba and the local structural relationships.
To overcome the causal limitation, we exploit the mathematical parallels between state space models and attention mechanisms. Recognizing that essentially acts as a query matrix, we integrate a semantic prompt into the observation equation [35].
Inspired by Spatial-Mamba [34] and Mamba-IRv2 [35], we extend the standard Mamba by incorporating structure-aware fusion and prompt enhancement, and propose the SAPM module, as shown in Figure 3d. Rather than redefining the Mamba framework, SAPM improves its performance through structure-aware and prompt-enhanced methods, as illustrated in Figure 3e,f. The core operations of SAPM are formulated by three key equations, namely the state transition equation, the grouped structure-aware state fusion (GSASF) equation, and the prompt-enhanced observation equation:
where is the original state variable, and denotes the structural perception state variable. Equation (18) is a practical implementation of the structure-aware formulation defined in Equation (16). The term represents the weight of a depth-wise filter at location in group with dilation factor . The neighborhood set is defined as . refers to the neighboring states of within , where denotes the image width. The term is a pixel-wise learnable weight, and is the semantic prompt vector.
In the GSASF equation, the state is divided into channel groups, each processed with a depth-wise convolution with dilation factors . We then employ a pixel-adaptive weighting module to generate a weight map for each group. This module consists of a convolution, a Leaky ReLU activation, followed by another convolution and a Sigmoid activation:
These weight maps are normalized along the channel dimension and multiplied element-wise with their corresponding group features. Finally, the weighted group outputs are concatenated along the channel dimension to obtain . In this way, local neighborhood information is introduced into the state representation while keeping the long-range modeling ability of Mamba.
To construct the prompt , SAPM maintains a learnable prompt pool , where denotes the length of tokens and is the state dimension. Given a flattened input feature map , a routing network projects the channel dimension from to using a fully connected layer, followed by a LogSoftmax to produce normalized log-probabilities representing the likelihood of each prompt being selected for each spatial location.
We then apply the Gumbel–Softmax reparameterization [36] to obtain a differentiable discrete assignment, yielding a binary routing mask . The prompt is computed as and incorporated into via residual addition, forming a prompt-enhanced observation equation. This mechanism endows the model with attention-like behavior, enabling pixel-wise semantic querying across the image and alleviating perception gaps in unscanned regions [35].
2.4. Semi-Supervised Learning for Source-Free Active Domain Adaptation
To effectively leverage both the actively selected labeled target samples and the remaining unlabeled samples , we employ a SSL framework based on the Mean Teacher paradigm [37]. The framework consists of a student model parameterized by and a teacher model parameterized by , which share an identical architecture.
In the training phase, the student model parameters are optimized via backpropagation, whereas the teacher model parameters are updated using the exponential moving average (EMA) of the student parameters:
where is the smoothing coefficient, set to 0.996.
We apply distinct data augmentation strategies to construct a consistency regularization constraint. For the labeled set , the student model is trained using standard supervised learning. The supervised loss is defined as the summation of the Cross-Entropy loss and the Dice loss:
where is the one-hot ground truth (GT) label, and is the student’s predicted probability for class at pixel .
For the unlabeled data , weak augmentation is applied to the teacher input to generate pseudo-labels, while CutMix [38] is employed for data augmentation on the student input. To mitigate the noise in pseudo-labels, we apply a confidence thresholding mechanism. The unsupervised consistency loss is computed as the pixel-wise cross-entropy between the student’s prediction on the strongly augmented view and the teacher’s high-confidence pseudo-labels:
where is the indicator function that selects pixels where the teacher’s maximum probability exceeds the confidence threshold , is the hard pseudo-label derived from the teacher, and is the student’s prediction under CutMix augmentation.
The total loss function is formulated as:
where is set to 2 in our experiments. is initialized to 0 and kept at 0 for the first 200 iterations, and then linearly increased from 0.5 to 1.0 over iterations 200–400 to gradually incorporate the unsupervised loss.
