eXCube2: Explainable Brain-Inspired Spiking Neural Network Framework for Emotion Recognition from Audio, Visual and Multimodal Audio–Visual Data
N. K. Kasabov, A. Yang, Z. Wang, I. Abouhassan, A. Kassabova, T. Lappas

TL;DR
eXCube2 is a brain-inspired AI framework using spiking neural networks to recognize emotions from audio, visual, and combined data, offering better explainability and adaptability.
Contribution
eXCube2 introduces a novel brain-inspired spiking neural network framework for emotion recognition with explainability and adaptability.
Findings
eXCube2 achieved above 80% accuracy on single-modality data and 88.9% on multimodal data.
The framework enables brain-inspired mapping of audio and visual inputs for emotion recognition.
It supports neuromorphic hardware for reduced power consumption and improved performance.
Abstract
This paper introduces a biomimetic framework and novel brain-inspired AI (BIAI) models based on spiking neural networks (SNNs) for emotional state recognition from audio (speech), visual (face), and integrated multimodal audio–visual data. The developed framework, named eXCube2, uses a three-dimensional SNN architecture NeuCube that is spatially structured according to a human brain template. The BIAI models developed in eXCube2 are trainable on spatio- and spectro-temporal data using brain-inspired learning rules. Such models are explainable in terms of revealing patterns in data and are adaptable to new data. The eXCube2 models are implemented as software systems and tested on speech and video data of subjects expressing emotional states. The use of a brain template for the SNN structure enables brain-inspired tonotopic and stereo mapping of audio inputs, topographic mapping of visual…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
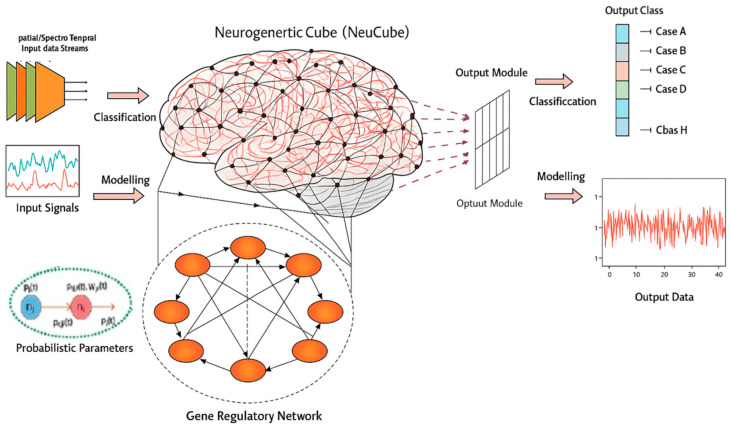 Figure 1
Figure 1 Figure 2
Figure 2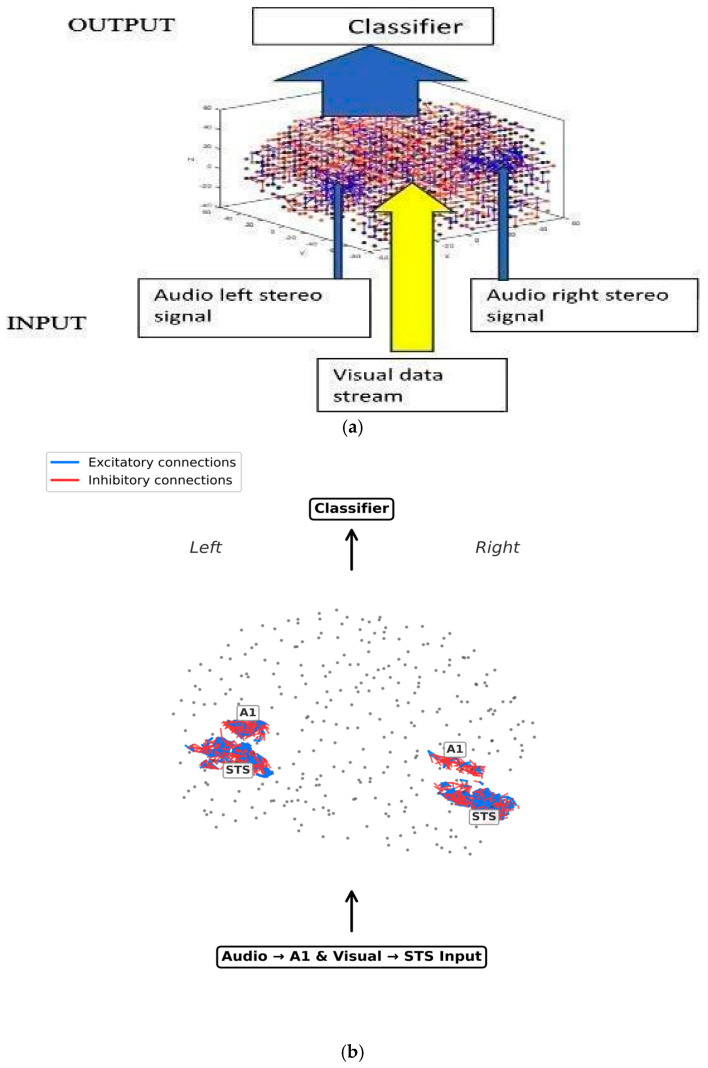 Figure 3
Figure 3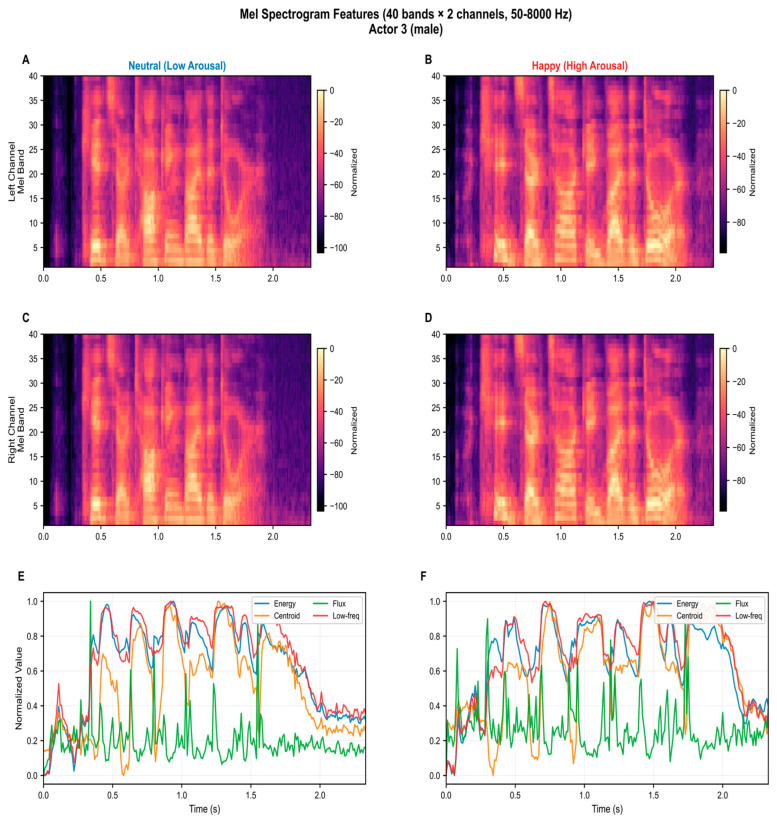 Figure 4
Figure 4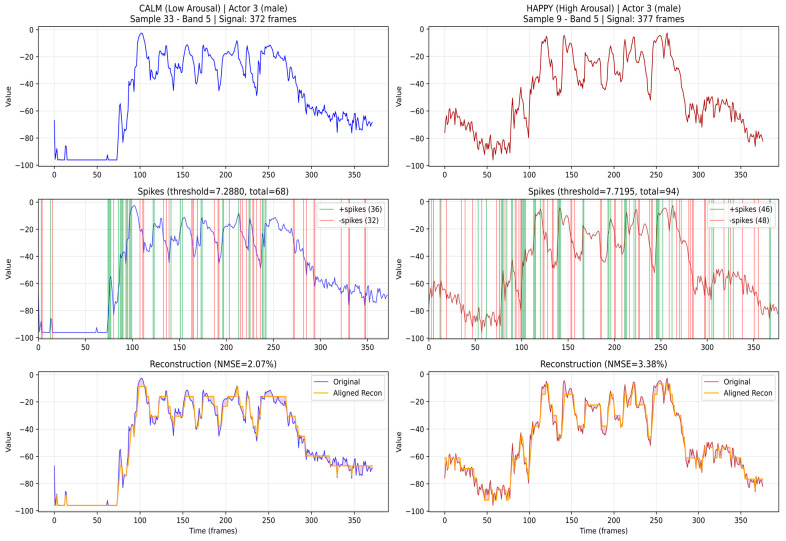 Figure 5
Figure 5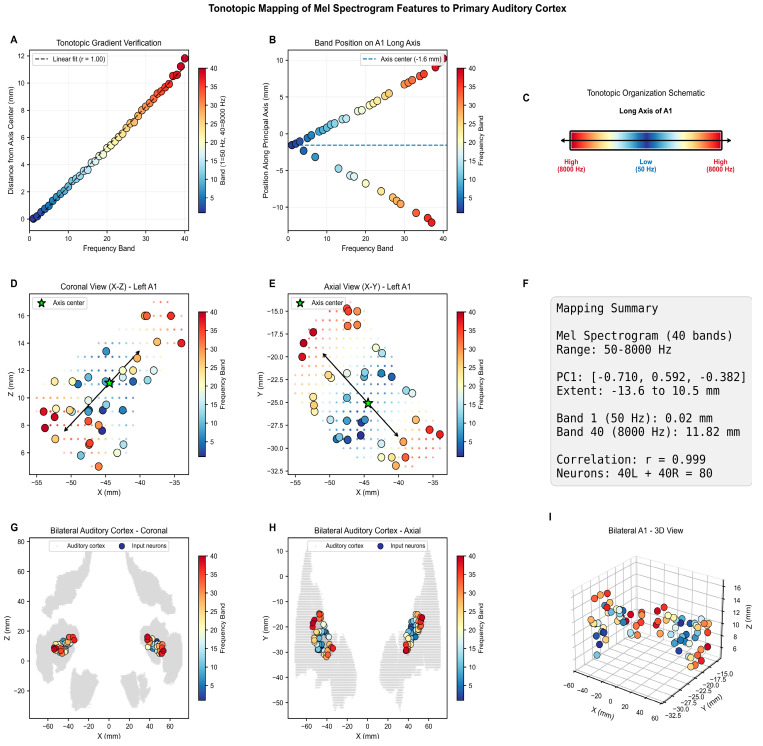 Figure 6
Figure 6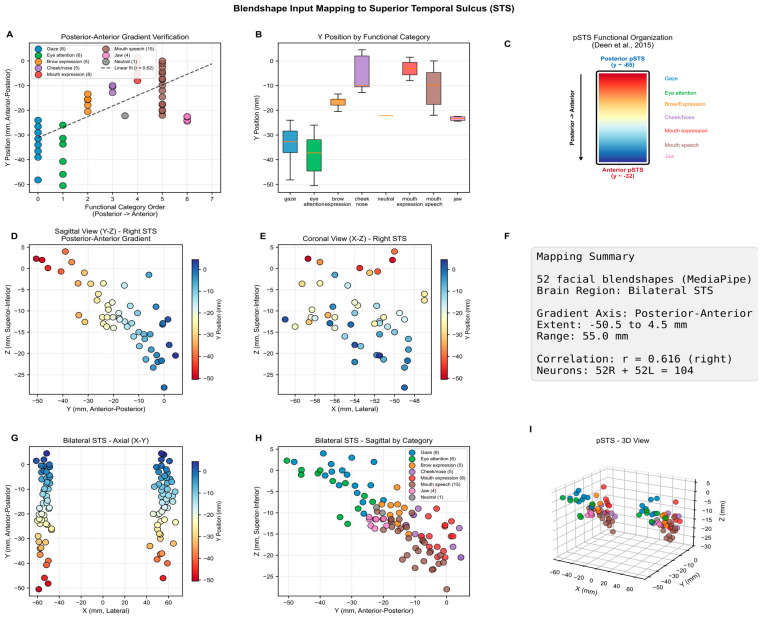 Figure 7
Figure 7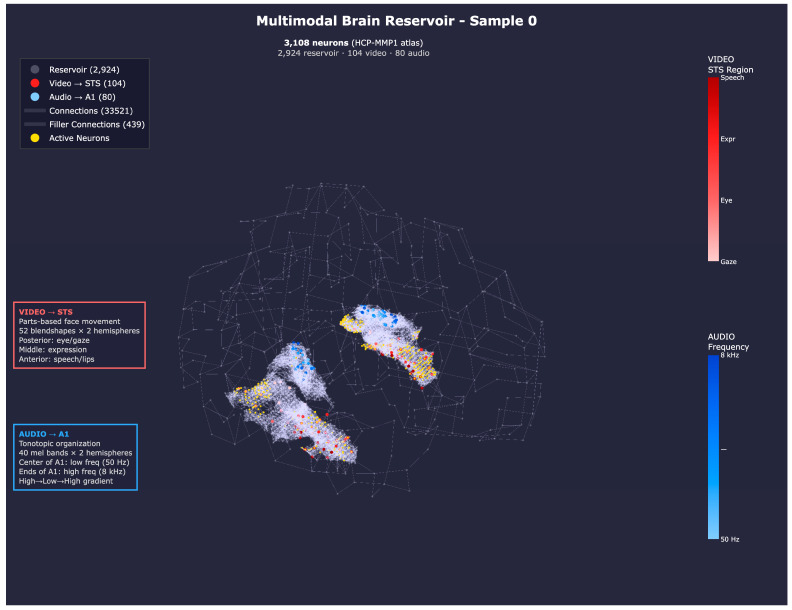 Figure 8
Figure 8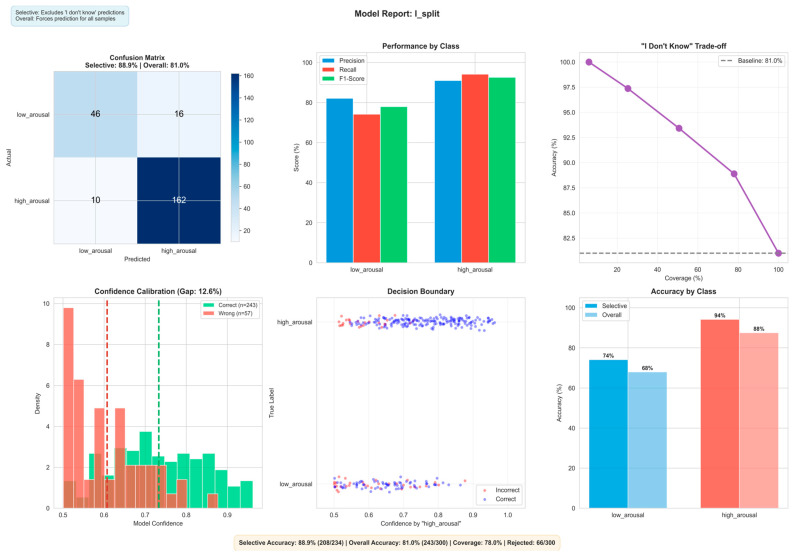 Figure 9
Figure 9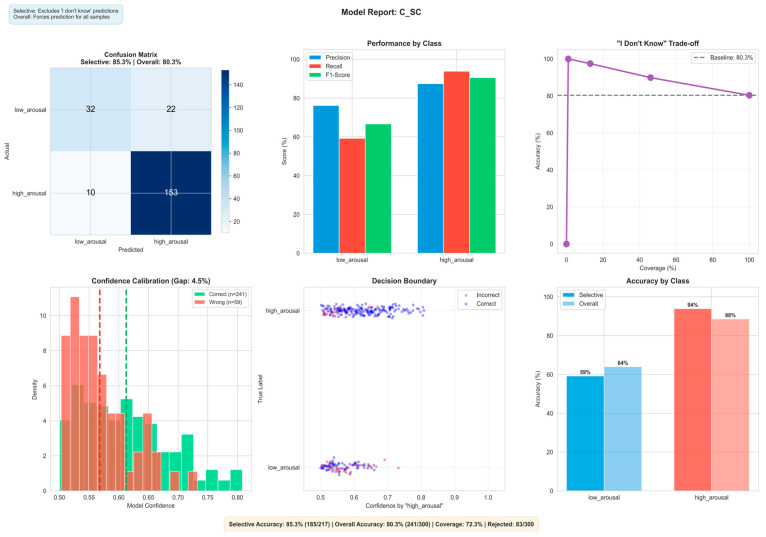 Figure 10
Figure 10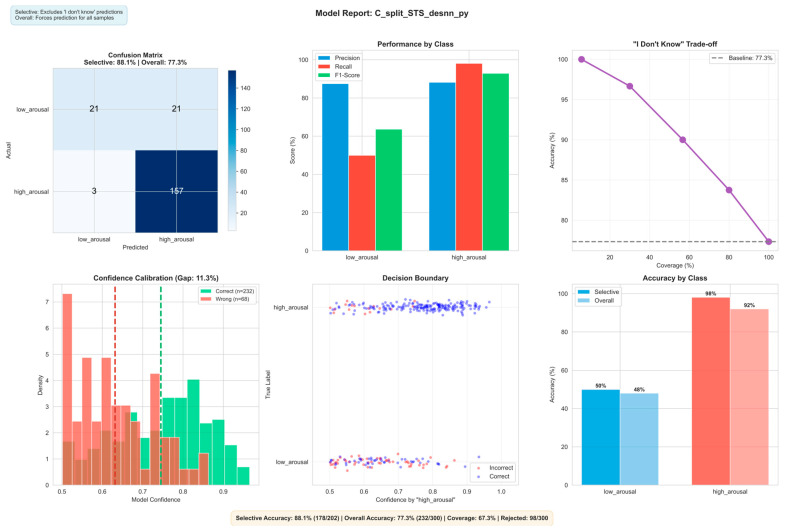 Figure 11
Figure 11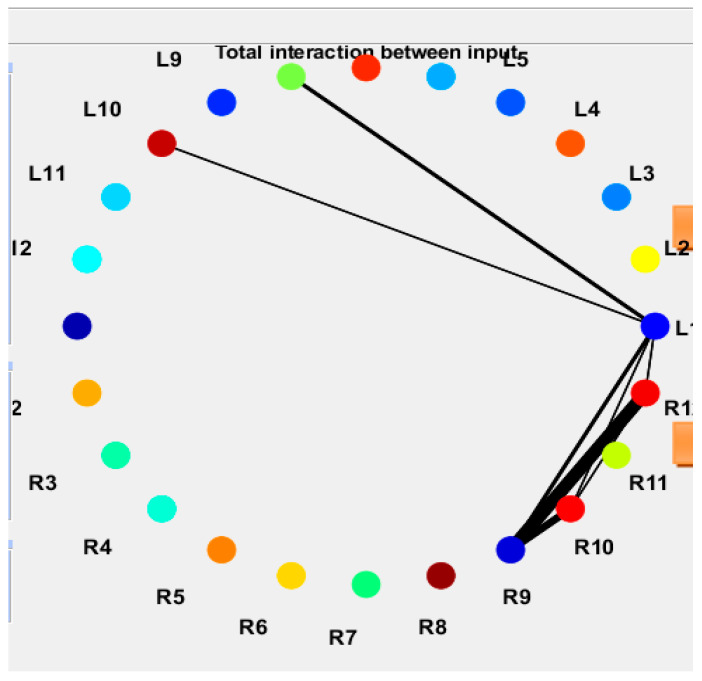 Figure 12
Figure 12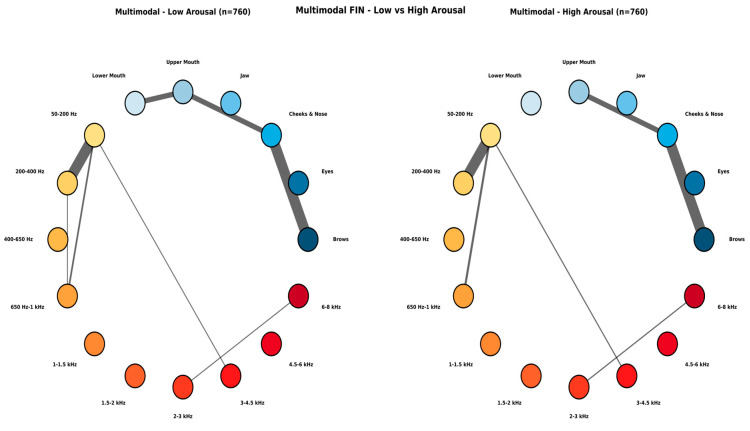 Figure 13
Figure 13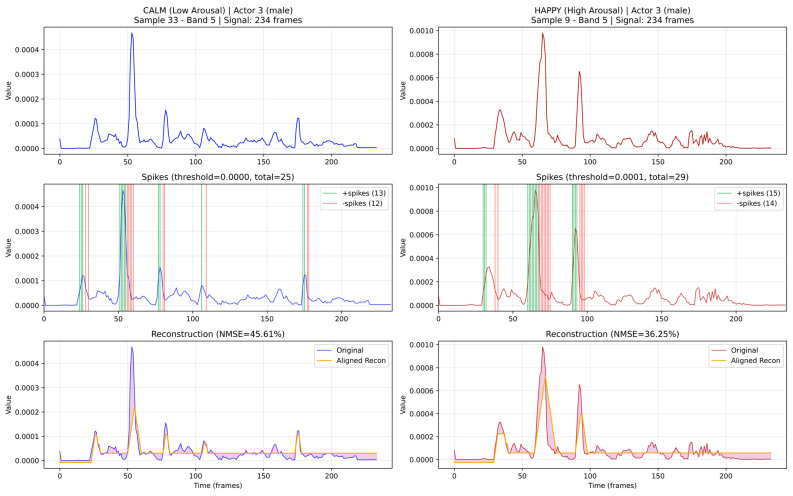 Figure 14
Figure 14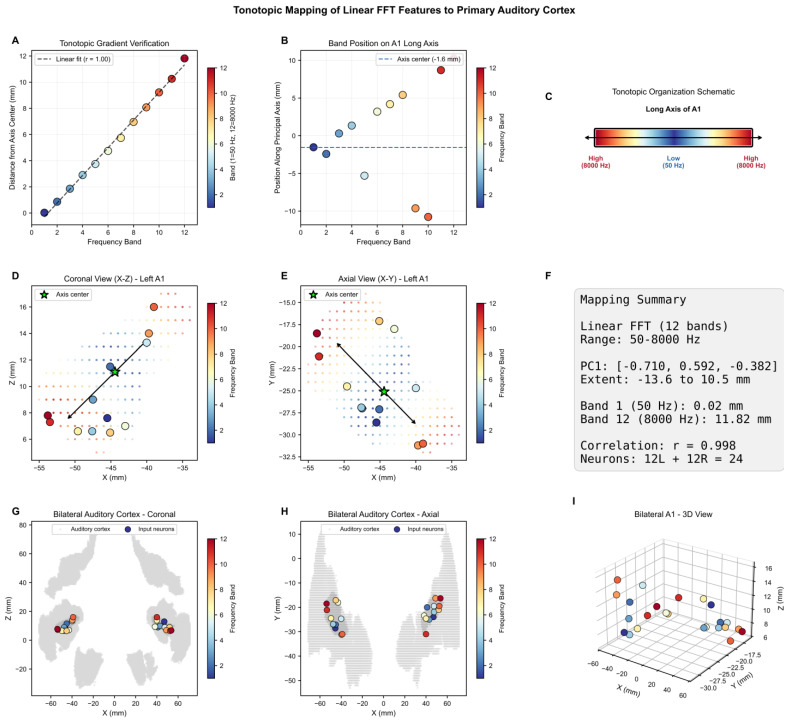 Figure 15
Figure 15Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEmotion and Mood Recognition · Neuroscience and Music Perception · EEG and Brain-Computer Interfaces
1. Introduction: Toward Brain-Inspired Biomimetic Systems for Audio, Visual and Audio–Visual Pattern Recognition
1.1. Problem Definition
Current technologies for speech recognition and face recognition have advanced significantly in recent years, driven by modern statistical and neural network methods [1,2,3,4,5,6,7,8,9,10,11]. However, voice and face data can be used to address many other challenging AI problems [12,13,14,15,16]. An open problem is the development of AI systems that use voice and vision data to recognize and explain human brain states, such as emotional states and brain diseases. Current voice and computer vision technologies need to be further developed, and new approaches must be created to make AI systems closer to human perception, human expression, and human understanding, and perhaps even human consciousness [14]. One way to target this goal is to develop brain-inspired AI systems (BIAI).