3. Experiments and Results
3.1. Dataset
To evaluate the effectiveness and generalizability of our RUGS strategy and SFADA-Net, we employed four diverse medical imaging datasets: BraTS-2021 [39,40], BraTS-SSA 2023 [41], BraTS-PED 2023 [42], and BraTS-MEN 2023 [43]. Each case consists of four MRI modalities: T1-weighted (T1), contrast-enhanced T1-weighted (T1CE), T2-weighted (T2), and T2-weighted fluid attenuated inversion recovery (T2-FLAIR).
BraTS-2021: This dataset comprises 1251 adult glioma cases annotated by experienced radiologists.BraTS-SSA 2023: Specifically gathered from Sub-Saharan Africa, this dataset contains 60 annotated cases. It is included to assess model performance under the domain shift caused by population differences and data scarcity in the African region.BraTS-PED 2023: This dataset consists of 99 pediatric glioma cases. It evaluates the model’s ability to handle the differences between pediatric and adult tumor anatomy.BraTS-MEN 2023: Focusing on adult intracranial meningioma, this dataset introduces a distinct tumor type. We randomly sampled 100 annotated cases from this collection for training and testing.
3.2. Model Training and Implementation Details
Our framework was implemented in PyTorch 2.0.1 on an NVIDIA RTX 3090 GPU, with input images cropped to patches. The training procedure involved two stages: source domain pre-training and domain adaptation. In both stages, the model was optimized using SGD, with the learning rate updated via a Poly scheduler with power 0.9.
Regarding data preprocessing, all MRI scans were co-registered to the same anatomical template, resampled to an isotropic resolution of 1 × 1 × 1 mm^3^, and skull-stripped. To mitigate intensity variations across different patients and scanners, each MRI modality was independently normalized using Z-score standardization based on the non-zero brain regions. As the datasets utilized in our experiments provided complete multi-modal data for all cases, specific mechanisms for handling missing modalities were not required in this study. To mitigate overfitting and enhance model robustness during model training, we adopted a diverse set of data augmentation techniques, including spatial transformations, Gaussian noise, contrast adjustments and axis mirroring.
In the pre-training stage, the source domain dataset was randomly split into training, validation, and testing sets with a ratio of 7:1:2. The model was trained in a fully supervised manner for 300 epochs with a batch size of 32 and an initial learning rate of 0.01, using the supervised loss .
For the adaptation stage, we first employed the RUGS strategy to select valuable samples. To simulate clinical annotation scenarios, we accessed target labels solely during this phase, with a labeling budget of 5%. The RUGS hyperparameters , , and the capacity of were set to 0.1, 0.5, 400, and five times the budget, respectively. Subsequent training utilized these labeled samples in the SSL framework described in Section 2.4. The model was trained for 20k iterations with a batch size of 16 (4 labeled, 12 unlabeled) and an initial learning rate of 0.001. We adopted 5-fold cross-validation and an early stopping mechanism with a patience of 10.
In the inference phase, we deployed our 2D network to 3D MRI volumes in a slice-by-slice manner, and subsequently reconstructed the 3D volumes by stacking the resulting 2D predictions along the longitudinal axis. Although 2D inference inherently lacks inter-slice constraints, we deliberately omitted all 3D post-processing steps to isolate and rigorously evaluate the intrinsic baseline performance of the SFADA framework.
3.3. Comparison with State-of-the-Art Methods
To quantitatively assess the accuracy of the tumor segmentation results, we employed four metrics: Dice Similarity Coefficient (DSC), Sensitivity, Precision, and the 95th percentile Hausdorff distance (HD95). For the four datasets, we calculated the average quantitative results of each method for three tumor sub-regions: Whole Tumor (WT), Tumor Core (TC), and Enhancing Tumor (ET). For each metric, both the mean value and the standard deviation are reported. The standard deviation was computed based on the metric values of all individual test samples from a single experimental run, reflecting the performance variability across cases.
3.3.1. Quantitative Comparison of Backbones on the Source Domain
Given that the BraTS-2021 dataset contains the most extensive patient data and annotations, we selected it as the source domain for model pre-training. To demonstrate the improved performance of SFADA-Net, we benchmarked it against several state-of-the-art (SOTA) segmentation models, including U-Net [12], UNETR [44], SwinUNETR-V2 [45], TransAttUnet [9], VM-UNet [11], and Swin-UMamba [13].