Current brain-inspired systems are mostly based on spiking neural networks (SNNs) [9,17]. An example is the brain-inspired SNN architecture NeuCube, introduced in [18].
The aim of the proposed novel eXCube2 SNN framework is to recognize emotional states from audio, visual, and multimodal audio–visual data using for the first time a brain-inspired approach. While based on the NeuCube architecture, the eXCube2 framework is a novel one that introduces new methods for the problem in hand.
1.2. Related Work
1.2.1. Audio-Based Emotional State Recognition
Recognising emotions from speech has been approached using both classical machine learning and deep learning. Traditional methods extract acoustic descriptors such as pitch, energy, and spectral shape from the speech signal and classify them using support vector machines (SVM) or similar classifiers. On the RAVDESS dataset, this ap-proach achieves approximately 62.48% unweighted accuracy for three class (low/neutral/high) arousal detection [19,20], establishing a conventional baseline.
Deep learning methods improve on this by learning features directly from the audio. Issa et al. [21] trained a convolutional neural network (CNN) on multiple audio representations, achieving 71.61% on RAVDESS across 8 emotion classes under speaker-independent evaluation. Mustaqeem and Kwon [22] combined convolutional and recurrent layers to capture both short-term and long-term temporal patterns, reaching 80%.
A further step came with large pre-trained speech models such as wav2vec 2.0 and HuBERT, which learn general speech representations from thousands of hours of unlabelled recordings before being applied to emotion recognition. Pepino et al. [23] showed that wav2vec 2.0 features achieve 84.1 ± 1.2% on RAVDESS (8 classes, 5-fold cross-validation). These models require substantial computational resources for pre-training, and their accuracy can degrade significantly under strict speaker-independent evaluation conditions [24]. They are not incrementally adaptable to new accents and pronunciations.
1.2.2. Visual and Multimodal Emotion Recognition
Facial expression recognition typically relies on geometric features such as facial landmark positions and movements, or on visual features learned by CNNs from face images. Combining audio and visual information through multimodal fusion generally improves accuracy, as the two signals provide complementary cues about emotional state.
On RAVDESS, Luna-Jiménez et al. [25] evaluated a multimodal system combining a pre-trained audio CNN with a recurrent network for facial features, achieving 80.08% on 8-class emotion recognition under speaker-independent 5-fold cross-validation. Audio alone reached 76.58% and face alone 57.08%. In a follow-up study [26], replacing the audio component with a fine-tuned wav2vec 2.0 model and incorporating facial action units improved multimodal accuracy to 86.70% under the same protocol.
1.2.3. Spiking Neural Networks for Emotion Recognition
Spiking neural networks (SNNs) offer a biologically grounded alternative to conventional deep learning, representing information through discrete temporal events rather than continuous activations. Despite their natural suitability for processing temporal signals, relatively few studies have applied SNNs to emotion recognition. Mansouri-Benssassi and Ye [27] evaluated SNNs for both facial and speech emotion recognition on RAVDESS, finding that SNNs maintained significantly higher accuracy than CNNs and SVMs under noisy conditions, demonstrating greater robustness to real-world signal degradation. Wysoski et al. [9] presented an earlier evolving SNN framework for audio–visual processing, followed by the use of NeuCube SNN [28]. Transformer-inspired SNN architectures for multimodal classification have also been explored [29], reflecting growing interest in neuromorphic approaches for affective computing. All these used traditional feedforward SNN and not a brain-inspired SNN architecture.
1.2.4. Transformer-Based Audio–Visual Models
Most of the Transformer-based models are directed to speech recognition, speaker separation, e.g., [30,31], which is a different task from emotional state recognition, still their models are worth analysing as they deal with audio–visual data processing.
MMST proposes a Multimodal Sparse Transformer Network for noise-robust audio–visual speech recognition (AVSR) by strengthening motion-aware visual modelling and improving attention selectivity over long input sequences [30]. The framework aligns and models three streams—audio (A), lip appearance (V), and lip motion (O)—where motion is explicitly captured via optical flow and encoded with a spatiotemporal front-end. To better inject dynamic articulatory cues into the visual representation, the authors introduce Cross-Modal Attention Fusion (CMAF), which uses visual features as queries and motion features as keys/values to produce an enhanced visual embedding for decoding. In addition, MMST adopts a top-q sparse attention strategy within the Transformer, retaining only the most relevant attention positions for each query to suppress irrelevant context and improve robustness in long-range temporal modelling. Experiments on standard AVSR benchmarks (including LRW for word-level pretraining and LRS2/LRS3 for sentence-level evaluation) show that both sparsification and motion-aware fusion contribute to a consistent WER improvements. On LRS2, introducing sparse attention yields an approximately 1.6% absolute WER reduction compared with a baseline such as TM-seq2seq, while incorporating the motion stream with CMAF provides a further ~1.4% absolute WER reduction over simple concatenation-based fusion; the gains are reported to be especially evident under low-SNR noise conditions, indicating enhanced robustness in adverse acoustic environments [30].
1.2.5. LSTM Models for Audio–Visual Data Processing
Most of the LSTM models are directed to speech recognition, e.g., [32,33], which is a different task from emotional state recognition; nevertheless, their models are worth analysing as they deal with both speech and image in their integration.
Reference [32] addresses audio–visual speech recognition (AVSR) by proposing a multimodal recurrent neural network (multimodal RNN) that jointly models the temporal/sequential structure of both audio and visual streams, unlike prior deep AVSR approaches that typically ignore the sequential nature of one modality. The model consists of three parts: (1) an audio encoder based on (uni-/bi-)LSTM; (2) a visual encoder that uses a CNN on mouth-region frames followed by (uni-/bi-)LSTM to capture visual dynamics; and (3) a fusion module that combines the two modalities using a learned multimodal layer built on weighted state summaries of each stream [32]. Experiments are conducted on the benchmark AVletters dataset: 10 speakers (5 male, 5 female), each pronouncing isolated letters A–Z with 3 repetitions, totalling 780 utterances. Visual input is the mouth ROI at 60 × 80 pixels, with 23–79 video frames per utterance; audio is represented using 26-dimensional MFCC features, with 12–40 MFCC frames per utterance. For fusion strategies, the multimodal-layer fusion is reported as the strongest in most SNR conditions and is used as the main configuration thereafter. In direct comparison against the classical AVletters approach by Matthews et al., the proposed multimodal RNN achieves higher best accuracies across all noise levels, with particularly large gains under severe noise: 87.7% (clean) and 70.0% (0 dB) versus 86% (clean) and 42% (0 dB) for Matthews et al. [32]. These results indicate that explicitly modelling both modalities as sequences and learning a trainable fusion layer provides substantial robustness benefits when the acoustic channel is degraded.
Reference [33] studies audio–visual speech recognition (AVSR) using a high-frame-rate 3D audio–visual corpus and proposes a framework that remains useful even when visual input is unavailable at test time. The authors argue that most prior AVSR work relies on 2D corpora with relatively low video sampling rates, whereas their 3D facial motion capture provides visual features at up to 100 Hz and enables direct extraction of discriminative articulatory motion cues. Methodologically, they introduce a visual feature-generation-based bimodal CNN: an inversion LSTM-RNN is trained to predict visual features from audio, and a bimodal CNN-HMM integrates audio with either (i) ground-truth visual features or (ii) LSTM-generated visual features, thereby eliminating the strict requirement for true visual modality at inference time [33]. Experiments use a multi-speaker Mandarin Chinese 3D audio–visual corpus containing 28 speakers (14 female, 14 male) and designed with seen/unseen speaker splits in development and test sets to assess generalisation.
Reference [34] presents a hybrid deep-learning approach for speech emotion recognition (SER) that integrates 1D convolutional neural networks (CNNs) with stacked Residual Bidirectional LSTMs (RBi-LSTMs) to jointly model local spectro-temporal patterns and longer-range temporal dependencies in emotional speech. The method uses a holistic multi-feature representation, combining MFCCs (with derivatives), Chroma, Mel-spectrogram features, Zero-Crossing Rate (ZCR), and RMS energy; these per-frame descriptors are concatenated into a 260-dimensional feature vector and padded to a fixed sequence length of 130-time steps to form a consistent model input of shape (130, 260) [34]. The evaluation is conducted on a combined dataset created by merging two standard SER corpora: RAVDESS and TESS, with the goal of improving variability exposure and generalization. The merged dataset is split into 70% training (3976 samples), 15% validation (852 samples), and 15% held-out test (852 samples); the task covers eight emotion classes [34]. On the held-out test set, the proposed CNN–RBiLSTM model achieves 96.83% test accuracy with test loss = 0.1324. The class-wise report indicates strong and relatively balanced performance, with macro/weighted averages around 0.96–0.97 and the main confusions concentrated in comparatively weaker classes such as calm (lower precision) and sad (lower recall). The authors attribute the overall performance to (i) the complementary information captured by the multi-feature input and (ii) improved temporal modelling and training stability provided by residual connections in the bidirectional LSTM stack [34].
1.3. Positioning of Our Present Work
Several gaps remain in the current literature. Explainability is rarely addressed, with most deep learning models offering little insight into the spatio-temporal patterns they have learned and into adaptability to new data. While brain-template-structured SNNs have been applied to emotion recognition from neuroimaging data such as EEG [17,18], no prior work has combined tonotopic and topographic input mappings within a brain-template SNN for emotional state recognition from audio, visual, and multimodal audio–visual data. The eXCube2 framework addresses these gaps by combining a brain-template-structured 3D SNN with biologically motivated input mappings, STDP-based learning, and interpretable connectivity patterns, remaining suitable for neuromorphic hardware deployment. In this sense, this is the first attempt to show that brain-inspired SNN architectures can capture and explain emotional states from audio, visual and audio–visual data, achieving also better or competitive accuracy to the other methods.
2. Methods: A General eXCube2 Framework and Models for Emotional State Recognition Based on Audio-, Visual and Multimodal Audio–Visual Data
2.1. Why Use Brain-Inspired SNN and the NeuCube Architecture for Audio–Visual Data?
Spiking neural networks (SNNs) are biologically inspired artificial neural networks in which information is represented as binary events (spikes), similar to action potentials in the brain, and learning is also inspired by principles observed in the brain. SNNs are also universal computational mechanisms [17]. Learning in SNNs refers to changes in the connection weights in the network. Many learning paradigms, such as Spike-Timing-Dependent Plasticity (STDP), are inspired by the Hebbian learning principle. In STDP, synaptic weights are adjusted based on the temporal order of the incoming spike (pre-synaptic) and the output spike (post-synaptic). This synaptic weight adjustment determines synaptic potentiation, known as long-term potentiation (LTP), when the synaptic weight increases (positive change). On the other hand, synaptic depression, known as long-term depression (LTD), occurs when the synaptic weight decreases (negative change). If a pre-synaptic spike arrives before (after) a post-synaptic spike, the synaptic link between the two neurons is potentiated (depressed). Thus, learning in the network depends on spike times, which leads to changes in synaptic strength.
STDP is defined mathematically in Equation (1):
where is the change in weight as a function of the difference between the pre- and post-synaptic spike times, τ+ and τ− are the LTP and LTD time constants, respectively, and and are the maximum adjustment to synaptic weight when approaches zero.
Overall, an SNN trained with the STDP rule can capture spatio- and spectro-temporal patterns from data, where input neurons are spatially distributed, and connection weights learn temporal associations between them.
Izhikevich [35] has shown that similar activation patterns (called ‘polychronous waves’) can be generated in an SNN reservoir with recurrent connections to represent short-term memory. This is a further extension of the ‘synfire chain’ theory by Abeles [36]. The above principles are utilized in [37,38,39,40] for the creation of spatio-temporal associative memories in SNN, which is a brain-inspired principle in audio–visual perception [41].
The eXCube2 architecture is based on the NeuCube SNN brain-inspired architecture (Figure 1) [18,42].
The functionality of the NeuCube architecture is described as follows [18]:
Temporal inputs (features) are converted into spike trains.
Inputs are mapped spatially into a 3D SNNcube that consists of spiking neurons spatially organized in a topological 3D map. For modelling cognitive brain-related data, the SNNcube is built using a brain template, such as MNI, etc. (e.g., [43,44,45,46]).
An output classifier/regressor SNN is connected to neurons from the SNNcube, e.g., deSNN [47].
The SNNcube structure is initialized as a small world connectivity 3D structure of spiking neurons.
Unsupervised learning is performed in the SNNcube using STDP.
Supervised learning is performed in the output SNN module, e.g., deSNN for classification.
The learned connectivity patterns in the SNNcube can be interpreted as deep knowledge, representing deep spatio-temporal patterns in the data. Learned connectivity patterns in the deSNN output module can be interpreted for rule extraction related to outputs [48,49].
The model is further trained and adapted using new data, during which connections are modulated within the SNNcube and additional output neurons are generated in the deSNN classifier to capture emerging patterns and previously unseen classes.
2.2. The General eXCube2 Framework
The problem of detecting an emotional state using audio, visual, or both modalities is represented here as a classification problem (Figure 2).
The eXCube2 architecture applies brain-inspired tonotopic mapping of audio signals and topographic (retinotopic) mapping of images into the 3D SNNcube, and the learned or recalled patterns in the SNNcube are then classified (Figure 3a,b).
2.3. Experimental Data
For the initial development and testing of the eXCube2, we use part of the Ryerson Audio–Visual Database of Emotional Speech and Song (RAVDESS): a dynamic, multimodal set of facial and vocal expressions in North American English [50,51]. The dataset is available at https://zenodo.org/records/1188976 (accessed 30 November 2025), along with https://zenodo.org/records/3255102 (accessed 1 December 2025). Examples of the data are available at https://www.youtube.com/watch?v=cxMK2J0P7J0 (accessed 30 November 25)
The Ryerson Audio–Visual Database of Emotional Speech and Song (RAVDESS) contains 7356 files (total size: 24.8 GB). The dataset includes 24 professional actors (12 female and 12 male) vocalizing two lexically matched statements in a neutral North American accent. Speech includes calm, happy, sad, angry, fearful, surprised, and disgust expressions, and song contains calm, happy, sad, angry, and fearful emotions. Each expression is produced at two levels of emotional intensity (normal, strong), with an additional neutral expression. All conditions are available in three modality formats: audio-only (16-bit, 48 kHz, .wav format), audio–video (720 p H.264, AAC 48 kHz, .mp4 format), and video-only (no sound). The RAVDESS was developed by Dr Steven R. Livingstone [51].