As shown in Table 1, SFADA-Net outperforms competing models across multiple metrics. Notably, it surpasses U-Net with DSC improvements of 1.79% and 2.06% for WT and TC, respectively. Furthermore, the lower HD95 scores demonstrate its superior boundary delineation precision. Figure 4 further visualizes the full per-case distribution of DSC and HD95, clearly demonstrating the superior median performance, smaller variance, and fewer outliers of our SFADA-Net even on the source domain.
Figure 5 illustrates qualitative brain tumor segmentation results of different methods on the BraTS-2021 dataset. Each row represents a different patient case, with the original MRI scan displayed in the leftmost column. This performance advantage can be primarily attributed to the sample selection mechanism rather than the subsequent training strategy. Our proposed method achieves clearer delineation of tumor subregions and higher overlap with the ground truth, particularly in the arrow-marked areas. In these areas, it successfully recovers finer tumor details and subtle structures (such as small enhancing components and precise boundaries) that are frequently missed or inaccurately segmented by other approaches.
3.3.2. Quantitative Comparison of Adaptation Strategies with SFADA-Net
To assess the effectiveness of the proposed RUGS strategy, we compare it with two SOTA SFDA methods, DPL [21] and UPL [22]. For active sample selection, we evaluate five strategies under an identical annotation budget: (1) Random: selects samples randomly; (2) LC [46]: selects samples with the least confidence; (3) Core-set [31]: selects samples based on a set-cover problem; (4) STDR [25]: selects samples with maximal and minimal distribution shifts from the source and (5) UGTST [24]: selects samples based on global uncertainty and diversity.
Furthermore, we incorporate two representative SSL methods for comparison: (1) URPC [47]: enforces multi-scale prediction consistency via a pyramid network to exploit unlabeled data; and (2) ABD [48]: employs a confidence-guided bidirectional displacement module to suppress unreliable regions and generate complementary training samples. Both baselines were trained on the same randomly selected labeled subset.
Finally, we include three baselines to establish performance bounds: (1) Source only: directly uses the model pre-trained in the source domain for inference in the target domain, serving as the lower bound; (2) Target only: trains a model from scratch using labeled target data without source pre-training; and (3) Fine-tune: fine-tunes the pretrained source model using the fully annotated target training set based on supervised learning.
To ensure a fair comparison, all methods are implemented using the SFADA-Net backbone and evaluated via 5-fold cross-validation. Quantitative results for the BraTS-SSA, PED, and MEN datasets are summarized in Table 2, Table 3 and Table 4, respectively.
On the BraTS-SSA 2023 dataset (Table 2), RUGS achieves the highest DSC among all compared methods. Compared with conventional active learning strategies including LC and Core-set, RUGS leverages region-level uncertainty and UGCS to effectively avoid redundant sample selection. Compared with the SSL methods (URPC and ABD), our method selects more informative samples for annotation, enabling the fine-tuned model to achieve superior brain tumor segmentation and higher segmentation accuracy. Notably, our method’s performance closely approaches full fine-tuning, reducing the supervision gap to within 0.12–1.02% DSC while demonstrating robust boundary delineation with consistently low HD95 across all regions.
On the BraTS-PED 2023 dataset (Table 3), RUGS maintained an advantage over other methods. While “Source only” suffered a substantial drop in the TC region (40.94%), RUGS restored the TC DSC to 84.10%, surpassing the Core-set (82.76%) and UGTST (82.11%) strategies. This significant performance recovery demonstrates the capability of RUGS to accommodate the anatomical discrepancies between pediatric and adult brain tumors. RUGS effectively captures the core morphological alterations of pediatric tumors, which are the key factors accounting for the failure of “Source only”. Similarly, in the ET region, RUGS achieved the highest score of 58.42%. The method also demonstrated superior boundary control, recording an HD95 of 12.10 mm for TC, which outperformed SFDA methods, positioning it closest to “Fine-tune”.