For the experimental study, the following labelling of the data has been used:
- Class 0 = Low arousal: neutral, calm, sad;
- Class 1 = High arousal: happy, angry, fearful, disgust, surprised.
We adopt binary arousal classification (high vs. low) rather than the full 8-class categorization for several reasons. First, arousal is a well-established dimension of emotional state, and the RAVDESS emotions naturally partition along this axis. Second binary arousal detection is directly applicable to real-world screening, such as patient monitoring or confrontation detection, and can serve as a first-pass filter before finer-grained assessment.
2.4. Audio Feature Extraction and Feature Encoding in eXCube2
Different features can be extracted from raw sound data and used for different applications. In the context of brain state recognition, this paper uses mel-spectrogram features, after considering and comparing them with three other possible feature types, as shown in Table 1.
Each feature is mapped into the 3D SNN as an input neuron. Table 1 presents the audio features investigated in this study.
The audio features are mapped into the SNNcube as input neurons to both the left and right areas of the SNNcube, which correspond to the left and right auditory cortex according to the selected brain template. Each of the above features can be used in the development and implementation of an eXCube2 model for specific applications. Mel-spectrogram features, as used in the current implementation of eXCube2, are shown in Figure 4.
The extracted audio features are then encoded into spikes using different possible encoding schemes. Figure 5 illustrates the encoding of the data from Figure 4 (top) using the Step-Forward method [17] (middle), as well as the reconstruction of the original signals from the spike trains (bottom), with the reconstruction error quantified by the normalized MSE. For a comparison, an example of 24 linear-fft feature extraction, encoding, and mapping, is given in Appendix A, Figure A1.
2.5. Tonotopic Mapping of Audio Features into a 3D SNNcube of the eXCube2 Framework
We employed a tonotopic mapping of audio features to the SNN reservoir, replicating the spatial organization of the human primary auditory cortex (A1), where neurons are arranged according to their preferred frequency. A1 follows a characteristic high → low → high frequency gradient along the long axis of Heschl’s gyrus: the cochlea unrolls frequency linearly, but the cortex folds this representation into two adjacent au-ditory fields (A1 and R) that meet at a low-frequency boundary, producing a mirror-symmetric gradient. This organization has been consistently demonstrated from early fMRI work [53], through high-resolution 7T studies confirming robust tonotopic gradient reversals centered on Heschl’s gyrus [54,55]. Following this principle, the extracted features are mapped into a pre-structured eXCube2 SNN using MNI brain template coordinates and a tonotopic assignment of spatial locations to the selected features. Figure 6 illustrates the mapping of the 40 × 2 = 80 mel-spectrogram features into the SNNcube, and the corresponding algorithm is presented in Table 2. For a comparative analysis, tonotopic mapping of linear-fft 24 audio features into the SNNcube is shown in Figure A2.
2.6. Visual Feature Extraction and Their Topographic Mapping in the eXCube2 Framework
Visual features are extracted from the RAVDESS video files as 52 facial blendshapes using MediaPipe Face Landmarker [50,51]. These comprise 5 brow features (browDownLeft/Right, browInnerUp, browOuterUpLeft/Right), 8 eye features (eyeBlinkLeft/Right, eyeSquintLeft/Right, eyeWideLeft/Right), 3 cheek features (cheekPuff, cheekSquintLeft/Right), 2 nose features (noseSneerLeft/Right), 4 jaw features (jawOpen, jawForward, jawLeft/Right), 28 mouth features (mouthSmileLeft/Right, mouthFrownLeft/Right, mouthPucker, mouthShrugUpper/Lower, among others), tongueOut, and a neutral baseline.
The 52 blendshape features are mapped bilaterally to the superior temporal sulcus (STS), which processes dynamic facial aspects including expressions, gaze, and speech movements [56]. Although STS-based face processing has often been characterized as right-hemisphere dominant, large-sample fMRI evidence shows this lateralization is weak, with only half of subjects showing clear right dominance [57], and TMS confirms that both left and right STS contribute causally to expression recognition [58]. The right STS exhibits clearer functional segregation between gaze, expression, and speech regions, while the left STS shows more distributed representations of the same movements [59], suggesting complementary rather than redundant hemispheric contributions.
Within each hemisphere, features are mapped topographically following the dorsoventral organization of STS [59]: dorsal regions (higher Z coordinates) encode upper-face features (brow, eye, and nose movements) while ventral regions (lower Z) encode lower-face features (mouth and jaw movements). The mapping occupies coordinates X = 28–60 mm (lateral), Y = −62 to −42 mm (posterior temporal), and Z = −11 to 16 mm (ventral to mid-level).
This topographic mapping of the visual features is shown in Figure 7.
2.7. Mapping Multimodal Audio–Visual Data into an eXCube2 Model
The audio and visual features described in the previous sections are combined to in the design of a multimodal audio–visual eXCube2 system. The extraction of audio and visual features is synchronized at 10 ms. A snapshot of the resulting feature activity for an exemplar multimodal data sample is shown in Figure 8.
2.8. Training of eXCube2 Models on Audio, Visual and Audio–Visual Data
Separate eXCube2 models are constructed for audio-only, visual-only, and multimodal audio–visual data using the features described above. For unsupervised training of the SNNcube, Spike-Timing-Dependent Plasticity (STDP) is employed (see [17]), with the training and testing parameters summarized in Table 3. Further experimental details and parameter settings for the training and testing procedures are provided in Appendix A.3.
After training each SNNcube model, state vectors are extracted from the reservoir and used to train a classifier in a supervised mode.
2.9. State Vector Extraction from a Trained SNNcube and Their Classification
Different approaches can be used to extract state vector from a trained SNNcube.
(a)Spike Count: This method sums the total number of spikes per neuron across all timesteps for each sample:
where denotes the spike activity of neuron i at time t. In this case, temporal information is aggregated into a single value per neuron, and the state vector is represented by the spike counts of all neurons.(b)DeSNN weight-based state vectors: Alternatively, state vectors can be derived using the DeSNN encoding rule (see [47]), which computes a scalar value for each neuron based on its spiking activity. Specifically, each neuron’s value is determined by two properties of its spike train: the timing of its first spike (via rank-order coding) and its total spike count (via a drift component):
where = 5.0, m = 0.8, = 0.8, = 0.01.
The collection of these values across all reservoir neurons forms the state vector for a given sample. The extracted state vectors are used to train a classifier to recognize two emotional states as two classes, corresponding to arousal and calm. In practice, simple spike counting performs comparably to DeSNN encoding because the reservoir has already transformed temporal information into spatial patterns. Through recurrent dynamics and STDP learning, different neurons become selective to different temporal motifs, and their firing patterns implicitly encode the temporal evolution of the input. Moreover, STDP strengthens connections between neurons that fire in consistent sequences, thereby em-bedding temporal structure into the network connectivity. Spike counting on reservoir neurons captures discriminative information, because each neuron’s firing reflects inte-grated temporal patterns across the network through learned connectivity. The reservoir performs temporal feature extraction.
Once the state vectors are extracted from the trained SNNcube, different classification methods have been applied and compared to classify these vectors into the two output classes as described in Table 4.
In the current implementation of the eXCube2 framework, the Learned Prototype classifier is used, as its clustering capability is well suited to the experimental data. Other classifiers can be employed for different applications while still using the same eXCube2 framework.
3. Experimental Results, Interpretability and Explainability of the eXCube2 Models
3.1. Classification Results on the Experimental Data
Table 5 compares classification performance obtained using three eXCube2 models for: (1) multimodal data; (2) audio data only; (3) visual data only. The eXCube2 model can operate on the integrated multimodal input as well as on each modality separately. Using different methods for state vector extraction and classification yields comparable results, with accuracies consistently in the range of around 80%.
Legend:
- ▪I = Input neurons only (spike-encoded features)
- ▪R = Reservoir neurons only
- ▪I + R = Combined input + Reservoir neurons
- ▪SC = Spike count (sum of spikes over time)
- ▪split = Separate positive/negative spike counts (doubles feature dimensionality)
- ▪STS = Superior Temporal Sulcus brain region reservoir neurons only (audio–visual integration)
- ▪A1 = Primary Auditory Cortex brain region reservoir neurons only
- ▪py = DeSNN Python V1.0 implementation (from NeuCubePy library)
- ▪hybrid = DeSNN connecxtion weights analysis.
Using the introduced “don’t know” output with a confidence threshold in the range 0.55–0.65 improves the effective classification accuracy to up to 89% by rejecting low-confidence samples, as shown in Table 6.
More details of the three classification models and their interpretation are presented in Figure 9, Figure 10 and Figure 11, respectively, and in the next sub-section. They explain the best state vector extraction method and random seed initiated for the learned prototype according to accuracy.
3.2. Interpretation of the Classification Results
The multimodal model uses input neurons with their positive and negative spikes represented as two different features. The model achieves 88.9% selective accuracy using ‘I don’t know’ at a 78.0% coverage of the full data, and 81.0% accuracy on the full predictions. High arousal accuracies dominate at 88–94%, whereas low arousal accuracies range from 68–74%. This is also most likely due to class imbalance from the raw dataset; however the multimodal model bridges this discrepancy more than the other models. Where more data is available such as with the high arousal, we can see that the accuracy percentages reach the high 80 s/mid 90 s. The multimodal model also covers more of the full data, whilst reaching higher accuracies compared to the unimodal models.
The audio model uses a combined input and reservoir spike count, achieving 85.3% selective accuracy using “I don’t know” at a 72.3% coverage of the full data, and 80.3% accuracy on the full predictions. High arousal accuracies dominate at 88–94%, whereas low arousal accuracies range from 59–64%. This is most likely due to class imbalance from the raw dataset. The model performs slightly better than the video model on low arousal. Where more data is available such as with the high arousal, we can see that the accuracy percentages reach the high 80 s.
The video eXCube2 model uses a combined input and reservoir spike count, where inputs have their positive and negative spikes represented as two different features. This is concatenated with the deSNN_py state vector extracted from STS neurons in the reservoir, meaning only the relevant neurons related to visual processing are used. The model achieves 88.1% selective accuracy using “I don’t know” at a 67.3% coverage of the full data, and 77.3% accuracy on the full predictions. High arousal accuracies dominate at 92–96%, whereas low arousal accuracies range from 48–50%. This is also most likely due to class imbalance from the raw dataset. The model is much better at detecting high arousal versus the audio model, but worse off for low arousal. Where more data is available such as with the high arousal, we can see that the accuracy percentages reach the 90 s. The selective prediction mechanism “don’t know”, allows for the model to abstain from low-confidence predictions by thresholding the classifier’s softmax output.
Figure 9, Figure 10 and Figure 11 present the scope-accuracy tradeoff curves for all three models. At full coverage (100%), the multimodal model achieves 81.0% accuracy. As the confidence threshold increases, coverage decreases while accuracy improves, at 78% coverage, accuracy reaches 88.9%. This tradeoff is continuous and configurable at deployment time without retraining.
The abstention capability has direct practical utility. In client-facing applications or streaming scenarios where data is readily available, the system can request additional information when uncertain and defer prediction until confidence is sufficient. This is analogous to a clinician requesting further tests before diagnosis. While experimental evaluation requires forced prediction on a fixed test set, in deployed systems the “don’t know” response enables the model to maintain high reliability on the predictions it does make, which is preferable to forcing unreliable predictions.
In terms of scalability, the models offer several inherent advantages. Learning is local through STDP and DeSNN state vectors, eliminating the need for backpropagation through time and the associated memory overhead. Computation is also inherently sparse, as the spiking reservoir only processes activity when spikes occur rather than performing dense matrix operations at every timestep. The architecture is also modular, as additional brain regions, data modalities, or feature types can be incorporated by mapping new inputs to their corresponding cortical areas within a single unified reservoir. Because all regions share the same recurrent dynamics, activity in one area influences processing in another as it unfolds in time, enabling genuine cross-modal interaction rather than independent parallel streams combined after the fact.
Furthermore, the spiking architecture is well-suited for future deployment on neuromorphic chips, which could offer significant gains in energy efficiency and processing speed through hardware-level spike routing. However, in its current software implementation the model is sequential on two levels: within each sample, the reservoir must process timesteps in order as the activity at each step depends on all preceding steps, and across samples, the incremental learning procedure updates the reservoir after each training instance, meaning samples cannot be processed in parallel. One potential mitigation is training multiple reservoirs independently and averaging their learned weights, though how effectively such ensemble strategies translate to spiking architectures remains an open question.
Reproducibility: All classification results are reported as means with 95% confidence intervals computed over 30 independent random seeds. The narrow confidence intervals (typically ±0.1–0.2 percentage points) confirm high stability across classifier initializations. For example, the multimodal model achieves 82.1% [95% CI: 82.0, 82.3] overall accuracy.
Computational Cost: Table 7 reports the computational cost of each pipeline stage for a data length 3–5 s, measured on a single CPU core (Apple M-series, no GPU required).
End-to-end inference time from raw video to emotion prediction is approximately 2.1 s, dominated by the reservoir forward pass (1.0 s) and feature extraction (1.0 s). Total training time for the full pipeline is approximately 49 min for 1520 samples. The SNN reservoir contains 3108 LIF neurons with a sparse connectivity matrix 27,741–45,214 non-zero connections (0.3–0.5% density), requiring <1 MB in sparse format. The complete trained model (reservoir weights + classifier) occupies <40 MB.
For comparative analysis, Appendix B, Table A1, shows classification using typical machine learning methods on feature vectors, directly extracted from raw data, rather than from the SNNcube of an eXCube2 model. The experiments demonstrate that using state vector features extracted from a trained SNNcube in the eXCube2 model lead to a much higher accuracy, along with interpretability, explainability and adaptability of the models, when compared with the accuracy of models than use features extracted directly from raw data.
The proposed eXCube2 framework allows for the system to be used by new speakers in an on-line interactive mode, rather than tested by recorded speakers from the RAVDESS benchmark data set. Examples of using the system by an English speaking male of Chinese origin and a female of European origin are given in Table A2 and Table A3 of Appendix B.
3.3. Explainability of the eXCube2 Models
The eXCube2 models provide informative representations at multiple levels of their structure and dynamics. First, the spatial mapping of features is itself interpretable, as it follows a brain template and incorporates established neuroscience knowledge (e.g., Figure 6, Figure 7 and Figure A1).
More importantly, the models capture dynamic interactions between features. This is illustrated in Figure 12, which shows spike-time associations between 24 linear-fft features (see Appendix A.1 for their mapping into the SNNcube). The learned associations are visualized as arcs between features represented as nodes (L denotes the left hemisphere; R denotes the right hemisphere). The thicker the arc, the more frequently spikes at one node are followed by spikes at the connected node in the next time step (10 ms), indicating stronger temporal coupling. This provides a spike-based representation of information exchange within the model.
Figure 13 shows feature interaction between most prominent audio and visual features of the audio-visual eXCube2 model when mel-spectrogram audio features are used along with the face features. In both classes of emotional states, audio–audio interactions dominate, concentrated among low-frequency bands (50 Hz to 1 kHz), with no notable differences in cross-modal connections emerging. In the low arousal condition, the connection between 50–200 Hz and 200–400 Hz is stronger, an additional link appears between 200 and 400 Hz and between 650 Hz and 1 kHz, and the upper and lower mouth regions are connected. In the high arousal condition, these three connections weaken or disappear, suggesting a decoupling of both the low-frequency audio bands and the mouth regions.