On the more challenging BraTS-MEN 2023 dataset (Table 4), performance gaps between different methods became more pronounced. The significant difference between “Source only” and “Fine-tune” indicates a substantial domain shift from the BraTS-2021 to the BraTS-MEN dataset. Meningiomas are fundamentally distinct from gliomas in terms of structural and signal intensity characteristics, which leads to performance degradation of baseline domain adaptation strategies. However, RUGS achieved DSC of 76.23%, 88.57%, and 78.87% for WT, TC, and ET, respectively, all higher than those of other SOTA methods, with a particularly notable advantage in the WT region. In terms of boundary accuracy, RUGS also yielded lower HD95, with 29.80 mm, 18.40 mm, and 27.45 mm for WT, TC, and ET.
Figure 6 provides visual comparisons of brain tumor segmentation results across the three datasets. Our method consistently outputs maps that closely align with the ground truth, offering sharper boundary delineation and accurate subregion identification. For the whole tumor, our approach ensures complete spatial coverage, effectively mitigating the boundary discontinuities and irregular artifacts prevalent in competing methods. Within the NCR/NET and ED, it generates structurally cohesive predictions with notably fewer scattered false positives. Furthermore, our model successfully preserves the fine details of small or highly irregular lesions, which are often over-smoothed or entirely missed by the baselines.
3.3.3. Quantitative Comparison of Backbones Under RUGS on Target Domain
To further investigate the impact of the network architecture on domain adaptation performance, we compared SFADA-Net with several SOTA segmentation models on the BraTS-SSA 2023 dataset. To ensure a fair and controlled comparison, all competing backbones—including UNet, UNETR, SwinUNETR-V2, TransAttUnet, VM-UNet, and Swin-UMamba—were trained using the proposed RUGS active learning strategy under the same annotation budget. The quantitative results are summarized in Table 5. The results indicate that SFADA-Net consistently outperforms the other models across all metrics. Our method exhibits superior adaptability to domain shifts, yielding more accurate tumor delineation and better boundary preservation compared to other models.
3.4. Ablation Studies
3.4.1. Impact of Sample Selection Parameters
We first evaluate the impact of from 1% to 10% on the model using the BraTS-SSA 2023 and BraTS-MEN 2023 dataset, as depicted in Figure 7a, where denotes the percentage of target-domain data manually annotated. Increasing initially improves segmentation accuracy, but the improvement becomes limited as gets larger. Specifically, increasing from 5% to 10% doubles the annotation cost but results in very little performance gain. To achieve a favorable trade-off between accuracy and labeling cost, we employ at 5% for all other experiments.
Moreover, we examine the influence of the capacity of selected by RUA. As shown in Figure 7b, while a larger candidate pool initially benefits the model by offering higher diversity, performance drops when the size becomes excessive. We attribute this to the introduction of noisy or redundant instances within an overly large pool. Thus, we set the candidate set capacity to five times .
Finally, we assess the influence of in UGCS, which regulates the uncertainty-diversity trade-off. As presented in Figure 7c, smaller overemphasize uncertainty and provide only modest gains. Model performance peaks at across the two target domains, while further increasing leads to a performance decline. Based on these observations, we set for all other experiments.
3.4.2. Impact of Key Components
The SFADA-Net model is built upon a UNet-like segmentation architecture [12] and integrates the SAPM and DPMKC modules. We conducted ablation experiments on the BraTS-2021 dataset to evaluate each component (Table 6). Incorporating Mamba, SAPM, or DPMKC individually into the baseline consistently improves segmentation metrics. Specifically, the SAPM and DPMKC modules provide more distinct performance gains compared to the SSM alone. Most notably, the simultaneous integration of both SAPM and DPMKC yields the most significant boost in DSC and a substantial reduction in HD95 across all tumor subregions, outperforming all single-module configurations. This confirms that the proposed modules work synergistically to maximize the overall segmentation accuracy.
Table 7 compares the performance of different models in terms of complexity and computational efficiency, specifically evaluating the parameter count, floating-point operations (FLOPs), and inference time across current mainstream architectures and our ablation configurations. The experimental results show that our proposed model maintains a relatively compact scale, with fewer parameters than several mainstream Transformer-based and Mamba-based networks. In terms of computational cost, our method also maintains a moderate level of FLOPs without excessive demand. Although the introduction of the SAPM and DPMKC modules increases inference time and computational overhead compared to the baseline model, the complete model still achieves faster inference speed than other Mamba-based architectures. Overall, the experiment validates that SFADA-Net improves segmentation performance without excessively consuming computational resources.
The ablation study results summarized in Table 8 demonstrate the consistent performance gains achieved by integrating the RUGS strategy components on the BraTS-MEN 2023 dataset. Starting from the baseline (B), which relies solely on pre-trained pseudo-labels, the introduction of RUA provides a more robust selection mechanism than the conventional Entropy-based method, notably elevating the WT DSC from 68.15% to 72.85% while simultaneously reducing the HD95. Furthermore, the full configuration incorporating UGCS proves more effective than the Core-set strategy; while Core-set offers competitive sensitivity, UGCS achieves substantially better boundary delineation and precision.
4. Discussion
Quantitative results in Table 2, Table 3 and Table 4 indicate that SFADA-Net, combined with RUGS, outperforms existing SFDA and SFADA methods across multiple target domains (BraTS-SSA, BraTS-PED, and BraTS-MEN). Our method achieves segmentation performance comparable to fully supervised training while using only 5% of annotated data. This effectiveness stems from the combined sample selection strategy and network architecture. Within RUGS, RUA filters out most low-entropy background regions and aggregates pixel-level uncertainty into semantically meaningful regions. UGCS balances sample diversity and uncertainty, reducing redundancy in purely uncertainty-based selection. This performance advantage can be primarily attributed to the sample selection mechanism rather than the subsequent training strategy. While semi-supervised methods such as URPC and ABD incorporate sophisticated consistency regularization or pseudo-label refinement techniques, their effectiveness is inherently limited by the quality and representativeness of the initially labeled samples. As shown in Table 2, Table 3 and Table 4, even when equipped with advanced semi-supervised learning modules, these methods underperform compared to our approach, which emphasizes the selection of informative and diverse samples prior to adaptation. What this really means is that, under low-annotation budgets, it is not the complexity of the training objective but the strategic selection of samples that makes the difference.
Moreover, SFADA-Net surpasses SOTA networks in both source and target domains (Table 1 and Table 5). The SAPM module captures long-range dependencies with linear complexity, crucial for delineating complex brain tumor structures. Specifically, the GSASF equation captures neighborhood structural information, and the prompt mechanism enhances querying semantic information. The DPMKC module complements Mamba by preserving local details, ensuring global consistency does not compromise local precision. This synergy is particularly beneficial for MRI with variable tumor textures.
In clinical settings, privacy regulations often hinder cross-center data sharing. Our source-free setting addresses this by using only source-pretrained weights and unlabeled target samples, eliminating source data access. Experiments confirm this framework effectively handles domain shifts caused by variations in equipment, demographics, and pathology. Furthermore, by actively selecting a small subset of target samples for annotation, we mitigate pseudo-label errors in unsupervised methods and achieve more reliable domain adaptation.
Although the proposed SFADA method outperforms SOTA methods on the majority of target-domain samples, it still has performance bottlenecks in some challenging samples. Figure 8 shows representative failure cases from the three target domains. In the top row, the WT and TC are generally well-delineated, under-segmentation is still observed around the boundaries between the ED region (blue) and the ET region (yellow). In the middle row, confusion between partial ED regions and NCR/NET regions (green) is observed, with the model misclassifying the green regions. In the bottom row (cases with extremely small, low-contrast lesions), the proposed method successfully detects ED regions missed by multiple baseline methods, yet there remains the problem of incomplete coverage of tumor regions.
Beyond the aforementioned failure cases and performance bottlenecks in challenging clinical scenarios, the proposed SFADA framework has several limitations. First, the current implementation operates on 2D slices to mitigate memory constraints, disregarding the volumetric context of MRI. Future work will extend the framework to 3D to fully leverage inter-slice correlations. Second, RUGS relies on the initial pre-trained model quality; significant domain shifts may compromise uncertainty estimation reliability. Finally, validation was restricted to brain tumor segmentation. Future studies will evaluate the proposed method’s robustness across broader medical imaging tasks.