4. Conclusions, Discussions, Limitations and Future Work
The paper presents a novel SNN-based framework eXCube2 for the recognition and classification of emotional states from audio, visual or combined audio–visual data. The framework consists of modules for feature extraction, spike encoding, mapping features into a 3D SNN, pre-structured according to a brain template, training the SNNcube, extracting state vectors from the SNNcube, training a classifier on the state vectors, recalling and adapting the system to new data, as well as visualisation and dynamic explanation of the processing. Each module is grounded in brain-inspired information processing principles.
We have used a benchmark data set to illustrate our new approach, but the goal of the paper is not to achieve perfect statistical validation results on the benchmark RAVDESS data set through cross-validation. In Appendix B new experimental results on the same data with cross validation tests are shown when feature vectors are extracted from the raw data rather than from the SNNcube (Table A1). The goal is for the framework to be further adapted and tested on new speakers of different accents, pronunciations and culture-based expression. In Appendix B we have tested the framework on a new male speaker of Chinese origin (Table A2) and a female speaker of European origin (Table A3) with satisfactory results. The framework allows for further testing and adaptation on new speakers.
Several limitations of the current study should be noted. The eXCube2 models address the problem of binary arousal classification (high vs. low). Addressing the problem of full eight-emotion taxonomy available in RAVDESS is another problem that can follow. The RAVDESS dataset, while well-established, consists of acted emotional expressions from 24 North American English speakers. Generalization to spontaneous emotions, diverse languages, and cross-corpus settings remains to be demonstrated. The acoustic features used for data visualisation in this study, including RMS energy, spectral centroid, spectral flux, and low-frequency energy, are associated with emotional dimensions at the population level. However, these relationships are not deterministic. Individual variation in vocal expression, cultural differences, and speaker-specific characteristics mean that the same emotion may manifest with different acoustic profiles across speakers and contexts. The visualisations presented in this work should therefore be interpreted as illustrative of general trends rather than universal patterns.
The current model uses a 3108-neuron reservoir, which serves as a proof-of-concept. The software architecture supports scaling to substantially larger reservoirs, which may enable finer-grained temporal pattern capture. Class balancing in the training set was achieved through sample duplication rather than data augmentation techniques (e.g., pitch shifting, noise injection), which may limit the diversity of learned representations for the minority class.
At each stage of the framework, multiple methods can be employed, some of which were explored in this work. An integrated eXCube2 system has been developed for audio–visual data, combining three models for audio-only, visual-only, and multimodal processing. The system was evaluated on benchmark datasets for each modality and their integration, achieving accuracies of up to around 89% when confidence-based rejection is applied.
Future work can involve development of eXCube2 models of audio-visual data for other problems rather than emotional state recognition. SNN models have already been used for mental state assessment based on audio–visual data. The work [30] proposes a Transformer-based multimodal mental health assessment framework that models audio–visual–text cues from interview sessions using a cross-attention fusion mechanism to capture inter-modal dependencies relevant to distress and mood assessment. The approach uses strong pretrained feature extractors for each modality—wav2vec 2.0 for audio, ResNet-50 for facial/visual features, and BERT for text embeddings—followed by modality-specific Transformer encoders to learn intra-modality temporal/contextual structure [30]. The central methodological contribution is a Cross-Attention Transformer Block that performs dynamic fusion: for each target modality X∈{A,V,T}, the model computes cross-attention using X as the query and the concatenation of the other modalities as keys/values, enabling the system to selectively attend to complementary signals conditioned on task relevance. This design is explicitly positioned as an improvement over static concatenation/early fusion, with added interpretability through attention-weight visualization. The evaluation uses two publicly available datasets: the Bipolar Disorder Corpus and the Extended Distress Analysis Interview Corpus (E-DAIC), both consisting of audio–visual interview recordings with corresponding text transcriptions and mental-health/emotion-related labels. Preprocessing includes the following: audio resampled to 16 kHz and normalized; video keyframes extracted at 1 fps, with face detection/alignment using MTCNN and resized to 224 × 224; text tokenized with the BERT tokenizer and padded to fixed length [30].
Another application area of SNN is targeting moving object recognition. Paper [31] presents a Transformer-based Spiking Neural Network (SNN) for multimodal audio–visual classification, targeting accurate fusion under SNN constraints while emphasizing efficiency. The proposed model, termed SMMT, integrates unimodal spiking backbones with a Spiking Cross-Attention (SCA) module that performs bidirectional audio↔vision interaction and incorporates relative position bias and dropout to improve temporal/positional modelling and generalization. Audio is represented via log-mel spectrograms (STFT-based), consistent with standard environmental sound processing [31].
The above examples point to a future use of the eXCube2 framework in a wider range of domains using one or both audio–visual modalities, including: monitoring response to treatment over time [14]; evaluation of user satisfaction in online services [61]; human–robot interaction [62]; chatbots [28]; interactive games, and related applications.
The three models are implemented as Python software tools (V1.0), enabling the design and experimentation of eXCube2 models across sound, image, and video data. The use of an SNNcube together with evolving classifiers supports scalability to larger datasets, adaptability to new data, and explainability of the underlying dynamic processes. A software module is developed to dynamically visualize and explain the activity of eXCube2 during recall on new data.
Importantly, the SNN-based implementation of Brain-Inspired AI (BIAI) makes the framework suitable for deployment on neuromorphic hardware platforms, enabling reduced power consumption, smaller device size, and improved efficiency, while preserving adaptability and explainability [63,64,65,66,67]. Ultimately, the use of shared brain templates for both biological and artificial systems may help bring human–machine symbiosis closer in the future.
Future work will focus on: (1) evaluating additional classifiers for the extracted state vectors (e.g., [68,69]); (2) in addition to audio–visual data, using brain data (e.g., EEG, fMRI) and other data modalities to integrate in an eXCube2 model [48,70]; (3) further extending the concept of evolving spatio-temporal associative memory based on brain principles [39,71]; and (4) implementing the models on contemporary software and hardware platforms for real-world applications [17,66,72,73]. The proposed framework can be integrated with Transformer-based systems [74,75,76,77,78,79,80,81,82,83,84] making them brain-inspired and more efficient. It also extends the theoretical studies on emotion recognition methods [85,86] and the methods for abnormal brain state diagnosis (e.g., Parkinson’s disease, Alzheimer’s disease, ADHD, dementia) [16,87].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Chern I.C. Hung K.H. Chen Y.T. Hussain T. Gogate M. Hussain A. Tsao Y. Hou J.C. Audio-visual speech enhancement and separation by utilizing multi-modal self-supervised embeddings Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW)Rhodes Island, Greece 4–10 June 202315
- 2Saraceno G. Deep Learning and Memorizing of Spectro-Temporal Data (Music) in the Spatio-Temporal Brain Master’s Thesis University of Trento Trento, Italy 2017
- 3Zhang H. Zhang B. Huang W. Tian Q. Gabor wavelet associative memory for face recognition IEEE Trans. Neural Netw.20051627527810.1109/TNN.2004.84181115732406 · doi ↗ · pubmed ↗
- 4Liu W. Quan Y. Liu Y. Yan D.-M. Bi-directional modality fusion network for audio-visual event localization Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)Singapore 23–27 May 202248684872
- 5Lacheze L. Guo Y. Benosman R. Gas B. Couverture C. Audio/video fusion for objects recognition Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems St. Louis, MO, USA 10–15 October 2009652657
- 6Wang D. Chen J. Supervised Speech Separation Based on Deep Learning: An Overview IEEE/ACM Trans. Audio Speech Lang. Process.2018261702172610.1109/TASLP.2018.284215931223631 PMC 6586438 · doi ↗ · pubmed ↗
- 7Zheng X. Wei Y. Audio-visual event and sound source localization based on spatial-channel feature fusion Proceedings of the International Conference on Signal and Image Processing (ICSIP)Suzhou, China 20–22 July 2022106110
- 8Kasabov N. Postma E. van den Herik J. AVIS: A connectionist-based framework for integrated auditory and visual information processing Inf. Sci.200012312714810.1016/S 0020-0255(99)00114-0 · doi ↗