5. Conclusions
In this study, we presented a novel SFADA framework for cross-center brain tumor segmentation. To address the challenges of data privacy, domain shift, and high annotation costs, we introduced the RUGS strategy. By aggregating uncertainty over multiple superpixel regions and leveraging Core-set selection, RUGS efficiently selects both informative and representative samples for annotation. Furthermore, SFADA-Net synergizes local feature extraction with long-range dependency modeling by integrating DPMKC and the SAPM module. Extensive validation on four multi-modal MRI datasets demonstrates that our approach consistently outperforms SOTA domain adaptation and active learning methods, achieving high segmentation accuracy under a limited annotation budget and approaching fully supervised performance. In terms of clinical implementation, our method effectively reduces the manual annotation workload for radiologists, enables rapid, low-cost deployment of AI-assisted diagnosis models in compliance with data privacy regulations, and facilitates the clinical translation of domain adaptation approaches.
Nevertheless, this study has several limitations. 2D slice-wise independent processing may overlook inter-slice contextual information in 3D MRI volumes. In addition, RUGS depends on source-pretrained model quality, with degraded uncertainty estimation under large domain shifts. Finally, the evaluation is limited to brain tumor segmentation tasks. Future work will extend the framework to full 3D volumetric processing, develop more robust uncertainty estimation techniques for large domain gaps, and validate the method on additional medical imaging tasks and modalities to further enhance its clinical applicability.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sledzinska P. Bebyn M.G. Furtak J. Kowalewski J. Lewandowska M.A. Prognostic and predictive biomarkers in gliomas Int. J. Mol. Sci.2021221037310.3390/ijms 22191037334638714 PMC 8508830 · doi ↗ · pubmed ↗
- 2Nandu H. Wen P.Y. Huang R.Y. Imaging in neuro-oncology Ther. Adv. Neurol. Disord.20181111910.1177/1756286418759865 PMC 583317329511385 · doi ↗ · pubmed ↗
- 3Galanaud D. Nicoli F. Chinot O. Confort-Gouny S. Figarella-Branger D. Roche P. Fuentes S. Le Fur Y. Ranjeva J.-P. Cozzone P.J. Noninvasive diagnostic assessment of brain tumors using combined in vivo mr imaging and spectroscopy Magn. Reson. Med.2006551236124510.1002/mrm.2088616680716 · doi ↗ · pubmed ↗
- 4Villanueva-Meyer J.E. Mabray M.C. Cha S. Current clinical brain tumor imaging Neurosurgery 20178139741510.1093/neuros/nyx 10328486641 PMC 5581219 · doi ↗ · pubmed ↗
- 5Yuh W.T.C. Christoforidis G.A. Koch R.M. Sammet S. Schmalbrock P. Yang M. Knopp M.V. Clinical magnetic resonance imaging of brain tumors at ultrahigh field: A state-of-the-art review Top. Magn. Reson. Imaging TMRI 200617536110.1097/RMR.0b 013e 318030040417198222 PMC 3535276 · doi ↗ · pubmed ↗
- 6Hashmi S. Lugo J. Elsayed A. Saggurthi D. Elseiagy M. Nurkamal A. Walia J. Maani F.A. Yaqub M. Optimizing brain tumor segmentation with mednext: Brats 2024 ssa and pediatricsar Xiv 20242411.15872
- 7Mc Dermott D.M. Hack J.D. Cifarell C.P. Vargo J.A. Tumor cavity recurrence after stereotactic radiosurgery of surgically resected brain metastases: Implication of deviations from contouring guidelines Stereotact. Funct. Neurosurg.201997243010.1159/00049615630763944 PMC 7427836 · doi ↗ · pubmed ↗
- 8Takahashi S. Sakaguchi Y. Kouno N. Takasawa K. Ishizu K. Akagi Y. Aoyama R. Teraya N. Bolatkan A. Shinkai N. Comparison of vision transformers and convolutional neural networks in medical image analysis: A systematic review J. Med. Syst.2024488410.1007/s 10916-024-02105-839264388 PMC 11393140 · doi ↗ · pubmed ↗